predicting the treatment effect in diabetes patients using ... · predicting the treatment effect...
TRANSCRIPT

Predicting the treatment effect in diabetes patients using classification models
1Haoting Zhang, 2Lingyun Shao, 3Chengyu Xi
1 Guanghua International School of Shanghai, Shanghai 200040, China, e-mail: [email protected]
2Shanghai Huashan Hospital affiliated to Fudan University, Shanghai 200040, China, e-mail: [email protected]
3School of Information, Zhejiang University of Finance & Economics, Hangzhou, 310000, China, e-mail: [email protected]
Abstract
The objective of this study is to explore the prediction of treatment effect in diabetes patients using classification models, especially Decision Tree. The data of the diabetic patients are from the Health Facts database of the United States. Models (mainly Decision Tree, and also Rule Induction and Naïve Bayes) are constructed using RapidMiner 5.3, so that the predictors will be searched and used to predict whether the diabetic patients will be readmitted within 30 days. In this way, every individual patient can be assessed according to their different characteristics, and their treatment can be personalized accordingly to decrease the chances of readmitting within 30 days. Another finding is that, medical management, which isn’t directly related to the disease itself, can actually make a big difference in therapeutic effect. In conclusion, using classification models such as Decision Tree is an effective way to predict and personalize treatment effect of patients.
Keywords: Classification model, Data mining, Decision Tree, Medical information system
1. Introduction
Improving the treatment of patients who suffer from diabetes and reducing their readmission, have
been a target for medical field for a long time. However, every patient has his/her unique situation, and it is not suitable to treat every patient in the same way, even if the method is the most advanced in the field. Therefore, we need a personalized way of curing diabetes rather than a general one. In this study, various models are tested to ensure that they are effective in predicting whether patients are well enough and avoid readmitting to the hospital. Once all the characteristics of the patients are input into the model, the model will find the potential markers for predicting whether the patient will be readmitted into the hospital within 30 days. The model is constructed by RapidMiner 5.3. RapidMiner is a software platform used for business and industrial applications as well as for research, education, training, rapid prototyping, and application development and supports all steps of the data mining process including results visualization, validation and optimization [1]. 2. Related Works
Data mining as an interdisciplinary subfield of computer science aims at extracting useful
information from a large database or big data, and turning it into an understandable form through visualization. Recent years, numerous efforts have been taken to apply data mining process to many fields, such as games [2], business [3], science and engineering [4], and especially, medical treatment [5][6].
One of the useful applications in the medical treatment is Diabetes, which is a group of metabolic disease that still has no curable medical treatment till now. However, there exist some medical treatments that can keep the glucose serum at a healthy level. Thus, accurate and timely medical treatment is very important. Some researchers have explored the probability of combining data mining tools with medical treatments of diabetes. Breault et al. [7] used the classification tree approach to mine a diabetic data warehouse containing information of 30,383 diabetes patients and ultimately leaded to a find, which is unexpected, that the variable associated with bad glycemic control most is younger age. Sapna and Tamilarasi [8] applied fuzzy systems along with genetic algorithm and neural networks to
Predicting the treatment effect in diabetes patients using classification models Haoting Zhang, Lingyun Shao, Chengyu Xi
International Journal of Digital Content Technology and its Applications(JDCTA) Volume 8, Number 5, October 2014
136

analyze the heart rate variability so as to detect the diabetic autonomic neuropathy which is an available predictor of mortality of diabetes patients. Sanakal and Jayakumari [9] used fuzzy C-means clustering and support vector machine to analyze a set of medical data (consists of 768 cases) of diabetes so as to receive the prognosis of diabetes. Rajesh and Sangeetha [10] explored the data mining methods and techniques to identify the suitable methods or techniques for classifying diabetes data and mining useful patterns and eventually found that C4.5 algorithm is the most suitable and has a classification rate of 91%. Wren and Garner [11] used a data-mining approach to analyze all the electronically available scientific literature including over 12 million Medline records so as to identify factors related with the pathology of type 2 diabetes mellitus (T2DM) and surprisingly discovered that epigenetic changes are the causal factors in the pathogenesis of T2DM.
