semantic search spring 2007 computer engineering department sharif university of technology
TRANSCRIPT

Semantic Search
Spring 2007
Computer Engineering Department
Sharif University of Technology

Semantic web - Computer Engineering Dept. - Spring 20072
Outline
• Traditional search concepts• Semantic Search

Semantic web - Computer Engineering Dept. - Spring 20073
Traditional search
• Originated from Information Retrieval research• Enhanced for the Web
– Crawling and indexing– Web specific ranking
• An information need is represented by a set of keywords– Very simple interface– Users does not have to be experts
• Similarity of each document in the collection with the query is estimated
• A ranking is applied on the results to sort out the results and show them to the users

Semantic web - Computer Engineering Dept. - Spring 20074
Representation of documents
structure
Accentsspacing stopwords
Noungroups stemming
Manual indexingDocs
structure Full text
Index terms

Semantic web - Computer Engineering Dept. - Spring 20075
Retrieval process
UserInterface
Text Operations
Query Operations Indexing
Searching
Ranking
Index
Text
query
user need
user feedback
ranked docs
retrieved docs
logical viewlogical view
inverted file
DB Manager Module
Text Database
Text

Semantic web - Computer Engineering Dept. - Spring 20076
Indexing
Tokenizer
Token stream. Friends Romans Countrymen
Linguistic modules
Modified tokens. friend roman countryman
Indexer
Inverted index.
friend
roman
countryman
2 4
2
13 16
1
Documents tobe indexed.
Friends, Romans, countrymen.

Semantic web - Computer Engineering Dept. - Spring 20077
Retrieval models
• A retrieval model specifies how the similarity of a document to a query is estimated.
• Three basic retrieval models:– Boolean model– Vector model– Probabilistic model

Semantic web - Computer Engineering Dept. - Spring 20078
Boolean model
• Query is specified using logical operators: AND, OR and NOT
• Merge of the posting lists is the basic operation• Consider processing the query:
Brutus AND Caesar– Locate Brutus in the Dictionary;
• Retrieve its postings.– Locate Caesar in the Dictionary;
• Retrieve its postings.– “Merge” the two postings:
128
34
2 4 8 16 32 64
1 2 3 5 8 13
21
Brutus
Caesar

Semantic web - Computer Engineering Dept. - Spring 20079
Boolean queries: Exact match
• The Boolean Retrieval model is being able to ask a query that is a Boolean expression:– Boolean Queries are queries using AND, OR and
NOT to join query terms• Views each document as a set of words
• Is precise: document matches condition or not.
• Primary commercial retrieval tool for 3 decades.
• Professional searchers (e.g., lawyers) still like Boolean queries:– You know exactly what you’re getting.

Semantic web - Computer Engineering Dept. - Spring 200710
Example: WestLaw http://www.westlaw.com/
• Largest commercial (paying subscribers) legal search service (started 1975; ranking added 1992)
• Tens of terabytes of data; 700,000 users• Majority of users still use boolean queries• Example query:
– What is the statute of limitations in cases involving the federal tort claims act?
– LIMIT! /3 STATUTE ACTION /S FEDERAL /2 TORT /3 CLAIM
• /3 = within 3 words, /S = in same sentence

Semantic web - Computer Engineering Dept. - Spring 200711
Ranking search results
• Boolean queries give inclusion or exclusion of docs.
• Often we want to rank/group results– Need to measure proximity from query to each doc.– Need to decide whether docs presented to user are
singletons, or a group of docs covering various aspects of the query.

Semantic web - Computer Engineering Dept. - Spring 200712
Spell correction
• Two principal uses– Correcting document(s) being indexed
– Retrieve matching documents when query contains a spelling error
• Two main flavors:– Isolated word
• Check each word on its own for misspelling• Will not catch typos resulting in correctly spelled words e.g., from
form
– Context-sensitive• Look at surrounding words, e.g., I flew form Heathrow to Narita.

Semantic web - Computer Engineering Dept. - Spring 200713
Isolated word correction
• Fundamental premise – there is a lexicon from which the correct spellings come
• Two basic choices for this– A standard lexicon such as
• Webster’s English Dictionary
• An “industry-specific” lexicon – hand-maintained
– The lexicon of the indexed corpus• E.g., all words on the web
• All names, acronyms etc.
• (Including the mis-spellings)

Semantic web - Computer Engineering Dept. - Spring 200714
Isolated word correction
• Given a lexicon and a character sequence Q, return the words in the lexicon closest to Q
• What’s “closest”?
• We have several alternatives– Edit distance– Weighted edit distance– n-gram overlap

Semantic web - Computer Engineering Dept. - Spring 200715
Edit distance
• Given two strings S1 and S2, the minimum number of basic operations to covert one to the other
• Basic operations are typically character-level– Insert– Delete– Replace
• E.g., the edit distance from cat to dog is 3.
• Generally found by dynamic programming.

Semantic web - Computer Engineering Dept. - Spring 200716
n-gram overlap
• Enumerate all the n-grams in the query string as well as in the lexicon
• Use the n-gram index (recall wild-card search) to retrieve all lexicon terms matching any of the query n-grams
• Threshold by number of matching n-grams

Semantic web - Computer Engineering Dept. - Spring 200717
Example with trigrams
• Suppose the text is november– Trigrams are nov, ove, vem, emb, mbe, ber.
• The query is december– Trigrams are dec, ece, cem, emb, mbe, ber.
• So 3 trigrams overlap (of 6 in each term)
• How can we turn this into a normalized measure of overlap?

