singing voice separation from music with u-net and
TRANSCRIPT

Final Presentation of Project, Gyeong-Tae Lee & Jae-Hak Jeong @ N25 #3229, Jun 13, 2019 1
GCT634 Spring 2019 - Musical Applications of Machine Learning
Property of KAIST, All Rights Reserved.
Gyeong-Tae Lee & Jae-Hak [email protected] / [email protected]
Human-Machine Interaction LABNOVIC+, Department of Mechanical Engineering, KAIST
Singing Voice Separation from Music with U-Net and Performance Evaluation by Genre
Final Presentation of GCT634 Project - #4@ N25 #3229 Paik Nam June Hall, Jun 13, 2019

Final Presentation of Project, Gyeong-Tae Lee & Jae-Hak Jeong @ N25 #3229, Jun 13, 2019 2
GCT 634Musical Applications of MLBriefing of Final Project
- Paper review : 7 ( Traditional Method : 3 / Deep Learning Method : 4 )- Datasets collected : 6 ( ccMixter / MedleyDB / DSD100 / MUSDB18 / GTZAN / Mir-1k )- Code implemented : 1 ( U-Net )- Output obtained : Training with ccMixter + MUSDB18 / Test with MUSDB18
Singing VoiceSeparation

Final Presentation of Project, Gyeong-Tae Lee & Jae-Hak Jeong @ N25 #3229, Jun 13, 2019 3
GCT 634Musical Applications of MLIntroduction
• The singing voice separation estimates what the vocal and accompaniment would sound like in isolation.• A clean vocal is helpful for some MIR tasks, such as singer identification and lyric transcription.• As a commercial application, it is evident that the karaoke industry would benefit from such technology.
• Traditional Methods- Bayesian Method [1]- REpeating Pattern Extraction Technique (REPET) [2]- Non-negative Matrix Factorization (NMF) [3]
• Deep Learning Methods- Deep Neural Network (DNN) [4]- Convolutional encoder-decoder architectures [5]- Deep U-Net Convolutional Networks (U-Net) [6]
[1] Alexey Ozerov, Pierrick Philippe, Frdric Bimbot, and Rmi Gribonval. Adaptation of bayesian models for single-channel source separation and its application to voice/music separation in popular songs. IEEE Transactions on Audio, Speech, and Language Processing, 15(5):1564–1578, 2007.[2] Paris Zafar Rafii and Bryan Pardo. Repeating pattern extraction technique (REPET): A simple method for music/voice separation. IEEE transactions on audio, speech, and language processing, 21(1):73–84, 2013.[3] Paris Smaragdis, Cedric Fevotte, Gautham J Mysore, Nasser Mohammadiha, and Matthew Hoffman. Static and dynamic source separation using nonnegative factorizations: A unified view. IEEE Signal Processing Magazine, 31(3):66–75, 2014.[4] Andrew JR Simpson, Gerard Roma, and Mark D Plumbley. Deep karaoke: Extracting vocals from musical mixtures using a convolutional deep neural network. In International Conference on Latent Variable Analysis and Signal Separation, pages 429–436. Springer, 2015.[5] Pritish Chandna, Marius Miron, Jordi Janer, and Emilia G´omez. Monoaural audio source separation using deep convolutional neural networks. In International Conference on Latent Variable Analysis and Signal Separation, pages 258–266. Springer, 2017.[6] Andreas Jansson, Eric Humphrey, Nicola Montecchio, Rachel Bittner, Aparna Kumar, and Tillman Weyde. Singing voice separation with deep u-net convolutional networks. In 18th International Society for Music Information Retrieval Conference, Suzhou, China, 2017.
U-Net Mask
Convolutional Encoder-Decoder Mask

Final Presentation of Project, Gyeong-Tae Lee & Jae-Hak Jeong @ N25 #3229, Jun 13, 2019 4
GCT 634Musical Applications of MLVocal separation with U-Net
Encodes the image into a small and deep representation
Decoded to the original size of the image by upsampling layers
Low Level Skip Connection• Concatenate the layers at
same level• Information flow between
the high resolution input and output
Plain ReLU
Batch normalization
Deconv(transposed conv)
Decoder layer
conv2D
Batch normalization
Leaky ReLU
Encoder layer
Pre-processing• Downsampling 8192Hz• STFT window size 1024, hop 768,
extract patches 128 (11 sec.)• Spectrogram normalized
Training• Vocal & Mix in / Soft Mask out• Loss function: !","norm of the
difference between target and masked input spectrogram

