semantic web 0 (0) 1 1 ios press how to improve jaccard’s ... · semantic web 0 (0) 1 1 ios press...
TRANSCRIPT

Semantic Web 0 (0) 1 1IOS Press
How to improve Jaccard’s feature-basedsimilarity measureSilvia Likavec, Ilaria Lombardi ∗ and Federica CenaDipartimento di Informatica, Università di Torino, Corso Svizzera 185, 10149 Torino, ItalyE-mail: [email protected], [email protected], [email protected]
Abstract. Similarity is one of the most straightforward ways to relate two objects and guide the human perception of the world.It has an important role in many areas, such as Information Retrieval, Natural Language Processing (NLP), Semantic Web andRecommender Systems. To help applications in these areas achieve satisfying results in finding similar concepts, it is importantto simulate human perception of similarity and assess which similarity measure is the most adequate.
In this work we wanted to gain some insights into Tversky’s and more specifically Jaccard’s feature-based semantic similaritymeasure on instances in a specific ontology. We experimented with various variations of this measure trying to improve its per-formance. We propose Sigmoid similarity as an improvement of Jaccard’s similarity measure. We also explored the performanceof some hierarchy-based approaches and showed that feature-based approaches outperform them on two specific ontologies wetested. We also tried to incorporate hierarchy-based information into our measures and, even though they do bring some slightimprovement, it seems that it is not worth complicating the measures with this information, since the measures only based onfeatures show very comparable performance. We performed two separate evaluations with real evaluators. The first evaluationincludes 137 subjects and 25 pairs of concepts in the recipes domain and the second one includes 147 subjects and 30 pairs ofconcepts in the drinks domain. To our knowledge these are some of the most extensive evaluations performed in the field.
Keywords: Similarity, properties, feature-based similarity, hierarchy, ontology, instances
1. Introduction
Similarity is one of the main guiding principleswhich humans use to categorise the objects surround-ing them. Even though in psychology the focus is onhow people organise and classify objects, in computerscience similarity plays a fundamental role in informa-tion processing and finds its application in many areasfrom Artificial Intelligence to Cognitive Science, fromNatural Language Processing to Recommender Sys-tems. Semantic similarity can be employed in many ar-eas, such as text mining, dialogue systems, Web pageretrieval, image retrieval from the Web, machine trans-lation, ontology mapping, word-sense disambiguation,item recommendation, to name just a few. Due to thewidespread usage and relevance of semantic similar-ity, its accurate calculation which closely mirrors hu-
*Corresponding author. E-mail: [email protected]
man judgement brings improvements in the above andmany other areas.
Usually, semantic similarity measures have beentested on WordNet [11]. WordNet is a taxonomic hier-archy of natural language terms developed at Prince-ton University. The concepts are organised in synsets,which group the words with the similar meaning. Moregeneral terms are found at the top of the underlyinghierarchy, whereas more specific terms are found atthe bottom. Two important datasets used to test simi-larity measures on WordNet are the ones proposed by[28] and [20]. These datasets are manually composedand contain rated lists of domain-independent pairs ofwords.
However, with the diffusion of ontologies as knowl-edge representation structures in many areas, there isa need to find similar and related objects in specificdomain ontologies used in various applications, ratherthan just testing the similarity of concepts in Wordnet
1570-0844/0-1900/$35.00 c© 0 – IOS Press and the authors. All rights reserved

2 Likavec et al. / How to improve Jaccard’s feature-based similarity measure
. In these cases, the features of domain objects play animportant role in their description, along with the un-derlying hierarchy which organises the concepts intomore general and more specific concepts. The experi-ments with feature-based and hierarchy-based seman-tic similarity measures on specific domain ontologiesare rare and without conclusive results [23,34]. Hence,we decided to carry out some experiments with Jac-card’s feature-based similarity measure on two spe-cific domain ontologies, trying to draw some con-clusions on the best use practices and case specificcharacteristics. For our first experiment, we chose thedomain of recipes using the slightly modified Wiki-taaable dataset1 used in [7]. For our second experi-ment, we chose the domain of drinks, developed previ-ously by our research team for different purposes. Ac-tually, it is difficult to find a publicly available ontologywith defined properties, which is an important require-ment for testing our approach. In addition, the domainswhich could be tested with non-expert users are verylimited, since the users should be able to evaluate thesimilarity of all (or at least most of) the couples pro-posed in the test. This is the reason we could not haveused any of the medical ontologies available, since inmedical domain only expert evaluators are needed.
There are many different similarity measures around.It is not very clear which measure is the most suit-able in which situation and comparative studies arerare [21,29]. Above all, the evaluation of the measureswith users is limited often to very few participants. Onthe contrary, our experiments involve 137 and 147 realevaluators respectively, which is a significant numberof participants compared to other studies.
Thus, we aimed to gain more insight into the be-haviour of Jaccard’s feature-based similarity measurefor ontology instances calculated from property-valuepairs for compared objects and compare its perfor-mance to hierarchy-based measures. We experimentedwith various variations of Jaccard’s feature-based sim-ilarity measure and we report here our findings. Thesame variations of Jaccard’s measure (and more gen-erally Tversky’s measure) could be applied to otherfeature-based similarity measures as well. Also, wetried to combine Jaccard’s similarity measure with hi-erarchy based approaches.
Our aim was to avoid any dependency on theweighting parameters which mark the contribution ofeach feature (known also as relevance factors). These
1http://wikitaaable.loria.fr/rdf/
parameters can be tuned for each single domain, butwe wanted to test the contribution of each feature withits equal share.
The main contributions of this work are the follow-ing:
1. a proposal for new feature-based similarity mea-sures, which could take underlying hierarchy intoaccount
2. new datasets which can be used for the evaluationof feature-based similarity measures.
The paper is organised as follows. In Section 2we provide the background on the basic concepts weuse in our work. In Section 3, we provide some de-tails about the semantic similarity measures we will bedealing with: feature-based semantic similarity mea-sures and hierarchy-based semantic similarity mea-sures. For the sake of completeness we also give somebackground on Information Content similarity mea-sures, although we will not be dealing with them in thispaper. In Section 4 we report on the semantic similaritymeasures we dealt with and propose six possible im-provements of the basic Jaccard’s similarity measure.We also give details of the variations of each of thesesix similarity measures which might include or not thehierarchy-based similarity. The results of our exten-sive evaluation are reported in Section 5 followed bya Section 6 which summarises some additional workswhich exploit feature-based semantic similarity mea-sures. We conclude in Section 7 drawing some conclu-sions and pointing some directions for future work.
2. Background on semantic knowledgerepresentation
This section provides a background on the main no-tions used in this work.
2.1. Conceptual hierarchies
A conceptual hierarchy provides a taxonomy (a treeor a lattice) of concepts organised using the partialorder IS-A relation, which specialises more generalclasses into more specific classes [3,32]. The IS-A re-lation is asymmetric and transitive and defines a hier-archical structure of the ontology, enabling the inheri-tance of characteristics from parent classes to descen-dant classes. W.r.t. to similarity calculation, it enablesthe employment of hierarchy-based approaches.