Semantic web - Computer Engineering Dept. - Spring 200718
One option – Jaccard coefficient
• A commonly-used measure of overlap
• Let X and Y be two sets; then the J.C. is
• Equals 1 when X and Y have the same elements and zero when they are disjoint
• X and Y don’t have to be of the same size
• Always assigns a number between 0 and 1– Now threshold to decide if you have a match– E.g., if J.C. > 0.8, declare a match
YXYX /

Semantic web - Computer Engineering Dept. - Spring 200719
Phrase queries
• Want to answer queries such as “stanford university” – as a phrase
• Thus the sentence “I went to university at Stanford” is not a match. – The concept of phrase queries has proven easily
understood by users; about 10% of web queries are phrase queries
• No longer suffices to store only
<term : docs> entries

Semantic web - Computer Engineering Dept. - Spring 200720
Biword indexes
• Index every consecutive pair of terms in the text as a phrase
• For example the text “Friends, Romans, Countrymen” would generate the biwords– friends romans– romans countrymen
• Each of these biwords is now a dictionary term
• Two-word phrase query-processing is now immediate.

Semantic web - Computer Engineering Dept. - Spring 200721
Longer phrase queries
• stanford university palo alto can be broken into the Boolean query on biwords:
stanford university AND university palo AND palo alto
Without the docs, we cannot verify that the docs matching the above Boolean query do contain the phrase.
Can have false positives!

Semantic web - Computer Engineering Dept. - Spring 200722
Solution 2: Positional indexes
• Store, for each term, entries of the form:<number of docs containing term;
doc1: position1, position2 … ;
doc2: position1, position2 … ;
etc.>

Semantic web - Computer Engineering Dept. - Spring 200723
Positional index example
• Can compress position values/offsets
• Nevertheless, this expands postings storage substantially
<be: 993427;1: 7, 18, 33, 72, 86, 231;2: 3, 149;4: 17, 191, 291, 430, 434;5: 363, 367, …>
Which of docs 1,2,4,5could contain “to be
or not to be”?

Semantic web - Computer Engineering Dept. - Spring 200724
Processing a phrase query
• Extract inverted index entries for each distinct term: to, be, or, not.
• Merge their doc:position lists to enumerate all positions with “to be or not to be”.
– to:
• 2:1,17,74,222,551; 4:8,16,190,429,433; 7:13,23,191; ...
– be:
• 1:17,19; 4:17,191,291,430,434; 5:14,19,101; ...
• Same general method for proximity searches

Semantic web - Computer Engineering Dept. - Spring 200725
Vector model of retrieval
• Documents are represented as vectors of terms• In each entry a weight is considered.• The weight is tfxidf:
– term frequency (tf )• or wf, some measure of term density in a doc
– inverse document frequency (idf ) • measure of informativeness of a term: its rarity across the whole
corpus• could just be raw count of number of documents the term occurs in (idfi
= 1/dfi)• but by far the most commonly used version is:
dfnidf
i
i log

Semantic web - Computer Engineering Dept. - Spring 200726
Why turn docs into vectors?
• First application: Query-by-example– Given a doc d, find others “like” it.
• Now that d is a vector, find vectors (docs) “near” it.

Semantic web - Computer Engineering Dept. - Spring 200727
Intuition
Postulate: Documents that are “close together” in the vector space talk about the same things.
t1
d2
d1
d3
d4
d5
t3
t2
θ
φ

Semantic web - Computer Engineering Dept. - Spring 200728
Cosine similarity
• Distance between vectors d1 and d2 captured by the cosine of the angle x between them.
• Note – this is similarity, not distance– No triangle inequality for similarity.
t 1
d 2
d 1
t 3
t 2
θ

Semantic web - Computer Engineering Dept. - Spring 200729
Cosine similarity
• Cosine of angle between two vectors
• The denominator involves the lengths of the vectors.
n
i ki
n
i ji
n
i kiji
kj
kjkj
ww
ww
dd
ddddsim
1
2,1
2,
1 ,,),(
Normalization

Semantic web - Computer Engineering Dept. - Spring 200730
Measures for a search engine
• How fast does it index– Number of documents/hour– (Average document size)
• How fast does it search– Latency as a function of index size
• Expressiveness of query language– Ability to express complex information needs– Speed on complex queries

Semantic web - Computer Engineering Dept. - Spring 200731
Measures for a search engine
• All of the preceding criteria are measurable: we can quantify speed/size; we can make expressiveness precise
• The key measure: user happiness– What is this?– Speed of response/size of index are factors– But blindingly fast, useless answers won’t make a user
happy
• Need a way of quantifying user happiness

Semantic web - Computer Engineering Dept. - Spring 200732
Unranked retrieval evaluation:Precision and Recall
• Precision: fraction of retrieved docs that are relevant = P(relevant|retrieved)
• Recall: fraction of relevant docs that are retrieved = P(retrieved|relevant)
• Precision P = tp/(tp + fp)• Recall R = tp/(tp + fn)
Relevant Not Relevant
Retrieved tp fp
Not retrieved fn tn

Semantic web - Computer Engineering Dept. - Spring 200733
Precision/Recall
• You can get high recall (but low precision) by retrieving all docs for all queries!
• Recall is a non-decreasing function of the number of docs retrieved
• In a good system, precision decreases as either number of docs retrieved or recall increases– A fact with strong empirical confirmation

