regresiÓn lineal simple regresiÓn lineal...
TRANSCRIPT

REGRESIÓN LINEAL SIMPLE
REGRESIÓN LINEAL MÚLTIPLE
N A Z IR A C A LLE JA
Regresión lineal
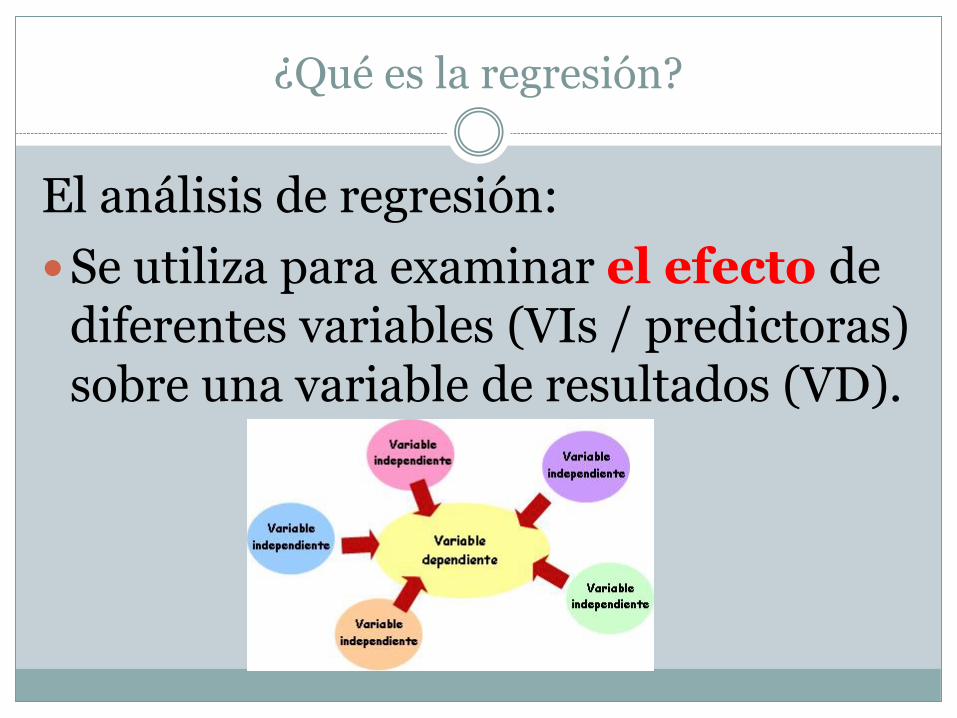
¿Qué es la regresión?
El análisis de regresión:
Se utiliza para examinar el efecto de diferentes variables (VIs / predictoras) sobre una variable de resultados (VD).
¿Qué es la regresión?
El análisis de regresión:
Intenta describir la naturaleza de la asociación mediante la creación de un modelo matemático de "mejor ajuste" .

¿Qué es la regresión?
El uso del término “predicción” es central.
Se analiza si una variable predice (explica / impacta) a otra variable.

¿Qué es la regresión?
Al utilizar la regresión lineal asumimos que:
Las variables están medidas a nivel cuantitativo,
y las variables se asocian de manera lineal.

¿Qué es la regresión?
Ejemplo:
Asociación entre:
Consumo de tabaco Pérdida de fijación dentaly

