par´ametros o medidas estad´ısticas temas 4, 5, 6 y...
TRANSCRIPT

Estadıstica AdministrativaDiplomatura en Gestion y Administracion Publica
Curso Segundo
Facultad de Derecho
Universidad de Sevilla
Parametros o medidas estadısticasTemas 4, 5, 6 y Complementos.
Version 2006-2007α
Jose A. Mayor Gallego
Departamento de Estadıstica e Investigacion Operativa
Universidad de Sevilla

Indice
1. Introduccion 1
2. TEMA 4. Parametros centrales o de tendencia central. 4
2.1. Media aritmetica . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2.2. Media geometrica . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.3. Mediana . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.4. Los cuartiles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.5. Los percentiles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
2.6. La moda . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
3. TEMA 5. Parametros de dispersion 16
3.1. Varianza y desviacion tıpica . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
3.2. Coeficiente de variacion de Pearson . . . . . . . . . . . . . . . . . . . . . . . 21
3.3. El recorrido intercuartılico . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
3.4. Coeficiente ∆x . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
4. TEMA 5. Medidas de forma. Otras medidas 24
4.1. Medidas o parametros de forma . . . . . . . . . . . . . . . . . . . . . . . . . 24
4.1.1. Coeficiente de asimetrıa de Pearson . . . . . . . . . . . . . . . . . . 24
4.1.2. Coeficiente de asimetrıa de Fisher . . . . . . . . . . . . . . . . . . . 25
4.1.3. Coeficiente de curtosis o aplastamiento . . . . . . . . . . . . . . . . . 25
4.2. Medidas de concentracion. Curva de Lorenz. Indice de Gini . . . . . . . . . 26
5. Complementos: Deteccion de valores singulares. Diagramas de caja 29
5.1. Introduccion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
5.2. Deteccion de valores singulares . . . . . . . . . . . . . . . . . . . . . . . . . 30
5.3. Diagrama de caja o “Box-Plot” . . . . . . . . . . . . . . . . . . . . . . . . . 31

F.Derecho[Diplom.Gest.Adm.Pub.]. Estadıstica Administrativa. Curso 2006-2007. Temas 4-5-6. 1
1. Introduccion
Podemos definir las medidas estadısticas o parametros estadısticos como ciertosvalores “representativos” de una masa de datos, en el sentido de condensar en ellos lainformacion contenida en dichos datos, en relacion a sus valores mas caracterısticos o ala forma en la que se reparten. Estas medidas estadısticas nos daran informacion sobre lasituacion, dispersion y otros patrones de comportamiento de los datos, de manera que seaposible captar rapidamente la estructura de los mismos y tambien la comparacion entredistintos conjuntos de datos.
Habitualmente se consideran cuatro tipos de medidas o parametros,
a) Parametros centrales o de tendencia central. Estan destinados a definir valorescentrales o caracterısticos de la serie de datos. Por ejemplo, la serie de datos ordenada,
1, 3, 3, 3, 4, 5, 5, 5, 7
se reparte alrededor del valor central 4.
b) Parametros de dispersion. Sirven para caracterizar la forma en que se reparten losdatos, unos con respecto a los otros, o todos con respecto a un valor central. Porejemplo, dadas las dos series siguientes,
6, 6, 7, 7, 8, 9, 9, 10, 10 1, 2, 4, 6, 8, 10, 12, 14, 15
Ambas se reparten en torno al valor central 8, sin embargo la primera esta menosdispersa alrededor de dicho valor que la segunda.
c) Parametros de forma. Recogen la existencia de ciertos patrones de tipo geometricoen la distribucion de frecuencias, como son el grado de simetrıa o el mayor o menoraplanamiento.
d) Otros parametros. Parametros de diversidad y concentracion.
Como en el tema anterior, en lo que sigue, haremos mencion numerosas veces a los datosque se proporcionan en los siguientes ejemplos, tanto directamente, como ya resumidosnumericamente.
Jose A. Mayor Gallego. Universidad de Sevilla

