recent results in non-asymptotic shannon theory dror baron supported by afosr, darpa, nsf, onr, and...
Post on 21-Dec-2015
215 views
TRANSCRIPT

Recent Results in Non-Asymptotic Shannon Theory
Dror Baron
Supported by AFOSR, DARPA, NSF, ONR, and Texas InstrumentsJoint work with M. A. Khojastepour, R. G. Baraniuk, and S. Sarvotham
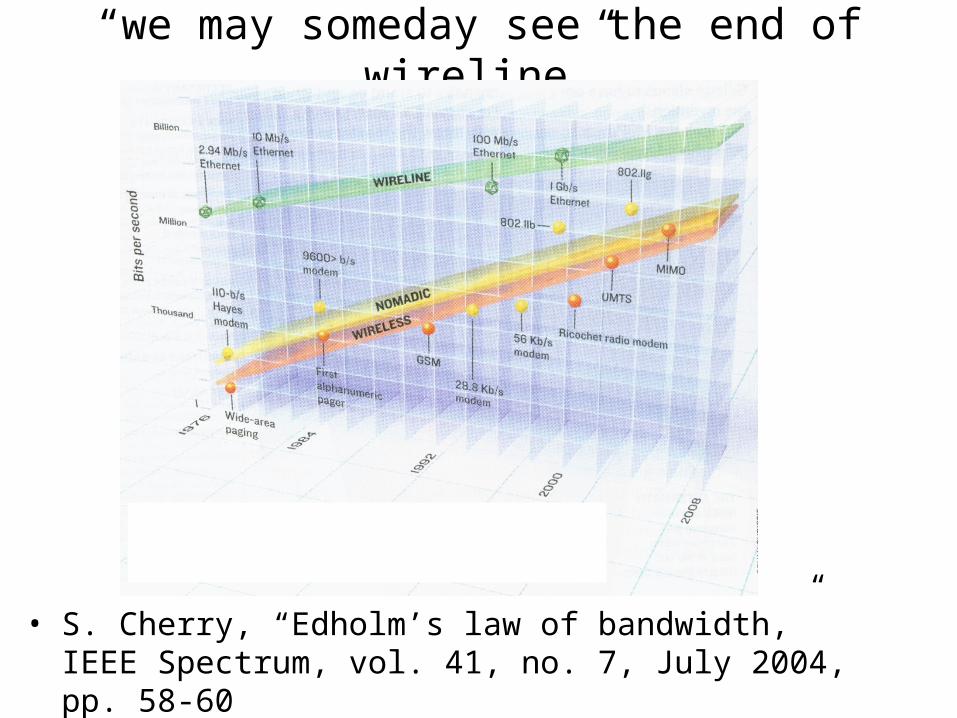
“we may someday see the end of wireline”
• S. Cherry, “Edholm’s law of bandwidth,” IEEE Spectrum, vol. 41, no. 7, July 2004, pp. 58-60

But will there ever be enough data rate?
• R. Lucky, 1989:“We are not very good at predicting uses until the actual service becomes available. I am not worried; we will think of something when it happens.”
There will always be new applications that gobble up more data rate!

How much can we improve wireless?
• Spectrum is limited natural resource• Information theory says we need lots of power for
high data rates - even with infinite bandwidth!
• Solution: transmit more power BUT– Limited by environmental concerns– Will batteries support all that power?
• Sooner or later wireless rates will hit a wall!

Where can we improve?
• Algorithms and hardware gains– Power-efficient computation – Efficient power amplifiers– Advances in batteries– Directional antennas
• Communication gains– Channel coding – Source coding– Better source and channel models

Where will “the last dB” of communication gains come from?
Network information theory (Shannon theory)

