revision for midterm 3 part 3 prof. sin-min lee department of computer science
Post on 19-Dec-2015
215 views
TRANSCRIPT

Revision for Midterm 3 Part 3
Prof. Sin-Min Lee
Department of Computer Science


Set Operators
• Relation is a set of tuples, so set operations should apply: , , (set difference)
• Result of combining two relations with a set operator is a relation; hence all its elements must be tuples having the same structure
• Hence, scope of set operations limited to union compatible relationsunion compatible relations

Union Compatible Relations
• Two relations are union compatibleunion compatible if– Both have same number of columns– Names of attributes are the same in both– Attributes with the same name in both relations
have the same domain
• Union compatible relations can be combined using unionunion, intersectionintersection, and setset differencedifference

ExampleTables: PersonPerson (SSN, Name, Address, Hobby) ProfessorProfessor (Id, Name, Office, Phone)are not union compatible. But Name (PersonPerson) and Name (ProfessorProfessor)
are union compatible so
Name (PersonPerson) - Name (ProfessorProfessor)
makes sense.

Cartesian Product• If RR and SS are two relations, RR SS is the set of all
concatenated tuples <x,y>, where x is a tuple in RR and y is a tuple in S S (but see naming problem next)(but see naming problem next)
• RR SS is expensive to compute:– Factor of two in the size of each row– Quadratic in the number of rows
A B C D A B C D x1 x2 y1 y2 x1 x2 y1 y2 x3 x4 y3 y4 x1 x2 y3 y4 x3 x4 y1 y2 RR SS x3 x4 y3 y4 RR SS

Renaming in Cartesian ProductResult of expression evaluation is a relation.
Attributes of relation must have distinct names.
So what do we do if they don’t?E.g., suppose R(A,B) and S(A,C)
and we wish to compute RR SS .
One solution is to rename the attributes of the answer:
RR S( R.A, R.B, S.A, S.C)S( R.A, R.B, S.A, S.C)
Although onlyAlthough only A A needs to be renamed, it is“cleaner” to needs to be renamed, it is“cleaner” to rename them all.rename them all.

Renaming Operator• Previous solution is used whenever possible but it
won’t work when R is the same as S.
• Renaming operator resolves this. It allows to assign any desired names, say A1, A2,… An , to the attributes of the n column relation produced by expression expr with the syntax
expr [A1, A2, … An]

Example
This is a relation with 4 attributes: StudId, CrsCode1, ProfId, CrsCode2
TranscriptTranscript (StudId, CrsCode, Semester, Grade)
TeachingTeaching (ProfId, CrsCode, Semester)
StudId, CrsCode (TranscriptTranscript)[StudId, CrsCode1]
ProfId, CrsCode(TeachingTeaching) [ProfId, CrsCode2]

Derived Operation: Join
A (generalgeneral or thetatheta) join join of R and S is the expression R join-condition S
where join-condition is a conjunction of terms: Ai oper Bi
in which Ai is an attribute of R; Bi is an attribute of S; and oper is one of =, <, >, , .
The meaning is:
join-condition´ (R S)
where join-condition and join-condition´ are the same, except for possible renamings of attributes caused by the Cartesian product.

Theta Join – Example
Employee(Employee(Name,Id,MngrId,SalaryName,Id,MngrId,Salary) Manager(Manager(Name,Id,SalaryName,Id,Salary)
Output the names of all employees that earnmore than their managers.EmployeeEmployee.Name (EmployeeEmployee MngrId=Id AND Salary>Salary ManagerManager)
The join yields a table with attributes: EmployeeEmployee.Name, EmployeeEmployee.Id, EmployeeEmployee.Salary, Employee.MngrId
ManagerManager.Name, ManagerManager.Id, ManagerManager.Salary

Relational Algebra
• Relational algebra operations operate on relations and produce relations (“closure”)f: Relation -> Relation f: Relation x Relation
-> Relation• Six basic operations:
– Projection (R)– Selection (R)– Union R1 [ R2
– Difference R1 – R2
– Product R1 £ R2
– (Rename) (R)

Equijoin Join - Example
Name,CrsCode(StudentStudent Id=StudId Grade=‘A’ (TranscriptTranscript))
Id Name Addr Status111 John ….. …..222 Mary ….. …..333 Bill ….. …..444 Joe ….. …..
StudId CrsCode Sem Grade 111 CSE305 S00 B 222 CSE306 S99 A 333 CSE304 F99 A
Mary CSE306Bill CSE304
The equijoin is used veryfrequently since it combinesrelated data in different relations.
StudentStudent TranscriptTranscript
EquijoinEquijoin: Join condition is a conjunction of equalities.

