regressionsanalysstaff.adajon/s0001m/regr-komp-s0001m-jan09.pdfluleå tekniska universitet...
TRANSCRIPT

Matematik Kerstin Vännman 2009-01-14
REGRESSIONSANALYS
S0001M

INNEHÅLL 1. Inledning............................................................................................................................ 1 2. Enkel regressionsanalys..................................................................................................... 1 3. Undersökning av modellantagandena................................................................................ 7 4. Korrelationskoefficient...................................................................................................... 10 5. Konfidensintervall för förväntat Y-värde.......................................................................... 13 6. Prognosintervall................................................................................................................. 14 7. Om inflytelserika observationer ........................................................................................ 16 8. Om tolkning av regression och korrelation ....................................................................... 18 9. Multipel linjär regression .................................................................................................. 20 10. Residualanalys och analys av inflytelserika observationer ............................................. 25 11. Prognosintervall samt konfidensintervall för förväntat Y-värde..................................... 28 12. Kollinearitet ..................................................................................................................... 30 13. Dummyvariabler.............................................................................................................. 33 14. Att välja ut en lämplig modell ......................................................................................... 37 15. Appendix ......................................................................................................................... 38

Luleå tekniska universitet 2008-09-29 Matematik S0001M Kerstin Vännman
– 1 –
Regressionsanalys
1. Inledning Regressionsanalys är en av de mest använda statistiska metoderna inom många olika tillämpningsområden för att beskriva och bestämma samband mellan två eller flera olika variabler. Det är även en metod för att bygga modeller som förklarar så mycket som möjligt av variationen i en viss studerad situation.
2. Enkel linjär regression Exempel 1. Koloxid och rökning
Att rökning påverkar vår hälsa är numera ett känt faktum. Det finns ett stort antal fak-torer som kan mätas i samband med cigarrettrökning. The Federal Trade Commission i USA graderar årligen olika cigarettmärken efter deras innehåll vad gäller bl a tjära, ni-kotin. Dessa ämnen påverkar mängden koloxid som kommer från cigarettröken. I tabell 1 nedan framgår mätningar gjorda i laboratorium med en s k rökmaskin för 25 olika ci-garettmärken.
Tabell 1. Mängd tjära (i mg), mängd nikotin (i mg), vikt (i g) samt koloxid, CO, (i mg) för 25 olika cigarrettmärken. Datat finns på www.amstat.org/publications/jse/archive.htm och finns även publicerat i Mendenhall and Sincich (1992). Statistics for Engineers and the Sciences (3rd ed).
Märke Tjärmängd Nikotinmängd Vikt CO Alpine 14.1 0.86 0.9853 13.6 Benson&Hedges 16.0 1.06 1.0938 16.6 BullDurham 29.8 2.03 1.1650 23.5 CamelLights 8.0 0.67 0.9280 10.2 Carlton 4.1 0.40 0.9462 5.4 Chesterfield 15.0 1.04 0.8885 15.0 GoldenLights 8.8 0.76 1.0267 9.0 Kent 12.4 0.95 0.9225 12.3 Kool 16.6 1.12 0.9372 16.3 L&M 14.9 1.02 0.8858 15.4 LarkLights 13.7 1.01 0.9643 13.0 Marlboro 15.1 0.90 0.9316 14.4 Merit 7.8 0.57 0.9705 10.0 MultiFilter 11.4 0.78 1.1240 10.2 NewportLights 9.0 0.74 0.8517 9.5 Now 1.0 0.13 0.7851 1.5 OldGold 17.0 1.26 0.9186 18.5 PallMallLight 12.8 1.08 1.0395 12.6 Raleigh 15.8 0.96 0.9573 17.5 SalemUltra 4.5 0.42 0.9106 4.9 Tareyton 14.5 1.01 1.0070 15.9 True 7.3 0.61 0.9806 8.5 ViceroyRichLight 8.6 0.69 0.9693 10.6 VirginiaSlims 15.2 1.02 0.9496 13.9 WinstonLights 12.0 0.82 1.1184 14.9
Det som är intressant att studera är hur mängden CO varierar och hur den påverkas av tjär- och nikotininnehållet i cigaretten. Kan vi t ex hitta en modell som på något en-kelt sätt beskriver sambandet mellan CO och nikotin?
Kerstin Vännman S0001M 2009-01-14
– 2 –
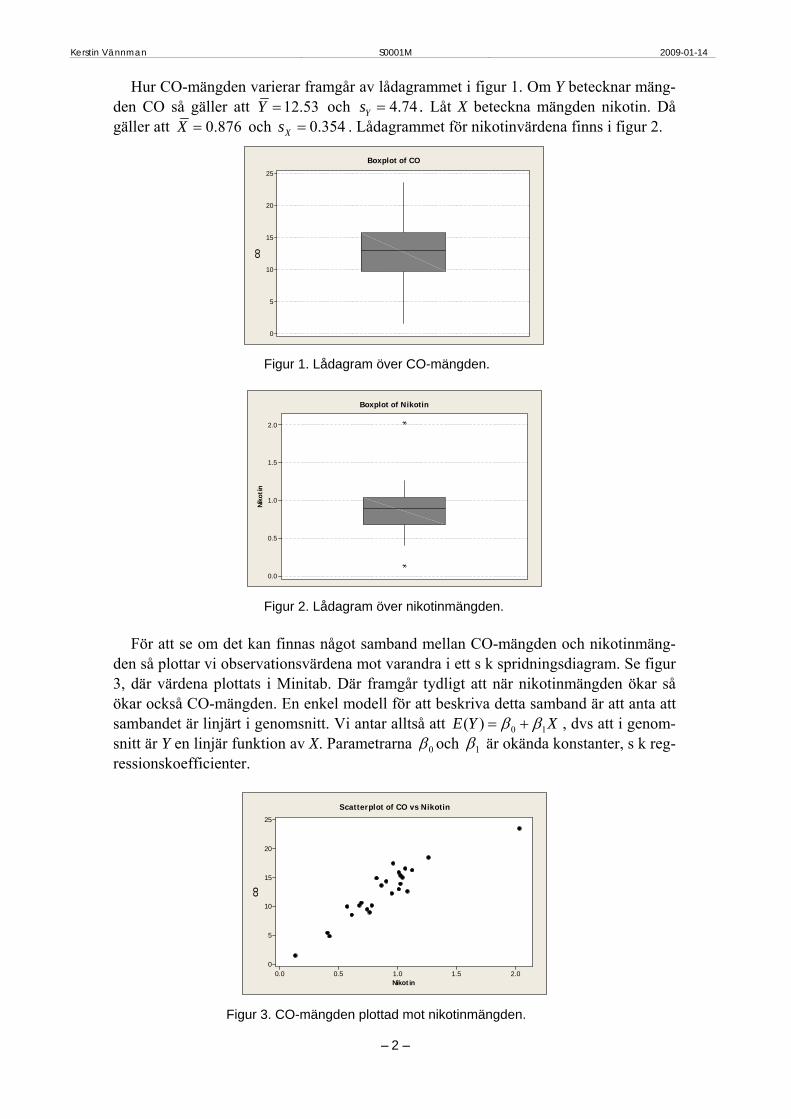
Hur CO-mängden varierar framgår av lådagrammet i figur 1. Om Y betecknar mäng-den CO så gäller att 12.53Y = och 4.74Ys = . Låt X beteckna mängden nikotin. Då gäller att 0.876X = och . Lådagrammet för nikotinvärdena finns i figur 2. 0.354Xs =
CO
25
20
15
10
5
0
Boxplot of CO
Figur 1. Lådagram över CO-mängden.
Niko
tin
2.0
1.5
1.0
0.5
0.0
Boxplot of Nikotin
Figur 2. Lådagram över nikotinmängden.
För att se om det kan finnas något samband mellan CO-mängden och nikotinmäng-den så plottar vi observationsvärdena mot varandra i ett s k spridningsdiagram. Se figur 3, där värdena plottats i Minitab. Där framgår tydligt att när nikotinmängden ökar så ökar också CO-mängden. En enkel modell för att beskriva detta samband är att anta att sambandet är linjärt i genomsnitt. Vi antar alltså att XYE 10)( ββ += , dvs att i genom-snitt är Y en linjär funktion av X. Parametrarna 0β och 1β är okända konstanter, s k reg-ressionskoefficienter.
Nikotin
CO
2.01.51.00.50.0
25
20
15
10
5
0
Scatterplot of CO vs Nikotin
Figur 3. CO-mängden plottad mot nikotinmängden.

Kerstin Vännman S0001M 2009-01-14
– 3 –
Om vi dessutom gör vissa tilläggsantaganden enligt nedan så kan vi använda oss av regressionsanalys för att uppskatta sambandet och även med viss given grad av säkerhet uttala oss om våra skattningar. Vi antar då att variationen, eller bruset, kring linjen XYE 10)( ββ += kan beskrivas med hjälp av en normalfördelning med vänte-värde 0 och standardavvikelse σ. Denna standardavvikelse ska vara konstant och får inte bero av Y eller X. Dessutom antas att bruset kring linjen eller feltermerna
1 2, ,..., nε ε ε är oberoende stokastiska variabler. Vi ska se längre fram hur vi kan under-söka om ovanstående antaganden är rimliga. Modellen kan sammanfattas som
(1) 0 1
1 2
, där (0, ), 1, 2,..., , , ,..., är oberoende stokastiska variabler,
CO-mängden, nikotinmängden, 0.1 2.1.
β β ε ε σε ε ε
= + + ∈ =
= = <
i i i i
n
Y X N i n
Y X <X
Här görs ingen detaljerad beskrivning av regressionsanalysen utan enbart en över-siktlig sammanfattning och tolkning. För mer detaljer hänvisas till någon lärobok i reg-ressionsanalys. Vi kommer att använda Minitab för att göra beräkningarna i regres-sionsanalysen och göra tolkningar från Minitabutskrifterna. Om vi i Minitab använder kommandot Stat/Regression/Regression med Response (Y ): CO-mängden och Predic-tor (X ): nikotinmängden får vi resultatet i tabell 2.
Tabell 2. Resultatet från Minitab av regressionsanalysen av modellen i (1).
Regression Analysis: CO versus Nikotin The regression equation is CO = 1.66 + 12.4 Nikotin Predictor Coef SE Coef T P Constant 1.6647 0.9936 1.68 0.107 Nikotin 12.395 1.054 11.76 0.000 S = 1.82845 R-Sq = 85.7% R-Sq(adj) = 85.1% Analysis of Variance Source DF SS MS F P Regression 1 462.26 462.26 138.27 0.000 Residual Error 23 76.89 3.34 Total 24 539.15
Den översta raden i tabell 2 visar skattningen av det förväntade sambandet mellan den beroende variabeln Y = CO och den förklarande variabeln (oberoende variabeln) X = Nikotin i form av en rät linje, den s k skattade regressionslinjen:
(2) ˆ 1.66 12.4 , för 0.1 2.1.Y X X= + < <
Här används beteckningen för det s k predikterade Y-värdet, d v s det värde som den skattade regressionslinjen i (2) ger på CO-mängden för ett givet värde X på nikotin-mängden. I figur 4 är den skattade regressionslinjen uppritad tillsammans med observa-tionspunkterna. Denna figur fås med hjälp av kommandot Stat/Regression/Fitted Line Plot i Minitab.
Y
En allmän skattad regressionslinje betecknar vi här med (3) . 0 1Y b b X= +

Kerstin Vännman S0001M 2009-01-14
– 4 –
Nikotin
CO
2.01.51.00.50.0
30
25
20
15
10
5
0
S 1.82845R-Sq 85.7%R-Sq(adj) 85.1%
Fitted Line PlotCO = 1.665 + 12.40 Nikotin
Figur 4. Den skattade regressionslinjen i (2) tillsammans med observationsvärdena.
Den skattade linjens regressionskoefficienter (under rubriken ”Coef” i tabell 2), 0 (linjens intercept) och 11.6647b = 12.395b = (linjens riktningskoefficient), har be-
stämts med hjälp av minsta-kvadrat-metoden. Det innebär att och har beräknats så att
0b 1b
(4) 2 2
1 1
ˆresidualkvadratsumman ( )n n
i ii i
e Y Y= =
= = −∑ ∑ i
har minimerats. Värdet på denna minimerade residualkvadratsumma står i tabell 2 i va-riansanalystabellen under rubriken ”SS” på raden märkt ”Residual Error”, dvs 76.89. I formel (4) betecknar n det totala antalet observationer, dvs 25 i vårt exempel. Om man ersätter med i i (4) och deriverar (4) partiellt med avseende på 0 och 1b och därefter sätter derivatorna till 0, så finner man att de skattade regressionskoefficienterna blir
iY Xbb 10 + b
(5) 0 1 ,b Y b X= −
(6) 11
2
1
( )(
( )
n
i ii
n
ii
)X X Y Yb
X X
=
=
− −=
−
∑
∑.
Den skattade regressionskoefficienten 1b är en uppskattning av 1β i modellen, dvs
av den genomsnittliga förändringen i Y om X ändras 1 enhet. Tolkat i ord för 1b i (2) betyder det att, om nikotinmängden ökar 1 mg så ökar i genomsnitt CO-mängden med 12.4 mg. Den skattade regressionskoefficienten 0 är en uppskattning av 0b β i modellen, d v s av genomsnittsvärdet på Y då X = 0. I många fall är 0b -värdet inte meningsfullt att tolka. Den skattade modellen i (2) gäller inte för X = 0, eftersom vi inte har observationsvärden kring det X-värdet. Den skattade linjen samt 0 och 1b kan bara tolkas för det intervall av X inom vilket det finns observationsvärden. Att extrapolera modellen och tolka den utanför detta X-intervall är mycket riskabelt och ska undvikas.
b
Regressionstabellen innehåller ytterligare intressant information. Vi ser t ex från ta-bell 2 att ”R-Sq” %. Det kan tolkas som att 85.7% av den totala variationen i CO-värdena förklaras av den skattade regressionslinjen (2).
2 85.7R= =2R kallas förklaringsgrad

Kerstin Vännman S0001M 2009-01-14
– 5 –
eller determinationskoefficient och definieras som andel förklarad Y–variation på föl-jande sätt:
(7)
2
2 1
2
1
ˆ( )regressionskvadratsumman
totala kvadratsumman ( )
n
iin
ii
Y YR
Y Y
=
=
−= =
−
∑
∑
eller som ”1 – andel oförklarad Y-variation” , dvs
(8)
2
2 1
2
1
ˆ( )residualkvadratsumman1 1totala kvadratsumman ( )
n
i iin
ii
Y YR
Y Y
=
=
−= − = −
−
∑
∑
När minsta-kvadrat-metoden har använts för att skatta 0β och 1β gäller att den totala kvadratsumman kan delas upp i regressionskvadratsumman och residualkvadratsum-man, dvs
(9) totala kvadratsumman = = regressionskvadratsumman + residualkvadratsumman
Därav följer tolkningen 2R = andel av regressionen förklarad Y-variation = 1 – andel oförklarad Y-variation . Vi kan beräkna 2R utgående från den s k variansanalystabellen som står i tabell 2. Där finner vi att residualkvadratsumman är 76.89, regressionskvad-ratsumman är 462.26 och den totala kvadratsumman är 539.15 = 462.26 + 76.89, och vi får
(10) 2 462.26 76.891 0.857 85.7%.539.15 539.15
R = = − = =
En förklaringsgrad på 85.7% är allmänt sett en ganska hög förklaringsgrad.
Vi ser också från tabell 2 att ”S” = residualspridningen = = 1.82845. Det kan tol-kas som att den genomsnittliga spridningen av observationspunkterna kring den skat-tade regressionslinjen är 1.83. Jämför denna spridning med standardavvikelsen för CO-värdena sY = 4.74. Genom att ta med nikotinhalten som en förklarande variabel i vår modell så har vi minskat den oförklarade spridningen för CO-värdena. Vi kan även räk-na ut utgående från variansanalystabellen eftersom det gäller att residualvariansen
es
es
(11)
2
2 1
ˆ( )residualkvadratsumman
2 2
n
i ii
e
Y Ys
n n=
−= =
− −
∑
Vi får från tabell 2 att residualvariansen blir , d v s residualsprid-ningen blir
2 76.89 / 23 3.34es = =3.3430 1.83.es = = Värdet 3.34 återfinns även i variansanalystabellen i
tabell 2 under rubriken ”MS” på raden betecknad ”Residual Error”.

