podstawowe operacje na plikach danych · standardowo w menu edytora danych znajdują się...
TRANSCRIPT

Podstawowe operacje na plikach danych
Standardowo w menu edytora danych znajdują się następujące polecenia:
operacje na plikach danych, wczytywanie i zapisywanie danych; kopiowanie, wklejanie itp.; zarządzanie paskami narzędzi i stanu; operacje na danych; operacje na zmiennych; analizy statystyczne i raportowanie; tworzenie wykresów; informacje o zmiennych, konfigurowanie menu rozwija-nego; przechodzenie między oknami, zmiana atrybutów okien; uzyskiwanie pomocy.
W można pracować podobnie jak w arkuszach kalku-lacyjnych bezpośrednio usuwać czy też wpisywać dane do komórek bazydanych. Ten styl pracy nie jest jednak godny polecenia w przypadku pracyna dużych zbiorach danych, gdyż dokonywane w ten sposób zmiany nie sąw żaden sposób dokumentowane. Lepszym rozwiązaniem jest korzystaniez dostępnych w SPSS poleceń pozwalających na przekształcanie danych. Pra-cując w ten sposób, zawsze mamy możliwość prześledzenia historii zmiandokonywanych w bazie danych (śledząc komendy w oknie języka poleceńSPSS). Jeśli jednak zdecydujemy się na pracę z danymi poprzez bezpośred-nie usuwanie, wycinanie i wklejanie komórek, warto wcześniej utworzyćkopię pliku z danymi. Ostrożności nigdy nie za wiele, dlatego w trakciepracy z plikami danych należy zwracać szczególną uwagę na komunika-ty programu z ostrzeżeniami dotyczącymi konsekwencji przeprowadzanychprzez nas operacji.
4.1 Struktura zbiorów danych
Dane analizowane za pomocą pakietu SPSS for Windows zorganizowane sąw zmienne i obserwacje. Zmienne są odpowiednikiem cechy statystycznej(np. wiek, płeć itp.) i ich własności są przedmiotem analiz wykonywanych zapomocą pakietu SPSS for Windows; każda obserwacja to pojedynczy badanyobiekt (respondent, faktura, wynik eksperymentu, itp.). Struktura danychjest podobna do struktury danych arkuszy kalkulacyjnych (np. MS Excel,Lotus 1-2-3).
21
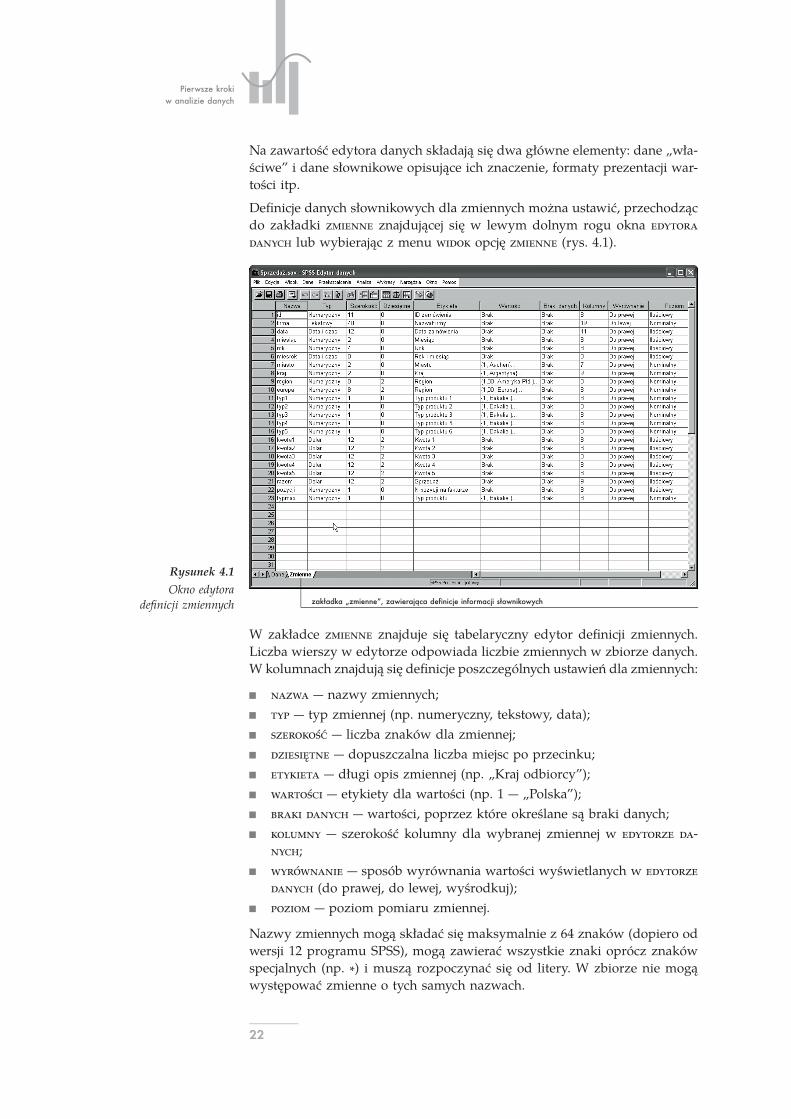
Pierwsze krokiw analizie danych
Na zawartość edytora danych składają się dwa główne elementy: dane „wła-ściwe” i dane słownikowe opisujące ich znaczenie, formaty prezentacji war-tości itp.
Definicje danych słownikowych dla zmiennych można ustawić, przechodzącdo zakładki znajdującej się w lewym dolnym rogu okna lub wybierając z menu opcję (rys. 4.1).
zakładka „zmienne”, zawierająca definicje informacji słownikowych
Rysunek 4.1Okno edytora
definicji zmiennych
W zakładce znajduje się tabelaryczny edytor definicji zmiennych.Liczba wierszy w edytorze odpowiada liczbie zmiennych w zbiorze danych.W kolumnach znajdują się definicje poszczególnych ustawień dla zmiennych:
nazwy zmiennych; typ zmiennej (np. numeryczny, tekstowy, data); liczba znaków dla zmiennej; dopuszczalna liczba miejsc po przecinku; długi opis zmiennej (np. „Kraj odbiorcy”); etykiety dla wartości (np. 1 „Polska”); wartości, poprzez które określane są braki danych; szerokość kolumny dla wybranej zmiennej w -; sposób wyrównania wartości wyświetlanych w (do prawej, do lewej, wyśrodkuj); poziom pomiaru zmiennej.
Nazwy zmiennych mogą składać się maksymalnie z 64 znaków (dopiero odwersji 12 programu SPSS), mogą zawierać wszystkie znaki oprócz znakówspecjalnych (np. ∗) i muszą rozpoczynać się od litery. W zbiorze nie mogąwystępować zmienne o tych samych nazwach.
22