F.Derecho[Diplom.Gest.Adm.Pub.]. Estadıstica Administrativa. Curso 2006-2007. Temas 4-5-6. 2
EJEMPLO 1 Se han estudiado 150 familias con hijos observando para cada una el numerode los mismos, habiendose obtenido los siguientes datos,
0 0 0 1 1 6 5 1 0 0 50 0 0 0 0 1 1 1 1 1 15 4 4 4 3 3 4 2 0 0 03 0 1 2 2 2 2 2 2 2 32 2 2 2 2 3 2 3 3 4 12 2 2 2 2 3 3 2 3 2 30 0 0 0 1 1 1 2 1 1 10 0 2 2 2 2 3 2 1 1 22 2 2 2 2 3 2 2 2 2 21 1 1 1 2 2 2 2 2 2 13 3 3 3 3 3 3 3 3 3 32 2 2 2 2 2 2 2 2 2 21 1 1 1 1 1 1 1 1 1 12 2 2 2 2 2 2
Una vez clasificados, originan la siguiente tabla,
xi ni fi Ni Fi
0 20 20/150 20 20/1501 35 35/150 55 55/1502 62 62/150 117 117/1503 24 24/150 141 141/1504 5 5/150 146 146/1505 3 3/150 149 149/1506 1 1/150 150 1
150 1
y realizando los calculos, resulta,
xi ni fi Ni Fi
0 20 0′13333 20 0′133331 35 0′23333 55 0′366672 62 0′41333 117 0′780003 24 0′16000 141 0′940004 5 0′03333 146 0′973335 3 0′02000 149 0′993336 1 0′00667 150 1′00000
150 1
4
Jose A. Mayor Gallego. Universidad de Sevilla
F.Derecho[Diplom.Gest.Adm.Pub.]. Estadıstica Administrativa. Curso 2006-2007. Temas 4-5-6. 3
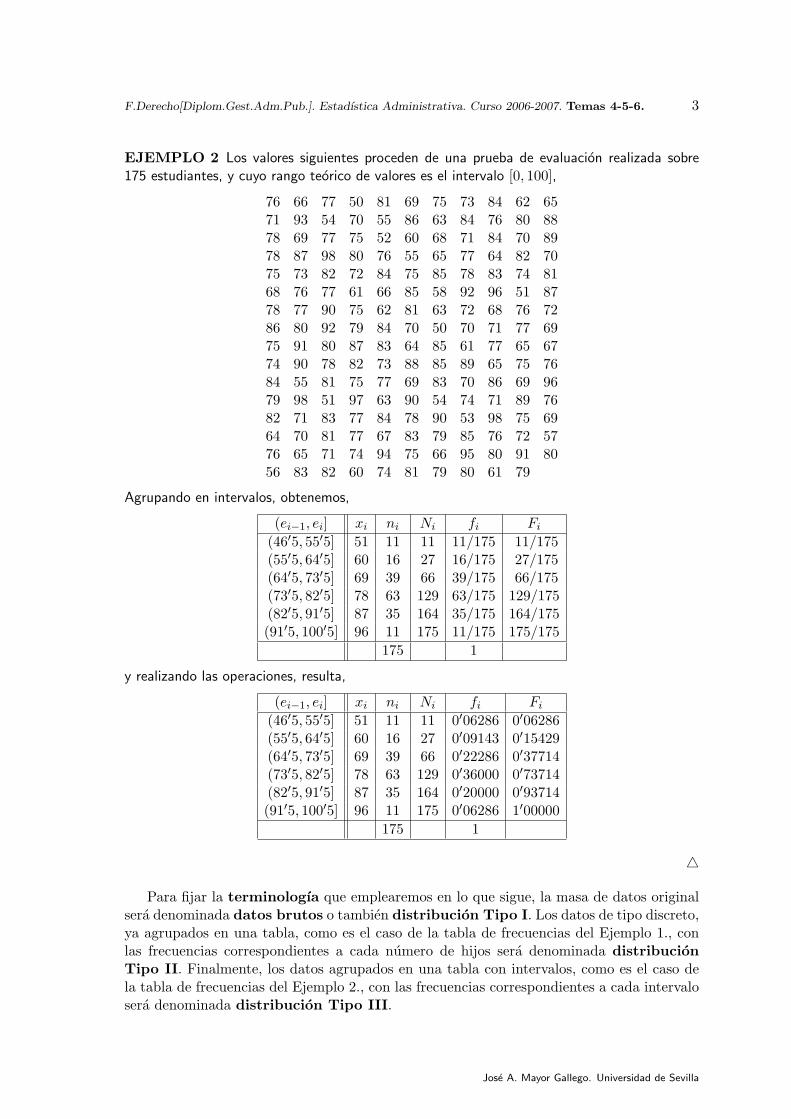
EJEMPLO 2 Los valores siguientes proceden de una prueba de evaluacion realizada sobre175 estudiantes, y cuyo rango teorico de valores es el intervalo [0, 100],
76 66 77 50 81 69 75 73 84 62 6571 93 54 70 55 86 63 84 76 80 8878 69 77 75 52 60 68 71 84 70 8978 87 98 80 76 55 65 77 64 82 7075 73 82 72 84 75 85 78 83 74 8168 76 77 61 66 85 58 92 96 51 8778 77 90 75 62 81 63 72 68 76 7286 80 92 79 84 70 50 70 71 77 6975 91 80 87 83 64 85 61 77 65 6774 90 78 82 73 88 85 89 65 75 7684 55 81 75 77 69 83 70 86 69 9679 98 51 97 63 90 54 74 71 89 7682 71 83 77 84 78 90 53 98 75 6964 70 81 77 67 83 79 85 76 72 5776 65 71 74 94 75 66 95 80 91 8056 83 82 60 74 81 79 80 61 79
Agrupando en intervalos, obtenemos,
(ei−1, ei] xi ni Ni fi Fi
(46′5, 55′5] 51 11 11 11/175 11/175(55′5, 64′5] 60 16 27 16/175 27/175(64′5, 73′5] 69 39 66 39/175 66/175(73′5, 82′5] 78 63 129 63/175 129/175(82′5, 91′5] 87 35 164 35/175 164/175(91′5, 100′5] 96 11 175 11/175 175/175
175 1
y realizando las operaciones, resulta,
(ei−1, ei] xi ni Ni fi Fi
(46′5, 55′5] 51 11 11 0′06286 0′06286(55′5, 64′5] 60 16 27 0′09143 0′15429(64′5, 73′5] 69 39 66 0′22286 0′37714(73′5, 82′5] 78 63 129 0′36000 0′73714(82′5, 91′5] 87 35 164 0′20000 0′93714(91′5, 100′5] 96 11 175 0′06286 1′00000
175 1
4
Para fijar la terminologıa que emplearemos en lo que sigue, la masa de datos originalsera denominada datos brutos o tambien distribucion Tipo I. Los datos de tipo discreto,ya agrupados en una tabla, como es el caso de la tabla de frecuencias del Ejemplo 1., conlas frecuencias correspondientes a cada numero de hijos sera denominada distribucionTipo II. Finalmente, los datos agrupados en una tabla con intervalos, como es el caso dela tabla de frecuencias del Ejemplo 2., con las frecuencias correspondientes a cada intervalosera denominada distribucion Tipo III.
Jose A. Mayor Gallego. Universidad de Sevilla

F.Derecho[Diplom.Gest.Adm.Pub.]. Estadıstica Administrativa. Curso 2006-2007. Temas 4-5-6. 4
2. TEMA 4. Parametros centrales o de tendencia central.
2.1. Media aritmetica
La media aritmetica de una serie de datos es sin duda el parametro mas conocido de losdestinados a proporcionar un valor central. Se define como la suma de todas las observacionesdividida por el numero total de las mismas. Simbolicamente, si tenemos n observaciones,
X1, X2, . . . , Xn
se suele denotar la media aritmetica como X y se define como,
X =1n
n∑i=1
Xi
Por ejemplo, los datos 1, 2, 4, 5, 7, 8, 9, 10, 11, 13, tienen como media aritmetica,
X =1 + 2 + 4 + 5 + 7 + 8 + 9 + 10 + 11 + 13
10=
7010
= 7
Sobre la media aritmetica hay que hacer las siguientes consideraciones,
1. La media aritmetica solo es aplicable a valores numericos.
2. Es un parametro unico. Un conjunto de datos numericos solo tiene una media ar-itmetica.
3. La media aritmetica generalmente no es un valor observado. Por ejemplo,
1 + 4 + 63
= 3′666..
4. La media aritmetica no depende del orden en el que esten los datos
5. La media aritmetica es un parametro sensible a la presencia de valores muy separadosde la masa principal de datos. Por ejemplo, la serie de valores,
1, 1, 2, 2, 2, 4, 4, 4, 70
posee un valor fuertemente diferente del resto, el 70. La media aritmetica calculadacon los 8 primeros valores es 2’5, lo que constituye un valor central razonable. Por elcontrario, si se considera tambien el ultimo valor, la media aritmetica resulta ser 10,que es un valor muy poco significativo.
6. Propiedades de linealidad.
aX = aX, siendo a un numero real cualquiera. Esto significa, en palabras corri-entes y molientes, que si tenemos un conjunto de valores con una media aritmeticadeterminada, y multiplicamos esos valores por un numero o factor, la media ar-itmetica de los nuevos valores obtenidos es la media aritmetica de los antiguosvalores, multiplicada por dicho factor.
Jose A. Mayor Gallego. Universidad de Sevilla