Kerstin Vännman S0001M 2009-01-14
– 6 –
I tabell 2 finns även en rubrik ”DF” som står för frihetsgrader (degrees of freedom). Varje kvadratsumma associeras med ett antal frihetsgrader. Frihetsgraderna visar på hur många olika linjära uttryck av observationsvärdena, som behövs för att kunna beräkna kvadratsumman. Till den totala kvadratsumman hör n – 1 = 24 frihetsgrader. När man har en enkel regressionsmodell, d v s med två regressionsparametrar ( 0β och 1β ) asso-cieras residualkvadratsumman med n – 2 = 23 frihetsgrader. Av de totala 24 frihetsgra-derna blir då vid enkel regressionsanalys 1 frihetsgrad över till regressionskvadratsum-man. Det betyder att det går att beräkna regressionskvadratsumman med hjälp av ett enda linjärt uttryck i observationsvärdena. Medelkvadratsumman (MS) definieras sedan som kvadratsumman (SS) dividerat med sina motsvarande frihetsgrader (DF).
Under förutsättning att modellantagandena i (1) gäller så kan vi inte bara beskriva det skattade sambandet med sammanfattningsmåtten enligt ovan utan även testa intres-santa hypoteser eller bilda konfidensintervall. Om (1) gäller så kan man visa att för de skattade regressionskoefficienterna bk , k = 0, 1, gäller följande:
(12) k
k
b
bs
kβ− är observationer från en t-fördelning med n – 2 frihetsgrader, k = 0,1.
Här betecknar
k standardavvikelsen för och den ges numeriskt i tabell 2 under rub-
riken ”SE Coef” bredvid ”Coef”. Uttryckt i formel gäller bs kb
(13) 0
21 ,b eX
Xs sn TSS
= +
(14) 1
2
1, där ( )
ne
b XiX
ss TSS XTSS =
= = ∑ i X− .
Med hjälp av (12) kan vi undersöka om det är värt att ta med X i modellen, dvs om vi
kan påstå att 1β är signifikant skild från 0. Det gör vi genom att testa hypotesen 0 1:H 0β = mot hypotesen 1 1:H 0β ≠ på signifikansnivån α. Om 1 0β = så påverkas
inte Y av X. Som testvariabel använder vi det som i tabell 2 står under rubriken ”T”, på svenska ofta kallad för t–kvoten, dvs
(15) T = t-kvot = k
k
b
bs
.
Beslutsstrategien blir: förkasta nollhypotesen på signifikansnivån α om 0H / 2 ( 2t kvot t nα )− > − , d v s vi anser att 1 0β ≠ , och att det därmed är värt att ta in X i modellen, om t-kvoten är tillräckligt långt borta från 0. Vad som är tillräckligt långt borta från 0 bestäms av t-fördelningen med n – 2 frihetsgrader. Nu behöver vi inte slå upp det kritiska t-värdet i t-fördelningstabellen utan kan istället jämföra det värde som står under rubriken ”P” i tabell 2 med den förutbestämda signifikansnivån α . Om P-värdet < α så betyder det att

Kerstin Vännman S0001M 2009-01-14
– 7 –
/ 2 ( 2t kvot t nα− > − ) , dvs kan förkastas. Detta är alltså det som kallas för direktme-toden i Vännman, kapitel 9.
0H
Om vi bestämmer oss för att arbeta med signifikansnivån 0.05 så ser vi från tabell 2 att t-kvoten för X-variabeln nikotin är stor (11.76) och motsvarande P-värde ≤ 0.0005 < 0.05. Vi kan alltså påstå att 1β signifikant skild från 0, dvs regressionskoefficienten för X-variabeln nikotin är signifikant skild från 0 på 5%-nivån och att det är värt att ta med nikotinmängden som en förklarande variabel i modellen (1).
Värdet på t-kvoten för interceptet är däremot inte tillräckligt långt borta från 0 för att vi ska kunna påstå att 0β är signifikant skild från 0 på 5%-nivån. Den slutsatsen kan vi dra av att P-värdet för interceptet är 0.107 > 0.05. Här kan vi alltså inte påvisa att värdet på 0β är skilt från 0 utan det skulle kunna vara 0. Men man bör ändå inte sätta interceptet till 0 och därmed tvinga linjen genom origo, om det inte är så att man har tillräckligt många observationer nära 0 och samtidigt att teorin säger att interceptet ska vara 0. I detta fall låter vi interceptet skattas med 1.66.
Om vi vill uppskatta hur stor effekten av nikotinmängden är på CO-mängden med en rimlig grad av säkerhet så bildar vi ett konfidensintervall. Med hjälp av resultatet i (12) får vi att ett konfidensintervall för kβ med konfidensgraden 1 – α blir (16) , k = 0, 1. / 2 ( 2)
kk bb t n sα± − ⋅
Med 1 – α = 0.95 får vi följande konfidensintervall för 1β : (17) 0.02512.395 (23) 1.054 12.395 2.06 1.054 12.4 2.2.t± ⋅ = ± ⋅ = ± Därmed får vi att [10.2, 14.6] är ett 95% konfidensintervall för 1β och med 95% säker-het kan vi göra följande tolkning: om nikotinmängden ökar med 1 mg så ökar den ge-nomsnittliga CO-mängden mellan 10.2 mg och 14.6 mg.
3. Undersökning av modellantagandena Modellen i (1) innehåller flera olika delantaganden. Vi antar att XYE 10)( ββ += , d v s att i genomsnitt är Y en linjär funktion av X. Dessutom antar vi att iε , som är variatio-nen kring linjen XYE 10)( ββ += eller bruset kring linjen, kan beskrivas med hjälp av en normalfördelning med väntevärde 0 och standardavvikelse σ. Denna standardavvi-kelse σ ska vara konstant och får inte bero av Y eller X. Slutligen antas att feltermerna
1 2, ,..., nε ε εi
är oberoende stokastiska variabler. För att undersöka om dessa modellanta-gandena är rimliga använder vi oss av residualerna ˆ
i ie Y Y= − . Vi kan tänka oss som observationer på
ieiε i (1). Genom att plotta residualerna på olika sätt kan vi se om
modellen i (1) är rimlig. Ibland är det bättre att, istället för residualerna ovan, arbeta med en typ av standardi-
serade residualer ii e , som på engelska kallas ”studentized residuals”. I Minitab kal-
las dessa för ”Standardized residuals”. På svenska säger vi standardiserade (eller stu-dentiserade) residualer. Residualplotterna över de standardiserade residualer blir lättare att tolka och avslöjar tydligare om modellen inte är rimlig än vad residualerna gör.
/e s
För att se om modellantagandena, som gjorts om förväntat Y-värde samt om stan-dardavvikelsen σ är rimliga, så plottar vi residualerna mot X. Vi kan då undersöka om antagande XYE 10)( ββ += är rimligt samt om standardavvikelsen σ är konstant, Man

Kerstin Vännman S0001M 2009-01-14
– 8 –
kan vid enkel regression lika gärna plotta residualerna mot . De två residualplotterna bär vid enkel regression på samma information. I figur 5 har vi plottat dels residualerna och dels de standardiserade residualerna mot X.
Y
Nikotin
Stan
dard
ized
Res
idua
l
2.01.51.00.50.0
2
1
0
-1
-2
-3
Residuals Versus Nikotin(response is CO)
Nikotin
Res
idua
l
2.01.51.00.50.0
4
3
2
1
0
-1
-2
-3
-4
Residuals Versus Nikotin(response is CO)
Figur 5. Standadiserade residualer samt residualer plottade mot nikotinmängden.
Om modellantagandena är rimliga bör vi ha de flesta standardiserade residualerna slumpmässigt fördelade inom ett band mellan –2 och +2 och i stort sett ingen standardi-serad residual utanför intervallet [–3, 3]. Minitab markerar standardiserade residualer utanför intervallet [–2, 2] med ett R i utskriften om man anger detta. Dessa bör upp-märksammas eftersom de kan vara uteliggare och visar att modellen inte stämmer så bra i den punkten. Om vi ser ett ”bananformat” mönster eller en kurvatur i residualplotten, så betyder det att antagandet att XYE 10)( ββ += inte är så bra utan bör kunna förbättras, t ex genom en transformation av Y eller X eller också genom att fler förklarande variabler tas in i modellen. Om vi ser ett trattformat mönster i residualplotten så betyder det att standardavvikelsen σ inte är konstant utan beror av X.
I figur 5 ser vi en residual som avviker från de övriga. Det är residualen som hör ihop med nikotinvärdet 2.03. Värdet på den standardiserade residualen i den punkten är –3, och den punkten kan betraktas som en uteliggare. Det innebär att det observationsvärde som hör ihop med nikotinvärdet 2.03 kan vara felaktigt eller av andra orsaker inte stämmer med modellen. Den hör dessutom till den observationspunkt som har störst värde på nikotinmängden. Men om en punkt avviker i X-led så behöver det inte innebära någon nackdel. Däremot kan man misstänka att det observationsvärdet kan vara en s k inflytelserik punkt. Vi återkommer till detta längre fram.

Kerstin Vännman S0001M 2009-01-14
– 9 –
Det finns ingen antydan till kurvatur eller ”bananformat” mönster i residualplotten i figur 5. Det tyder på att antagandet att XYE 10)( ββ += är rimligt.
Ytterligare ett mönster man ska titta efter är en trattform. Eventuellt sprider residua-lerna som hör till nikotinvärden > 0.5 ut sig mer än residualerna som hör till nikotinvär-den < 0.5. Men samtidigt är det bara tre punkter som har nikotinvärden < 0.5 och alla de ligger på en och samma sida om 0-linjen. Det gör att det saknas ett tydligt trattmönster. Det finns alltså ingen anledning att ifrågasätta antagandet om konstant va-rians.
För att se om normalfördelningsantagandet av residualerna är rimligt så gör vi ett normalfördelningsdiagram över residualerna. Se figur 6. Där ser vi att normalfördel-ningsantagandet verkar rimligt eftersom residualerna i stort sett ligger längs en linje i normalfördelningsdiagrammet. Vi kan sammanfatta våra resultat med att konstatera att residualanalysen inte antyder några allvarliga modellfel.
Residual
Perc
ent
543210-1-2-3-4
99
95
90
80
70
60504030
20
10
5
1
Normal Probability Plot of the Residuals(response is CO)
Figur 6. Residualerna plottade i ett normalfördelningsdiagram.
Här kommer en kort sammanfattning om vad man bör tänka på när man gör en reg-ressionsanalys.
I regressionsanalystabellen får man skattningarna av regressionskoefficienterna i modellen i (1) och dessutom ger följande mått viktig information: • 2R = andel förklarad variation. Den bör vara hög. • = residualspridningen. Den bör vara låg. es• t-kvoten för X-variabeln. För att X-variabeln ska ingå i modellen bör dess t-kvot till
beloppet vara så stor att motsvarande P-värde är klart mindre än en förutbestämd signifikansnivå, t ex 0.01 eller 0.05.
Men det räcker inte att studera ovanstående mått utan dessutom ska man göra en re-sidualanalys för att se om modellantagandena är rimliga eller om modellen måste för-bättras. Följande plotter ska göras: • Plotta de studentiserade residualerna eller residualerna mot eller X för att under-
söka om E(Y) är rimligt, om standardavvikelsen σ är konstant och om det finns ute-liggare. Om de flesta studentiserade residualerna ligger slumpmässigt kring 0 inom ett band mellan –2 och 2, och ingen kurvatur eller trattform framträder, så finns inget som antyder modellfel. Om man ser ett tydligt kurvmönster behöver modellen förbättras genom att E(Y) ändras. Om man ser en tydlig trattform så är
Y

