query evaluation and optimization main steps 1.translate into ra: select/project/join 2.greedy...
TRANSCRIPT

Query Evaluation and Optimization
Main Steps1.Translate into RA: select/project/join2.Greedy optimization of RA: by pushing selection and projection into RA expression 3.Select best implementation for each operator4.Cost-based estimation and selection of best join order
1

Greedy optimization of RA: pushing selection and projection into RA
expression
2

Selection and Indexing
• If we have a S.C condition supportedby an existing index we use the index• If we have a conjunction, such asS.A>5 and S.B <10 with indexes onboth, then we can select the better ofthe two (optimization)• If there is no index, do we create one?
3

Selecting best implementation for each operator
• Selection: use an index if appropriate is available. Otherwise visit all the blocks
• Projection: trivial, unless we need to eliminate duplicates—using sorting or hashing.
• Joins– Nested loop, reasonable only with indexes– Nested Block Join– Sort-Merge Join– Has Join
4

5
40
T1
60
T2
30
T3
10
T4
20
T5
10 T6
60 T7
40 T8
20 T9
R SC C
R JOIN S?

6
For each r R do
For each s S do
if r.C = s.C then output r,s pair
40 T1
60 T2
30 T3
10 T4
20 T5
10 T6
60 T7
40 T8
20 T9
R S
Nested-Loop Join (NLJ)
• R is called the outer relation and S the inner relation of the join.
• Requires no indices and can be used with any kind of join condition.
• Expensive since it examines every pair of tuples in the two relations.

Nested-Loop Join (Cont.)• In the worst case, if there is enough memory only to hold one block
of each relation, the estimated cost is
• nR bS + bR block transfers
• If the smaller relation fits entirely in memory, use that as the inner
relation.– Reduces cost to br + bs block transfers and 2 seeks
• Block nested-loops algorithm (next slide) is preferable.

Block Nested-Loop Join
• Variant of nested-loop join in which every block of inner relation is paired with every block of outer relation.
for each block Br of r do begin
for each block Bs of s do begin
for each tuple tr in Br do begin
for each tuple ts in Bs do begin
Check if (tr,ts) satisfy the join condition
if they do, add tr • ts to the result.
endend
endend

Block Nested-Loop Join (Cont.)
• Worst case estimate: bR bS + bR block transfers
– Each block in the inner relation S is read once for each block in the outer relation R.
• Best case: bR+ bS block transfers.
• Many Improvements proposed to nested loop and block nested loop algorithms including:– Scan inner loop forward and backward alternately, to make use
of the blocks remaining in buffer (with LRU replacement)
– Use index on inner relation if available (next slide)
E.g.Compute student takes, with R=student as the outer relation, S= takes the inner relation,
– Number of records of student: 5,000 takes: 10,000
– Number of blocks of student: 100 takes: 400

10
(1) Create an index for S.C if one is not already there
(2) For each r R do
X index-lookup(S.C, r.C)
For each s X, output (r,s)
40 T1
60 T2
30 T3
10 T4
20 T5
10 T6
60 T7
40 T8
20 T9
R
S
Index Join (IJ)

Merge-Join
11

12
– If the two tables fit in memory we can use bubble sorting
– External sorting must be used otherwise.• This is the litmus test for big data
processing• http://sortbenchmark.org/
2014, 4.27 TB/minApache Spark
100 TB in 1,406 seconds 207 Amazon EC2 i2.8xlarge nodes x (32 vCores - 2.5Ghz Intel Xeon E5-2670 v2, 244GB memory, 8x800 GB SSD) Reynold Xin, Parviz Deyhim, Xiangrui Meng, Ali Ghodsi, Matei
Zaharia Databricks
Sort-Merge Join (SMJ)

