predictability and anticipation” - 15/05/15 - alessandra ...masta/ss15/alessandra_frank13.pdf ·...
TRANSCRIPT

"Predictability and Anticipation” - 15/05/15 - Alessandra Zarcone
Uncertainty Reduction as a Measure of Cognitive Load in Sentence Comprehension
Stefan L. Frank (2013) Topics in Cognitive Science, 5(3), 475-494.
1

Information and cognitive load during language processing
2

Information and cognitive loadIntuition:!
❖ information processing is central to cognition!
❖ more informative stimuli → higher cognitive load
Research question:!
❖ to what extent is cognitive load predicted by the amount of information conveyed by each word in a sentence?
READING TIMES
?
3

Quantifying a word’s information content
❖ surprisal: to what extent the word came unexpected
❖ more unexpected words → more information!
❖ a word’s surprisal is a predictor of the cognitive load experienced encountering the word (Hale 2001; Levy 2008)!
❖ word reading times correlate with surprisal values (Boston et al. 2008, 2011; Demberg & Keller, 2008, Frank & Bod 2011)
CONTEXTSt+1 = � logP (wt+1|wt1)
4

Quantifying a word’s information content
❖ entropy: how uncertain we are about what is being communicated at a certain point (it decreases with each upcoming word)
❖ maximal uncertainty: all interpretations are equally probable!
❖ minimal uncertainty: we are certain about one particular interpretation (P(x) = 1)
H(X) = �X
x2X
P (x) logP (x)POSSIBLE
INTERPRETATIoNS
P(x|wt1) after the first w
5

Quantifying a word’s information content❖ Lisa raised… her hand / her child P(x1) ≈ P(x2) ≈ 0.5"
❖ The student raised… her hand* P(x1) ≈ 0.9; P(x2) ≈ 0.1!
❖ The parent raised… her child* P(x1) ≈ 0.1; P(x2) ≈ 0.9"
❖ entropy at wt1:
how uncertain we are about x at wt
❖ reduction in entropy: how uncertain we are about x at wt+1 compared to wt
probability at"raised"
H(X;wt
1) = �X
x2X
P (x|wt
1) logPwt
1
�H(X;wt+1) = H(X;wt1)�H(X;wt+1
1 )
uncertainty at wt+1uncertainty at wt*examples from Bicknell et al. (2010) 6

Entropy reduction and cognitive load❖ Entropy reduction at wt+1 predicts cognitive load at wt+1!
❖ Hale (2003, 2006, 2011): entropy reduction computed on a probabilistic grammar!
❖ Blache and Rauzy (2011): entropy reduction computed over the probability of POS assignments!
❖ Wu et al (2010): effect of entropy reduction (computed over possible structures at t+1, not over complete sentences) on RTs!
❖ Frank (2010): simple LM over input sequences (predicting POS), RTs depend on both surprisal and entropy reduction
GOAL: predicting actual words7