¿Qué es la regresión?
Línea de ajuste de la asociación entreel consumo de tabaco (número de cigarros fumados por día) y la pérdida de fijación dental (en mm).N = 28 fumadores.
self-reported cigarettes smoked/day
me
an
atta
chm
en
t le
vel (
mm
)
10 20 30
12
34
56
smoking amount and attachment level (28 smokers)
Número de cigarros fumados por día (autorreporte)
Pér
did
a m
edia
de
fija
ció
n d
enta
l (
mm
)
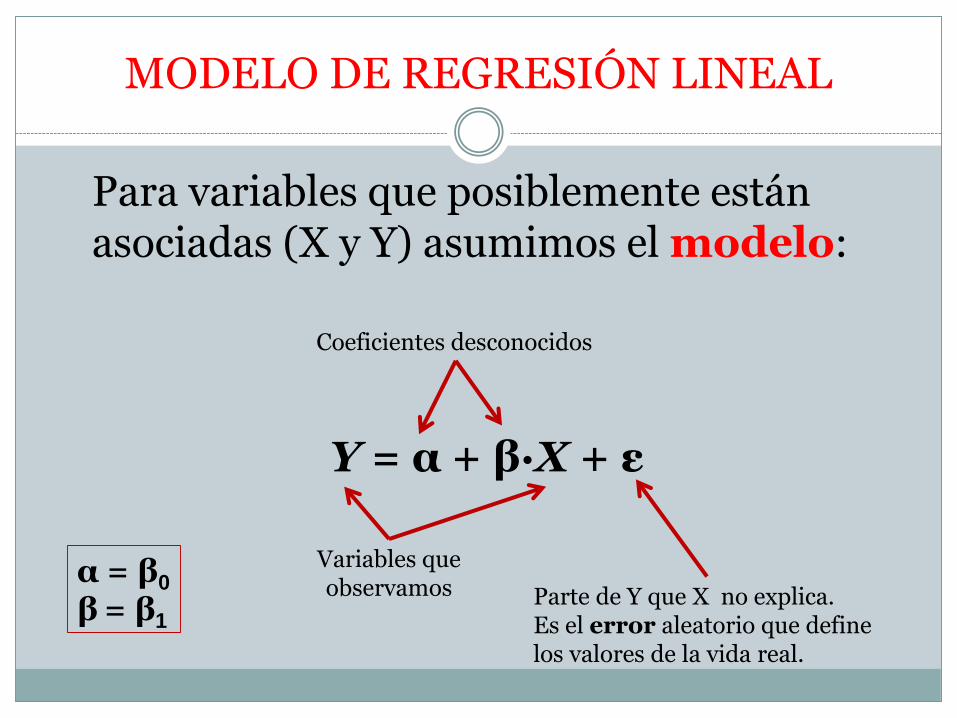
MODELO DE REGRESIÓN LINEAL
Para variables que posiblemente están asociadas (X y Y) asumimos el modelo:
Y = α + β·X + ε
Coeficientes desconocidos
Variables que observamos Parte de Y que X no explica.
Es el error aleatorio que define los valores de la vida real.
α = β0
β = β1
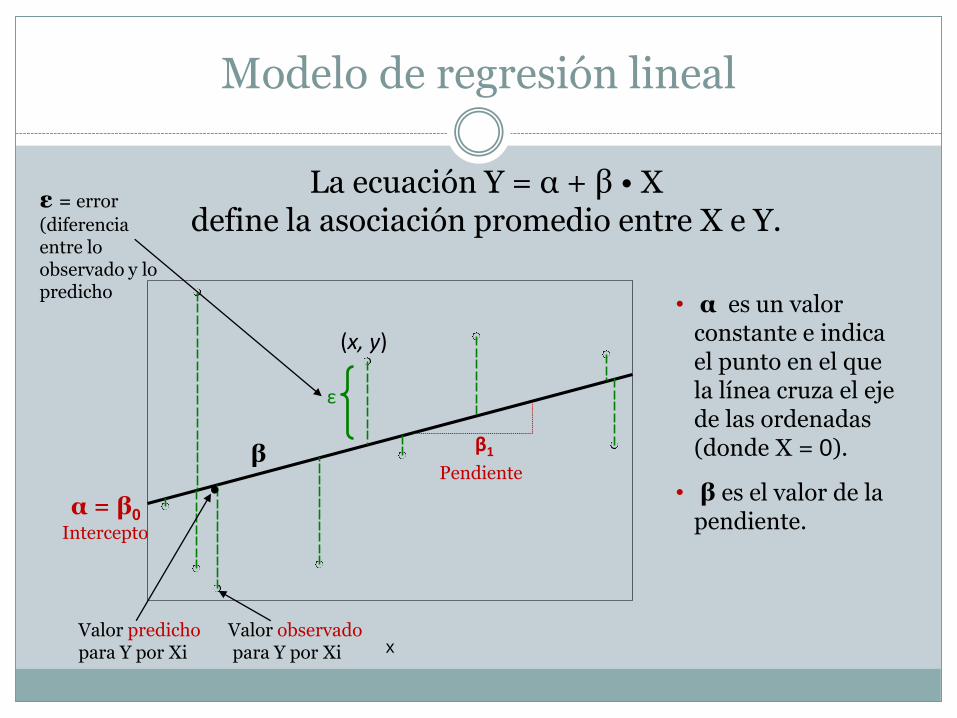
Modelo de regresión lineal
x
ε
β1
(x, y)
La ecuación Y = α + β • X define la asociación promedio entre X e Y.
• α es un valor constante e indica el punto en el que la línea cruza el eje de las ordenadas (donde X = 0).
• β es el valor de la pendiente.
β
α = β0
Intercepto
ε = error
(diferencia entre lo observado y lo predicho
Valor predichopara Y por Xi
Valor observadopara Y por Xi
Pendiente

