semantic enrichment for ontology mapping
TRANSCRIPT

Xiaomeng Su
Semantic Enrichment forOntology Mapping
Department of Computer and Information ScienceNorwegian University of Science and Technology
N-7491 Trondheim, Norway

NTNU TrondheimNorges teknisk-naturvitenskapelige universitetDoktor ingeniøravhandling 2004:116
Institutt for datateknikk og informasjonsvitenskap
ISBN 82-471-6453-1ISSN 1503-8181

Abstract
System interoperability is an important issue, widely recognized ininformation technology intensive organizations and in the research com-munity of information systems. The wide adoption of the World WideWeb to access and distribute information further stress the need for sys-tem interoperability. Initiatives like the Semantic Web strive to allow soft-ware agents to locate and integrate data in a more intelligent way via theuse of ontologies. The Semantic Web offers a compelling vision, yet itraises a number of research challenges. One of the key challenges is tocompare and map different ontologies, which evidently appears in inte-gration tasks.
The main aim of the work is to introduce a method for finding seman-tic correspondences among component ontologies with the intention tosupport interoperability of Information Systems. The approach bringstogether techniques in modeling, computation linguistics, informationretrieval and agent communication in order to provide a semi-automaticmapping method and a prototype mapping system that support the pro-cess of ontology mapping for the purpose of improving semantic inter-operability in heterogeneous systems.
The approach consists of two phases: enrichment phase and map-ping phase. The enrichment phase is based on analysis of the extensioninformation the ontologies have. The extension we make use of in thiswork is written documents that are associated with the concepts in theontologies. The intuition is that given two to-be-compared ontologies,we construct representative feature vectors for each concept in the twoontologies. The documents are ”building material” for the constructionprocess, as they reflect the common understanding of the domain. Out-puts of the enrichment phase are ontologies with feature vector as en-richment structure. The mapping phase takes the enriched ontology andcomputes similarity pair wise for the element in the two ontologies. Thecalculation is based on the distance of the feature vectors. Further re-finements are employed to re-rank the result via the use of WordNet. Anumber of filters, variables, heuristics can be tuned to include/excludecertain mapping correspondences.
The approach has been implemented in a prototype system - iMapperand has been evaluated through a controlled accuracy evaluation with aset of test users on two limited but real world cases. The system is testedunder different configuration of variables to indicate the robustness of

ii
the approach. The preliminary case studies show encouraging result.The applicability of the approach is demonstrated in an attempt to
use the mapping assertions generated by the approach to bridge com-munication between heterogeneous systems. We present a frameworkwhere the mapping assertions are used to improve system interoperabil-ity in multi-agent systems. Furthermore, to demonstrate the practicalfeasibility of the approach, we show how to instantiate the framework ina running agent platform - AGORA.
The future direction of this work includes studies on extended cus-tomizability, user studies, model quality and technical method revision.

Contents
Preface xv
I Background and Context 1
1 Introduction 31.1 Background . . . . . . . . . . . . . . . . . . . . . . . . . . . 31.2 About the Problem . . . . . . . . . . . . . . . . . . . . . . . 41.3 Objectives . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71.4 Approach and Scope . . . . . . . . . . . . . . . . . . . . . . 71.5 Way of Working and Major Contributions . . . . . . . . . . 81.6 Publications . . . . . . . . . . . . . . . . . . . . . . . . . . . 101.7 Thesis Outline . . . . . . . . . . . . . . . . . . . . . . . . . . 12
2 Basic Ontology Concepts 152.1 The Semantic Web . . . . . . . . . . . . . . . . . . . . . . . . 152.2 The Role of Ontology . . . . . . . . . . . . . . . . . . . . . . 18
2.2.1 Shared Vocabularies and Conceptulizations . . . . . 182.2.2 Types of Ontologies . . . . . . . . . . . . . . . . . . 192.2.3 Beneficial Applications . . . . . . . . . . . . . . . . . 21
2.3 Ontology Languages . . . . . . . . . . . . . . . . . . . . . . 232.3.1 Traditional Ontology Languages . . . . . . . . . . . 242.3.2 Web Standards . . . . . . . . . . . . . . . . . . . . . 262.3.3 Web-based Ontology Specification Languages . . . 27
2.4 Ontology Engineering . . . . . . . . . . . . . . . . . . . . . 292.4.1 Life Cycle of an Ontology . . . . . . . . . . . . . . . 292.4.2 Ontology-based Architectures . . . . . . . . . . . . 30
2.5 Concluding Remarks . . . . . . . . . . . . . . . . . . . . . . 32
iii

iv CONTENTS
3 Technological Overview 353.1 Information Retrieval . . . . . . . . . . . . . . . . . . . . . . 35
3.1.1 Vector Space Models . . . . . . . . . . . . . . . . . . 353.2 Computational Linguistics . . . . . . . . . . . . . . . . . . . 39
3.2.1 Morphological Analysis . . . . . . . . . . . . . . . . 403.2.2 Part-of-Speech Tagging . . . . . . . . . . . . . . . . 433.2.3 Lexical Semantics . . . . . . . . . . . . . . . . . . . . 44
3.3 Concluding Remarks . . . . . . . . . . . . . . . . . . . . . . 49
4 State-of-the-Art Survey 534.1 Ontology Heterogeneity . . . . . . . . . . . . . . . . . . . . 53
4.1.1 Ontology Mismatch . . . . . . . . . . . . . . . . . . 534.1.2 Current Approaches and Techniques . . . . . . . . . 56
4.2 Ontology Mapping Concepts . . . . . . . . . . . . . . . . . 584.2.1 Definition and Scope of Ontology Mapping . . . . . 584.2.2 Application Domains . . . . . . . . . . . . . . . . . 594.2.3 Terminology . . . . . . . . . . . . . . . . . . . . . . . 60
4.3 Automatic Ontology Mapping Tools . . . . . . . . . . . . . 614.3.1 Automatic Schema Matching . . . . . . . . . . . . . 614.3.2 Systems for Ontology Merging and Mapping . . . . 634.3.3 A Comparison of the Studied Systems . . . . . . . . 71
4.4 Concluding Remarks . . . . . . . . . . . . . . . . . . . . . . 73
II Design and Architecture 77
5 Ontology Comparison and Semantic Enrichment 795.1 Prerequisites . . . . . . . . . . . . . . . . . . . . . . . . . . . 79
5.1.1 Scope and Assumption . . . . . . . . . . . . . . . . . 805.1.2 The RML Modeling Language . . . . . . . . . . . . 81
5.2 The Abstract Ontology Mapping Model . . . . . . . . . . . 845.3 Semantic Discrepancies . . . . . . . . . . . . . . . . . . . . . 855.4 Mapping Assertions . . . . . . . . . . . . . . . . . . . . . . 865.5 Semantic Enrichment of Ontology . . . . . . . . . . . . . . 895.6 Extension Analysis-based Semantic Enrichment . . . . . . 90
5.6.1 The Concept of Intension and Extension . . . . . . . 905.6.2 Extension Analysis for Semantic Enrichment . . . . 91
5.7 Feature Vector as Generalization of Extension . . . . . . . 925.7.1 Feature Vectors . . . . . . . . . . . . . . . . . . . . . 94

CONTENTS v
5.7.2 Steps in Constructing Feature Vectors . . . . . . . . 945.7.3 Document Assignment . . . . . . . . . . . . . . . . . 945.7.4 Feature Vector Construction . . . . . . . . . . . . . . 955.7.5 Feature Vectors as Semantic Enrichment . . . . . . . 98
5.8 Concluding Remarks . . . . . . . . . . . . . . . . . . . . . . 98
6 Ontology Mapping Approach 1016.1 Algorithm Overview . . . . . . . . . . . . . . . . . . . . . . 1016.2 The Similarity Calculation for Concepts . . . . . . . . . . . 1036.3 Adjust Similarity Value with WordNet . . . . . . . . . . . . 104
6.3.1 WordNet . . . . . . . . . . . . . . . . . . . . . . . . . 1046.3.2 The Path Length Measurement . . . . . . . . . . . . 105
6.4 The Similarity Calculation for Complex Elements . . . . . 1086.4.1 Relations . . . . . . . . . . . . . . . . . . . . . . . . . 1086.4.2 Clusters . . . . . . . . . . . . . . . . . . . . . . . . . 1086.4.3 Ontologies . . . . . . . . . . . . . . . . . . . . . . . . 110
6.5 Further Refinements . . . . . . . . . . . . . . . . . . . . . . 1106.5.1 Heuristics for Mapping Refinement Based on the
Calculated Similarity . . . . . . . . . . . . . . . . . . 1116.5.2 Managing User Feedback . . . . . . . . . . . . . . . 1116.5.3 Other Matchers and Combination of Similarity Val-
ues . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1126.6 Application Scenarios . . . . . . . . . . . . . . . . . . . . . . 1126.7 Concluding Remarks . . . . . . . . . . . . . . . . . . . . . . 113
III Implementation and Assessment 115
7 The Prototype Realization 1177.1 Components in the Realization . . . . . . . . . . . . . . . . 1177.2 The Modeling Environment . . . . . . . . . . . . . . . . . . 1187.3 The CnS Client as a Classifier . . . . . . . . . . . . . . . . . 1207.4 The iMapper System . . . . . . . . . . . . . . . . . . . . . . 1237.5 Concluding Remarks . . . . . . . . . . . . . . . . . . . . . . 127
8 Case Studies and Evaluation 1298.1 Experiment Design . . . . . . . . . . . . . . . . . . . . . . . 129
8.1.1 Performance Criteria . . . . . . . . . . . . . . . . . . 1298.1.2 Domains and Source Ontologies . . . . . . . . . . . 132

vi CONTENTS
8.1.3 Experiment Setup . . . . . . . . . . . . . . . . . . . . 1368.2 The Analysis Results . . . . . . . . . . . . . . . . . . . . . . 138
8.2.1 Filters and Variables . . . . . . . . . . . . . . . . . . 1398.2.2 Quality of iMapper’s Predictions . . . . . . . . . . . 1418.2.3 Further Experiment . . . . . . . . . . . . . . . . . . . 1448.2.4 Discussion . . . . . . . . . . . . . . . . . . . . . . . . 151
8.3 Concluding Remarks . . . . . . . . . . . . . . . . . . . . . . 152
9 Applicability of the Approach – A Scenario 1559.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . 1559.2 Agent Communication . . . . . . . . . . . . . . . . . . . . . 157
9.2.1 KQML . . . . . . . . . . . . . . . . . . . . . . . . . . 1589.2.2 FIPA . . . . . . . . . . . . . . . . . . . . . . . . . . . 159
9.3 The Explanation Ontology . . . . . . . . . . . . . . . . . . . 1609.3.1 Explanation Interaction Protocol . . . . . . . . . . . 1629.3.2 Explanation Profile . . . . . . . . . . . . . . . . . . . 1649.3.3 Explanation Strategy . . . . . . . . . . . . . . . . . . 165
9.4 A Working Through Example . . . . . . . . . . . . . . . . . 1669.4.1 Two Product Catalogues . . . . . . . . . . . . . . . . 1669.4.2 A Specific Explanation Interaction Protocol . . . . . 1689.4.3 A Specific Explanation Profile and Strategy . . . . . 170
9.5 Implementing the Explanation Ontology in AGORA . . . . 1749.5.1 The AGORA Multi-agent System . . . . . . . . . . . 1749.5.2 Implementing Explanation Algorithm in AGORA . 177
9.6 Concluding Remarks . . . . . . . . . . . . . . . . . . . . . . 178
10 Conclusions and Future Work 18110.1 Summary of Contributions . . . . . . . . . . . . . . . . . . . 18110.2 Limitation and Future Directions . . . . . . . . . . . . . . . 184
10.2.1 Extended Customizability . . . . . . . . . . . . . . . 18410.2.2 User Studies on Semantic Enrichment . . . . . . . . 18510.2.3 Model Quality . . . . . . . . . . . . . . . . . . . . . . 18610.2.4 Technical Method Revision . . . . . . . . . . . . . . 187
A Nomenclature 189A.1 Abbreviations . . . . . . . . . . . . . . . . . . . . . . . . . . 189

CONTENTS vii
B XML Formats Used in the iMapper System 191B.1 Ontology Exported from RefEdit . . . . . . . . . . . . . . . 191B.2 Classification Results Returned by CnS Client . . . . . . . . 195B.3 Mapping Assertions Generated by iMapper . . . . . . . . . 195
C The Plan and Action File Formats in AGORA 197C.1 DTD of the Plan File . . . . . . . . . . . . . . . . . . . . . . 197C.2 DTD of the Action File . . . . . . . . . . . . . . . . . . . . . 198
D The KQML Reserved Performatives 201

viii CONTENTS

List of Figures
2.1 The basic layer of data representation standards for the Se-mantic Web . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
2.2 Classification of types of ontologies, based on the level offormality (adopted from [81]). . . . . . . . . . . . . . . . . . 20
2.3 Classification of ontology specification languages. . . . . . 232.4 States and activities in the ontology life-cycle [57]. . . . . . 292.5 A generic architecture of ontology-based applications, adopted
from [111]. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
3.1 The cosine of β is used to measure the similarity betweend j and q. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
3.2 Examples of two steps in the morphological parser. . . . . 423.3 A portion of the WordNet 2.0 entry for the noun book. . . . 473.4 Hypernym chains for sense one of noun book. . . . . . . . . 49
4.1 Framework of issues on ontology integration, from [83]. . . 544.2 Hard problems in ontology mismatches. . . . . . . . . . . . 574.3 Classification of schema matching approaches, from [135]. 624.4 Chimaera in name resolution mode suggesting a merge of
Mammal and Mammalia. . . . . . . . . . . . . . . . . . . . 654.5 PROMPT screenshot. . . . . . . . . . . . . . . . . . . . . . . 674.6 FCA-merge process. . . . . . . . . . . . . . . . . . . . . . . . 674.7 The MOMIS Architecture. . . . . . . . . . . . . . . . . . . . 694.8 The GLUE Architecture. . . . . . . . . . . . . . . . . . . . . 704.9 Characteristics of studied ontology mapping and merging
systems. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72
5.1 Graphical notations of basic RML constructs. . . . . . . . . 825.2 Graphical notations of RML abstraction mechanism. . . . . 83
ix

x LIST OF FIGURES
5.3 Mapping assertion metamodel (Adapted from Sari Hakkarainen[1999]). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 87
5.4 Semantic enrichment in ontology comparison. . . . . . . . 905.5 Semantic enrichment through extension analysis. . . . . . . 915.6 Representative feature vector as enrichment structure. . . . 935.7 Two phases of the whole mapping process. . . . . . . . . . 935.8 Overview of the semantic enrichment process. . . . . . . . 955.9 Contributions from relevant parts when calculating fea-
ture vector for non-leaf concept. . . . . . . . . . . . . . . . . 97
6.1 Two phases of the whole mapping process. . . . . . . . . . 1016.2 Major steps in the mapping phase. . . . . . . . . . . . . . . 1036.3 Example on hyponymy relation in WordNet used for the
path length measurement. . . . . . . . . . . . . . . . . . . . 1066.4 Example of calculating cluster similarity. . . . . . . . . . . . 109
7.1 Components of the system. . . . . . . . . . . . . . . . . . . 1187.2 The Referent Modeling Editor. . . . . . . . . . . . . . . . . . 1197.3 CnS Client in the classification mode. . . . . . . . . . . . . . 1217.4 The iMapper architecture. . . . . . . . . . . . . . . . . . . . 1227.5 The GUI of iMapper system. . . . . . . . . . . . . . . . . . . 125
8.1 Precision and recall for the mapping results. . . . . . . . . 1318.2 Snapshots of the product catalogue extracted from UNSPSC.1338.3 Snapshots of the product catalogue extracted from eCl@ss. 1348.4 Snapshots of the travel ontology extracted from Open Di-
rectory Project . . . . . . . . . . . . . . . . . . . . . . . . . . 1378.5 Snapshots of the travel ontology extracted from Yahoo di-
rectory . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1378.6 Precision versus recall curve for the two tasks. . . . . . . . 1438.7 Precision versus recall curves pre and after using WordNet
for postprocessing in tourism domain. . . . . . . . . . . . . 1448.8 Precision versus recall curves pre and after using WordNet
for postprocessing in product catalogue domain. . . . . . . 1458.9 Precision recall curves at three confidence level in the case
of individual based gold standard in tourism domain. . . . 1478.10 Precision recall curves at three confidence levels in the case
of group discussion based gold standard in tourism domain.148

LIST OF FIGURES xi
8.11 Precision recall curves at high confidence level in the caseof individual and group based gold standard in tourismdomain. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 149
8.12 Precision recall curves at medium confidence level in thecase of individual and group based gold standard in tourismdomain. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 150
8.13 Precision recall curves at low confidence level in the caseof individual and group based gold standard in tourismdomain. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 151
8.14 Precision recall curves when structure information is turnedon/off in tourism domain. . . . . . . . . . . . . . . . . . . . 152
9.1 The composition of an explanation mechanism. . . . . . . . 1619.2 An ER model of the general explanation interaction protocol.1639.3 An ER model of the the main concepts in the explanation
profile. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1649.4 Segments of two product catalogues. . . . . . . . . . . . . . 1679.5 A specific explanation interaction protocol. . . . . . . . . . 1699.6 Agora node functions. . . . . . . . . . . . . . . . . . . . . . 1759.7 Simple agent architecture. . . . . . . . . . . . . . . . . . . . 176

xii LIST OF FIGURES

List of Tables
3.1 An example of a tagged output using the Penn Treebanktagset. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
3.2 Scope of the current WordNet 2.0 release in terms of num-ber of words, synsets, and senses. . . . . . . . . . . . . . . 46
3.3 Noun relations in WordNet. . . . . . . . . . . . . . . . . . . 473.4 Verb relations in WordNet. . . . . . . . . . . . . . . . . . . 483.5 Adjective and adverb relations in WordNet. . . . . . . . . 48
8.1 The product catalogue ontologies – characteristics of thefraction of the ontologies used for the experiment. . . . . . 132
8.2 The tourism ontologies - characteristics of the fraction ofthe ontologies used for the experiment. . . . . . . . . . . . 135
8.3 Summary of the manually discovered mappings. . . . . . . 1428.4 Analysis of the inter-user agreement. . . . . . . . . . . . . . 144
9.1 An example of mappings between two product catalogues. 1689.2 Meaning of performatives in the Explanation Ontology. . . 171
A.1 Abbreviations used in the thesis. . . . . . . . . . . . . . . . 189
C.1 Explanation of plan DTD. . . . . . . . . . . . . . . . . . . . 198
D.1 List of KQML reserved performatives. . . . . . . . . . . . . 201
xiii

xiv

Preface
This thesis is submitted to the Norwegian University of Science and Tech-nology (NTNU) in partial fulfillment of the requirements for the degreedoktor ingeniør. The work has been carried out at the Information SystemsGroup (IS-gruppen), within the department of Computer and Informa-tion Science (IDI), under the supervision of Professors Arne Sølvberg andJon Atle Gulla. Part of the work was conducted while I was having a sixmonth research stay at the Business Informatics Group, Free Universityof Amsterdam. The work presented in this thesis has been financed byAccenture Norway, for which I am grateful.
Acknowledgments
I thank my supervisors for their time, patience, discussions and valuablecomments. I also enjoyed the freedom that was given during the pursu-ing of my research directions.
Part of the work has been carried out at the Business InformaticsGroup, Free University of Amsterdam. I would like to thank ProfessorHans Akkermans for inviting me to work with his group. I would alsolike to thank fellow colleagues there, in particular, Ziv Baida, Vera Kart-seva, Michel Klein, and Borys Omelayenko, for inspiring discussions andpractical support.
I enjoyed cooperating with professor Mihhail Matskin, who gave mevaluable guidance and constructive criticism. To Sari Hakkarainen, I amgrateful for her guidance and help in the early phase of my thesis writingas well as proof reading in the final stage of the work.
Thanks to all at IDI, in particular my colleagues in the InformationSystems group, for the stimulating working atmosphere. A warm thankto Darijus Strasunskas, whom I shared office with for three years. I have
xv

xvi PREFACE
great memories.To friends both in Norway and in China, it is a great pleasure to record
my appreciation of the joy I shared with them and the help I receivedfrom them. A warm thank to the group, which I have shared lunch withfor the last two years, for all the jokes, laughters and lively discussions.
To my parents, I own thanks for their wonderful love and encour-agement. I would also like to thank my brother, since he insisted that Ishould do so. My sincere thank goes to Jinghai for his support, under-standing and encouragement all the way through.
Xiaomeng SuOctober 27, 2004

Part I
Background and Context
1


Chapter 1
Introduction
System interoperability is an important issue, widely recognized in in-formation technology intensive enterprises and in the research commu-nity of information systems (IS). Increasing dependence and coopera-tion among organizations have created a need for many organizationsto access remote as well as local information sources. The wide adop-tion of the World Wide Web to access and distribute informations furtherstresses the need for systems interoperability.
1.1 Background
The current World Wide Web has well over 4.2 billion pages [63], but thevast majority of them are in human readable format only. As a conse-quence software agents cannot understand and process this information,and much of the potential of the Web has so far remain untapped.
In response, researchers have created the vision of the Semantic Web[12], where data has structure and ontologies describe the semantics ofthe data. The idea is that ontologies allow users to organize informationinto taxonomies of concepts, each with their attributes, and describe rela-tionships between concepts. When data is marked up using ontologies,software agents can better understand the semantics and therefore moreintelligently locate and integrate data for a wide variety of tasks.
Ontology as a branch of philosophy is the science of what is, that isthe kinds and structures of objects, properties, events, processes and rela-tions in every area of reality. Philosophical ontology seeks a classificationthat is exhaustive in the sense that all types of entities are included in the
3

4 CHAPTER 1. INTRODUCTION
classification [147]. In information systems, a more pragmatic view toontologies is taken, where an ontology is considered a kind of agreementon a domain representation. As such, an engineering viewpoint of on-tologies is often taken in information system, as reflected in a commonlycited definition: an ontology is a formal, explicit specification of a sharedconceptualization [64]. ’Conceptualization’ refers to an abstract modelof phenomena in the world by having identified the relevant concepts ofthose phenomena. ’Explicit’ means that the type of concepts used, andthe constraints on their use are explicitly defined. ’Formal’ refers to thefact that the ontology should be machine readable. ’Shared’ reflects thatontology should capture consensual knowledge accepted by the commu-nities.
Ontology is a key factor for enabling interoperability in the SemanticWeb [12]. Ontologies are central to the Semantic Web because they allowapplications to agree on the terms that they use when communicating. Itfacilitates communication by providing precise notions that can be usedto compose messages (queries, statements) about the domain. For thereceiving party, the ontology helps to understand messages by provid-ing the correct interpretation context. Thus, ontologies, if shared amongstakeholders, may improve system interoperability across ISs in differentorganizations and domains.
However, it has long been argued that there is no one single universalshared ontology, which will be applauded by all players. It seems clearthat ontologies face the same or even harder problems with respect toheterogeneity as any other piece of information [168]. The attempts toimprove system interoperability will therefore rely on the reconciliationof different ontologies used in different systems. The reconciliation is of-ten approached by manual or semi-automated integration of ontologies.The technical issue here is to help resolving ontology mismatches thatevidently appear in semantic integration.
1.2 About the Problem
The Semantic Web offers a compelling vision, but it also raises many dif-ficult challenges. The Semantic Web proposes to standardize a semanticmarkup method for resources based on the one hand on a uniform for-malism, XML, and on the other hand on an organization of knowledgeinto ontologies. In this perspective, it is necessary to carry out complex

1.2. ABOUT THE PROBLEM 5
tasks such as answering queries or globally computing on distributedinformation sources managed by distinct, heterogeneous entities. Thescientific difficulties are linked to the exact definition of the formalismsto be chosen, to the impossibility of maintaining a worldwide central-ization of the ontologies, which raises problems of application interoper-ability. Other challenges concern robustness because minor errors mustin no event have major consequences, and the scalability of these tech-niques that must work in a reasonable time with the huge amounts ofdistributed data present on the whole Web and with ontologies whichcan contain hundreds of thousands of semantic concepts, even when theyonly concern specialized fields.
Among the above listed scientific challenges, the key focus of thiswork is on comparing and mapping different ontologies. Given the de-centralized nature of the development of the web, the number of on-tologies will be huge. Many of these ontologies will describe similardomains, but using different terminologies and others will have over-lapping domains. To integrate data from disparate ontologies, we mustknow the semantic correspondence between their elements.
To motivate the importance of ontology comparison, we give two ex-amples on its usage in the relevant application domains.
1. Ontology integration: Many works on ontology comparison has beenmotivated by ontology integration: given a set of independentlydeveloped ontologies, construct a single global ontology. In a databasesetting, this is the problem of integrating independently developedschemas into a global view. The first step in integrating the ontolo-gies is to identify and characterize inter-ontology correspondences.This is the process of ontology comparison. Once the correspon-dence are identified, matching elements can be confirmed or recon-ciled under a coherent, integrated ontology.
2. Message translation: In an Electronic Commerce setting, trading part-ners frequently exchange messages that describe business transac-tions. Usually, each trading partner uses its own message format.Message format may differ in both syntax (i.e., EDI, XML or customdata structure) and semantics (i.e., different referent ontologies). Toenable systems to exchange messages, application developers needto convert messages between the formats required by different trad-ing partners. Part of the message translation problem is translating

6 CHAPTER 1. INTRODUCTION
between different message ontologies. Translating between differ-ent message ontologies is, in part, an ontology mapping problem.Today, application designers need to specify manually how mes-sage formats are related. A mapping operation would reduce theamount of manual work by generating a draft mapping betweenthe two message ontologies, which an application designer can sub-sequently validate and modify if needed. In the Semantic Web set-ting, this contributes to mapping messages between autonomousagents.
In order to achieve integration of ontologies, it is necessary to inte-grate both syntax and semantics of the involving ontologies. There isa wide agreement on syntactical issues in the software community, andsyntax problem may be solved if there is a willingness among the actorsto do so. For instance, [64] describes a mechanism for defining ontolo-gies that are portable over representation systems. Definitions written ina standard format for predicate calculus are translated by a system calledOntolingua into specialized representations, including frame based lan-guages as well as relational languages. The deep and unsolved problemsare thus with the semantic integration issue. As stated in [73] , the inte-gration of ontologies remains an expensive, time consuming and manualactivity, even though ontology interchange formats exist.
Summing up, as one of the fundamental elements of the ontologyintegration process, mapping processes typically involve analyzing theontologies and comparing them to determine the correspondence amongconcepts and detect possible conflicts. A set of mapping assertions is themain output of a mapping process. The mapping assertions can be useddirectly in a translator component, which translates statements that areformulated by different ontologies. Alternatively, a follow-up integrationprocess can use the mappings to detect merging points.
So, interoperability among applications in heterogeneous systems de-pends critically on the ability to map between their corresponding on-tologies. Today, matching between ontologies is still largely done byhand, in a labor-intensive and error-prone process [124]. As a conse-quence, semantic integration issues have now become a key bottleneckin the deployment of a wide variety of information management appli-cations.

1.3. OBJECTIVES 7
1.3 Objectives
The purpose of the work is to introduce a method for finding semantic cor-respondence among the ontologies with the intention to support interoperabilityof ISs. The overall purpose is decomposed into the intermediate goals ofthis work. The goals of this work are to:
1. introduce a theoretical framework for ontology comparison and forspecification of mappings between ontologies,
2. propose a method for semantic enrichment and discovery of se-mantic correspondence between the ontologies,
3. provide an analysis of the implementation and evaluation of themethod in empirical experiments, and
4. analyze the applicability of the mapping approach in supportinginteroperability.
In the sequel we will explain how the above objectives have been ap-proached and motivate for the main decisions made during work on thethesis.
1.4 Approach and Scope
Ontology mapping concerns the interpretations of models of a Universeof Discourse (UoD), which in their turn are interpretations of the UoD.There is no argumentation for these interpretations to be the only existingor complete conceptualizations of the state of affairs in the real world.We assume that the richer a description of a UoD is, the more accurateconceptualization we achieve of the same UoD through interpretation ofthe descriptions.
Hence, the starting point for comparing and mapping heterogeneoussemantics in ontology mapping is to semantically enrich the ontologies.Semantic enrichment facilitates ontology mapping by making explicitdifferent kinds of ”hidden” information concerning the semantics of themodeled objects. The underlying assumption is that the more semanticsthat are explicitly specified about the ontologies, the more feasible theircomparison becomes.
The semantic enrichment techniques may be based on different the-ories and make use of a variety of knowledge sources [71]. We base our

8 CHAPTER 1. INTRODUCTION
approach on extension analysis, i.e. the instance information that a con-cept possesses. The instances that we use are documents that have beenassociated with the concepts. The idea behind is that written documentsthat are used in a domain inherently carry the conceptualizations that areshared by the members of the community. This approach is in particu-lar attractive on the World Wide Web, because huge amounts of free textresources are available.
On the other hand, we also consider information retrieval (IR) tech-nique as one of the vital components of our approach. With informationretrieval, a concept node in the first ontology is considered a query to bematched against the collection of concept nodes in the second ontology.Ontology mapping thus becomes a question of finding concept nodesfrom the second ontology that best relate to the query node. One of themajor advantages of employing IR is domain independence.
Converging the above two ideas, it becomes clear that the enrichedsemantic information of a concept needs to be represented in a way thatis compatible with an IR framework. Given that vector space model isthe most used one in IR, it is natural to think of representing the instanceinformation in vectors, where the documents under one concept becomebuilding material for the feature vector of that concept.
In some cases, ontologies exist without any available instance infor-mation. We tackle that by assigning instance to the ontologies. That iswhere document classification comes into play, aiming at automating theprocess of assigning documents to concept nodes.
1.5 Way of Working and Major Contributions
Considering the research methodology in the above context, the way ofworking consists of a descriptive analysis phase, a normative develop-ment and construction phase and an empirical evaluation phase. All to-gether the phases include the following steps.
1. The survey of ontology mapping methods step includes an investiga-tion of existing methods of ontology mapping and an analysis ofthe process of ontology mapping, together with the properties char-acterizing such a process.
2. The survey of applicable parts of information retrieval and computationallinguistics step includes an investigation of applicable parts of the

1.5. WAY OF WORKING AND MAJOR CONTRIBUTIONS 9
relevant theories and an analysis of the linguistic basis of the theo-ries.
3. The analysis of requirements step includes an inventory of the prob-lems in mapping of ontology concepts on the specification level andan analysis of the raised requirements.
4. The development of semantic enrichment instruments step includes aspecification of the component (result of extension analysis) to beused for semantic enrichment of ontology and stepwise instruc-tions for its construction.
5. The development of mapping algorithm step includes definition of anabstract ontology mapping algorithm and description of the step-wise calculation of correspondence of ontology concepts based onthe enriched structure as specified in the previous step.
6. The prototype application step includes development and implemen-tation of a prototypical environment for ontologies based on themapping algorithm in the previous step.
7. The empirical application step includes experimental evaluation ofthe approach of using semantic enrichment and the proposed map-ping algorithm in two case studies.
8. The applicability analysis step includes the experiment of using thediscovered mappings to improve semantic interoperability in a multi-agent environment - AGORA.
The application of the above way of working has resulted in the con-tributions of this thesis and the earlier deliverables as described below.
A major contribution of this thesis is the development and specifica-tion of an approach to semantic integration of ontologies. The work hasbeen directed to improve interoperability across heterogeneous systems,in particular to improve that of the multi-agent systems.
During the work it has been natural to incorporate results from ear-lier and parallel work done by other members of the Information Sys-tem Group and the Distributed Intelligent System Group. Some relevantvenues have also been explored by formulating proper tasks for diplomastudents that I have supervised at the institute.
My own contribution are in particular related to the following:

10 CHAPTER 1. INTRODUCTION
1. establish a particular approach to use extension based semantic en-richment method for ontology mapping and integration,
2. propose an architecture for a system to support our approach aswell as implement the system in a prototype, and
3. present the results from the validation experiment that evaluatesour approach against user performed manual activities.
The major contribution of the thesis as a whole may be summarizedas follows:
1. The thesis has, apart from proposing and experimenting with a par-ticular approach for semantic integration of ontologies, contributedto the understanding of semantic distance between ontologies ingeneral.
2. Moreover, the work has shown the feasibility of using the discov-ered mappings to improve interoperability in a multi-agent envi-ronment - AGORA.
3. Finally, the work has laid the ground for analyzing and experiment-ing with other mapping approaches and different combinations ofthem as well.
1.6 Publications
This thesis is partly based on papers presented at conferences publishedduring the work that I was part of, as listed below:
• Xiaomeng Su and Lars Ilebrekke A comparative study of ontology lan-guages and tools, in Proceedings of Conference on Advanced Infor-mation System Engineering (CAiSE’ 02). Toronto, Canada, 2002,LNCS, Springer-Verlag.
This is a state-of-the-art paper, presenting a result of our initial lit-erature study on ontology engineering languages and tools. It re-views existing ontology languages and tools with respect to a qual-ity evaluation framework.
• Xiaomeng Su and Lars Ilebrekke, Using a Semiotic Framework for aComparative Study of Ontology Languages and Tools, book chapter in J.

1.6. PUBLICATIONS 11
Krogstie, T. Halpin and K. Siau (Eds.), Information Modeling Meth-ods and Methodologies, IDEA Group Publishing. 2004.
This is an extended version of the previous state-of-the-art paper.
• Xiaomeng Su, Terje Brasethvik and Sari Hakkarainen Ontology map-ping through analysis of model extension, The 15th Conference on Ad-vanced Information Systems Engineering (CAiSE ’03), CAiSE Fo-rum, Short Paper Proceedings, Published by Technical Universityof Aachen (RWTH), Klagenfurt/Velden, Austria, 16-20 June, 2003
This is a position paper, introducing the basic design rationale ofthe approach and intended way of implementation. It gives anoverview of the ideas of the approach.
• Xiaomeng Su, Sari Hakkarainen and Terje Brasethvik, Semantic en-richment for improving system interoperablity, in Proceedings of the19th ACM Symposium on Applied Computing (SAC’04), ACM Press,Nicosia, Cyprus, March, 2004.
This is a core paper, following up the ideas generated from the pre-vious position paper. It presents the specification, design and im-plementation of the iMapper approach in detail, constituting thebase of this thesis.
• Xiaomeng Su and Jon Atle Gulla, Semantic enrichment for ontologymapping, in Proceedings of the 9th International Conference on Nat-ural Language to Information Systems (NLDB04), LNCS Springer-Verlag. 2004
This is a follow up paper of the previous SAC’04 paper. It de-scribes the added linguistic analysis functionality of the mappingalgorithm using WordNet. More over, the evaluation of the systemin terms of precision/recall of the mapping prediction in two casestudies is presented.
• Xiaomeng Su, Mihhai Matskin and Jinghai Rao, Implementing Ex-planation Ontology for Agent System, In Proceeding of IEEE Inter-national Conference on Web Intelligence (WI’03), IEEE ComputerSociety, Halifax, Canada, 2003.
This paper describes the applicability of the mapping approach inan agent communication setting. It presents both the theoreticalframework for using the results in an agent environment and the

12 CHAPTER 1. INTRODUCTION
practical example on integrating the result into a running agentplatform – AGORA.
1.7 Thesis Outline
In this chapter, an introduction to the thesis is given. The backgroundof the work, the main problem tackled, the overall objectives, the way ofworking and the main contributions achieved are described. The struc-ture of the rest of the thesis follows the way of working, and it implicitlyincludes a descriptive, normative and empirical part. The outline of thethesis is as follows.
Related work and underlying existing theories are outlined in the de-scriptive part. Chapter 2 introduces the basic concepts of ontology engi-neering in order to provide basic understanding of ontologies, which arethe basis of this work. Chapter 3 provides a brief overview of the variousfields of research that are referred to and have influenced the work pre-sented in this thesis. In chapter 4 a brief survey of state-of-the-art in thedevelopment of ontology languages and tools are given. In addition, ageneral taxonomy of different ontology mapping methods is proposed.
The main contributions of this thesis are presented in the normativepart. A novel ontology mapping framework, a semantic enrichment methodand a ontology mapping algorithm are introduced. Chapter 5 proposesand specifies an extension analysis based semantic enrichment method inthe context of ontology mapping. The modeling language used in the ex-amples throughout the thesis is described in this chapter as well. Chapter6 introduces a computational framework for mapping of ontology ele-ments that are semantically enriched. Chapter 7 describes the prototypeimplementation of the computational framework.
Two case studies underlying an evaluation of the proposed approachand technique are discussed in the empirical part. Chapter 8 presents ex-periences from two case studies as well as an analysis of empirical ob-servations of the proposed semantic enrichment and mapping methods.The application domain of the first case study is the product catalogueintegration task. The performance of the prototype system is evaluatedin terms of precision and recall. In the same chapter, another case studyin the application domain of tourism sector are presented, which also isaimed at evaluating the validity of the proposed approach. Chapter 9presents a scenario where the mapping results generated by the system

1.7. THESIS OUTLINE 13
can be used to improve system interoperability in a multi-agent environ-ment – AGORA.
Finally, Chapter 10 outlines a number of directions for future work,presents the conclusions and summarizes the contributions of the work.

14 CHAPTER 1. INTRODUCTION

Chapter 2
Basic Ontology Concepts
This chapter introduces the basic concepts of ontology engineering. Itsmain goal is to provide basic understanding of ontologies, which are thebasis of this work. This chapter is partly based on previously publishedpapers [159] [160].
2.1 The Semantic Web
”...The Semantic Web is an extension of the current web inwhich information is given well-defined meaning, better en-abling computers and people to work in co-operation.”
Tim Berners-Lee, James Hendler, Ora Lassila,The semantic Web, Scientific American, May, 2001
The Web today enables people to access documents and services on theInternet. Today’s methods require human intelligence. The interface toservices is represented in web pages written in natural language, whichmust be understood and acted upon by a human. The Semantic Web is anextension of the current Web in which information is given well-definedmeaning, enabling computers and people to work in better cooperation.The vision of the Semantic Web was first introduced by Tim Berners-Lee [12]. An example in [13] illustrated how the Semantic Web mightbe useful. ”Suppose you want to compare the price and choice of flowerbulbs that grow best in your zip code, or you want to search online cat-alogs from different manufactures for equivalent replacement parts for a
15

16 CHAPTER 2. BASIC ONTOLOGY CONCEPTS
Volvo 740. The raw information that may answer these questions, mayindeed be on the Web, but it is not in a machine-usable form. You stillneed a person to discern the meaning of the information and its rele-vances to your needs”.
The Semantic Web addresses this problem in two ways. First, it willenable communities to expose their data so that a program does not haveto strip the formatting, pictures and ads from a Web page to guess atthe relevant bits of information. Secondly, it will allow people to write(generate) files which explain - to a machine - the relationships betweendifferent sets of data. For example, one will be able to make a ”semanticlink” between a database with a ”zip-code” column and a form with a”zip” field that they actually mean the same thing. This will allow ma-chines to follow links and facilitate the integration of data from manydifferent sources.
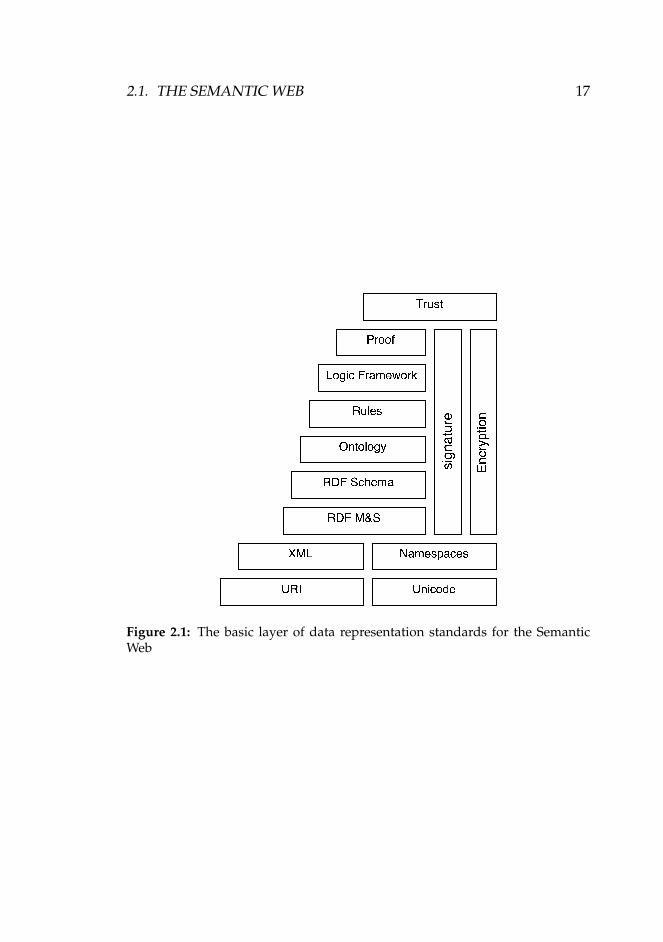
The Semantic Web will be built on layers of enabling standards. Fig-ure 2.1 shows the enabling standards of the Semantic Web.
• Uniform Resource Identifiers (URIs) is a fundamental componentof the current Web, which provides the ability to uniquely identifyresources as well as relations among resources.
• eXtensible Markup Language (XML) is a fundamental componentfor syntactical interoperability.
• The Resource Description Framework (RDF) family of standardsleverages URI and XML to allow documents being described in theform of metadata.
• RDF Schema (RDFS) is an extension of RDF, which defines a simplemodeling language on top of RDF.
• The ontology layer provides more meta-information such as cardi-nality of relationships, the transitivity of relationships etc.
• The logic layer enables the writing of rules.
• The proof layer executes the use of rules and evaluates, togetherwith the trust layer, mechanism for applications to decide whetherto trust the given proof or not.
• Digital signatures are used to detect alterations to documents.
2.1. THE SEMANTIC WEB 17
Figure 2.1: The basic layer of data representation standards for the SemanticWeb

18 CHAPTER 2. BASIC ONTOLOGY CONCEPTS
2.2 The Role of Ontology
The word ontology comes from the Greek ontos for being and logos for word.It is a relatively new term in the long history of philosophy, introduced by the19th century German philosophers to distinguish the study of being as suchfrom the study of various kinds of beings in the natural sciences. The moretraditional term is Aristotle’s word category (kathgoria), which he used for clas-sifying anything that can be said or predicated about anything [151] [150]. Theterm ”ontology” has been used in many ways and across different com-munities [65] [66]. Ontology as a branch of philosophy is the science ofwhat is, that is the kinds and structures of objects, properties, events, pro-cesses and relations in every area of reality. Philosophical ontology seeksa classification that is exhaustive in the sense that all types of entities areincluded in the classification [147] [146]. In information systems, a morepragmatic view to ontology is taken, where ontology is considered as akind of agreement on a domain representation. As such, an engineeringviewpoint of ontology is often taken in information systems, as reflectedin a commonly cited definition: ontology is an explicit account or repre-sentation of a conceptualization [166]. This conceptualization includes aset of concepts, their definitions and their inter-relationships. Preferablythis conceptualization is shared or agreed. We also observed that ontolo-gies is a natural continuation of thesaurus in digital library research andconceptual schemas in database and information system research.
Next, we will briefly describe the way an ontology explicates conceptsand their properties. Furthermore, we list the benefits of this explicationin different typical application scenarios.
2.2.1 Shared Vocabularies and Conceptulizations
In general, every person has her individual view on the world and thethings she has to deal with every day. However, there is a common basisof understanding in terms of the language we use to communicate witheach other. Terms from natural language can therefore be assumed to be ashared vocabulary relying on (mostly) common understanding of certainconcepts with little variety. We often call this idea a ”conceptualization”of the world. Such conceptualizations provide terminologies that can beused for communication.
The example of natural language already shows that a conceptual-ization is never universally valid, but rather it is only valid for a limited

2.2. THE ROLE OF ONTOLOGY 19
number of persons committing to that conceptualization. This fact is re-flected in the existence of different languages which differ more or less.Things get even worse when we are not concerned with every day lan-guage but with terminologies developed for specific areas. In these cases,we often find situations where even the same term may refer to differentphenomena. The use of the term ”ontology” in philosophy and its usein computer science may well serve as an example. The consequence is aseparation into different groups that share a common terminology and itsconceptualization. These groups, which commit to the same ontologiesare also called information communities or ontology groups [55].
The main problem with the use of a shared vocabulary according to aspecific conceptualization of the world is that much of the information re-mains implicit. Ontologies have been set out to overcome the problem ofimplicit and hidden knowledge by making the conceptualization of a do-main explicit. This corresponds to one of the early definitions of the termontology in computer science [64]: ”An ontology is a formal explicit specifi-cation of a shared conceptualization”. A conceptualization refers to an abstractmodel of some phenomenon in the world that identifies the relevant con-cepts of the phenomenon. Explicit means that the type of concepts usedand the constraints on their use are explicitly defined. Formal refers to thefact that the ontology should be machine understandable. Shared reflectsthe notion that an ontology captures consensual knowledge, that is, it isnot restricted to one individual but accepted by a group [56].
An ontology is used to make assumptions about the meaning of aterm available. It can also be seen as an explication of the context a termis normally used in. Lenat [91] [92] for example, describes context interms of twelve independent dimensions that have to be shown in or-der to understand a piece of knowledge completely and also shows howthese dimensions can be explicated using the Cyc ontology.
2.2.2 Types of Ontologies
There are different ways in which an ontology may explicate a concep-tualization and the corresponding context knowledge. This may rangefrom a purely informal natural language description of a term corre-sponding to a glossary up to strictly formal approaches with the expres-sive power of full first order predicate logic or even beyond (e.g., On-tolingua [64] [58]).
There exist several ways to categorize types of ontologies. Jasper and

20 CHAPTER 2. BASIC ONTOLOGY CONCEPTS
Figure 2.2: Classification of types of ontologies, based on the level of formality(adopted from [81]).
Uschold distinguish two ways in which the mechanisms for the concep-tualization of domain knowledge by an ontology can be compared [167].
Level of Formality
One of the well-known divisions to categorize types of ontologies is bytheir level of formality: ranging from a list of terms to concepts havingrelations and axioms. Figure 2.2 summarizes these distinctions. It alsoincludes other terminologies for these differences as used by for example[33], discussing lightweight and heavyweight ontologies.
Extent of Explication
The other comparison criterion is the extent of explication that is reachedby the ontology. This criterion is very much connected with the expres-sive power of the specification language used. The least expressive spec-ification of an ontology consists of an organization of terms in a networkusing two-placed relations. This idea goes back to the use of semanticnetworks. More expressive ontology languages like RDF schema contain

2.2. THE ROLE OF ONTOLOGY 21
class definitions with associated properties that can be restricted by socalled constraint properties. However, default values and value rangedescriptions are not expressive enough to cover all possible conceptual-izations. A greater expressive power can be provided by allowing classesto be specified by logical formulas. These formulas can be restricted to adecidable subset of first order logic. This is the approach of descriptionlogic [45]. Nevertheless there are also approaches allowing for more ex-pressive description. In Ontolingua, for example, classes can be definedby arbitrary KIF-expressions. Beyond the expressiveness of first orderpredicate logic there are also special purpose languages that have an ex-tended expressiveness to cover specific needs of their application areas.
On the other hand, the above two criteria are not the only methods ofcategorizing ontologies. Other variations include level of generality [65],ontology base and commitment layer [78] [122].
2.2.3 Beneficial Applications
In [36], it is stated that ontologies are used in e-commerce to enable machine-based communication between buyers and sellers, vertical integrationof markets (such as verticalNet www.verticalnet.com), and descriptionreuse between different marketplaces. Search engines also use ontolo-gies to find pages with words that are syntactically different but semtan-ically similar. In particular, the following area will benefit from the useof ontologies.
Semantic Web
The Semantic Web aims at tackling the growing problems of traversingthe expanding web space, where currently most web resources can onlybe found by syntactical matches. The Semantic Web relies heavily on for-mal ontologies that structure underlying data for the purpose of compre-hensive and transportable machine understanding. They properly definethe meaning of data and metadata [152]. In general, one may consider theSemantic Web more as a vision than a concrete application.
Knowledge Management
Knowledge management deals with acquiring, maintaining and access-ing knowledge of an organization. The technologies of the Semantic Web

22 CHAPTER 2. BASIC ONTOLOGY CONCEPTS
build the foundation to move from a document oriented view of knowl-edge management to a knowledge pieces oriented view where knowl-edge pieces are connected in a flexible way. Intelligent push service, theintegration of knowledge management and business process as well asconcepts and methods for supporting the vision of ubiquitous knowl-edge are urgently needed. Ontologies are the key means to achieve thisfunctionality. They are used to annotate unstructured information withsemantic information, to integrate information and to generate user spe-cific views that make knowledge access easier. Applications of ontologiesin knowledge management are described in [162] [39].
Interoperability
An important application area for ontology is the integration of existingsystems. In order to enable machines to understand each other we needto explicate the context of each system in a formal way. Ontologies arethen used as inter-lingua for providing interoperability since they serveas a common format for data interchange [153] [166]. Such a feature isspecially desirable in large scale web commerce environments [129] [56].
Information Retrieval
Common information retrieval techniques either rely on a specific encod-ing of available information or simple full-text analysis. Both approachessuffer from problems like the query entered by the user may not be com-pletely consistent with the vocabulary of the documents and the recallof a query will be reduced since related information with slightly differ-ent encoding is not matched. Using ontology to explicate the vocabularymay overcome some of the problems. When used for the description ofavailable documents as well as for query formulation, an ontology servesas a common basis for matching queries against potential results on a se-mantic level. In some cases, the ontology can also be directly used as auser interface to navigate through available document [19]. On the otherhand, commercial shopping sites, e.g. IBM’s, have a dictionary of terms(simple ontology) that they use to help the search function. To summa-rize, information retrieval benefits from the use of ontologies, becauseontologies help to decouple description and query vocabulary and in-crease retrieval performance [67].

