product named entity recognition for chinese query questions based on a skip-chain crf model
TRANSCRIPT

ORIGINAL ARTICLE
Product named entity recognition for Chinese query questionsbased on a skip-chain CRF model
Zhifeng Hao · Hongfei Wang · Ruichu Cai ·Wen Wen
Received: 27 December 2011 / Accepted: 16 March 2012 / Published online: 11 May 2012
© Springer-Verlag London Limited 2012
Abstract As more and more commercial information can
be obtained from the Internet, product named entity recog-
nition plays an important role in market intelligence
management. In this paper, a product named entity recog-
nitionmethod based on a skip-chain CRFmodel is proposed.
This method considers not only the dependence between
neighboring words but also the fact that product named
entities are often connected by a connective. In this situation,
the dependence between the words around the connective is
more important than the dependence between neighboring
words. This information improves the result of product
named entity recognition as shown in the experiments.
Experimental results on corpuses ofmobile phone and digital
camera demonstrate that the skip-chain CRF model works
well and produces better results than the linear-chain CRF
model.
Keywords Chinese query ·
Product named entity recognition · Skip-chain CRF ·
Conditional random fields
1 Introduction
With the developing of information technology, more and
more commercial information can be obtained from the
Internet. However, most of the information in the Internet
is unstructured or semi-structured, which is difficult to be
directly analyzed. Thus, how to extract key information
becomes a crucial and valuable problem in many business
IE applications [1].
As one of the key problems in this area, product named
entity recognition plays an important role in market intelli-
gence management, enterprise content management and
enterprise competitive intelligence collection [1]. As pointed
by JM Pierre, effective product named entity recognition
technology means that analysis of large collections of
unstructured text documents can be processed quickly, inex-
pensively, and with a minimum of human intervention, then
human users can concentrate on higher level problems [2].
Compared with traditional named entity recognition [3],
differences on expression forms and structures between
product named entity (PRONE) and traditional named entity
make PRO NER more difficult. Up to now, less work has
been done in PRO NER. In these existing works, two main
approaches have been applied, that is, rule-based approaches
and statistical model-based approaches. Rule-based
approaches [2, 4] have bad portability, for rules should be
redefined or regenerated when applied in new domains.
Statistical model-based approaches apply statistical models
integrated with some heuristic information and external
knowledge bases. One category of statistical approaches
adopts generative models [1, 5]. But for these approaches,
strict independence assumptions are needed and label bias
problem is the underlying problem. The other category of
statistical approaches applies discriminative models such as
linear-chain CRF model [6, 7]. These approaches can rep-
resent rich overlapping features and do not require strict
independence assumptions, but some important dependence
information is missed in this model.
Thus, CRF models can solve problems like various
expressive and structural forms in PRO NER and are the
Z. Hao · H. Wang (&)
Faulty of Applied Mathematics, Guangdong University
of Technology, Guangzhou 510006, PA, China
e-mail: [email protected]
Z. Hao · R. Cai · W. Wen
Faulty of Compute Science, Guangdong University
of Technology, Guangzhou 510006, PA, China
123
Neural Comput & Applic (2013) 23:371–379
DOI 10.1007/s00521-012-0922-5

most suitable in existing approaches. But linear-chain CRF
in PRO NER assumes that dependencies between neigh-
boring labels are the strongest [8], which misses some other
more important dependence information. Thus, skip-chain
CRF, a model with rich dependence expression ability, is
first introduced to solve the PRO NER in this paper.
The main contributions of this paper are as follows: (1)
A skip-chain CRF model is firstly introduced to solve the
problem caused by connectives. (2) The proposed model
does not only represent dependencies between neighboring
labels, but also represents the dependencies between labels
in the formal of coordinative relation, which contains much
more important information. (3) A set of features is defined
which can express rich context information around words
well.
The remaining of this paper is organized as follows.
