scrapy workshop
TRANSCRIPT


Karthik Ananth
Who am I?
● Leading professional services @ Scrapinghub● I have vision to synergise data generation and analytics
● Open source promoter

APIs
Why Web Scraping
Semantic web

What is Web Scraping
The main goal in scraping is to extract structured data from unstructured sources, typically, web pages.

What for
● Monitor prices● Leads generation● Aggregate information● Your imagination is the limit

Do you speak HTTP?
Headers, Query String
Status Codes
Methods
Persistence
GET, POST, PUT, HEAD…
2XX, 3XX, 4XX, 418 , 5XX, 999
Accept-language, UA*…
Cookies

Standard Library
HTTP for humans
Let’s perform a request
urllib2
python-requests

import requests
req = requests.get('http://scrapinghub.com/about/')
Show me the code!
What now?

HTML is not a regular language

lxml pythonic binding for the C libraries libxml2 and libxslt
beautifulsoup html.parser, lxml, html5lib
HTML Parsers

import requestsimport lxml.htmlreq = requests.get(‘http://nyc2015.pydata.org/schedule/') tree = lxml.html.fromstring(req.text)for tr in tree.xpath('//span[@class="speaker"]'): name = tr.xpath('text()') url = tr.xpath('@href') print name print url
Show me the code!

“Those who don't understand xpath are cursed to reinvent it, poorly.”

Scrapy-ify early on

“An open source and collaborative framework for extracting the data you need from websites. In a fast, simple, yet extensible way.”

$ conda install -c scrapinghub scrapy

$ scrapy shell <url>
An interactive shell console
Invaluable tool for developing and debugging your spiders

An interactive shell console
>>> response.url
'http://example.com'
>>> response.xpath('//h1/text()')
[<Selector xpath='//h1/text()' data=u'Example Domain'>]
>>> view(response) # open in browser
>>> fetch('http://www.google.com') # fetch other URL
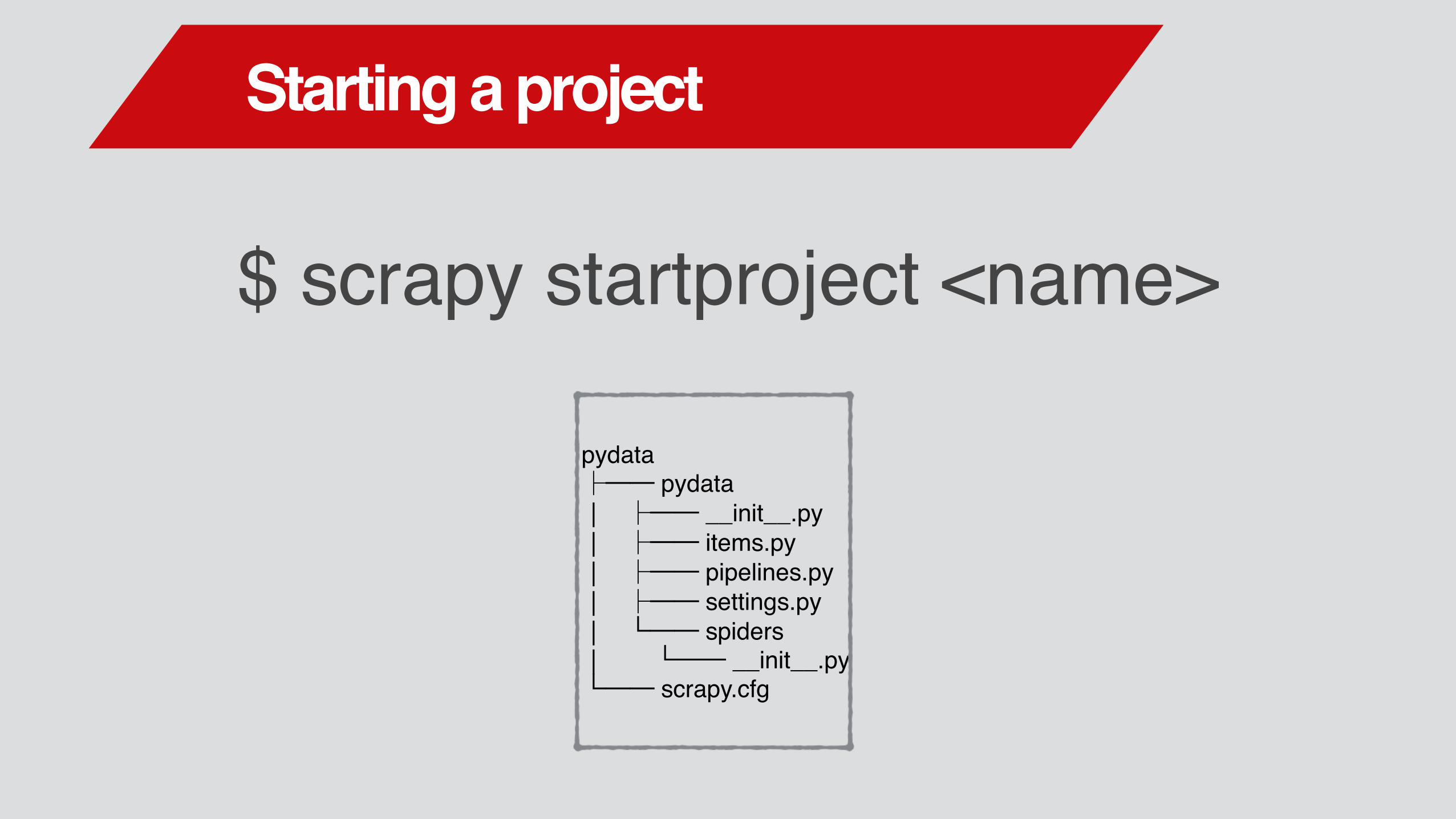
$ scrapy startproject <name>
pydata├── pydata│ ├── __init__.py│ ├── items.py│ ├── pipelines.py│ ├── settings.py│ └── spiders│ └── __init__.py└── scrapy.cfg
Starting a project

What is a spider

import scrapy
class MySpider(scrapy.Spider): name = 'example.com' allowed_domains = ['example.com'] start_urls = [ 'http://www.example.com/', ]
def parse(self, response): msg = 'A response from %s just arrived!' % response.url self.logger.info(msg)
What is a Spider?

import scrapy
class MySpider(scrapy.Spider): name = 'example.com' allowed_domains = ['example.com'] start_urls = [ ‘http://www.example.com/' ]
def parse(self, response): for h3 in response.xpath(‘//h3/text()’).extract(): yield {‘title’: h3}
for url in response.xpath('//a/@href').extract(): yield scrapy.Request(url, callback=self.parse)
What is a Spider? 1.0

Batteries included
● Logging● Stats collection● Testing: contracts● Telnet console: inspect a Scrapy process

Avoid getting banned
● Rotate your User Agent● Disable cookies● Randomized download delays● Use a pool of rotating IPs● Crawlera

A service daemon to run Scrapy spiders
$ scrapyd-deploy
Deployment 1.0
scrapyd

Scrapy Cloud
$ shub deploy

TONS of Open SourceFully remote distributed team
About us

Mandatory Sales Slide
try.scrapinghub.com/pydatanyc
Crawl the web, at scale• cloud-based platform
• smart proxy rotator
Get data, hassle-free• off-the-shelf datasets
• turn-key web scraping

We’re hiring!

Thanks