processing life science data at scale - using semantic web technologies
TRANSCRIPT

© Insight 2014. All Rights Reserved
Processing Life Science Data at Scale – using Semantic Web Technologies
Ali Hasnain, Naoise Dunne, Dietrich Rebholz-Schuhmann

© Insight 2014. All Rights Reserved© Insight 2014. All Rights Reserved
Presenters and Contributors
Ali Hasnain
Dietrich Rebholz-Schuhmann
Naoise Dunne

•Motivation•Query Federation•Infrastructure•Graph Aggregation•Visualization•Hands On Session
Agenda

© Insight 2014. All Rights Reserved
Session 0: Motivation

The Web is evolving...
WWW (Tim Berners-Lee)“There was a second part of the dream […] we could then use computers to help us analyse it, make sense of what we re doing, where we individually fit in, and how we can better work together.”

© Insight 2014. All Rights Reserved© Insight 2014. All Rights Reserved 6 of 46
Two Key Ingredients
1. RDF – Resource Description FrameworkGraph based Data – nodes and arcs• Identifies objects (URIs)• Interlink information (Relationships)
2. Vocabularies (Ontologies)• provide shared understanding of a domain• organise knowledge in a machine-comprehensible way• give an exploitable meaning to the data

© Insight 2014. All Rights Reserved© Insight 2014. All Rights Reserved
Why Graphs?
TGFβ-3
transforming growth factor, beta 3
Homo sapiens
CCCCGGCGCAGCGCGGCCGCAGCAGCCTCCGCCCCCCGCACGGTGTGAGCGCCCGACGCGGCCGAGGCGG …
14q24
nci:has_description
nih:sequence
nih:organism
nih:location
nih:organism
TGFβ-3
Platelet activation, signalling,aggregation
Response to elevated platelet cytosol Ca2+
Platelet degranulation
rea:process
rea:processrea:process
Gene Database Pathway
Database

© Insight 2014. All Rights Reserved© Insight 2014. All Rights Reserved
Why Graphs?
TGFβ-3
transforming growth factor, beta 3
Homo sapiens
CCCCGGCGCAGCGCGGCCGCAGCAGCCTCCGCCCCCCGCACGGTGTGAGCGCCCGACGCGGCCGAGGCGG …
14q24
nci:has_description
nih:sequence
nih:organism
nih:location
nih:organism
TGFβ-3
Platelet activation, signalling,aggregation
Response to elevated platelet cytosol Ca2+
Platelet degranulation
rea:process
rea:processrea:process
Gene Database Pathway
Database
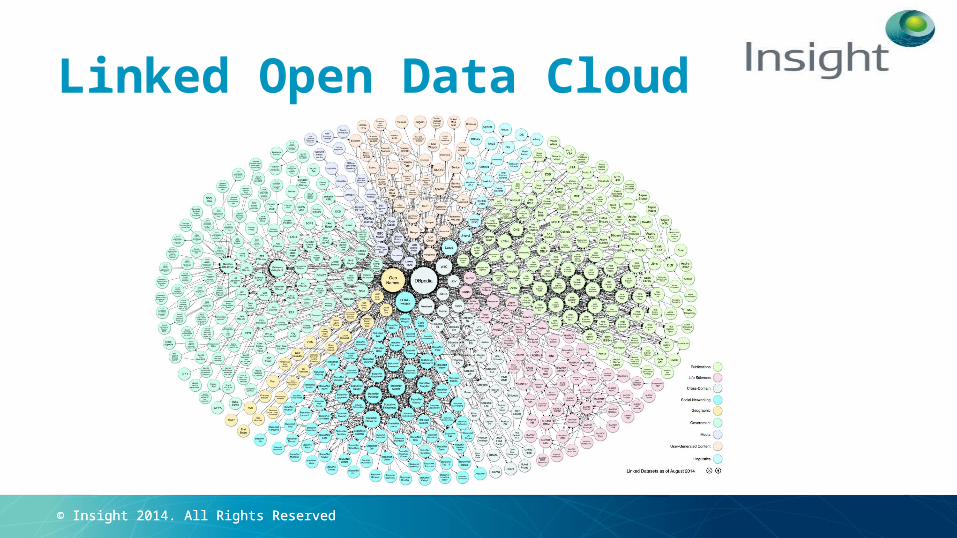
© Insight 2014. All Rights Reserved© Insight 2014. All Rights Reserved
Linked Open Data Cloud

© Insight 2014. All Rights Reserved© Insight 2014. All Rights Reserved
Life Sciences….