Section 2 introduces and analyzes the related work about
PRO NER. In Sect. 3, we present the PRO NER problem
and its difficulties. Section 4 introduces our solution for the
PRO NER: a skip-chain CRF model. The experimental
results and analysis are presented in Sect. 5. Conclusion
and future works are given in Sect. 6.
2 Related work
The main existing PRO NER approaches can be divided
into two classes as described in detail in this section. The
advantages and disadvantages of these methods are also
introduced.
2.1 Rule-based approaches
Rule-based approaches mainly perform PRO NER with
some rules defined manually or generated automatically.
Pierre [2] developed an English NER system capable of
identifying product names in product reviews. It employed
a simple Boolean classifier for identifying product names,
which is similar to string pattern matching. But this method
produces bad results in the condition that a lot of new
product names are not contained in the training corpus.
Bick and his colleagues solved the name entity recognition
problem using a constraint-grammar-based parser for
Danish [4]. This rule-based approach is highly dependent
on the performance of the Danish parser and has bad
portability.
2.2 Statistical model-based approaches
Statistical model-based approaches usually apply statistical
models integrated with some heuristics and external
knowledge bases. For example, a bootstrapping approach is
presented for English NER [9] using two successive
learners (parsing-based decision list and hidden Markov
model). The major advantage of this method is that the
manual annotation of a sizable training corpus can be
avoided, but it suffers from two problems: one is that it is
difficult to find sufficient concept-based seeds for boot-
strapping; the other is that it is highly dependent on
parser’s performance. Jun Zhao and his colleagues used a
hierarchical hidden Markov model-based statistical model
to recognize the named entity in Chinese documents about
digital products and mobile phones [1]. However, hierar-
chical hidden Markov model is a generative model.
Generative models have their own inherent disadvantages:
they need to make strict independence assumptions, but
most data sequence cannot be presented as a series of
factors that are independent with each other. So, it cannot
represent the data sequence very well. Huang et al. [6] first
introduced the CRF model into product named entity rec-
ognition, in which a modified Viterbi algorithm combined
with some constraint rules is applied to get the N-Best
results. Then, some rules are applied to filter the N-Best
results which may still include bad results. It shows that it
can get a good final result. In the work of Luo et al. [7],
some domain ontology features are introduced to a linear-
chain CRF, and their result shows it can improve the per-
formance. But the linear-chain CRF model in this approach
only describes dependencies between neighboring labels,
on the assumption that those dependencies are the strongest
[8]. This assumption ignores some more important depen-
dence information, and it shows that this information can
improve the performance of CRF models easily.
For advantages of CRF models mentioned in Sect. 1,
CRF models are more appropriate for PRO NER than other
models. However, the linear-chain CRF model misses
some more important dependence information in some
situations. For example, through observing the data set,
sequences like “诺基亚 5230 和诺基亚 5233 哪个好
(which is better between Nokia 5230 and Nokia 5233)”
often occur, the words around the word “和 (and)” often
belong to the same type. Obviously, in this example, the
dependence between “5230” and “诺基亚 (Nokia),” which
are connected by “和 (and),” is more important than
dependence between “诺基亚 (Nokia)” and “和 (and).”
This kind of information will help recognition, but a linear-
chain CRF cannot present it. So, in this paper, a skip-chain
CRF is proposed to include this kind of information.
3 Problem statements
3.1 A formalization description of PRO NER problem
As a subfield of named entity recognition, PRO NER can
be formalized as a NER problem that consists of two steps:
372 Neural Comput & Applic (2013) 23:371–379
123

(1) Modeling stepGiven a labeled and processed training set, the purpose
is to find an appropriate distribution PðyjxÞ by maximizing
the likelihood PðyjxÞ of the training set, that is:
PðyjxÞ ¼ arg maxPðyjxÞ
YTðx;yÞ
PðyjxÞ; PðyjxÞ 2 P;
or
k ¼ arg maxk
YTðx;yÞ
Pðyjx : kÞ; k 2 R1;
where x is the observation sequence instance, y is the labelsequence instance correspondingly, and T represents the
training set consisted of the pair (x, y). λ means the
parameter vector of distribution PðyjxÞ which belongs to a
l-dimensional space of real numbers, P in the first formula
represents a space of distribution functions that define the
conditional probability PðyjxÞ: This step provides an
approach for finding a specific model that can describe the
relationship between the space of observation sequences
and the space of label sequences well.