Traditional point to point information theory
• Single source• Single transmitter• Single receiver• Single communication stream
• Most aspects are well-understood
Channel DecoderEncoder
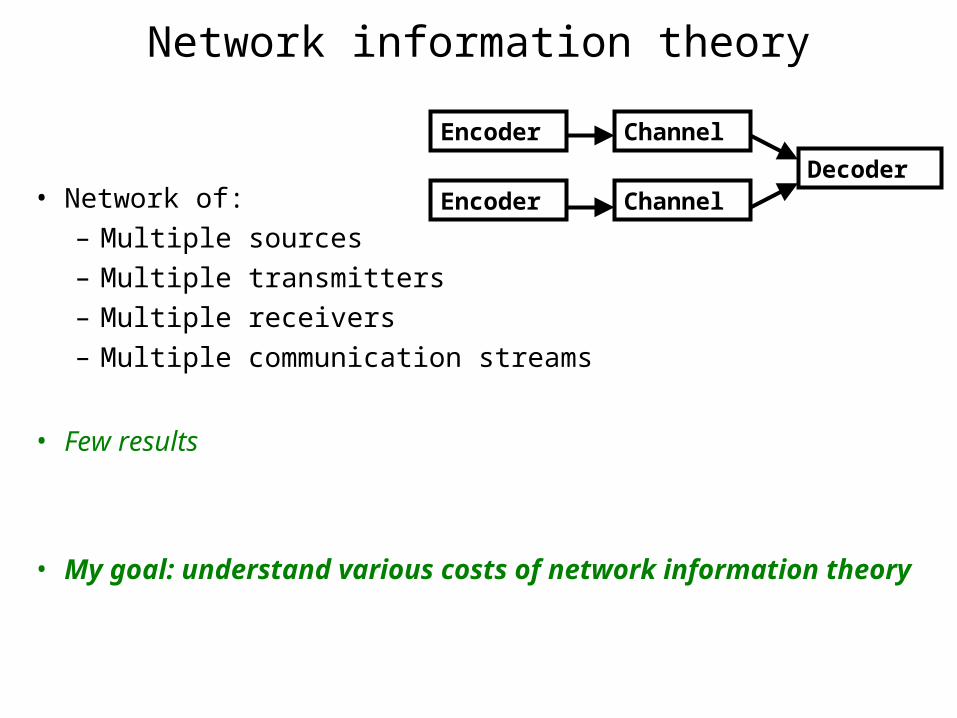
Network information theory
• Network of:– Multiple sources– Multiple transmitters– Multiple receivers– Multiple communication streams
• Few results
• My goal: understand various costs of network information theory
Channel
Decoder
Encoder
Encoder Channel

What costs has information theory overlooked?

Channel coding has arrived…
• Turbo codes [Berrou et al., 1993]– ~0.5 dB gap to capacity (rate R below capacity)– BER=10-5
– Block length n=6.5£104
• Regular LDPC codes [Gallager, 1963]
• Irregular LDPC [Richardson et al., 2001]– 0.13 dB gap to capacity– BER=10-6
– n=106
Channel DecoderEncoder
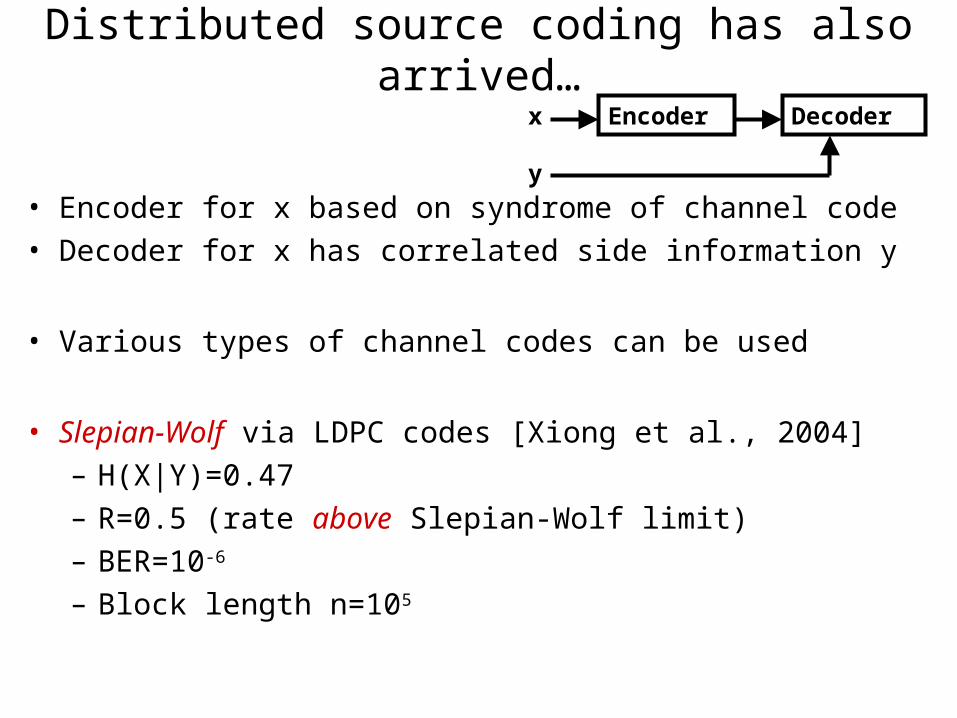
Distributed source coding has also arrived…
• Encoder for x based on syndrome of channel code• Decoder for x has correlated side information y
• Various types of channel codes can be used
• Slepian-Wolf via LDPC codes [Xiong et al., 2004]– H(X|Y)=0.47– R=0.5 (rate above Slepian-Wolf limit)– BER=10-6
– Block length n=105
DecoderEncoderx
y