Natural Join• Special case of equijoin + a special projection
– join condition equates all and only those attributes with the same name (condition doesn’t have to be explicitly stated)
– duplicate columns eliminated (projected out) from the result
TranscriptTranscript (StudId, CrsCode, Sem, Grade)Teaching (Teaching (ProfId, CrsCode, Sem)
TranscriptTranscript TeachingTeaching = StudId, Transcript.CrsCode, Transcript.Sem, Grade, ProfId
( TranscriptTranscript CrsCode=CrsCode AND Sem=Sem Sem Teaching Teaching ) [StudId, CrsCode, Sem, Grade, ProfId ]

Natural Join (cont’d)
• More generally:RR SS = attr-list (join-cond (RR × SS) )
where attr-list = attributes (RR) attributes (SS)(duplicates are eliminated) and join-cond has the form: A1 = A1 AND … AND An = An
where {A1 … An} = attributes(RR) attributes(SS)

Natural Join Example
• List all Ids of students who took at least two different courses:
StudId ( CrsCode CrsCode2 ( TranscriptTranscript
TranscriptTranscript [StudId, CrsCode2, Sem2, Grade2] )) We don’t want to join on CrsCode, Sem, and Grade attributes, hence renaming!
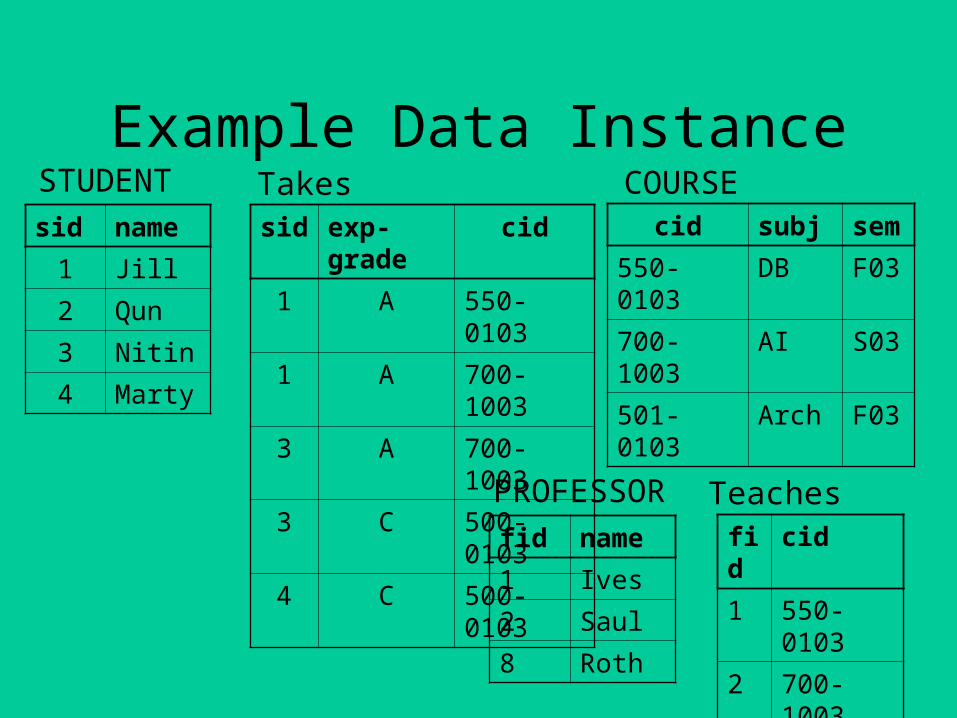
Example Data Instance
sid name
1 Jill
2 Qun
3 Nitin
4 Marty
fid name
1 Ives
2 Saul
8 Roth
sid exp-grade cid
1 A 550-0103
1 A 700-1003
3 A 700-1003
3 C 500-0103
4 C 500-0103
cid subj sem
550-0103 DB F03
700-1003 AI S03
501-0103 Arch F03
fid cid
1 550-0103
2 700-1003
8 501-0103
STUDENT Takes COURSE
PROFESSOR Teaches