(2) Inference stepGiven the model trained in the modeling step, the
inference step aims to find the label sequence y 2 L (Lrepresents the space of label sequence), which satisfies the
following conditions given the observation sequence x:
y ¼ arg maxy
PðyjxÞ; y 2 L:
This step provides an approach for finding the most
possible label sequence y given an observation sequence x.
3.2 Difficulties of PRO NER
As a new field of NER, PRONER has its own characteristics
distinguished fromgeneral NER. These characteristics result
in the following difficulties.
1. Few open corpus resources about PRO NER can be
obtained because labeling a big corpus is expensive.
This is one of the bottlenecks for statistical model
applications. Though some corpus libraries are avail-
able, such as the one built by FUJITSU R&D CENTER
and the Institute of Automation Chinese Academy of
Sciences [6], this library is not open for commercial
secrets.
2. Remarkable featurewords that clearly indicate a product
named entity cannot be found in sentence. This is quite
different from the traditional name entity recognition
problem, for the latter usually contains remarkable
entity words like “市 (city),” “公司 (company),”“街
(street),”“公园 (garden)” and so on.
3. The same product probably has different names. For
example, “索爱 x10i” is an abbreviation of “索尼爱立
信 x10i,” both of them stand for the same mobile
phone.
4. Cross-language phenomenon is common in product
names, for example, “HTC 渴望 (Desire)” is another
form of “HTC Desire,” which is hard to be recognized
very well.
4 A skip-chain CRF model for product named entityrecognition
4.1 Linear-chain CRF
Linear-chain CRF model [10] is the most basic and sim-
plest model of CRF models; skip-chain CRF used in this
paper is an improved version of linear-chain CRF.
A linear-chain CRF approach has been applied in PRO
NER and shown its effectiveness [6, 7]. It models depen-
dencies between neighboring labels, based on the
assumption that those dependencies are the strongest [8].
However, sometimes, the assumption disaccords with the
fact and ignores some other more important dependencies
as shown in Sect. 2.
Because of its first-order Markov assumption among
labels, a linear-chain CRF cannot represent the important
dependencies between words connected by a connective.
To relax this assumption, a skip-chain CRF is proposed that
also take these important dependencies into consideration.
These dependencies are represented in our model by add-
ing factors that depend on the labels of words connected by
a connective, such as in the sequence “诺基亚 5230 和诺
基亚 5233哪个好(which is better between Nokia 5230 and
Nokia 5233),” “5230” and “诺基亚 (Nokia)” are connected
by a connective “和 (and),” and they are all parts of a
product named entity. In general, words connected by a
connective are very possible to have the same labels or
relative labels such as different parts of a product named
entity. Our model is inspired by the skip-chain CRF model
proposed by Sutton and McCallum [8], which takes
advantage of the dependencies between the labels of distant
but similar words.
4.2 Skip-chain model
A skip-chain CRF is essentially a linear-chain CRF with
additional skip edges between words connected by a con-
nective. Information on both endpoints of the skip edges
can be used to recognize the class of either endpoint. As we
Neural Comput & Applic (2013) 23:371–379 373
123

have observed from the corpus, the number of skip edges in
a question is small, so the difficulty increased by the skip
edges can be ignored [8].
