satoshi imamura hiroshi sasaki naoto fukumoto koji inoue kazuaki murakami kyu shu university
DESCRIPTION
Optimizing Power-Performance Trade-off for Parallel Applications through Dynamic Core and Frequency Scaling. Satoshi Imamura Hiroshi Sasaki Naoto Fukumoto Koji Inoue Kazuaki Murakami Kyu shu University. Many-core Processors. Multi-core processor is currently mainstream - PowerPoint PPT PresentationTRANSCRIPT

Optimizing Power-Performance Trade-off
for Parallel Applications throughDynamic Core and Frequency Scaling
Satoshi Imamura Hiroshi Sasaki Naoto FukumotoKoji Inoue Kazuaki Murakami
Kyushu University
1

Many-core Processors• Multi-core processor is currently mainstream• Core counts on a chip increase as technology size shrinks• Many-core processor era is coming
o 10s and 100s of cores on a chipo Execute a multi-threaded program for high performance
2
TILERA ”TILE-Gx100” ブロック図http://www.tilera.com/products/processors/TILE-Gx_Family

Challenge of Many-core
• Demand for low power consumptiono Ex: Large scale data centers• Reduce peak power consumption by power
capping
3
Programs need to be efficiently executed
under power consumption constraint

Two Knobs to Determine Performance
• CPU frequency & the number of cores
• Characteristics of multi-threaded programs differ among/within programs
• Sensitivity to CPU frequency• Parallelism
4
Need to choose the proper configurationaccording to the kind of programs and their
behaviors

Experimental Environment
5
Configuration of processor
Processor AMD Opteron 6136
Number of cores
8
L1 I/D cacheL2 cacheShared L3 cache
128 KB512 KB12 MB
Main memory 16 GB (DDR3-1333)
Bus speed 6.4 GT/s
Technology size 45 nm
CPU0 CPU1
CPU2 CPU3
32-core AMD four socket system
C0 C1 C2 C3L2 L2 L2 L2
Shared L3Memory controller
Number of
cores
CPU frequency
[GHz]
Supply voltage
[V]
1 – 5 2.4 1.30
6 – 8 1.9 1.21
9 – 12 1.5 1.13
13 – 19 1.1 1.04
20 – 32 0.8 0.95
Conventional execution & Power constraint:The power when all 32 cores run on 0.8 GHz

Characteristics among
Programs
6
1 4 8 12 16 24 320
5
10
15
20
25
30
35 0.8GHz 1.1GHz1.5GHz 1.9GHz2.4GHz
Number of cores
No
rmali
zed
per-
form
an
ce
1 4 8 12 16 24 320
5
10
15
20
0.8GHz1.1GHz1.5GHz
Number of cores
No
rmali
zed
Per-
form
an
ce
1 4 8 12 16 24 320
1
2
3
4
5
0.8GHz 1.1GHz1.5GHz 1.9GHz2.4GHz
Number of cores
No
rmali
zed
per-
form
an
ce
blackscholes
x264
dedup

Characteristics within a Program
7IPS : Instructions Per Second
1 2 3 4 50
5000000000
10000000000
15000000000
20000000000
25000000000
[email protected] [email protected] [email protected]@1.1GHz [email protected]
Execution loops
IPS
4 8 12 16 32
4 8 12 16 32
4 8 12 16 32
4 8 12 16 32
4 8 12 16 32
bett
er

Our Goal
• Maximize performance of parallel programs on many-core under power consumption constrainto Variety of characteristics among/within programs
• Sensitivity to CPU frequency• Scalability to core counts
o Choose the optimal trade-off point between core counts and CPU frequency dynamically
8

Overview of DCFS(Dynamic Core and Frequency Scaling)• Optimize core counts and CPU frequency
dynamically according to characteristics of programo High parallelism
• Parallel processing with the maximum available core countso Medium/low parallelism
• Restrict the number of active cores• Reallocate the power budget to increase CPU frequency
91 4 8 16 24 32
0
5
10
15
20
25
30
35
0.8GHz
1.1GHz
Number of cores
No
rmali
zed
per-
form
an
ce
blackscholes
1 4 8 16 24 320
1
2
3
4
5
0.8GHz1.1GHz
Number of cores
No
rmali
zed
per-
form
an
ce
dedup

DCFS Algorithm• Two phases
o In Training phase• Change the configuration of core counts and CPU
frequency periodically• Measure IPS during execution with each configuration• Estimate the optimal configuration using measured
IPS
o In Execution phase• Execute with the optimal configuration• Detect behavior changes of executed program
10Execution time
Execution phase
Training Phase
Execution phase
Execution phase
Execution phase
Execution phase