2.3. ONTOLOGY LANGUAGES 23
Figure 2.3: Classification of ontology specification languages.
Service Retrieval
The ability to rapidly locate useful online service (e.g. software appli-cations, software components, process models, or service organizations),as opposed to simple useful documents, is becoming increasingly criti-cal in many domains. Berstain and Klein describes a novel service re-trieval approach based on the sophisticated use of process ontologies[14]. The evaluation suggested that using process ontology-based queriesproduced retrieval precision higher than that of existing service retrievalapproaches, while retaining polynomial complexity for query enactment.Along this line of work are also approaches that try to combine servicesto fulfill the users’ needs [164] [133].
2.3 Ontology Languages
Over the years, a number of ontology languages have been developed,focusing on different aspects of ontology modelling. Many ontology lan-guages have their roots in first order logic. Some of them have particularfocus on modelling ontology in a formal yet intuitive way (mainly frame-based languages, Ontolingua, F-logic, OCML and OKBC compatible lan-guages), while others (mainly various description logic based languages

24 CHAPTER 2. BASIC ONTOLOGY CONCEPTS
like LOOM, OIL and OWL) are more concerned with finding an appro-priate subset of first order logic with decidable and complete subsump-tion inference procedures. Within the vision of the Semantic Web [12],RDF(S) is proposed as a modelling language particularly designed forthe Semantic Web metadata and applications. In general, the web lan-guages offer only elementary modelling support, but they form a soundbase for other languages to build on top of them. Newly developed lan-guages like OIL, DAML+OIL, and OWL are just like that. In this section,we briefly introduce these languages. For a comparative study of thedifferent languages, we refer to [159] [160] [37].
Figure 2.3 depicts the different languages and how they are relatedto each other. The categorization is adopted from [34].
2.3.1 Traditional Ontology Languages
CycL. CycL is a formal language whose syntax derives from first-orderpredicate calculus and was first developed in the Cyc project [91] [92] inthe 80s, which aims at providing a general ontology for commonsenseknowledge. The Cycorp has created a large knowledge base for com-mon sense knowledge using the CycL language. To express real-worldconcepts, the language has a vocabulary of terms (about 160), which canbe combined into meaningful CycL expressions. The main concepts ofCycL are: constants (the vocabulary or words of the language like thing,concept, etc.), variables (stand for constant or formulas), formulas (com-bine terms into meaningful expression), predicates (express relationshipbetween terms) and micro-theories. Micro-theories are sets of formulas,but they can also participate in formulas, i.e. reification.
Ontolingua. The term Ontolingua denotes both the system and thelanguage [50]. The Ontolingua language is based on KIF (KnowledgeInterchange Format) and the Frame Ontology. KIF has a declarative se-mantic and is based on first order predicate calculus. It provides defini-tions for objects, function, relation and logic constants. KIF is a languagefor knowledge exchange and is tedious to use for the development ofontologies. Therefore, the Frame Ontology is built on top of KIF and pro-vides definitions in an object oriented paradigm, like class, subclass-of,instance-of etc. But ad hoc axioms (model sentences, which are alwaystrue) cannot be expressed in Frame Ontology. Ontolingua lets the de-veloper decide whether to use the full expressive power of KIF, whereaxioms can be expressed, or to be more restricted during the specifica-

2.3. ONTOLOGY LANGUAGES 25
tion by using only the Frame Ontology. An ontology using Ontolingua istypically defined by: relations, classes (treated as unary relations), func-tions (a special kind of relation), individuals (distinguished objects) andaxioms (relate the relations).
F-logic (Frame Logic). F-logic [82] was developed in the late 80s. Itis a logic language integrated with the object-oriented (or frame-based)paradigm. Some fundamental concepts from the object-oriented mod-elling paradigm have a direct representation in F-logic, such as the con-cepts of class, method, type and inheritance. One of the main problemswith the object-oriented approaches lack of formal logic semantics isovercome by the logical foundation of F-logic. There are many similar-ities between F-logic and Ontolingua, since both try to integrate framesinto a logical framework. But the frame-based modelling primitives areexplicitly defined as first class citizens in the semantics of F-logic, whileOntolingua treats them as second-order terms defined by KIF axioms.On the other hand, F-logic lacks the powerful reification mechanism On-tolingua inherits from KIF, which allows the use of formulas as terms ofmeta-formulas.
OKBC (Open Knowledge-Base Connectivity). OKBC specifies a knowl-edge model of knowledge representation systems (classes, slots, facetsand individuals) as well as a set of operations based on this model (e.g.,find a frame, match a name, delete a frame) [31]. An application usesthese operations to access and modify the knowledge stored in an OKBCcompliant system. The OKBC knowledge model supports an object-orientedrepresentation of knowledge and provides a set of constructs commonlyfound in that modelling paradigm, including: constants, frames, slots,facets, classes, individuals and knowledge bases. For representation ofaxioms and rules, the OKBC knowledge model is not sufficient. OKBCis complementary to KIF, which provides a declarative language for de-scribing knowledge. KIF does not include elements to manipulate orquery the ontology and the knowledge base. On the other hand, KIFis more expressive than OKBC, as OKBC focuses on modelling elementsthat are efficiently supported by most of the knowledge representationsystems.
OCML (Operational Conceptual Modelling Language). OCML was de-veloped at the Knowledge Media Institute (KMI) at the Open Universityin the VITAL project [119] [44]. Its primary purpose was to provide op-erational knowledge modelling facilities. To achieve this, it supports thespecification of three types of constructs: functional terms (specify an ob-

26 CHAPTER 2. BASIC ONTOLOGY CONCEPTS
ject in the domain of investigation), control terms (specify actions andorder of execution in modelling problem solving behaviour) and logicalexpression (to specify relations). Further, interpreters for functional andcontrol terms as well as a proof system are included. The operational na-ture of OCML makes it possible to support quick prototyping, which is adesirable feature for model validation. OCML provides a set of base on-tologies (including meta, functions, relations, sets, numbers, lists, strings,mapping, frames, inferences, environment and task-method) that formsa rich modelling library for building other ontologies on top of it.
LOOM. LOOM [96] is a knowledge representation system developedat the University of Southern Californias Information Science Institutein the early 90s. It was designed to support the construction and main-tenance of model-based applications. To that end, Loom model spec-ification language facilitates the specification of explicit domain mod-els, while LOOM behaviour specification language provides program-ming paradigms (object-oriented and rule-based) that can be employedto query and manipulate the models. In that sense, LOOM is also anoperational language. The main feature of LOOM is its powerful classi-fication mechanism, which integrates a sophisticated concept definitionlanguage with reasoning. Having its root in Description Logic, LOOMhas a powerful classifier that could: at the concept and relation level, in-fer the existence of subsumption relations between defined concepts, andat the instance or fact level, infer new factual relations (class membershipfor instance). The language and the system are in continuous update.
Telos. Telos is a language intended to support the development ofinformation system, developed at University of Toronto [120]. The lan-guage was founded on concepts from knowledge representation but alsobrought in ideas from requirement languages and deductive database(an object-oriented framework which supports aggregation, generaliza-tion and classification). Other Telos features include: an explicit repre-sentation of time, and primitives to specifying integrity constraints anddeductive rules.
2.3.2 Web Standards
XML (Extensible Markup Language). XML [20] is the universal format forstructured documents and data on the Web, proposed by the W3C. Themain contribution of XML is that it provides a common and commu-nicable syntax for web documents. XML itself is not an ontology lan-

2.3. ONTOLOGY LANGUAGES 27
guage, but XML-Schemas, which define the structure, constraints andthe semantics of XML documents, can to some extent, be used to specifyontologies. Since XML-schema is created mainly for the verification ofXML documents and its modeling primitives are more application ori-ented rather than concept oriented, it is in general not viewed as an on-tology language.
RDF (Resource Description Framework). RDF [89] was developed bythe W3C (World Wide Web Consortium) as part of its semantic web ef-fort. It is a framework for describing and interchanging metadata, bymeans of resources (subjects, available or imaginable entities) properties(predicates, describing the resources) and statements (the object, a valueassigned to a property in a resource). RDF Schema [21] further extendsRDF by adding more modelling primitives commonly found in ontol-ogy languages like domain and range restriction on property, class andproperty taxonomy, etc. More expressive constructs like axioms cannotbe expressed in RDF Schema. In combination, RDF Schema enables therepresentation of class, property and constraint and RDF allows the rep-resentation of instances and facts, thus making it a qualified lightweightontology language. While RDF and RDFS are different, they are compli-mentary. The combination of the two is usually denoted as RDF(S).
2.3.3 Web-based Ontology Specification Languages
SHOE (Simple HTML Ontology Extension). SHOE [73] [95] is an extensionof HTML to incorporate semantic knowledge in ordinary web documentsby annotating html pages with ontologies. SHOE provides modellingprimitives to both specify ontologies and annotate web pages. Each pagewill declare which ontologies it is using, and therefore makes it possiblefor agents, which are aware of the semantics, to perform more intelligentsearching. SHOE allows declaring classification of entities, relationshipsbetween entities and inference rule (in the form of horn clause with nonegation), as well as ontology inclusion and versioning information.
OIL (Ontology Inference Layer). OIL [35] [53] is an initiative funded bythe European Union programme for Information Society Technologiesas part of the On-To-Knowledge project. OIL is both a representationand exchange language for ontologies. The language synthesized workfrom different communities (modelling primitives from frame-based lan-guages; semantics of the primitive defined by Description Logic; andXML syntax) to achieve the aim of providing a general-purpose markup

28 CHAPTER 2. BASIC ONTOLOGY CONCEPTS
language for the Semantic Web. OIL is also compatible with RDF(S) as itis defined as an extension of RDF(S). The language is defined in a layeredapproach. The three layers are: Standard OIL (mainstream modellingprimitives usually found in ontology language), Instance OIL (includesindividual into the ontology) and Heavy OIL (not yet defined, but aimsat additional reasoning capabilities). OIL provides a predefined set ofaxioms (like disjoint class, covering, etc.) but does not allow definingarbitrary axioms.
DAML+OIL. DAML+OIL [75] [76] is a product of efforts in mergingtwo languages - DAML (DARPA Agent Modelling Language) and OIL.DAML+OIL is a language based on RDF(S) with richer modelling primi-tives. In general, what DAML+OIL adds to RDF Schema is the additionalways to constrain the allowed values of properties, and what propertiesa class may have. The differences between OIL and DAML +OIL aresubtle, as the same effect can be achieved by using different constructof the two languages (For instance, DAML+OIL has no direct equivalentto OILs covered axiom, however, the same effect can be achieved usinga combination of unionOf and subClass) . In addition, DAML+OIL hasbetter compatibility with RDF(S) (for instance, OIL has explicit OIL in-stances, while DAML+OIL relies on RDF for instance). DAML+OIL isalso a proposed W3C recommendation for semantic markup languagefor web resources.
OWL (Web Ontology Language). OWL [107] is a semantic markup lan-guage for publishing and sharing ontologies on the web. OWL is thelatest W3C proposed recommendation for that purpose. The languageincorporates learning from the design and application of DAML+OIL.OWL has three increasingly-expressive sublanguages, namely, OWL Lite(Classification hierarchy and simple constraints), OWL DL (adding classaxioms, Boolean combinations of class expression and arbitrary cardi-nality) and OWL Full (Permits also meta-modelling facilities in RDF(S)).Ontology developers should consider which sublanguage best suits theirneeds. The choice between OWL Lite and OWL DL depends on the ex-tent to which users require the more-expressive constructs provided byOWL DL. The choice between OWL DL and OWL Full mainly dependson to which extent the users require the meta-modelling facilities of RDFSchema. The reason why OWL DL contains the full vocabulary but re-stricts how it may be used is to provide logical inference engines withcertain properties desirable for optimization.

2.4. ONTOLOGY ENGINEERING 29
Figure 2.4: States and activities in the ontology life-cycle [57].
2.4 Ontology Engineering
2.4.1 Life Cycle of an Ontology
The design of an ontology is an iterative maturing process. This meansthe ontology will become to full development, become mature, by evolv-ing through intermediate states to reach a desired or final condition.
As soon as the ontology becomes important, the ontology engineer-ing process has to be considered as a project, and therefore project man-agement methods must be applied. [57] recognized that planning andspecification are important activities. The authors list the activities thatneed to be performed during the ontology development process. The au-thors explain that the life of an ontology moves on through the followingstates: specification, conceptualization, formalization, integration, implementa-tion, and maintenance. Knowledge acquisition, documentation and evaluationare support activities that are carried out during the majority of thesestates (c.f. figure 2.4).
Ontology design is a project, and should be treated as such, especiallywhen it becomes large. Project Management and software engineeringtechniques and guidelines should be adapted and applied to ontologyengineering. For a comparative study of ontology guidelines, we referto [72].

30 CHAPTER 2. BASIC ONTOLOGY CONCEPTS
Figure 2.5: A generic architecture of ontology-based applications, adopted from[111].
2.4.2 Ontology-based Architectures
Effective and efficient work with the Semantic Web in general and on-tology in particular, must be supported by advanced tools enabling thefull powers of the technology. [163] suggests to review the different toolsin an ontology-based architecture instead of focusing on individual toolsseparately. In fact, many of the current ontology engineering environ-ments provide a broad range of services rather than only one service. Fig-ure 2.5 sketches a decomposed design of ontology-based applications,highlighting the different elements that will contribute to the success ofthe applications.
The Ontology Layer
The components in this layer serves the common goal of the acquisitionof ontologies. In particular, it requires the following elements.
• Ontology extraction applies Natural Language Processing (NLP)techniques in domain documents to determine the most relevantconcepts and their relationships in a domain.

2.4. ONTOLOGY ENGINEERING 31
• Ontology learning is a more generic term applied to all bottom-upapproaches of ontology acquisition that start from a given set ofdata that reflects the human communication and interaction pro-cess.
• Ontology annotation tool is used to create an instance set on thebasis of an existing ontology.
• Ontology editor is an application intended for creating or editingontologies manually by a knowledge engineer.
• Ontology evaluation tools aim at improving the quality of ontolo-gies.
• Ontology mapping, aligning and merge tools provide support forusers to find similarities and differences between sources ontolo-gies.
The Middleware Layer
Ontology middleware plays the role of hiding the ontology layer in sys-tems and providing advanced services to applications such as ontolgoymanagement, storage, query and inference.
• Ontology storage facilities (also called ontology server) provide databaselike functionality for the persistent storage and selective retrieval ofontologies.
• The goal of query is to provide high level access to the ontologythrough questions formulated in a query language that is easy bothfor people to write and for machines to evaluate.
• Inference engines process the knowledge structures captured in on-tologies to reason implicit knowledge in the ontologies.
• Ontology management is the set of techniques that are necessary toefficiently use multiple variants of ontologies, and it includes issueslike version control, security, access right and trust managementetc.
• Ontology transfer refers to the ability of middleware to connect on-tology servers over the network.

32 CHAPTER 2. BASIC ONTOLOGY CONCEPTS
The Application Layer
The application layer is the home of ontology-based applications, andsoftware which supports users to access, organize, exchange and aggre-gate information through the use of ontologies [167]. Example applica-tions are:
• Ontology-based search and browsing support different informationseeking modes for accessing large collection of instance sets or dataitems referred by the ontology.
• Ontology-based sharing provides interoperability between differ-ent systems through the use of referring to common ontology.
2.5 Concluding Remarks
This chapter has aimed at outlining the theoretical background of thework. It has introduced the basic concepts of ontology engineering withthe intention to provide basic understanding of ontologies, which are thebasis of this work. Here is a summary of some of the main points wediscussed:
• The Semantic Web will be built on layers of enabling technology,and ontology will be a core element for the Semantic Web.
• An ontology is a formal explicit specification of a shared conceptu-alization.
• Ontologies can be classified according to their level of formality andextent of explication.
• A number of applications ranging from system interoperability toknowledge management can benefit from using ontology as a coreelement.
• There exist several ontology specification languages with differentfocuses. Among them, DAML+OIL and OWL are W3C ontologylanguage recommendations.
• The design of an ontology is an iterative maturing process.

2.5. CONCLUDING REMARKS 33
• To enable the full power of ontology, a variety of tools are needed.They can be classified into three layers, i.e., ontology layer, middle-ware layer, and application layer.

34 CHAPTER 2. BASIC ONTOLOGY CONCEPTS

Chapter 3
Technological Overview
This chapter provides a brief overview of the various fields of researchthat are referred to and have influenced the work presented in this the-sis. The aim of the chapter is not to give a complete overview of thefields; rather to provide an overview of the basic concepts of the relevanttechniques that have been adopted for this work.
3.1 Information Retrieval
Information retrieval (IR) deals with the representation, storage, organi-zation of, and access to information items. The representation and or-ganization of the information items should provide the user with easyaccess to the information in which she is interested [3].
In the past 20 years, the area of information retrieval has grown wellbeyond its primary goals of indexing text and searching for useful doc-uments in a collection. Nowadays, research in IR includes modeling,document classification and categorization, systems architecture, user in-terfaces, data visualization, filtering, languages, search engines etc. Thepart that is related to this work in particular is the vector space model.
3.1.1 Vector Space Models
The vector space model is one of the three classical retrieval models (theother two being boolean model and probabilistic model) [141] [142]. Thevector space model recognizes that the use of binary weights in the boolean
35

36 CHAPTER 3. TECHNOLOGICAL OVERVIEW
Figure 3.1: The cosine of β is used to measure the similarity between d j and q.
model is too limiting, and proposes a framework in which partial match-ing is possible. This is accomplished by assigning non-binary weightsto index terms in queries and in documents. These term weights are ulti-mately used to compute the degree of similarity between a document anda query. The procedure can be divided into three stages. The first stage isthe document indexing where content bearing terms are extracted fromthe document text. The second stage is the weighting of the indexedterms to enhance retrieval of documents relevant to the user. The laststage ranks the document with respect to the query according to a simi-larity measure1.
Document Indexing
In [142], it is defined that:
Definition 3.1 Let ki be an index term. d j be a document, and wi, j ≥ 0 bea weight associated with the pair (ki, d j) . This weight quantifies the impor-tance of the index term for describing the document semantic contents. Forthe vector model, the weight wi, j associated with a pair (ki, d j) is positive andnon-binary. Therefore, the vector for a document d j is represented by ~d j =(w1, j, w2, j, · · · , wt, j) , where t is the total number of index terms in the sys-tem. Further, the index terms in the query are also weighted. Let wi,q be theweight associated with the pair [ki, q]. Then, the query vector ~q is defined as~q = (w1,q, w2,q, · · · , wt,q)
Therefore, a document d j and a user query q are represented as t-dimensional vectors as shown in figure 3.1.
1Though, in commercial search engines, documents are ranked not only based onsimilarity, but also on static qualities, like popularity, document length, language, etc.

3.1. INFORMATION RETRIEVAL 37
It is obvious that many of the words in a document do not describethe document’s content, words like the, is. By using automatic docu-ment indexing those non significant words (function words) are removedfrom the document vector, so the document will only be represented bycontent bearing words [142]. This indexing can be based on term fre-quency, where terms that have both high and low frequency within adocument are considered to be function words [142]. In practice, termfrequency has been difficult to implement in automatic indexing. Insteada common words stop list is used to remove high frequency words (stopwords) [142]. In general, 40-50% of the total number of words in a docu-ment are removed with the help of a stop word list [142]2.
Non linguistic methods for indexing have also been implemented.Probabilistic indexing is based on the assumption that there is some sta-tistical difference in the distribution of content bearing words, and func-tion words [108]. Probabilistic indexing ranks the terms in the collectionw.r.t. the term frequency in the whole collection. The function words aremodeled by a Poisson distribution over all documents, as content bear-ing terms cannot be modeled. The use of Poisson model has been expandto Bernoulli model [28]. Recently, an automatic indexing method whichuses serial clustering of words in text has been introduced [16]. The valueof such clustering indicates whether a word is content bearing.
Term Weighting
Term weighting has been explained by controlling the exhaustivity andspecificity of the search, where the exhaustivity is related to recall andspecificity to precision. The term weighting for the vector space modelhas entirely been based on single term statistics. There are three mainfactors that affect term weighting: term frequency factor, collection fre-quency factor and length normalization factor. These three factor aremultiplied together to make the resulting term weight.
A common weighting scheme for terms within a document is to usethe frequency of occurrence. The term frequency is somewhat contentdescriptive for the documents and is generally used as the basis of aweighted document vector [140]. It is also possible to use binary doc-ument vector, but the results have not been as good compared to termfrequency when using the vector space model [140].
2However, there are search engines that do not use stop words at all.

38 CHAPTER 3. TECHNOLOGICAL OVERVIEW
There are various weighting schemes for discriminating one docu-ment from the other. In general this factor is called collection frequencydocument. Most of them, e.g. the inverse document frequency, assumethat the importance of a term is inversely proportional with the numberof documents the term appears in. Experimentally it has been shown thatthese document discrimination factors lead to a more effective retrieval,i.e., an improvement in precision and recall [140].
The third possible weighting factor is a document length normaliza-tion factor. Long documents have usually a much larger term set thanshort documents, which makes long documents more likely to be re-trieved than short documents [140].
Different weight schemes have been investigated and the best results,w.r.t. recall and precision, are obtained by using term frequency with in-verse document frequency and length normalization [140] [90].The t f −id f weighting is therefore, defined as follows:
Definition 3.2 Let N be the total number of documents in the systems and nibe the number of documents in which the index term ki appears. Let f reqi, j bethe raw frequency of term ki in the document d j. Then the normalized frequencyfi, j of term ki in document d j is given by
fi, j =f reqi, j
maxl f reql, j(3.1)
where the maximum is computed over all terms which are mentioned in the textof document d j. further, let id fi, inverse document frequency for ki, be given by
idfi = logNni
(3.2)
Then, the tf-idf term weighting scheme is given by
wi, j = fi, j ∗ logNni
(3.3)
Several variations of the above expression for the weight wi, j are de-scribed in an interesting paper by Salton and Burckley in 1988 [139].However, in general, the above expression should provide a good weight-ing schema for many collections.
For the query term weight, Salton and Buckley suggest
wi,q = (0.5 +0.5 f reqi,q
maxl f reql,q) ∗ log
Nni
(3.4)

3.2. COMPUTATIONAL LINGUISTICS 39
where f reqi,q is the raw frequency of the term ki in the text of the infor-mation request q.
Similarity Coefficients
The similarity in vector space models is determined by using associativecoefficients based on the inner product of the document vector and queryvector, where word overlap indicates similarity. The inner product isusually normalized. The most popular similarity measure is the cosinecoefficient, which measures the angle between the document vector andthe query vector as shown in figure 3.1. That is,
sim(di, q) =~d j •~q
|~d j| ∗ |~q|=
∑ti=1 wi, j ∗ wi,q√
∑ti=1 w2
i, j ∗√
∑ti=1 w2
i,q
(3.5)
Other measures are e.g., Jaccard and Dice coefficients [138].
3.2 Computational Linguistics
Computational Linguistics is an interdisciplinary field which centers aroundthe use of computers to process or produce human language (also knownas ’natural language’, to distiguish it from computer languages) [79]. Tothis field, linguistics contributes an understanding of the special proper-ties of language data, and provides theories and descriptions of languagestructure and use. Computer Science contributes theories and techniquesfor designing and implementing computer systems.
Computational Linguistics is largely an applied field, concerned withpractical problems. There are as many applications as there are reasonsfor computers to process or produce language: for example, in situationswhere humans are unavailable, too expensive, too slow, or busy doingtasks that humans are better at than machines. Some current applicationareas include translating from one language to another (Machine Transla-tion), finding relevant documents in large collections of text (InformationRetrieval), and answering questions about a subject area (expert systemswith natural language interfaces).
The linguistic side can be broken down into many smaller pieces, e.g.phonetics, phonology, the lexicon, morphology, syntax, semantics, prag-matics, and so on (following divisions of linguistic theory). The parts

40 CHAPTER 3. TECHNOLOGICAL OVERVIEW
that are relevant to this work include: morphological analysis of words,part-of-speech tagging and lexical semantics. We will briefly review eachof the technique in the sequel.
3.2.1 Morphological Analysis
Morphology
Morphology is the study of the way words are built up from smallermeaning-bearing units, morphemes. A morpheme is often defined as thethe minimal meaning-bearing unit in a language. So for example theword fox consists of a single morpheme (the morpheme fox), while theword cats consists of two: the morpheme cat and the morpheme -s.
It is often useful to distinguish two broad classes of morphemes: stemsand affixes. The exact details of the distinction vary from language to lan-guage, but intuitively, the stem is the ”main” morpheme of the word,supplying the main meaning, while the affixes add ”additional” mean-ings to various kinds.
Affixes are further divided into prefixes, suffixes, infixes and circumfixes.Prefixes precede the stems, suffixes follow the stem, circumfixes do both,and infixes are inserted inside the stem.
There are two broad classes of ways to form words from morphemes:inflection and derivation. Inflection is the combination of a word stem witha grammatical morpheme, usually resulting in a word of the same class asthe original stem, and usually filling some syntactic function like agree-ment. For example, English has the inflectional morpheme -s for markingthe plural on nouns, and -ed for marking the past tense on verbs. Deriva-tion is the combination of a word stem with a grammatical morpheme,usually resulting in a word of a different class, often with a meaning hardto predict exactly. For example the verb computerize can take the deriva-tional suffix -ation to produce the noun computerization.
Morphological Parsing
The goal of morphological parsing is to find out what morphemes a givenword is built from. For example, a morphological parser should be ableto tell us that the word cats is the plural form of the noun stem cat, andthat the word mice is the plural form of the noun stem mouse. So, giventhe string cats as input, a morphological parser should produce an outputthat looks similar to cat N PL.

3.2. COMPUTATIONAL LINGUISTICS 41
Morphological parsing yields information that is useful in many NLPapplications. In parsing, e.g., it helps to know the agreement features ofwords. Similarly, grammar checkers need to know agreement informa-tion to detect such mistakes. But morphological information also helpsspell checkers to decide whether something is a possible word or not,and in information retrieval it is used to search not only cats, if that’s theuser’s input, but also for cat.
To get from the surface form of a word to its morphemes, it is usuallyproceeded in two steps. First, the words are split up into its possiblecomponents. So, cat + s will be made out of cats, using + to indicatemorpheme boundaries. In this step, spelling rules will also be taken intoaccount, so that there are two possible ways of splitting up foxes, namelyfoxe + s and fox + s. The first one assumes that foxe is a stem and s thesuffix, while the second one assumes that the stem is fox and that the ehas been introduced due to the spelling rules.
In the second step, a lexicon of stems and affixes is used to look upthe categories of the stems and the meaning of the affixes. So, cat + swill get mapped to cat NP PL, and fox + s to fox N PL. We will also findout now that foxe is not a legal stem. This tells us that splitting foxes intofoxe + s was actually an incorrect way of splitting foxes, which should bediscarded. But note that for the word houses splitting it into house + s iscorrect.
Figure 3.2 illustrates the two steps of the morphological parser withsome examples.
The automaton that is used for performing the mapping between thetwo levels is the finite-state transducer or FST. Two transducer are usedin the parsing process: one to do the mapping from the surface formto the intermediate form and the other one to do the mapping from theintermediate form to the underlying form. We will not go into the detailof FST in this work. For details, we refer to [79].
Stemming
While building a transducer from a lexicon plus rules is the standardalgorithm for morphological parsing, there are simpler algorithms thatdon’t require the large online lexicon demanded by the algorithm. Theseare used especially in Information Retrieval. Since a document with theword cats might not match the user search keyword cat, some IR systemsfirst run a stemmer on the keywords and on the words in the document.

42 CHAPTER 3. TECHNOLOGICAL OVERVIEW
Figure 3.2: Examples of two steps in the morphological parser.
Since morphological parsing in IR is only used to help form equivalenceclasses, the details of the suffixes are irrelevant, and what matters is de-terming that two words have the same stem.
One of the most widely used such stemming algorithm is the sim-ple and efficient Porter algorithm [134]. The Porter stemming algorithm(or Porter stemmer) is a process for removing the common morpholog-ical and inflexional endings from words in English. Its main use is aspart of a term normalisation process that is usually done when settingup Information Retrieval systems. Porter algorithm can be think of as alexicon-free FST. Porter stemming can be adapted to other languages aswell.
Terminology
Based on the above discussion, we put forward our way of usage forthe relevant terms in this area. Throughout the work, we will use thefollowing terms consistently according to their specific meaning:
• Word - any word in a document. A word may take on several wordforms.
• Word forms - most words can take on several different word forms,for example through inflections or other morphological variations.

3.2. COMPUTATIONAL LINGUISTICS 43
• Base form - denotes the main word form of the word. In caseswhere lemmatization is performed according to a dictionary, thebase form is the dictionary entry of a set of word forms. Base formis also known as lemma.
• Phrase - a combination (i.e. a sequence) of words.
• Term - refers to both words and phases, i.e., a term can be ”a particu-lar word or a combination of words, especially one used to mean somethingvery specific or one used in a specialized area of knowledge or work” [47].
• Stem - is the form of a word after its endings are removed.
• Stemming - is the process of removing word endings.
• Lemmatization - is the process of finding out the base form of aword.
• Stop words - are small, frequently occurring words that are oftenignored when typed into a database or search engine search. Someexamples: THE, AN, A, OF.
3.2.2 Part-of-Speech Tagging
Part-of-speech tagging is the process of assigning a part-of-speech, likenoun, verb, pronoun, preposition, adverb, adjective or other lexical classmarker to each word in a sentence.
The input to a tagging algorithm is a string of words of a naturallanguage sentence and a specified tagset (a finite list of Part-of-speechtags). The output is a single best POS tag for each word. In general,there are two types of taggers: one attaches syntactic roles to each word(subject, object, etc.) and the other attaches only functional roles (Noun,Verb, etc.). For example, table 3.1 shows an example of a sentence and apotential tagged output using the Penn Treebank tagset [101].
Tags plays an important role in Natural Language applications likespeech recognition, natural language parsing , information retrieval andinformation extraction. Lots of work has been done on POS taggingfor English. The earliest algorithms for automatically assigning part-of-speech were based on a two-stage architecture [84]. The first stage used adictionary to assign each word a list of potential part-of-speech. The sec-ond stage used large lists of hand written disambiguation rules to narrow

44 CHAPTER 3. TECHNOLOGICAL OVERVIEW
Does that flight serve dinner ?VBZ DT NN VB NN ?
Tag Description ExampleVBZ Verb, 3sg present eatsDT Determiner a, theNN Noun, singular or mass catVB Verb, base form eat? Sentence-final punc. (. ! ?)
Table 3.1: An example of a tagged output using the Penn Treebank tagset.
down the list to a single part-of-speech for each word. Disambiguationoccurs when a word may have multiple part-of-speech. For example, theword book is ambiguous, meaning it can be a noun, or a verb. To disam-biguate, a rule-based tagger can have a hand-written rule which specify,for example, that an ambiguous word is a noun rather than a verb if itfollows a determiner.
Taggers can be characterized as rule-based or stochastic. Rule-basedtaggers use hand-written rules to distinguish the tag ambiguity. Stochas-tic taggers generally resolve tagging ambiguities by using a training cor-pus to compute the probability of a given word having a given tag ina given context. They are either HMM (Hidden Markov Model) based,choosing the tag sequence which maximizes the product of word likeli-hood and tag sequence probability, or cue-based, using decision trees ormaximum entropy models to combine probabilistic features.
3.2.3 Lexical Semantics
Lexical semantics is the study of the systematic meaning-related connec-tions among words and the internal meaning-related structure of eachword. Each individual entry in the lexicon is called a lexeme. A lexemeshould be thought of as a pairing of particular orthographic and phono-logical form with some form of symbolic meaning representation. Theterm sense is used to refer to a lexeme’s meaning component. The lexiconis therefore a finite list of lexemes.

3.2. COMPUTATIONAL LINGUISTICS 45
Relations Among Lexemes and Their Senses
A variety of relations can hold among lexemes and among their senses.We introduce a list of them that have had significant computational im-plications.
• Homonymy refers to lexemes with the same form but unrelated mean-ings. For example, the lexeme wood and would are homonymy sincethey share the same phonological forms.
• Polysemy refers to the notion of a single lexeme with multiple mean-ings. For example the lexeme serve in serve read meat and that in servethe country.
• Synonym holds between different lexemes with the same or similarmeaning, such as price and fair.
• Hyponymy relations hold between lexemes that are in class-inclusionrelationships. For example, puppy is a hyponym of dog.
• Meronymy describes the part-whole relation, e.g. car and wheel.
• Antonym holds between different lexemes that differ in a significantway on at least one essential semantic dimension, e.g. cheap andexpensive.
WordNet
The usefulness of lexical relations in linguistic, psycho-linguistic, andcomputational research has led to a number of efforts to create large elec-tronic databases of such relations. WordNet is so far, the most well de-veloped and widely used lexical database for English [52] [114] [112].
WordNet consists of three separate databases, one for nouns, one forverbs and a third for adjectives and adverbs. Each of the three databasesconsists of a set of lexical entries corresponding to unique orthographicalforms, accompanied by sets of senses associated with each form. Table3.2 gives some idea of the scope of WordNet 2.0 release. The databasecan be accessed directly with a browser (locally or over the Internet), orprogramatically through the use of API.
In their complete form, WordNet’s sense entries consist of a set ofsynonyms (synset in WordNet terminology), a dictionary-style defini-tion, or gloss, and some example uses. Figure 3.3 shows the WordNet

46 CHAPTER 3. TECHNOLOGICAL OVERVIEW
POS Unique forms Synsets Number of sensesNoun 114648 79689 141690Verb 11306 13508 24632
Adjective 21436 18563 31015Adverb 4669 3664 5808Totals 152059 115424 203145
Table 3.2: Scope of the current WordNet 2.0 release in terms of number of words,synsets, and senses.
entry for the noun book. Synset is the fundamental basis for synonymyin WordNet. Consider the following example of a synset: {ledger, leger,account book, book of account}. The dictionary like definition, or gloss, ofthis synset describes it as a record in which commercial accounts are recorded.Each of the lexical entries included in the synset can, therefore, be used toexpress this notion in some setting. In practice, synsets are the ones thatactually constitute the senses associated with WordNet entries. Specifi-cally, it is this exact synset, with its associated definition and examples,that makes up one of the sense for each of the entries listed in the synset.
Looking at this from a more theoretical point of view, each synsetcan be taken to represent a concept that has become lexicalized in thelanguage. Thus, instead of representing concepts using logical terms,WordNet represents them as lists comprised of the lexical entries thatcan be used to express that concept.
Of course, a simple listing of lexical entries would not be much moreuseful than an ordinary online dictionary. The power of WordNet lies inits set of domain-independent lexical relations. These relations can holdamong WordNet synsets. They are, for the most part, restricted to itemswith the same part-of-speech. Table 3.3, 3.4, and 3.5 show a subset ofthe relations associated with each of the four part-of-speech, along witha brief definition and an example.
Following the hypernym relations, each synset is related to its imme-diately more general and more specific synsets. To find chains of moregeneral or more specific synsets, one can simply follow a transitive chainof hypernym and hyponym relations. Figure 3.4 shows the hypernymchain for book (sense 1). This chain eventually leads to the top of the hi-erarchy entity. Note that WordNet does not have a single top concept,rather it has several top concepts and they are called unique beginners.

3.2. COMPUTATIONAL LINGUISTICS 47
Figure 3.3: A portion of the WordNet 2.0 entry for the noun book.
Relation Definition ExampleHypernym synset which is the more
general class of anothersynset
breakfast –> meal
Hyponym synset which is a particu-lar kind of another synset
meal –> lunch
Holonym synsets which is the wholeof which another synset ispart
flower –> plant
Meronyms synsets which the parts ofanother synset
bumper –> car
Antonyms synsets which are oppositein meaning
man <–> woman
Table 3.3: Noun relations in WordNet.

48 CHAPTER 3. TECHNOLOGICAL OVERVIEW
Relation Definition ExampleHypernym synset which is the more
general class of anothersynset
fly –> travel
Troponym synset which is one par-ticular way to perform an-other synset
walk –> stroll
Entails synset which is entailed byanother synset
snore –> sleep
Antonyms synsets which are oppositein meaning
increase <–> decrease
Table 3.4: Verb relations in WordNet.
Relation Definition ExampleA-value-of adjective synset which
represents a value for anominal target synset
slow –> speed
Antonyms synsets which are oppositein meaning
quickly <–> slowly
Table 3.5: Adjective and adverb relations in WordNet.

3.3. CONCLUDING REMARKS 49
Figure 3.4: Hypernym chains for sense one of noun book.
For nouns, there are 25 unique beginners.Lexicons for other languages that resemble the structure and func-
tion of WordNet have been constructed as well. EuroWordNet is a multi-lingual database with WordNet for several European languages (Dutch,Italian, Spanish, German, French, Czech and Estonian). The EuroWord-Net is structured in the same way as the American wordnet for English(Princeton WordNet) in terms of synsets (sets of synonymous words)with basic semantic relations between them. Each wordnet representsa unique language-internal system of lexicalizations. In addition, thewordnets are linked to an Inter-Lingual-Index, based on the PrincetonWordNet. Via this index, the languages are interconnected so that it ispossible to go from the words in one language to similar words in anyother language [48].
3.3 Concluding Remarks
This chapter has covered a wide range of issues concerning the support-ive technologies that we used in this work. We consider Information

50 CHAPTER 3. TECHNOLOGICAL OVERVIEW
Retrieval technique, in particular, vector space model, a vital componentof the algorithm we proposed. The following are among the highlights:
• In vector model, both documents and queries are represented inhigh-dimensional vectors. Each element in the vector reflects thesignificance of a particular index word to the document or the query.The significance is measured by term weight.
• There are three main factors affect term weighting: term frequencyfactor, collection frequency factor and length normalization factor.These three factor are multiplied together to make the resultingterm weight.
• The similarity in vector space models is determined by using as-sociative coefficients based on the inner product of the documentvector and query vector, where word overlap indicates similarity.
• We employ the vector space model to represent concepts and fur-ther calculate similarities between them, which will be introducedin chapter 5 and chapter 6.
The second major supportive technology we are using comes fromcomputational linguistics. The parts that are relevant to this work in-clude: morphological analysis of word, part-of-speech tagging and lexi-cal semantics. Some of the highlights are:
• Morphology is the study of the way words are built up from smallermeaning-bearing units, morphemes.
– The goal of morphological parsing is to find out what mor-phemes a given word is built from.
– To get the morphemes from the surface form of a word throughmorphological analysis, it is usually proceeded in two steps.First, the words are split up into its possible components. Sec-ond, a lexicon of stems and affixes is used to look up the cate-gories of the stems and the meaning of the affixes.
– Morphological analysis can be automated by using FST.
• Part-of-speech tagging is the process of assigning a part-of-speechlike noun, verb, pronoun, preposition, adverb, adjective or otherlexical class marker to each word in a sentence.