Likavec et al. / How to improve Jaccard’s feature-based similarity measure 3
2.2. Ontologies
Ontologies enable explicit specification of domainelements and their properties, hierarchical organisationof domain elements, exact description of any existingrelationships between them and employment of rigor-ous reasoning mechanisms. An ontology can be seenas a “formal, explicit specification of a shared concep-tualisation” [12]. They are expressed with standard for-mats and languages (e.g., OWL.2), which allow for ex-tensibility and re-usability.
Two layers can be identified in an ontology: ontol-ogy definition layer which contains the classes whichdescribe the concepts in the domain, and the instancelayer which contains all the distinct individuals in thedomain.
Relations between resources are defined by meansof properties. Two types of properties exist:
(i) object properties linking individuals among them-selves;
(ii) data type properties linking individuals and datatype values.3
In this work, we only considered object properties,since the treatment of data type properties (such as lit-eral values) requires further semantic analysis.
Instances in the ontology (also called individuals)describe concrete individuals. They are defined withindividual axioms which provide their class member-ships (property rdf:type), individual identities andvalues for their properties. All the properties of in-stances are inherited from the classes the instances be-long to. A specific value is associated to each prop-erty and some properties can have more than onevalue. Properties of instances enable the employmentof feature-based similarity measure to ontology in-stances.
3. Semantic similarity measures
In this section we give some details of the three maincategories of semantic similarity measures, namelyfeature-based, hierarchy-based and information content-based. As a result of trying to improve and combinethe above approaches, many hybrid similarity mea-sures were born. In our experiments we only dealt
2http://www.w3.org/TR/owl-ref3In OWL, there is also the notion of annotation prop-
erty (owl:AnnotationProperty) and ontology property(owl:OntologyProperty), used in OWL DL.
with Tversky’s feature-based measure, its improve-ments and its combination with hierarchy-based mea-sures. We include information-content-based measuresfor the completeness sake only.
3.1. Feature-based similarity measures
Calculation of similarity based on properties goesback to Tversky’s work on Features of Similarity [31]where similarity between two objects O1 and O2 is afunction of their common and distinctive features:
simT (O1,O2) =
=α(ψ(O1) ∩ ψ(O2))
β(ψ(O1) \ ψ(O2)) + γ(ψ(O2) \ ψ(O1)) + α(ψ(O1) ∩ ψ(O2)).
(1)
In the formula above ψ(O) describes all the relevantfeatures of the object O, and α, β, γ ∈ R are constantswhich allow for different treatment of the various com-ponents. For α = 1 common features of the two objectshave maximal importance. For β = γ non-directionalsimilarity measure is obtained. Depending on the val-ues for α, β, γ, we obtain the following variations ofTversky’s similarity:
– Jaccard’s or Tanimoto similarity for α = β = γ =
1;– Dice’s or Sørensen’s similarity for α = 1 and β =
γ = 0.5.We will be using the following notation:– common features of O1 and O2: cf(O1,O2) =
ψ(O1) ∩ ψ(O2),– distinctive features of O1: df(O1) = ψ(O1)\ψ(O2)
and– distinctive features of O2: df(O2) = ψ(O2)\ψ(O1).In order to calculate the above similarities for do-
main objects O1 and O2, we need to calculate for eachproperty p they have in common, how much it con-tributes to common features of O1 and O2, distinctivefeatures of O1 and distinctive features of O2, respec-tively. We denote these values by cfp, df1p and df2p.
Hence, we have to compare the property-value pairsbetween instances for each property they have in com-mon. We will include in common features the caseswhen the two objects have the same value for the givenproperty p. We will include in distinctive features ofeach object the cases when the two objects have differ-ent values for the given property p.
We consider equal the properties defined withowl:EquivalentProperty. Repeating the above process

4 Likavec et al. / How to improve Jaccard’s feature-based similarity measure
for each property O1 and O2 have in common, we ob-tain all common and distinctive features of O1 and O2:
cf(O1,O2) = Σni=1cfpi (O1,O2)
df(O1) = Σni=1df
1pi
(O1) df(O2) = Σni=1df
2pi
(O2)
where n is the number of common properties definedfor O1 and O2. Then the above similarity measures be-come:
Jaccard’s similarity:
simJ(O1,O2) =cf(O1,O2)
df(O1) + df(O2) + cf(O1,O2)(2)
Dice’s similarity:
simD(O1,O2) =2cf(O1,O2)
df(O1) + df(O2) + 2cf(O1,O2)(3)
3.1.1. Mathematical propertiesHere we provide the reader with some basic mathe-
matical properties of the Jaccard’s similarity measurewhich we would deal with in the rest of the paper.
1. Boundaries∀O1,O2, 0 ≤ simJ(O1,O2) ≤ 1.
2. Maximal similarityIf O1 ≡ O2, then simJ(O1,O2) = 1.
3. Commutativity∀O1,O2, simJ(O1,O2) = simJ(O2,O1).
4. MonotonicityIf cf(O1,O2) ≤ cf(O1,O3) and df(O1) = df(O2),then simJ(O1,O2) ≤ simJ(O1,O3).If cf(O1,O2) ≤ cf(O1,O3) and df(O2) = df(O3),then simJ(O1,O3) ≤ simJ(O2,O3).
3.2. Hierarchy-based similarity measures
Hierarchy-based or distance-based similarity mea-sures use the underlying conceptual hierarchy directlyand calculate the distance between concepts by cal-culating the number of edges or the number of nodeswhich have to be traversed in order to reach one con-cept from another. The hierarchy-based measure wasfirst introduced in [24] as a simple shortest path con-necting the compared concepts and was the basis forthe development of many measures of semantic simi-larity. A discussion and comparison with informationcontent-based approaches can be found in [5]. In thissection we give more details about three hierarchy-
based measures we used in our experiments: Leacockand Chodorow’s measure [15], Wu and Palmer’s mea-sure [33] and Li’s measure [16].
3.2.1. Leacock and Chodorow’s similarity measureThe first measure we will look at is Leacock and
Chodorow’s similarity measure [15] which was orig-inally used for word sense disambiguation in a localcontext classifier. The most similar nouns from thetraining set are substituted for the ambiguous ones intesting. In order to calculate the distances betweenwords, the authors use the normalised path length inWordNet [11] between all the senses of the comparedwords and measure the path length in nodes:
simLC(a, b) = − log( N p2 × max
). (4)
N p is the number of nodes in the path p from a to b,whereas max is the maximum depth of the hierarchy.The distance between two words belonging to the samesynset is 1.
If we want to express this measure as a function ofdistances between nodes we obtain the following for-mula:
simLC(a, b) = − log(dist(a, b)2 × max
). (5)
dist(a, b) is the distance between a and b calculated asthe shortest path length between these two nodes.
The disadvantage of this similarity measure is thatmany pairs of non-similar words are estimated as sim-ilar, due to the equal edge lengths in their hierarchy.
3.2.2. Wu and Palmer’s similarity measureWu and Palmer’s similarity measure [33] is based
on the depths in the hierarchy of the two words beingcompared and on the depth of their common subsumer,which characterises their commonalities. If we denoteby c the first subsuming node for the two comparednodes a and b, their similarity is calculated as follows:
simWP(a, b) =2Nc
Na + Nb. (6)
Nn is the number of nodes along the path from the noden to the root.
This measure can also be expressed as a function ofdistances between nodes as follows:
simWP(a, b) =2dist(c, r)
dist(a, r) + dist(b, r). (7)

Likavec et al. / How to improve Jaccard’s feature-based similarity measure 5
dist(n, r) is the distance of n from the root, again calcu-lated as the shortest path length between the two nodes.In [33] this measure was used in lexical selection prob-lems in machine translation where the performance ofinexact matches based on verb meanings is evaluated.
3.2.3. Li’s similarity measureLi et al. [16] proposed an approach for calculating
the similarity between sentences which uses seman-tic information and word order information in the sen-tence. Similarity of singular words is calculated usingthe shortest path length between words dist and thedepth h of their common subsumer as follows:
simL(a, b) = e−αdist(a,b) eβh − e−βh
eβh + e−βh . (8)
where α ∈ [0, 1], β ∈ (0, 1] are parameters which con-trol the contribution of shortest path length and depth,respectively. As β → ∞, the depth of a word in thesemantic nets is not considered. Their optimal valuesdepend on the knowledge base used and for WordNetthey are α = 0.2 and β = 0.45. For the proposedbenchmark dataset, the optimal values are α = 0.2 andβ = 0.6 (obtained experimentally). If the words aand b belong to the same synset then dist(a, b) = 0, ifthey do not belong to the same synset but the synsetsfor a and b contain one or more common words, thendist(a, b) = 1 and for the remaining cases the actualpath length between a and b is calculated. This mea-sure was introduced for purely theoretical purposes, asan improvement of the existing similarity measures.
3.3. Information content-based similarity measures
The measures seen above work on single knowl-edge structures and they do not need external sourcesfor similarity calculation. In this section we presentthe most important approach which uses an externalcorpus to compute the similarity. The foundationalwork on information content-based similarity is due toResnik [25,26]. His approach is based on the fact thatthe more abstract classes provide less information con-tent, whereas more concrete and detailed classes lowerdown in the hierarchy are more informative. The clos-est class that subsumes two compared classes, calleda most informative subsumer is the class which pro-vides the shared information for both, and measurestheir similarity. In order to calculate the informationcontent of a concept in a IS-A taxonomy, Resnik turnsto an external text corpus and calculates the probabilityof occurrence of the class in this corpus as its relative
frequency (each word in the text corpus is counted asan occurrence of each class that contains it.). The in-formation content of a class in a taxonomy is given bythe negative logarithm of the probability of occurrenceof the class in a text corpus as follows:
simR(a, b) = maxc∈S (a,b)[− log p(C)] (9)
where p(c) is the probability of encountering an in-stance of concept c, and S (a, b) is the set of all con-cepts that subsume a and b. According to Resnikthis approach performs better than hierarchy-based ap-proaches, based on human similarity judgements as abenchmark. He used this similarity measure to resolvethe problems of ambiguity in natural language.
3.4. Advantages and disadvantages ofhierarchy-based and information content-basedsimilarity measures - a discussion
Since they only depend on the underlying hierarchyof the domain ontology, the hierarchy-based similaritymeasures are fairly simple and require a low computa-tional cost. The known problem with hierarchy-basedsimilarity measures is that all the edges in the hierar-chy are considered to be of the same length, so manysimilarity values are not correct. The accuracy of thesemeasures have been surpassed by more complex ap-proaches which exploit additional semantic informa-tion.
The problem with Resnik’s similarity measure is theexcessive information content value of many polyse-mous words (i.e. word senses not taken into account)and multi-worded synsets. Also, the information con-tent values are not calculated for individual words butfor synsets, hence the synsets containing commonlyoccurring ambiguous words would have excessive in-formation content values. To deal with the problem ofexcessive information content value of many polyse-mous words, Resnik proposes weighted word similar-ity which takes into account all senses of the words be-ing compared.
The main problem with information content-basedsimilarity measures is their dependance on externalcorpora for the calculation of term frequencies. Thisrequires disambiguation and annotation of terms inthe corpus, very often done manually, hence affect-ing the applicability of this approach to large corpora.Also, with the change of corpora or the ontology, theterm frequencies have to be recalculated. One step to-wards mitigating this problem was the introduction of