Kerstin Vännman S0001M 2009-01-14
– 10 –
inte standardavvikelsen σ konstant. Ibland kan en transformation av Y-värdena förbättra modellen. Om man ser uteliggare utanför intervall [–3, 3] så ska de observationsvärden som ger upphov till uteliggarna undersökas, så att de inte är felaktiga.
• Gör ett normalfördelningsdiagram över residualerna. Om punkerna följer en krökt kurva istället för en rät linje så är inte normalfördelningsantagandet rimligt. Ibland kan en transformation av Y-värdena förbättra modellen. Det gäller speciellt om man får trattform i residualplotten ovan samtidigt som residualerna uppvisar en sned fördelning.
Sedan man genomfört residualanalysen bör man även undersöka om det finns några in-flytelserika punkter. Hur detta går till beskrivs längre fram.
4. Korrelationkoefficient Om vi sammanfattar resultaten av regressionsanalysen i avsnitt 2–3 ovan så kan vi kon-statera att residualanalysen inte antyder några allvarliga modellfel av modellen i (1) och att den skattade regressionslinjen i (2) förklarar 85.7 % av den totala variationen bland CO-värden på det sätt som beskrivits tidigare. Vidare ser vi att den skattade residual-spridningen är . Dessutom gäller att regressionskoefficienten 11.83es = β , som mäter effekten av nikotinmängden på CO-mängden, är signifikant skild från 0 på t ex 5% sig-nifikansnivå, eftersom P-värdet för 1b ≤ 0.0005 < 0.05. Allt detta sammantaget visar att vi har ett starkt samband mellan nikotinmängden och CO-mängden. Om sambandet hade varit svagt eller bara slumpmässigt så skulle 2R vara nära 0 och 1β skulle inte vara signifikant skilt från 0 på 5% signifikansnivå.
Ibland används ett annat mått på det linjära sambandet mellan två variabler, X och Y, som kallas korrelationskoefficienten mellan X och Y. När man talar om korrelations-koefficienten menas oftast Pearsons korrelationskoefficient, som betecknas med r och definieras som
(18) 1
2 2
1 1
( )( )
( ) (
n
i ii
n n
i ii i
X X Y Yr
)X X Y Y
=
= =
− −=
− −
∑
∑ ∑.
Korrelationskoefficienten kan anta värden mellan –1 och 1. Om det är ett fullständigt linjärt samband mellan X och Y så blir korrelationskoefficienten 1 om Y växer med X och –1 om Y avtar med X. Om punkterna är slumpmässigt utspridda i planet blir korre-lationskoefficienten nära 0. Värden på r mellan 0 och 1 eller mellan 0 och –1 visar på olika grad av linjärt samband. I tabell 3 framgår att korrelationskoefficienten mellan ni-kotinmängden och CO-mängden är 0.926. Det är ett starkt linjärt samband, vilket vi re-dan tidigare konstaterat med hjälp av måtten från regressionsanalysen.
Tabell 3. Resultatet från Minitab av korrelationsberäkningen.
Correlations: CO; Nikotin Pearson correlation of CO and Nikotin = 0.926

Kerstin Vännman S0001M 2009-01-14
– 11 –
Vid enkel regression finns det ett direkt samband mellan korrelationskoefficienten r och förklaringsgraden R2 . Då gäller att (19) , 2 2r R= d v s om korrelationskoefficienten i (18) kvadreras så fås förklaringsgraden.
Det finns också ett samband mellan korrelationskoefficienten r och den skattade re-gressionskoefficienten enligt följande formel 1b
(20) 1X
Y
sr bs
= ,
där och är standardavvikelsen för X-värdena respektive Y-värdena, dvs Xs Ys
(21) 2
1
1 ( )1
n
X ii
s Xn =
= −− ∑ X
(22) 2
1
1 ( )1
n
Y ii
s Yn =
= −− ∑ Y .
Observera att korrelationskoefficienten enbart mäter ett linjärt samband. Det kan alltså finnas t ex ett kvadratiskt samband, men detta avslöjar inte korrelationskoeffi-cienten. Däremot ser vi det direkt i spridningsdiagrammet. Det är alltså viktigt att inte nöja sig med att beräkna ett sammanfattningsmått, som en korrelationskoefficient eller en förklaringsgrad, utan man bör samtidigt göra ett spridningsdiagram för att kunna göra en bra tolkning av sambandet.
I figur 7–10 nedan visas några olika simulerade material med 25 observationer. I fi-gur 7 ser vi ett starkt negativt samband med r = –0.96 och 2R = 91%. I figur 8 ser vi ett ganska svagt positivt samband med r = 0.54 och 2R = 29%. I figur 9 ser vi ett mycket svagt samband med r = 0.07 och 2R = 0.5%, dvs här finns troligtvis inget samband alls och 1β kan inte påvisas vara signifikant skilt från 0 på 5% signifikansnivå. I figur 10 finns ett tydligt kvadratiskt samband men det är inte linjärt så korrelationskoefficienten och förklaringsgraden blir nära 0.
x1
y1_1
2520151050
15.0
12.5
10.0
7.5
5.0
S 0.933375R-Sq 91.3%R-Sq(adj) 90.9%
Fitted Line Ploty1_1 = 14.83 - 0.4012 x1
Figur 7. Simulerat material med n = 25, r = –0.96, R2 = 91%.

Kerstin Vännman S0001M 2009-01-14
– 12 –
x1
y2_1
2520151050
13
12
11
10
9
S 0.933375R-Sq 28.7%R-Sq(adj) 25.6%
Fitted Line Ploty2_1 = 9.825 + 0.07878 x1
Figur 8. Simulerat material med n = 25, r = 0.54, R2 = 29%.
x1
y3_1
2520151050
12
11
10
9
8
S 0.933375R-Sq 0.5%R-Sq(adj) 0.0%
Fitted Line Ploty3_1 = 9.825 + 0.00878 x1
Figur 9. Simulerat material med n = 25, r = 0.07, R2 = 0.5%.
x1
y4_1
2520151050
60
50
40
30
20
10
0
S 14.4365R-Sq 0.0%R-Sq(adj) 0.0%
Fitted Line Ploty4_1 = 25.25 - 0.0024 x1
Figur 10. Simulerat material med n = 25, r = –0.001, R2 = 0.0002%.

Kerstin Vännman S0001M 2009-01-14
– 13 –
5. Konfidensintervall för förväntat Y-värde. När man gör en regressionsanalys kan man vara intresserad av olika saker. Man kan exempelvis vilja hitta en bra modell till den situation man studerar. Man kan också vilja uppskatta, med viss given säkerhet, den effekt som en viss förklarande variabel har på den studerade storheten, t ex med 95% säkerhet vilja bestämma hur mycket ett grams ökning av nikotinmängden i en cigarett påverkar CO-mängden vid rökning. Detta gjorde vi tidigare genom att bilda ett konfidensintervall för 1β . Man kan även vara intresserad av att uppskatta, med viss given säkerhet, den förväntade CO-mängden då nikotinmängden är 0.7 mg. I detta fall vill man beräkna ett konfidensintervall för
XYE 10)( ββ += för ett visst givet värde på 0 0.7X X= = . Då resonerar man på föl-jande sätt.
Vi skattar först 0 0 1 0( )E Y Xβ β= + med 0 0 1 0 . Under förutsättning att modellantagandena i (1) gäller så kan man visa att för så gäller följande:
Y b b X= +0Y
(23) 0
0
ˆ
ˆ ( )
Y
Y E Ys
− 0 är observerat värde från t(n – 2),
där
(24) 0
220
ˆ1
( )1 och ( )n
e XYiX
X Xs s TSS X Xn TSS =
−= + = −∑ i
0
.
Med hjälp av resultatet i (23) får vi att ett konfidensintervall för väntevärdet
0 0 1( )E Y Xβ β= + , då 0X X= , med konfidensgraden 1 – α blir (25) .
00 / 2ˆ ( 2) YY t n sα± − ⋅
Om vi med 95% säkerhet vill uppskatta den förväntade CO-mängden då nikotinmäng-den är 0.7 mg får vi först göra följande beräkningar. Från (2) ser vi att (26) 0 1.66 12.4 0.7 10.34.Y = + ⋅ = Från tabell 1, sidan 1, kan vi beräkna och XX TSS och får (27) 0.8764 och 3.0086.XX TSS= = Från tabell 2, sidan 3, fås ”S” = residualspridningen = = 1.82845, vilket ger oss föl-jande värde på spridningen för
es0Y
(28) 0
2
ˆ1 (0.7 0.8764)1.82845 0.4102.25 3.0086Ys −
= + =
Med 1 – α = 0.95 får vi då följande konfidensintervall för den förväntade CO-mängden då nikotinmängden är 0.7 mg:

Kerstin Vännman S0001M 2009-01-14
– 14 –
(29) , 0.02510.34 (23) 0.4102 10.34 2.06 0.4102 10.34 0.85t± ⋅ = ± ⋅ = ± d v s intervallet [9.4, 11.2]. Därmed får vi att [9.4, 11.2] är ett 95% konfidensintervall för den förväntade CO-mängden då nikotinmängden är 0.7 mg och med 95% säkerhet kan vi säga att om nikotinmängden är 0.7 mg så innehåller intervallet [9.4, 11.2] den genomsnittliga (förväntade) CO-mängden.
Om vi istället beräknar konfidensintervallet då nikotinmängden är 2 mg så blir ett 95% konfidensintervall för den förväntade CO-mängden (30) [23.8, 29.1].
Om vi jämför bredden på intervallen i (29) och (30) så ser vi att intervallet i (30) med bredd 5.3 är betydligt bredare än intervallet i (29) med bredd 1.8. Det beror på att X-värdet 2 ligger längre bort från den genomsnittliga nikotinmängden 0.88X = än vad 0.7 gör. Av formlerna (24) och (25) framgår att ju längre bort från X vi bildar konfidensintervallet ju bredare blir det.
Minitab kan beräkna konfidensintervallet för direkt så att vi inte behöver genomföra beräkningarna i formlerna (24) och (25). Minitab ritar även ut konfidensin-tervallsgränserna för alla värden på X i diagrammet där den skattade linjen ritas ut. Se figur 11.
0( )E Y
6. Prognosintervall för ett framtida värde på Y
I avsnittet ovan var det den förväntade CO-mängden som var av intresse att skatta. Det kan vi tänka oss som ett genomsnittsvärde som visar vad som händer i ”långa loppet” med CO-mängden för ett visst givet värde på nikotinmängden X. Om vi istället är in-tresserade av att göra en prognos, d v s säga något om ett nytt framtida observations-värde på CO-mängden, så får vi resonera något annorlunda.
När vi bildar ett konfidensintervall för den förväntade CO-mängden så behöver vi bara ta hänsyn till den osäkerhet som ges av skattningen av . Det gör vi med hjälp av spridningen
0. Men när vi ska bilda ett s k prognosintervall, dvs ett intervall som
med given sannolikhet ska innehålla ett nytt framtida observationsvärde , så har vi ytterligare en osäkerhet att ta hänsyn till. Dels har vi den osäkerhet som beror på att vi måste skatta , dvs spridningen
0. Dels vi har också den osäkerhet som är för-
knippad med en ny observation och som uttrycks med spridningen . Vi måste ta hänsyn till båda dessa spridningar och det gör vi genom att utnyttja följande resultat.
0( )E YYs
0Y
0( )E Y Ys0Y es
Under förutsättning att modellantagandena i (1) gäller så kan man visa att följande resultat gäller:
(31) 0 0ˆ
pr
Y Ys− är observerat värde från t(n – 2),
där
(32) 2
20
1
( )11 och ( )n
pr e X iiX
X Xs s TSS X Xn TSS =
−= + + = −∑ .

Kerstin Vännman S0001M 2009-01-14
– 15 –
Om vi jämför formel (32) med formel (24) så ser vi att följande samband råder mellan 2prs och .
0
2Ys
(33) . 0
2 2ˆpr e Ys s s= + 2
Med hjälp av resultatet i (31) blir ett prognosintervall för , då0Y 0X X= , (34) . 0 / 2
ˆ ( 2) prY t n sα± − ⋅
Men sannolikheten 1 – α innehåller intervallet i (34) ett nytt framtida observationsvär-de då 0X X= . Intervallet i (34) kallas ibland också för prediktionsintervall.
För att beräkna ett 95% prognosintervall för CO-mängden då nikotinmängden är 0.7 mg kan vi utnyttja beräkningarna från formel (28). Därifrån får vi att Eftersom enligt tabell 2, sidan 3, så ger (33) att
00.4102.Ys =
1.82845es =
(35) 2 2 21.82845 0.4102 3.5115, d v s 1.8739.pr prs s= + = = Från (26) får vi att 0 Vi kan därmed beräkna ett 95% prog-nosintervall för CO-mängden då nikotinmängden är 0.7 mg som
ˆ 1.66 12.4 0.7 10.34.Y = + ⋅ =
(36) , 0.02510.34 (23) 1.8739 10.34 2.06 1.8739 10.34 3.87t± ⋅ = ± ⋅ = ± d v s intervallet [6.4, 14.3]. Med 95% sannolikhet så kommer ett nytt (framtida) obser-vationsvärde på CO-mängden då nikotinmängden är 0.7 mg att bli mellan 6.4 mg och 14.3 mg. Vi kan även direkt få prognosintervallet uträknat med hjälp av Minitab. Mini-tab ritar även ut prognosintervallsgränserna för alla värden på X i diagrammet där den skattade linjen ritas ut. Se figur 11.
Nikotin
CO
2.01.51.00.50.0
35
30
25
20
15
10
5
0
S 1.82845R-Sq 85.7%R-Sq(adj) 85.1%
Regression95% CI95% PI
Fitted Line PlotCO = 1.665 + 12.40 Nikotin
Figur 11. Den skattade regressionslinjen tillsammans med både konfidensintervall för förväntat Y-värde (streckad kurva) och prognosintervall (prickad kurva) för exempel 1.
Om vi jämför prognosintervallet, då X = 0.7, i (36) med konfidensintervallet för den förväntade CO-mängden, då X = 0.7, i (29), så ser vi att prognosintervallet är betydligt bredare. Det beror på att det är osäkrare att göra en prognos, d v s uttala oss om ett framtida värde på CO-halten för given nikotinmängd, än att uppskatta ett genomsnitts-värde i modellen.