Formally, our skip-chain CRF is defined as a general
CRF with two clique templates: one is for the adjacent
label nodes that are also contained in a linear-chain CRF,
and the other is for the label nodes on skip edges. Given an
observation sequence, assuming S = {(j, j + 2)} is the set
of all pairs of label nodes on skip edges, the probability of a
label sequence Y conditioned on X is modeled as:
P Y jXð Þ ¼ 1
ZðYÞYIi¼1
wi yi; yi�1;Xð ÞYJ
ðj;jþ2Þ2Swj;jþ2ðyj; yjþ2;XÞ
where wi is the factor for the adjacent label nodes, wj;jþ2 is
the factor for the label nodes on skip edges. They are
defined as below:
wi yi; yi�1;Xð Þ ¼ expXk
kk � fk yi; yi�1;X; ið Þ( )
wj;jþ2 yj; yjþ2;X� � ¼ exp
Xl
gl � flðyj; yjþ2;X; j; jþ 2Þ( )
where fk yi; yi�1;X; ið Þ is the feature on linear-chain edges,
flðyj; yjþ2;X; j; jþ 2Þ is the feature on skip edges; in our
work, they are both indicator function and detailed features
will be described in Sect. 5. h1 ¼ fkkgK1
k¼1 are the param-
eters of the linear-chain template, h2 ¼ fglgK2
l¼1 are the
parameters of the skip edge template. The factor graph of
our model is shown in Fig. 1.
In this paper, L-BFGS algorithm [11] is applied to
estimate parameters θ of our skip-chain CRF model, and
loopy belief propagation algorithm [12] is used to perform
approximate inference.
4.3 Workflow of PRO NER
In this paper, only two kinds of product named entities are
considered, namely product brand name (PBN) and product
type name (PTN), which are important parts of a product
name. So, the result of PBN and PTN recognition will
directly affect the final result of product named entity
recognition. The work of product named entity recognition
will be the follow-up work in future, which is not taken
into consideration here.
Five labels are used in the model: b1, b2, t1, t2 and o.
Here, b1 and t1 denote the starting part of brand name and
type name, respectively. b2 and t2 mean the rest part of the
brand name and type name, respectively, o means other
words. Our workflow is summarized in Fig. 2, and the
detail is as follows:
1. Preprocessing: Word segmentation and POS tagging
are conducted on the raw input text using the open-
source software ICTCLAS [14]. ICTCLAS allows
adding the user dictionary that leads to better results
than other segmentation tools. In this paper, a partic-
ular designed user dictionary composed of English and
Chinese official brand names is used.
2. Inducing features: Convert words in sequence to a
feature vector with scalable dimensions. The following
features are contained in the feature vector:
(a) POS tag: the POS tag of the word has a one-size
window at both sides. For example, the POS tag
of the adjective “便宜 (cheap)” is adj.
(b) in_brdict: If the word is in the brand dictionary, it
has a two-size window on the left. For example,
the word “Nokia” is in the brand dictionary.
(c) in_lbodict: If the current word is in the left-
boundary dictionary, it has a one-size window on
the left. The left-boundary dictionary contains
words that often occur on the left of product
names, for example “买 (buy).”
(d) in_rbodict: If the current word is in the right-
boundary dictionary, it has a one-size window on
the right. The right-boundary dictionary contains
words that often occur on the right of product
names, for example “卖 (sell).”
(e) in_dict: If the current word is in the connect-word
dictionary, for example, the current word “和
(and)” is in the connect-word dictionary.
(f) has_n: If there are some numbers in the current
word, it has a three-size window on both sides,
like “5230.”
(g) has_l: If there are some letters in the current
word, it also has a three-size window on both
sides, like “n97.”
3. Training the skip-chain model: Input the feature
vectors of training set and L-BFGS algorithm is
applied to estimate the weight of each feature.
4. Getting labels sequence: Input the feature vector of a
test question into the trained model, loopy belief
propagation algorithm is applied to find the appropriate
labels sequence of the test question.