Regresión lineal vs. Correlación
• La correlación es una medida de la fuerza de la asociación.ρ2 (coeficiente de determinación) puede describirse como el porcentaje de variación en Y que es explicado por la variaciónen X.
• La regresión intenta describir la forma de la asociación.
El parámetro β (la pendiente) está relacionada con ρ:
X
Y

Encontrar la línea del mejor ajuste
Para encontrar la línea que ajuste mejor se evalúa qué tan cercanamente se ajusta cada una de las posibles líneas a los datos observados.
Para ello se calculan las distanciasverticales de todos los puntos (x,y) a la línea.
Estas distancias se llaman “residuales” y corresponden al error, ei .

Encontrar la línea del mejor ajuste
x
La línea de mejor ajuste se define como aquélla en la que la suma de los cuadrados de los residuales es mínima.

Encontrar la línea del mejor ajuste
Los coeficientes de la línea de mejor ajuste, a y b (las estimaciones de α y β, respectivamente), pueden calcularse con las fórmulas:
i
i
i ii
xx
yyxxb
2)(
))((
xbya

Ejemplo: Pérdida de fijación dental y cigarros fumados por día
self-reported cigarettes smoked/day
me
an
atta
chm
en
t le
vel (
mm
)
10 20 30
12
34
56
smoking amount and attachment level (28 smokers)Consumo de tabaco y pérdida de fijación dental (28 fumadores)
Número de cigarros fumados por día (autorreporte)
Pér
did
a m
edia
de
fija
ció
n d
enta
l (
mm
)

Ejemplo: Pérdida de fijación dental y cigarros fumados por día
Este resultado de SPSS dice que:
a = 2.319, b = 0.067
La línea de mejor ajuste es: Y = 2.319 + 0.067 × X
Donde Y = nivel promedio de fijación y
X = cigarros fumados por día.
Coef ficientsa
2.319 .635 3.653 .001
.067 .032 .380 2.098 .046
(Constant)
c igarettes sm oked/day
Model
1
B Std. Er ror
Unstandardized
Coeffic ients
Beta
Standardized
Coeffic ients
t Sig.
Dependent Variable: mean attachment levela.
α
β

Y = 2.319 + 0.067 × X puede interpretarse como:
Ejemplo: Pérdida de fijación dental y cigarros fumados por día
También :“Cada paquete fumado al día (20 cigarros) se asocia con una pérdida adicional de 0.067 × 20 = 1.34 mm de fijación dental."
“Cada cigarro fumado extra por día se asocia con una pérdida adicional de 0.067 mm de fijación dental."

Las predicciones basadas en regresión
La mejor estimación (estimación puntual o predicción) de Y a partir de X es:
y = a + bx
Ejemplo:
¿Qué nivel de fijación dental tendrá alguien que fuma 30 cigarros al día?