Kerstin Vännman S0001M 2009-01-14
– 16 –
7. Om inflytelserika observationer.
I figur 4 och figur 11 ser vi att det finns en observation som ligger en bra bit bort från de övriga i X-led. Det är den som svarar mot nikotinmängden X = 2.03. Den visade sig också som en uteliggare i residualanalysen tidigare. Man kan fråga sig om denna obser-vation också är inflytelserik. En observation anses inflytelserik om resultatet i regres-sionsanalysen ändras mycket i fall observationen utesluts ur datamaterialet.
Förutom att undersöka residualerna efter en gjord regressionsanalys så bör man också undersöka om det finns några inflytelserika punkter. Om det finns sådana obser-vationer är det viktigt att man upptäcker dem och kan undersöka om de eventuellt kan vara felaktiga. Residualplotterna visar om vi har observationer som kraftigt avviker i Y-led. För att upptäcka om det finns observationer som kraftigt avviker i X-led så beräknar vi de s k ”leverage-värdena”. Leverage betyder hävstång och det finns ännu inte något svenskt fackuttryck för ”leverage-värden”. Varje observation har ett le-verage-värde och lite förenklat kan man säga att det är ett mått på hur långt borta från X observationsvärdet ligger. Om en observationspunkt ligger långt borta från X och samtidigt avviker från en eventuell linjär trend, som det övriga materialet har, så har den punkten en stor hävstångseffekt och drar linjen till sig. Om den punkten utesluts så förändras linjens lutning kraftigt och det observationsvärdet har alltså stort inflytande. För att upptäcka sådana punkter beräknas leverage-värdena för varje observations-punkt. Leverage för observation nr i definieras som (37) = i:te diagonalelementet i ”hattmatrisen” . ih 1( )T T−=H X X X X Vid enkel regression är en matris där första kolonnen består av n stycken 1:or och andra kolonnen är 1
X 2n×, , nX X… . Om anses observation nr i inflytelserik.
Beteckningen K står för antal skattade parametrar i väntevärdet för Y . Vid enkel linjär regression är K = 2.
2 /ih K> ⋅ n
Minitab beräknar leverage-värdena för varje observationspunkt om man använder kommandot Stat/Regression/Regression och kryssar för HI(leverage) under Storage. Sedan kan man sammanställa leverage-värdena i ett lådagram för att se om det finns några som är alltför stora. Se figur 12. Med hjälp av musen kan man se att de två största leverage-värdena kommer från rad 3, som hör till märket BullDurham (leverage-värde = 0.48) samt rad 16, som hör till märket Now (leverage värdet = 0.23). Båda dessa är större än den kritiska gräns 2 · 2/25 = 0.16. Detta värde har lagts in som referenslinje i lådagrammet i figur 12.
Leverage-värdena ligger alltid mellan 0 och 1. Ju större leverage-värde desto större inflytande har motsvarande observationsvärde. Det finns olika tumregler för när man ska anse ett leverage-värde för stort. En sådan tumregel är den som anges ovan. Ett generellt råd är att alltid undersöka observationspunkterna med de största leverage-vär-dena, som ju enkelt syns i lådagrammet. Leverage-värden < 0.2 anses inte ge upphov till inflytelserika punkter. Observationsvärden med leverage-värden > 0.5 anses mycket inflytelserika och måste undersökas närmare och eventuellt uteslutas. Ett leverage-värde > 0.2 anses riskabelt därför att alltför mycket av datamaterialets information om sambandet mellan Y och X kommer från en enda observation. En observation som har leverage-värde nära 1 styr till mycket stor del regressionslinjens utseende.

Kerstin Vännman S0001M 2009-01-14
– 17 –
HI1
0.5
0.4
0.3
0.2
0.1
0.0
0.16
Boxplot of HI1
Figur 12. Leverage-värdena som hör till regressionen i tabell 2 i form av lådagram. Referenslinjen vid 0.16 svarar mot den kritiska gränsen för leverage-värdena.
Från figur 12 ser vi att de två största leverage-värdena, som nämnts ovan, syns tyd-
ligt som extrema uteliggare. Dessa två värden bör undersökas så att de inte är felaktiga på något sätt.
För att undersöka om det finns observationer som är extrema om man tar hänsyn till variation i både X-led och Y-led så finns flera olika mått. Ett vanligt förekommande mått är DFITS, som betyder Difference in FITS. DFITS är ett mått på ändringen i om i:te observationen utesluts, dvs DFITS kan utläsas som skillnaden i anpassat värde (fitted value) om i:te observationen utesluts. Om det är så att ändras mycket om i:te observationen utesluts så har den i:te observationen stort inflytande på regressionslin-jen. Det är viktigt att upptäcka sådana observationer. DFITS-värdena kan vara både po-sitiva och negativa och som allmän tumregel gäller att observationer med DFITS-vär-den > 1 eller < –1 bör undersökas.
iY
iY
Vi låter beteckna det predikterade värdet i den i:te punkten beräknat utifrån den skattade modellen där den i:te observationen uteslutits. På motsvarande sätt betecknar
( )e i residualspridningen för den skattade modellen där den i:te observationen uteslutits. DFITS-måttet definieras då som
( )ˆ
i iY
s
(38) ( )
( )
ˆ ˆi i
ie i i
Y YDFITS
s h−
= i ,
där definieras i (37) och ih ( )e i is h är en skattning av spridningen för . iY
Observation nr i är inflytelserik om 2 /iDFITS K n> . Beteckningen K står för K = antal regressionsparametrar i väntevärdet för Y. Vid enkel linjär regression är K = 2. Minitab beräknar DFITS-värdena för varje observationspunkt om man använder kom-mandot Stat/Regression/Regression och kryssar för DFITS under Storage. Sedan kan man sammanställa DFITS -värdena i ett lådagram för att se om det finns några som är alltför stora. Se figur 13, där referenslinjerna som svarar mot
2 / 2 2 / 25 0.57K n± = ± = ± har lagts in. Rad 3, som hör till märket BullDurham har ett alltför stort DFITS-värde på –2.81 samt rad 16, som hör till märket Now, har DFITS-värdet –0.60.
DFITS-värdena kan vara både positiva och negativa. Ju större iDFITS desto större inflytande har motsvarande observationsvärde. Vi ser i figur 13 det kraftigt avvikande DFITS-värdet –2.81 som en avlägsen uteliggare. Det är detta värde som hör ihop med rad 3 och märket BullDurham.

Kerstin Vännman S0001M 2009-01-14
– 18 –
DFI
T1
1
0
-1
-2
-3
0.57
-0.57
Boxplot of DFIT1
Figur 13. DFITS-värdena som hör till regressionen i tabell 2 i form av lådagram. Referenslinjerna svarar mot de kritiska gränserna för DFITS-värdena.
Denna cigarett har visat sig ha värden på nikotinmängd och CO-mängd som gör den kraftigt inflytelserika både vad gäller leverage- och DFITS-värden. Det gör att modellen bör skattas utan denna observation för att se vad som händer. I figur 14 ser vi hur den skattade linjen ändras då rad 3 har uteslutits. Jämfört med den tidigare modellen, se figur 4, så är det en tydlig ändring av den skattade modellen, vilket beror på att rad 3 har en kraftigt inflytelserik observation.
Nikotin
CO
1.41.21.00.80.60.40.20.0
20
15
10
5
0
S 1.58842R-Sq 86.6%R-Sq(adj) 86.0%
Fitted Line PlotCO = - 0.238 + 14.86 Nikotin
Figur 14. Den skattade regressionslinjen då rad 3 uteslutits.
Om man har enstaka inflytelserika observationer så bör man även göra analysen utan dessa och se hur mycket resultaten ändras. Sedan bör resultaten av de båda analyserna redovisas. Detta kan påverka de slutsatser man drar. Man bör inte utesluta observa-tioner fullständigt om man inte kan visa på att de är felaktiga eller på annat sätt teore-tiskt förklara varför de inte bör vara med. Om man har möjlighet är det bra om man kan skaffa fler observationer som ligger i närheten av dem som är inflytelserika för att kun-na dra säkrare slutsatser.
8. Om tolkning av regression och korrelation När man tolkar resultaten från en regressionsanalys eller en korrelationskoefficient så måste man vara försiktig och inte övertolka samband. Till att börja med så ska man inte extrapolera resultat och uttala sig om vad som händer utanför det X-intervall man har mätvärden i. Den skattade modellen gäller enbart för de X-värden som ligger inom det X-intervall där man har observerade värden.
Man kan inte heller alltid dra slutsatser om ett sambands kausala riktning, dvs vad som är orsak och vad som är verkan. En korrelationskoefficient mäter endast styrkan av

Kerstin Vännman S0001M 2009-01-14
– 19 –
det linjära sambandet. Den förklarar inte vad detta samband kan bero på. I tabell 4 nedan visas värden, hämtade från en klassisk lärobok i statistik av Yule & Kendall, som beskriver antalet lösta radiolicenser och antal fall av mentala defekter i England 1924–1937. Korrelationskoefficenten i detta material är 0.99. Se också figur 15. Det visar inte på något sätt att radiolyssnandet ökar benägenheten för psykiska defekter eller vice versa. Detta är ett typiskt exempel på s k nonsenskorrelation.
När man använder regressionsanalys på datamaterial som inte uppkommit genom kontrollerade och planerade försök så måste man generellt vara försiktig i sina tolk-ningar och stödja dessa på allmänna teorier inom det område som man studerar. Är det t ex ekonomiska eller samhällsvetenskapliga data man undersöker så måste tolkningarna göras utifrån ekonomiska respektive samhällsvetenskapliga teorier också.
I tekniska och naturvetenskapliga situationer kan det vara lättare att göra planerade försök och i sådana situationer är regressionsanalys ett kraftfullt verktyg. Men även där kan man råka ut för situationer med okända bakomliggande variabler som påverkar för-söket och gör att resultaten kan misstolkas. Därför är det viktigt när man gör planerade försök att hålla alla andra kända påverkande faktorer, som ej ingår i försöket, så kon-stanta som möjligt.
Tabell 4. Y = Antal personer med mentala defekter per 10 000 av befolkningen och X = Antal lösta radiolicenser i tusental i England under 1924-1937. Från Yule & Kendall (1954).
År X Y År X Y 1924 1350 8 1931 4620 16 1925 1960 8 1932 5497 18 1926 2270 9 1933 6260 19 1927 2483 10 1934 7012 20 1928 2730 11 1935 7618 21 1929 3091 11 1936 8131 22 1930 3647 12 1937 8593 23
X
Y
900080007000600050004000300020001000
25
20
15
10
S 0.726190R-Sq 98.4%R-Sq(adj) 98.3%
Fitted Line PlotY = 4.582 + 0.002204 X
Figur 15. Datamaterialet från tabell 3. Y = Antal personer med mentala defekter per 10 000 av befolkningen och X = Antal lösta radiolicenser i tusental i England under 1924-1937. Från Yule & Kendall (1954). Detta är ett exempel på nonsenssamband.

Kerstin Vännman S0001M 2009-01-14
– 20 –
9. Multipel linjär regression Vid enkel linjär regression hade vi en förklarande variabel i modellen. I många situa-tioner behövs mer än en förklarande variabel för att på ett bra sätt ge en rimlig modell. Begreppen från enkel regression kan enkelt generaliseras till en multipel regression, där två eller fler förklarande variabler används. Vi studerar först ett exempel med två för-klarande variabler. Exempel 2. Oktanhalt
I ett planerat försök ville man studera hur tillsatser av etanol och tetraetylbly i bensin påverkar oktantalet. Försöket gjordes så att man bestämde fyra olika intressanta värden, s k nivåer, på var och en av variablerna etanol och tetraetylbly. För varje kombination av dessa nivåer mättes därefter oktantalet. De olika mätningarna gjordes i slumpmässig ordning. Resultatet framgår av tabell 5 nedan, där variablerna etanol och tetraetylbly anges med kodade värden.
Tabell 5. Oktantalet i bensin vid olika nivåer av variablerna etanol och tetraetylbly (kodade en-heter). Materialet är hämtad från Afifi och Azen: Statistical Analysis: A Computer Oriented Approach.
Etanol Tetraetylbly Oktantal Etanol Tetraetylbly Oktantal 2 2 96.3 4 2 96.2 2 3 95.7 4 3 100.1 2 4 99.9 4 4 103.3 2 5 99.4 4 5 104.3 3 2 95.1 5 2 97.8 3 3 97.8 5 3 102.2 3 4 99.3 5 4 104.7 3 5 104.9 5 5 108.8
Vi ska nu försöka hitta en modell som på ett enkelt sätt beskriver hur etanol och tet-
raetylbly påverkar oktantalet. Eftersom vi inte vet enligt vilken funktion som oktantalet beror på etonal och tetraetylbly, så gör vi en första approximation med en Taylorut-veckling av första ordningen. Det innebär att vi antar att det förväntade oktantalet kan beskrivas med följande uttryck
(39) 0 1 1 2( )i iE Y X X 2iβ β β= + + , där Y = oktantalet, 1X = etanol och 2X = tetraetylbly. Om vi dessutom antar att slump-felet är normalfördelat så får vi följande multipla regressionsmodell:
(40) 0 1 1 2 2
1 2
1 2 1
, där (0, ), 1, 2,..., , , ,..., är oberoende stokastiska variabler,
oktantalet, etanol, tetraetylbly, 2 5, 2 5.2
β β β ε ε σε ε ε
= + + + ∈ =
= = = ≤ ≤ ≤
i i i i i
n
Y X X N i n
Y X X X ≤X
Vi kan nu, utgående från värdena i tabell 5, uppskatta parametrarna i modellen i (40) med minsta-kvadratmetoden. Se Appendix för hur skattningarna tas fram. Om vi i Mi-nitab använder kommandot Stat/Regression/Regression med Response (Y ): och Predic-tors: etanol och bly får vi resultatet i tabell 6.