© Insight 2014. All Rights Reserved© Insight 2014. All Rights Reserved
Relevant trends ongoing in the public
• “Health wearables”• Generating data, private data, data streams
• Personalized medicine• Genomics information available, but also biomarker analysis• Health-related, sports, nutrition, aging
• Treatment according to specific genomic parameters
• Systems medicine, translational medicine

Distributed Biomedical Repositories (Demo)
http://safe.sels.insight-centre.org/
12Insight Centre for Data Analytics

© Insight 2014. All Rights Reserved
Session 1: Accessing Data- Query Federation
Ali Hasnain, Naoise Dunne, Dietrich Rebholz-Schuhmann

© Insight 2014. All Rights Reserved
Distributed Biomedical Repositories

© Insight 2014. All Rights Reserved
SPARQL Query Federation Approaches
•SPARQL Endpoint Federation (SEF)
•Linked Data Federation (LDF)
•Distributed Hash Tables (DHTs)
•Hybrid of SEF+LDF

© Insight 2014. All Rights Reserved
SPARQL Query Federation Approaches

© Insight 2014. All Rights Reserved
SPARQL Endpoint Federation Approaches• Most commonly used approaches• Make use of SPARQL endpoints URLs• Fast query execution• RDF data needs to be exposed via SPARQL
endpoints• E.g., HiBISCus, FedX, SPLENDID, ANAPSID, LHD
etc.

© Insight 2014. All Rights Reserved
Linked Data Federation Approaches• Data needs not be exposed via SPARQL endpoints
• Uses URI lookups at runtime
• Data should follow Linked Data principles
• Slower as compared to previous approaches
• E.g., LDQPS, SIHJoin, WoDQA etc.

© Insight 2014. All Rights Reserved
Query federation on top of Distributed Hash Tables
• Uses DHT indexing to federate SPARQL queries
• Space efficient
• Cannot deal with whole LOD
• E.g., ATLAS

© Insight 2014. All Rights Reserved
Hybrid of SEF+LDFFederation over SPARQL endpoints and Linked Data
Can potentially deal with whole LOD
E.g., ADERIS-Hybrid

© Insight 2014. All Rights Reserved© Insight 2014. All Rights Reserved
SPARQL Endpoint Federation
S1
S2
S3
S4
RDF RDF RDF RDF
Parsing/Rewriting
Source Selection
Federator Optimzer
Integrator
Rewrite query and get Individual Triple
Patterns
Identify capable source against Individual Triple
Patterns
Generate optimized sub-query Exe. Plan
Integrate sub-queries results
Execute sub-queries
Curtsey Muhammad Saleem (AKSW)

© Insight 2014. All Rights Reserved© Insight 2014. All Rights Reserved
FedBench (LD3): Return for all US presidents their party membership and news pages about them.
SELECT ?president ?party ?page WHERE {?president rdf:type dbpedia:President .?president dbpedia:nationality dbpedia:United_States .?president dbpedia:party ?party .?x nyt:topicPage ?page .?x owl:sameAs ?president .}
dbpedia
RDF
Source Selection Algorithm
Triple pattern-wise source selection
S1TP1 =
KEGG
RDF
ChEBI
RDF
NYT
RDF
SWDF
RDF
LMDB
RDF
Jamendo
RDF
Geo Names
RDF
DrugBank
RDF
S1 S2 S3 S4 S5 S6 S7 S8 S9
//TP1
//TP3//TP4
//TP5
//TP2
TP2 = S1
Source Selection
Curtsey Muhammad Saleem (AKSW)

© Insight 2014. All Rights Reserved© Insight 2014. All Rights Reserved
FedBench (LD3): Return for all US presidents their party membership and news pages about them.
SELECT ?president ?party ?page WHERE {?president rdf:type dbpedia:President .?president dbpedia:nationality dbpedia:United_States .?president dbpedia:party ?party .?x nyt:topicPage ?page .?x owl:sameAs ?president .}
dbpedia
RDF
Source Selection Algorithm
Triple pattern-wise source selection
S1TP1 =
KEGG
RDF
ChEBI
RDF
NYT
RDF
SWDF
RDF
LMDB
RDF
Jamendo
RDF
Geo Names
RDF
DrugBank
RDF
S1 S2 S3 S4 S5 S6 S7 S8 S9
//TP1
//TP3//TP4
//TP5
//TP2
TP2 = S1
TP3 = S1
Source Selection
Curtsey Muhammad Saleem (AKSW)