Hey! Did you notice those block lengths?
• Information theory provides results in the asymptotic regime– Channel coding: 8>0, rate R=C- achievable
with !0 as n!1 – Slepian-Wolf coding: 8>0, rate R=H(X|Y)+
achievable with !0 as n!1
• Best practical results achieved for n¸105
• Do those results require large n?

But we live in a finite world…
• Real world data doesn’t always have n¸106
– IP packets– Emails, text messages– Sensornet applications
(small battery ! small n)
• How do those methods perform for n=104? 103?
• How quickly can we approach the performance limits of information theory?

And we don’t know the statistics either!
• Lossless coding (single source):– Length-n input x~Ber(p) – Encode with wrong parameter q– K-L divergence penalty with variable rate codesPerformance loss (minor bitrate penalty)
• Channel coding, distributed source coding:– Encode with wrong parameter q<p<0.5– Fixed rate codes based on joint-typicality– Typical set Tq for q is smaller than Tp for p• As n!1, Pr(error)!1Performance collapse!

Main challenges
• How quickly can we approach the performance limits of information theory?
• Will address for channel coding and Slepian-Wolf
• What can we do when the source statistics are unknown?
• Will address for Slepian-Wolf

But first . . .
What does the prior art indicate?

Underlying problem
• Shannon [1958]:“This inverse problem is perhaps the more natural in applications: given a required level of probability of error, how long must the code be?”– Motivation may have been phone and space
communication– “Small” probability of codeword error
• Wireless paradigm:Given k bits, what are the minimal channel resources to attain probability of error ?– Can retransmit packet fix “large” – n depends on packet length– Need to characterize R(n,)

Error exponents
• Fix rate R<C and codeword length n– Bounds on probability of error– Random coding Pr[error]·2-nEr(R)
– Sphere packing Pr[error]¸2-nEsp(R)+o(n)
– Er(R)=Esp(R) for R near C

Error exponents
• Fix rate R<C and codeword length n– Bounds on probability of error– Random coding Pr[error]·2-nEr(R)
– Sphere packing Pr[error]¸2-nEsp(R)+o(n)
– Er(R)=Esp(R) for R near C
• Shannon’s regime:“This inverse problem is perhaps the more natural in applications: given a required level of probability of error, how long must the code be?”– Fix R<CE(R)=O(1) log()=O(n) good for “small”

Error exponents
• Fix rate R<C and codeword length n– Bounds on probability of error– Random coding Pr[error]·2-nEr(R)
– Sphere packing Pr[error]¸2-nEsp(R)+o(n)
– Er(R)=Esp(R) for R near C
• Wireless paradigm:Given k bits, what are the minimal channel resources to attain probability of error ?– Fix nE(R)=O(1)– o(n) term dominatesBounds diverge
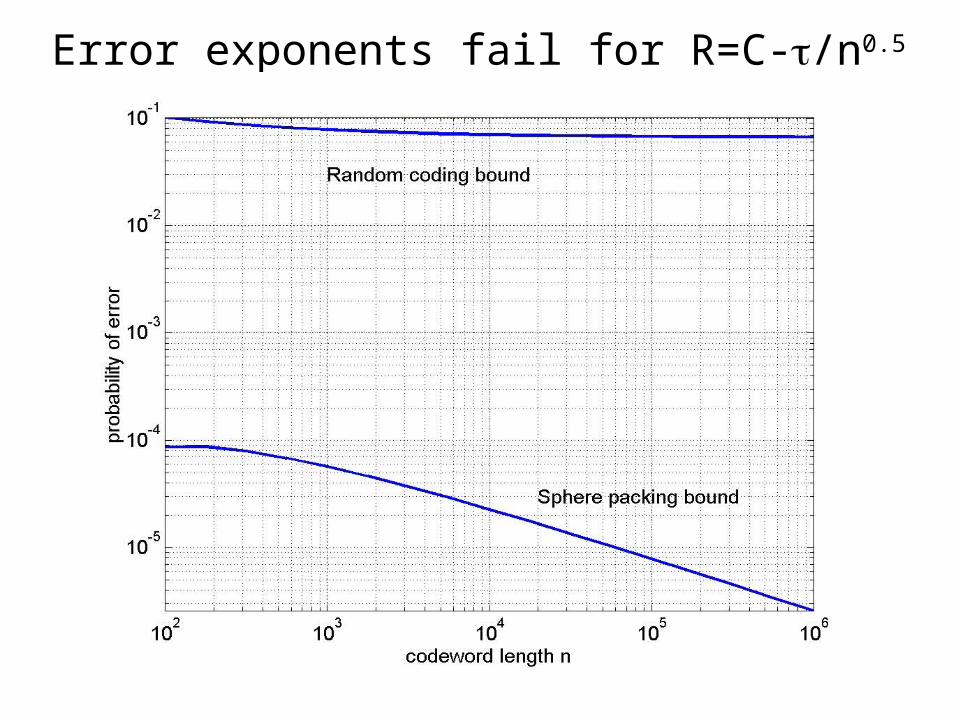
Error exponents fail for R=C-/n0.5