Podstawowe operacjena plikach danych
Jako nazw zmiennych nie można używać zastrzeżonych słów: ALL, AND,BY, EQ, GE, GT, LE, LT, NE, NOT, OR, TO, WITH. Duże i małe litery nie sąrozróżniane w nazwach zmiennych, tzn. nazwy zmiennych nAzWa1 i nazwa1są dla SPSS identyczne. Nazwy zmiennych nie mogą kończyć się kropką.
W SPSS for Windows można definiować zmienne różnego typu:
są to liczby, np. 100.86 lub 1 000 000 znak oddzielającyczęść dziesiętną zależy od konfiguracji systemu Windows; są to liczby w formacie numerycznym, w którym prze-cinkami oddzielone są kolejne potęgi tysiąca, a kropka oddziela częścidziesiętne, np. 100.86 lub 1,000,000.15; części dziesiętne zapisywane są po przecinku, a tysiące pokropce, np. 100,86 lub 1.000.000,15; liczby w postaci xEy = x ·10y, np. 1.0086E2 lub 1e+6(zamiast litery E możemy mieć D lub znak wykładnika y); zmienne zawierające daty lub czas; format zapisu waluty USD, np. $100,86; formaty liczbowe zdefiniowane przez użytkow-nika, np. waluty; zmienne tekstowe.
SPSS pozwala na zadeklarowanie wielu dodatkowych, rzadziej używanychformatów zmiennych z poziomu języka poleceń.
Zmiennym możemy przypisywać etykiety ( ) o długości do256 znaków. Etykietą taką może być np. treść pytania, opis zmiennej, jejpełna nazwa itp. W wynikach analiz zamiast nazw zmiennych wykorzysty-wane są etykiety, co w efekcie powoduje, że otrzymujemy raport gotowydo zaprezentowania innym osobom. Jeżeli jednak użytkownik woli używaćw raportach nazw zmiennych, może zmienić ustawienia domyślne progra-mu dotyczące sposobu raportowania.
Także każdej wartości zmiennej (zwykle jakościowej) możemy przypisać ety-kietę ( ). Może ona składać się z 60 znaków. Etykiety przy-pisujemy i modyfikujemy w oknie dialogowym . Okno towywołujemy po kliknięciu na komórkę w kolumnie , wybierając widoczny w prawym rogu tej komórki kwadracik.
W praktyce często zdarza się, że jakaś informacja nie jest dostępna lub niema zastosowania (np. jeśli firma nie działała w styczniu, to nie poda in-formacji o przychodach w tym miesiącu). Sytuacji takiej w zbiorze danychodpowiadają brakujące obserwacje. W zbiorze danych są one reprezentowa-ne przez pustą wartość brak danych. Wartość ta nie jest brana pod uwagęw większości analiz (np. przy obliczaniu średniej).
W SPSS for Windows występują dwa rodzaje braków danych:
Systemowe braki danych są to wartości automatycznie przypisywaneprzez SPSS for Windows pustym komórkom w zbiorze danych. W edy-torze danych komórki takie są oznaczane przez kropkę.
23