F.Derecho[Diplom.Gest.Adm.Pub.]. Estadıstica Administrativa. Curso 2006-2007. Temas 4-5-6. 5
X + Y = X + Y . Esto significa, en palabras corrientes y molientes, que dadosdos conjuntos de valores con la misma cantidad de los mismos, y sumamos unosvalores con los otros, el primero con el primero, el segundo con el segundo, etc.,la media aritmetica de las sumas obtenidas es la suma de las medias aritmeticasde los valores originales.
Finalizado el repaso de las propiedades, ya podemos pues dar un primer resumen en for-ma de parametro central para las observaciones de los Ejemplos 1.[hijos] y 2.[puntuaciones].Como globalmente no se observan valores muy extremos, podemos usar la media aritmetica,que este caso resulta ser,
Media aritmetica de hijos.
X =1
150(0 + 0 + 0 + 1 + 1 + · · ·+ 2 + 2 + 2) = 1′813..
Media aritmetica de puntuaciones.
X =1
175(76 + 66 + · · ·+ 79) = 75′5
Ahora vamos a ver como se halla la media aritmetica en el caso de que los datos ya estenclasificados en una tabla de frecuencias. Se pueden presentar dos casos: que los datos noesten agrupados en clases o intervalos (Distribucion Tipo II), o que sı lo esten (DistribucionTipo III). Veamos cada uno pormenorizadamente.
(A) Datos no agrupados en intervalos. Distribucion Tipo II. Con la notacion que estamosempleando para modalidades y frecuencias, tendremos,
X =1n
n∑i=1
Xi =1n
k∑i=1
nixi
Ası, para los datos del Ejemplo 1.[numero de hijos], ya agrupados por sus frecuencias.La media aritmetica se obtendra de la siguiente forma,
X =1
150(0× 20 + 1× 35 + 2× 62 + 3× 24 + 4× 5 + 5× 3 + 6× 1) = 1′813..
(B) Datos agrupados en intervalos. Distribucion Tipo III. Se calcula casi exactamenteigual pero empleando las marcas de clase, xi, que actuan como modalidades, es decir,
X =1n
k∑i=1
nixi
Vamos a considerar nuevamente los datos del Ejemplo 2. Tenemos numerosos datos yademas con muchos valores distintos, por los que han sido clasificados en intervalos o clases.La marca de clase se toma como valor representativo de todas las observaciones de esa clase.Entonces, la media aritmetica se halla de la siguiente forma,
X =1
175(51× 11 + 60× 16 + 69× 39 + 78× 63 + 87× 35 + 96× 11) = 75′6
Jose A. Mayor Gallego. Universidad de Sevilla

F.Derecho[Diplom.Gest.Adm.Pub.]. Estadıstica Administrativa. Curso 2006-2007. Temas 4-5-6. 6
OBSERVACION: este valor no es exactamente la media aritmetica de los datos originaleso brutos pues la agrupacion en intervalo, como sabemos, produce perdida de informacion,sin embargo es un valor bastante aproximado cuya obtencion ha requerido calculos menoslaboriosos.
Para terminar este apartado, mencionamos la existencia de otros tipos de medias comoson la media geometrica y la media armonica.
2.2. Media geometrica
Dados los n valores, X1, X2,...,Xn, de una variable X, que supondremos que solo asumevalores mayores que cero, su media geometrica es la raız n-esima del producto de dichosvalores.
Por ejemplo, dados los valores 3, 6, 11, su media geometrica sera la raız cubica delproducto de estos valores,
XG = 3√
3× 6× 11 = 3√
198 = 5′8285
y la media geometrica de 1 y 9 sera,
XG = 2√
1× 9 = 3
La formula general para calcular esta media, tanto para distribucion Tipo I como TipoII y Tipo III, es,
XG = n
√√√√ n∏i=1
Xi = n
√√√√ k∏i=1
xnii
Aplicacion economica: Supongamos que un producto tiene un valor inicial de 10 euros,y durante tres anos consecutivos sube de precio segun el ındice 1′05, un 1′03 y un 1′06respectivamente. Vamos a calcular el ındice medio de incremento.
El que el primer ano el ındice sea 1′05 significa que al final del ano, el precio pasa de 10a 10× 1′05 = 10′5 euros, es decir, sube medio euro.
El segundo ano el precio pasa a ser 10′5× 1′03 = 10× 1′05× 1′03. Finalmente, al cabodel tercer ano, el precio sera
10× 1′05× 1′03× 1′06
Pero ahora supongamos que queremos calcular un ındice anual medio que aplicadode lugar a la subida anterior. Vamos a llamarle I a ese ındice que buscamos. El precioal final serıa,
10× I × I × I = 10× I3
Y como el precio final es el mismo, tendremos 10× I3 = 10× 1′05× 1′03× 1′06, o sea,
I3 = 1′05× 1′03× 1′06
y por consiguiente,I = 3
√1′05× 1′03× 1′06
Jose A. Mayor Gallego. Universidad de Sevilla

F.Derecho[Diplom.Gest.Adm.Pub.]. Estadıstica Administrativa. Curso 2006-2007. Temas 4-5-6. 7
es decir, la media geometrica de los tres ındices. El calculo de esta cantidad se deja alalumno como pequeno ejercicio.
NOTA: Se verifica XG ≤ X, es decir, la media geometrica es siempre menor o igual que lamedia aritmetica.
2 COMPLEMENTO NO EVALUABLE: Media armonica. Dados los n valores, X1,X2,...,Xn, de una variable X, que supondremos que solo asume valores distintos de cero, sumedia armonica se define como,
XH =n
1X1
+1
X2+
1X3
+ · · ·+ 1Xn
Por ejemplo, dados los valores 4, 2, 8, su media armonica sera,
XH =3
14
+12
+18
= 3′428
y la media armonica de 1 y 9 sera,
XH =2
11
+19
= 1′8
La formula general para calcular esta media, tanto para distribucion Tipo I como Tipo II yTipo III, es,
XH =n
n∑i=1
1Xi
=n
k∑i=1
ni
xi
NOTA: Se verifica XH ≤ XG ≤ X.
2
2.3. Mediana
La mediana es un parametro que, como la media aritmetica, constituye un valor central,pero al contrario de esta, no esta ligada al valor numerico de las observaciones sino a suposicion relativa dentro de la masa total de datos. Si tenemos una distribucion de Tipo Icon n observaciones numericas,
X1, X2, . . . , Xn
para hallar su mediana, en primer lugar se ordenan los valores de menor a mayor y acontinuacion se aplica la siguiente regla,
• si n es impar. La mediana es el valor central de las observaciones ordenadas.
• si n es par. La mediana es la suma de los dos valores centrales, dividida por 2.
Jose A. Mayor Gallego. Universidad de Sevilla