How quickly can we approach the channel capacity?
(known statistics)

Binary symmetric channel (BSC) setup
• s2{1,…,M} input message• x, y, and z binary length-n sequences• z~Bernoulli(n,p) implies crossover probability p• Code (f,g,n,M,) includes:
– Encoder x=f(s)2{1,…,M}– Rate R=log(M)/n– Channel y=xz– Decoder g reconstructs s by s’=g(y)– Error probability Pr[g(y)s]·
sEncoder f
x=f(s)Decoder g
z~Ber(n,p)
s’=g(y)y
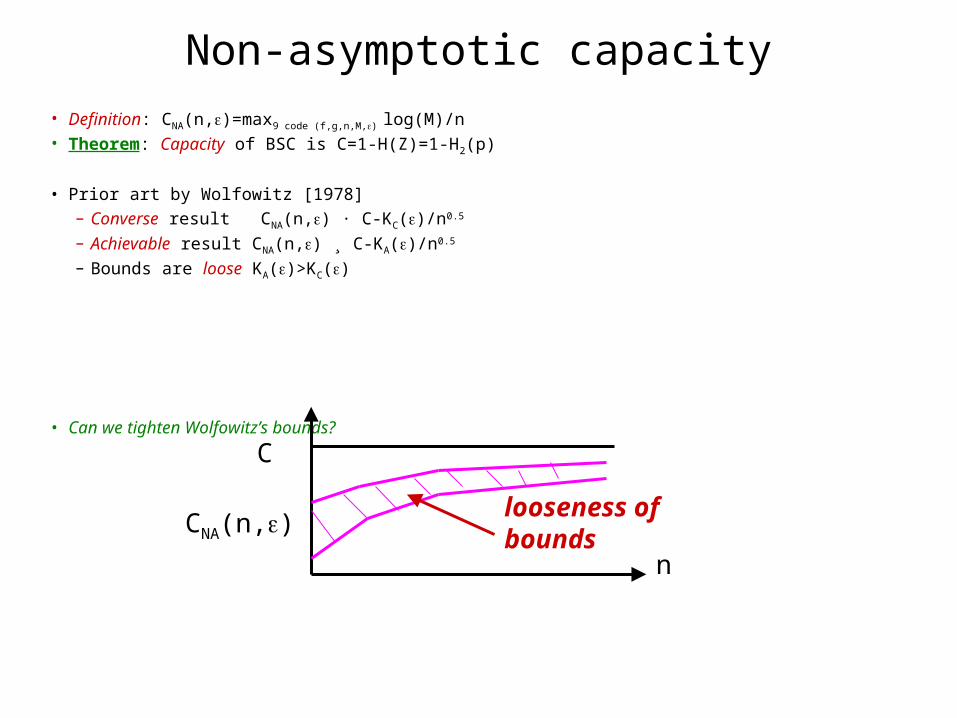
Non-asymptotic capacity• Definition: CNA(n,)=max9 code (f,g,n,M,) log(M)/n• Theorem: Capacity of BSC is C=1-H(Z)=1-H2(p)
• Prior art by Wolfowitz [1978]– Converse result CNA(n,) · C-KC()/n0.5
– Achievable result CNA(n,) ¸ C-KA()/n0.5
– Bounds are loose KA()>KC()
• Can we tighten Wolfowitz’s bounds?
n
CNA(n,) looseness of bounds
C