5 Experiments and analysis
5.1 Purpose of our experiments
This paper focuses on recognizing two types of named
entities: PBN and PTN. In order to verify the performance
of the proposed method, four experiments are designed: (1)
an experiment on training corpus, (2) an experiment for
374 Neural Comput & Applic (2013) 23:371–379
123

comparing the performance of linear-chain CRF and skip-
chain CRF on the natural mobile phone test corpus, (3) a
comparison experiment on a manual mobile phone test
corpus, (4) a portability experiment, a skip-chain CRF
model, is applied on a camera test corpus to estimate its
portability.
In the experiments, precision, recall and F1 score are
used to evaluate the performance, and they are, respec-
tively, denoted as P, R and F1, respectively. They are
defined below:
Pi ¼ Correcti
Returnedi;
Ri ¼ Correcti
Ni
;
F1i ¼ 2 � Pi � Ri
Pi þ Ri
;
where Correcti is the number of correct recognized entity i,Returnedi is the number of recognized entity i, Ni is the
number of entity i in testing data set.
In the experiments, the MALLET implementation of
CRFs [13] is used. MALLET uses a quasi-Newton method
called L-BFGS to find these feature weights efficiently and
loopy belief propagation algorithm to perform approximate
inference.
5.2 Data set
Experimental data set consists of 750 questions crawled from
Baidu knows,1 a famous question–answer website in China.
Most of them are about mobile phones and the rest are about
cameras. Among the questions about mobile phones, 205
randomly selected samples are used as training corpus. In the
remaining questions, 200 randomly selected samples are
used as natural test corpus, and 200 samples that contain
more than one mobile phone are manually selected from the
rest as our manual test corpus. Hundred questions about
cameras are also selected as our portability test corpus. The
details of these four corpuses are summarized in Table 1.
5.3 Results and analysis
5.3.1 Test of training algorithm
First, a skip-chain model is applied on the training corpus
to test the performance of training algorithm, and the result
is illustrated in Table 2.
Results in Table 2 show that the proposed model has
good performance on the training corpus, the precisions of
X:the ith word isa connective
like” (and)”
iy +1iy 2+iy-2iy -1iy
Fig. 1 Factor graph of skip-chain CRFs
Sequences in thetraining corpus
Segmentation and POS tagging
Inducing features
Training Model
Skip -Chain CRF model
An incoming sequence
Segmentation and POS tagging
Inducing features
Tagging Labels
Label sequence
Prep
roce
ssin
g
Prep
roce
ssin
g
(a) Training part of model (b) Inference part of model
Fig. 2 Workflow of PRO NER in our work
1 Baidu knows: http://zhidao.baidu.com/.
Neural Comput & Applic (2013) 23:371–379 375
123

four labels are all very high, and the precisions of t1 and t2are a little lower, this is because letters and numbers in time
or price may disturb the recognition.