F.Derecho[Diplom.Gest.Adm.Pub.]. Estadıstica Administrativa. Curso 2006-2007. Temas 4-5-6. 8
Ası, los siete datos 7, 3, 1, 9, 17, 15, 8, primero se ordenan,
1, 3, 7, 8, 9, 15, 17
y por consiguiente tienen como mediana el valor 8. Y los seis datos, 15, 7, 3, 1, 9, 8, primerose ordenan,
1, 3, 7, 8, 9, 15
por lo que tienen como mediana el valor (7 + 8)/2 = 7′5. Para representar la medianausaremos la notacion Me.
Hay que tener en cuenta que si el numero de datos es muy elevado, el calculo de lamediana puede ser muy laborioso. El tal caso es usual disponer de una tabla con los datosclasificados. Veamos como se calcula la mediana en tales casos, segun la distribucion sea deTipo II o de Tipo III.
A. Datos no agrupados en intervalos o clases. Distribucion Tipo II.
Volvamos al Ejemplo 1., de los hijos observados sobre 150 familias. Ademas de clasificarlos datos, ordenando las observaciones, se hallara la frecuencia acumulada,
xi ni Ni
0 20 201 35 552 62 1173 24 1414 5 1465 3 1496 1 150
Dividiendo el numero total de observaciones por 2, obtenemos 150/2 = 75, y entonces, enla tabla, buscamos la primera observacion cuya frecuencia acumulada supere dicho valor.En este caso, dicha observacion es 2, que es la mediana.
En algunos casos puede ocurrir que una frecuencia acumulada coincida exactamente conel numero de observaciones dividido por dos. Por ejemplo, en la siguiente tabla,
xi ni Ni
1 10 103 20 304 14 447 26 708 10 809 8 88
la mitad del numero de observaciones es 88/2 = 44 que coincide con la frecuencia acumuladade la modalidad x3 = 4. Para hallar la mediana en esta situacion, se tomara dicho valory el siguiente y se calculara la media aritmetica de los dos valores. La mediana sera pues(4 + 7)/2 = 5′5.
Jose A. Mayor Gallego. Universidad de Sevilla

F.Derecho[Diplom.Gest.Adm.Pub.]. Estadıstica Administrativa. Curso 2006-2007. Temas 4-5-6. 9
B. Datos agrupados en intervalos.Distribucion Tipo III.
Vamos a considerar nuevamente los datos del Ejemplo 2., agrupados en la misma formaque vimos para el caso similar en la media aritmetica,
(ei−1, ei] xi ni Ni
(46′5, 55′5] 51 11 11(55′5, 64′5] 60 16 27(64′5, 73′5] 69 39 66(73′5, 82′5] 78 63 129(82′5, 91′5] 87 35 164(91′5, 100′5] 96 11 175
Se buscara el primer intervalo cuya frecuencia acumulada supere la mitad de las obser-vaciones, es decir, 175/2 = 87′5. En este caso, dicho intervalo es (73′5, 82′5]. Este intervalose denomina intervalo mediano y su marca de clase, 78. La mediana se calcula empleandola formula siguiente,
Me = ei−1 +n/2−Ni−1
niai
donde,
ei−1 es el extremo inferior del intervalo mediano.
ai es la amplitud del intervalo mediano, o sea, ai = ei − ei−1.
Ni−1 es la frecuencia acumulada del intervalo anterior o previo al mediano.
ni es el numero de observaciones en el intervalo mediano.
En nuestro caso, tendremos,
Me = 73′5 +175/2− 66
63× 9 = 76′57..
Observemos que la mediana es el valor que divide una serie de observaciones ordenadas,en dos partes iguales. Por depender de los valores a traves de su orden, la mediana es pocosensible a la existencia de valores muy separados de la masa principal de datos, por ellos,si nuestros datos contienen valores de este tipo, sera preferible usar la mediana en vez de lamedia aritmetica como parametro central.
Por ejemplo, dada la serie de valores 1, 1, 2, 2, 2, 4, 4, 4, 70, ya considerada cuando seestudio la media aritmetica, la mediana es 2 y este valor es mas indicativo que la mediaaritmetica, que es 10, pues al contrario que esta, no se ve influenciado por el valor 70. Eneste sentido, se dice que la mediana es un parametro resistente o robusto, y que la mediaaritmetica no lo es.
2.4. Los cuartiles
En este apartado vamos estudiar los cuartiles. Estos parametros son parientes cercanosde la mediana, y realmente no todos son parametros de tendencia central. No obstante losexplicamos aquı debido a su estrecha relacion con la mediana.
Jose A. Mayor Gallego. Universidad de Sevilla