Key to solution – Packing typical sets
• Need to encode typical set TZ for z
– Code needs to “cover” z2Tz
Need Pr(z2TZ)¼ Probability of codeword error
• What about rate?– Output space = 2n possible sequences– Can’t pack more than 2n/|Tz| sets into outputM·2n/|Tz| – Minimal cardinality Tmin covers CNA·1-log(|Tmin|)
Tz
output space

What’s the cardinality of Tmin?
• Consider empirical statistics nz=i zi, PZ=nz/n
– p<0.5 Pr(z) monotone decreasing in nz
Minimal Tmin has form Tmin,{z: PZ·}
• Determine () with central limit theorem (CLT)
– E[PZ]=p, Var(PZ)=p(1-p)/n
Pz~N(p,p(1-p)/n)
• Asymptotic– =p+– LLN: 0
• Non-asymptotic– =p+[p(1-p)/n]0.5
– CLT: ! ()

Tight non-asymptotic capacity• Theorem:
– CNA(n,)=C-K()/n0.5+o(n-0.5)– K()=-1() [p(1-p)]0.5 log((1-p)/p)– Gap to capacity is K()/n0.5+o(n-0.5)
• Note: o(n-0.5) asymptotically negligible w.r.t. K/n0.5
Tightened Wolfowitz bounds up to o(n-0.5) Gap to capacity of LDPC codes 2-3x greater We know how quickly we can approach C
n
CNA(n,) tight bound
C
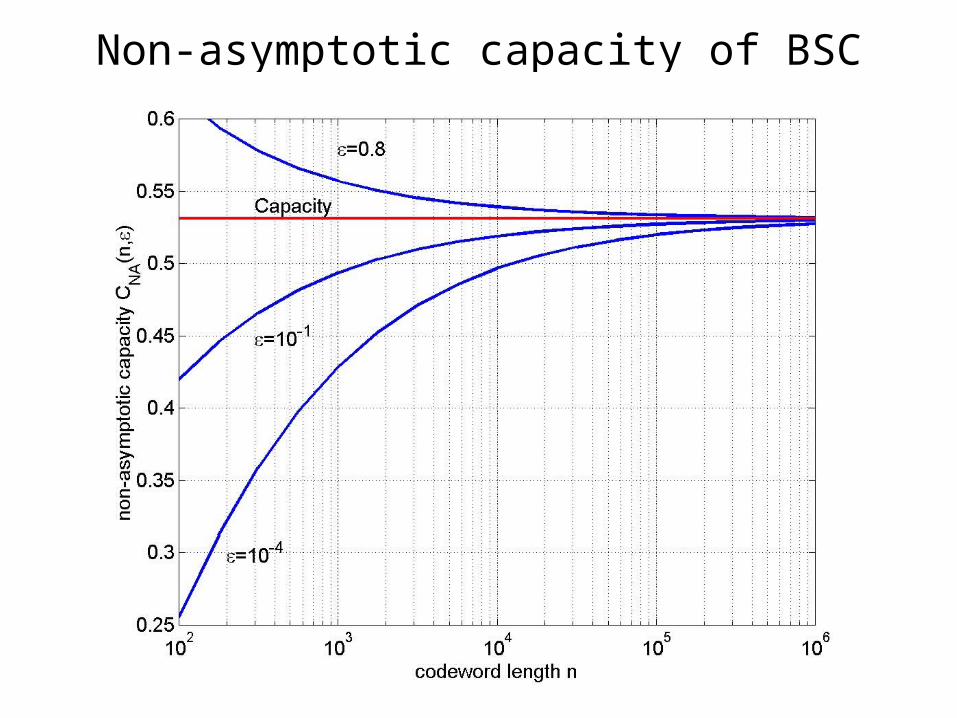
Non-asymptotic capacity of BSC

Gaussian channel results
• Continuous channel
• Power constraint i(xi)2 · nP
• Shannon [1958] derived CNA(n,) for Gaussian channel via cone packing (non-i.i.d. codebook)
• Information spectrum bounds on probabilities of error indicate Gaussian codebooks are sub-optimal
i.i.d. codebooks aren’t good enough!
sEncoder f
x=f(s)Decoder g
z~N(0,2)
s’=g(y)y

Excess power of Gaussian channel

How quickly can we approach the Slepian-Wolf limit?
(known statistics)