Natural Join and IntersectionNatural join: special case of join where is implicit – attributes with same name must be equal:
STUDENT Takes ⋈ ´ STUDENT ⋈STUDENT.sid = Takes.sid Takes
Intersection: as with set operations, derivable from difference
A-B B-A
A B
A B

Division
• A somewhat messy operation that can be expressed in terms of the operations we have already defined
• Used to express queries such as “The fid's of faculty who have taught all subjects”
• Paraphrased: “The fid’s of professors for which there does not exist a subject that they haven’t taught”

Division Using Our Existing Operators
• All possible teaching assignments: Allpairs:
• NotTaught, all (fid,subj) pairs for which professor fid has not taught subj:
• Answer is all faculty not in NotTaught:
fid,subj (PROFESSOR £ subj(COURSE))
Allpairs - fid,subj(Teaches COURSE)⋈fid(PROFESSOR) - fid(NotTaught)
´ fid(PROFESSOR) - fid(fid,subj (PROFESSOR £ subj(COURSE)) -fid,subj(Teaches COURSE))⋈

Division: R1 R2
• Requirement: schema(R1) ¾ schema(R2)• Result schema: schema(R1) – schema(R2)• “Professors who have taught all courses”:
• What about “Courses that have been taught by all faculty”?
fid (fid,subj(Teaches ⋈ COURSE) subj(COURSE))

Division
• Goal: Produce the tuples in one relation, r, that match all tuples in another relation, s– rr (A1, …An, B1, …Bm)– ss (B1 …Bm)– rr/ss, with attributes A1, …An, is the set of all
tuples <a> such that for every tuple <b> in ss, <a,b> is in rr
• Can be expressed in terms of projection, set difference, and cross-product

Division (cont’d)

Division - Example• List the Ids of students who have passed all
courses that were taught in spring 2000• Numerator:
– StudId and CrsCode for every course passed by every student:
StudId, CrsCode (Grade ‘F’ (TranscriptTranscript) )
• Denominator:– CrsCode of all courses taught in spring 2000
CrsCode (Semester=‘S2000’ (TeachingTeaching) )
• Result is numerator/denominator

Relational Calculus
• Important features:– Declarative formal query languages for relational mode
l
– Based on the branch mathematical logic known as predicate calculus
– Two types of RC:• 1) tuple relational calculus
• 2) domain relational calculus
– A single statement can be used to perform a query

Tuple Relational Calculus
• based on specifying a number of tuple variables
• a tuple variable refers to any tuple

Generic Form
• {t | COND (t)} – where– t is a tuple variable and – COND(t) is Boolean expression involving t

Simple example 1
• To find all employees whose salary is greater than $50,000– {t| EMPLOYEE(t) and t.Salary>5000}
• where
• EMPLOYEE(t) specifies the range of tuple variable t
– The above operation selects all the attributes

Simple example 2
• To find only the names of employees whose salary is greater than $50,000– {t.FNAME, t.NAME| EMPLOYEE(t) and
t.Salary>5000}
• The above is equivalent to• SELECT T.FNAME, T.LNAME• FROM EMPLOYEE T• WHERE T.SALARY > 5000

Elements of a tuple calculus
• In general, we need to specify the following in a tuple calculus expression:– Range Relation (I.e, R(t)) = FROM– Selected combination= WHERE– Requested attributes= SELECT

More Example:Q0
• Retrieve the birthrate and address of the employee(s) whose name is ‘John B. Smith’
• {t.BDATE, t.ADDRESS| EMPLOYEE(t) AND t.FNAME=‘John’ AND t.MINIT=‘B” AND t.LNAME=‘Smith}

