programming for geographical information analysis: advanced skills
DESCRIPTION
Programming for Geographical Information Analysis: Advanced Skills. Online mini-lecture: Introduction to Complex Networks Dr Andy Evans. This Lecture. Types of Network Random Spatial Scall-free Small-world Network Statistics. Network types. - PowerPoint PPT PresentationTRANSCRIPT

Programming for Geographical Information Analysis:
Advanced Skills
Online mini-lecture: Introduction to Complex Networks
Dr Andy Evans

Types of NetworkRandomSpatial Scall-freeSmall-world
Network Statistics
This Lecture

Network types
Various types of abstract graph have been suggested. We mentioned two in lecture four: the tree and the lattice.
Some appear to be more useful for understanding real world social and environmental networks.
The simplest of these is the Random Graph.
Nodes are connected randomly in some manner.

Erdős–Rényi Construction
Produces the simplest Random Graph.Edges are progressively added, with each node having the same probability of being involved.

Spatial Graphs
Where the ability to connect between nodes is constrained by space.Generally this means a higher probability of connection to nearby nodes.Various types: including random-spatial.

Caveman Graphs
Individual highly-connected groups.No connection between groups.

Network statistics
Distribution/average of node degree.
Distances:Eccentricity: distance from a node to the node furthest from it.Average path length: average eccentricity.Radius: minimum eccentricity in the graph.Diameter: maximum eccentricity in the graph.
Global clustering: how many nodes are connected in complete connection triangles (triadic closures) as a proportion of the connected triplets in the graph.

Network statistics
Trees
Low average degreeNarrow degree
distributionLow clusteringHigh APL
Lattices
Low average degreeNarrow degree
distributionLow clusteringHigh APL

Network statistics
Random
Low average degree
Normal degree distribution
Low clusteringLow APL
Spatial
Medium average degree
Narrow degree range
Medium clustering
Long APL
Caveman
High average degree
Narrow degree
rangeHigh clusteringInfinite APL

Scale-free Networks
Barabási and Albert looked at the real networks, including the internet.
They saw the distribution of links matched an inverse power law.
Number of nodes of degree k = k-x
This relationship is constant, whatever k, i.e. The distribution is scale-free.

Barabási–Albert construction
Attach more edges to those nodes that already have more edges.Probability of attachment proportional to node degree.Produces a scale-free network.

Scale-free Networks
Still a fairly high number of nodes of 5+ degree.
These are known as Hubs.
Basis (kinda) for the Google PageRank algorithm.
Networks have a high resistance.
High clustering, but degree of clustering relates to network size. Large networks = smaller clustering.

Scale-free Networks
Scale-free networks seem like the kinds of networks that might be good for modelling people.
But, does social clustering really change with size of network?
There is some evidence that human group sizes are limited.

Dunbar Number
Robin Dunbar suggests that human brain size suggests ~150 people, which seems to match pre-industrial communities.
But others have found a wide range of figures.
There is some evidence that once groups grow above this limit the core group doesn’t scale, but a new hierarchy of group management develops.
Either way, the core group size is unlikely to scale with the network.

♫♪ It’s a small world afterall ♫♪
How is it we often meet complete strangers with whom we have a mutual acquaintance?
It’s said that you’re only six mutual associates away from anyone in the world (“Six Degrees of Separation”).
Stanley Milgram (1967) sent packages to people in Nebraska and Kansas, with instructions to pass them to people they thought might be closer to targets in Massachusetts. Took an average of 5 steps to arrive.
How can this be possible given the following..?Every person knows only around a thousand people.There are six billion people on the globe.

The Kevin Bacon Game
Can you link any actor to Bacon via co-stars in films?
Anyone whose co-starred in a film with Kevin Bacon has a Bacon Number of one.Anyone who’s been in a film with a co-star of Bacon has a Bacon Number of two, etc.

Six Degrees of Kevin Bacon
Steve McFadden has a Bacon number of twoSteve McFadden was in Buster (1988) with Phil CollinsPhil Collins was in Balto (1995) with Kevin Bacon
Barbara Windsor has a Bacon number of three.Barbara Windsor was in Comrades (1987) with Robert Stephens Robert Stephens was in Chaplin (1992) with Diane Lane Diane Lane was in My Dog Skip (2000) with Kevin Bacon

Is Kevin Bacon the centre of the Universe?
The Internet Movie Database has ~850,000 connected films. Each film has an average number of actors of 61. Yet the maximum Bacon Number found so far is only 12.The average number of films between any actor and Bacon is only 2.980 films.
So why is this so? Because social groups are a form of network known as Small World graphs.

