pci 2014 18th panhellenic conference in informatics clustering documents using the 3-gram graph...
TRANSCRIPT

National Technical University of Athens
John Violos, Konstantinos Tserpes, Athanasios Papaoikonomou, Magdalini Kardara, Theodora Varvarigou
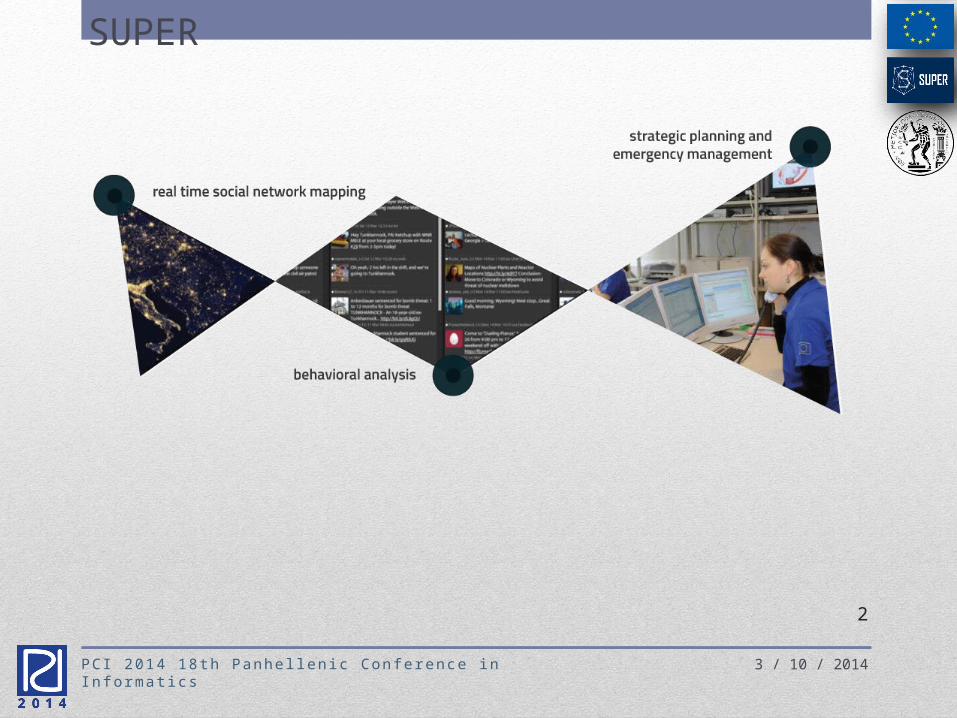
SUPERSocial sensors for secUrity Assessments and
Proactive EmeRgencies management
PCI 2014 18th Panhe l len ic Conference in In format ics
Clustering Documents using the 3-Gram Graph Representation Model
3 / 10 / 2014
2
SUPER
3 / 10 / 2014PCI 2014 18th Panhe l len ic Conference in In format ics

3
SUPER
Hurricane Sandy 2012• 20 million tweets • 10pics/sec Instagram
Virginia U.S. 2011 5.8 Richter• 40.000 tweets hit the 1st
min
3 / 10 / 2014PCI 2014 18th Panhe l len ic Conference in In format ics

Detect Topic Communities in Social Networks.
• Texts of Users, • Social Graph,• Actions (likes, follow).
4
Topic Communities
3 / 10 / 2014PCI 2014 18th Panhe l len ic Conference in In format ics