Almost all of the state-of-the-art literatures concentrate on finding out the casual factors of diabetes disease, prognosis of diabetes mellitus and classification of diabetes with different symptoms. Strack et al. [12] applied multivariable logistic regression in analysis of finding out the relationship between HbA1c and readmission. However, still few researches propose the methods or approaches that can predict the medical treatment effect in diabetes. This paper has constructed some classification models, say decision tree, Rule Induction and Naïve Bayes, through RapidMiner 5.3, which is known as an effective data-mining tool, to predict the treatment effect in diabetes patients, i.e., whether the patients will be readmitted within 30 days. Based on the predicting result, doctors can easily know whether the medical treatment will work. If it does not work, doctors can further redesign the treatment plan until the prediction result is satisfactory. Thus, personalized medical treatment of different diabetes patients can be realized. 3. Data Preparation, Correlation Analysis and Modeling Method
The data used in this study are downloaded fromhttp://archive.ics.uci.edu/ml/datasets/Diabetes+130
-US+hospitals+for+years+1999-2008, the Health Facts database (Cerner Corporation, Kansas City, MO), which is a national data warehouse that collects comprehensive clinical records across hospitals throughout the United States [12]. The features included are as follows - encounter identifier (ID), patient number, race, gender, age, weight, admission type, discharge disposition, admission source, time in hospital, payer code, medical specialty, number of lab procedures, number of procedures, number of medications, number of outpatient visits, number of emergency visits, number of inpatient visits, primary diagnosis, secondary diagnosis, additional secondary diagnosis, number of diagnoses, glucose serum test result, A1c test result, change of medications, diabetes medications, 24 features for medications, and, finally, whether the patient is readmitted within 30 days.
To ensure that the data is valid, those features with incomplete data are excluded- race, weight, payer code, medical specialty, secondary diagnosis and additional secondary diagnosis. Also, as a “label” in the process of running the models in RapidMiner, it is better to change the data type of the feature “readmission” from polynominal (which means the feature has more than two nominal values) into binominal (which means the feature has exactly two nominal values). To do this, the function “Vlookup” in Microsoft Excel is used. Both “No” (no record of readmission) and “>30” (the patient is readmitted in more than 30 days) are considered as “Good”, while “<30” (the patient is readmitted within less than 30 days) is considered as “Bad”. Therefore, the feature “readmission” has two possible result, that is, either “Good” or “Bad”, after using “Vlookup”.
Thereafter, we found out that the result “Good” was much more frequent than the result “Bad” in the feature “readmission”. About 9000 patients in every 10000 have got “Good” in “readmission”. That is to say, if the model predicts that the patient won’t be readmitted within 30 days for all patients, the final accuracy will still be around 90%. However, under no circumstances can patients who are in high risk of being readmitted be found out if the model runs like that. After all, our aim was to find out those patients with potential problems. Therefore, before the data were analyzed, suitable data should be chosen so that the number of patients with “Bad” in readmission was equal to the number of those with “Good” in readmission. We chose 1000 patients with “Good” results to match another 1000 with “Bad” results to avoid the data imbalance.
To build a valid model, it is necessary to know which features among those in the data are the most relevant to the labeled feature “readmission”. We used a Correlation Matrix in RapidMiner to calculate the correlations between “readmission” and the other features. Features with correlation which is bigger than 0.0500 will be included in Decision Tree. Meanwhile, the features which can be controlled by
Predicting the treatment effect in diabetes patients using classification models Haoting Zhang, Lingyun Shao, Chengyu Xi
137

doctors or nurses are especially important. These features should be included in the model even if their correlation with readmission is less than 0.0500, because if the patient is predicted to be readmitted within 30 days, doctors or nurses can control these features by, for example, increasing number of procedures, or giving a glucose serum test to the patient, so that the possibility that the frequency of readmission within 30 days can be decreased according to the model. After the process of correlation, Decision Tree is used, which is a classification model.