The model
8
Section 3 describes a self-paced reading study in which reading-time data are collectedon sentences for which the model estimates information values.3 As presented inSection 4, an analysis of these word-information and reading-time measures reveals thatsurprisal and entropy reduction have independent effects, confirming the entropy-reduc-tion hypothesis. Further analyses, discussed in Section 5, were intended to uncover a cog-nitively relevant distinction between the surprisal and entropy-reduction informationmeasures. However, no evidence was found that the two measures correspond to cogni-tively distinct representations, processes, or strategies. As concluded in Section 6, findingsuch a distinction may require more rigorous, theory-driven experiments.
2. Estimating word information
2.1. Model architecture
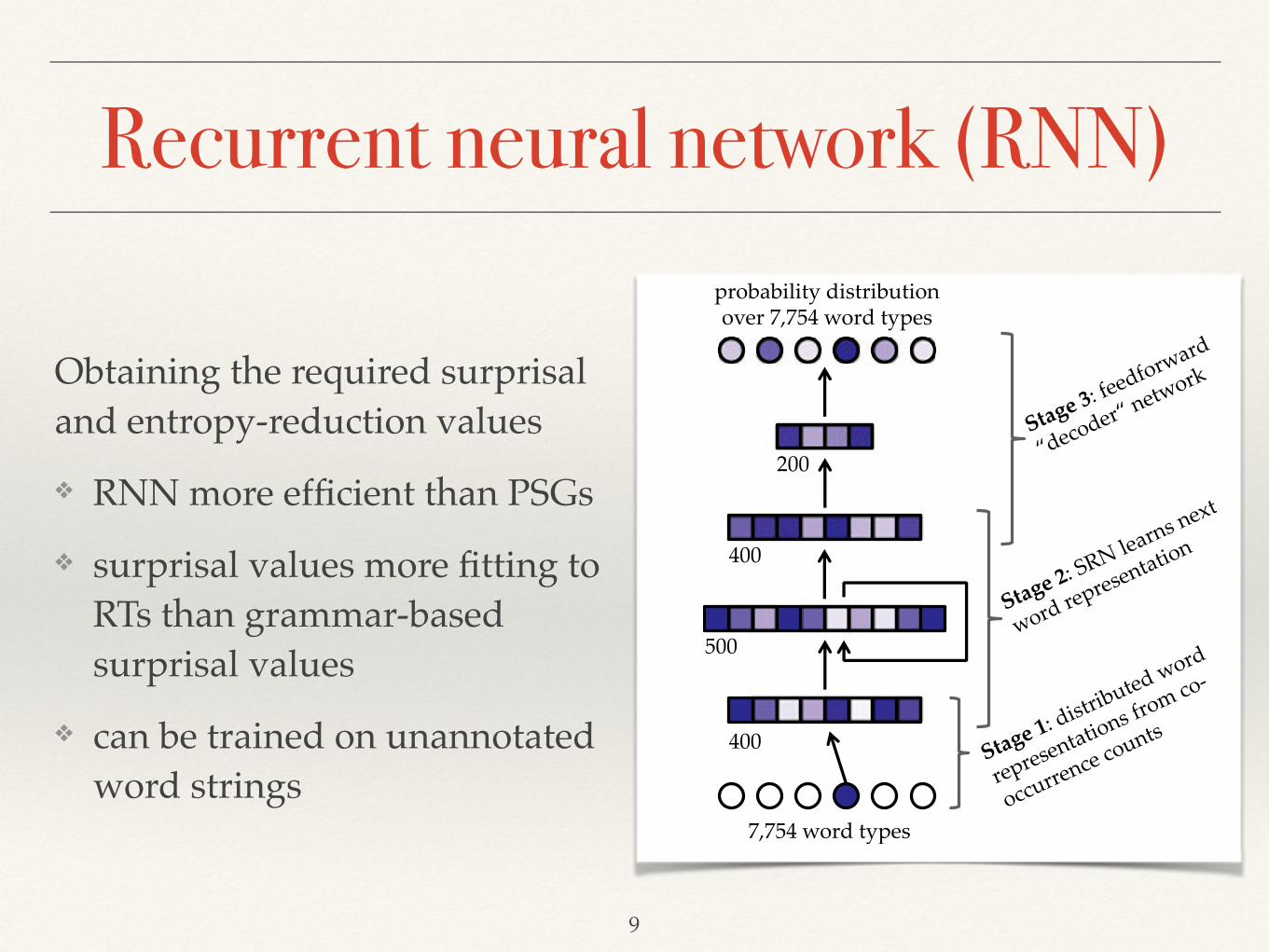
Fig. 1 presents the architecture of the recurrent neural network (RNN) that was usedas the probabilistic language model for estimating word-surprisal and entropy-reductionvalues. This network is not proposed as a cognitive model; rather, it serves as a tool forobtaining the required word-information measures with several advantages over alterna-tive models. For one, RNNs process more efficiently than phrase-structure grammars (orother structure-assigning models), which is of particular importance for computingentropy. Also, they can be trained on unannotated sentences (i.e., word strings instead oftree structures). In addition, RNNs have been shown to estimate surprisal values that fitreading times better than do grammar-based surprisal estimates (Frank & Bod, 2011).This was also demonstrated by Fernandez Monsalve et al. (2012), using the very same
Fig. 1. Architecture of neural network language model, and its three learning stages. Numbers indicate thenumber of units in each network layer. Reproduced from Fernandez Monsalve et al. (2012).
478 S. L. Frank / Topics in Cognitive Science 5 (2013)
Recurrent neural network (RNN)
Obtaining the required surprisal and entropy-reduction values!
❖ RNN more efficient than PSGs!
❖ surprisal values more fitting to RTs than grammar-based surprisal values!
❖ can be trained on unannotated word strings
9