Pierwsze krokiw analizie danych
Zdefiniowane braki danych są to wartości wskazane przez użytkow-nika jako kody brakujących wartości, umożliwiają rozróżnianie przyczynpowodujących brak informacji.
Mogą one być:dyskretne, np. 1 „brak odpowiedzi”, 2 „nie wiem”;należeć do pewnego przedziału, np. (−1, 9999);przybierać jedną wartość i należeć do pewnego przedziału, np. bra-kiem danych jest obserwacja, jeżeli jej wartość należy do przedziału(−1,−9999) lub jest równa 1000.
Braki danych można definiować wybierając w kolumnie ko-mórkę reprezentującą wybraną zmienną.
SPSS pozwala także na określenie skali pomiarowej dla każdej ze zmiennych.I tak, w kolumnie możemy zadeklarować , lub poziom pomiarowy zmiennej. W niektórych procedurach anali-tycznych i wykresach ustawienia te mogą mieć wpływ na sposób traktowaniazmiennej w analizach i prezentacji zmiennej na wykresach.
Obok zmiennych definiowanych przez użytkownika istnieją także zmiennesystemowe, np. zmienna numerująca obserwacje ($casenum), czy zmiennatypu data. Zmienne te możemy wykorzystywać w obrębie języka poleceńprogramu SPSS oraz w przekształceniach realizowanych z użyciem interfejsugraficznego.
W zbiorze danych oprócz wartości zmiennych przechowywany jest równieżsłownik zawierający definicje wszystkich zmiennych i dodatkowe informacjedotyczące danych, dlatego raz zdefiniowane etykiety, typ i kody brakówdanych będą pojawiać się przy każdej następnej sesji pracy z tym plikiemdanych.
Pełny opis zbioru danych możemy uzyskać za pomocą polecenia z menu . Informacje o pliku wypisywane są w oknie edytora ra-portów. Opis poszczególnych zmiennych uzyskujemy, wykorzystując opcje z menu (rys. 4.2).
przechodzi do wybranej zmiennejw oknie edytora danych
wkleja nazwę wybranej zmiennejdo okna języka poleceń
Rysunek 4.2Informacja o zmiennych
24
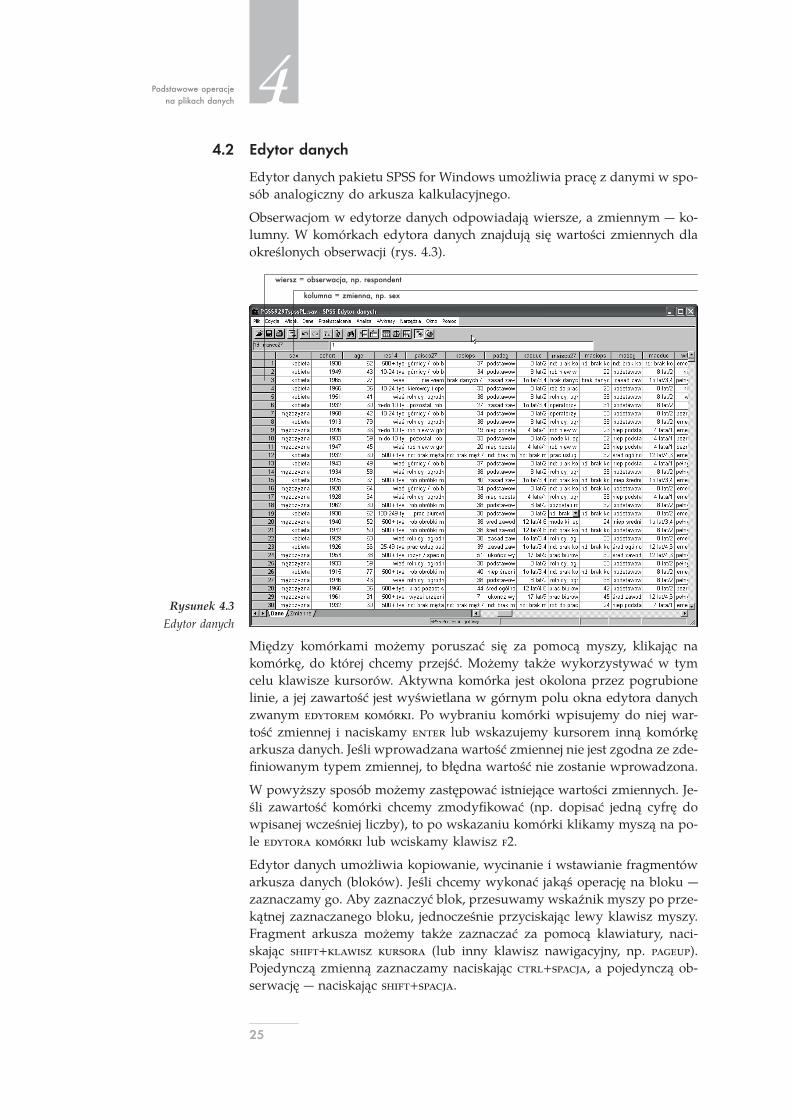
Podstawowe operacjena plikach danych
4.2 Edytor danych
Edytor danych pakietu SPSS for Windows umożliwia pracę z danymi w spo-sób analogiczny do arkusza kalkulacyjnego.
Obserwacjom w edytorze danych odpowiadają wiersze, a zmiennym ko-lumny. W komórkach edytora danych znajdują się wartości zmiennych dlaokreślonych obserwacji (rys. 4.3).
wiersz = obserwacja, np. respondent
kolumna = zmienna, np. sex
Rysunek 4.3Edytor danych
Między komórkami możemy poruszać się za pomocą myszy, klikając nakomórkę, do której chcemy przejść. Możemy także wykorzystywać w tymcelu klawisze kursorów. Aktywna komórka jest okolona przez pogrubionelinie, a jej zawartość jest wyświetlana w górnym polu okna edytora danychzwanym . Po wybraniu komórki wpisujemy do niej war-tość zmiennej i naciskamy lub wskazujemy kursorem inną komórkęarkusza danych. Jeśli wprowadzana wartość zmiennej nie jest zgodna ze zde-finiowanym typem zmiennej, to błędna wartość nie zostanie wprowadzona.
W powyższy sposób możemy zastępować istniejące wartości zmiennych. Je-śli zawartość komórki chcemy zmodyfikować (np. dopisać jedną cyfrę dowpisanej wcześniej liczby), to po wskazaniu komórki klikamy myszą na po-le lub wciskamy klawisz 2.
Edytor danych umożliwia kopiowanie, wycinanie i wstawianie fragmentówarkusza danych (bloków). Jeśli chcemy wykonać jakąś operację na bloku zaznaczamy go. Aby zaznaczyć blok, przesuwamy wskaźnik myszy po prze-kątnej zaznaczanego bloku, jednocześnie przyciskając lewy klawisz myszy.Fragment arkusza możemy także zaznaczać za pomocą klawiatury, naci-skając + (lub inny klawisz nawigacyjny, np. ).Pojedynczą zmienną zaznaczamy naciskając +, a pojedynczą ob-serwację naciskając +.
25

Pierwsze krokiw analizie danych
Zaznaczony blok możemy kopiować do schowka, naciskając + (-/), wycinać + (/) oraz usuwać . Znajdu-jący się w schowku blok możemy umieścić w arkuszu danych +(/). Przed wstawieniem bloku do arkusza zaznaczamy obszar,w który ma on być wstawiony. Jeśli typ zmiennych w tym obszarze różnisię od typu zmiennych w kopiowanym bloku, zostanie dokonana automa-tyczna konwersja.
Operacje kopiowania, wycinania, usuwania i wklejania możemy przeprowa-dzić także przy użyciu prawego przycisku myszy.
Wprowadzenie dowolnej wartości do komórki lub wiersza poza zakresem(poniżej) istniejących obserwacji powoduje automatyczne dodanie nowej ob-serwacji do zbioru. Jeśli chcemy wstawić nową obserwację między istniejąceobserwacje, to z menu wybieramy polecenie . Nowezmienne wstawiamy poleceniem z menu . Powyższeoperacje można także wykonać za pomocą prawego przycisku myszy, klika-jąc na numer wiersza, przed którym chcemy wstawić obserwacje i wybierającopcję .
Aby wstawić nową zmienną, postępujemy podobnie. Klikamy na nazwęzmiennej, przed którą chcemy wstawić nową zmienną i wybieramy opcję . Zmienne i obserwacje usuwamy po zaznaczeniu odpowia-dających im kolumn lub wierszy i wydaniu polecenia z menu lub korzystając z prawego przycisku myszy.
Do wybranej obserwacji przechodzimy za pomocą polecenia z menu (rys. 4.4). Natomiast do kolumny odpowiadającej wybranejzmiennej przechodzimy, wybierając opcję z menu . Na-stępnie w oknie dialogowym zaznaczamy nazwę zmiennej na liście i naci-skamy przycisk .
Rysunek 4.4Przeszukiwanie danych
Jeśli analizy wykonywane są dla podgrupy obserwacji, to numery obserwacjinieuwzględnianych w analizach są przekreślone.
W edytorze danych zamiast wartości zmiennych możemy wyświetlać przy-pisane wartościom etykiety. Etykiety będą wyświetlane w edytorze danychjeśli z menu wybierzemy . Do arkusza danych mo-żemy wprowadzać etykiety zamiast wartości zmiennych. W tym celu powybraniu komórki klikamy na kwadracik z prawej strony wybranej komór-ki, a następnie z listy wybieramy żądaną etykietę. Taki tryb wprowadzaniadziała wyłącznie wtedy, gdy w menu wybrana została opcja .
26

