program unit a program unit b program unit t...... function 1 function 2 function 8.... component 1...
TRANSCRIPT

Program unit A
Program unit B
Program unit T
.
.
.
Function 1
Function 2
Function 8
.
.
Component 1
WholeSystem
(e.g. regression
testing)Component 3
.
Unit Testing Functional Testing Component TestingSystem Testing
Structural (white-box) testing more functional (Black-box) testing
Different Levels of Testing

Using Configuration Management tool• Naming Convention and Promotion Policies are
needed along with configuration Management tool– There must be a clear rule about promoting the artifact
from one stage of development / test to another.– Once the artifact is promoted to a certain stage, it is
locked at that stage.– It is also important to promote related artifacts such as
code, help text and test cases
.
.
Unit-testedPrivate Copies
FormallyInspected
FunctionallyTested
Integration& System Tested
Golden Copy
promotepromote
promote promote

Integration Testing• This is the step after the individual pieces of code or
modules (programs) are tested.
• A set of programs do not exist in vacuum. They are “inter-related” mostly in some manner through:
– Calling and passing controls– Calling and passing data or passing “pointers” to data
• Integration test looks at the inter-action:
1. “structural” composition (or decomposition) and test the related code (modules / programs).
2. The “call” relationship neighborhood and test the “neighborhood”
3. The path created by the relationship and test the “path”
** Object Oriented relationship such as inheritance is addressed differently.

Types of Integration tests based onStructural Decomposition
• There are 4 major types of integration test for Structural Decomposition Based test:
1. Top- down2. Bottom-up3. Combination (Sandwich)4. Big Bang

Top-down
i) Once the root modules is “completed”, we need to build 3 stubs to perform integration test of root module with stubs.ii) As the next level module is completed, we would build more stubs to perform the next level of integration testiii) Continue this process until all the all the completed modules are tested
“completed” here means unit tested

Bottom-UP
i) Once a set of bottom modules are completed we would build a driver, at the next higher level, to run the integration test.ii) Continue this process until all the all the completed modules are tested

Combination (Sandwich)
- Once a module is completed, we would build the appropriate driver or stubs to perform the integration test.- Continue this process until all the modules are tested
If this is completedfirst, we may chooseto build 3 stubs to test
If these two are completed,we may choose to builda driver to test ; may also buildtwo (green) stubs.
“Combo” is a more likely scenario - - -making “integration” managementa complex job that needs some toolhelp.

Big-Bang
- Wait for all the modules to be completed and perform one integration (one link-edit). Then test all the integrated modules together.
This scenario happens more likelyat the over-all system or component test time

Some Metrics for Integration Test based on Structural Decomposition
• For Top-down approach with n nodes, there is a potential need to construct as much as (n-1) stubs.
• For Bottom-up approach with n nodes and v leaves, there is a potential need to construct as much as (n - v) drivers.
• For both cases there may be as much as (n – v + edges) number of test sessions (e.g. cases or scenarios)

Simple Construct Example for the Metrics
A
B C D E
• There are 5 nodes and 4 leaves and 4 edges:
1. n- 1 = 5 -1 = 4 stubs2. n - v = 5 - 4 = 1 driver3. n - v+ edges = 5 - 4 + 4 = 5 test
sessions
Number of test sessions potentially = 5:
(Top-down) (Bottom-up)1. A is complete: E is complete: test with 4 stubs test with driver A
2. B is complete: D is complete: test with 3 stubs test with driver A 3. C is complete: C is complete: test with 2 stubs test with driver A
4. D is complete: B is complete: test with 1 stub test with driver A
5. E is complete: A is complete: test all modules test all modules

Slightly Modified Example for the Metrics
A
B
C D
ENumber of test sessions = 6:
(Top-down) (Bottom-up)1. A is complete: E is complete: test with 2 stubs test with driver A
2. B is complete: D is complete: test with 2 stubs test with driver B 3. B is complete: C is complete: test with A test with driver B
4. C is complete: B is complete: test with B test with C and D
5. D is complete: B is complete: test with B test with driver A
6. E is complete: A is complete: test all modules test all modules
• There are 5 nodes and 3 leaves and 4 edges:
1. n- 1 = 5 -1 = 4 stubs2. n - v = 5 - 3 = 2 drivers3. n - v+ edges = 5 – 3 + 4 = 6 test
sessions

Pair-Wise Integration(Sandwich-like)
• One of the key drawbacks to top-down or bottom-up testing for Decomposition-based integration testing is the need for constructing drivers and stub.
• Pair wise integration testing waits for a “related pair” of modules to be completed and then test them. Thus it eliminates the stubs and drivers. There is also a potential reduction in test sessions ---- just # of edges
“Related” via edge connection

Example of Pair-Wise Testing
A
EBB
A
DC
C D E
Pair-wise test sessions : 4
1. A – B2. B – C3. B – D4. A – E
Pair-wise test sessions : 4
1. A – B2. A – C3. A – D4. A – E

“Neighborhood” Integration Testing
• Neighborhood of a node is the set of nodes that are one edge away from the given node.– Thus the neighborhood of a node, n, are all the predecessors
and successor nodes of n.– # of neighborhoods = # of interior nodes + source node .
• There are some positive and negative characteristics with neighborhood integration testing:– Positives:
• Less test sessions • ** Possibly give more of a “behavior” view of a “thread”
– Negative:• May be harder to locate bugs• Wait for the completion (timing) of a neighborhood before testing

