siggraph course 30: performance-driven facial animation section: marker-less face capture and...
Post on 21-Dec-2015
220 views
TRANSCRIPT

SIGGRAPH Course 30:Performance-Driven Facial AnimationSIGGRAPH Course 30:Performance-Driven Facial Animation
Section:
Marker-less Face Capture and Automatic Model Construction
Part 1: Chris Bregler, NYU
Part 2: Li Zhang, Columbia University

Face Tracking ApproachesFace Tracking Approaches
• Marker-based hardware motion capture systems
• Tom Tolles (House of Moves) presentation 9:00 (earlier)
• Parag Havaldar (Sony Pictures Imageworks) presentation at 2:15 pm

Marker-based Face Capture:Marker-based Face Capture:

Marker-less Face Capture:Marker-less Face Capture:

Early Computer Face CaptureEarly Computer Face Capture
Kass, M., Witkin, A., & Terzopoulos, D. (1987) Snakes: Active contour models.
• Single Camera Input
• 2D Output
• Off-line
• Interactive-Refinement
• Make-up
• Contour / Local Features
• Hand Crafted
• Linear Models / Tracking

• Disney:

Early “Markerless Facecapture”Early “Markerless Facecapture”
• Disney:
Step-Mother Eleanor Audley

Early Computer Face CaptureEarly Computer Face Capture
Kass, M., Witkin, A., & Terzopoulos, D. (1987) Snakes: Active contour models.
• Single Camera Input
• 2D Output
• Off-line
• Interactive-Refinement
• Make-up
• Contour / Local Features
• Hand Crafted
• Linear Models / Tracking

Markerless Face Capture - Overview -Markerless Face Capture - Overview -
• Single / Multi Camera Input
• 2D / 3D Output
• Off-line / Real-time
• Interactive-Refinement / Face Dependent / Independent
• Make-up / Natural
• Flow / Contour / Texture / Local / Global Features
• Hand Crafted / Data Driven
• Linear / Nonlinear Models / Tracking

Common FrameworkCommon Framework
Error = Feature Error + Model Error
Tracking = Error Minimization

Difference:Difference:
Error = Feature Error + Model Error
Tracking = Error Minimization

Difference:Difference:
Error = Feature Error + Model Error
Tracking = Error Minimization

Difference:Difference:
Error = Feature Error + Model Error
Tracking = Error Minimization

Tracking = Error MinimizationTracking = Error Minimization
Kass, M., Witkin, A., & Terzopoulos, D. (1987) Snakes: Active contour models.

Tracking = Error MinimizationTracking = Error Minimization
Error = Feature Error + Model Error

Tracking = Error MinimizationTracking = Error Minimization
Error = Optical Flow + Model Error
Most general feature:

Tracking = Error MinimizationTracking = Error Minimization
Err(u,v) = || I(x,y) – J(x+u, y+v) ||

-
Basics in Optical Flow:Lucas-Kanade 1D Image
Intensity
x
u ?F G
∑ −≈x
tx xFuxF 2))()((
∑ −+=x
xGuxFuE 2))()(()(
Linearization:
Spatial Gradient Temporal Gradient

∑∈
−++=ROIyx
xGvyuxFvuE,
2))(),((),(
∑∈
−+≈ROIyx
tyx yxFvyxFuyxF,
2)),(),(),((
Spatial Gradient Temporal Gradient
ROI
ROI
(u,v)
F G
Lucas-Kanade: 2D Image

Minimize E(u,v):
0
0
=∂∂
=∂∂
vEuE
⎥⎥⎦
⎤
⎢⎢⎣
⎡=⎥
⎦
⎤⎢⎣
⎡
⎥⎥⎦
⎤
⎢⎢⎣
⎡
∑∑
∑∑∑∑
yt
xt
yyx
yxx
FF
FF
v
u
FFF
FFF2
2
=>
C
D
=⎥⎦
⎤⎢⎣
⎡v
u
=⎥⎦
⎤⎢⎣
⎡v
uC
-1
D
Lucas-Kanade: Error Minimization: 2D Image

Marker-less Face Capture:Marker-less Face Capture:
In general: ambiguous using local features

-
= E(V)
Optical Flow
I (1) - I(1) v t 1
I (2) - I(2) v t 2
I (n) - I(n) vt n
...
2

V
-
= E(V)
Optical Flow
I (1) - I(1) v t 1
I (2) - I(2) v t 2
I (n) - I(n) vt n
...
2

V
-
= E(V)
V
Model
Optical Flow + Model
I (1) - I(1) v t 1
I (2) - I(2) v t 2
I (n) - I(n) vt n
...
2

V
-
= E(V)
V
Model
I (1) - I(1) v t 1
I (2) - I(2) v t 2
I (n) - I(n) vt n
...
2
V = M( )
Optical Flow + Model

V
-
V
Model
Optical Flow + linearized Model
V = M 2
Z + H V
2
Z + C

Optical Flow + 3D Model
DeCarlo, Metaxas, 1999 Eisert et al 2003

Optical Flow + MPEG4 Model
--> MediaPlayer (Eisert et al)