Here we are concerned with decision trees for classification where the leaves represent classifications and the branches represent feature-based splits that lead to the classifications [13]. Decision Tree can create a classification model according to the input attributes of example set so as to predict the value of an output class. What we are doing is to test whether it is accurate to predict whether the patient will be readmitted within 30 days using Decision Tree. The 2000 sets of data (1000 with “Good” result and the other 1000 with “Bad” result) are split in a ratio of 7:3. 70% of the data are used as training data, and the other 30% are used as testing data. The training data help the Decision Tree to work out a classification model. Whether the model produced by the Decision Tree is accurate can be tested by the testing data. The 18 features (except for the labeled “readmission”) of the sets of testing data are input into the model produced. The model works automatically, and the feature “readmission” will be the output. Then the output worked out is compared with the real value of “readmission”, and therefore the accuracy can be calculated. 4. Results
The result of correlation is shown in Fig 1. In the process of calculating correlation, 15 of the
features showed a correlation of bigger than 0.0500 (absolute value) with readmission, which are shown in table 1.
These 15 features showed a closer correlation with readmission, compared to other features, and therefore are included in the model. Features which can be controlled by doctors or nurses include the duration in hospital, number of lab tests, number of medications, and glucose serum test result, which are shown in table 1 (correlation >0.0500). Similarly, HbA1c test results can also bring changes in medications, and diabetes medications, which aren’t in the table above. These are the 18 features which are included in Decision Tree.
Table 1. Correlation between 18 features and readmission
Feature Value of correlation
Discharge disposition 0.3356
Admission type 0.3012
Number of procedures 0.0888
Number of lab procedures 0.0558
Metformin -0.0506
Insulin -0.0704
Glucose serum test result -0.0748
Number of outpatient visits -0.0823
Number of medications -0.0933
Time in hospital -0.0934
Number of emergency visits -0.0989
Number of diagnoses -0.1118
Admission source -0.1157
Pioglitazone -0.1278
Number of inpatient visits -0.2798
Predicting the treatment effect in diabetes patients using classification models Haoting Zhang, Lingyun Shao, Chengyu Xi
138

F
igure 1. B
ar chart which illustrates correlation betw
een readmission and other features. T
he higher the absolute value of correlation is, the more correlative
is the relationship between this feature and “readm
ission”. That is to say, if the figure is closer to 1 or -1, then the tw
o characteristics are more correlative. 1 and
-1 are the maxim
um values of correlation m
atrix, indicating that the two features are m
aximized relevant, w
hile 0 indicates that the two features are not relevant
at all.
Predicting the treatment effect in diabetes patients using classification models Haoting Zhang, Lingyun Shao, Chengyu Xi
139

The modeling process of Decision Tree is shown in Fig 2 and Fig 3. The prediction accuracy and the resulted Decision Tree are shown in Fig 4 and Fig 5 respectively. According to the accuracy calculated, for those “readmission” values which are “Bad”, the accuracy (i.e. the possibility that a person who will be readmitted within 30 days, is detected to be “Bad” by the model) is 77.26%. For those “readmission” values which are “Good”, the accuracy (i.e. the possibility that a person who won’t be readmitted within 30 days, is detected as being “Good”) is 73.75%. The overall accuracy is 75.50%, which is satisfactory.
Figure 2. The main process. Data are input from Excel, and goes to the split validation. The split validation outputs the result of Decision Tree and the accuracy of the model.
Figure 3. Process of split validation. In the box “Decision Tree”, 70% of data are trained using Decision Tree, and result of Decision Tree is applied in the remaining 30% testing data in the box “Apply Model”. The accuracy of the model is calculated in the box “Performance”.
Figure 4. The accuracy of Decision Tree in this case. 77.26% of patients who are actually “Bad” in readmission result are predicted by the model correctly, while 73.75% of those who are “Good” in readmission result are predicted correctly. These two figures are quite close, and result in an overall accuracy of 75.50%.