Podstawowe operacjena plikach danych
4.3 Tworzenie nowego zbioru danych
Nowy zbiór danych tworzymy, wybierając z menu opcję , a na-stępnie . Kolejnym krokiem jest zdefiniowanie zmiennych, które będąwystępowały w zbiorze danych. Zmienne definiujemy po przejściu do za-kładki w lewym dolnym rogu . W oknie edytoradefinicji zmiennych wpisujemy nazwę zmiennej, typ i inne parametry opi-sane w rozdziale 4.1.
Dane mogą być wprowadzane do programu SPSS analogicznie jak w przy-padku arkuszy kalkulacyjnych lub pobierane z pliku zewnętrznego. W przy-padku wprowadzania danych bezpośrednio do okna edytora danych pro-gramu SPSS warto pamiętać, iż istnieją też inne możliwości wprowadzaniadanych, np. za pomocą SPSS Data Entry.
Przy definiowaniu i tworzeniu wielu zmiennych wygodnie jest korzystaćz kreatorów ułatwiających definiowanie właściwości i ich kopiowanie po-między zmiennymi. Kreatory te dostępne są w menu .
Pierwszy z nich uruchamiany jest po wybraniu z menu opcji . Kreator ten jest szczególnie użyteczny w sytuacji, gdy dane do pro-gramu SPSS wczytaliśmy z zewnętrznej aplikacji, a chcemy dokonać zmianformatów, dopisać etykiety itp.
Pierwsze okno kreatora definicji zmiennych pyta o listę zmiennych, dla któ-rych chcemy dokonać definicji różnych własności (rys. 4.5).
lista opisywanych zmiennych
zawężenie zakresuskanowanych obserwacji
zawężenie zakresuwyświetlanych wartości zmiennych
Rysunek 4.5Wybór zmiennych
Zmienne te zostaną następnie zeskanowane, tzn. kreator sprawdzi ich roz-kład. Ponieważ w przypadku bardzo dużych zbiorów danych proceduraskanowania może zająć dużo czasu, możemy ograniczyć proces skanowaniado zadanej liczby rekordów ( ).Ograniczeniu można także poddać liczbę wyświetlanych wartości zmien-nych ( ). Zwiększanie zadeklaro-wanej w tym oknie domyślnej wartości powoduje zwiększanie obciążeniakomputera. Zadeklarowana domyślnie wartość 200 zwykle wystarczy, aby
27

Pierwsze krokiw analizie danych
zorientować się co do poziomu pomiaru zmiennej. Zmienne, których defi-nicje chcemy zmienić, wybieramy przenosząc je do listy - poprzez kliknięcie na strzałkę pomiędzy listami.
W kolejnym oknie kreatora (rys. 4.6) możemy zobaczyć listę wybranychzmiennych z sugerowanym poziomem pomiaru i informacją, czy wartościdanej zmiennej posiadają etykiety (kwadrat bez krzyżyka obok poziomu po-miaru zmiennej). W oknie tym możemy definiować etykiety zmiennych i po-ziom pomiaru cechy oraz obejrzeć rozkład zeskanowanych wartości. W tabelietykiet i wartości zmiennej można zaznaczyć, które wartości mają być trak-towane jako braki danych. Szczególnie użyteczne są tu opcje pozwalające naautomatyczne utworzenie etykiet wartości w oparciu o wartości zmiennej( ) i kopiowanie własności pomiędzy zmiennymi ().
informacjeo typiei dostępnościetykiet
definiowanieetykiet wartości,kodów, brakówdanych
definicjapoziomupomiaru
definicjaetykietzmiennych definicja typu zmiennej
Rysunek 4.6Definicja własności
zmiennych
Po wybraniu właściwych opcji dla poszczególnych zmiennych klikamy lub , jeśli chcemy by własności zdefiniowane w tym oknie zostały wkle-jone do okna języka poleceń.
Innym przydatnym kreatorem jest kreator kopiowania własności, urucha-miany poprzez wybranie z menu opcji . Kreator tento kompleksowe narzędzie do przejmowania informacji słownikowych, ta-kich jak: etykiety, formaty, kodowanie braków danych itp. w obrębie jednegopliku danych lub pomiędzy plikami.
Pierwsze okno (rys. 4.7) zawiera pytanie o to, czy kopiowanie własnościzmiennych będzie się odbywać pomiędzy plikami danych ( ), czy w obrębie jednego pliku danych ( ).
Jeśli chcemy kopiować własności z innego pliku danych, wskazujemy ścież-kę dostępu do niego po wybraniu przycisku . Plik taki możnanazwać plikiem słownikowym w stosunku do pliku roboczego.
28

Podstawowe operacjena plikach danych
Rysunek 4.7Wskazanie źródła danych
z informacjamio kopiowanych własnościach
Kolejny krok kreatora to zdefiniowanie sposobu przejmowania własnościpomiędzy zmiennymi (rys. 4.8). Jeśli przejmowanie odbywa się pomiędzyplikami, w tym oknie kreatora aktywne będą wszystkie opcje.
porównywaniepo nazwie zmiennej
kopiowaniez wybranej zmiennej
kopiowanie informacjio pliku danych
Rysunek 4.8Wskazanie zmiennych
źródłowych i docelowych dlakopiowanych własności
Pierwsza z nich: , powoduje porównanie nazw zmiennychpomiędzy zbiorami i pojawienie się na liście tylko tychzmiennych, których nazwy w obu zbiorach się powtarzają. Opcja ta ma po-dopcję: , .
29