But first . . .
Slepian-Wolf Review

Slepian-Wolf setup
• x and y are correlated length-n sequences
• Code (fX,fY,gX,gY,n,MX,MY,X,Y) includes:
– Encoders fX(x)2{1,…,MX}, fY(y)2{1,…,MY}
– Rates RX=log(MX)/n, RY=log(MY)/n
– Decoder g reconstructs x and y by gX(fX(x),fY(y))
and gY(fX(x),fY(y))
– Error probabilities Pr[gX(fX(x),fY(y))x]·X and Pr[gY(fX(x),fY(y))y]·Y
xEncoder fX
fX(x)
Decoder gy
Encoder fY
fY(y)
gX(fX(x),fY(y))
gY(fX(x),fY(y))

Slepian-Wolf theorem
• Theorem: [Slepian&Wolf,1973]
– RX¸H(X|Y) (conditional entropy)
– RY¸H(Y|X)
– RX+RY¸H(X,Y) (joint entropy)
RX
RY
H(Y|X)
H(Y)
H(X)H(X|Y)
Slepian-Wolf rate region

Slepian-Wolf with binary symmetric correlation structure
(known statistics)

Binary symmetric correlation setup
• y, z, and z are length-n Bernoulli sequences • Correlation channel z is independent of y• Bernoulli parameters p,q2[0,0.5), r=p(1-q)+(1-p)q • Code (f,g,n,M,) includes:
– Encoder f(x)2{1,…,M}– Rate R=log(M)/n– Decoder g(f(x),y)2{0,1}n
– Error probability Pr[g(f(x),y)x]·
x~Ber(r)
Encoder fy~Ber(p)
z~Ber(q)
f(x)2{1,…,M}
Decoder g
g(f(x),y)2{0,1}n