Number of “neighborhoods”
• Number of neighborhoods in a call graph may be viewed as:– Number of interior nodes (that form neighborhoods around
them) AND– 1 neighborhood around the root node
• Numerically:– Interior nodes = all nodes – ( source node + sink nodes)
– # of Neighborhood = interior nodes + source node
– # of Neighborhood = all nodes – sink nodes
Note that source node is the 1 root-node in our case:1.we should start with the neighborhood around the root2.then consider all the neighborhoods around the interior nodes

Example of Neighborhood Integration Testing
A
EBB
A
DC
C D E
Total nodes = 5Sink nodes = 3
Neighborhood = 5 – 3 = 2
Total nodes = 5Sink nodes = 4
Neighborhood = 5 - 4 = 1
A
E
A
B DCB
A
C D E
neighborhood(1) neighborhood (2) (1) neighborhood
B

How many neighborhoods are there?
A
B CD
I J
FG HE
There are ( 10 nodes – 5 sink nodes) = 5 neighborhoods
- 1 around the root (start here --- so there is some potential wait time) - 1 around B - 1 around E - 1 around C - 1 around D

“Path-Based” Integration Test
• Instead of just focusing on the interfaces of the “related” modules in integration test, it would be more meaningful to also focus on the “interactions” among these related modules.
• An extension of the neighborhood would be to trace a complete “thread” of interactions among the modules and test that “thread” or “path.”

Some Definitions for Path-based Integration Test
• Source node is the point where program execution starts
• Sink node is the point where the program execution stops
• A module execution path is a sequence of statements that begins with a source node and ends with a sink node, with no intervening sink nodes.
• A message is a “mechanism” with which one unit of code transfers control to another unit of code; control return is also a message
• An MM-path (module-to-module path) is an interleaved sequence of i) module execution paths and ii) messages– Sequence of “nodes” represent a module execution path
– Sequence of “edges” represent the messages
• An MM-Path Graph is the directed graph in which nodes are from the module execution paths and edges are passing of control/messages.

A Simple Example of an MM-Path
1
2
3 4
5
6
1
2
3
4
1
2 3
4
5
A1= <1,2,3,6>; A2=<1,2,4> ; A3 = <5,6>Module Execution Paths: B1= <1,2> ; B2 = <3,4> C1= <1,2,4,5> ; C2= <1,3,4,5>
(Module A) (Module B) (Module C)
Source nodes : A1 and A5Sink nodes: A4 and A6
Source nodes : B1 and B3Sink nodes: B2 and B4
Source nodes : C1Sink nodes: C5
Note:Should modules A and B be recoded ?
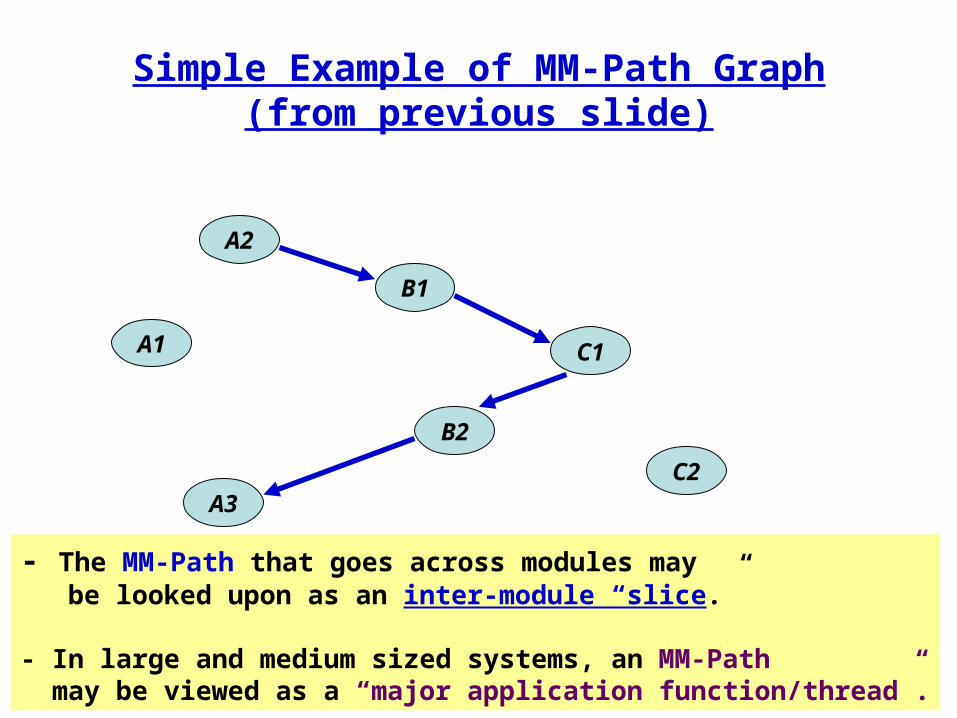
Simple Example of MM-Path Graph(from previous slide)
A2
B1
C1A1
C2
B2
A3
- The MM-Path that goes across modules may be looked upon as an inter-module “slice.”
- In large and medium sized systems, an MM-Path may be viewed as a “major application function/thread”.