predictive cheminformatics: best practices for determining...
TRANSCRIPT

Predictive Cheminformatics: Best Practices for Determining Model Domain Applicability
Curt M. BrenemanFebruary 22, 2007
Sanibel Conference - 2007

Exploring Chemical DataExploring Chemical Data
WISDOM
DATA
INFORMATION
UNDERSTANDING
KNOWLEDGE

Predictive Predictive CheminformaticsCheminformatics::Models and Statistical MethodsModels and Statistical Methods
“If your experiment needs statistics, you ought to have done a better experiment”- Ernest Rutherford“But what if you haven’t done the experiment yet?”

Prediction of Chemical BehaviorPrediction of Chemical Behavior
– Datasets, Information and Descriptors
– Modeling and Mining Methods
– Validation Methods

Chemical Space and Model ApplicabilityChemical Space and Model Applicability

QSARQSAR: Quantitative Structure: Quantitative Structure--Activity RelationshipsActivity Relationships
• The process by which chemical structure is quantitatively correlated with a well-defined observable endpoint
– Biological (QSAR) or Chemical (QSPR) endpoints
• Structure-Activity Relationships
– Hypothesis: Similar molecules have similar activities• What does “similarity” really mean?

MolecularMolecular SimilaritySimilarity– Similar structure…– Similar function?– Similar in what
way?– How to use this
information?

Problem Definition and Method SelectionProblem Definition and Method Selection
Too FocusedToo Broad
Solution will depend on dataset quality and characteristics
Which approach makes sense?
Descriptors Model Activity
NN
Cl
O
AAACCTCATAGGAAGCATACCAGGAATTACATCA…
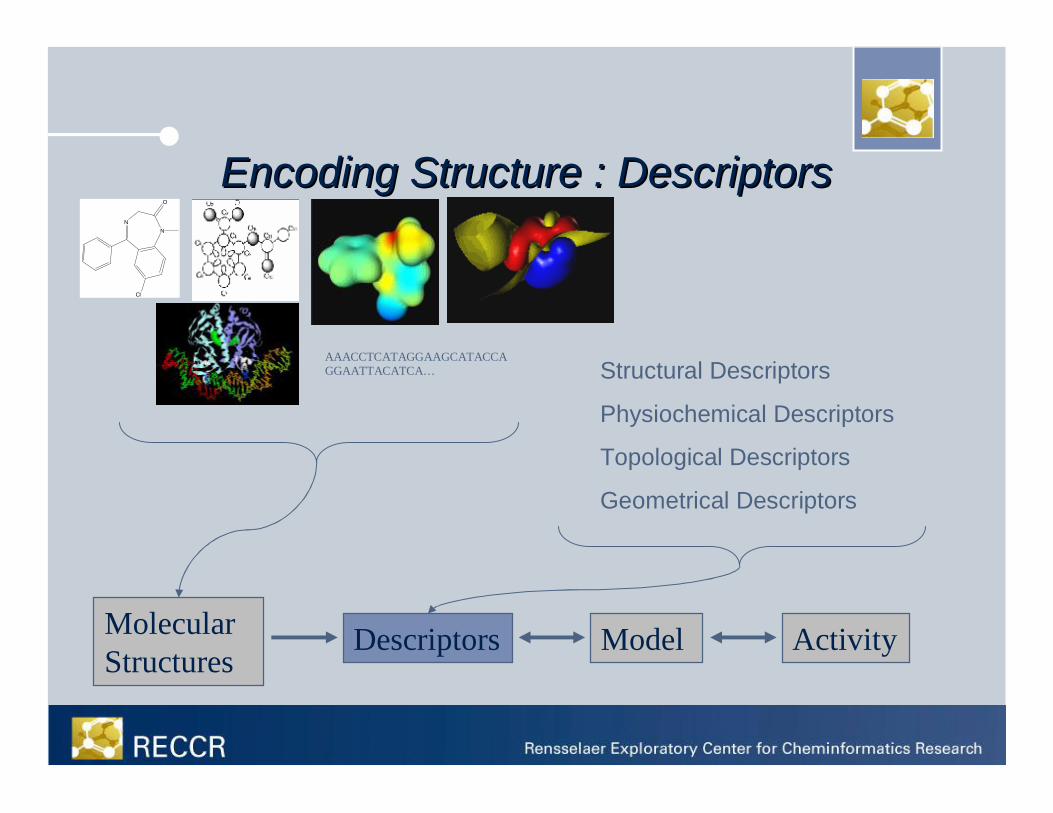
MolecularStructures
Structural Descriptors
Physiochemical Descriptors
Topological Descriptors
Geometrical Descriptors
Encoding Structure : DescriptorsEncoding Structure : Descriptors

