predicting gene functions from text using a cross- species approach emilia stoica and marti hearst...
Post on 21-Dec-2015
217 views
TRANSCRIPT

Predicting Gene Functions from Text Using a Cross-
Species Approach
Emilia Stoica and Marti HearstSIMS
University of California, Berkeley

Motivation
Want to extract the functions of genes (functional annotation) from MEDLINE documents
The marked accumulation of lipid droplets in LNCaP cells...is accompanied by an increase in phospholipid synthesis. The increase in PAP-2 might be related to changes in lipid metabolism… Since PAP-2 plays a pivotal role in the control of signal transduction by lipid mediator mediators, the ability of androgens to stimulate this enzyme in prostatic cells may provide opportunity for cross-talk between signaling pathways involving lipid mediators and androgens.

Motivation
Currently functional annotation is done by hand: human curators read each document and annotate genes with functions based on evidence in text
Goal: automate functional annotation

Gene Ontology (GO)
Gene Ontology (GO) controlled vocabulary for functional annotation
July 2005 ~ 17,600 terms (GO codes) organized in 3 distinct acyclic graphs of molecular functions, biological processes and cellular locations
More general terms are parents of less general terms: development (GO:0007275) is parent of embryonic development (GO:0001756)

Challenges
GO tokens may not explicitly occur in text PubMed 10692450, negative regulation of cell proliferation (GO:0008285), occurs as inhibition of cell proliferation
GO tokens may not occur contiguous in text PubMed 10734056, G-protein coupled receptor protein signaling pathway (GO:0007186) Results indicate that CCR1-mediated responses are regulated …in the signaling pathway, by receptor phosphorylation at the level of receptor G/protein coupling…CCR1 binds MIP-1 alpha.

Challenges
Assigning GO codes to genes simply because the GO tokens occur in text yields a large number of false positives, because either:
a) the text does not contain evidence to support the annotation, or
b) the text contains evidence for the annotation, but the curator knows the gene to be involved in a function that is more general or more specific than the GO code matched in text

Challenges
Evidence for annotation: e.g., the text should mention co-purification, co-immunoprecipitation experiments
Algorithms that take into account the evidence for annotation (e.g., annotate a gene with a GO code only if the text contains words like co-purification) do not perform any better than algorithms that ignore the evidence

Related Work
Mainly in the context of BioCreative competition Chiang and Yu: find phrase patterns commonly
used in sentences describing gene functions (e.g., “gene plays an important role in”, “gene is involved in”); final assignments made with a Naïve Bayes classifier
Ray and Craven:learn a statistical model for each GO code (which words are likely to co-occur in the paragraphs containing GO codes); a multinomial Naïve Bayes classifier decides between candidates
Rice et al. use SVM

Related Work
Couto et al. annotate a gene with a GO code if the information content of the GO code (computed as a function of words that match in text), is larger than the information content computed as a function of the GO tokens
Verspoor et al. expand GO tokens with words that frequently co-occur in a training set; use a categorizer that explores the structure of the Gene Ontology to find best hits
Ehler and Ruch combine pattern matching and TF*IDF weighting

