research article evolutionary feature selection for big...
TRANSCRIPT

Research ArticleEvolutionary Feature Selection for Big Data ClassificationA MapReduce Approach
Daniel Peralta1 Sara del Riacuteo1 Sergio Ramiacuterez-Gallego1 Isaac Triguero23
Jose M Benitez1 and Francisco Herrera1
1Department of Computer Science and Artificial Intelligence CITIC-UGR University of Granada 18071 Granada Spain2Department of Respiratory Medicine Ghent University 9000 Ghent Belgium3VIB Inflammation Research Center 9052 Zwijnaarde Belgium
Correspondence should be addressed to Daniel Peralta dperaltadecsaiugres
Received 27 February 2015 Accepted 14 June 2015
Academic Editor Sangmin Lee
Copyright copy 2015 Daniel Peralta et al This is an open access article distributed under the Creative Commons Attribution Licensewhich permits unrestricted use distribution and reproduction in any medium provided the original work is properly cited
Nowadays many disciplines have to deal with big datasets that additionally involve a high number of features Feature selectionmethods aim at eliminating noisy redundant or irrelevant features that may deteriorate the classification performance Howevertraditionalmethods lack enough scalability to copewith datasets ofmillions of instances and extract successful results in a delimitedtime This paper presents a feature selection algorithm based on evolutionary computation that uses the MapReduce paradigm toobtain subsets of features frombig datasetsThe algorithmdecomposes the original dataset in blocks of instances to learn from themin the map phase then the reduce phase merges the obtained partial results into a final vector of feature weights which allows aflexible application of the feature selection procedure using a threshold to determine the selected subset of features The featureselection method is evaluated by using three well-known classifiers (SVM Logistic Regression and Naive Bayes) implementedwithin the Spark framework to address big data problems In the experiments datasets up to 67 millions of instances and up to2000 attributes have been managed showing that this is a suitable framework to perform evolutionary feature selection improvingboth the classification accuracy and its runtime when dealing with big data problems
1 Introduction
Learning from very large databases is a major issue for mostof the current data mining and machine learning algorithms[1] This problem is commonly named with the term ldquobigdatardquo which refers to the difficulties and disadvantages ofprocessing and analyzing huge amounts of data [2ndash4] It hasattracted much attention in a great number of areas such asbioinformatics medicine marketing or financial businesses[5] because of the enormous collections of raw data that arestored Recent advances on Cloud Computing technologiesallow for adapting standard data mining techniques in orderto apply them successfully over massive amounts of data[4 6 7]
The adaptation of data mining tools for big data problemsmay require the redesigning of the algorithms and theirinclusion in parallel environments Among the different
alternatives the MapReduce paradigm [8 9] and its dis-tributed file system [10] originally introduced by Googleoffer an effective and robust framework to address theanalysis of big datasets This approach is currently taken intoconsideration in data mining rather than other paralleliza-tion schemes such as MPI (Message Passing Interface) [11]because of its fault-tolerant mechanism and its simplicityMany recent works have been focused on the parallelizationof machine learning tools using the MapReduce approach[12 13]
Recently new andmore flexible workflows have appearedto extend the standardMapReduce approach such as ApacheSpark [14] which has been successfully applied over variousdata mining and machine learning problems [15ndash17]
Data preprocessing methods and more concretely datareduction models are intended to clean and simplify inputdata [18] Thus they attempt to accelerate data mining
Hindawi Publishing CorporationMathematical Problems in EngineeringVolume 2015 Article ID 246139 11 pageshttpdxdoiorg1011552015246139
2 Mathematical Problems in Engineering
algorithms and also to improve their accuracy by eliminatingnoisy and redundant dataThe specialized literature describestwo main types of data reduction models On the onehand instance selection [19 20] and instance generation [21]processes are focused on the instance level On the otherhand feature selection [22ndash25] and feature extraction [26]models work at the level of characteristics
Among the existing techniques evolutionary approacheshave been successfully used for feature selection techniques[27] Nevertheless an excessive increment of the individualsize can limit their applicability being unable to provide apreprocessed dataset in a reasonable time when dealing withvery large problems In the current literature there are noapproaches to tackle the feature space with evolutionary bigdata models
Themain objective of this paper is to enable EvolutionaryFeature Selection (EFS) models to be applied on big data Todo this a MapReduce algorithm has been developed whichsplits the data and performs a bunch of EFS processes inparallel in the map phase and then combines the solutionsin the reduce phase to get the most interesting featuresThis algorithmwill be denoted ldquoMapReduce for EvolutionaryFeature Selectionrdquo (MR-EFS)
More specifically the purposes of this paper are
(i) to design an EFS technique over the MapReduceparadigm for big data
(ii) to analyze and illustrate the scalability of the proposedscheme in terms of classification accuracy and timenecessary to build the classifiers
To analyze the proposed approach experiments ontwo big data classification datasets with up to 67 millionsinstances and up to 2000 features will be carried out focusingon the CHC algorithm [28] as EFS method With thecharacteristics selected by this model its influence on theclassification performance of the Spark implementation ofthree different algorithms (Support Vector Machine LogisticRegression and Naive Bayes) available in MLlib [29] will beanalyzed
The rest of the paper is organized as follows Section 2provides some background information about EFS andMapReduce Section 3 describes the MapReduce algorithmproposed for EFS The empirical results are discussed andanalyzed in Section 4 Finally Section 5 summarizes theconclusions of the paper
2 Background
This section describes the topics used in this paper Section 21presents some preliminaries about EFS and its main draw-backs to deal with big data classification problems Section 22introduces the MapReduce paradigm as well as two of themain frameworks for big data Hadoop and Spark
21 Feature Selection Problems with Big Datasets Featureselection models attempt to reduce a dataset by removingirrelevant or redundant featuresThe feature selection processseeks to obtain a minimum set of attributes such that the
results of the data mining techniques that are applied overthe reduced dataset are as close as possible (or even better) tothe results obtained using all attributes [25] This reductionfacilitates the understanding of the patterns extracted andincreases the speed of posterior learning stages
Feature selection methods can be classified into threecategories
(i) Wrapper methods The selection criterion is part ofthe fitness function and therefore depends on thelearning algorithm [30]
(ii) Filtering methods The selection is based on data-related measures such as separability or crowding[22]
(iii) Embedded methods The optimal subset of features isbuilt within the classifier construction [24]
For more information about specific feature selectionmethods the reader can refer to the published surveys on thetopic [22ndash24]
A recent interesting proposal for applying feature selec-tion to big datasets is presented in [31] In that paper theauthors describe an algorithm that is able to efficiently copewith ultrahigh-dimensional datasets and select a small subsetof interesting features from them However the number ofselected features is assumed to be several orders ofmagnitudelower than the total of features and the algorithm is designedto be executed in a single machine Therefore this approachis not scalable to arbitrarily large datasets
A particular way of tackling feature selection is by usingevolutionary algorithms [27] Usually the set of features isencoded as a binary vector where each position determinesif a feature is selected or not This allows to perform featureselection with the exploration capabilities of evolutionaryalgorithms However they lack the scalability necessary toaddress big datasets (from millions of instances onwards)The main problems found when dealing with big data are asfollows
(i) Runtime The complexity of EFS models is at leastO(119899
2119863) where 119899 is the number of instances and 119863
the number of featuresWhen either of these variablesbecomes too large the application of EFS may be tootime-consuming for real situations
(ii) Memory consumption Most EFS methods need tostore the entire training dataset in memory alongwith additional computation data and results Whenthese data are too big their size could easily exceedthe available RAMmemory
In order to overcome these weaknesses distributed parti-tioning procedures are used within a MapReduce paradigmthat divide the dataset into disjoint subsets that are manage-able by EFS methods
22 Big Data MapReduce Hadoop and Spark This sec-tion describes the main solutions for big data process-ing Section 221 focuses on the MapReduce programmingmodel whilst Section 222 introduces two of the mainframeworks to deal with big data
Mathematical Problems in Engineering 3
Map Shuffle Reduce
Split0
Split1
Split2
Part0
Part1
Part2
OutputInput data
Figure 1 Flowchart of the MapReduce framework
221 MapReduce MapReduce [8 9] is one of the mostpopular programming models to deal with big data It wasproposed by Google in 2004 and designed for processinghuge amounts of data using a cluster of machines TheMapReduce paradigm is composed of two phases map andreduce In general terms in the map phase the input datasetis processed producing some intermediate results Then thereduce phase combines them in some way to form the finaloutput
The MapReduce model is based on a basic data structureknown as the ⟨key value⟩ pair In the map phase eachapplication of the map function receives a single ⟨key value⟩pair as input and generates a list of intermediate ⟨key value⟩pairs as output This is represented by the following form
map (key1 value1) 997888rarr (key2 value2) (1)
Then the MapReduce library groups all intermediate⟨key value⟩ pairs by key Finally the reduce function takesthe aggregated pairs and generates a new ⟨key value⟩ pair asoutput This is depicted by the following form
reduce (key2 value2 ) 997888rarr (key2 value3) (2)
A flowchart of the MapReduce framework is presented inFigure 1
222 Hadoop and Spark Different implementations of theMapReduce programming model have appeared in the lastyearsThemost popular one is ApacheHadoop [32] an open-source framework written in Java that allows the processingandmanagement of large datasets in a distributed computingenvironment In addition Hadoop works on top of theHadoop Distributed File System (HDFS) which replicatesthe data files in many storage nodes facilitating rapid datatransfer rates among nodes and allowing the system tocontinue operating without interruption when one or severalnodes fail
In this paper Apache Hadoop is used to implement theproposal MR-EFS as described in Section 32
Another Apache project that is tightly related to Hadoopis Spark [14] It is a cluster computing framework originallydeveloped in the UC Berkeley AMP Lab for large-scale
data processing that improves the efficiency by the use ofintensive memory Spark uses HDFS and has high-levellibraries for stream processing and for machine learning andgraph processing such as MLlib [29]
For this work several classifiers included in MLlib areused to test the MR-EFS algorithm SVM Naive Bayesand Logistic Regression Their parameters are specified inSection 41
3 MR-EFS MapReduce for EvolutionaryFeature Selection
This section describes the proposed MapReduce approachfor EFS as well as its integration in a generic classificationprocess In particular the MR-EFS algorithm is based on theCHC algorithm to perform feature selection as described inSection 31
First MR-EFS is applied over the original dataset toobtain a vector of weights that indicates the relevance ofeach attribute (Section 32) Then this vector is used withinanotherMapReduce process to produce the resulting reduceddataset (Section 33) Finally the reduced dataset is used by aclassification algorithm
31 CHCAlgorithm for Feature Selection TheCHCalgorithm[28] is a binary-coded genetic algorithm that combines a veryhigh selective pressure with an elitist selection strategy alongwith several components that introduce diversity The mainparts of CHC are the following
(i) Half Uniform Crossover (HUX) This crossover oper-ator aims at enforcing a high diversity and reducingthe risk of premature convergence It selects at ran-dom half of the bits that are different between bothparents Then it obtains two offspring that are at themaximum Hamming distance from their parents
(ii) Elitist selection In each generation the new popula-tion is composed of the best individuals (those withthe best values of the fitness function) among boththe current and the offspring populations In case ofdraw between a parent and an offspring the parent isselected
(iii) Incest prevention Two individuals are not allowedto mate if the Hamming similarity between themexceeds a threshold 119889 (usually initialized to 119889 = 1198712where 119871 is the chromosome length) The threshold isdecremented by one when no offspring is obtained inone generation which indicates that the algorithm isconverging
(iv) Restarting process When 119889 = 0 (which happensafter several generations without any new offspring)the population is considered to be stagnated Insuch a case a new population is generated the bestindividual is kept and the remaining individuals havea certain percentage of their bits flipped
The basic execution scheme of CHC is shown inFigure 2This algorithmnaturally adapts to a feature selection
4 Mathematical Problems in Engineering
Parents Offspring
HUX
HUX
HUX
Incestprevention
If no offspring is generated
Restart population
Yes
No
Select best
d = 0
New population
dlarrd minus 1
Figure 2 Flowchart of the CHC algorithm
problem as each feature can be represented as a bit inthe solution vectorThus each position of the vector indicatesif the corresponding feature is selected or not Thereforethis approach falls within the wrapper method categoryaccording to the classification established in Section 21 Thefitness function used to evaluate new individuals applies a 119896-Nearest Neighbors classifier (119896-NN) [33] over the dataset thatwould be obtained after removing the corresponding featuresThe fitness value is the weighted sum of the 119896-NN accuracyand the feature reduction rate
32 MR-EFS Algorithm This section describes the paral-lelization of the CHC algorithm by using a MapReduceprocedure to obtain a vector of weights
Let 119879 be a training set stored in HFDS and random-ized as described in [34] Let 119898 be the number of maptasks The splitting procedure of MapReduce divides 119879 in119898 disjoint subsets of instances Then each 119879
119894subset (119894 isin
1 2 119898) is processed by the corresponding Map119894task
As this partitioning is performed sequentially all subsets willhave approximately the same number of instances and therandomization of the 119879 file ensures an adequate balance ofthe classes
Themap phase over each 119879119894consists of the EFS algorithm
(in this case based on CHC) as described in Section 31Therefore the output of each map task is a binary vectorfi = 119891
1198941 119891119894119863 where 119863 is the number of features thatindicates which features were selected by the CHC algorithmThe reduce phase averages all the binary vectors obtaininga vector x as defined in (3) where 119909
119895is the proportion of
EFS applications that include the feature 119895 in their resultThis vector is the result of the overall EFS process and isused to build the reduced dataset that will be used for furthermachine learning purposes
x = 1199091 119909119863
119909119895=
1119898
119898
sum119894=1
119891119894119895 119895 isin 1 2 119863
(3)
sum
Initial Map Reduce Final
Mappers training set
Original trainingdataset
CHC
CHC
CHC
0 1 1 0
1 1 1 0
0 1 0 0
middot middot middot
middot middot middot
middot middot middot
01 03 02 00
Figure 3 Flowchart of MR-EFS algorithm
In the implementation used for the experiments thereduce phase is carried out by a single task which reducesthe runtime by decreasing theMapReduce overhead [35]Thewhole MapReduce process for EFS is depicted in Figure 3 Itis noteworthy that the whole procedure is performed withina single iteration of the MapReduce workflow avoidingadditional disk accesses
33 Dataset Reduction with MapReduce Once vector x iscalculated the objective is to remove the less promisingfeatures from the original dataset To do so in a scalablemanner an additional MapReduce process was designedFirst vector x is binarized using a threshold 120579
b = 1198871 119887119863
119887119895=
1 if 119909119895ge 120579
0 otherwise
(4)
Vector b indicates which features will be selected forthe reduced dataset The number of selected features (1198631015840 =sum119863
119895=1 119887119895) can be controlled with 120579 with a high threshold onlya few features will be selected while a lower threshold allowsmore features to be picked
Mathematical Problems in Engineering 5
Initial Map Final
Original trainingtestdataset
Mappers trainingtest set
Result of EPS
+
Threshold
Reduced dataset
0 1 1 0middot middot middot
0 1 1 0middot middot middot
0 1 1 0middot middot middot
0 1 1 0middot middot middot
middot middot middot middot middot middot
middot middot middot middot middot middot
middot middot middot middot middot middot
01 03 02 00middot middot middot
Figure 4 Flowchart of the dataset reduction process
The MapReduce process for the dataset reduction worksas follows Each map processes an instance and generatesa new one that only contains the features selected in bFinally the instances generated are concatenated to form thefinal reduced dataset without the need of a reduce step Thedataset reduction process using the result of MR-EFS and anarbitrary threshold is depicted in Figure 4
4 Experimental Framework and Analysis
This section describes the performed experiments and theirresults First Section 41 describes the datasets and themethods used for the experiments Section 42 details theunderlying hardware and software support Finally Sections43 and 44 present the results obtained using two differentdatasets
41 Datasets and Methods This experimental study uses twolarge binary classification datasets in order to analyze thequality of the solutions provided by the MR-EFS algorithm
First the epsilon dataset was used which is composed of500 000 instances with 2000 numerical features This datasetwas artificially created for the Pascal Large Scale LearningChallenge [36] in 2008Theversion provided by LIBSVM[37]was used
Additionally this study includes the dataset used at thedata mining competition of the Evolutionary Computationfor Big Data and Big Learning held on July 14 2014 inVancouver (Canada) under the international conferenceGECCO-2014 (from now on it is referred to as ECBDL14)
[38] This dataset has 631 features (including both numericaland categorical attributes) and it is composed of approxi-mately 32 million instances Moreover the class distributionis not balanced 98 of the instances belong to the negativeclass
In order to deal with the imbalance problem the MapRe-duce approach of the Random Oversampling (ROS) algo-rithm presented in [39] was applied over the original trainingset for ECBDL14 The aim of ROS is to replicate the minorityclass instances from the original dataset until the number ofinstances from both classes is the same
Despite the inconvenience of increasing the size of thedataset this technique was proven in [39] to yield bet-ter performance than other common approaches to dealwith imbalance problems such as undersampling and cost-sensitive methods These two approaches suffer from thesmall sample size problem for the minority class when theyare used within a MapReduce model
Themain characteristics of these datasets are summarizedin Table 1 For each dataset the number of instances for bothtraining and test sets and the number of attributes are shownalong with the number of splits in which MR-EFS dividedeach dataset Note that the imbalanced version of ECBDL14 isnot used in the experiments as only the balanced ECBDL14-ROS version is considered
The parameters for the CHC algorithm are presented inTable 2
After applying MR-EFS over the described datasets thebehavior of the obtained reduced datasets was tested usingthree different classifiers implemented in Spark availablein MLlib SVM [40] Logistic Regression [41] and Naive
6 Mathematical Problems in Engineering
Table 1 Summary of the used big data classification datasets
Dataset Training instances Test instances Features Splits Instances per splitEpsilon 400 000 100 000 2000 512 sim780ECBDL14 31 992 921 2 897 917 631 mdash mdashECBDL14-ROS 65 003 913 2 897 917 631 32 768 sim1984
Table 2 Parameter specification for all the methods involved in theexperimentation
Algorithm Parameters
CHC
119896 value for 119896-NN 1Trade-off between reduction and accuracy 05Proportion of flipped bits in restarting process 005Population size 40Number of evaluations 1000
Naive Bayes Lambda 10 (default)
LogisticRegression
Iterations 100 (default)StepSize 10 (default)miniBatchFraction 10
SVM
Regularization parameter 00 05Iterations 100 (default)StepSize 10 (default)miniBatchFraction 10
Bayes [42] The reader may refer to the provided referencesor to the MLlib guide [43] for further details about theirinternal functioningThe parameters used for these classifiersare listed in Table 2 Particularly two different variants ofSVM were used modifying the regularization parameterwhich allows the algorithm to calculate simpler models bypenalizing complex models in the objective function
In the remainder of this paper two metrics are used toevaluate the performance of the three classifiers when appliedover the obtained reduced datasets
(i) Area Under the Curve (AUC) This measure is definedas the area under the Receiver Operating Charac-teristic (ROC) curve In this work this value isapproximated with the formula in (5) where TPR isthe True Positive Rate and TNR is the True NegativeRate These values can be directly obtained fromthe confusion matrix and are not affected by theimbalance of the dataset
AUC =TPR + TNR
2 (5)
(ii) Training runtime It is the time (in seconds) used totrain or build the classifier
Note that for this study the test runtime is much lessaffected by the feature selection process because at that pointthe classifier has already been built For the sake of simplicityonly training runtimes are reported
42 Hardware and Software Used The experiments for thispaper were carried out on a cluster of twenty computingnodes plus a master node Each one of these compute nodeshas the following features
(i) Processors 2 x Intel Xeon CPU E5-2620
(ii) Cores 6 per processor (12 threads)
(iii) Clock speed 200GHz
(iv) Cache 15MB
(v) Network QDR InfiniBand (40Gbps)
(vi) Hard drive 2 TB
(vii) RAM 64GB
Both Hadoop master processesmdashthe NameNode and theJobTrackermdashare hosted in the master node The formercontrols the HDFS coordinating the slave machines by themeans of their respectiveDataNode processes while the latteris in charge of the TaskTrackers of each compute node whichexecute the MapReduce framework Spark follows a similarconfiguration as the master process is located on the masternode and the worker processes are executed on the slavemachines Both frameworks share the underlying HDFS filesystem
These are the details of the software used for the experi-ments
(i) MapReduce implementation Hadoop 200-cdh471MapReduce 1 (Clouderarsquos open-source Apache Had-oop distribution)
(ii) Spark version Apache Spark 100
(iii) Maximum maps tasks 320 (16 per node)
(iv) Maximum reducer tasks 20 (1 per node)
(v) Operating system CentOS 66
Note that the total number of cores of the cluster is 240However a higher number of maps were kept to maximizethe use of the cluster by allowing a higher parallelism and abetter data locality thereby reducing the network overload
43 Experiments with the Epsilon Dataset This sectionexplains the results obtained for the epsilon dataset FirstSection 431 describes the performance of the feature selec-tion procedure and compares it with a sequential approachThen Section 432 describes the results obtained in theclassification
Mathematical Problems in Engineering 7
Table 3 Execution times (in seconds) over the epsilon subsets
Instances Sequential CHC MR-EFS Splits1000 391 419 12000 1352 409 25000 8667 413 510 000 39 576 431 1015 000 91 272 445 1520 000 159 315 455 20400 000 mdash 6531 512
431 Feature Selection Performance The complexity order ofthe CHC algorithm is approximately O(1198992119863119901) where 119901 isthe number of evaluations of the fitness function (a 119896-NNclassifier in this case) 119899 is the number of instances and 119863 isthe number of features Therefore the algorithm is quadraticwith respect to the number of instances
When the dataset is divided into 119898 splits within MR-EFS each one of the 119898 map tasks has complexity orderO((119899
21198982)119863119901) which is 1198982 times faster than applying CHCover the whole dataset If 119899
119888cores are available for the map
tasks the complexity of the map phase within the MR-EFS procedure is approximately O(lceil119898119899
119888rceil(11989921198982)119863119901) This
demonstrates the scalability of the approach presented in thispaper even if themaps are executed sequentially (119899
119888= 1) the
procedure is still one order of magnitude faster than feedinga single CHC with all the instances at once
In order to verify the performance of MR-EFS withrespect to the sequential approach a set of experimentswere performed using subsets of the epsilon dataset Botha sequential CHC algorithm and the parallel MR-EFS (with1000 instances per split) were applied over those subsetsThe obtained execution times are presented in Table 3 andFigure 5 along with the runtime of MR-EFS over the wholedataset
The sequential runtimes described a quadratic shapein concordance with the complexity order of CHC whichclearly states that the time necessary to tackle the wholedataset would be impractical In opposite the runtime ofMR-EFS for the small datasets was nearly constant The casewith 1000 instances is particular in the sense that MR-EFSonly executed one map task therefore it executed a singleCHC with 1000 instances The time difference between CHCand MR-EFS in this case reflects the overhead introduced bythe latter Even though his overhead increased slightly as thenumber of map tasks grew it represented a minor part of theoverall runtime
As for the full dataset with 512 splits the number ofinstances for each map task in MR-EFS is around 780 As thenumber of cores used for the experiments was 240 the mapphase in MR-EFS should be roughly three times slower thanthe sequential CHC with 1000 instances according to thecomplexity orders previously detailed The times in Table 3show a higher time gap because MR-EFS includes as well theother phases of theMapReduce framework (namely splittingshuffle and reduce) which are nonnegligible for a dataset ofsuch size Nevertheless the overall MR-EFS execution time is
0 5000 10000 15000 20000
0
50000
100000
150000
Number of instances
Tim
e (s)
Sequential CHCMR-EFSMR-EFS (full dataset)
Figure 5 Execution times of the sequential CHC and MR-EFS
064
066
068
070
500 1000 1500 2000Features
AUC
ClassifierLogistic RegressionNaive BayesSVM-00SVM-05
SetTrainingTest
Figure 6 Accuracy with the epsilon dataset Note that the numberof features decreases as the threshold increases
highly scalable as shown by the fact that MR-EFS was able toprocess the 400 000 instances faster than the time needed byCHC to process 5000 instances
432 Classification Results This section presents the resultsobtained by applying several classifiers over the full epsilondataset with its features previously selected by usingMR-EFSThe dataset was split among 512 map tasks each of whichcomputed around 780 instances
The AUC values are shown in Table 4 and Figure 6 bothfor training and test sets using three different thresholdsfor the dataset reduction step Note that the zero-thresholdcorresponds to the original dataset without performing any
8 Mathematical Problems in Engineering
Table 4 AUC results for the Spark classifiers using epsilon
Threshold Features Logistic Regression Naive Bayes SVM (120582 = 00) SVM (120582 = 05)Training Test Training Test Training Test Training Test
000 2000 06786 06784 07038 07008 06440 06433 06440 06433055 721 06985 07000 07154 07127 06855 06865 06855 06865060 337 06873 06867 07054 07030 06805 06799 06805 06799065 110 06496 06497 06803 06794 06492 06493 06492 06493
Table 5 Training runtime (in seconds) for the Spark classifiers using epsilon
Threshold Features Logistic Regression Naive Bayes SVM (120582 = 00) SVM (120582 = 05)000 2000 36729 60514 33418 33169055 721 40935 34042 40970 38684060 337 48816 30733 50546 48993065 110 50186 26426 46744 47374
Table 6 Size of the epsilon dataset for each threshold
Threshold Set MB HDFS blocks
000 Training 817918 128Test 204480 32
055 Training 294652 47Test 73663 12
060 Training 137721 22Test 34430 6
065 Training 45060 8Test 11265 2
feature selectionThebest results for eachmethod are stressedin boldface The table shows that the accuracy was improvedby the removal of the adequate features as the threshold 055allowed for obtaining higher AUC values The accuracy gainwas especially large for SVMMoreover more than half of thefeatures were removed which reduces significantly the sizeof the dataset and therefore the complexity of the resultingclassifier
A threshold of value 060 also got to improve the accuracyresults while reducing even further the size of the datasetFinally for the 065 thresholds only SVM saw its AUCimproved
It is also noteworthy that the two variants of SVMobtained the same results for all the tested thresholds Thisfact indicates that the complexity of the obtained SVMmodelis relatively low
The training runtime of the different algorithms anddatabases is shown in Table 5 and Figure 7 The obtainedresults were seemingly the opposite to the expectationsexcept for Naive Bayes the classifiers needed more time toprocess the datasets as their number of features decreases
However this behavior can be explained as the datasetgets smaller it occupies less HDFS blocks and thereforethe full parallel capacity of the cluster is not exploited Thesize of each version of the epsilon dataset and the numberof HDFS blocks that are needed to store it are shown inTable 6 The computer cluster is composed of 20 machinestherefore when the number of blocks is lower than 20 some
300
400
500
600
500 1000 1500 2000Features
Run
time (
s)
Logistic RegressionNaive Bayes
SVM-00SVM-05
Classifier
Figure 7 Training runtime with the epsilon dataset Note that thenumber of features decreases as the threshold increases
of the machines remain idle because they have no HDFSblock to process Moreover even if the number of blocks isslightly above 20 the affectedHDFS blocksmay not be evenlydistributed among the computing nodes This demonstratesthe capacity of Spark to deal with big databases as thesize of the database (more concretely the number of HDFSblocks) increases the framework is able to distribute theprocesses more evenly exploiting data locality increasing theparallelism and reducing the network overhead
In order to deal with this problem the same experimentswere repeated over the epsilon dataset after reorganizing thefiles with a smaller block size For each of the eight sets theblock size 119878
119887was calculated according to (6) where 119904 is the
size of the dataset in bytes and 119899119888is the number of cores in
the cluster
119878119887= 2119870
119870 = lfloorlog2119904
119899119888
rfloor (6)
Mathematical Problems in Engineering 9
Table 7 Training runtime (in seconds) for the Spark classifiers using epsilon with customized block size
Threshold Features Logistic Regression Naive Bayes SVM (120582 = 00) SVM (120582 = 05)000 2000 32194 48348 30094 30647055 721 25692 31319 25672 25698060 337 23616 24859 23123 22803065 110 30770 30826 25405 26123
Table 8 AUC values for the Spark classifiers using ECBDL14-ROS
Threshold Features Logistic Regression Naive Bayes SVM (120582 = 00) SVM (120582 = 05)Training Test Training Test Training Test Training Test
000 631 05821 05808 06714 06506 05966 06046 05875 05897055 234 06416 06352 06673 06489 06369 06307 06228 06148060 119 06309 06235 06732 06516 05884 05841 06116 06054065 46 05017 05022 06136 06093 05032 05039 05000 05000
Table 9 Training runtime (in seconds) for the Spark classifiers using ECBDL14-ROS
Threshold Features Logistic Regression Naive Bayes SVM (120582 = 00) SVM (120582 = 05)000 631 464919 158152 528388 506587055 234 210766 61350 232122 217918060 119 116298 32206 135285 122672065 46 97838 21509 91432 86428
The runtime for the dataset with the block size cus-tomized for each subset is displayed in Table 7 and Figure 8It is observed that the runtime was smaller than that withthe default block size Furthermore the curves show theexpected behavior as the number of features of the datasetwas reduced the runtime decreased In the extreme case(for threshold 065) the runtime increased again becausewith such a small dataset the synchronization times of Sparkbecome bigger than the computing times even with thecustomized block size
In the next section MR-EFS is tested over a very largedataset validating these observations
44 Experiments with the ECBDL14-ROS Dataset This sec-tion presents the classification accuracy and runtime resultsobtained with the ECBDL14-ROS dataset As describedin Section 41 a random oversampling technique [39] waspreviously applied over the original ECBDL14 dataset toovercome the problems originated by its imbalanceTheMR-EFS method was applied using 32 768 map tasks thereforeeach map task computed around 1984 instances
The obtained results in terms of accuracy are depictedin Table 8 and Figure 9 MR-EFS improved the results inall cases with different thresholds The accuracy gain wasespecially important for the Logistic Regression and SVMalgorithms As expected the SVM with 120582 = 00 obtainedbetter results than the onewith120582 = 05 as the latter attemptedto reduce the complexity of the obtained model Howeverit is noteworthy that for 119 features SVM-05 was able tooutperform SVM-00 This hints that after removing noisyfeatures the simpler obtained models represented better the
300
400
500 1000 1500 2000Features
Run
time (
s)
Logistic RegressionNaive Bayes
SVM-00SVM-05
Classifier