6 Likavec et al. / How to improve Jaccard’s feature-based similarity measure
intrinsic computation of information content [30] aswe will see in Section 6. The methods based on in-trinsic information content outperform corpora-relyingapproaches.
In this work, we particularly focus on feature-basedand hierarchy-based similarity measures since theydo not require external knowledge sources for theirapplication, rather they rely solely on the domainontology. Feature-based similarity measures evaluateboth common and distinctive features of compared ob-jects, hence exploiting more semantic information thanhierarchy-based approaches. But this information hasto be available, which is not always the case. Otherwisethe applicability and accuracy of these measures is hin-dered. Feature-based similarity measures can also beapplied in cross-ontology settings.
4. Variations of Jaccard’s feature-based similaritymeasure
In this section we present the variations of Tver-sky’s, or more preciselly, Jaccard’s similarity measurefrom Section 3.1 which we evaluated in our experi-ments. We experimented with 6 basic modifications ofJaccard’s similarity (see Equation 2). For each of these7 measures, we present 2 further variations, which aimto take the underlying hierarchical structure into ac-count in different ways. We actually did the same cal-culations also with Dice’s measure (see Equation 3)but the results were almost always worse, so we willnot tackle Dice’s measure any further.
4.1. Basic modifications of Jaccard’s similaritymeasure
Our first assumption was that common features con-tribute to the similarity calculation in more substantialway than distinctive features. Hence, the first modifi-cation of Jaccard’s measure, called Common-squaredJaccard’s similarity, was to consider squares of onlythe values two objects have in common, giving moreimportance to common features. The following for-mula illustrates this measure:
simCS Q(O1,O2) =cf2(O1,O2)
df(O1) + df(O2) + cf2(O1,O2)
(10)
For comparison purposes, the second modificationof Jaccard’s measure, called Squared Jaccard’s sim-
ilarity, was to consider squares of all the values as inthe following formula:
simS Q(O1,O2) =cf2(O1,O2)
df2(O1) + df2(O2) + cf2(O1,O2)
(11)
We also tried the following two modifications:Normalised Jaccard’s similarity (Eq 12) and Nor-malised common-squared Jaccard’s similarity (Eq 13),given below:
simN(O1,O2) =
=
cf(O1,O2)(cf(O1,O2)+df(O1))(cf(O1,O2)+df(O2))
df(O1)cf(O1,O2)+df(O1) +
df(O2)cf(O1,O2)+df(O2) +
cf(O1,O2)(cf(O1,O2)+df(O1))(cf(O1,O2)+df(O2))
(12)
simNCS Q(O1,O2) =
=
cf2(O1,O2)(cf(O1,O2)+df(O1))(cf(O1,O2)+df(O2))
df(O1)cf(O1,O2)+df(O1) +
df(O2)cf(O1,O2)+df(O2) +
cf2(O1,O2)(cf(O1,O2)+df(O1))(cf(O1,O2)+df(O2))
(13)
The Normalised common-squared Jaccard’s similar-ity measure for ontological objects was first introducedin [6] and was further developed in [17] as a wayto calculate similarity between shapes and in [18] forimproving recommendation accuracy and diversity.
We also tried to converte Li’s similarity formula [16]into feature based formula. Since the similarity mea-sure increases with the increasing number of commonfeatures, common features can be taken as an argu-ment of the sigmoid function. Furthermore, the simi-larity values should decrease with the increasing num-ber of distinctive features, hence the distinctive fea-tures should be an argument of the negative sigmoidfunction translated by 1. So we obtained the followingfunction:
simS (O1,O2) =ecf(O1,O2) − 1ecf(O1,O2) + 1
(1 −edf(O1)+df(O2) − 1edf(O1)+df(O2) + 1
)
=2(ecf(O1,O2) − 1)
(ecf(O1,O2) + 1)(edf(O1)+df(O2) + 1)
(14)

Likavec et al. / How to improve Jaccard’s feature-based similarity measure 7
This result is similar to just taking the distinctivefeatures as an argument to inverse exponential func-tion since these two functions have similar graphs andbehaviour for arguments greater than 0. But the ex-ponential in the denominator increases very fast, sothe similarity values were getting extremely small veryquickly. Hence we decided to leave just the distinc-tive features in the denominator. Adding 1 prevents thecase of the division with zero when there are no dis-tinctive features among the compared objects. Also,we need to divide by 2 so that the final result is in theinterval [0, 1). So the final Sigmoid similarity has thefollowing formula:
simS (O1,O2) =ecf(O1,O2) − 1
(ecf(O1,O2) + 1)(df(O1) + df(O2) + 1)
(15)
Finally, the last measure which we considered wasthe sigmoid function of Jaccard’s similarity as follows:
simJS (O1,O2) =esimJ (O1,O2) − 1esimJ (O1,O2) + 1
(16)
We call this measure Sigmoid Jaccard’s similarity.
4.1.1. Mathematical propertiesIt is straightforward that the previously introduced
mathematical properties (boundaries, maximal simi-larity, commutativity and monotonicity) are preservedfor simCS Q, simS Q, simN and simNCS Q, since they aresimple modifications of the original simJ measure.
Let us first consider simJS measure since it is sim-pler than simS measure. The values of simJS belong to[0, e−1
e+1 ) since the values of the sigmoid function be-long to [0, 1), for positive arguments. Hence, its maxi-mum value is e−1
e+1 when simJ = 1. Sigmoid function isa monotone function so the monotonicity is preserved.Commutativity is straightforward.
As far as simS measure is concerned, its valuesbelong to [0, 1) and the maximal value is obtainedwhen the compared objects do not have any distinctivefeatures. Commutativity and monotonicity are againstraightforward.
Next, we will see how we tried to include the hier-archical information into these measures.
4.2. Feature-based similarity combined withhierarchical information
The basic question we wanted to answer with theseexperiments was how much the actual hierarchical in-
formation contributes to the similarity of two objectsand if this information can be simulated by proper-ties. Basically, the hierarchical information could beeither integrated into the measures by considering therdf:type property (basic measures) or it could be in-tegrated into the measures by excluding the rdf:typeproperty and including the hierarchical information insome different way. We also tried to see how includ-ing both would affect the performance. We decided todistinguish the following two variations of each of theabove described basic measures:V1: the measures without considering the propertyrdf:type but including the hierarchical informa-tion in the feature-based similarity formula. Inthis case, since the greater distance between twoobjects means that they are less similar, we de-cided that the distance between objects counts astheir distinctive feature. In the following formulasdist(O1,O2) is the number of edges along the pathconnecting O1 and O2 and max is the maximumdepth of the class hierarchy.
simJnth(O1,O2) =
=cf(O1,O2)
df(O1) + df(O2) + cf(O1,O2) +dist(O1,O2)
2max
(17)
simS Qnth(O1,O2) =
=cf2(O1,O2)
df2(O1) + df2(O2) + cf2(O1,O2) +dist2(O1,O2)
(2max)2
(18)
The equations for simCS Qnth, simNnth, simNCS Qnth
are analogous to the equations above. The onesthat are worth writing out explicitly are simS nth
and simJS nth.
simS nth(O1,O2) =
=2(ecf(O1,O2) − 1)
(ecf(O1,O2) + 1)(df(O1) + df(O2) + 1 +dist(O1,O2)
2max )
(19)
simJS (O1,O2) =esimJnth(O1,O2) − 1esimJnth(O1,O2) + 1
(20)