Kerstin Vännman S0001M 2009-01-14
– 21 –
Tabell 6. Resultatet från Minitab av regressionsanalysen av modellen i (40)
Regression Analysis: Oktan versus Etanol; Bly The regression equation is Oktan = 84,5 + 1,83 Etanol + 2,68 Bly Predictor Coef SE Coef T P Constant 84,543 1,583 53,40 0,000 Etanol 1,8350 0,3120 5,88 0,000 Bly 2,6850 0,3120 8,61 0,000 S = 1,39528 R-Sq = 89,3% R-Sq(adj) = 87,7% Analysis of Variance Source DF SS MS F P Regression 2 211,53 105,76 54,33 0,000 Residual Error 13 25,31 1,95 Total 15 236,84
Om vi enbart hade tagit med etanol som förklarande variabel så hade vi fått resultatet i tabell 7.
Tabell 7. Resultatet från Minitab av regressionsanalysen med enbart etanol som förklarande variabel.
Regression Analysis: Oktan versus Etanol The regression equation is Oktan = 93,9 + 1,83 Etanol Predictor Coef SE Coef T P Constant 93,940 2,859 32,86 0,000 Etanol 1,8350 0,7780 2,36 0,033 S = 3,47946 R-Sq = 28,4% R-Sq(adj) = 23,3% Analysis of Variance Source DF SS MS F P Regression 1 67,34 67,34 5,56 0,033 Residual Error 14 169,49 12,11 Total 15 236,84
Om vi enbart hade tagit med tetraetylbly som förklarande variabel så hade vi fått re-sultatet i tabell 8.
Tabell 8. Resultatet från Minitab av regressionsanalysen med enbart bly som förklarande variabel.
Regression Analysis: Oktan versus Bly The regression equation is Oktan = 91,0 + 2,68 Bly Predictor Coef SE Coef T P Constant 90,965 2,114 43,04 0,000 Bly 2,6850 0,5752 4,67 0,000 S = 2,57256 R-Sq = 60,9% R-Sq(adj) = 58,1% Analysis of Variance Source DF SS MS F P Regression 1 144,18 144,18 21,79 0,000 Residual Error 14 92,65 6,62 Total 15 236,84

Kerstin Vännman S0001M 2009-01-14
– 22 –
2
Från tabell 7 ser vi att etanol ensam förklarar 28.4% av den totala variationen hos oktantalet medan tetraetylbly ensam förklarar 60.9% av den totala variationen hos ok-tanhalten, enligt tabell 8. Tar vi däremot med både etanol och tetraetylbly samtidigt i modellen enligt (40) så förklarar den skattade modellen 89.3% av den totala variationen hos oktanhalten. Se tabell 6.
Förklaringsgraden definieras som tidigare i formel (7) eller (8), men nu är
(41) , 0 1 1 2Y b b X b X= + + där 0 , 1 och 2 är minsta-kvadrat-metodens skattningar av b b b 0β , 1β respektive 2β i modellen i (40). Se Appendix för hur skattningarna tas fram.
När vi har en modell med två förklarande variabler skattar vi alltså ett plan i 1X -2X -Y-rummet. Från tabell 6 ser vi att det skattade planet i exempel 2 är
(42) . 1 2ˆ 84.5 1.83 2.68Y X= + + X
Det skattade planet kan vi rita upp som ett plan i Minitab. Se figur 16.
Om vi tolkar koefficienterna i (42) i ord så får vi att för fixt värde på 1X = etanol så ökar oktantalet i genomsnitt 2.68 enheter om tetraetylbly ökar en enhet. Samtidigt ser vi att för fixt värde på 2X = tetraetylbly så ökar oktantalet i genomsnitt 1.83 enheter om etanol ökar en enhet.
54
Y-predikterat
95
100
Bly
105
32 3 24 5Etanol
Surface Plot of Y-predikterat vs Bly; Etanol
Figur 16. Det skattade planet i (42). Liksom vid den enkla regressionen gäller att den totala kvadratsumman kan delas
upp i en regressionskvadratsumma och en residualkvadratsumma enligt formel (9). Men nu blir tillhörande frihetsgrader annorlunda. Se tabell 6. Det innebär att residual-variansen beräknas som
(43)
2
2 1
ˆ( )residualkvadratsumman
3 3
n
i ii
e
Y Ys
n n=
−= =
− −
∑
Observera att (43) gäller i fallet med 2 förklarande variabler. Se Appendix för den all-männa situationen.

Kerstin Vännman S0001M 2009-01-14
– 23 –
Eftersom vi nu har tre regressionsparametrar ( 0β , 1β och 2β ) associeras residual-kvadratsumman med n – 3 = 16 – 3 = 13 frihetsgrader. Av de totala 15 frihetsgraderna blir då vid denna regressionsanalys, med två förklarande variabler, 2 frihetsgrader över till regressionskvadratsumman. Residualspridningen får vi som tidigare genom att dra roten ur residualvariansen. Från tabell 6 ser vi att den blir ”S” = 1. . Det innebär att observationsvärdena av oktantalet sprider i genomsnitt ut sig 1.4 enheter i Y-led kring det skattade planet i (42).
39528 1.4≈
Vid multipel regression är det meningsfullt att föra in ett nytt mått som har med för-klaringsgrad att göra. Det är den justerade förklaringsgraden, som betecknas med Ra
2 . Den justerade förklaringsgraden definieras, när vi har 2 förklarande variabler och där-med 3 regressionsparametrar, som
(44) 2 2residualkvadratsumman/( 3) 11 1totala kvadratsumman /( 1) 3a
n nR Rn n
(1 )− −= − = − −
− −.
Observera att (44) gäller i fallet med 2 förklarande variabler. Se Appendix för den all-männa situationen.
Om den justerade förklaringsgraden i (44) jämförs med förklaringsgraden definierad enligt formel (8) så framgår det att i 2
aR tar man hänsyn till hur många frihetsgrader som respektive kvadratsumma har. Det görs inte i 2R . Det innebär att 2R kan fås att bli godtyckligt nära 1 genom att ta medtillräckligt många ”nonsensvariabler” i modellen. Det betyder att 2R inte indikerar att modellen blivit sämre när ”nonsensvariabler” lagts till. Men det gör den justerade förklaringsgraden 2
aR . Den justerade förklaringsgraden är ett mått som används när man jämför modeller med olika många förklarande variab-ler. Då väljer man oftast den modell som visar högst värde på den justerade förklarings-graden 2
aR . Förklaringsgraden 2R kan alltid tolkas som andel förklarad Y-variation, men den
tolkningen gäller inte för den justerade förklaringsgraden 2aR . De två olika måtten bär
alltså på delvis olika information och båda behövs vid multipel regression. Precis som vid enkel regression kan vi även här testa intressanta hypoteser eller bilda
konfidensintervall. Om modellen i formel (40) gäller så kan man visa att för de skattade regressionskoefficienterna , k = 0, 1, 2 gäller följande: kb
(45) k
k
b
bs
kβ− är observationer från en t-fördelning med n – 3 frihetsgrader.
Här betecknar
kb standardavvikelsen för kb och den ges numeriskt i tabell 6 under rub-riken ”SE Coef” bredvid ”Coef”. Uttryckt i formel så blir det mer komplicerat än i fallet med den enkla regressionen. Se Appendix. Observera att antalet frihetsgrader i t-fördelningen blir n – 3 eftersom det är 3 regressionsparametrar som skattas. Se Appendix för det allmänna fallet.
s
Med hjälp av (45) kan vi, liksom tidigare, undersöka om det är värt att ta med 1X re-spektive 2X i modellen, d v s testa om vi kan påstå att 1β respektive 2β är signifikant skild från 0. Det gör vi genom att på signifikansnivån α testa nollhypotesen
0 1:H 0β = , givet att X2 ingår i modellen
mot hypotesen

Kerstin Vännman S0001M 2009-01-14
– 24 –
0
1 1:H β ≠ , givet att X2 ingår i modellen, respektive nollhypotesen
0 2:H 0β = , givet att X1 ingår i modellen
mot hypotesen
1 2:H 0β ≠ , givet att X1 ingår i modellen
Som testvariabel använder vi det som i tabell 6 står under rubriken ”T”, dvs t–kvoten
(46) T = t-kvot = k
k
b
bs
.
Beslutsstrategien blir: förkasta nollhypotesen på signifikansnivån α om 0H / 2 ( 3t kvot t nα )− > − , d v s vi anser att 0kβ ≠ , och att det därmed är värt att ta in kX i modellen, om t-kvoten är tillräckligt långt borta från 0. Vad som är tillräckligt långt borta från 0 bestäms av t-fördelningen med n – 3 frihetsgrader. Nu behöver vi inte slå upp det kritiska t-värdet i t-fördelningstabellen utan kan istället jämföra det värde som står under rubriken ”P” i tabell 6 med den förutbestämda signifikansnivån α . Om P-värdet < α så betyder det att
/ 2 ( 3t kvot t nα− > − ) , dvs 0 kan förkastas. Detta är alltså ekvivalent med resone-manget vid enkel regression, se sidorna 6–7.
H
Om vi bestämmer oss för att arbeta med signifikansnivån 0.01 så ser vi från tabell 6 att t-kvoten för 1X -variabeln etanol är 5.88 och motsvarande P-värde = 0.000 < 0.01. Vi kan alltså påstå att 1β är signifikant skild från 0, dvs regressionskoefficienten för
1X -variabeln etanol är signifikant skild från 0 på 1%-nivån och att det är värt att ta med etanolmängden som en förklarande variabel i modellen (40) givet att även tetraetylbly ingår i modellen. Om tetraetylbly inte ingår i modellen visar tabell 7 att att regressionskoefficienten för variabeln etanol inte är signifikant skild från 0 på 1%-nivån eftersom då är P-värdet för etanol 0.033 > 0.01. Det är alltså viktigt att båda variablerna är med samtidigt i modellen.
Från tabell 6 ser vi också att t-kvoten för 2X -variabeln tetraetylbly är 8.61 och motsvarande P-värde = 0.000 < 0.01. Vi kan alltså påstå att 2β är signifikant skild från 0, dvs regressionskoefficienten för 2X -variabeln tetraetylbly är signifikant skild från 0 på 1%-nivån och att det är värt att ta med tetraetylbly som en förklarande variabel i mo-dellen (40), givet att även etanolvariabeln ingår i modellen. Det är alltså viktigt att båda variablerna är med samtidigt i modellen.
Om vi, med en rimlig grad av säkerhet, vill uppskatta hur stor effekten av etanol är på oktantalet, givet att tetraetylbly hålls på konstant nivå, så bildar vi ett konfidensin-tervall. Med hjälp av resultatet i (45) får vi att ett konfidensintervall för kβ med konfi-densgraden 1 – α blir (47) , k = 0, 1, 2. / 2 ( 3)
kk bb t n sα± − ⋅
Kerstin Vännman S0001M 2009-01-14
– 25 –
Med 1 – α = 0.99 får vi följande konfidensintervall för 1β : (48) 0.0051.8350 (13) 0.3120 1.8350 3.01 0.3120 1.835 0.939.t± ⋅ = ± ⋅ = ± och för 2β :
(49) 0.0052.6850 (13) 0.3120 2.6850 3.01 0.3120 2.685 0.939.t± ⋅ = ± ⋅ = ±
Genom att avrunda intervallgränserna så att intervallet inte minskar får vi att [0.8, 2.8] är ett 99% konfidensintervall för 1β . Det kan vi i ord uttrycka som att med 99% säkerhet gäller att, för fixt värde på tetraetylbly, så ökar oktantalet i genomsnitt mellan 0.8 och 2.8 enheter om etanolvariabeln ökar med en kodad enhet.
På motsvarande sätt får vi att [1.7, 3.7] är ett 99% konfidensintervall för 2β . Tolkat i ord blir det att med 99% säkerhet gäller att, för fixt värde på etanol, så ökar oktantalet i genomsnitt mellan 1.7 och 3.7 enheter om tetraetylblyvariabeln ökar med en kodad en-het.
Observera att vid tolkningarna av konfidensintervallen är det viktigt att det framgår att förändringen i oktanhalten gäller då den ena variabeln hålls konstant medan den andra ökar med en enhet.
10. Residualanalys och analys av inflytelserika observationer
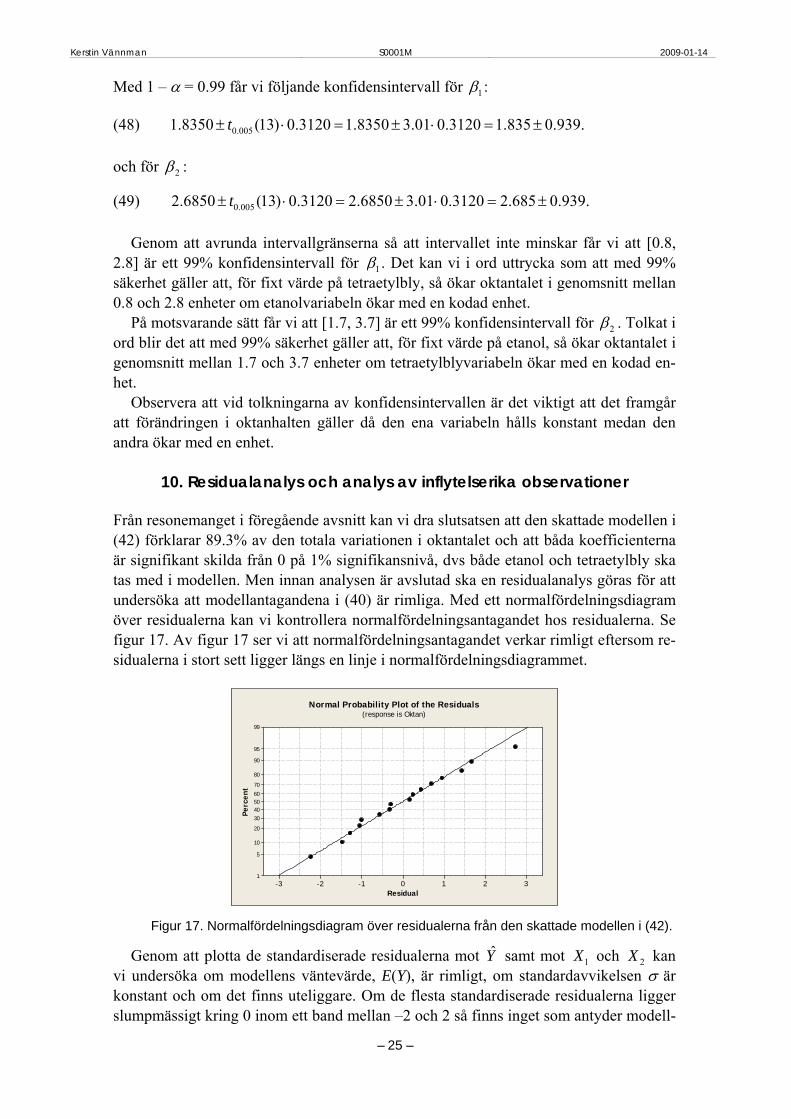
Från resonemanget i föregående avsnitt kan vi dra slutsatsen att den skattade modellen i (42) förklarar 89.3% av den totala variationen i oktantalet och att båda koefficienterna är signifikant skilda från 0 på 1% signifikansnivå, dvs både etanol och tetraetylbly ska tas med i modellen. Men innan analysen är avslutad ska en residualanalys göras för att undersöka att modellantagandena i (40) är rimliga. Med ett normalfördelningsdiagram över residualerna kan vi kontrollera normalfördelningsantagandet hos residualerna. Se figur 17. Av figur 17 ser vi att normalfördelningsantagandet verkar rimligt eftersom re-sidualerna i stort sett ligger längs en linje i normalfördelningsdiagrammet.
Residual
Perc
ent
3210-1-2-3
99
95
90
80
70
60504030
20
10
5
1
Normal Probability Plot of the Residuals(response is Oktan)
Figur 17. Normalfördelningsdiagram över residualerna från den skattade modellen i (42).
Genom att plotta de standardiserade residualerna mot samt mot 1Y X och 2X kan vi undersöka om modellens väntevärde, E(Y), är rimligt, om standardavvikelsen σ är konstant och om det finns uteliggare. Om de flesta standardiserade residualerna ligger slumpmässigt kring 0 inom ett band mellan –2 och 2 så finns inget som antyder modell-