Figure 8 Training runtime with the epsilon dataset with cus-tomized block size Note that the number of features decreases asthe threshold increases
true knowledge underlying the data With even less featuresboth variants of SVM obtained roughly the same accuracy
To conclude this study the runtime necessary to trainthe classifiers with all variants of ECBDL14-ROS is presentedin Table 9 and Figure 10 In this case the runtime behavedas expected the time was roughly linear with respect to thenumber of features for all testedmodelsThismeans thatMR-EFS was able to improve both the runtime and the accuracyfor all those classifiers
10 Mathematical Problems in Engineering
050
055
060
065
200 400 600Features
AUC
ClassifierLogistic RegressionNaive BayesSVM-00SVM-05
SetTrainingTest
Figure 9 Accuracy with the ECBDL14-ROS dataset Note that thenumber of features decreases as the threshold increases
0
1000
2000
3000
4000
5000
Run
time (
s)
200 400 600Features
Logistic RegressionNaive Bayes
SVM-00SVM-05
Classifier
Figure 10 Training runtime with the ECBDL14-ROS dataset Notethat the number of features decreases as the threshold increases
5 Concluding Remarks
This paper presents MR-EFS an Evolutionary Feature Selec-tion algorithm designed upon the MapReduce paradigmintended to preprocess big datasets so that they becomeaffordable for other machine learning techniques such asclassification techniques that are currently not scalableenough to deal with such datasets The algorithm has beenimplemented using Apache Hadoop and it has been appliedover two different large datasets The resulting reduceddatasets have been tested using three different classifiersimplemented inApache Spark over a cluster of 20 computers
The theoretical evaluation of themodel highlights the fullscalability of MR-EFS with respect to the number of featuresin the dataset in comparison with a sequential approachThis behavior has been further confirmed after the empiricalprocedures
According to the obtained classification results it can beclaimed thatMR-EFS is able to reduce adequately the numberof features of large datasets leading to reduced versionsof them that are at the same time smaller to store fasterto compute and easier to classify These facts have beenobserved with the two different datasets and for all testedclassifiers
For the epsilon dataset the relation between the reduceddatasets size and the number of nodes is forced to modifythe HDFS block size proving that the hardware resourcescan be optimally used by Hadoop and Spark with the correctdesign One of the obtained reduced ECDBL14-ROS datasetswith more than 67 million instances and several hundredfeatures could be processed by the classifiers in less thanhalf of the time than that of the original dataset and with animprovement of around 5 in terms of AUC
Conflict of Interests
The authors declare that there is no conflict of interestsregarding the publication of this paper
Acknowledgments
This work is supported by the Research Projects TIN2014-57251-P P10-TIC-6858 P11-TIC-7765 P12-TIC-2958 andTIN2013-47210-P D Peralta and S Ramırez-Gallego holdtwo FPU scholarships from the Spanish Ministry of Educa-tion and Science (FPU1204902 FPU1300047) I Trigueroholds a BOF postdoctoral fellowship from the Ghent Univer-sity
References
[1] E Alpaydin Introduction to Machine Learning MIT PressCambridge Mass USA 2nd edition 2010
[2] MMinelliMChambers andADhirajBigData BigAnalyticsEmerging Business Intelligence and Analytic Trends for TodayrsquosBusinesses (Wiley CIO) Wiley 1st edition 2013
[3] V Marx ldquoThe big challenges of big datardquo Nature vol 498 no7453 pp 255ndash260 2013
[4] A Fernandez S del Rıo V Lopez et al ldquoBig data with cloudcomputing an insight on the computing environment MapRe-duce and programming frameworksrdquo Wiley InterdisciplinaryReviews Data Mining and Knowledge Discovery vol 4 no 5pp 380ndash409 2014
[5] E Merelli M Pettini and M Rasetti ldquoTopology driven model-ing the IS metaphorrdquo Natural Computing 2014
[6] S Sakr A Liu DM Batista andM Alomari ldquoA survey of largescale data management approaches in cloud environmentsrdquoIEEE Communications Surveys and Tutorials vol 13 no 3 pp311ndash336 2011
[7] J Bacardit and X Llora ldquoLarge-scale data mining usinggenetics-based machine learningrdquo Wiley Interdisciplinary
Mathematical Problems in Engineering 11
Reviews Data Mining and Knowledge Discovery vol 3 no 1pp 37ndash61 2013
[8] J Dean and SGhemawat ldquoMapReduce simplified data process-ing on large clustersrdquo Communications of the ACM vol 51 no1 pp 107ndash113 2008
[9] J Dean and S Ghemawat ldquoMap reduce a flexible data process-ing toolrdquo Communications of the ACM vol 53 no 1 pp 72ndash772010
[10] S Ghemawat H Gobioff and S-T Leung ldquoThe google file sys-temrdquo in Proceedings of the 19th ACM Symposium on OperatingSystems Principles (SOSP rsquo03) pp 29ndash43 October 2003
[11] M Snir and S Otto MPImdashThe Complete Reference The MPICore MIT Press Boston Mass USA 1998
[12] W Zhao H Ma and Q He ldquoParallel k-means clustering basedon MapReducerdquo in Cloud Computing M Jaatun G Zhao andC Rong Eds vol 5931 of Lecture Notes in Computer Sciencepp 674ndash679 Springer Berlin Germany 2009
[13] A Srinivasan T A Faruquie and S Joshi ldquoData and taskparallelism in ILP using MapReducerdquo Machine Learning vol86 no 1 pp 141ndash168 2012
[14] M Zaharia M Chowdhury T Das et al ldquoResilient distributeddatasets a fault-tolerant abstraction for in-memory clustercomputingrdquo in Proceedings of the 9th USENIX Conferenceon Networked Systems Design and Implementation pp 1ndash14USENIX Association 2012
[15] K Thomas C Grier J Ma V Paxson and D Song ldquoDesignand evaluation of a real-time URL spam filtering servicerdquo inProceedings of the IEEE Symposium on Security and Privacy (SPrsquo11) pp 447ndash462 Berkeley Calif USA May 2011
[16] R S Xin J Rosen M Zaharia M J Franklin S Shenker andI Stoica ldquoShark SQL and rich analytics at scalerdquo in Proceedingsof the ACM SIGMOD International Conference on Managementof Data (SIGMOD rsquo13) pp 13ndash24 ACM June 2013
[17] M S Wiewiorka A Messina A Pacholewska S Maffioletti PGawrysiak and M J Okoniewski ldquoSparkSeq fast scalable andcloud-ready tool for the interactive genomic data analysis withnucleotide precisionrdquo Bioinformatics vol 30 no 18 pp 2652ndash2653 2014
[18] S Garcıa J Luengo and F Herrera Data Preprocessing in DataMining Springer 1st edition 2015
[19] H Brighton and C Mellish ldquoAdvances in instance selection forinstance-based learning algorithmsrdquo Data Mining and Knowl-edge Discovery vol 6 no 2 pp 153ndash172 2002
[20] J A Olvera-Lopez J A Carrasco-Ochoa J F Martınez-Trinidad and J Kittler ldquoA reviewof instance selectionmethodsrdquoArtificial Intelligence Review vol 34 no 2 pp 133ndash143 2010
[21] J S Sanchez ldquoHigh training set size reduction by spacepartitioning and prototype abstractionrdquo Pattern Recognitionvol 37 no 7 pp 1561ndash1564 2004
[22] I Guyon and A Elisseeff ldquoAn introduction to variable andfeature selectionrdquo Journal of Machine Learning Research vol 3pp 1157ndash1182 2003
[23] H Liu and L Yu ldquoToward integrating feature selection algo-rithms for classification and clusteringrdquo IEEE Transactions onKnowledge and Data Engineering vol 17 no 4 pp 491ndash5022005
[24] Y Saeys I Inza and P Larranaga ldquoA review of feature selectiontechniques in bioinformaticsrdquo Bioinformatics vol 23 no 19 pp2507ndash2517 2007
[25] H Liu and H Motoda Computational Methods of FeatureSelection Chapman amp HallCRC Data Mining and KnowledgeDiscovery Series Chapman amp HallCRC Press 2007
[26] J A Lee andMVerleysenNonlinear Dimensionality ReductionSpringer 2007
[27] B de la Iglesia ldquoEvolutionary computation for feature selectionin classification problemsrdquo Wiley Interdisciplinary ReviewsDataMining and Knowledge Discovery vol 3 no 6 pp 381ndash4072013
[28] L J Eshelman ldquoThe CHC adaptative search algorithm howto have safe search when engaging in nontraditional geneticrecombinationrdquo in Foundations of Genetic Algorithms G J ERawlins Ed pp 265ndash283MorganKaufmann SanMateo CalifUSA 1991
[29] MLlib Website httpssparkapacheorgmllib[30] R Kohavi and G H John ldquoWrappers for feature subset
selectionrdquo Artificial Intelligence vol 97 no 1-2 pp 273ndash3241997
[31] M Tan I W Tsang and L Wang ldquoTowards ultrahighdimensional feature selection for big datardquo Journal of MachineLearning Research vol 15 pp 1371ndash1429 2014
[32] T White Hadoop The Definitive Guide OrsquoReilly Media 3rdedition 2012
[33] T Cover and P Hart ldquoNearest neighbor pattern classificationrdquoIEEE Transactions on Information Theory vol 13 no 1 pp 21ndash27 1967
[34] I Triguero D Peralta J Bacardit S Garcıa and F HerreraldquoMRPR a MapReduce solution for prototype reduction in bigdata classificationrdquoNeurocomputing vol 150 pp 331ndash345 2015
[35] C-T Chu S Kim Y-A Lin et al ldquoMap-reduce for machinelearning on multicorerdquo in Advances in Neural InformationProcessing Systems pp 281ndash288 2007
[36] Pascal large scale learning challenge httplargescalemltu-berlindeinstructions
[37] Epsilon in the LIBSVM website httpwwwcsientuedutwsimcjlinlibsvmtoolsdatasetsbinaryhtmlepsilon
[38] ECBDL14 dataset Protein structure prediction and contactmapfor the ECBDL2014 Big Data Competition httpcrunchernclacukbdcomp
[39] S del Rıo V Lopez J M Benıtez and F Herrera ldquoOn the useof MapReduce for imbalanced big data using Random ForestrdquoInformation Sciences vol 285 pp 112ndash137 2014
[40] M A Hearst S T Dumais E Osman J Platt and B ScholkopfldquoSupport vector machinesrdquo IEEE Intelligent Systems and TheirApplications vol 13 no 4 pp 18ndash28 1998
[41] D W Hosmer Jr and S Lemeshow Applied Logistic RegressionJohn Wiley amp Sons 2004
[42] R O Duda and P E Hart Pattern Classification and SceneAnalysis vol 3 Wiley New York NY USA 1973
[43] MLlib guide httpsparkapacheorgdocslatestmllib-guidehtml
Submit your manuscripts athttpwwwhindawicom
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical Problems in Engineering
Hindawi Publishing Corporationhttpwwwhindawicom
Differential EquationsInternational Journal of
Volume 2014
Applied MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Probability and StatisticsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical PhysicsAdvances in
Complex AnalysisJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
OptimizationJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
CombinatoricsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Operations ResearchAdvances in
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Function Spaces
Abstract and Applied AnalysisHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of Mathematics and Mathematical Sciences
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Algebra
Discrete Dynamics in Nature and Society
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Decision SciencesAdvances in
Discrete MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom
Volume 2014 Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Stochastic AnalysisInternational Journal of

2 Mathematical Problems in Engineering
algorithms and also to improve their accuracy by eliminatingnoisy and redundant dataThe specialized literature describestwo main types of data reduction models On the onehand instance selection [19 20] and instance generation [21]processes are focused on the instance level On the otherhand feature selection [22ndash25] and feature extraction [26]models work at the level of characteristics
Among the existing techniques evolutionary approacheshave been successfully used for feature selection techniques[27] Nevertheless an excessive increment of the individualsize can limit their applicability being unable to provide apreprocessed dataset in a reasonable time when dealing withvery large problems In the current literature there are noapproaches to tackle the feature space with evolutionary bigdata models
Themain objective of this paper is to enable EvolutionaryFeature Selection (EFS) models to be applied on big data Todo this a MapReduce algorithm has been developed whichsplits the data and performs a bunch of EFS processes inparallel in the map phase and then combines the solutionsin the reduce phase to get the most interesting featuresThis algorithmwill be denoted ldquoMapReduce for EvolutionaryFeature Selectionrdquo (MR-EFS)
More specifically the purposes of this paper are
(i) to design an EFS technique over the MapReduceparadigm for big data
(ii) to analyze and illustrate the scalability of the proposedscheme in terms of classification accuracy and timenecessary to build the classifiers
To analyze the proposed approach experiments ontwo big data classification datasets with up to 67 millionsinstances and up to 2000 features will be carried out focusingon the CHC algorithm [28] as EFS method With thecharacteristics selected by this model its influence on theclassification performance of the Spark implementation ofthree different algorithms (Support Vector Machine LogisticRegression and Naive Bayes) available in MLlib [29] will beanalyzed
The rest of the paper is organized as follows Section 2provides some background information about EFS andMapReduce Section 3 describes the MapReduce algorithmproposed for EFS The empirical results are discussed andanalyzed in Section 4 Finally Section 5 summarizes theconclusions of the paper
2 Background
This section describes the topics used in this paper Section 21presents some preliminaries about EFS and its main draw-backs to deal with big data classification problems Section 22introduces the MapReduce paradigm as well as two of themain frameworks for big data Hadoop and Spark
21 Feature Selection Problems with Big Datasets Featureselection models attempt to reduce a dataset by removingirrelevant or redundant featuresThe feature selection processseeks to obtain a minimum set of attributes such that the
results of the data mining techniques that are applied overthe reduced dataset are as close as possible (or even better) tothe results obtained using all attributes [25] This reductionfacilitates the understanding of the patterns extracted andincreases the speed of posterior learning stages
Feature selection methods can be classified into threecategories
(i) Wrapper methods The selection criterion is part ofthe fitness function and therefore depends on thelearning algorithm [30]
(ii) Filtering methods The selection is based on data-related measures such as separability or crowding[22]
(iii) Embedded methods The optimal subset of features isbuilt within the classifier construction [24]
For more information about specific feature selectionmethods the reader can refer to the published surveys on thetopic [22ndash24]
A recent interesting proposal for applying feature selec-tion to big datasets is presented in [31] In that paper theauthors describe an algorithm that is able to efficiently copewith ultrahigh-dimensional datasets and select a small subsetof interesting features from them However the number ofselected features is assumed to be several orders ofmagnitudelower than the total of features and the algorithm is designedto be executed in a single machine Therefore this approachis not scalable to arbitrarily large datasets
A particular way of tackling feature selection is by usingevolutionary algorithms [27] Usually the set of features isencoded as a binary vector where each position determinesif a feature is selected or not This allows to perform featureselection with the exploration capabilities of evolutionaryalgorithms However they lack the scalability necessary toaddress big datasets (from millions of instances onwards)The main problems found when dealing with big data are asfollows
(i) Runtime The complexity of EFS models is at leastO(119899
2119863) where 119899 is the number of instances and 119863
the number of featuresWhen either of these variablesbecomes too large the application of EFS may be tootime-consuming for real situations
(ii) Memory consumption Most EFS methods need tostore the entire training dataset in memory alongwith additional computation data and results Whenthese data are too big their size could easily exceedthe available RAMmemory
In order to overcome these weaknesses distributed parti-tioning procedures are used within a MapReduce paradigmthat divide the dataset into disjoint subsets that are manage-able by EFS methods
22 Big Data MapReduce Hadoop and Spark This sec-tion describes the main solutions for big data process-ing Section 221 focuses on the MapReduce programmingmodel whilst Section 222 introduces two of the mainframeworks to deal with big data
Mathematical Problems in Engineering 3
Map Shuffle Reduce
Split0
Split1
Split2
Part0
Part1
Part2
OutputInput data
Figure 1 Flowchart of the MapReduce framework
221 MapReduce MapReduce [8 9] is one of the mostpopular programming models to deal with big data It wasproposed by Google in 2004 and designed for processinghuge amounts of data using a cluster of machines TheMapReduce paradigm is composed of two phases map andreduce In general terms in the map phase the input datasetis processed producing some intermediate results Then thereduce phase combines them in some way to form the finaloutput
The MapReduce model is based on a basic data structureknown as the ⟨key value⟩ pair In the map phase eachapplication of the map function receives a single ⟨key value⟩pair as input and generates a list of intermediate ⟨key value⟩pairs as output This is represented by the following form
map (key1 value1) 997888rarr (key2 value2) (1)
Then the MapReduce library groups all intermediate⟨key value⟩ pairs by key Finally the reduce function takesthe aggregated pairs and generates a new ⟨key value⟩ pair asoutput This is depicted by the following form
reduce (key2 value2 ) 997888rarr (key2 value3) (2)
A flowchart of the MapReduce framework is presented inFigure 1
222 Hadoop and Spark Different implementations of theMapReduce programming model have appeared in the lastyearsThemost popular one is ApacheHadoop [32] an open-source framework written in Java that allows the processingandmanagement of large datasets in a distributed computingenvironment In addition Hadoop works on top of theHadoop Distributed File System (HDFS) which replicatesthe data files in many storage nodes facilitating rapid datatransfer rates among nodes and allowing the system tocontinue operating without interruption when one or severalnodes fail
In this paper Apache Hadoop is used to implement theproposal MR-EFS as described in Section 32
Another Apache project that is tightly related to Hadoopis Spark [14] It is a cluster computing framework originallydeveloped in the UC Berkeley AMP Lab for large-scale
data processing that improves the efficiency by the use ofintensive memory Spark uses HDFS and has high-levellibraries for stream processing and for machine learning andgraph processing such as MLlib [29]
For this work several classifiers included in MLlib areused to test the MR-EFS algorithm SVM Naive Bayesand Logistic Regression Their parameters are specified inSection 41
3 MR-EFS MapReduce for EvolutionaryFeature Selection
This section describes the proposed MapReduce approachfor EFS as well as its integration in a generic classificationprocess In particular the MR-EFS algorithm is based on theCHC algorithm to perform feature selection as described inSection 31
First MR-EFS is applied over the original dataset toobtain a vector of weights that indicates the relevance ofeach attribute (Section 32) Then this vector is used withinanotherMapReduce process to produce the resulting reduceddataset (Section 33) Finally the reduced dataset is used by aclassification algorithm
31 CHCAlgorithm for Feature Selection TheCHCalgorithm[28] is a binary-coded genetic algorithm that combines a veryhigh selective pressure with an elitist selection strategy alongwith several components that introduce diversity The mainparts of CHC are the following
(i) Half Uniform Crossover (HUX) This crossover oper-ator aims at enforcing a high diversity and reducingthe risk of premature convergence It selects at ran-dom half of the bits that are different between bothparents Then it obtains two offspring that are at themaximum Hamming distance from their parents
(ii) Elitist selection In each generation the new popula-tion is composed of the best individuals (those withthe best values of the fitness function) among boththe current and the offspring populations In case ofdraw between a parent and an offspring the parent isselected
(iii) Incest prevention Two individuals are not allowedto mate if the Hamming similarity between themexceeds a threshold 119889 (usually initialized to 119889 = 1198712where 119871 is the chromosome length) The threshold isdecremented by one when no offspring is obtained inone generation which indicates that the algorithm isconverging
(iv) Restarting process When 119889 = 0 (which happensafter several generations without any new offspring)the population is considered to be stagnated Insuch a case a new population is generated the bestindividual is kept and the remaining individuals havea certain percentage of their bits flipped
The basic execution scheme of CHC is shown inFigure 2This algorithmnaturally adapts to a feature selection
4 Mathematical Problems in Engineering
Parents Offspring
HUX
HUX
HUX
Incestprevention
If no offspring is generated
Restart population
Yes
No
Select best
d = 0
New population
dlarrd minus 1
Figure 2 Flowchart of the CHC algorithm
problem as each feature can be represented as a bit inthe solution vectorThus each position of the vector indicatesif the corresponding feature is selected or not Thereforethis approach falls within the wrapper method categoryaccording to the classification established in Section 21 Thefitness function used to evaluate new individuals applies a 119896-Nearest Neighbors classifier (119896-NN) [33] over the dataset thatwould be obtained after removing the corresponding featuresThe fitness value is the weighted sum of the 119896-NN accuracyand the feature reduction rate
32 MR-EFS Algorithm This section describes the paral-lelization of the CHC algorithm by using a MapReduceprocedure to obtain a vector of weights
Let 119879 be a training set stored in HFDS and random-ized as described in [34] Let 119898 be the number of maptasks The splitting procedure of MapReduce divides 119879 in119898 disjoint subsets of instances Then each 119879
119894subset (119894 isin
1 2 119898) is processed by the corresponding Map119894task
As this partitioning is performed sequentially all subsets willhave approximately the same number of instances and therandomization of the 119879 file ensures an adequate balance ofthe classes
Themap phase over each 119879119894consists of the EFS algorithm
(in this case based on CHC) as described in Section 31Therefore the output of each map task is a binary vectorfi = 119891
1198941 119891119894119863 where 119863 is the number of features thatindicates which features were selected by the CHC algorithmThe reduce phase averages all the binary vectors obtaininga vector x as defined in (3) where 119909
119895is the proportion of
EFS applications that include the feature 119895 in their resultThis vector is the result of the overall EFS process and isused to build the reduced dataset that will be used for furthermachine learning purposes
x = 1199091 119909119863
119909119895=
1119898
119898
sum119894=1
119891119894119895 119895 isin 1 2 119863
(3)
sum
Initial Map Reduce Final
Mappers training set
Original trainingdataset
CHC
CHC
CHC
0 1 1 0
1 1 1 0
0 1 0 0
middot middot middot
middot middot middot
middot middot middot
01 03 02 00
Figure 3 Flowchart of MR-EFS algorithm
In the implementation used for the experiments thereduce phase is carried out by a single task which reducesthe runtime by decreasing theMapReduce overhead [35]Thewhole MapReduce process for EFS is depicted in Figure 3 Itis noteworthy that the whole procedure is performed withina single iteration of the MapReduce workflow avoidingadditional disk accesses
33 Dataset Reduction with MapReduce Once vector x iscalculated the objective is to remove the less promisingfeatures from the original dataset To do so in a scalablemanner an additional MapReduce process was designedFirst vector x is binarized using a threshold 120579
b = 1198871 119887119863
119887119895=
1 if 119909119895ge 120579
0 otherwise
(4)
Vector b indicates which features will be selected forthe reduced dataset The number of selected features (1198631015840 =sum119863
119895=1 119887119895) can be controlled with 120579 with a high threshold onlya few features will be selected while a lower threshold allowsmore features to be picked
Mathematical Problems in Engineering 5
Initial Map Final
Original trainingtestdataset
Mappers trainingtest set
Result of EPS
+
Threshold
Reduced dataset
0 1 1 0middot middot middot
0 1 1 0middot middot middot
0 1 1 0middot middot middot
0 1 1 0middot middot middot
middot middot middot middot middot middot
middot middot middot middot middot middot
middot middot middot middot middot middot
01 03 02 00middot middot middot
Figure 4 Flowchart of the dataset reduction process
The MapReduce process for the dataset reduction worksas follows Each map processes an instance and generatesa new one that only contains the features selected in bFinally the instances generated are concatenated to form thefinal reduced dataset without the need of a reduce step Thedataset reduction process using the result of MR-EFS and anarbitrary threshold is depicted in Figure 4
4 Experimental Framework and Analysis
This section describes the performed experiments and theirresults First Section 41 describes the datasets and themethods used for the experiments Section 42 details theunderlying hardware and software support Finally Sections43 and 44 present the results obtained using two differentdatasets
41 Datasets and Methods This experimental study uses twolarge binary classification datasets in order to analyze thequality of the solutions provided by the MR-EFS algorithm
First the epsilon dataset was used which is composed of500 000 instances with 2000 numerical features This datasetwas artificially created for the Pascal Large Scale LearningChallenge [36] in 2008Theversion provided by LIBSVM[37]was used
Additionally this study includes the dataset used at thedata mining competition of the Evolutionary Computationfor Big Data and Big Learning held on July 14 2014 inVancouver (Canada) under the international conferenceGECCO-2014 (from now on it is referred to as ECBDL14)
[38] This dataset has 631 features (including both numericaland categorical attributes) and it is composed of approxi-mately 32 million instances Moreover the class distributionis not balanced 98 of the instances belong to the negativeclass
In order to deal with the imbalance problem the MapRe-duce approach of the Random Oversampling (ROS) algo-rithm presented in [39] was applied over the original trainingset for ECBDL14 The aim of ROS is to replicate the minorityclass instances from the original dataset until the number ofinstances from both classes is the same
Despite the inconvenience of increasing the size of thedataset this technique was proven in [39] to yield bet-ter performance than other common approaches to dealwith imbalance problems such as undersampling and cost-sensitive methods These two approaches suffer from thesmall sample size problem for the minority class when theyare used within a MapReduce model
Themain characteristics of these datasets are summarizedin Table 1 For each dataset the number of instances for bothtraining and test sets and the number of attributes are shownalong with the number of splits in which MR-EFS dividedeach dataset Note that the imbalanced version of ECBDL14 isnot used in the experiments as only the balanced ECBDL14-ROS version is considered
The parameters for the CHC algorithm are presented inTable 2
After applying MR-EFS over the described datasets thebehavior of the obtained reduced datasets was tested usingthree different classifiers implemented in Spark availablein MLlib SVM [40] Logistic Regression [41] and Naive
6 Mathematical Problems in Engineering
Table 1 Summary of the used big data classification datasets
Dataset Training instances Test instances Features Splits Instances per splitEpsilon 400 000 100 000 2000 512 sim780ECBDL14 31 992 921 2 897 917 631 mdash mdashECBDL14-ROS 65 003 913 2 897 917 631 32 768 sim1984
Table 2 Parameter specification for all the methods involved in theexperimentation
Algorithm Parameters
CHC
119896 value for 119896-NN 1Trade-off between reduction and accuracy 05Proportion of flipped bits in restarting process 005Population size 40Number of evaluations 1000
Naive Bayes Lambda 10 (default)
LogisticRegression
Iterations 100 (default)StepSize 10 (default)miniBatchFraction 10
SVM
Regularization parameter 00 05Iterations 100 (default)StepSize 10 (default)miniBatchFraction 10
Bayes [42] The reader may refer to the provided referencesor to the MLlib guide [43] for further details about theirinternal functioningThe parameters used for these classifiersare listed in Table 2 Particularly two different variants ofSVM were used modifying the regularization parameterwhich allows the algorithm to calculate simpler models bypenalizing complex models in the objective function
In the remainder of this paper two metrics are used toevaluate the performance of the three classifiers when appliedover the obtained reduced datasets
(i) Area Under the Curve (AUC) This measure is definedas the area under the Receiver Operating Charac-teristic (ROC) curve In this work this value isapproximated with the formula in (5) where TPR isthe True Positive Rate and TNR is the True NegativeRate These values can be directly obtained fromthe confusion matrix and are not affected by theimbalance of the dataset
AUC =TPR + TNR
2 (5)
(ii) Training runtime It is the time (in seconds) used totrain or build the classifier
Note that for this study the test runtime is much lessaffected by the feature selection process because at that pointthe classifier has already been built For the sake of simplicityonly training runtimes are reported
42 Hardware and Software Used The experiments for thispaper were carried out on a cluster of twenty computingnodes plus a master node Each one of these compute nodeshas the following features
(i) Processors 2 x Intel Xeon CPU E5-2620
(ii) Cores 6 per processor (12 threads)
(iii) Clock speed 200GHz
(iv) Cache 15MB
(v) Network QDR InfiniBand (40Gbps)
(vi) Hard drive 2 TB
(vii) RAM 64GB
Both Hadoop master processesmdashthe NameNode and theJobTrackermdashare hosted in the master node The formercontrols the HDFS coordinating the slave machines by themeans of their respectiveDataNode processes while the latteris in charge of the TaskTrackers of each compute node whichexecute the MapReduce framework Spark follows a similarconfiguration as the master process is located on the masternode and the worker processes are executed on the slavemachines Both frameworks share the underlying HDFS filesystem
These are the details of the software used for the experi-ments
(i) MapReduce implementation Hadoop 200-cdh471MapReduce 1 (Clouderarsquos open-source Apache Had-oop distribution)
(ii) Spark version Apache Spark 100
(iii) Maximum maps tasks 320 (16 per node)
(iv) Maximum reducer tasks 20 (1 per node)
(v) Operating system CentOS 66
Note that the total number of cores of the cluster is 240However a higher number of maps were kept to maximizethe use of the cluster by allowing a higher parallelism and abetter data locality thereby reducing the network overload
43 Experiments with the Epsilon Dataset This sectionexplains the results obtained for the epsilon dataset FirstSection 431 describes the performance of the feature selec-tion procedure and compares it with a sequential approachThen Section 432 describes the results obtained in theclassification
Mathematical Problems in Engineering 7
Table 3 Execution times (in seconds) over the epsilon subsets
Instances Sequential CHC MR-EFS Splits1000 391 419 12000 1352 409 25000 8667 413 510 000 39 576 431 1015 000 91 272 445 1520 000 159 315 455 20400 000 mdash 6531 512
431 Feature Selection Performance The complexity order ofthe CHC algorithm is approximately O(1198992119863119901) where 119901 isthe number of evaluations of the fitness function (a 119896-NNclassifier in this case) 119899 is the number of instances and 119863 isthe number of features Therefore the algorithm is quadraticwith respect to the number of instances
When the dataset is divided into 119898 splits within MR-EFS each one of the 119898 map tasks has complexity orderO((119899
21198982)119863119901) which is 1198982 times faster than applying CHCover the whole dataset If 119899
119888cores are available for the map
tasks the complexity of the map phase within the MR-EFS procedure is approximately O(lceil119898119899
119888rceil(11989921198982)119863119901) This
demonstrates the scalability of the approach presented in thispaper even if themaps are executed sequentially (119899
119888= 1) the
procedure is still one order of magnitude faster than feedinga single CHC with all the instances at once
In order to verify the performance of MR-EFS withrespect to the sequential approach a set of experimentswere performed using subsets of the epsilon dataset Botha sequential CHC algorithm and the parallel MR-EFS (with1000 instances per split) were applied over those subsetsThe obtained execution times are presented in Table 3 andFigure 5 along with the runtime of MR-EFS over the wholedataset
The sequential runtimes described a quadratic shapein concordance with the complexity order of CHC whichclearly states that the time necessary to tackle the wholedataset would be impractical In opposite the runtime ofMR-EFS for the small datasets was nearly constant The casewith 1000 instances is particular in the sense that MR-EFSonly executed one map task therefore it executed a singleCHC with 1000 instances The time difference between CHCand MR-EFS in this case reflects the overhead introduced bythe latter Even though his overhead increased slightly as thenumber of map tasks grew it represented a minor part of theoverall runtime
As for the full dataset with 512 splits the number ofinstances for each map task in MR-EFS is around 780 As thenumber of cores used for the experiments was 240 the mapphase in MR-EFS should be roughly three times slower thanthe sequential CHC with 1000 instances according to thecomplexity orders previously detailed The times in Table 3show a higher time gap because MR-EFS includes as well theother phases of theMapReduce framework (namely splittingshuffle and reduce) which are nonnegligible for a dataset ofsuch size Nevertheless the overall MR-EFS execution time is
0 5000 10000 15000 20000
0
50000
100000
150000
Number of instances
Tim
e (s)
Sequential CHCMR-EFSMR-EFS (full dataset)
Figure 5 Execution times of the sequential CHC and MR-EFS
064
066
068
070
500 1000 1500 2000Features
AUC
ClassifierLogistic RegressionNaive BayesSVM-00SVM-05
SetTrainingTest
Figure 6 Accuracy with the epsilon dataset Note that the numberof features decreases as the threshold increases
highly scalable as shown by the fact that MR-EFS was able toprocess the 400 000 instances faster than the time needed byCHC to process 5000 instances