Semantic web - Computer Engineering Dept. - Spring 200734
Typical (good) 11 point precisions
0
0.2
0.4
0.6
0.8
1
0 0.2 0.4 0.6 0.8 1
Recall
Pre
cis
ion
Semantic web - Computer Engineering Dept. - Spring 200735
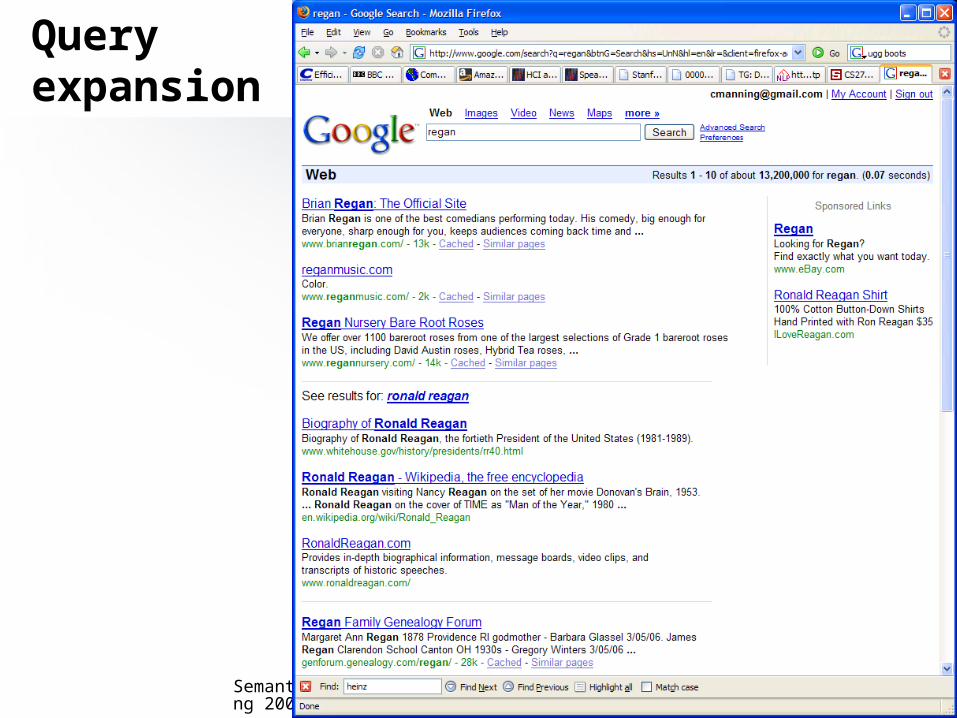
Queryexpansion

Semantic web - Computer Engineering Dept. - Spring 200736
Relevance Feedback
• Relevance feedback: user feedback on relevance of docs in initial set of results– User issues a (short, simple) query– The user marks returned documents as relevant or non-
relevant.– The system computes a better representation of the
information need based on feedback.– Relevance feedback can go through one or more
iterations.
• Idea: it may be difficult to formulate a good query when you don’t know the collection well, so iterate
Semantic web - Computer Engineering Dept. - Spring 200737
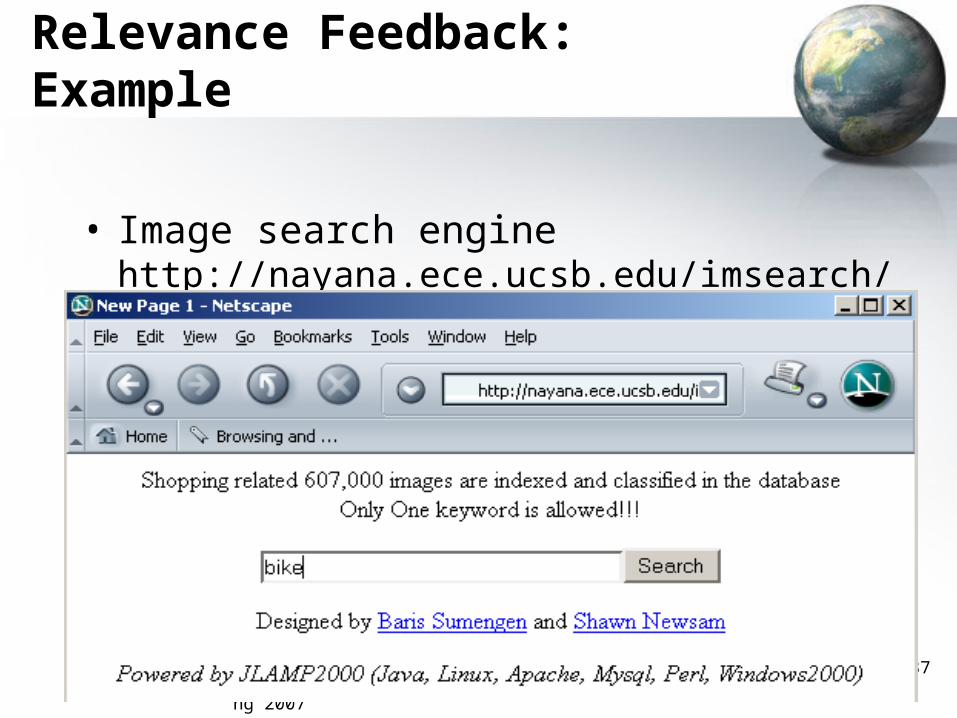
Relevance Feedback: Example
• Image search engine http://nayana.ece.ucsb.edu/imsearch/imsearch.html

Semantic web - Computer Engineering Dept. - Spring 200738
Results for Initial Query

Semantic web - Computer Engineering Dept. - Spring 200739
Relevance Feedback

Semantic web - Computer Engineering Dept. - Spring 200740
Results after Relevance Feedback

Semantic web - Computer Engineering Dept. - Spring 200741
Rocchio Algorithm
• The Rocchio algorithm incorporates relevance feedback information into the vector space model.
• Want to maximize sim (Q, Cr) - sim (Q, Cnr)
• The optimal query vector for separating relevant and non-relevant documents (with cosine sim.):
• Qopt = optimal query; Cr = set of rel. doc vectors; N = collection size
• Unrealistic: we don’t know relevant documents.
rjrj Cd
jrCd
jr
opt dCN
dC
Q
11