Kerstin Vännman S0001M 2009-01-14
– 26 –
fel. Om man ser ett tydligt kurvmönster behöver modellen förbättras genom att E(Y) ändras. Om man ser en tydlig trattform eller annat mönster som tyder på icke-konstant spridning hos de standardiserade residualerna så är inte standardavvikelsen σ konstant. I figur 18–20 visas de tre residualplotterna.
Fitted Value
Stan
dard
ized
Res
idua
l
1081041009692
2
1
0
-1
-2
Residuals Versus the Fitted Values(response is Oktan)
Figur 18. Standardiserade residualerna från den skattade modellen i (42) plottade mot predikterade oktantalen . Y
I residualplotten mot i figur 18 ser vi en uteliggare med en standardiserad residual på drygt 2 vid -värdet ungefär 93. Denna uteliggare gör diagrammet i figur 18 något svårtolkat. Bortser vi från den så kan vi dra slutsatsen att det inte finns något tydligt kurvmönster. Det betyder att antagandet som gjorts för E(Y) verkar rimligt.
YY
Om vi återigen bortser från uteliggaren så tycks spridningen hos residualerna öka nå-got med ökande värde på , vilket antyder icke-konstant spridning. Men tar vi hänsyn till uteliggaren kan vi inte dra slutsatsen om ökad spridning. Vi måste gå vidare och studera residualplotterna mot 1
Y
X och mot 2X i figur 19 och 20 för att kunna ta reda på om det finns eventuella modellfel.
Etanol
Stan
dard
ized
Res
idua
l
5432
2
1
0
-1
-2
Residuals Versus Etanol(response is Oktan)
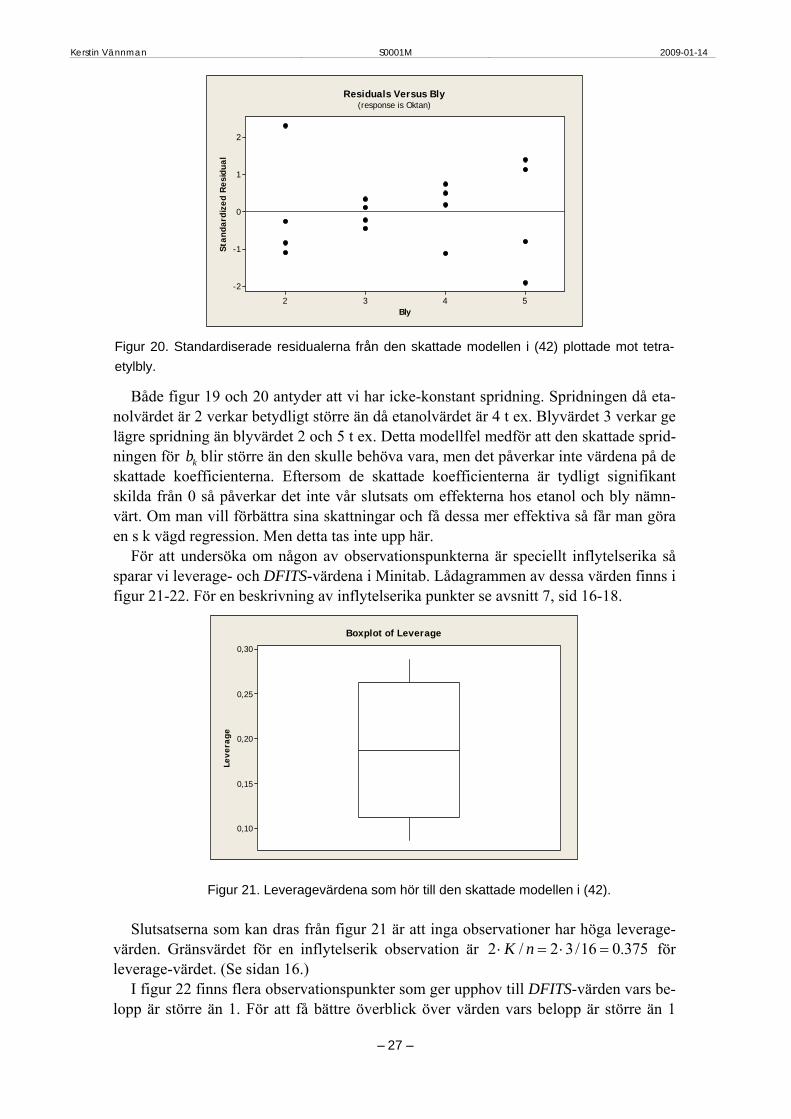
Figur 19. Standardiserade residualerna från den skattade modellen i (42) plottade mot etanol.
Kerstin Vännman S0001M 2009-01-14
– 27 –
Bly
Stan
dard
ized
Res
idua
l
5432
2
1
0
-1
-2
Residuals Versus Bly(response is Oktan)
Figur 20. Standardiserade residualerna från den skattade modellen i (42) plottade mot tetra-etylbly.
Både figur 19 och 20 antyder att vi har icke-konstant spridning. Spridningen då eta-nolvärdet är 2 verkar betydligt större än då etanolvärdet är 4 t ex. Blyvärdet 3 verkar ge lägre spridning än blyvärdet 2 och 5 t ex. Detta modellfel medför att den skattade sprid-ningen för kb blir större än den skulle behöva vara, men det påverkar inte värdena på de skattade koefficienterna. Eftersom de skattade koefficienterna är tydligt signifikant skilda från 0 så påverkar det inte vår slutsats om effekterna hos etanol och bly nämn-värt. Om man vill förbättra sina skattningar och få dessa mer effektiva så får man göra en s k vägd regression. Men detta tas inte upp här.
För att undersöka om någon av observationspunkterna är speciellt inflytelserika så sparar vi leverage- och DFITS-värdena i Minitab. Lådagrammen av dessa värden finns i figur 21-22. För en beskrivning av inflytelserika punkter se avsnitt 7, sid 16-18.
Leve
rage
0,30
0,25
0,20
0,15
0,10
Boxplot of Leverage
Figur 21. Leveragevärdena som hör till den skattade modellen i (42). Slutsatserna som kan dras från figur 21 är att inga observationer har höga leverage-
värden. Gränsvärdet för en inflytelserik observation är 2 / 2 3/16 0.375K n⋅ = ⋅ = för leverage-värdet. (Se sidan 16.)
I figur 22 finns flera observationspunkter som ger upphov till DFITS-värden vars be-lopp är större än 1. För att få bättre överblick över värden vars belopp är större än 1

Kerstin Vännman S0001M 2009-01-14
– 28 –
görs en ”dotplot” i Minitab. Se figur 23. Där framgår att två observationer har DFITS-värden vars belopp är större än 1. De svarar mot rad 1(Etanol = 2, Tetraetylbly = 2) och rad 4 (Etanol = 2, Tetraetylbly = 5) i tabell 5. De kan betraktas som inflytelserika. De måste undersökas närmare så att de inte är felaktiga. Om det finns möjlighet att ta fram fler mätvärden, så ska det göras för de iX -värden som gett upphov till höga DFITS-vär-den.
Använder vi det mer specifika gränsvärdet för DFITS-värdena så blir det här 2 / 2 3/16 0.87.K n = = Från figur 23 ser vi att inga nya värden definieras som infly-telserika, förutom de två som redan har upptäckts.
DFI
TS
2,0
1,5
1,0
0,5
0,0
-0,5
-1,0
-1,5
Boxplot of DFITS
Figur 22. DFITS-värdena som hör till den skattade modellen i (42).
DFITS1,51,00,50,0-0,5-1,0-1,5
Dotplot of DFITS
Figur 23. DFITS-värdena som hör till den skattade modellen i (42).
11. Prognosintervall samt konfidensintervall för förväntat Y-värde.
På motsvarande sätt som vid enkel regression kan man, för givna värden på X-variab-lerna, vid multipel regression bilda ett konfidensintervall för det förväntade Y-värdet,
0 , eller ett prognosintervall för Y. Antag att vi vill bilda dels ett 99% kon-fidensintervall för det förväntade oktantalet i exempel 2 och dels ett 99% prognosinter-vall givet att etanolvärdet är 2 och tetrablyvärdet är 5. För att bilda konfidensintervallet utgår vi ifrån följande:
( )E Y

Kerstin Vännman S0001M 2009-01-14
– 29 –
(50) 0
0
ˆ
ˆ ( )
Y
Y E Ys
− 0 är observerat värde från en t-fördelning med n – 3 frihetsgrader,
där
0 är det predikterade Y-värdet för de givna X-värdena och 0Y är den skattade stan-
dardavvikelse för 0 . Standardavvikelsen kan inte uttryckas lika enkelt som i formel (24), så det uttrycket skrivs inte ut här. Se Appendix. Resultatet i (50) gäller under för-utsättning att modellantagandena i (40) är uppfyllda. Observera att frihetsgraderna i t-fördelningen blir n – 3 eftersom det är tre regressionsparametrar som behöver skattas i modellen i (40). Se Appendix för det allmänna fallet.
Y sY
Med hjälp av resultatet i (50) får vi att ett konfidensintervall för väntevärdet , för givna X-värden, med konfidensgraden 1 – α blir
0( )E Y
(51)
00 / 2ˆ ( 3) YY t n sα± − ⋅
För att bilda prognosintervallet för en framtida ny observation, , utgår vi ifrån föl-jande:
0Y
(52) 0 0ˆ
pr
Y Ys− är observerat värde från en t-fördelning med n – 3 frihetsgrader, där
prs är den skattade spridningen förknippat med prognosintervallet. Liksom vid enkel regression gäller följande samband mellan och . 2
prs0
2Ys
(53) . 0
2 2ˆpr e Ys s s= + 2
Med hjälp av resultatet i (52) blir ett prognosintervall en framtida ny observation, , för givna X-värden,
0Y
(54) . 0 / 2
ˆ ( 3) prY t n sα± − ⋅
Beräkningarna av intervallen gör vi i Minitab och får resultatet i tabell 9.
Tabell 9. Predikterat värde (Fit), skattad spridning förknippat med konfidensintervallet (SE Fit), 99% konfidensintervall för väntevärdet (99% CI), samt 99% prognosintervall (99% PI), givet att och .
0( )E Y
=1 2X =2 5X Predicted Values for New Observations New Obs Fit SE Fit 99% CI 99% PI 1 101,638 0,748 (99,384; 103,891) (96,868; 106,407) Values of Predictors for New Observations New Obs Etanol Bly 1 2,00 5,00

Kerstin Vännman S0001M 2009-01-14
– 30 –
Om vi tolkar resultatet av konfidensintervallet i tabell 9 i ord så får vi följande. Med 99% säkerhet kan vi säga att, om etanolvärdet är 2 i kodad enhet och tetraetylvärdet är 5 i kodad enhet, så innehåller intervallet [99.3, 103.9] det förväntade oktantalet.
Prognosintervallet i tabell 9 kan tolkas på följande sätt. Med 99% sannolikhet så kommer ett nytt (framtida) observationsvärde på oktantalet då etanolvärdet är 2 i kodad enhet och tetraetylvärdet är 5 i kodad enhet att bli mellan 96.8 och 106.5.
På samma sätt som vid enkel regression så kommer alltid, för givna värden på X-va-riablerna, prognosintervallet att vara bredare än konfidensintervallet för förväntat Y-värde. Det beror på att det är osäkrare att uttala sig om ett enskild observationsvärde än om ett förväntat värde, som är ett genomsnittsvärde. Detta framgår även av formel (53).
12. Kollinearitet
I exempel 2 i föregående avsnitt såg vi att modellen förbättrades om vi tog med två va-riabler samtidigt istället för att bara ha en av dem med i modellen. Det kan ju vara värt att pröva hur det blir i exempel 1 i avsnitt 1 om vi försöker förklara CO-mängden med hjälp av både nikotinmängd och tjärmängd samtidigt. Från tabell 2, sidan 3, såg vi att nikotinmängden ensam förklarar 85.7% av variationen och att regressionskoefficienten för nikotinmängden var signifikant skild från 0 på en mycket låg signifikansnivå. Om vi istället tar in både nikotinhalt och tjärmängd samtidigt i modellen får vi resultatet i ta-bell 10. Den förutsätter då modellen
(55)
0 1 1 2 2
1 2
1 2
1 2
, där (0, ), 1, 2,..., , , ,..., är oberoende stokastiska variabler,
CO-mängden, nikotinmängden, tjärmängden,0.1 2.1, 0.9 29.9.
β β β ε ε σε ε ε
= + + + ∈ =
= = =≤ ≤ ≤ ≤
i i i i i
n
Y X X N i n
Y X XX X
Tabell 10. Resultatet från Minitab av regressionsanalysen av modellen i (55) The regression equation is CO = 3,09 - 2,65 Nikotin + 0,962 Tjära Predictor Coef SE Coef T P Constant 3,0896 0,8438 3,66 0,001 Nikotin -2,646 3,787 -0,70 0,492 Tjära 0,9625 0,2367 4,07 0,001 S = 1,41252 R-Sq = 91,9% R-Sq(adj) = 91,1% Analysis of Variance Source DF SS MS F P Regression 2 495,26 247,63 124,11 0,000 Residual Error 22 43,89 2,00 Total 24 539,15
Från tabell 10 ser vi att förklaringsgraden blev 91.9 % och den justerade förklarings-
graden blev 91.1%. Det kan jämföras med den enkla regressionen där enbart nikotin in-går, som har en justerad förklaringsgrad på 85.1%. Se tabell 2, sidan 3. Den justerade förklaringsgraden har alltså ökat när vi inför tjärmängden i modellen, vilket är bra. Men samtidigt blev regressionskoefficienten 1β för nikotin inte signifikant skild från 0 på 1% signifikansnivå. Men regressionskoefficienten 2β för tjärmängden är signifikant skild från 0 på t ex 1% signifikansnivå.