Users write texts about :• Interests• Habits• Events in their life
Cluster texts in topics => Cluster their writers in topic communities.
5
Text Clustering
3 / 10 / 2014PCI 2014 18th Panhe l len ic Conference in In format ics
6
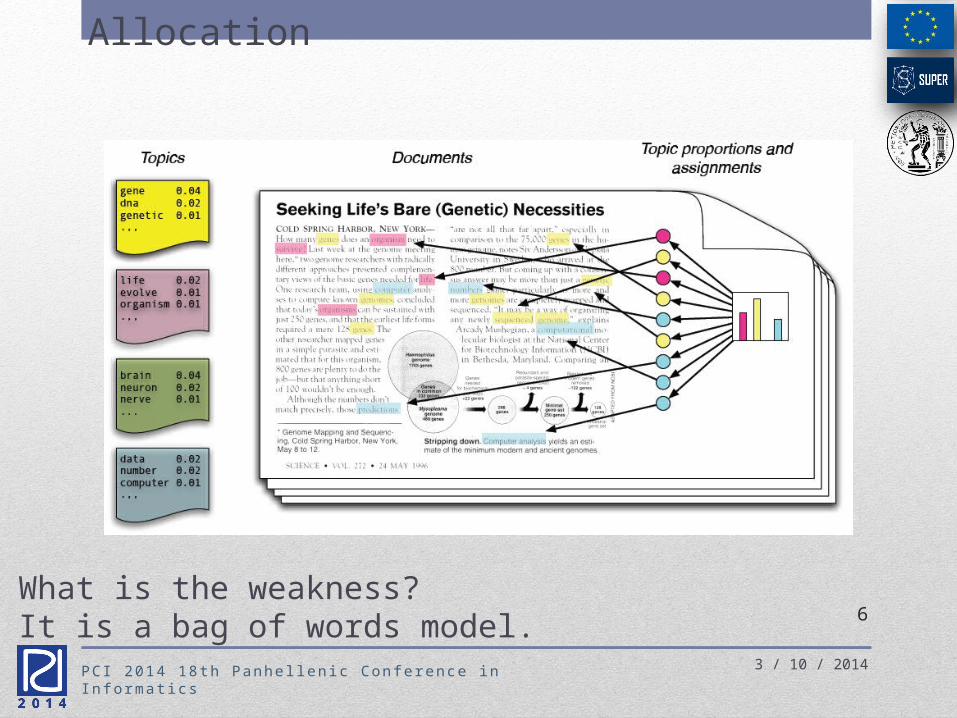
LDA Latent Dirichlet
Allocation
What is the weakness?It is a bag of words model.
3 / 10 / 2014PCI 2014 18th Panhe l len ic Conference in In format ics

The sequence of words is a valuable information.
FurthermoreDerivative of Words are Similar Words.
We need a representation model:• Keeps the information of the word sequence.• Captures the similarity between derivatives of
words.
A good solution is the N-Gram Graphs!7
Sequence of Words
3 / 10 / 2014PCI 2014 18th Panhe l len ic Conference in In format ics
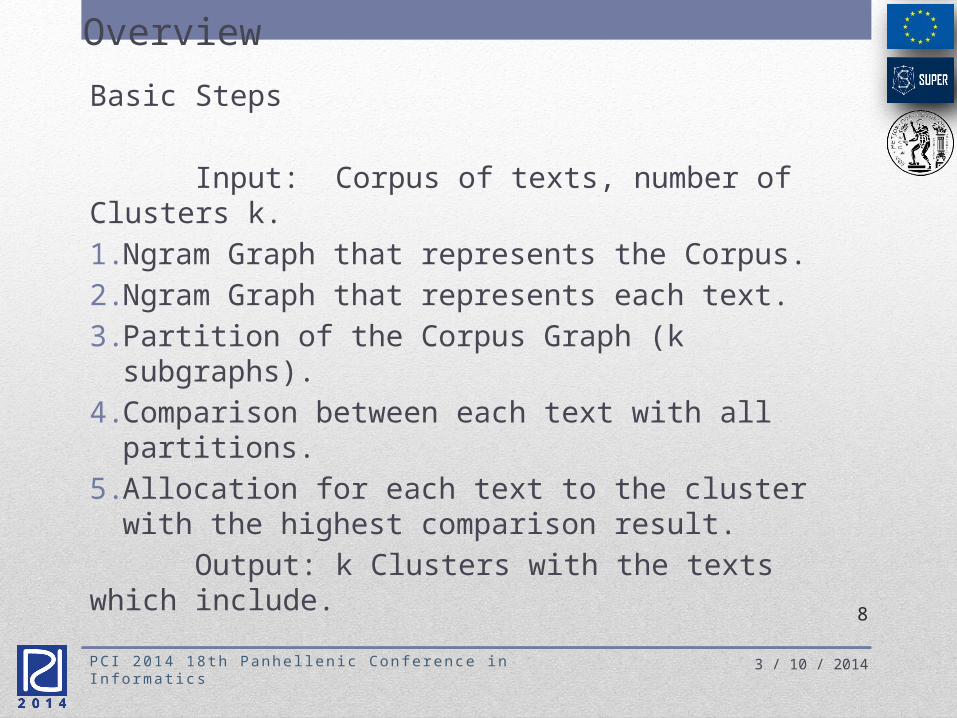
Basic Steps
Input: Corpus of texts, number of Clusters k.1. Ngram Graph that represents the Corpus.2. Ngram Graph that represents each text.3. Partition of the Corpus Graph (k subgraphs).4. Comparison between each text with all
partitions.5. Allocation for each text to the cluster with
the highest comparison result. Output: k Clusters with the texts which include. 8
Overview
PCI 2014 18th Panhe l len ic Conference in In format ics 3 / 10 / 2014