Formal Specification of tuple Relational Calculus
• A general format:• {t1.A1, t2.A2,…,tn.An |COND ( t1 ,t2 ,…, tn, tn+1,
tn+2,…,tn+m)}– where– t1,…,tn+m are tuple var
– Ai : attributeR(ti)– COND (formula)
• Where COND corresponds to statement about the world, which can be True or False

Elements of formula
• A formula is made of Predicate Calculus atoms:– an atom of the from R(ti)– ti.A op tj.B op{=, <,>,..}– F1 And F2 where F1 and F2 are formulas– F1 OR F2– Not (F1)– F’=(t) (F) or F’= (t) (F)
Y friends (Y, John) X likes(X, ICE_CREAM)
•

Example Queries Using the Existential Quantifier
• Retrieve the name and address of all employees who work for the ‘ Research ’ department
• {t.FNAME, t.LNAME, t.ADDRESS| EMPLOYEE(t) AND ( d) (DEPARTMENT (d) AND d.DNAME=‘Research’ AND d.DNUMBER=t.DNO)}

More Example
• For every project located in ‘Stafford’, retrieve the project number, the controlling department number, and the last name, birthrate, and address of the manger of that department.

Cont.
• {p.PNUMBER,p.DNUM,m.LNAME,m.BDATE, m.ADDRESS|PROJECT(p) and EMPLOYEE(M) and P.PLOCATION=‘Stafford’ and ( d) (DEPARTMENT(D) AND P.DNUM=d.DNUMBER and d.MGRSSN=m.SSN))}

Logical Equivalences
• There are two logical equivalences that will be heavily used:– pq p q
(Whenever p is true, q must also be true.) x. p(x) x. p(x)
(p is true for all x)
• The second can be a lot easier to check!

Normalization
Review on Keys • superkey: a set of attributes which will uniquely
identify each tuple in a relation• candidate key: a minimal superkey• primary key: a chosen candidate key• secondary key: all the rest of candiate keys• prime attribute: an attribute that is a part of a
candidate key (key column)• nonprime attribute: a nonkey column

Normalization
Functional Dependency Type by Keys • ‘whole (candidate) key nonprime attribute’: full
FD (no violation)• ‘partial key nonprime attribute’: partial FD
(violation of 2NF)• ‘nonprime attribute nonprime attribute’:
transitive FD (violation of 3NF)• ‘not a whole key prime attribute’: violation of
BCNF

Functional Dependencies• Let R be a relation schema
R and R
• The functional dependency
holds on R iff for any legal relations r(R), whenever two tuples t1 and t2
of r have same values for , they have same values for .
t1[] = t2 [] t1[ ] = t2 [ ]
• On this instance, A B does NOT hold, but B A does hold.
1 41 53 7
A B

1. Closure • Given a set of functional dependencies, F, its
closure, F+ , is all FDs that are implied by FDs in F.
• e.g. If A B, and B C,
• then clearly A C

Armstrong’s Axioms• We can find F+ by applying Armstrong’s Axioms:
– if , then (reflexivity)– if , then (augmentation)– if , and , then (transitivity)
• These rules are – sound (generate only functional dependencies that actually
hold) and – complete (generate all functional dependencies that hold).

Additional rules• If and , then (union)
• If , then and (decomposition)
• If and , then
(pseudotransitivity)
The above rules can be inferred from Armstrong’s
axioms.

Example• R = (A, B, C, G, H, I)
F = { A B A CCG HCG I B H}
• Some members of F+
– A H • by transitivity from A B and B H
– AG I • by augmenting A C with G, to get AG CG
and then transitivity with CG I
– CG HI • by augmenting CG I to infer CG CGI, and augmenting of CG H to infer CGI HI, and then transitivity

2. Closure of an attribute set• Given a set of attributes A and a set of FDs F, closure of A under F is
the set of all attributes implied by A
• In other words, the largest B such that:• A B• Redefining super keys:• The closure of a super key is the entire relation schema• Redefining candidate keys:• 1. It is a super key• 2. No subset of it is a super key