Kerstin Vännman S0001M 2009-01-14
– 31 –
Vad beror det på att nikotinmängden tycks sakna betydelse om tjärmängden tas med i modellen medan nikotinmängden ensam förklarar så stor andel av CO-variationen? Orsaken till detta visar sig om vi tittar på korrelationen mellan tjärmängd och nikotin-mängd. Korrelationskoefficienten mellan tjärmängd och nikotinmängd är 0.98, d v s vi har en mycket stark korrelation mellan 1X och 2X . Det framgår också tydligt om vi gör en regressionsanalys med 1X som beroende variabel och 2X som förklarande variabel. Se figur 24.
Tjära
Niko
tin
302520151050
2,0
1,5
1,0
0,5
0,0
S 0,0777703R-Sq 95,4%R-Sq(adj) 95,2%
Fitted Line PlotNikotin = 0,1309 + 0,06103 Tjära
Figur 24. Skattad regressionslinje med nikotinmängd som beroende variabel och tjärmängd som förklarande variabel, där det syns ett tydligt linjärt samband.
Om det finns ett starkt linjärt samband mellan två X-variabler, som här mellan niko-
tinmängd och tjärmängd, så kan standardavvikelserna för regressionskoefficienterna för 1X och 2X bli så stora att en (ibland båda regressionskoefficienterna) inte blir signifi-
kant skild från 0. Om 1X och 2X är i stort sett linjärt beroende så bär de på samma in-formation och det räcker att använda en av variablerna i modellen. Att införa den andra variabeln tillför ingen ny information.
Det allra bästa är om de ingående X-variablerna är helt okorrelerade. Då får man de säkraste skattningarna av regressionskoefficienterna. Detta gäller t ex i exempel 2, som var ett planerat försök. Om X-variablerna är fullständigt korrelerade, d v s har korrela-tionskoefficient 1 så kan man inte beräkna minsta-kvadrat-metodens skattningar över-huvudtaget. Se Appendix. Om de förklarande variablerna är mycket starkt korrelerade så blir skattningarna i regressionsmodellen mycket osäkra, d v s får stor spridning. Reg-ressionsanalys kan då vara en olämplig metod att använda. Om de förklarande variab-lerna är mycket starkt korrelerade säger man att kollinearitet föreligger.
Ser man det geometriskt så innebär det att det plan man anpassar till punkterna 1 2 , blir mycket instabilt om 1( , , ), 1, 2,...=i i iY X X i n X och 2X är starkt korrelerade. Ett
sådant plan blir mycket känsligt för små förändringar av punkterna. Det betyder att skattningarna i modellen är osäkra. För att få ett stabilare plan måste punkterna i det skattade 1 2( , )X X -planet vara mer utspridda både i 1X -led och 2X -led, t ex som i det planerade försöket i exempel 2.
Om man har starkt linjärt korrelerade X-variabler, vilket man kan ha i vissa datama-terial, så måste man vara uppmärksam på detta problem. Det kallas för multikollinea-ritet om man har två eller fler X-variabler som kan vara starkt korrelerade. Man bör inte

Kerstin Vännman S0001M 2009-01-14
– 32 –
n
ta med starkt korrelerade X-variabler i samma modell. Det enklaste sättet att uppmärk-samma multikollinearitet är att studera korrelationsmatrisen för X-variablerna innan man använder regressionsanalys. Om man upptäcker att en variabel i en regressions-analys inte längre är signifikant skild från 0, när en ny variabel tas in, kan man miss-tänka multikollinearitet. Då bör man pröva olika kombinationer av X-variabler för att försöka hitta en lämplig modell.
Ibland kan det finnas icke-statistiska motiveringar till varför korrelerade X-variabler bör ingå i samma modell. Om modellen enbart ska användas till att göra prognoser så kan man ta med korrelerade X-variabler i regressionsanalysen. Spridningen för predikterade värdet påverkas nämligen inte så mycket av multikollinearitet. Men vill man ha säkra skattningar av koefficienterna i modellen så ska man inte använda sig av regressionsanalys utan använda någon metod som fungerar även för X-variabler med multikollinearitet. Men sådana metoder tas inte upp här.
För att se vilken modell man bör använda för att få en bra skattad modell för CO-mängden i exempel 1 så prövar vi med att ta med tjärmängden ensam. Resultatet fram-går av tabell 11. Om vi nu jämför resultaten i tabell 2, tabell 10 och tabell 11 så ser vi att residualspridningen är minst för modellen med enbart tjärmängden med. Det är även den modellen som har störst justerad förklaringsgrad. Dessutom är regressionskoeffi-cienten signifikant skild från 0 på en mycket låg signifikansnivå. Det är alltså modellen med enbart tjärmängden med som är den lämpligaste i detta fall, d v s
(56)
0 1
1 2
, där (0, ), 1, 2,..., , , ,..., är oberoende stokastiska variabler,
CO-mängden, tjärmängden, 0.9 29.9.
i i i i
n
Y X N i
Y XX
β β ε ε σε ε ε
= + + ∈ =
= =≤ ≤
Att dessutom ta med nikotinhalten bidrar inte med något ny information. Men innan
man är helt nöjd med modellen i (56) och dess skattningar i tabell 11 så ska man göra en residualanalys och en analys av inflytelserika punkter. Detta överlämnas åt läsaren.
Tabell 11. Resultatet från Minitab av regressionsanalysen med enbart tjärmängden med i mo-dellen.
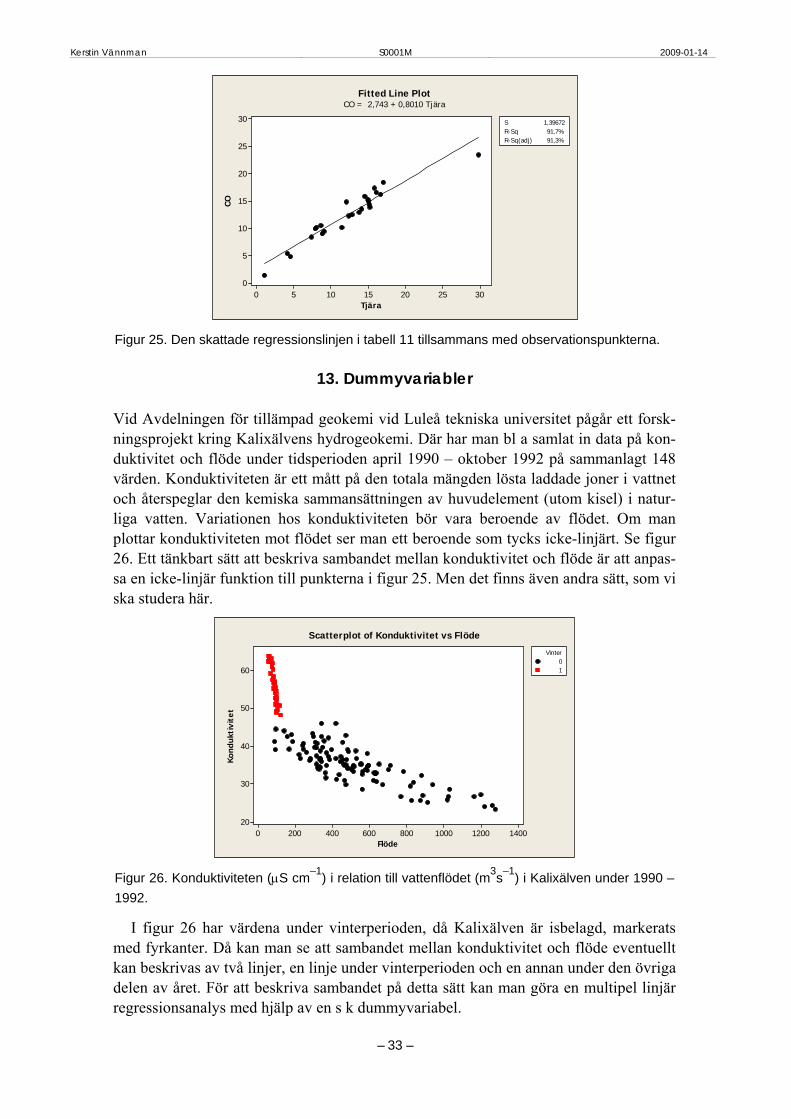
Regression Analysis: CO versus Tjära The regression equation is CO = 2,74 + 0,801 Tjära Predictor Coef SE Coef T P Constant 2,7433 0,6752 4,06 0,000 Tjära 0,80098 0,05032 15,92 0,000 S = 1,39672 R-Sq = 91,7% R-Sq(adj) = 91,3% Analysis of Variance Source DF SS MS F P Regression 1 494,28 494,28 253,37 0,000 Residual Error 23 44,87 1,95 Total 24 539,15
Kerstin Vännman S0001M 2009-01-14
– 33 –
Tjära
CO
302520151050
30
25
20
15
10
5
0
S 1,39672R-Sq 91,7%R-Sq(adj) 91,3%
Fitted Line PlotCO = 2,743 + 0,8010 Tjära
Figur 25. Den skattade regressionslinjen i tabell 11 tillsammans med observationspunkterna.
13. Dummyvariabler Vid Avdelningen för tillämpad geokemi vid Luleå tekniska universitet pågår ett forsk-ningsprojekt kring Kalixälvens hydrogeokemi. Där har man bl a samlat in data på kon-duktivitet och flöde under tidsperioden april 1990 – oktober 1992 på sammanlagt 148 värden. Konduktiviteten är ett mått på den totala mängden lösta laddade joner i vattnet och återspeglar den kemiska sammansättningen av huvudelement (utom kisel) i natur-liga vatten. Variationen hos konduktiviteten bör vara beroende av flödet. Om man plottar konduktiviteten mot flödet ser man ett beroende som tycks icke-linjärt. Se figur 26. Ett tänkbart sätt att beskriva sambandet mellan konduktivitet och flöde är att anpas-sa en icke-linjär funktion till punkterna i figur 25. Men det finns även andra sätt, som vi ska studera här.
Flöde
Kond
ukti
vite
t
1400120010008006004002000
60
50
40
30
20
01
Vinter
Scatterplot of Konduktivitet vs Flöde
Figur 26. Konduktiviteten (μS cm–1) i relation till vattenflödet (m3s–1) i Kalixälven under 1990 – 1992.
I figur 26 har värdena under vinterperioden, då Kalixälven är isbelagd, markerats med fyrkanter. Då kan man se att sambandet mellan konduktivitet och flöde eventuellt kan beskrivas av två linjer, en linje under vinterperioden och en annan under den övriga delen av året. För att beskriva sambandet på detta sätt kan man göra en multipel linjär regressionsanalys med hjälp av en s k dummyvariabel.

Kerstin Vännman S0001M 2009-01-14
– 34 –
Vi definierar variablerna Y = konduktivitet samt 1X = flöde. Sedan för vi en variabel 2X = vinter, där variabeln 2X definieras som
2
0, under den del av året som inte är vinter,1, under vinterperioden.
X ⎧= ⎨
⎩
En sådan 0/1-variabel kallas för en dummyvariabel eller indikatorvariabel. Sedan defi-nierar vi en tredje variabel 3 1= ⋅ 2X X X . Vi antar nu den multipla regressionsmodellen
(57)
0 1 1 2 2 3 3
1 2
1 2 3 1 2
1 2
, där (0, ), 1, 2,..., , , ,..., är oberoende stokastiska variabler,
konduktivitet, flöde, vinter, 58 1275, 0 1.
β β β β ε ε σε ε ε
= + + + + ∈ =
= = = = ⋅≤ ≤ ≤ ≤
i i i i i i
n
Y X X X N i
Y X X X X XX X
n
Denna modell kan vi nu dela upp i två delar beroende på om variabeln 2X = vinter
är 0 eller 1 och vi får följande förväntade värde på Y: (58) Ej vinter ( 2X = 0): 0 1( ) 1β β= +E Y X , (59) Vinter ( 2X = 1): 0 1 1 2 3 3 0 2 1 3( ) ( ) ( ) 1β β β β β β β β= + + + = + + +E Y X X X . Vi ser från (58) och (59) att om både 2 0β = och 3 0β = så är linjerna för vinter och ej vinter lika. Om 2 0β ≠ medan 3 0β = så har linjerna samma lutning men olika inter-cept. Om 2 0β = medan 3 0β ≠ så har linjerna olika lutning, men samma intercept. Om både 2 0β ≠ och 3 0β ≠ har vi två olika linjer i de två grupperna med både olika lut-ning och olika intercept. Vi skattar nu parametrarna βk , k = 1, 2, 3, med hjälp av mul-tipel regressionsanalys. Då kan vi även testa om de två linjerna har olika lutning och olika intercept. Tittar vi i figur 25 så kan vi vänta oss två olika linjer med signifikant skilda lutningar och skilda intercept. Resultatet framgår av tabell 12.
Tabell 12. Resultatet från Minitab av regressionsanalysen av modellen (56). Regression Analysis: Konduktivitet versus Flöde; Vinter; Vinter*Flöde The regression equation is Konduktivitet = 43,2 - 0,0159 Flöde + 36,1 Vinter - 0,255 Vinter*Flöde Predictor Coef SE Coef T P Constant 43,2382 0,5597 77,25 0,000 Flöde -0,0159028 0,0009880 -16,10 0,000 Vinter 36,112 2,386 15,13 0,000 Vinter*Flöde -0,25528 0,02732 -9,34 0,000 S = 2,69944 R-Sq = 93,6% R-Sq(adj) = 93,5% Analysis of Variance Source DF SS MS F P Regression 3 15439,6 5146,5 706,27 0,000 Residual Error 144 1049,3 7,3 Total 147 16489,0