Predicting the treatment effect in diabetes patients using classification models Haoting Zhang, Lingyun Shao, Chengyu Xi
140
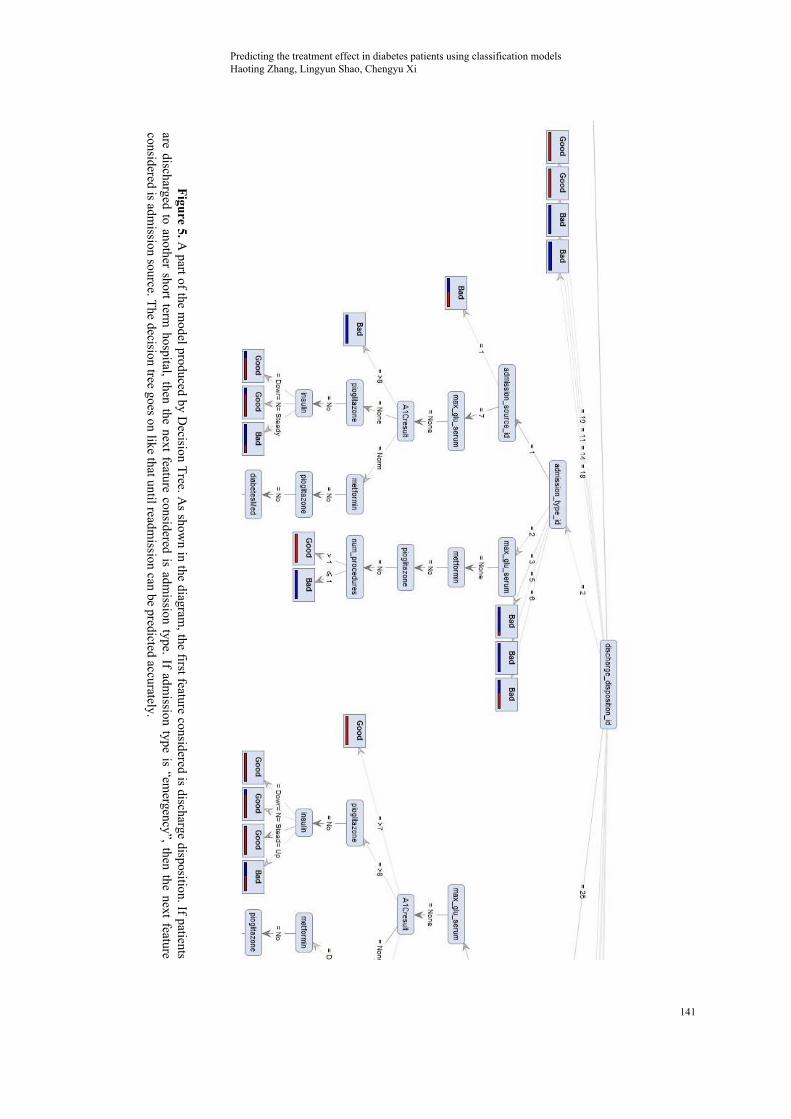
Figu
re 5. A part of the m
odel produced by Decision T
ree. As show
n in the diagram, the first feature considered is discharge disposition. If patients
are discharged to another short term hospital, then the next feature considered is adm
ission type. If admission type is “em
ergency”, then the next feature considered is adm
ission source. The decision tree goes on like that until readm
ission can be predicted accurately.
Predicting the treatment effect in diabetes patients using classification models Haoting Zhang, Lingyun Shao, Chengyu Xi
141

Since Decision Tree, Rule Induction and Naïve Bayes (Kernel) all have accuracy above 75%, they could be used in predicting whether patients would be readmitted within 30 days after leaving the hospital. The accuracy of these models was shown in fig. 6.
Figure 6. Accuracy of Decision Tree, Rule Induction and Naïve Bayes. In this study, their accuracy is in the range of 75.17% and 77.00%.
5. Discussion and Conclusions
From the result of correlation, we found out that discharge disposition and admission type had the
highest correlation value. However, these two features were not tightly linked to the disease itself, but linked to medical management. Therefore, we came up with a conclusion: Medical management is extremely important in increasing patients’ probability of not being readmitted. What kind of environment does the hospital provide to the patient during and after the treatment (e.g. discharged to home or another short term hospital, or to home with home health service, or to a long term care hospital, etc.) is as important, if not more telling, as the treatment itself.
In this study, we find out that using classification models in RapidMiner can give us a significant prediction of whether patients will be readmitted within 30 days, by simply inputting the patients’ data into the decision tree model and running it. The model can itself calculate a result. If the result is “Bad”, which means the patient is likely to be readmitted within 30 days, doctors and nurses can try to adjust the features of the patients (time in hospital, number of lab procedures, number of procedures, number of medications, glucose serum test, HbA1c test, change in medications, and diabetes medications). After personalizing the treatment, the model can be run once again to see whether the result is changed to “Good”. If it is changed, then the adjusted data can be the new plan of treatment for the patient. After treating the patient in a way which makes his/her realistic data matched to the adjusted one, he/she will have a lower possibility of being readmitted.