Semantic web - Computer Engineering Dept. - Spring 200742
Rocchio 1971 Algorithm (SMART)
• Used in practice:
• qm = modified query vector; q0 = original query vector; α,β,γ: weights (hand-chosen or set empirically); Dr = set of known relevant doc vectors; Dnr = set of known irrelevant doc vectors
• New query moves toward relevant documents and away from irrelevant documents
• Tradeoff α vs. β/γ : If we have a lot of judged documents, we want a higher β/γ.
• Term weight can go negative– Negative term weights are ignored (set to 0)
nrjrj Dd
jnrDd
jr
m dD
dD
110

Semantic web - Computer Engineering Dept. - Spring 200743
Types of Query Expansion
• Global Analysis: (static; of all documents in collection)
– Controlled vocabulary• Maintained by editors (e.g., medline)
– Manual thesaurus• E.g. MedLine: physician, syn: doc, doctor, MD, medico
– Automatically derived thesaurus• (co-occurrence statistics)
– Refinements based on query log mining• Common on the web
• Local Analysis: (dynamic)– Analysis of documents in result set

Semantic web - Computer Engineering Dept. - Spring 200744
Probabilistic relevance feedback
• Rather than reweighting in a vector space…• If user has told us some relevant and some
irrelevant documents, then we can proceed to build a probabilistic classifier, such as a Naive Bayes model:– P(tk|R) = |Drk| / |Dr|
– P(tk|NR) = |Dnrk| / |Dnr|
• tk is a term; Dr is the set of known relevant documents; Drk is the subset that contain tk; Dnr is the set of known irrelevant documents; Dnrk is the subset that contain tk.

Semantic web - Computer Engineering Dept. - Spring 200745
Binary Independence Model
n
i i
i
qNRxp
qRxpqROdqRO
1 ),|(
),|()|(),|(
• Since xi is either 0 or 1:
01 ),|0(
),|0(
),|1(
),|1()|(),|(
ii x i
i
x i
i
qNRxp
qRxp
qNRxp
qRxpqROdqRO

46
Iteratively estimating pi
1. Assume that pi constant over all xi in query– pi = 0.5 (even odds) for any given doc
2. Determine guess of relevant document set:– V is fixed size set of highest ranked documents on this model
(note: now a bit like tf.idf!)
3. We need to improve our guesses for pi and ri, so– Use distribution of xi in docs in V. Let Vi be set of documents
containing xi • pi = |Vi| / |V|
– Assume if not retrieved then not relevant • ri = (ni – |Vi|) / (N – |V|)
4. Go to 2. until converges then return ranking

Semantic web - Computer Engineering Dept. - Spring 200747
Bayesian Networks for Text Retrieval (Turtle and Croft 1990)
• Standard probabilistic model assumes you can’t estimate P(R|D,Q)– Instead assume independence and use P(D|R)
• But maybe you can with a Bayesian network*• What is a Bayesian network?
– A directed acyclic graph– Nodes
• Events or Variables– Assume values.
– For our purposes, all Boolean
– Links• model direct dependencies between nodes

Semantic web - Computer Engineering Dept. - Spring 200748
Bayesian Networks
a b
c
a,b,c - propositions (events).
p(c|ab) for all values for a,b,c
p(a)
p(b)
• Bayesian networks model causal relations between events
•Inference in Bayesian Nets:•Given probability distributionsfor roots and conditional probabilities can compute apriori probability of any instance• Fixing assumptions (e.g., b was observed) will cause recomputation of probabilities
Conditional dependence

Semantic web - Computer Engineering Dept. - Spring 200749
Bayesian Nets for IR: Idea
Document Network
Query Network
Large, butCompute once for each document collection
Small, compute once forevery query
d1 dnd2
t1 t2 tn
r1 r2 r3rk
di -documents
ti - document representationsri - “concepts”
I
q2q1
cmc2c1 ci - query concepts
qi - high-level concepts
I - goal node
Semantic web - Computer Engineering Dept. - Spring 200750
Web search basics
The Web
Ad indexes
Web Results 1 - 10 of about 7,310,000 for miele. (0.12 seconds)
Miele, Inc -- Anything else is a compromise At the heart of your home, Appliances by Miele. ... USA. to miele.com. Residential Appliances. Vacuum Cleaners. Dishwashers. Cooking Appliances. Steam Oven. Coffee System ... www.miele.com/ - 20k - Cached - Similar pages
Miele Welcome to Miele, the home of the very best appliances and kitchens in the world. www.miele.co.uk/ - 3k - Cached - Similar pages
Miele - Deutscher Hersteller von Einbaugeräten, Hausgeräten ... - [ Translate this page ] Das Portal zum Thema Essen & Geniessen online unter www.zu-tisch.de. Miele weltweit ...ein Leben lang. ... Wählen Sie die Miele Vertretung Ihres Landes. www.miele.de/ - 10k - Cached - Similar pages
Herzlich willkommen bei Miele Österreich - [ Translate this page ] Herzlich willkommen bei Miele Österreich Wenn Sie nicht automatisch weitergeleitet werden, klicken Sie bitte hier! HAUSHALTSGERÄTE ... www.miele.at/ - 3k - Cached - Similar pages
Sponsored Links
CG Appliance Express Discount Appliances (650) 756-3931 Same Day Certified Installation www.cgappliance.com San Francisco-Oakland-San Jose, CA Miele Vacuum Cleaners Miele Vacuums- Complete Selection Free Shipping! www.vacuums.com Miele Vacuum Cleaners Miele-Free Air shipping! All models. Helpful advice. www.best-vacuum.com
Web spider
Indexer
Indexes
Search
User