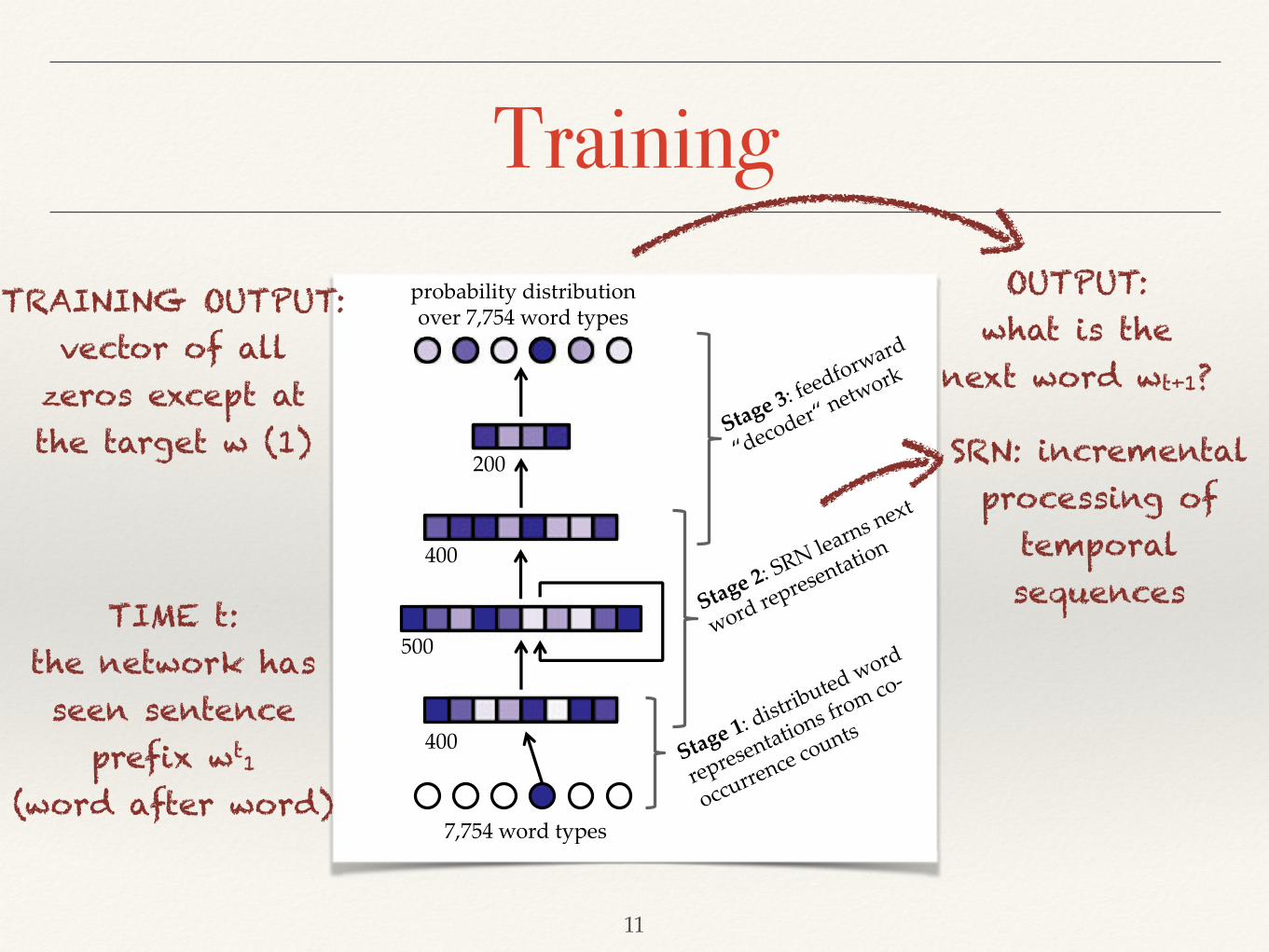
indicated in Fig. 1) the hidden layer receives not only external input but also its own pre-vious state. That previous state, in turn, depends on even earlier inputs and previous states,so that the processing of the current input depends on the entire input stream so far. TheSRN learned to predict, at each point in the training corpus, the next word’s vector repre-sentation given the sequence of word vectors corresponding to the sentence so far.
2.2.3. Stage 3: Decoding predicted word representationsAfter processing the input sequence wt
1, the output of the trained SRN from Stage 2 isa 400-dimensional vector that combines the 7,754 individual word representations, some-how weighted by each word’s estimated probability of being wtþ1. A feedforward “deco-der” network was trained to disentangle that complex mix of vectors. It took as inputthe SRN’s output vector at each point in the training sentences, while it received theactual next word as target output. That target output was encoded as 7,754-dimensionalvector consisting of all 0s except for a single 1 at the element corresponding to thetarget word.
2.3. Obtaining word-information values
The model was used to compute surprisal and entropy-reduction values for each wordof the experimental sentences (see Section 3). This was done at 10 intervals over thecourse of Stage 3 training: after presenting 2K, 5K, 10K, 20K, 50K, 100K, 200K, and350K sentences, and after presenting the full training corpus once and twice. In this man-ner, a range of information values was obtained for each word token.
2.3.1. SurprisalThe decoder network’s output activations at each time step are rescaled to constitute a
probability distribution over word types. That is, the model’s output after processing
Table 1Clustering of word representations. Each column corresponds to a syntactic category from which one word(shown in bold font) was chosen at random. That word’s ten nearest neighbors are listed in order of increas-ing Euclidean distance
Noun (singular) Noun (plural) Verb (present) Verb (past) Adjective Adverb Preposition
nightmare parents agree stood equal maybe beyondverdict pupils argue sat identical unfortunately beneathrealization teachers confirm stayed absolute meanwhile ontoportrait mothers depend waited part-time although despitepacket patients listen walked agricultural wherever besidemattress workers cope remained accurate instead amongsuccession relatives admit paused electrical fortunately unlikeskull clients fail lived enormous nevertheless throughoutrifle employers respond stared informal perhaps alongsideplea children rely laughed artificial unless regardingscrutiny lawyers appreciate rang adequate hence ignoring
480 S. L. Frank / Topics in Cognitive Science 5 (2013)
Recurrent neural network (RNN)
Word representations!
❖ BNC sentences containing only high-frequency words (7.754 lexical items, 702.412 sentences)!
❖ vector-based word type representations(PMI between words)!
❖ co-occurrence information is semantically meaningful
NEAREST NEIGHBORS
10
Section 3 describes a self-paced reading study in which reading-time data are collectedon sentences for which the model estimates information values.3 As presented inSection 4, an analysis of these word-information and reading-time measures reveals thatsurprisal and entropy reduction have independent effects, confirming the entropy-reduc-tion hypothesis. Further analyses, discussed in Section 5, were intended to uncover a cog-nitively relevant distinction between the surprisal and entropy-reduction informationmeasures. However, no evidence was found that the two measures correspond to cogni-tively distinct representations, processes, or strategies. As concluded in Section 6, findingsuch a distinction may require more rigorous, theory-driven experiments.
2. Estimating word information
2.1. Model architecture
Fig. 1 presents the architecture of the recurrent neural network (RNN) that was usedas the probabilistic language model for estimating word-surprisal and entropy-reductionvalues. This network is not proposed as a cognitive model; rather, it serves as a tool forobtaining the required word-information measures with several advantages over alterna-tive models. For one, RNNs process more efficiently than phrase-structure grammars (orother structure-assigning models), which is of particular importance for computingentropy. Also, they can be trained on unannotated sentences (i.e., word strings instead oftree structures). In addition, RNNs have been shown to estimate surprisal values that fitreading times better than do grammar-based surprisal estimates (Frank & Bod, 2011).This was also demonstrated by Fernandez Monsalve et al. (2012), using the very same
Fig. 1. Architecture of neural network language model, and its three learning stages. Numbers indicate thenumber of units in each network layer. Reproduced from Fernandez Monsalve et al. (2012).
478 S. L. Frank / Topics in Cognitive Science 5 (2013)
Training
SRN: incremental processing of
temporal sequences
OUTPUT: what is the
next word wt+1?
TIME t: the network has seen sentence
prefix wt1
(word after word)
TRAINING OUTPUT: vector of all
zeros except at the target w (1)
11