How to find the best configuration
• Find the best core counts for each CPU frequencyo Decrement core counts until IPS declines
• Select the configuration with the highest IPS
11
1 4 8 12 16 24 320
5
10
15
20
0.8GHz 1.1GHz1.5GHz 1.9GHz2.4GHz
Number of cores
Norm
ali
zed
Per-
form
an
ce
x264

Evaluation Result
12
• DCFS-3, DCFS-10:o Our proposed technique without detecting behavior changeso Execution with the configuration estimated in Training phase
for constant 3 or 10 seconds
• DCFS-WD:o Our proposed technique with detecting behavior changes
blac
ksch
oles
swap
tions
vips
ferr
et
cann
eal
stre
amcl
u...
freq
min
ex2
64
body
trac
k
dedu
p
geom
ean
Avg.
0
0.5
1
1.5
2
[email protected] DCFS-3 DCFS-10 DCFS-WD
No
rmali
zed
perf
orm
an
ce High
parallelismMiddle/low parallelism

Evaluation Result
13
• Almost no performance improvement for high parallelism programso Execution with all cores maximizes performanceo Performance degradation due to overhead of Training
phase
blac
ksch
oles
swap
tions
vips
ferr
et
cann
eal
stre
amcl
u...
freq
min
ex2
64
body
trac
k
dedu
p
geom
ean
Avg.
0
0.5
1
1.5
2
[email protected] DCFS-3 DCFS-10 DCFS-WD
No
rmali
zed
perf
orm
an
ce High
parallelismMiddle/low parallelism

Evaluation Result
14
blac
ksch
oles
swap
tions
vips
ferr
et
cann
eal
stre
amcl
u...
freq
min
ex2
64
body
trac
k
dedu
p
geom
ean
Avg.
0
0.5
1
1.5
2
[email protected] DCFS-3 DCFS-10 DCFS-WD
No
rmali
zed
perf
orm
an
ce High
parallelismMiddle/low parallelism
• Almost no performance improvement despite of middle/low parallelismo Two most memory-bound programs in PARSEC*o Small performance improvement by increasing CPU
frequency* Bienia, C. et al, “PARSEC vs. SPLASH-2: A quantitative comparison of two multithreaded benchmark suites on chip-multiprocessors”, IISWC 2008.
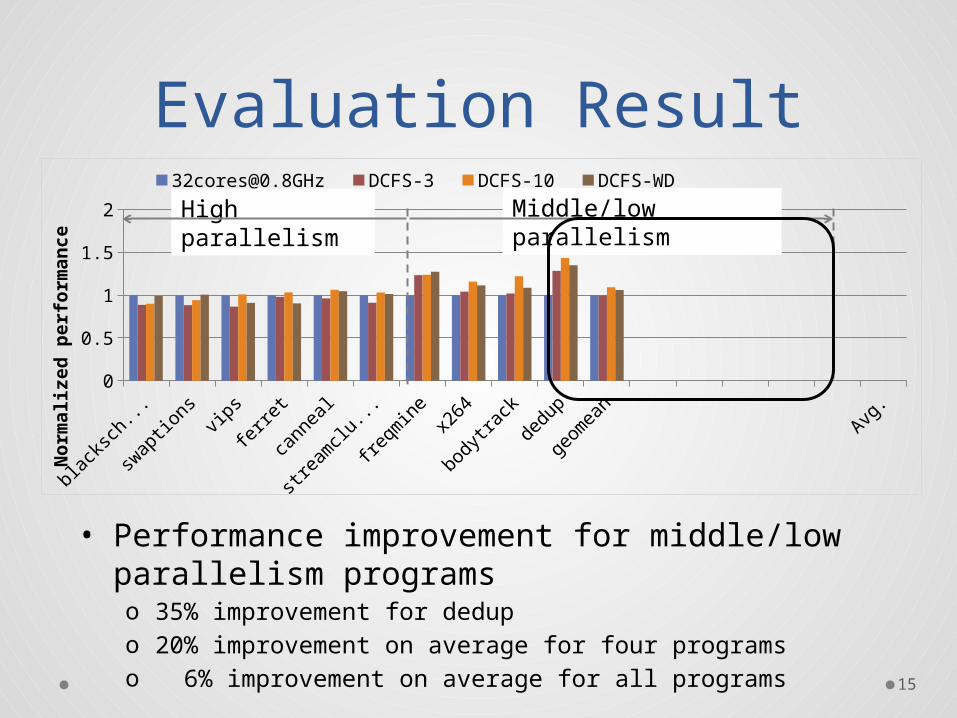
Evaluation Result
15
blac
ksch
oles
swap
tions
vips
ferr
et
cann
eal
stre
amcl
u...
freq
min
ex2
64
body
trac
k
dedu
p
geom
ean
Avg.
0
0.5
1
1.5
2
[email protected] DCFS-3 DCFS-10 DCFS-WD
No
rmali
zed
perf
orm
an
ce High
parallelismMiddle/low parallelism
• Performance improvement for middle/low parallelism programso 35% improvement for dedupo 20% improvement on average for four programso 6% improvement on average for all programs