3.3. CONCLUDING REMARKS 51
– The input to a tagging algorithm is a string of words of a nat-ural language sentence and a specified tagset( a finite list ofPart-of-speech tags). The output is a single best POS tag foreach word.
– Taggers can be characterized as rule-based or stochastic. Rule-based taggers use hand-written rules to distinguish the tagambiguity. Stochastic taggers generally resolve tagging ambi-guities by using a training corpus to compute the probabilityof a given word having a given tag in a given context.
• Lexical semantics is the study of the systematic meaning-relatedconnections among words and the internal meaning-related struc-ture of each word.
– A variety of relations can hold among lexemes and amongtheir senses. We introduce a list of them that have had sig-nificant computational implications.
– WordNet is a large database of lexical relations for Englishwords.
• In our work, the relevant linguistic analysis part has been imple-mented by using third party software.
• In this work, we mainly explore the hypernym/hyponym relationsin WordNet with the intention to augment the mapping process.

52 CHAPTER 3. TECHNOLOGICAL OVERVIEW

Chapter 4
State-of-the-Art Survey
The aim of this chapter is to provide a state of the art survey of tools andenvironment for automatic ontology mapping. We start with an intro-duction to the problem of ontology heterogeneity, which is characterizedby different kinds of mismatches between ontologies. This kind of het-erogeneity hampered us from a combined usage of multiple ontologies,which is needed in many applications. To solve the heterogeneity prob-lem, the mismatches need to be reconciled. This means that we needto map and align different ontologies. A number of approaches havebeen proposed in the literature. We conduct a feature analysis of the ap-proaches and compare their characteristics. To lay the foundation of aclearer elaboration, we also examine the relevant terminology used inontology mapping related literature.
4.1 Ontology Heterogeneity
4.1.1 Ontology Mismatch
Differences between ontologies are called mismatches in [83], and will beused throughout this work. Figure 4.1 depicts a framework of issues,related to the integration of ontologies, [83]. Among the three issues dis-cussed: practical problems, mismatches between ontologies and version-ing, the main concern in this thesis is mismatches between ontologies. Theyare further divided into language level and ontology level. The former con-forms to the syntactic layer, and the latter to the semantic layer.
53

54 CHAPTER 4. STATE-OF-THE-ART SURVEY
Figure 4.1: Framework of issues on ontology integration, from [83].
Language Level Mismatches
Mismatches at the language level occur when ontologies written in differ-ent ontology languages are combined. Chalupsky [30] [29] defines mis-match in syntax and expressivity. In [83], four types of mismatches areidentified.
• Syntax. Different ontology languages often use different syntaxes.For example, to define the class of car in RDF Schema, one uses<rdfs:Class ID = "Car">. In LOOM, the expression(defconcept Car) is used to define the same class.
• Logical representation. A slightly more complicated mismatch at thislevel is the difference in representation of logic notions. For ex-ample, in some languages, it is possible to state explicitly that twoclasses are disjoint (e.g. disjoint A B), whereas it is necessary to usenegation in subclass statements in other languages (e.g. A subclass-of (NOT B), B subclass-of (Not A))
• Semantics of primitives. A more subtle possible difference at the lan-guage level is the semantics of language constructs. Despite thefact that sometimes the same name is used for a language constructin two languages, the semantics may differ, e.g., there are severalinterpretation of A equalTo B.
• Language expressivity. The mismatch at the language level with the

4.1. ONTOLOGY HETEROGENEITY 55
most impact is the difference in expressivity between two languages.This difference implies that some languages are able to express thingsthat are not expressible in other languages. For example, some lan-guages have constructs to negation, whereas others have not.
Ontology Level Mismatches
Mismatches at the ontology level happen when two or more ontologiesthat describe partly overlapping domains are combined. These mismatchesmay occur when the ontologies are written in the same language, as wellas when they use different languages. Several classification frameworkhave been proposed in the literature [170] [169] [174] [29]. In [83], Kleintried to integrate the different types of mismatches discussed in the aboveframeworks. On the ontology level a distinction is made between con-ceptualization and explication, as described in [171]. A conceptualizationmismatch is a difference in the way a domain is interpreted, whereas anexplication mismatch is a difference in the way the conceptualization isspecified.
Conceptualization mismatches are further divided into model cover-age and concept scope (granularity).
• Scope. Two classes seem to represent the same concept, but do nothave the same instances, although they may intersect. The classicalexample is the class ”employee”, where several administrations useslightly different concepts of employee, as mentioned by Wieder-hold [174].
• Model coverage and granularity. This is a mismatch in the part ofthe domain that is covered by the ontology, or the level of detail towhich that domain is modeled. Chalupsky [29] gives the exampleof an ontology about cars: one ontology might model cars but nottrucks. Another one might represent trucks but only classify theminto a few categories, while a third ontology might make very fine-grained distinctions between types of trucks based on their physicalstructure, weight, purpose, etc.
Explication mismatches are divided into terminological, modeling styleand encoding.
• Two types of differences can be classified as terminological mismatches.

56 CHAPTER 4. STATE-OF-THE-ART SURVEY
– Synonym terms. Concepts are represented by different names.One example is the use of term ”car” in one ontology and theterm ”automobile” in another ontology.
– Homonym terms. The meaning of the same term is differentin different context. For example, the term ”conductor” has adifferent meaning in a music domain than it has in an electricengineering domain.
• Modeling style is related to the paradigm and conventions taken bythe developers.
– Paradigm. Different paradigms can be used to represent con-cepts such as time, action, plans, causality, propositional atti-tudes, etc. For example, one model might use temporal rep-resentations based on interval logic while another might use arepresentation based on point [29].
– Concept description. This type of differences are called model-ing conventions in [29]. Several choices can be made for themodeling of concepts in the ontologies. For example, a dis-tinction between two classes can be modeled using a qualify-ing attribute or by introducing separate class.
• One last mismatch in the explication category is encoding. Encodingmismatches are differences in value formats, like measuring dis-tance in miles or in kilometers.
4.1.2 Current Approaches and Techniques
The focus of this work is on ontology level mismatch (semantic mis-match). There are also approaches to tackle syntactic mismatches. Wewill briefly describe some of those in order to give a complete picture ofthe state of the art.
Solving Language Mismatches
In [83] four approaches to enable interoperability between different on-tologies at the language level have been identified.
• Aligning the metamodel. The constructs in the language are formallyspecified in a general model [17].
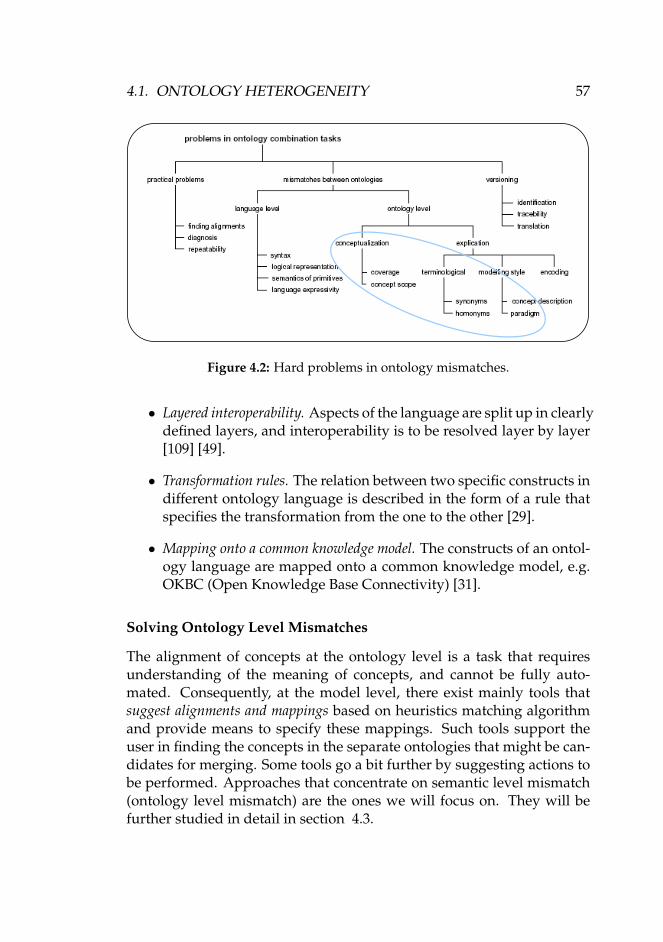
4.1. ONTOLOGY HETEROGENEITY 57
Figure 4.2: Hard problems in ontology mismatches.
• Layered interoperability. Aspects of the language are split up in clearlydefined layers, and interoperability is to be resolved layer by layer[109] [49].
• Transformation rules. The relation between two specific constructs indifferent ontology language is described in the form of a rule thatspecifies the transformation from the one to the other [29].
• Mapping onto a common knowledge model. The constructs of an ontol-ogy language are mapped onto a common knowledge model, e.g.OKBC (Open Knowledge Base Connectivity) [31].
Solving Ontology Level Mismatches
The alignment of concepts at the ontology level is a task that requiresunderstanding of the meaning of concepts, and cannot be fully auto-mated. Consequently, at the model level, there exist mainly tools thatsuggest alignments and mappings based on heuristics matching algorithmand provide means to specify these mappings. Such tools support theuser in finding the concepts in the separate ontologies that might be can-didates for merging. Some tools go a bit further by suggesting actions tobe performed. Approaches that concentrate on semantic level mismatch(ontology level mismatch) are the ones we will focus on. They will befurther studied in detail in section 4.3.

58 CHAPTER 4. STATE-OF-THE-ART SURVEY
Finally, in order to integrate ontologies, it is important to distinguishmismatches that are hard to solve, and those that are not. Both [83]and [171] conclude that conceptualization mismatches often need humanintervention to be solved. The same view is stated in [174], where scopedifferences are stated to be hard to solve. Most explication mismatchescan be solved automatically, but the terminological mismatches may bedifficult. Encoding mismatches can be quite easily solved with a wrap-per or a transformation step [83]. Figure 4.2 depicts the framework onceagain, where the circle marks up mismatches that can be hard to recon-cile.
4.2 Ontology Mapping Concepts
In this section, we set the context and scope for ontology mapping. Wefirst outline the definition and scope of ontology mapping and discussthe relevant term usage in literature. We proceed with some motivatingapplications where ontology mapping plays an important role.
4.2.1 Definition and Scope of Ontology Mapping
In the ontology-related research literature, the concept of ”mapping” hasa range of meanings, including integration, unification, merging, map-ping, etc. To provide a clearer context for discussion, we list some of thedefinitions that we considered compatible with our potential usage of theterm.
• In [97], it is defined that a mapping will be a set of formulae that providethe semantic relationships between the concepts in the models.
• In [124], it is said that Mapping is to establish correspondences amongthe source ontologies, and to determine the set of overlapping concepts,concepts that are similar in meaning but have different names or struc-ture, and concepts that are unique to each of the sources. Further, tworelevant concepts: merging and alignment are also defined. Mergingis to create a single coherent ontology that includes the informationfrom all the sources. Alignment is to make the source ontologiesconsistent and coherent with one another but kept separately.
• In [24], it is stated that the aim of mapping is to map concepts inthe various ontologies to each other, so that a concept in one ontology

4.2. ONTOLOGY MAPPING CONCEPTS 59
corresponds to a query (i.e. view) over the other ontologies.
To sum up, we consider a general definition of ontology mapping tobe determining a set of correspondence that identify similar elements in differentontologies. A well defined mapping process can be considered as a com-ponent which provides a mapping service. This service can be pluggedinto various applications. For example, an ontology integration applica-tion can use the discovered mappings as the first step towards an inte-grated ontology.
Two tasks have to be conducted in the ontology mapping process.One is to discover the correspondences between ontology elements andthe other is to describe and define the discovered mappings so that otherfollow-up components could make use of them. For the first task, sev-eral different approaches have been proposed in the literature [124] [43][154] [11] [106] [110] [32]. Mapping correspondences are produced inroughly two ways: (1) applying a set of matching rules or (2) evaluat-ing interesting similarity measures that compare a set of possible corre-spondence and help to choose valid correspondence from them. Theseheuristics often use syntactic information such as the names of the con-cepts or nesting relationships between concepts. They might also use se-mantic information such as the inter-relationship between concepts (slotsof frames in [124]), the types of the concepts, or the labeled-graph struc-ture of the models [23] [110]. Other techniques use data instances be-longing to input models to estimate the likelihood of these correspon-dences [154] [43]. Several systems also have powerful features for theefficient capture of user interaction [124] [106] . A detailed comparisonof the different approaches will be discussed in detail in section 4.3. Thework presented in [97] [24] [99] discussed the necessary components thatshould be included in the mapping correspondences and the desired fea-tures of the correspondences, including: (1) the ability to answer queriesover a model, (2) inference of mapping formulas, and (3) compositional-ity of mappings.
4.2.2 Application Domains
We motivate the study of ontology mapping by demonstrating first therole it plays in several applications. Mapping between ontologies is thefoundation of several classes of applications.
• Information Integration and the Semantic Web. In many contexts, data

60 CHAPTER 4. STATE-OF-THE-ART SURVEY
resides in a multitude of data sources. In the Semantic Web con-text, an ontology captures the semantics of data. Data integrationenables users to ask queries in a uniform fashion, without havingto access each data source independently. In an information inte-gration system, users ask queries over a mediated ontology, whichcaptures only the aspects of the domain that are salient to the ap-plication. The mediated ontology is solely a logical one and map-pings are used to describe the relationship between the mediatedontology and the local ontologies. In addition to query, mappingsbetween ontologies are necessary for agents to interoperate.
• Ontology merging. Several applications require that we combinemultiple ontologies into a single coherent ontology [97] [106]. Insome cases, these are independently developed ontologies that modeloverlapping domains. In others, we merge two ontologies thatevolved from a single base ontology. In both cases, the first stepin merging ontologies is to create a mapping between them, whichidentify similarities and conflicts between the source ontologies.Once the mapping is given, the challenge of a merge algorithm isreduced to create a minimal ontology that covers the given ones.
4.2.3 Terminology
Based on the above discussion, we put forward our way of usage for therelevant terms. We have tried to be consistent as far as possible with defi-nitions and descriptions found elsewhere. Throughout this work, we willuse the following terms consistently according to their specific meaning:
• Merging, integrating. Creating a new ontology from two or moreexisting ontologies with overlapping parts.
• Aligning. Bring two or more ontologies into mutual agreement,making them consistent and coherent with one and another.
• Mapping. Relating similar (according to some metric) concepts orrelations from different sources to each other by specifying the cor-respondence between them.
• Mapping assertions, correspondence assertions. The specification of themappings, which describe the relation between the source ontologyconcepts, as well as other mapping relevant information.

4.3. AUTOMATIC ONTOLOGY MAPPING TOOLS 61
• Articulation. The points of linkage between two aligned ontologies,i.e. the specification of the alignment.
• Translating. Changing the representation formalism of an ontologywhile preserving the semantics.
• Transforming. Changing the semantics of an ontology slightly (pos-sibly also changing the representation) to make it suitable for pur-poses other than the original one.
• Combining. Using two or more different ontologies for a task inwhich their mutual relations are relevant.
4.3 Automatic Ontology Mapping Tools
The creation of mappings will rarely be completely automated. How-ever, automated tools can significantly speed up the process by propos-ing plausible mappings. In large domains, while many mappings mightbe fairly obvious, some parts need expert intervention. There are severalapproaches for building such tools. The first is to use a wide range ofheuristics to generate mappings. The heuristics are often based on struc-ture or based on naming. In some cases, domain independent heuristicsmay be augmented by more specific heuristics for the particular repre-sentation language or application domain. A second approach is to learnmappings. In particular, manually provided mappings present exam-ples for a learning algorithm that can generalize and suggest subsequentmappings.
In this section we first discuss the relevant research in database area,namely automatic schema matching. Thereafter, we demonstrate a listof ontology mapping approaches and provide a brief comparison amongthe approaches.
4.3.1 Automatic Schema Matching
Mapping between models has been approached in several research areas.One closely related topic with ontology mapping is schema matchingin database research. Integrating heterogeneous data sources is a fun-damental problem in databases, which has been studied extensively inthe last two decades both from a formal and from a practical point ofview [144] [94] [27] [77] [6].

62 CHAPTER 4. STATE-OF-THE-ART SURVEY
Figure 4.3: Classification of schema matching approaches, from [135].
Even though ontologies are more semantically complex and are of-ten larger than database schema, the two topics still share many features.Given the substantial efforts that have been directed into schema man-agement, it is worthwhile to give a brief account of the state-of-art in thatarea.
In [135], a comprehensive survey on schema matching was reported.Schema matching is defined as determining a set of correspondence that iden-tify similar elements in different schemas. Figure 4.3 shows the classica-tion scheme together with some sample approaches. For each individualmatch operator, the following largely-orthogonal classication criteria areidentified:
• Instance vs schema: matching approaches can consider instancedata (i.e., data contents) or only schema-level information.
• Element vs structure matching: match can be performed for indi-vidual schema elements, such as attributes, or for combinations ofelements, such as complex schema structures.
• Language vs constraint: a matcher can use a linguistically-basedapproach (e.g., based on names and textual descriptions of schema

4.3. AUTOMATIC ONTOLOGY MAPPING TOOLS 63
elements) or a constraint-based approach (e.g., based on keys andrelationships).
• Matching cardinality: the overall match result may relate one ormore elements of one schema to one or more elements of the other,yielding four cases: 1:1, 1:n, n:1, n:m. In addition, each mappingelement may interrelate one or more elements of the two schemas.Furthermore, there may be different match cardinalities at the in-stance level.
• Auxiliary information: most matchers rely not only on the inputschemas but also on auxiliary information, such as dictionaries,global schemas, previous matching decisions, and user input.
Note that this classication does not distinguish between different typesof schemas (relational, XML, object oriented, etc.) and their internal rep-resentation, because algorithms depend mostly on the kind of informa-tion they exploit, not on its representation.
Further, the individual matchers can be combined either by usingmultiple matching criteria (e.g., name and type equality) within an in-tegrated hybrid matcher or by combining multiple match results pro-duced by different match algorithms within a composite matcher. In[135], seven published prototype implementation were compared accord-ing to the classification criteria, including SemInt [93], LSD [42], SKAT[118], TranScm [115], DIKE [131] [132], ARTEMIS [26], and CUPID [98].One of the conclusions is that ”more attention should be given to the utiliza-tion of instance-level information and reuse opportunities to perform match.”[135].
4.3.2 Systems for Ontology Merging and Mapping
In this section we will describe a number of systems that can be usedto support automatic ontology mapping. Due to the close relatedness ofontology mapping and merging, tools that are used for merging are in-cluded here as well. The systems demonstrated here are not intendedto be exhaustive. They were primarily chosen based on their relevanceto this research, and to illustrate the diversity of existing solutions. Foreach tool we provide a short introduction and an overall comparison ofthese systems is presented in the end. We first present Chimaera, a web-based ontology merging and diagnosing environment. Then, we present

64 CHAPTER 4. STATE-OF-THE-ART SURVEY
PROMPT, an algorithm used in Protege for ontology merging. Next isFCA-Merge, which merges ontologies using documents on the same do-main for the ontologies to be merged. We go on to present MOMIS,which merges ontologies by means of ontology clustering and finally wepresent GLUE, which performs ontology mapping by machine learningtechniques.
Chimaera
Chimaera [106] is an ontology merging and diagnosis tool developed bythe Stanford University Knowledge Systems Laboratory (KSL). Its initialdesign goal was to provide substantial assistance with the task of merg-ing KBs produced by multiple authors in multiple settings. Later, it tookon another goal of supporting testing and diagnosing ontologies as well.Finally, inherent in the goals of supporting merging and diagnosis arerequirements for ontology browsing and editing. It is mainly targetedat lightweight ontologies. Its design and implementation are based onother applications such as the Ontolingua ontology development envi-ronment [50]. Chimaera is built on a platform that handles any OKBCcompliant [31] representation system.
The two major tasks in merging ontologies that Chimaera support are(1) coalesce two semantically identical terms from different ontologies sothat they are referred to by the same name in the resulting ontology, and(2) identify terms that should be related by subsumption, disjointness,or instance relationships and provide support for introducing those re-lationships. There are many auxiliary tasks inherent in these tasks, suchas identifying the locations for editing, performing the edits, identifyingwhen two terms could be identical if they had small modifications suchas a further specialization on a value-type constraint, etc.
Chimaera generates name resolution lists that help the user in themerging task by suggesting terms each of which is from a different ontol-ogy that are candidates to be merged or to have taxonomic relationshipsnot yet included in the merged ontology. It also generates a taxonomyresolution list where it suggests taxonomy areas that are candidates forreorganization. It uses a number of heuristic strategies for finding suchedit points. Figure 4.4 shows the result of someone loading in two on-tologies (Test1 and Test2) and then choosing the name resolution modefor the ontologies.

4.3. AUTOMATIC ONTOLOGY MAPPING TOOLS 65
Figure 4.4: Chimaera in name resolution mode suggesting a merge of Mammaland Mammalia.
PROMPT
PROMPT [124] is a tool for semi-automatic guided ontology merging. Itis a plugin for Protege [126] [121] [123]. PROMPT leads the user throughthe ontology-merging process, identifying possible points of integration,and making suggestions regarding what operations should be done next,what conflicts need to be resolved, and how those conflicts can be re-solved. PROMPT’s ontology-merging process is interactive. A user makesmany of the decisions, and PROMPT either performs additional actionsautomatically based on the users choices or creates a new set of sugges-tions and identifies additional conflicts among the input ontologies.
The tool takes into account different features in the source ontologiesto make suggestions and to look for conflicts. These features include:
• names of classes and slots (e.g., if frames have similar names andthe same type, then they are good candidates for merging),
• class hierarchy (e.g., if the user merges two classes and PROMPThas already thought that their superclasses were similar, it will havemore confidence in that suggestion, since these superclasses playthe same role to the classes that the user said are the same),
• slot attachment to classes (e.g., if two slots from different ontologies

66 CHAPTER 4. STATE-OF-THE-ART SURVEY
are attached to a merged class and their names, facets, and facetvalues are similar, these slots are candidates for merging), and
• facets and facet values (e.g., if a user merges two slots, then theirrange restrictions are good candidates for merging).
In addition to providing suggestions to the user, PROMPT identifiesconflicts. Some of the conflicts that PROMPT identifies are:
• name conflicts (more than one frame with the same name),
• dangling references (a frame refers to another frame that does notexist),
• redundancy in the class hierarchy (more than one path from a classto a parent other than root),
• slot-value restrictions that violate class inheritance.
Figure 4.5 shows the screenshot of PROMPT. The main window (inthe background) shows a list of current suggestions in the top left paneand the explanation for the selected suggestion at the bottom. The right-hand side of the window shows the evolving merged ontology. Theinternal screen presents the two source ontologies side-by-side (the su-perscript m marks the classes that have been merged or moved into theevolving merged ontology).
Summarizing, PROMPT gives iterative suggestions for concept mergesand changes, based on linguistic and structural knowledge, and it pointsthe user to possible effects of these changes.
FCA-Merge
FCA-Merge is a method for merging ontologies, which follows a bottom-up approach offering a global structural description of the merging pro-cess [154]. For the source ontologies, it extracts instances from a given setof domain-specific text documents by applying natural language process-ing techniques. Based on the extracted instances mathematically foundedtechniques taken from Formal Concept Analysis are applied. FormalConcept Analysis [61] is applied to derive a lattice of concepts as a struc-tural result of FCA-Merge. The produced result is explored and trans-formed to the merged ontology by the ontology engineer.
4.3. AUTOMATIC ONTOLOGY MAPPING TOOLS 67
Figure 4.5: PROMPT screenshot.
Figure 4.6: FCA-merge process.

68 CHAPTER 4. STATE-OF-THE-ART SURVEY
This method is based on application-specific instances of the two givenontologies O1 and O2 that are to be merged. The overall process of merg-ing two ontologies is depicted in figure 4.6 and consists of three steps,namely (i) instance extraction and computing of two formal contexts K1and K2, (ii) the FCA-Merge core algorithm that derives a common con-text and computes a concept lattice, and (iii) the interactive generation ofthe final merged ontology based on the concept lattice.
MOMIS
The Mediator Environment for Multiple Information Sources (MOMIS),developed by the database research group at the University of Mod-ena and Reggio Emilia, aims at constructing synthesized, integrated de-scriptions of information coming from multiple heterogeneous sources.MOMIS [9] [10] [8] [7] (see figure 4.7) follows a semantic approach toinformation integration based on the conceptual schema, or metadata, ofthe information sources. In the MOMIS system, each data source pro-vides a schema and a global virtual schema of all the sources is semi-automatically obtained. The global schema has a set of mapping descrip-tions that specify the semantic mapping between the global schema andthe sources schema.
The system architecture is composed of functional elements that com-municate using the CORBA standard. A data model, ODMI3, and alanguage, ODLI3 are used to describe information source. ODLI3 andODMI3 have been defined as subset of the corresponding ones in ODMG,augmented by primitives to perform integration.
To interact with a specific local source, MOMIS uses a Wrapper, whichhas to be placed over each source. The wrapper translates metadata de-scriptions of a source into the common ODLI3 representation. The GlobalVirtual Schema (GSB) module processes and integrates descriptions re-ceived from wrappers to derive the global shared schema by interactingwith different service modules, namely ODB-Tools, an integrate envi-ronment for reasoning on object oriented database based on DescriptionLogics, WordNet lexical database that supports the mediator in buildinglexicon-derived relationships, and ARTEMIS tool that performs the clus-tering operation [26].
In order to create a global virtual schema of involved sources, MOMISgenerates a common thesaurus of terminological intensional and exten-sional relationships describing intra and inter-schema knowledge about
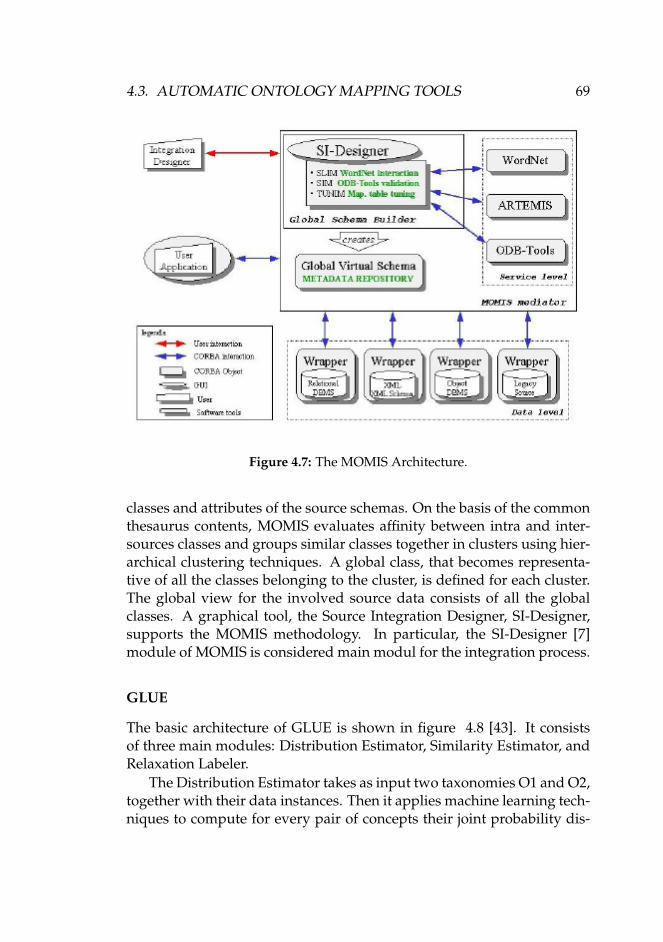
4.3. AUTOMATIC ONTOLOGY MAPPING TOOLS 69
Figure 4.7: The MOMIS Architecture.
classes and attributes of the source schemas. On the basis of the commonthesaurus contents, MOMIS evaluates affinity between intra and inter-sources classes and groups similar classes together in clusters using hier-archical clustering techniques. A global class, that becomes representa-tive of all the classes belonging to the cluster, is defined for each cluster.The global view for the involved source data consists of all the globalclasses. A graphical tool, the Source Integration Designer, SI-Designer,supports the MOMIS methodology. In particular, the SI-Designer [7]module of MOMIS is considered main modul for the integration process.
GLUE
The basic architecture of GLUE is shown in figure 4.8 [43]. It consistsof three main modules: Distribution Estimator, Similarity Estimator, andRelaxation Labeler.
The Distribution Estimator takes as input two taxonomies O1 and O2,together with their data instances. Then it applies machine learning tech-niques to compute for every pair of concepts their joint probability dis-

70 CHAPTER 4. STATE-OF-THE-ART SURVEY
Figure 4.8: The GLUE Architecture.

4.3. AUTOMATIC ONTOLOGY MAPPING TOOLS 71
tributions. The Distribution Estimator uses a set of base learners and ameta-learner. Next, GLUE feeds the above numbers into the SimilarityEstimator, which applies a user-supplied similarity function to computea similarity value for each pair of concepts. The output from this mod-ule is a similarity matrix between the concepts in the two taxonomies.The Relaxation Labeler module then takes the similarity matrix, togetherwith domain-specific constraints and heuristic knowledge, and searchesfor the mapping configuration that best satisfies the domain constraintsand the common knowledge, taking into account the observed similari-ties. This mapping configuration is the output of GLUE.
4.3.3 A Comparison of the Studied Systems
To effectively compare the above studied systems, we need to develop ancomparison framework. In [125], a set of evaluation criteria for ontologymapping and merging tools was proposed, namely:
• Input requirements. Tools vary on the kind of information they takeinto account for analysis, e.g. some of them only compare tax-onomies (subclass hierarchies), while others also looks at propertiesand their restrictions. They may work on classes, instances or both.Some methods make use of mappings to a common thesaurus orfoundational ontology.
• Level of user interaction. Tools might work automatically (batch mode)or interactively. In the latter case, they can build on feedback fromthe user to improve the quality of the mapping.
• Type of output. The output of the analysis can be a set of articulationrules (defining similarities and differences), a single merged on-tology, an instantiated mapping ontology in a particular language,paris of related concepts, etc.
• Content of output. As with input, tools differ on what kind of ele-ments in the ontology they relate in their output.
We studied the characteristics of the proposed approaches using a setof criteria, which combines the evaluation framework in [125] and theclassification schema in section 4.3.1. Figure 4.9 shows what the fivestudied systems have in common and in difference according to the setof criteria.
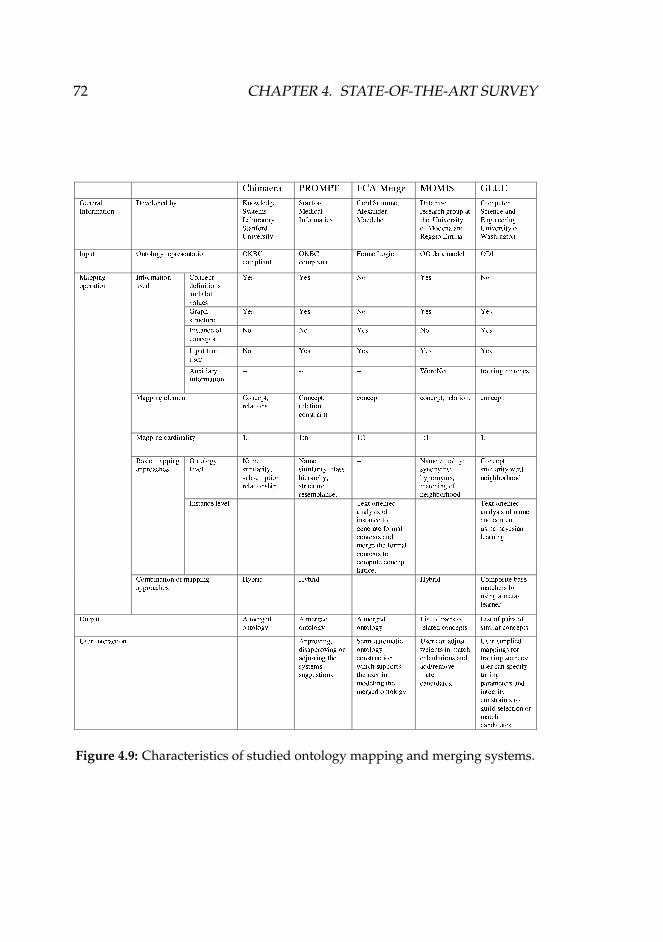
72 CHAPTER 4. STATE-OF-THE-ART SURVEY
Figure 4.9: Characteristics of studied ontology mapping and merging systems.

4.4. CONCLUDING REMARKS 73
The figure shows that most of the system are heuristically based andthey use more than one basic mapping approach, either in a hybrid wayor in a combined way. Most systems provide both structural level andelement level matching, in particular name and graph structure basedmatch. However, only two of the systems consider instance data and 1:1match is the main focus. The elements that are compared include con-cepts and relations for most of the systems, whereas comparing morecomplicated structures, like constraints or axioms is not yet supported.Most prototypes have been developed in the context of a particular ap-plication domain and some of them also use auxiliary information likethesauri to enhance the match. For matching learning based technique(GLUE), additional training set is needed. The main forms of output area merged ontology or a list of pairs of related concepts.
Even though each language choose a particular representation lan-guage to base their implementation on, it is possible to map the sourceontology to most common types of ontology representation languages.This is also partly because most the studied systems consider only thecore elements of ontologies, like concepts and relations, which most ofthe representation languages support. Furthermore, it is possible to trans-late between different representational languages [30].
4.4 Concluding Remarks
In this chapter, we have elaborated the different kinds of mismatches thatcould happen in ontology integration and sketched the current solutionsto reconcile different mismatches. We have argued that mappings arecrucial components for many applications. Many work on ontology map-ping have been done in the context of a particular application domain.Since the problem is so fundamental, we believe the field would benefitfrom treating it as an independent problem. We also studied the rele-vant terminology related to ontology mapping and defined our specificmeaning to the terms.
Several existing ontology mapping methods have been analyzed andsituated in a table of comparison. The methods have been compared withrespect to the kind of knowledge source they make use of, the input andoutput requirement and level of user interactions. Five approaches toontology mapping have been described into more detail in order to illus-trate the problems and solutions that are characteristic for the methods

74 CHAPTER 4. STATE-OF-THE-ART SURVEY
in ontology mapping. Based on the survey, we have identified a list ofrequirements that an ontology mapping approach should meet, some ofwhich we hope to target in our own work.
• The approach should be able to generate mappings automatically.
• Users should be able to intervene the process.
• Users should be able to accept, reject and add mappings.
• All the information that is useful for derive mappings should bestudied by the approach.
• The use of each particular type of information should be able toswitch on/off conveniently.
• There is a need for making use of instance information (if available)to augment the mapping process, because instance level data cangive important insight into the contents and meaning of ontologyelements. This is especially true when useful schema informationis limited, as is often the case for semi-structured data.
• Hierarchy information of the concept should be considered.
• Information on what source has been used to derive the mapping(and why it is derived) is necessary.
• Due to the semi-automatic nature of the mapping process, visuallanguage is needed to represent the ontologies so that knowledgeengineers can easily navigate the ontology structure, locate any ele-ment and ultimately approve/disapprove the suggested mappings.
• The derived mappings need to be defined and organized systemat-ically, so that other components can make use of the mappings invarious settings.
• It should be possible to conduct reasoning among the derived map-pings.
The literature study also confirmed that the process of ontology mappingis a difficult problem, since it concerns semantic interpretation of models,where the semantics is only partially available in the syntactic structureof the models. The models are created by different people, at different

4.4. CONCLUDING REMARKS 75
times, in different styles and for different purposes. Therefore, completeautomation of ontology mapping process can be motivated only if in-complete results can be accepted and the validity of correspondence as-sertions can be compromised. However, it should be possible to designheuristic methods and tools to assist a user in discovering correspon-dences between ontologies and checking the validity of the proposedcorrespondences.

76 CHAPTER 4. STATE-OF-THE-ART SURVEY

Part II
Design and Architecture
77


Chapter 5
Ontology Comparison andSemantic Enrichment
A framework for analysis and development of ontology comparison tech-niques is described in this chapter. A background for the semantic enrich-ment method and the ontology mapping algorithm is set out. A novelmethod of semantic enrichment based on extension analysis is proposed.We start by outlining prerequisites of our work in section 5.1, includingthe scope and assumption of the work and also a brief introduction to themodeling language used in this work. Ontology comparison is neededdue to the existence of semantic discrepancy among different ontologies.We briefly review the cause of semantic discrepancy and the classificationof different discrepancies in section 5.3. The different semantic discrep-ancy are reflected in the meta model of mapping assertions in section5.4. The meaning of semantic enrichment in its broad sense and in itsparticular usage in our work is explained in section 5.5 and section 5.6respectively. Section 5.7 describes in detail the enrichment technique wepropose in this work. This chapter is partly based on perviously pub-lished papers [155] [156] [158].
5.1 Prerequisites
In this section, we list the scope and assumption of work and briefly de-scribe the modeling language RML as well, which is chosen to be theunderling modeling language for the ontologies in question.
79

80 CHAPTER 5. SEMANTIC ENRICHMENT
5.1.1 Scope and Assumption
The word ontology has been used to describe artifacts with different de-grees of structure. These range from simple taxonomies (such as the Ya-hoo! hierarchy), to metadata schemes (such as the Dublin Core [46]), tological theories. We now define the scope and assumption of our work.We start with the definition of ontology as the underlying model for theontologies that we aim to compare. An ontology1 specifies a conceptual-ization of a domain in terms of concepts2, and relations3. Concepts aretypically organized into a tree structure based on subsumption relation-ships among concepts.To be more exact:
Definition 5.1 (Ontology) An ontology is a sign system O := (L,F , G , C ,R, T ),which consists of
• A lexicon L: the lexicon contains a set of lexical entries for concepts, Lc,and a set of lexical entries for relations, Lr. Their union is the lexion L :=Lc ∪ Lr.
• A set of concepts C: for each c ∈ C, there exists at least one statementconcerning c in the ontology.
• A set of relations R: a relation r (r ∈ R) specifies a pair (DM, RG),where DM, RG ∈ C. DM is called the domain concept of relation r, andRG the range concept of r. An instance i1 of DM may be related via r toanother instance i2, only if i2 ∈ RG.
• A taxonomy T : Concepts are taxonomically related by the acyclic, tran-sitive relation T , (T ⊂ C ∗ C). T (C1, C2) means that C1 is a sub-concept of C2. There is a ROOT concept in C, and it holds that ∀c ∈C , T (c, ROOT).
• C1 is a subconcept of C2, if C1 is a specification or a part of C2, or inother words, if C2 is a generalization or an aggregation of C1.
• Two reference function F , G: with F , 2Lc → 2C and G, 2L
R → 2R.F and G link sets of lexical entries {Li} ⊂ L to the set of concepts andrelations they refer to, respectively, in the ontologies. In general one lexical
1We use the term ontology and concept model interchangeably in the rest of the paperunless otherwise explicitly specified
2Also called classes, entities.3Also called attributes, slots, or properties in the literature

5.1. PREREQUISITES 81
entry may refer to several concepts or relations and one concept or relationmay be referred by several lexical entries.
This model summarizes the features which most of the ontology lan-guages support. Other features like has-value constraint in DescriptionLogic or additional axioms in F-Logic are too diverse to be included intoa common model. Starting from the definition we further elaborate thescope and assumption of our work :
1. The ontologies that are to be compared, are expressing overlappingknowledge in a common domain.
2. Ontologies can be expressed in different representational languages[159]. Though we assume that it is possible to translate betweendifferent formats, in practice, a particular representation must bechosen for the input ontologies.
3. Our approach is based on the Referent Modeling Language (RML)[148], which is an Extended ER-like (Entity Relationship) graphiclanguage with strong abstraction mechanism and a sound formalbasis. The language has an XML representation.
5.1.2 The RML Modeling Language
The Referent Model Language (RML) is a concept modelling languagetargeted towards applications in areas of information management andheterogeneous organisation of data [148] [149]. It has a formal basis fromset theory and provides a simple and compact graphical modelling nota-tion for set theoretic definitions of concepts and their relations.
RML defines constructs for modelling of concepts, the selection ofconstructs is based on the concept types given by [22]:
• Individual concepts - individual concepts apply to individuals. Indi-viduals can be either specific or generic.
• Class concepts - concepts that apply to collections of individuals.
• Relation concepts - concepts that refer to relations among objects (in-dividual or class concepts)4
4There is a somewhat blurred distinction beween class concepts and relation concepts,as a relation may be considered a class concept in its own right. The concept of ”mar-
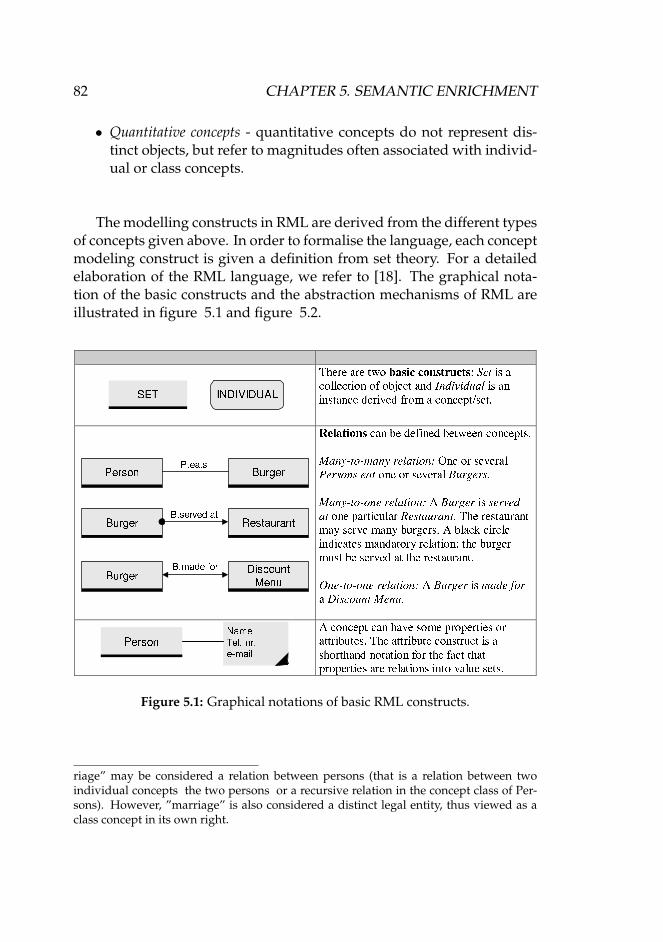
82 CHAPTER 5. SEMANTIC ENRICHMENT
• Quantitative concepts - quantitative concepts do not represent dis-tinct objects, but refer to magnitudes often associated with individ-ual or class concepts.
The modelling constructs in RML are derived from the different typesof concepts given above. In order to formalise the language, each conceptmodeling construct is given a definition from set theory. For a detailedelaboration of the RML language, we refer to [18]. The graphical nota-tion of the basic constructs and the abstraction mechanisms of RML areillustrated in figure 5.1 and figure 5.2.
Figure 5.1: Graphical notations of basic RML constructs.
riage” may be considered a relation between persons (that is a relation between twoindividual concepts the two persons or a recursive relation in the concept class of Per-sons). However, ”marriage” is also considered a distinct legal entity, thus viewed as aclass concept in its own right.
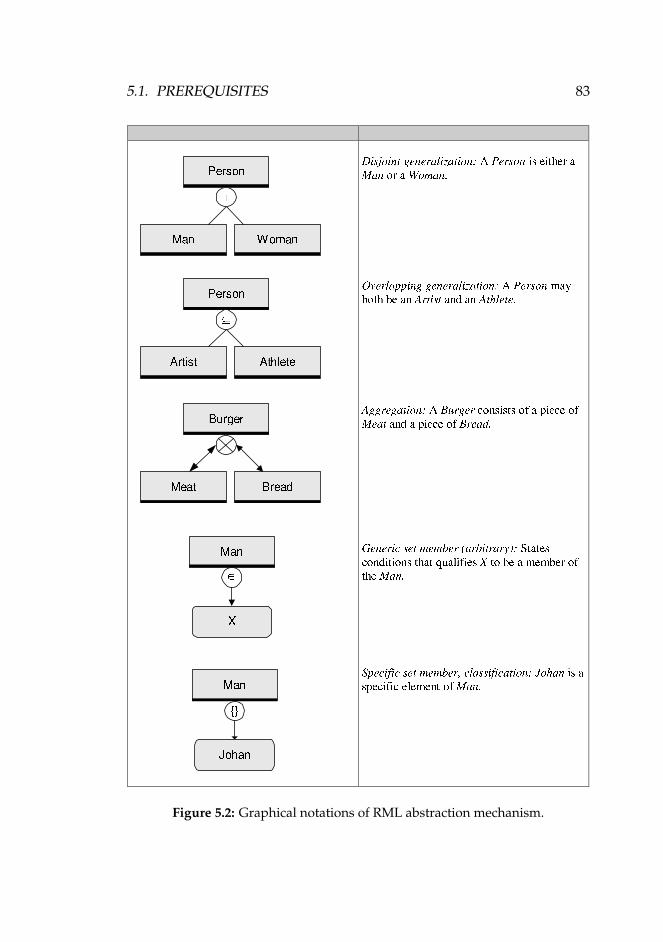
5.1. PREREQUISITES 83
Figure 5.2: Graphical notations of RML abstraction mechanism.