Section 3 describes a self-paced reading study in which reading-time data are collectedon sentences for which the model estimates information values.3 As presented inSection 4, an analysis of these word-information and reading-time measures reveals thatsurprisal and entropy reduction have independent effects, confirming the entropy-reduc-tion hypothesis. Further analyses, discussed in Section 5, were intended to uncover a cog-nitively relevant distinction between the surprisal and entropy-reduction informationmeasures. However, no evidence was found that the two measures correspond to cogni-tively distinct representations, processes, or strategies. As concluded in Section 6, findingsuch a distinction may require more rigorous, theory-driven experiments.
2. Estimating word information
2.1. Model architecture
Fig. 1 presents the architecture of the recurrent neural network (RNN) that was usedas the probabilistic language model for estimating word-surprisal and entropy-reductionvalues. This network is not proposed as a cognitive model; rather, it serves as a tool forobtaining the required word-information measures with several advantages over alterna-tive models. For one, RNNs process more efficiently than phrase-structure grammars (orother structure-assigning models), which is of particular importance for computingentropy. Also, they can be trained on unannotated sentences (i.e., word strings instead oftree structures). In addition, RNNs have been shown to estimate surprisal values that fitreading times better than do grammar-based surprisal estimates (Frank & Bod, 2011).This was also demonstrated by Fernandez Monsalve et al. (2012), using the very same
Fig. 1. Architecture of neural network language model, and its three learning stages. Numbers indicate thenumber of units in each network layer. Reproduced from Fernandez Monsalve et al. (2012).
478 S. L. Frank / Topics in Cognitive Science 5 (2013)
Surprisal and entropy-reduction values
!
Surprisal values:!
❖ the RNN returns a probability distribution (aka surprisal values) over word types
St+1 = � logP (wt+1|wt1)
12

Surprisal and entropy-reduction values
Entropy values: over probabilities of sentences!
❖ what we have encountered so far is known (up to wt)!
❖ the complete sentence we expect to encounter is not (from wt on)!
❖ big search space: only next n word window and 40 most probable wt+1 considered
!
Entropy reduction: over the probability of strings in Wn-1 !
!
P (wt+nt+1 |wt
1)
if positive: decrease in entropy13

Reading-time data
14

Reading-time collection
❖ word-reading times over individual sentences drawn semi-randomly from freely available novels!
❖ 361 sentences at least 5 words long, interpretable out of context, and containing only highly-frequent words!
❖ self-paced reading (N = 70)!
❖ one-word-at-a-time (no moving window)
+shewouldsoonbefoundifshetriedtohide
15