Semantic Search

Semantic web - Computer Engineering Dept. - Spring 200752
Ontology Meta Search Engines
• This group do retrieval by putting a system on top of a current search engine
• There are two types of this systems
• Using Filetype feature of search engines
• Swangling

Semantic web - Computer Engineering Dept. - Spring 200753
Filetype Feature
• Google started indexing RDF documents some time in late 2003
• In the first type, there is a search engine that only searches specific file types (e.g. RSS, RDF, OWL)
• In fact we just forward the keywords of the queries with filetype feature to Google
• The main concern of such systems is on the visualization and browsing of results

Semantic web - Computer Engineering Dept. - Spring 200754
OntoSearch
• A basis system with Google as its “heart”
• Abilities:– The ability to specify the types of file(s) to be returned (OWL,
RDFS, all)
– The ability to specify the types of entities to be matched by each keyword (concept, attribute, values, comments, all)
– The ability to specify partial or exact matches on entities.
– Sub-graph matching eg concept animal with concept pig within 3 links; concepts with particular attributes

Semantic web - Computer Engineering Dept. - Spring 200755
Ontology Meta Search Engines
• In the second type we use traditional search engines again
• But since semantic tags are ignored by the underlying search engine, an intermediate format for documents and user queries are used
• A technique named Swangle is used for this purpose
• With this technique RDF triples are translated into strings suitable for underlying search engine

Semantic web - Computer Engineering Dept. - Spring 200756
Swangling
• Swangling turns a SW triple into 7 word like terms– One for each non-empty subset of the three components with
the missing elements replaced by the special “don’t care” URI
– Terms generated by a hashing function (e.g., SHA1)
• Swangling an RDF document means adding in triples with swangle terms.– This can be indexed and retrieved via conventional search
engines like Google
• Allows one to search for a SWD with a triple that claims “Ossama bin Laden is located at X”

Semantic web - Computer Engineering Dept. - Spring 200757
A Swangled Triple
<rdf:RDF xmlns:s="http://swoogle.umbc.edu/ontologies/swangle.owl#"</rdf>
<s:SwangledTriple><rdfs:comment>Swangled text for [http://www.xfront.com/owl/ontologies/camera/#Camera, http://www.w3.org/2000/01/rdf-schema#subClassOf, http://www.xfront.com/owl/ontologies/camera/#PurchaseableItem] </rdfs:comment>
<s:swangledText>N656WNTZ36KQ5PX6RFUGVKQ63A</s:swangledText> <s:swangledText>M6IMWPWIH4YQI4IMGZYBGPYKEI</s:swangledText> <s:swangledText>HO2H3FOPAEM53AQIZ6YVPFQ2XI</s:swangledText> <s:swangledText>2AQEUJOYPMXWKHZTENIJS6PQ6M</s:swangledText> <s:swangledText>IIVQRXOAYRH6GGRZDFXKEEB4PY</s:swangledText> <s:swangledText>75Q5Z3BYAKRPLZDLFNS5KKMTOY</s:swangledText> <s:swangledText>2FQ2YI7SNJ7OMXOXIDEEE2WOZU</s:swangledText></s:SwangledTriple>

Semantic web - Computer Engineering Dept. - Spring 200758
Swangler Architecture
WebSearchEngine
FiltersSemanticMarkup
InferenceEngine
LocalKB
SemanticMarkup
SemanticMarkup
Extractor
Encoder(“swangler”)
RankedPages
EncodedMarkup
SemanticWeb Query

Semantic web - Computer Engineering Dept. - Spring 200759
What’s the point?
• We’d like to get our documents into Google– Swangle terms look like words to Google and other search
engines.
• On the other side, this translation is done for user queries too.– Add rules to the web server so that, when a search spider
asks for document X the document swangled(X) is returned
• We could also use Swanglish – hashing each triple into N of the 50K most common English words

Semantic web - Computer Engineering Dept. - Spring 200760
Crawler Based Search Engines
They have a crawler and ranking of their own
Semantic web - Computer Engineering Dept. - Spring 200761

Semantic web - Computer Engineering Dept. - Spring 200762
Swoogle Architecture
metadata creation
data analysis
interface
SWD discovery
SWD MetadataWeb Service
Web Server
SWD Cache
The Web
The WebCandidate
URLs Web Crawler
SWD Reader
IR analyzer SWD analyzer
Agent Service
Swoogle 2: 340K SWDs, 48M triples, 5K SWOs, 97K classes, 55K properties, 7M individuals (4/05)
Swoogle 3: 700K SWDs, 135M triples, 7.7K SWOs, (11/05)

Semantic web - Computer Engineering Dept. - Spring 200763
Crawler Based Ontology Search Engines
Discovery Crawling of SW documents is different from html
documents In SW we express knowledge using URI in RDF
triples. Unlike html hyperlinks, URIs in RDF may point to a non existing entity
Also RDF may be embedded in html documents or be stored in a separate file.