Computing the closure for A
• Simple algorithm
• 1. Start with B = A.
• 2. Go over all functional dependencies, , in F+
• 3. If B, then
• Add to B
• 4. Repeat till B changes

Example• R = (A, B, C, G, H, I)F = { A B
A CCG HCG I B H}
• (AG) + ?
• 1. result = AG
2. result = ABCG (A C and A B)
3. result = ABCGH (CG H and CG AGBC)
4. result = ABCGHI(CG I and CG AGBCH
Is (AG) a candidate key ?
1. It is a super key.
2. (A+) = BC, (G+) = G.
YES.

Uses of attribute set closures
• Determining superkeys and candidate keys
• Determining if A B is a valid FD• Check if A+ contains B
• Can be used to compute F+


Perform lossless-join decompositions of each of the following scheme into BCNF schemes: R(A, B, C, D, E) with dependency set {AB CDE, C D, D E}
A B C D A B C D
C D D EA B C E A B C D
C DD E A B C A B C

Given the FDs {B D, AB C, D B} and the relation {A, B, C, D}, give a two distinct lossless join decomposition to BNCF indicating the keys of each of the resulting relations.
A B C D
B D A B C
A B C D
B D A C D

Definition of MVD
• A multivalued dependency (MVD) X ->->Y is an assertion that if two tuples of a relation agree on all the attributes of X, then their components in the set of attributes Y may be swapped, and the result will be two tuples that are also in the relation.

Example
• The name-addr-phones-beersLiked example illustrated the MVD
name->->phones
and the MVD
name ->-> beersLiked.

Picture of MVD X ->->Y
X Y others
equal
exchange

MVD Rules
• Every FD is an MVD.– If X ->Y, then swapping Y ’s between two tuples that
agree on X doesn’t change the tuples.– Therefore, the “new” tuples are surely in the
relation, and we know X ->->Y.
• Complementation : If X ->->Y, and Z is all the other attributes, then X ->->Z.



Fourth Normal Form
• The redundancy that comes from MVD’s is not removable by putting the database schema in BCNF.
• There is a stronger normal form, called 4NF, that (intuitively) treats MVD’s as FD’s when it comes to decomposition, but not when determining keys of the relation.

4NF Definition
• A relation R is in 4NF if whenever X ->->Y is a nontrivial MVD, then X is a superkey.
– “Nontrivial means that:1. Y is not a subset of X, and
2. X and Y are not, together, all the attributes.
– Note that the definition of “superkey” still depends on FD’s only.

BCNF Versus 4NF
• Remember that every FD X ->Y is also an MVD, X ->->Y.
• Thus, if R is in 4NF, it is certainly in BCNF.– Because any BCNF violation is a 4NF
violation.
• But R could be in BCNF and not 4NF, because MVD’s are “invisible” to BCNF.

Normalization
Good Decomposition • dependency preserving decomposition
- it is undesirable to lose functional dependencies during decomposition
• lossless join decomposition
- join of decomposed relations should be able to create the original relation (no spurious tuples)


Decomposition and 4NF
• If X ->->Y is a 4NF violation for relation R, we can decompose R using the same technique as for BCNF.
1. XY is one of the decomposed relations.
2. All but Y – X is the other.



Example
Drinkers(name, addr, phones, beersLiked)
FD: name -> addr
MVD’s: name ->-> phones
name ->-> beersLiked
• Key is {name, phones, beersLiked}.
• All dependencies violate 4NF.

Example, Continued
• Decompose using name -> addr:
1. Drinkers1(name, addr) In 4NF, only dependency is name -> addr.
2. Drinkers2(name, phones, beersLiked) Not in 4NF. MVD’s name ->-> phones and
name ->-> beersLiked apply. No FD’s, so all three attributes form the key.

Example: Decompose Drinkers2
• Either MVD name ->-> phones or name ->-> beersLiked tells us to decompose to:– Drinkers3(name, phones)– Drinkers4(name, beersLiked)

BCNF
• Given a relation schema R, and a set of functional dependencies F, if every FD, A B, is either:
• 1. Trivial
• 2. A is a superkey of R
• Then, R is in BCNF (Boyce-Codd Normal Form)
• Why is BCNF good ?