© Insight 2014. All Rights Reserved© Insight 2014. All Rights Reserved
FedBench (LD3): Return for all US presidents their party membership and news pages about them.
SELECT ?president ?party ?page WHERE {?president rdf:type dbpedia:President .?president dbpedia:nationality dbpedia:United_States .?president dbpedia:party ?party .?x nyt:topicPage ?page .?x owl:sameAs ?president .}
dbpedia
RDF
Source Selection Algorithm
Triple pattern-wise source selection
S1TP1 =
KEGG
RDF
ChEBI
RDF
NYT
RDF
SWDF
RDF
LMDB
RDF
Jamendo
RDF
Geo Names
RDF
DrugBank
RDF
S1 S2 S3 S4 S5 S6 S7 S8 S9
//TP1
//TP3//TP4
//TP5
//TP2
TP2 = S1
TP3 = S1 TP4 = S4
Source Selection
Curtsey Muhammad Saleem (AKSW)

© Insight 2014. All Rights Reserved© Insight 2014. All Rights Reserved
FedBench (LD3): Return for all US presidents their party membership and news pages about them.
SELECT ?president ?party ?page WHERE {?president rdf:type dbpedia:President .?president dbpedia:nationality dbpedia:United_States .?president dbpedia:party ?party .?x nyt:topicPage ?page .?x owl:sameAs ?president .}
dbpedia
RDF
Source Selection Algorithm
Triple pattern-wise source selection
S1TP1 =
KEGG
RDF
ChEBI
RDF
NYT
RDF
SWDF
RDF
LMDB
RDF
Jamendo
RDF
Geo Names
RDF
DrugBank
RDF
S1 S2 S3 S4 S5 S6 S7 S8 S9
//TP1
//TP3//TP4
//TP5
//TP2
TP2 = S1
TP3 = S1 TP4 = S4
TP5 = S1 S2 S4-S9
Source Selection
Total triple pattern-wise sources selected = 1+1+1+1+8 => 12
Curtsey Muhammad Saleem (AKSW)

© Insight 2014. All Rights Reserved
SPARQL Query Federation Engine•FedX
•SPLENDID
•HiBISCuS+FedX
•HiBISCuS+SPLENDID
•ANAPSID
•BioFed
•LHD
•DARQ

© Insight 2014. All Rights Reserved
Overview of Implementation details of Federated Sparql Query Engines

© Insight 2014. All Rights Reserved
System Features of Federated Sparql Query Engines

© Insight 2014. All Rights Reserved
System’s Support for SPARQL Query Construct

© Insight 2014. All Rights Reserved
Session 2: Infrastructuretrends in big linked data infrastructure

© Insight 2014. All Rights Reserved
Mixed data sources and query tools
Cancer AtlasCurated Federated cluster(Indexed)
HBASEDistributed Database
DrugBank
Sparql 1.1Ad hocFederated
Federation RDD and MapReduce
MongoDistributed Database
Gremlin
TitianDistributedGraph Database

© Insight 2014. All Rights Reserved
IntroductionCloud computing frameworks tailored for managing and analyzing big data-sets are powering ever larger clusters of computers.This presentation will describe the infrastructure that is required to serve a linked data flavour of big data

© Insight 2014. All Rights Reserved
What is Big Data?“Big Data is characterized by High Volume, Velocity
and Variety requiring specific Technology and Analytical Methods for its transformation into Value” - Gartner
• Volume - Data is too big to fit on even largest server
• Velocity - Data need handling based on speed • Variety - heterogeneous Data - comes in
many forms• Veracity - (sometimes) Quality of the data

© Insight 2014. All Rights Reserved Infographic summerizing 4 Vs

© Insight 2014. All Rights Reserved
The nature of applications What is the nature of application this kind of
infrastructure enablesZebra fish (Jeremy Freeman)• needed to map and manipulate the brain at scale
to understand Zebrafish neural activity• Scales too great for one processor

© Insight 2014. All Rights Reserved
Using spark

© Insight 2014. All Rights Reserved
How can I get me one?How to enable your research with cutting edge
distributed computing with little effort

© Insight 2014. All Rights Reserved
DistributedHigh Utilisation & Scalability
The Rise of distributed Datacenter Schedulers

