recommender systems
TRANSCRIPT

Recommender Systems
Class Algorithmic Methods of Data MiningProgram M. Sc. Data ScienceUniversity Sapienza University of RomeSemester Fall 2015Lecturer Carlos Castillo http://chato.cl/
Sources:● Ricci, Rokach and Shapira: Introduction to Recommender
Systems Handbook [link]● Bobadilla et al. Survey 2013 [link]● Xavier Amatriain 2014 tutorial on rec systems [link]● Ido Guy 2011 tutorial on social rec systems [link]● Alex Smola's tutorial on recommender systems [link]

2
Why recommender systems?

3
Definition
Recommender systems are software tools and techniques providing suggestions for
items to be of use to a user.

4
User-based recommendations

5

6
Assumptions
● Users rely on recommendations● Users lack sufficient personal
expertise● Number of items is very large
– e.g. around 1010 books in Amazon
● Recommendations need to be personalized
Amazon as of December 2015

7
Who uses recommender systems?
● Retailers and e-commerce in general– Amazon, Netflix, etc.
● Service sites, e.g. travel sites● Media organizations● Dating apps● ...

8
Why?
● Increase number of items sold– 2/3 of Netflix watched are recommendations
– 1/3 of Amazon sales are from recommendations
– ...

9
Why? (cont.)
● Sell more diverse items● Increase user satisfaction
– Users enjoy the recommendations
● Increase user fidelity– Users feel recognized (but not creeped out)
● Understand users (see next slides)

10
By-products
● Recommendations generate by-products● Recommending requires understanding users
and items, which is valuable by itself● Some recommender systems are very good at
this (e.g. factorization methods)● Automatically identify marketing profiles● Describe users to better understand them

11
The recommender system problem
Estimate the utility for a user of an item for which the user has not expressed utility
What information can be used?

12
Types of problem
● Find some good items (most common)● Find all good items● Annotate in context (why I would like this)● Recommend a sequence (e.g. tour of a city)● Recommend a bundle (camera+lens+bag)● Support browsing (seek longer session)● ...

13
Data sources
● Items, Users– Structured attributes, semi-structured or
unstructured descriptions
● Transactions– Appraisals
● Numerical ratings (e.g. 1-5)● Binary ratings (like/dislike)● Unary ratings (like/don't know)
– Sales
– Tags/descriptions/reviews

14
Recommender system process
Why is part of the processing done offline?

15
Aspects of this process
● Data preparation– Normalization, removal of outliers, feature selection,
dimensionality reduction, ...
● Data mining– Clustering, classification, rule generation, ...
● Post-processing– Visualization, interpretation, meta-mining, ...

16
Desiderata for recommender system
● Must inspire trust● Must convince users to
try the items● Must offer a good
combination of novelty, coverage, and precision
● Must have a somewhat transparent logic
● Must be user-tunable

17
Human factors
● Advanced systems are conversational● Transparency and scrutability
– Explain users how the system works
– Allow users to tell the system it is wrong
● Help users make a good decision● Convince users in a persuasive manner● Increase enjoyment to users● Provide serendipity

18
Serendipity
● “An aptitude for making desirable discoveries by accident”
● Don't recommend items the user already knows● Delight users by expanding their taste
– But still recommend them something somewhat familiar
● It can be controlled by specific parameters
Peregrinaggio di tre giovani figliuoli del re di Serendippo; Michele Tramezzino, Venice, 1557. Tramezzino claimed to have heard the story from one Christophero Armeno who had translated the Persian fairy tale into Italian adapting Book One of Amir Khusrau's Hasht-Bihisht of 1302 [link]

19
High-level approaches
● Memory-based– Use data from the past in a somewhat “raw” form
● Model-based– Use models built from data from the past

20
Approaches
● Collaborative filtering● Content-based (item features)● Knowledge-based (expert system)● Personalized learning to rank
– Estimate ranking function
● Demographic● Social/community based
– Based on connections
● Hybrid (combination of some of the above)