BCNF
• What if the schema is not in BCNF ?
• Decompose (split) the schema into two pieces.
• Careful: you want the decomposition to be lossless

Achieving BCNF Schemas• For all dependencies A B in F+, check if A is a superkey
• By using attribute closure
• If not, then • Choose a dependency in F+ that breaks the BCNF rules, say A B
• Create R1 = A B
• Create R2 = A (R – B – A)
• Note that: R1 ∩ R2 = A and A AB (= R1), so this is lossless decomposition
• Repeat for R1, and R2• By defining F1+ to be all dependencies in F that contain only attributes in R1
• Similarly F2+

Example 1
B C
• R = (A, B, C)• F = {A B, B C}• Candidate keys = {A}
• BCNF = No. B C violates.
• R1 = (B, C)
• F1 = {B C}
• Candidate keys = {B}
• BCNF = true
• R2 = (A, B)
• F2 = {A B}
• Candidate keys = {A}
• BCNF = true

Example 2-1
A B
• R = (A, B, C, D, E)
• F = {A B, BC D}
• Candidate keys = {ACE}
• BCNF = Violated by {A B, BC D} etc…
• R1 = (A, B)
• F1 = {A B}
• Candidate keys = {A}
• BCNF = true
• R2 = (A, C, D, E)
• F2 = {AC D}
• Candidate keys = {ACE}
• BCNF = false (AC D)
• From A B and BC D by pseudo-transitivity
AC D
• R3 = (A, C, D)
• F3 = {AC D}
• Candidate keys = {AC}
• BCNF = true
• R4 = (A, C, E)• F4 = {} [[ only trivial ]]
• Candidate keys = {ACE}
• BCNF = true