© Insight 2014. All Rights Reserved
The qualities of a big data Infrastructure• Distributed
• Data and its processing is shared on large cluster multiple cheap commodity servers
• loose coupling, isolation, location transparency, data locality & app-level composition
• High Utilisation• The infrastructure give the best use of computing resources
• Resilience (handling failure)• The infrastructure stays responsive in the face of failure and can “heal”
• Scalability • grows to meet demand (Elastic), responsive under varying workload (Load
balanced)• Operationally efficient
• Needs to be highly automated, be very easy to maintain

© Insight 2014. All Rights Reserved
Why Datacenter schedulers? Schedulers run your Distributed Apps
• are an operating system kernel for the cloud• Schedulers coordinate execution of work on
cluster• help you to get as many compute resources as
you want whenever you want it• Abstract some scalability and load balancing
issues

© Insight 2014. All Rights Reserved
Benefits of using a Scheduler• Efficiency - best use of computing resources• Agility - change your application mix with no
turnaround• Scalability - grow to the current demand of your
app• Modularity - 2 level schedulers have plugin
frameworks that allow quick repurposing of core and no reliance on one vendor (more later)

© Insight 2014. All Rights Reserved
Datacenter schedulersSchedulers help you focus on your own work and not the infrastructure.“its great to be able to focus on what it is you want
to be doing rather than worrying about how do you get what it is you need in order to be able to get stuff done” - John Wilkes (Google)

© Insight 2014. All Rights Reserved Quick history of distributed schedulers
2004 mapreduce paper
2004 Google Borg
2011 Hadoop1.02003 Google filesystem
2003 2004 2005 2006 2007 2008 2009 2010 2011 2012 2013 2014 2015
2008 Hadoop released
2013 Yarn
2010 Spark Paper
2010 Nexus (Mesos)
2005 Hadoop started
2013 Mesos Released
2011 Mesos Paper
2014 Kubernetes
2014 Google Omega paper
History of Datacenter Schedulers
2003 Slurm
© Insight 2014. All Rights Reserved
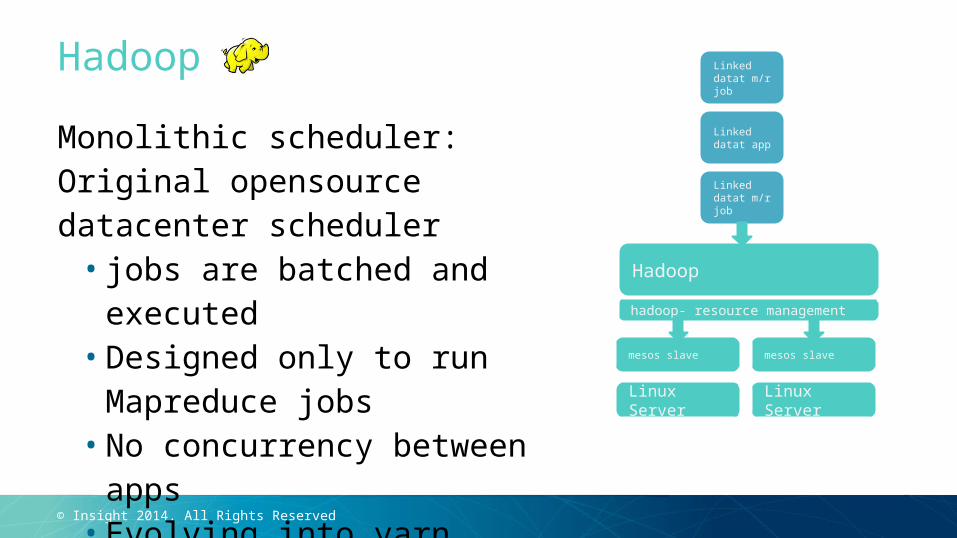
HadoopMonolithic scheduler: Original opensource datacenter scheduler
• jobs are batched and executed
• Designed only to run Mapreduce jobs
• No concurrency between apps
• Evolving into yarn
Hadoop
Linux Server
Linux Server
hadoop- resource management
mesos slavemesos slave
Linked datat m/r job
Linked datat m/r job
Linked datat app