Experimental Descriptors
Physicochemical Descriptors
Topological Descriptors
Constitutional Descriptors
Electrostatic Descriptors
Quantum-chemical Descriptors
Thermodynamic Descriptors
Descriptor TypesDescriptor Types
Descriptors Model ActivityMolecularStructures

Descriptor ChoicesDescriptor Choices
• No particular class of descriptors address all problems
– May be chosen to be problem specific
– May be chosen to be method specific

Descriptors Model ActivityMolecularStructures
•Hierarchy of descriptors (data content)
Molecular formulae / simple descriptive information
‘2D descriptors’ (e.g. connectivity information)
‘3D descriptors’ (e.g. shape/property hybrids)
Electronic wavefunction or simulation-based
INFO
RM
ATI
ON
CO
NTE
NT
CO
MP
LEXI
TY
CO
MP
UTA
TIO
N T
IME
OB
FUS
CA
TIO
N
Descriptor HierarchyDescriptor Hierarchy

Dataset and Descriptor AnalysisDataset and Descriptor Analysis– Standard deviation of experimental activity > 1.0 is recommended
(Gedeck, 2006)
– Low collinearity between descriptors is desirable
– Molecule to descriptor ratio should be high– 5:1 ratio or higher on traditional QSAR (Topliss, 1972.)– Special case of data strip mining (Embrechts, 1999.)
– Consistent scaling of descriptors between training, test, and validation sets is essential
– Single conformation models do not fully represent dynamic systems– May need ensemble-weighted molecular descriptors

Model Building and ValidationModel Building and Validation
DATASET
Test set
PredictiveModel
Prediction
Training set
Training Validation
Bootstrap sample k
Tuning /Prediction
LearningModel
Y-scrambling method validation
Models will not reveal mechanism

Metrics for Measuring ModelsMetrics for Measuring Models
For training set we use:• LMSE: least mean square error for training set
• r2 : correlation coefficient for training set
• R2: PRESS R2
• For validation/test set we can use:– LMSE: least mean square error for validation set – q2 : 1 – rtest2– Q2: 1 – Rtest2
( )∑=
−=n
iii yy
nLMSE
1
2ˆ1
( )( )
( ) ( )1
2 2
1 1
ˆ ˆ
ˆ
n
i ii
n n
i ii i
y y y yr
y y y y
=
= =
− −=
− −
∑
∑ ∑)( )
( )∑
∑
=
=
−
−−=
train
train
n
ii
n
iii
yy
yyR
1
2
1
2
2ˆ
1
( )
( )∑
∑
=
=
−
−= n
ii
n
iii
yy
yyQ
1
2
1
2
2ˆ

Model Parsimony RulesModel Parsimony Rules
• Simple models are better
• Interpretable models are better
• Reality: need to balance predictive ability and interpretability

Case StudiesCase Studies
• Protein Bioseparations : Appropriate Descriptors
• Caco-2 Model : Feature Selection effects
• hERG Inhibitors: Classification Improvement