F.Derecho[Diplom.Gest.Adm.Pub.]. Estadıstica Administrativa. Curso 2006-2007. Temas 4-5-6. 10
Ya hemos visto que la mediana, en la serie ordenada de datos, basicamente divide lamasa de datos en dos partes iguales, es decir, deja a derecha e izquierda el 50 % de losmismos. Podemos considerar tambien valores que dividen el conjunto de los datos en cuatropartes iguales, es decir, dejan a su izquierda el 25 %, el 50 % y el 75 % de las observaciones.Dichos valores se denominan cuartiles y se denotan como Q1, Q2 y Q3, respectivamente. Esclaro que Q2 = Me por definicion. Veamos como se calcula Q1.
Si tenemos una distribucion de Tipo I con n observaciones numericas,
X1, X2, . . . , Xn
para hallar el primer cuartil, se ordenan los valores de menor a mayor y a continuacion sebusca en dicha serie ordenada el primer valor cuyo numero de orden supere n/4
Ası, los siete datos 7, 3, 1, 9, 17, 15, 8, primero se ordenan,
1, 3, 7, 8, 9, 15, 17
y al ser n/4 = 7/4 = 1′75, Q1 sera la observacion que en la serie ordenada ocupa el lugar 2,es decir, Q1 = 3.
Puede ocurrir que el orden de la observacion coincida exactamente con n/4 (sucedecuando n es multiplo de 4), en tal caso, el primer cuartil se obtiene tomando dicha obser-vacion y la siguiente, y calculando su media aritmetica. Por ejemplo si tenemos los docedatos,
1, 3, 7, 8, 9, 9, 10, 12, 13, 13, 14, 15
n/4 = 3, luego el primer cuartil es la media aritmetica entre el tercer y cuarto valor de laserie de observaciones,
Q1 = (7 + 8)/2 = 7′5
Para hallar Q3, el procedimiento es analogo pero considerando 3n/4 en vezde n/4.
Hay que tener en cuenta que si el numero de datos es muy elevado, el calculo de loscuartiles puede ser muy laborioso. El tal caso es usual disponer de una tabla con los datosclasificados. Veamos como se calculan en tales casos, segun los datos no esten agrupados enclases o sı lo esten.
A. Datos no agrupados en intervalos o clases. Distribucion Tipo II.
Volvamos al ejemplo, ya estudiado para la media aritmetica y la mediana, de los hi-jos observados sobre 150 familias. Ademas de clasificar los datos, se hallara la frecuenciaacumulada,
xi ni Ni
0 20 201 35 552 62 1173 24 1414 5 1465 3 1496 1 150
Jose A. Mayor Gallego. Universidad de Sevilla

F.Derecho[Diplom.Gest.Adm.Pub.]. Estadıstica Administrativa. Curso 2006-2007. Temas 4-5-6. 11
Dividiendo el numero total de observaciones por 4, obtenemos 150/4 = 37′5, y entonces,en la tabla, buscamos la primera observacion cuya frecuencia acumulada supere dicho valor.En este caso, dicha observacion es 1, que es el primer cuartil Q1. Para calcular el tercercuartil, Q3 buscaremos la primera observacion cuya frecuencia acumulada supere 3n/4 =450/4 = 112′5, dicha observacion es Q3 = 2.
En algunos casos puede ocurrir que una frecuencia acumulada coincida exactamente conel numero de observaciones dividido por cuatro. Por ejemplo, observar la siguiente tabla,
xi ni Ni
1 10 103 12 224 18 407 30 708 10 809 8 88
En este caso, la cuarta parte del numero de observaciones es 22 que coincide con lafrecuencia acumulada de 3. Para hallar Q1 en esta situacion, se tomara dicho valor y elsiguiente y se calculara la media aritmetica de los dos valores. El primer cuartil sera porconsiguiente Q1 = (3 + 4)/2 = 3′5. Una situacion similar se puede presentar en el calculode Q3 siendo el procedimiento a seguir totalmente analogo.
B. Datos agrupados en intervalos. Distribucion Tipo III.
Vamos a considerar nuevamente los datos del Ejemplo 2., agrupados en la misma formaque vimos para el caso similar en la media aritmetica, anadiendo una columna con lafrecuencia acumulada,
(ei−1, ei] xi ni Ni
(46′5, 55′5] 51 11 11(55′5, 64′5] 60 16 27(64′5, 73′5] 69 39 66(73′5, 82′5] 78 63 129(82′5, 91′5] 87 35 164(91′5, 100′5] 96 11 175
Para hallar Q1, se buscara el primer intervalo cuya frecuencia acumulada supere lacuarta parte de las observaciones, esto es, 175/4 = 43′75. En este caso, dicho intervaloes (64′5, 73′5]. Seguidamente Q1 se calculara aplicando la siguiente formula,
Q1 = ei−1 +n/4−Ni−1
niai
donde,
ei−1 es el extremo inferior del intervalo hallado.
ai es la amplitud de dicho intervalo, es decir, ai = ei − ei−1
Ni−1 es la frecuencia acumulada del intervalo previo o precedente al considerado.
ni es el numero de observaciones en el intervalo considerado.
Jose A. Mayor Gallego. Universidad de Sevilla

F.Derecho[Diplom.Gest.Adm.Pub.]. Estadıstica Administrativa. Curso 2006-2007. Temas 4-5-6. 12
En nuestro caso, tendremos,
Q1 = 64′5 +175/4− 27
39× 9 = 68′365..
Para hallar Q3, se buscara el primer intervalo cuya frecuencia acumulada supere lastres cuartas partes de las observaciones, esto es, (3× 175)/4 = 131′25. En este caso,dicho intervalo o clase es (82′5, 91′5]. Q3 se calculara aplicando la siguiente formula,
Q3 = ei−1 +3n/4−Ni−1
niai
siendo,
ei−1 es el extremo inferior del intervalo hallado.
ai es la amplitud de dicho intervalo, es decir, ai = ei − ei−1
Ni−1 es la frecuencia acumulada del intervalo previo o precedente al considerado.
ni es el numero de observaciones en el intervalo considerado.
En nuestro caso, tendremos,
Q3 = 82′5 +525/4− 129
35× 9 = 83′078..
OBSERVACION: Al igual que la mediana, los cuartiles tienen la propiedad de ser re-sistentes o robustos frente a la existencia de observaciones muy separadas de la masaprincipal de datos.
OBSERVACION: Es necesario notar, como hicimos al principio de este apartado, que loscuartiles, salvo Q2 que coincide con la mediana, no son en rigor parametros de tendenciacentral. Podrıan denominarse parametros de posicion ya que determinan la posicion opunto que separa determinados porcentajes del total de las observaciones. No obstante, porsu similitud con la mediana los hemos explicado aquı.
2.5. Los percentiles
De forma similar a como se han definido los cuartiles, se definen los percentiles comoaquellos valores que delimitan por su izquierda el 1%, el 2%, el 3 %, etc, y ası hasta el 100 %de las observaciones. Hay pues 100 percentiles que denotamos como Pc1, Pc2, Pc3,..., Pc100.Realmente ya conocemos algunos percentiles, por ejemplo, Pc25 = Q1, Pc50 = Me = Q2 yPc75 = Q3.
Si tenemos una distribucion de Tipo I con n observaciones numericas,
X1, X2, . . . , Xn
para hallar el percentil k-esimo, es decir, Pck, se ordenan los valores de menor a mayor y acontinuacion se busca en dicha serie ordenada el primer valor cuyo numero de orden superek × n/100.
Jose A. Mayor Gallego. Universidad de Sevilla

