processadors de llenguatge ii - etic upfrramirez/pl2/l01.pdf · practicas/seminarios: 40% ... en...
TRANSCRIPT


Temas
Sintaxis Semántica Verificación formal Compilación de programas Programación Lógica Programación Funcional Programación Concurrente
Si hay tiempo… Programación Imperativa Programación Orientada a Objectos

Evaluación
Examen teoría: 60% Practicas/seminarios: 40% Practicas = (practicas + examen)/2
Participación
*Se han de aprobar tanto examen (teoria y practicas) como practicas.

Libros
Programming Languages Design and Implementation Terrence Pratt and Marvin Zelkowitz Prentice Hall (2001)
Concepts of Programming Languages Robert Sebesta Addison Wesley (2002)
Modern compiler implementation in ML Andrew W. Appel
Cambridge University Press (1997)

Contacto
Clase Prácticas Email [email protected] Horas oficina: martes 12-2.30pm Anuncios, documentacion, … http://www.dtic.upf.edu/~rramirez/PL2/

Prácticas/seminarios
Seminarios (3): grupos de 2-4
Prácticas (6): grupos de 2

Processadors de Llenguatge II
Introducción Pratt 1.2, 1.3.1, 1.3.2

Programming Languages
Main issues in language design, impl. and usage Syntax -- What a program looks like Semantics -- What a program means → programming paradigm Implementation -- How a program executes Verification – is the program 100% correct?

Programming Languages
A programming paradigm is a fundamental style of computer programming for solving specific software engineering problems.
Paradigms differ in the concepts and abstractions used to represent the elements of a program (such as objects, functions, variables, constraints...) and the steps that compose a computation (assignation, evaluation,...).
A programming language can support multiple paradigms. For example programs written in C++ can be purely procedural, or purely object-oriented, or contain elements of both paradigms.
P.e., in object-oriented programming, programmers can think of a program as a collection of interacting objects, while in functional programming a program can be thought of as a sequence of stateless function evaluations.

Programming Languages
Which language for a specific problem? Pascal, C -- procedural, statement
oriented C++, Java, Smalltalk -- Object oriented ML, Lisp -- Functional Prolog -- Logic-based

Language expressiveness
Existe un programa que puede ser escrito en un lenguaje para el cual no hay realmente programa equivalente en alguno de los otros lenguajes?
e.g. existe un programa que puede ser escrito en Prolog para el cual no haya equivalente en Pascal?

Language expressiveness
Church’s thesis Any computable function can be
computed by a Turing machine.
Why do we need all these different languages?

Language Goals
1950s--1960s Compile programs to execute efficiently. Programmers cheap; Machines expensive. Direct connection between language features and
hardware - goto statements, ...
Today CPU power and memory very cheap; programmers
expensive. Compile programs that are built efficiently Direct connection between language features and design
concepts - encapsulation, inheritance, ...

Attributes of a good language
Clarity, simplicity – a language should provide a clear, simple and unified set of concepts to be used as primitives to develop algorithms.
Orthogonality -every combination of features is meaningful – easier to remember if few exceptions
Naturalness for the application - program structure reflects the logical structure of algorithm
Support for abstraction - program data reflects problem being solved

Attributes of a good language (cont)
Ease of program verification - verifying that program correctly performs its required function
Programming environment - external support for the language
Portability of programs - transportability of the resulting programs from the computer on which they are developed to other computer systems
Cost of use - program execution, program translation, program creation, and program maintenance

Language paradigms Imperative programming Basic concept is machine state Program consists of a sequence of statements:
Stat1; Stat2; ...
Execution of each statement to change state, i.e. change the value of one or more locations in memory.
Functional programming Idea is to find a function that produces the answer, i.e.
what is the function that we must apply to the initial state to get the answer.
Function composition is major operation: f1(f2(f3(X))) Programming consists of building the function that
computes the answer

Language paradigms (cont) Logic programming Based on predicate logic State what the problem is, as opposed to how to solve the problem. Execution is deduction. father(X,Y), father(Y,Z) grandfather(X,Z)
Object-oriented programming Data Objects are built Limited set of functions operate on these data Complex objects are designed as extensions of simpler objects
(inheritance) Syntax: Set of objects (classes) containing data and methods.