Semantic web - Computer Engineering Dept. - Spring 200764
Semantic Web Crawler
• Such crawlers should have the following properties
Should crawl on heterogeneous web resources (owl, oil, daml, rdf, xml, html)
Avoid circular links
Completing RDF holes
Aggregating RDF chunks

Semantic web - Computer Engineering Dept. - Spring 200765
Metadata Creation
• Web document metadata– When/how
discovered/fetched
– Suffix of URL
– Last modified time
– Document size
• SSWD metadata– Language features
• OWL species
• RDF encoding
– Statistical features• Defined/used terms
• Declared/used namespaces
• Ontology Ratio
– Ontology Rank
• Ontology annotation– Label– Version– Comment
• Related Relational Metadata– Links to other SWDs
• Imported SWDs• Referenced SWDs • Extended SWDs• Prior version
– Links to terms• Classes/Properties
defined/used

Semantic web - Computer Engineering Dept. - Spring 200766
Digesting
• Digest– But the main point is that count, type and meaning
of relations in SW is more complete than the current web

Semantic web - Computer Engineering Dept. - Spring 200767
RDF graph Resource
Web
SWT
SWD
usespopulates defines
officialOntoisDefinedBy
owl:imports…
rdfs:seeAlsordfs:isDefinedBy
SWO
isUsedByisPopulatedBy
rdfs:subClassOf
sameNamespace, sameLocalnameExtends class-property bond
1
23
4 5
6 7
Term Search
Document Search
literal
Semantic Web Navigation Model
Navigating the HTML web is simple; there’s just one kind of link. The SW has more kinds of links and hence more navigation paths.

Semantic web - Computer Engineering Dept. - Spring 200768
foaf:Person foaf:Agentrdfs:subClassOf foaf:mbox
foaf:Personrdf:type
mailto:[email protected]
foaf:mbox
rdfs:domain
owl:InverseFunctionalProperty owl:Class
rdfs:range
owl:Thingrdf:typerdf:type rdf:type
foaf:Personrdf:type
http://www.cs.umbc.edu/~finin/foaf.rdf
rdfs:seeAlso
http://www.cs.umbc.edu/~finin/foaf.rdf http://www.cs.umbc.edu/~dingli1/foaf.rdf
http://xmlns.com/foaf/0.1/index.rdf
http://xmlns.com/foaf/0.1/index.rdf http://www.w3.org/2002/07/owlowl:imports
An Example
We navigate the Semantic Web via links in the physical layer of RDF documents and also via links in the “logical” layer defined by the semantics of RDF and OWL.

Semantic web - Computer Engineering Dept. - Spring 200769
Rank has its privilege
• Google introduced a new approach to ranking query results using a simple “popularity” metric.– It was a big improvement!
• Swoogle ranks its query results also– When searching for an ontology, class or property,
wouldn’t one want to see the most used ones first?
• Ranking SW content requires different algorithms for different kinds of SW objects– For SWDs, SWTs, individuals, “assertions”,
molecules, etc…

Semantic web - Computer Engineering Dept. - Spring 200770
Ranking SWDs
• For offline ranking it is possible to use the references idea of PageRank.
• In OntoRank values for each ontology is calculated very similar to PageRank in traditional search engines like google
• Ranking based on “Referencing”• identify and rank of referrer• Number of citation by others• Distance of reference from origin to target
• Types of links:• Import• Extend• Instantiate • Prior version• ..

Semantic web - Computer Engineering Dept. - Spring 200771
An Example
http://www.cs.umbc.edu/~finin/foaf.rdf
http://xmlns.com/wordnet/1.6/
http://xmlns.com/foaf/1.0/
EX
TM
TM
TM
http://www.w3.org/2000/01/rdf-schema
wPR =0.2wPR =0.2
wPR =100wPR =100
wPR =3wPR =3
wPR =300wPR =300
OntoRank =0.2OntoRank =0.2
OntoRank =100OntoRank =100
OntoRank =103OntoRank =103
OntoRank =403OntoRank =403

Semantic web - Computer Engineering Dept. - Spring 200772
Crawler Based Ontology Search Engines
• Service– User interface
– Services to application systems

Semantic web - Computer Engineering Dept. - Spring 200773
Find “Time” Ontology
We can use a set of keywords to search ontology. For example, “time, before, after” are basic concepts for a “Time” ontology.
Demo1

Semantic web - Computer Engineering Dept. - Spring 200774
Digest “Time” Ontology (document view)Demo2(a)
Semantic web - Computer Engineering Dept. - Spring 200775
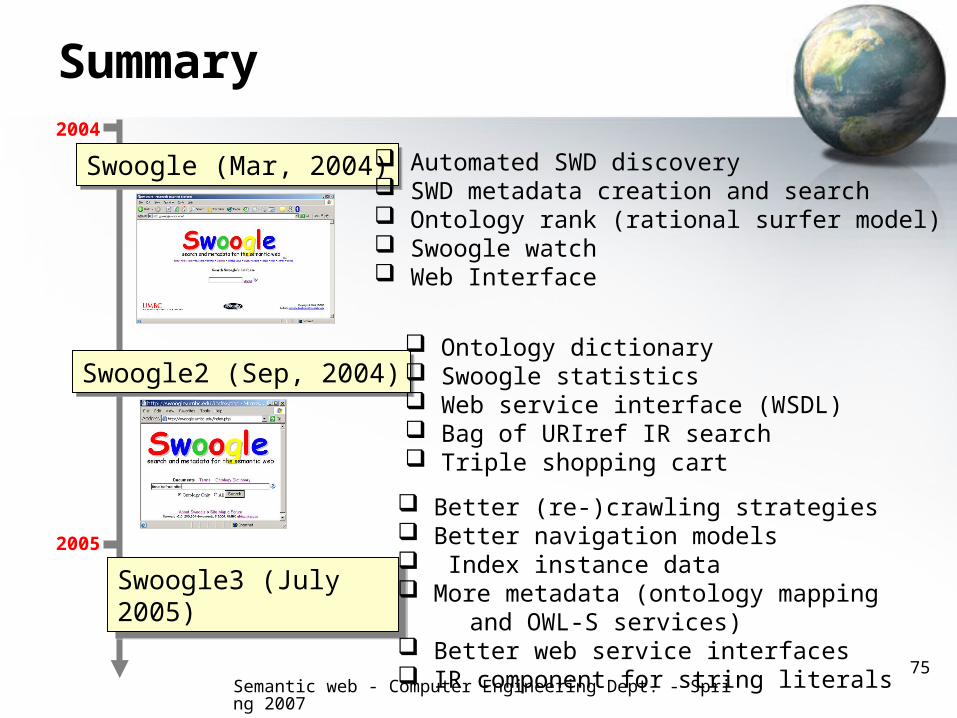
Summary
Swoogle (Mar, 2004)Swoogle (Mar, 2004)
Swoogle2 (Sep, 2004)Swoogle2 (Sep, 2004)
Swoogle3 (July 2005)Swoogle3 (July 2005)
Automated SWD discovery SWD metadata creation and search Ontology rank (rational surfer model) Swoogle watch Web Interface
Ontology dictionary Swoogle statistics Web service interface (WSDL) Bag of URIref IR search Triple shopping cart
Better (re-)crawling strategies Better navigation models Index instance data More metadata (ontology mapping and OWL-S services) Better web service interfaces IR component for string literals
2005
2004