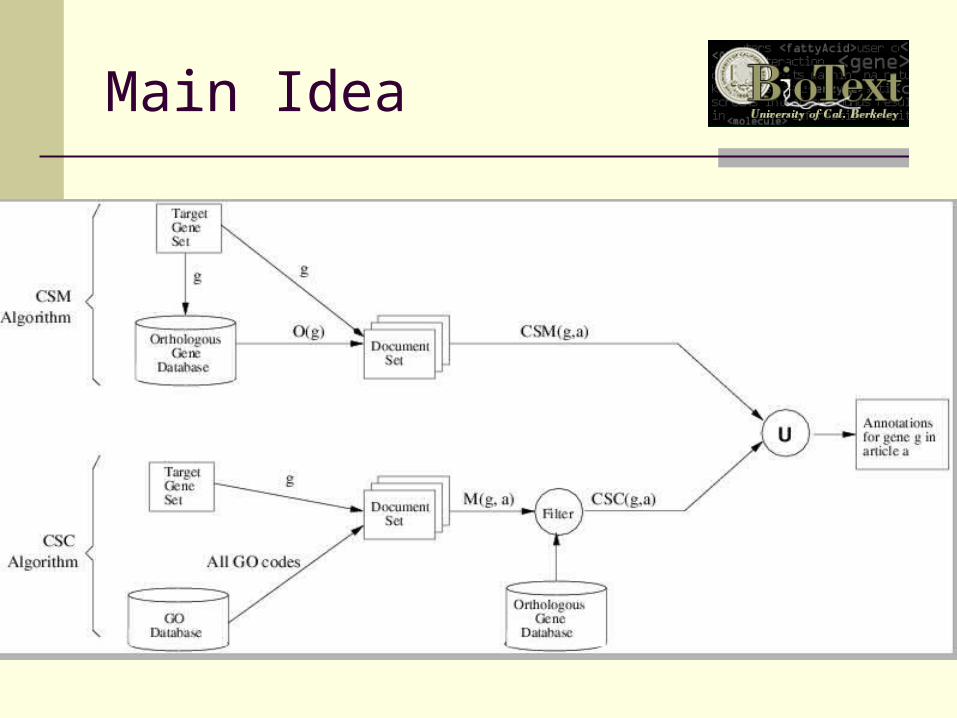
Main Idea
To predict GO codes for target genes in target species, use the GO codes annotated to their orthologous genes (genes from a different species that have evolved directly from an ancestral gene)
Assumption: Since there is an overlap between the genomes of the two species, their orthologs may share some functions, and consequently some GO codes
Main Idea

General procedure
Eliminate stop words, punctuation characters and divide the text into tokens using space as delimiter
Analyze text at sentence level Normalize and match different variations of gene
names using the algorithm of Bhalotia et al. For every sentence that has the target gene, we
consider a GO code to be found if the sentence contains a percentage of GO tokens larger than a threshold (0.75 for CSM and 1 for CSC)

CSM Algorithm
CSM(g, a): For a target gene g we search in article a for only the GO codes annotated to its ortholog
Eliminate annotations of orthologs marked with IEA and ISS codes to avoid circular reference

CSC Algorithm
General observation: if two GO codes tend to occur together in a database, then a gene annotated with one GO code is likely to be annotated with the other one as well
If one GO code tends to occur in the orthologous genes’ annotations when another one does not, then for the target species, these two GO codes may not be allowed to co-occur
Example: if text has rRNA transcription (GO:0009303) nucleolus (GO:0005737) and extracellular (GO:0005576), then extracellular should be eliminated

CSC Algorithm
For every pair of GO codes in the orthologous genes database, compute a X2 coefficient
N: the total number of GO codes O11: # of times the ortholog is annotated with both GO1 and GO2
O12: # of times the ortholog is annotated with GO1 but not GO2
O21: # of times the ortholog is annotated with GO2 but not GO1
O12: # of times the ortholog is not annotated with GO1 or GO2
)(*)(*)(*)(
)**(*)**(*
2221221221111211
2112221121122211
OOOOOOOO
OOOOOOOON
X2

CSC Algorithm
M(g,a) = GO codes matched in article a for gene g O(g) = GO codes annotated to the ortholog of g o = size of O(g), p = percentage (0.2)
CSC(g,a) ={}; for every GO1 in M(g,a)
count = 0; for every GO2 in O(g) if((X2(GO1,GO2)>3.84) && (GO1 ne
GO2)) count++; if(count > p*o)
add GO1 to CSC(g,a);

Algorithm

Results on BioCreative Dataset
Task 2.2: Annotate 138 human genes with GO codes using 99 full text articles; for each annotation, provide the passage of text the annotation was based upon
Annotations from participants were manually judged by human curators
A prediction was considered “perfect” if the passage of text contains the gene name and provides evidence for annotating the gene with the GO code