Pierwsze krokiw analizie danych
Po jej zaznaczeniu na liście pojawią się wszystkie zmiennez zewnętrznego pliku danych także te, których nazwy nie są współdzie-lone pomiędzy plikami.
Jeśli następnie na liście tej zaznaczymy wszystkie zmienne, będzie to ozna-czało, iż na końcu analizowanego pliku danych zostaną dodane nowe, pustezmienne o nazwach i własnościach przejętych z pliku zewnętrznego.
Druga opcja: - , jest aktywna niezależnie od tego, czy wła-sności zmiennych są kopiowane pomiędzy plikami danych, czy w obrębiepojedynczego pliku danych. Pozwala ona na wskazanie dowolnej zmiennejna liście i dowolnej liczby zmiennych na liście - . Wybór jest w tym wypadku niezależny od nazwywybranych zmiennych, tzn. własności można kopiować pomiędzy zmienny-mi o dowolnych nazwach. Przykładowo, mając baterię pytań mierzonych natej samej skali od 1 „zdecydowanie się zgadzam”, do 5 „zdecydowaniesię nie zgadzam”, wystarczy nadać etykiety pierwszej z nich, a następniew kreatorze wskazać, iż przejmowanie własności z tej zmiennej ma się od-bywać na wszystkie pozostałe cechy mierzone na tej samej skali.
Ostatnia opcja: —
, aktywna jest tylko przy kopiowaniu własności pomiędzy plikamidanych. Ogranicza ona kopiowanie własności tylko do tych, które dotycząogólnie pliku danych, a nie poszczególnych zmiennych.
Po wybraniu pomiędzy jakimi zmiennymi, czy zbiorami chcemy kopiowaćwłasności, przechodzimy do kolejnego okna kreatora (rys. 4.9).
Rysunek 4.9Wybór kopiowanych
pomiędzy zmiennymiwłasności
Na tym etapie decydujemy o kopiowanych pomiędzy zmiennymi własno-ściach. Są to:
, ,
30

Podstawowe operacjena plikach danych
, zmiennych, zmiennych, danych w komórkach, .
Z opcją związane są dwie podopcje: lub .Pierwsza z nich daje priorytet etykietom ze zmiennych, z których kopiujemywłasności, czyli jeśli zmienna, do której dodajemy etykiety ma już etykiety,to zostaną one zastąpione. Druga z opcji powoduje nadanie etykiet tylkotym wartościom zmiennej przejmującej własności, które takich etykiet sąpozbawione. Jeśli jednak zmienna ma dla danej wartości etykiety, to niezostaną one zastąpione pozostaną etykiety pierwotne tej zmiennej. Opcjata jest wykorzystywana do uzupełniania brakujących etykiet.
Rysunek 4.10Wybór kopiowanych
własności pliku danych
Kolejny krok kreatora dotyczy przejmowania własności pomiędzy zbioramidanych (rys. 4.10). Spośród własności zbioru danych możemy kopiować:
opcja ta jest związana z wykorzy-staniem definicji zestawów zmiennych reprezentujących pytania z możli-wością wyboru wielu odpowiedzi, budowanych w ramach modułu SPSSTables; ta opcja dotyczy zestawów zmiennych zadekla-rowanych poprzez wybranie z menu opcji .Tak zdefiniowane zestawy są wykorzystywane do ograniczania liczbyzmiennych prezentowanych w oknach dialogowych do tych, które zosta-ły zawarte w wybranych zestawach zestawem zmiennych mogą byćnp. zmienne metryczkowe. są to komentarze odnoszące się do całego pliku danychdodane uprzednio przez użytkownika, po wybraniu z menu opcji .
31

Pierwsze krokiw analizie danych
Każda z wymienionych własności ma podopcje i . Analogicz-nie jak w przypadku etykiet wartości, pierwsza z opcji nadpisuje istniejącewłasności w pliku roboczym, natomiast druga uzupełnia istniejące własnościo te z pliku słownikowego.
Dodatkowo w tym oknie można wybrać jeszcze dwie własności:
powoduje automatyczne wskazanie zmiennej wa-żącej w pliku roboczym w oparciu o jej definicję w pliku słownikowym(zmienna o tej samej nazwie powinna znajdować się w pliku roboczym). jest to krótka etykieta pliku danych (max 60 znaków), defi-niowana za pomocą polecenia FILE LABELS.
Ostatnie okno kreatora jest pytaniem o to, czy wykonać zdefiniowane zajego pomocą czynności, czy też wkleić je do okna języka poleceń.
4.4 Wczytywanie i zapisywanie zbioru danych
Zbiór danych wczytujemy do SPSS for Windows, wybierając z menu opcje , a następnie . Za pomocą tego polecenia możemy wczy-tywać zbiory zapisane w następujących formatach:
SPSS for Windows (*.sav) plik danych SPSS for Windows;SPSS/PC+ (*.sys) plik danych SPSS for DOS;SYSTAT (*.syd) pliki programu statystycznego SYSTAT;SYSTAT (*.sys) pliki programu statystycznego SYSTAT (starsza wersjaplików);SPSS Portable (*.por) plik danych SPSS w formacie transportowym;Excel (*.xls) plik arkusza kalkulacyjnego Microsoft Excel do wersji 4włącznie;Lotus (*.w*) plik arkusza kalkulacyjnego Lotus Notes do wersji 3włącznie;SYLK (*.slk) format plików zawierających łącza symboliczne, wyko-rzystywany przez niektóre arkusze kalkulacyjne;dBase (*.dbf ) pliki danych dla baz danych w formacie dBase;SAS Long File Name (*.sas7bdat) plik programu SAS od wersji 7 z dłu-gimi rozszerzeniami;SAS Short File Name (*.sd7) plik programu SAS od wersji 7 z krótkimirozszerzeniami;SAS v6 for Windows (*.sd2) pliki programu SAS do wersji 6.08 dlaWindows i OS2;SAS v6 for UNIX (*.ssd01) wersja 6 programu SAS dla UNIX;SAS Transport (*.xpt) pliki transportowe programu SAS;Pliki tekstowe (*.txt) lub (*.dat) pliki tekstowe w różnych formatach.
Dodatkowo szereg rzadziej wykorzystywanych opcji wczytywania różnychpostaci plików danych dostępny jest z poziomu języka poleceń.
32