RECCR Online Data Prep ToolsRECCR Online Data Prep Tools

RECCR Online Descriptor ToolsRECCR Online Descriptor Tools

RECCR Machine Learning ToolsRECCR Machine Learning Tools

• Hydrophobic Interaction Chromatography for Protein Separation • Prediction of retention time• Selectivity prediction for optimization of bioseparations• 528 descriptors originally generated
– Electronic TAE surface analysis– pH-sensitive Shape/Property (PPEST)– MOE
Case 1: Protein Affinity DataCase 1: Protein Affinity Data““oror……Why having appropriate descriptors Why having appropriate descriptors
is essentialis essential””
ph 5.0 ph 6.0 ph 7.0 ph 8.0 PPEST ph 7.0

1POC EP ph 6.0
1POC EP ph 4.0
1POC EP ph 7.0
1POC EP ph 5.0
1POC EP ph 8.0
Protein PEST (pH Sensitive Descriptors)Protein PEST (pH Sensitive Descriptors)
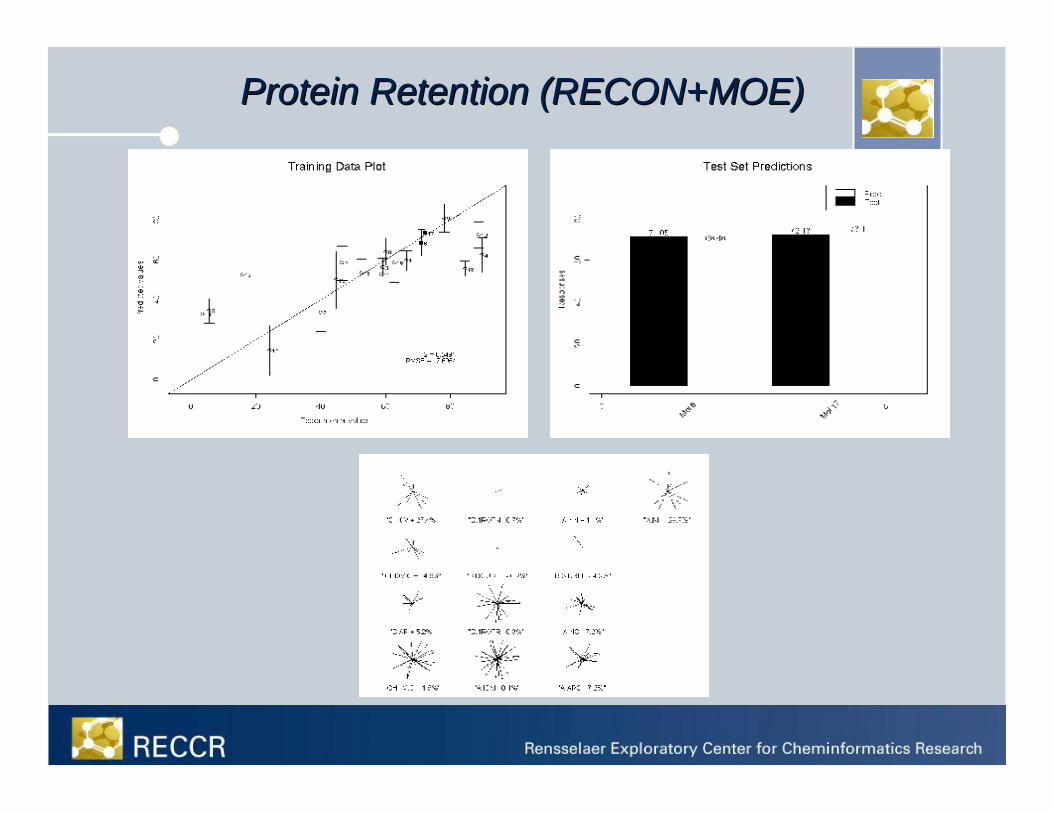
Protein Retention (RECON+MOE)Protein Retention (RECON+MOE)

Protein Retention (RECON+Protein Retention (RECON+PPESTPPEST+MOE)+MOE)