21
Collaborative filtering

22
Collaborative Filtering approach
● User has seen/liked certain items● Community has seen/liked certain items● Recommend to users items similar to the ones
they have seen/liked– Based on finding similar users
– Based on finding similar items

23
Algorithmic elements
● M users and N items
● Transaction matrix RM x N
● Active user● Method to compute similarity of users● Method to sample high-similarity users● Method to aggregate their ratings on an item

24
k nearest users algorithm
● Compute common elements with other users● Compute distance between rating vectors● Pick top 3 most similar users● For every unrated item
– Average rating of 3 most similar users
● Recommend highest score unrated items

25
Ratings data
1 2 3 4 5 6 7 8 9 10
11
12
1 1 5 2 3
2 5 1 5 4 5 3 2
3 5 5 1 3 2 4
4 3 5 4 5 1
5 2 5 4 4 5
6 4 3 1 4 2
7 4 1 4 5 4 1
ITEMSU
SE
RS

26
Try it! Generate recommendations
1 2 3 4 5 6 7 8 9 10
11
12
1 1 5 2 3
2 5 1 5 4 5 3 2
3 5 5 1 3 2 4
4 3 5 4 5 1
5 2 5 4 4 5
6 4 3 1 4 2
7 4 1 4 5 4 1
ITEMSU
SE
RS
Given the red userDetermine 3 nearest usersAverage their ratings on unrated itemsPick top 3 unrated elements

27
Compute user intersection size
1 2 3 4 5 6 7 8 9 10
11
12
1 1 5 2 3
2 5 1 5 4 5 3 2
3 5 5 1 3 2 4
4 3 5 4 5 1
5 2 5 4 4 5
6 4 3 1 4 2
7 4 1 4 5 4 1
ITEMSU
SE
RS
0
3
3
3
1
3

28
Compute user similarity
1 2 3 4 5 6 7 8 9 10
11
12
1 1 5 2 3
2 5 1 5 4 5 3 2
3 5 5 1 3 2 4
4 3 5 4 5 1
5 2 5 4 4 5
6 4 3 1 4 2
7 4 1 4 5 4 1
ITEMSU
SE
RS
0
3 0.33
3 2.67
3 0.00
1 3.00
3 0.67

29
Pick top-3 most similar
1 2 3 4 5 6 7 8 9 10
11
12
2 5 1 5 4 5 3 2
4 3 5 4 5 1
5 2 5 4 4 5
7 4 1 4 5 4 1
ITEMSU
SE
RS 3 0.33
3 0.00
3 0.67

30
Estimate unrated items
1 2 3 4 5 6 7 8 9 10
11
12
2 5 1 5 4 5 3 2
4 5.0 3 1.0 2.0 5 4 4.5 - 4.0 5 3.5 1
5 2 5 4 4 5
7 4 1 4 5 4 1
ITEMSU
SE
RS 3 0.33
3 0.00
3 0.67

31
Recommend top-3 estimated
1 2 3 4 5 6 7 8 9 10
11
12
2 5 1 5 4 5 3 2
4 5.0 3 1.0 2.0 5 4 4.5 - 4.0 5 3.5 1
5 2 5 4 4 5
7 4 1 4 5 4 1
ITEMSU
SE
RS 3 0.33
3 0.00
3 0.67