Results
16
training. Importantly, accuracy increases monotonically, showing that the model does notsuffer from overfitting.
4.2. Relation between surprisal and entropy reduction
Considering that both surprisal and entropy reduction express the information conveyedby words, one would expect these two values to correlate strongly. This should be the case inparticular for n = 1, because DH1 ¼ "
Pwtþ1
Pðwtþ1jwt1Þ logPðwtþ1jwt
1Þ, which equals theexpected value of the surprisal of wtþ1. Indeed, surprisal and DH1 correlate considerably but,as Fig. 3 shows, this correlation is fairly weak for n = 3 and virtually absent for n = 4.
4.3. Effect of word information
A mixed-effects regression model (Baayen, Davidson, & Bates, 2008) was fitted to thelog-transformed reading times9 (see Appendix B for details). This “baseline” model did notinclude factors for surprisal or entropy reduction, but it did have several well-known predic-tors of word-reading time such as: word length, frequency, and forward transitional probabil-ity (i.e., the word’s probability given the previous word). To factor out effects of the previousword, its length, frequency, and forward probability were also included. As recommended by
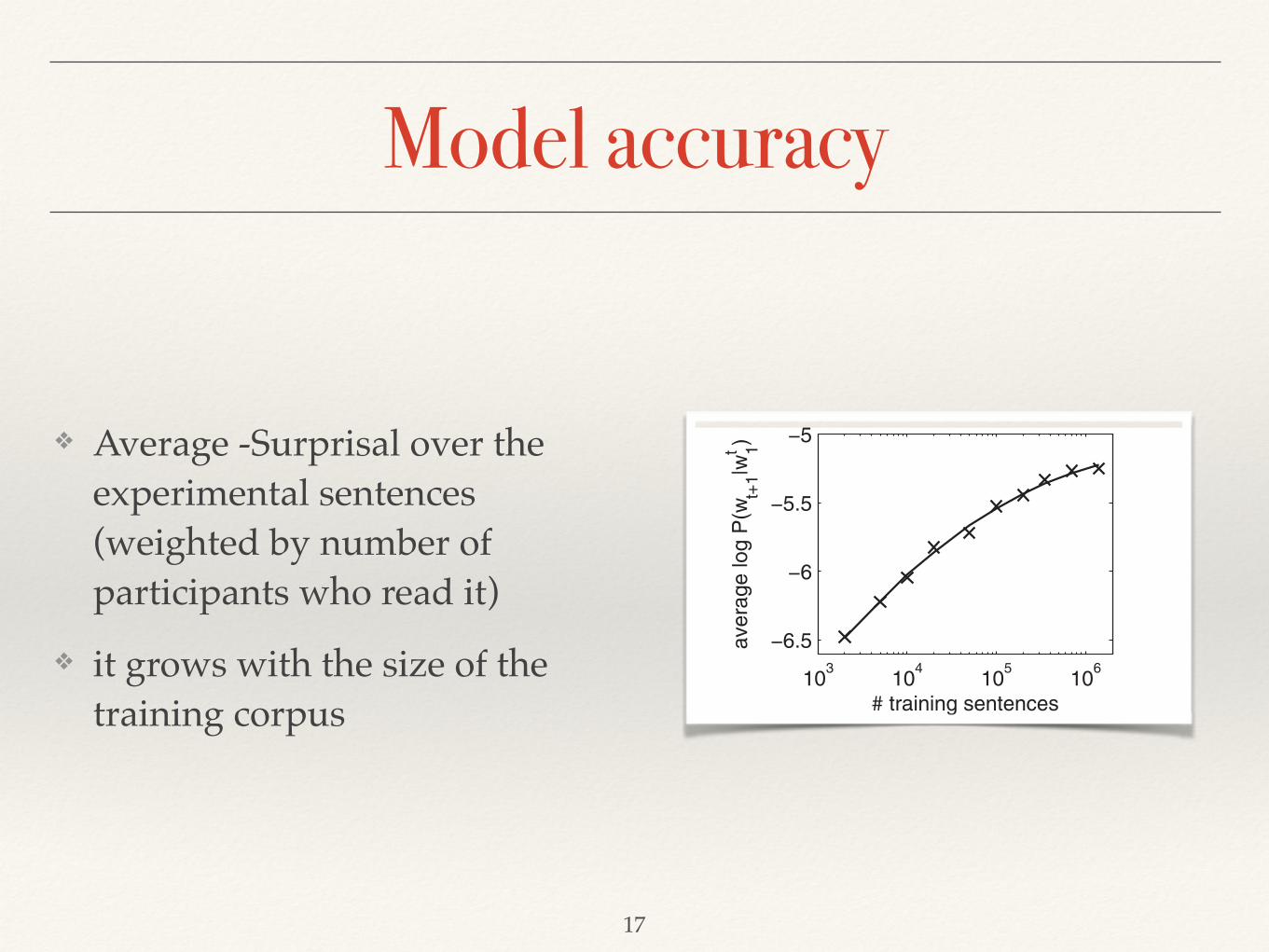
Fig. 2. Accuracy of the language model as a function of the number of sentences presented in Stage 3training.
Fig. 3. Coefficient of correlation (where each item is weighted by the number of participants for which ittook part in the analysis) between estimates of surprisal and DHn, as a function of n and of the number ofsentences on which the network was trained. Because of the very long computation time for DH4, thesevalues are obtained from the fully trained model only.
484 S. L. Frank / Topics in Cognitive Science 5 (2013)
Model accuracy
❖ Average -Surprisal over the experimental sentences (weighted by number of participants who read it)!
❖ it grows with the size of the training corpus