84 CHAPTER 5. SEMANTIC ENRICHMENT
5.2 The Abstract Ontology Mapping Model
To discuss more precisely the ontology mapping task, we introduce theabstract ontology mapping model. The overall process of ontology map-ping is defined as: given two ontologies Oa and Ob, mapping one on-tology with another means that for each element in ontology Oa, findcorresponding element(s), which has same or similar semantics, in on-tology Ob and vice verse. The comparison activity focuses on basic ele-ments first (i.e., concepts or entities); then it deals with those modelingconstructs that represents associations among basic elements (i.e., rela-tionships). We give definition to the relevant terminology as follows:
Definition 5.2 (Element) an ontology element is one of the following: a con-cept, a relation or a cluster. Concepts are called basic elements, while relationsand clusters are complex elements. A cluster is a fragment of the whole ontol-ogy5.
Definition 5.3 (Abstract mapping model) An ontology mapping model is a5-tuple [S, T, F , R(si, t j), A)] where
1. S is a set composed of logical views (representation) for the elements in thesource ontology.
2. T is a set composed of logical views (representation) for the elements in thetarget ontology.
3. F is a framework for representing ontology elements and calculating re-lationships between elements in the two ontologies.
4. R(si, t j) is a ranking function which associates a real number with anelement si ∈ S and an element t j ∈ T. Such ranking defines an orderamong the elements in source ontology with regard to one element t j inthe target ontology.
5. A is a set composed of mapping assertions. A mapping assertions is a for-mal description of the mapping result, which supports further descriptionof the exact nature of the derived mappings.
In other words, we can define the mapping process as: S, T F ,R−→ A, i.e.given the ontologies S, T as input, using the framework and the ranking
5its definition will be presented in chapter 6.

5.3. SEMANTIC DISCREPANCIES 85
function to produce A as output. The model is abstracted away from anyspecific implementation detail, yet it outlines in a higher level the task athand. There are different ways to fulfill the model. Our approach, whichwill be introduced in this thesis, can be seen as one concrete implementa-tion of the model. The rest of this chapter together with the next chapterwill discuss the process and each of the individual components in greaterdetail.
5.3 Semantic Discrepancies
As mentioned earlier, the process of ontology comparison consists ofboth identifying similarities and analyzing discrepancies among ontol-ogy structures. There are various causes for the ontology diversity. It canbe different perspectives, equivalence among constructs of the model,and incompatible design specifications.
Owing to these causes, conflicts inevitably exist in the representa-tion of the same objects in different ontologies. Two types of conflictsare broadly distinguished: terminological discrepancy and structural dis-crepancy.
• Terminological discrepancies arise, as people from different organiza-tions, or from different areas of the same organizations, often referto the same things using their own terminology and names.This re-sults in a proliferation of names as well as a possible inconsistencyamong terminologies in the component ontologies. The terminol-ogy discrepancies are classified as:
– a synonym that occurs when the same object or relationship inthe UoD is represented by different names6 in the componentontologies.
– a homonym that occurs when different objects or relationshipsin the UoD are presented by the same name in the componentontologies.
• Structural discrepancies arise as a result of a different choice of mod-eling constructs or integrity constraints. The following types ofstructural discrepancies can be distinguished:
6A name can be either a single word or a phase.

86 CHAPTER 5. SEMANTIC ENRICHMENT
– type discrepancies arise when the same phenomena in a UoDhave been modeled using different ontology constructs. Forexample, a real world phenomenon can be classified into cat-egories. At least two different ways can represent that. One isto use a number of subtypes to a given entity type. Anotheris to use an attribute that has a fixed set of values in order toindicate the same category to which an object in the UoD be-longs.
– dependency discrepancies arise when a group of concepts are re-lated among themselves with different dependencies in dif-ferent ontologies. For example, the relationship ProjectLeaderbetween Project and Person is 1:1 in one ontology, but m:n inanother.
An ontology integration technique may analyze discrepancies amongontology constructs in order to support identification of correspondences,to support canonization, or to support conflict analysis. In this work, thefocus is on the comparison step of the integration process. In the nextsection, the notion of mapping assertion is described. The implication ofdifferent discrepancies is reflected in the correspondence assertion.
5.4 Mapping Assertions
In order to describe, store and transmit the derived mappings in a sys-tematic way, a model for describing the mappings is defined. In [71], anotion of correspondence assertion is introduced for that purpose. Weadopt that correspondence assertion model as a base for organizing dif-ferent aspects of the mappings.
In order to compare different comparison methods, it is important toidentify the possible types of semantic relationships between the com-pared ontology structures. Also it is important to include the emergingmethods which use some method of semantic enrichment into develop-ment or analysis of comparison techniques. Therefore, the mapping as-sertion also contains references to semantic enrichment structures, i.e. thesource of the assertion, if any. The intension of the concept is to providean explanation why the particular assertion is chosen. The mapping as-sertion also contains a measurable degree of correspondence. It is usedwith the intention to cover comparison methods leading to competitiveassertions which may be selected through ranking.
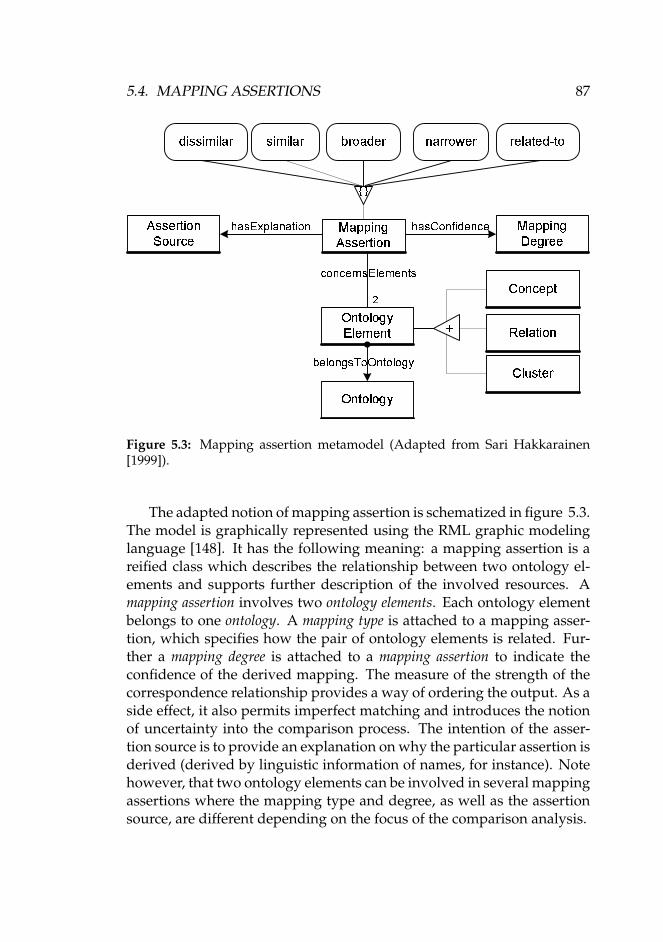
5.4. MAPPING ASSERTIONS 87
Figure 5.3: Mapping assertion metamodel (Adapted from Sari Hakkarainen[1999]).
The adapted notion of mapping assertion is schematized in figure 5.3.The model is graphically represented using the RML graphic modelinglanguage [148]. It has the following meaning: a mapping assertion is areified class which describes the relationship between two ontology el-ements and supports further description of the involved resources. Amapping assertion involves two ontology elements. Each ontology elementbelongs to one ontology. A mapping type is attached to a mapping asser-tion, which specifies how the pair of ontology elements is related. Fur-ther a mapping degree is attached to a mapping assertion to indicate theconfidence of the derived mapping. The measure of the strength of thecorrespondence relationship provides a way of ordering the output. As aside effect, it also permits imperfect matching and introduces the notionof uncertainty into the comparison process. The intention of the asser-tion source is to provide an explanation on why the particular assertion isderived (derived by linguistic information of names, for instance). Notehowever, that two ontology elements can be involved in several mappingassertions where the mapping type and degree, as well as the assertionsource, are different depending on the focus of the comparison analysis.

88 CHAPTER 5. SEMANTIC ENRICHMENT
The output of comparing these structures is a set of mapping asser-tions. Each mapping is described in a way that is consistent with theassertion model. A more precise definition of such assertions is given inthe following.
Definition 5.4 (Mapping assertion) A mapping assertion describes the rela-tionship between two ontology elements, and it has the four following compo-nents:
• a pair of ontology elements,
• a type of correspondence,
• a degree of correspondence, and
• a set of sources of assertion.
In the following, we discuss the above concepts further.
• An ontology element is a valid expression in an ontology modelinglanguage either on the specification or the instantiation level. In ourwork, an ontology element can be a concept or a relation or a cluster.
• A type of correspondence is one of the following five types - similar,narrower, broader, related-to and dissimilar. The first four types arecommonly used in thesauri [176]. Technically, the term dissimilaris used to specify the situation when two concepts have the same(similar) names, but denote two different things (i.e. homonym).Note, however, the intention with related-to is to cover complexinter-schema relationships, which do not fall into the category ofsimilarity and subset. For example, to connect concept country inone ontology with city in another ontology, the inter-schema rela-tionship belongs-to might be specified. As it is impossible to enu-merate all these kind of ad hoc relationships, we unified them un-der related-to. It is, of course, possible to specify in more detail theexact nature of the relationship, when related-to is chosen.
• The degree of correspondence specifies how strongly a particular map-ping type holds between two ontology elements. It is used to de-scribe and modify a mapping type assigned between two ontol-ogy elements. It measures the strength of their correspondence of agiven type.

5.5. SEMANTIC ENRICHMENT OF ONTOLOGY 89
• The source of assertion denotes the enrichment structures involved,which lead to the choice of a specific type of correspondence, ifany. The mapping assertion contains the reference to the sources ofthe assertion in order to enable description and classification of themethods involving semantic enrichment. The intention of source ofassertion is to provide an explanation why a particular assertion isproposed.
The careful reader will have noticed that concept like mapping degree ismodeled as a class rather than using a primitive date type directly (in thatcase, it would have been number). The reason is a matter of flexibilityand extensibility. Model it into a class makes it possible to add attributesor relations more easily in the future.
To make the result useful in a wider context, it is important to becompatible with current web standards. Therefore, the model is also rep-resented by using the Ontology Web Language OWL [130] . By exportingthe results in OWL making it possible for other OWL-aware applicationsto process and reason the mapping results. In addition, thanks to the for-mal semantic of OWL, translating the model into OWL gives us a moreprecise semantic definition for each of the concepts and relations. Theformality allows using inference engines to check consistency or com-pleteness of the mappings.
5.5 Semantic Enrichment of Ontology
The first step in handling semantic heterogeneity should be the attemptto enrich the semantic information of concepts in ontologies, as it is wellunderstood that the richer information the ontologies possesses, the higherprobability that high quality mappings will be derived [71]. An ontologymapping method based on semantic enrichment involves usage of alter-native knowledge sources than the original ontology. A semantically en-riched ontology expresses more of the semantics of the UoD (Universe ofDiscourse) than the original ontology by introducing often generic, addi-tional information about an application domain in the UoD. The seman-tic enrichment techniques may be based on different theories and makeuse of a variety of knowledge sources [71], such as concept hierarchy, theshared thesaurus, the linguistic knowledge, the fuzzy terminology andthe extension analysis. An abstract description of any semantic enrich-ment techniques may contain the following components.

90 CHAPTER 5. SEMANTIC ENRICHMENT
Figure 5.4: Semantic enrichment in ontology comparison.
• A semantically enriched ontology, E(O), expresses more of the seman-tics of a UoD than an original component ontology O, where anenrichment structure introduces additional information about itsontology structures.
• An enrichment structure, C, is a structure that captures the enrichedknowledge. The syntax and semantics of such an enrichment struc-ture are defined in a language of the chosen enrichment technique.
Figure 5.4 depicts the impact of semantic enrichment on the processof ontology comparison. The intuition is, that by semantically enrichingthe two compared ontology, O1 and O2, into E(O1) and E(O2), we trans-form the problem of comparing O1 and O2 into that between E(O1) andE(O2).
In our work, we instantiate the enrichment structure C with a repre-sentative feature vector, which comes out as the result of extension anal-ysis of the relevant ontologies. In the next section, we discuss the aboveconcepts in greater detail.
5.6 Extension Analysis-based Semantic Enrichment
5.6.1 The Concept of Intension and Extension
The concepts of intension and extension7 have been introduced to un-derstand the meaning of individual words and expressions [15]. The ex-tension of an expression means the object or the set of objects in the realword to which the expression refers. The extension of the word dog is
7Also called terminological and extensional

5.6. EXTENSION ANALYSIS-BASED SEMANTIC ENRICHMENT 91
Figure 5.5: Semantic enrichment through extension analysis.
the set of all dogs. The intension of an expression means its sense, whicha person normally understands by the expression. For example, the in-tension of the word dog might be something like ”hairy mammal withfour legs and tail often kept as pet”.
An ontology often (but not always) specifies the intensional part ofthe UoD, which identifies the concepts in the domain and the relationsbetween them. The extensional part consists of facts about specific in-dividuals in the domain, with which the model is populated. There arestill different opinions on whether it is the intension or the extension thatbest decides the semantics of a concept. It is, nevertheless, widely ac-cepted that the more we know about the intension and the extension, themore likely that we are closer to the complete understanding of the con-cepts. It is from this intuition, that we develop our enrichment techniqueon the bases of extension analysis, as depicted in figure 5.5.
5.6.2 Extension Analysis for Semantic Enrichment
Ontology mapping concerns the interpretation of models of a Universeof Discourse (UoD), which in turn are interpretations of the UoD. Thereis no argumentation for these interpretations to be the only existing orcomplete conceptualizations of the state of affairs in the real world. Weassume that the richer a description of a UoD is, the more accurate con-ceptualization we achieve of the same UoD through interpretation of thedescriptions.

92 CHAPTER 5. SEMANTIC ENRICHMENT
Hence, the starting point for comparing and mapping heterogeneoussemantics in ontology mapping is to semantically enrich the ontologies.Semantic enrichment facilitates ontology mapping by making explicitdifferent kinds of ”hidden” information concerning the semantics of themodeled objects. The underlying assumption is that the more semanticsthat is explicitly specified about the ontologies, the more feasible theircomparison becomes. The semantic enrichment techniques may be basedon different theories and make use of a variety of knowledge sources [71].We base our approach on extension analysis, i.e. instance information aconcept possesses. The instances we use are documents that have beenclassified to the concepts. The idea behind is that written documentsused in a domain inherently carry the conceptualizations that are sharedby the members of the community. This approach is in particular attrac-tive on the World Wide Web, because huge amounts of free text resourcesare available.
The belief is that the semantic meaning of a concept should be aug-mented with its extensions [87]8. Therefore, the concept is semanticallyenriched with a generalization of the information its instances provide.The generalization takes the form of a high-dimensional vector. Theseconcept vectors are ultimately used to compute the degree of similaritybetween pairs of concepts.
As illustrated in figure 5.6, the intuition is that given two ontologiesA and B, we construct a representative feature vector for each conceptin the two ontologies. The documents are ”building materials” for theconstruction process. Then with the feature vectors at hand, we calcu-late a similarity measure sim(ai, b j) pair wise for the concepts in the twoontologies.
5.7 Feature Vector as Generalization of Extension
In figure 5.7, we show that the whole ontology mapping process aremade of two phases, semantic enrichment phase and the mapping phase.We have been focusing on the semantic enrichment phase in this chapter.The main task in the semantic enrichment phase is to generate the enrich-ment structure, namely, the representative feature vector. We first definewhat is a feature vector of a concept, and proceed with the procedures to
8Though in certain approaches, e.g. Description Logics, an intensional definition isbelieved to best describe the semantic meaning.
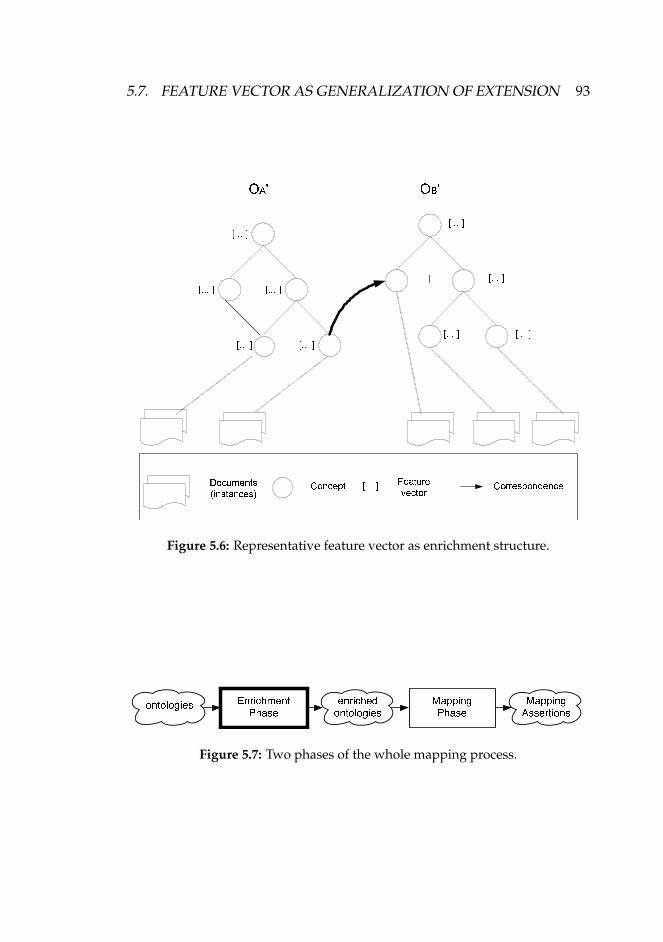
5.7. FEATURE VECTOR AS GENERALIZATION OF EXTENSION 93
Figure 5.6: Representative feature vector as enrichment structure.
Figure 5.7: Two phases of the whole mapping process.

94 CHAPTER 5. SEMANTIC ENRICHMENT
generate feature vectors.
5.7.1 Feature Vectors
Definition 5.5 (Feature vector) Let Ck be the feature vector of concept K, andlet V be the collection of all index words in the document collection.
Ck = (weight1, weight2, . . . , weightt)V = (word1, word2, . . . , wordt).Ck
i denotes the representativeness of index word Vi to concept K.
We give a simple example to illustrate the structure of a feature vector.For example, if
K = AccommodationV = (bed, breakfast, car, computer, flight, hotel, price, travel, tree, water)9
the feature vector CAccommodation = (0.44, 0.5, 0, 0, 0.2, 0.8, 0.8, 0.4, 0, 0)it means, for instance, index word bed has a representativeness of 0.44
to the concept Accommodation, while word car has no representativenesswhen it comes to concept Accommodation.
We now describe in detail how the feature vectors are generated. Boththe steps and the algorithm will be elaborated.
5.7.2 Steps in Constructing Feature Vectors
Figure 5.8 shows the two steps performed in the semantic enrichmentprocess. The algorithm takes the two to-be mapped ontologies in RMLformat, together with document sets, as input. There can be one or twodocument sets. In the former case, we assume the documents are rel-evant to both ontologies, while in the latter, it is assumed that the twodocument sets share the same vocabulary.
5.7.3 Document Assignment
Document assignment step aims to automatically assign documents toone or more predefined categories based on their contents. We use alinguistically based classifier CnS (Classification and Search) [19] to as-sociate documents with the ontologies. Multiple association is allowed.This is a semi-automatic process, where users need to manually adjustthe assignment results to guarantee the correct assignments.
9In reality, the vocabulary dimension is much higher.

5.7. FEATURE VECTOR AS GENERALIZATION OF EXTENSION 95
Figure 5.8: Overview of the semantic enrichment process.
Alternatively, for a basic method of assigning documents to concepts,we may consider each concept as a query that is fired against a general-purpose search engine, which maintains the documents in question. Eachdocument in the result set that has a ranking value greater than a cer-tain minimum threshold is then assigned to the query concept. Whichmethod to choose is partially determined by the kind of resources thatare readily accessible.
The assigning of documents to concepts is necessary when no in-stance knowledge of the ontology is available. However, if documentshave already been assigned to specific concepts, we can skip the first stepand construct feature vector for the concepts directly10.
5.7.4 Feature Vector Construction
The above step provides as output two ontologies, where documentshave been assigned to each concepts in the ontologies. The next step
10An example, where documents have already been assigned to concepts is Open Di-rectory Project http://dmoz.org/

96 CHAPTER 5. SEMANTIC ENRICHMENT
is to calculate a feature vector for each concept in the two ontologies re-spectively. To calculate a feature vector for each concept, we first need toestablish feature vectors for each document that belongs to the concept.
The second step concerns building up feature vectors for each con-cepts in the two ontologies. The intuition is that for each concept a fea-ture vector can be calculated based on the documents assigned to it. Fol-lowing a classic Rocchio algorithm [1], the feature vector for concept aiis computed as the average vector over all document vectors that belongto concept ai. Following the same idea, the feature vector of a non-leafconcept is computed as the centroid vector of its instance vector, sub con-cepts vector and related concepts vector. Thus, hierarchical and contex-tual information is partially taken into consideration. The output of thisstep is two intermediate ontologies, O
′A and O
′B , where each concept has
been associated with a feature vector as depicted in figure 5.6.Three sub-steps constitute the process. The first two steps aim at
building document vectors, while the third step use the document vec-tors to build feature vectors for concepts.
1. Pre-processing.The first step is to transform documents, which typ-ically are strings of characters, into a representation suitable for thetask. The text transformation is of the following kind: removeHTML (or other) tags; remove stop words; perform word stem-ming (lemmatization). Auxiliary information like stop words list,English lexicon (WordNet in this particular case) are used to per-form the necessary linguistic transformation.
2. Document representation.We use the vector space model [142] toconstruct the generalization of the documents. In vector space model,documents are represented by vectors of words. There are severalways to determining the weight of word i in a document d. Weuse the standard tf/idf weighting [142], which assigns the weightto word i in document d in proportion to the number of occurrencesof word in the document, and inverse proportion to the number ofdocuments in the collection for which the word occurs. Thus, foreach document d in a document collection D, a weighted vector isconstructed as follows:
~d = (w1, . . . , wn) (5.1)
where wi is is the weight of word i in document d.
wi = fi ∗ log (N/ni) (5.2)

5.7. FEATURE VECTOR AS GENERALIZATION OF EXTENSION 97
Figure 5.9: Contributions from relevant parts when calculating feature vectorfor non-leaf concept.
where fi is the frequency of word i in document d, N is the numberof documents in the collection D and ni is the number of documentsthat contains word i.
3. Concept vector construction.We differentiate here leaf concept andnon-leaf concept in the ontology. Leaf concepts are those whichhave no sub-concepts.
• For each leaf concept, the feature vector is calculated as an av-erage vector on the documents vectors that have already beenassigned to this concept. Let Ck be the feature vector for con-cept concept K and let D j be the collection of documents thathave been assigned to that concept K. Then for each feature iof the concept concept vector, it is calculated as:
Cki =
∑D j∈K
wi j∣∣D j∣∣ (5.3)
• When it comes to non-leaf concepts, the feature vector Ck fora non-leaf concept K is calculated by taking into considerationcontributions from the documents that have been assigned toit, its direct sub concepts and the concepts with which con-cept K has relation 11. Figure 5.9 illustrates that contributionsfrom the instance, the sub-concepts and the related concepts
11At this point, all ad hoc relations other than subsumption are treated as related-to.

98 CHAPTER 5. SEMANTIC ENRICHMENT
are counted in when calculating feature vectors for such non-leaf concepts. Let D j be the collection of documents that havebeen assigned to that concept K, let St be the collection of itsdirect sub concepts and let Sr be the collection of its relatedconcepts. The ith element of Ck is defined as:
Cki = α ∗
∑D j∈K
wi j∣∣D j∣∣ + β ∗
∑St∈K
wit
|St|+ γ ∗
∑Sr∈K
wir
|Sr|(5.4)
whereα +β+γ = 1. α ,β and γ are used as tuning parametersto control the contributions from the concepts instances, subconcepts, and related concepts respectively.
5.7.5 Feature Vectors as Semantic Enrichment
The above steps give us a feature vector for each concept in the ontolo-gies. What does a feature vector tell us? As we mentioned earlier, the in-tention to have a feature vector is to capture and explicit the extensionalinformation a concept bears. From the way we build up the feature vec-tors, it is reasonable to say that a feature vector is a statistical measure andrepresentation of a concept’s extensional information. Representing thisinformation in a feature vector gives a computational convenient way tostudy it and read information out of it.
5.8 Concluding Remarks
The framework proposed in this chapter intends to capture the semanticsof comparison of various aspects of ontologies. It can be interpreted as adescriptive framework, aimed at supporting analysis and developmentof methods and tools for ontology comparison. The intention is to cap-ture the specific properties of conflicts and correspondences the existingmethods handle and consider in ontology comparison. The frameworkclarifies the extent to which the existing ontology comparison methodsdetect different kinds of correspondences.
The method we proposed is not universally applicable, however. Therelevant scope and assumptions of our work have therefore been elabo-rated. We introduced the abstract mapping model to formalize the map-ping task in an implementation independent fashion. The concept of se-

5.8. CONCLUDING REMARKS 99
mantic discrepancy is included with the intention to set the design con-sideration for mapping assertions. The mapping assertion model, on theother hand, describes the structure and intended semantic meaning ofthe mapping results.
The particular semantic enrichment method used in this work (i.e.extension analysis based) has been elaborated both in terms of the en-richment structure and in terms of the construction process. The twosteps that constitutes the semantic enrichment phase, namely documentassignment and feature vector construction have been extensively dis-cussed. The second phase of the whole approach, the mapping phase,will be explained in the next chapter.

100 CHAPTER 5. SEMANTIC ENRICHMENT

Chapter 6
Ontology Mapping Approach
In this chapter, an approach for mapping of semantically enriched ontolo-gies is proposed. The defined steps for mapping are intended to supporta knowledge worker or application engineer in the problematic task ofontology mapping or integration. The current version of the prototypeimplementation of the algorithm is for the purpose of experiments withthe proposed approach. Parts of the work in this chapter have been pub-lished before [158] [157].
6.1 Algorithm Overview
The focal point of this chapter is the second phase of the approach, namelythe mapping phase, as illustrated in figure 6.1.
A novel algorithm for ontology mapping is specified in the followingsections. The basic idea of mapping assertion analysis from Chapter 5are further developed and applied in practice for comparison of relevantelements of two ontologies. The algorithm takes as input semanticallyenriched elements of two ontologies and produces as output suggestionsto the user for possible correspondences. As figure 6.2 illustrates, thealgorithm has the following five main components.
Figure 6.1: Two phases of the whole mapping process.
101

102 CHAPTER 6. ONTOLOGY MAPPING APPROACH
• The mapper performs a computation of a correspondence measurefor the pairs of compared ontology elements, based on the similar-ity of their enriched structures.
• The enhancer utilizes an electronic lexicon to adjust the similarityvalues that have been computed by the mapper, with the intentionof re-ranking the mapping assertions in the result list.
• The presenter determines which recommendations to suggest to theuser, based on the partial ordering of correspondence measures andthe current configuration profile.
• The exporter translates and exports the mapping results to a desiredformat so that other follow-up applications can import and use theresults in a loosely coupled way.
• The configuration profile is a user profile to assign individual variablevalues for different tuning parameters and a threshold value forexclusion of mappings with low similarity.
The mapping algorithm is used to semi-automate the process of com-paring and mapping two semantically enriched ontologies representedin RML. It analyses the extension and intension of ontology elements inorder to determine quantitatively the measure of similarity in the twocompared elements. Based on the degree of similarity among elementpairs, the algorithm produces a set of ranked suggestions. The user isin control of accepting, rejecting or altering the assertions. The level ofautomatic exclusion from user presentation is adjustable.
The mapping phase starts with the mapper taking the two semanti-cally enriched ontologies as input and calculating similarity values forthe concepts in the two ontologies. The enhancer works in a plug-in man-ner and updates the initially computed similarity values for the map-ping assertions. Next, the mapper works on the refined mapping resultsfor concepts to calculate correspondences for more complex structures,ranging from relations, to clusters to ontologies. Then, the results arepresented to the user for possible manual inspection before they are ex-ported. Sections 6.2, 6.3, 6.4 describe each of the step in greater detail.Further refinement of the algorithm for the sake of more accurate map-pings is presented in section 6.5. Prerequisites to apply the algorithm arediscussed in section 6.6 and possible application scenarios that satisfy

6.2. THE SIMILARITY CALCULATION FOR CONCEPTS 103
Figure 6.2: Major steps in the mapping phase.
the prerequisites are identified in the same section. Finally, section 6.7summarizes the chapter.
6.2 The Similarity Calculation for Concepts
To find concept pairs that are similar, we calculate a similarity value forconcepts pairwise in the two ontologies. A threshold value is defined bythe user to exclude pairs that have too low similarity values. The calcu-lation of concept similarity is the foundation for similarity calculation ofother more complex elements.
The similarity of two concepts in two ontologies is directly calculatedas the cosine measure between the two representative feature vectors. Lettwo feature vectors for concept a and b respectively, both of length n, begiven. The cosine similarity between concept a and concept b is definedas:
sim(a, b) = sim(Ca, Cb) =~Ca ∗ ~Cb
|Ca| ∗ |Cb|=
n
∑i=1
(Cai ∗ Cb
i )√∑n
i=1(Cai )2 ∗
√∑n
i=1(Cbi )2
(6.1)where

104 CHAPTER 6. ONTOLOGY MAPPING APPROACH
• Ca and Cb are feature vectors for concept a and b, respectively
• n is the dimension of the feature vectors
• |Ca| and∣∣Cb
∣∣ are the lengths of the two vectors, respectively
For concept a in ontology A, to find the most related concept b inontology B, the top k ranked concept nodes in ontology B are selectedaccording to the initial similarity measure calculated above. Those pairsthat are not selected, either because of its similarity value is lower thanthe threshold value or because it is not in the top k ranked, their similarityvalues will be deduced to zero.
The chosen pairs are further evaluated by other matching strategies.For instance, if one concept has a similar name as concept a, its similaritymeasure will get a boost, which results in the change of its rank in theresult set. How large the boost is can be tuned by a parameter. This leadsus to the next section, where adjusting similarity value is elaborated.
6.3 Adjust Similarity Value with WordNet
Given the central position of concept similarity calculation, it is desir-able to make the suggestions as accurate as possible. This requires addi-tional technique to adjust the similarity value. We use a electronic lexiconWordNet for that purpose.
We start this section with a brief description of WordNet. Then we in-troduce the path length measurement which is used to compute semanticrelatedness of concepts.
6.3.1 WordNet
WordNet1 is a lexical database constructed on lexicographic and psy-cholinguistic principles, under active development for the past 20 yearsat the Cognitive Science laboratory at Princeton Unversity. It contains138,838 English words [113]. English nouns, verbs, adjectives and ad-verbs are organized into synonym sets, each representing one underlyinglexical concept.
In WordNet each unique meaning of a word is presented by a syn-onym set or synset. Each synset has a gloss that explains the concept the
1http://www.cogsci.princeton.edu/wn/

6.3. ADJUST SIMILARITY VALUE WITH WORDNET 105
synset represents. For example the words car, auto, automobile, and moto-car constitute a single synset that has the following gloss: four wheel motorvehicle, usually propelled by an internal combustion engine.
Synsets are connected to each other through explicit semantic rela-tions that are defined in WordNet. These relations only connect wordsense that are used in the same part of speech. Noun synsets are con-nected to each other through hypernym, hyponym, meronym, and holonymrelations.
If a noun synset A is connected to another noun synset B through is-a-kind-of relation then B is said to be hypernym of synset A and A a hyponymof B. In the car example, the synset containing car is a hypernym of thesynset containing ambulance and the ambulance synset is a hyponym ofthe car synset. If a noun synset A is connected to another noun synset Bthrough the is-a-part-of relation then A is said to be a meronym of B andB a holonym of A. In the car example, the synset containing bumper is ameronym of car and car is a holonym of bumper. Noun synset A is relatedto adjective synset B through the attribute relation when B is a value of A.For example the adjective fast is a value of the noun synset speed.
Taxonomic or is-a relations also exist for verb synsets. Verb synset Ais a hypernym of verb synset B if to B is one way to A. Synset B is called atroponym of A. For example the verb synset containing the word operateis a hypernym of drive since to drive is one way to operate. Converselydrive is a troponym of operate. Adjective synsets are related to each otherthrough the similar to relation. For example, the synset containing theadjective. For example fast is similar to rapid. Verb and adjective synsetsare also related to each other through cross-reference also-see links.
While there are other relations in WordNet, those described abovemake up more than 93% of the total number of links in WordNet. Ourapproach does not explore beyond the scope described above.
6.3.2 The Path Length Measurement
With the initial mapping suggested by the previous step, the users canchoose to go for a post processing step to strengthen the prominent map-pings. WordNet [52] may be used to strengthen the mappings whoseconcept names have a close relatedness in WordNet. The goal is to up-date the similarity value two concepts have based on the distance of thetwo concepts in WordNet.
As we explained in the introduction, in WordNet, nouns are orga-

106 CHAPTER 6. ONTOLOGY MAPPING APPROACH
Figure 6.3: Example on hyponymy relation in WordNet used for the path lengthmeasurement.
nized into taxonomies where each node is a set of synonyms (a synset)representing a single sense. If a word has multiple senses, it will appearin multiple synsets at various locations in the taxonomy. These synsetscontain bidirectional pointers to other synsets to express a variety of se-mantic relations. The semantic relation among synsets in WordNet thatwe use in this experiment is that of hyponymy/hypernymy, or the is-a-kind-of relation, which relates more general and more specific senses.Verbs are structured in a similar hierarchy with the relation being tro-ponymy in stead of hypernymy.
One way to measure the semantic similarity between two words aand b is to measure the distance between them in WordNet. This can bedone by finding the paths from each sense of a to each sense of b andthen selecting the shortest such path. Note that path length is measuredin nodes rather than links. So the length between sister nodes is 3. Thelength of the path between member of the same synset is 1. In the exam-ple of figure 6.3, the length between car and automobile is 1, since theybelong to the same synset. Similarly, the path between car and bike is 4and the path between car and fork is 12.
we did not make any effort in joining together the 11 different topnodes of the noun taxonomy. As a consequence, a path cannot always befound between two nouns. When that happens, the algorithm returns a

6.3. ADJUST SIMILARITY VALUE WITH WORDNET 107
”not related” message.The path length measurement above gives us a simple way of calcu-
lating relatedness between two words. However, there are issues thatneed to be addressed.
• Word form. When looking up a word in WordNet, the word is firstlemmatized. So the distance between system and systems is 0.
• Multiple part-of-speech. The path length measurement can onlycompare words that have the same part-of-speech. This impliesthat we don not compare, for instance, a noun and a verb, since theyare located in different taxonomy trees. The words we compare inthis context are concept names in the ontologies. Even though mostof the names are made of single noun or noun phrase, verbs andadjectives do occasionally appear in a concept name label. In somecases, one word would have more than one part-of-speech (for in-stance, ”backpacking” is both a noun and a verb in WordNet). Forthese words, we first check if it is a noun and if the answer is yes,we treat it as a noun. In the case of ”backpacking”, for instance, itwill be treated as a noun and its verb sense will be disregarded. Ifit is not a noun, we check if the word is a verb and if the answer isyes, we treat it as a verb. Words that are neither nouns, verbs noradjectives will be disregarded. This makes sense since the differ-ent part-of-speech of the same word are usually quite related andchoosing one of them would be representative enough.
• Compound nouns. Those compound nouns which have an entryin WordNet (for example, ”jet lag”, ” travel agent” and ”bed andbreakfast”) will be treated as single words. Others like ”railroadtransportation” , which have no entry in WordNet, will be split intotokens (”railroad” and ”transportation” in the example) and its re-latedness to other word will be calculated as an average over therelatedness between each token and the other word. For instance,the relatedness between ”railroad transportation” and ”train” willbe the average relatedness of ”railroad” with ”train” and ”trans-portation” with ”train”.
We have integrated the Java WordNet Library (JWNL) [38], a JavaAPI, into the system for accessing the WordNet relational dictionary and

108 CHAPTER 6. ONTOLOGY MAPPING APPROACH
calculate semantic relatedness based on the path length measurement de-scribed above. The computed relatedness will be amplified by a tun-ing parameter and then will be added to the similarity values computedin the previous step. The changing of similarity values will change theranks of the involved mappings. The intension is that the more likelyto be correct ones will be strengthened by that post processing proce-dure and be ranked high in the results. Whether the post processing stepachieves that goal or not has to be checked by the evaluation process,which comes in chapter 8.
6.4 The Similarity Calculation for Complex Elements
Based on the correspondences calculated for the concepts, we could fur-ther expand the correspondence discovery into other elements and struc-tures in the ontologies. In this section, we introduce how similarity be-tween relations and between clusters of concepts are defined.
6.4.1 Relations
The similarity of relations is calculated based on the corresponding do-main concepts and range concepts of the relations. Precisely, the similar-ity between relation R(X, Y) and R′(X′, Y′) is defined as the arithmeticmean value of the similarity values their domain and range conceptshave:
sim(R, R′) =(sim(X, X′) + sim(Y, Y′))
2(6.2)
where
• X and X’ are domain concepts of R and R’, respectively
• Y and Y’ are the range concepts of R and R’ respectively
• the sim(X, X′) and sim(Y, Y′) can be calculated by equation 6.1 forconcepts similarity.
6.4.2 Clusters
Based on the correspondences calculated for the concepts, we could fur-ther expand the correspondence discovery into more complex structures.For this, we define the concept of cluster. A cluster is a group of related

6.4. THE SIMILARITY CALCULATION FOR COMPLEX ELEMENTS 109
Figure 6.4: Example of calculating cluster similarity.
concepts, which includes a center concept a and its k-nearest neighbors.A cluster of 1-nearest neighbor includes a center concept and its directparent, and its direct children. A cluster of 2-nearest neighbor includesthe grandparent, the siblings and the grandchildren, in addition to the1-nearest neighbor. The correspondences between clusters in two ontolo-gies reveal ”areas” that are likely to be similar. This helps knowledgeworkers to locate and concentrate on a bigger granularity level.
The similarity of clusters is calculated based on the weighted percent-age of established mappings between member concepts in proportion tothe number of all connections between the two clusters. Figure 6.4 il-lustrate an example of two 1-nearest neighbor cluster, A and B, where a2and b2 are the center concepts of A and B respectively. Four mappingsbetween member concepts exist, namely (a1, b1), (a2, b2), (a4, b3) and (a4,b4). That situation given, the similarity between cluster A and cluster Bis therefore computed as:
sim(A, B) =(sim(a1, b1) + sim(a2, b2) + sim(a4, b3) + sim(a4, b4))
4 ∗ 5(6.3)
We define the equation of calculating two cluster similarity as:
sim(X, Y) =∑(ai ,b j)∈M sim(ai, b j)
|X| ∗ |Y| (6.4)
where
• X and Y are clusters of k-nearest neighbor. X = {a1, a2, a3, · · · , an}and Y = {b1, b2, b3, · · · , bm}.

110 CHAPTER 6. ONTOLOGY MAPPING APPROACH
• M is a subset of the cartesian product of X and Y, where M ⊆ X ∗Y, M = {(ai, b j)|(ai ∈ X) ∩ (b j ∈ Y) ∩ (sim(ai, b j) > 0)}
• |X| and |Y| are number of elements in the two sets, respectively.
• the sim(ai, b j) is calculated by equation 6.1 for concepts similarity.
6.4.3 Ontologies
Extending the idea of cluster similarity one step further, we come to thepoint where the similarity between two ontologies can be quantified asthe weighted percentage of established mappings in proportion to all theconnections between concepts in the two ontologies, as defined in thefollowing equation.
sim(O1, O2) =∑(ai ,b j)∈M sim(ai, b j)
|O1| ∗ |O2|(6.5)
where
• O1 and O2 are two ontologies. O1 = {a1, a2, a3, · · · , an} and O2 ={b1, b2, b3, · · · , bm}. ai (i=1...n) are the concepts in O1 and b j (j=1...m)are the concepts in O2.
• M is a subset of the cartesian product of O1 and O2, where M ⊆O1 ∗O2, M = {(ai, b j)|(ai ∈ O1) ∩ (b j ∈ O2) ∩ (sim(ai, b j) > 0)}
• |O1| and |O2| are number of concepts in the two ontologies, respec-tively.
• the sim(ai, b j) is calculated by equation 6.1 for concepts similarity.
Such a value is in particular useful when several ontologies in a do-main need to be merged, for this value could help revealing the mostsimilar two, which constitute good candidates for the merging process.
6.5 Further Refinements
In the design of the system, we noticed that to achieve more accuratemapping results, further refinements of the results are always welcome.Even though our current implementation does not directly incorporatethem into the system, due to the reason of keeping focus and marginally

6.5. FURTHER REFINEMENTS 111
cost/benefit gain, it is still advisable to discuss them in theory and pre-pare the system architecture in such a way that adding them will be rel-atively easy and require the lest possible extra efforts. There are mainlythree kinds of efforts which fall in the realm of our further refinementtechniques. We will discuss them in turn.
6.5.1 Heuristics for Mapping Refinement Based on the Calcu-lated Similarity
To further improve the mapping accuracy, it is desirable to incorporatecommonsense knowledge and domain constraints into the mapping pro-cess. For that purpose, domain independent and domain dependentheuristic rules are defined. The goal is to update the similarity two el-ements take based on the execution of the heuristic rules.
The heuristic rules can be domain independent or domain dependent.Some example domain independent heuristic rules are listed as follows.
• If all children of concept A match concept B, then A also matches B.
• Two concepts match if their children also match.
• Two concepts match if their parent match and k% of their childrenalso match.
• If all children of concept A match concept B, A also matches B.
The domain dependent heuristic rules incorporate domain knowl-edge into the mapping process. For example, a domain dependent heuris-tic rule in the tourism domain can be that if concept B is a descendant ofconcept A and B matches hotel, it is unlikely that A matches Bed and Breakfast
6.5.2 Managing User Feedback
In the design of the mapping system, we observed that in general fullyautomatic solutions to the mapping problem are not possible due to thepotentially high degrees of semantic heterogeneity between ontologies.We thus allow an interactive mapping process, e.g. to allow users tomanually add, confirm, reject, or alter mapping assertions. On the otherhand, users’ actions on the mapping results is a good source to improvethe algorithm performance in the next round of mapping result calcula-tion or updating.