Language paradigms (cont)
Concurrent programming Program = set of processes Each process execute sequentially Processes execute concurrently Processes communicate and synchronize their
execution. Involve safety and progress properties.

Processadors de Llenguatge II
Language Syntax Pratt 3.1, 3.3.1

Program structure
Language = Syntax + Semantics
The syntax of a language is concerned with the form of a program: how expressions, commands, declarations etc. are put together to result in the final program.
The semantics of a language is concerned with the meaning of a program: how the programs behave when executed on computers.

Program structure
Just like in natural language:
Semantics (Meaning) You have in your mind, to express a conditional, when true do
something, when false, do something else. Syntax (Form/Structure)
C: if (condition) { …part1… } else { …part2… }
Pascal: if condition begin…part1…end else begin…part2…end
LISP: if (condition) (part1) (part2))

Program structure
Syntax What a program looks like Useful notations for describing PL’s syntax:
BNF grammars (context free grammars) Regular grammars
Semantics What the program means Static semantics - Semantics determined at compile time:
var A: integer; Type and storage for A Dynamic semantics - Semantics determined during execution:
X = ``ABC'' X a string; value of X Useful notations:
Informal: English documents (e.g. ref manuals, etc.) Formal: operational semantics, axiomatic semantics, etc.

BNF grammars Definition: (Some preliminaries)
1. An alphabet is a set whose elements are called symbols.
2. A word (or string) w, over an alphabet A is a finite sequence of symbols from the alphabet. i.e. w ∈An where n ∈ N. When n=0, the word is called an empty word/string and is denoted as ε.
3. The set of words of length n over an alphabet A, is denoted as An.
4. The set of words over an alphabet A, is denoted as A* where:
A* = ∪ An n∈N

BNF grammars Definition:
1. A context-free grammar G, is a quadruple (V,Σ,R,S) where:
a. V is an alphabet b. Σ is a set of terminals, where Σ ⊆ V
(V – Σ is known as the set of non-terminals) c. R is a set of production rules such that R ⊆ (V – Σ) x V* d. S is the start symbol, where S ∈ (V – Σ)
2. The language generated by grammar G (denoted L(G)), is the set of words over Σ, which can be produced by R.

BNF grammars Nonterminal: A finite set of symbols:
<sentence> <subject> <predicate> <verb> <article> <noun>
Terminal: A finite set of symbols: the, boy, girl, ran, ate, cake
Start symbol: One of the nonterminals: <sentence>

Backus-Naur form (BNF) grammars
Rules (productions): A finite set of replacement rules: <sentence> ::= <subject> <predicate> <subject> ::= <article> <noun> <predicate>::= <verb> <article> <noun> <verb> ::= ran | ate <article> ::= the <noun> ::= boy | girl | cake
Replacement Operator: Replace any nonterminal by a right hand side value using any rule (written ⇒)

Example BNF sentences <sentence> ⇒ <subject> <predicate> First rule ⇒ <article> <noun> <predicate> Second rule ⇒ the <noun> <predicate> Fifth rule ... ⇒ the boy ate the cake
Also from <sentence> you can derive ⇒ the cake ate the boy Syntax does not imply correct semantics
Note: Rule <A> ::= <B><C> This BNF rule also written with equivalent (CFG) syntax: A → BC

Languages Any string derived from the start symbol is a
sentential form.
A language generated by grammar G (written L(G) ) is the set of all strings over the terminal alphabet (i.e., sentences) derived from start symbol.
That is, a language is the set of sentential forms containing only terminal symbols.