© Insight 2014. All Rights Reserved
Mesos2 level scheduler : More flexible
• Can Schedule many kinds of applications
• Frameworks (such as spark) are delegated the per application scheduling
• Mesos responsible for resource distribution between applications and enforcing overall fairness
• Very modular, due to 2 level scheduling. frameworks manage apps as they like
Mesos
Linux Server
Linux Server
Mesos - resource management
Mesos - scheduler jobs
frameworkchronos
mesos slave
frameworkspark
frameworkmarathon
mesos slave
Hadoop M/R job
Linked data job
Linked datat app

© Insight 2014. All Rights Reserved
Schedulers RecapScheduler allow you to use your cluster as one
machine• ease operations• provide elasticity and load balancing• Can run both batch and longer running jobs• Are Efficient, Agile, scalable and modular

© Insight 2014. All Rights Reserved
Managing Failure in Infrastructure
“Everything fails all the time”Werner Vogels (CTO Amazon)

© Insight 2014. All Rights Reserved
Handling FailureThe harsh reality: all distributed infrastructures must deal with failurefor the designers of applications running on distributed infrastructure (even Mesos), a great number of design mistakes need to be avoided...

© Insight 2014. All Rights Reserved
Fallacies of distributed computing• The most common misconceptions that lead to failure of Network
infrastructure:• The network is reliable.• Latency is zero.• Bandwidth is infinite.• The network is secure.• Topology doesn’t change.• There is one administrator.• Transport cost is zero.• The network is homogeneous
All prove to be false in the long run and all cause big trouble and painful learning experiences.

© Insight 2014. All Rights Reserved
How successful infrastructure avoids failureNo Single point of failuremultiple masters, multiple copies of data, and redundancy on all services. Use elections between masters, use distributed locks and thresholds.
Design Applications to Expect FailureApplications should continue to function even if the underlying physical hardware fails.Evolving infrastructure eases this by the use schedulers and container managers.
Special Channel for failuresProvides the means to delegate errors as messages on their own channel or service. Techniques include log aggregation and shared monitoring services.

© Insight 2014. All Rights Reserved
Operationally efficientUsing Containers for better Quality of Service

© Insight 2014. All Rights Reserved
ContainersContainers run your application in isolation in a portable and repeatable fashion“Because of the way that ... containers separate the application constraints from infrastructure concerns, we help solve that dependency hell.” - Docker

© Insight 2014. All Rights Reserved
Why Containers
Containers Are: • Small (footprint)• Portable• Fast
Containers Allow:• Resiliency
• can be redeployed in seconds• Operationally efficiency
• The infrastructure can “heal”• Scalability
• on a single server allows resources (such as CPU) to be dialed up or down

© Insight 2014. All Rights Reserved
Containers vs. VMs
Virtual Machinesemulate a virtual hardware, require considerable overhead in CPU, Disk and Memory
Containersuse shared operating systems much more efficient than hypervisors in system resource terms

© Insight 2014. All Rights Reserved
Containers vs. VMs

© Insight 2014. All Rights Reserved
ContainersBut which container to use.
Many choices exist…LXC, Docker, Rocket

© Insight 2014. All Rights Reserved
Docker - our container of choiceWhy Docker?• Best of breed at the moment• integrates natively with Mesos and Kubernetes • Has great infrastructure including • Docker registry for looking up containers• Docker compose for combining containers
Alternatives• Rockit - More secure as uses init.d but Linux only

© Insight 2014. All Rights Reserved
Container StandardisationBut choosing a container is not a commitment...Looks like standardisation around the corner via open container:
https://www.opencontainers.org/
Initiative Sponsors: Apcera, AT&T, AWS, Cisco, ClusterHQ, CoreOS, Datera, Docker, EMC, Fujitsu, Google, Goldman Sachs, HP, Huawei, IBM, Intel, Joyent, Kismatic, Kyup, the Linux Foundation, Mesosphere, Microsoft, Midokura, Nutanix, Oracle, Pivotal, Polyverse, Rancher, Red Hat, Resin.io, Suse, Sysdig, Twitter, Verizon, VMWare

© Insight 2014. All Rights Reserved
Recap: ContainersContainers Are: • Small (footprint), Portable, Fast• Allow you to repeatedly deploy applications• Work well with schedulers such as Mesos• Help with Resiliency and scalability

© Insight 2014. All Rights Reserved
Putting it all togetherInsights Linked Data infrastructure