17
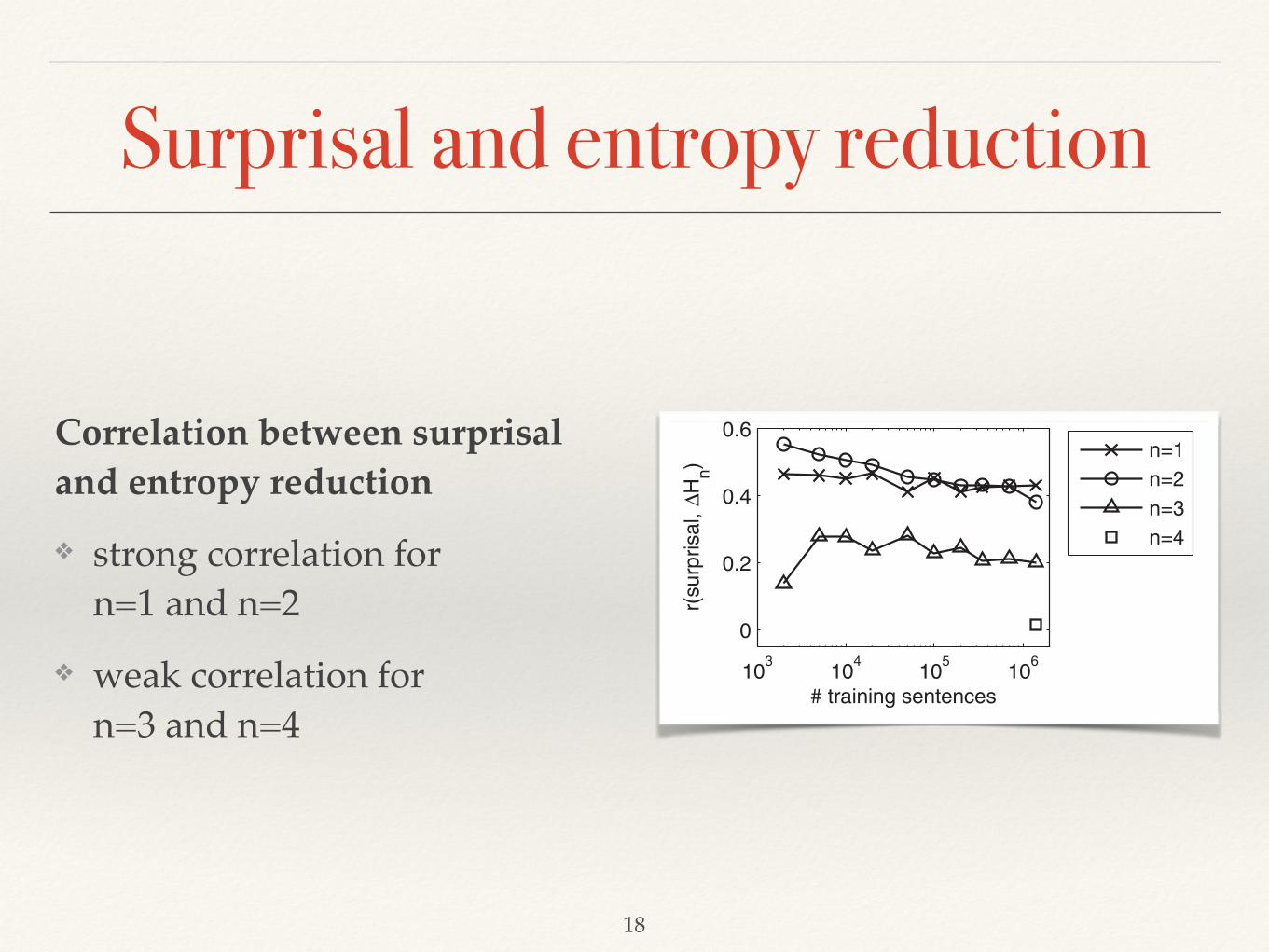
Surprisal and entropy reduction
Correlation between surprisal and entropy reduction!
❖ strong correlation for n=1 and n=2!
❖ weak correlation for n=3 and n=4
training. Importantly, accuracy increases monotonically, showing that the model does notsuffer from overfitting.
4.2. Relation between surprisal and entropy reduction
Considering that both surprisal and entropy reduction express the information conveyedby words, one would expect these two values to correlate strongly. This should be the case inparticular for n = 1, because DH1 ¼ "
Pwtþ1
Pðwtþ1jwt1Þ logPðwtþ1jwt
1Þ, which equals theexpected value of the surprisal of wtþ1. Indeed, surprisal and DH1 correlate considerably but,as Fig. 3 shows, this correlation is fairly weak for n = 3 and virtually absent for n = 4.
4.3. Effect of word information
A mixed-effects regression model (Baayen, Davidson, & Bates, 2008) was fitted to thelog-transformed reading times9 (see Appendix B for details). This “baseline” model did notinclude factors for surprisal or entropy reduction, but it did have several well-known predic-tors of word-reading time such as: word length, frequency, and forward transitional probabil-ity (i.e., the word’s probability given the previous word). To factor out effects of the previousword, its length, frequency, and forward probability were also included. As recommended by
Fig. 2. Accuracy of the language model as a function of the number of sentences presented in Stage 3training.
Fig. 3. Coefficient of correlation (where each item is weighted by the number of participants for which ittook part in the analysis) between estimates of surprisal and DHn, as a function of n and of the number ofsentences on which the network was trained. Because of the very long computation time for DH4, thesevalues are obtained from the fully trained model only.
484 S. L. Frank / Topics in Cognitive Science 5 (2013)
18