Utilización del modelo estimado para predecir
La mejor estimación del nivel de pérdida de fijación dental promedio de las personas que fuman 30
cigarrillos / día es:
Y = 2.319 + 0.067 × X
Y = 2.319 + (0.067 x 30) = 4.329 mm

Bondad de ajuste
Una medida clave de la fuerza de la asociación es la “Media Cuadrática de Error", las MCE o MSE, que es básicamente la media de los residuales elevados al cuadrado.
Si este valor es pequeño con respecto a la varianza de la muestra de y’s, entonces se considera que el modelo de regresión es una buena explicación de la asociación.
i iii i bxay
ne
nMSE
22 )(2
1
2
1

Bondad de ajuste
La MCE o MSE también se utiliza para estimar el error estándar (ES) de b.
Hay que tener en cuenta que:
1. El ES(b) ↓ en la medida en que MCE ↓
2. El ES(b) ↓ en la medida en que sx↑
Es decir, se obtienen mejores estimaciones de β cuando la línea constituye un buen ajuste, y cuando los puntajes de X son más dispersos.
2)1()(
xsn
MSEbSE

Bondad de ajuste
El ajuste del modelo se prueba con el estadístico F:
ANOVAb
7.896 1 7.896 4.401 .046a
46.645 26 1.794
54.541 27
Regression
Residual
Total
Model
1
Sum of Squares df Mean Square F Sig.
Predictors: (Constant), self report cigs./daya.
Dependent Variable: mean attachment level (mm)b.
Descriptive Statistics
3.5397 1.42128 28
18.1786 8.05101 28
mean attachment level (mm)
self report cigs./day
Mean Std. Deviation N
Número de cigarros fumados por día (autorreporte)
Número de cigarros fumados por día (autorreporte)
Pérdida media de fijación dental (mm)
Pérdida media de fijación dental (mm)

Inferencia para los coeficientes de regresión
Es posible probar H0: β = 0 vs H1: β ≠ 0 utilizando el estadístico t:
)(bSE
bt

Ejemplo: Pérdida de fijación dental y cigarros fumados por día
1. Hipótesis de investigación:
El autorreporte de cigarros fumados por día está relacionado con la fijación dental.
2. Hipótesis estadísticas:
H0: β = 0
H1: β ≠ 0.
3. Prueba estadística:
Prueba t para la regresión lineal.

Ejemplo: Pérdida de fijación dental y cigarros fumados por día
4. Regla de decisión:
Puede rechazarse Ho, con p < 0.05 , si |t26 |> 2.056.
5. Cálculos:
098.2032.0
067.0t
Coef ficientsa
2.319 .635 3.653 .001
.067 .032 .380 2.098 .046
(Constant)
c igarettes sm oked/day
Model
1
B Std. Er ror
Unstandardized
Coeffic ients
Beta
Standardized
Coeffic ients
t Sig.
Dependent Variable: mean attachment levela. p(|t26| > 2.098) = 0.046).

Ejemplo: Pérdida de fijación dental y cigarros fumados por día
6. Resultados
Se rechaza Ho.
7. Conclusión:
Existe relación entre el número de cigarros fumados diariamente y la fijación dental.

Intervalo de confianza para β
Un intervalo de confianza de 1-α para β es:
)(2/1,2 bSEtb n
b: Constante (pendiente de la línea de regresión)t: valor de t en tablasn–2: grados de libertad% de confianza: 1-α: 1-error tipo 1 / 2 (dos colas)SE(b): Media cuadrática de b
2)1()(
xsn
MSEbSE

Intervalo de confianza para β
Ejemplo:
Pérdida de fijación dental y cigarros fumados por día
El intervalo de confianza de 95% para β es:
0.001 - 0.013
)(2/1,2 bSEtb n
032.0056.2067.0
b = 0.067n = 28gl = 26α = 05/2 colas = .025t = 2.056SE(b) = 0.032
0.067 ± 0.066

REGRESIÓN
LINEAL
MÚLTIPLE

REGRESIÓN LINEAL MÚLTIPLE
La regresión múltiple es una extensión muy utilizada de la regresión lineal.
El modelo de regresión lineal se puede ampliar para incluir múltiples variables independientes.
Y = α + β1 • X1 + β2 • X2 + ... + βk Xk • + ε.
Examina el efecto de múltiples predictores X1, X2, …Xk
sobre una VD (Y).