5.3.2 Comparison of linear-chain CRF with skip-chainCRF
Then, the open test experiments are conducted aimed at
comparing the performance of linear-chain CRF model and
skip-chain CRF model on two opening corpuses. First,
these two models are applied on the opening natural cor-
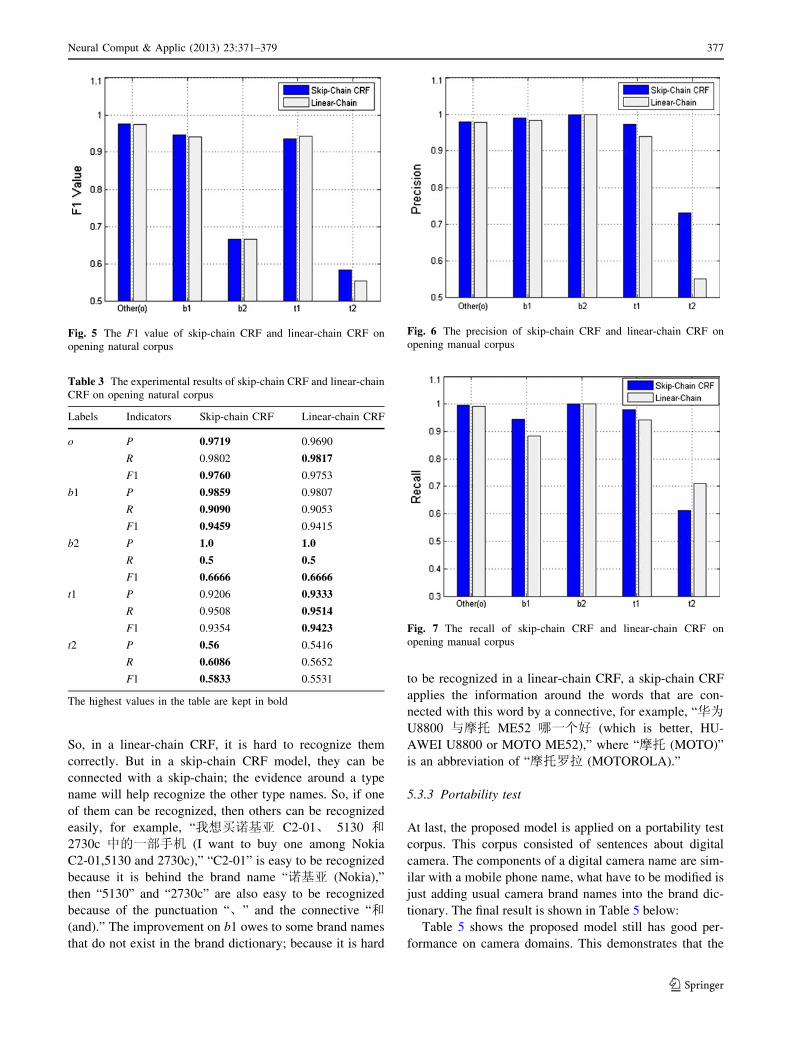
pus, respectively; the results are shown in Figs. 3, 4 and 5.
The detail of data is shown in Table 3.
Results demonstrate that the performance of skip-chain
CRF is slightly better than linear-chain CRF’s. This is
because in the opening natural corpus, there are not many
sentences that contain two or more mobile phones, and most
mobile phone names in these sentences are regular and are
easy to recognize without the help of skip-chain. These
mobile phone names often occur in the form of a regular
brand name followedwith a type name that just has oneword,
for example, “三星 i5800多少钱? (How much is a Anycall
i5800?).” In the situation that a sentence contains more than
onemobile phone names and themobile phone names are not
regular, skip-chain CRFwill have better performance, which
is demonstrated in the following.
Skip-chain CRF and linear-chain CRF model are con-
ducted on the opening manual corpus. This corpus
consisted of sentences with more than one mobile phone
names, these mobile phone names are often connected by
some connectives, and some of these names are not regular,
for example, some abbreviations of brand names that are
not in brand dictionary,”索爱 (abbreviations of Sony
Ericsson),”“摩托 (abbreviations of Motorola)” and so on.
The results of these two models are shown in Figs. 6, 7 and
8. The details are shown in Table 4.
Table 4 shows that skip-chain CRF performs much
better than linear-chain CRF. This is because some type
names occur in a sentence without a brand name in front of
them, they may contain letters or numbers, but these evi-
dences are not enough to prove they are type names, as the
price or other words may also contain letters or numbers.