432 Classification Results This section presents the resultsobtained by applying several classifiers over the full epsilondataset with its features previously selected by usingMR-EFSThe dataset was split among 512 map tasks each of whichcomputed around 780 instances
The AUC values are shown in Table 4 and Figure 6 bothfor training and test sets using three different thresholdsfor the dataset reduction step Note that the zero-thresholdcorresponds to the original dataset without performing any
8 Mathematical Problems in Engineering
Table 4 AUC results for the Spark classifiers using epsilon
Threshold Features Logistic Regression Naive Bayes SVM (120582 = 00) SVM (120582 = 05)Training Test Training Test Training Test Training Test
000 2000 06786 06784 07038 07008 06440 06433 06440 06433055 721 06985 07000 07154 07127 06855 06865 06855 06865060 337 06873 06867 07054 07030 06805 06799 06805 06799065 110 06496 06497 06803 06794 06492 06493 06492 06493
Table 5 Training runtime (in seconds) for the Spark classifiers using epsilon
Threshold Features Logistic Regression Naive Bayes SVM (120582 = 00) SVM (120582 = 05)000 2000 36729 60514 33418 33169055 721 40935 34042 40970 38684060 337 48816 30733 50546 48993065 110 50186 26426 46744 47374
Table 6 Size of the epsilon dataset for each threshold
Threshold Set MB HDFS blocks
000 Training 817918 128Test 204480 32
055 Training 294652 47Test 73663 12
060 Training 137721 22Test 34430 6
065 Training 45060 8Test 11265 2
feature selectionThebest results for eachmethod are stressedin boldface The table shows that the accuracy was improvedby the removal of the adequate features as the threshold 055allowed for obtaining higher AUC values The accuracy gainwas especially large for SVMMoreover more than half of thefeatures were removed which reduces significantly the sizeof the dataset and therefore the complexity of the resultingclassifier
A threshold of value 060 also got to improve the accuracyresults while reducing even further the size of the datasetFinally for the 065 thresholds only SVM saw its AUCimproved
It is also noteworthy that the two variants of SVMobtained the same results for all the tested thresholds Thisfact indicates that the complexity of the obtained SVMmodelis relatively low
The training runtime of the different algorithms anddatabases is shown in Table 5 and Figure 7 The obtainedresults were seemingly the opposite to the expectationsexcept for Naive Bayes the classifiers needed more time toprocess the datasets as their number of features decreases
However this behavior can be explained as the datasetgets smaller it occupies less HDFS blocks and thereforethe full parallel capacity of the cluster is not exploited Thesize of each version of the epsilon dataset and the numberof HDFS blocks that are needed to store it are shown inTable 6 The computer cluster is composed of 20 machinestherefore when the number of blocks is lower than 20 some
300
400
500
600
500 1000 1500 2000Features
Run
time (
s)
Logistic RegressionNaive Bayes
SVM-00SVM-05
Classifier
Figure 7 Training runtime with the epsilon dataset Note that thenumber of features decreases as the threshold increases
of the machines remain idle because they have no HDFSblock to process Moreover even if the number of blocks isslightly above 20 the affectedHDFS blocksmay not be evenlydistributed among the computing nodes This demonstratesthe capacity of Spark to deal with big databases as thesize of the database (more concretely the number of HDFSblocks) increases the framework is able to distribute theprocesses more evenly exploiting data locality increasing theparallelism and reducing the network overhead
In order to deal with this problem the same experimentswere repeated over the epsilon dataset after reorganizing thefiles with a smaller block size For each of the eight sets theblock size 119878
119887was calculated according to (6) where 119904 is the
size of the dataset in bytes and 119899119888is the number of cores in
the cluster
119878119887= 2119870
119870 = lfloorlog2119904
119899119888
rfloor (6)
Mathematical Problems in Engineering 9
Table 7 Training runtime (in seconds) for the Spark classifiers using epsilon with customized block size
Threshold Features Logistic Regression Naive Bayes SVM (120582 = 00) SVM (120582 = 05)000 2000 32194 48348 30094 30647055 721 25692 31319 25672 25698060 337 23616 24859 23123 22803065 110 30770 30826 25405 26123
Table 8 AUC values for the Spark classifiers using ECBDL14-ROS
Threshold Features Logistic Regression Naive Bayes SVM (120582 = 00) SVM (120582 = 05)Training Test Training Test Training Test Training Test
000 631 05821 05808 06714 06506 05966 06046 05875 05897055 234 06416 06352 06673 06489 06369 06307 06228 06148060 119 06309 06235 06732 06516 05884 05841 06116 06054065 46 05017 05022 06136 06093 05032 05039 05000 05000
Table 9 Training runtime (in seconds) for the Spark classifiers using ECBDL14-ROS
Threshold Features Logistic Regression Naive Bayes SVM (120582 = 00) SVM (120582 = 05)000 631 464919 158152 528388 506587055 234 210766 61350 232122 217918060 119 116298 32206 135285 122672065 46 97838 21509 91432 86428
The runtime for the dataset with the block size cus-tomized for each subset is displayed in Table 7 and Figure 8It is observed that the runtime was smaller than that withthe default block size Furthermore the curves show theexpected behavior as the number of features of the datasetwas reduced the runtime decreased In the extreme case(for threshold 065) the runtime increased again becausewith such a small dataset the synchronization times of Sparkbecome bigger than the computing times even with thecustomized block size
In the next section MR-EFS is tested over a very largedataset validating these observations
44 Experiments with the ECBDL14-ROS Dataset This sec-tion presents the classification accuracy and runtime resultsobtained with the ECBDL14-ROS dataset As describedin Section 41 a random oversampling technique [39] waspreviously applied over the original ECBDL14 dataset toovercome the problems originated by its imbalanceTheMR-EFS method was applied using 32 768 map tasks thereforeeach map task computed around 1984 instances
The obtained results in terms of accuracy are depictedin Table 8 and Figure 9 MR-EFS improved the results inall cases with different thresholds The accuracy gain wasespecially important for the Logistic Regression and SVMalgorithms As expected the SVM with 120582 = 00 obtainedbetter results than the onewith120582 = 05 as the latter attemptedto reduce the complexity of the obtained model Howeverit is noteworthy that for 119 features SVM-05 was able tooutperform SVM-00 This hints that after removing noisyfeatures the simpler obtained models represented better the
300
400
500 1000 1500 2000Features
Run
time (
s)
Logistic RegressionNaive Bayes
SVM-00SVM-05
Classifier
Figure 8 Training runtime with the epsilon dataset with cus-tomized block size Note that the number of features decreases asthe threshold increases
true knowledge underlying the data With even less featuresboth variants of SVM obtained roughly the same accuracy
To conclude this study the runtime necessary to trainthe classifiers with all variants of ECBDL14-ROS is presentedin Table 9 and Figure 10 In this case the runtime behavedas expected the time was roughly linear with respect to thenumber of features for all testedmodelsThismeans thatMR-EFS was able to improve both the runtime and the accuracyfor all those classifiers
10 Mathematical Problems in Engineering
050
055
060
065
200 400 600Features
AUC
ClassifierLogistic RegressionNaive BayesSVM-00SVM-05
SetTrainingTest
Figure 9 Accuracy with the ECBDL14-ROS dataset Note that thenumber of features decreases as the threshold increases
0
1000
2000
3000
4000
5000
Run
time (
s)
200 400 600Features
Logistic RegressionNaive Bayes
SVM-00SVM-05
Classifier
Figure 10 Training runtime with the ECBDL14-ROS dataset Notethat the number of features decreases as the threshold increases
5 Concluding Remarks
This paper presents MR-EFS an Evolutionary Feature Selec-tion algorithm designed upon the MapReduce paradigmintended to preprocess big datasets so that they becomeaffordable for other machine learning techniques such asclassification techniques that are currently not scalableenough to deal with such datasets The algorithm has beenimplemented using Apache Hadoop and it has been appliedover two different large datasets The resulting reduceddatasets have been tested using three different classifiersimplemented inApache Spark over a cluster of 20 computers
The theoretical evaluation of themodel highlights the fullscalability of MR-EFS with respect to the number of featuresin the dataset in comparison with a sequential approachThis behavior has been further confirmed after the empiricalprocedures
According to the obtained classification results it can beclaimed thatMR-EFS is able to reduce adequately the numberof features of large datasets leading to reduced versionsof them that are at the same time smaller to store fasterto compute and easier to classify These facts have beenobserved with the two different datasets and for all testedclassifiers
For the epsilon dataset the relation between the reduceddatasets size and the number of nodes is forced to modifythe HDFS block size proving that the hardware resourcescan be optimally used by Hadoop and Spark with the correctdesign One of the obtained reduced ECDBL14-ROS datasetswith more than 67 million instances and several hundredfeatures could be processed by the classifiers in less thanhalf of the time than that of the original dataset and with animprovement of around 5 in terms of AUC
Conflict of Interests
The authors declare that there is no conflict of interestsregarding the publication of this paper
Acknowledgments
This work is supported by the Research Projects TIN2014-57251-P P10-TIC-6858 P11-TIC-7765 P12-TIC-2958 andTIN2013-47210-P D Peralta and S Ramırez-Gallego holdtwo FPU scholarships from the Spanish Ministry of Educa-tion and Science (FPU1204902 FPU1300047) I Trigueroholds a BOF postdoctoral fellowship from the Ghent Univer-sity
References
[1] E Alpaydin Introduction to Machine Learning MIT PressCambridge Mass USA 2nd edition 2010
[2] MMinelliMChambers andADhirajBigData BigAnalyticsEmerging Business Intelligence and Analytic Trends for TodayrsquosBusinesses (Wiley CIO) Wiley 1st edition 2013
[3] V Marx ldquoThe big challenges of big datardquo Nature vol 498 no7453 pp 255ndash260 2013
[4] A Fernandez S del Rıo V Lopez et al ldquoBig data with cloudcomputing an insight on the computing environment MapRe-duce and programming frameworksrdquo Wiley InterdisciplinaryReviews Data Mining and Knowledge Discovery vol 4 no 5pp 380ndash409 2014
[5] E Merelli M Pettini and M Rasetti ldquoTopology driven model-ing the IS metaphorrdquo Natural Computing 2014
[6] S Sakr A Liu DM Batista andM Alomari ldquoA survey of largescale data management approaches in cloud environmentsrdquoIEEE Communications Surveys and Tutorials vol 13 no 3 pp311ndash336 2011
[7] J Bacardit and X Llora ldquoLarge-scale data mining usinggenetics-based machine learningrdquo Wiley Interdisciplinary
Mathematical Problems in Engineering 11
Reviews Data Mining and Knowledge Discovery vol 3 no 1pp 37ndash61 2013
[8] J Dean and SGhemawat ldquoMapReduce simplified data process-ing on large clustersrdquo Communications of the ACM vol 51 no1 pp 107ndash113 2008
[9] J Dean and S Ghemawat ldquoMap reduce a flexible data process-ing toolrdquo Communications of the ACM vol 53 no 1 pp 72ndash772010
[10] S Ghemawat H Gobioff and S-T Leung ldquoThe google file sys-temrdquo in Proceedings of the 19th ACM Symposium on OperatingSystems Principles (SOSP rsquo03) pp 29ndash43 October 2003
[11] M Snir and S Otto MPImdashThe Complete Reference The MPICore MIT Press Boston Mass USA 1998
[12] W Zhao H Ma and Q He ldquoParallel k-means clustering basedon MapReducerdquo in Cloud Computing M Jaatun G Zhao andC Rong Eds vol 5931 of Lecture Notes in Computer Sciencepp 674ndash679 Springer Berlin Germany 2009
[13] A Srinivasan T A Faruquie and S Joshi ldquoData and taskparallelism in ILP using MapReducerdquo Machine Learning vol86 no 1 pp 141ndash168 2012
[14] M Zaharia M Chowdhury T Das et al ldquoResilient distributeddatasets a fault-tolerant abstraction for in-memory clustercomputingrdquo in Proceedings of the 9th USENIX Conferenceon Networked Systems Design and Implementation pp 1ndash14USENIX Association 2012
[15] K Thomas C Grier J Ma V Paxson and D Song ldquoDesignand evaluation of a real-time URL spam filtering servicerdquo inProceedings of the IEEE Symposium on Security and Privacy (SPrsquo11) pp 447ndash462 Berkeley Calif USA May 2011
[16] R S Xin J Rosen M Zaharia M J Franklin S Shenker andI Stoica ldquoShark SQL and rich analytics at scalerdquo in Proceedingsof the ACM SIGMOD International Conference on Managementof Data (SIGMOD rsquo13) pp 13ndash24 ACM June 2013
[17] M S Wiewiorka A Messina A Pacholewska S Maffioletti PGawrysiak and M J Okoniewski ldquoSparkSeq fast scalable andcloud-ready tool for the interactive genomic data analysis withnucleotide precisionrdquo Bioinformatics vol 30 no 18 pp 2652ndash2653 2014
[18] S Garcıa J Luengo and F Herrera Data Preprocessing in DataMining Springer 1st edition 2015
[19] H Brighton and C Mellish ldquoAdvances in instance selection forinstance-based learning algorithmsrdquo Data Mining and Knowl-edge Discovery vol 6 no 2 pp 153ndash172 2002
[20] J A Olvera-Lopez J A Carrasco-Ochoa J F Martınez-Trinidad and J Kittler ldquoA reviewof instance selectionmethodsrdquoArtificial Intelligence Review vol 34 no 2 pp 133ndash143 2010
[21] J S Sanchez ldquoHigh training set size reduction by spacepartitioning and prototype abstractionrdquo Pattern Recognitionvol 37 no 7 pp 1561ndash1564 2004
[22] I Guyon and A Elisseeff ldquoAn introduction to variable andfeature selectionrdquo Journal of Machine Learning Research vol 3pp 1157ndash1182 2003
[23] H Liu and L Yu ldquoToward integrating feature selection algo-rithms for classification and clusteringrdquo IEEE Transactions onKnowledge and Data Engineering vol 17 no 4 pp 491ndash5022005
[24] Y Saeys I Inza and P Larranaga ldquoA review of feature selectiontechniques in bioinformaticsrdquo Bioinformatics vol 23 no 19 pp2507ndash2517 2007
[25] H Liu and H Motoda Computational Methods of FeatureSelection Chapman amp HallCRC Data Mining and KnowledgeDiscovery Series Chapman amp HallCRC Press 2007
[26] J A Lee andMVerleysenNonlinear Dimensionality ReductionSpringer 2007
[27] B de la Iglesia ldquoEvolutionary computation for feature selectionin classification problemsrdquo Wiley Interdisciplinary ReviewsDataMining and Knowledge Discovery vol 3 no 6 pp 381ndash4072013
[28] L J Eshelman ldquoThe CHC adaptative search algorithm howto have safe search when engaging in nontraditional geneticrecombinationrdquo in Foundations of Genetic Algorithms G J ERawlins Ed pp 265ndash283MorganKaufmann SanMateo CalifUSA 1991
[29] MLlib Website httpssparkapacheorgmllib[30] R Kohavi and G H John ldquoWrappers for feature subset
selectionrdquo Artificial Intelligence vol 97 no 1-2 pp 273ndash3241997
[31] M Tan I W Tsang and L Wang ldquoTowards ultrahighdimensional feature selection for big datardquo Journal of MachineLearning Research vol 15 pp 1371ndash1429 2014
[32] T White Hadoop The Definitive Guide OrsquoReilly Media 3rdedition 2012
[33] T Cover and P Hart ldquoNearest neighbor pattern classificationrdquoIEEE Transactions on Information Theory vol 13 no 1 pp 21ndash27 1967
[34] I Triguero D Peralta J Bacardit S Garcıa and F HerreraldquoMRPR a MapReduce solution for prototype reduction in bigdata classificationrdquoNeurocomputing vol 150 pp 331ndash345 2015
[35] C-T Chu S Kim Y-A Lin et al ldquoMap-reduce for machinelearning on multicorerdquo in Advances in Neural InformationProcessing Systems pp 281ndash288 2007
[36] Pascal large scale learning challenge httplargescalemltu-berlindeinstructions
[37] Epsilon in the LIBSVM website httpwwwcsientuedutwsimcjlinlibsvmtoolsdatasetsbinaryhtmlepsilon
[38] ECBDL14 dataset Protein structure prediction and contactmapfor the ECBDL2014 Big Data Competition httpcrunchernclacukbdcomp
[39] S del Rıo V Lopez J M Benıtez and F Herrera ldquoOn the useof MapReduce for imbalanced big data using Random ForestrdquoInformation Sciences vol 285 pp 112ndash137 2014
[40] M A Hearst S T Dumais E Osman J Platt and B ScholkopfldquoSupport vector machinesrdquo IEEE Intelligent Systems and TheirApplications vol 13 no 4 pp 18ndash28 1998
[41] D W Hosmer Jr and S Lemeshow Applied Logistic RegressionJohn Wiley amp Sons 2004
[42] R O Duda and P E Hart Pattern Classification and SceneAnalysis vol 3 Wiley New York NY USA 1973
[43] MLlib guide httpsparkapacheorgdocslatestmllib-guidehtml
Submit your manuscripts athttpwwwhindawicom
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical Problems in Engineering
Hindawi Publishing Corporationhttpwwwhindawicom
Differential EquationsInternational Journal of
Volume 2014
Applied MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Probability and StatisticsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical PhysicsAdvances in
Complex AnalysisJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
OptimizationJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
CombinatoricsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Operations ResearchAdvances in
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Function Spaces
Abstract and Applied AnalysisHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of Mathematics and Mathematical Sciences
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Algebra
Discrete Dynamics in Nature and Society
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Decision SciencesAdvances in
Discrete MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom
Volume 2014 Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Stochastic AnalysisInternational Journal of

Mathematical Problems in Engineering 3
Map Shuffle Reduce
Split0
Split1
Split2
Part0
Part1
Part2
OutputInput data
Figure 1 Flowchart of the MapReduce framework
221 MapReduce MapReduce [8 9] is one of the mostpopular programming models to deal with big data It wasproposed by Google in 2004 and designed for processinghuge amounts of data using a cluster of machines TheMapReduce paradigm is composed of two phases map andreduce In general terms in the map phase the input datasetis processed producing some intermediate results Then thereduce phase combines them in some way to form the finaloutput
The MapReduce model is based on a basic data structureknown as the ⟨key value⟩ pair In the map phase eachapplication of the map function receives a single ⟨key value⟩pair as input and generates a list of intermediate ⟨key value⟩pairs as output This is represented by the following form
map (key1 value1) 997888rarr (key2 value2) (1)
Then the MapReduce library groups all intermediate⟨key value⟩ pairs by key Finally the reduce function takesthe aggregated pairs and generates a new ⟨key value⟩ pair asoutput This is depicted by the following form
reduce (key2 value2 ) 997888rarr (key2 value3) (2)
A flowchart of the MapReduce framework is presented inFigure 1
222 Hadoop and Spark Different implementations of theMapReduce programming model have appeared in the lastyearsThemost popular one is ApacheHadoop [32] an open-source framework written in Java that allows the processingandmanagement of large datasets in a distributed computingenvironment In addition Hadoop works on top of theHadoop Distributed File System (HDFS) which replicatesthe data files in many storage nodes facilitating rapid datatransfer rates among nodes and allowing the system tocontinue operating without interruption when one or severalnodes fail
In this paper Apache Hadoop is used to implement theproposal MR-EFS as described in Section 32
Another Apache project that is tightly related to Hadoopis Spark [14] It is a cluster computing framework originallydeveloped in the UC Berkeley AMP Lab for large-scale
data processing that improves the efficiency by the use ofintensive memory Spark uses HDFS and has high-levellibraries for stream processing and for machine learning andgraph processing such as MLlib [29]
For this work several classifiers included in MLlib areused to test the MR-EFS algorithm SVM Naive Bayesand Logistic Regression Their parameters are specified inSection 41
3 MR-EFS MapReduce for EvolutionaryFeature Selection
This section describes the proposed MapReduce approachfor EFS as well as its integration in a generic classificationprocess In particular the MR-EFS algorithm is based on theCHC algorithm to perform feature selection as described inSection 31
First MR-EFS is applied over the original dataset toobtain a vector of weights that indicates the relevance ofeach attribute (Section 32) Then this vector is used withinanotherMapReduce process to produce the resulting reduceddataset (Section 33) Finally the reduced dataset is used by aclassification algorithm
31 CHCAlgorithm for Feature Selection TheCHCalgorithm[28] is a binary-coded genetic algorithm that combines a veryhigh selective pressure with an elitist selection strategy alongwith several components that introduce diversity The mainparts of CHC are the following
(i) Half Uniform Crossover (HUX) This crossover oper-ator aims at enforcing a high diversity and reducingthe risk of premature convergence It selects at ran-dom half of the bits that are different between bothparents Then it obtains two offspring that are at themaximum Hamming distance from their parents
(ii) Elitist selection In each generation the new popula-tion is composed of the best individuals (those withthe best values of the fitness function) among boththe current and the offspring populations In case ofdraw between a parent and an offspring the parent isselected
(iii) Incest prevention Two individuals are not allowedto mate if the Hamming similarity between themexceeds a threshold 119889 (usually initialized to 119889 = 1198712where 119871 is the chromosome length) The threshold isdecremented by one when no offspring is obtained inone generation which indicates that the algorithm isconverging
(iv) Restarting process When 119889 = 0 (which happensafter several generations without any new offspring)the population is considered to be stagnated Insuch a case a new population is generated the bestindividual is kept and the remaining individuals havea certain percentage of their bits flipped
The basic execution scheme of CHC is shown inFigure 2This algorithmnaturally adapts to a feature selection
4 Mathematical Problems in Engineering
Parents Offspring
HUX
HUX
HUX
Incestprevention
If no offspring is generated
Restart population
Yes
No
Select best
d = 0
New population
dlarrd minus 1
Figure 2 Flowchart of the CHC algorithm
problem as each feature can be represented as a bit inthe solution vectorThus each position of the vector indicatesif the corresponding feature is selected or not Thereforethis approach falls within the wrapper method categoryaccording to the classification established in Section 21 Thefitness function used to evaluate new individuals applies a 119896-Nearest Neighbors classifier (119896-NN) [33] over the dataset thatwould be obtained after removing the corresponding featuresThe fitness value is the weighted sum of the 119896-NN accuracyand the feature reduction rate
32 MR-EFS Algorithm This section describes the paral-lelization of the CHC algorithm by using a MapReduceprocedure to obtain a vector of weights
Let 119879 be a training set stored in HFDS and random-ized as described in [34] Let 119898 be the number of maptasks The splitting procedure of MapReduce divides 119879 in119898 disjoint subsets of instances Then each 119879
119894subset (119894 isin
1 2 119898) is processed by the corresponding Map119894task
As this partitioning is performed sequentially all subsets willhave approximately the same number of instances and therandomization of the 119879 file ensures an adequate balance ofthe classes
Themap phase over each 119879119894consists of the EFS algorithm
(in this case based on CHC) as described in Section 31Therefore the output of each map task is a binary vectorfi = 119891
1198941 119891119894119863 where 119863 is the number of features thatindicates which features were selected by the CHC algorithmThe reduce phase averages all the binary vectors obtaininga vector x as defined in (3) where 119909
119895is the proportion of
EFS applications that include the feature 119895 in their resultThis vector is the result of the overall EFS process and isused to build the reduced dataset that will be used for furthermachine learning purposes
x = 1199091 119909119863
119909119895=
1119898
119898
sum119894=1
119891119894119895 119895 isin 1 2 119863
(3)
sum
Initial Map Reduce Final
Mappers training set
Original trainingdataset
CHC
CHC
CHC
0 1 1 0
1 1 1 0
0 1 0 0
middot middot middot
middot middot middot
middot middot middot
01 03 02 00
Figure 3 Flowchart of MR-EFS algorithm
In the implementation used for the experiments thereduce phase is carried out by a single task which reducesthe runtime by decreasing theMapReduce overhead [35]Thewhole MapReduce process for EFS is depicted in Figure 3 Itis noteworthy that the whole procedure is performed withina single iteration of the MapReduce workflow avoidingadditional disk accesses
33 Dataset Reduction with MapReduce Once vector x iscalculated the objective is to remove the less promisingfeatures from the original dataset To do so in a scalablemanner an additional MapReduce process was designedFirst vector x is binarized using a threshold 120579
b = 1198871 119887119863
119887119895=
1 if 119909119895ge 120579
0 otherwise
(4)
Vector b indicates which features will be selected forthe reduced dataset The number of selected features (1198631015840 =sum119863
119895=1 119887119895) can be controlled with 120579 with a high threshold onlya few features will be selected while a lower threshold allowsmore features to be picked
Mathematical Problems in Engineering 5
Initial Map Final
Original trainingtestdataset
Mappers trainingtest set
Result of EPS
+
Threshold
Reduced dataset
0 1 1 0middot middot middot
0 1 1 0middot middot middot
0 1 1 0middot middot middot
0 1 1 0middot middot middot
middot middot middot middot middot middot
middot middot middot middot middot middot
middot middot middot middot middot middot
01 03 02 00middot middot middot
Figure 4 Flowchart of the dataset reduction process
The MapReduce process for the dataset reduction worksas follows Each map processes an instance and generatesa new one that only contains the features selected in bFinally the instances generated are concatenated to form thefinal reduced dataset without the need of a reduce step Thedataset reduction process using the result of MR-EFS and anarbitrary threshold is depicted in Figure 4
4 Experimental Framework and Analysis
This section describes the performed experiments and theirresults First Section 41 describes the datasets and themethods used for the experiments Section 42 details theunderlying hardware and software support Finally Sections43 and 44 present the results obtained using two differentdatasets
41 Datasets and Methods This experimental study uses twolarge binary classification datasets in order to analyze thequality of the solutions provided by the MR-EFS algorithm
First the epsilon dataset was used which is composed of500 000 instances with 2000 numerical features This datasetwas artificially created for the Pascal Large Scale LearningChallenge [36] in 2008Theversion provided by LIBSVM[37]was used
Additionally this study includes the dataset used at thedata mining competition of the Evolutionary Computationfor Big Data and Big Learning held on July 14 2014 inVancouver (Canada) under the international conferenceGECCO-2014 (from now on it is referred to as ECBDL14)
[38] This dataset has 631 features (including both numericaland categorical attributes) and it is composed of approxi-mately 32 million instances Moreover the class distributionis not balanced 98 of the instances belong to the negativeclass
In order to deal with the imbalance problem the MapRe-duce approach of the Random Oversampling (ROS) algo-rithm presented in [39] was applied over the original trainingset for ECBDL14 The aim of ROS is to replicate the minorityclass instances from the original dataset until the number ofinstances from both classes is the same
Despite the inconvenience of increasing the size of thedataset this technique was proven in [39] to yield bet-ter performance than other common approaches to dealwith imbalance problems such as undersampling and cost-sensitive methods These two approaches suffer from thesmall sample size problem for the minority class when theyare used within a MapReduce model
Themain characteristics of these datasets are summarizedin Table 1 For each dataset the number of instances for bothtraining and test sets and the number of attributes are shownalong with the number of splits in which MR-EFS dividedeach dataset Note that the imbalanced version of ECBDL14 isnot used in the experiments as only the balanced ECBDL14-ROS version is considered
The parameters for the CHC algorithm are presented inTable 2
After applying MR-EFS over the described datasets thebehavior of the obtained reduced datasets was tested usingthree different classifiers implemented in Spark availablein MLlib SVM [40] Logistic Regression [41] and Naive
6 Mathematical Problems in Engineering
Table 1 Summary of the used big data classification datasets
Dataset Training instances Test instances Features Splits Instances per splitEpsilon 400 000 100 000 2000 512 sim780ECBDL14 31 992 921 2 897 917 631 mdash mdashECBDL14-ROS 65 003 913 2 897 917 631 32 768 sim1984
Table 2 Parameter specification for all the methods involved in theexperimentation
Algorithm Parameters
CHC
119896 value for 119896-NN 1Trade-off between reduction and accuracy 05Proportion of flipped bits in restarting process 005Population size 40Number of evaluations 1000
Naive Bayes Lambda 10 (default)
LogisticRegression
Iterations 100 (default)StepSize 10 (default)miniBatchFraction 10
SVM
Regularization parameter 00 05Iterations 100 (default)StepSize 10 (default)miniBatchFraction 10
Bayes [42] The reader may refer to the provided referencesor to the MLlib guide [43] for further details about theirinternal functioningThe parameters used for these classifiersare listed in Table 2 Particularly two different variants ofSVM were used modifying the regularization parameterwhich allows the algorithm to calculate simpler models bypenalizing complex models in the objective function
In the remainder of this paper two metrics are used toevaluate the performance of the three classifiers when appliedover the obtained reduced datasets
(i) Area Under the Curve (AUC) This measure is definedas the area under the Receiver Operating Charac-teristic (ROC) curve In this work this value isapproximated with the formula in (5) where TPR isthe True Positive Rate and TNR is the True NegativeRate These values can be directly obtained fromthe confusion matrix and are not affected by theimbalance of the dataset
AUC =TPR + TNR
2 (5)
(ii) Training runtime It is the time (in seconds) used totrain or build the classifier
Note that for this study the test runtime is much lessaffected by the feature selection process because at that pointthe classifier has already been built For the sake of simplicityonly training runtimes are reported
42 Hardware and Software Used The experiments for thispaper were carried out on a cluster of twenty computingnodes plus a master node Each one of these compute nodeshas the following features
(i) Processors 2 x Intel Xeon CPU E5-2620
(ii) Cores 6 per processor (12 threads)
(iii) Clock speed 200GHz
(iv) Cache 15MB
(v) Network QDR InfiniBand (40Gbps)
(vi) Hard drive 2 TB
(vii) RAM 64GB
Both Hadoop master processesmdashthe NameNode and theJobTrackermdashare hosted in the master node The formercontrols the HDFS coordinating the slave machines by themeans of their respectiveDataNode processes while the latteris in charge of the TaskTrackers of each compute node whichexecute the MapReduce framework Spark follows a similarconfiguration as the master process is located on the masternode and the worker processes are executed on the slavemachines Both frameworks share the underlying HDFS filesystem
These are the details of the software used for the experi-ments
(i) MapReduce implementation Hadoop 200-cdh471MapReduce 1 (Clouderarsquos open-source Apache Had-oop distribution)
(ii) Spark version Apache Spark 100
(iii) Maximum maps tasks 320 (16 per node)
(iv) Maximum reducer tasks 20 (1 per node)
(v) Operating system CentOS 66
Note that the total number of cores of the cluster is 240However a higher number of maps were kept to maximizethe use of the cluster by allowing a higher parallelism and abetter data locality thereby reducing the network overload
43 Experiments with the Epsilon Dataset This sectionexplains the results obtained for the epsilon dataset FirstSection 431 describes the performance of the feature selec-tion procedure and compares it with a sequential approachThen Section 432 describes the results obtained in theclassification
Mathematical Problems in Engineering 7
Table 3 Execution times (in seconds) over the epsilon subsets
Instances Sequential CHC MR-EFS Splits1000 391 419 12000 1352 409 25000 8667 413 510 000 39 576 431 1015 000 91 272 445 1520 000 159 315 455 20400 000 mdash 6531 512
431 Feature Selection Performance The complexity order ofthe CHC algorithm is approximately O(1198992119863119901) where 119901 isthe number of evaluations of the fitness function (a 119896-NNclassifier in this case) 119899 is the number of instances and 119863 isthe number of features Therefore the algorithm is quadraticwith respect to the number of instances
When the dataset is divided into 119898 splits within MR-EFS each one of the 119898 map tasks has complexity orderO((119899
21198982)119863119901) which is 1198982 times faster than applying CHCover the whole dataset If 119899
119888cores are available for the map
tasks the complexity of the map phase within the MR-EFS procedure is approximately O(lceil119898119899
119888rceil(11989921198982)119863119901) This
demonstrates the scalability of the approach presented in thispaper even if themaps are executed sequentially (119899
119888= 1) the
procedure is still one order of magnitude faster than feedinga single CHC with all the instances at once
In order to verify the performance of MR-EFS withrespect to the sequential approach a set of experimentswere performed using subsets of the epsilon dataset Botha sequential CHC algorithm and the parallel MR-EFS (with1000 instances per split) were applied over those subsetsThe obtained execution times are presented in Table 3 andFigure 5 along with the runtime of MR-EFS over the wholedataset
The sequential runtimes described a quadratic shapein concordance with the complexity order of CHC whichclearly states that the time necessary to tackle the wholedataset would be impractical In opposite the runtime ofMR-EFS for the small datasets was nearly constant The casewith 1000 instances is particular in the sense that MR-EFSonly executed one map task therefore it executed a singleCHC with 1000 instances The time difference between CHCand MR-EFS in this case reflects the overhead introduced bythe latter Even though his overhead increased slightly as thenumber of map tasks grew it represented a minor part of theoverall runtime