REGRESIÓN LINEAL MÚLTIPLE
Los coeficientes se estiman minimizando los
residuales cuadrados.
En esta situación más complicada no hay
fórmulas sencillas para las estimaciones.
Generalmente se utiliza una computadora para el
cálculo de los coeficientes.
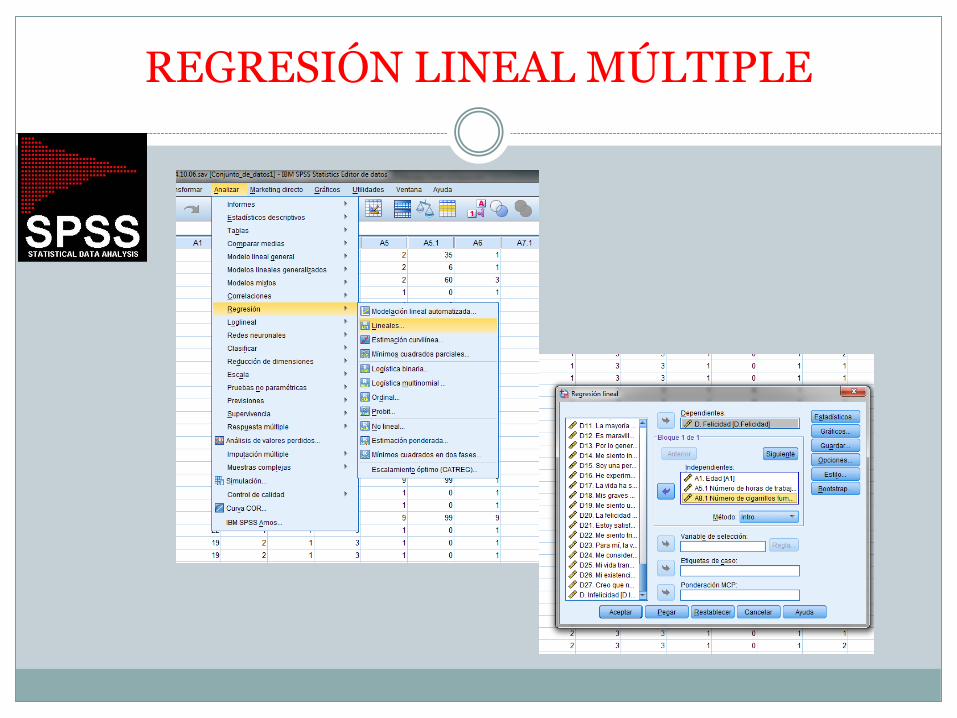
REGRESIÓN LINEAL MÚLTIPLE

En el ejemplo del efecto del número de cigarros fumados (Y) sobre la pérdida de fijación dental (X1), se puede agregar la edad como un segundo predictor (X2):
Regresión lineal múltiple
X1
X2
Y
.402
.440

Regresión lineal múltiple
El ajuste del modelo mejoracon una segunda variable predictiva buena.
ANOVAb
18.425 2 9.213 6.377 .006a
36.116 25 1.445
54.541 27
Regression
Residual
Total
Model
1
Sum of Squares df Mean Square F Sig.
Predictors: (Constant), age (yrs), self report cigs ./daya.
Dependent Variable: mean attachment level (mm)b. Pérdida media de fijación dental (mm)
Edad, Número de cigarros fumados por día (autorreporte)