32
Improvements?
● How would you improve the algorithm?● How would you provide explanations?

33
Item-based collaborative filtering
1 2 3 4 5 6 7 8 9 10
11
12
1 1 5 2 3
2 5 1 5 4 5 3 2
3 5 5 1 3 2 4
4 3 5 4 5 ? 1
5 2 5 4 4 5
6 4 3 1 4 2
7 4 1 4 5 4 1
ITEMSU
SE
RS
● Would user 4 like item 11?
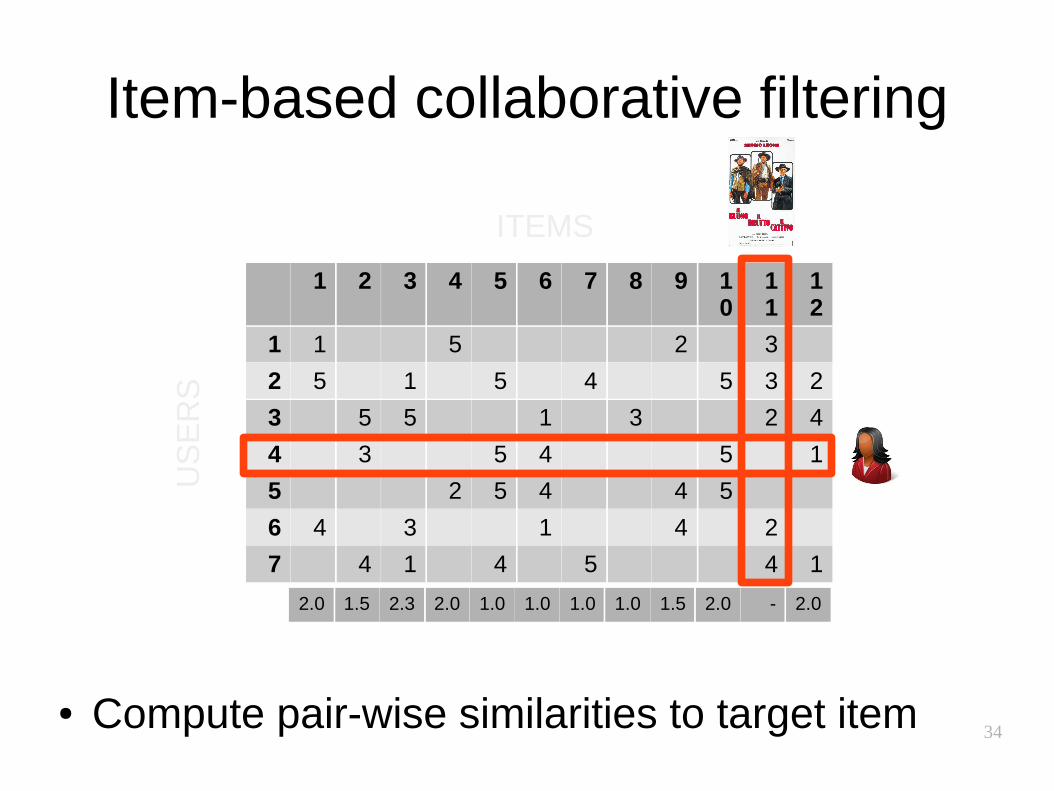
34
Item-based collaborative filtering
1 2 3 4 5 6 7 8 9 10
11
12
1 1 5 2 3
2 5 1 5 4 5 3 2
3 5 5 1 3 2 4
4 3 5 4 5 1
5 2 5 4 4 5
6 4 3 1 4 2
7 4 1 4 5 4 1
ITEMSU
SE
RS
● Compute pair-wise similarities to target item
2.0 1.5 2.3 2.0 1.0 1.0 1.0 1.0 1.5 2.0 - 2.0

35
Item-based collaborative filtering
1 2 3 4 5 6 7 8 9 10
11
12
1 1 5 2 3
2 5 1 5 4 5 3 2
3 5 5 1 3 2 4
4 3 5 4 5 1
5 2 5 4 4 5
6 4 3 1 4 2
7 4 1 4 5 4 1
ITEMSU
SE
RS
● Pick k most similar items
1.0 1.0 1.0 1.0 -

36
Item-based collaborative filtering
1 2 3 4 5 6 7 8 9 10
11
12
1 1 5 2 3
2 5 1 5 4 5 3 2
3 5 5 1 3 2 4
4 3 5 4 5 4.5 1
5 2 5 4 4 5
6 4 3 1 4 2
7 4 1 4 5 4 1
ITEMSU
SE
RS
● Average ratings of target user on item
1.0 1.0 1.0 1.0 -

37
Performance implications
● Similarity between users is uncovered slowly● Similarity between items is supposedly static
– Can be precomputed!
● Item-based clusters can also be precomputed
[source]

38
Weaknesses
● Assumes standardized products– E.g. a touristic destination at any time of the year
and under any circumstance is the same item
● Does not take into account context● Requires a relatively large number of
transactions to yield reasonable results

39
Cold-start problem
● What to do with a new item?● What to do with a new user?

40
Assumptions
● Collaborative filtering assumes the following:– We take recommendations from friends
– Friends have similar tastes
– A person who have similar tastes to you, could be your friend
– Discover people with similar tastes, use them as friends
● BUT, people's tastes are complex!