• Human intestinal cell line • Predicts drug absorption• 27 molecules with tested permeability• 718 descriptors generated
– Electronic TAE– Shape/Property (PEST)– Traditional
Case 2: CacoCase 2: Caco--2 Data2 Data““oror……Why feature selection is crucialWhy feature selection is crucial””
-8 -7 -6 -5 -4 -3
-8
-7
-6
-5
-4
-3
Observed RT (min)
Pred
icte
d R
T (m
in)
Observed values
Pre
dict
ed v
alue
s

Feature Importance Feature Importance StarplotStarplotCacoCaco--2 : 31 Descriptors2 : 31 Descriptors
ABSDRN6
a.don
KB54
SMR.VSA2
BNP8
DRNB10
KB11
PEOE.VSA.FPPOS
ANGLEB45
PIPB53
DRNB00
PEOE.VSA.4
SlogP.VSA6
apol
ABSFUKMIN
PIPB04
PEOE.VSA.FPOL
PIPMAX
BNPB50
BNPB21
PEOE.VSA.FHYD
PEOE.VSA.PPOS
EP2
SlogP.VSA9
ABSKMIN
PEOE.VSA.FNEG
BNPB31
FUKB14
pmiZ
SIKIA
SlogP.VSA0

Feature Importance Feature Importance StarplotStarplotCacoCaco--2 : 15 Descriptors2 : 15 Descriptors
a.don
KB54
SMR.VSA2
ANGLEB45
DRNB10
ABSDRN6
PEOE.VSA.FPPOS
DRNB00
PEOE.VSA.FNEG
ABSKMIN
SIKIA
pmiZ
BNPB31
FUKB14
SlogP.VSA0

CacoCaco--2 Bagged SVM Predictions2 Bagged SVM Predictions
Caco-2 - 718 Variables
-8 -7 -6 -5 -4 -3
-8
-7
-6
-5
-4
-3
Observed RT (min)
Pred
icte
d R
T (m
in)
Observed values
Pre
dict
ed v
alue
s
-8 -7 -6 -5 -4 -3
-8
-7
-6
-5
-4
-3
Observed RT (min)
Pred
icte
d R
T (m
in)
Pre
dict
ed v
alue
s
Observed values
Caco-2 - 15 Variables

Case 3: Case 3: hERGhERG Channel Inhibition AnalysisChannel Inhibition Analysis

hERGhERG: ROC Curve Comparisons: ROC Curve ComparisonsClassification improvement via feature selectionClassification improvement via feature selection
Before Feature Selection After Feature Selection

45 109 36
hERGhERG Channel Blind Test SetChannel Blind Test Set

General Characteristics of General Characteristics of HighHigh--quality Predictive Modelsquality Predictive Models
• All descriptors used in the model are significant, – None of the descriptors account for single peculiarities
• No leverage or outlier compounds in the training set(Gisbert, 2006.)
• Cross-validation performance should show:– Significantly better performance than that of randomized tests – Training set and external test set homogeneity.

Pitfalls In QSAR: Pitfalls In QSAR: Addressed by Best PracticesAddressed by Best Practices
• Data Sets – Problems: Compilation of data, outliers, size of samples – Solutions: Well-standardized assays, clear and unambiguous endpoints
• Descriptors – Problems: Collinearity, Interpretability, error in data, too many variables – Solutions: Domain knowledge, combined descriptors, feature selection
• Statistical Methods– Problems: Overfitting of data, non-linearity, interpretability– Solutions: Simple models using validation
“Development of QSARs is more of an art than a science”- Mark T.D. Cronin and T. Wayne Schultz

The Eight Commandments of Successful The Eight Commandments of Successful QSPR/QSAR ModelingQSPR/QSAR Modeling
1. There should be a PLAUSIBLE (not necessarily known or well understood) mechanism or connection between the descriptors and response. Otherwise we could be doing numerology…
2. Robustness: you cannot keep tweaking parameters until you find one that works just right for a particular problem or dataset and then apply it to another. A generalizable model should be applicable across a broad range of parameter space.
3. Know the domain of applicability of the model and stay within it. What is sauce for the goose is sauce for the gander, but not necessarily for the alligator.
4. Likewise, know the error bars of your data.