En el ejemplo del efecto del número de cigarros fumados (Y) sobre la pérdida de fijación dental (X1), se puede agregar la edad como un segundo predictor (X2):
Y = α + β1 • X1 + β2 • X2 + ε
Y = -1.065 + .071 • X1 + .074 • X2 + ε
Coef ficientsa
-1.065 1.377 -.774 .446 -3.901 1.770
.071 .029 .402 2.467 .021 .012 .130
.074 .028 .440 2.700 .012 .018 .131
(Constant)
self r epor t c igs./day
age (y rs)
Model
1
B Std. Er ror
Unstandardized
Coefficients
Beta
Standardized
Coefficients
t Sig. Lower Bound Upper Bound
95% Confidence Interval for
B
Dependent Variable: mean attachment level (mm)a.
Regresión lineal múltiple
α
β1
β2
Número de cigarros fumados por día
Pérdida media de fijación dental (mm)
Edad
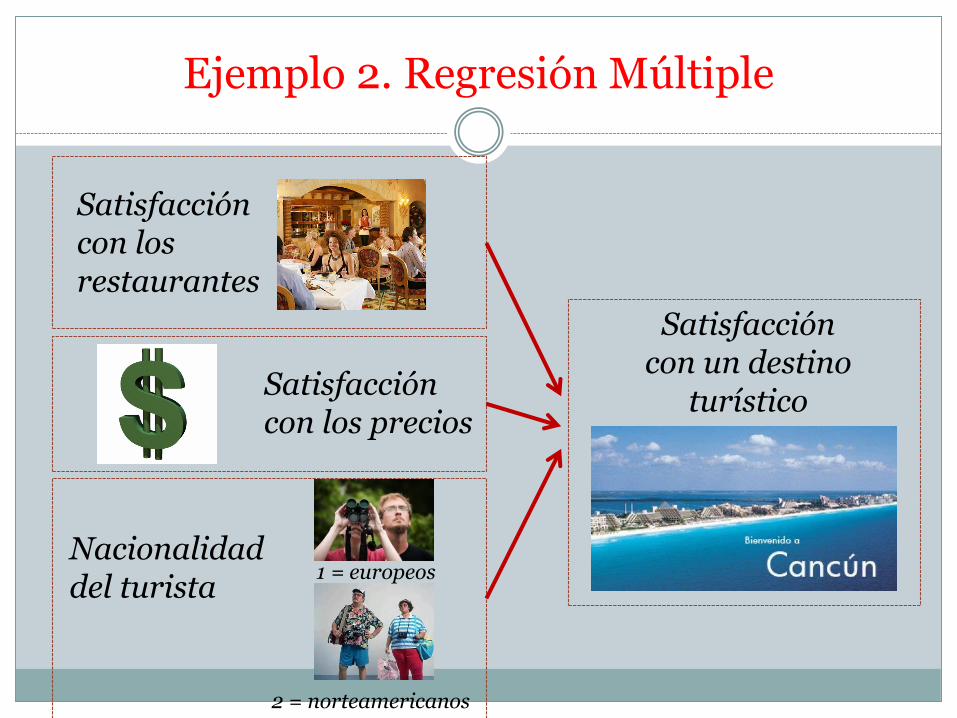
Ejemplo 2. Regresión Múltiple
Satisfacción con un destino
turístico
Satisfacción con los restaurantes
Satisfacción con los precios
Nacionalidad del turista
1 = europeos
2 = norteamericanos
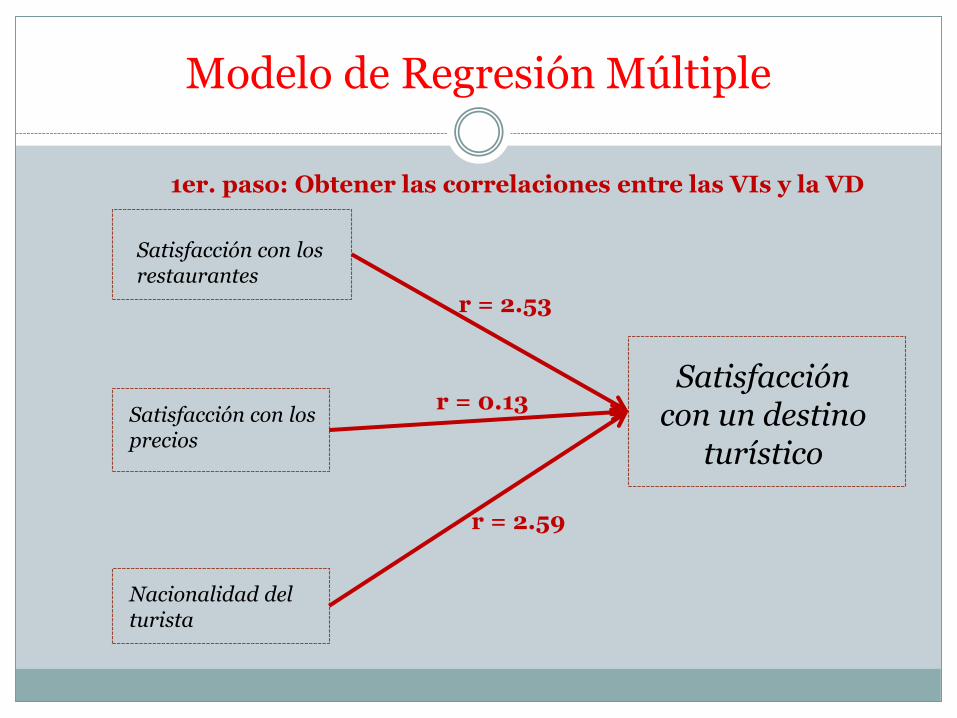
Modelo de Regresión Múltiple
Satisfacción con un destino
turístico
Satisfacción con los restaurantes
Satisfacción con los precios
Nacionalidad del turista
r = 2.53
r = 0.13
r = 2.59
1er. paso: Obtener las correlaciones entre las VIs y la VD