8 Likavec et al. / How to improve Jaccard’s feature-based similarity measure
V2: the original measures considering the propertyrdf:type and including the hierarchical infor-mation in the feature-based similarity formula.This approach counts the hierarchical informa-tion twice in a way but in two subtle ways. In-cluding the property rdf:type takes into ac-count all the objects which are of the samerecipe type, whereas including the hierarchi-cal information accounts for the distance be-tween the compared objects. These measures(simJh, simS Qh, simCS Qh, simNh, simNCS Qh, simS h
and simJS h) showed slightly better performanceresults with respect to the original measures, aswe will see in Section 5. But, in our opinion,the gained improvement does not justify the in-creased complexity and execution times of theproposed variants.
Let us illustrate our ideas with some simple ex-amples. In the recipe domain, all the recipes couldbe instances of the class Recipe or there could ex-ist an underlying hierarchy of recipe types and eachrecipe could be an instance of its corresponding recipetype. In our case, instead of having all the recipes in-stances of DishType, we made the recipes instancesof various dish types, such as BreadDish, CakeDish,PastaDish etc. This choice has the following conse-quences:
– instead of having the same values for the propertyrdf:type for all the dishes, we can distinguishthem according to various values for the propertyrdf:type;
– in case we want to take the hierarchical informa-tion into account, we can calculate the distancebetween various dishes, rather than assume thatthey all have the same similarity, since they allhave the same parent. Since we deal with the in-stances in the ontology, we decided to considerthem “descendants” of their classes, otherwise theinstances of one class would all be equal.
5. Evaluation
The most commonly used datasets to test similar-ity measures are the ones proposed by [28] and [20].Rubenstein and Goodenough’s experiment dates backto 1965. They asked 51 native English speakers to as-sess the similarity of 65 English noun pairs on a scalefrom 0 (semantically unrelated) to 4 (highly related).Miller and Charles’ experiment in 1991 considered asubset of 30 noun pairs and their similarity was re-
assessed by 38 undergraduate students. The correlationw.r.t Rubenstein and Goodenough results was 0.97.[26] repeated the same experiment in 1995 with 10subjects. The correlation w.r.t. Miller and Charles re-sults was 0.96. Finally, [22] repeated the experimentsin 2009 with 101 participants, both English and non-English native speakers. His average correlation w.r.t.Rubenstein and Goodenough was 0.97, and 0.95 w.r.t.Miller and Charles. We can see that similarity judge-ments by various groups of people over a long periodof time remain stable.
All the experiments cited above [28,20,26,22] weredealing with common English nouns and the correla-tion with these results was mostly used to test similar-ity measures on WordNet [11]. But our focus is differ-ent. We wanted to experiment with the similarity mea-sures on specific domain ontologies, which representsmore complex entities. We needed data representationwhere features of domain objects are explicitly pro-vided, which is not the case with WordNet.
Our experiment was conducted with the goal ofevaluating the feature-based similarity of instances inits various forms and its comparison with hierarchy-based approaches. In our first experiment we evalu-ated our approach in the domain of recipes using theslightly modified Wikitaaable dataset4 used in [7]. Inour second experiment we evaluated our approach inthe drinks domain using an ontology developed pre-viously by our research team. We assumed that bothdatasets represent information known by a wide rangeof people, without the need be an expert to assess thesimilarity of the proposed domain items. The datasetsused in our experiments are available here:http://www.di.unito.it/ lombardi/SimilarityTest/
5.1. Hypotheses
We wanted to verify that:H1: Jaccard’s feature-based similarity measure per-
forms better than hierarchy-based approaches;H2: it is possible to improve Jaccard’s feature-based
similarity;H3: hierarchical information is encoded better with
features than with underlying hierarchy;H4: combining the hierarchy and feature-based ap-
proach beyond linear combination further im-proves the Jaccard’s similarity measure and itsvariations.
4http://wikitaaable.loria.fr/rdf/

Likavec et al. / How to improve Jaccard’s feature-based similarity measure 9
5.2. Subjects
A total of 137 people (60 female and 77 male, av-erage age 30) took part in the first test and 147 (65female and 82 male, average age 32) took part in thesecond one.
They were selected among authors’ colleagues andamong the second and third year undergraduate stu-dents at the Faculty of Philosophy at the University ofTorino, Italy. The participants were recruited accord-ing to an availability sampling strategy.5 All the partic-ipants were native Italian speakers.
5.3. Materials
We designed two experiments to test our hypothe-ses.
In the first experiment, we designed a web ques-tionnaire with 25 pairs of recipes, chosen from Wik-itaaable dataset, covering a range of recipes expectedto be judged very similar to not similar at all. The orig-inal recipes from the dataset were translated to Ital-ian. The original dataset contains 1666 recipes. Theproperties defined for the recipes are the following:rdf:type, can_be_eaten_as, has_ingredient,suitable_for_diet, not_suitable_for_diet andhas_origin. This dataset provided us with a goodsetting to test our approach. We only made the fol-lowing slight modifications: in the original ontologyall the recipes were instances of Recipe, whereas weneeded to use the hierarchical structure of the ontologyto test hierarchy-based similarity measures, as well asincorporate the hierarchical information into our mea-sures, hence we made the recipes instances of variousDish_Type’s. In the original ontology rdf:type isa property, whereas in our case, we once used it as aproperty and once as an underlying hierarchical infor-mation. Figure 1 shows the basic Wikitaaable taxon-omy of recipes, but only including the top categoriesand the ones from which we used the instances to testour approach. The properties are omitted for clarity.
The main dish types are: RollDish, CrepeDish,BakedGoodDish, BeverageDish, SoupAndStuffDish,
5Although a more suitable way to obtain a representative sampleis random sampling, this strategy is time consuming and not finan-cially justifiable. Hence, much research is based on samples obtainedthrough non-random selection, such as the availability sampling, i.e.a sampling of convenience, based on subjects available to the re-searcher, often used when the population source is not completelydefined.
PancakeDish, MousseDish, SweetDish, SaladDish,SaltedDish, SauceDish, WaffleDish, PreserveDish,SpecialDietDish. The recipes we used in our eval-uation did not belong to all recipe groups, since thecomplexity of the test would have been too high andwe would have obtained random answers from theusers.
In the second experiment, we again used a webquestionnaire, this time containing 30 pairs of drinkschosen from the ontology describing drinks. Theoriginal ontology has 148 classes, with the maindrink classes being: Water, AlcoholicBeverage,DrinkInACup, PlantOriginDrink and SoftDrink.The properties defined for the drinks are the following:has_alcoholic_content, has_caloric_content,has_ ingredient, is_sparkling, is_suitable_forand rdf:type. Figure 2 shows the basic taxonomy ofdrinks, again only including the main categories andomitting the properties.
In each experiment the participants were asked toasses the similarity of these 25 pairs (respectively 30pairs) by anonymously assigning them a similarityvalue on the scale from 1 to 10 (1 meaning not similarat all, 10 meaning very similar). The ordering of pairswas random. The users’ similarity values were thenturned into the values from the [0, 1] interval to makethem match the similarity values produced by variousalgorithms.
In each experiment, the participant group P was di-vided into two groups: P1 was used as a referencegroup and P2 was used as a control group to measurethe correlation of judgments among human subjects,as in [25]. We experimented with different partitions ofP1 and P2 and obtained similar results.
In this paper we considered the following feature-based similarity measures:
1. Tversky’s similarity where α = β = γ = 1, alsoknown as Jaccard’s or Tanimoto similarity simJ;
2. Common-squared Jaccard’s similarity simCS Q;3. Squared Jaccard’s similarity simS Q;4. Normalized Jaccard’s similarity simN ;5. Normalized common-squared Jaccard’s similar-
ity simNCS Q;6. Sigmoid similarity simS ;7. Sigmoid Jaccard’s similarity simJS ;For the comparison, we considered the following
edge-based similarity measures:1. Leacock and Chodorow’s similarity simLC;2. Wu and Palmer’s similarity simWP;3. Li’s similarity simL.