Relation to general Slepian-Wolf setup
• x, y, and z are Bernoulli• Correlation z independent of y • Focus on encoding x at rate approaching H(Z)
• Neglect well-known encoding of y at rate RY=H(Y)
RX
RY
H(Y|X)
H(Y)
H(X)H(Z)
our setup
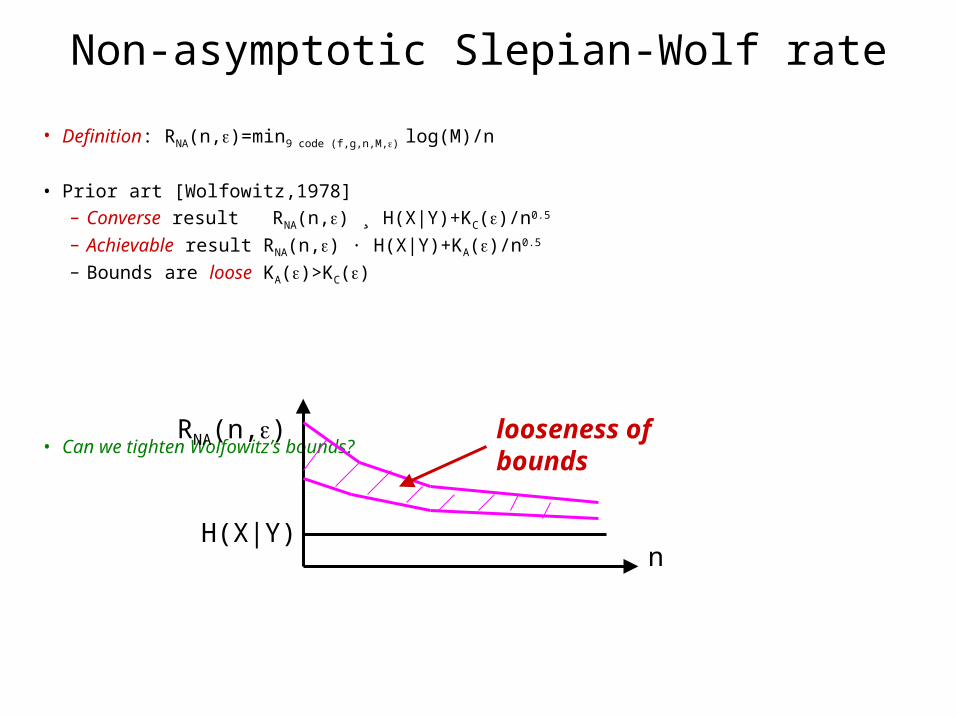
Non-asymptotic Slepian-Wolf rate
• Definition: RNA(n,)=min9 code (f,g,n,M,) log(M)/n
• Prior art [Wolfowitz,1978]– Converse result RNA(n,) ¸ H(X|Y)+KC()/n0.5
– Achievable result RNA(n,) · H(X|Y)+KA()/n0.5
– Bounds are loose KA()>KC()
• Can we tighten Wolfowitz’s bounds?
n
RNA(n,) looseness of bounds
H(X|Y)
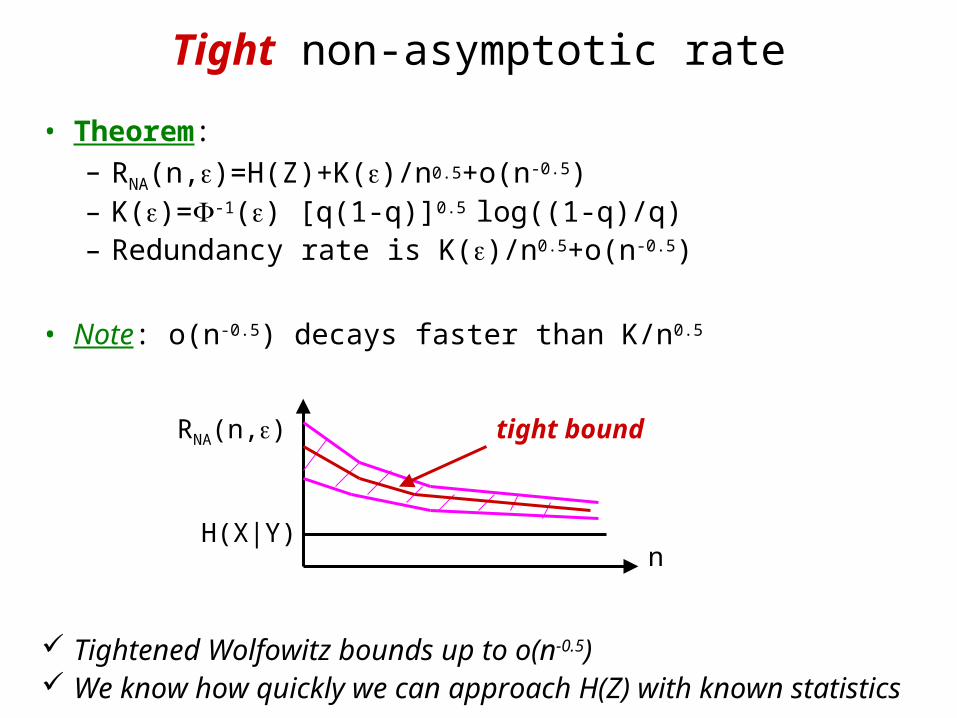
Tight non-asymptotic rate
• Theorem: – RNA(n,)=H(Z)+K()/n0.5+o(n-0.5)– K()=-1() [q(1-q)]0.5 log((1-q)/q)– Redundancy rate is K()/n0.5+o(n-0.5)
• Note: o(n-0.5) decays faster than K/n0.5
Tightened Wolfowitz bounds up to o(n-0.5) We know how quickly we can approach H(Z) with
known statistics
n
RNA(n,) tight bound
H(X|Y)

What can we do when the source statistics are unknown?
(universality)

Universal setup
• Unknown Bernoulli parameters p, q, r
• Encoder observes x and ny=iyi
• Communication of ny requires log(n) bits
• Variable rate used
– Need distribution for nz
– Distribution depends on nx and ny (not x)
– Codebook size Mnx,ny
x~Ber(r)
Encoder fy~Ber(p)
z~Ber(q)
f(x)2{1,…,Mnx,ny}
Decoder g
g(f(x),y)2{0,1}n
ny=iyi

Distribution of nz
• CLT was key to solution with known statistics• How can we apply CLT when q is unknown?
• Consider a numerical example – p=0.3, q=0.1, r=p(1-q)+(1-p)q
– PX=r, PY=p, PZ=q (empirical = true)
– We plot Pr(nz|nx,ny) as function of nz2{0,…,n}