F.Derecho[Diplom.Gest.Adm.Pub.]. Estadıstica Administrativa. Curso 2006-2007. Temas 4-5-6. 13
Calculemos por ejemplo Pc40 para los siete datos 7, 3, 1, 9, 17, 15, 8. Primeramente seordenan,
1, 3, 7, 8, 9, 15, 17
y al ser 40× 7/100 = 2′8, Pc40 sera la observacion que en la serie ordenada ocupa el lugar3, o sea, la tercera observacion, es decir, Pc40 = 7.
A continuacion veremos como calcular los percentiles en distribuciones de Tipo II y deTipo III.
A. Datos no agrupados en intervalos o clases. Distribucion Tipo II.
Volvamos al ejemplo, ya estudiado para la media aritmetica y la mediana, de los hi-jos observados sobre 150 familias. Ademas de clasificar los datos, se hallara la frecuenciaacumulada,
xi ni Ni
0 20 201 35 552 62 1173 24 1414 5 1465 3 1496 1 150
Hallemos por ejemplo el percentil 60. Primero calculamos 60×n/100 = 60× 150/100 =90. Y ahora buscamos la modalidad cuya frecuencia acumulada supere esta cantidad. Lafrecuencia acumulada correspondiente es 117, y por consiguiente el percentil buscado esPc60 = 2.
B. Datos agrupados en intervalos. Distribucion Tipo III.
Vamos a considerar nuevamente los datos del Ejemplo 2., agrupados en la misma formaque vimos para el caso similar en la media aritmetica, anadiendo una columna con lafrecuencia acumulada,
(ei−1, ei] xi ni Ni
(46′5, 55′5] 51 11 11(55′5, 64′5] 60 16 27(64′5, 73′5] 69 39 66(73′5, 82′5] 78 63 129(82′5, 91′5] 87 35 164(91′5, 100′5] 96 11 175
Hallemos por ejemplo el percentil 70. Primeramente se buscara el primer intervalo cuyafrecuencia acumulada supere 70 × n/100 = 70 × 175/100 = 122′5. En este caso, dichointervalo es (73′5, 82′5] pues su frecuencia acumulada es 129 que es la primera de la listaque supera 122′5. Seguidamente Pc70 se calculara aplicando la siguiente formula,
Pck = ei−1 +k × n/100−Ni−1
niai
donde,
ei−1 es el extremo inferior del intervalo hallado.
Jose A. Mayor Gallego. Universidad de Sevilla

F.Derecho[Diplom.Gest.Adm.Pub.]. Estadıstica Administrativa. Curso 2006-2007. Temas 4-5-6. 14
ai es la amplitud de dicho intervalo, es decir, ai = ei − ei−1
Ni−1 es la frecuencia acumulada del intervalo previo o precedente al considerado.
ni es el numero de observaciones en el intervalo considerado.
En nuestro caso, tendremos,
Pc70 = 73′5 +70× 175/100− 66
63× 9 = 81′571..
OBSERVACION: Al igual que la mediana y los cuartiles, los percentiles tambien tienenla propiedad de ser resistentes o robustos frente a la existencia de observaciones muyseparadas de la masa principal de datos.
OBSERVACION: Como en el apartado anterior, es necesario notar que los percentiles noson en general parametros de tendencia central. Como antes, podrıan denominarse paramet-ros de posicion ya que determinan la posicion o punto que separa determinados porcentajesdel total de las observaciones. No obstante, por su similitud, se explican en esta seccion.
OBSERVACION: Los percentiles son cantidades que proporcionan informacion relevantesobre la situacion de una unidad estadıstica en relacion al conjunto de todas.
Por ejemplo, si en un estudio de las estaturas de un conjunto de personas se verificaque Pc95 = 176 cm., esto significa que una persona de 176 cm. o mas pertenece al 5 % deindividuos mas altos.
Y si en un estudio de los salarios de los trabajadores de una gran empresa, fuera Pc10 =1200 EUROS, un trabajador que gane 970 EUROS pertenece al grupo formado por el 10 %que menos gana.
2.6. La moda
La moda es la observacion mas frecuente, esto es, la mas observada. Al contrario delas medidas estudiadas hasta ahora, puede ser hallada tanto para datos cualitativos comocuantitativos. Se denota por Mo.
Por ejemplo, consideremos las observaciones cuantitativas,
3, 4, 3, 5, 6, 7, 6, 5, 4, 3, 4, 5, 6, 2, 6, 7, 8, 4, 5, 4, 6, 4, 7
la moda sera 4 por ser el valor mas observado. Puede ocurrir que halla dos valores que seanlos mas observados, en tal caso ambos son moda, es decir, hay dos modas. Por ejemplo,
1, 2, 3, 4, 3, 4, 3, 4, 3, 4, 5, 6, 7, 3, 4, 10
tiene dos modas, 3 y 4. En este caso se dice que la serie de observaciones es bimodal.Analogamente puede haber tres modas, cuatro, etc.
Si las observaciones son cualitativas, el calculo de la moda se hace igualmente hallandola que mas se repite. Por ejemplo, si observamos el estado civil de 15 personas y obtenemoslos valores,
C,S, C,C,C,D,C, S,C,C, C, C, D, S, S
Jose A. Mayor Gallego. Universidad de Sevilla

F.Derecho[Diplom.Gest.Adm.Pub.]. Estadıstica Administrativa. Curso 2006-2007. Temas 4-5-6. 15
siendo S :sin pareja, C :casado o con pareja, D :divorciado. La moda sera C, que es el valormas frecuente.
Veamos como calcular la moda cuando tenemos una tabla de frecuencias para las dis-tintas modalidades.
A. Datos no agrupados en intervalos o clases. Distribucion Tipo II.
Volvamos al ejemplo de los hijos observados sobre 150 familias.
xi ni Ni
0 20 201 35 552 62 1173 24 1414 5 1465 3 1496 1 150
En este caso, la moda sera Mo = 2 pues es la modalidad que presenta mayor frecuenciaabsoluta. Recuerdese que podrıa darse el caso de que hubiera mas de una moda.
B. Datos agrupados en intervalos. Distribucion Tipo III.
Vamos a considerar nuevamente los datos del Ejemplo 2.,
(ei−1, ei] xi ni Ni
(46′5, 55′5] 51 11 11(55′5, 64′5] 60 16 27(64′5, 73′5] 69 39 66(73′5, 82′5] 78 63 129(82′5, 91′5] 87 35 164(91′5, 100′5] 96 11 175
Buscaremos la clase o intervalo que tenga asociado el rectangulo de mayor altura en elhistograma. Recordemos [vease Tema 3.] que las alturas se calculan mediante la formulahi = ni/ai.
Notemos que si todos los intervalos tienen la misma amplitud o anchura, dicho intervalode mayor altura asociada sera tambien el de mayor frecuencia, siendo esta situacion lade nuestro ejemplo.
Esta clase o intervalo se denomina intervalo modal, y una primera aproximacion dela moda serıa la marca de clase de dicho intervalo modal. En nuestro ejemplo, el intervalosera (73′5, 82′5] y una primera aproximacion de la moda serıa su marca de clase, es decir,78. Usualmente NO emplearemos esta aproximacion.
Nosotros calcularemos un valor mas aproximado y apropiado de la moda aplicando lasiguiente expresion,
Mo = ei−1 +δ1
δ1 + δ2ai
siendo,
Jose A. Mayor Gallego. Universidad de Sevilla