Semantic web - Computer Engineering Dept. - Spring 200776
Applications and use cases
• Supporting Semantic Web developers, e.g.,– Ontology designers– Vocabulary discovery– Who’s using my ontologies or data?– Etc.
• Searching specialized collections, e.g.,– Proofs in Inference Web– Text Meaning Representations of news stories in
SemNews
• Supporting SW tools, e.g.,– Discovering mappings between ontologies

Semantic web - Computer Engineering Dept. - Spring 200777
Semantic Search Engines
• There are some restrictions for current search engines
• One interesting example : ”Matrix”
• Another example is java
• Semantic web is introduced to overcome this problem.
• The most important tool in semantic web for improving search results is context concept and its correspondence with Ontologies. This type of search engines uses such ontological definitions

Semantic web - Computer Engineering Dept. - Spring 200778
Two Levels of the Semantic Web
• Deep Semantic Web: – Intelligent agents performing inference – Semantic Web as distributed AI– Small problem … the AI problem is not yet solved
• Shallow Semantic Web: using SW/Knowledge Representation techniques for– Data integration– Search– Is starting to see traction in industry

Semantic web - Computer Engineering Dept. - Spring 200779
Problems with current search engines
• Current search engines = keywords:– high recall, low precision– sensitive to vocabulary– insensitive to implicit content

Semantic web - Computer Engineering Dept. - Spring 200780
Semantic Search Engines
• It is possible to categorize this type of search engines to three groups. – Context Based Search Engines
• They are the largest one, aim is to add semantic operations for better results.
– Evolutionary Search Engines • Use facilities of semantic web to accumulate information on a
topic we are researching on.
– Semantic Association Discovery Engines • They try to find semantic relations between two or more terms.

Semantic web - Computer Engineering Dept. - Spring 200781
Context Based Search Engines

Semantic web - Computer Engineering Dept. - Spring 200782
Context Based Search Engines
• 1) Crawling the semantic web: – There is not much difference between these crawlers and
ordinary web crawlers
– many of the implemented systems uses an existing web crawler as underlying system.
– Its better to develop a crawler that understands special semantic tags.
– One of the important features of theses crawlers should be the exploration of ontologies that are referred from existing web pages

Semantic web - Computer Engineering Dept. - Spring 200783
Annotation Methods
• Annotation is perquisite of Search in semantic web.• There are different approaches which spawn in a broad
spectrum from complete manual to full automatic methods.
• Selection of an appropriate method depends on the domain of interest
• In general meta-data generation for structured data is simpler

Semantic web - Computer Engineering Dept. - Spring 200784
Annotation Methods
• Annotations can be categorized based on following aspects: Type of meta-data
• Structural : non contextual information about content is expressed (e.g. language and format)
• Semantic: The main concern is on the detailed content of information and usually is stored as RDF triples

Semantic web - Computer Engineering Dept. - Spring 200785
Annotation Methods
• Generation approach– A simple approach is to generate meta-data without
considering the overall theme of the page. (Without Ontology)
– Better approach is to use an ontology in the generation process.
• Using a previously specified ontology for that type, generate meta-data that instantiates concepts and relations of ontology for that page
• The main advantage of this method is the usage of contextual information.

Semantic web - Computer Engineering Dept. - Spring 200786
Annotation Methods
• Source of generation– The ordinary source of meta-data generation is a
page itself
– Sometimes it is beneficial to use other complementary sources, like using network available resources for accumulating more information for a page
• For example for a movie it might be possible to use IMDB to extract additional information like director, genre, etc.

Semantic web - Computer Engineering Dept. - Spring 200787
Evolutionary Search Engines
• The advanced type of search is some thing like research• Here we aim at gathering some information about
specific topic• It can be something like search by Teoma search engine • For example if we give the name of a singer to the search
engine it should be able to find some related data to this singer like biography, posters, albums and so on.

Semantic web - Computer Engineering Dept. - Spring 200788
Evolutionary Search Engines
• These engines usually use on of the commercial search engines as their base component for searching and they augment returned result by these base engines.
• This augmented information is gathered from some data-insensitive web resources.

Semantic web - Computer Engineering Dept. - Spring 200789
Evolutionary Search Engines Architecture

Semantic web - Computer Engineering Dept. - Spring 200790
Evolutionary Search Engines
• It has some similarities with previous category’s architecture
• Here we crawl and generate annotation just for some well know informational web pages i.e. CDNow, Amazon, IMDB
• After this phase we collect annotations in a repository.

Semantic web - Computer Engineering Dept. - Spring 200791
Evolutionary Search Engines
• Whenever a sample user posed a query two processes must be performed:first, we should give this query to a usual search
engine (usually Google) to obtaining raw results. Second, system will attempt to detect the context and
its corresponding ontology for the user’s request in order to extract some key concepts.
Later we use these concepts to fetch some information from our metadata repository.
The last step in this architecture is combining and displaying results.