Fig. 3 The precision of skip-chain CRF and linear-chain CRF on
opening natural corpus
Fig. 4 The recall of skip-chain CRF and linear-chain CRF on
opening natural corpus
Table 1 The detail of each corpus
Other (o) Front part of
brand name (b1)End part of
brand name (b2)Front part of
type name (t1)End part of
type name (t2)
Training corpus 1539 255 10 315 59
Natural test corpus 766 169 4 206 23
Manual test corpus 782 213 0 298 31
Portability test corpus 893 108 0 119 21
Table 2 Training algorithm test result
Other
(o)Front part of
brand name
(b1)
End part of
brand name
(b2)
Front part of
type name
(t1)
End part of
type name
(t2)
P 0.9782 1.0 1.0 0.9648 0.8545
R 0.9922 0.9529 0.6 0.9587 0.7966
F1 0.9851 0.9759 0.7499 0.9617 0.8245
The highest values in the table are kept in bold
376 Neural Comput & Applic (2013) 23:371–379
123
So, in a linear-chain CRF, it is hard to recognize them
correctly. But in a skip-chain CRF model, they can be
connected with a skip-chain; the evidence around a type
name will help recognize the other type names. So, if one
of them can be recognized, then others can be recognized
easily, for example, “我想买诺基亚 C2-01、 5130 和
2730c 中的一部手机 (I want to buy one among Nokia
C2-01,5130 and 2730c),” “C2-01” is easy to be recognized
because it is behind the brand name “诺基亚 (Nokia),”
then “5130” and “2730c” are also easy to be recognized
because of the punctuation “、” and the connective “和
(and).” The improvement on b1 owes to some brand names
that do not exist in the brand dictionary; because it is hard
to be recognized in a linear-chain CRF, a skip-chain CRF
applies the information around the words that are con-
nected with this word by a connective, for example, “华为
U8800 与摩托 ME52 哪一个好 (which is better, HU-
AWEI U8800 or MOTO ME52),” where “摩托 (MOTO)”
is an abbreviation of “摩托罗拉 (MOTOROLA).”
5.3.3 Portability test
At last, the proposed model is applied on a portability test
corpus. This corpus consisted of sentences about digital
camera. The components of a digital camera name are sim-
ilar with a mobile phone name, what have to be modified is
just adding usual camera brand names into the brand dic-
tionary. The final result is shown in Table 5 below:
Table 5 shows the proposed model still has good per-
formance on camera domains. This demonstrates that the
Fig. 5 The F1 value of skip-chain CRF and linear-chain CRF on
opening natural corpus
Fig. 6 The precision of skip-chain CRF and linear-chain CRF on
opening manual corpus
Fig. 7 The recall of skip-chain CRF and linear-chain CRF on
opening manual corpus
Table 3 The experimental results of skip-chain CRF and linear-chain
CRF on opening natural corpus
Labels Indicators Skip-chain CRF Linear-chain CRF
o P 0.9719 0.9690
R 0.9802 0.9817
F1 0.9760 0.9753
b1 P 0.9859 0.9807
R 0.9090 0.9053
F1 0.9459 0.9415
b2 P 1.0 1.0
R 0.5 0.5
F1 0.6666 0.6666
t1 P 0.9206 0.9333
R 0.9508 0.9514
F1 0.9354 0.9423
t2 P 0.56 0.5416
R 0.6086 0.5652
F1 0.5833 0.5531
The highest values in the table are kept in bold
Neural Comput & Applic (2013) 23:371–379 377
123

skip-chain CRF has good portability and can be easily
applied on other domains with little modification. There
still be some characteristics in camera corpus, for example,
camera names and camera battery names often occur in a
sentence together, and their forms are very similar. This
may lead to recognize a camera battery name as a camera
name. In this case, further modifications need to be made
such as adding some boundary features that indicate battery
names and so on. These modifications are easy to make.
6 Conclusion
In this paper, the problem caused by connectives in PRO
NER is first considered, and a skip-chain CRF model is
proposed to solve this problem. The proposed model does
not only consider the dependence information between
neighboring labels but also takes advantage of dependence
information between words that have coordinating relation,
and outperforms the existing linear-chain CRF approach.
Since phenomena such as nested entities often occur in
product named entities, and they make recognition work
more complex, hierarchical CRF models with skip-chain
can be applied to improve the performance.