112 CHAPTER 6. ONTOLOGY MAPPING APPROACH
Currently, we track the users’ actions on the mapping results into alog file. This leaves room for integrating learning components in an iter-ative mapping process.
6.5.3 Other Matchers and Combination of Similarity Values
Even though our approach is based mainly on the idea of exploring ex-tension of concepts for deriving similarity pairs, it is desirable to havethe flexibility for adding other complementary mapping strategies intothe algorithm. This is because, to achieve high mapping accuracy fora large variety of different ontologies, a single technique is unlikely tobe successful. An example of an alternative mapping strategy may beone that is based on studying and comparing the data type of relevantelements. Hence, it is necessary to combine different approaches in aneffective way.
We therefore introduce the coordinator component in the system ar-chitecture to be responsible for combining the similarity values returnedby different mapping components. The coordinator assigns to each map-ping strategy a weight that indicates how much that particular strategywill contribute to the whole picture. Then the coordinator combines thereturned similarity values via a weighted sum.
6.6 Application Scenarios
The proposed mapping algorithm is not universally applicable, however.In order to successfully apply the algorithm, the component ontologies,i.e. any two ontologies considered as input, should fulfill the followingtwo conditions.
• There exists a fair amount of textual resources that reflect the exten-sion of the relevant ontologies.
• The component ontologies need to be semantically enriched by useof the linguistic instrument as described in Chapter 5, or an equiv-alent feature vector construction system.
The first requirement for the algorithm presumes that the extensionof the concerned ontologies is in the format of textual resources so thattextual analysis techniques can be applied in the process of extractingessential information from extensions. The second requirement for the

6.7. CONCLUDING REMARKS 113
algorithm presumes that prior to the mapping, the ontology structureshave to be semantically enriched using the semantic enrichment systemof Chapter 5, or equivalent.
Given the above requirements, there are several scenarios where thisalgorithm can naturally fit in. One is document retrieval and publicationbetween different web portals. Users may conform to their local ontolo-gies through which the web portals are organized. It is desirable to havesupport for automated exchange of documents between the portals andstill let the users keep their perspectives. To achieve this, we need tomap terms in one ontology to their equivalents in the other portal ontol-ogy. Using the documents that have been assigned to each category toenrich the concepts and compute afterwards similarity for pairs of ontol-ogy concepts fits nicely with our approach.
Another area is product catalogue integration. In accordance with[54] different customers will make use of different classification schemas(UNSPSC, UCEC, and eCl@ss, to name a few). We need to define linksbetween different classification schemas that relate the various concepts.Establishing such a connection helps to classify new products in otherclassification schemas and this in turn will enable a full fledged B2B busi-ness, where a certain number of well know standard vocabularies coexistamong business partners and mapping relates their mutual vocabular-ies [74].
Service matching is yet another good candidate to apply the method,though we have to assume that there are some service description hi-erarchies (the MIT process handbook [100], for instance) and that theprovider and the requester are using different classification schemas. Byusing some extension description of the service hierarchy, we can com-pute a feature vector for each service concept. Then the matching can beconducted by calculating the distance between the representative featurevectors.
6.7 Concluding Remarks
In this chapter the particular problems in computational comparison ofontology elements have been analyzed and a novel approach to meetthe requirements arising from the analysis has been proposed. The al-gorithm supports a semi-automatic computation of correspondences be-tween concepts, based on the enriched structures. In addition, this al-

114 CHAPTER 6. ONTOLOGY MAPPING APPROACH
gorithm also takes advantage of hierarchies or taxonomies of concepts.This is reflected in the way non-leaf concepts similarity is calculated. Thealgorithm produces a set of ranked suggestions of possible concept cor-respondences. Concept correspondence plays a central role in the wholealgorithm, for it is the foundation for computing correspondences forother ontology elements and structures.
In order to produce more accurate concept correspondence sugges-tions, additional resources are used to update the similarity value. Word-Net has been used extensively in computational linguistics for tasks rang-ing from relationship discovery to word sense disambiguation [5]. Weused it mainly for calculating semantic relatedness of concepts in Word-Net hierarchy.
Based on the suggested concept correspondences, the correspondencebetween relations in two ontologies, the correspondences between clus-ters in the two ontologies, and ultimately the correspondence betweentwo ontologies are defined in sequel. The correspondence in a biggergranularity level (cluster and ontology level for instance) is complemen-tary to the more fine grind single concept level correspondence. Theformer helps user to have a quick overview of the distribution and thelatter provides the user with more detailed information. The algorithmcompares solely the representative feature vectors, i.e. the enrichmentstructures and the name of the concepts. In that respect, the algorithm ismodeling language independent.
Further refinement techniques for the purpose of even more accu-rate mappings are discussed. These includes using domain independentor domain dependent heuristic rules to update the results, logging userfeedback for learning components, and combining other mapping strate-gies into the algorithm.
Finally, we have also identified the conditions under which the algo-rithm will most likely succeed. Three example scenarios which meet theconditions are introduced and how the algorithm can be applied in thesescenarios are discussed as well.

Part III
Implementation andAssessment
115


Chapter 7
The Prototype Realization
A prototype of the approach has been implemented in order to verifythat the proposed approach is an applicable solution. It also paves theway for evaluating the approach in a quantitative manner, as describedin the next chapter. This chapter is focused on functionality specification,rather than technical details.
7.1 Components in the Realization
The system architecture is composed of three separately developed partsthat communicate using XML.
• The modeling environment: to build the necessary ontologies, weneed a modeling environment. During the work, it has been natu-ral to incorporate previous modeling methodologies and tools ac-cumulated in the Information System group into our system. Wehave not developed any new modeling tools, rather we have usedthe current baseline of modeling support in the Information SystemGroup [70] [69] [145] [175] [143] [2] [25] [85] [51] [18].
• The CnS Client: to classify documents when no instance are avail-able, we need a classifier. The CnS (Classification ’n’ Search) is aclient for model-based classification and retrieval of documents. Inour context, we use only the classification function of the CnS. Theclient interacts with the server side classification component andpresents the results through a graphical user interface, which al-lows user manual adjusting of the classification results. The im-
117

118 CHAPTER 7. THE PROTOTYPE REALIZATION
Figure 7.1: Components of the system.
plementation of the CnS client and the classification componentwas part of another doctoral thesis, and is described in more de-tail in [18].
• The iMapper system: to implement the process of constructingfeature vectors and generating mappings, we have developed theiMapper as the core part of our system. The prototype is devel-oped as a stand alone java application, which communicates withthe other software components through XML file exchange.
Figure 7.1 illustrates the three parts and how they interact with eachother. The modeling environment is responsible for constructing/importingthe ontologies in RML format. The ontologies are passed on to CnS forassigning documents to the relevant ontology elements. The ontologies,together with the classification results stored in XML, are delivered to theiMapper system for the mapping process. In the rest of the chapter, wepresent each part in greater detail.
7.2 The Modeling Environment
The referent model language and the corresponding tools are developedat the Information Systems group at IDI, NTNU. The RML languageis a recent language that initially springs out from the PPP integratedmodelling environment [70]. PPP initially contained support for sev-eral modelling languages; a Process Model Language PrM, an extendedER modelling language (ONE-R) and a rule modelling language (PLD),

7.2. THE MODELING ENVIRONMENT 119
Figure 7.2: The Referent Modeling Editor.
and also comprised specifications and partial implementations of exten-sive methodology support; versioning mechanisms [2], view generation[143], concepts and notation for hierarchical modelling [145], prototyp-ing and execution [175] as well as explanation generation and translationof models [69]. Work on cooperative support in terms of enabling discus-sions and awareness in the process of constructing models was carriedout in [51]. Later work have refined the initial modelling languages andalso added new languages. The most recent are the RML concept mod-elling language [148], the APM workflow modelling language [25], andthe task modeling and dialogue modeling languages for user interfacedesign [165].
The toolset we are using for the ontology constructing process con-sists of the following components:
• The RML modelling editor, RefEdit. The editor is a standalone Win-dows tool that stores the models as XML files. Figure 7.2 shows asnapshot of the RefEdit modeling tool.
• The XML based model repository with support for importing/exporting,consistency checking and versioning (in progress).

120 CHAPTER 7. THE PROTOTYPE REALIZATION
In this thesis, we have focused on semantic issues rather than syntacticalissues, and have assumed that the same representation language is usedin both ontologies and furthermore, we have picked RML as our repre-sentation language. For the approach to be useful in a wider context, wehave to cope with ontologies that are represented in other languages andtransfer them into RML. This requires the toolset to have an extensiveimport/export support for different representation formats.
7.3 The CnS Client as a Classifier
Figure 7.3 shows the CnS Client in classification mode with a fragmentof a particular ontology of ”collaboration technology” and a small set ofcorresponding documents. The ontology fragment shows the hierarchyof collaborative processes, which is defined as an aggregation of coor-dination, production and other activities. The fragment also shows thespecialization of the concepts representing coordination and productionactivities.
The classification of a document according to the domain model amountsto selecting the model concepts considered relevant for this document. Inthe classification mode, the toolbar provides the user with the options ofgetting suggestions from the server-side model-matcher as well as quick-keys for accepting or rejecting these suggestions. The Fast classifica-tion button lets the user accept whatever suggestions the server provideswithout further examination our alternative to automatic classification.The document management function allows the user to manage a localset of documents that are under classification, these may be divided infolders.
While working in a classification mode, a user may switch betweenworking with one document at a time or a selection of documents si-multaneously a summary view. Figure 7.3(a) shows the summary viewof all the selected documents. In this view the user has first receivedsuggestions from the model-matcher and is now manually refining thesesuggestions. Suggestions are marked with a green triangle. In the doc-ument list, documents with unprocessed suggestions are marked with asmall green triangle, while documents where the user has made actualselections (or accepted the suggestions) is marked with a filled rectangle.Green triangles illustrate concepts that have suggestions; the size of thetriangle (along the bottom line) illustrates the percentage of documents
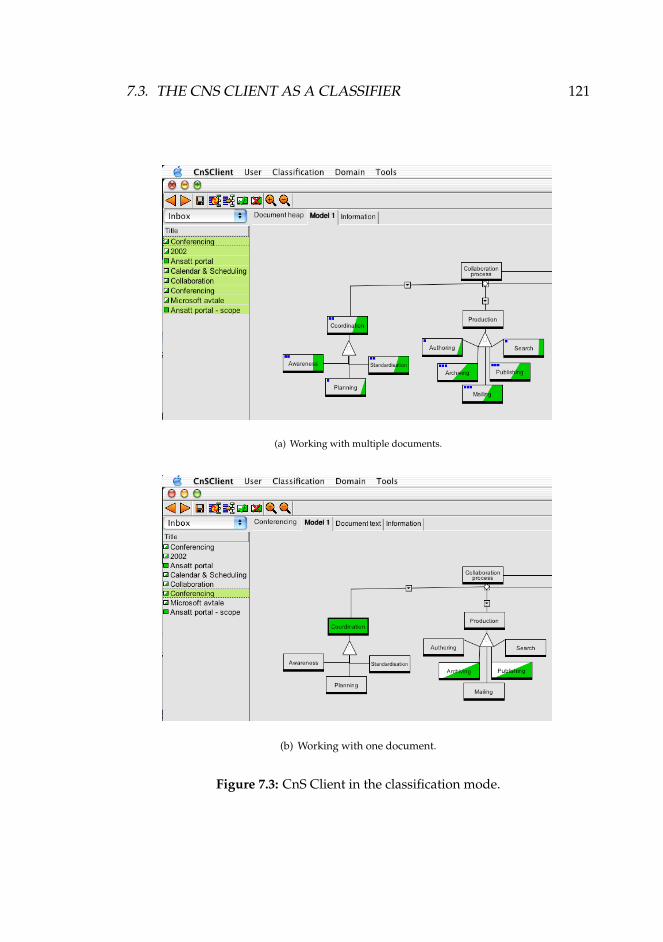
7.3. THE CNS CLIENT AS A CLASSIFIER 121
(a) Working with multiple documents.
(b) Working with one document.
Figure 7.3: CnS Client in the classification mode.
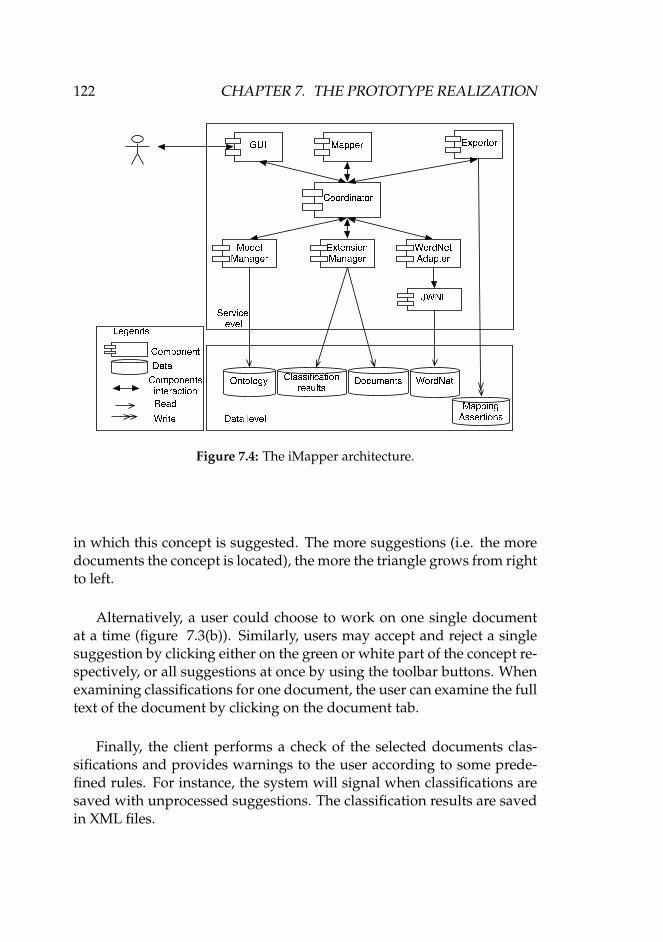
122 CHAPTER 7. THE PROTOTYPE REALIZATION
Figure 7.4: The iMapper architecture.
in which this concept is suggested. The more suggestions (i.e. the moredocuments the concept is located), the more the triangle grows from rightto left.
Alternatively, a user could choose to work on one single documentat a time (figure 7.3(b)). Similarly, users may accept and reject a singlesuggestion by clicking either on the green or white part of the concept re-spectively, or all suggestions at once by using the toolbar buttons. Whenexamining classifications for one document, the user can examine the fulltext of the document by clicking on the document tab.
Finally, the client performs a check of the selected documents clas-sifications and provides warnings to the user according to some prede-fined rules. For instance, the system will signal when classifications aresaved with unprocessed suggestions. The classification results are savedin XML files.

7.4. THE IMAPPER SYSTEM 123
7.4 The iMapper System
As the core part of the whole mapping system, figure 7.4 shows anoverview of the iMapper system architecture. In the storage level, fivekinds of data exist:
• Ontology represented in RML is stored in an XML file. The ontolo-gies are exported from the Referent modeling editor, RefEdit. TheXML format used to export ontology in RefEdit are presented inappendix B.
• Classification results returned by the CnS client are stored in XMLformat, documenting which concept has which documents as in-stances. The relevant XML format is explained in appendix B
• The real documents are stored in plain txt or html formats.
• We use the WordNet lexical database version 2.01. In our setting, weuse only the dictionary files (plain text).
• The final mapping assertions are stored in an XML file. The relevantXML format is presented in appendix B.
In the service level, the system is composed of eight functional ele-ments that communicate through well defined java interfaces:
• Model Manager is the component that reads the ontology and pro-vides model related service, including finding a particular conceptby its name or ID, getting the attribute of a concept, getting all thesub concepts of a given concept, getting all the related concepts ofa given concept and so on.
• Extension Manager reads the classification results and the relevantdocuments to build feature vectors for the ontology concepts, bothleaf and non-leaf concepts. Within this module, a linguistic ana-lyzer is responsible for preprocessing the documents if necessary,performing morphological processing if required, and of coursebuilding up the document term frequency matrix. The morpholog-ical processing is performed using the default morphological pro-cessor in the JWNL, which will be introduced next in the list. The
1http://www.cogsci.princeton.edu/wn/wn2.0

124 CHAPTER 7. THE PROTOTYPE REALIZATION
main service provided by this module is getting feature vectors fora given concept.
• JWNL (Java WordNet Library) is a java API for accessing WordNet-style relational dictionaries [38]. It is an open source project andprovides API-level access to WordNet data. It is pure Java (usesno native code), so it is completely portable. Apart from data ac-cess, it also provides functionality such as relationship discoveryand morphological processing. JWNL implements a default mor-phological processor, but also leaves space for using any other usercustomized morphological processors. The basic usage of JWNL isto look up WordNet index words for a given token, find relation-ships of a given type between two words (such as ancestry), findthe path from the source synset to the target synset, and find chainsof pointers of a given type (for example, get the hypernym tree of agiven synset).
• WordNet Adapter is the component that wraps up JWNL and pro-vides services that are needed in this application. To get WordNetrelated services, other components will interact with the WordNetAdapter rather than with JWNL. In the future, when a newer ver-sion JWNL is in place, only WordNet Adapter needs to be updatedto cope with the change. This guarantees the minimum updatingefforts. Apart from mediating between JWNL and other systemcomponents, WordNet Adapter also implements higher level ser-vices like get relatedness of two words using a particular measure-ment (path length measurement, the most informative class mea-sures and so on).
• Mapper is the component that computes similarity values for con-cepts in the two ontologies. As a core component, it uses the ser-vices other supportive components provides. To get concepts andthe relations, it uses the Model Manager; for the initial mappings, itgets feature vector from Extension Manager; and for the post pro-cessing, it gets word relatedness from WordNet Adapter. The onlyservices provided by Mapper is to return the mapping results fortwo given ontologies.
• The Graphical User Interface (GUI) of iMapper is shown in figure 7.5.The figure illustrates a mapping process and the obtained mapping

7.4. THE IMAPPER SYSTEM 125
Figure 7.5: The GUI of iMapper system.
assertions. Both ontologies are represented visually in RML (Ref-erent Modelling Language) [148] [137]. Steps in the approach aretrigged in sequence by the user through pushing the relevant but-tons. As a result, a list of top ranked mapping assertion will begenerated and listed in the table at the lower part of the frame (seefigure 7.5 ). An ID uniquely identifies each mapping assertion. Itconcerns two concepts, one from the ontology in the left, the otherfrom the right. The fourth column of the table describes what kindof mapping relation holds between these two. A confidence levelis given to indicate the probability that this prediction is true. Anexplanation about the source of the mapping assertion is given inthe last column. For example, in figure 7.5, mapping assertion 1states that concept family travel in the left ontology is most simi-lar to concept family in the right ontology with a similarity value of0.793 and this mapping is derived mainly from both extension anal-ysis and WordNet relatedness calculation. When the user selects onemapping assertion (by clicking the row of that assertion in the map-ping table), the corresponding concepts in the two ontologies arehighlighted, making it possible for the user to get a clear overview

126 CHAPTER 7. THE PROTOTYPE REALIZATION
of the relevant locations of the concepts in the ontologies. The usercould sort the mapping assertions according to any of the columnby clicking the relevant column heading. It is also possible for theuser to edit, delete or add mapping assertions.
• The service provided by Exporter is straightforward, that is to savethe mapping assertions in XML format after the user has approvedor adjusted the mapping results.
• Coordinator is responsible for controlling the interactions amongcomponents, sequencing the sub-tasks, and passing informationamong components. In the future, when new matchers are addedinto the architecture, it is also the Coordinator that combines thenewly plugin components into the existing mapping strategy.
In developing the architecture for this version of iMapper, one designgoal was to make testing out different combination of mapping strategiesas simple, and require as little extra code, as possible. A major compo-nent of this was making iMapper run off a configuration file. This re-sulted in a plugin-style architecture. For example, in the configurationfile, you specify whether lemmatization is turned on or off via the lemma-tization tag. Also, the various tuning parameters are defined in the con-figuration file so that changing their values becomes easy and does notaffect any other part the system. The configuration file is loaded duringinitialization.
For morphological analysis, we used JWNL. An alternative way isto use the linguistic workbench developed at Norwegian University ofScience and Technology (NTNU) [80]. In that setting, documents areprocessed through a chain of components that each transform the doc-ument contents into different middle products. The workbench consistsof 8 components: POS (Part-Of-Speech) tagging, Lemmatization, Phrasedetection, Language detection, Stop-word removal, word class filtering,weirdness test and XSL style sheet. Each component is running as anXML-RPC server and each has a specific port number for addressing.XML is used as the data exchange format between various components.This architecture assures to use the workbench in a flexible way, sinceeach task can be executed independently and the order of the tasks canbe controlled freely.

7.5. CONCLUDING REMARKS 127
7.5 Concluding Remarks
In the chapter, we have elaborated the three different parts of the system,namely, the modeling environment, the CnS software and the iMapper.The implementation is of prototype quality and we have tried to inte-grate available tools into the system. We further discussed in length thefunctional settings of the three parts respectively.
The modeling environment consists of an RML editor and a modelrepository. It is employed to build or import ontologies. The CnS soft-ware is implemented as a standalone java application, which supportsthe semi-automatic assignment of documents to ontology elements. Bothprovide inputs in XML format to the iMapper. The iMapper systemconsists of eight components: Model Manager, Extension Manager, JWNL,WordNet Adapter, Mapper, Exportor and GUI. The eight parts work to-gether to perform the task of predicting mappings. What is the quality ofthe predicted mappings is the subject of the coming evaluation chapter.

128 CHAPTER 7. THE PROTOTYPE REALIZATION

Chapter 8
Case Studies and Evaluation
A comprehensive evaluation of the match processing strategies supportedby the iMapper system has been performed on two domains. One do-main is described by two different catalogues applying two different on-tologies. The other domain is tourism, where two different vocabulariesand conceptual structures are found in, e.g., the Open Directory Project(ODP) and Yahoo!. The main goal was to evaluate the matching accu-racy of iMapper, to measure the relative contributions from the differentcomponents of the system, and to verify that iMapper can contribute tohelping the user in performing the labor intensive mapping task. The de-sign and methodology of the evaluation are described first. Afterwards,the results and analysis of the results are presented. This chapter is partlybased on previous published paper [157].
8.1 Experiment Design
8.1.1 Performance Criteria
Traditionally, in database schema integration tasks, the performance ofthe mapping algorithm is measured according to system performanceor in some case, based merely on a feature analysis [6]. System perfor-mance evaluations consider measures such as response time and algo-rithm complexity. More user oriented evaluation metrics have also beenproposed. They borrow ideas from information retrieval and focus on theusefulness of the suggested mappings [125] [43] [110] [41] [40]. The use-fulness is typically measured based on the classical precision and recall
129

130 CHAPTER 8. CASE STUDIES AND EVALUATION
measures, although the two measures have been given adjusted interpre-tations in the task of mapping.
System performance criteria are not relevant for our trial, since ourimplementation is a prototype, which has not been implemented withsystem performance criteria in mind. Moreover, in reality, even thoughcertain time and resource limitation will apply, the task of mapping isgenerally not a time or resource critical task.
Precision and recall measures are designed to compare the set of cor-rectly identified mappings in the automatically suggested mapping re-sults with the correct set of mappings predefined by the users. One obvi-ous problem with these measures is that correctness is a subjective mea-sure, which are bound to be different from user to user. This makes thecorrect set of mappings a more or less moving target. In standard infor-mation retrieval tests such as the TREC series1 the predefined relevantdocument sets are determined by expert judges. In the context of ontol-ogy mapping, such kind of predefined tasks and results are so far notavailable. We therefore measure only the relative usefulness of the ap-proach in different settings by tuning a number of variables in order tosuggest in what circumstances, the algorithm is likely to be useful, aswell as measuring the robustness of the system.
Following the discussion above, we use the following measures onour trial. To evaluate the quality of the match operations, we comparethe match result returned by the automatically matching process (P) withmanually determined match result (R). We determine the true positives,i.e. correctly identified matches (I). Figure 8.1 illustrates these sets. Basedon the cardinalities of these sets, the following quality measures are com-puted.
• Precision = |I|/|P| , is the fraction of the automatic discovered map-ping which is correct, that is, belong to the manually determinedmappings. It estimates the reliability of the automatic procedurefor the match prediction relative to the manual procedure.
• Recall = |I|/|R| , is the the fraction of the correct matches (the set R)which has been discovered by the mapping process. It specifies theshare of real matches that are found.
1Text REtrieval Conference. http://trec.nist.gov

8.1. EXPERIMENT DESIGN 131
Figure 8.1: Precision and recall for the mapping results.
Precision and recall have been used extensively to evaluate the re-trieval performance of retrieval algorithms in the information retrievalfield [3] and have also been used in other studies [41] [124].
For each mapping the system predicated, there is a similarity degreeassociated with it. The degree indicates the confidence of the predication.It also provides a practical way to rank the mappings. As the mappingsare ranked in a descending order of the degree, we can calculate preci-sion at different recall levels by gradually adding more mappings intoconsideration. We plot the precision versus recall curve at 11 standardrecall levels [3]. Precision versus recall figures are useful because they al-low us to evaluate quantitatively both the quality of the overall mappingcollection and the breadth of the mapping algorithm. Further, they aresimple, intuitive, and can be combined in a single curve.
Finally, for this version of the experiment, we made evaluation onlyon concept-concept mappings, whereas the more complex mappings be-tween relations, clusters, etc are not in focus. Two reasons account for thechoice:
• Concept-concept mappings are the bases for any other more com-plex mappings and ensuring its high quality will form a sound basefor the other type of mappings.
• When user manual work is involved, we have to carefully limitedthe scope and complexity of the task. Therefore, the more complexmappings are omitted in this version of the evaluation.
Thus, even though the purpose of the experiment is to test the perfor-mance of the proposed approach in general, the results should be inter-
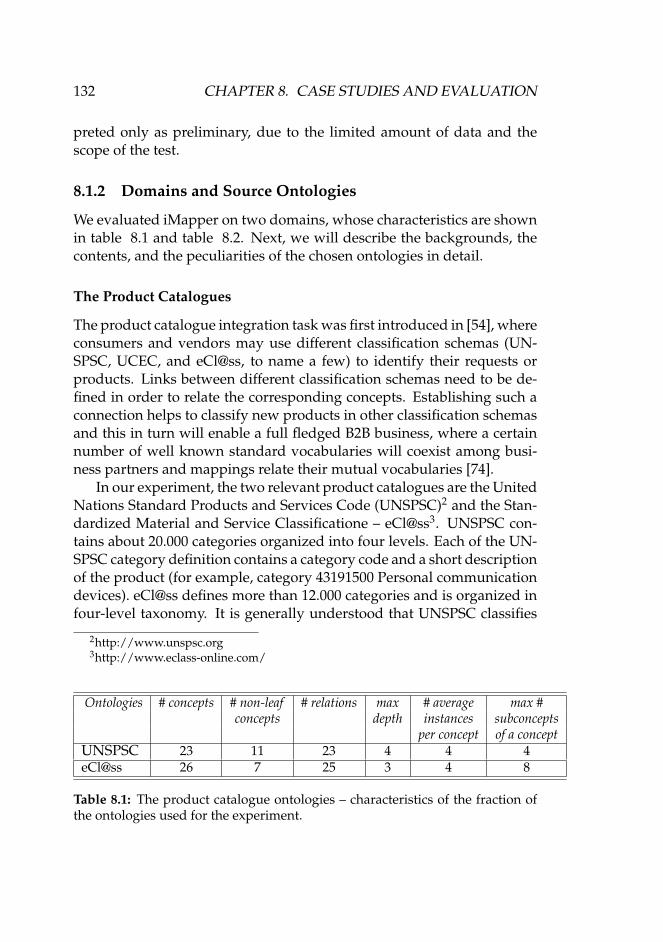
132 CHAPTER 8. CASE STUDIES AND EVALUATION
preted only as preliminary, due to the limited amount of data and thescope of the test.
8.1.2 Domains and Source Ontologies
We evaluated iMapper on two domains, whose characteristics are shownin table 8.1 and table 8.2. Next, we will describe the backgrounds, thecontents, and the peculiarities of the chosen ontologies in detail.
The Product Catalogues
The product catalogue integration task was first introduced in [54], whereconsumers and vendors may use different classification schemas (UN-SPSC, UCEC, and eCl@ss, to name a few) to identify their requests orproducts. Links between different classification schemas need to be de-fined in order to relate the corresponding concepts. Establishing such aconnection helps to classify new products in other classification schemasand this in turn will enable a full fledged B2B business, where a certainnumber of well known standard vocabularies will coexist among busi-ness partners and mappings relate their mutual vocabularies [74].
In our experiment, the two relevant product catalogues are the UnitedNations Standard Products and Services Code (UNSPSC)2 and the Stan-dardized Material and Service Classificatione – eCl@ss3. UNSPSC con-tains about 20.000 categories organized into four levels. Each of the UN-SPSC category definition contains a category code and a short descriptionof the product (for example, category 43191500 Personal communicationdevices). eCl@ss defines more than 12.000 categories and is organized infour-level taxonomy. It is generally understood that UNSPSC classifies
2http://www.unspsc.org3http://www.eclass-online.com/
Ontologies # concepts # non-leaf # relations max # average max #concepts depth instances subconcepts
per concept of a conceptUNSPSC 23 11 23 4 4 4eCl@ss 26 7 25 3 4 8
Table 8.1: The product catalogue ontologies – characteristics of the fraction ofthe ontologies used for the experiment.

8.1. EXPERIMENT DESIGN 133
Figure 8.2: Snapshots of the product catalogue extracted from UNSPSC.

134 CHAPTER 8. CASE STUDIES AND EVALUATION
Figure 8.3: Snapshots of the product catalogue extracted from eCl@ss.

8.1. EXPERIMENT DESIGN 135
Ontologies # concepts # non-leaf # relations max # average max #concepts depth instances subconcepts
per concept of a conceptODP travel ontology 66 15 78 5 10 8Yahoo travel ontol-ogy
60 14 80 5 11 7
Table 8.2: The tourism ontologies - characteristics of the fraction of the ontolo-gies used for the experiment.
products from a suppliers perspective, while eCl@ss is from a buyer’sperspective.
For our current experiment, two small segments of the relevant cata-logues, both of which concern the domain of computer and telecommu-nication equipments, are selected. They contain 23 - 26 concepts (cor-responding to the categories) and are organized in 3 - 4 levels by gen-eralization relationships. Two datasets of product descriptions collectedfrom online computer vendor websites are classified according to UN-SPSC and eCl@ss. The classification is performed in two steps. First isthe automatic classification by the CnS client, then come human adjust-ments of the automatic results. The classified product descriptions areviewed as the instances of the relevant concepts.
Tourism Ontologies
The second domain we choose is the tourism section. The two ontolo-gies are constructed based on vocabularies and structures from relevanttravel sections of the Open Directory Project (ODP)4 and Yahoo! Cate-gory5. In both ODP and Yahoo!, categories are organized in hierarchiesaugmented with related-to links. However the exact nature of the hier-archical relationship is not specified. Therefore, it is not clear whether aspecific hierarchical relationship is a generalization abstraction (is-a rela-tionship) or aggregation abstraction (part-of relationship) or somethingelse. Accordingly, we further specify the two ontologies by making ex-plicit the nature of the hierarchical relationships using our own modelingknowledge. For example, it is reasonable to say that travel is an aggrega-tion of lodging, destination, transportation and preparation, while busi-ness travel is a kind of special travel. It is worth noting that we did notchange the hierarchical structure or vocabulary of the original categories,
4http://dmoz.org/5htto://www.yahoo.com

136 CHAPTER 8. CASE STUDIES AND EVALUATION
because we wanted to maintain as much as possible the original designrationale of its respective creators. The refined ontologies are then mod-eled in Referent Modeling Language with the tool - refedit6. Figure 8.4and figure 8.5 show the snapshots of the two tourism ontologies. 60-66concepts are included in the ontologies.
The Open Directory Project aims to build the largest human-editeddirectory of Internet resources and is maintained by community editorswho evaluate sites to classify them in the right directory. Yahoo! cat-egory is maintained by the Yahoo! directory team for the inclusion ofweb sites into Yahoo! directory. We consider the web pages under onecategory the instances of that category. As a result, in this domain, un-like the product catalogue example above, instances of each concept arealready directly available without the need to classify them. For each cat-egory we downloaded the first 12 web site introductions. If there is lessthan 12 instances in the category, we downloaded all that is available. Avery small number of categories (more in ODP than in Yahoo!) have noinstance classified and we just leave them as they are. It is worth reiter-ating here that even if a concept has no instance information available,a match involving that concept is still possible since the sub-concepts ofthis concept will contribute to the construction of its feature vector.
These two sets of ontologies constitute good targets for the mappingexperiment. First, the two ontologies in each pair cover similar subjectdomains and on the other hand, they were developed independentlyof each other and therefore there was no intentional correlation amongterms in the ontologies. In addition, the domains are relatively easy tounderstand for everyone.
8.1.3 Experiment Setup
For the manual part, we conducted a user study in the Information Sys-tem Group at the Norwegian University of Science and Technology. 6users have conducted the manual mapping independently. All of themhave good knowledge of modeling in general. None of the users hadaddressed the problem of mapping ontologies prior to the experiment.For each of the two mapping tasks, each participant received a packagecontaining:
1. a diagrammatic representation of the two ontologies to be matched
6http://www.idi.ntnu.no/˜ppp/referent/

8.1. EXPERIMENT DESIGN 137
Figure 8.4: Snapshots of the travel ontology extracted from Open DirectoryProject
Figure 8.5: Snapshots of the travel ontology extracted from Yahoo directory

138 CHAPTER 8. CASE STUDIES AND EVALUATION
2. a brief instruction of the mapping task
3. a scoring sheet to fill in the user identified mappings
The participants performed the mapping independently at their con-venience in their own offices. They were asked to use their backgroundknowledge to perform the judgment. They were also informed that:
1. no cardinality constraints, meaning one to many, many to one andmany to many mappings are allowed
2. any pair of concepts can make a legal mapping, meaning leaf toleaf, leaf to non-leaf, non-leaf to non-leaf are allowed
3. to help the user making decision, they can use numbers to indicatehow confident they are towards each match (3 for fairly confident, 2for likely and 1 for need to know more to suggest the match). It alsohelps to compare system performance when different confidencelevel are considered
After they finished the task, they sent back the scoring sheets for analysis.The product catalogue mapping task was performed first and the tourismontology mapping task was conducted a month later. Both use the same6 participants.
8.2 The Analysis Results
The primary goal of our experiment is to evaluate the quality of iMap-per’s suggestions and examine the contribution from different compo-nent of the system. We also aim at testing the robustness of the approachby a series of sensitivity analysis. In addition, we analyze the overlap-ping between ontologies by studying the inter-user manual mapping dif-ferences.
This section presents the result of our evaluation. We start by explain-ing the different variable that may affect the results before we present theinitial results. The different variables also constitute the subjects of a se-ries of sensitivity tests.

8.2. THE ANALYSIS RESULTS 139
8.2.1 Filters and Variables
Filters
Filters are used for choosing a selection of mapping candidates from thelist of ranked mapping pairs returned by the mapping algorithms. Usu-ally, for every element in the ontologies, the algorithm delivers a largeset of match candidates. In the literature, people argue that many of themapping algorithm are of limited usefulness, because too many false pos-itive are generated. It will be an overwhelming task for a user to selectthe right mappings from the wrong ones if too many candidates are pre-sented to the user. It is therefore of vital importance that the mappingsare filtered and ranked in a correct way.
It is not evident, though, which criteria can be useful for selecting adesirable subset from the initially suggested mappings and present themto the user. For a set of n mapping pairs, as many as 2n different subsetscan be formed. In our approach, we used basically two filters:
• Cardinality to constrain if we want a 1:1 mapping or a n:m mapping.We use parameter CARDINALITY to denote this.
• Threshold to remove mappings with low confidence scores. We useparameter THRESHOLD VALUE to denote this.
Variables
A number of variables affect the results. They are subjected to a sensitiv-ity test.
• Desired Mapping Results. Both precision and recall are relative mea-sures that depend on the desired mapping results7 – the user identi-fied mappings. For a meaningful assessment of mapping quality,the desired mapping result must be specified precisely. In this ex-periment, we have two versions of the desired mapping results.One is developed by 6 users independently, the other is based ongroup discussion. The intention is to test if different user effortswill lead to different mapping results and to what extend will thedifferent desired mapping results affect the final precision and re-call values. Another variable in the gold standard is related to the
7Also being referred to as ”gold standard”.

140 CHAPTER 8. CASE STUDIES AND EVALUATION
fact that we allow users to specify a confidence level to each map-ping they suggest. 3 for fairly confident, 2 for likely and 1 for needto know more to suggest the match. Therefore, two variables arerelevant here:
– DESIRED MAPPING RESULT to indicate wether the gold stan-dard is individual or group discussion based.
– CONFIDENCE LEVEL to specify whether only confident map-pings are included into the gold standard (when set confi-dence level to 3) or less confident ones are included as well(when confidence level is 2 or 1)8.
• Structural Information. Recall in chapter 5, for non-leaf concepts,contributions from the instances, the sub-nodes and the related nodesare counted in when calculating feature vectors for such non-leafconcepts. Let D j be the collection of documents that have been as-signed to that node K, let St be the collection of its direct sub nodesand let Sr be the collection of its related nodes. The ith element ofCk is defined as:
Cki = α ∗
∑D j∈K
wi j∣∣D j∣∣ + β ∗
∑St∈K
wit
|St|+ γ ∗
∑Sr∈K
wir
|Sr|
where α +β +γ = 1, and α ,β and γ are used as tuning parametersto control the contributions from the concepts instances, sub con-cepts, and related concepts respectively. For instance, if we assign1 to α, 0 to β and γ , it means that no structure information will becounted.
• WordNet Contribution. In chapter 6, we mentioned that the contri-bution from WordNet postprocessing will be adjusted by a tuningparameter – RELATEDNESS WEIGHT. If RELATEDNESS WEIGHT= 0, it means WordNet contributions are not counted.
8confidence level 2 includes all the mapping that have a confidence level equal orbigger than 2, and confidence level 1 includes those that are equal or bigger than 1.