Semantic web - Computer Engineering Dept. - Spring 200792
Evolutionary Search Engines
• Main problems and challenge in these types of engines are :Concept extraction from user’s requestSelecting proper annotation to show and
their order

Semantic web - Computer Engineering Dept. - Spring 200793
Evolutionary Search Engines
• Concept extraction from user’s request• there are some problems that lead to
misunderstanding of input query by system; – Inherent ambiguity in query specified by user – Complex terms that must be decomposed to understand.

Semantic web - Computer Engineering Dept. - Spring 200794
Evolutionary Search Engines
• Selecting proper annotation to show and their order: – often we find a huge number of potential
metadata related to the initial request and we should choose those ones that are more useful for user.
– A simple approach is using other concepts around our core concept (which we extracted it before) in base ontology
– if we have more than one core concept we must focus on those concepts that are on the path between these concepts.

Semantic web - Computer Engineering Dept. - Spring 200795
Displaying the Results
• Results are displayed using a set of templates• Each class of object has an associated set of templates• The templates specify the class and the properties and a
HTML template • A template is identified for each node in the ordered list
and the HTML is generated• The HTML is included in the results page

Semantic web - Computer Engineering Dept. - Spring 200796
W3C Search
• W3C Semantic Search has five different data sources: People, Activities, Working Groups, Documents, and News
• Both ABS and W3C Semantic Search have a basic ontology about people, places, events, organizations, vocabulary terms, etc.
• The plan is to augment a traditional search with data from the Semantic Web
Semantic web - Computer Engineering Dept. - Spring 200797
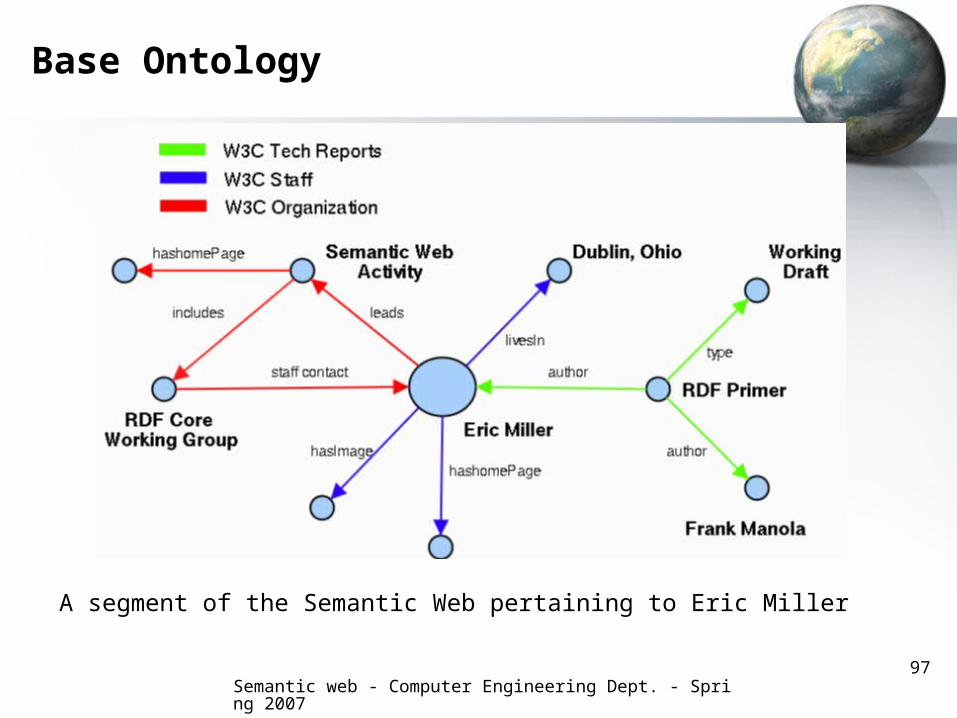
Base Ontology
A segment of the Semantic Web pertaining to Eric Miller

Semantic web - Computer Engineering Dept. - Spring 200798
Sample Applications-W3C Search

Semantic web - Computer Engineering Dept. - Spring 200799
Activity Based Search
• ABS contains data from many sites, such as AllMusic, Ebay, Amazon, AOL Shopping, TicketMaster, Weather.com and Mapquest
• There are millions of triples in the ABS Semantic Web• TAP knowledge base has a broad range of domains
including people, places, organizations, and products • Resources have a rdf:type and rdfs:label

Semantic web - Computer Engineering Dept. - Spring 2007100
Sample Applications-ABS

Semantic web - Computer Engineering Dept. - Spring 2007101
Sample Applications-ABS

Semantic web - Computer Engineering Dept. - Spring 2007102
References• T. Finin, J. Mayfield, C. Fink, A. Joshi, and R. S. Cost, “Information
retrieval and the semantic web,” in Proceedings of the 38th International Conference on System Sciences, Hawaii, United States of America, 2005.
• T. Finin, L. Ding, R. Pan, A. Joshi, P. Kolari, A. Java, and Y. Peng, “Swoogle: Searching for knowledge on the semantic web,” in Proceedings of the AAAI 05, 2005.
• R. Guha, R. McCool, and E. Miller, “Semantic search,” in Proc. of the12th international conference on World Wide Web, New Orleans, 2003, pp. 700–709.
• Y. Zhang, W. Vasconcelos, and D. Sleeman, “OntoSearch: An ontology search engine,” in The Twenty-fourth SGAI International Conference on Innovative Techniques and Applications of Artificial Intelligence, Cambridge, 2004.