© Insight 2014. All Rights Reserved
Linked Data Infrastructure
Mesos
Mesos - scheduler short jobs Mesos - scheduler long run jobs
Spark Fwk Chronos Fwk
Marathon Framework
OS Monitor
Mesos Monitor
Linux Server
Linux Server
Linux Server
Mesos - resource management
mesos client Docker mesos
client Docker mesos client Docker
Resources cpu mem disk Managed by Mesos
Applications work with frameworks to get resources they need
Frameworks Negotiate with mesos to run their jobs
DatastoresHDT, Neo4JgraphX Granatum RevealedGraph
Jobs
Docker manages isolation on Linux servers

© Insight 2014. All Rights Reserved
Linked Data Infrastructure
Mesos
Linux Server
Linux Server
Linux Server
Mesos - resource management
Mesos - scheduler short jobs Mesos - scheduler long run jobs
Spark Fwk
Chronos Fwk
DatastoresHDT, Neo4J
Marathon
graphX
mesos client Docker
OS Monitor
Mesos Monitor
mesos client Docker mesos
client Docker
We use graph X for large graph batch jobs
We use both HDT(RDF Store)Neo4J (Graph)
Granatum Revealed
We deploy specialised linked data applicationsto cluster

© Insight 2014. All Rights Reserved
RecapTo provide linked data at scale and with the right service mix, infrastructures need to consider:
• Services to help application to be Distributed Scalable
• High Utilisation of computing resources • Know how you will handle failure• Operationally efficient
We suggest, using schedulers such as mesos with containers (Docker), use suitable frameworks (GraphX/Spark) and datastores (Neo4J)

© Insight 2014. All Rights Reserved
Thank youQ & A

© Insight 2014. All Rights Reserved
Graph Aggregation at scale
Naoise Dunne, Ali Hasnain, Dietrich Rebholz-Schuhmann

© Insight 2014. All Rights Reserved
Linked DataA method of publishing structured data so that it can be interlinked.
• Normally represented as RDF• Normally queried using
SPARQL
4 principles of linked data1. Use URIs to name (identify) things.2. Use HTTP URIs so can be looked up3. Provide metadata about what thing is.
- use open standards RDF, SPARQL, etc.
4. Link to other things using their HTTP URI-based names

© Insight 2014. All Rights Reserved
Linked data as a graphLinked data can be considered a Heterogeneous
Graph
What do we mean by Heterogeneous Graph?• Linked data graphs share graph structure but have mixed characteristics • Nodes (Vertices) contain different data• Links (Edges) Mix of directed and undirected• Linked Data Graph can be weighted or not• Can have a mix of classes and types from differing Ontologies
What do these graphs look like?

© Insight 2014. All Rights Reserved graphs within a Heterogeneous Graph

© Insight 2014. All Rights Reserved
Comparing AggregationApproaches

© Insight 2014. All Rights Reserved
Linked data as a graphAs Linked data graphs share graph structure and can be connected we can reason over them using graph algorithms.
Popular approaches to querying graphs are:• Declarative pattern matching - SPARQL • graph traversal languages - Cypher, Gremlin• distributed graph data structures - GraphX

© Insight 2014. All Rights Reserved
Comparing Graph Query ApproachesGremlin - graph traversalA “pure” graph traversal language based on xpath, allows powerful expression of graph algorithms, but at cost of concisenessCharacteristics
• Great for expressing most graph algorithms
• can be scaled • uses adjacency tables
Prosgreat at localized searches (shortest path for instance)interoperable with most databaseConsCan be difficult to understand
Graph X - message passingDSL rather than language. For “programmers” Scala, Java and Python APIs.Characteristics
• Resilient Distributed Property Graph
• index-free adjacency• Vertex/Edge table
ProsBest (in list) distributed executionPowerful mix of table and traversalhas a set of optimised operators ConsNot a database, data needs to be loaded and stored separately
SPARQL -declarativeDeclarative language, allowing better expression and abstracting the writer from optimisation problemsCharacteristics
• Stores Triples (tuples)• Vendor normally optimise
popular queries.• Often built on RDBMS
ProsIs Expressive languageEasy to express search patternsConsDifficult to scalePoor at traversal

© Insight 2014. All Rights Reserved
Comparing Graph Query ApproachesGremlin - graph traversalA “pure” graph traversal language based on xpath, allows powerful expression of graph algorithms, but at cost of conciseness
Graph X - message passingDSL rather than language. Scala, Java and Python APIs.
SPARQL -declarativeis a declarative language, allowing better expression and abstracting the writer from optimisation problems
Abstract Concrete
Considerable work (for vendors) to scale Little work to scale
Optimised for aggregation
Optimised for connections
Global Local