Podstawowe operacjena plikach danych
Po wywołaniu opcji na ekranie otwiera się okno dialogowe . W oknie tym ustalamy typ i nazwę zbioru.
W przypadku plików w formacie danych SPSS (*.sav) przed otwarciem plikumożna sprawdzić jego zawartość za pomocą polecenia , wy-bierając z menu opcję . Informacja o pliku wyświetlanajest w oknie raportu.
Zbiór danych zapisujemy w formacie SPSS for Windows pod obecną na-zwą poleceniem . Jeśli chcemy zmienić nazwę zbioru lub zapisać danew innym formacie używamy polecenia .
Proste zbiory tekstowe (ASCII) wczytujemy do programu poleceniem z menu . Wybranie tej opcji uruchamia kreator pobieraniaplików tekstowych.
Po wskazaniu ścieżki dostępu do pliku tekstowego uruchamia się pierwszeokno kreatora z podglądem zawartości wczytywanego pliku oraz z pyta-niem, czy użytkownik chce wskazać predefiniowany format takiego pliku(rys. 4.11).
wybór plikuopisującego strukturędanych tekstowych
Rysunek 4.11Pytanie o plik
z predefiniowanymformatem danych
Jeśli plik o określonej strukturze był już kiedyś pobierany za pomocą kre-atora i definicja jego struktury została zapisana do pliku szablonu (*.tpf ),to możemy się do niej odwołać. Wykorzystanie takiego pliku zwalnia nasz konieczności przechodzenia przez kolejne kroki kreatora. Jeśli nie mamytakiego szablonu, musimy przejść do kolejnego kroku kreatora.
W drugim kroku definiujemy format wczytywanego pliku (rys. 4.12). Zbiorytekstowe mogą mieć format:
wartości zmiennych są zapisywane w tej samej kolejnościi oddzielone separatorem (np. przecinek, spacja itp.); wartości zmiennych zapisywane są w kolumnachdanych o stałej szerokości.
33

Pierwsze krokiw analizie danych
deklaracja rodzajupliku tekstowego
deklaracja wierszaz nazwami zmiennych
Rysunek 4.12Wybór typu pliku
tekstowego
Na tym etapie deklarujemy także, czy w pierwszym wierszu pliku teksto-wego znajdują się nazwy zmiennych.
Trzeci krok kreatora (rys. 4.13) umożliwia bardziej szczegółową definicjęsposobu czytania tego pliku. Możemy w nim określić, od którego wierszama się rozpocząć czytanie danych w opcji podajemy numer wiersza.
pomijanie wierszyna początku pliku
deklaracja liczbyobserwacji w wierszu
pobieranie próbybądź wszystkich danych
Rysunek 4.13Definicja sposobu i zakresu
pobieranych danych
Możemy zadeklarować też, czy jeden wiersz zajmuje jedną obserwację, czyteż np. w jednym wierszu zostało zapisane w pliku tekstowym kilka obser-wacji w drugim przypadku w opcji podajemy liczbę zmiennych dla jednej obserwacji. Jeśli za-miast pliku separowanego w poprzednim oknie wybraliśmy format kolum-nowy, to zamiast tej opcji pojawi się opcja . Opcja ta pozwala kilka wierszy pliku tekstowego trakto-wać jako jedną obserwację.
34

Podstawowe operacjena plikach danych
W tym kroku możemy też zdecydować, czy chcemy wczytać wszystkie ob-serwacje ( ?), czy też np. pierwszychN obserwacji lub wylosować w przybliżeniu jakiś ich procent.
Czwarty krok kreatora jest inny dla plików separowanych (rys. 4.14) i innydla plików w formacie kolumnowym.
deklaracja sposobuseparowaniaciągu znakówwartości tekstowej
rodzaje separatorawartości
Rysunek 4.14Definicja operatorazmiennych w pliku
separowanym
Dla plików w formacie separowanym jest to pytanie o rodzaj separatorazmiennych ( ?), np. przeci-nek, średnik, tabulacja oraz o to, w obrębie jakiej pary znaków podane sąwartości zmiennych tekstowych ( ?) apostro-fów, cudzysłowów czy innych zadeklarowanych przez użytkownika znaków.
Dla plików w formacie kolumnowym musimy za pomocą myszy wskazać,w której kolumnie kończą się wartości dla jednej zmiennej i zaczynają dladrugiej.
W kroku piątym możemy zmienić nazwy i format zmiennych na etapie ichwczytywania do edytora danych SPSS (rys. 4.15).
deklaracja formatu
Rysunek 4.15Definicja nazw
i formatów zmiennych
35

Pierwsze krokiw analizie danych
Ostatni, szósty krok, pozwala na zapisanie definicji utworzonych w poprzed-nich krokach do postaci pliku szablonu (*.tpf ) na potrzeby późniejszegowykorzystania (rys. 4.16).
zapis pliku opisującegostrukturę danychtekstowych
wykonanie lub wklejeniedo okna języka poleceń
zaczytanie danychdo pamięci
Rysunek 4.16Tworzenie pliku
szablonu definicjioraz buforowanie danych
Możemy też podjąć decyzję o wykonaniu pobierania pliku ( - , ) lub zapisu do okna językapoleceń ( ?), w celudokumentacji lub późniejszego wykonania zestawu instrukcji.
W kroku tym możemy też wybrać opcję . Jej włączeniespowoduje utworzenie kopii pliku danych w pamięci wirtualnej, co poprawiszybkość dalszych analiz prowadzonych na tym pliku.
Pozostawienie tej opcji wyłączonej skutkuje czymś w rodzaju otwarcia po-wiązania z tym plikiem, ale bez jego pełnego wczytania. W efekcie każdaanaliza będzie pobierała od początku dane z pliku tekstowego. Przykłado-wo, jeśli między dwoma analizami (np. dwukrotne liczenie średniej dla tejsamej zmiennej) przybędzie obserwacji w pliku tekstowym, to nowsza ana-liza będzie prowadzona na powiększonym pliku danych.
Jak widać, wczytywanie danych w formacie tekstowym jest bardziej złożoneniż w przypadku otwierania plików danych z innych formatów i wymagadokładnej znajomości struktury pliku danych. Niemniej umiejętność wczy-tywania plików z formatu tekstowego może być niezbędna w sytuacji, gdymamy do czynienia z systemami baz danych stworzonymi wiele lat temu czyteż niekiedy w przypadku korzystania z systemów baz danych osadzonychna innych platformach systemowych. Do dziś w wielu instytucjach korzystasię z plików tekstowych jako standardu archiwizacji danych. Wykorzystu-jąc język poleceń programu SPSS można wczytywać pliki tekstowe naweto dużo bardziej złożonej strukturze.
36