As for the full dataset with 512 splits the number ofinstances for each map task in MR-EFS is around 780 As thenumber of cores used for the experiments was 240 the mapphase in MR-EFS should be roughly three times slower thanthe sequential CHC with 1000 instances according to thecomplexity orders previously detailed The times in Table 3show a higher time gap because MR-EFS includes as well theother phases of theMapReduce framework (namely splittingshuffle and reduce) which are nonnegligible for a dataset ofsuch size Nevertheless the overall MR-EFS execution time is
0 5000 10000 15000 20000
0
50000
100000
150000
Number of instances
Tim
e (s)
Sequential CHCMR-EFSMR-EFS (full dataset)
Figure 5 Execution times of the sequential CHC and MR-EFS
064
066
068
070
500 1000 1500 2000Features
AUC
ClassifierLogistic RegressionNaive BayesSVM-00SVM-05
SetTrainingTest
Figure 6 Accuracy with the epsilon dataset Note that the numberof features decreases as the threshold increases
highly scalable as shown by the fact that MR-EFS was able toprocess the 400 000 instances faster than the time needed byCHC to process 5000 instances
432 Classification Results This section presents the resultsobtained by applying several classifiers over the full epsilondataset with its features previously selected by usingMR-EFSThe dataset was split among 512 map tasks each of whichcomputed around 780 instances
The AUC values are shown in Table 4 and Figure 6 bothfor training and test sets using three different thresholdsfor the dataset reduction step Note that the zero-thresholdcorresponds to the original dataset without performing any
8 Mathematical Problems in Engineering
Table 4 AUC results for the Spark classifiers using epsilon
Threshold Features Logistic Regression Naive Bayes SVM (120582 = 00) SVM (120582 = 05)Training Test Training Test Training Test Training Test
000 2000 06786 06784 07038 07008 06440 06433 06440 06433055 721 06985 07000 07154 07127 06855 06865 06855 06865060 337 06873 06867 07054 07030 06805 06799 06805 06799065 110 06496 06497 06803 06794 06492 06493 06492 06493
Table 5 Training runtime (in seconds) for the Spark classifiers using epsilon
Threshold Features Logistic Regression Naive Bayes SVM (120582 = 00) SVM (120582 = 05)000 2000 36729 60514 33418 33169055 721 40935 34042 40970 38684060 337 48816 30733 50546 48993065 110 50186 26426 46744 47374
Table 6 Size of the epsilon dataset for each threshold
Threshold Set MB HDFS blocks
000 Training 817918 128Test 204480 32
055 Training 294652 47Test 73663 12
060 Training 137721 22Test 34430 6
065 Training 45060 8Test 11265 2
feature selectionThebest results for eachmethod are stressedin boldface The table shows that the accuracy was improvedby the removal of the adequate features as the threshold 055allowed for obtaining higher AUC values The accuracy gainwas especially large for SVMMoreover more than half of thefeatures were removed which reduces significantly the sizeof the dataset and therefore the complexity of the resultingclassifier
A threshold of value 060 also got to improve the accuracyresults while reducing even further the size of the datasetFinally for the 065 thresholds only SVM saw its AUCimproved
It is also noteworthy that the two variants of SVMobtained the same results for all the tested thresholds Thisfact indicates that the complexity of the obtained SVMmodelis relatively low
The training runtime of the different algorithms anddatabases is shown in Table 5 and Figure 7 The obtainedresults were seemingly the opposite to the expectationsexcept for Naive Bayes the classifiers needed more time toprocess the datasets as their number of features decreases
However this behavior can be explained as the datasetgets smaller it occupies less HDFS blocks and thereforethe full parallel capacity of the cluster is not exploited Thesize of each version of the epsilon dataset and the numberof HDFS blocks that are needed to store it are shown inTable 6 The computer cluster is composed of 20 machinestherefore when the number of blocks is lower than 20 some
300
400
500
600
500 1000 1500 2000Features
Run
time (
s)
Logistic RegressionNaive Bayes
SVM-00SVM-05
Classifier
Figure 7 Training runtime with the epsilon dataset Note that thenumber of features decreases as the threshold increases
of the machines remain idle because they have no HDFSblock to process Moreover even if the number of blocks isslightly above 20 the affectedHDFS blocksmay not be evenlydistributed among the computing nodes This demonstratesthe capacity of Spark to deal with big databases as thesize of the database (more concretely the number of HDFSblocks) increases the framework is able to distribute theprocesses more evenly exploiting data locality increasing theparallelism and reducing the network overhead
In order to deal with this problem the same experimentswere repeated over the epsilon dataset after reorganizing thefiles with a smaller block size For each of the eight sets theblock size 119878
119887was calculated according to (6) where 119904 is the
size of the dataset in bytes and 119899119888is the number of cores in
the cluster
119878119887= 2119870
119870 = lfloorlog2119904
119899119888
rfloor (6)
Mathematical Problems in Engineering 9
Table 7 Training runtime (in seconds) for the Spark classifiers using epsilon with customized block size
Threshold Features Logistic Regression Naive Bayes SVM (120582 = 00) SVM (120582 = 05)000 2000 32194 48348 30094 30647055 721 25692 31319 25672 25698060 337 23616 24859 23123 22803065 110 30770 30826 25405 26123
Table 8 AUC values for the Spark classifiers using ECBDL14-ROS
Threshold Features Logistic Regression Naive Bayes SVM (120582 = 00) SVM (120582 = 05)Training Test Training Test Training Test Training Test
000 631 05821 05808 06714 06506 05966 06046 05875 05897055 234 06416 06352 06673 06489 06369 06307 06228 06148060 119 06309 06235 06732 06516 05884 05841 06116 06054065 46 05017 05022 06136 06093 05032 05039 05000 05000
Table 9 Training runtime (in seconds) for the Spark classifiers using ECBDL14-ROS
Threshold Features Logistic Regression Naive Bayes SVM (120582 = 00) SVM (120582 = 05)000 631 464919 158152 528388 506587055 234 210766 61350 232122 217918060 119 116298 32206 135285 122672065 46 97838 21509 91432 86428
The runtime for the dataset with the block size cus-tomized for each subset is displayed in Table 7 and Figure 8It is observed that the runtime was smaller than that withthe default block size Furthermore the curves show theexpected behavior as the number of features of the datasetwas reduced the runtime decreased In the extreme case(for threshold 065) the runtime increased again becausewith such a small dataset the synchronization times of Sparkbecome bigger than the computing times even with thecustomized block size
In the next section MR-EFS is tested over a very largedataset validating these observations
44 Experiments with the ECBDL14-ROS Dataset This sec-tion presents the classification accuracy and runtime resultsobtained with the ECBDL14-ROS dataset As describedin Section 41 a random oversampling technique [39] waspreviously applied over the original ECBDL14 dataset toovercome the problems originated by its imbalanceTheMR-EFS method was applied using 32 768 map tasks thereforeeach map task computed around 1984 instances
The obtained results in terms of accuracy are depictedin Table 8 and Figure 9 MR-EFS improved the results inall cases with different thresholds The accuracy gain wasespecially important for the Logistic Regression and SVMalgorithms As expected the SVM with 120582 = 00 obtainedbetter results than the onewith120582 = 05 as the latter attemptedto reduce the complexity of the obtained model Howeverit is noteworthy that for 119 features SVM-05 was able tooutperform SVM-00 This hints that after removing noisyfeatures the simpler obtained models represented better the
300
400
500 1000 1500 2000Features
Run
time (
s)
Logistic RegressionNaive Bayes
SVM-00SVM-05
Classifier
Figure 8 Training runtime with the epsilon dataset with cus-tomized block size Note that the number of features decreases asthe threshold increases
true knowledge underlying the data With even less featuresboth variants of SVM obtained roughly the same accuracy
To conclude this study the runtime necessary to trainthe classifiers with all variants of ECBDL14-ROS is presentedin Table 9 and Figure 10 In this case the runtime behavedas expected the time was roughly linear with respect to thenumber of features for all testedmodelsThismeans thatMR-EFS was able to improve both the runtime and the accuracyfor all those classifiers
10 Mathematical Problems in Engineering
050
055
060
065
200 400 600Features
AUC
ClassifierLogistic RegressionNaive BayesSVM-00SVM-05
SetTrainingTest
Figure 9 Accuracy with the ECBDL14-ROS dataset Note that thenumber of features decreases as the threshold increases
0
1000
2000
3000
4000
5000
Run
time (
s)
200 400 600Features
Logistic RegressionNaive Bayes
SVM-00SVM-05
Classifier
Figure 10 Training runtime with the ECBDL14-ROS dataset Notethat the number of features decreases as the threshold increases
5 Concluding Remarks
This paper presents MR-EFS an Evolutionary Feature Selec-tion algorithm designed upon the MapReduce paradigmintended to preprocess big datasets so that they becomeaffordable for other machine learning techniques such asclassification techniques that are currently not scalableenough to deal with such datasets The algorithm has beenimplemented using Apache Hadoop and it has been appliedover two different large datasets The resulting reduceddatasets have been tested using three different classifiersimplemented inApache Spark over a cluster of 20 computers
The theoretical evaluation of themodel highlights the fullscalability of MR-EFS with respect to the number of featuresin the dataset in comparison with a sequential approachThis behavior has been further confirmed after the empiricalprocedures
According to the obtained classification results it can beclaimed thatMR-EFS is able to reduce adequately the numberof features of large datasets leading to reduced versionsof them that are at the same time smaller to store fasterto compute and easier to classify These facts have beenobserved with the two different datasets and for all testedclassifiers
For the epsilon dataset the relation between the reduceddatasets size and the number of nodes is forced to modifythe HDFS block size proving that the hardware resourcescan be optimally used by Hadoop and Spark with the correctdesign One of the obtained reduced ECDBL14-ROS datasetswith more than 67 million instances and several hundredfeatures could be processed by the classifiers in less thanhalf of the time than that of the original dataset and with animprovement of around 5 in terms of AUC
Conflict of Interests
The authors declare that there is no conflict of interestsregarding the publication of this paper
Acknowledgments
This work is supported by the Research Projects TIN2014-57251-P P10-TIC-6858 P11-TIC-7765 P12-TIC-2958 andTIN2013-47210-P D Peralta and S Ramırez-Gallego holdtwo FPU scholarships from the Spanish Ministry of Educa-tion and Science (FPU1204902 FPU1300047) I Trigueroholds a BOF postdoctoral fellowship from the Ghent Univer-sity
References
[1] E Alpaydin Introduction to Machine Learning MIT PressCambridge Mass USA 2nd edition 2010
[2] MMinelliMChambers andADhirajBigData BigAnalyticsEmerging Business Intelligence and Analytic Trends for TodayrsquosBusinesses (Wiley CIO) Wiley 1st edition 2013
[3] V Marx ldquoThe big challenges of big datardquo Nature vol 498 no7453 pp 255ndash260 2013
[4] A Fernandez S del Rıo V Lopez et al ldquoBig data with cloudcomputing an insight on the computing environment MapRe-duce and programming frameworksrdquo Wiley InterdisciplinaryReviews Data Mining and Knowledge Discovery vol 4 no 5pp 380ndash409 2014
[5] E Merelli M Pettini and M Rasetti ldquoTopology driven model-ing the IS metaphorrdquo Natural Computing 2014
[6] S Sakr A Liu DM Batista andM Alomari ldquoA survey of largescale data management approaches in cloud environmentsrdquoIEEE Communications Surveys and Tutorials vol 13 no 3 pp311ndash336 2011
[7] J Bacardit and X Llora ldquoLarge-scale data mining usinggenetics-based machine learningrdquo Wiley Interdisciplinary
Mathematical Problems in Engineering 11
Reviews Data Mining and Knowledge Discovery vol 3 no 1pp 37ndash61 2013
[8] J Dean and SGhemawat ldquoMapReduce simplified data process-ing on large clustersrdquo Communications of the ACM vol 51 no1 pp 107ndash113 2008
[9] J Dean and S Ghemawat ldquoMap reduce a flexible data process-ing toolrdquo Communications of the ACM vol 53 no 1 pp 72ndash772010
[10] S Ghemawat H Gobioff and S-T Leung ldquoThe google file sys-temrdquo in Proceedings of the 19th ACM Symposium on OperatingSystems Principles (SOSP rsquo03) pp 29ndash43 October 2003
[11] M Snir and S Otto MPImdashThe Complete Reference The MPICore MIT Press Boston Mass USA 1998
[12] W Zhao H Ma and Q He ldquoParallel k-means clustering basedon MapReducerdquo in Cloud Computing M Jaatun G Zhao andC Rong Eds vol 5931 of Lecture Notes in Computer Sciencepp 674ndash679 Springer Berlin Germany 2009
[13] A Srinivasan T A Faruquie and S Joshi ldquoData and taskparallelism in ILP using MapReducerdquo Machine Learning vol86 no 1 pp 141ndash168 2012
[14] M Zaharia M Chowdhury T Das et al ldquoResilient distributeddatasets a fault-tolerant abstraction for in-memory clustercomputingrdquo in Proceedings of the 9th USENIX Conferenceon Networked Systems Design and Implementation pp 1ndash14USENIX Association 2012
[15] K Thomas C Grier J Ma V Paxson and D Song ldquoDesignand evaluation of a real-time URL spam filtering servicerdquo inProceedings of the IEEE Symposium on Security and Privacy (SPrsquo11) pp 447ndash462 Berkeley Calif USA May 2011
[16] R S Xin J Rosen M Zaharia M J Franklin S Shenker andI Stoica ldquoShark SQL and rich analytics at scalerdquo in Proceedingsof the ACM SIGMOD International Conference on Managementof Data (SIGMOD rsquo13) pp 13ndash24 ACM June 2013
[17] M S Wiewiorka A Messina A Pacholewska S Maffioletti PGawrysiak and M J Okoniewski ldquoSparkSeq fast scalable andcloud-ready tool for the interactive genomic data analysis withnucleotide precisionrdquo Bioinformatics vol 30 no 18 pp 2652ndash2653 2014
[18] S Garcıa J Luengo and F Herrera Data Preprocessing in DataMining Springer 1st edition 2015
[19] H Brighton and C Mellish ldquoAdvances in instance selection forinstance-based learning algorithmsrdquo Data Mining and Knowl-edge Discovery vol 6 no 2 pp 153ndash172 2002
[20] J A Olvera-Lopez J A Carrasco-Ochoa J F Martınez-Trinidad and J Kittler ldquoA reviewof instance selectionmethodsrdquoArtificial Intelligence Review vol 34 no 2 pp 133ndash143 2010
[21] J S Sanchez ldquoHigh training set size reduction by spacepartitioning and prototype abstractionrdquo Pattern Recognitionvol 37 no 7 pp 1561ndash1564 2004
[22] I Guyon and A Elisseeff ldquoAn introduction to variable andfeature selectionrdquo Journal of Machine Learning Research vol 3pp 1157ndash1182 2003
[23] H Liu and L Yu ldquoToward integrating feature selection algo-rithms for classification and clusteringrdquo IEEE Transactions onKnowledge and Data Engineering vol 17 no 4 pp 491ndash5022005
[24] Y Saeys I Inza and P Larranaga ldquoA review of feature selectiontechniques in bioinformaticsrdquo Bioinformatics vol 23 no 19 pp2507ndash2517 2007
[25] H Liu and H Motoda Computational Methods of FeatureSelection Chapman amp HallCRC Data Mining and KnowledgeDiscovery Series Chapman amp HallCRC Press 2007
[26] J A Lee andMVerleysenNonlinear Dimensionality ReductionSpringer 2007
[27] B de la Iglesia ldquoEvolutionary computation for feature selectionin classification problemsrdquo Wiley Interdisciplinary ReviewsDataMining and Knowledge Discovery vol 3 no 6 pp 381ndash4072013
[28] L J Eshelman ldquoThe CHC adaptative search algorithm howto have safe search when engaging in nontraditional geneticrecombinationrdquo in Foundations of Genetic Algorithms G J ERawlins Ed pp 265ndash283MorganKaufmann SanMateo CalifUSA 1991
[29] MLlib Website httpssparkapacheorgmllib[30] R Kohavi and G H John ldquoWrappers for feature subset
selectionrdquo Artificial Intelligence vol 97 no 1-2 pp 273ndash3241997
[31] M Tan I W Tsang and L Wang ldquoTowards ultrahighdimensional feature selection for big datardquo Journal of MachineLearning Research vol 15 pp 1371ndash1429 2014
[32] T White Hadoop The Definitive Guide OrsquoReilly Media 3rdedition 2012
[33] T Cover and P Hart ldquoNearest neighbor pattern classificationrdquoIEEE Transactions on Information Theory vol 13 no 1 pp 21ndash27 1967
[34] I Triguero D Peralta J Bacardit S Garcıa and F HerreraldquoMRPR a MapReduce solution for prototype reduction in bigdata classificationrdquoNeurocomputing vol 150 pp 331ndash345 2015
[35] C-T Chu S Kim Y-A Lin et al ldquoMap-reduce for machinelearning on multicorerdquo in Advances in Neural InformationProcessing Systems pp 281ndash288 2007
[36] Pascal large scale learning challenge httplargescalemltu-berlindeinstructions
[37] Epsilon in the LIBSVM website httpwwwcsientuedutwsimcjlinlibsvmtoolsdatasetsbinaryhtmlepsilon
[38] ECBDL14 dataset Protein structure prediction and contactmapfor the ECBDL2014 Big Data Competition httpcrunchernclacukbdcomp
[39] S del Rıo V Lopez J M Benıtez and F Herrera ldquoOn the useof MapReduce for imbalanced big data using Random ForestrdquoInformation Sciences vol 285 pp 112ndash137 2014
[40] M A Hearst S T Dumais E Osman J Platt and B ScholkopfldquoSupport vector machinesrdquo IEEE Intelligent Systems and TheirApplications vol 13 no 4 pp 18ndash28 1998
[41] D W Hosmer Jr and S Lemeshow Applied Logistic RegressionJohn Wiley amp Sons 2004
[42] R O Duda and P E Hart Pattern Classification and SceneAnalysis vol 3 Wiley New York NY USA 1973
[43] MLlib guide httpsparkapacheorgdocslatestmllib-guidehtml
Submit your manuscripts athttpwwwhindawicom
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical Problems in Engineering
Hindawi Publishing Corporationhttpwwwhindawicom
Differential EquationsInternational Journal of
Volume 2014
Applied MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Probability and StatisticsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical PhysicsAdvances in
Complex AnalysisJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
OptimizationJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
CombinatoricsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Operations ResearchAdvances in
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Function Spaces
Abstract and Applied AnalysisHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of Mathematics and Mathematical Sciences
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Algebra
Discrete Dynamics in Nature and Society
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Decision SciencesAdvances in
Discrete MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom
Volume 2014 Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Stochastic AnalysisInternational Journal of

4 Mathematical Problems in Engineering
Parents Offspring
HUX
HUX
HUX
Incestprevention
If no offspring is generated
Restart population
Yes
No
Select best
d = 0
New population
dlarrd minus 1
Figure 2 Flowchart of the CHC algorithm
problem as each feature can be represented as a bit inthe solution vectorThus each position of the vector indicatesif the corresponding feature is selected or not Thereforethis approach falls within the wrapper method categoryaccording to the classification established in Section 21 Thefitness function used to evaluate new individuals applies a 119896-Nearest Neighbors classifier (119896-NN) [33] over the dataset thatwould be obtained after removing the corresponding featuresThe fitness value is the weighted sum of the 119896-NN accuracyand the feature reduction rate
32 MR-EFS Algorithm This section describes the paral-lelization of the CHC algorithm by using a MapReduceprocedure to obtain a vector of weights
Let 119879 be a training set stored in HFDS and random-ized as described in [34] Let 119898 be the number of maptasks The splitting procedure of MapReduce divides 119879 in119898 disjoint subsets of instances Then each 119879
119894subset (119894 isin
1 2 119898) is processed by the corresponding Map119894task
As this partitioning is performed sequentially all subsets willhave approximately the same number of instances and therandomization of the 119879 file ensures an adequate balance ofthe classes
Themap phase over each 119879119894consists of the EFS algorithm
(in this case based on CHC) as described in Section 31Therefore the output of each map task is a binary vectorfi = 119891
1198941 119891119894119863 where 119863 is the number of features thatindicates which features were selected by the CHC algorithmThe reduce phase averages all the binary vectors obtaininga vector x as defined in (3) where 119909
119895is the proportion of
EFS applications that include the feature 119895 in their resultThis vector is the result of the overall EFS process and isused to build the reduced dataset that will be used for furthermachine learning purposes
x = 1199091 119909119863
119909119895=
1119898
119898
sum119894=1
119891119894119895 119895 isin 1 2 119863
(3)
sum
Initial Map Reduce Final
Mappers training set
Original trainingdataset
CHC
CHC
CHC
0 1 1 0
1 1 1 0
0 1 0 0
middot middot middot
middot middot middot
middot middot middot
01 03 02 00
Figure 3 Flowchart of MR-EFS algorithm
In the implementation used for the experiments thereduce phase is carried out by a single task which reducesthe runtime by decreasing theMapReduce overhead [35]Thewhole MapReduce process for EFS is depicted in Figure 3 Itis noteworthy that the whole procedure is performed withina single iteration of the MapReduce workflow avoidingadditional disk accesses
33 Dataset Reduction with MapReduce Once vector x iscalculated the objective is to remove the less promisingfeatures from the original dataset To do so in a scalablemanner an additional MapReduce process was designedFirst vector x is binarized using a threshold 120579
b = 1198871 119887119863
119887119895=
1 if 119909119895ge 120579
0 otherwise
(4)
Vector b indicates which features will be selected forthe reduced dataset The number of selected features (1198631015840 =sum119863
119895=1 119887119895) can be controlled with 120579 with a high threshold onlya few features will be selected while a lower threshold allowsmore features to be picked
Mathematical Problems in Engineering 5
Initial Map Final
Original trainingtestdataset
Mappers trainingtest set
Result of EPS
+
Threshold
Reduced dataset
0 1 1 0middot middot middot
0 1 1 0middot middot middot
0 1 1 0middot middot middot
0 1 1 0middot middot middot
middot middot middot middot middot middot
middot middot middot middot middot middot
middot middot middot middot middot middot
01 03 02 00middot middot middot
Figure 4 Flowchart of the dataset reduction process
The MapReduce process for the dataset reduction worksas follows Each map processes an instance and generatesa new one that only contains the features selected in bFinally the instances generated are concatenated to form thefinal reduced dataset without the need of a reduce step Thedataset reduction process using the result of MR-EFS and anarbitrary threshold is depicted in Figure 4
4 Experimental Framework and Analysis
This section describes the performed experiments and theirresults First Section 41 describes the datasets and themethods used for the experiments Section 42 details theunderlying hardware and software support Finally Sections43 and 44 present the results obtained using two differentdatasets
41 Datasets and Methods This experimental study uses twolarge binary classification datasets in order to analyze thequality of the solutions provided by the MR-EFS algorithm
First the epsilon dataset was used which is composed of500 000 instances with 2000 numerical features This datasetwas artificially created for the Pascal Large Scale LearningChallenge [36] in 2008Theversion provided by LIBSVM[37]was used
Additionally this study includes the dataset used at thedata mining competition of the Evolutionary Computationfor Big Data and Big Learning held on July 14 2014 inVancouver (Canada) under the international conferenceGECCO-2014 (from now on it is referred to as ECBDL14)
[38] This dataset has 631 features (including both numericaland categorical attributes) and it is composed of approxi-mately 32 million instances Moreover the class distributionis not balanced 98 of the instances belong to the negativeclass
In order to deal with the imbalance problem the MapRe-duce approach of the Random Oversampling (ROS) algo-rithm presented in [39] was applied over the original trainingset for ECBDL14 The aim of ROS is to replicate the minorityclass instances from the original dataset until the number ofinstances from both classes is the same
Despite the inconvenience of increasing the size of thedataset this technique was proven in [39] to yield bet-ter performance than other common approaches to dealwith imbalance problems such as undersampling and cost-sensitive methods These two approaches suffer from thesmall sample size problem for the minority class when theyare used within a MapReduce model
Themain characteristics of these datasets are summarizedin Table 1 For each dataset the number of instances for bothtraining and test sets and the number of attributes are shownalong with the number of splits in which MR-EFS dividedeach dataset Note that the imbalanced version of ECBDL14 isnot used in the experiments as only the balanced ECBDL14-ROS version is considered
The parameters for the CHC algorithm are presented inTable 2
After applying MR-EFS over the described datasets thebehavior of the obtained reduced datasets was tested usingthree different classifiers implemented in Spark availablein MLlib SVM [40] Logistic Regression [41] and Naive
6 Mathematical Problems in Engineering
Table 1 Summary of the used big data classification datasets
Dataset Training instances Test instances Features Splits Instances per splitEpsilon 400 000 100 000 2000 512 sim780ECBDL14 31 992 921 2 897 917 631 mdash mdashECBDL14-ROS 65 003 913 2 897 917 631 32 768 sim1984
Table 2 Parameter specification for all the methods involved in theexperimentation
Algorithm Parameters
CHC
119896 value for 119896-NN 1Trade-off between reduction and accuracy 05Proportion of flipped bits in restarting process 005Population size 40Number of evaluations 1000
Naive Bayes Lambda 10 (default)
LogisticRegression
Iterations 100 (default)StepSize 10 (default)miniBatchFraction 10
SVM
Regularization parameter 00 05Iterations 100 (default)StepSize 10 (default)miniBatchFraction 10
Bayes [42] The reader may refer to the provided referencesor to the MLlib guide [43] for further details about theirinternal functioningThe parameters used for these classifiersare listed in Table 2 Particularly two different variants ofSVM were used modifying the regularization parameterwhich allows the algorithm to calculate simpler models bypenalizing complex models in the objective function
In the remainder of this paper two metrics are used toevaluate the performance of the three classifiers when appliedover the obtained reduced datasets
(i) Area Under the Curve (AUC) This measure is definedas the area under the Receiver Operating Charac-teristic (ROC) curve In this work this value isapproximated with the formula in (5) where TPR isthe True Positive Rate and TNR is the True NegativeRate These values can be directly obtained fromthe confusion matrix and are not affected by theimbalance of the dataset
AUC =TPR + TNR
2 (5)
(ii) Training runtime It is the time (in seconds) used totrain or build the classifier
Note that for this study the test runtime is much lessaffected by the feature selection process because at that pointthe classifier has already been built For the sake of simplicityonly training runtimes are reported
42 Hardware and Software Used The experiments for thispaper were carried out on a cluster of twenty computingnodes plus a master node Each one of these compute nodeshas the following features
(i) Processors 2 x Intel Xeon CPU E5-2620
(ii) Cores 6 per processor (12 threads)
(iii) Clock speed 200GHz
(iv) Cache 15MB
(v) Network QDR InfiniBand (40Gbps)
(vi) Hard drive 2 TB
(vii) RAM 64GB
Both Hadoop master processesmdashthe NameNode and theJobTrackermdashare hosted in the master node The formercontrols the HDFS coordinating the slave machines by themeans of their respectiveDataNode processes while the latteris in charge of the TaskTrackers of each compute node whichexecute the MapReduce framework Spark follows a similarconfiguration as the master process is located on the masternode and the worker processes are executed on the slavemachines Both frameworks share the underlying HDFS filesystem
These are the details of the software used for the experi-ments
(i) MapReduce implementation Hadoop 200-cdh471MapReduce 1 (Clouderarsquos open-source Apache Had-oop distribution)
(ii) Spark version Apache Spark 100
(iii) Maximum maps tasks 320 (16 per node)
(iv) Maximum reducer tasks 20 (1 per node)
(v) Operating system CentOS 66
Note that the total number of cores of the cluster is 240However a higher number of maps were kept to maximizethe use of the cluster by allowing a higher parallelism and abetter data locality thereby reducing the network overload
43 Experiments with the Epsilon Dataset This sectionexplains the results obtained for the epsilon dataset FirstSection 431 describes the performance of the feature selec-tion procedure and compares it with a sequential approachThen Section 432 describes the results obtained in theclassification
Mathematical Problems in Engineering 7
Table 3 Execution times (in seconds) over the epsilon subsets
Instances Sequential CHC MR-EFS Splits1000 391 419 12000 1352 409 25000 8667 413 510 000 39 576 431 1015 000 91 272 445 1520 000 159 315 455 20400 000 mdash 6531 512
431 Feature Selection Performance The complexity order ofthe CHC algorithm is approximately O(1198992119863119901) where 119901 isthe number of evaluations of the fitness function (a 119896-NNclassifier in this case) 119899 is the number of instances and 119863 isthe number of features Therefore the algorithm is quadraticwith respect to the number of instances
When the dataset is divided into 119898 splits within MR-EFS each one of the 119898 map tasks has complexity orderO((119899
21198982)119863119901) which is 1198982 times faster than applying CHCover the whole dataset If 119899
119888cores are available for the map
tasks the complexity of the map phase within the MR-EFS procedure is approximately O(lceil119898119899
119888rceil(11989921198982)119863119901) This
demonstrates the scalability of the approach presented in thispaper even if themaps are executed sequentially (119899
119888= 1) the
procedure is still one order of magnitude faster than feedinga single CHC with all the instances at once
In order to verify the performance of MR-EFS withrespect to the sequential approach a set of experimentswere performed using subsets of the epsilon dataset Botha sequential CHC algorithm and the parallel MR-EFS (with1000 instances per split) were applied over those subsetsThe obtained execution times are presented in Table 3 andFigure 5 along with the runtime of MR-EFS over the wholedataset
The sequential runtimes described a quadratic shapein concordance with the complexity order of CHC whichclearly states that the time necessary to tackle the wholedataset would be impractical In opposite the runtime ofMR-EFS for the small datasets was nearly constant The casewith 1000 instances is particular in the sense that MR-EFSonly executed one map task therefore it executed a singleCHC with 1000 instances The time difference between CHCand MR-EFS in this case reflects the overhead introduced bythe latter Even though his overhead increased slightly as thenumber of map tasks grew it represented a minor part of theoverall runtime
As for the full dataset with 512 splits the number ofinstances for each map task in MR-EFS is around 780 As thenumber of cores used for the experiments was 240 the mapphase in MR-EFS should be roughly three times slower thanthe sequential CHC with 1000 instances according to thecomplexity orders previously detailed The times in Table 3show a higher time gap because MR-EFS includes as well theother phases of theMapReduce framework (namely splittingshuffle and reduce) which are nonnegligible for a dataset ofsuch size Nevertheless the overall MR-EFS execution time is
0 5000 10000 15000 20000
0
50000
100000
150000
Number of instances
Tim
e (s)
Sequential CHCMR-EFSMR-EFS (full dataset)
Figure 5 Execution times of the sequential CHC and MR-EFS
064
066
068
070
500 1000 1500 2000Features
AUC
ClassifierLogistic RegressionNaive BayesSVM-00SVM-05
SetTrainingTest
Figure 6 Accuracy with the epsilon dataset Note that the numberof features decreases as the threshold increases
highly scalable as shown by the fact that MR-EFS was able toprocess the 400 000 instances faster than the time needed byCHC to process 5000 instances
432 Classification Results This section presents the resultsobtained by applying several classifiers over the full epsilondataset with its features previously selected by usingMR-EFSThe dataset was split among 512 map tasks each of whichcomputed around 780 instances
The AUC values are shown in Table 4 and Figure 6 bothfor training and test sets using three different thresholdsfor the dataset reduction step Note that the zero-thresholdcorresponds to the original dataset without performing any
8 Mathematical Problems in Engineering
Table 4 AUC results for the Spark classifiers using epsilon
Threshold Features Logistic Regression Naive Bayes SVM (120582 = 00) SVM (120582 = 05)Training Test Training Test Training Test Training Test
000 2000 06786 06784 07038 07008 06440 06433 06440 06433055 721 06985 07000 07154 07127 06855 06865 06855 06865060 337 06873 06867 07054 07030 06805 06799 06805 06799065 110 06496 06497 06803 06794 06492 06493 06492 06493
Table 5 Training runtime (in seconds) for the Spark classifiers using epsilon
Threshold Features Logistic Regression Naive Bayes SVM (120582 = 00) SVM (120582 = 05)000 2000 36729 60514 33418 33169055 721 40935 34042 40970 38684060 337 48816 30733 50546 48993065 110 50186 26426 46744 47374
Table 6 Size of the epsilon dataset for each threshold
Threshold Set MB HDFS blocks
000 Training 817918 128Test 204480 32
055 Training 294652 47Test 73663 12
060 Training 137721 22Test 34430 6
065 Training 45060 8Test 11265 2
feature selectionThebest results for eachmethod are stressedin boldface The table shows that the accuracy was improvedby the removal of the adequate features as the threshold 055allowed for obtaining higher AUC values The accuracy gainwas especially large for SVMMoreover more than half of thefeatures were removed which reduces significantly the sizeof the dataset and therefore the complexity of the resultingclassifier