© Insight 2014. All Rights Reserved
Other Graph Query LanguagesGremlin - graph traversalA “pure” graph traversal language based on xpath, allows powerful expression of graph algorithms, but at cost of conciseness
AlternativesNetwork XA python DSL for graphs
Graph X - Message passingDSL rather than language. For “programmers” Scala, Java and Python APIs. Very scaleable.
AlternativesGraphLabvery powerful commercial productGiraffeA hadoop API for graphs
SPARQL -DeclarativeDeclarative language, allowing better expression and abstracting the writer from optimisation problems
AlternativesCypherHas pattern matching constructs, can do much the same as sparql on Neo4J database

© Insight 2014. All Rights Reserved
Working with linked data with Gremlin

© Insight 2014. All Rights Reserved
How to Aggregate Graphs with Sparql?

© Insight 2014. All Rights Reserved
What is Graph AggregationCondenses a large graph into a structurally similar but smaller graph by collapsing vertices and edgesImagine the LOD cloud, and how the aggregate may look

© Insight 2014. All Rights Reserved
What is Graph AggregationPREFIX : <http://example.org/> PREFIX rdf:<http://www.w3.org/1999/02/22-rdf-syntax-ns#>
CONSTRUCT { _:b0 a ?t1; :count COUNT(?sub.s) . _:b1 a ?t2; :count COUNT(?obj.o). _:b2 a rdf:Statement; rdf:predicate ?p; rdf:subject _:b0; rdf:object _:b1; :count ?prop_count } WHERE { GRAPH_AGGREGATION { ?s ?p ?o {?s a ?t1} GROUP BY ?t1 AS ?sub {?o a ?t2} GROUP BY ?t2 AS ?obj }}

The Famous LOD Cloud
http://lod-cloud.net/

The Famous LOD Cloud (from a different Angel)

Gagg: Two-steps Aggregation
● Relation & measure● Subject dimension(s)
& measure● Object dimension(s) &
measure
Uses aggregation functions and a template similar to CONSTRUCT queries

© Insight 2014. All Rights Reserved
How do we Aggregate Linked data at scale

© Insight 2014. All Rights Reserved
Scaling SPARQLSo you still want to use sparql at scaleHow do we query RDF data with SPARQL at Big data scale?Clustering
• Some vendors/platforms provide clustered triple-stores
FederationBecame available in Sparql 1.1 with SERVICE keyword
• Federation emerged with great promises.• For distributed computing, sparql federation has limitations (for
now).• Query planning for SPARQL is NP Complete

© Insight 2014. All Rights Reserved
Complementing Sparql with Graph algorithmWhen not SPARQL • For distributed computing,
declarative languages such as SPARQL are (for now) problematic
• you cannot know if query is NP or EXP time.
• Difficult to create query plans especially with fast or changing graphs
• Have to rely on federation which is still being researched
Why Graph Traversal• Proven to scale • Graphs traversal lower level
but easier to tune so that it is in P time.
• Most popular algorithm are local (as in) only query neighbouring nodes at any time -thus easier to break up across compute nodes

© Insight 2014. All Rights Reserved
Thank youQ & A

© Insight 2014. All Rights Reserved
Sparql Federation example
Q: How are the protein targets of the gleevec drug differentially expressed, which pathways are they involved in?
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>PREFIX cco: <http://rdf.ebi.ac.uk/terms/chembl#>PREFIX chembl_molecule: <http://rdf.ebi.ac.uk/resource/chembl/molecule/>PREFIX biopax3:<http://www.biopax.org/release/biopax-level3.owl#>PREFIX atlasterms: <http://rdf.ebi.ac.uk/terms/atlas/>PREFIX sio: <http://semanticscience.org/resource/>PREFIX dcterms: <http://purl.org/dc/terms/>PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
SELECT distinct ?dbXref (str(?pathwayname) as ?pathname) ?factorLabel WHERE {
# query chembl for gleevec (CHEMBL941) protein targets ?act a cco:Activity; cco:hasMolecule chembl_molecule:CHEMBL941 ; cco:hasAssay ?assay . ?assay cco:hasTarget ?target . ?target cco:hasTargetComponent ?targetcmpt . ?targetcmpt cco:targetCmptXref ?dbXref . ?targetcmpt cco:taxonomy . ?dbXref a cco:UniprotRef
# query for pathways by those protein targets SERVICE <http://www.ebi.ac.uk/rdf/services/reactome/sparql> { ?protein rdf:type biopax3:Protein . ?protein biopax3:memberPhysicalEntity [biopax3:entityReference ?dbXref] . ?pathway biopax3:displayName ?pathwayname . ?pathway biopax3:pathwayComponent ?reaction . ?reaction ?rel ?protein . }
# get Atlas experiment plus experimental factor where protein is expressed SERVICE <http://www.ebi.ac.uk/rdf/services/atlas/sparql> { ?probe atlasterms:dbXref ?dbXref . ?value atlasterms:isMeasurementOf ?probe . ?value atlasterms:hasFactorValue ?factor . ?value rdfs:label ?factorLabel . }}