Tablas en Regresión Múltiple
Hay tres tablas generales que deben interpretarse en los resultados del análisis de regresión.
1ª Resumen del modelo
2ª ANOVA
3ª Coeficientes
2o. paso: Correr el análisis
3er. paso: Interpretar los resultados

Regresión múltiple en SPSS
1ª tabla
La información que se toma de esta tabla es el R2, que es la proporción de variación en la VD que es explicada por las VIs. Se expresa como porcentaje.
También se llama coeficiente de determinación.
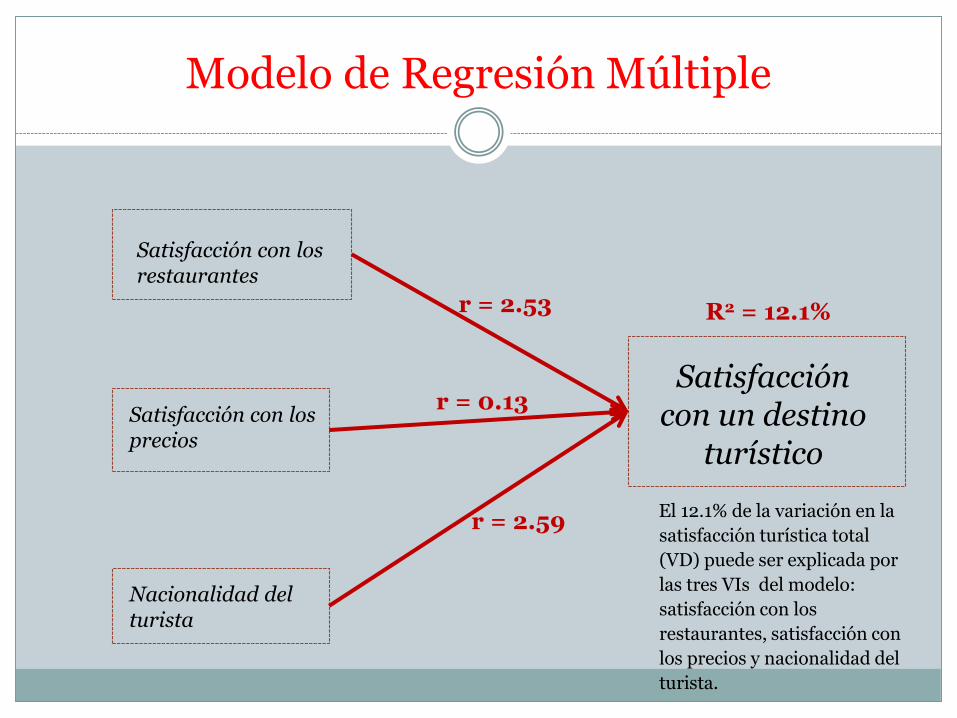
Modelo de Regresión Múltiple
Satisfacción con un destino
turístico
Satisfacción con los restaurantes
Satisfacción con los precios
Nacionalidad del turista
R2 = 12.1%
El 12.1% de la variación en la
satisfacción turística total
(VD) puede ser explicada por
las tres VIs del modelo:
satisfacción con los
restaurantes, satisfacción con
los precios y nacionalidad del
turista.
r = 2.53
r = 0.13
r = 2.59

Regresión múltiple en SPSS
2ª tabla
La tabla prueba el modelo.
Muestra si la proporción de varianza explicada en la primera tabla es significativa.
También dice si el efecto total de las VIs sobre la VD es significativa.