8.2. THE ANALYSIS RESULTS 141
8.2.2 Quality of iMapper’s Predictions
Baseline Filter and Variable Configuration
To compare the situation in different configurations, we need a baselineconfiguration of the filters and variables. Since the variables will be sub-jected to sensitivity test later, we need to first determine the values of thefilters. For both domains, we set the different variable values as follows:
• α=0.5 β=0.25 γ=0.25
• RELATEDNESS WEIGHT = 0
• CONFIDENCE LEVEL = 1
• DESIRED MAPPING RESULT = individual
If we assume that deleting a mapping takes as much user efforts asadding one, at precision 50% half of the suggestions are false positive,which means the user has no extra gain or pay in using the tool. Morethan 50% means the user can save some efforts if using the tool compareto manual work all by herself while less than 50% means user will haveto user more efforts in using the tool. Therefore, we compare differentconfiguration of the filters by comparing the recall value at precision 50%.The configuration which gets the highest recall value will be chosen. Asa result of this comparison, we determined the value for the two filters asfollows:
• For the product catalogue task
– CARDINALITY = 3– THRESHOLD VALUE = 0.2
• For the tourism domain
– CARDINALITY = 4– THRESHOLD VALUE = 0.4
• Only mappings that satisfy both the cardinality and threshold con-straints are included in the final results.
The results obtained by using the baseline configuration above will bereferred to as baseline version later on. The last parameter in the baselineconfiguration – desired mapping results, will be discussed in the begin-ning of next section.
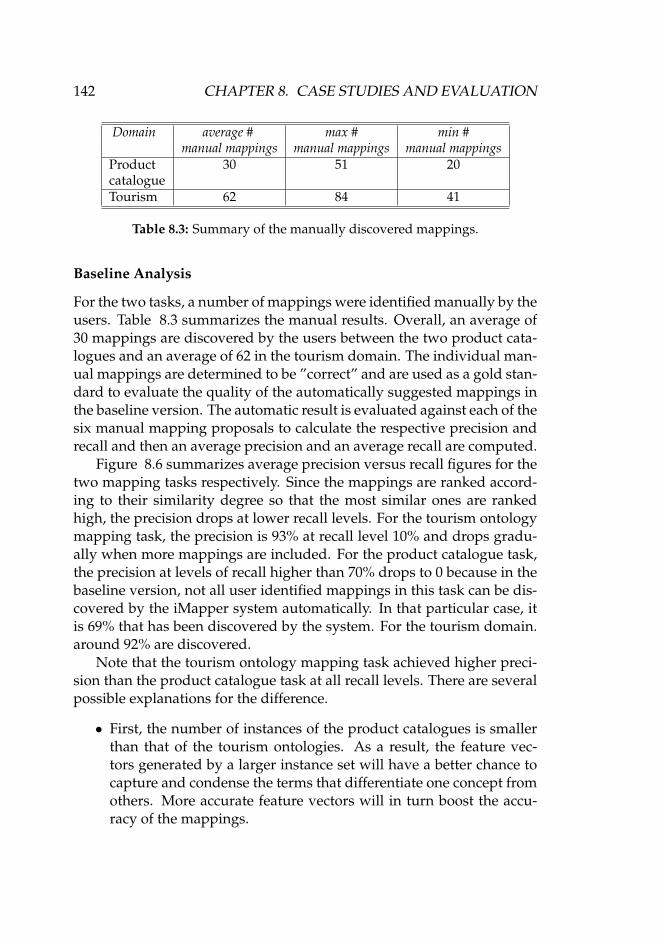
142 CHAPTER 8. CASE STUDIES AND EVALUATION
Domain average # max # min #manual mappings manual mappings manual mappings
Productcatalogue
30 51 20
Tourism 62 84 41
Table 8.3: Summary of the manually discovered mappings.
Baseline Analysis
For the two tasks, a number of mappings were identified manually by theusers. Table 8.3 summarizes the manual results. Overall, an average of30 mappings are discovered by the users between the two product cata-logues and an average of 62 in the tourism domain. The individual man-ual mappings are determined to be ”correct” and are used as a gold stan-dard to evaluate the quality of the automatically suggested mappings inthe baseline version. The automatic result is evaluated against each of thesix manual mapping proposals to calculate the respective precision andrecall and then an average precision and an average recall are computed.
Figure 8.6 summarizes average precision versus recall figures for thetwo mapping tasks respectively. Since the mappings are ranked accord-ing to their similarity degree so that the most similar ones are rankedhigh, the precision drops at lower recall levels. For the tourism ontologymapping task, the precision is 93% at recall level 10% and drops gradu-ally when more mappings are included. For the product catalogue task,the precision at levels of recall higher than 70% drops to 0 because in thebaseline version, not all user identified mappings in this task can be dis-covered by the iMapper system automatically. In that particular case, itis 69% that has been discovered by the system. For the tourism domain.around 92% are discovered.
Note that the tourism ontology mapping task achieved higher preci-sion than the product catalogue task at all recall levels. There are severalpossible explanations for the difference.
• First, the number of instances of the product catalogues is smallerthan that of the tourism ontologies. As a result, the feature vec-tors generated by a larger instance set will have a better chance tocapture and condense the terms that differentiate one concept fromothers. More accurate feature vectors will in turn boost the accu-racy of the mappings.
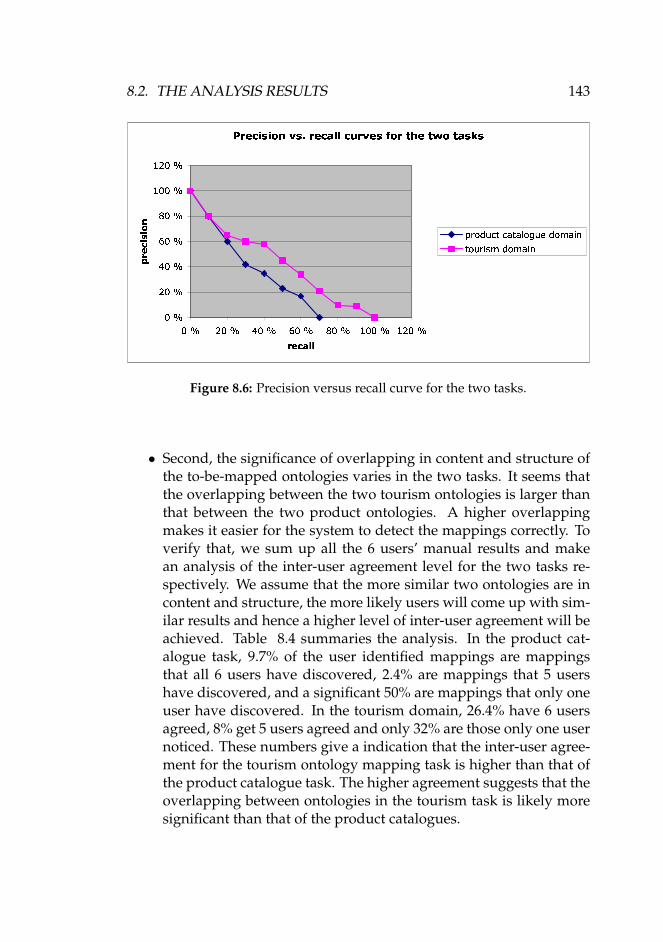
8.2. THE ANALYSIS RESULTS 143
Figure 8.6: Precision versus recall curve for the two tasks.
• Second, the significance of overlapping in content and structure ofthe to-be-mapped ontologies varies in the two tasks. It seems thatthe overlapping between the two tourism ontologies is larger thanthat between the two product ontologies. A higher overlappingmakes it easier for the system to detect the mappings correctly. Toverify that, we sum up all the 6 users’ manual results and makean analysis of the inter-user agreement level for the two tasks re-spectively. We assume that the more similar two ontologies are incontent and structure, the more likely users will come up with sim-ilar results and hence a higher level of inter-user agreement will beachieved. Table 8.4 summaries the analysis. In the product cat-alogue task, 9.7% of the user identified mappings are mappingsthat all 6 users have discovered, 2.4% are mappings that 5 usershave discovered, and a significant 50% are mappings that only oneuser have discovered. In the tourism domain, 26.4% have 6 usersagreed, 8% get 5 users agreed and only 32% are those only one usernoticed. These numbers give a indication that the inter-user agree-ment for the tourism ontology mapping task is higher than that ofthe product catalogue task. The higher agreement suggests that theoverlapping between ontologies in the tourism task is likely moresignificant than that of the product catalogues.
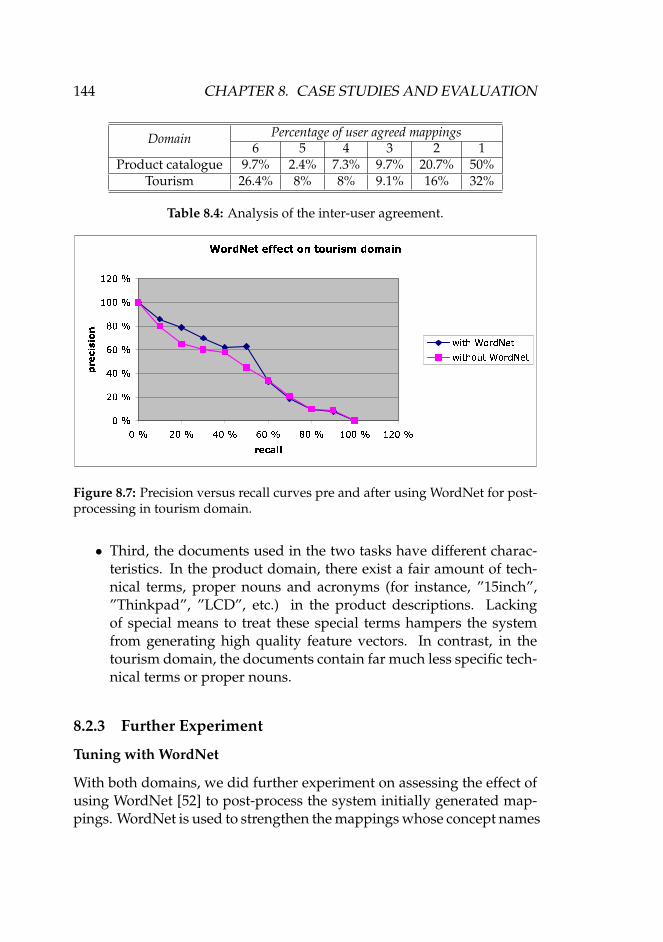
144 CHAPTER 8. CASE STUDIES AND EVALUATION
Percentage of user agreed mappingsDomain6 5 4 3 2 1
Product catalogue 9.7% 2.4% 7.3% 9.7% 20.7% 50%Tourism 26.4% 8% 8% 9.1% 16% 32%
Table 8.4: Analysis of the inter-user agreement.
Figure 8.7: Precision versus recall curves pre and after using WordNet for post-processing in tourism domain.
• Third, the documents used in the two tasks have different charac-teristics. In the product domain, there exist a fair amount of tech-nical terms, proper nouns and acronyms (for instance, ”15inch”,”Thinkpad”, ”LCD”, etc.) in the product descriptions. Lackingof special means to treat these special terms hampers the systemfrom generating high quality feature vectors. In contrast, in thetourism domain, the documents contain far much less specific tech-nical terms or proper nouns.
8.2.3 Further Experiment
Tuning with WordNet
With both domains, we did further experiment on assessing the effect ofusing WordNet [52] to post-process the system initially generated map-pings. WordNet is used to strengthen the mappings whose concept names
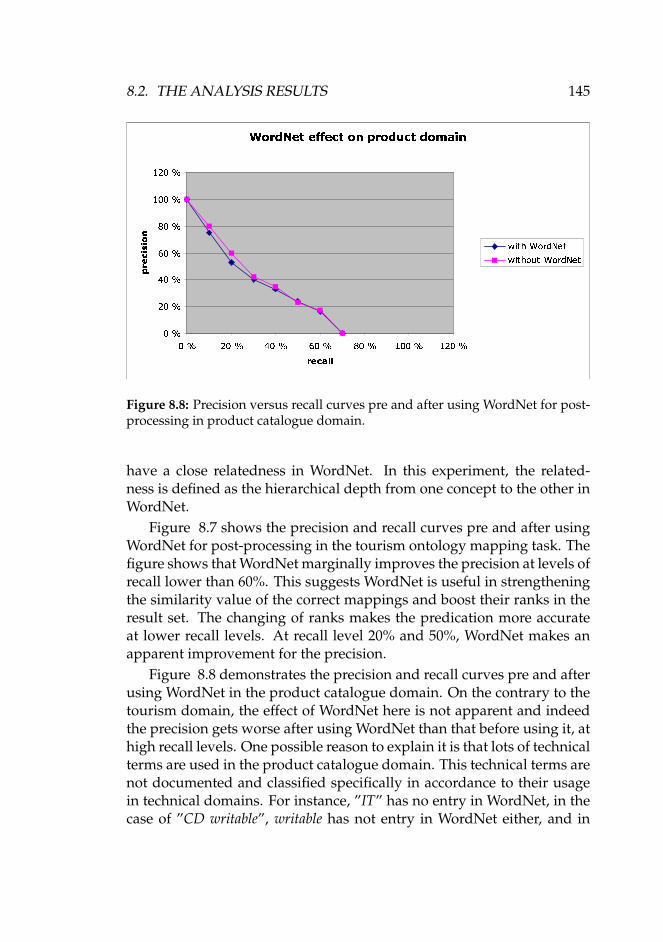
8.2. THE ANALYSIS RESULTS 145
Figure 8.8: Precision versus recall curves pre and after using WordNet for post-processing in product catalogue domain.
have a close relatedness in WordNet. In this experiment, the related-ness is defined as the hierarchical depth from one concept to the other inWordNet.
Figure 8.7 shows the precision and recall curves pre and after usingWordNet for post-processing in the tourism ontology mapping task. Thefigure shows that WordNet marginally improves the precision at levels ofrecall lower than 60%. This suggests WordNet is useful in strengtheningthe similarity value of the correct mappings and boost their ranks in theresult set. The changing of ranks makes the predication more accurateat lower recall levels. At recall level 20% and 50%, WordNet makes anapparent improvement for the precision.
Figure 8.8 demonstrates the precision and recall curves pre and afterusing WordNet in the product catalogue domain. On the contrary to thetourism domain, the effect of WordNet here is not apparent and indeedthe precision gets worse after using WordNet than that before using it, athigh recall levels. One possible reason to explain it is that lots of technicalterms are used in the product catalogue domain. This technical terms arenot documented and classified specifically in accordance to their usagein technical domains. For instance, ”IT” has no entry in WordNet, in thecase of ”CD writable”, writable has not entry in WordNet either, and in

146 CHAPTER 8. CASE STUDIES AND EVALUATION
the case of ”portable”, its only noun sense is related to ”a small light type-writer” which has not much to do with ”portable computer” in WordNet.This plus a relatively small set of concepts lead to the effect that Word-Net strengthened the pairs in a more or less random way, which in turnresults in slightly worsening the situation.
We also noticed the limitations for using WordNet to calculate con-cept relatedness in both domains. In WordNet, nouns are grouped intoseveral hierarchies by hyponymy/hypernymy relations, each with a dif-ferent unique beginner. Topic related semantic relations are absent inWordNet, so travel agent and travel have no relation between them. Andin fact, they are in two different taxonomies, since travel agent is in the tax-onomy which has entity as top node and travel is in the taxonomy whereact is the top node. This results in a not-related result being returnedwhen applying the path length measure for measuring the relatedness ofthe two terms. That result however does not mirror the human judgment.A possible way to overcome this limitation is to augment WordNet withdomain specific term relations or use other domain specific lexicons.
In this experiment, we used the path length measurement to estimatethe semantic relatedness of terms in WordNet. There are other measuresbeing proposed in the literature, for instance, the most informative classmeasures [136]. It would be interesting to see the performance of otheralternative measurements.
Desired Mapping Results
To test the effect that the desired mapping results have on the precisionrecall figures, we gathered the users and made an extended user studyon the tourism domain 6 months after the first user study. Five out of sixusers participated the extended user study9. The five users sat together,discussed the ontologies and made decisions jointly. As a result, a groupdiscussion based gold standard came into being.
A group of precision recall curves are generated using different com-binations of the confidence levels and individual vs. group gold stan-dards:
• Precision recall curves under individual based gold standard atthree confidence levels.
9One is not available in Trondheim at that time.
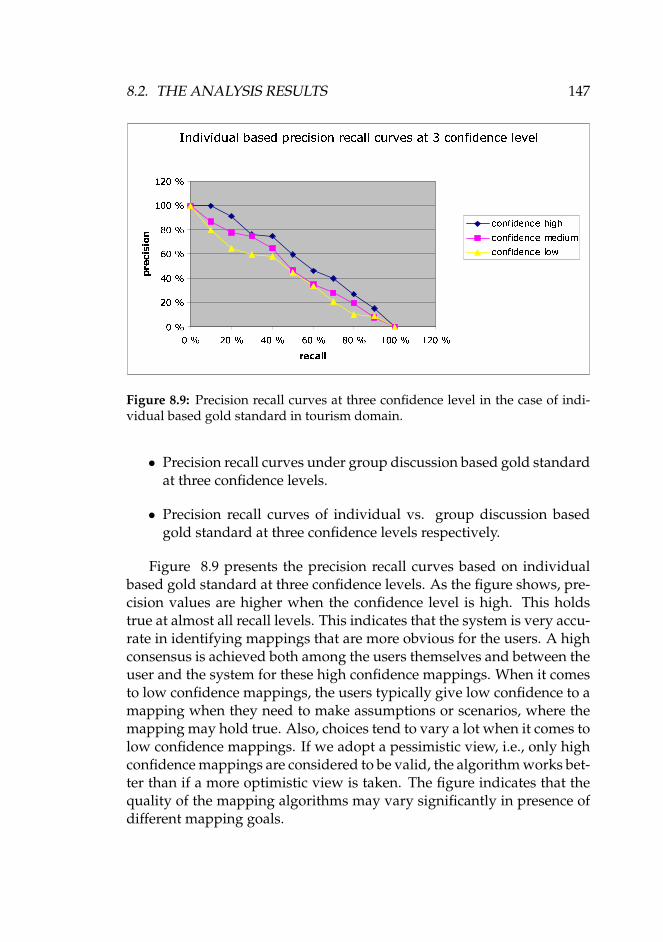
8.2. THE ANALYSIS RESULTS 147
Figure 8.9: Precision recall curves at three confidence level in the case of indi-vidual based gold standard in tourism domain.
• Precision recall curves under group discussion based gold standardat three confidence levels.
• Precision recall curves of individual vs. group discussion basedgold standard at three confidence levels respectively.
Figure 8.9 presents the precision recall curves based on individualbased gold standard at three confidence levels. As the figure shows, pre-cision values are higher when the confidence level is high. This holdstrue at almost all recall levels. This indicates that the system is very accu-rate in identifying mappings that are more obvious for the users. A highconsensus is achieved both among the users themselves and between theuser and the system for these high confidence mappings. When it comesto low confidence mappings, the users typically give low confidence to amapping when they need to make assumptions or scenarios, where themapping may hold true. Also, choices tend to vary a lot when it comes tolow confidence mappings. If we adopt a pessimistic view, i.e., only highconfidence mappings are considered to be valid, the algorithm works bet-ter than if a more optimistic view is taken. The figure indicates that thequality of the mapping algorithms may vary significantly in presence ofdifferent mapping goals.
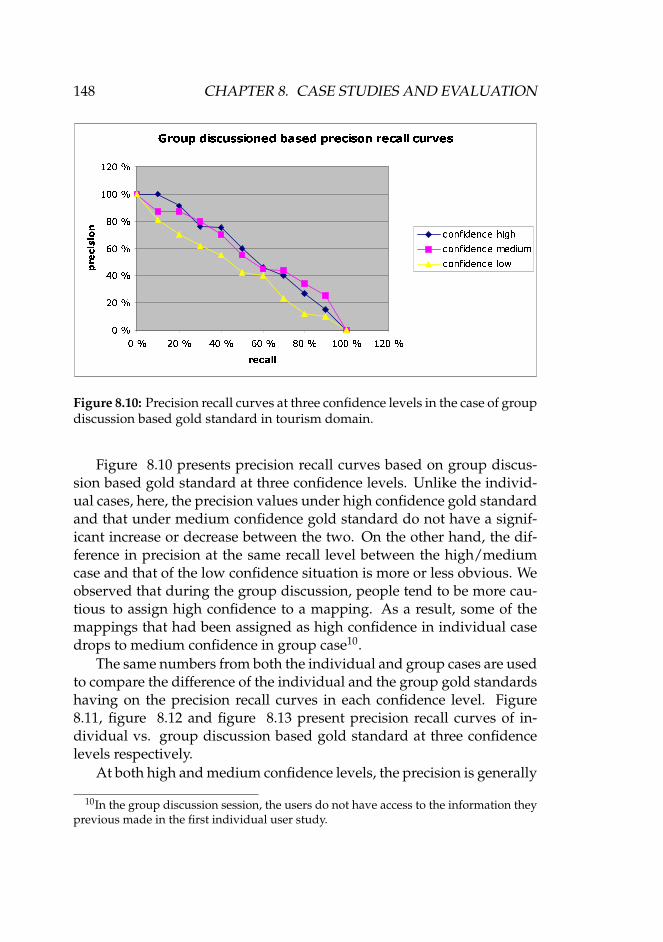
148 CHAPTER 8. CASE STUDIES AND EVALUATION
Figure 8.10: Precision recall curves at three confidence levels in the case of groupdiscussion based gold standard in tourism domain.
Figure 8.10 presents precision recall curves based on group discus-sion based gold standard at three confidence levels. Unlike the individ-ual cases, here, the precision values under high confidence gold standardand that under medium confidence gold standard do not have a signif-icant increase or decrease between the two. On the other hand, the dif-ference in precision at the same recall level between the high/mediumcase and that of the low confidence situation is more or less obvious. Weobserved that during the group discussion, people tend to be more cau-tious to assign high confidence to a mapping. As a result, some of themappings that had been assigned as high confidence in individual casedrops to medium confidence in group case10.
The same numbers from both the individual and group cases are usedto compare the difference of the individual and the group gold standardshaving on the precision recall curves in each confidence level. Figure8.11, figure 8.12 and figure 8.13 present precision recall curves of in-dividual vs. group discussion based gold standard at three confidencelevels respectively.
At both high and medium confidence levels, the precision is generally
10In the group discussion session, the users do not have access to the information theyprevious made in the first individual user study.
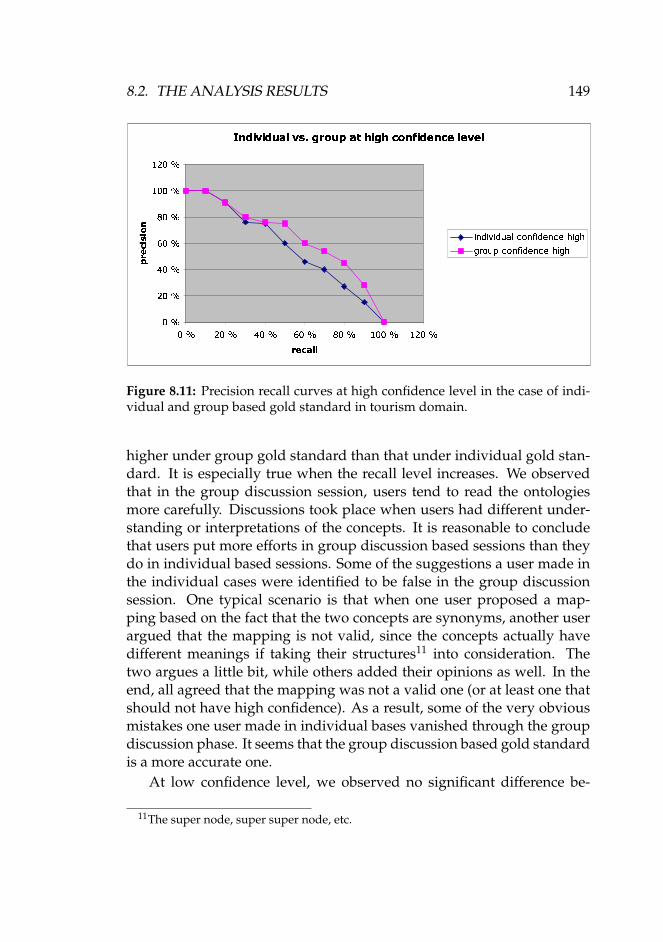
8.2. THE ANALYSIS RESULTS 149
Figure 8.11: Precision recall curves at high confidence level in the case of indi-vidual and group based gold standard in tourism domain.
higher under group gold standard than that under individual gold stan-dard. It is especially true when the recall level increases. We observedthat in the group discussion session, users tend to read the ontologiesmore carefully. Discussions took place when users had different under-standing or interpretations of the concepts. It is reasonable to concludethat users put more efforts in group discussion based sessions than theydo in individual based sessions. Some of the suggestions a user made inthe individual cases were identified to be false in the group discussionsession. One typical scenario is that when one user proposed a map-ping based on the fact that the two concepts are synonyms, another userargued that the mapping is not valid, since the concepts actually havedifferent meanings if taking their structures11 into consideration. Thetwo argues a little bit, while others added their opinions as well. In theend, all agreed that the mapping was not a valid one (or at least one thatshould not have high confidence). As a result, some of the very obviousmistakes one user made in individual bases vanished through the groupdiscussion phase. It seems that the group discussion based gold standardis a more accurate one.
At low confidence level, we observed no significant difference be-
11The super node, super super node, etc.
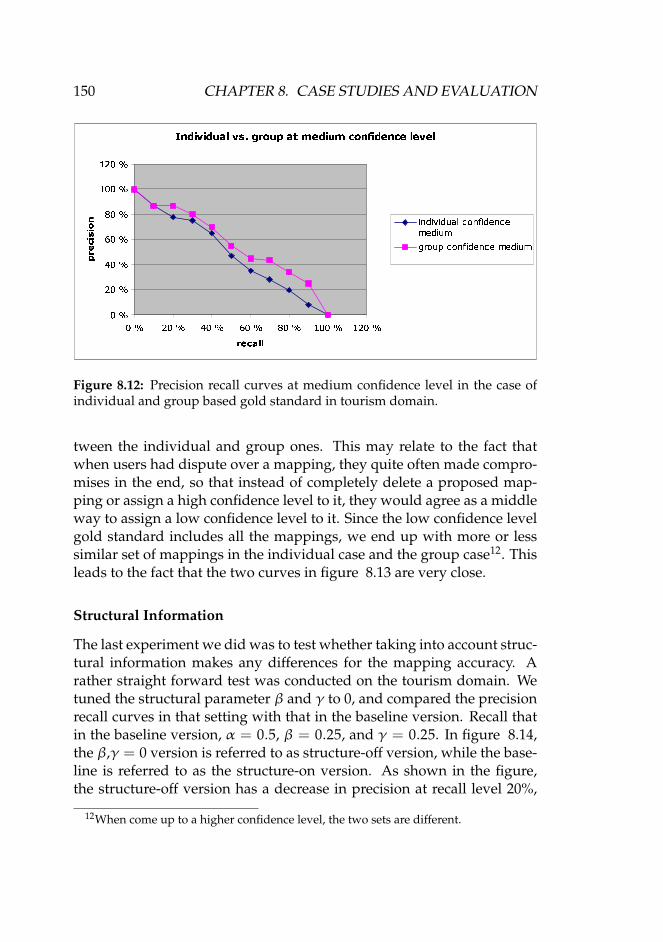
150 CHAPTER 8. CASE STUDIES AND EVALUATION
Figure 8.12: Precision recall curves at medium confidence level in the case ofindividual and group based gold standard in tourism domain.
tween the individual and group ones. This may relate to the fact thatwhen users had dispute over a mapping, they quite often made compro-mises in the end, so that instead of completely delete a proposed map-ping or assign a high confidence level to it, they would agree as a middleway to assign a low confidence level to it. Since the low confidence levelgold standard includes all the mappings, we end up with more or lesssimilar set of mappings in the individual case and the group case12. Thisleads to the fact that the two curves in figure 8.13 are very close.
Structural Information
The last experiment we did was to test whether taking into account struc-tural information makes any differences for the mapping accuracy. Arather straight forward test was conducted on the tourism domain. Wetuned the structural parameter β and γ to 0, and compared the precisionrecall curves in that setting with that in the baseline version. Recall thatin the baseline version, α = 0.5, β = 0.25, and γ = 0.25. In figure 8.14,the β,γ = 0 version is referred to as structure-off version, while the base-line is referred to as the structure-on version. As shown in the figure,the structure-off version has a decrease in precision at recall level 20%,
12When come up to a higher confidence level, the two sets are different.
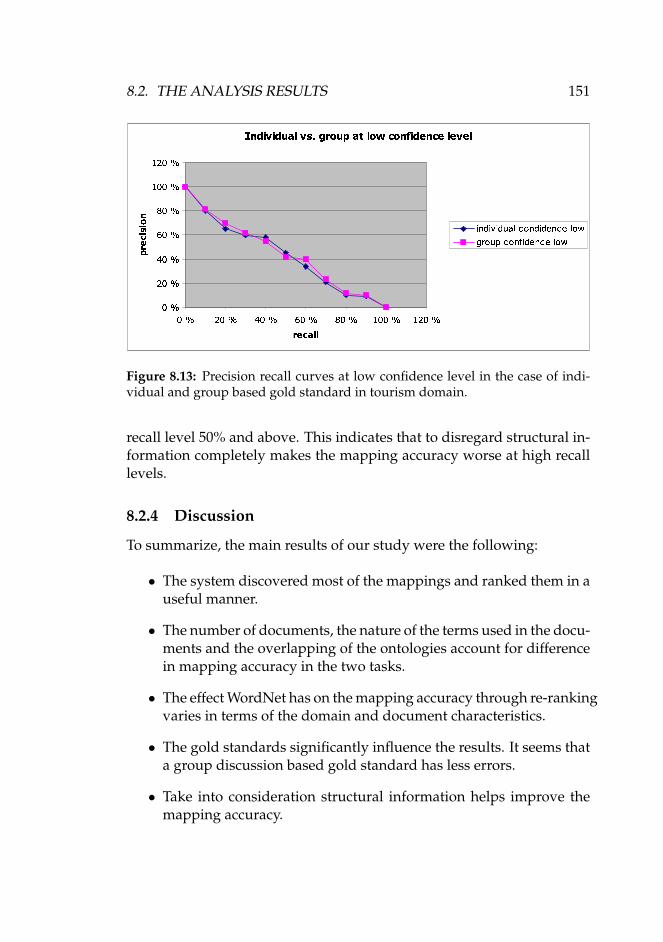
8.2. THE ANALYSIS RESULTS 151
Figure 8.13: Precision recall curves at low confidence level in the case of indi-vidual and group based gold standard in tourism domain.
recall level 50% and above. This indicates that to disregard structural in-formation completely makes the mapping accuracy worse at high recalllevels.
8.2.4 Discussion
To summarize, the main results of our study were the following:
• The system discovered most of the mappings and ranked them in auseful manner.
• The number of documents, the nature of the terms used in the docu-ments and the overlapping of the ontologies account for differencein mapping accuracy in the two tasks.
• The effect WordNet has on the mapping accuracy through re-rankingvaries in terms of the domain and document characteristics.
• The gold standards significantly influence the results. It seems thata group discussion based gold standard has less errors.
• Take into consideration structural information helps improve themapping accuracy.
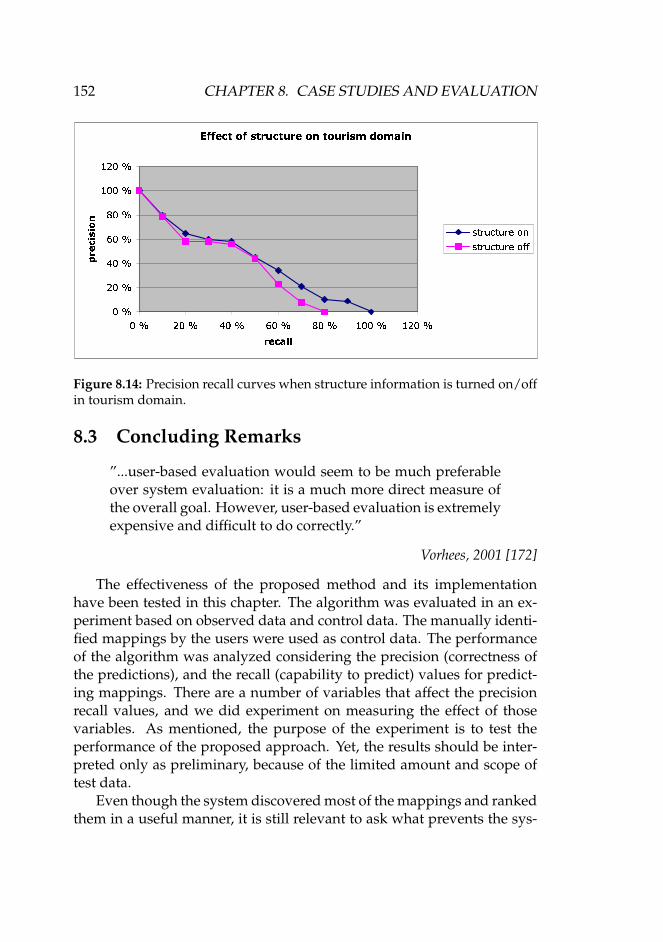
152 CHAPTER 8. CASE STUDIES AND EVALUATION
Figure 8.14: Precision recall curves when structure information is turned on/offin tourism domain.
8.3 Concluding Remarks
”...user-based evaluation would seem to be much preferableover system evaluation: it is a much more direct measure ofthe overall goal. However, user-based evaluation is extremelyexpensive and difficult to do correctly.”
Vorhees, 2001 [172]
The effectiveness of the proposed method and its implementationhave been tested in this chapter. The algorithm was evaluated in an ex-periment based on observed data and control data. The manually identi-fied mappings by the users were used as control data. The performanceof the algorithm was analyzed considering the precision (correctness ofthe predictions), and the recall (capability to predict) values for predict-ing mappings. There are a number of variables that affect the precisionrecall values, and we did experiment on measuring the effect of thosevariables. As mentioned, the purpose of the experiment is to test theperformance of the proposed approach. Yet, the results should be inter-preted only as preliminary, because of the limited amount and scope oftest data.
Even though the system discovered most of the mappings and rankedthem in a useful manner, it is still relevant to ask what prevents the sys-

8.3. CONCLUDING REMARKS 153
tem from achieving even better precision and recall figures. There areseveral reasons that prevent iMapper from correctly mapping the con-cepts. One reason is some of the questionable mappings the users iden-tified. For example, one user mapped Destination with Hitchhiking andAutomotive with Railroad transportation. On the other hand, there are alsoplausible mappings which the system discovered but no user has identi-fied. For example, the system maps Backpacking with Budget travel but ithas not been reported in any of the user’s results. Further, the successfulmapping is based on the successful construction of representative featurevectors which could differentiate one concept from another. The qualityof the feature vectors is affected by the number of instance documentsand the natural language processing techniques to extract textual infor-mation from the document in order to construct the feature vectors. Asolution to this problem is to use more document instances and employmore sophisticated textual processing techniques.
Our evaluation experiment was not ideal. We were limited by avail-able resources and, in some case, by circumstances. We had 2 domainsand 6 users in the experiment. The numbers are still too small. Suchan experiment however would still give some credible indications on theperformance of the system. The question is whether taking precision andrecall figure in isolation from other mapping algorithms is meaningful.What is needed here is a larger scale experiment that compares differentsystems with similar experiment settings. This requires the communityto develop resources like standard source ontologies, benchmark resultsand evaluation measures. Ideally, we need a system that resembles thekind of function TREC [173] has in the Information Retrieval community.Another negative aspect of the evaluation is that we are aiming to de-velop a matcher that is as accurate as human users. As we don’t knowhow human users make the match (i.e., we’re not working with a cogni-tive theory of meaning) this seems to be a moving target. What we aremissing here is an underlying theory (i.e., a cognitive theory of meaning)that would guide our research and would tell us what our automaticmatcher needs to simulate or mimic.
On the other hand, the usefulness of the approach can also be mea-sured according to the amount of human work required to reach the per-fect match by adjusting the automatically suggested matches against theamount of human work required to come up with a perfect match fromscratch. Due to time and resource limitations, evaluation in this line hasnot been possible so far. However, based on the discussion in this chapter,

154 CHAPTER 8. CASE STUDIES AND EVALUATION
we suggest the following points to be considered in order to effectivelymeasure the amount of human work:
• The time that a user needs to achieve the perfect results in the twosettings (adjusting the suggested one vs. from scratch) is a possibleindications of user efforts.
• Another way of measuring user efforts is to track down the user’ssteps when performing the tasks. It is reasonable to assume thataccepting a suggested mapping takes less effort than adding oneor deleting one. By assigning proper weights to the accept, add,delete, and adjust steps, we could come up with quantitative mea-sures of the efforts used in the two settings.
• The definition of the perfect results is still a tricky one. The processof mapping often involves multiple players. In that case, the per-fect results would be a result of the social negotiation of meaning.As an added motivation, it would be also interesting to investigatewhether the suggested mappings help the players to achieve theagreement with less efforts or not (easier or faster).

Chapter 9
Applicability of the Approach– A Scenario
As we mentioned earlier, one way to utilize the derived mapping asser-tions is to use them to bridge communications between heterogeneoussystems. This chapter presents a scenario where the derived mappingassertions are used to improve system interoperability in multi-agent sys-tems. We start with a brief recount of the system semantic interoperabil-ity problem in a multi-agent setting. Thereafter, we introduce the ideaof using explanation as a way to approach that problem. The explana-tion process is expressed in terms of an explanation ontology shared bythe agents who participate in the explanation session. The explanationontology is defined in a way general enough to support a variety of ex-planation mechanisms. This chapter describes the explanation ontologyand provides a working through example illustrating how the proposedgeneric ontology can be used to develop specific explanation mechanism.Furthermore, the ontology is being integrated into a running agent plat-form - AGORA to demonstrate the practical usefulness of the approach.Parts of this chapter have been published before [161].
9.1 Introduction
Over the past few years, researchers and industry have both been in-volved in a great drive towards enabling interoperability between di-verse information sources through the explicit modelling of concepts usedin communication. Semantic Web is one of the most significant endeav-
155

156 CHAPTER 9. APPLICABILITY OF THE APPROACH
ours to that end. The hope is that the Semantic Web can alleviate some ofthe problems with the current web, and let computers process the inter-changed data in a more intelligent way.
Ontology is a key factor for enabling interoperability in the semanticweb [12]. It includes an explicit description of the assumptions regardingboth the domain structure and the terms used to describe the domain.Ontologies are central to the semantic web because they allow applica-tions to agree on the terms that they use when communicating. Ontologyfacilitates communication by providing precise notions that can be usedto compose message (queries, statements) about the domain. For the re-ceiving party, ontology helps to understand messages by providing thecorrect interpretation context. Within a multi-agent system, agents rep-resent their view of the world by explicitly defined ontologies. A multi-agent system is achieved through the reconciliation of these views by acommitment to common ontologies that permit agents to interoperateand cooperate. Thus, ontologies, if shared among stakeholders, will im-prove system interoperability across agent systems.
However, it is highly doubtable that there will be one single universalshared ontology, which will be applauded by all players. Besides, whenontologies are developed independently of each other in a large, dis-tributed environment such as the web, it is inevitable that the same pieceof domain knowledge will be captured in different ontologies. Therefore,it is highly likely that the involved agent systems may use different on-tologies to represent their view of the domain. The problem of improvingsystem interoperability will therefore boils down to the reconciliation ofdifferent ontologies used in different agent systems.
This reconciliation usually exists in the form of mappings that relateconcepts in the two ontologies. The mappings are normally computedoff-line, either manually or automatically (in most case, semi-automatically).The mapping approach presented in the previous chapters can be usedfor that purpose. Also, a number of approaches introduced in the lit-erature can be used for deriving mappings as well. This chapter con-centrates on how to explore the mapping derived by other methods andhow to incorporate them into agent systems in order to achieve the goalof greater semantic interoperability within and across agent systems. Im-itating the human way of communication, we propose to view the map-pings as a source of explanations to clarify mismatches that occur duringagent communications.
We base our research on a running agent platform, called AGORA.

9.2. AGENT COMMUNICATION 157
The AGORA system is a multi-agent system environment, which pro-vides support for cooperation between agents [103] [104]. Ontologies areused during communication to give semantic meaning to the contents ofmessages sent between agents. For AGORA, the need for concept expla-nation arises when two agents use different ontologies to identify whatis in fact similar or related concepts. For example, if two agents want tobuy and sell cars, it is possible that they use different product ontologies.A simple mismatch would be that one uses the term car, while the otheruses automobile. It is however clear that they have overlapping interestand mechanism should be developed to enable them to communicate.
Explanation, like any other kind of agent communication, is a com-plex task and a range of agreements has to be made before any mean-ingful communication could ever happen. Therefore, in order to use ex-planation for reaching consensus on terms used in heterogeneous multi-agent systems, we first need the agreement to use a consensual termi-nology for enabling the explanation process. We denote the agreed con-ceptualization of the explanation process by the term explanation ontol-ogy. Committing to the explanation ontology is a prerequisite for suc-cessful explanation. According to the minimum ontology commitmentrule [166], we try to keep our ontology simple and small. We believe thata commitment to such ontology is essential and necessary. The ontologyconsists of three parts, an explanation interaction protocol, an explana-tion profile and an explanation strategy. Furthermore, the explanationontology is seamlessly integrated into the current AGORA system.
The rest of the chapter is organized as follows. First, we introducesome of the basic concepts and terminology in the literature of agentcommunication in order to lay a clearer foundation for the discussionafterwards. Then, we present the proposed explanation ontology, whichincludes the interaction protocol, the explanation profile and the expla-nation strategy. Next, an example is provides to illustrate the idea. Then,we demonstrate how it can be incorporated into AGORA. Related workand future study will conclude the chapter.
9.2 Agent Communication
Agents exchange information and knowledge using Agent Communica-tion Language (ACL) [62] [88]. ”Existing ACLs” are KQML with its manydialects and variants [59] [86], and FIPA ACL [60].

158 CHAPTER 9. APPLICABILITY OF THE APPROACH
9.2.1 KQML
The KQML (Knowledge Query and Manipulation Language) language1
is divided into three layers: the content layer, the message layer, and thecommunication layer.
• The content layer bears the actual content of the message, in theprograms own representation language.
• The communication layer encodes a set of features to the messagewhich describe the lower level communication parameters, suchas the identity of the sender and recipient, and a unique identifierassociated with the communication.
• The message layer forms the core of the the KQML language, anddetermines the kinds of interactions one can have with a KQML-speaking agent. The primary function of the message layer is tosupply a speech act or performative which the sender attaches tothe content (such as, that it is an assertion, a query, a command, orany of a set of known performatives).
The KQML language has a set of reserved performatives (commu-nicative acts), with some associated arguments. The arguments (param-eters) are indexed by keywords and connected to the respective value(key/value pairs). The syntax of KQML is based on the familiar s-expressionused in Lisp, i.e., a balanced parenthesis list [88]. The following illus-trates the syntax:
(KQML performative:sender:content:receiver:reply-with:language:ontology)
A KQML message form agent joe representing a query about the price ofa share of IBM stock might be encoded as:
1The KQML Web page at the University of Maryland, Baltimore County:http://www.cs.umbc.edu/kqml

9.2. AGENT COMMUNICATION 159
(ask-one:sender joe:content (PRICE IBM ?price):receiver stock-server:reply-with ibm-stock:language LPROLOG:ontology NYSE-TICKS)
In this message, the KQML performative is ask-one, the content is priceibm ?price, the ontology assumed by the query is identified by the tokennyse-ticks, the receiver of the message is to be a server identified as stock-server and the query is written in a language called LPROLOG. The valueof the :content keyword is the content layer, the values of the :reply-with,:sender, :receiver keywords form the communication layer and the perfor-mative name (ask-one, in this case), with the :language, :ontology form themessage layer.
KQMLs reserved performatives are included in appendix D, but theyare neither a minimal required set nor a closed one. In [59] it is empha-sized that developers should try to follow the reserved performatives (beKQML compliant), and by that enable interoperability.
9.2.2 FIPA
The Foundation for Intelligent Physical Agents (FIPA)2 is a non-profitassociation whose purpose is to ”promote the success of emerging agent-based applications, services and equipment”. FIPA’s goal is to maximizeinteroperability across agent-based systems.
The FIPA Agent Communication Language (FIPA ACL), like KQML,is based on speech act theory: messages are actions, or communicativeacts3, as they are intended to perform some action by virtue of beingsent.
Apart from speech act theory-based communicative acts, FIPA ACLalso deals with message exchange interaction protocols, and content lan-guage representations. In short, there are three group of specifications inFIPA ACL.
• FIPA Communicative Act (CAs) specifications deal with different
2The Foundation for Intelligent Physical Agent, website: http://www.fipa.org3FIPA’s communicative acts roughly equals performatives in KQML

160 CHAPTER 9. APPLICABILITY OF THE APPROACH
utterances for ACL messages. Like KQML, FIPA has a set of re-served communicative acts as well.
• FIPA Interaction Protocols (IPs) specifications deal with pre-agreedmessage exchange protocols for ACL messages. Agents exchangesequences of messages to communicate. The communication pat-terns they follow are called interaction protocols. Agents shouldknow or be able to figure out the next move, according to a mes-sage received from another agent and its state. The current FIPAspecification provides the normative description of a set of high-level interaction protocols, including requesting an action, contractnet protocol and several kinds of auctions.
• FIPA Content Language (CL) Specifications deal with different rep-resentations of the content of ALC messages. The current specifi-cation defines the framework for using several languages as con-tent language, including, FIPA SL (Semantic Language), FIPA CCL(Constraint Choice Language), KIF (Knowledge Interchange For-mat), and RDF (Resource Description Framework).
KQML and FIPA ACL are almost identical with respect to their ba-sic concepts and the principles they observe and differ primarily in thedetails of their semantic framework. For a comparison of the two lan-guages, we refer to [88]. In this work, however, the differences is not thefocus. The system, AGORA, which we will introduce later on, is bothKQML and FIPA compliant.
Both KQML and FIPA ACL try to maximize interoperability acrossagent-based systems by requesting the participant agents to follow thesame communication framework. However, at a semantic level, hetero-geneity still exists. When two ”KQML/FIPA-speaking” agents use twodifferent ontology to define their contents, they will still not be able tounderstand each other even though the syntax of the message and theintended meaning of the message (such as if it is a request or a inform,etc.) is predefined in ACL. This work therefore is intended to tackle in-teroperability problem at the semantic level.
9.3 The Explanation Ontology
We believe two types of knowledge are required for the agents engagedinto an explanation process:
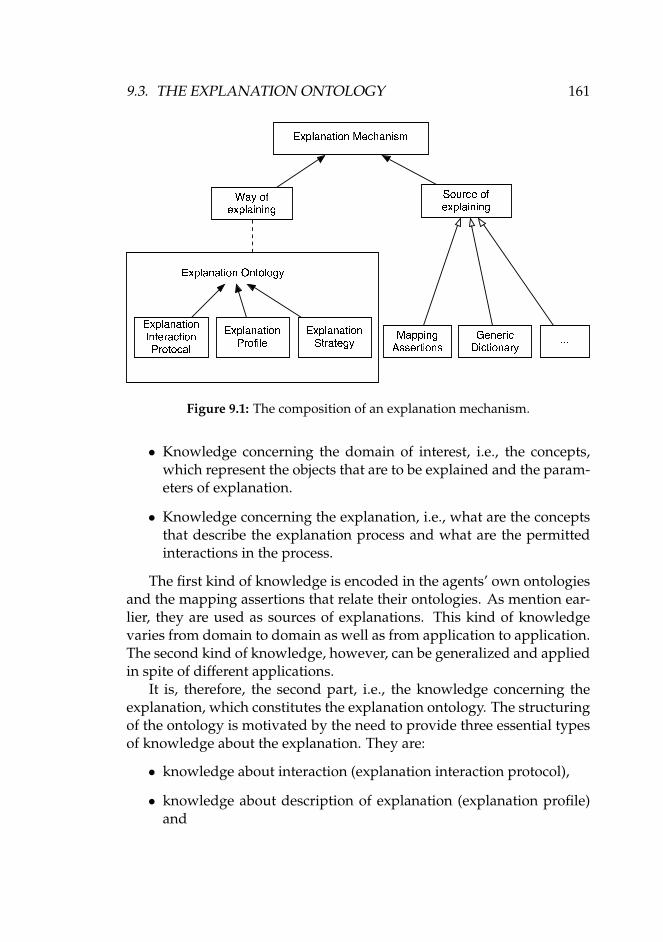
9.3. THE EXPLANATION ONTOLOGY 161
Figure 9.1: The composition of an explanation mechanism.
• Knowledge concerning the domain of interest, i.e., the concepts,which represent the objects that are to be explained and the param-eters of explanation.
• Knowledge concerning the explanation, i.e., what are the conceptsthat describe the explanation process and what are the permittedinteractions in the process.
The first kind of knowledge is encoded in the agents’ own ontologiesand the mapping assertions that relate their ontologies. As mention ear-lier, they are used as sources of explanations. This kind of knowledgevaries from domain to domain as well as from application to application.The second kind of knowledge, however, can be generalized and appliedin spite of different applications.
It is, therefore, the second part, i.e., the knowledge concerning theexplanation, which constitutes the explanation ontology. The structuringof the ontology is motivated by the need to provide three essential typesof knowledge about the explanation. They are:
• knowledge about interaction (explanation interaction protocol),
• knowledge about description of explanation (explanation profile)and

162 CHAPTER 9. APPLICABILITY OF THE APPROACH
• knowledge about how explanations are derived (explanation strat-egy).
Each of the three classes provides an essential type of information aboutthe explanation, as characterized in the rest of the section.
As a summary, figure 9.1 illustrates the different components in-volved in a complete explanation mechanism as well as their relationsbetween each other. Two components constitute the explanation mech-anism, namely, the way of explaining and the source of explaining. Eachof them corresponds to one of the two types of knowledge listed in thebeginning of this section. The knowledge about way of explaining is fur-ther partitioned into three parts: explanation interaction protocol, explana-tion profile and explanation strategy. The three parts together is named ex-planation ontology. The knowledge about source of explaining may comefrom the mapping assertions, which can be generated using for example,the iMapper system, or from a generic electronic dictionary or any othersources that relate the concepts in the two agent ontologies. The rest ofthe chapter focuses on the explanation ontology.
The generic explanation ontology is intended to capture similaritiesbetween different explanation mechanisms. It can be used as classifica-tion framework that permits the analysis of the explanation mechanismsavailable, and more important to develop new ones. Furthermore, bycommitting to the same high-level concepts, the communication amongagents is facilitated, in a more flexible way.
It should be noted that while we define a particular generic ontologyfor interaction, for profile, and for strategy, the construction of alternativeapproaches in each case is allowed. Our intention here is not to prescribea single approach in each of the three areas, but rather to provide genericapproaches that will be useful for the majority of cases. In the followingthree sub sections we discuss the resulting explanation interaction proto-col, explanation profile, and explanation strategy in greater detail.
9.3.1 Explanation Interaction Protocol
An explanation interaction protocol defines how the explanation is per-formed. In particular, it describes the dataflow and possible interactionsamong participants during the explanation process.
The concept of explanation interaction protocol is a pre-specified pat-tern of message exchange between agents. It is a pragmatic solution for

9.3. THE EXPLANATION ONTOLOGY 163
Figure 9.2: An ER model of the general explanation interaction protocol.
agent conversation, so that an agent can engage in meaningful conversa-tion with other agents, simply by carefully following the interaction pro-tocol. There can be different explanation interaction protocols. A generalexplanation interaction protocol is build based on generalizing the com-monalities of different protocols. Figure 9.2 identifies the main conceptsof the general protocol. The concept protocol defines a generic explana-tion interaction protocol. There are several roles involved in the protocol.Each role is played by one or more agents (participants). Possible involvedroles are Initiator, the agent who asks for explanation; Explainer, the agentwho provides explanation; and Explanation Manager, who mediates theexplanation. A protocol is also guided by a number of explanation rules.Each rule tells what action for a role to take when a certain precondition ismet.
By refining the concepts in the general protocol we can define differ-ent specific protocols. The refinement of a concept is achieved by restrict-ing the value set of an attribute or by adding new attribute to concepts.For example, we define the concept protocol has an attribute has-role,whose minimum cardinality is 2. By that, we say at least two agents (ini-tiator and explainer) need to be engaged into a protocol. However, whendefining a mediated explanation protocol, we restrict the minimum car-dinality to 3, since an explanation manager, who functions as a mediator,is added into the interaction. We consider a general framework for pre-senting such protocols as well as some of the specific protocols. A specificexplanation interaction protocol is presented in the example section.