© Insight 2014. All Rights Reserved
Why use Graph algorithms
Polynomial timeA lot of queries on linked data can be expressed as well known graph traversal algo. that work in P time such as Dijkstra for positive weighted directed graph. Because these alog are localised suit distributed computed.

© Insight 2014. All Rights Reserved
More pure Dijkstra using CypherMATCH (from: Location {LocationName:"x"}), (to: Location
{LocationName:"y"}) , paths = allShortestPaths((from)-[:CONNECTED_TO*]->(to))WITH REDUCE(dist = 0, rel in rels(paths) | dist +
rel.distance) AS distance, pathsRETURN paths, distance ORDER BY distance LIMIT 1
The other approach used an inbuilt function - this shows a closer approximation of the actual algorithm

© Insight 2014. All Rights Reserved
Dijkstra Psudocodedist[s]←0 (distance to
source vertex is zero)forall v V–{s}∈do dist[v]←∞ (set all other
distances to infinity)S← ∅ (S,the set of visited vert
is initially empty)Q←V (Q,the queue
initially contains all vertices)whileQ≠ ∅ (while the queue
is not empty)dou← mindistance(Q,dist) (select the element of Q with the
min.distance)S←S {u} ∪ (add u to list of
visited vertices)forall v neighbors[u]∈
do if dist[v]>dist[u]+w(u,v) (if new shortest path found)then d[v]←d[u]+w(u,v) (set new value of shortest path)
(if desired,add trace back code)returndist

© Insight 2014. All Rights Reserved
Thank youQ & A

© Insight 2014. All Rights Reserved
VisualizationAli Hasnain, Naoise Dunne, Dietrich Rebholz-
Schuhmann

© Insight 2014. All Rights Reserved
Visualization
• Visualize your Data!• Visualize to easily Query your Data• Example Tools
• ReVeaLD• FedViz

© Insight 2014. All Rights Reserved
ReVeaLD Search PlatformReVeaLD :- Real-Time Visual Explorer and Aggregator of Linked Data, is a user-driven domain-specific search platform.
Intuitively formulate advanced search queries using a click-input-select mechanism
Visualize the results in a domain–suitable format.
Assembly of the query is governed by a Domain Specific Language (DSL), which in this case is the Granatum Biomedical Semantic Model (CanCO)

© Insight 2014. All Rights Reserved
ReVeaLD Search PlatformAvailability:http://140.203.155.7:31005/explorer
Demo: https://www.youtube.com/watch?v=6HHK4ASIkJM&hd=1

© Insight 2014. All Rights Reserved
DSL Visual RepresentationConcept Map Visualization is used.

© Insight 2014. All Rights Reserved
Visual Query Builder

© Insight 2014. All Rights Reserved
Visual Query Model

© Insight 2014. All Rights Reserved
FedViz: A Visual Interface for SPARQL Queries Formulation and Execution
FedViz is an online application that provides Biologist a flexible visual interface to formulate and execute both federated and non-federated SPARQL queries.
It translates the visually assembled queries into SPARQL equivalent and execute using query engine (FedX).
Availability: http://srvgal86.deri.ie/FedViz/index.html

© Insight 2014. All Rights Reserved
FedViz: A Visual Interface for SPARQL Queries Formulation and Execution

© Insight 2014. All Rights Reserved
Using FedViz: Step by Step

© Insight 2014. All Rights Reserved
Hands On SessionNaoise Dunne, Ali Hasnain

© Insight 2014. All Rights Reserved
Hands on sessionThis tutorial is available from
https://goo.gl/JjfJ0f