Final Presentation of Project, Gyeong-Tae Lee & Jae-Hak Jeong @ N25 #3229, Jun 13, 2019 5
GCT 634Musical Applications of MLEvaluation
• Quantitative evaluation of singing voice separation performance
• Signal to Distortion / Interference / Artifact Ratio
• Meaning
• SDR : how similar !"#$.&'()* with !+",.&'()*• SIR : how discriminative !"#$.&'()* with !-./$0+"• SAR: how well reconstructed from spectrogram
est.vocal ref.vocal mixture ref.vocal( , ) ( , )NSDR SDR s s SDR s s= -
2ref.vocal
10 2interf noise artif
2ref.vocal
10 2interf
2ref.vocal interf noise
10 2interf noise artif
: 10 log
: 10log
: 10log
sSDR
e e e
sSIR
e
s e eSAR
e e e
=+ +
=
+ +=
+ +
2ref.vocal interf
10 2noise
: 10 logs e
SNRe+
=
interf
artif
ee
est.vocal ref.vocal interf noise artifs s e e e= + + +
= interface: residual of the background music (inst.)
= artifact: noise due to the reconstruction (ex. glitch from STFT phase st.)
= normalized SDR : SDR without reference SDR

Final Presentation of Project, Gyeong-Tae Lee & Jae-Hak Jeong @ N25 #3229, Jun 13, 2019 6
GCT 634Musical Applications of MLSDR / SAR / SIR
• Condition• Training: ccMixter + MUSDB18 (200 songs) / Test: MUSDB18• Source : downsampled to 8192 Hz, 47 sec of length• Calculates SDR: from 0:05 – 0:10 (start from 5 sec., 5 sec. length)
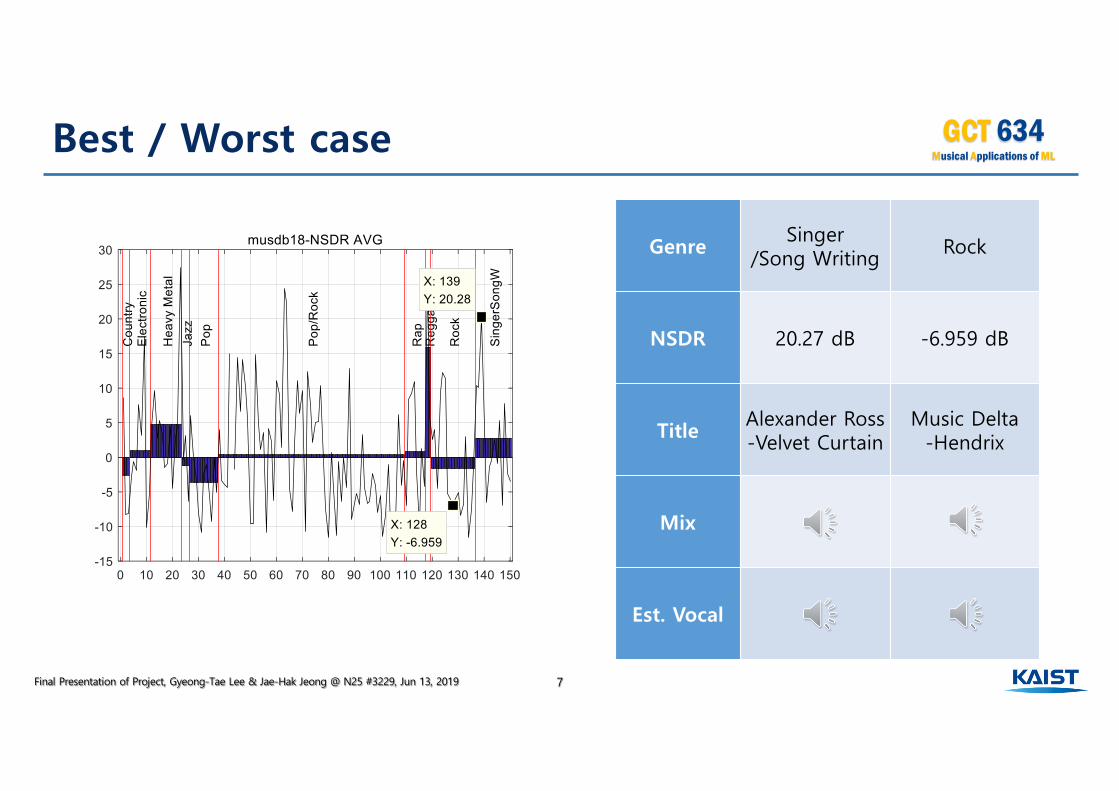
Final Presentation of Project, Gyeong-Tae Lee & Jae-Hak Jeong @ N25 #3229, Jun 13, 2019 7
GCT 634Musical Applications of ML
GenreSinger
/Song WritingRock
NSDR 20.27 dB -6.959 dB
TitleAlexander Ross-Velvet Curtain
Music Delta-Hendrix
Mix
Est. Vocal
Best / Worst case

Final Presentation of Project, Gyeong-Tae Lee & Jae-Hak Jeong @ N25 #3229, Jun 13, 2019 8
GCT 634Musical Applications of MLDiscussion
• Dependency on Genre• Best Genre : singer / song writing – low level accompaniment
à because of phase reuse, there is still jittering.• Worst Genre : rock – full accompaniment
• Outlier of Genre• Heavy metal: High level because of evaluation only on accompaniment• Electronic: most of audio files consists of only accompaniment• Reggae: looks like high performance but beat remains
• Minor Info.• MUSDB18 : wrong label ( from 17 to 118 )
• Future research• U-Net with Phase recover like Wave U-Net• Joint with Vocal detection