Word information and reading times
Mixed-effect regression models fitted to log(RT)!
❖ baseline model (no surprisal or entropy reduction) including well-known RT predictors!
❖ model 1: baseline factors and surprisal!
❖ model 2: baseline factors and entropy reduction!
❖ model 3: baseline factors, surprisal and entropy reduction
19

Mixed-effect regression models fitted to log(RT)
❖ spillover effect:RTs on a word predicted much more strongly by surprisal and entropy reduction at the previous word (effect of task)!
❖ either information measure has a statistically significant effect over and above the other (and over and above the baseline predictors)!
❖ larger information content → larger RTs!
❖ the effects grow with the model accuracy
✓
contribute to a growing body of evidence that the amount of information conveyed by aword in sentence context is indicative of the amount of cognitive effort required for pro-cessing, as can be observed from word-reading times. A considerable number of previousstudies have shown that surprisal can serve as a cognitively relevant measure for a word’sinformation content. In contrast, the relevance of entropy reduction as a cognitivemeasure has not been investigated this thoroughly before.
It is tempting to take the independent effects of surprisal and entropy reduction asevidence for the presence of two distinct cognitive representations or processes, onerelated to surprisal, the other to entropy reduction. If the two information measures areindeed cognitively distinct, it may be possible to discover a corresponding dissociation inthe reading-time data. For example, the difference between surprisal and entropy reduc-tion may correspond to a difference in reading strategies, such that some participantsshow a stronger effect of surprisal and others of entropy reduction. Whether this is thecase can be investigated by including in the regression analysis by-subject random slopes,which capture how participants vary in their sensitivity to surprisal or entropy reduction.Crucially, it can be either assumed that there is no correlation between readers’ sensitivityto surprisal and to entropy reduction, or that such a correlation does exist. In the firstcase, the random slopes of surprisal are uncorrelated to those of entropy reduction. In thesecond case, a correlation coefficient between the two sets of slopes is also estimated.
Fig. 4. Goodness-of-fit of surprisal (left) and entropy reduction (right) for n = 3, over and above all otherpredictors, as a function of language model accuracy. Plotted are the estimated v2-statistics (9) and fittedsecond-degree polynomials.
Fig. 5. Goodness-of-fit of entropy reduction as a function of lookahead distance n.
486 S. L. Frank / Topics in Cognitive Science 5 (2013)
20
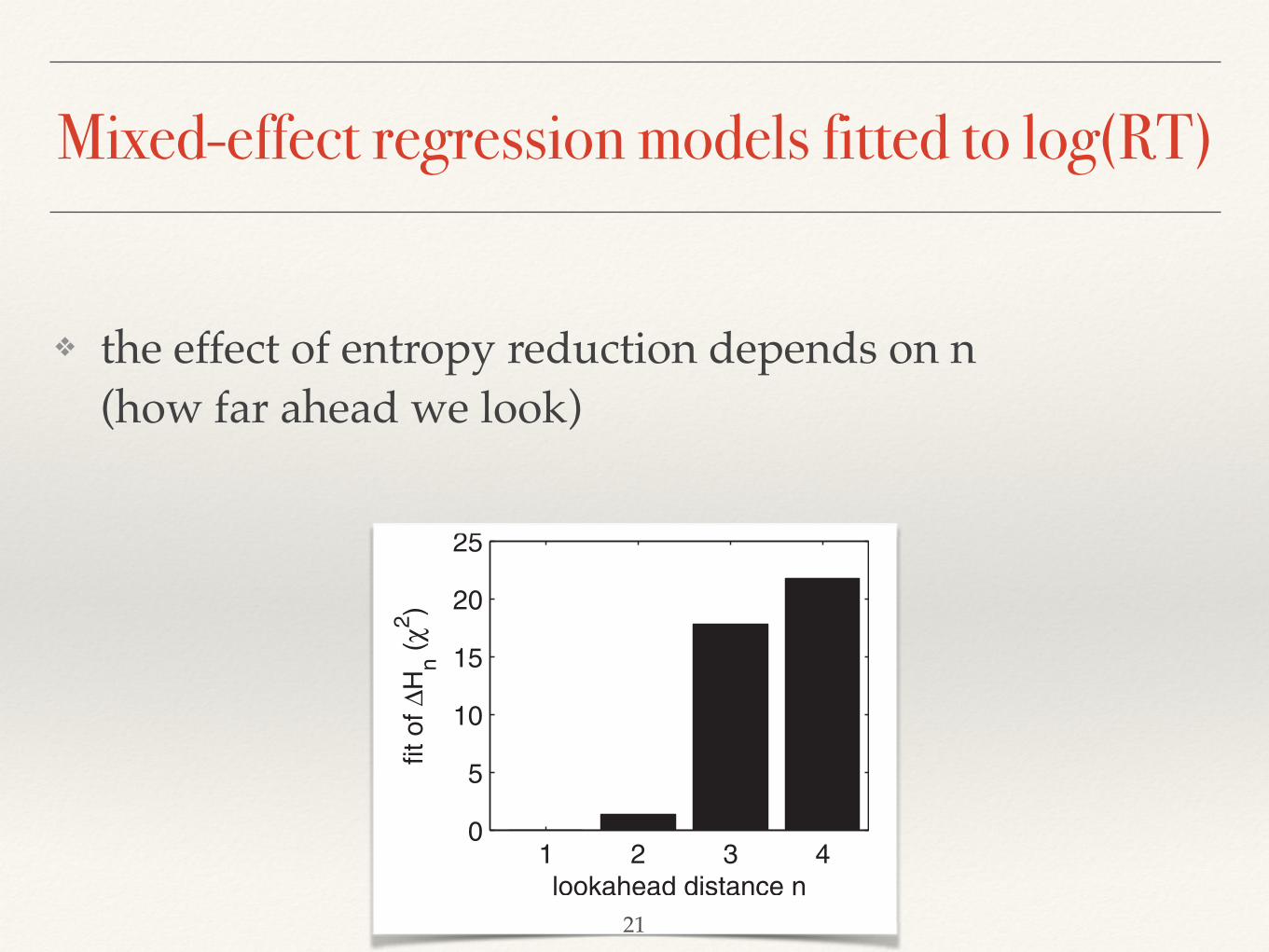
Mixed-effect regression models fitted to log(RT)
❖ the effect of entropy reduction depends on n (how far ahead we look)