Conclusions• Challenge of many-core processors
o Maximizing performance under power constraint
• Proposed technique: DCFSo Optimize core counts and CPU frequency dynamicallyo Detect behavior changes of executed program
• Evaluationo Max 35% performance improvement
• 6% performance improvement for ten benchmarkso No performance improvement for high parallelism
and memory-bound programs
16

Future Work• Improve the algorithm of our technique to
find the best configuration and to detect behavior changes
• Evaluate under different power consumption constraints
• Evaluate on different platforms
17

Thank you for your attention.
I would appreciate if you could
ask me questions slowly.
18

19
1 2 3 4 5 6 7 8 9 10 11 120
1
2
3
4
5
6
7
1 2 3 4 5 6 7 8 9 10 11 120
0.51
1.52
2.53
3.54
4.5
1 2 3 4 5 6 7 8 9 10 11 120
2
4
6
8
10
12
1 2 3 4 5 6 7 8 9 10 11 120
0.51
1.5
22.5
33.5
1 2 3 4 5 6 7 8 9 10 11 120
2
4
6
8
10
1 2 3 4 5 6 7 8 9 10 11 120
2
4
6
8
10
12
blackscholes
bodytrack
canneal
dedup
ferret
freqmine

1 2 3 4 5 6 7 8 9 10 11 120
0.51
1.52
2.53
3.54
4.55
1 2 3 4 5 6 7 8 9 10 11 120
2
4
6
8
1 2 3 4 5 6 7 8 9 10 11 120
0.51
1.52
2.53
3.54
4.55
1 2 3 4 5 6 7 8 9 10 11 120
2
4
6
8
10
12
streamcluster
swaptions
vips x264

Backup Slides
21

Experimental Environment
22
Configuration of processor
Processor AMD Opteron 6136
Number of cores 8
L1 I/D cacheL2 cacheShared L3 cache
128 KB512 KB12 MB
Main memory 16 GB (DDR3-1333)
Bus speed 6.4 GT/s
Technology size 45 nm
CPU0 CPU1
CPU2 CPU3
32-core AMD four socket system C0 C1 C2 C3
L2 L2 L2 L2
Shared L3Memory controller

Power Constraint Assumption
• Power consumption constraint ( ):o The power when all cores run on minimum available CPU frequency
• Max CPU frequency is decided by core counts under
23
intconstraP
Number of
cores
CPU frequency
[GHz]
Supply voltage
[V]
1 – 5 2.4 1.30
6 – 8 1.9 1.21
9 – 12 1.5 1.13
13 – 19 1.1 1.04
20 – 32 0.8 0.95
Conventional execution
intconstraP

How to Determine Max CPU
Frequency• The Power consumption constraint
• The power consumption when N cores run
• Choose maximum CPU frequency and supply voltage according to this inequation in each core count
24
2minminint VfCNaP allcoresconstra
: The switching activity of the circuit, : Total number of cores, : Capacitance per core, : Minimum operating frequency, : Minimum supply voltage
aallcoresN
C minfminV
2VfCNaP coresNcores
12minmin
2
int
VfN
VfN
P
P
allcores
cores
constra
Ncores

Implementation of DCFS• Training phase
o Change the configuration periodicallyo Execute with each configuration for a short period
(“Training period”)o Measure IPS as indicator of performanceo Compare measured IPS to estimate the optimal
configuration
• Execution phaseo Execute with the optimal configurationo Measure IPS periodically to detect phase changes of
program
• No need of static analysis and modification of programs 25

Detail Implementation of DCFS
• Periodical reading performance counterso Use Linux “perf-tools”
• Thread allocation to the specified coreo Use Linux standard API “sched_setaffinity(2)”
• Training period: 30 ms
• Measure IPS every 1 second to detect phase changeso IPS increases or decreases by more than 10%
26