Also, the importance of medical management is emphasized. The place that the patient stays does a lot to the treatment effect, according to the correlation result. Therefore, providing patients with a suitable environment to stay in is crucial, and can change the result of their treatment.
Our future work will look into the possibility of developing a prescriptive optimization method so that the program can find the best personalized way of treating diabetes patients by itself, which means it will no longer be necessary for humans to be involved in personalizing the treatment.
6. Acknowledgement
The work has been supported by China National Natural Science Foundation (Nos. 51375429, 51475410, 51175462), and Zhejiang Natural Science Foundation of China (No. LY13E050010).
Predicting the treatment effect in diabetes patients using classification models Haoting Zhang, Lingyun Shao, Chengyu Xi
142

7. References
[1] Rapidminer, Rapidminer Studio 6 User Manual, May 2014. [2] Inderpal Bhandari, Edward Colet, Jennifer Parker, Zachary Pines, and Rajiv Pratap, "Advanced
scout: data mining and knowledge discovery in NBA data", Data Mining and Knowledge Discovery, vol. 1, no.1, pp. 121-125, 1997.
[3] Michael J. Berry, and Gordon Linoff, Data Mining Techniques: for Marketing, Sales, and Customer Support, John Wiley & Sons, Inc., 1997.
[4] Bo Lin, and Yanping Chen, "Application in the construction of teaching resources database data mining", Proceedings of 2nd International Conference on Software Engineering, Knowledge Engineering and Information Engineering (SEKEIE), Atlantis Press, 2014.
[5] Chao-Ton Su, Chien-Hsin Yang, Kuang-Hung Hsu, and Wen-ko Chiu, "Data mining for the diagnosis of type II diabetes from three-dimensional body surface anthropometrical scanning data", Computers & Mathematics with Applications, vol. 51, no.6, pp. 1075-1092, 2006.
[6] Fadi Almasalha, Dianhui Xu, Gail M. Keenan, Ashfaq Khokhar, Yingwei Yao, Yu-C. Chen, Andy Johnson, R. Ansari, and Diana J. Wilkie, "Data mining nursing care plans of End-of-Life patients: a study to improve healthcare decision making", International Journal of Nursing Knowledge, vol. 24, no. 1, pp. 15-24, 2013.
[7] Joseph L. Breault, Colin R. Goodall, and Peter J. Fos, "Data mining a diabetic data warehouse", Artificial Intelligence in Medicine, vol. 26, no. 1, pp. 37-54, 2002.
[8] S. Sapna, and A. Tamilarasi, "Fuzzy relational equation in preventing diabetic heart attack", Journal of Computer Applications, vol. 1, no. 4, pp. 26-29, 2008.
[9] Ravi Sanakal, and Smt. T Jayakumari, "Prognosis of diabetes using data mining approach-fuzzy C means clustering and support vector machine", International Journal of Computer Trends and Technology (IJCTT), vol. 11, no. 2, pp. 94-98, 2014.
[10] K. Rajesh, and V. Sangeetha, "Application of data mining methods and techniques for diabetes diagnosis", International Journal of Engineering and Innovative Technology, vol. 2, no. 3, pp. 224-229, 2012.
[11] Jonathan D. Wren, and Harold R. Garner, "Data-mining analysis suggests an epigenetic pathogenesis for type 2 diabetes", BioMed Research International, vol. 2005, no. 2, pp. 104-112, 2005.
[12] Beata Strack, Jonathan P. DeShazo, Chris Gennings, Juan L. Olmo, Sebastian Ventura, Krzysztof J. Cios, and John N. Clore, “Impact of HbA1c measurement on hospital readmission rates: analysis of 70,000 clinical database patient records”, BioMed Research International, Volume 2014, Article ID: 781670, 2014.
[13] Sung-Hyuk Cha, and Charles Tappert, "A genetic algorithm for constructing compact binary decision trees", Journal of Pattern Recognition Research, vol. 4, no.1, pp. 1-13, 2009.
Predicting the treatment effect in diabetes patients using classification models Haoting Zhang, Lingyun Shao, Chengyu Xi
143