contribute to a growing body of evidence that the amount of information conveyed by aword in sentence context is indicative of the amount of cognitive effort required for pro-cessing, as can be observed from word-reading times. A considerable number of previousstudies have shown that surprisal can serve as a cognitively relevant measure for a word’sinformation content. In contrast, the relevance of entropy reduction as a cognitivemeasure has not been investigated this thoroughly before.
It is tempting to take the independent effects of surprisal and entropy reduction asevidence for the presence of two distinct cognitive representations or processes, onerelated to surprisal, the other to entropy reduction. If the two information measures areindeed cognitively distinct, it may be possible to discover a corresponding dissociation inthe reading-time data. For example, the difference between surprisal and entropy reduc-tion may correspond to a difference in reading strategies, such that some participantsshow a stronger effect of surprisal and others of entropy reduction. Whether this is thecase can be investigated by including in the regression analysis by-subject random slopes,which capture how participants vary in their sensitivity to surprisal or entropy reduction.Crucially, it can be either assumed that there is no correlation between readers’ sensitivityto surprisal and to entropy reduction, or that such a correlation does exist. In the firstcase, the random slopes of surprisal are uncorrelated to those of entropy reduction. In thesecond case, a correlation coefficient between the two sets of slopes is also estimated.
Fig. 4. Goodness-of-fit of surprisal (left) and entropy reduction (right) for n = 3, over and above all otherpredictors, as a function of language model accuracy. Plotted are the estimated v2-statistics (9) and fittedsecond-degree polynomials.
Fig. 5. Goodness-of-fit of entropy reduction as a function of lookahead distance n.
486 S. L. Frank / Topics in Cognitive Science 5 (2013)
21

Discussion
22

Discussion
❖ Entropy reduction a significant predictor of RT, over and above many other factors (including surprisal)!
❖ Increasing n improves fit → what matters is uncertainty about the complete sentence!
❖ more information conveyed by a word → more cognitive effort
23

Discussion❖ Do surprisal and entropy reduction correspond to two distinct cognitive
processes? (null hypothesis: they are cognitively indistinguishable)!
❖ different reading strategies between participants?by-subject random slopes for surprisal or entropy reduction help the model’s fit but the two sets of slopes are positively correlated (participants who are sensitive to one are also sensitive to the other)!
❖ different strategies depending on sentence type?no correlation between by-sentence random slopes for surprisal and entropy reduction no correlation if we consider by-part-of-speech slopes either no correlation if we consider function vs. content words either
no evidence of a dissociation24

Conclusion
❖ Surprisal and entropy reduction are complementary formalizations of the same notion of how much a word contributes to the communication!
❖ They are ways to quantify the extent of a cognitive mechanism that is responsible for incremental revision of a semantic representation (to what extent a revision is needed)
revision vs. prediction?
25