164 CHAPTER 9. APPLICABILITY OF THE APPROACH
Figure 9.3: An ER model of the the main concepts in the explanation profile.
9.3.2 Explanation Profile
The explanation profile defines the main concepts that are used in theexplanation. It is presented in figure 9.3. We use RDF Schema to encodethe profile in order to be compatible with the semantic Web initiative.
The main concepts in the explanation are query and explanation. Eachquery is in correspondence with a number of explanations. Each queryconsists of one source element, one source ontology and one target ontol-ogy. Each explanation concerns two ontology elements, one source andone target. Each ontology element belongs to an ontology. An explana-tion also has a type, which defines the kind of relationship between thecorresponding source and target ontology elements. Ideally, the corre-spondence between ontology elements should be translation where se-mantics of the concept are completely preserved. However, transforma-tions (mappings that lose some of the semantics) are also permitted toallow for approximate explanation. Thus the type of an explanation canbe one of the following:
1. Similar concept (car ≈ automobile)
2. Narrower concept (station wagon is a car)

9.3. THE EXPLANATION ONTOLOGY 165
3. Broader concept (car is-a-kind-of vehicle)
4. Related concept (car is related with transport)
A degree is associated with each explanation to suggest the confidenceof the mapping. Additional explanation method can be easily added,by making another instance of ExplanationType, for example, logical ex-pression.
It is worth to note that the explanation profile is not intended to be anexhaustive list of methods for solving semantic heterogeneity betweenagents, rather it serves as an anchor point for accommodating potentialuseful techniques which deals with resolving ontology mismatch. Newlyagreed explanation methods can be added into the explanation ontologyand be integrated into the AGORA system afterwards.
9.3.3 Explanation Strategy
The explanation strategy describes how the explainer does the analysisof discrepancy and what are the evaluation criteria for the initiator todecide whether to accept a certain explanation or not.
For the explainer, different strategies may be configured by using dif-ferent combinations of the following aspects:
• Source of explanation. The explainer may use different informa-tion sources to derive explanation. Possible sources are mappingsbetween local ontologies, mappings between local and global on-tologies, and external lexicon (e.g., WordNet [112]).
• Ranking strategy. When multiple explanations are available for agiven concept, a ranking strategy is need to determine which oneto use in the first place. The ranking strategy may take the form ofa set of ranking rules or to employ a ranking function to calculate anumerical figure for each explanation in the result set.
• Termination criteria. The explainer could terminate the process,when no more explanation is available, or when a predefined max-imum round of explanation is exceeded.
On the initiator side, two main aspects define its strategy:
1. Acceptance criteria. This is the strategy about when to accept anexplanation, when to reject and when to ask for more explanation.

166 CHAPTER 9. APPLICABILITY OF THE APPROACH
2. Termination criteria. It defines when to terminate the explanationprocess.
Based on the general framework discussed above, specific configurationsof explanation strategy can be introduced (for example, the explanationstrategy in next section).
9.4 A Working Through Example
In order to better illustrate the idea of how to make use of the generic ex-planation ontology presented above to develop new explanation mecha-nism, we have considered the application scenario of an electronic mar-ket place. In an electronic market place, where buyers and sellers arebrought together, each individual participant, (possibly software agent)may use its own product catalogue to represent the required and avail-able products respectively [54]. In that context, making it possible foragents to understand what is required and what is offered becomes non-trivial. We see explanation as one way of solutions. A specific explana-tion interaction protocol, the generic explanation profile, and a specificexplanation strategy constitute this specific explanation mechanism.
9.4.1 Two Product Catalogues
We have given an extensive account of the product catalogue integrationproblem in chapter 8. Here we use the same context. Let us look at thetwo product catalogue extracts in figure 9.4.
The first product encoding standard UNSPSC contains about 20.000categories organized into four levels. Each of the UNSPSC category def-initions contains a category code and a short description of the prod-uct (for example, category 43191500 Personal communication devices).Another product catalogue is eCl@ss , which defines more than 12.000categories and is organized in four-level taxonomy. It is generally un-derstood that UNSPSC classifies products from a suppliers perspective,while eCl@ss is from a users perspective.
We assume that a supplier uses the UNSPSC standard, while a buyeruses the eCl@ss standard. We further assume that the mappings betweentwo standards are maintained by a service agent. The mappings can bederived either by the mapping approach described in this work or any
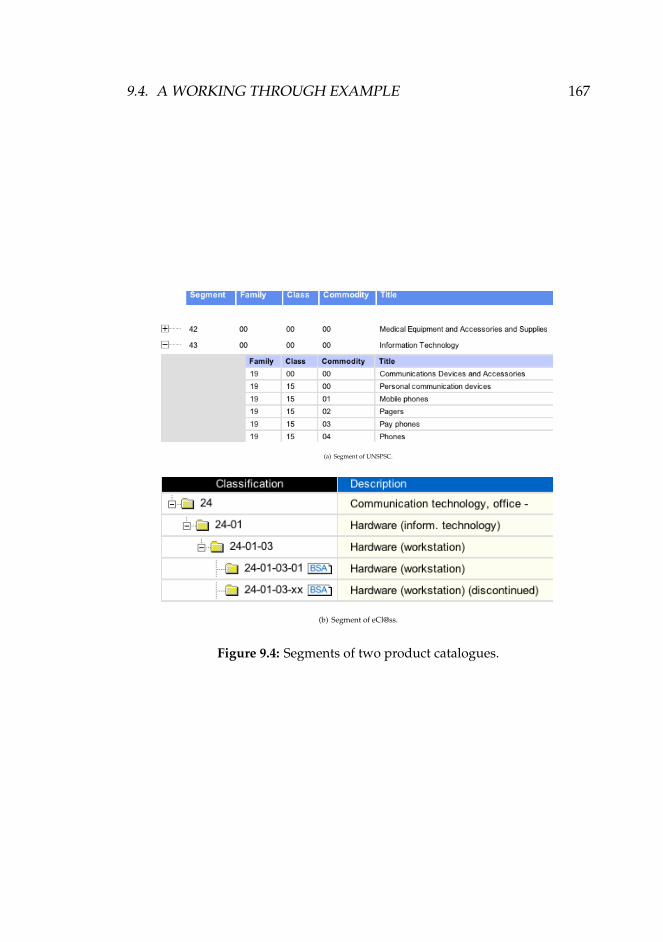
9.4. A WORKING THROUGH EXAMPLE 167
(a) Segment of UNSPSC.
(b) Segment of eCl@ss.
Figure 9.4: Segments of two product catalogues.

168 CHAPTER 9. APPLICABILITY OF THE APPROACH
UNSPSC eCl@ss Type Confidence43211507 Workstationor personal computers
240103 Hardware(workstation)
Similar .95
43211901 Monitors 240106 Screen Similar .90
Table 9.1: An example of mappings between two product catalogues.
other mapping algorithms introduced in other works. In general, a map-ping process typically involves analyzing the ontologies and comparingthem to determine the correspondence among concepts and detect pos-sible conflicts. A set of mapping assertions is the main output of a map-ping process. A couple of typical mapping assertions are presented inthe following table 9.1. The mapping assertions can be used directly ina translator component, which translates statements that are formulatedby different ontologies. Or a follow-up integration process can use themappings to detect merging points. Here, our usage of mapping resultsfalls into the translator category.
9.4.2 A Specific Explanation Interaction Protocol
As illustrated in section 9.3.1, a specific explanation interaction protocolcan be introduced by refining and instantiating the generic protocol. Fig-ure 9.5 presents one of such specific protocols using AUML [127]. Thisprotocol uses the FIPA (The Foundation for Intelligent Physical Agents)reserved communicative acts, thus allow maximum interoperability withother FIPA compliant agent system.
This protocol has three roles, among which the Explanation Manageracts as a mediator between Initiator and Explainers. The rules that gov-ern the process of the interaction are:
1. The Initiator requires help from the explanation manager.
2. The Explanation Manager acts as an auctioneer to choose one ormore Explainers to provide explanation service. The Explainerswho know both source ontology and target ontology have the high-est rank. If no Explainer is willing to provide such service, a failuremessage is sent to the Initiator. Otherwise, the Explanation Man-ager confirms to provide an explanation.
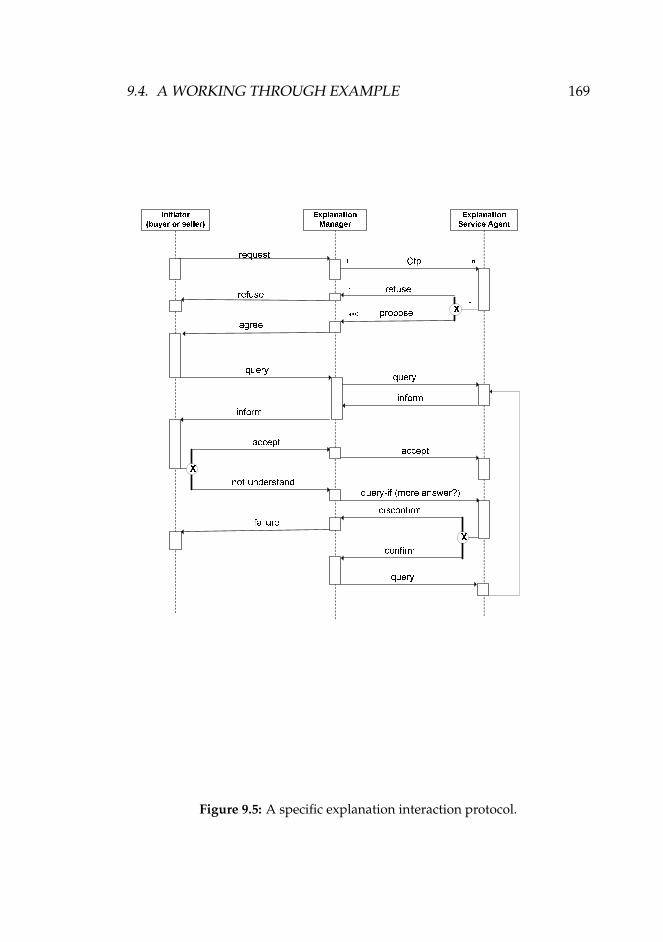
9.4. A WORKING THROUGH EXAMPLE 169
������������
�� �����
���� ��� ����������� �"!���#��$"!#%&%'!�)(
*,+�-% �.�"���/�&�#�01��"� 2.!�
3
�)�#4�� ��
5'6 4�����7
8�99����:
3
������ �;�,:
*+�-�% ���"�<�/�&�#�= !#�?>#� @A!1BC2.!�"�
D 4��E F
F
G�HJIF
8�K������
���#4L� ��
�� �;�M�
5'6 4��;��7
6 �N:)OP� 6 Q �;���,:)8 6 Q
8�99���#:
���������O 5 4SR/7T�����U8 6 ��VW����X;Y
3
QZ5 �9,� 6 4 5 ��74�8 5&[ �;�)�
9� 6 4 5 ��7
������M�
Figure 9.5: A specific explanation interaction protocol.

170 CHAPTER 9. APPLICABILITY OF THE APPROACH
3. During explanation, the Explanation Manager acts as a messagemediator between the Initiator and the Explainers.
4. After getting a query the Explanation Manager tries to consult theExplainer to produce an explanation. The Explainers can explainthe terms by different strategies presented in section 9.4.3. If no ex-planation can be produced then a failure message is sent out. Oth-erwise, and explanation result is sent to the Initiator.
5. Upon receiving the explanation, the Initiator examines the explana-tion and replies whether it is satisfied with the proposed explana-tion (the accept message) or not (the not-understand message). Theformer reply terminates the explanation exchange while the laterwill iterate the protocol for more explanations.
The rules prescribed above are formally represented by using precon-ditions and actions. Each precondition is uniquely identified by the per-formatives in this explanation interaction protocol. Each performativehas unique meaning in the context of explanation ontology (Table 9.2).They may have other meaning in other ontologies. For instance, Informin the explanation ontology means the explainer agent informs about theexplanation while in another trading ontology, Inform may well denoteinforming the result of a business act. A combination of performativeand a specific ontology indicate a unique intended act in the scope of theagent system.
In this implementation, the Explanation Manager Agent manages theinteraction protocol in terms of initializing and terminating the process aswell as mediating messages between the Initiator and Explainer. This so-lution allows simultaneous running several interaction protocols for thesame concept explanation or performs one after another (if the previousprotocol doesnt satisfy the Initiator).
9.4.3 A Specific Explanation Profile and Strategy
The generic explanation profile is used to instantiate queries and expla-nations that are passed between agents.
Based on the general framework in section 9.3.3, a specific expla-nation strategy is developed. For the Explainer, a hybrid approach forexplanation derivation is proposed. The hybrid approach contains lo-cal ontology alignment, global ontology alignment and term alignment. They
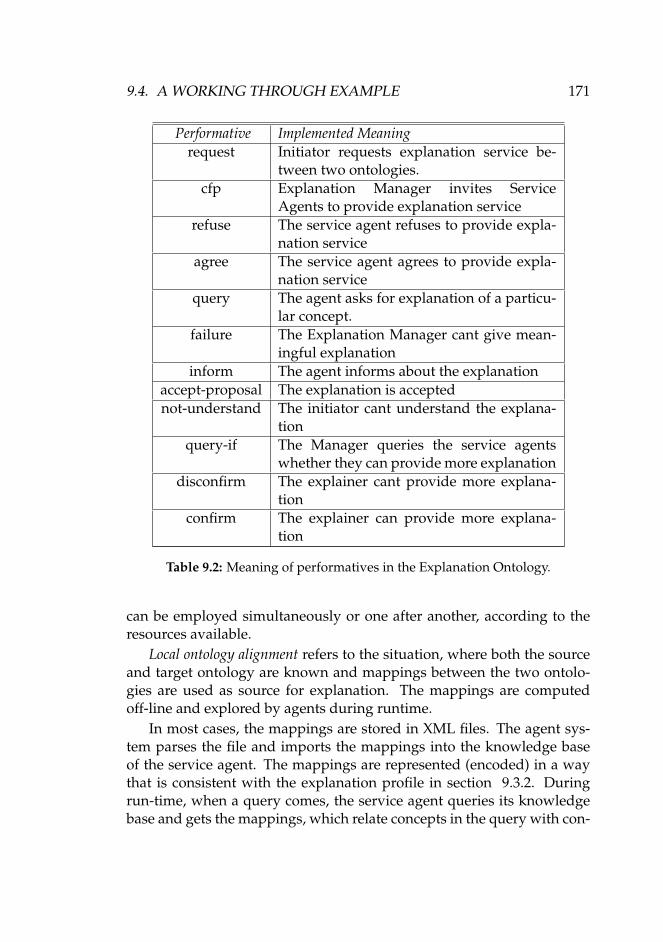
9.4. A WORKING THROUGH EXAMPLE 171
Performative Implemented Meaningrequest Initiator requests explanation service be-
tween two ontologies.cfp Explanation Manager invites Service
Agents to provide explanation servicerefuse The service agent refuses to provide expla-
nation serviceagree The service agent agrees to provide expla-
nation servicequery The agent asks for explanation of a particu-
lar concept.failure The Explanation Manager cant give mean-
ingful explanationinform The agent informs about the explanation
accept-proposal The explanation is acceptednot-understand The initiator cant understand the explana-
tionquery-if The Manager queries the service agents
whether they can provide more explanationdisconfirm The explainer cant provide more explana-
tionconfirm The explainer can provide more explana-
tion
Table 9.2: Meaning of performatives in the Explanation Ontology.
can be employed simultaneously or one after another, according to theresources available.
Local ontology alignment refers to the situation, where both the sourceand target ontology are known and mappings between the two ontolo-gies are used as source for explanation. The mappings are computedoff-line and explored by agents during runtime.
In most cases, the mappings are stored in XML files. The agent sys-tem parses the file and imports the mappings into the knowledge baseof the service agent. The mappings are represented (encoded) in a waythat is consistent with the explanation profile in section 9.3.2. Duringrun-time, when a query comes, the service agent queries its knowledgebase and gets the mappings, which relate concepts in the query with con-

172 CHAPTER 9. APPLICABILITY OF THE APPROACH
cepts in the target ontology. When the result set consists of more thanone mapping, a ranking strategy is used to decide which one to use asexplanation to the query term. The ranking strategy consists of severalrules, which defines what kind of mappings has higher priority in whichcircumstance. For instance, a rule defines that mappings, which are oftype similar and has confidence greater than 0.8, should rank higher thanmappings that are of type narrow or broader. Based on the ranking strat-egy, the result set is ordered. Finally, the top ranked mapping is chosen;wrapped in a way consistent with the explanation ontology and sent backas a reply message to the initiator.
In the example we introduced in section 9.4.1, the mappings betweenthe two standards are represented (encoded) by committing to the expla-nation profile in section 9.3.2. An example representation is like the fol-lowing, which says that element 43211507 (workstation or personal com-puters) in UNSPSC is similar to element 240103 (Hardware workstation)in eCl@ss and their similarity degree is 0.95 .
<explanation rdf:ID = explanation-00 ><source rdf:resource = UNSPSC:43211507><sourceOntology rdf:resource = http://www.unspsc.org />
</source><target rdf:resource = eCl@ss:240103>
<targetOntology rdf:resource = http://www.elcass.de /></target><type rdf:resource = similar /><confidence rdf:resource = 0.9 />
</explanation>
Global alignment considers the case that the mappings between thesource ontology and the target ontology are not available, but both theinitiator and explainer know a third-party ontology so that all terms inthe source ontology and target ontology can be explained by the third-party ontology. In this example, the third party ontology is NAICS4
(North American Industry Classification Systems)]. We assume that map-pings between NAICS and the initiators local ontology (eCl@ss) and map-pings between NAICS and the source ontology (UNSPSC) can be ac-cessed by the initiator and the explainer respectively. A NAICS term
4http://www.census.gov/epcd/www/naics.html

9.4. A WORKING THROUGH EXAMPLE 173
display terminals (33411131005) which has a mapping both to monitor andscreen can be used as an explanation. So, if both the initiator and theexplainer know about NAICS, the initiator will require the explanationservice for NAICS.
Term alignment intends to use linguistically related terms as a sourcefor explanation. It is employed when no specific mappings of the two in-volved ontology are known in prior. A general purpose lexical databaseWordNet is used as external resources to derive synonyms (similar con-cepts), hypermyms (broader concepts) and hyponyms (narrower con-cepts) of the query concept. The ranking strategy is made up of a set ofrules as well. High ranked term is chosen and wrapped up into messageaccording to the explanation ontology.
For example, monitor has a direct synonym display in WordNet, sothe explainer who offers term alignment service gives display as the firstexplanation. However, display is not in the vocabulary of eCl@ss, so theInitiator cant understand it either. Then the explainer provides a newexplanation screen which is hyponym of display and at the same senseof monitor. The Initiator understands screen so that the explanation isaccepted. The WordNet doesnt give the explicit value of confidence, butit ranks the explanation by estimated frequency. The confidence in thiscase is calculated by the normalization of the ranks and total amount ofexplanations. An encoding of the message is show below.
<explanation rdf:ID = explanation-00 ><source rdf:resource = monitor>
<sourceOntology rdf:resource = http://www.unspsc.org /></source><target rdf:resource = display>
<targetOntology rdf:resource =http://www.cogsci.princeton.edu/~wn//>
</target><type rdf:resource = similar /><confidence rdf:resource = 1 /></explanation>
On the initiator side, the decision on whether to accept an explanationor not is based on the notion of understanding. The idea that an agent un-derstands a concept is based on the fact that the suggested concept existsin its vocabulary set (ontology) and the confidence level associated withthat explanation is satisfactory. Hence, an agent accepts an explanation if

174 CHAPTER 9. APPLICABILITY OF THE APPROACH
the explanation proposes a concept that the agent could locate in its ownontology and the confidence level is above a minimum threshold value.Otherwise, the agent may ask for another round of explanation or giveup the process. Agent may pre-define a maximum threshold to restrainthe number of rounds that can be performed.
9.5 Implementing the Explanation Ontology in AGORA
We implemented the explanation ontology in the AGORA system.
9.5.1 The AGORA Multi-agent System
The AGORA system is a multi-agent environment, which provides sup-ports for cooperative work between agents. The concept of cooperativenode [102] is a central element of the system architecture.
Agora Node Functions
The cooperative node is an infrastructure element where agents partici-pating in a cooperative activity can register themselves and get supportfor communication, coordination and negotiation. Such a cooperativenode is being referred to as an Agora node5. Basic functionality of theAgora node is presented in figure 9.6.
Each Agora node has a Communication Adapter, Manager Agent,Negotiation and Coordination Agents. The Communication Adapter al-lows agents to communicate in Agent Communication Language (ACL),which is compliant with both FIPA ACL [60] and KQML [59]. Communi-cation can happen directly between agents or indirectly via Agora wherethey are registered. The complexity of the Manager Agent can be differ-ent for different applications, however, basic matchmaking functionalityis provided by default in all Managers. The default matchmaker can beoverridden in order to support more advance functionality, such as:
• semantical matchmaking using ontology and semantic relations
• advanced event handling – a decision making procedure for start-ing matchmaking process, including filtering events, reasoning aboutnecessity of matchmaking, selective matchmaking etc.
5Note that AGORA refers to the multi-agent system, while Agora refers to one coop-erative node.

9.5. IMPLEMENTING THE EXPLANATION ONTOLOGY IN AGORA175
Figure 9.6: Agora node functions.
• decision making about registration of particular negotiation and/orcoordination agent
• processing queries about registered activities, ontology used andother general information
• handling agent registration/unregistration protocols
• pro-active reasoning with available knowledge
• history maintenance and analysis
Negotiator and Coordinator are agents which manage, correspond-ingly, negotiation and coordination protocols. In particularly, they canimplement functionality of auctioneers in auctions or managers in Con-tract Net Protocol.
Agora nodes are generated dynamically and they can constitute a net-work of interrelated nodes.
The AGORA Agent Architecture
Agents in the system are generated by an agent deployment block and,by default, they have a Linear Planner, a Knowledge Base and an Execu-tor Module. The default agent implementation can be overridden by a
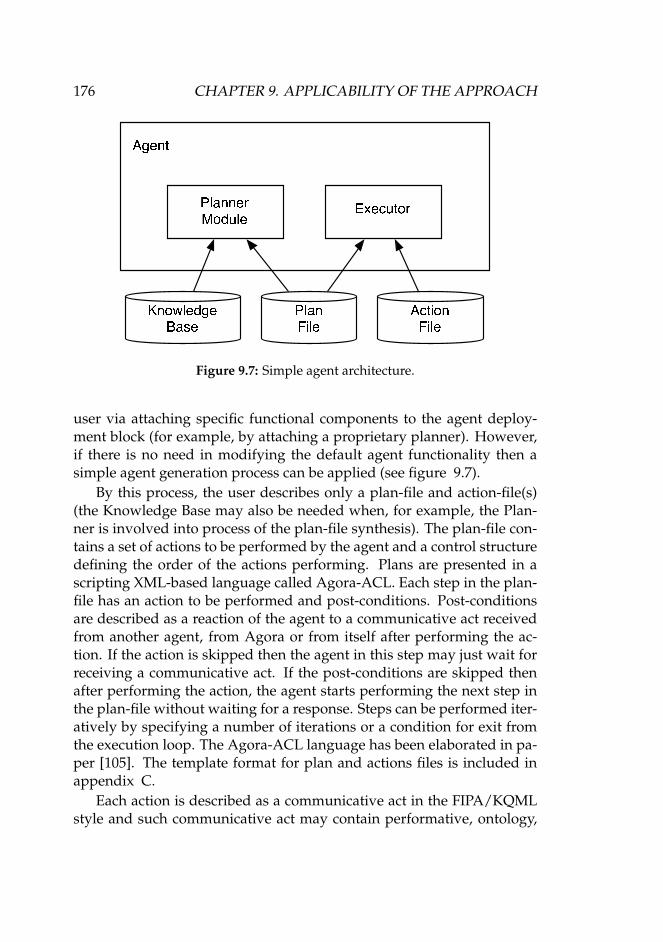
176 CHAPTER 9. APPLICABILITY OF THE APPROACH
Figure 9.7: Simple agent architecture.
user via attaching specific functional components to the agent deploy-ment block (for example, by attaching a proprietary planner). However,if there is no need in modifying the default agent functionality then asimple agent generation process can be applied (see figure 9.7).
By this process, the user describes only a plan-file and action-file(s)(the Knowledge Base may also be needed when, for example, the Plan-ner is involved into process of the plan-file synthesis). The plan-file con-tains a set of actions to be performed by the agent and a control structuredefining the order of the actions performing. Plans are presented in ascripting XML-based language called Agora-ACL. Each step in the plan-file has an action to be performed and post-conditions. Post-conditionsare described as a reaction of the agent to a communicative act receivedfrom another agent, from Agora or from itself after performing the ac-tion. If the action is skipped then the agent in this step may just wait forreceiving a communicative act. If the post-conditions are skipped thenafter performing the action, the agent starts performing the next step inthe plan-file without waiting for a response. Steps can be performed iter-atively by specifying a number of iterations or a condition for exit fromthe execution loop. The Agora-ACL language has been elaborated in pa-per [105]. The template format for plan and actions files is included inappendix C.
Each action is described as a communicative act in the FIPA/KQMLstyle and such communicative act may contain performative, ontology,

9.5. IMPLEMENTING THE EXPLANATION ONTOLOGY IN AGORA177
receiver, content, language and some other fields specified in [59] [60].For more details about the AGORA system we refer to [102] [103]
[104] .
9.5.2 Implementing Explanation Algorithm in AGORA
In order to support the explanation function, we need to integrate theexplanation ontology into the AGORA architecture. The following re-quirements should be met:
1. Agents should be registered at some Agora node to get platformsupport.
2. The interaction protocol needs to be implemented.
3. The explanation profile needs to be incorporated into the agentmessage content.
4. The explanation strategy should be implemented by the involvedagents.
The first requirement can easily be satisfied. When an explanationprocess is triggered, a new Agora node (Explanation Agora) is created,where Initiator, Explainer and Negotiation agents are registered (Nego-tiation agent plays a role of the Manager Agent described in the section9.3).
The second one is met by defining the interaction protocol using Agoraplan file. The plan-file can be written manually (by the user) or gen-erated automatically by the agent planner. Upon registration, Initiator,Explainer and Manager all import their plan and action files. Agent in-teraction will then be executed under the guidance of the plan/actionfile.
The third requirement is managed by encoding the explanation pro-file in the content part of the message. The explanation profile here canbe viewed as a type system for the content. Within the content is a RDFstatement.
The fourth requirement is met by defining appropriate action files forthe involved agents. For service agents, a strategy on how to derive ex-planation is implemented either directly by the action file or by writinga code URI (Universal Recourse Identifier) in the action file. That URIpoints to a computation component, which in our case is a Java class.

178 CHAPTER 9. APPLICABILITY OF THE APPROACH
The code URI solution is used only when the action file is not enoughto express the algorithm. Depending on whether the service agent per-forms ontology alignment or term alignment, it uses different derivationstrategy as is discussed in section 9.3.3. The set of rules that define rank-ings of result sets are instantiated by interacting with the user, which theagent is working on behalf of. For initiator, a strategy on evaluating theproposed explanation is implemented by a Java component. That com-ponent has access to the agent’s own ontology collection and is capableof locating specific concepts in the ontology. The minimum threshold forconfidence level is set by the user and can be tuned if necessary.
9.6 Concluding Remarks
The problem of semantic interoperability (ontology mismatch, databaseschema integration, heterogeneous information source the specific ter-minology varies depending on the sub field) has been discussed in manyworks. This chapter has focused on the aspect of using the derived map-pings to facilitate agent communication in a heterogeneous environment.
Bailin and Tuszkowski introduced the idea of ontology negotiation intheir work [4]. They developed an ontology negotiation protocol in theform of application program interface (API), which can be used to enableagents to cooperate in performing a task, even if they are based on dif-ferent ontology. Their work shares similar intention with ours but differsin the proposed solution. One of the major differences between Bailinswork and ours stems from the fact that we consider generic frameworkfor the explanation process as well as specific explanation mechanismsthat commit to the generic framework. Furthermore, we also think of in-tegrating and implementing the explanation ontology into the AGORAsystem.
Olivares-Ceja and Guzman-Arenas in their work deal with the issueof imperfect understanding among agents [128]. They use a method simthat finds the most similar concept in OB corresponding to another con-cept in OA. They present two algorithms, one to measure the similar-ity between both concepts; the other to gauge du(A, OB), the degree ofunderstanding that agent A has about the ontology of agent B. The pro-cedures use word comparison, since no agent can measure du directly,through object comparison. sim is also compared with conf, a methodthat finds the confusion among words in a hierarchy.

9.6. CONCLUDING REMARKS 179
In this chapter, we have presented how to use incremental explana-tion as a way for two agents, who use different ontologies, to come to apartial understanding if they have overlapping interest.
We present a generic explanation ontology, which provides three typesof essential knowledge about the explanation. They are explanation in-teraction protocol, explanation profile and explanation strategy. The genericontology can be used to develop specific explanation solutions as illus-trated by a working through example. It could also be used as a classifi-cation framework to compare different explanation mechanisms.
The problem of semantic interoperability is hard and our researchquestion is how much we may achieve of mutual understanding by, e.g.explanation. To examine our solution, we integrate the approach into anagent system AGORA. This also provides an anchor point for accommo-dating potential useful semantic reconciling techniques into agent sys-tems. For the generic explanation ontology we proposed to be really use-ful in a wider context, the quality of the ontology, i.e. how complete andvalid it is, need to be further investigated. Another aspect we are plan-ning to investigate is to develop more specific explanation mechanismsto test the flexibility of the generic ontology.

180 CHAPTER 9. APPLICABILITY OF THE APPROACH

Chapter 10
Conclusions and Future Work
We have presented an approach to ontology mapping using semantic en-richment based on modeling and linguistic analysis. In this chapter, themain contributions of this thesis are outlined and a number of directionsfor future work are presented in the sequel.
10.1 Summary of Contributions
Recall in chapter 1, the objectives of the work were defined as: the pur-pose of the work is to introduce a method for finding semantic correspondenceamong the ontologies with the intention to support interoperability of ISs. Theoverall purpose is decomposed into the intermediate goals of this work.The goals of this work are to:
• introduce a theoretical framework for ontology comparison and forspecification of mappings between ontologies,
• propose a method for semantic enrichment and discovery of se-mantic correspondence between the ontologies,
• provide an analysis of the implementation and evaluation of themethod in empirical experiments, and
• analyze the applicability of the mapping approach in supportinginteroperability.
We discuss our contributions according to these objectives. In thisthesis, the overall problem of determining mapping assertions in ontol-
181

182 CHAPTER 10. CONCLUSIONS AND FUTURE WORK
ogy mapping is approached with focus on making use of the extensionof the ontologies. The main contribution of this work are:
• A notion of mapping assertion has been introduced to describe,store and transmit the mappings in a systematic way. It has thefollowing meaning.
– A mapping assertion is a reified class which describes the rela-tionship between two ontology elements and supports furtherdescription of the involved resources.
– A mapping assertion involves two ontology elements. Each on-tology element belongs to one ontology. A mapping type is at-tached to a mapping assertion, which specifies how the pairof ontology elements is related. Further a mapping degree isattached to a mapping assertion to indicate the confidence ofthe derived mapping. Finally the assertion source is to providean explanation on why the particular assertion is derived (de-rived by linguistic information of names, for instance).
– The measure of the strength of the correspondence relation-ship provides a way of ordering the output. As a side effect, italso permits imperfect matching and introduces the notion ofuncertainty into the comparison process.
• The specification and prototype realization of the approach.
– The whole approach can be partitioned into two phases: thesemantic enrichment phase and the mapping phase.
– The ontologies are semantically enriched by feature vectors,which are constructed using the extension information of theontologies.
– The extension in that case are written documents classified toconcepts.The constructing process are aided by linguistic anal-ysis of documents.
– The enrichment structures are used to compute similarities be-tween ontology elements.
– The similarity values are further rearranged using relatednessanalysis with the help of WordNet.
– The similarity values are the basis for inclusion or exclusion ofa mapping assertion in the final result.

10.1. SUMMARY OF CONTRIBUTIONS 183
– The generated mapping assertions are ranked and presentedto the user for final approval. The approved results can besaved and exported.
– The implementation of the prototype consists of three partsthat use XML to exchange information. They are: the mod-eling environment - RefEdit, the CnS document classificationcomponent, and the iMapper mapping component.
• A controlled accuracy evaluation has been performed with a setof test users on two limited but real world cases. The evaluationshows encouraging results. Furthermore, the system is tested un-der different configuration of variables to indicate the robustness ofthe approach. The results show a number of tendencies.
– The system discovered most of the mappings and ranked themin a useful manner.
– The number of documents, the nature of the terms used in thedocuments and the overlapping of the ontologies account fordifference in mapping accuracy in the two tasks.
– The effect WordNet has on the mapping accuracy through re-ranking varies in terms of the domain and document charac-teristics.
– The gold standards significantly influence the results. It seemsthat a group discussion based gold standard has less errors.
– Take into consideration structural information helps improvethe mapping accuracy.
• A trial to use the mapping assertions with the intention to bridgecommunications between heterogeneous systems has been presented.In order to adapt its usage in the specific multi-agent setting, anumber of agent communication related issues have been discussed.
– A brief recount of the system semantic interoperability prob-lem in a multi-agent setting has been presented.
– We propose to use explanation as a way to approach that prob-lem.
– The explanation process is expressed in terms of an explana-tion ontology shared by the agents who participate to the ex-planation session.

184 CHAPTER 10. CONCLUSIONS AND FUTURE WORK
– The explanation ontology is defined in a way general enoughto support a variety of explanation mechanisms. It providesthree types of essential knowledge about the explanation. Theyare explanation interaction protocol, explanation profile andexplanation strategy.
– The mapping assertions are used as source of explanation inthe explanation strategy part.
– The explanation ontology is being integrated into a runningagent platform - AGORA to demonstrate the practical feasi-bility of the approach.
The experience gained from the case studies, also supported by theexperimental results, indicates that the proposed approach is a promisingline of research in the comparison and integration of ontologies. Alsoit has shown that the methods are applicable in different domains suchas the product catalogue domain and the tourism domain. The mainadvantage of the approach is twofold:
• First, the enrichment structure tries to capture both the extensionaland structural information about the UoD in a unified way, andin the meantime, the semantic enrichment structure captures thegeneric information about the UoD, thus facilitating the compari-son on a higher abstraction level.
• Second, the prototype is implemented in a user customizable wayto facilitate different configuration requirements.
10.2 Limitation and Future Directions
The following sections outline directions of future work related to theresults presented in this thesis that were not in the scope of this work.
10.2.1 Extended Customizability
The current situation with heterogeneous styles in distributed modelingin practice suggests a need for functional customizability of any tool thatattempts to support the ontology mapping or integration process. Func-tional customizability here means individually adjustable variables inthe algorithm depending on the application domain, the modeling group

10.2. LIMITATION AND FUTURE DIRECTIONS 185
and the organization. The experiences from the two case studies in chap-ter 8 imply that the choice of values of these parameters is highly ap-plication domain dependent. Preferably, the values should be adjustedafter running a number of test cases from the particular domain. In theontology mapping comparison algorithm proposed in the thesis, thereare a number of user adjustable values, which affect the performance ofthe mapping tool.
• The user can express her preference on deciding a limit for whichsimilarity threshold a mapping assertion has to have in order to beincluded in the result.
• The user can express her preference on the cardinality of mappingassertions.
• The user can express her preference when it comes to which subcomponent of the system should be tuned on or off.
• The user can express her preference when it comes to deciding theimportance of the contribution from one sub component to the finalresult.
In a more general mapping or integration algorithm, there should alsobe the following adjustable parameter values to increase its customizabil-ity.
• The user may express her preference when it comes to decidingwhat kind of ontology elements are compared.
• The user may express her preference on the inclusion of other map-ping algorithms and the order of execution of the different algo-rithms as well as the way to come up with the combined similarityvalue when multiple algorithms are concerned.
10.2.2 User Studies on Semantic Enrichment
Given that the shown benefits of semantic ontology enrichment usinglinguistic analysis of documents can only be achieved if there is a certaindegree of user involvement. There is no guarantee that the whole processof ontology mapping would be improved when it comes to comparingefforts used in the semi automatic process versus the efforts used in com-pletely manual way. An empirical investigation of human performance

186 CHAPTER 10. CONCLUSIONS AND FUTURE WORK
when using semantic enrichment technique for supporting the process ofontology mapping should be conducted.
An empirical investigation of human performance would serve in re-vealing laps and disadvantages of using the proposed approach, or al-ternatively in showing a real process improvement. The analyzed pa-rameters of performance should be in measures of the subjects’ cognitiveefforts (length of processing time, for instance) and result of the process(precision and recall) when completing the task. The variances in thesettings of the task (variables) can be altered to attribute difference to dif-ferent causes. An important line of future research is to investigate whichempirical tools are applicable to carry out these experiments.
10.2.3 Model Quality
The quality of the component ontologies affects the ontology mappingand integration process in several ways. The method to ontology map-ping proposed in this thesis presumes a high quality in the componentontologies. In [160], it is identified that an ontology is of high quality if itis:
• being externalized by modelers and physically available and acces-sible,
• syntactically correct according to the ontology language,
• semantically valid and complete, regarding the domain knowledgein question,
• comprehensible by its social audience,
• comprehensible by its technical audience to ensure automatic ma-nipulation, and
• finally, if it is a result of social agreement, when involving multiplemodelers.
Previous studies suggested that at least for a third party or a computerprogram, to compare or integrate distributed ontologies, the quality ofthe component ontologies is critical. It was observed that the ontologymapping process might be affected by poor model quality in the follow-ing ways. For any mapping to be correct, it is crucial to be able to in-terpret the component ontologies correctly. A correct interpretation is

10.2. LIMITATION AND FUTURE DIRECTIONS 187
dependent on the clarity of the semantics in the ontologies, correct us-age of syntax, and on the presentation of the ontologies and its graphics,documentation and modeling techniques.
However, individuals develop the component ontologies with theirown personal modeling preferences and practices. A tool that attempts tosupport the process of ontology comparison or integration needs to dealwith the problems of model quality to offer relevant support. To alleviatethe above mentioned conflicting situations there should be support
• to investigate and understand the impact of model and modelinglanguage quality on the mapping task,
• to analyze the quality and clean up mistakes, e.g. [32] [68], and
• to negotiate about the disagreements, e.g. [116] [117].
10.2.4 Technical Method Revision
The main issue, when it comes to revision of the enrichment and map-ping techniques, is what are the exact characteristics of ontology struc-tures that make it so hard to compare them. A thorough and in-depthempirical analysis on how people in reality performing the mapping taskis needed. Relevant questions that need to be answered in the empiricalstudy include the following.
• What are the scale and complexity of the mapping tasks?
• What are the main results expected from a mapping task? Doesthe result reflect the right interpretation of the UoD or the socialagreement among knowledge engineers?
• What kind of time and resource constraints are there in a typicalmapping task?
• When will knowledge engineers stops refining the mapping resultand call it a closure?
Answering the above question would help us in identifying whatis the cognitive theory of meaning that would guide our research andwould tell us what our automatic matcher needs to simulate or mimic.
Finally, the proposed algorithm is not aimed to automate completelythe process of ontology mapping, but to support a knowledge engineer

188 CHAPTER 10. CONCLUSIONS AND FUTURE WORK
in that task. It is therefore not enough to only test the performance andanalyze the soundness of the proposed approach. The usage aspect isimportant, not only because the approach is novel, and can be improved,but also because it can not fully be evaluated without reference to a usergroup verifying the support. To that end, we suggest that the useful-ness of the approach can be measured according to the amount of humanwork required to reach the perfect match by adjusting the automaticallysuggested matches against the amount of human work required to comeup with a perfect match from scratch.