Podstawowe operacjena plikach danych
4.5 Współpraca z relacyjnymi bazami danychi arkuszami kalkulacyjnymi z wykorzystaniem ODBC
Pakiet SPSS for Windows może korzystać z danych zawartych w relacyj-nych bazach danych i arkuszach kalkulacyjnych. Dotyczy to zdecydowanejwiększości współcześnie tworzonych aplikacji bazodanowych. SPSS umożli-wia jednoczesny dostęp do wielu tabel takich aplikacji jak: Access, Paradox,Oracle, MS SQL, DB2, Sybase, Progress, Informix itp.
Warunkiem koniecznym bezpośredniego pobrania danych do SPSS jest po-siadanie sterowników ODBC do danego typu bazy danych. Wraz z pro-gramem SPSS dostarczany jest pakiet sterowników do wszystkich wymie-nionych powyżej baz danych. Można też skorzystać z narzędzi dostępowychoferowanych przez producenta danej bazy danych. Mechanizm ODBC możezostać także wykorzystany do pobierania danych z arkuszy kalkulacyjnych.
Aby wczytać bazę danych, przechodzimy do menu i wybieramy opcję . Wybranie opcji spowoduje urucho-mienie . W pierwszym kroku pojawiasię pytanie o źródło danych (rys. 4.17).
listazdefinio-wanychźródełdanych
Rysunek 4.17Kreator przejmowania
baz danych źródła danych
Należy wówczas z listy dostępnych źródeł danych wybrać właściwe, np.Sprzedaż. Jeżeli na liście nie ma właściwej pozycji, należy ją dodać, wciskającprzycisk .
Jako źródło danych możemy zdefiniować nie tylko typ bazy, ale także kon-kretny plik danego typu. Jeśli nie zrobimy przypisania do konkretnej bazydanych jako źródła, pojawi się wtedy okno dialogowe pozwalające na wska-zanie ścieżki dostępu do konkretnego pliku.
37

Pierwsze krokiw analizie danych
Jeśli na bazę danych zostały nałożone przez administratora ograniczeniadostępu, to w następnej kolejności pojawi się okno dialogowe z pytaniem o:
nazwę użytkownika ;hasło ;nazwę serwera .
W drugim kroku wybieramy całe tabele lub poszczególne zmienne, którechcemy wczytać do SPSS (rys. 4.18). Okno dialogowe podzielone jest nadwie części po lewej znajduje się lista dostępnych tabel i zmiennych, poprawej lista zmiennych, które zostaną pobrane do SPSS.
tabelew źródło-wej baziedanych
zmiennew źródło-wej baziedanych
Rysunek 4.18Kreator przejmowania
baz danych pobieranie zmiennych
Aby przenieść tabelę, wystarczy ją zaznaczyć i przeciągnąć do pola po prawejstronie okna, przy wciśniętym lewym przycisku myszy.
Podobnie można przenieść tylko wybrane zmienne. Aby uzyskać dostępdo zmiennych, należy w polu po lewej stronie nacisnąć na znak plus oboknazwy tabeli, w której znajduje się dana zmienna. Po wskazaniu zmiennych,które chcemy wczytać do SPSS, należy nacisnąć przycisk .
W kroku trzecim definiujemy relacje między tabelami (rys. 4.19).
Wybór opcji spowoduje automatyczne połą-czenie tabel na bazie odpowiadających sobie zmiennych w różnych tabelach.
Można także zdefiniować powiązanie między tabelami samodzielnie, prze-ciągając (przy wciśniętym lewym przycisku myszy) zmienną z jednej tabelina odpowiadającą jej zmienną w drugiej tabeli.
Korzystając ze znajdujących się w oknie po prawej stronie przycisków, możnaustalić typ relacji jako:
wybiera tylko odpowiadające sobie rekordyz tabel;
38