Kerstin Vännman S0001M 2009-01-14
– 35 –
Vi ser från tabell 12 att den skattade modellen förklarar 93.6% av den totala variatio-nen i konduktiviteten och att samtliga regressionskoefficienter är tydligt signifikant skilda från 0 på en mycket låg signifikansnivå, eftersom samtliga P-värden < 0.0005. Att regressionskoefficienten för Vinter är signifikant skild från 0 betyder att de två olika linjerna har olika intercept. Att regressionskoefficienten för Vinter*Flode är signifikant skild från 0 betyder att de två olika linjerna har olika lutning. Det betyder att flödets effekt på konduktiviteten är olika under de två olika tidsperioderna. Från tabell 12 får vi enkelt de två olika skattade linjerna genom att sätta vintervariabeln 2X till 0 eller 1. Resultatet blir
(60) Ej vinter (X2 = 0): 1
ˆ 43.2 0.0159= −Y X (61) Vinter (X2 = 1): . 1 1
ˆ 43.2 0.0159 36.1 0.255 79.3 0.271= − + − = −Y X X 1X
Om vi gör en residualanalys av den skattade modellen ovan får vi följande diagram. Se figur 27–230.
Fitted Value
Stan
dard
ized
Res
idua
l
6050403020
4
3
2
1
0
-1
-2
-3
-4
Residuals Versus the Fitted Values(response is Konduktivitet)
Figur 27. Standardiserade residualerna som hör till den skattade modellen i tabell 12 plottade mot den predikterade konduktiviteten . Y
I residualplotten i figur 27 ser vi två grupper längs -axeln, en för höga predikterade värden och en för låga. Det svarar mot vintergruppen respektive ej vinter och indikerar inte något modellfel. Däremot kan vi se att spridningarna tycks olika i de två grupperna. De standardiserade residualerna sprider ut sig mer i gruppen ej vinter (låga predikterade värdena) jämfört med vintergruppen. Detta syns ännu tydligare i figur 29. Även figur 26 antyder icke-konstant spridning. Vi har alltså ett modellfel här, d v s residualspridningen beror av variabeln 2
Y
X . Detta modellfel gör att spridningarna för regressionsskattningarna inte blir så effektiva, d v s så låga som möjligt. Men samti-digt påverkar det inte våra slutsatser nämnvärt eftersom vi har så tydligt signifikanta koefficienter.
I residualplotten i figur 27 ser vi också tre uteliggare, vars standardiserade residualer är större än 2.5. De tycks tillhöra ”ej vinter”-gruppen. Observationsvärdena som hör till dessa kan alltså inte beskrivas så bra med den framtagna skattade modellen.
Residualplotten i figur 28 visar också på icke-konstant varians. Det antyder att resi-dualspridningen även beror av variabeln 1X . Även i figur 28 syns de tre uteliggarna.

Kerstin Vännman S0001M 2009-01-14
– 36 –
Flöde
Stan
dard
ized
Res
idua
l
1400120010008006004002000
4
3
2
1
0
-1
-2
-3
-4
Residuals Versus Flöde(response is Konduktivitet)
Figur 28. Standardiserade residualerna som hör till den skattade modellen i tabell 12 plottade mot flödet X1 .
Vinter
Stan
dard
ized
Res
idua
l
1,00,80,60,40,20,0
4
3
2
1
0
-1
-2
-3
-4
Residuals Versus Vinter(response is Konduktivitet)
Figur 29. Standardiserade residualerna som hör till den skattade modellen i tabell 12 plottade mot vintervariabeln X2 .
Residual
Perc
ent
1050-5-10
99,9
99
9590
80706050403020
10
5
1
0,1
Normal Probability Plot of the Residuals(response is Konduktivitet)
Figur 30. Residualerna som hör till den skattade modellen i tabell 12 plottade i ett normalför-delningsdiagram.

Kerstin Vännman S0001M 2009-01-14
– 37 –
I residualplotten i figur 29 syns tydligt att spridningen är lägre på vintern jämfört med ej vinter. Här syns också att uteliggarna hör till perioden ej vinter. Ingen av figu-rerna 27–29 indikerar någon kurvatur. Det innebär att det finns ingen anledning att ändra uttrycket för E(Y) i formel (56).
Figur 30 antyder att residualerna skulle vara något snedfördelade, d v s att normal-fördelningsantagandet inte är helt uppfyllt. Men inte heller det modellfelet gör att våra slutsatser kommer att ändras eftersom vi har ett sådant stort antal observationer att Centrala gränsvärdessatsen ger att de beräknade P-värdena är approximativt riktiga.
Residualanalysen hittills visar visserligen på brister i modellen men dessa brister skapar inga större problem vid tolkningen. Det finns ett modellantagande som inte är undersökt och det är om residualerna är oberoende. Det undersöker vi genom att plotta residualerna i tidsordning. I detta material så svarar det mot observationsordningen. Se figur 31.
Observation Order
Res
idua
l
1401301201101009080706050403020101
10
5
0
-5
-10
Residuals Versus the Order of the Data(response is Konduktivitet)
Figur 31. Residualerna som hör till den skattade modellen i tabell 12 plottade i tidsordning.
I figur 31 kan vi se ett böljande mönster, vilket antyder positivt korrelerade residua-ler. Om man har positivt korrelerade residualer, s k positiv autokorrelation, så tenderar höga residualvärden att följas av höga och låga residualvärden att följas av låga. Man kan även visa att vi har positiv autokorrelation med hjälp av det s k Durbin-Watsontes-tet, men vi tar inte upp det här. Denna autokorrelation är det mest besvärande modell-felet och här behöver man bilda en ny modell som tar hänsyn till detta. Men inte heller detta tas upp här.
Det kan nämnas att om vi tar hänsyn till autokorrelationen så kommer det att visa sig att de tidigare slutsatserna kring modellen inte ändras speciellt mycket. Vi kan konsta-tera att vi har en rimligt bra skattad modell och har tydligt visat att flödets effekt på konduktiviteten är olika under de två olika tidsperioderna och fått en skattning av detta.
14. Att välja ut en lämplig modell
Ibland har man ett stort antal tänkbara förklarande variabler och man vet inte vilka som kan tänkas vara intressanta att ta med i modellen. Det finns flera olika sätt att resonera för att komma fram till en tänkbar modell. Ett sätt är följande. Börja med att göra en multipel regression med alla de förklarande variabler som man tror har betydelse. Om någon eller några av dessa har P-värden som är större än den förutbestämda signifi-kansnivån så överväg att ta bort dessa variabler så att det bara finns kvar variabler vars

Kerstin Vännman S0001M 2009-01-14
– 38 –
koefficienter är signifikant skilda från 0. Ta då bort en variabel i taget för att se vad som händer. På grund av ett visst beroende mellan variablerna så kan P-värdena ändras för de kvarvarande variablerna när en variabel tas bort ur modellen. När samtliga i mo-dellen ingående variabler har regressionskoefficienter som är signifikant skilda från 0 så är man nöjd med den modellen.
Ett annat sätt att resonera är följande. Börja som ovan och ta bort en i taget av icke-signifikanta variabler men studera samtidigt hur den justerade förklaringsgraden ändras. Så länge som den ökar är det värt att ta bort variabler men inte om den minskar. Det kan då innebära att en variabel med icke-signifikant koefficient blir kvar i modellen. Det kan vara acceptabelt om det finns en saklogisk förklaring, som inte beror av data, att den ska ingå. Det kan också vara acceptabelt om syftet med modellen är prediktion och inte att uppskatta de enskilda effekterna.
Om man är tveksam till om en variabel ska tas med eller ej i modellen kan ibland också residualanalysen vara ett stöd. Man väljer alltså den modell vars residualer inte tyder på modellfel eller uppvisar ett mer fördelaktigt residualmönster.
Det finns även mer sofistikerade metoder för att välja rätt modell som baseras på PRESS-statistikan eller Mallows Cp eller som bygger på korsvalidering. Men detta be-rörs inte här.
15. Appendix Här anges kortfattat de formler som gäller för regressionsanalysen vid en godtycklig regressionssituation med K – 1 förklarande variabler och följande modellantagande.
(A1) 0 1 1 2 2 1 1,
1 2
... , där (0, ), 1, 2,..., ,
, ,..., är oberoende stokastiska variabler.
β β β β ε
ε σε ε ε
− −= + + + + +
∈ =i i i K K i
i
n
Y X X XN i n
i
Observera att K = antal regressionsparametrar i modellen .
Det predikterade Y-värdet, Yi och den skattade modellen blir
(A2) 0 1 1 2 2 1 1
ˆ ... ,− −= + + + +i i i KY b b X b X b X K i . Modellen i (A1) kan skrivas mer kortfattat i matrisform på följande sätt. (A3) = +Y Xβ ε där
(A4) 01 111 1,1
1 1, 1
1 , = , ,
1
β ε
β ε
−
− −
⎛ ⎞ ⎛ ⎞⎛ ⎞ ⎛ ⎞⎜ ⎟ ⎜ ⎟⎜ ⎟ ⎜ ⎟= =⎜ ⎟ ⎜ ⎟⎜ ⎟ ⎜ ⎟
⎜ ⎟ ⎜ ⎟⎜ ⎟⎜ ⎟⎝ ⎠ ⎝ ⎠⎝ ⎠⎝ ⎠
Y X β ε… K
n n K n K
Y X X
Y X X=
n
Låt vektorn b beteckna vektorn av skattade regressionskoefficienter, d v s

Kerstin Vännman S0001M 2009-01-14
– 39 –
(A5) . 0
1−
⎛ ⎞⎜ ⎟= ⎜ ⎟⎜ ⎟⎝ ⎠
b
K
b
b
Enligt minsta-kvadrat-metoden fås b som lösningen till det överbestämda ekvations-systemet. (A6) . =Xb Y Under förutsättning att matrisen är inverterbar så kan lösningen, d v s skattning-arna av regressionskoefficienterna, skrivas som
X XT
(A7) 1( )−=b X X X YT T
Om kolonnerna i matrisen är linjärt beroende så är inte matrisen inverterbar. Det betyder att om två av X-variablerna är fullständigt linjärt korrelerade så existerar inte skattningarna av
X X XT
βk . Om två av X-variablerna är starkt linjärt korrelerade så blir skattningarna av βk mycket osäkra och får en mycket stor spridning. Därför ska inte starkt linjärt korrelerade X-variabler ingå samtidigt i en regressionsmodell.
Variansanalystabellen som hör till modellen i (A1) kan skrivas som
Variation Frihetsgrader (DF)
Kvadratsumma (SS)
Medelkvadratsumma (MS)
Regression
K – 1
2
1
ˆ( )=
−∑n
ii
Y Y 2
1
ˆ(=
−∑n
ii
Y Y ) /(K – 1)
Residual
n – K
2
1
ˆ( )n
i ii
Y Y=
−∑ 2
1
ˆ(n
i ii
Y Y=
−∑ ) /(n – K)
Total
n – 1
2
1
( )=
−∑n
ii
Y Y
Residualspridningen, som skattar σ, definieras som
(A8) 2=es se , där
(A9)
2
2 1
ˆ( )residualkvadratsumman
n
i ii
e
Y Ys
n K n K=
−= =
− −
∑,
d v s är samma som medelkvadratsumman för residualerna i variansanalystabellen ovan.
2es
Förklaringsgraden, som anger andel förklarad Y-variation, definieras som
(A10)
2
2 1
2
1
ˆ( )regressionskvadratsumman
totala kvadratsumman ( )
n
iin
ii
Y YR
Y Y
=
=
−= =
−
∑
∑,

Kerstin Vännman S0001M 2009-01-14
– 40 –
eller som ”1 – andel oförklarad Y-variation” , dvs
(A11)
2
2 1
2
1
ˆ( )residualkvadratsumman1 1totala kvadratsumman ( )
n
i iin
ii
Y YR
Y Y
=
=
−= − = −
−
∑
∑
Den justerade förklaringsgraden, som används vid jämförelse av modeller med olika
många förklarande variabler, definieras som
(A12) 2 2residualkvadratsumman/( ) 11 1totala kvadratsumman /( 1)
(1 )− −= − = − −
− −an K nR Rn n K
Under förutsättning att modellen i (A1) är giltig så gäller nedanstående resultat.
(A13) k
k
b
bs
kβ− , k = 0, 1, ..., K – 1, är observerat värde från en t-fördelning med n – K
frihetsgrader där (A14) är diagonalelementen i varians-kovariansmatrisen . 2
kbs 2 1( )−=S X XTes
(A15) 0
0
ˆ
ˆ ( )
Y
Y E Ys
− 0 är observerat värde från en t-fördelning med n – K frihetsgrader,
(A16) 0 0ˆ
pr
Y Ys− är observerat värde från en t-fördelning med n – K frihetsgrader, där
(A17) och
0
2 2ˆpr e Ys s s= + 2
(A18)
0
2 2 1ˆ 0 0( )T T
eYs s −= X X X X
är en 0X 1×n matris bestående av givna X-värden.
Vid test av hypoteser samt beräkning av konfidensintervall för regressionskoeffi-
cienterna βk kan man utgå från (A13). Vid beräkning av konfidensintervall för E(Y) kan man utgå från (A15). Vid beräkning av prognosintervall för Y kan man utgå från (A16).
Låt beteckna det predikterade värdet i den i:te punkten beräknat utifrån den skattade modellen där den i:te observationen uteslutits. På motsvarande sätt låt ( ) be-teckna residualspridningen för den skattade modellen där den i:te observationen uteslu-tits. Ett mått på inflytelserika observationspunkter är:
( )ˆ
i iYe is

Kerstin Vännman S0001M 2009-01-14
– 41 –
(A19) ( )
( )
ˆ ˆi i
ie i i
Y YDFITS
s h−
= i ,
där ( )e i is h är en skattning av spridningen för och i definieras i formel (A20). DFITSi är ett mått på ändringen i om i:te observationen utesluts.
iY hiY
Observation nr i är inflytelserik om 2 /iDFITS K n> . En tumregel är också att observation nr i är inflytelserik om 1>iDFITS .
Ett annat mått på inflytelserika punkter är leveragevärdet. Leverage för observation nr i definieras som i:te diagonalelementet i ”hattmatrisen”, d v s ih
(A20) = i:te diagonalelementet i ”hattmatrisen” . ih 1( )T T−=H X X X X
Om anses observation nr i inflytelserik. En tumregel är också att om 2 /ih K> ⋅ n
max( ) ≤ 0.2 anses inte någon observation inflytelserik, ih 0.2 < ih ≤ 0.5 anses i:te observationen riskabel, kan vara inflytelserik, > 0.5 anses i:te observationen inflytelserik. ih