A threshold of value 060 also got to improve the accuracyresults while reducing even further the size of the datasetFinally for the 065 thresholds only SVM saw its AUCimproved
It is also noteworthy that the two variants of SVMobtained the same results for all the tested thresholds Thisfact indicates that the complexity of the obtained SVMmodelis relatively low
The training runtime of the different algorithms anddatabases is shown in Table 5 and Figure 7 The obtainedresults were seemingly the opposite to the expectationsexcept for Naive Bayes the classifiers needed more time toprocess the datasets as their number of features decreases
However this behavior can be explained as the datasetgets smaller it occupies less HDFS blocks and thereforethe full parallel capacity of the cluster is not exploited Thesize of each version of the epsilon dataset and the numberof HDFS blocks that are needed to store it are shown inTable 6 The computer cluster is composed of 20 machinestherefore when the number of blocks is lower than 20 some
300
400
500
600
500 1000 1500 2000Features
Run
time (
s)
Logistic RegressionNaive Bayes
SVM-00SVM-05
Classifier
Figure 7 Training runtime with the epsilon dataset Note that thenumber of features decreases as the threshold increases
of the machines remain idle because they have no HDFSblock to process Moreover even if the number of blocks isslightly above 20 the affectedHDFS blocksmay not be evenlydistributed among the computing nodes This demonstratesthe capacity of Spark to deal with big databases as thesize of the database (more concretely the number of HDFSblocks) increases the framework is able to distribute theprocesses more evenly exploiting data locality increasing theparallelism and reducing the network overhead
In order to deal with this problem the same experimentswere repeated over the epsilon dataset after reorganizing thefiles with a smaller block size For each of the eight sets theblock size 119878
119887was calculated according to (6) where 119904 is the
size of the dataset in bytes and 119899119888is the number of cores in
the cluster
119878119887= 2119870
119870 = lfloorlog2119904
119899119888
rfloor (6)
Mathematical Problems in Engineering 9
Table 7 Training runtime (in seconds) for the Spark classifiers using epsilon with customized block size
Threshold Features Logistic Regression Naive Bayes SVM (120582 = 00) SVM (120582 = 05)000 2000 32194 48348 30094 30647055 721 25692 31319 25672 25698060 337 23616 24859 23123 22803065 110 30770 30826 25405 26123
Table 8 AUC values for the Spark classifiers using ECBDL14-ROS
Threshold Features Logistic Regression Naive Bayes SVM (120582 = 00) SVM (120582 = 05)Training Test Training Test Training Test Training Test
000 631 05821 05808 06714 06506 05966 06046 05875 05897055 234 06416 06352 06673 06489 06369 06307 06228 06148060 119 06309 06235 06732 06516 05884 05841 06116 06054065 46 05017 05022 06136 06093 05032 05039 05000 05000
Table 9 Training runtime (in seconds) for the Spark classifiers using ECBDL14-ROS
Threshold Features Logistic Regression Naive Bayes SVM (120582 = 00) SVM (120582 = 05)000 631 464919 158152 528388 506587055 234 210766 61350 232122 217918060 119 116298 32206 135285 122672065 46 97838 21509 91432 86428
The runtime for the dataset with the block size cus-tomized for each subset is displayed in Table 7 and Figure 8It is observed that the runtime was smaller than that withthe default block size Furthermore the curves show theexpected behavior as the number of features of the datasetwas reduced the runtime decreased In the extreme case(for threshold 065) the runtime increased again becausewith such a small dataset the synchronization times of Sparkbecome bigger than the computing times even with thecustomized block size
In the next section MR-EFS is tested over a very largedataset validating these observations
44 Experiments with the ECBDL14-ROS Dataset This sec-tion presents the classification accuracy and runtime resultsobtained with the ECBDL14-ROS dataset As describedin Section 41 a random oversampling technique [39] waspreviously applied over the original ECBDL14 dataset toovercome the problems originated by its imbalanceTheMR-EFS method was applied using 32 768 map tasks thereforeeach map task computed around 1984 instances
The obtained results in terms of accuracy are depictedin Table 8 and Figure 9 MR-EFS improved the results inall cases with different thresholds The accuracy gain wasespecially important for the Logistic Regression and SVMalgorithms As expected the SVM with 120582 = 00 obtainedbetter results than the onewith120582 = 05 as the latter attemptedto reduce the complexity of the obtained model Howeverit is noteworthy that for 119 features SVM-05 was able tooutperform SVM-00 This hints that after removing noisyfeatures the simpler obtained models represented better the
300
400
500 1000 1500 2000Features
Run
time (
s)
Logistic RegressionNaive Bayes
SVM-00SVM-05
Classifier
Figure 8 Training runtime with the epsilon dataset with cus-tomized block size Note that the number of features decreases asthe threshold increases
true knowledge underlying the data With even less featuresboth variants of SVM obtained roughly the same accuracy
To conclude this study the runtime necessary to trainthe classifiers with all variants of ECBDL14-ROS is presentedin Table 9 and Figure 10 In this case the runtime behavedas expected the time was roughly linear with respect to thenumber of features for all testedmodelsThismeans thatMR-EFS was able to improve both the runtime and the accuracyfor all those classifiers
10 Mathematical Problems in Engineering
050
055
060
065
200 400 600Features
AUC
ClassifierLogistic RegressionNaive BayesSVM-00SVM-05
SetTrainingTest
Figure 9 Accuracy with the ECBDL14-ROS dataset Note that thenumber of features decreases as the threshold increases
0
1000
2000
3000
4000
5000
Run
time (
s)
200 400 600Features
Logistic RegressionNaive Bayes
SVM-00SVM-05
Classifier
Figure 10 Training runtime with the ECBDL14-ROS dataset Notethat the number of features decreases as the threshold increases
5 Concluding Remarks
This paper presents MR-EFS an Evolutionary Feature Selec-tion algorithm designed upon the MapReduce paradigmintended to preprocess big datasets so that they becomeaffordable for other machine learning techniques such asclassification techniques that are currently not scalableenough to deal with such datasets The algorithm has beenimplemented using Apache Hadoop and it has been appliedover two different large datasets The resulting reduceddatasets have been tested using three different classifiersimplemented inApache Spark over a cluster of 20 computers
The theoretical evaluation of themodel highlights the fullscalability of MR-EFS with respect to the number of featuresin the dataset in comparison with a sequential approachThis behavior has been further confirmed after the empiricalprocedures
According to the obtained classification results it can beclaimed thatMR-EFS is able to reduce adequately the numberof features of large datasets leading to reduced versionsof them that are at the same time smaller to store fasterto compute and easier to classify These facts have beenobserved with the two different datasets and for all testedclassifiers
For the epsilon dataset the relation between the reduceddatasets size and the number of nodes is forced to modifythe HDFS block size proving that the hardware resourcescan be optimally used by Hadoop and Spark with the correctdesign One of the obtained reduced ECDBL14-ROS datasetswith more than 67 million instances and several hundredfeatures could be processed by the classifiers in less thanhalf of the time than that of the original dataset and with animprovement of around 5 in terms of AUC
Conflict of Interests
The authors declare that there is no conflict of interestsregarding the publication of this paper
Acknowledgments
This work is supported by the Research Projects TIN2014-57251-P P10-TIC-6858 P11-TIC-7765 P12-TIC-2958 andTIN2013-47210-P D Peralta and S Ramırez-Gallego holdtwo FPU scholarships from the Spanish Ministry of Educa-tion and Science (FPU1204902 FPU1300047) I Trigueroholds a BOF postdoctoral fellowship from the Ghent Univer-sity
References
[1] E Alpaydin Introduction to Machine Learning MIT PressCambridge Mass USA 2nd edition 2010
[2] MMinelliMChambers andADhirajBigData BigAnalyticsEmerging Business Intelligence and Analytic Trends for TodayrsquosBusinesses (Wiley CIO) Wiley 1st edition 2013
[3] V Marx ldquoThe big challenges of big datardquo Nature vol 498 no7453 pp 255ndash260 2013
[4] A Fernandez S del Rıo V Lopez et al ldquoBig data with cloudcomputing an insight on the computing environment MapRe-duce and programming frameworksrdquo Wiley InterdisciplinaryReviews Data Mining and Knowledge Discovery vol 4 no 5pp 380ndash409 2014
[5] E Merelli M Pettini and M Rasetti ldquoTopology driven model-ing the IS metaphorrdquo Natural Computing 2014
[6] S Sakr A Liu DM Batista andM Alomari ldquoA survey of largescale data management approaches in cloud environmentsrdquoIEEE Communications Surveys and Tutorials vol 13 no 3 pp311ndash336 2011
[7] J Bacardit and X Llora ldquoLarge-scale data mining usinggenetics-based machine learningrdquo Wiley Interdisciplinary
Mathematical Problems in Engineering 11
Reviews Data Mining and Knowledge Discovery vol 3 no 1pp 37ndash61 2013
[8] J Dean and SGhemawat ldquoMapReduce simplified data process-ing on large clustersrdquo Communications of the ACM vol 51 no1 pp 107ndash113 2008
[9] J Dean and S Ghemawat ldquoMap reduce a flexible data process-ing toolrdquo Communications of the ACM vol 53 no 1 pp 72ndash772010
[10] S Ghemawat H Gobioff and S-T Leung ldquoThe google file sys-temrdquo in Proceedings of the 19th ACM Symposium on OperatingSystems Principles (SOSP rsquo03) pp 29ndash43 October 2003
[11] M Snir and S Otto MPImdashThe Complete Reference The MPICore MIT Press Boston Mass USA 1998
[12] W Zhao H Ma and Q He ldquoParallel k-means clustering basedon MapReducerdquo in Cloud Computing M Jaatun G Zhao andC Rong Eds vol 5931 of Lecture Notes in Computer Sciencepp 674ndash679 Springer Berlin Germany 2009
[13] A Srinivasan T A Faruquie and S Joshi ldquoData and taskparallelism in ILP using MapReducerdquo Machine Learning vol86 no 1 pp 141ndash168 2012
[14] M Zaharia M Chowdhury T Das et al ldquoResilient distributeddatasets a fault-tolerant abstraction for in-memory clustercomputingrdquo in Proceedings of the 9th USENIX Conferenceon Networked Systems Design and Implementation pp 1ndash14USENIX Association 2012
[15] K Thomas C Grier J Ma V Paxson and D Song ldquoDesignand evaluation of a real-time URL spam filtering servicerdquo inProceedings of the IEEE Symposium on Security and Privacy (SPrsquo11) pp 447ndash462 Berkeley Calif USA May 2011
[16] R S Xin J Rosen M Zaharia M J Franklin S Shenker andI Stoica ldquoShark SQL and rich analytics at scalerdquo in Proceedingsof the ACM SIGMOD International Conference on Managementof Data (SIGMOD rsquo13) pp 13ndash24 ACM June 2013
[17] M S Wiewiorka A Messina A Pacholewska S Maffioletti PGawrysiak and M J Okoniewski ldquoSparkSeq fast scalable andcloud-ready tool for the interactive genomic data analysis withnucleotide precisionrdquo Bioinformatics vol 30 no 18 pp 2652ndash2653 2014
[18] S Garcıa J Luengo and F Herrera Data Preprocessing in DataMining Springer 1st edition 2015
[19] H Brighton and C Mellish ldquoAdvances in instance selection forinstance-based learning algorithmsrdquo Data Mining and Knowl-edge Discovery vol 6 no 2 pp 153ndash172 2002
[20] J A Olvera-Lopez J A Carrasco-Ochoa J F Martınez-Trinidad and J Kittler ldquoA reviewof instance selectionmethodsrdquoArtificial Intelligence Review vol 34 no 2 pp 133ndash143 2010
[21] J S Sanchez ldquoHigh training set size reduction by spacepartitioning and prototype abstractionrdquo Pattern Recognitionvol 37 no 7 pp 1561ndash1564 2004
[22] I Guyon and A Elisseeff ldquoAn introduction to variable andfeature selectionrdquo Journal of Machine Learning Research vol 3pp 1157ndash1182 2003
[23] H Liu and L Yu ldquoToward integrating feature selection algo-rithms for classification and clusteringrdquo IEEE Transactions onKnowledge and Data Engineering vol 17 no 4 pp 491ndash5022005
[24] Y Saeys I Inza and P Larranaga ldquoA review of feature selectiontechniques in bioinformaticsrdquo Bioinformatics vol 23 no 19 pp2507ndash2517 2007
[25] H Liu and H Motoda Computational Methods of FeatureSelection Chapman amp HallCRC Data Mining and KnowledgeDiscovery Series Chapman amp HallCRC Press 2007
[26] J A Lee andMVerleysenNonlinear Dimensionality ReductionSpringer 2007
[27] B de la Iglesia ldquoEvolutionary computation for feature selectionin classification problemsrdquo Wiley Interdisciplinary ReviewsDataMining and Knowledge Discovery vol 3 no 6 pp 381ndash4072013
[28] L J Eshelman ldquoThe CHC adaptative search algorithm howto have safe search when engaging in nontraditional geneticrecombinationrdquo in Foundations of Genetic Algorithms G J ERawlins Ed pp 265ndash283MorganKaufmann SanMateo CalifUSA 1991
[29] MLlib Website httpssparkapacheorgmllib[30] R Kohavi and G H John ldquoWrappers for feature subset
selectionrdquo Artificial Intelligence vol 97 no 1-2 pp 273ndash3241997
[31] M Tan I W Tsang and L Wang ldquoTowards ultrahighdimensional feature selection for big datardquo Journal of MachineLearning Research vol 15 pp 1371ndash1429 2014
[32] T White Hadoop The Definitive Guide OrsquoReilly Media 3rdedition 2012
[33] T Cover and P Hart ldquoNearest neighbor pattern classificationrdquoIEEE Transactions on Information Theory vol 13 no 1 pp 21ndash27 1967
[34] I Triguero D Peralta J Bacardit S Garcıa and F HerreraldquoMRPR a MapReduce solution for prototype reduction in bigdata classificationrdquoNeurocomputing vol 150 pp 331ndash345 2015
[35] C-T Chu S Kim Y-A Lin et al ldquoMap-reduce for machinelearning on multicorerdquo in Advances in Neural InformationProcessing Systems pp 281ndash288 2007
[36] Pascal large scale learning challenge httplargescalemltu-berlindeinstructions
[37] Epsilon in the LIBSVM website httpwwwcsientuedutwsimcjlinlibsvmtoolsdatasetsbinaryhtmlepsilon
[38] ECBDL14 dataset Protein structure prediction and contactmapfor the ECBDL2014 Big Data Competition httpcrunchernclacukbdcomp
[39] S del Rıo V Lopez J M Benıtez and F Herrera ldquoOn the useof MapReduce for imbalanced big data using Random ForestrdquoInformation Sciences vol 285 pp 112ndash137 2014
[40] M A Hearst S T Dumais E Osman J Platt and B ScholkopfldquoSupport vector machinesrdquo IEEE Intelligent Systems and TheirApplications vol 13 no 4 pp 18ndash28 1998
[41] D W Hosmer Jr and S Lemeshow Applied Logistic RegressionJohn Wiley amp Sons 2004
[42] R O Duda and P E Hart Pattern Classification and SceneAnalysis vol 3 Wiley New York NY USA 1973
[43] MLlib guide httpsparkapacheorgdocslatestmllib-guidehtml
Submit your manuscripts athttpwwwhindawicom
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical Problems in Engineering
Hindawi Publishing Corporationhttpwwwhindawicom
Differential EquationsInternational Journal of
Volume 2014
Applied MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Probability and StatisticsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical PhysicsAdvances in
Complex AnalysisJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
OptimizationJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
CombinatoricsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Operations ResearchAdvances in
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Function Spaces
Abstract and Applied AnalysisHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of Mathematics and Mathematical Sciences
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Algebra
Discrete Dynamics in Nature and Society
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Decision SciencesAdvances in
Discrete MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom
Volume 2014 Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Stochastic AnalysisInternational Journal of

Mathematical Problems in Engineering 5
Initial Map Final
Original trainingtestdataset
Mappers trainingtest set
Result of EPS
+
Threshold
Reduced dataset
0 1 1 0middot middot middot
0 1 1 0middot middot middot
0 1 1 0middot middot middot
0 1 1 0middot middot middot
middot middot middot middot middot middot
middot middot middot middot middot middot
middot middot middot middot middot middot
01 03 02 00middot middot middot
Figure 4 Flowchart of the dataset reduction process
The MapReduce process for the dataset reduction worksas follows Each map processes an instance and generatesa new one that only contains the features selected in bFinally the instances generated are concatenated to form thefinal reduced dataset without the need of a reduce step Thedataset reduction process using the result of MR-EFS and anarbitrary threshold is depicted in Figure 4
4 Experimental Framework and Analysis
This section describes the performed experiments and theirresults First Section 41 describes the datasets and themethods used for the experiments Section 42 details theunderlying hardware and software support Finally Sections43 and 44 present the results obtained using two differentdatasets
41 Datasets and Methods This experimental study uses twolarge binary classification datasets in order to analyze thequality of the solutions provided by the MR-EFS algorithm
First the epsilon dataset was used which is composed of500 000 instances with 2000 numerical features This datasetwas artificially created for the Pascal Large Scale LearningChallenge [36] in 2008Theversion provided by LIBSVM[37]was used
Additionally this study includes the dataset used at thedata mining competition of the Evolutionary Computationfor Big Data and Big Learning held on July 14 2014 inVancouver (Canada) under the international conferenceGECCO-2014 (from now on it is referred to as ECBDL14)
[38] This dataset has 631 features (including both numericaland categorical attributes) and it is composed of approxi-mately 32 million instances Moreover the class distributionis not balanced 98 of the instances belong to the negativeclass
In order to deal with the imbalance problem the MapRe-duce approach of the Random Oversampling (ROS) algo-rithm presented in [39] was applied over the original trainingset for ECBDL14 The aim of ROS is to replicate the minorityclass instances from the original dataset until the number ofinstances from both classes is the same
Despite the inconvenience of increasing the size of thedataset this technique was proven in [39] to yield bet-ter performance than other common approaches to dealwith imbalance problems such as undersampling and cost-sensitive methods These two approaches suffer from thesmall sample size problem for the minority class when theyare used within a MapReduce model
Themain characteristics of these datasets are summarizedin Table 1 For each dataset the number of instances for bothtraining and test sets and the number of attributes are shownalong with the number of splits in which MR-EFS dividedeach dataset Note that the imbalanced version of ECBDL14 isnot used in the experiments as only the balanced ECBDL14-ROS version is considered
The parameters for the CHC algorithm are presented inTable 2
After applying MR-EFS over the described datasets thebehavior of the obtained reduced datasets was tested usingthree different classifiers implemented in Spark availablein MLlib SVM [40] Logistic Regression [41] and Naive
6 Mathematical Problems in Engineering
Table 1 Summary of the used big data classification datasets
Dataset Training instances Test instances Features Splits Instances per splitEpsilon 400 000 100 000 2000 512 sim780ECBDL14 31 992 921 2 897 917 631 mdash mdashECBDL14-ROS 65 003 913 2 897 917 631 32 768 sim1984
Table 2 Parameter specification for all the methods involved in theexperimentation
Algorithm Parameters
CHC
119896 value for 119896-NN 1Trade-off between reduction and accuracy 05Proportion of flipped bits in restarting process 005Population size 40Number of evaluations 1000
Naive Bayes Lambda 10 (default)
LogisticRegression
Iterations 100 (default)StepSize 10 (default)miniBatchFraction 10
SVM
Regularization parameter 00 05Iterations 100 (default)StepSize 10 (default)miniBatchFraction 10
Bayes [42] The reader may refer to the provided referencesor to the MLlib guide [43] for further details about theirinternal functioningThe parameters used for these classifiersare listed in Table 2 Particularly two different variants ofSVM were used modifying the regularization parameterwhich allows the algorithm to calculate simpler models bypenalizing complex models in the objective function
In the remainder of this paper two metrics are used toevaluate the performance of the three classifiers when appliedover the obtained reduced datasets
(i) Area Under the Curve (AUC) This measure is definedas the area under the Receiver Operating Charac-teristic (ROC) curve In this work this value isapproximated with the formula in (5) where TPR isthe True Positive Rate and TNR is the True NegativeRate These values can be directly obtained fromthe confusion matrix and are not affected by theimbalance of the dataset
AUC =TPR + TNR
2 (5)
(ii) Training runtime It is the time (in seconds) used totrain or build the classifier
Note that for this study the test runtime is much lessaffected by the feature selection process because at that pointthe classifier has already been built For the sake of simplicityonly training runtimes are reported
42 Hardware and Software Used The experiments for thispaper were carried out on a cluster of twenty computingnodes plus a master node Each one of these compute nodeshas the following features
(i) Processors 2 x Intel Xeon CPU E5-2620
(ii) Cores 6 per processor (12 threads)
(iii) Clock speed 200GHz
(iv) Cache 15MB
(v) Network QDR InfiniBand (40Gbps)
(vi) Hard drive 2 TB
(vii) RAM 64GB
Both Hadoop master processesmdashthe NameNode and theJobTrackermdashare hosted in the master node The formercontrols the HDFS coordinating the slave machines by themeans of their respectiveDataNode processes while the latteris in charge of the TaskTrackers of each compute node whichexecute the MapReduce framework Spark follows a similarconfiguration as the master process is located on the masternode and the worker processes are executed on the slavemachines Both frameworks share the underlying HDFS filesystem
These are the details of the software used for the experi-ments
(i) MapReduce implementation Hadoop 200-cdh471MapReduce 1 (Clouderarsquos open-source Apache Had-oop distribution)
(ii) Spark version Apache Spark 100
(iii) Maximum maps tasks 320 (16 per node)
(iv) Maximum reducer tasks 20 (1 per node)
(v) Operating system CentOS 66
Note that the total number of cores of the cluster is 240However a higher number of maps were kept to maximizethe use of the cluster by allowing a higher parallelism and abetter data locality thereby reducing the network overload
43 Experiments with the Epsilon Dataset This sectionexplains the results obtained for the epsilon dataset FirstSection 431 describes the performance of the feature selec-tion procedure and compares it with a sequential approachThen Section 432 describes the results obtained in theclassification
Mathematical Problems in Engineering 7
Table 3 Execution times (in seconds) over the epsilon subsets
Instances Sequential CHC MR-EFS Splits1000 391 419 12000 1352 409 25000 8667 413 510 000 39 576 431 1015 000 91 272 445 1520 000 159 315 455 20400 000 mdash 6531 512
431 Feature Selection Performance The complexity order ofthe CHC algorithm is approximately O(1198992119863119901) where 119901 isthe number of evaluations of the fitness function (a 119896-NNclassifier in this case) 119899 is the number of instances and 119863 isthe number of features Therefore the algorithm is quadraticwith respect to the number of instances
When the dataset is divided into 119898 splits within MR-EFS each one of the 119898 map tasks has complexity orderO((119899
21198982)119863119901) which is 1198982 times faster than applying CHCover the whole dataset If 119899
119888cores are available for the map
tasks the complexity of the map phase within the MR-EFS procedure is approximately O(lceil119898119899
119888rceil(11989921198982)119863119901) This
demonstrates the scalability of the approach presented in thispaper even if themaps are executed sequentially (119899
119888= 1) the
procedure is still one order of magnitude faster than feedinga single CHC with all the instances at once
In order to verify the performance of MR-EFS withrespect to the sequential approach a set of experimentswere performed using subsets of the epsilon dataset Botha sequential CHC algorithm and the parallel MR-EFS (with1000 instances per split) were applied over those subsetsThe obtained execution times are presented in Table 3 andFigure 5 along with the runtime of MR-EFS over the wholedataset
The sequential runtimes described a quadratic shapein concordance with the complexity order of CHC whichclearly states that the time necessary to tackle the wholedataset would be impractical In opposite the runtime ofMR-EFS for the small datasets was nearly constant The casewith 1000 instances is particular in the sense that MR-EFSonly executed one map task therefore it executed a singleCHC with 1000 instances The time difference between CHCand MR-EFS in this case reflects the overhead introduced bythe latter Even though his overhead increased slightly as thenumber of map tasks grew it represented a minor part of theoverall runtime
As for the full dataset with 512 splits the number ofinstances for each map task in MR-EFS is around 780 As thenumber of cores used for the experiments was 240 the mapphase in MR-EFS should be roughly three times slower thanthe sequential CHC with 1000 instances according to thecomplexity orders previously detailed The times in Table 3show a higher time gap because MR-EFS includes as well theother phases of theMapReduce framework (namely splittingshuffle and reduce) which are nonnegligible for a dataset ofsuch size Nevertheless the overall MR-EFS execution time is
0 5000 10000 15000 20000
0
50000
100000
150000
Number of instances
Tim
e (s)
Sequential CHCMR-EFSMR-EFS (full dataset)
Figure 5 Execution times of the sequential CHC and MR-EFS
064
066
068
070
500 1000 1500 2000Features
AUC
ClassifierLogistic RegressionNaive BayesSVM-00SVM-05
SetTrainingTest
Figure 6 Accuracy with the epsilon dataset Note that the numberof features decreases as the threshold increases
highly scalable as shown by the fact that MR-EFS was able toprocess the 400 000 instances faster than the time needed byCHC to process 5000 instances
432 Classification Results This section presents the resultsobtained by applying several classifiers over the full epsilondataset with its features previously selected by usingMR-EFSThe dataset was split among 512 map tasks each of whichcomputed around 780 instances
The AUC values are shown in Table 4 and Figure 6 bothfor training and test sets using three different thresholdsfor the dataset reduction step Note that the zero-thresholdcorresponds to the original dataset without performing any
8 Mathematical Problems in Engineering
Table 4 AUC results for the Spark classifiers using epsilon
Threshold Features Logistic Regression Naive Bayes SVM (120582 = 00) SVM (120582 = 05)Training Test Training Test Training Test Training Test
000 2000 06786 06784 07038 07008 06440 06433 06440 06433055 721 06985 07000 07154 07127 06855 06865 06855 06865060 337 06873 06867 07054 07030 06805 06799 06805 06799065 110 06496 06497 06803 06794 06492 06493 06492 06493
Table 5 Training runtime (in seconds) for the Spark classifiers using epsilon
Threshold Features Logistic Regression Naive Bayes SVM (120582 = 00) SVM (120582 = 05)000 2000 36729 60514 33418 33169055 721 40935 34042 40970 38684060 337 48816 30733 50546 48993065 110 50186 26426 46744 47374
Table 6 Size of the epsilon dataset for each threshold
Threshold Set MB HDFS blocks
000 Training 817918 128Test 204480 32
055 Training 294652 47Test 73663 12
060 Training 137721 22Test 34430 6
065 Training 45060 8Test 11265 2
feature selectionThebest results for eachmethod are stressedin boldface The table shows that the accuracy was improvedby the removal of the adequate features as the threshold 055allowed for obtaining higher AUC values The accuracy gainwas especially large for SVMMoreover more than half of thefeatures were removed which reduces significantly the sizeof the dataset and therefore the complexity of the resultingclassifier
A threshold of value 060 also got to improve the accuracyresults while reducing even further the size of the datasetFinally for the 065 thresholds only SVM saw its AUCimproved
It is also noteworthy that the two variants of SVMobtained the same results for all the tested thresholds Thisfact indicates that the complexity of the obtained SVMmodelis relatively low
The training runtime of the different algorithms anddatabases is shown in Table 5 and Figure 7 The obtainedresults were seemingly the opposite to the expectationsexcept for Naive Bayes the classifiers needed more time toprocess the datasets as their number of features decreases
However this behavior can be explained as the datasetgets smaller it occupies less HDFS blocks and thereforethe full parallel capacity of the cluster is not exploited Thesize of each version of the epsilon dataset and the numberof HDFS blocks that are needed to store it are shown inTable 6 The computer cluster is composed of 20 machinestherefore when the number of blocks is lower than 20 some
300
400
500
600
500 1000 1500 2000Features
Run
time (
s)
Logistic RegressionNaive Bayes
SVM-00SVM-05
Classifier
Figure 7 Training runtime with the epsilon dataset Note that thenumber of features decreases as the threshold increases
of the machines remain idle because they have no HDFSblock to process Moreover even if the number of blocks isslightly above 20 the affectedHDFS blocksmay not be evenlydistributed among the computing nodes This demonstratesthe capacity of Spark to deal with big databases as thesize of the database (more concretely the number of HDFSblocks) increases the framework is able to distribute theprocesses more evenly exploiting data locality increasing theparallelism and reducing the network overhead
In order to deal with this problem the same experimentswere repeated over the epsilon dataset after reorganizing thefiles with a smaller block size For each of the eight sets theblock size 119878
119887was calculated according to (6) where 119904 is the
size of the dataset in bytes and 119899119888is the number of cores in
the cluster
119878119887= 2119870
119870 = lfloorlog2119904
119899119888
rfloor (6)
Mathematical Problems in Engineering 9
Table 7 Training runtime (in seconds) for the Spark classifiers using epsilon with customized block size
Threshold Features Logistic Regression Naive Bayes SVM (120582 = 00) SVM (120582 = 05)000 2000 32194 48348 30094 30647055 721 25692 31319 25672 25698060 337 23616 24859 23123 22803065 110 30770 30826 25405 26123
Table 8 AUC values for the Spark classifiers using ECBDL14-ROS
Threshold Features Logistic Regression Naive Bayes SVM (120582 = 00) SVM (120582 = 05)Training Test Training Test Training Test Training Test
000 631 05821 05808 06714 06506 05966 06046 05875 05897055 234 06416 06352 06673 06489 06369 06307 06228 06148060 119 06309 06235 06732 06516 05884 05841 06116 06054065 46 05017 05022 06136 06093 05032 05039 05000 05000
Table 9 Training runtime (in seconds) for the Spark classifiers using ECBDL14-ROS
Threshold Features Logistic Regression Naive Bayes SVM (120582 = 00) SVM (120582 = 05)000 631 464919 158152 528388 506587055 234 210766 61350 232122 217918060 119 116298 32206 135285 122672065 46 97838 21509 91432 86428
The runtime for the dataset with the block size cus-tomized for each subset is displayed in Table 7 and Figure 8It is observed that the runtime was smaller than that withthe default block size Furthermore the curves show theexpected behavior as the number of features of the datasetwas reduced the runtime decreased In the extreme case(for threshold 065) the runtime increased again becausewith such a small dataset the synchronization times of Sparkbecome bigger than the computing times even with thecustomized block size
In the next section MR-EFS is tested over a very largedataset validating these observations
44 Experiments with the ECBDL14-ROS Dataset This sec-tion presents the classification accuracy and runtime resultsobtained with the ECBDL14-ROS dataset As describedin Section 41 a random oversampling technique [39] waspreviously applied over the original ECBDL14 dataset toovercome the problems originated by its imbalanceTheMR-EFS method was applied using 32 768 map tasks thereforeeach map task computed around 1984 instances
The obtained results in terms of accuracy are depictedin Table 8 and Figure 9 MR-EFS improved the results inall cases with different thresholds The accuracy gain wasespecially important for the Logistic Regression and SVMalgorithms As expected the SVM with 120582 = 00 obtainedbetter results than the onewith120582 = 05 as the latter attemptedto reduce the complexity of the obtained model Howeverit is noteworthy that for 119 features SVM-05 was able tooutperform SVM-00 This hints that after removing noisyfeatures the simpler obtained models represented better the
300
400
500 1000 1500 2000Features
Run
time (
s)
Logistic RegressionNaive Bayes
SVM-00SVM-05
Classifier
Figure 8 Training runtime with the epsilon dataset with cus-tomized block size Note that the number of features decreases asthe threshold increases
true knowledge underlying the data With even less featuresboth variants of SVM obtained roughly the same accuracy
To conclude this study the runtime necessary to trainthe classifiers with all variants of ECBDL14-ROS is presentedin Table 9 and Figure 10 In this case the runtime behavedas expected the time was roughly linear with respect to thenumber of features for all testedmodelsThismeans thatMR-EFS was able to improve both the runtime and the accuracyfor all those classifiers
10 Mathematical Problems in Engineering
050
055
060
065
200 400 600Features
AUC
ClassifierLogistic RegressionNaive BayesSVM-00SVM-05
SetTrainingTest
Figure 9 Accuracy with the ECBDL14-ROS dataset Note that thenumber of features decreases as the threshold increases
0
1000
2000
3000
4000
5000
Run
time (
s)
200 400 600Features
Logistic RegressionNaive Bayes
SVM-00SVM-05
Classifier
Figure 10 Training runtime with the ECBDL14-ROS dataset Notethat the number of features decreases as the threshold increases
5 Concluding Remarks
This paper presents MR-EFS an Evolutionary Feature Selec-tion algorithm designed upon the MapReduce paradigmintended to preprocess big datasets so that they becomeaffordable for other machine learning techniques such asclassification techniques that are currently not scalableenough to deal with such datasets The algorithm has beenimplemented using Apache Hadoop and it has been appliedover two different large datasets The resulting reduceddatasets have been tested using three different classifiersimplemented inApache Spark over a cluster of 20 computers