Podstawowe operacjena plikach danych
lub wybiera wszystkie rekordyz tabeli, od której wychodzi strzałka i odpowiadające rekordy z tabeli,do której dochodzi strzałka.
przyciskidefinio-waniarelacji
Rysunek 4.19Kreator przejmowania
baz danych ustalanierelacji między tabelami
Różnica pomiędzy i sprowadza się do wskazania, z której z dwóch połączonychtabel mają być wczytane wszystkie obserwacje.
Kolejny krok umożliwia definiowanie warunków wczytywania obserwacji(rys. 4.20).
lista funkcji, z których można skorzystać przy nakładaniu warunków pobierania danych
tworzenie okna dialogowego z zapytaniem o wartość parametru
włączenieopcjilosowaniapróby
Rysunek 4.20Kreator przejmowania
baz danych nakładanie warunków
pobierania danych
39
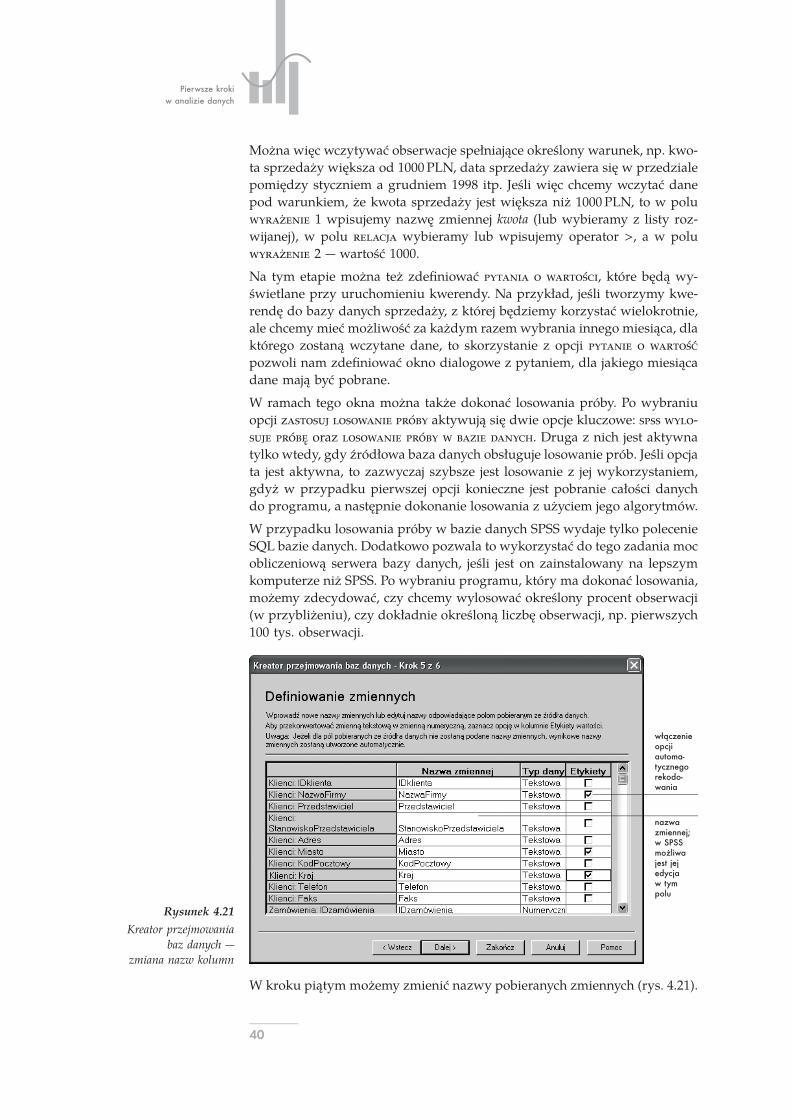
Pierwsze krokiw analizie danych
Można więc wczytywać obserwacje spełniające określony warunek, np. kwo-ta sprzedaży większa od 1000 PLN, data sprzedaży zawiera się w przedzialepomiędzy styczniem a grudniem 1998 itp. Jeśli więc chcemy wczytać danepod warunkiem, że kwota sprzedaży jest większa niż 1000 PLN, to w polu 1 wpisujemy nazwę zmiennej kwota (lub wybieramy z listy roz-wijanej), w polu wybieramy lub wpisujemy operator >, a w polu 2 wartość 1000.
Na tym etapie można też zdefiniować , które będą wy-świetlane przy uruchomieniu kwerendy. Na przykład, jeśli tworzymy kwe-rendę do bazy danych sprzedaży, z której będziemy korzystać wielokrotnie,ale chcemy mieć możliwość za każdym razem wybrania innego miesiąca, dlaktórego zostaną wczytane dane, to skorzystanie z opcji pozwoli nam zdefiniować okno dialogowe z pytaniem, dla jakiego miesiącadane mają być pobrane.
W ramach tego okna można także dokonać losowania próby. Po wybraniuopcji aktywują się dwie opcje kluczowe: - oraz . Druga z nich jest aktywnatylko wtedy, gdy źródłowa baza danych obsługuje losowanie prób. Jeśli opcjata jest aktywna, to zazwyczaj szybsze jest losowanie z jej wykorzystaniem,gdyż w przypadku pierwszej opcji konieczne jest pobranie całości danychdo programu, a następnie dokonanie losowania z użyciem jego algorytmów.
W przypadku losowania próby w bazie danych SPSS wydaje tylko polecenieSQL bazie danych. Dodatkowo pozwala to wykorzystać do tego zadania mocobliczeniową serwera bazy danych, jeśli jest on zainstalowany na lepszymkomputerze niż SPSS. Po wybraniu programu, który ma dokonać losowania,możemy zdecydować, czy chcemy wylosować określony procent obserwacji(w przybliżeniu), czy dokładnie określoną liczbę obserwacji, np. pierwszych100 tys. obserwacji.
włączenieopcjiautoma-tycznegorekodo-wania
nazwazmiennej;w SPSSmożliwajest jejedycjaw tympolu
Rysunek 4.21Kreator przejmowania
baz danych zmiana nazw kolumn
W kroku piątym możemy zmienić nazwy pobieranych zmiennych (rys. 4.21).
40

Podstawowe operacjena plikach danych
W oknie dialogowym po lewej stronie znajdują się nazwy tabel i zmien-nych w źródłowej bazie danych. W prawej części okna znajdują się nazwy,jakie zostaną nadane zmiennym po wczytaniu ich do programu SPSS (- ). W oknie tym można też zdecydować o konwersji zmiennejprzyjmującej w bazie danych wartości tekstowe na wartości numeryczne.Konwersji dokonuje się poprzez zaznaczenie kwadratu dla danej zmiennejw kolumnie .
W wyniku konwersji zmiennej kraj przyjmującej wartości Albania, Bułgariaitp. otrzymamy zmienną kraj przyjmującą wartość 1 dla Albanii i 2 dla Buł-garii, natomiast wartości tekstowe posłużą do automatycznego stworzeniaetykiet dla tych zmiennych, czyli wartość 1 będzie miała etykietę Albania,a wartość 2 Bułgaria. Dokonanie takiej transformacji zapewni później szyb-sze operacje na danych w obrębie programu SPSS, niż w sytuacji, gdy po-zostawimy taką zmienną jako zmienną tekstową.
Ostatni, szósty krok, pozwala na zapisanie kwerendy w postaci komendw oknie języka poleceń SPSS jako zapytania SQL lub jako pliku (rys. 4.22).
kod SQL
wykonanielubwklejeniedo oknajęzykapoleceń
Rysunek 4.22Kreator przejmowania
baz danych kwerenda w postaci SQL
Z zapisanej kwerendy możemy skorzystać, wybierając z menu opcję , a następnie opcję . W kroku tymmożemy też wybrać opcję . Jej włączenie spowodujeutworzenie kopii pliku danych w pamięci wirtualnej. Wybranie tej opcji po-prawia szybkość dalszych analiz prowadzonych na tym pliku. Pozostawienietej opcji wyłączonej skutkuje otwarciem powiązania z tym plikiem, ale bezjego pełnego wczytania.
41