The Way to Change Core Counts
• Use “Thread Packing*” o Change core counts while the number of threads
is constanto No need to modify source codes
⇒ Easy implementation
27*Cochran, R. et al, “Pack & Cap: Adaptive DVFS and Thread Packing Under Power Caps”, Micro, 2011
Core Core Core Core
Thread
Thread
Thread
Thread
Idle Core Idle Idle
Thread
Thread
Thread
Thread
Core Core Core Core
Thread
Thread
Thread
Thread
Idle Core Idle Idle
Thread
Thread
Thread
Thread
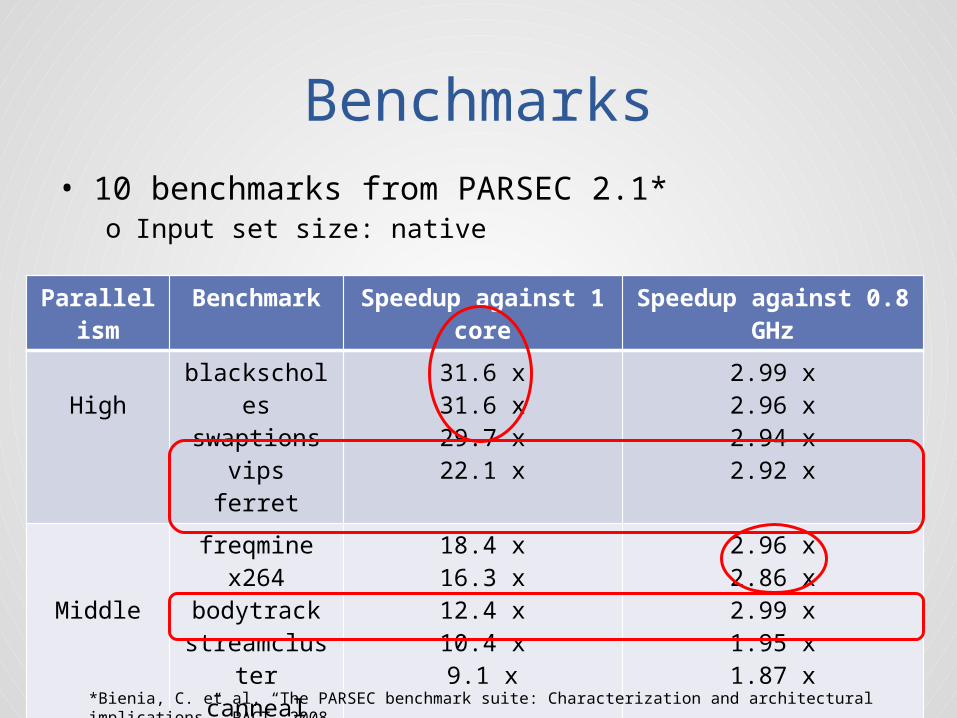
Benchmarks• 10 benchmarks from PARSEC 2.1*
o Input set size: native
28
Parallelism
Benchmark
Speedup against 1 core
Speedup against 0.8 GHz
Highblackschole
sswaptions
vipsferret
31.6 x31.6 x29.7 x22.1 x
2.99 x2.96 x2.94 x2.92 x
Middle
freqminex264
bodytrackstreamclust
ercanneal
18.4 x16.3 x12.4 x10.4 x9.1 x
2.96 x2.86 x2.99 x1.95 x1.87 x
Low dedup 3.1 x 2.86 x*Bienia, C. et al, “The PARSEC benchmark suite: Characterization and architectural implications”, PACT, 2008