• Dependency preservation ???• We can check: • A B (R1), AC D (R3), • but we lost BC D• So this is not a dependency• -preserving decomposition
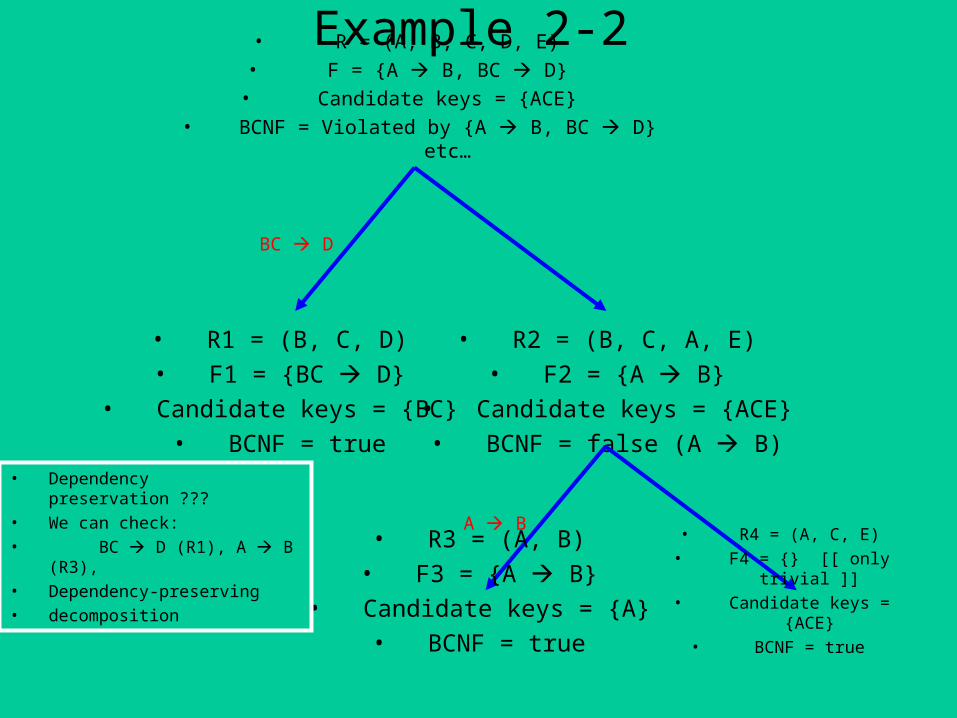
Example 2-2
BC D
• R = (A, B, C, D, E)
• F = {A B, BC D}
• Candidate keys = {ACE}
• BCNF = Violated by {A B, BC D} etc…
• R1 = (B, C, D)
• F1 = {BC D}
• Candidate keys = {BC}
• BCNF = true
• R2 = (B, C, A, E)
• F2 = {A B}
• Candidate keys = {ACE}
• BCNF = false (A B)
A B• R3 = (A, B)
• F3 = {A B}
• Candidate keys = {A}
• BCNF = true
• R4 = (A, C, E)• F4 = {} [[ only trivial ]]
• Candidate keys = {ACE}
• BCNF = true
• Dependency preservation ???
• We can check:
• BC D (R1), A B (R3),
• Dependency-preserving
• decomposition
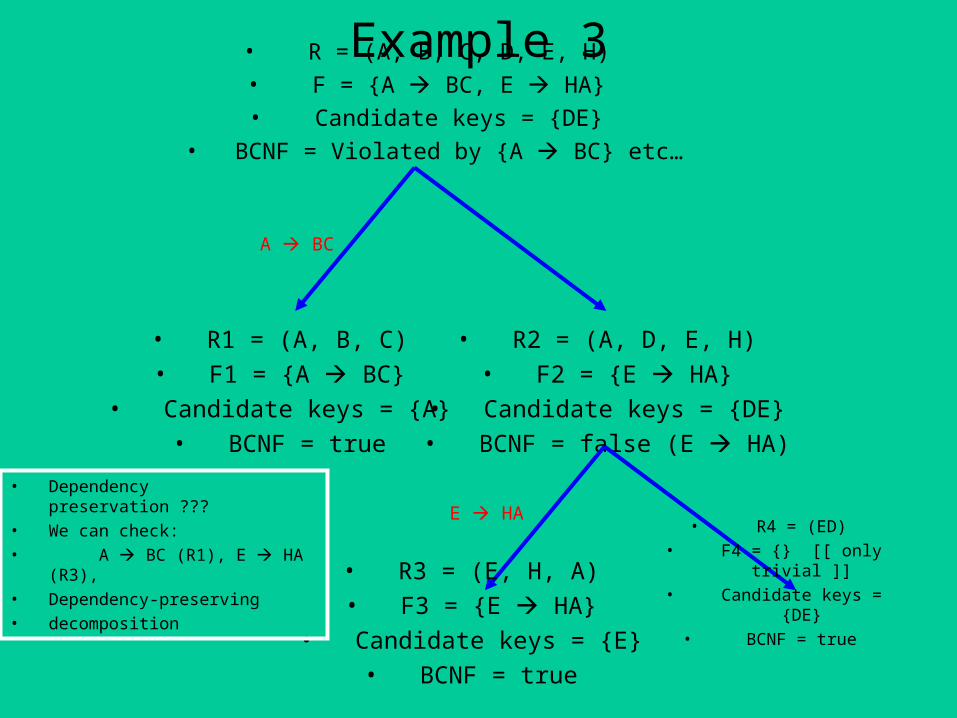
Example 3
A BC
• R = (A, B, C, D, E, H)• F = {A BC, E HA}• Candidate keys = {DE}
• BCNF = Violated by {A BC} etc…
• R1 = (A, B, C)
• F1 = {A BC}
• Candidate keys = {A}
• BCNF = true
• R2 = (A, D, E, H)
• F2 = {E HA}
• Candidate keys = {DE}
• BCNF = false (E HA)
E HA
• R3 = (E, H, A)
• F3 = {E HA}
• Candidate keys = {E}
• BCNF = true
• R4 = (ED)• F4 = {} [[ only trivial ]]• Candidate keys = {DE}
• BCNF = true
• Dependency preservation ???
• We can check:
• A BC (R1), E HA (R3),
• Dependency-preserving
• decomposition