Pr(nz|nx,ny) for n=102

Pr(nz|nx,ny) for n=103

Pr(nz|nx,ny) for n=104
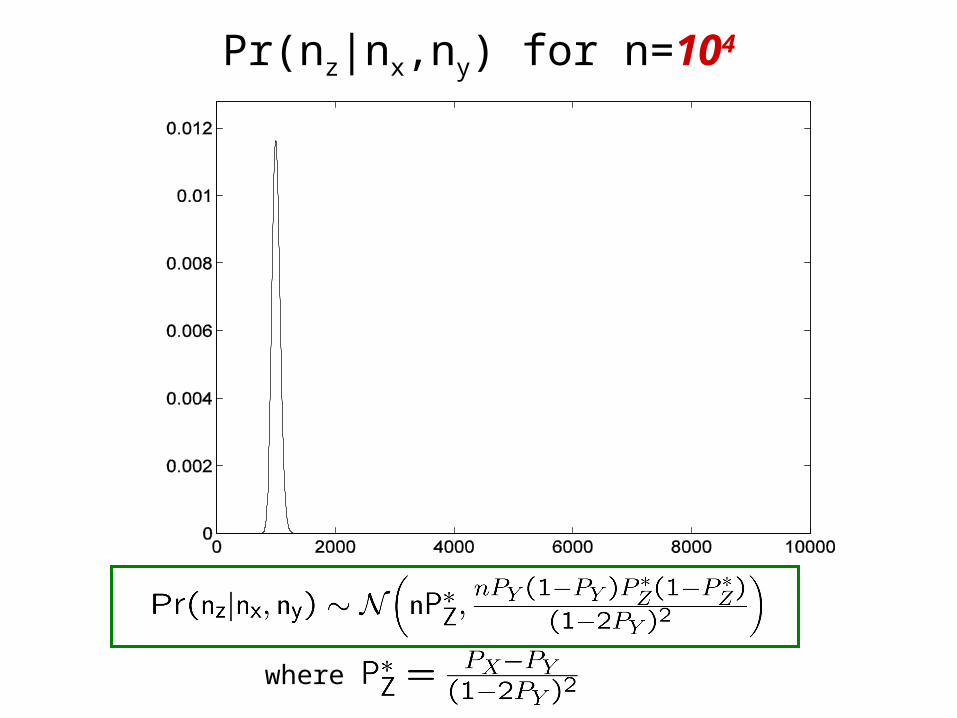
Pr(nz|nx,ny) for n=104
where

Universal rate
• Theorem:
– RNA(n,)=H(P*Z)+K’()/n0.5+o(n-0.5)
– K’()=f(PY)K()
– f(PY)=2[PY(1-PY)]0.5/|1-2PY|
f(PY)!0
f(PY)!1

Why is f(PY) small when PY is small?
• Known statistics Var(nz)=nq(1-q) regardless of empirical statistics
• PY!0 can estimate nZ with small variance Universal scheme outperforms known statistics
when PY is small
• Key issue: variable rate coding (universal) beats fixed rate coding (known statistics)
Can cut down expected redundancy (known statistics) by communicating ny to encoder
• log(n) bits for ny will save O(n0.5)

Redundancy for PY¼0.5
• f(PY) blows up as PY approaches 0.5
• Redundancy is O(n-0.5) with enormous constant
• Another scheme has O(n-1/3) redundancy
• Better performance for PY=0.5+O(n-1/6)
Universal redundancy can be huge!
• Ongoing research: improvement of O(n-1/3)

Numerical example• n=104
• q=0.1
• Slepian-Wolf requires nH2(q)=4690 bits
• Non-asymptotic approach (known statistics) with =10-2 requires nRNA(n,)=4907 bits
• Universal approach with PY=0.3 requires 5224 bits
• With PY=0.4 we need 5863 bits
• In practice, penalty for universality is huge!

Summary• Network information theory (Shannon theory) may
enable to increase wireless data rates• Practical channel codes and distributed source
codes approaching limits, rely on large n
• How quickly can we approach the performance limits of information theory?CNA=C-K()/n1/2+o(n-1/2)
RNA=H(Z)+K()/n1/2+o(n-1/2)Gap to capacity of LDPC codes 2-3x greater

Universality• What can we do when the source statistics
are unknown? (Slepian Wolf)PY<0.5: H(P*
Z)+K’()/n1/2+o(n-1/2)
PY¼0.5: H(P*Z)+O(n-1/3) – can be huge!
• Universal channel coding with feedback for BSC
– Capacity-achieving code requires PY=0.5Universality with current scheme is O(n-1/3)
Channel DecoderEncoder
feedback

Further directions
• Gaussian channel (briefly discussed)– Shannon [1958] derived CNA(n,) for Gaussian
channel with cone packing (non-i.i.d. codebook)– Gaussian codebooks are sub-optimal!
• Other channels:
– CNA(n,) ¸ C-KA()/n0.5 via information spectrum
– Gaussian codebook distribution sub-optimalMust consider non-i.i.d. codebook constructions
• Penalties for finite n and unknown statistics exist everywhere in Shannon theory!!
www.dsp.rice.edu