References
1. Zhao J, Liu F (2008) Product named entity recognition in Chinese
text. Lang Resour Eval 42(2):197–217
2. Pierre JM (2002) Mining knowledge from text collections using
automatically generated metadata. In: Proceedings of fourth
international conference on practical aspects of knowledge
management
3. Yu Hk, Zhang H, Liu Q, Lv X, Shi S (2006) Chinese named
entity identification using cascaded hidden Markov model. J
Commun 27(2):87–93 (in Chinese)
4. Bick E (2004) A named entity recognizer for Danish. In: Pro-
ceedings of 4th international conference on language resources
and evaluation, pp 305–308
5. Liu F, Zhao J, Lv B, Xu B, Yu H, Xia Y (2006) Study on product
named entity recognition for business information extraction. J
Chin Info Process 20(1):7–13 (in chinese)
6. Huang L, Liu Q (2008) Method for Chinese product name rec-
ognition based on conditional random fields. Appl Res Comput
25:1829–1831 (in Chinese)
7. Luo F, Xiao H, Chang W (2011) Product named entity recogni-
tion using conditional random fields. In: 2011 Fourth
international conference on business intelligence and financial
engineering
8. Sutton C, McCallum A (2007) An introduction to conditional
random fields for relational learning. In: Getoor L, Taskar B (eds)
Introduction to statistical relational learning. MIT Press,
Cambridge
9. Niu C, Li W, Ding Jh, Srihari RK (2003) A bootstrapping
approach to named entity classification using successive learners.
In: Proceedings of the 41st ACL, Sapporo, Japan, pp 335–342
10. Lafferty J, McCallum A, Pereira F (2001) Conditional random
fields: Probabilistic models for segmenting and labeling sequence
data. In: Proceedings of the international conference on machine
learning (ICML-2001)
11. McCallum A, Wellner B (2005) Conditional models of identity
uncertainty with application to noun coreference. In: Saul LK,
Weiss Y, Bottou L (eds) Advances in neural information pro-
cessing systems, vol 17. MIT Press, Cambridge, pp 905–912
Fig. 8 The F1 value of skip-chain CRF and linear-chain CRF on
opening manual corpus
Table 4 The experimental result of skip-chain CRF and linear-chain
CRF on opening manual corpus
Labels Indicators Skip-chain CRF Linear-chain CRF
o P 0.9798 0.9773
R 0.9961 0.9923
F1 0.9879 0.9847
b1 P 0.9901 0.9842
R 0.9436 0.8826
F1 0.9663 0.9306
b2 P 1.0 1.0
R 1.0 1.0
F1 1.0 1.0
t1 P 0.9733 0.9397
R 0.9798 0.9429
F1 0.9765 0.9413
t2 P 0.7307 0.55
R 0.6129 0.7096
F1 0.6666 0.6197
The highest values in the table are kept in bold
Table 5 Skip-chain CRF on portability test corpus
o b1 b2 t1 t2
P 0.9897 0.8991 1.0 0.8916 0.4
R 0.9720 0.9907 1.0 0.8991 0.4761
F1 0.9807 0.9427 1.0 0.8953 0.4347
378 Neural Comput & Applic (2013) 23:371–379
123

12. Taskar B, Abbeel P, Koller D (2002) Discriminative probabilistic
models for relational data. In: Eighteenth conference on uncer-
tainty in artificial intelligence (UAI02)
13. McCallum AK (2002) MALLET: a machine learning for lan-
guage toolkit. http://mallet.cs.umass.edu
14. Zhang HP, Yu HK, Xiong DY, Liu Q (2003) HHMM-based
Chinese lexical analyzer ICTCLAS. SIGHAN ‘03. In: Proceed-
ings of the second SIGHAN Workshop affiliated with 41th ACL,
vol 17, pp 184–187
Neural Comput & Applic (2013) 23:371–379 379
123