Results on BioCreative Dataset
Our research was conducted after the competition has past, so our annotations could not be judged by human curators
We measure our performance using the “perfect predictions” other systems made (unfair to our system as we ignore relevant predictions we make that other systems do not find)
Our prediction is correct if it matches a perfect prediction (e.g., vhl is annotated with transcription (GO:0006350) in PubMed 12169961 “vhl inhibits
transcription elongation, mRNA stability and PKC activity”)
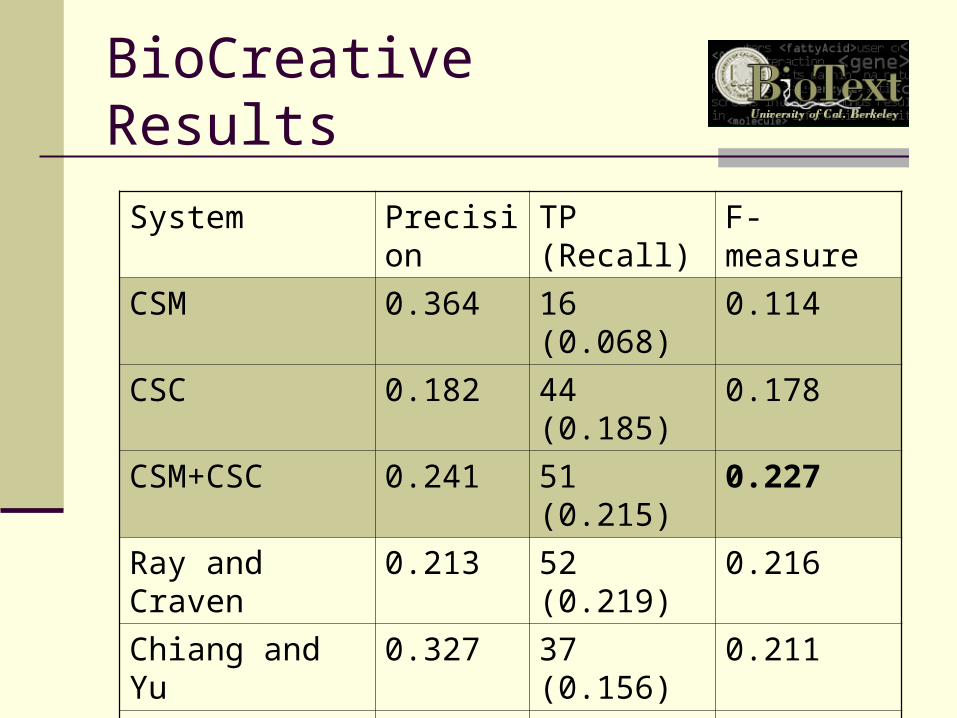
BioCreative Results
System Precision TP (Recall) F-measure
CSM 0.364 16 (0.068) 0.114
CSC 0.182 44 (0.185) 0.178
CSM+CSC 0.241 51 (0.215) 0.227
Ray and Craven 0.213 52 (0.219) 0.216
Chiang and Yu 0.327 37 (0.156) 0.211
Ehler and Ruch 0.123 78 (0.329) 0.179
Couto et al. 0.089 58 (0.245) 0.131
Verspoor et al. 0.055 19 (0.080) 0.065
Rice et al. 0.035 16 (0.068) 0.046

Results on EBI Human and MGI datasets
EBI human: 4,410 genes and 5,714 abstracts MGI: 2,188 genes and 1,947 abstracts
Dataset System Precision Recall F-measure
EBI CSM 0.289 0.033 0.060
CSM+CSC 0.163 0.092 0.118
Chiang and Yu 0.318 0.063 0.105
MGI CSM 0.328 0.049 0.086
CSC+CSC 0.168 0.121 0.140
Chiang and Yu 0.332 0.051 0.089

Conclusions and Future Work
We propose an algorithm that annotates genes with GO codes using the information available from other species
Experimental results on three datasets show that our algorithm consistently achieves higher F-measure than other solutions
Improvements to our algorithm: - combine or use a voting scheme between the predictions our system makes and the predictions of a machine learning system
- investigate how effective are other genes with sequences similar to the target gene (but not orthologous to the gene) for predicting the GO codes