41
Ordinary people andextraordinary tastes
[Goel et al. 2010]
Distribution of user eccentricity: the median rank of consumed items.
In the null model, users select items proportional to item popularity

42
Matrix factorization approaches

43
2D projection of interests
[Koren et al. 2009]

44
SVD approach
● R is the matrix of ratings– n users, m items
● U is a user-factor matrix● S is a diagonal matrix, strength of each factor● V is a factor-item matrix● Matrices USV can be computed used an
approximate SVD method

45
General factorization approach
● R is the matrix of ratings– n users, m items
● P is a user-factor matrix● Q is a factor-item matrix
(Sometimes we force P, Q to be non-negative: factors are easier to interpret!)


47
Computing expected ratings
● Given:– user vector
– item vector
● Expected rating is

48
Model directly observed ratings
● Ro are the observed ratings
● We want to minimize a reconstruction error● Second term avoids over-fitting
– Parameter λ found by cross-validation
● Two basic optimization methods

49
1. Stochastic gradient descend
● Compute reconstruction error
● Update in opposite direction to gradient
http://sifter.org/~simon/journal/20061211.html learning speed

50
Illustration: batch gradient descent vs stochastic gradient descent
Batch: gradient Stochastic: single-example gradient
[source]

51
A simpler example of gradient descent
Fit a set of n two-dimensional data points (x i,yi) with a line L(x)=w1+w2x, means minimizing:
The update rule is to take a random point and do:
https://en.wikipedia.org/wiki/Stochastic_gradient_descent

52
2. Alternating least squares
● With vectors p fixed:– Find vectors q that minimize above function
● With vectors q fixed– Find vectors p that minimize above function
● Iterate until convergence● Slower in general, but parallelizes better


54
Ratings are not normally-distributed
[Marlin et al. 2007, Hu et al. 2009]
Sometimes referred to as the “J” distribution of ratings
Amazon(DVDs, Videos, Books)

55
How you label ratings matters

56
In general, there are many biases
● Some movies always get better (or worse) ratings than others
● Some people always give better (or worse) ratings than others
● Some systems make people give better (or worse) ratings than others, e.g. labels
● Time-sensitive user preferences

57
Other approaches

58
Other approaches
● Association rules (sequence-mining based)● Regression (e.g. using a neural network)
– e.g. based on user characteristics, number of ratings in different tags/categories
● Clustering● Learning-to-rank

59
Hybrid methods (some types)
● Weighted– E.g. average recommended scores of two methods
● Switching– E.g. use one method when little info is available, a
different method when more info is available
● Cascade– E.g. use a clustering-based approach, then refine
using a collaborative filtering approach

60
Context-sensitive methods
● Context: where, when, how, ...● Pre-filter● Post-filter● Context-aware methods
– E.g. tensor factorization

61
Evaluation

62
Evaluation methodologies
● User experiments● Precision @ Cut-off● Ranking-based metrics
– E.g. Kendall's Tau
● Score-based metrics– E.g. RMSE
http://www-users.cs.umn.edu/~cosley/research/gl/evaluating-herlocker-tois2004.pdf

63
Example user testing
● [Liu et al. IUI 2010] News recommender

64
Score-based metric: RMSE
● “Root of mean square error”
● Problem with all score-based metrics: niche items with good ratings (by those who consumed them)

65
Evaluation by RMSE
[Slide from Smola 2012]

66
Evaluation by RMSE
BIAS
TEMPORALFACTORS
[Slide from Smola 2012]

67
Netflix challenge results
● It is easy to provide reasonable results
● It is hard to improve them