What is the N-Grams?
An N-gram is a contiguous sequence of N items from a given sequence of text.
The items can be phonemes, syllables, letters, words.
In our research we use letters and N=3
An example“home_phone”“hom”, “ome, “me_” , “e_p”, “_ph”, “pho”, “hon”, “one” 9
N-GRAMS (1)
PCI 2014 18th Panhe l len ic Conference in In format ics 3 / 10 / 2014

NGrams are used in many applications.
• Approximate string matching.• Find likely candidates for the correct spelling
of a misspelled word.• Language identification.• Species identification from a small sequence
of DNA.
10
N-GRAMS (2)
PCI 2014 18th Panhe l len ic Conference in In format ics 3 / 10 / 2014

• Nodes are all the NGrams of a text.• Edges join only the neighbor NGrams.
How many edges will be added is defined by a threshold.
Edges :• Weighted or Unweighted• Directed or Undirected
11
N-Gram Graph
PCI 2014 18th Panhe l len ic Conference in In format ics 3 / 10 / 2014
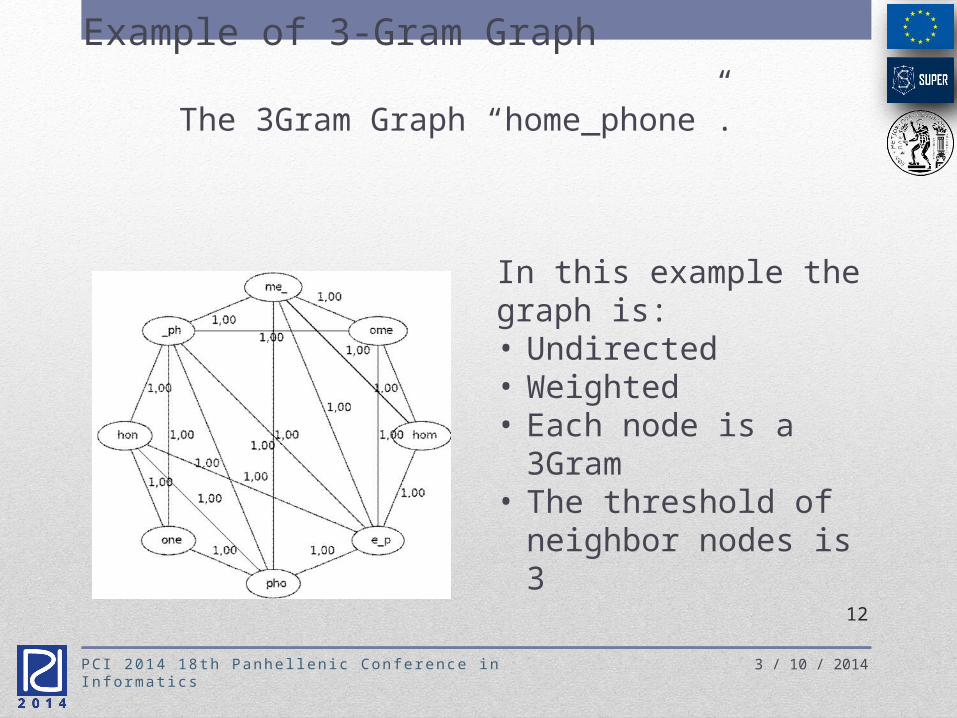
The 3Gram Graph “home_phone”.
In this example the graph is: • Undirected• Weighted• Each node is a
3Gram• The threshold of
neighbor nodes is 3
12
Example of 3-Gram Graph
3 / 10 / 2014PCI 2014 18th Panhe l len ic Conference in In format ics