Appendix A
Nomenclature
A.1 Abbreviations
Table A.1: Abbreviations used in the thesis.
Abbreviation Full nameACL Agent Communication LanguageAI Artificial IntelligenceAPI Application Program InterfaceAUML Agent-based Unified Modeling LanguageB2B Business to BusinessCnS Classification ’n’ SearchDAML DARPA Agent Markup LanguageDL Description LogiceClass Standardized Material and Service ClassificationER Entity RelationshipFCA Formal Concept AnalysisFIPA Foundation for Intelligent Physical AgentsFST Finite State TransducerGUI Graphical User InterfaceIR Information RetrievalIS Information SystemsJWNL Java WordNet LibraryKIF Knowledge Interchange Format
189

190 APPENDIX A. NOMENCLATURE
KQML Knowledge Query and Manipulation LanguageNLP Natural Language ProcessingOCML Operational Conceptual Modeling LanguageOIL Ontology Inference LayerOKBC Open Knowledge-Base ConnectivityOWL Web Ontology LanguagePOS Part-Of-SpeechPPP Phenomenon, Process and ProgramRDF Resource Description FrameworkRDFS Resource Description Framework SchemaRML Referent Modeling LanguageRPC Remote Procedure CallSHOE Simple HTML Ontology ExtensionUoD Universe of DiscourseUNSPSC the United Nations Standard Products and Services CodeURI Uniform Resource IdentifiersW3C World Wide Web ConsortiumXML eXtensible Markup LanguageXSL eXtensible Stylesheet Language

Appendix B
XML Formats Used in theiMapper System
This chapter presents the XML formats used in the various componentsof the iMapper system. We use examples to explain each format.
B.1 Ontology Exported from RefEdit
The modeler uses RefEdit to graphically model the ontology and save itas an XML file. Both graphical informations (layout and positions etc.)and semantic information of the model are stored in the file. An exampleis shown below.
<?xml version="1.0" encoding="ISO-8859-1" ?><!DOCTYPE referent-diagram SYSTEM "referent.dtd"><!--file generated by p3app--><referent-diagram>
<generator app="refedit" version="Version: 2.3c"verdate="Sun 6 Feb 2000"/>%% representing both the graphical and semantic information%% of a referent.%% An aggregation is attached to this referent.<referent id="x1">
<position x="441" y="196"/><dimension width="80" height="30"/><text>
191

192 APPENDIX B. XML FORMATS USED IN THE IMAPPER SYSTEM
<position x="481" y="211"/><string> Travel </string>
</text><aggregation id="x2" idref="x1">
<position x="474" y="226"/></aggregation></referent>......%% represent a subset operation other operations include isa |%% member-of | element-of | disjoint.<operation id="x67" type="subset" direction="up"><position x="206" y="305"/><dimension width="24" height="24"/></operation>......%% connect referent(s) with operations.<relation>
<relation-end idref="x3" cardinality="many" coverage="partial"/><relation-end idref="x2" cardinality="many" coverage="partial"/><nodes><dot><position x="268" y="266"/></dot><dot>
<position x="474" y="241"/></dot>
</nodes></relation>......%% represent a direct ad hoc relation between referents.<operation-link><link-from idref="x7"/><link-to idref="x67"/><nodes>
<dot><position x="159" y="338"/>

B.1. ONTOLOGY EXPORTED FROM REFEDIT 193
</dot><dot>
<position x="206" y="329"/></dot></nodes></operation-link>
...
...</referent-diagram>
The complete DTD used for the referent modeling file is presented asfollows.
<!ELEMENT referent-diagram ( generator?,(referent|operation|dataset|
element|relation|operation-link|canvas-text)* ) ><!ELEMENT generator EMPTY><!ATTLIST generator app CDATA #REQUIRED><!ATTLIST generator version CDATA #IMPLIED><!ATTLIST generator verdate CDATA #IMPLIED>
<!ELEMENT referent (position, dimension, text*, aggregation*,attribute*)><!ATTLIST referent id ID #REQUIRED>
<!ELEMENT position EMPTY><!ATTLIST position x CDATA #REQUIRED><!ATTLIST position y CDATA #REQUIRED>
<!ELEMENT dimension EMPTY><!ATTLIST dimension width CDATA #REQUIRED><!ATTLIST dimension height CDATA #REQUIRED>
<!ELEMENT text (position, string)><!ATTLIST text hadjust CDATA #IMPLIED> <!-- XXX --><!ATTLIST text vadjust CDATA #IMPLIED> <!-- XXX -->
<!ELEMENT string (#PCDATA)>

194 APPENDIX B. XML FORMATS USED IN THE IMAPPER SYSTEM
<!ELEMENT attribute (position, dimension, text*)>
<!ELEMENT aggregation (position)><!ATTLIST aggregation id ID #REQUIRED><!ATTLIST aggregation idref IDREF #REQUIRED>
<!ELEMENT operation (position, dimension) ><!ATTLIST operation id ID #REQUIRED ><!ATTLIST operation type (isa | subset | member-of | element-of |disjoint) "isa"><!ATTLIST operation direction ( up | right | down | left ) "up">
<!ELEMENT dataset (position, dimension, text*) ><!ATTLIST dataset id ID #REQUIRED>
<!ELEMENT element (position, dimension, text*) ><!ATTLIST element id ID #REQUIRED>
<!ELEMENT relation (relation-end, relation-end, nodes*) >
<!ELEMENT relation-end EMPTY><!ATTLIST relation-end idref IDREF #REQUIRED><!ATTLIST relation-end cardinality (one|many) #IMPLIED ><!ATTLIST relation-end coverage (full|partial) #IMPLIED >
<!ELEMENT nodes (dot+) >
<!ELEMENT dot (position, text*) >
<!ELEMENT operation-link (link-from, link-to, nodes*) >
<!ELEMENT link-from EMPTY ><!ATTLIST link-from idref IDREF #REQUIRED >
<!ELEMENT link-to EMPTY ><!ATTLIST link-to idref IDREF #REQUIRED >
<!ELEMENT canvas-text (text*)>

B.2. CLASSIFICATION RESULTS RETURNED BY CNS CLIENT 195
B.2 Classification Results Returned by CnS Client
The XML format used for storing and transferring the document classifi-cation results is simple and straight forward.
<?xml version="1.0"?><!-- DOCTYPE referent.linguistics --><document><referentExtension referent="x1"><instance docName="odp1.txt"></instance><instance docName="odp6.txt"></instance>
...</referentExtension>
...</document>
B.3 Mapping Assertions Generated by iMapper
The iMapper generate the candidate mappings and store them in an XMLfile like the following.
<document><sourceOntology name = "Yahoo Travel Ontology"><targetOntology name = "ODP Travel Ontology"><mappingAssertion id = "1">
<sourceReferent id = "x1"> Hotel </sourceReferent><targetReferent id = "x7"> Hotel and Motel </targetReferent><assertionType> similar </assertionType><degree> 0.89 </degree><explanation> extension derived + wordnet enhanced</explanation>
</mappingAssertion><mappingAssertion ...>...</mappingAssertion..>....</document>

196 APPENDIX B. XML FORMATS USED IN THE IMAPPER SYSTEM

Appendix C
The Plan and Action FileFormats in AGORA
C.1 DTD of the Plan File
Table C.1 explains the elements of the XML Document Type Definition(DTD) for the plan file, which is:
<!DOCTYPE plancollection[<!ELEMENT plancollection (name,plan+) ><!ELEMENT plan (id,category,startstep,step+) ><!ELEMENT step (id,action?, iteratecount?, accept+) ><!ELEMENT accept (postcondition,(nextstep|nextplan))><!ELEMENT postcondition (performative,ontology)><!ELEMENT nextstep (#PCDATA) ><!ELEMENT performative (#PCDATA) ><!ELEMENT ontology (#PCDATA) ><!ELEMENT name (#PCDATA) ><!ELEMENT id (#PCDATA) ><!ELEMENT iteratecount (#PCDATA) ><!ELEMENT category (#PCDATA) ><!ELEMENT startstep (#PCDATA) ><!ELEMENT action (#PCDATA) ><!ELEMENT nextplan (#PCDATA) >]>
197

198APPENDIX C. THE PLAN AND ACTION FILE FORMATS IN AGORA
Element Explanationplancollection The plancollection element corresponds to the plancol-
lection object.Plan The DTD describes that a plan must an identification
name, belong to a special category (for future exten-sions), must have a reference to a start step in the planand a plan must contain at least one or more steps.
step A step must have an id. A step may have a reference toan action, a counter on how many times this step hasbeen performed and must at least one accept element.
accept An accept element must consist of a set of post condi-tion and a reference to another step or plan (future ex-tension) if a Message Wrapper satisfy the combinationof performative and ontology.
nextstep An id (name) of a step.performative A performative.ontology An ontology.postcondition A postcondition must consist of the combination of
performative and ontology.iterationcount Explains how many times this step can be executed.action A name of an action a step should perform .
Table C.1: Explanation of plan DTD.
C.2 DTD of the Action File
<!DOCTYPE actionset[<!ELEMENT actionset (action+) ><!ELEMENT action (id,wrapper)><!ELEMENT wrapper (performative,receiver,content?,inreplyto?,
replywith?,language?,ontology><!ELEMENT id (#PCDATA) ><!ELEMENT performative (#PCDATA) ><!ELEMENT sender (#PCDATA) ><!ELEMENT receiver (#PCDATA) ><!ELEMENT content (#PCDATA) ><!ELEMENT inreplyto (#PCDATA) ><!ELEMENT replywith (#PCDATA) >

C.2. DTD OF THE ACTION FILE 199
<!ELEMENT language (#PCDATA) ><!ELEMENT ontology (#PCDATA) >]>

200APPENDIX C. THE PLAN AND ACTION FILE FORMATS IN AGORA

Appendix D
The KQML ReservedPerformatives
Category Reserved PerformativesBasic informational performa-tives
Tell, deny, cancel, untell
Basic query performatives Evaluate, reply, ask-if, ask-about,ask-one, ask-all, sorry
Basic effector performatives Achieve, unachievedMulti-response query performa-tives
Stream-about, stream-all
Generator performatives Standby, ready, rest, discard, gener-ator
Capability definition performa-tives
Advertise
Notification performatives Subscribe, monitorNetworking performatives Register, unregister, forward, broad-
cast, pipe, breakFacilitation performatives Broker-one, broker-all, recommend-
one, recommend-all, recruit-one,recruit-all
Table D.1: List of KQML reserved performatives.
201

202 APPENDIX D. THE KQML RESERVED PERFORMATIVES

Bibliography
[1] K. Aas and L. Eikvil. Text categorisation: A survey. Technical re-port, Norwegian Computing Center, Oslo, 1999.
[2] R. Andersen. A Configuration Management Approach for SupportingCooperative Information System Development. PhD thesis, NorwegianUniversity of Science and Technology, 1994.
[3] R. Baeze-Yates and B. Ribeiro-Neto. Modern Information Retrieval.Addison Wesley, 1999.
[4] S. Bailin and W. Truszkowski. Ontology negotiation between sci-entific archives. In Proceedings of the Thirteenth International Confer-ence on Scientific and Statistical Database Management (SSDBM 2001).IEEE Press, July 2001.
[5] S. Banerjee and T. Pedersen. Extended gloss overlaps as a measureof semantic relatedness. In Proceedings of the Eighteenth InternationalJoint Conference on Articificial Intelligence IJCAI-2003, 2003.
[6] C. Batini and M. Lenzerini. A comparative analysis of method-ologies for database schema integration. ACM Computer Surveys.,18(4), 1986.
[7] D. Beneventano, S. Bergamaschi, I. Benetti, A. Corni, F. Guerra, andG. Malvezzi. Si-designer: A tool for intelligent integration of infor-mation. In 34th Annual Hawaii International Conference on SystemSciences (HICSS-34). IEEE Computer Society, 2001.
[8] D. Beneventano, S. Bergamaschi, F. Guerra, and M. Vincini. Themomis approach to information integration. In ICEIS 2001, Pro-ceedings of the 3rd International Conference on Enterprise InformationSystems, Portugal, 2001.
203

204 BIBLIOGRAPHY
[9] S. Bergamaschi, S. Castano, and M. Vincini. Semantic integrationof semistructured and structured data sources. SIGMOD Record,28(1):54–59, 1999.
[10] S. Bergamaschi, F. Guerra, and M. Vincini. A data integrationframework for e-commerce product classification. In Proceeding ofthe first semantic web conference (ISWC-2002), pages 379–393, 2002.
[11] S. Bergamaschi, F. Guerra, and M. Vincini. Product classificationintegration for e-commerce. In DEXA Workshops, pages 861–867,2002.
[12] T. Berners-Lee. The semantic web. Scientific american, 284(5):35–43,2001.
[13] T. Berners-Lee and E. Miller. The semantic web lifts off. In ERCIMNews NO. 51, October 2002.
[14] A. Bernstein and M. Klein. Towards high-precision service re-trieval. In Proceedings of the First International Semantic Web Con-ference 2002, pages 84–101, 2002.
[15] M. Boman, J. A. Bubenko, P. Johannesson, and B. Wangler. Concep-tual Modelling. Prentices Hall, 1997.
[16] A. Bookstein, S. T. Klein, and T. Raita. Detecting content bearingwords by serial clustering. In SIGIR Forum (ACM Special InterestGroup on Information Retrieval), pages 319–327, 1995.
[17] S. Bowers and L. Delcambre. Representing and transformingmodel-based information. In Proceedings of the First Workshop on theSemantic Web at the Fourth European Conference on Digital Libraries,Lisbon, Portugal, 2000.
[18] T. Brasethvik. Conceptual modelling for domain specific document de-scription and retrieval- An approach to semantic document modelling.PhD thesis, IDI, Norwegian University of Science and Technology(NTNU), 2004.
[19] T. Brasethvik and J. A. Gulla. Natural language analysis for seman-tic document modeling. Data and Knowledge Engineering, 38(1):45–62, 2001.

BIBLIOGRAPHY 205
[20] T. Bray, J. Paoli, C. M. Sperberg-McQueen, and E. Maler. Extensi-ble markup language (xml) 1.0 (second edition), w3c recommen-dation 6 october 2000. http://www.w3.org/TR/2000/REC-xml-20001006.
[21] D. Brickley and R. Guha. Resource description framework schemaspecification 1.0, 2000.
[22] M. Bunge. The Philosophy of science - from problem to theory, revisededition. Transaction Publishers, 1998.
[23] D. Calvanese, S. Castano, F. Guerra, D. Lembo, M. Melchiorri,G. Terracina, D. Ursino, and M. Vincini. Towards a comprehensiveframework for semantic integration of highly heterogeneous datasources. In Proceedings of the 8th International Workshop on KnowledgeRepresentation meets Databases (KRDB 2001), 2001.
[24] D. Calvanese, D. G. Giuseppe, and M. Lenzerini. Ontology of inte-gration and integration of ontologies. In Proceedings of the Interna-tional Workshopon Description Logic (DL 2001), 2001.
[25] S. Carlsen. Conceptual Modelling and Composition of flexible workflowmodels. PhD thesis, Norwegian University of Science and Technol-ogy, 1997.
[26] S. Castano, V. D. Antonellis, and S. D. C. di Vimercati. Global view-ing of heterogeneous data sources. IEEE Transaction on Knowledgeand Data Engineering, 13(2):277–297, 2001.
[27] T. Catarci and M. Lenzerini. Representing and using interschemaknowledge in cooperative information systems. Journal of Intelli-gent Cooperative Information Systems, 2(4):375–398, 1993.
[28] S. Chakrabarti, B. Dom, R. Agrawal, and P. Raghavan. Scalable fea-ture selection, classification and signature generation for organiz-ing large text databases into hierarchical topic taxonomies. VLDBJournal, 7(3):163–178, 1998.
[29] H. Chalupsky. Ontomorph: A translation system for symboliclogic. In A. G. Cohn, F. Giunchiglia, and B. Selman, editors,KR2000: Principles of Knowledge Representation and Reasoning, pages471–482, San Francisco, CA, 2000. Morgan Kaufmann.

206 BIBLIOGRAPHY
[30] H. Chalupsky. A translation system for symbolic knowledge. InProceedings of the 7th International Conference on Principles of Knowl-edge Representation and Reasoning, 2000.
[31] V. Chaudhri, A. Farquhar, R. Fikes, P. Karp, and J. Rice. Okbc: Aprogrammatic foundation for knowledge base interoperability. InProceedings of AAAI-98, pages 600–607, 1998.
[32] O. Corcho, M. Fernandez-Lopez, and A. Gomez-Perez. Webode:an integrated workbench for ontology representation, reasoningand exchange. In Proceeding of Knowledge Engineering and Knowl-edge Management Ontologies and the Semantic Web. LNAI, Springer.,2002.
[33] O. Corcho, M. Fernandez-Lopez, and A. Gomez-Perez. Method-ologies, tools and languages for building ontologies: where is theirmeeting point? Data and Knowledge Engineering, 46(1):41–64, 2003.
[34] O. Corcho and A. Gomez-Perez. A roadmap to ontology specifica-tion languages. In Proceedings of the 12th International Conference onKnowledge Engineering and Knowledge Management, 2002.
[35] S. Decker, M. Erdmann, D. Fensel, I. Horrocks, M. Klein, and F. vanHarmelen. Oil in a nutshell. In Proceedings of EKAW’00, France,2000.
[36] S. Decker, S. Melnik, F. van Harmelen, D. Fensel, M. C. A. Klein,J. Broekstra, M. Erdmann, and I. Horrocks. The semantic web: Theroles of xml and rdf. IEEE Internet Computing, 15(3):63–74, 2000.
[37] M. Denny. Ontology building: A survey of editing tools. Technicalreport, XML com, 2002.
[38] J. Didion. Jwnl (java wordnet library),http://sourceforge.net/projects/jwordnet/, 2004.
[39] R. Dieng-Kuntz. Corporate semantic webs. ERCIM news, October2002.
[40] H. H. Do, S. Melnik, and E. Rahm. Comparison of schema match-ing evaluation. In Proceedings of the GI-Workshop Web and Database,Erfurt, 2001.

BIBLIOGRAPHY 207
[41] H. H. Do and E. Rahm. Coma-a system for flexible combinationof schema matching approaches. In Proceeding of the 28th VLDBconference., 2002.
[42] A. Doan, P. Domingos, and A. Halevy. Reconciling achemas of dis-parate data sources: a machine learning approach. In Proceedings ofACM SIGMOD Conference, pages 509–520, 2001.
[43] A. Doan, J. Madhavan, P. Domingos, and A. Halevy. Learning tomap between ontologies on the semantic web. In Proceedings ofWWW-2002, 11th International WWW Conference, Hawaii, 2002.
[44] J. Domingue and E. Motta. Knowledge modeling in webonto andocml. http://kmi.open.ac.uk/projects/ocml/, 1999.
[45] F. M. Donini, M. Lenzerini, D. Nardi, and A. Schaerf. Reasoningin description logic. In Principles of Knowledge Representation. CSLIPublications, 1996.
[46] DublinCore. http://www.dublincore.org.
[47] Encarta. World english dictionary, developed for microsoft bybloomsbury pulishing.
[48] EuroWordNet. http://www.illc.uva.nl/eurowordnet/. 2004.
[49] J. Euzenat. Towards a principled approach to semantic interoper-ability. In A. Gomez-Perez, M. Gruninger, H. Stuckenschmidt, andM. Uschold, editors, Workshop on Ontologies and Information Sharing,IJCAI01, Seattle, USA, 2001.
[50] A. Farquhar, R. Fikes, and J. Rice. The ontolingua server: A toolfor collaborative ontology construction. In Proceeding of the 10thKnowledge Acquisition for Knowledge-based Systems workshop, 1996.
[51] B. A. Farshchian. A Framework for Supporting Shared Interaction inDistributed Product Development Projects. PhD thesis, NorwegianUniversity of Science and Technology, 2001.
[52] C. Fellbaum. WordNet: An Electronic Lexical Database. MIT Press,1998.

208 BIBLIOGRAPHY
[53] D. Fensel, M. Crubezy, F. van Harmelen, and I. Horrocks. Oil &upml: A unifying framework for the knowledge web. In proceed-ings of ECAI 2000, Berlin, Germany, 2000.
[54] D. Fensel, Y. Ding, B. Omelayenko, E. Schulten, G. Botquin,M. Brown, and A. Flett. Product data integration in b2b e-commerce. IEEE Intelligent Systems (Special Issue on Intelligent E-Business), 16(4):54–59, 2001.
[55] D. Fensel, M. Erdmann, and R. Studer. Ontology groups: Semanti-cally enriched subsets of the www. In Proceedings of the InternationalWorkshop on Intelligent Information Integration at the 21st Geman An-nual Conference on Artificial Intelligence, Germany, 1997.
[56] D. Fensel, J. Hendler, H. Lieberman, and W. Wahlster. Spinning theSemantic Web, chapter 1, Introduction, pages 1–8. MIT Press, 2003.
[57] M. Fernandez, A. Gomez-Perez, and N. Juristo. Methontology:From ontological arts towards ontological engineering. In Proceed-ings of the AAAI’97 Spring Symposium Series on Ontological Engineer-ing, Stanford, USA, March 1997.
[58] R. Fikes and A. Farquhar. Large-scale repositories of highly expres-sive ontologies. IEEE Intelligent System, pages 73–79, 1999.
[59] T. Finin, Y. Labrou, and J. Mayfield. Kqml as an agent communi-cation language. In J. M. Bradshaw, editor, Software Agents, pages291–316. AAAI Press/The MIT Press: Menlo Park, CA, 1997.
[60] FIPA. Foundation for intelligent and physical agents.
[61] B. Ganter and R. Wille. Formal Concept Analysis: mathematical foun-dations. Springer, 1999.
[62] M. R. Genesereth, A. M. Keller, and O. M. Duschka. Softwareagents. CACM, 37(7):48–53, 1994.
[63] Google. www.google.com, 2004.
[64] T. R. Gruber. Translation approach to portable ontology specifica-tion. Knowledge Acquisition, 5(2):199–220, 1993.

BIBLIOGRAPHY 209
[65] N. Guarino. Formal ontology in information systems. In Proceed-ings of FOIS’98 (Formal Ontology in Information Systems), pages 3–15.IOS Press, 1998.
[66] N. Guarino and P. Giaretta. Ontologies and knowledge bases: to-wards a terminological clarification. In N. Mars, editor, TowardsVery Large Knowledge Bases: Knowledge Building and Knowledge Shar-ing, pages 25–32. IOS Press, 1995.
[67] N. Guarino, C. Masolo, and G. Vetere. Ontoseek: content-basedacess to the web. IEEE Intelligent Systems, 3(14):70–80, 1999.
[68] N. Guarino and C. Welty. Evaluating ontological decisions withontoclean. Communication of ACM, 45(2):61–65, 2002.
[69] J. A. Gulla. Explanation Generation in Information Systems Engineer-ing. PhD thesis, Norwegian University of Science and Technology,1993.
[70] J. A. Gulla, O. I. Lindland, and G. Willumsen. Ppp - an integratedcase environment. In Proceedings of the Third International Confer-ence on Advanced Information Systems Engineering (CAiSE’91), Trond-heim, Norway, 1991. Springer.
[71] S. Hakkarainen. Dynamic aspect and semantic enrichment in schemacomparison. PhD thesis, Stockholm University, 1999.
[72] S. Hakkarainen, L. Hella, S. Tuxen, and G. Sindre. Evaluatingthe quality of web-based ontology building methods: A frame-work and a case study. In Proceedings of the 6th International BalticConference on Database and Information Systems, Riga, Latvia, 2004.Springer.
[73] J. Heflin, J. Hendler, and S. Luke. Coping with changing ontologiesin a distributed environment. In Proceeding of the AAAI workshop onontology management, 1999.
[74] B. Hofreiter and C. Huemer. Towards syntax-independent b2b.ERCIM news, October 2002.
[75] I. Horrocks, P. F. Patel-Schneider, and F. van Harmelen. Review-ing the design of daml+oil: An ontology language for the semanticweb. In Proceedings of AAAI 2002, pages 792–797, 2002.

210 BIBLIOGRAPHY
[76] I. Horrocks, F. van Harmelen, and P. F. Patel-Schneider. Refer-ence description of the daml+oil (march 2001) ontology markuplanguage. http://www.daml.org/2001/03/reference.html, 2001.
[77] R. Hull. Managing semantic heteogeneity in databases: A theo-retical perspective. Proceeding of the 16th ACM SIGACT SIGMODSIGART Symposium on Principle of Database systems (PODS’97),pages 51–61, 1997.
[78] M. Jarrar and R. Meersman. Formal ontology engineering inthe dogma approach. In On the Move to Meaningful Internet Sys-tems, 2002 - Confederated International Conferences DOA, CoopIS andODBASE 2002, California, USA, 2002. Springer.
[79] D. Jurafsky and J. H. Martin. Speech and Language Processing: Anintroduction to natual language processing, computational linguistics,and speech recognition. Prentice Hall, 2000.
[80] H. Kaada. Linguistic workbench for document analysis and textdata mining. Master’s thesis, Norwegian University of Science andTechnology, 2002.
[81] C. M. Keet. Aspects of ontology integration. Technical report,School of Computing, Napier University, 2004.
[82] M. Kifer, G. Lausen, and J. Wu. Logical foundations of object-oriented and frame-based languages. Journal of the ACM, 1995.
[83] M. Klein. Combining and relating ontologies: an analysis of prob-lems and solutions. In Proceedings of the 17th International Joint Con-ference on Artificial Intelligence (IJCAI-01), Workshop: Ontologies andInformation Sharing, Seattle, USA, 2001.
[84] S. Klein and R. F. Simmons. A computational approach to gram-matical coding of english words. Journal of the ACM, 10(3):334–347,1963.
[85] J. Krogstie and A. Sølvberg. Information systems engineering -conceptual modeling in a quality perspective, 1999. NorwegianUniversity of Technology and Science.

BIBLIOGRAPHY 211
[86] Y. Labrou and T. Finin. A proposal for a new kqml specification.Technical Report TR-CS-97-03, University of Maryland BaltimoreCounty, 1997.
[87] Y. Labrou and T. Finin. Yahoo! as an ontology- using yahoo! cate-gories to describe documents. In Proceeding of the 8th InternationalConference on Information and Knowledge Management, pages 180–187, 1999.
[88] Y. Labrou, T. Finin, and Y. Peng. The current landscape of agentcommunication languages. Intelligent Systems, 14:2, 1999.
[89] O. Lassila and R. R. Swick. Resource description framework (rdf)model and syntax specification, w3c recommendation 22. february19. 1999.
[90] D. L. Lee, H. Chuang, and K. Seamons. Document ranking and thevector-space model. IEEE Software, 14(2):67–75, 1997.
[91] D. Lenat and R. Guha. Building large knowledge-based systems.representation and inference in the cyc project, 1990. Addison-Wesley, Reading, Massachusetts.
[92] D. B. Lenat. Cys: A large-scale investment in knowledge infras-tructure. Communications of the ACM, 38(11), 1995.
[93] W. Li, C. Clifton, and S. Liu. Database integration using neuralnetwork: implementation and experiences. Data and Knowledge En-gineering, 33(1):49–84, 2000.
[94] W. Litiwin, L. Mark, and N. Roussopoulos. Interoperability of mul-tiple automous databases. ACM Computer Survey, 22(3):267–293,1990.
[95] S. Luke and J. Heflin. Shoe 1.01 pro-posed specification, shoe project, april 2000.http://www.cs.umd.edu/projects/plus/SHOE/spec.html, 2000.
[96] R. MacGregor. Using a description classifier to enhance deductiveinference. In Proc. Seventh IEEE Conference on AI Application, Florida,pages 93–97, 1991.

212 BIBLIOGRAPHY
[97] J. Madhavan, P. A. Bernstein, P. Domingos, and A. Halevy. Rep-resenting and reasoning about mappings between domain models.In Proceedings of the Eighteenth National Conference on Artificial Intelli-gence and Fourteenth Conference on Innovative Applications of ArtificialIntelligence (AAAI 2002), pages 80–86, Edmonton, Alberta, Canada.,2002. AAAI Press.
[98] J. Madhavan, P. A. Bernstein, and E. Rahm. Generic schema match-ing using cupid. In Proceeding of Very Large Database Conference(VLDB), 2001.
[99] A. Maedche, B. Motik, N. Silva, and R. Volz. Mafra - a mappingframework for distributed ontologies. In Proceedings of the 13th Eu-ropean Conference on Knowledge Engineering and Knowledge Manage-ment EKAW, Madrid, Spain, 2002.
[100] T. W. Malone, K. Crowston, J. Lee, and B. Pentland. Tools for in-venting organizations: Toward a handbook of organizational pro-cesses. Technical Report 141, MIT, 1993.
[101] M. P. Marcus, B. Santorini, and M. A. Marcinkiewicz. Buildinga large annotated corpus of english. Computational Linguistics,19(2):313–330, 1993.
[102] M. Matskin. Intelligence in networks, the fifth international con-ference smartnet’99. In T. Yongchareon, F. A. Aagesen, and V. Wu-wongse, editors, Multi-Agent Support for Modelling Co-operativeWork, pages 419–432, Thailand, 1999. Kluwer Academic Publish-ers.
[103] M. Matskin, O. J. Kirkeluten, S. B. Krossnes, and Ø. Sæle. Agora:A multi-agent platform and its implementation. In Proceedings ofthe 2000 International Conference on Artificial Intelligence (IC-AI’2000),Las Vegas, Nevada, USA, 2000. CSREA Press.
[104] M. Matskin, O. J. Kirkeluten, S. B. Krossnes, and Ø. Sæle. Agora:An infrastructure for cooperative work support in multi-agent sys-tems. In Infrastructure for Agents, Multi-Agents, and Scalable Multi-Agent Systems. Springer Verlag, Lecture Notes in Computer Sci-ence, Volume 1887, 2001.

BIBLIOGRAPHY 213
[105] M. Matskin and A. Zaslavsky. A scripting language for both agentcommunication and mobility. In Proceedings of the Fifth InternationalBaltic Conference, BalticDBIS, 2002.
[106] D. McGuinness, R. Fikes, J. Rice, and S. Wilder. An environmentfor merging and testing large ontologies. In Proceedings of the 7thInternational Conference on Principles of Knowledge Representation andReasoning, Colorado, USA, 2000.
[107] D. McGuinness and F. van Harmelen eds. Owl web ontology lan-guage overview w3c proposed recommendation. 15 December2003.
[108] C. T. Meadow. Academic Press. Text Information Retrieval Systems,1992.
[109] S. Melnik and S. Decker. A layered approach to information mod-eling and interoperability on the web. In Proceedings of the ECDL2000 Workshop on the Semantic Web, Lisbon, Portugal, 2000.
[110] S. Melnik, H. Garcia-Molina, and E. Rahm. Similarity flooding: Aversatile graph matching algorithm and its application to schemamatching. In Proceedings of the International Conference on Data En-gineering (ICDE), 2002.
[111] P. Mika and H. Akkermans. Analysis of the state-of-the-art inontology-based knowledge management. Technical report, VrijeUniversiteit, Amsterdam, 2003.
[112] G. A. Miller. Wordnet: a lexical database for english. Communica-tion of ACM, 38(11):39–41, 1995.
[113] G. A. Miller. Wizard of the new wordsmiths: His idea to link wordsrewrote the dictionary, the star ledger, January 2002.
[114] G. A. Miller, R. Beckwith, C. Fellbaum, D. Gross, and K. J. Miller.Introduction to wordnet - an online lexical database. InternationalJournal of Lexicography, 4(3):235–244, 1990.
[115] T. Milo and S. Zohar. Using schema matching to simplify heteroge-neous data translation. In Proceedings of 24th Internation Conferenceon Very Large Data Bases (VLDB98), pages 122–133, 1998.

214 BIBLIOGRAPHY
[116] M. Missikoff. Harmonise: An ontology-based approach for seman-tic interoperability. ERCIM news, October 2002.
[117] M. Missikoff and F. Taglino. Business and enterprise ontology man-agement with symontox. In I. Horrocks and J. A. Hendler, editors,Proceedings of the First International Semantic Web Conference, Sardi-nai, Italy, 2002. Springer.
[118] P. Mitra, G. Wiederhold, and M. Kersten. A graph oriented modelfor articulation of ontology interdependencies. In Proceedings of Ex-tending Database Technologies, pages 86–100. Springer. LNCS 1777,2000.
[119] E. Motta. An overview of the ocml modeling language. KnowledgeEngineering Methods and Languages, 1998.
[120] J. Mylopoulos, A. Borgida, M. Jarke, and M. Koubarakis. Telos:Representing knowledge about information systems. InformationSystems, 8(4):325–362, 1990.
[121] N. F. Noy, R. W. Fergerson, and M. A. Musen. The knowledgemodel of protege-2000: Combining interoperability and flexibility.In Proceeding of 2th International Conference on Knowledge Engineeringand Knowledge Management (EKAW’2000), 2000.
[122] N. F. Noy and C. Hafner. The state of art in ontology design. AIMagazine, 3(18):53–74, 1997.
[123] N. F. Noy and D. L. McGuinness. Ontology devel-opment 101: A guide to creating your first ontology.Technical report, SMI-2001-0880, 2001. ”http://smi-web.stanford.edu/pubs/SMI Abstracts/SMI-2001-0880.html”.
[124] N. F. Noy and M. A. Musen. Prompt: algorithm and tool for au-tomated ontology merging and alignment. In Proceeding of Seven-teenth National Conference on Artificial Intelligence (AAAI-2000), 2000.
[125] N. F. Noy and M. A. Musen. Evaluating ontology-mapping tools:Requirements and experience. In n the Proceedings of the Workshopon Evaluation of Ontology Tools at EKAW’02 (EON2002), Siguenza,Spain, 2002.

BIBLIOGRAPHY 215
[126] N. F. Noy, M. Sintek, S. Decker, M. Crubezy, R. W. Fergerson, andM. A. Musen. Creating semantic web contents with protege-2000.IEEE Intelligent Systems, 16(2):60–71, 2001.
[127] J. J. Odell, H. van Dyke Parunak, and B. Bauer. Representingagent interaction protocols in uml. In M. Wooldridge, editor, Agentoriented software engineering, pages 121–140. Springer LNCS 1957,2001.
[128] J. M. Olivares-Ceja and A. Guzman-Arenas. Concept similaritymeasures the understanding between two agents. In Proceedingsof the 9th International Conference on Applications of Natual Languageto Information Systems (NLDB’04), Manchester, UK, June 23-25 2004.Springer.
[129] B. Omelayenko. Integrating vocabularies: Discovering and rep-resenting vocabulary maps. In Proceeding of the first semantic webconference (ISWC-2002). Springer-Verlag LNCS 2342, 2002.
[130] OWL. Web ontology language reference,http://www.w3.org/tr/owl-ref/.
[131] L. Palopoli, D. Sacca, G. Terracina, and D. Ursino. A unified graph-based framework for deriving nominal interschema properties,type conflicts and object cluster similarities. In Proceedings of 4thInternational Conference on Cooperative Information Systems (CoopIS),pages 34–45. IEEE Computer Society, 1999.
[132] L. Palopoli, G. Terracina, and D. Ursino. The system dike: Towardsthe semi-automatic synthesis of cooperative information systemsand data warehouses. In ADBIS-DASFAA Symposium 2000, pages108–117. Matfyz Press, 2000.
[133] M. Paolucci, N. Srinivasan, K. Sycara, and T. Nishimura. Towarda semantic choreography of web services: From wsdl to daml-s.In Proceedings of the First International Conference on Web Services(ICWS’03), pages 22–26, Las Vegas, Nevada, USA, June 2003.
[134] M. F. Porter. An algorithm for suffix stripping. In Readings in Infor-mation Retrieval. Morgan Kaufmann, 1997.
[135] E. Rahm and P. A. Bernstein. A survey of approaches to automaticschema matching. The VLDB Journal, 10:334–350, 2001.

216 BIBLIOGRAPHY
[136] P. Resnik. Wordnet and distributionaly analysis: A class-based ap-proach to lexical discovery. In Statistically-based Natural LanguageProcessing Techniques: Papers from the 1992 AAAI Workshop. AAAIPress, 1992.
[137] RML. Referent modelling languagehttp://www.idi.ntnu.no/ ppp.
[138] G. Salton. Automatic Text Processing. Addison-Wesley PublishingCompany, 1988.
[139] G. Salton and C. Buckley. Term-weighting appraoches in automaticretrieval. Information Processing & Management, 24(5):513–523, 1988.
[140] G. Salton and C. Buckley. Term weighting approaches in automatictext retrieval. Information Processing and Management, 32(4):431–443,1996.
[141] G. Salton and M. E. Lesk. Conputer evaluation of indexing and textprocessing. Journal of the ACM, 15(1):8–36, 1968.
[142] G. Salton and M. J. McGill. An Introduction to Modern InformationRetrieval. McGraw-Hill, 1983.
[143] A. Seltveit. Complexity Reduction in Information Systems Modelling.PhD thesis, Norwegian University of Science and Technology, 1994.
[144] A. Sheth and J. Larson. Federated database systems for manag-ing distributed, heterogeneous, and autonomous databases. ACMComputer Survey, 22(3), 1990.
[145] G. Sindre. HICONS: A General Diagrammatic Framework for Hierar-chical Modelling. PhD thesis, Norwegian University of Science andTechnology, 1990.
[146] B. Smith. Basic concepts of formal ontologies. In Proceedings ofFormal Ontologies in Information Systems. IOS Press, 1998.
[147] B. Smith. Ontologies and information systems, 2003.
[148] A. Sølvberg. Data and what they refer to. In P. P. Chen, editor,Concept Modeling: Historical Perspectives and Future Trends. SpringerVerlag, 1998.

BIBLIOGRAPHY 217
[149] A. Sølvberg. Intorduction to concept modellng for information sys-tems, 2002.
[150] J. F. Sowa. Ontology, metadata, and semiotics. In B. Ganter andG. W. Mineau, editors, Proceedings of ICCS’2000: Conceptual Struc-tures: Logical, Linguistic, and Computational Issues, Darmstadt, Ger-many, August 2000. Springer.
[151] J. F. Sowa. Guided tour of ontologyhttp://www.jfsowa.com/ontology/guided.htm. 2002.
[152] S. Staab, J. Angele, S. Decker, M. Erdmann, A. Hotho, A. Maedche,R. Studer, and Y. Sure. Semantic community web portals. In Pro-ceedings of the 9th World Wide Web Conference, Amsterdam, Nether-lands, 2000.
[153] H. Stuckenschmidt. Ontology-based Information Sharing in WeaklyStructured Environments. PhD thesis, Vrije Universiteit Amsterdam,2003.
[154] G. Stumme and A. Maedche. Fca-merge: Bottom-up merging ofontologies. In Proceedings of the International Joint Conference on Ar-tificial Intelligence IJCAI01., Seattle, USA, 2001.
[155] X. Su. Improving semantic interoperability through analysis ofmodel extension. In Proceeding of CAiSE’03 Doctoral Consortium,Velden, Austria, 2003.
[156] X. Su. Ontology mapping through analysis of model extension. InProceeding of the CAiSE Forum 2003, 2003.
[157] X. Su and J. A. Gulla. Semantic enrichment for ontolog mapping. InProceeding of the 9th International Conference on Applications of Natu-ral Language to Information System (NLDB’04), Manchestr, UK, 2004.Springer.
[158] X. Su, S. Hakkarainen, and T. Brasethvik. Semantic enrichmentfor improving systems interoperability. In Proceeding of the 2004ACM Symposium on Applied Computing, pages 1634–1641, Nicosia,Cyprus, 2004. ACM Press.

218 BIBLIOGRAPHY
[159] X. Su and L. Ilebrekke. A comparative study of ontology lan-guages and tools. In Proceeding of the Seventh IFIP-WG8.1 Interna-tional Workshop on Evaluating of Modeling Methods in Systems Analy-sis and Design (EMMSAD’02), 2002.
[160] X. Su and L. Ilebrekke. Using a semiotic framework for a compar-ative study of ontology languages and tools. In T. H. J. Krogstieand K. Siau, editors, Information Modeling Methods and Methodolo-gies. IDEA Group Publishing, 2004.
[161] X. Su, M. Matskin, and J. Rao. Implementing explanation ontol-ogy for agent system. In Proceeding of the 2003 IEEE/WIC Interna-tional Conference on Web Intelligence (WI 2003). IEEE Computer So-ciety Press, 2003.
[162] Y. Sure, A. Maeche, and S. Staab. Leveraging coporate skill knowl-edge - from proper to ontoproper. In Proceedings of the Third In-ternational Conference on Practical Aspects of Knowledge Management,Basel, Switzerland, October 2000.
[163] Y. Sure and R. Studer. On-to-knowledge methodology final ver-sion. Technical report, On-To-Knowledge Deliverable 18, 2002.
[164] K. Sycara, M. Paolucci, A. Ankolekar, and N. Srinivasan. Auto-mated discovery, interaction and composition of semantic web ser-vices. Journal of Web Semantics, 1(1), September 2003.
[165] H. Traetteberg. Model-based User Interface Design. PhD thesis, Nor-wegian University of Science and Technology, 2002.
[166] M. Uschold and M. Gruninger. Ontologies: principles, methodsand applications. Knowledge Engineering Review, 11(2), 1996.
[167] M. Uschold and R. Jasper. A framework for understanding andclassifying ontology applications. In Proceedings of the IJCAI99Workshop on Ontologies and Problem-Solving Methods(KRR5), Swe-den, 1999.
[168] A. Valente, T. Russ, R. MacGrecor, and W. Swartout. Building and(re)using an ontology for air campaign planning. IEEE IntelligentSystems, 14(1):27–36, 1999.

BIBLIOGRAPHY 219
[169] P. Visser and T. Bench-Capon. On the reusablity of ontologies inknowledge-system design. In Proceeding of the seventh InternationalWorkshop on Database and Expert Systems Applications, pages 256–261, 1996.
[170] P. Visser, D. M. Jones, T. Bench-Capon, , and M. Shave. An analysisof ontological mismatches: Heterogeneity versus interoperability.In AAAI 1997 Spring Symposium on Ontological Engineering, Stan-ford, USA, 1997.
[171] P. Visser, D. M. Jones, T. Bench-Capon, and M. Shave. Assessingheterogeneity by classifying ontology mismatches. In Proceedings ofthe International Conference on Formal Ontology in Information Systems(FOIS98), Trento, Italy, 1998.
[172] E. M. Vorhees. The philosophy of retrieval evaluation. In Proceed-ings of the Workshop of the Cross-Language Evaluation Forum, 2001.
[173] E. M. Vorhees and D. M. Tice. The trec-8 question answering trackevaluation. Technical report, NIST special publication, 1999.
[174] G. Wiederhold. An algebra for ontology composition. In Proceed-ings of 1994 Monterey Workshop on Formal Methods, pages 56–61, CA,USA, 1994.
[175] G. Willumsen. Executable Conceptual Models in Information SystemsEngineering. PhD thesis, Norwegian University of Science andTechnology, 1993.
[176] M. Wilson and B. Matthews. Migrating thesauri to the semanticweb. ERCIM news, october 2002.