10 Likavec et al. / How to improve Jaccard’s feature-based similarity measure
DISH TYPE
BAKED GOOD
BREAD
BISCUIT
SALTED
CAKE
CASSEROLE
CREPE
MOUSSE
PANCAKE
MEATPIE
ROLL
SALTED SAUCE
SEA FOOD
STEW
SAUCE
WAFFLE
SWEET
SOUP & STUFF
SOUP
RICE
PASTA
SALAD
FROZEN DESSERT
VEGETABLE
SPECIAL DIET DISH
PRESERVE
Fig. 1. Recipe taxonomy
Fig. 2. Drinks taxonomy
For each of the feature-based measures, we consid-ered the following variants:V1. the measure without the rdf:type property but
combined with underlying hierarchy (measuressimJnth, simS Qnth, simCS Qnth, simNnth, simNCS Qnth,simS nth, simJS nth);
V2. the measure with the rdf:type property com-bined with underlying hierarchy (measures simJh,simS Qh, simCS Qh, simNh, simNCS Qh, simS h, simJS h).
For all the feature-based measures we also tested theDice’s similarity, but in almost all the cases it showed
worse performance than Jaccard’s similarity, so wewill not report the results here.
5.4. Measures
We used the Spearman rank correlation coefficient ρto measure the accuracy of similarity judgement.
The Spearman rank correlation coefficient mea-sures statistical dependence between two ranked vari-ables. It actually describes the relationship betweentwo variables using a monotonic function. It is equalto the Pearson correlation between the ranked vari-ables. For a sample of size n, the two sets of values

Likavec et al. / How to improve Jaccard’s feature-based similarity measure 11
X = {x1, . . . , xn} and Y = {y1, . . . , yn} are converted toranks {r(x1), . . . , r(xn)} and {r(yi), . . . , r(yn)} and thenthe Pearson coefficient is calculated as follows:
ρ =Σn
i=1(r(xi) − r(x))(r(yi) − r(y))√Σn
i=1(r(xi) − r(x)2(r(yi) − r(y))2
where r(x) and r(y) are the sample means of the twosets of ranked values. The value of Spearman coeffi-cient ranges from +1 (indicating a strong similar rank)to −1 (indicating a strong dissimilar rank). Value 0means there is no correlation.
5.5. Implementation and performance
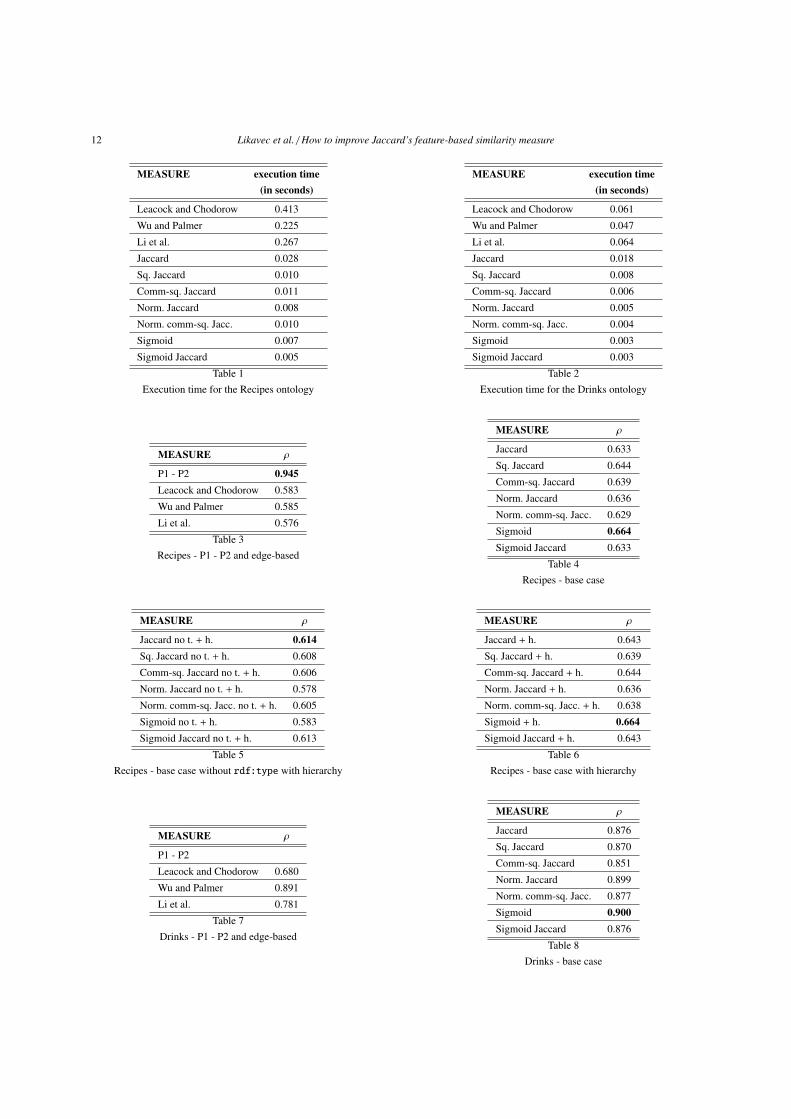
The test software to compare the different mea-sures has been developed in Java, using the ApacheJena library to extract data from the ontology. Thetest has been performed on a MacBook Pro with a2.66 GHz Intel Core i7 processor and 8 GB 1067MHz DDR3 RAM. Tables 1 and 2 show the execu-tion time for the different measures obtained in theRecipes and the Drinks experiments, respectively. Inboth cases, feature-based approaches significantly out-perform hierarchy-based ones. A possible explanationfor this could be that hierarchy-based approaches needto traverse the hierarchy to calculate the distance be-tween two nodes, while feature-based ones simplyneed to extract properties and their values for the twonodes.
5.6. Results and discussion
For the first experiment (Recipes) Table 3 reportsthe Spearman rank correlation between the referencegroup P1 and control group P2, as well as the Spear-man rank correlation between the participant group Pand the hierarchy-based approaches. Tables 4, 5, 6 re-port the Spearman rank correlation between each ofthe above measures and the participant group P for thebase case and for the 2 variations introduced in Sec-tion 4. The best performing measure in each group isreported in bold.
For the second experiment (Drinks) Table 7 reportsthe Spearman rank correlation between the referencegroup P1 and control group P2, as well as the Spear-man rank correlation between the participant group Pand the hierarchy-based approaches. Tables 8, 9, 10 re-port the Spearman rank correlation between each ofthe above measures and the participant group P for the
base case and for the 2 variations introduced in Sec-tion 4.
5.6.1. Participants group and the hierarchy-basedapproaches
The correlation for both experiments with the hu-man subjects, i.e. the comparison of the two groups ofparticipants (row P1-P2), is 0.945 (respectively 0.977)and similar to the one reported in [25]. From this goodcorrelation we can conclude that the participants’ re-sponses were coherent among themselves in both ex-periments and that we can trust the human ratings.
Furthermore, w.r.t. the correlation of participantsgroup with hierarchy-based approaches we can see thatin the first experiment (Recipes) with hierarchy-basedapproaches we obtained similar results for all threemeasures (the best one being Wu and Palmer’s mea-sure) and they all have a relatively weak positive cor-relation with the human judgement. In the second ex-periment (Drinks) the performance is better (the bestone again being Wu and Palmer’s measure).
This can be explained with the fact that the under-lying hierarchy in the ontology of drinks is designedmirroring better the human categorisation than the on-tology of recipes (which was indeed flat at the begin-ning and we performed only minimal changes to ob-tain the main categories of recipes). But it also showshow dependant the measure is on the ontology design.
5.6.2. Base case group of feature-based similaritiesand the comparison with hierarchy-basedapproaches
The first group of feature-based similarity measurescontains the original Jaccard’s similarity measure simJ
and the six basic modifications proposed in Section 4(simCS Q, simS Q simN , simNCS Q, simS and simJS ).
Tables 4 and 8 show the results for the base case forall 7 similarity measures in both experiments, wherethe property rdf:type was included in the calcula-tions and no further hierarchical information was takeninto account.
Looking at the Tables 4 and 8 we can see that in eachexperiment there are a few measures which improvethe basic Jaccard’s similarity simJ . But the one that isconsistently better is Sigmoid similarity simS .
Hence, we confirmed our hypothesis H2 that it ispossible to improve the original Jaccard’s formulationof similarity measure by using the Sigmoid similaritymeasure simS .
Furthermore, in the first experiment (Recipes) allthe feature-based measures in Table 4 perform betterthan the hierarchy-based measures from Table 3. In
12 Likavec et al. / How to improve Jaccard’s feature-based similarity measure
MEASURE execution time(in seconds)
Leacock and Chodorow 0.413
Wu and Palmer 0.225
Li et al. 0.267
Jaccard 0.028
Sq. Jaccard 0.010
Comm-sq. Jaccard 0.011
Norm. Jaccard 0.008
Norm. comm-sq. Jacc. 0.010
Sigmoid 0.007
Sigmoid Jaccard 0.005
Table 1Execution time for the Recipes ontology
MEASURE execution time(in seconds)
Leacock and Chodorow 0.061
Wu and Palmer 0.047
Li et al. 0.064
Jaccard 0.018
Sq. Jaccard 0.008
Comm-sq. Jaccard 0.006
Norm. Jaccard 0.005
Norm. comm-sq. Jacc. 0.004
Sigmoid 0.003
Sigmoid Jaccard 0.003
Table 2Execution time for the Drinks ontology
MEASURE ρ
P1 - P2 0.945Leacock and Chodorow 0.583
Wu and Palmer 0.585
Li et al. 0.576
Table 3Recipes - P1 - P2 and edge-based
MEASURE ρ
Jaccard 0.633
Sq. Jaccard 0.644
Comm-sq. Jaccard 0.639
Norm. Jaccard 0.636
Norm. comm-sq. Jacc. 0.629
Sigmoid 0.664Sigmoid Jaccard 0.633
Table 4Recipes - base case
MEASURE ρ
Jaccard no t. + h. 0.614Sq. Jaccard no t. + h. 0.608
Comm-sq. Jaccard no t. + h. 0.606
Norm. Jaccard no t. + h. 0.578
Norm. comm-sq. Jacc. no t. + h. 0.605
Sigmoid no t. + h. 0.583
Sigmoid Jaccard no t. + h. 0.613
Table 5Recipes - base case without rdf:type with hierarchy
MEASURE ρ
Jaccard + h. 0.643
Sq. Jaccard + h. 0.639
Comm-sq. Jaccard + h. 0.644
Norm. Jaccard + h. 0.636
Norm. comm-sq. Jacc. + h. 0.638
Sigmoid + h. 0.664Sigmoid Jaccard + h. 0.643
Table 6Recipes - base case with hierarchy
MEASURE ρ
P1 - P2
Leacock and Chodorow 0.680
Wu and Palmer 0.891
Li et al. 0.781
Table 7Drinks - P1 - P2 and edge-based
MEASURE ρ
Jaccard 0.876
Sq. Jaccard 0.870
Comm-sq. Jaccard 0.851
Norm. Jaccard 0.899
Norm. comm-sq. Jacc. 0.877
Sigmoid 0.900Sigmoid Jaccard 0.876
Table 8Drinks - base case