A mix of strongly Clustered groups with a few hub individuals who know many groups (cause the social groups to overlap).
Fall between extremes in the level of local clustering and average path length like the scale-free networks.But, more realistic clustering – which doesn’t scale.
Small World graphs
Kevin
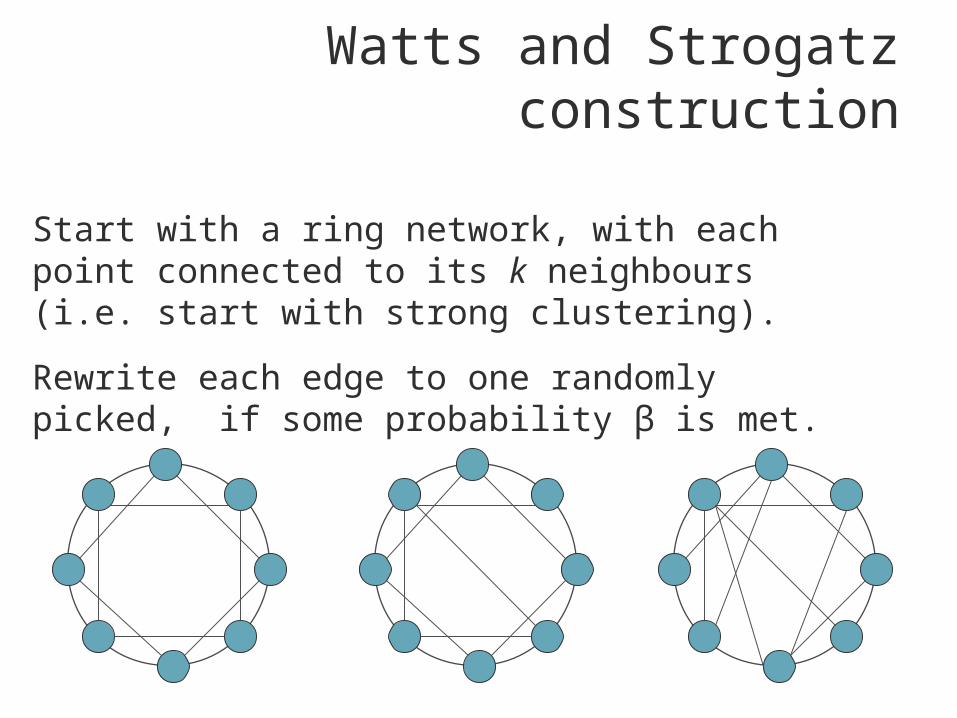
Watts and Strogatz construction
Start with a ring network, with each point connected to its k neighbours (i.e. start with strong clustering).
Rewrite each edge to one randomly picked, if some probability β is met.

More characteristics
Average Path Length is proportional to ln(vertices).Average Path Length is inversely proportional to ln(associates).
The Average Path Length decreases extremely rapidly as lynchpins / shortcuts increase slightly from nothing.Shortcuts cross vast areas of variable space to link with unexpected groups.Very robust to random losses – at worst flows will route to another hub.

Spatial graphs
Shortcuts are rare (it’s easier to link to nearby nodes than stretch to the other side of a net) so they rarely show Small World characteristics.
In such networks the Average Path Length scales more linearly with the number of vertices.

Example of a real network
Disease spread.2001 UK Foot and Mouth epizootic.
Farm-to-farm spread by air: spatial network.Farm-to-farm spread by cattle movements: small-world
network.

Foot and Mouth daily casesCutting movements improved on 1967.Cases decreased when probability of inflection lowered.
Initial May 5th predictions 400d-1
24 Feb 10 Mar 24 Mar 7 Apr 29 Apr0
10
20
30
40
50
Source: BBC / MAFF 4 May 2001
Healthy cull policy
24hr cull policy
1967

Uses of Small World theory
The spread of disease (Watts, 1999).Spreading is controlled by…
The length of time that someone is infectious.The length of time someone is removed (sick but not infectious,
or if infinite = immune or dead).The infection probability / rate between 0 and 1.
People are either Susceptible, Infectious or Removed.Watts mapped the proportions of these groups in Small World societies and physically limited networks for different disease parameters.

Violent deadly diseasesSmall World
Such diseases reach equilibrium when people are removed faster than the disease spreads.
There’s a massive difference in deaths dependent on shortcuts.
Hence cutting off diseased population is vital.
Equi
libriu
m fr
actio
n of
Su
scep
tible
peo
ple
0
1
0 1Tipping pointDisease takes off Everyone dies
Fraction of shortcuts = 0Fraction of shortcuts = 0.9
Probability of infection

Other characteristics of disease spread
If the disease infects the whole population, the time to do so is also strongly dependent on the fraction of shortcuts.
In physically limited graphs, however, the spread is about the same whatever the range over which vertices can connect.
Diseases are worse in Small World situations, but more easily controlled.

Other uses of Small World theory
Spread of information / fashion / “memes”.The resilience of networks to attack.The efficiency of distribution systems.

Software
Masses of software E.g. Inflow
Network CentralitySmall-World Networks Cluster Analysis Network Density Prestige / Influence Structural Equivalence Network Neighborhood External / Internal Ratio Weighted Average Path Length Shortest Paths & Path Distribution

Other key statistics
Centrality: various measures, including degree, but two are:
Betweenness centrality: number of shortest paths passing through a node.
Closeness centrality: average of shortest paths to all other nodes.
Node degree (or other) correlation: how similar are nodes to their neighbours?