High-End Production:
Optical Flow + 3D Model
Disney Gemeni-ProjectWilliams et al 2002
EA Universal CaptureBorshukov et al 2002-2006

More “forgiving” Error Norm
- Faces change appearance
L2
D
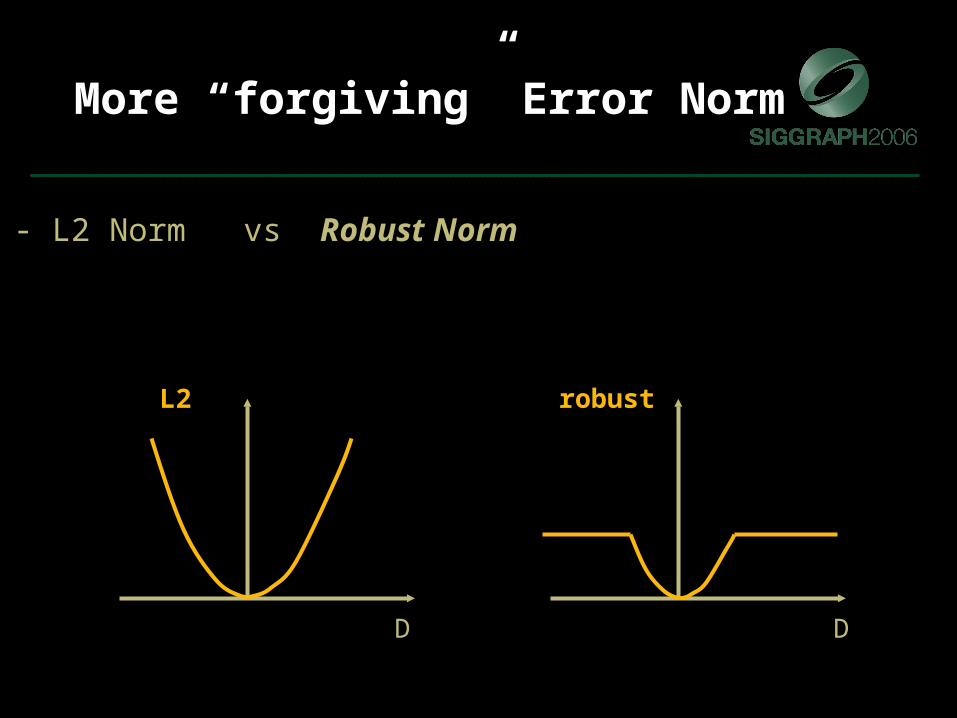
More “forgiving” Error Norm
- L2 Norm vs Robust Norm
L2 robust
D D

-
Robust Error with EM layers
I (1) - I(1) v t 1
I (2) - I(2) v t 2
I (n) - I(n) vt n
...
2

-
Robust Error with EM layers
I (1) - I(1) v t 1
I (2) - I(2) v t 2
I (n) - I(n) vt n
...
20.1
0.2
0.9
-
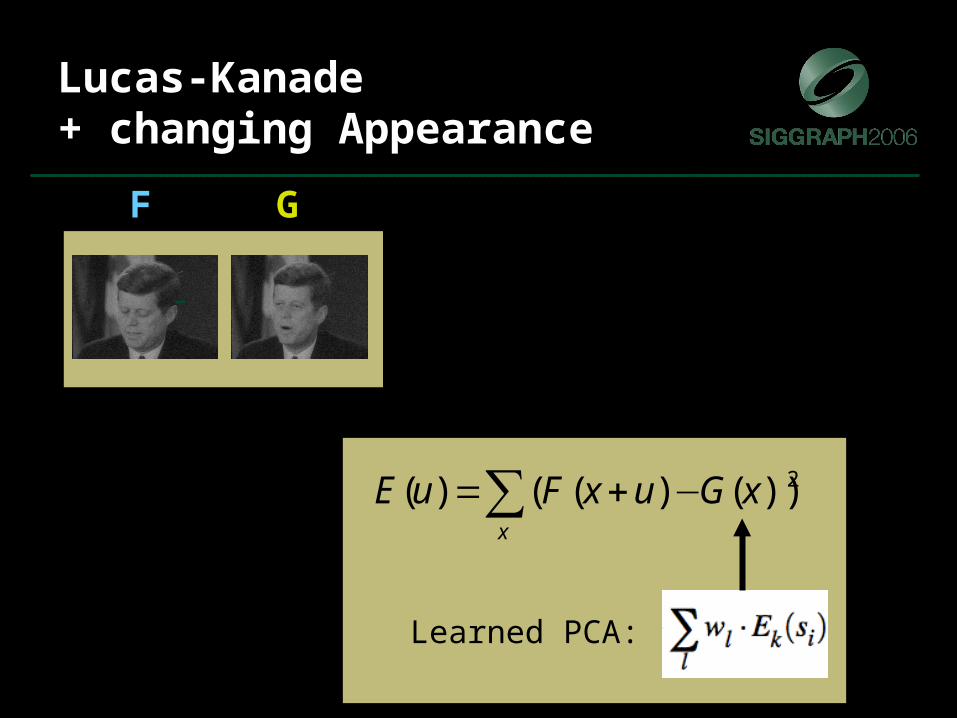
Lucas-Kanade+ changing Appearance
F G
∑ −+=x
xGuxFuE 2))()(()(
Learned PCA:

Optical Flow and PCAOptical Flow and PCA
Eigen Tracking (Black and Jepson)

2D texture and contours + PCA2D texture and contours + PCA
Active Appearance Models (AAM): (Cootes et al)

2D texture and mesh + PCA2D texture and mesh + PCA
QuickTime™ and aYUV420 codec decompressor
are needed to see this picture.