Derivations A derivation is a sequence of sentential forms starting
from start symbol.
Grammar: B → 0B | 1B | 0 | 1 Derivation: B ⇒ 0B ⇒ 01B ⇒ 010 Each derivation step is the application of a production
rule.

Derivations Derivations may not be unique S → SS | (S) | () S ⇒ SS ⇒(S)S ⇒(())S ⇒(())() S ⇒ SS ⇒ S() ⇒(S)() ⇒(())() Different derivations but get the same
parse tree

Parse tree A parse tree is a hierarchical synt. structure Internal node denote non-terminals Leaf nodes denote terminals. Grammar: B → 0B | 1B | 0 | 1 Derivation: B ⇒ 0B ⇒ 01B ⇒ 010 From derivation get parse tree as shown in the right.
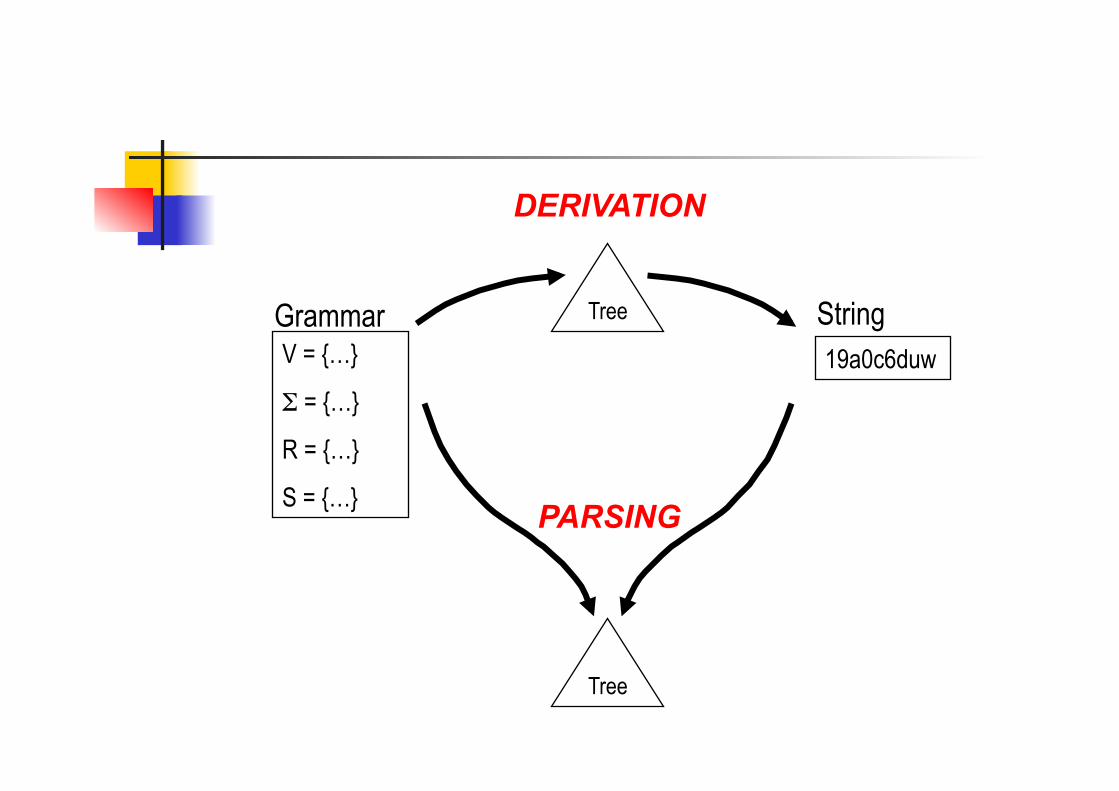
Grammar V = {…}
Σ = {…}
R = {…}
S = {…}
String 19a0c6duw
Tree
DERIVATION
Tree
PARSING

Ambiguity But from some grammars you can get 2 different parse trees for the same string: ()()(). Each corresponds to a unique derivation: S ⇒ SS ⇒ SSS ⇒()SS ⇒()()S ⇒()()()
A grammar is ambiguous if some sentence has 2 distinct parse trees. We desire unambiguous grammars to understand semantics.