The theoretical evaluation of themodel highlights the fullscalability of MR-EFS with respect to the number of featuresin the dataset in comparison with a sequential approachThis behavior has been further confirmed after the empiricalprocedures
According to the obtained classification results it can beclaimed thatMR-EFS is able to reduce adequately the numberof features of large datasets leading to reduced versionsof them that are at the same time smaller to store fasterto compute and easier to classify These facts have beenobserved with the two different datasets and for all testedclassifiers
For the epsilon dataset the relation between the reduceddatasets size and the number of nodes is forced to modifythe HDFS block size proving that the hardware resourcescan be optimally used by Hadoop and Spark with the correctdesign One of the obtained reduced ECDBL14-ROS datasetswith more than 67 million instances and several hundredfeatures could be processed by the classifiers in less thanhalf of the time than that of the original dataset and with animprovement of around 5 in terms of AUC
Conflict of Interests
The authors declare that there is no conflict of interestsregarding the publication of this paper
Acknowledgments
This work is supported by the Research Projects TIN2014-57251-P P10-TIC-6858 P11-TIC-7765 P12-TIC-2958 andTIN2013-47210-P D Peralta and S Ramırez-Gallego holdtwo FPU scholarships from the Spanish Ministry of Educa-tion and Science (FPU1204902 FPU1300047) I Trigueroholds a BOF postdoctoral fellowship from the Ghent Univer-sity
References
[1] E Alpaydin Introduction to Machine Learning MIT PressCambridge Mass USA 2nd edition 2010
[2] MMinelliMChambers andADhirajBigData BigAnalyticsEmerging Business Intelligence and Analytic Trends for TodayrsquosBusinesses (Wiley CIO) Wiley 1st edition 2013
[3] V Marx ldquoThe big challenges of big datardquo Nature vol 498 no7453 pp 255ndash260 2013
[4] A Fernandez S del Rıo V Lopez et al ldquoBig data with cloudcomputing an insight on the computing environment MapRe-duce and programming frameworksrdquo Wiley InterdisciplinaryReviews Data Mining and Knowledge Discovery vol 4 no 5pp 380ndash409 2014
[5] E Merelli M Pettini and M Rasetti ldquoTopology driven model-ing the IS metaphorrdquo Natural Computing 2014
[6] S Sakr A Liu DM Batista andM Alomari ldquoA survey of largescale data management approaches in cloud environmentsrdquoIEEE Communications Surveys and Tutorials vol 13 no 3 pp311ndash336 2011
[7] J Bacardit and X Llora ldquoLarge-scale data mining usinggenetics-based machine learningrdquo Wiley Interdisciplinary
Mathematical Problems in Engineering 11
Reviews Data Mining and Knowledge Discovery vol 3 no 1pp 37ndash61 2013
[8] J Dean and SGhemawat ldquoMapReduce simplified data process-ing on large clustersrdquo Communications of the ACM vol 51 no1 pp 107ndash113 2008
[9] J Dean and S Ghemawat ldquoMap reduce a flexible data process-ing toolrdquo Communications of the ACM vol 53 no 1 pp 72ndash772010
[10] S Ghemawat H Gobioff and S-T Leung ldquoThe google file sys-temrdquo in Proceedings of the 19th ACM Symposium on OperatingSystems Principles (SOSP rsquo03) pp 29ndash43 October 2003
[11] M Snir and S Otto MPImdashThe Complete Reference The MPICore MIT Press Boston Mass USA 1998
[12] W Zhao H Ma and Q He ldquoParallel k-means clustering basedon MapReducerdquo in Cloud Computing M Jaatun G Zhao andC Rong Eds vol 5931 of Lecture Notes in Computer Sciencepp 674ndash679 Springer Berlin Germany 2009
[13] A Srinivasan T A Faruquie and S Joshi ldquoData and taskparallelism in ILP using MapReducerdquo Machine Learning vol86 no 1 pp 141ndash168 2012
[14] M Zaharia M Chowdhury T Das et al ldquoResilient distributeddatasets a fault-tolerant abstraction for in-memory clustercomputingrdquo in Proceedings of the 9th USENIX Conferenceon Networked Systems Design and Implementation pp 1ndash14USENIX Association 2012
[15] K Thomas C Grier J Ma V Paxson and D Song ldquoDesignand evaluation of a real-time URL spam filtering servicerdquo inProceedings of the IEEE Symposium on Security and Privacy (SPrsquo11) pp 447ndash462 Berkeley Calif USA May 2011
[16] R S Xin J Rosen M Zaharia M J Franklin S Shenker andI Stoica ldquoShark SQL and rich analytics at scalerdquo in Proceedingsof the ACM SIGMOD International Conference on Managementof Data (SIGMOD rsquo13) pp 13ndash24 ACM June 2013
[17] M S Wiewiorka A Messina A Pacholewska S Maffioletti PGawrysiak and M J Okoniewski ldquoSparkSeq fast scalable andcloud-ready tool for the interactive genomic data analysis withnucleotide precisionrdquo Bioinformatics vol 30 no 18 pp 2652ndash2653 2014
[18] S Garcıa J Luengo and F Herrera Data Preprocessing in DataMining Springer 1st edition 2015
[19] H Brighton and C Mellish ldquoAdvances in instance selection forinstance-based learning algorithmsrdquo Data Mining and Knowl-edge Discovery vol 6 no 2 pp 153ndash172 2002
[20] J A Olvera-Lopez J A Carrasco-Ochoa J F Martınez-Trinidad and J Kittler ldquoA reviewof instance selectionmethodsrdquoArtificial Intelligence Review vol 34 no 2 pp 133ndash143 2010
[21] J S Sanchez ldquoHigh training set size reduction by spacepartitioning and prototype abstractionrdquo Pattern Recognitionvol 37 no 7 pp 1561ndash1564 2004
[22] I Guyon and A Elisseeff ldquoAn introduction to variable andfeature selectionrdquo Journal of Machine Learning Research vol 3pp 1157ndash1182 2003
[23] H Liu and L Yu ldquoToward integrating feature selection algo-rithms for classification and clusteringrdquo IEEE Transactions onKnowledge and Data Engineering vol 17 no 4 pp 491ndash5022005
[24] Y Saeys I Inza and P Larranaga ldquoA review of feature selectiontechniques in bioinformaticsrdquo Bioinformatics vol 23 no 19 pp2507ndash2517 2007
[25] H Liu and H Motoda Computational Methods of FeatureSelection Chapman amp HallCRC Data Mining and KnowledgeDiscovery Series Chapman amp HallCRC Press 2007
[26] J A Lee andMVerleysenNonlinear Dimensionality ReductionSpringer 2007
[27] B de la Iglesia ldquoEvolutionary computation for feature selectionin classification problemsrdquo Wiley Interdisciplinary ReviewsDataMining and Knowledge Discovery vol 3 no 6 pp 381ndash4072013
[28] L J Eshelman ldquoThe CHC adaptative search algorithm howto have safe search when engaging in nontraditional geneticrecombinationrdquo in Foundations of Genetic Algorithms G J ERawlins Ed pp 265ndash283MorganKaufmann SanMateo CalifUSA 1991
[29] MLlib Website httpssparkapacheorgmllib[30] R Kohavi and G H John ldquoWrappers for feature subset
selectionrdquo Artificial Intelligence vol 97 no 1-2 pp 273ndash3241997
[31] M Tan I W Tsang and L Wang ldquoTowards ultrahighdimensional feature selection for big datardquo Journal of MachineLearning Research vol 15 pp 1371ndash1429 2014
[32] T White Hadoop The Definitive Guide OrsquoReilly Media 3rdedition 2012
[33] T Cover and P Hart ldquoNearest neighbor pattern classificationrdquoIEEE Transactions on Information Theory vol 13 no 1 pp 21ndash27 1967
[34] I Triguero D Peralta J Bacardit S Garcıa and F HerreraldquoMRPR a MapReduce solution for prototype reduction in bigdata classificationrdquoNeurocomputing vol 150 pp 331ndash345 2015
[35] C-T Chu S Kim Y-A Lin et al ldquoMap-reduce for machinelearning on multicorerdquo in Advances in Neural InformationProcessing Systems pp 281ndash288 2007
[36] Pascal large scale learning challenge httplargescalemltu-berlindeinstructions
[37] Epsilon in the LIBSVM website httpwwwcsientuedutwsimcjlinlibsvmtoolsdatasetsbinaryhtmlepsilon
[38] ECBDL14 dataset Protein structure prediction and contactmapfor the ECBDL2014 Big Data Competition httpcrunchernclacukbdcomp
[39] S del Rıo V Lopez J M Benıtez and F Herrera ldquoOn the useof MapReduce for imbalanced big data using Random ForestrdquoInformation Sciences vol 285 pp 112ndash137 2014
[40] M A Hearst S T Dumais E Osman J Platt and B ScholkopfldquoSupport vector machinesrdquo IEEE Intelligent Systems and TheirApplications vol 13 no 4 pp 18ndash28 1998
[41] D W Hosmer Jr and S Lemeshow Applied Logistic RegressionJohn Wiley amp Sons 2004
[42] R O Duda and P E Hart Pattern Classification and SceneAnalysis vol 3 Wiley New York NY USA 1973
[43] MLlib guide httpsparkapacheorgdocslatestmllib-guidehtml
Submit your manuscripts athttpwwwhindawicom
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical Problems in Engineering
Hindawi Publishing Corporationhttpwwwhindawicom
Differential EquationsInternational Journal of
Volume 2014
Applied MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Probability and StatisticsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical PhysicsAdvances in
Complex AnalysisJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
OptimizationJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
CombinatoricsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Operations ResearchAdvances in
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Function Spaces
Abstract and Applied AnalysisHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of Mathematics and Mathematical Sciences
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Algebra
Discrete Dynamics in Nature and Society
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Decision SciencesAdvances in
Discrete MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom
Volume 2014 Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Stochastic AnalysisInternational Journal of
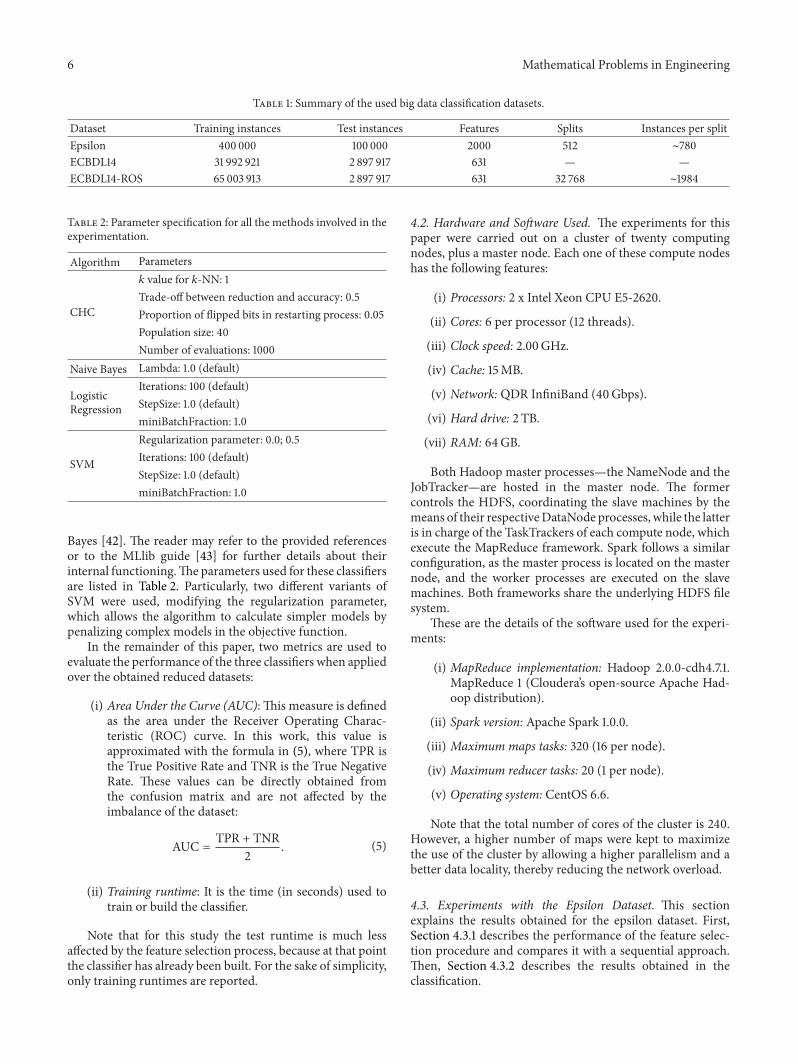
6 Mathematical Problems in Engineering
Table 1 Summary of the used big data classification datasets
Dataset Training instances Test instances Features Splits Instances per splitEpsilon 400 000 100 000 2000 512 sim780ECBDL14 31 992 921 2 897 917 631 mdash mdashECBDL14-ROS 65 003 913 2 897 917 631 32 768 sim1984
Table 2 Parameter specification for all the methods involved in theexperimentation
Algorithm Parameters
CHC
119896 value for 119896-NN 1Trade-off between reduction and accuracy 05Proportion of flipped bits in restarting process 005Population size 40Number of evaluations 1000
Naive Bayes Lambda 10 (default)
LogisticRegression
Iterations 100 (default)StepSize 10 (default)miniBatchFraction 10
SVM
Regularization parameter 00 05Iterations 100 (default)StepSize 10 (default)miniBatchFraction 10
Bayes [42] The reader may refer to the provided referencesor to the MLlib guide [43] for further details about theirinternal functioningThe parameters used for these classifiersare listed in Table 2 Particularly two different variants ofSVM were used modifying the regularization parameterwhich allows the algorithm to calculate simpler models bypenalizing complex models in the objective function
In the remainder of this paper two metrics are used toevaluate the performance of the three classifiers when appliedover the obtained reduced datasets
(i) Area Under the Curve (AUC) This measure is definedas the area under the Receiver Operating Charac-teristic (ROC) curve In this work this value isapproximated with the formula in (5) where TPR isthe True Positive Rate and TNR is the True NegativeRate These values can be directly obtained fromthe confusion matrix and are not affected by theimbalance of the dataset
AUC =TPR + TNR
2 (5)
(ii) Training runtime It is the time (in seconds) used totrain or build the classifier
Note that for this study the test runtime is much lessaffected by the feature selection process because at that pointthe classifier has already been built For the sake of simplicityonly training runtimes are reported
42 Hardware and Software Used The experiments for thispaper were carried out on a cluster of twenty computingnodes plus a master node Each one of these compute nodeshas the following features
(i) Processors 2 x Intel Xeon CPU E5-2620
(ii) Cores 6 per processor (12 threads)
(iii) Clock speed 200GHz
(iv) Cache 15MB
(v) Network QDR InfiniBand (40Gbps)
(vi) Hard drive 2 TB
(vii) RAM 64GB
Both Hadoop master processesmdashthe NameNode and theJobTrackermdashare hosted in the master node The formercontrols the HDFS coordinating the slave machines by themeans of their respectiveDataNode processes while the latteris in charge of the TaskTrackers of each compute node whichexecute the MapReduce framework Spark follows a similarconfiguration as the master process is located on the masternode and the worker processes are executed on the slavemachines Both frameworks share the underlying HDFS filesystem
These are the details of the software used for the experi-ments
(i) MapReduce implementation Hadoop 200-cdh471MapReduce 1 (Clouderarsquos open-source Apache Had-oop distribution)
(ii) Spark version Apache Spark 100
(iii) Maximum maps tasks 320 (16 per node)
(iv) Maximum reducer tasks 20 (1 per node)
(v) Operating system CentOS 66
Note that the total number of cores of the cluster is 240However a higher number of maps were kept to maximizethe use of the cluster by allowing a higher parallelism and abetter data locality thereby reducing the network overload
43 Experiments with the Epsilon Dataset This sectionexplains the results obtained for the epsilon dataset FirstSection 431 describes the performance of the feature selec-tion procedure and compares it with a sequential approachThen Section 432 describes the results obtained in theclassification
Mathematical Problems in Engineering 7
Table 3 Execution times (in seconds) over the epsilon subsets
Instances Sequential CHC MR-EFS Splits1000 391 419 12000 1352 409 25000 8667 413 510 000 39 576 431 1015 000 91 272 445 1520 000 159 315 455 20400 000 mdash 6531 512
431 Feature Selection Performance The complexity order ofthe CHC algorithm is approximately O(1198992119863119901) where 119901 isthe number of evaluations of the fitness function (a 119896-NNclassifier in this case) 119899 is the number of instances and 119863 isthe number of features Therefore the algorithm is quadraticwith respect to the number of instances
When the dataset is divided into 119898 splits within MR-EFS each one of the 119898 map tasks has complexity orderO((119899
21198982)119863119901) which is 1198982 times faster than applying CHCover the whole dataset If 119899
119888cores are available for the map
tasks the complexity of the map phase within the MR-EFS procedure is approximately O(lceil119898119899
119888rceil(11989921198982)119863119901) This
demonstrates the scalability of the approach presented in thispaper even if themaps are executed sequentially (119899
119888= 1) the
procedure is still one order of magnitude faster than feedinga single CHC with all the instances at once
In order to verify the performance of MR-EFS withrespect to the sequential approach a set of experimentswere performed using subsets of the epsilon dataset Botha sequential CHC algorithm and the parallel MR-EFS (with1000 instances per split) were applied over those subsetsThe obtained execution times are presented in Table 3 andFigure 5 along with the runtime of MR-EFS over the wholedataset
The sequential runtimes described a quadratic shapein concordance with the complexity order of CHC whichclearly states that the time necessary to tackle the wholedataset would be impractical In opposite the runtime ofMR-EFS for the small datasets was nearly constant The casewith 1000 instances is particular in the sense that MR-EFSonly executed one map task therefore it executed a singleCHC with 1000 instances The time difference between CHCand MR-EFS in this case reflects the overhead introduced bythe latter Even though his overhead increased slightly as thenumber of map tasks grew it represented a minor part of theoverall runtime
As for the full dataset with 512 splits the number ofinstances for each map task in MR-EFS is around 780 As thenumber of cores used for the experiments was 240 the mapphase in MR-EFS should be roughly three times slower thanthe sequential CHC with 1000 instances according to thecomplexity orders previously detailed The times in Table 3show a higher time gap because MR-EFS includes as well theother phases of theMapReduce framework (namely splittingshuffle and reduce) which are nonnegligible for a dataset ofsuch size Nevertheless the overall MR-EFS execution time is
0 5000 10000 15000 20000
0
50000
100000
150000
Number of instances
Tim
e (s)
Sequential CHCMR-EFSMR-EFS (full dataset)
Figure 5 Execution times of the sequential CHC and MR-EFS
064
066
068
070
500 1000 1500 2000Features
AUC
ClassifierLogistic RegressionNaive BayesSVM-00SVM-05
SetTrainingTest
Figure 6 Accuracy with the epsilon dataset Note that the numberof features decreases as the threshold increases
highly scalable as shown by the fact that MR-EFS was able toprocess the 400 000 instances faster than the time needed byCHC to process 5000 instances
432 Classification Results This section presents the resultsobtained by applying several classifiers over the full epsilondataset with its features previously selected by usingMR-EFSThe dataset was split among 512 map tasks each of whichcomputed around 780 instances
The AUC values are shown in Table 4 and Figure 6 bothfor training and test sets using three different thresholdsfor the dataset reduction step Note that the zero-thresholdcorresponds to the original dataset without performing any
8 Mathematical Problems in Engineering
Table 4 AUC results for the Spark classifiers using epsilon
Threshold Features Logistic Regression Naive Bayes SVM (120582 = 00) SVM (120582 = 05)Training Test Training Test Training Test Training Test
000 2000 06786 06784 07038 07008 06440 06433 06440 06433055 721 06985 07000 07154 07127 06855 06865 06855 06865060 337 06873 06867 07054 07030 06805 06799 06805 06799065 110 06496 06497 06803 06794 06492 06493 06492 06493
Table 5 Training runtime (in seconds) for the Spark classifiers using epsilon
Threshold Features Logistic Regression Naive Bayes SVM (120582 = 00) SVM (120582 = 05)000 2000 36729 60514 33418 33169055 721 40935 34042 40970 38684060 337 48816 30733 50546 48993065 110 50186 26426 46744 47374
Table 6 Size of the epsilon dataset for each threshold
Threshold Set MB HDFS blocks
000 Training 817918 128Test 204480 32
055 Training 294652 47Test 73663 12
060 Training 137721 22Test 34430 6
065 Training 45060 8Test 11265 2
feature selectionThebest results for eachmethod are stressedin boldface The table shows that the accuracy was improvedby the removal of the adequate features as the threshold 055allowed for obtaining higher AUC values The accuracy gainwas especially large for SVMMoreover more than half of thefeatures were removed which reduces significantly the sizeof the dataset and therefore the complexity of the resultingclassifier
A threshold of value 060 also got to improve the accuracyresults while reducing even further the size of the datasetFinally for the 065 thresholds only SVM saw its AUCimproved
It is also noteworthy that the two variants of SVMobtained the same results for all the tested thresholds Thisfact indicates that the complexity of the obtained SVMmodelis relatively low
The training runtime of the different algorithms anddatabases is shown in Table 5 and Figure 7 The obtainedresults were seemingly the opposite to the expectationsexcept for Naive Bayes the classifiers needed more time toprocess the datasets as their number of features decreases
However this behavior can be explained as the datasetgets smaller it occupies less HDFS blocks and thereforethe full parallel capacity of the cluster is not exploited Thesize of each version of the epsilon dataset and the numberof HDFS blocks that are needed to store it are shown inTable 6 The computer cluster is composed of 20 machinestherefore when the number of blocks is lower than 20 some
300
400
500
600
500 1000 1500 2000Features
Run
time (
s)
Logistic RegressionNaive Bayes
SVM-00SVM-05
Classifier
Figure 7 Training runtime with the epsilon dataset Note that thenumber of features decreases as the threshold increases
of the machines remain idle because they have no HDFSblock to process Moreover even if the number of blocks isslightly above 20 the affectedHDFS blocksmay not be evenlydistributed among the computing nodes This demonstratesthe capacity of Spark to deal with big databases as thesize of the database (more concretely the number of HDFSblocks) increases the framework is able to distribute theprocesses more evenly exploiting data locality increasing theparallelism and reducing the network overhead
In order to deal with this problem the same experimentswere repeated over the epsilon dataset after reorganizing thefiles with a smaller block size For each of the eight sets theblock size 119878
119887was calculated according to (6) where 119904 is the
size of the dataset in bytes and 119899119888is the number of cores in
the cluster
119878119887= 2119870
119870 = lfloorlog2119904
119899119888
rfloor (6)
Mathematical Problems in Engineering 9
Table 7 Training runtime (in seconds) for the Spark classifiers using epsilon with customized block size
Threshold Features Logistic Regression Naive Bayes SVM (120582 = 00) SVM (120582 = 05)000 2000 32194 48348 30094 30647055 721 25692 31319 25672 25698060 337 23616 24859 23123 22803065 110 30770 30826 25405 26123
Table 8 AUC values for the Spark classifiers using ECBDL14-ROS
Threshold Features Logistic Regression Naive Bayes SVM (120582 = 00) SVM (120582 = 05)Training Test Training Test Training Test Training Test
000 631 05821 05808 06714 06506 05966 06046 05875 05897055 234 06416 06352 06673 06489 06369 06307 06228 06148060 119 06309 06235 06732 06516 05884 05841 06116 06054065 46 05017 05022 06136 06093 05032 05039 05000 05000
Table 9 Training runtime (in seconds) for the Spark classifiers using ECBDL14-ROS
Threshold Features Logistic Regression Naive Bayes SVM (120582 = 00) SVM (120582 = 05)000 631 464919 158152 528388 506587055 234 210766 61350 232122 217918060 119 116298 32206 135285 122672065 46 97838 21509 91432 86428
The runtime for the dataset with the block size cus-tomized for each subset is displayed in Table 7 and Figure 8It is observed that the runtime was smaller than that withthe default block size Furthermore the curves show theexpected behavior as the number of features of the datasetwas reduced the runtime decreased In the extreme case(for threshold 065) the runtime increased again becausewith such a small dataset the synchronization times of Sparkbecome bigger than the computing times even with thecustomized block size
In the next section MR-EFS is tested over a very largedataset validating these observations
44 Experiments with the ECBDL14-ROS Dataset This sec-tion presents the classification accuracy and runtime resultsobtained with the ECBDL14-ROS dataset As describedin Section 41 a random oversampling technique [39] waspreviously applied over the original ECBDL14 dataset toovercome the problems originated by its imbalanceTheMR-EFS method was applied using 32 768 map tasks thereforeeach map task computed around 1984 instances
The obtained results in terms of accuracy are depictedin Table 8 and Figure 9 MR-EFS improved the results inall cases with different thresholds The accuracy gain wasespecially important for the Logistic Regression and SVMalgorithms As expected the SVM with 120582 = 00 obtainedbetter results than the onewith120582 = 05 as the latter attemptedto reduce the complexity of the obtained model Howeverit is noteworthy that for 119 features SVM-05 was able tooutperform SVM-00 This hints that after removing noisyfeatures the simpler obtained models represented better the
300
400
500 1000 1500 2000Features
Run
time (
s)
Logistic RegressionNaive Bayes
SVM-00SVM-05
Classifier
Figure 8 Training runtime with the epsilon dataset with cus-tomized block size Note that the number of features decreases asthe threshold increases
true knowledge underlying the data With even less featuresboth variants of SVM obtained roughly the same accuracy
To conclude this study the runtime necessary to trainthe classifiers with all variants of ECBDL14-ROS is presentedin Table 9 and Figure 10 In this case the runtime behavedas expected the time was roughly linear with respect to thenumber of features for all testedmodelsThismeans thatMR-EFS was able to improve both the runtime and the accuracyfor all those classifiers
10 Mathematical Problems in Engineering
050
055
060
065
200 400 600Features
AUC
ClassifierLogistic RegressionNaive BayesSVM-00SVM-05
SetTrainingTest
Figure 9 Accuracy with the ECBDL14-ROS dataset Note that thenumber of features decreases as the threshold increases
0
1000
2000
3000
4000
5000
Run
time (
s)
200 400 600Features
Logistic RegressionNaive Bayes
SVM-00SVM-05
Classifier
Figure 10 Training runtime with the ECBDL14-ROS dataset Notethat the number of features decreases as the threshold increases
5 Concluding Remarks
This paper presents MR-EFS an Evolutionary Feature Selec-tion algorithm designed upon the MapReduce paradigmintended to preprocess big datasets so that they becomeaffordable for other machine learning techniques such asclassification techniques that are currently not scalableenough to deal with such datasets The algorithm has beenimplemented using Apache Hadoop and it has been appliedover two different large datasets The resulting reduceddatasets have been tested using three different classifiersimplemented inApache Spark over a cluster of 20 computers
The theoretical evaluation of themodel highlights the fullscalability of MR-EFS with respect to the number of featuresin the dataset in comparison with a sequential approachThis behavior has been further confirmed after the empiricalprocedures
According to the obtained classification results it can beclaimed thatMR-EFS is able to reduce adequately the numberof features of large datasets leading to reduced versionsof them that are at the same time smaller to store fasterto compute and easier to classify These facts have beenobserved with the two different datasets and for all testedclassifiers
For the epsilon dataset the relation between the reduceddatasets size and the number of nodes is forced to modifythe HDFS block size proving that the hardware resourcescan be optimally used by Hadoop and Spark with the correctdesign One of the obtained reduced ECDBL14-ROS datasetswith more than 67 million instances and several hundredfeatures could be processed by the classifiers in less thanhalf of the time than that of the original dataset and with animprovement of around 5 in terms of AUC
Conflict of Interests
The authors declare that there is no conflict of interestsregarding the publication of this paper
Acknowledgments
This work is supported by the Research Projects TIN2014-57251-P P10-TIC-6858 P11-TIC-7765 P12-TIC-2958 andTIN2013-47210-P D Peralta and S Ramırez-Gallego holdtwo FPU scholarships from the Spanish Ministry of Educa-tion and Science (FPU1204902 FPU1300047) I Trigueroholds a BOF postdoctoral fellowship from the Ghent Univer-sity
References
[1] E Alpaydin Introduction to Machine Learning MIT PressCambridge Mass USA 2nd edition 2010
[2] MMinelliMChambers andADhirajBigData BigAnalyticsEmerging Business Intelligence and Analytic Trends for TodayrsquosBusinesses (Wiley CIO) Wiley 1st edition 2013
[3] V Marx ldquoThe big challenges of big datardquo Nature vol 498 no7453 pp 255ndash260 2013
[4] A Fernandez S del Rıo V Lopez et al ldquoBig data with cloudcomputing an insight on the computing environment MapRe-duce and programming frameworksrdquo Wiley InterdisciplinaryReviews Data Mining and Knowledge Discovery vol 4 no 5pp 380ndash409 2014
[5] E Merelli M Pettini and M Rasetti ldquoTopology driven model-ing the IS metaphorrdquo Natural Computing 2014
[6] S Sakr A Liu DM Batista andM Alomari ldquoA survey of largescale data management approaches in cloud environmentsrdquoIEEE Communications Surveys and Tutorials vol 13 no 3 pp311ndash336 2011
[7] J Bacardit and X Llora ldquoLarge-scale data mining usinggenetics-based machine learningrdquo Wiley Interdisciplinary
Mathematical Problems in Engineering 11
Reviews Data Mining and Knowledge Discovery vol 3 no 1pp 37ndash61 2013
[8] J Dean and SGhemawat ldquoMapReduce simplified data process-ing on large clustersrdquo Communications of the ACM vol 51 no1 pp 107ndash113 2008
[9] J Dean and S Ghemawat ldquoMap reduce a flexible data process-ing toolrdquo Communications of the ACM vol 53 no 1 pp 72ndash772010
[10] S Ghemawat H Gobioff and S-T Leung ldquoThe google file sys-temrdquo in Proceedings of the 19th ACM Symposium on OperatingSystems Principles (SOSP rsquo03) pp 29ndash43 October 2003
[11] M Snir and S Otto MPImdashThe Complete Reference The MPICore MIT Press Boston Mass USA 1998
[12] W Zhao H Ma and Q He ldquoParallel k-means clustering basedon MapReducerdquo in Cloud Computing M Jaatun G Zhao andC Rong Eds vol 5931 of Lecture Notes in Computer Sciencepp 674ndash679 Springer Berlin Germany 2009
[13] A Srinivasan T A Faruquie and S Joshi ldquoData and taskparallelism in ILP using MapReducerdquo Machine Learning vol86 no 1 pp 141ndash168 2012
[14] M Zaharia M Chowdhury T Das et al ldquoResilient distributeddatasets a fault-tolerant abstraction for in-memory clustercomputingrdquo in Proceedings of the 9th USENIX Conferenceon Networked Systems Design and Implementation pp 1ndash14USENIX Association 2012
[15] K Thomas C Grier J Ma V Paxson and D Song ldquoDesignand evaluation of a real-time URL spam filtering servicerdquo inProceedings of the IEEE Symposium on Security and Privacy (SPrsquo11) pp 447ndash462 Berkeley Calif USA May 2011
[16] R S Xin J Rosen M Zaharia M J Franklin S Shenker andI Stoica ldquoShark SQL and rich analytics at scalerdquo in Proceedingsof the ACM SIGMOD International Conference on Managementof Data (SIGMOD rsquo13) pp 13ndash24 ACM June 2013
[17] M S Wiewiorka A Messina A Pacholewska S Maffioletti PGawrysiak and M J Okoniewski ldquoSparkSeq fast scalable andcloud-ready tool for the interactive genomic data analysis withnucleotide precisionrdquo Bioinformatics vol 30 no 18 pp 2652ndash2653 2014
[18] S Garcıa J Luengo and F Herrera Data Preprocessing in DataMining Springer 1st edition 2015
[19] H Brighton and C Mellish ldquoAdvances in instance selection forinstance-based learning algorithmsrdquo Data Mining and Knowl-edge Discovery vol 6 no 2 pp 153ndash172 2002
[20] J A Olvera-Lopez J A Carrasco-Ochoa J F Martınez-Trinidad and J Kittler ldquoA reviewof instance selectionmethodsrdquoArtificial Intelligence Review vol 34 no 2 pp 133ndash143 2010
[21] J S Sanchez ldquoHigh training set size reduction by spacepartitioning and prototype abstractionrdquo Pattern Recognitionvol 37 no 7 pp 1561ndash1564 2004
[22] I Guyon and A Elisseeff ldquoAn introduction to variable andfeature selectionrdquo Journal of Machine Learning Research vol 3pp 1157ndash1182 2003
[23] H Liu and L Yu ldquoToward integrating feature selection algo-rithms for classification and clusteringrdquo IEEE Transactions onKnowledge and Data Engineering vol 17 no 4 pp 491ndash5022005
[24] Y Saeys I Inza and P Larranaga ldquoA review of feature selectiontechniques in bioinformaticsrdquo Bioinformatics vol 23 no 19 pp2507ndash2517 2007
[25] H Liu and H Motoda Computational Methods of FeatureSelection Chapman amp HallCRC Data Mining and KnowledgeDiscovery Series Chapman amp HallCRC Press 2007
[26] J A Lee andMVerleysenNonlinear Dimensionality ReductionSpringer 2007
[27] B de la Iglesia ldquoEvolutionary computation for feature selectionin classification problemsrdquo Wiley Interdisciplinary ReviewsDataMining and Knowledge Discovery vol 3 no 6 pp 381ndash4072013
[28] L J Eshelman ldquoThe CHC adaptative search algorithm howto have safe search when engaging in nontraditional geneticrecombinationrdquo in Foundations of Genetic Algorithms G J ERawlins Ed pp 265ndash283MorganKaufmann SanMateo CalifUSA 1991
[29] MLlib Website httpssparkapacheorgmllib[30] R Kohavi and G H John ldquoWrappers for feature subset
selectionrdquo Artificial Intelligence vol 97 no 1-2 pp 273ndash3241997
[31] M Tan I W Tsang and L Wang ldquoTowards ultrahighdimensional feature selection for big datardquo Journal of MachineLearning Research vol 15 pp 1371ndash1429 2014
[32] T White Hadoop The Definitive Guide OrsquoReilly Media 3rdedition 2012
[33] T Cover and P Hart ldquoNearest neighbor pattern classificationrdquoIEEE Transactions on Information Theory vol 13 no 1 pp 21ndash27 1967
[34] I Triguero D Peralta J Bacardit S Garcıa and F HerreraldquoMRPR a MapReduce solution for prototype reduction in bigdata classificationrdquoNeurocomputing vol 150 pp 331ndash345 2015
[35] C-T Chu S Kim Y-A Lin et al ldquoMap-reduce for machinelearning on multicorerdquo in Advances in Neural InformationProcessing Systems pp 281ndash288 2007
[36] Pascal large scale learning challenge httplargescalemltu-berlindeinstructions
[37] Epsilon in the LIBSVM website httpwwwcsientuedutwsimcjlinlibsvmtoolsdatasetsbinaryhtmlepsilon
[38] ECBDL14 dataset Protein structure prediction and contactmapfor the ECBDL2014 Big Data Competition httpcrunchernclacukbdcomp
[39] S del Rıo V Lopez J M Benıtez and F Herrera ldquoOn the useof MapReduce for imbalanced big data using Random ForestrdquoInformation Sciences vol 285 pp 112ndash137 2014
[40] M A Hearst S T Dumais E Osman J Platt and B ScholkopfldquoSupport vector machinesrdquo IEEE Intelligent Systems and TheirApplications vol 13 no 4 pp 18ndash28 1998
[41] D W Hosmer Jr and S Lemeshow Applied Logistic RegressionJohn Wiley amp Sons 2004
[42] R O Duda and P E Hart Pattern Classification and SceneAnalysis vol 3 Wiley New York NY USA 1973
[43] MLlib guide httpsparkapacheorgdocslatestmllib-guidehtml
Submit your manuscripts athttpwwwhindawicom
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical Problems in Engineering
Hindawi Publishing Corporationhttpwwwhindawicom
Differential EquationsInternational Journal of
Volume 2014
Applied MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Probability and StatisticsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical PhysicsAdvances in
Complex AnalysisJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
OptimizationJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
CombinatoricsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Operations ResearchAdvances in
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Function Spaces
Abstract and Applied AnalysisHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of Mathematics and Mathematical Sciences
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Algebra
Discrete Dynamics in Nature and Society
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Decision SciencesAdvances in
Discrete MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom
Volume 2014 Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Stochastic AnalysisInternational Journal of

Mathematical Problems in Engineering 7
Table 3 Execution times (in seconds) over the epsilon subsets
Instances Sequential CHC MR-EFS Splits1000 391 419 12000 1352 409 25000 8667 413 510 000 39 576 431 1015 000 91 272 445 1520 000 159 315 455 20400 000 mdash 6531 512
431 Feature Selection Performance The complexity order ofthe CHC algorithm is approximately O(1198992119863119901) where 119901 isthe number of evaluations of the fitness function (a 119896-NNclassifier in this case) 119899 is the number of instances and 119863 isthe number of features Therefore the algorithm is quadraticwith respect to the number of instances
When the dataset is divided into 119898 splits within MR-EFS each one of the 119898 map tasks has complexity orderO((119899