Lucas-Kanade + Apearance ModelsLucas-Kanade + Apearance Models
Lucas-Kanade AAMs: (Baker & Matthews)
QuickTime™ and aYUV420 codec decompressor
are needed to see this picture.
Affine Flow + PCA + Robust Norm Affine Flow + PCA + Robust Norm
QuickTime™ and aCinepak decompressor
are needed to see this picture.
Disney: Gemeni-Project

Solution based on Factorization Solution based on Factorization
- We want 3 things:- 3D non-rigid shape model- for each frame:
- 3D Pose- non-rigid configuration (deformation)
-> Tomasi-Kanade-92:
W = P S
Rank 3

Solution based on Factorization Solution based on Factorization
- We want 3 things:- 3D non-rigid shape model- for each frame:
- 3D Pose- non-rigid configuration (deformation)
-> PCA-based representations:
W = P non-rigid S
Rank K

Space-Time FactorizationSpace-Time Factorization
Complete 2D Tracks or Flow Matrix-Rank <= 3*K
Nonrigid flow or Markerset -> “Rigid Stabilization + Blendshapes”

Space-Time FactorizationSpace-Time Factorization
Irani, 1999
Bregler, Hertzmann, Biermann, 2000
Torresani, Yang, Alexander, Bregler, 2001
Brand, 2001
Xiao, Kanade, 2004
Torresani, Hertzmann, 2004

From Pixels to 3D Blend Shapes From Pixels to 3D Blend Shapes (Torresani et al 01,02)(Torresani et al 01,02)
QuickTime™ and aYUV420 codec decompressor
are needed to see this picture.

Trajectory ConstraintsTrajectory Constraints
t=2t=1
t=F
. .. .
=.
.
..
3D positions of point i for the K modes of deformation
frames
Q’ miwi : full trajectory
Space-Time Tracking Space-Time Tracking (Torresani Bregler 2002)(Torresani Bregler 2002)
QuickTime™ and aCinepak decompressor
are needed to see this picture.

• Non-Rigid Models (Lorenzo Torresani, Aaron Hertzmann, et al)
– Rank Based Tracking
– 3D Basis Shapes
– Probabilistic Tracking / Models
– Occlusion
– Dynamical Systems
• Non-Rigid Models (Lorenzo Torresani, Aaron Hertzmann, et al)
– Rank Based Tracking
– 3D Basis Shapes
– Probabilistic Tracking / Models
– Occlusion
– Dynamical Systems
From Pixels to 3D Blend Shapes From Pixels to 3D Blend Shapes (Torresani et al 01,02)(Torresani et al 01,02)

• Non-Rigid Models (Lorenzo Torresani, Aaron Hertzmann, et al)
– Rank Based Tracking
– 3D Basis Shapes
– Probabilistic Tracking / Models
– Occlusion
– Dynamical Systems
• Non-Rigid Models (Lorenzo Torresani, Aaron Hertzmann, et al)
– Rank Based Tracking
– 3D Basis Shapes
– Probabilistic Tracking / Models
– Occlusion
– Dynamical Systems
p ( I(pj,t ) | “point pj,t is visible”) = N ( I(pj,t )| µj ; 2 )
p ( I(pj,t ) | “pixel pj,t is an outlier”) = c
From Pixels to 3D Blend Shapes From Pixels to 3D Blend Shapes (Torresani et al 01,02)(Torresani et al 01,02)
zt = A * zt-1 + nt

QuickTime™ and aCinepak decompressor
are needed to see this picture.
From Pixels to 3D Blend Shapes From Pixels to 3D Blend Shapes (Torresani et al 01,02)(Torresani et al 01,02)

QuickTime™ and aCinepak decompressor
are needed to see this picture.
From Pixels to 3D Blend Shapes From Pixels to 3D Blend Shapes (Torresani et al 01,02)(Torresani et al 01,02)

Disney Gemeni ProjectDisney Gemeni Project
QuickTime™ and aCinepak decompressor
are needed to see this picture.

Markerless Face Capture - Summary -Markerless Face Capture - Summary -
• Single / Multi Camera Input
• 2D / 3D Output
• Real-time / Off-line
• Interactive-Refinement / Face Dependent / Independent
• Make-up / Natural
• Flow / Contour / Texture / Local / Global Features
• Hand Crafted / Data Driven
• Linear / Nonlinear Models / Tracking