Why Ambiguity is a problem Most common cause is due to infix binary operations
<expr> ::= <num> | <expr> – <expr> Grammar 1 – 2 – 3 String
<expr>
<expr> – <expr>
<expr> – <expr> <num>
<num> <num>
1 2
3
<expr>
<expr> – <expr>
<expr> – <expr> <num>
<num> <num>
2 3
1
Parse
Which One?

Why Ambiguity is a problem It may be true that (1-2)-3 = 1-(2-3) and different parse trees doesn’t
matter. Such cases, are not true in general, and we must assume the more conservative position: different parse trees have different meaning.
<expr> ::= <num> | <expr> – <expr> Grammar 1 – 2 – 3 String
Parse
<expr>
1 2
–
<expr>
3
<expr>
<expr> – <expr> <num>
<num> <num>
<expr>
2 3
–
<expr>
1
<expr>
<expr> – <expr> <num>
<num> <num>
(1-2)-3 1-(2-3)
Which One? Different Parse Trees,
Different Meaning!

Why Ambiguity is a problem <expr> ::= <num> | <expr> – <expr> ambiguous
To make it unambiguous, I want the ‘–’ to be… Left associative:
<expr> ::= <num> | <expr> – <num>
Right Assocative: <expr> ::= <num> | <num> – <expr>

Why Ambiguity is a problem Several programming languages allow 2 forms of
conditional statements: 1. If boolean_exp then statement1 2. If boolean_exp then statement1 else statement2
If boolean_exp1 then if boolean_exp2 then S1 else S2

Exercise 1 Is the following grammar (of arithmetic expressions) an
ambiguous grammar ? Try to construct a derivation with two different parse trees.
<E> ::= <E> + <E> <E> ::= <E> *<E> <E> ::= ( <E> ) <E> ::= I

Exercise 1 - Answer <E> ::= <E> + <E> <E> ::= <E> *<E> 2 + 3 * 4 <E> ::= i
E E
E
+
I *
I I
2 3 4
E E
I + I I
2 3 4
E + *

To make it unambiguous (Case 1) + to be of a higher precedence than *
<expr> ::= <expr2> | <expr2> * <expr> <expr2> ::= <num> | <num> + <expr2>
1+2*3
<expr>
<expr2> * <expr>
<num> + <expr2>
<num> 1
2
<expr2>
<num>
3 (1+2)*3

Design of Rules From semantics
(what you want it to mean)… eg. “I want to express the idea of addition”
To abstract syntax (what components you need to capture the meaning)… eg. “I need an operator and two operands”
To concrete syntax … <expr> ::= <num> | <expr> + <expr>
To unambiguous concrete syntax. <expr> ::= <num> | <expr> + <num>
Unambiguous concrete syntax essential for a parser (parser takes a string, returns a syntax tree)

Implementation of Rules Divide the BNF rules into 2 groups:
Lexical rules Syntactic rules
Lexical rules are rules which deal with grouping individual symbols into meaningful words.
Syntactic rules are rules, which deal with the structure of the overall sentence.

Example <E> ::= <E> + <E> | <E> - <T> | <T> <T> ::= <T> * <F> | <T> / <F> | <F> <F> ::= <name> | <num> | (<E>) <name> ::= <alpha> | <alpha><alphanum> <alphanum> ::= <alpha><alphanum> | <digit><alphanum> | <alpha> | <digit> <num> ::= <digit> | <digit><num> <alpha> ::= a | b | c | … | A | B | C | … | Z <digit> ::= 0 | 1 | 2 | … | 9