21198982)119863119901) which is 1198982 times faster than applying CHCover the whole dataset If 119899
119888cores are available for the map
tasks the complexity of the map phase within the MR-EFS procedure is approximately O(lceil119898119899
119888rceil(11989921198982)119863119901) This
demonstrates the scalability of the approach presented in thispaper even if themaps are executed sequentially (119899
119888= 1) the
procedure is still one order of magnitude faster than feedinga single CHC with all the instances at once
In order to verify the performance of MR-EFS withrespect to the sequential approach a set of experimentswere performed using subsets of the epsilon dataset Botha sequential CHC algorithm and the parallel MR-EFS (with1000 instances per split) were applied over those subsetsThe obtained execution times are presented in Table 3 andFigure 5 along with the runtime of MR-EFS over the wholedataset
The sequential runtimes described a quadratic shapein concordance with the complexity order of CHC whichclearly states that the time necessary to tackle the wholedataset would be impractical In opposite the runtime ofMR-EFS for the small datasets was nearly constant The casewith 1000 instances is particular in the sense that MR-EFSonly executed one map task therefore it executed a singleCHC with 1000 instances The time difference between CHCand MR-EFS in this case reflects the overhead introduced bythe latter Even though his overhead increased slightly as thenumber of map tasks grew it represented a minor part of theoverall runtime
As for the full dataset with 512 splits the number ofinstances for each map task in MR-EFS is around 780 As thenumber of cores used for the experiments was 240 the mapphase in MR-EFS should be roughly three times slower thanthe sequential CHC with 1000 instances according to thecomplexity orders previously detailed The times in Table 3show a higher time gap because MR-EFS includes as well theother phases of theMapReduce framework (namely splittingshuffle and reduce) which are nonnegligible for a dataset ofsuch size Nevertheless the overall MR-EFS execution time is
0 5000 10000 15000 20000
0
50000
100000
150000
Number of instances
Tim
e (s)
Sequential CHCMR-EFSMR-EFS (full dataset)
Figure 5 Execution times of the sequential CHC and MR-EFS
064
066
068
070
500 1000 1500 2000Features
AUC
ClassifierLogistic RegressionNaive BayesSVM-00SVM-05
SetTrainingTest
Figure 6 Accuracy with the epsilon dataset Note that the numberof features decreases as the threshold increases
highly scalable as shown by the fact that MR-EFS was able toprocess the 400 000 instances faster than the time needed byCHC to process 5000 instances
432 Classification Results This section presents the resultsobtained by applying several classifiers over the full epsilondataset with its features previously selected by usingMR-EFSThe dataset was split among 512 map tasks each of whichcomputed around 780 instances
The AUC values are shown in Table 4 and Figure 6 bothfor training and test sets using three different thresholdsfor the dataset reduction step Note that the zero-thresholdcorresponds to the original dataset without performing any
8 Mathematical Problems in Engineering
Table 4 AUC results for the Spark classifiers using epsilon
Threshold Features Logistic Regression Naive Bayes SVM (120582 = 00) SVM (120582 = 05)Training Test Training Test Training Test Training Test
000 2000 06786 06784 07038 07008 06440 06433 06440 06433055 721 06985 07000 07154 07127 06855 06865 06855 06865060 337 06873 06867 07054 07030 06805 06799 06805 06799065 110 06496 06497 06803 06794 06492 06493 06492 06493
Table 5 Training runtime (in seconds) for the Spark classifiers using epsilon
Threshold Features Logistic Regression Naive Bayes SVM (120582 = 00) SVM (120582 = 05)000 2000 36729 60514 33418 33169055 721 40935 34042 40970 38684060 337 48816 30733 50546 48993065 110 50186 26426 46744 47374
Table 6 Size of the epsilon dataset for each threshold
Threshold Set MB HDFS blocks
000 Training 817918 128Test 204480 32
055 Training 294652 47Test 73663 12
060 Training 137721 22Test 34430 6
065 Training 45060 8Test 11265 2
feature selectionThebest results for eachmethod are stressedin boldface The table shows that the accuracy was improvedby the removal of the adequate features as the threshold 055allowed for obtaining higher AUC values The accuracy gainwas especially large for SVMMoreover more than half of thefeatures were removed which reduces significantly the sizeof the dataset and therefore the complexity of the resultingclassifier
A threshold of value 060 also got to improve the accuracyresults while reducing even further the size of the datasetFinally for the 065 thresholds only SVM saw its AUCimproved
It is also noteworthy that the two variants of SVMobtained the same results for all the tested thresholds Thisfact indicates that the complexity of the obtained SVMmodelis relatively low
The training runtime of the different algorithms anddatabases is shown in Table 5 and Figure 7 The obtainedresults were seemingly the opposite to the expectationsexcept for Naive Bayes the classifiers needed more time toprocess the datasets as their number of features decreases
However this behavior can be explained as the datasetgets smaller it occupies less HDFS blocks and thereforethe full parallel capacity of the cluster is not exploited Thesize of each version of the epsilon dataset and the numberof HDFS blocks that are needed to store it are shown inTable 6 The computer cluster is composed of 20 machinestherefore when the number of blocks is lower than 20 some
300
400
500
600
500 1000 1500 2000Features
Run
time (
s)
Logistic RegressionNaive Bayes
SVM-00SVM-05
Classifier
Figure 7 Training runtime with the epsilon dataset Note that thenumber of features decreases as the threshold increases
of the machines remain idle because they have no HDFSblock to process Moreover even if the number of blocks isslightly above 20 the affectedHDFS blocksmay not be evenlydistributed among the computing nodes This demonstratesthe capacity of Spark to deal with big databases as thesize of the database (more concretely the number of HDFSblocks) increases the framework is able to distribute theprocesses more evenly exploiting data locality increasing theparallelism and reducing the network overhead
In order to deal with this problem the same experimentswere repeated over the epsilon dataset after reorganizing thefiles with a smaller block size For each of the eight sets theblock size 119878
119887was calculated according to (6) where 119904 is the
size of the dataset in bytes and 119899119888is the number of cores in
the cluster
119878119887= 2119870
119870 = lfloorlog2119904
119899119888
rfloor (6)
Mathematical Problems in Engineering 9
Table 7 Training runtime (in seconds) for the Spark classifiers using epsilon with customized block size
Threshold Features Logistic Regression Naive Bayes SVM (120582 = 00) SVM (120582 = 05)000 2000 32194 48348 30094 30647055 721 25692 31319 25672 25698060 337 23616 24859 23123 22803065 110 30770 30826 25405 26123
Table 8 AUC values for the Spark classifiers using ECBDL14-ROS
Threshold Features Logistic Regression Naive Bayes SVM (120582 = 00) SVM (120582 = 05)Training Test Training Test Training Test Training Test
000 631 05821 05808 06714 06506 05966 06046 05875 05897055 234 06416 06352 06673 06489 06369 06307 06228 06148060 119 06309 06235 06732 06516 05884 05841 06116 06054065 46 05017 05022 06136 06093 05032 05039 05000 05000
Table 9 Training runtime (in seconds) for the Spark classifiers using ECBDL14-ROS
Threshold Features Logistic Regression Naive Bayes SVM (120582 = 00) SVM (120582 = 05)000 631 464919 158152 528388 506587055 234 210766 61350 232122 217918060 119 116298 32206 135285 122672065 46 97838 21509 91432 86428
The runtime for the dataset with the block size cus-tomized for each subset is displayed in Table 7 and Figure 8It is observed that the runtime was smaller than that withthe default block size Furthermore the curves show theexpected behavior as the number of features of the datasetwas reduced the runtime decreased In the extreme case(for threshold 065) the runtime increased again becausewith such a small dataset the synchronization times of Sparkbecome bigger than the computing times even with thecustomized block size
In the next section MR-EFS is tested over a very largedataset validating these observations
44 Experiments with the ECBDL14-ROS Dataset This sec-tion presents the classification accuracy and runtime resultsobtained with the ECBDL14-ROS dataset As describedin Section 41 a random oversampling technique [39] waspreviously applied over the original ECBDL14 dataset toovercome the problems originated by its imbalanceTheMR-EFS method was applied using 32 768 map tasks thereforeeach map task computed around 1984 instances
The obtained results in terms of accuracy are depictedin Table 8 and Figure 9 MR-EFS improved the results inall cases with different thresholds The accuracy gain wasespecially important for the Logistic Regression and SVMalgorithms As expected the SVM with 120582 = 00 obtainedbetter results than the onewith120582 = 05 as the latter attemptedto reduce the complexity of the obtained model Howeverit is noteworthy that for 119 features SVM-05 was able tooutperform SVM-00 This hints that after removing noisyfeatures the simpler obtained models represented better the
300
400
500 1000 1500 2000Features
Run
time (
s)
Logistic RegressionNaive Bayes
SVM-00SVM-05
Classifier
Figure 8 Training runtime with the epsilon dataset with cus-tomized block size Note that the number of features decreases asthe threshold increases
true knowledge underlying the data With even less featuresboth variants of SVM obtained roughly the same accuracy
To conclude this study the runtime necessary to trainthe classifiers with all variants of ECBDL14-ROS is presentedin Table 9 and Figure 10 In this case the runtime behavedas expected the time was roughly linear with respect to thenumber of features for all testedmodelsThismeans thatMR-EFS was able to improve both the runtime and the accuracyfor all those classifiers
10 Mathematical Problems in Engineering
050
055
060
065
200 400 600Features
AUC
ClassifierLogistic RegressionNaive BayesSVM-00SVM-05
SetTrainingTest
Figure 9 Accuracy with the ECBDL14-ROS dataset Note that thenumber of features decreases as the threshold increases
0
1000
2000
3000
4000
5000
Run
time (
s)
200 400 600Features
Logistic RegressionNaive Bayes
SVM-00SVM-05
Classifier
Figure 10 Training runtime with the ECBDL14-ROS dataset Notethat the number of features decreases as the threshold increases
5 Concluding Remarks
This paper presents MR-EFS an Evolutionary Feature Selec-tion algorithm designed upon the MapReduce paradigmintended to preprocess big datasets so that they becomeaffordable for other machine learning techniques such asclassification techniques that are currently not scalableenough to deal with such datasets The algorithm has beenimplemented using Apache Hadoop and it has been appliedover two different large datasets The resulting reduceddatasets have been tested using three different classifiersimplemented inApache Spark over a cluster of 20 computers
The theoretical evaluation of themodel highlights the fullscalability of MR-EFS with respect to the number of featuresin the dataset in comparison with a sequential approachThis behavior has been further confirmed after the empiricalprocedures
According to the obtained classification results it can beclaimed thatMR-EFS is able to reduce adequately the numberof features of large datasets leading to reduced versionsof them that are at the same time smaller to store fasterto compute and easier to classify These facts have beenobserved with the two different datasets and for all testedclassifiers
For the epsilon dataset the relation between the reduceddatasets size and the number of nodes is forced to modifythe HDFS block size proving that the hardware resourcescan be optimally used by Hadoop and Spark with the correctdesign One of the obtained reduced ECDBL14-ROS datasetswith more than 67 million instances and several hundredfeatures could be processed by the classifiers in less thanhalf of the time than that of the original dataset and with animprovement of around 5 in terms of AUC
Conflict of Interests
The authors declare that there is no conflict of interestsregarding the publication of this paper
Acknowledgments
This work is supported by the Research Projects TIN2014-57251-P P10-TIC-6858 P11-TIC-7765 P12-TIC-2958 andTIN2013-47210-P D Peralta and S Ramırez-Gallego holdtwo FPU scholarships from the Spanish Ministry of Educa-tion and Science (FPU1204902 FPU1300047) I Trigueroholds a BOF postdoctoral fellowship from the Ghent Univer-sity
References
[1] E Alpaydin Introduction to Machine Learning MIT PressCambridge Mass USA 2nd edition 2010
[2] MMinelliMChambers andADhirajBigData BigAnalyticsEmerging Business Intelligence and Analytic Trends for TodayrsquosBusinesses (Wiley CIO) Wiley 1st edition 2013
[3] V Marx ldquoThe big challenges of big datardquo Nature vol 498 no7453 pp 255ndash260 2013
[4] A Fernandez S del Rıo V Lopez et al ldquoBig data with cloudcomputing an insight on the computing environment MapRe-duce and programming frameworksrdquo Wiley InterdisciplinaryReviews Data Mining and Knowledge Discovery vol 4 no 5pp 380ndash409 2014
[5] E Merelli M Pettini and M Rasetti ldquoTopology driven model-ing the IS metaphorrdquo Natural Computing 2014
[6] S Sakr A Liu DM Batista andM Alomari ldquoA survey of largescale data management approaches in cloud environmentsrdquoIEEE Communications Surveys and Tutorials vol 13 no 3 pp311ndash336 2011
[7] J Bacardit and X Llora ldquoLarge-scale data mining usinggenetics-based machine learningrdquo Wiley Interdisciplinary
Mathematical Problems in Engineering 11
Reviews Data Mining and Knowledge Discovery vol 3 no 1pp 37ndash61 2013
[8] J Dean and SGhemawat ldquoMapReduce simplified data process-ing on large clustersrdquo Communications of the ACM vol 51 no1 pp 107ndash113 2008
[9] J Dean and S Ghemawat ldquoMap reduce a flexible data process-ing toolrdquo Communications of the ACM vol 53 no 1 pp 72ndash772010
[10] S Ghemawat H Gobioff and S-T Leung ldquoThe google file sys-temrdquo in Proceedings of the 19th ACM Symposium on OperatingSystems Principles (SOSP rsquo03) pp 29ndash43 October 2003
[11] M Snir and S Otto MPImdashThe Complete Reference The MPICore MIT Press Boston Mass USA 1998
[12] W Zhao H Ma and Q He ldquoParallel k-means clustering basedon MapReducerdquo in Cloud Computing M Jaatun G Zhao andC Rong Eds vol 5931 of Lecture Notes in Computer Sciencepp 674ndash679 Springer Berlin Germany 2009
[13] A Srinivasan T A Faruquie and S Joshi ldquoData and taskparallelism in ILP using MapReducerdquo Machine Learning vol86 no 1 pp 141ndash168 2012
[14] M Zaharia M Chowdhury T Das et al ldquoResilient distributeddatasets a fault-tolerant abstraction for in-memory clustercomputingrdquo in Proceedings of the 9th USENIX Conferenceon Networked Systems Design and Implementation pp 1ndash14USENIX Association 2012
[15] K Thomas C Grier J Ma V Paxson and D Song ldquoDesignand evaluation of a real-time URL spam filtering servicerdquo inProceedings of the IEEE Symposium on Security and Privacy (SPrsquo11) pp 447ndash462 Berkeley Calif USA May 2011
[16] R S Xin J Rosen M Zaharia M J Franklin S Shenker andI Stoica ldquoShark SQL and rich analytics at scalerdquo in Proceedingsof the ACM SIGMOD International Conference on Managementof Data (SIGMOD rsquo13) pp 13ndash24 ACM June 2013
[17] M S Wiewiorka A Messina A Pacholewska S Maffioletti PGawrysiak and M J Okoniewski ldquoSparkSeq fast scalable andcloud-ready tool for the interactive genomic data analysis withnucleotide precisionrdquo Bioinformatics vol 30 no 18 pp 2652ndash2653 2014
[18] S Garcıa J Luengo and F Herrera Data Preprocessing in DataMining Springer 1st edition 2015
[19] H Brighton and C Mellish ldquoAdvances in instance selection forinstance-based learning algorithmsrdquo Data Mining and Knowl-edge Discovery vol 6 no 2 pp 153ndash172 2002
[20] J A Olvera-Lopez J A Carrasco-Ochoa J F Martınez-Trinidad and J Kittler ldquoA reviewof instance selectionmethodsrdquoArtificial Intelligence Review vol 34 no 2 pp 133ndash143 2010
[21] J S Sanchez ldquoHigh training set size reduction by spacepartitioning and prototype abstractionrdquo Pattern Recognitionvol 37 no 7 pp 1561ndash1564 2004
[22] I Guyon and A Elisseeff ldquoAn introduction to variable andfeature selectionrdquo Journal of Machine Learning Research vol 3pp 1157ndash1182 2003
[23] H Liu and L Yu ldquoToward integrating feature selection algo-rithms for classification and clusteringrdquo IEEE Transactions onKnowledge and Data Engineering vol 17 no 4 pp 491ndash5022005
[24] Y Saeys I Inza and P Larranaga ldquoA review of feature selectiontechniques in bioinformaticsrdquo Bioinformatics vol 23 no 19 pp2507ndash2517 2007
[25] H Liu and H Motoda Computational Methods of FeatureSelection Chapman amp HallCRC Data Mining and KnowledgeDiscovery Series Chapman amp HallCRC Press 2007
[26] J A Lee andMVerleysenNonlinear Dimensionality ReductionSpringer 2007
[27] B de la Iglesia ldquoEvolutionary computation for feature selectionin classification problemsrdquo Wiley Interdisciplinary ReviewsDataMining and Knowledge Discovery vol 3 no 6 pp 381ndash4072013
[28] L J Eshelman ldquoThe CHC adaptative search algorithm howto have safe search when engaging in nontraditional geneticrecombinationrdquo in Foundations of Genetic Algorithms G J ERawlins Ed pp 265ndash283MorganKaufmann SanMateo CalifUSA 1991
[29] MLlib Website httpssparkapacheorgmllib[30] R Kohavi and G H John ldquoWrappers for feature subset
selectionrdquo Artificial Intelligence vol 97 no 1-2 pp 273ndash3241997
[31] M Tan I W Tsang and L Wang ldquoTowards ultrahighdimensional feature selection for big datardquo Journal of MachineLearning Research vol 15 pp 1371ndash1429 2014
[32] T White Hadoop The Definitive Guide OrsquoReilly Media 3rdedition 2012
[33] T Cover and P Hart ldquoNearest neighbor pattern classificationrdquoIEEE Transactions on Information Theory vol 13 no 1 pp 21ndash27 1967
[34] I Triguero D Peralta J Bacardit S Garcıa and F HerreraldquoMRPR a MapReduce solution for prototype reduction in bigdata classificationrdquoNeurocomputing vol 150 pp 331ndash345 2015
[35] C-T Chu S Kim Y-A Lin et al ldquoMap-reduce for machinelearning on multicorerdquo in Advances in Neural InformationProcessing Systems pp 281ndash288 2007
[36] Pascal large scale learning challenge httplargescalemltu-berlindeinstructions
[37] Epsilon in the LIBSVM website httpwwwcsientuedutwsimcjlinlibsvmtoolsdatasetsbinaryhtmlepsilon
[38] ECBDL14 dataset Protein structure prediction and contactmapfor the ECBDL2014 Big Data Competition httpcrunchernclacukbdcomp
[39] S del Rıo V Lopez J M Benıtez and F Herrera ldquoOn the useof MapReduce for imbalanced big data using Random ForestrdquoInformation Sciences vol 285 pp 112ndash137 2014
[40] M A Hearst S T Dumais E Osman J Platt and B ScholkopfldquoSupport vector machinesrdquo IEEE Intelligent Systems and TheirApplications vol 13 no 4 pp 18ndash28 1998
[41] D W Hosmer Jr and S Lemeshow Applied Logistic RegressionJohn Wiley amp Sons 2004
[42] R O Duda and P E Hart Pattern Classification and SceneAnalysis vol 3 Wiley New York NY USA 1973
[43] MLlib guide httpsparkapacheorgdocslatestmllib-guidehtml
Submit your manuscripts athttpwwwhindawicom
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical Problems in Engineering
Hindawi Publishing Corporationhttpwwwhindawicom
Differential EquationsInternational Journal of
Volume 2014
Applied MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Probability and StatisticsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical PhysicsAdvances in
Complex AnalysisJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
OptimizationJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
CombinatoricsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Operations ResearchAdvances in
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Function Spaces
Abstract and Applied AnalysisHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of Mathematics and Mathematical Sciences
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Algebra
Discrete Dynamics in Nature and Society
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Decision SciencesAdvances in
Discrete MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom
Volume 2014 Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Stochastic AnalysisInternational Journal of

8 Mathematical Problems in Engineering
Table 4 AUC results for the Spark classifiers using epsilon
Threshold Features Logistic Regression Naive Bayes SVM (120582 = 00) SVM (120582 = 05)Training Test Training Test Training Test Training Test
000 2000 06786 06784 07038 07008 06440 06433 06440 06433055 721 06985 07000 07154 07127 06855 06865 06855 06865060 337 06873 06867 07054 07030 06805 06799 06805 06799065 110 06496 06497 06803 06794 06492 06493 06492 06493
Table 5 Training runtime (in seconds) for the Spark classifiers using epsilon
Threshold Features Logistic Regression Naive Bayes SVM (120582 = 00) SVM (120582 = 05)000 2000 36729 60514 33418 33169055 721 40935 34042 40970 38684060 337 48816 30733 50546 48993065 110 50186 26426 46744 47374
Table 6 Size of the epsilon dataset for each threshold
Threshold Set MB HDFS blocks
000 Training 817918 128Test 204480 32
055 Training 294652 47Test 73663 12
060 Training 137721 22Test 34430 6
065 Training 45060 8Test 11265 2
feature selectionThebest results for eachmethod are stressedin boldface The table shows that the accuracy was improvedby the removal of the adequate features as the threshold 055allowed for obtaining higher AUC values The accuracy gainwas especially large for SVMMoreover more than half of thefeatures were removed which reduces significantly the sizeof the dataset and therefore the complexity of the resultingclassifier
A threshold of value 060 also got to improve the accuracyresults while reducing even further the size of the datasetFinally for the 065 thresholds only SVM saw its AUCimproved
It is also noteworthy that the two variants of SVMobtained the same results for all the tested thresholds Thisfact indicates that the complexity of the obtained SVMmodelis relatively low
The training runtime of the different algorithms anddatabases is shown in Table 5 and Figure 7 The obtainedresults were seemingly the opposite to the expectationsexcept for Naive Bayes the classifiers needed more time toprocess the datasets as their number of features decreases
However this behavior can be explained as the datasetgets smaller it occupies less HDFS blocks and thereforethe full parallel capacity of the cluster is not exploited Thesize of each version of the epsilon dataset and the numberof HDFS blocks that are needed to store it are shown inTable 6 The computer cluster is composed of 20 machinestherefore when the number of blocks is lower than 20 some
300
400
500
600
500 1000 1500 2000Features
Run
time (
s)
Logistic RegressionNaive Bayes
SVM-00SVM-05
Classifier
Figure 7 Training runtime with the epsilon dataset Note that thenumber of features decreases as the threshold increases
of the machines remain idle because they have no HDFSblock to process Moreover even if the number of blocks isslightly above 20 the affectedHDFS blocksmay not be evenlydistributed among the computing nodes This demonstratesthe capacity of Spark to deal with big databases as thesize of the database (more concretely the number of HDFSblocks) increases the framework is able to distribute theprocesses more evenly exploiting data locality increasing theparallelism and reducing the network overhead
In order to deal with this problem the same experimentswere repeated over the epsilon dataset after reorganizing thefiles with a smaller block size For each of the eight sets theblock size 119878
119887was calculated according to (6) where 119904 is the
size of the dataset in bytes and 119899119888is the number of cores in
the cluster
119878119887= 2119870
119870 = lfloorlog2119904
119899119888
rfloor (6)
Mathematical Problems in Engineering 9
Table 7 Training runtime (in seconds) for the Spark classifiers using epsilon with customized block size
Threshold Features Logistic Regression Naive Bayes SVM (120582 = 00) SVM (120582 = 05)000 2000 32194 48348 30094 30647055 721 25692 31319 25672 25698060 337 23616 24859 23123 22803065 110 30770 30826 25405 26123
Table 8 AUC values for the Spark classifiers using ECBDL14-ROS
Threshold Features Logistic Regression Naive Bayes SVM (120582 = 00) SVM (120582 = 05)Training Test Training Test Training Test Training Test
000 631 05821 05808 06714 06506 05966 06046 05875 05897055 234 06416 06352 06673 06489 06369 06307 06228 06148060 119 06309 06235 06732 06516 05884 05841 06116 06054065 46 05017 05022 06136 06093 05032 05039 05000 05000
Table 9 Training runtime (in seconds) for the Spark classifiers using ECBDL14-ROS
Threshold Features Logistic Regression Naive Bayes SVM (120582 = 00) SVM (120582 = 05)000 631 464919 158152 528388 506587055 234 210766 61350 232122 217918060 119 116298 32206 135285 122672065 46 97838 21509 91432 86428
The runtime for the dataset with the block size cus-tomized for each subset is displayed in Table 7 and Figure 8It is observed that the runtime was smaller than that withthe default block size Furthermore the curves show theexpected behavior as the number of features of the datasetwas reduced the runtime decreased In the extreme case(for threshold 065) the runtime increased again becausewith such a small dataset the synchronization times of Sparkbecome bigger than the computing times even with thecustomized block size
In the next section MR-EFS is tested over a very largedataset validating these observations
44 Experiments with the ECBDL14-ROS Dataset This sec-tion presents the classification accuracy and runtime resultsobtained with the ECBDL14-ROS dataset As describedin Section 41 a random oversampling technique [39] waspreviously applied over the original ECBDL14 dataset toovercome the problems originated by its imbalanceTheMR-EFS method was applied using 32 768 map tasks thereforeeach map task computed around 1984 instances
The obtained results in terms of accuracy are depictedin Table 8 and Figure 9 MR-EFS improved the results inall cases with different thresholds The accuracy gain wasespecially important for the Logistic Regression and SVMalgorithms As expected the SVM with 120582 = 00 obtainedbetter results than the onewith120582 = 05 as the latter attemptedto reduce the complexity of the obtained model Howeverit is noteworthy that for 119 features SVM-05 was able tooutperform SVM-00 This hints that after removing noisyfeatures the simpler obtained models represented better the
300
400
500 1000 1500 2000Features
Run
time (
s)
Logistic RegressionNaive Bayes
SVM-00SVM-05
Classifier
Figure 8 Training runtime with the epsilon dataset with cus-tomized block size Note that the number of features decreases asthe threshold increases
true knowledge underlying the data With even less featuresboth variants of SVM obtained roughly the same accuracy
To conclude this study the runtime necessary to trainthe classifiers with all variants of ECBDL14-ROS is presentedin Table 9 and Figure 10 In this case the runtime behavedas expected the time was roughly linear with respect to thenumber of features for all testedmodelsThismeans thatMR-EFS was able to improve both the runtime and the accuracyfor all those classifiers
10 Mathematical Problems in Engineering
050
055
060
065
200 400 600Features
AUC
ClassifierLogistic RegressionNaive BayesSVM-00SVM-05
SetTrainingTest
Figure 9 Accuracy with the ECBDL14-ROS dataset Note that thenumber of features decreases as the threshold increases
0
1000
2000
3000
4000
5000
Run
time (
s)
200 400 600Features
Logistic RegressionNaive Bayes
SVM-00SVM-05
Classifier
Figure 10 Training runtime with the ECBDL14-ROS dataset Notethat the number of features decreases as the threshold increases
5 Concluding Remarks
This paper presents MR-EFS an Evolutionary Feature Selec-tion algorithm designed upon the MapReduce paradigmintended to preprocess big datasets so that they becomeaffordable for other machine learning techniques such asclassification techniques that are currently not scalableenough to deal with such datasets The algorithm has beenimplemented using Apache Hadoop and it has been appliedover two different large datasets The resulting reduceddatasets have been tested using three different classifiersimplemented inApache Spark over a cluster of 20 computers
The theoretical evaluation of themodel highlights the fullscalability of MR-EFS with respect to the number of featuresin the dataset in comparison with a sequential approachThis behavior has been further confirmed after the empiricalprocedures
According to the obtained classification results it can beclaimed thatMR-EFS is able to reduce adequately the numberof features of large datasets leading to reduced versionsof them that are at the same time smaller to store fasterto compute and easier to classify These facts have beenobserved with the two different datasets and for all testedclassifiers
For the epsilon dataset the relation between the reduceddatasets size and the number of nodes is forced to modifythe HDFS block size proving that the hardware resourcescan be optimally used by Hadoop and Spark with the correctdesign One of the obtained reduced ECDBL14-ROS datasetswith more than 67 million instances and several hundredfeatures could be processed by the classifiers in less thanhalf of the time than that of the original dataset and with animprovement of around 5 in terms of AUC
Conflict of Interests
The authors declare that there is no conflict of interestsregarding the publication of this paper
Acknowledgments
This work is supported by the Research Projects TIN2014-57251-P P10-TIC-6858 P11-TIC-7765 P12-TIC-2958 andTIN2013-47210-P D Peralta and S Ramırez-Gallego holdtwo FPU scholarships from the Spanish Ministry of Educa-tion and Science (FPU1204902 FPU1300047) I Trigueroholds a BOF postdoctoral fellowship from the Ghent Univer-sity
References
[1] E Alpaydin Introduction to Machine Learning MIT PressCambridge Mass USA 2nd edition 2010
[2] MMinelliMChambers andADhirajBigData BigAnalyticsEmerging Business Intelligence and Analytic Trends for TodayrsquosBusinesses (Wiley CIO) Wiley 1st edition 2013
[3] V Marx ldquoThe big challenges of big datardquo Nature vol 498 no7453 pp 255ndash260 2013
[4] A Fernandez S del Rıo V Lopez et al ldquoBig data with cloudcomputing an insight on the computing environment MapRe-duce and programming frameworksrdquo Wiley InterdisciplinaryReviews Data Mining and Knowledge Discovery vol 4 no 5pp 380ndash409 2014
[5] E Merelli M Pettini and M Rasetti ldquoTopology driven model-ing the IS metaphorrdquo Natural Computing 2014
[6] S Sakr A Liu DM Batista andM Alomari ldquoA survey of largescale data management approaches in cloud environmentsrdquoIEEE Communications Surveys and Tutorials vol 13 no 3 pp311ndash336 2011
[7] J Bacardit and X Llora ldquoLarge-scale data mining usinggenetics-based machine learningrdquo Wiley Interdisciplinary
Mathematical Problems in Engineering 11
Reviews Data Mining and Knowledge Discovery vol 3 no 1pp 37ndash61 2013
[8] J Dean and SGhemawat ldquoMapReduce simplified data process-ing on large clustersrdquo Communications of the ACM vol 51 no1 pp 107ndash113 2008
[9] J Dean and S Ghemawat ldquoMap reduce a flexible data process-ing toolrdquo Communications of the ACM vol 53 no 1 pp 72ndash772010
[10] S Ghemawat H Gobioff and S-T Leung ldquoThe google file sys-temrdquo in Proceedings of the 19th ACM Symposium on OperatingSystems Principles (SOSP rsquo03) pp 29ndash43 October 2003
[11] M Snir and S Otto MPImdashThe Complete Reference The MPICore MIT Press Boston Mass USA 1998
[12] W Zhao H Ma and Q He ldquoParallel k-means clustering basedon MapReducerdquo in Cloud Computing M Jaatun G Zhao andC Rong Eds vol 5931 of Lecture Notes in Computer Sciencepp 674ndash679 Springer Berlin Germany 2009
[13] A Srinivasan T A Faruquie and S Joshi ldquoData and taskparallelism in ILP using MapReducerdquo Machine Learning vol86 no 1 pp 141ndash168 2012
[14] M Zaharia M Chowdhury T Das et al ldquoResilient distributeddatasets a fault-tolerant abstraction for in-memory clustercomputingrdquo in Proceedings of the 9th USENIX Conferenceon Networked Systems Design and Implementation pp 1ndash14USENIX Association 2012
[15] K Thomas C Grier J Ma V Paxson and D Song ldquoDesignand evaluation of a real-time URL spam filtering servicerdquo inProceedings of the IEEE Symposium on Security and Privacy (SPrsquo11) pp 447ndash462 Berkeley Calif USA May 2011
[16] R S Xin J Rosen M Zaharia M J Franklin S Shenker andI Stoica ldquoShark SQL and rich analytics at scalerdquo in Proceedingsof the ACM SIGMOD International Conference on Managementof Data (SIGMOD rsquo13) pp 13ndash24 ACM June 2013
[17] M S Wiewiorka A Messina A Pacholewska S Maffioletti PGawrysiak and M J Okoniewski ldquoSparkSeq fast scalable andcloud-ready tool for the interactive genomic data analysis withnucleotide precisionrdquo Bioinformatics vol 30 no 18 pp 2652ndash2653 2014
[18] S Garcıa J Luengo and F Herrera Data Preprocessing in DataMining Springer 1st edition 2015
[19] H Brighton and C Mellish ldquoAdvances in instance selection forinstance-based learning algorithmsrdquo Data Mining and Knowl-edge Discovery vol 6 no 2 pp 153ndash172 2002
[20] J A Olvera-Lopez J A Carrasco-Ochoa J F Martınez-Trinidad and J Kittler ldquoA reviewof instance selectionmethodsrdquoArtificial Intelligence Review vol 34 no 2 pp 133ndash143 2010
[21] J S Sanchez ldquoHigh training set size reduction by spacepartitioning and prototype abstractionrdquo Pattern Recognitionvol 37 no 7 pp 1561ndash1564 2004
[22] I Guyon and A Elisseeff ldquoAn introduction to variable andfeature selectionrdquo Journal of Machine Learning Research vol 3pp 1157ndash1182 2003
[23] H Liu and L Yu ldquoToward integrating feature selection algo-rithms for classification and clusteringrdquo IEEE Transactions onKnowledge and Data Engineering vol 17 no 4 pp 491ndash5022005
[24] Y Saeys I Inza and P Larranaga ldquoA review of feature selectiontechniques in bioinformaticsrdquo Bioinformatics vol 23 no 19 pp2507ndash2517 2007
[25] H Liu and H Motoda Computational Methods of FeatureSelection Chapman amp HallCRC Data Mining and KnowledgeDiscovery Series Chapman amp HallCRC Press 2007
[26] J A Lee andMVerleysenNonlinear Dimensionality ReductionSpringer 2007
[27] B de la Iglesia ldquoEvolutionary computation for feature selectionin classification problemsrdquo Wiley Interdisciplinary ReviewsDataMining and Knowledge Discovery vol 3 no 6 pp 381ndash4072013
[28] L J Eshelman ldquoThe CHC adaptative search algorithm howto have safe search when engaging in nontraditional geneticrecombinationrdquo in Foundations of Genetic Algorithms G J ERawlins Ed pp 265ndash283MorganKaufmann SanMateo CalifUSA 1991
[29] MLlib Website httpssparkapacheorgmllib[30] R Kohavi and G H John ldquoWrappers for feature subset
selectionrdquo Artificial Intelligence vol 97 no 1-2 pp 273ndash3241997