13

14
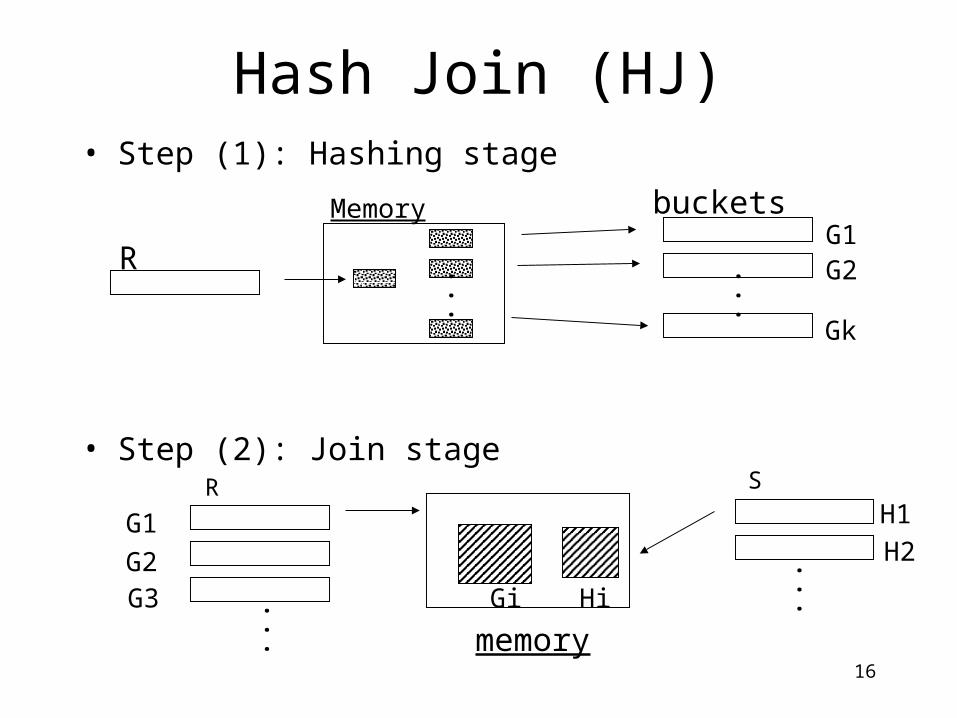
• Hash function h(v), range 1 k
Algorithm(1) Hashing stage (bucketizing): hash tuples into
buckets• Hash R tuples into G1,…,Gk buckets• Hash S tuples into H1,…,Hk buckets
(2) Join stage: join tuples in matching buckets • For i = 1 to k do
match tuples in Gi, Hi buckets
R
…
S
……
Hash Join (HJ)

15
• H(k) = k mod 3
0
1
2
R 0
1
2
S
40 T160 T230 T310 T420 T5
10 T660 T740 T820 T9
Hash Join (HJ)
16
• Step (1): Hashing stage
• Step (2): Join stage..
.
...
Memory bucketsG1G2
Gk
R
S
...
Gi
memory... Hi
RH1H2
G1
G2G3
Hash Join (HJ)

Summary of Join Algorithms
• Nested-loop join ok for “small” relations(relative to memory size)• Hash join usually best for equi-join if relationsnot sorted and no index• Merge join for sorted relations• Sort merge join good for non-equi-join• Consider index join if index exists• DBMS maintains statistics on data
17

Query Evaluation and Optimization
Main Steps1.Translate into RA: select/project/join2.Greedy optimization of RA: by pushing selection and projection into RA expression 3.Select best implementation for each operator4.Cost-based estimation and selection of best join order
18

©Silberschatz, Korth and Sudarshan1.19Database System Concepts - 6th Edition
Statistics collection commandsStatistics collection commands
Statistics collection commands
• DBMS has to collect statistics on tables/indexes
– For optimal performance
– Without stats, DBMS does stupid things…
• DB2
– RUNSTATS ON TABLE <userid>.<table> AND INDEXES ALL
• Oracle
– ANALYZE TABLE <table> COMPUTE STATISTICS
– ANALYZE TABLE <table> ESTIMATE STATISTICS (cheaper
than COMPUTE)
• Run the command after major update/index
construction

©Silberschatz, Korth and Sudarshan1.20Database System Concepts - 6th Edition
Join Ordering ExampleJoin Ordering Example
For all relations r1, r2, and r3,
(r1 r2) r3 = r1 (r2 r3 )
(Join Associativity)
If r2 r3 is quite large and r1 r2 is small, we choose
(r1 r2) r3
so that we compute and store a smaller temporary relation.

©Silberschatz, Korth and Sudarshan1.21Database System Concepts - 6th Edition
Estimation of the Size of Joins (Cont.)Estimation of the Size of Joins (Cont.)
If R S = {A} is not a key for R or S. If we assume that every tuple t in R produces tuples in R S, the number of tuples in R S is estimated to be:
If the reverse is true, the estimate obtained will be:
The lower of these two estimates is probably the more accurate one.
Can improve on above if histograms are available
Use formula similar to above, for each cell of histograms on the two relations
V(A,s), V(A,r) the average number of A-values in s and r
A special case: foreign keys

Statistics collection commands
Statistics collection commands• DBMS has to collect statistics on tables/indexes– For optimal performance– Without stats, DBMS does stupid things…• DB2– RUNSTATS ON TABLE <userid>.<table> AND INDEXES ALL• Oracle– ANALYZE TABLE <table> COMPUTE STATISTICS– ANALYZE TABLE <table> ESTIMATE STATISTICS (cheaperthan COMPUTE)• Run the command after major update/indexconstruction