The Eight Commandments of Successful The Eight Commandments of Successful QSPR/QSAR ModelingQSPR/QSAR Modeling
5. No cheating... no looking at the answer. This is the minimum requirement for developing a predictive model or hypothesis
6. Not all datasets contain a useful QSAR/QSPR “signal”. Don’t look too hard for something that isn’t there…
7. Consider the use of “filters” to scale and then remove correlated, invariant and “noise” descriptors from the data, and to remove outliers from consideration.
8. Use your head and try to understand the chemistry of the problem that you are working on – modeling is meant to assist human intelligence – not to replace it…


ACKNOWLEDGMENTS• Current and Former members of the DDASSL group
– Breneman Research Group (RPI Chemistry)• N. Sukumar• M. Sundling• Min Li• Long Han• Jed Zaretski• Theresa Hepburn• Mike Krein• Steve Mulick• Shiina Akasaka• Hongmei Zhang• C. Whitehead (Pfizer Global Research)• L. Shen (BNPI)• L. Lockwood (Syracuse Research Corporation)• M. Song (Synta Pharmaceuticals)• D. Zhuang (Simulations Plus)• W. Katt (Yale University chemistry graduate program)• Q. Luo (J & J)
– Embrechts Research Group (RPI DSES)– Tropsha Research Group (UNC Chapel Hill)– Bennett Research Group (RPI Mathematics)
• Collaborators:– Tropsha Group (UNC Chapel Hill - CECCR)– Cramer Research Group (RPI Chemical Engineering)
• Funding– NIH (GM047372-07)– NIH (1P20HG003899-01)– NSF (BES-0214183, BES-0079436, IIS-9979860)– GE Corporate R&D Center– Millennium Pharmaceuticals– Concurrent Pharmaceuticals– Pfizer Pharmaceuticals– ICAGEN Pharmaceuticals– Eastman Kodak Company– Chemical Computing Group (CCG)

References• Matthew W. B. Trotter,Sean B. Holden Support Vector Machines for ADME Property Classification QSAR (2003) 533-548.
• Saxena, A. K. and Prathipati, P. Comparison of MLR, PLS, and GA-MLR in QSAR analysis. Medicinal Chemistry Division, Central Drug Research Institute (CDRI). 9/1/2003.
• Cronin, Mark T.D. and Schultz, Wayne T. Pitfalls in QSAR. Journal of Molecular Structure (Theochem). 622. (2003) 39-51.
• Rajarshi. Guha, Peter C. Jurs, Determining the Validity of a QSAR Model – A Classification Approach J. Chem. Inf. Model 45, (2005) 65-73
• Sabcho. Dimitrov, Gergana Dimitrova, Todor Pavlov, Nadezhda Dimitrova, Grace Patlewicz, Jay Niemela, and OvanesMekenyan. A Stepwise Approach for Defining the Applicability Domain of SAR and QSAR Models J. Chem. Inf. Model 45, (2005) 839-849
• Rajarshi. Guha and Peter C. jurs. Interpreting Computational Neural Network QSAR Models: A Measure of Descriptor ImportanceJ. Chem. Inf. Model 45 (2005) 800-806
• R. Kawakami, et.al. A method for calibration and validation subset partitioning (Talanta 2005)
• Garg, Rajni. And Bhhatarai, Barun. From SAR to comparative QSAR: role of hydrophobicity in the design of 4-hydroxy-5,6-dihydropyran-2-ones HIV-1 protease inhibitors. Department of Chemistry, Clarkson University. Bioorganic & Medicinal Chemistry 13 (2005). 4078-4084.
• Shuxing. Zhang, Alexander Golbraikh, Scott Oloff, Harold Kohn, and Alexander Tropshal A Novel Automated Lazy Learning QSAR (ALL-QSAR) Approach: Method Development, Applications, and Virtual Screening of Chemical Databases Using Validated ALL-QSAR Models J. Chem. Inf. Model. 2006
• Peter Gedeck, Bernhard Rohde, and Christian Bartels QSAR –How Good Is It in practice? Comparison of Descriptor Sets on an Unbiased Cross Section of Corporate Data Sets J. Chem. Inf. Model. 46, (2006) 1924-1936
• Schneider, Gisbert. Development of QSAR Models . Eurekah Bioscience Database. 2006.