Analysis of canneal & streamclster
• Two most memory-bound programs in PARSEC*o Small performance improvement by increasing CPU frequency
29* Bienia, C. et al, “PARSEC vs. SPLASH-2: A quantitative comparison of two multithreaded benchmark suites on chip-multiprocessors”, IISWC 2008.
1 4 8 12 16 24 320123456789
10
0.8GHz
1.1GHz
1.5GHz
1.9GHz
2.4GHz
Number of cores
No
rmali
zed
per-
form
an
ce
1 4 8 12 16 24 320
2
4
6
8
10
12
0.8GHz 1.1GHz1.5GHz 1.9GHz2.4GHz
Number of cores
No
rmali
zed
per-
form
an
ce
canneal
streamcluster
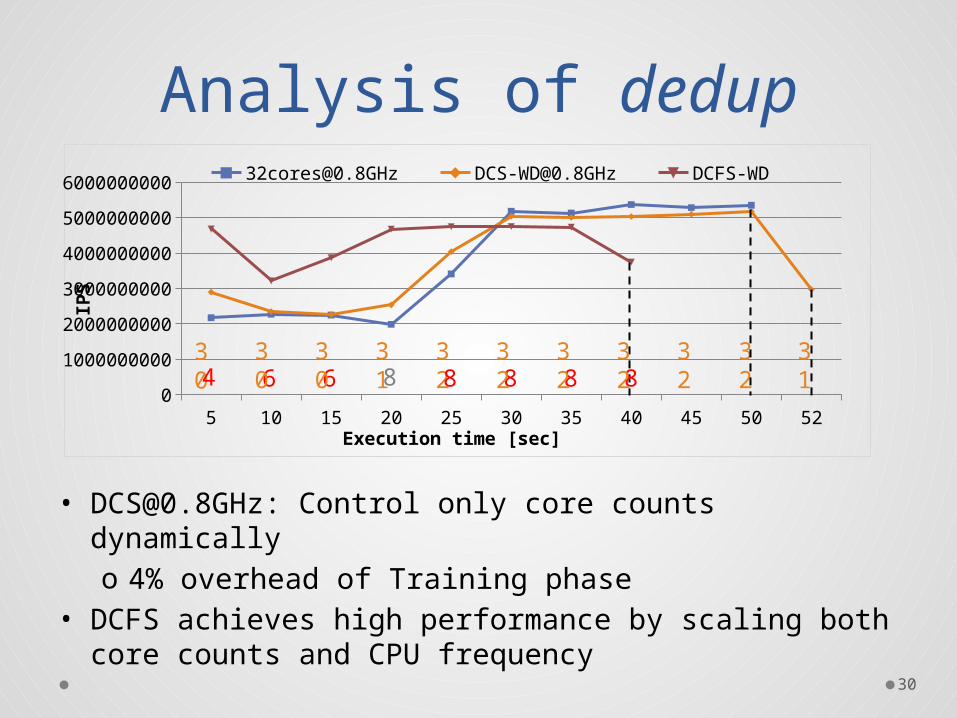
Analysis of dedup
• [email protected]: Control only core counts dynamicallyo 4% overhead of Training phase
• DCFS achieves high performance by scaling both core counts and CPU frequency
30
5 10 15 20 25 30 35 40 45 50 520
1000000000
2000000000
3000000000
4000000000
5000000000
6000000000 [email protected] [email protected] DCFS-WD
Execution time [sec]
IPS
30
31
32
314 6 6 8 8 8 8 8
30
30
32
32
32
32
32

Experiment Environment (Xeon)
31
Configuration of the processor
Processor Intel Xeon X5670
Number of processorsNumber of cores per processorTotal available number of cores
26
12 (2 × 6)
L1 I/D cacheL2 cacheShared L3 cache
32 KB256 KB12 MB
Main memory 16 GB (DDR3-1333)
Bus speed 6.4 GT/s
Technology size 32 nm

Maximum CPU Frequency and Supply
Voltage for Each Core Counts (Xeon)
32
Number of cores
CPU frequency
[GHz]
Supply voltage [V]
1, 2 2,927 1.350
3 2.527 1.132
4 2.261 1.023
5 2.218 0.968
6 1.995 0.914
7 1.862 0.859
8, 9 1.729 0.805
10 - 12 1.596 0.750

Evaluation Result (Xeon)
• Performance decrement for all programs except swaptionso Great or moderate scalability
• All 12 cores execution maximizes the performance⇒ Performance decrement due to overhead of Training phase
o For swaptions: High performance only when executed with power of two core counts⇒ Execution with eight cores maximizes the performance
33
blac
ksch
oles
swap
tions
vips
ferr
et
cann
eal
stre
amcl
u...
freq
min
ex2
64
body
trac
k
dedu
p
geom
ean
0
0.2
0.4
0.6
0.8
1
1.2
[email protected] DCFS-3 DCFS-10 DCFS-WD
No
rmali
zed
perf
orm
an
ce

Analysis of ferret
• Performance improvement by increasing core countso Execution with all cores maximizes performanceo Performance degradation due to overhead of Training phase
34
1 4 8 16 24 320
5
10
15
20
25
0.8GHz
1.1GHz
1.9GHz
2.4GHz
Number of cores
Norm
ali
zed
per-
form
an
ce

35
CPU0 CPU1
CPU2 CPU3
64 コア AMD 4 ソケットシステム
C0 C1 C7L2 L2 L2
共有 L3 キャッシュメモリコントローラ
・・・・・・

36
コア
スレッド
Idle Core Idle Idle
Thread
Thread
Thread
Thread
Idle Core Idle Idle
Thread
Thread
Thread
Thread
スレッド
スレッド
スレッド
スレッド
スレッド
スレッド
スレッド
コア コア コア コア コア コア コア
休止
スレッド
スレッド
スレッド
スレッド
スレッド
スレッド
スレッド
スレッド
コア 休止 休止 休止 コア 休止 休止