Example <E> ::= <E> + <E> | <E> - <T> | <T> <T> ::= <T> * <F> | <T> / <F> | <F> <F> ::= <name> | <num> | (<E>) <name> ::= <alpha> | <alpha><alphanum> <alphanum> ::= <alpha><alphanum> | <digit><alphanum> | <alpha> | <digit> <num> ::= <digit> | <digit><num> <alpha> ::= a | b | c | … | A | B | C | … | Z <digit> ::= 0 | 1 | 2 | … | 9
Syntactic Rules
Lexical Rules

Implementation of Rules Lexical Rules get implemented as a Lexical Analyzer:
Input : String of Characters Output : List of Tokens
Syntactic Rules get implemented as a Syntactic Analyzer: Input : List of Tokens Output : Parse Tree
Parser = Lexical Analyzer + Syntactic Analyzer. (Very often, ‘parser’ is used in a loose sense to refer to the syntactic analyzer)

Extended BNF This is a shorthand notation for BNF rules. It adds no
power to the syntax,only a shorthand way to write productions:
[ ] – Grouping from which one must be chosen Binary_E T [+|-] T
{ }* - Repetition - 0 or more E T {[+|-] T}*

Extended BNF { }+ - Repetition - 1 or more
Usage similar to { }*
{ }opt - Optional I if E then S | if E then S else S Can be written in EBNF as I if E then S { else S}opt

Extended BNF
Example: Identifier - a letter followed by 0 or more letters or digits:
Extended BNF Regular BNF I → L { L | D }*
L → a | b |... D → 0 | 1 |...

Extended BNF
Example: Identifier - a letter followed by 0 or more letters or digits:
Extended BNF Regular BNF I → L { L | D }* I → L | L M
L → a | b |... M → CM | C D → 0 | 1 |... C → L | D
L → a | b |...
D → 0 | 1 |...

Classes of grammars BNF: Backus-Naur Form - Context free - Type 2 - Already
described
Regular grammars: subclass of BNF - Type 3: BNF rules are restricted: A → t N | t where: N = nonterminal, t = terminal
Examples: Binary numbers: B → 0 B | 1 B | 0 | 1
Identifiers: I → a L | b L | c L |...| z L | a |...| y | z L → 1 L | 2 L |...| 9 L | 0 L | 1 |...| 9 | 0 | a L | b L | c L |...| z L | a
|...| y | z

Other classes of grammars The context free and regular grammars are important for programming language design.
Other classes have theoretical importance, but not in this course:
Context sensitive grammar: Type 1 – Rules: α → β where | α | ≤ | β | i.e., length of α ≤ length of β, α: string of non terminals, β: string of terminals & non terminals
Unrestricted, recursively enumerable: Type 0 - Rules: α → β. No restrictions on α and β.


Parsing BNF and extended BNF are notations for formally describing
program syntax.
Given the BNF grammar for the syntax of a programming language (say Java), how do we determine that a given Java program obeys all the grammar rules.
This is achieved by parsing.
Two main methods of parsing Top-down parsing (recursive-descent). Bottom-up parsing.

Implementation of Rules Grammar
<num> ::= <int> | <real>
<int> ::= <digit> | <digit><int> <real> ::= <int-part> . <fraction> <int-part> ::= <digit> | <int-part> <digit> <fraction> ::= <digit> | <digit> <fraction> <digit> ::= 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
Is “12.34” accepted by the grammar with <num> as the starting non-terminal?
Top-Down Parse => <num> => <int> (Try first choice) => <digit> (Try first choice) => 1 (Backtrack : “2.34” not parsed)

Implementation of Rules Grammar
<num> ::= <int> | <real>
<int> ::= <digit> | <digit><int> <real> ::= <int-part> . <fraction> <int-part> ::= <digit> | <int-part> <digit> <fraction> ::= <digit> | <digit> <fraction> <digit> ::= 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
Is “12.34” accepted by the grammar with <num> as the starting non-terminal?
Top-Down Parse => <num> => <int> (Try first choice) => <digit><int> (Try second choice) => 1<int> => 1<digit> (Try first choice) => 12 (Backtrack: “.34” not parsed)

Implementation of Rules Grammar
<num> ::= <int> | <real>
<int> ::= <digit> | <digit><int> <real> ::= <int-part> . <fraction> <int-part> ::= <digit> | <int-part> <digit> <fraction> ::= <digit> | <digit> <fraction> <digit> ::= 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
Is “12.34” accepted by the grammar with <num> as the starting non-terminal?
Top-Down Parse => <num> => <real> (Try second choice) => <int-part>.<fraction> => … => 12.34 (success!)