How to compare two NGram Graphs?
Containment Similarity (unweighted)
Value Similarity (weighted)
13
Graph Comparison
PCI 2014 18th Panhe l len ic Conference in In format ics 3 / 10 / 2014

14
Graph Partitioning
• k subgraphs• Min number of edges between the k
subgraphs.
There are many graph partitioning algorithms:
• Kernighan–Lin algorithm• Using the Edge betweenness centrality• Fast Kernel-based Multilevel Algorithm for Graph Clustering
A graph partition can represent a topic.
3 / 10 / 2014PCI 2014 18th Panhe l len ic Conference in In format ics

1. Random initial Partitioning2. For each node i, we compute the cost of
belonging the node i in each cluster.3. The node i is assigned in the cluster with the
min cost.4. We iterate until none node change Cluster.
15
Fast Kernel-based Multilevel Algorithm
PCI 2014 18th Panhe l len ic Conference in In format ics 3 / 10 / 2014
Reuters-21578
The most widely used test collection for text categorization research.
Data set: 18457 documents belonging to 428 labels.
Multi label documents: Each document belong to 0 - 29 labels.
The complete method was implemented using Java SE. 16
Experimental Results
PCI 2014 18th Panhe l len ic Conference in In format ics 3 / 10 / 2014

Precision Recall F-measure
3-Gram Graph 0.2871 0.2046 0.2419
LDA 0.5758 0.0256 0.0498
17
Experimental Results
3Gram Graph: recognizes the clusters which include many documents.
LDA: small clusters like broken parts of the gold standard clusters.
3 / 10 / 2014PCI 2014 18th Panhe l len ic Conference in In format ics

18
Precision & Recall
3 / 10 / 2014PCI 2014 18th Panhe l len ic Conference in In format ics

19
Advantages of the 3-Gram Graphs Clustering
• The method can catch the sequence of words.
• Derivatives of a word are not handled as different words.
• Big clusters can be recognized and more documents can be assigned to them.
• It supports document partial matching and soft membership.
• It can capture writing characteristics of a writer.
PCI 2014 18th Panhe l len ic Conference in In format ics3 / 10 / 2014

• Our method is not case sensitive.
• Punctuations and numbers are omitted.
• The partitions depend on the initial randomly clustering.
• Maximum nodes of a 3Gram Graph is = 19683.
20
General notes
PCI 2014 18th Panhe l len ic Conference in In format ics3 / 10 / 2014

21
• Experiment with 4Grams, 5Grams, 6Grams.
• Experiment with various sizes of threshold.
• Experiment with various graph similarity functions.
• Experiment with various graph partitioning algorithms.
• Remove Stop Words.
• Filter out edges which do not provide useful information.
Future work
3 / 10 / 2014PCI 2014 18th Panhe l len ic Conference in In format ics

Thank you for your attention!
SUPER
3 / 10 / 2014PCI 2014 18th Panhe l len ic Conference in In format ics