Likavec et al. / How to improve Jaccard’s feature-based similarity measure 13
MEASURE ρ
Jaccard no t. + h. 0.888
Sq. Jaccard no t. + h. 0.882
Comm-sq. Jaccard no t. + h. 0.868
Norm. Jaccard no t. + h. 0.889
Norm. comm-sq. Jacc. no t. + h. 0.898
Sigmoid no t. + h. 0.900Sigmoid Jaccard no t. + h. 0.888
Table 9Drinks - base case without rdf:type with hierarchy
MEASURE ρ
Jaccard + h. 0.861
Sq. Jaccard + h. 0.861
Comm-sq. Jaccard + h. 0.839
Norm. Jaccard + h. 0.889
Norm. comm-sq. Jacc. + h. 0.877
Sigmoid + h. 0.900Sigmoid Jaccard + h. 0.861
Table 10Drinks - base case with hierarchy
the second experiment (Drinks) all the feature-basedmeasures in Table 8 perform better than Leacock andChodorow’s measure and Li et al.’s measure and simN
and simS perform better even than Wu and Palmer’smeasure.
This shows that we can obtain better similarity re-sults by considering properties for instances in an on-tology, rather than hierarchy underlying the ontology.This confirms our hypothesis H1 that the feature-basedsimilarity shows better performance than hierarchy-based approaches. Often, other proposed methods inthe literature do not surpass Li’s measure, even whenthey surpass other hierarchy-based methods. On bothof our datasets, the best performing hierarchy-basedsimilarity measure is Wu and Palmer’s measure. Butall feature-based measures in the first experiment andsome of the measures in the second experiment surpassWu and Palmer’s measure and all surpass the other twohierarchy-based measures. This means that propertiesplay more important role than the underlying hierarchywhen describing ontological instances and their mutualsimilarity.
5.6.3. Substituting rdf:type with hierarchicalinformation
Tables 5 and 9 show the results for the 7 simi-larity measures in both experiments, where the prop-erty rdf:type was excluded from the calculationsand where we tried to simulate this information withhierarchical information. We tried to incorporate thehierarchy-based similarity by including the normaliseddistance between concepts (calculated as dist
2 max ) in thefeature-based formulae as a part of distinctive features.
In the first experiment (Recipes), better results areobtained by the simple base measure, hence by us-ing rdf:type instead of hierarchical information (Ta-ble 4), whereas in the second experiment (Drinks) re-sults are mostly better with the hierarchical informa-tion but without rdf:type (Table 9. But even in this
case, the Sigmoid measure simS nth performs better inbase case, showing consistent improvement.
But we cannot confirm our hypothesis H3 that hi-erarchical information is encoded better with featuresthan with underlying hierarchy, even though in the caseof best performing Sigmoid measure simS nth it is.
5.6.4. Including both, rdf:type and hierarchicalinformation
Finally, we wanted to combine hierarchical informa-tion with features to see if the similarity values couldbe improved. Just a linear combination of feature-based similarity and hierarchy-based similarity wouldnot yield better results, since hierarchy-based similar-ity would just decrease the correlation. Hence, we in-cluded the hierarchy information as in the above. Theresults are reported in Table 6 and Table 10.
In the first experiment (Recipes) we obtained smallimprovements for some basic measures, whereas in thesecond experiment (Drinks) only the Sigmoid measuresimS h brings very small improvement.
Hence, w.r.t. the hypothesis H4 we can conclude thatcombining the hierarchy and feature-based approachbeyond linear combination provides good correlationwith human judgement but sometimes better results areobtained without incorporating the underlying hierar-chy.
5.6.5. Concluding considerationsWe can see that in both domains, the consistently
best performing measure is the Sigmoid similaritysimS . In the domain of Recipes we obtained the im-provement of 4.9% for the base case, whereas in thedomain of Drinks we obtained the improvement of2.74% for the base case.
In both cases very small additional improvement isobtained by considering the underlying hierarchy to-gether with rdf:type. Hence, there is little benefit inadding this additional information to the basic similar-ity measures.

14 Likavec et al. / How to improve Jaccard’s feature-based similarity measure
Also, in both cases, there is an improvement w.r.t.the best hierarchy-based measure (Wu and Palmer):13.5% in the case of Recipes and 1.01% in thecase of Drinks. This again shows how dependant thehierarchy-based similarity measures are on the designof the underlying conceptual hierarchy.
We can see that even with relatively small number ofproperties defined for the concepts in the ontology, thefeature-based similarity outperforms hierarchy-basedapproaches. Of course, the number of defined proper-ties plays an important role in semantic similarity cal-culation.
The dataset used also plays an important role inthe similarity calculations. To the best of our knowl-edge, the datasets used in this work include signifi-cantly higher number of participants than many worksin the field. Usually, the similarity measures are testedon Wordnet [11], but we are providing the communitywith yet another rich dataset to experiment with.
We summarise here our main findings as the re-sponses to our hypotheses.H1: Jaccard’s feature-based similarity measure per-
forms better than hierarchy-based approaches;H2: it is possible to improve Jaccard’s feature-based
similarity. We propose Sigmoid similarity mea-sure as the improvement of the original Jaccard’smeasure which brings the improvement of 4.9%in the domain of recipes and of 2.74% in the do-main of drinks;
H3: we cannot say if the hierarchical information isencoded better with features than with underlyinghierarchy;
H4: combining the hierarchy and feature-based ap-proach beyond linear combination further im-proves the Jaccard’s similarity measure and itsvariations but to a very small degree, hence it isquestionable if these modifications are worth im-plementing.
5.7. Comparison with the performance on WordNet
Since most of the similarity measures in the liter-ature have been tested on WordNet, we include herethe comparison of our results with the correspondingresults provided in [29]. We include only the resultsfor Miller and Charles’ dataset [20], since the ones for[28] are not always available.
We can see that the hierarchy-based measures (Lea-cock and Chodorow, Wu and Palmer and Li et al.) per-form better on WordNet than on Wikitaaable datasetbut the performance is similar to the Drinks dataset.
This is due to the hierarchical structure of Wikitaaableand Drinks datasets. The hierarchy in Wikitaaable israther shallow, hence the information obtained fromthe underlying conceptual hierarchy is not so rich. Onthe other hand, the Drinks ontology has a deeper un-derlying hierarchy and provides more precise informa-tion. We can see that Tversky’s similarity measure per-forms better on Wikitaaable and Drinks datasets, sincethere are more properties defined for the concepts. Weinclude also the results for Tversky + hierarchy, Sig-moid Tversky + hierarchy, Norm. com. sq. Tversky,Norm. com. sq. Tversky + hierarchy (with type) andNorm. com. sq. Tversky + hierarchy (no type) whichperform even better than simple Tversky’s measure onWikitaaable and Drinks datasets.
6. Related work
In this section we give a brief summary of otherworks which deal with feature-based similarity. Theseapproaches calculate feature-based similarity in dif-ferent ways, starting from Tversky’s similarity mea-sure but taking into account different aspects w.r.t. us(antescendant classes, descendant classes etc., whereaswe compare property-value pairs). We include theseworks here to have a more complete picture of feature-based similarity measures. We did not test these mea-sures since the scope of our work was to evaluate theperformance of Tversky’s similarity measure and itsvariations calculating them from property-value pairsfor compared objects. The same variations of Tver-sky’s measure could be applied to other feature-basedsimilarity measures as well. Also, some of these mea-sures are not applicable in our context. For example,we cannot calculate the number of descendant classessince we deal with instances in the ontology.
An interesting approach to feature-based similaritycalculation is given in [22] and [23]. Both workstranslate the feature-based model into information con-tent (IC) model, with a slightly different formulation ofTversky’s formula where Tversky’s function describ-ing the saliency of the features is substituted by theinformation content of the concepts. In [22] IntrinsicInformation Content iIC, introduced in [30], is usedtaking into account the number of subconcepts of aconcept and a total number of concepts in a domain.In [23] Extended Information Content EIC is used in-stead of iIC where iIC is combined with EIC as a av-erage iIC for all the concepts connected to a certainconcept with different relations. Both approaches use