Regresión múltiple en SPSS
2ª tabla
En el ejemplo, la significancia (p) es .000, que es
menor al nivel de .05; por tanto, se concluye que el
modelo total es estadísticamente significativo, o
que las variables tienen un efecto combinado
significativo sobre la VD (la satisfacción total).

Regresión múltiple en SPSS
3ª tabla
Lo primero que se ve es la significancia para
determinar cuáles son los predictores significativos
de (o significativamente relacionados con) la VD.

Regresión múltiple en SPSS
3ª tabla
Los coeficientes beta estandarizados
indican la fuerza y dirección de la relación
(se interpretan como coeficientes de r).

Regresión múltiple en SPSS
3ª tabla
En el ejemplo, puede observarse que la
nacionalidad (p = .000) y la satisfacción con los
restaurantes (p = .000) son predictores
significativos de la satisfacción turística total.
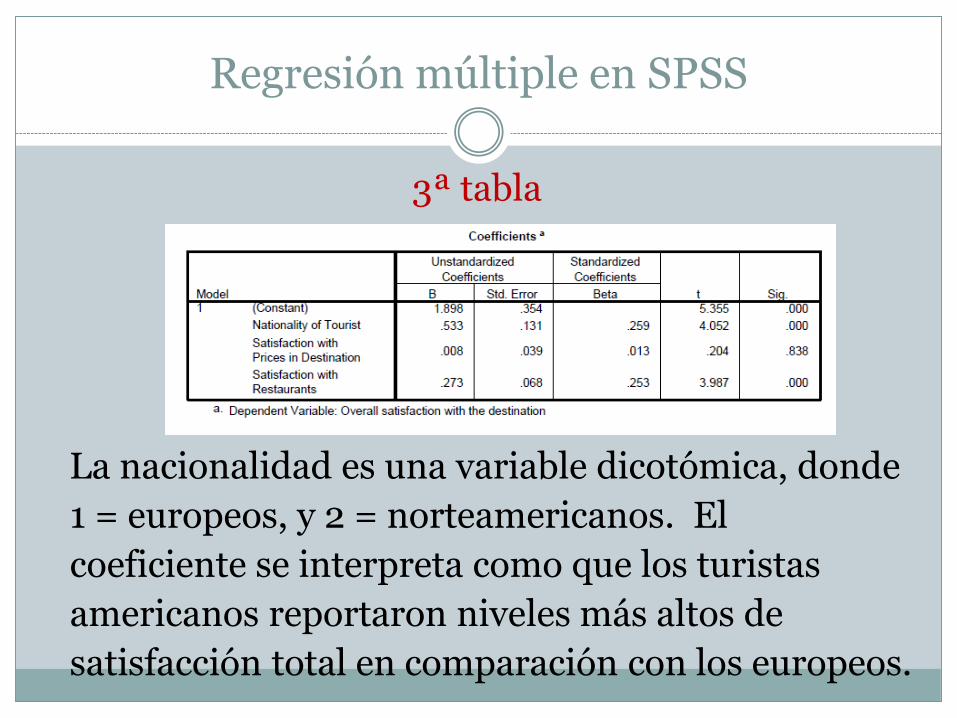
Regresión múltiple en SPSS
3ª tabla
La nacionalidad es una variable dicotómica, donde
1 = europeos, y 2 = norteamericanos. El
coeficiente se interpreta como que los turistas
americanos reportaron niveles más altos de
satisfacción total en comparación con los europeos.

Redacción de resultados de Regresión múltiple
“Se efectuó un análisis de regresión múltiple para examinar si la nacionalidad, la satisfacción con los restaurantes y la satisfacción con los precios impactan la satisfacción total con el destino. El modelo explicó 13.3% de la varianza , lo cual resultó significativo estadísticamente , F (3,216) = 11.09, p < .001. Los datos de los predictores individuales revelaron que la satisfacción con los restaurantes (b = .25, p < .001) y la nacionalidad (b = .26, p < .001) fueron predictores significativos de la satisfacción turística total con el destino.”

Redacción de resultados de Regresión múltiple
“Los niveles más altos de satisfacción con los restaurantes se asociaron con los niveles más altos de satisfacción total con el destino, y los turistas norteamericanos reportaron significativamente más satisfacción que los europeos”.