F.Derecho[Diplom.Gest.Adm.Pub.]. Estadıstica Administrativa. Curso 2006-2007. Temas 4-5-6. 16
ei−1 es el extremo inferior de la clase o intervalo modal.
δ1 = hi − hi−1
δ2 = hi − hi+1
hi = ni/ai, hi−1 = ni−1/ai−1, hi+1 = ni+1/ai+1
ni es la frecuencia de la clase o intervalo modal, ni−1 es la frecuencia del intervaloprevio al modal y ni+1 es la frecuencia del intervalo posterior al modal.
ai es la amplitud o anchura del intervalo modal, ai−1 es la amplitud o anchura delintervalo previo al modal y ai+1 es la amplitud o anchura del intervalo posterior almodal.
que para nuestros anteriores datos darıa como resultado,
ei−1 = 73′5
δ1 = 63/9− 39/9 = 24/9
δ2 = 63/9− 35/9 = 28/9
ai = 9
Y por consiguiente,
Mo = ei−1 +δ1
δ1 + δ2ai = 73′5 +
24/924/9 + 28/9
× 9 = 77′65..
Si hubiera dos o mas intervalos modales, cada uno proporcionarıa una moda. Tendrıamosentonces una distribucion multimodal, es decir, bimodal, trimodal, etc.
3. TEMA 5. Parametros de dispersion
3.1. Varianza y desviacion tıpica
La varianza es una medida de dispersion que se basa en la desviacion de las observacionescon respecto a su media aritmetica, y se denota por σ2
x (a veces se emplea la notacionmas simple σ2 por sobreentenderse que hace mencion a la variable X). Simbolicamente, sitenemos las observaciones numericas,
X1, X2, . . . , Xn
la varianza vendra dada por,
σ2x =
1n
n∑i=1
(Xi −X)2
Por ejemplo, consideremos las dos series de observaciones, que supondremos provienende medir una magnitud en dos poblaciones, 6, 6, 7, 7, 8, 9, 9, 10, 10 y 1, 2, 4, 6, 8, 10, 12,14, 15.
Jose A. Mayor Gallego. Universidad de Sevilla

F.Derecho[Diplom.Gest.Adm.Pub.]. Estadıstica Administrativa. Curso 2006-2007. Temas 4-5-6. 17
Ambas tienen como media aritmetica el valor 8. Sin embargo sus varianzas son, para laprimera serie,
σ2x =
19((6− 8)2 + (6− 8)2 + (7− 8)2 + (7− 8)2 + (8− 8)2+
+(9− 8)2 + (9− 8)2 + (10− 8)2 + (10− 8)2) = 2′22..
y para la segunda,
σ2x =
19((1− 8)2 + (2− 8)2 + (4− 8)2 + (6− 8)2 + (8− 8)2+
+(10− 8)2 + (12− 8)2 + (14− 8)2 + (15− 8)2) = 23′33..
Observemos que la segunda serie tiene una varianza muy superior a la primera. Enterminos generales podemos pues decir pues que esta mas dispersa. Mas adelante veremosque este parametro se ve afectado por el tipo de unidad empleada y tambien por el com-portamiento medio de las variables, por lo que definiremos un coeficiente corregido paraeliminar estas influencias.
En la varianza, las observaciones se elevan al cuadrado con lo cual se modifican lasunidades en las que esten medidas las observaciones. Por ejemplo, si las observaciones sonlongitudes y estan medidas en metros, la varianza vendra dada en metros cuadrados. Estono es ningun problema si se usa la varianza para comparar las dispersiones de varias seriesde observaciones. Pero si queremos por ejemplo estudiar conjuntamente la media aritmeticay la varianza, una comparacion directa puede no tener sentido al ser las unidades diferentes.Para resolver este problema se define otra medida de dispersion, la desviacion tıpica, que esla raız cuadrada positiva de la varianza. La desviacion tıpica se denota por σx. Es decir,
σx = +√
σ2x = +
√√√√ 1n
n∑i=1
(Xi −X)2
Ası, para las anteriores series de observaciones,
6, 6, 7, 7, 8, 9, 9, 10, 10 y 1, 2, 4, 6, 8, 10, 12, 14, 15
las desviaciones tıpicas son, respectivamente,√
2′22.. = 1′489.. y√
23′33.. = 4′830..
A efectos practicos, podemos emplear la siguiente expresion alternativa para calcular lavarianza,
σ2x =
1n
n∑i=1
X2i −X
2
que simbolicamente se puede expresar como X2 −X2.
Por ejemplo, para los datos 1, 2, 4, 6, 8, 10, 12, 14, 15, la media aritmetica es X = 8, y lamedia de los cuadrados,
X2 =1n
n∑i=1
X2i =
19(1 + 4 + 16 + 36 + 64 + 100 + 144 + 196 + 225) =
7869
= 87′33..
Jose A. Mayor Gallego. Universidad de Sevilla

F.Derecho[Diplom.Gest.Adm.Pub.]. Estadıstica Administrativa. Curso 2006-2007. Temas 4-5-6. 18
siendo pues la varianza,
σ2x = X2 −X
2 = 87′33..− 82 = 23′33..
2 COMPLEMENTO NO EVALUABLE: Demostracion de la expresion anterior.
σ2x =
1n
n∑i=1
(Xi −X)2 =1n
(n∑
i=1
X2i +
n∑i=1
X2 −
n∑i=1
2XiX
)=
=1n
(n∑
i=1
X2i +
n∑i=1
X2 − 2X
n∑i=1
Xi
)=
1n
n∑i=1
X2i + X
2 − 2X2 =
1n
n∑i=1
X2i −X
2
2
Observemos pues que el calculo de la varianza se reduce basicamente al calculo de dosmedias aritmeticas, la de las observaciones, y la de los cuadrados de las observaciones.Ası pues, siguen siendo validos los procedimientos que estudiamos para la media aritmeticacuando los datos se clasifican en tablas de frecuencias. Veamoslo a continuacion.
A. Datos no agrupados en intervalos o clases. Distribucion Tipo II.
Consideremos los datos del Ejemplo 1. Recuerdese que n = 150.
xi ni
0 201 352 623 244 55 36 1
En este caso, la varianza sera,
σ2x =
1n
k∑i=1
nix2i −X
2
y para los datos anteriores se tiene para la media aritmetica,
X =1
150(0× 20 + 1× 35 + 2× 62 + 3× 24 + 4× 5 + 5× 3 + 6× 1) = 1′813..
La media de los cuadrados se hara de forma totalmente similar pero operando con losvalores elevados al cuadrado, es decir,
1n
k∑i=1
nix2i =
1150
(02 × 20 + 12 × 35 + 22 × 62 + 32 × 24 + 42 × 5 + 52 × 3 + 62 × 1) = 4′6
y la varianza sera pues,
σ2x = 4′6− (1′813)2 = 1′313.. hijos2
Jose A. Mayor Gallego. Universidad de Sevilla