Likavec et al. / How to improve Jaccard’s feature-based similarity measure 15
MEASURE WordNet Wikitaaable Drinks
Leacock and Chodorow 0.74 0.583 0.680
Wu and Palmer 0.74 0.585 0.891
Li et al. 0.82 0.576 0.781
Tversky/Jaccard 0.73 0.633 0.875
Tversky + hierarchy N/A 0.643 0.861
Sigmoid N/A 0.664 0.900
Sigmoid + hierarchy (no type) N/A 0.583 0.900
Sigmoid + hierarchy (with type) N/A 0.664 0,900Table 11
Comparison with WordNet
the underlying ontology structure directly, where allthe defined semantic relations are used, rather than re-lying on an external corpus. Their new similarity mea-sure called FaITH is based on this novel framework.Also, this new IC calculation can be used to rewritethe existing similarity measures in order to calculaterelatedness, in addition to similarity.
An important work on feature-based similarity re-garding ontological concepts is described by [34].They start from Tversky’s assumption that similarity isdetermined by common and distinctive features of thecompared objects and consider the relations betweenconcepts as their features. They linearly combine twosimilarities. The first similarity is obtained from directconnections between two objects, as well as commonfeatures shared between both concepts (in this case thesimilarity between relations is calculated using Wu andPalmer’s measure [33]). The second similarity is basedon distinctive features of each object. Their approachcan be used to calculate similarity at the class level,as well as the similarity of instances. Furthermore, itis possible to take into account only specific relationswhich leads to context-aware similarity. The problemis that the proposed method is assessed only on 4 pairsof concepts.
[29] also introduce a new feature-based approachfor calculating ontology-based semantic similaritybased on taxonomical features. They evaluate the se-mantic distance between concepts by considering asfeatures the set of concepts that subsume each of them.Practically, the degree of disjunction between theirfeature sets (non-common subsumers) model the dis-tance between concepts, whereas the degree of over-lap (common subsumers) models their similarity. Theproblem with this approach is that If the input ontologyis not deep enough or built with enough taxonomicaldetails or it does not consider multiple inheritance, theknowledge needed for similarity calculation might be
scarse. The authors also provide a detailed survey ofmost of the ontology-based approaches and comparetheir performance on WordNet 2.0. From this analysisthey draw important conclusions about the advantagesand limitations of these approaches and give directionson their possible usage. A slightly different version ofthis measure was used by [2] on SNOMED CT ontol-ogy to evaluate the similarity of medical terms.
[27] and [21] propose similar measures for calcu-lating semantic similarity based on matching of theirsynonym sets, semantic neighbourhoods (semantic re-lations among classes) and features which are classi-fied into parts, functions and attributes. This enablesseparate treatment of these particular class descriptionsand introduction of specific weights which would re-flect their importance in different contexts. In [27]these similarities are calculated using Tversky’s for-mula, where parameters in the denominator are cal-culated taking into account the depth of the hierar-chies of different ontologies. Synonym sets and seman-tic neighbourhoods are useful when detecting equiv-alent or most similar classes across ontologies. Fea-tures are useful when detecting similar but not equiv-alent classes. [21] eliminate the need for the param-eters in the denominator in Tversky’s formula, hencethey do not rely on the depth of the corresponding on-tologies. This leads to matching based only on com-mon words for synset similarity calculation. Also, setsimilarities are calculated per relationship type. Finaly,their similarity does not have weights for different sim-ilarity components. The novelty of their work is the ap-plication of this and various other similarity measuresto MeSH ontology (Medical Subject Headings). Bothmethods can be used for cross-ontology similarity cal-culation.
A semantic similarity measure for OWL objects in-troduced by [13] is based on Lin’s information theo-retic similarity measure [19]. They compare semantic

16 Likavec et al. / How to improve Jaccard’s feature-based similarity measure
description of two services and define their semanticsimilarity as a ratio between the shared and total in-formation of the two objects. The semantic descriptionof an object is defined using its description sets whichcontain all the statements (triples) describing the givenobject and their information content is based on their“inferencibility”, i.e. the number of new RDF state-ments that can be generated by applying a certain setof inference rules to the predicate. They use their mea-sure to determine the similarity of semantic servicesannotated with OWL ontologies.
Similarity can find many applications is Recom-mender Systems. [9] developed a content-based movierecommender system based on Linked Open Data(LOD) in which they adapt a vector space model(VSM) approach to compute similarities between RDFresources. Their assumption is that two movies aresimilar if they have features in common. The wholeRDF graph is represented as a 3-dimensional matrixwhere each slice refers to one property in the ontol-ogy and for each property the similarity between twomovies is calculated using their cosine similarity.
Similarity among concepts can be also automati-cally learned. Similarity learning is an area of super-vised machine learning, closely related to regressionand classification, where the goal is to learn from ex-amples a similarity function that measures how similaror related two objects are. Similarity learning is usedin information retrieval to rank items, in face identifi-cation and in recommender systems. Moreover, manymachine learning approaches rely on some similaritymetric. This includes unsupervised learning such asclustering, which groups together close or similar ob-jects, or supervised approaches like K-nearest neigh-bour algorithm. Metric learning has been proposed asa preprocessing step for many of these approaches.
Automatic learning of similarity among conceptsin an ontology is used especially for ontology map-ping (also known as ontology alignment, or ontologymatching) [10], the process of determining correspon-dence between ontology concepts. This is necessaryfor integrating heterogeneous databases, developed in-dependently with their own data vocabulary or differ-ent domain ontologies.
There are several works which have exploited MLtechniques towards ontology alignment. [14] organ-ised the ontology mapping problem into a standard ma-chine learning framework, exploiting multiple conceptsimilarity measures (i.e, synset-based, Wu and Palmer,description-based, Lin). In [8] a multi-strategy learn-ing was used to obtain similar instances of hierarchies
to extract similar concepts using Naïve Bayes (NB)technique. In [1], following a parameter optimisationprocess on SVM, DT and neural networks (NN) clas-sifiers, an initial alignment was carried out. Then theuser’s feedback was used to improve the overall perfor-mance. All these works considered concepts belong-ing to different ontologies while we concentrated onconcepts in a same ontology.
7. Conclusions and future work
In this work we present some modifications of Jac-card’s feature-based similarity measure based on prop-erties defined in an ontology and their comparisonwith hierarchy-based approaches. We also propose animprovement of Jaccard’s similarity measure, namelySigmoid similarity measure simS .
We further proposed two variations of all the feature-based measures, to see how much the underlying hi-erarchical information contributes to accurate simi-larity measurement. We came to the conclusion thatthe underlying hierarchical information does providesome additional information when calculating similar-ity. However, the improved performance is very small,so it might not be worth adding the complexity to thesimilarity calculation.
In addition to Jaccard’s similarity measure, wetested 6 modifications of this measure and for eachof these measures additional 2 variations on slightlymodified Wikitaaable dataset in the domain of recipesand on Drinks ontology designed by our researcherspreviously. Our first evaluation included 137 subjectsand 25 pairs of concepts and our second evaluation in-cluded 147 subjects and 30 pairs of concepts. This isa significant number of real evaluators compared withother evaluations in the literature.
Our main finding is that the original Jaccard’s sim-ilarity measure could be improved by using Sigmoidsimilarity.
As a future work, it would be interesting to seehow the similarity measures would perform in thepresence of more properties or on a different dataset.MeSH and SNOWMED are some possible candi-date datasets, although in these cases expert opin-ion would be needed. Also, it would be interestingto add hierarchical structure among property values.For example, in the present approach we considerFusilli and Spaghetti two different domain items(hence, two different property values). But Fusilliand Spaghetti are both descendants of Pasta so they