[31] M Tan I W Tsang and L Wang ldquoTowards ultrahighdimensional feature selection for big datardquo Journal of MachineLearning Research vol 15 pp 1371ndash1429 2014
[32] T White Hadoop The Definitive Guide OrsquoReilly Media 3rdedition 2012
[33] T Cover and P Hart ldquoNearest neighbor pattern classificationrdquoIEEE Transactions on Information Theory vol 13 no 1 pp 21ndash27 1967
[34] I Triguero D Peralta J Bacardit S Garcıa and F HerreraldquoMRPR a MapReduce solution for prototype reduction in bigdata classificationrdquoNeurocomputing vol 150 pp 331ndash345 2015
[35] C-T Chu S Kim Y-A Lin et al ldquoMap-reduce for machinelearning on multicorerdquo in Advances in Neural InformationProcessing Systems pp 281ndash288 2007
[36] Pascal large scale learning challenge httplargescalemltu-berlindeinstructions
[37] Epsilon in the LIBSVM website httpwwwcsientuedutwsimcjlinlibsvmtoolsdatasetsbinaryhtmlepsilon
[38] ECBDL14 dataset Protein structure prediction and contactmapfor the ECBDL2014 Big Data Competition httpcrunchernclacukbdcomp
[39] S del Rıo V Lopez J M Benıtez and F Herrera ldquoOn the useof MapReduce for imbalanced big data using Random ForestrdquoInformation Sciences vol 285 pp 112ndash137 2014
[40] M A Hearst S T Dumais E Osman J Platt and B ScholkopfldquoSupport vector machinesrdquo IEEE Intelligent Systems and TheirApplications vol 13 no 4 pp 18ndash28 1998
[41] D W Hosmer Jr and S Lemeshow Applied Logistic RegressionJohn Wiley amp Sons 2004
[42] R O Duda and P E Hart Pattern Classification and SceneAnalysis vol 3 Wiley New York NY USA 1973
[43] MLlib guide httpsparkapacheorgdocslatestmllib-guidehtml
Submit your manuscripts athttpwwwhindawicom
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical Problems in Engineering
Hindawi Publishing Corporationhttpwwwhindawicom
Differential EquationsInternational Journal of
Volume 2014
Applied MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Probability and StatisticsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical PhysicsAdvances in
Complex AnalysisJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
OptimizationJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
CombinatoricsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Operations ResearchAdvances in
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Function Spaces
Abstract and Applied AnalysisHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of Mathematics and Mathematical Sciences
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Algebra
Discrete Dynamics in Nature and Society
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Decision SciencesAdvances in
Discrete MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom
Volume 2014 Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Stochastic AnalysisInternational Journal of

Mathematical Problems in Engineering 9
Table 7 Training runtime (in seconds) for the Spark classifiers using epsilon with customized block size
Threshold Features Logistic Regression Naive Bayes SVM (120582 = 00) SVM (120582 = 05)000 2000 32194 48348 30094 30647055 721 25692 31319 25672 25698060 337 23616 24859 23123 22803065 110 30770 30826 25405 26123
Table 8 AUC values for the Spark classifiers using ECBDL14-ROS
Threshold Features Logistic Regression Naive Bayes SVM (120582 = 00) SVM (120582 = 05)Training Test Training Test Training Test Training Test
000 631 05821 05808 06714 06506 05966 06046 05875 05897055 234 06416 06352 06673 06489 06369 06307 06228 06148060 119 06309 06235 06732 06516 05884 05841 06116 06054065 46 05017 05022 06136 06093 05032 05039 05000 05000
Table 9 Training runtime (in seconds) for the Spark classifiers using ECBDL14-ROS
Threshold Features Logistic Regression Naive Bayes SVM (120582 = 00) SVM (120582 = 05)000 631 464919 158152 528388 506587055 234 210766 61350 232122 217918060 119 116298 32206 135285 122672065 46 97838 21509 91432 86428
The runtime for the dataset with the block size cus-tomized for each subset is displayed in Table 7 and Figure 8It is observed that the runtime was smaller than that withthe default block size Furthermore the curves show theexpected behavior as the number of features of the datasetwas reduced the runtime decreased In the extreme case(for threshold 065) the runtime increased again becausewith such a small dataset the synchronization times of Sparkbecome bigger than the computing times even with thecustomized block size
In the next section MR-EFS is tested over a very largedataset validating these observations
44 Experiments with the ECBDL14-ROS Dataset This sec-tion presents the classification accuracy and runtime resultsobtained with the ECBDL14-ROS dataset As describedin Section 41 a random oversampling technique [39] waspreviously applied over the original ECBDL14 dataset toovercome the problems originated by its imbalanceTheMR-EFS method was applied using 32 768 map tasks thereforeeach map task computed around 1984 instances
The obtained results in terms of accuracy are depictedin Table 8 and Figure 9 MR-EFS improved the results inall cases with different thresholds The accuracy gain wasespecially important for the Logistic Regression and SVMalgorithms As expected the SVM with 120582 = 00 obtainedbetter results than the onewith120582 = 05 as the latter attemptedto reduce the complexity of the obtained model Howeverit is noteworthy that for 119 features SVM-05 was able tooutperform SVM-00 This hints that after removing noisyfeatures the simpler obtained models represented better the
300
400
500 1000 1500 2000Features
Run
time (
s)
Logistic RegressionNaive Bayes
SVM-00SVM-05
Classifier
Figure 8 Training runtime with the epsilon dataset with cus-tomized block size Note that the number of features decreases asthe threshold increases
true knowledge underlying the data With even less featuresboth variants of SVM obtained roughly the same accuracy
To conclude this study the runtime necessary to trainthe classifiers with all variants of ECBDL14-ROS is presentedin Table 9 and Figure 10 In this case the runtime behavedas expected the time was roughly linear with respect to thenumber of features for all testedmodelsThismeans thatMR-EFS was able to improve both the runtime and the accuracyfor all those classifiers
10 Mathematical Problems in Engineering
050
055
060
065
200 400 600Features
AUC
ClassifierLogistic RegressionNaive BayesSVM-00SVM-05
SetTrainingTest
Figure 9 Accuracy with the ECBDL14-ROS dataset Note that thenumber of features decreases as the threshold increases
0
1000
2000
3000
4000
5000
Run
time (
s)
200 400 600Features
Logistic RegressionNaive Bayes
SVM-00SVM-05
Classifier
Figure 10 Training runtime with the ECBDL14-ROS dataset Notethat the number of features decreases as the threshold increases
5 Concluding Remarks
This paper presents MR-EFS an Evolutionary Feature Selec-tion algorithm designed upon the MapReduce paradigmintended to preprocess big datasets so that they becomeaffordable for other machine learning techniques such asclassification techniques that are currently not scalableenough to deal with such datasets The algorithm has beenimplemented using Apache Hadoop and it has been appliedover two different large datasets The resulting reduceddatasets have been tested using three different classifiersimplemented inApache Spark over a cluster of 20 computers
The theoretical evaluation of themodel highlights the fullscalability of MR-EFS with respect to the number of featuresin the dataset in comparison with a sequential approachThis behavior has been further confirmed after the empiricalprocedures
According to the obtained classification results it can beclaimed thatMR-EFS is able to reduce adequately the numberof features of large datasets leading to reduced versionsof them that are at the same time smaller to store fasterto compute and easier to classify These facts have beenobserved with the two different datasets and for all testedclassifiers
For the epsilon dataset the relation between the reduceddatasets size and the number of nodes is forced to modifythe HDFS block size proving that the hardware resourcescan be optimally used by Hadoop and Spark with the correctdesign One of the obtained reduced ECDBL14-ROS datasetswith more than 67 million instances and several hundredfeatures could be processed by the classifiers in less thanhalf of the time than that of the original dataset and with animprovement of around 5 in terms of AUC
Conflict of Interests
The authors declare that there is no conflict of interestsregarding the publication of this paper
Acknowledgments
This work is supported by the Research Projects TIN2014-57251-P P10-TIC-6858 P11-TIC-7765 P12-TIC-2958 andTIN2013-47210-P D Peralta and S Ramırez-Gallego holdtwo FPU scholarships from the Spanish Ministry of Educa-tion and Science (FPU1204902 FPU1300047) I Trigueroholds a BOF postdoctoral fellowship from the Ghent Univer-sity
References
[1] E Alpaydin Introduction to Machine Learning MIT PressCambridge Mass USA 2nd edition 2010
[2] MMinelliMChambers andADhirajBigData BigAnalyticsEmerging Business Intelligence and Analytic Trends for TodayrsquosBusinesses (Wiley CIO) Wiley 1st edition 2013
[3] V Marx ldquoThe big challenges of big datardquo Nature vol 498 no7453 pp 255ndash260 2013
[4] A Fernandez S del Rıo V Lopez et al ldquoBig data with cloudcomputing an insight on the computing environment MapRe-duce and programming frameworksrdquo Wiley InterdisciplinaryReviews Data Mining and Knowledge Discovery vol 4 no 5pp 380ndash409 2014
[5] E Merelli M Pettini and M Rasetti ldquoTopology driven model-ing the IS metaphorrdquo Natural Computing 2014
[6] S Sakr A Liu DM Batista andM Alomari ldquoA survey of largescale data management approaches in cloud environmentsrdquoIEEE Communications Surveys and Tutorials vol 13 no 3 pp311ndash336 2011
[7] J Bacardit and X Llora ldquoLarge-scale data mining usinggenetics-based machine learningrdquo Wiley Interdisciplinary
Mathematical Problems in Engineering 11
Reviews Data Mining and Knowledge Discovery vol 3 no 1pp 37ndash61 2013
[8] J Dean and SGhemawat ldquoMapReduce simplified data process-ing on large clustersrdquo Communications of the ACM vol 51 no1 pp 107ndash113 2008
[9] J Dean and S Ghemawat ldquoMap reduce a flexible data process-ing toolrdquo Communications of the ACM vol 53 no 1 pp 72ndash772010
[10] S Ghemawat H Gobioff and S-T Leung ldquoThe google file sys-temrdquo in Proceedings of the 19th ACM Symposium on OperatingSystems Principles (SOSP rsquo03) pp 29ndash43 October 2003
[11] M Snir and S Otto MPImdashThe Complete Reference The MPICore MIT Press Boston Mass USA 1998
[12] W Zhao H Ma and Q He ldquoParallel k-means clustering basedon MapReducerdquo in Cloud Computing M Jaatun G Zhao andC Rong Eds vol 5931 of Lecture Notes in Computer Sciencepp 674ndash679 Springer Berlin Germany 2009
[13] A Srinivasan T A Faruquie and S Joshi ldquoData and taskparallelism in ILP using MapReducerdquo Machine Learning vol86 no 1 pp 141ndash168 2012
[14] M Zaharia M Chowdhury T Das et al ldquoResilient distributeddatasets a fault-tolerant abstraction for in-memory clustercomputingrdquo in Proceedings of the 9th USENIX Conferenceon Networked Systems Design and Implementation pp 1ndash14USENIX Association 2012
[15] K Thomas C Grier J Ma V Paxson and D Song ldquoDesignand evaluation of a real-time URL spam filtering servicerdquo inProceedings of the IEEE Symposium on Security and Privacy (SPrsquo11) pp 447ndash462 Berkeley Calif USA May 2011
[16] R S Xin J Rosen M Zaharia M J Franklin S Shenker andI Stoica ldquoShark SQL and rich analytics at scalerdquo in Proceedingsof the ACM SIGMOD International Conference on Managementof Data (SIGMOD rsquo13) pp 13ndash24 ACM June 2013
[17] M S Wiewiorka A Messina A Pacholewska S Maffioletti PGawrysiak and M J Okoniewski ldquoSparkSeq fast scalable andcloud-ready tool for the interactive genomic data analysis withnucleotide precisionrdquo Bioinformatics vol 30 no 18 pp 2652ndash2653 2014
[18] S Garcıa J Luengo and F Herrera Data Preprocessing in DataMining Springer 1st edition 2015
[19] H Brighton and C Mellish ldquoAdvances in instance selection forinstance-based learning algorithmsrdquo Data Mining and Knowl-edge Discovery vol 6 no 2 pp 153ndash172 2002
[20] J A Olvera-Lopez J A Carrasco-Ochoa J F Martınez-Trinidad and J Kittler ldquoA reviewof instance selectionmethodsrdquoArtificial Intelligence Review vol 34 no 2 pp 133ndash143 2010
[21] J S Sanchez ldquoHigh training set size reduction by spacepartitioning and prototype abstractionrdquo Pattern Recognitionvol 37 no 7 pp 1561ndash1564 2004
[22] I Guyon and A Elisseeff ldquoAn introduction to variable andfeature selectionrdquo Journal of Machine Learning Research vol 3pp 1157ndash1182 2003
[23] H Liu and L Yu ldquoToward integrating feature selection algo-rithms for classification and clusteringrdquo IEEE Transactions onKnowledge and Data Engineering vol 17 no 4 pp 491ndash5022005
[24] Y Saeys I Inza and P Larranaga ldquoA review of feature selectiontechniques in bioinformaticsrdquo Bioinformatics vol 23 no 19 pp2507ndash2517 2007
[25] H Liu and H Motoda Computational Methods of FeatureSelection Chapman amp HallCRC Data Mining and KnowledgeDiscovery Series Chapman amp HallCRC Press 2007
[26] J A Lee andMVerleysenNonlinear Dimensionality ReductionSpringer 2007
[27] B de la Iglesia ldquoEvolutionary computation for feature selectionin classification problemsrdquo Wiley Interdisciplinary ReviewsDataMining and Knowledge Discovery vol 3 no 6 pp 381ndash4072013
[28] L J Eshelman ldquoThe CHC adaptative search algorithm howto have safe search when engaging in nontraditional geneticrecombinationrdquo in Foundations of Genetic Algorithms G J ERawlins Ed pp 265ndash283MorganKaufmann SanMateo CalifUSA 1991
[29] MLlib Website httpssparkapacheorgmllib[30] R Kohavi and G H John ldquoWrappers for feature subset
selectionrdquo Artificial Intelligence vol 97 no 1-2 pp 273ndash3241997
[31] M Tan I W Tsang and L Wang ldquoTowards ultrahighdimensional feature selection for big datardquo Journal of MachineLearning Research vol 15 pp 1371ndash1429 2014
[32] T White Hadoop The Definitive Guide OrsquoReilly Media 3rdedition 2012
[33] T Cover and P Hart ldquoNearest neighbor pattern classificationrdquoIEEE Transactions on Information Theory vol 13 no 1 pp 21ndash27 1967
[34] I Triguero D Peralta J Bacardit S Garcıa and F HerreraldquoMRPR a MapReduce solution for prototype reduction in bigdata classificationrdquoNeurocomputing vol 150 pp 331ndash345 2015
[35] C-T Chu S Kim Y-A Lin et al ldquoMap-reduce for machinelearning on multicorerdquo in Advances in Neural InformationProcessing Systems pp 281ndash288 2007
[36] Pascal large scale learning challenge httplargescalemltu-berlindeinstructions
[37] Epsilon in the LIBSVM website httpwwwcsientuedutwsimcjlinlibsvmtoolsdatasetsbinaryhtmlepsilon
[38] ECBDL14 dataset Protein structure prediction and contactmapfor the ECBDL2014 Big Data Competition httpcrunchernclacukbdcomp
[39] S del Rıo V Lopez J M Benıtez and F Herrera ldquoOn the useof MapReduce for imbalanced big data using Random ForestrdquoInformation Sciences vol 285 pp 112ndash137 2014
[40] M A Hearst S T Dumais E Osman J Platt and B ScholkopfldquoSupport vector machinesrdquo IEEE Intelligent Systems and TheirApplications vol 13 no 4 pp 18ndash28 1998
[41] D W Hosmer Jr and S Lemeshow Applied Logistic RegressionJohn Wiley amp Sons 2004
[42] R O Duda and P E Hart Pattern Classification and SceneAnalysis vol 3 Wiley New York NY USA 1973
[43] MLlib guide httpsparkapacheorgdocslatestmllib-guidehtml
Submit your manuscripts athttpwwwhindawicom
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical Problems in Engineering
Hindawi Publishing Corporationhttpwwwhindawicom
Differential EquationsInternational Journal of
Volume 2014
Applied MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Probability and StatisticsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical PhysicsAdvances in
Complex AnalysisJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
OptimizationJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
CombinatoricsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Operations ResearchAdvances in
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Function Spaces
Abstract and Applied AnalysisHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of Mathematics and Mathematical Sciences
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Algebra
Discrete Dynamics in Nature and Society
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Decision SciencesAdvances in
Discrete MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom
Volume 2014 Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Stochastic AnalysisInternational Journal of

10 Mathematical Problems in Engineering
050
055
060
065
200 400 600Features
AUC
ClassifierLogistic RegressionNaive BayesSVM-00SVM-05
SetTrainingTest
Figure 9 Accuracy with the ECBDL14-ROS dataset Note that thenumber of features decreases as the threshold increases
0
1000
2000
3000
4000
5000
Run
time (
s)
200 400 600Features
Logistic RegressionNaive Bayes
SVM-00SVM-05
Classifier
Figure 10 Training runtime with the ECBDL14-ROS dataset Notethat the number of features decreases as the threshold increases
5 Concluding Remarks
This paper presents MR-EFS an Evolutionary Feature Selec-tion algorithm designed upon the MapReduce paradigmintended to preprocess big datasets so that they becomeaffordable for other machine learning techniques such asclassification techniques that are currently not scalableenough to deal with such datasets The algorithm has beenimplemented using Apache Hadoop and it has been appliedover two different large datasets The resulting reduceddatasets have been tested using three different classifiersimplemented inApache Spark over a cluster of 20 computers
The theoretical evaluation of themodel highlights the fullscalability of MR-EFS with respect to the number of featuresin the dataset in comparison with a sequential approachThis behavior has been further confirmed after the empiricalprocedures
According to the obtained classification results it can beclaimed thatMR-EFS is able to reduce adequately the numberof features of large datasets leading to reduced versionsof them that are at the same time smaller to store fasterto compute and easier to classify These facts have beenobserved with the two different datasets and for all testedclassifiers
For the epsilon dataset the relation between the reduceddatasets size and the number of nodes is forced to modifythe HDFS block size proving that the hardware resourcescan be optimally used by Hadoop and Spark with the correctdesign One of the obtained reduced ECDBL14-ROS datasetswith more than 67 million instances and several hundredfeatures could be processed by the classifiers in less thanhalf of the time than that of the original dataset and with animprovement of around 5 in terms of AUC
Conflict of Interests
The authors declare that there is no conflict of interestsregarding the publication of this paper
Acknowledgments
This work is supported by the Research Projects TIN2014-57251-P P10-TIC-6858 P11-TIC-7765 P12-TIC-2958 andTIN2013-47210-P D Peralta and S Ramırez-Gallego holdtwo FPU scholarships from the Spanish Ministry of Educa-tion and Science (FPU1204902 FPU1300047) I Trigueroholds a BOF postdoctoral fellowship from the Ghent Univer-sity
References
[1] E Alpaydin Introduction to Machine Learning MIT PressCambridge Mass USA 2nd edition 2010
[2] MMinelliMChambers andADhirajBigData BigAnalyticsEmerging Business Intelligence and Analytic Trends for TodayrsquosBusinesses (Wiley CIO) Wiley 1st edition 2013
[3] V Marx ldquoThe big challenges of big datardquo Nature vol 498 no7453 pp 255ndash260 2013
[4] A Fernandez S del Rıo V Lopez et al ldquoBig data with cloudcomputing an insight on the computing environment MapRe-duce and programming frameworksrdquo Wiley InterdisciplinaryReviews Data Mining and Knowledge Discovery vol 4 no 5pp 380ndash409 2014
[5] E Merelli M Pettini and M Rasetti ldquoTopology driven model-ing the IS metaphorrdquo Natural Computing 2014
[6] S Sakr A Liu DM Batista andM Alomari ldquoA survey of largescale data management approaches in cloud environmentsrdquoIEEE Communications Surveys and Tutorials vol 13 no 3 pp311ndash336 2011
[7] J Bacardit and X Llora ldquoLarge-scale data mining usinggenetics-based machine learningrdquo Wiley Interdisciplinary
Mathematical Problems in Engineering 11
Reviews Data Mining and Knowledge Discovery vol 3 no 1pp 37ndash61 2013
[8] J Dean and SGhemawat ldquoMapReduce simplified data process-ing on large clustersrdquo Communications of the ACM vol 51 no1 pp 107ndash113 2008
[9] J Dean and S Ghemawat ldquoMap reduce a flexible data process-ing toolrdquo Communications of the ACM vol 53 no 1 pp 72ndash772010
[10] S Ghemawat H Gobioff and S-T Leung ldquoThe google file sys-temrdquo in Proceedings of the 19th ACM Symposium on OperatingSystems Principles (SOSP rsquo03) pp 29ndash43 October 2003
[11] M Snir and S Otto MPImdashThe Complete Reference The MPICore MIT Press Boston Mass USA 1998
[12] W Zhao H Ma and Q He ldquoParallel k-means clustering basedon MapReducerdquo in Cloud Computing M Jaatun G Zhao andC Rong Eds vol 5931 of Lecture Notes in Computer Sciencepp 674ndash679 Springer Berlin Germany 2009
[13] A Srinivasan T A Faruquie and S Joshi ldquoData and taskparallelism in ILP using MapReducerdquo Machine Learning vol86 no 1 pp 141ndash168 2012
[14] M Zaharia M Chowdhury T Das et al ldquoResilient distributeddatasets a fault-tolerant abstraction for in-memory clustercomputingrdquo in Proceedings of the 9th USENIX Conferenceon Networked Systems Design and Implementation pp 1ndash14USENIX Association 2012
[15] K Thomas C Grier J Ma V Paxson and D Song ldquoDesignand evaluation of a real-time URL spam filtering servicerdquo inProceedings of the IEEE Symposium on Security and Privacy (SPrsquo11) pp 447ndash462 Berkeley Calif USA May 2011
[16] R S Xin J Rosen M Zaharia M J Franklin S Shenker andI Stoica ldquoShark SQL and rich analytics at scalerdquo in Proceedingsof the ACM SIGMOD International Conference on Managementof Data (SIGMOD rsquo13) pp 13ndash24 ACM June 2013
[17] M S Wiewiorka A Messina A Pacholewska S Maffioletti PGawrysiak and M J Okoniewski ldquoSparkSeq fast scalable andcloud-ready tool for the interactive genomic data analysis withnucleotide precisionrdquo Bioinformatics vol 30 no 18 pp 2652ndash2653 2014
[18] S Garcıa J Luengo and F Herrera Data Preprocessing in DataMining Springer 1st edition 2015
[19] H Brighton and C Mellish ldquoAdvances in instance selection forinstance-based learning algorithmsrdquo Data Mining and Knowl-edge Discovery vol 6 no 2 pp 153ndash172 2002
[20] J A Olvera-Lopez J A Carrasco-Ochoa J F Martınez-Trinidad and J Kittler ldquoA reviewof instance selectionmethodsrdquoArtificial Intelligence Review vol 34 no 2 pp 133ndash143 2010
[21] J S Sanchez ldquoHigh training set size reduction by spacepartitioning and prototype abstractionrdquo Pattern Recognitionvol 37 no 7 pp 1561ndash1564 2004
[22] I Guyon and A Elisseeff ldquoAn introduction to variable andfeature selectionrdquo Journal of Machine Learning Research vol 3pp 1157ndash1182 2003
[23] H Liu and L Yu ldquoToward integrating feature selection algo-rithms for classification and clusteringrdquo IEEE Transactions onKnowledge and Data Engineering vol 17 no 4 pp 491ndash5022005
[24] Y Saeys I Inza and P Larranaga ldquoA review of feature selectiontechniques in bioinformaticsrdquo Bioinformatics vol 23 no 19 pp2507ndash2517 2007
[25] H Liu and H Motoda Computational Methods of FeatureSelection Chapman amp HallCRC Data Mining and KnowledgeDiscovery Series Chapman amp HallCRC Press 2007
[26] J A Lee andMVerleysenNonlinear Dimensionality ReductionSpringer 2007
[27] B de la Iglesia ldquoEvolutionary computation for feature selectionin classification problemsrdquo Wiley Interdisciplinary ReviewsDataMining and Knowledge Discovery vol 3 no 6 pp 381ndash4072013
[28] L J Eshelman ldquoThe CHC adaptative search algorithm howto have safe search when engaging in nontraditional geneticrecombinationrdquo in Foundations of Genetic Algorithms G J ERawlins Ed pp 265ndash283MorganKaufmann SanMateo CalifUSA 1991
[29] MLlib Website httpssparkapacheorgmllib[30] R Kohavi and G H John ldquoWrappers for feature subset
selectionrdquo Artificial Intelligence vol 97 no 1-2 pp 273ndash3241997
[31] M Tan I W Tsang and L Wang ldquoTowards ultrahighdimensional feature selection for big datardquo Journal of MachineLearning Research vol 15 pp 1371ndash1429 2014
[32] T White Hadoop The Definitive Guide OrsquoReilly Media 3rdedition 2012
[33] T Cover and P Hart ldquoNearest neighbor pattern classificationrdquoIEEE Transactions on Information Theory vol 13 no 1 pp 21ndash27 1967
[34] I Triguero D Peralta J Bacardit S Garcıa and F HerreraldquoMRPR a MapReduce solution for prototype reduction in bigdata classificationrdquoNeurocomputing vol 150 pp 331ndash345 2015
[35] C-T Chu S Kim Y-A Lin et al ldquoMap-reduce for machinelearning on multicorerdquo in Advances in Neural InformationProcessing Systems pp 281ndash288 2007
[36] Pascal large scale learning challenge httplargescalemltu-berlindeinstructions
[37] Epsilon in the LIBSVM website httpwwwcsientuedutwsimcjlinlibsvmtoolsdatasetsbinaryhtmlepsilon
[38] ECBDL14 dataset Protein structure prediction and contactmapfor the ECBDL2014 Big Data Competition httpcrunchernclacukbdcomp
[39] S del Rıo V Lopez J M Benıtez and F Herrera ldquoOn the useof MapReduce for imbalanced big data using Random ForestrdquoInformation Sciences vol 285 pp 112ndash137 2014
[40] M A Hearst S T Dumais E Osman J Platt and B ScholkopfldquoSupport vector machinesrdquo IEEE Intelligent Systems and TheirApplications vol 13 no 4 pp 18ndash28 1998
[41] D W Hosmer Jr and S Lemeshow Applied Logistic RegressionJohn Wiley amp Sons 2004
[42] R O Duda and P E Hart Pattern Classification and SceneAnalysis vol 3 Wiley New York NY USA 1973
[43] MLlib guide httpsparkapacheorgdocslatestmllib-guidehtml
Submit your manuscripts athttpwwwhindawicom
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical Problems in Engineering
Hindawi Publishing Corporationhttpwwwhindawicom
Differential EquationsInternational Journal of
Volume 2014
Applied MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Probability and StatisticsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical PhysicsAdvances in
Complex AnalysisJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
OptimizationJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
CombinatoricsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Operations ResearchAdvances in
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Function Spaces
Abstract and Applied AnalysisHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of Mathematics and Mathematical Sciences
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Algebra
Discrete Dynamics in Nature and Society
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Decision SciencesAdvances in
Discrete MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom
Volume 2014 Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Stochastic AnalysisInternational Journal of

Mathematical Problems in Engineering 11
Reviews Data Mining and Knowledge Discovery vol 3 no 1pp 37ndash61 2013
[8] J Dean and SGhemawat ldquoMapReduce simplified data process-ing on large clustersrdquo Communications of the ACM vol 51 no1 pp 107ndash113 2008
[9] J Dean and S Ghemawat ldquoMap reduce a flexible data process-ing toolrdquo Communications of the ACM vol 53 no 1 pp 72ndash772010
[10] S Ghemawat H Gobioff and S-T Leung ldquoThe google file sys-temrdquo in Proceedings of the 19th ACM Symposium on OperatingSystems Principles (SOSP rsquo03) pp 29ndash43 October 2003
[11] M Snir and S Otto MPImdashThe Complete Reference The MPICore MIT Press Boston Mass USA 1998
[12] W Zhao H Ma and Q He ldquoParallel k-means clustering basedon MapReducerdquo in Cloud Computing M Jaatun G Zhao andC Rong Eds vol 5931 of Lecture Notes in Computer Sciencepp 674ndash679 Springer Berlin Germany 2009
[13] A Srinivasan T A Faruquie and S Joshi ldquoData and taskparallelism in ILP using MapReducerdquo Machine Learning vol86 no 1 pp 141ndash168 2012
[14] M Zaharia M Chowdhury T Das et al ldquoResilient distributeddatasets a fault-tolerant abstraction for in-memory clustercomputingrdquo in Proceedings of the 9th USENIX Conferenceon Networked Systems Design and Implementation pp 1ndash14USENIX Association 2012
[15] K Thomas C Grier J Ma V Paxson and D Song ldquoDesignand evaluation of a real-time URL spam filtering servicerdquo inProceedings of the IEEE Symposium on Security and Privacy (SPrsquo11) pp 447ndash462 Berkeley Calif USA May 2011
[16] R S Xin J Rosen M Zaharia M J Franklin S Shenker andI Stoica ldquoShark SQL and rich analytics at scalerdquo in Proceedingsof the ACM SIGMOD International Conference on Managementof Data (SIGMOD rsquo13) pp 13ndash24 ACM June 2013
[17] M S Wiewiorka A Messina A Pacholewska S Maffioletti PGawrysiak and M J Okoniewski ldquoSparkSeq fast scalable andcloud-ready tool for the interactive genomic data analysis withnucleotide precisionrdquo Bioinformatics vol 30 no 18 pp 2652ndash2653 2014
[18] S Garcıa J Luengo and F Herrera Data Preprocessing in DataMining Springer 1st edition 2015
[19] H Brighton and C Mellish ldquoAdvances in instance selection forinstance-based learning algorithmsrdquo Data Mining and Knowl-edge Discovery vol 6 no 2 pp 153ndash172 2002
[20] J A Olvera-Lopez J A Carrasco-Ochoa J F Martınez-Trinidad and J Kittler ldquoA reviewof instance selectionmethodsrdquoArtificial Intelligence Review vol 34 no 2 pp 133ndash143 2010
[21] J S Sanchez ldquoHigh training set size reduction by spacepartitioning and prototype abstractionrdquo Pattern Recognitionvol 37 no 7 pp 1561ndash1564 2004
[22] I Guyon and A Elisseeff ldquoAn introduction to variable andfeature selectionrdquo Journal of Machine Learning Research vol 3pp 1157ndash1182 2003
[23] H Liu and L Yu ldquoToward integrating feature selection algo-rithms for classification and clusteringrdquo IEEE Transactions onKnowledge and Data Engineering vol 17 no 4 pp 491ndash5022005
[24] Y Saeys I Inza and P Larranaga ldquoA review of feature selectiontechniques in bioinformaticsrdquo Bioinformatics vol 23 no 19 pp2507ndash2517 2007
[25] H Liu and H Motoda Computational Methods of FeatureSelection Chapman amp HallCRC Data Mining and KnowledgeDiscovery Series Chapman amp HallCRC Press 2007
[26] J A Lee andMVerleysenNonlinear Dimensionality ReductionSpringer 2007
[27] B de la Iglesia ldquoEvolutionary computation for feature selectionin classification problemsrdquo Wiley Interdisciplinary ReviewsDataMining and Knowledge Discovery vol 3 no 6 pp 381ndash4072013
[28] L J Eshelman ldquoThe CHC adaptative search algorithm howto have safe search when engaging in nontraditional geneticrecombinationrdquo in Foundations of Genetic Algorithms G J ERawlins Ed pp 265ndash283MorganKaufmann SanMateo CalifUSA 1991
[29] MLlib Website httpssparkapacheorgmllib[30] R Kohavi and G H John ldquoWrappers for feature subset
selectionrdquo Artificial Intelligence vol 97 no 1-2 pp 273ndash3241997
[31] M Tan I W Tsang and L Wang ldquoTowards ultrahighdimensional feature selection for big datardquo Journal of MachineLearning Research vol 15 pp 1371ndash1429 2014
[32] T White Hadoop The Definitive Guide OrsquoReilly Media 3rdedition 2012
[33] T Cover and P Hart ldquoNearest neighbor pattern classificationrdquoIEEE Transactions on Information Theory vol 13 no 1 pp 21ndash27 1967
[34] I Triguero D Peralta J Bacardit S Garcıa and F HerreraldquoMRPR a MapReduce solution for prototype reduction in bigdata classificationrdquoNeurocomputing vol 150 pp 331ndash345 2015
[35] C-T Chu S Kim Y-A Lin et al ldquoMap-reduce for machinelearning on multicorerdquo in Advances in Neural InformationProcessing Systems pp 281ndash288 2007
[36] Pascal large scale learning challenge httplargescalemltu-berlindeinstructions
[37] Epsilon in the LIBSVM website httpwwwcsientuedutwsimcjlinlibsvmtoolsdatasetsbinaryhtmlepsilon
[38] ECBDL14 dataset Protein structure prediction and contactmapfor the ECBDL2014 Big Data Competition httpcrunchernclacukbdcomp
[39] S del Rıo V Lopez J M Benıtez and F Herrera ldquoOn the useof MapReduce for imbalanced big data using Random ForestrdquoInformation Sciences vol 285 pp 112ndash137 2014
[40] M A Hearst S T Dumais E Osman J Platt and B ScholkopfldquoSupport vector machinesrdquo IEEE Intelligent Systems and TheirApplications vol 13 no 4 pp 18ndash28 1998
[41] D W Hosmer Jr and S Lemeshow Applied Logistic RegressionJohn Wiley amp Sons 2004
[42] R O Duda and P E Hart Pattern Classification and SceneAnalysis vol 3 Wiley New York NY USA 1973
[43] MLlib guide httpsparkapacheorgdocslatestmllib-guidehtml
Submit your manuscripts athttpwwwhindawicom
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical Problems in Engineering
Hindawi Publishing Corporationhttpwwwhindawicom
Differential EquationsInternational Journal of
Volume 2014
Applied MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Probability and StatisticsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical PhysicsAdvances in
Complex AnalysisJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
OptimizationJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
CombinatoricsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Operations ResearchAdvances in
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Function Spaces
Abstract and Applied AnalysisHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of Mathematics and Mathematical Sciences
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Algebra
Discrete Dynamics in Nature and Society
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Decision SciencesAdvances in
Discrete MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom
Volume 2014 Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Stochastic AnalysisInternational Journal of

Submit your manuscripts athttpwwwhindawicom
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical Problems in Engineering
Hindawi Publishing Corporationhttpwwwhindawicom
Differential EquationsInternational Journal of
Volume 2014
Applied MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Probability and StatisticsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Mathematical PhysicsAdvances in
Complex AnalysisJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
OptimizationJournal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
CombinatoricsHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Operations ResearchAdvances in
Journal of
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Function Spaces
Abstract and Applied AnalysisHindawi Publishing Corporationhttpwwwhindawicom Volume 2014
International Journal of Mathematics and Mathematical Sciences
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
The Scientific World JournalHindawi Publishing Corporation httpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Algebra
Discrete Dynamics in Nature and Society
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Decision SciencesAdvances in
Discrete MathematicsJournal of
Hindawi Publishing Corporationhttpwwwhindawicom
Volume 2014 Hindawi Publishing Corporationhttpwwwhindawicom Volume 2014
Stochastic AnalysisInternational Journal of