Implementation of Rules Grammar
<num> ::= <int> | <real>
<int> ::= <digit> | <digit><int> <real> ::= <int-part> . <fraction> <int-part> ::= <digit> | <int-part> <digit> <fraction> ::= <digit> | <digit> <fraction> <digit> ::= 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
Is “12.34” accepted by the grammar with <num> as the starting non-terminal?
Bottom-Up Parse => 12.34 => <digit>2.34 => <int>2.34 => <num>2.34 (Backtrack)

Implementation of Rules Grammar
<num> ::= <int> | <real>
<int> ::= <digit> | <digit><int> <real> ::= <int-part> . <fraction> <int-part> ::= <digit> | <int-part> <digit> <fraction> ::= <digit> | <digit> <fraction> <digit> ::= 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
Is “12.34” accepted by the grammar with <num> as the starting non-terminal?
Bottom-Up Parse => 12.34 => <digit>2.34 => <digit><digit>.34 => <digit><int>.34 => <int>.34 => <num>.34 (Backtrack)

Implementation of Rules Grammar
<num> ::= <int> | <real>
<int> ::= <digit> | <digit><int> <real> ::= <int-part> . <fraction> <int-part> ::= <digit> | <int-part> <digit> <fraction> ::= <digit> | <digit> <fraction> <digit> ::= 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
Is “12.34” accepted by the grammar with <num> as the starting non-terminal?
Bottom-Up Parse => 12.34 => … => <int-part>.34 => … => <int-part>.<fraction> => <real> => <num> (Success!)

Recursive descent parsing overview
A simple parsing algorithm
Shows the relationship between the formal description of a programming language and the ability to generate executable code.
Each non-terminal becomes a procedure. Recursively call the procedure to check different parts. (+) Simple Translation from BNF (–) Not Efficient

Recursive descent parsing Example of Top-down parsing.
<expression> ::= <term>+<term> | <term>-<term>
(Some details are left out; just get the idea) procedure Expression; begin Term; /* Call Term to find first term */ while ((nextchar=`+') or (nextchar=`-')) do begin nextchar:=getchar; /* Skip operator */ Term end end
procedure Term; begin ... end
First recognize a Term; as long as the next symbol is either a + or - , we recognize another Term.

Structure of a compiler

Attribute Grammars
Productions
E → E+T | T
T → T*P | P
P → I | (E)

Attribute Grammars Production Attribute E → E+T value(E1) = value(E2)+value(T) E → T value(E) = value(T) T → T*P value(T1) = value(T2)* value(P) T → P value(T) = value(P) P → I value(P) = value(I) P → (E) value(P) = value(E)
E1 is first E in production and E2 is second E in production
Technique often useful for passing data type information within a parse tree.

Example attributed tree

Use of attribute grammars First need to develop parse tree. Attribute grammars assume
you already have the derivation; it is not a parsing algorithm.
Functions for attributes can be arbitrary. Process to build attributes is mostly manual.
Attribute grammars may be used along with parsing to generate intermediate code.
As the parse tree is built, information from one nonterminal is passed to another nonterminal higher in the tree.
When parse is completed, all attribute values have already been computed.

Summary We need a formalism for describing the set of all
allowed programs in a programming language. BNF and EBNF grammars
Given a program P in a programming language L and the BNF grammar for L, we can find out whether P is a syntactically correct program in language L.
This activity is called parsing. The Recursive Descent Parsing technique is one such
parsing technique.