Likavec et al. / How to improve Jaccard’s feature-based similarity measure 17
could be considered as “almost” the same values forproperties.
Moreover, in this work we only consider object typeproperties. Taking data type properties, such as liter-als, into account might be an interesting area for fu-ture investigation. In this case, it would be necessaryto determine when two literal values can be consideredequal.
In addition, similar experiments can be applied tolinked open data [4] or any other data structure wherethe objects are described by means of their properties.
References
[1] B. Bagheri Hariri, H. Abolhassani, and H. Sayyadi. A neural-networks-based approach for ontology alignment. In SCIS &ISIS, volume 2006, pages 1248–1252, 2006.
[2] M. Batet, D. Sánchez, and A. Valls. An ontology-based mea-sure to compute semantic similarity in biomedicine. Journal ofBiomedical Informatics, 44(1):118–125, 2011.
[3] G. Beydoun, A. A. Lopez-Lorca, F. García-Sánchez, andR. Martínez-Béjar. How do we measure and improve the qual-ity of a hierarchical ontology? Journal of System Software,84(12):2363–2373, 2011.
[4] C. Bizer, T. Heath, and T. Berners-Lee. Linked Data - TheStory So Far. International Journal on Semantic Web and In-formation Systems, 5(3):1–22, 2009.
[5] A. Budanitsky and G. Hirst. Evaluating WordNet-based Mea-sures of Lexical Semantic Relatedness. Computational Lin-guistics, 32(1):13–47, 2006.
[6] F. Cena, S. Likavec, and F. Osborne. Property-based interestpropagation in ontology-based user model. In 20th Conferenceon User Modeling, Adaptation, and Personalization, UMAP2012, volume 7379 of LNCS, pages 38–50. Springer, 2012.
[7] A. Cordier, V. Dufour-Lussier, J. Lieber, E. Nauer, F. Badra,J. Cojan, E. Gaillard, L. Infante-Blanco, P. Molli, A. Napoli,and H. Skaf-Molli. Taaable: A case-based system for personal-ized cooking. In S. Montani and L. C. Jain, editors, SuccessfulCase-based Reasoning Applications-2, volume 494 of Studiesin Computational Intelligence, pages 121–162. Springer BerlinHeidelberg, 2014.
[8] J. David. Association rule ontology matching approach. In-ternational Journal on Semantic Web and Information Systems(IJSWIS), 3(2):27–49, 2007.
[9] T. Di Noia, R. Mirizzi, V. C. Ostuni, D. Romito, and M. Zanker.Linked open data to support content-based recommender sys-tems. In 8th International Conference on Semantic Systems,I-SEMANTICS ’12, pages 1–8. ACM, 2012.
[10] J. Euzenat and P. Shvaiko. Ontology Matching. Springer-Verlag New York, Inc., Secaucus, NJ, USA, 2007.
[11] C. Fellbaum, editor. WordNet: An Electronic Lexical Database.MIT Press, 1998.
[12] T. R. Gruber. A translation approach to portable ontology spec-ifications. Knowledge Acquisition Journal, 5(2):199–220, June1993.
[13] J. Hau, W. Lee, and J. Darlington. A semantic similarity mea-sure for semantic web services. In Web Service SemanticsWorkshop at WWW (2005, 2005.
[14] R. Ichise. Machine learning approach for ontology mappingusing multiple concept similarity measures. In Computer andInformation Science, 2008. ICIS 08. Seventh IEEE/ACIS Inter-national Conference on, pages 340–346. IEEE, 2008.
[15] C. Leacock and M. Chodorow. Combining local context andWordNet similarity for word sense identification, pages 305–332. In C. Fellbaum (Ed.), MIT Press, 1998.
[16] Y. Li, D. McLean, Z. Bandar, J. O’Shea, and K. A. Crockett.Sentence similarity based on semantic nets and corpus statis-tics. IEEE Transactions on Knowledge and Data Engineering,18(8):1138–1150, 2006.
[17] S. Likavec. Shapes as property restrictions and property-basedsimilarity. In O. Kutz, M. Bhatt, S. Borgo, and P. Santos,editors, 2nd Interdisciplinary Workshop The Shape of Things,volume 1007 of CEUR Workshop Proceedings, pages 95–105.CEUR-WS.org, 2013.
[18] S. Likavec, F. Osborne, and F. Cena. Property-based semanticsimilarity and relatedness for improving recommendation ac-curacy and diversity. International Journal on Semantic Weband Information Systems, 11(4):1–40, 2015.
[19] D. Lin. An information-theoretic definition of similarity. In15th International Conference on Machine Learning ICML’98, pages 296–304. Morgan Kaufmann Publishers Inc., 1998.
[20] G. A. Miller and W. G. Charles. Contextual correlates of se-mantic similarity. Language&Cognitive Processes, 6(1):1–28,1991.
[21] E. G. M. Petrakis, G. Varelas, A. Hliaoutakis, andP. Raftopoulou. X-similarity: Computing semantic similaritybetween concepts from different ontologies. Journal of DigitalInformation Management, 4(4):233–237, 2006.
[22] G. Pirró. A semantic similarity metric combining features andintrinsic information content. Data and Knowledge Engineer-ing, 68:1289–1308, 2009.
[23] G. Pirrò and J. Euzenat. A feature and information theoreticframework for semantic similarity and relatedness. In 9th In-ternational Semantic Web Conference, ISWC ’10, volume 6496of LNCS, pages 615–630. Springer, 2010.
[24] R. Rada, H. Mili, E. Bicknell, and M. Blettner. Developmentand application of a metric on semantic nets. IEEE Trans. onSystems Management and Cybernetics, 19(1):17–30, 1989.
[25] P. Resnik. Using information content to evaluate semantic sim-ilarity in a taxonomy. In 14th International Joint Conferenceon Artificial Intelligence, pages 448–453, 1995.
[26] P. Resnik. Semantic similarity in a taxonomy: An information-based measure and its application to problems of ambiguity innatural language. Journal of Artificial Intelligence Research,11:95–130, 1999.
[27] M. A. Rodriguez and M. J. Egenhofer. Determining semanticsimilarity among entity classes from different ontologies. IEEETransactions on Knowledge and Data Engineering, 2000.
[28] H. Rubenstein and J. B. Goodenough. Contextual correlatesof synonymy. Communications of the ACM, 8(10):627–633,1965.
[29] D. Sánchez, M. Batet, D. Isern, and A. Valls. Ontology-basedsemantic similarity: A new feature-based approach. ExpertSystems with Applications, 39(9):7718–7728, 2012.
[30] N. Seco, T. Veale, and J. Hayes. An intrinsic information con-tent metric for semantic similarity in wordnet. In R. L. de Mán-taras and L. Saitta, editors, 16th Eureopean Conference onArtificial Intelligence, ECAI ’04, including Prestigious Appli-cants of Intelligent Systems, PAIS ’04, pages 1089–1090. IOS

18 Likavec et al. / How to improve Jaccard’s feature-based similarity measure
Press, 2004.[31] A. Tversky. Features of similarity. Psychological Review,
84(4):327–352, 1977.[32] C. A. Welty and N. Guarino. Supporting ontological analy-
sis of taxonomic relationships. Data Knowledge Engeneering,39(1):51–74, 2001.
[33] Z. Wu and M. Palmer. Verbs semantics and lexical selection. In32nd Annual Meeting on Association for Computational Lin-
guistics, pages 133–138. Association for Computational Lin-guistics, 1994.
[34] P. D. H. Zadeh and M. Reformat. Assessment of semantic sim-ilarity of concepts defined in ontology. Information Sciences,250:21–39, 2013.