Reserve Slides

Critical Analysis of Dataset PropertiesCritical Analysis of Dataset Properties• Size of the dataset (Gedeck, 2006.)
• Quality of the dataset (Eva Gottmann, et.al. 2001) – Single protocols of data acquisition are more reliable.– Be aware of data compilations; different labs, different assays.
• Interpretation of outliers in identification of mechanism (Cronin, 2003.)– Found small and specifically reactive molecules had increased toxicity than
reported by QSAR
• Errors inherent in the dataset– Experimental error– Descriptor noise
Modeling method should match quality of dataset

– Large chemical databases very chemically diverse
– ALL-QSAR models -- locally weighted linear regression models
– Well-suited to modeling of sparse or unevenly distributed data sets
Modern QSAR AdventuresModern QSAR Adventures• Using Validated ALL-QSAR Models in Virtual Screening (Tropsha, 2004)
• Comparative QSAR hydrophobicity study on HIV-1 protease inhibitors(Garg, 2005)
– Established a working optimal value of ClogP
– Saw that molecules in small set fell outside range
– Determined that more diverse dataset is required

Validation StrategiesValidation Strategies
• Y-scrambling– Randomization of the modeled property
• External validation– Split ratio (training and test data sets)– Bootstraps– Leave-group-out– Leave-one-out

AcuteToxicity Example: Descriptor Complementarity
RECON Meta PLS Test Set
Actual
Pred
icted
RECON Meta PLS Training Set
Actual
Pre
dict
ed
MOE Meta PLS Training Set
Actual
Pre
dict
ed
MOE Meta PLS Test Set
Actual
Pre
dict
ed
RECON+MOE Meta PLS Training Set
Actual
Pre
dict
ed
RECON+MOE Meta PLS Test Set
Actual
Pre
dict
ed

Popularity of MethodsPopularity of Methods(a highly scientific analysis)(a highly scientific analysis)
• Genetic Algorithm– Single GA method
• 74,700 hits (Genetic Algorithm QSAR)– Combined with other methods (MLR, PLS, ANN)
• 98,600 hits (GA QSAR)
• Artificial Neural Network– 94,300 hits (Artificial Neural Network QSAR)
• Partial Least Squares– 56,400 hits (Partial Least Squares QSAR)
• Support Vector Machines– 31,300 hits (Support Vector Machines QSAR)

SoftwareSoftware
MOE
Sybyl
Almond / GRIND
Dragon
Pipeline Pilot – SciTegic
Proprietary solutions
RECON, PEST and many others…

Pitfalls In QSAR
• Data Sets – Problems– Solutions
• Descriptors – Problems– Solutions
• Statistical Methods– Problems– Solutions

• Support Vector Machines for ADME Property Classification (Trotter, 2003)
• Comparing MLR, PLS, and ANN QSPR Models(Erösa, 2004)
– Best model generated was an ANN with a Q2 of 0.85
• Comparison of MLR, PLS, and GA-MLR in QSAR analysis(Saxena, 2003)
– Training of 70, testing of 27, activity spanned five orders of magnitude
– Combined GA-MLR provided simple, robust models
Machine Learning MethodsMachine Learning Methods