F.Derecho[Diplom.Gest.Adm.Pub.]. Estadıstica Administrativa. Curso 2006-2007. Temas 4-5-6. 19
siendo la desviacion tıpica,
σx =√
1′313.. = 1′145.. hijos
B. Datos agrupados en intervalos. Distribucion Tipo III.
Vamos a considerar nuevamente los datos del Ejemplo 2. Recuerdese que n = 175. Ten-emos numerosos datos y ademas con muchos valores distintos. Podemos hacer la siguienteclasificacion agrupando los datos por intervalos o clases,
(ei−1, ei] xi x2i ni
(46′5, 55′5] 51 512 11(55′5, 64′5] 60 602 16(64′5, 73′5] 69 692 39(73′5, 82′5] 78 782 63(82′5, 91′5] 87 872 35(91′5, 100′5] 96 962 11
La marca de clase se toma como valor representativo de todas las observaciones de esaclase. Observese que, por comodidad para los calculos, hemos anadido a la tabla una nuevacolumna con los cuadrados de las marcas de clase. Se tiene pues,
X =1
175(51× 11 + 60× 16 + 69× 39 + 78× 63 + 87× 35 + 96× 11) = 75′6..
1n
k∑i=1
nix2i =
1175
(512×11+602×16+692×39+782×63+872×35+962×11) = 5836′99..
La varianza sera pues,
σ2x = 5836′99..− (75′6..)2 = 124′63.. puntos2
siendo la desviacion tıpica,
σx =√
124′63.. = 11′16.. puntos
OBSERVACION: Resaltemos que, al igual que ocurrıa con la media aritmetica, cuandolos datos se agrupan en intervalos, no vamos a obtener exactamente el mismo valor que siaplicaramos la formula directamente a los datos iniciales aunque sı un valor aproximado.
OBSERVACION: Es importante observar que, en forma analoga a como ocurre con lamedia aritmetica, la varianza tiene el inconveniente de ser sensible a la presencia de val-ores marcadamente separados de la masa principal de los datos, por ello serıa convenientedisponer de una medida de dispersion que no se viera muy afectada por tales valores. Enun apartado siguiente veremos una con dicha propiedad.
Jose A. Mayor Gallego. Universidad de Sevilla

F.Derecho[Diplom.Gest.Adm.Pub.]. Estadıstica Administrativa. Curso 2006-2007. Temas 4-5-6. 20
2 COMPLEMENTO NO EVALUABLE: Propiedades de la varianza.
σ2a+x = σ2
x, siendo a un numero real cualquiera.
σ2ax = a2σ2
x, siendo a un numero real cualquiera.
σ2x+y 6= σ2
x + σ2y en general.
σ2x = 0 si y solo si la variable X es constante.
DEMOSTRACION.
Primera.
σ2a+x =
1n
n∑i=1
(a + Xi − a−X)2 =1n
n∑i=1
(Xi −X)2 = σ2x
Segunda.
σ2ax =
1n
n∑i=1
(aXi − aX)2 = a2 1n
n∑i=1
(Xi −X)2 = a2σ2x
Tercera.
σ2x+y =
1n
n∑i=1
(Xi+Yi−X−Y )2 =1n
n∑i=1
((Xi−X)+(Yi−Y ))2 =1n
n∑i=1
(Xi−X)2+1n
n∑i=1
(Yi−Y )2
+21n
n∑i=1
(Xi −X)(Yi − Y )) = σ2x + σ2
y + 21n
n∑i=1
(Xi −X)(Yi − Y ))
Como puede verse, la varianza de la suma es la suma de las varianzas mas el doble de lacantidad,
1n
n∑i=1
(Xi −X)(Yi − Y ))
que no tiene por que ser cero. Esta cantidad, que estudiaremos en un Tema posterior, sedenomina covarianza entre X e Y .
Cuarta.
Si σ2x = 0 es obvio que al ser,
σ2x =
1n
n∑i=1
(Xi −X)2
se ha de verificar que,
(Xi −X)2 = 0 para todos los valores Xi
por consiguiente,Xi = X para todos los valores Xi
es decir, todos los valores Xi son iguales o constantes.
2
Jose A. Mayor Gallego. Universidad de Sevilla

F.Derecho[Diplom.Gest.Adm.Pub.]. Estadıstica Administrativa. Curso 2006-2007. Temas 4-5-6. 21
3.2. Coeficiente de variacion de Pearson
La varianza esta afectada por la magnitud media de las cantidades ası como por lasunidades en las que esten medidas.
Ejemplo: Las estaturas, en centımetros, de cinco alumnos de Primero de Ensenanza Se-cundaria Obligatoria son 145, 139, 135, 143 y 135. Y las de seis alumnos de Cuarto deEnsenanza Secundaria Obligatoria son 163, 174, 175, 169, 171 y 178.
La varianza de las estaturas de los alumnos de Primero es σ2x = 16′64. Y la de los de
Cuarto σ2x = 23′2222. Aparentemente los de cuarto presentan mas dispersion, no obstante
podemos plantearnos que el hecho de que los de Cuarto sean globalmente mas altos puedeafectar a la varianza, y es posible que intrınsecamente las estaturas de los de Cuarto estenmenos dispersas que las de los de Primero.
Para dilucidar esta cuestion los estadısticos han ideado el siguiente coeficiente denomi-nado coeficiente de variacion de Pearson,
Cvx =σx
|X|
Al dividir la desviacion tıpica por la media aritmetica compensamos el efecto o influenciade la magnitud global o media. Ası, en el ejemplo anterior, si calculamos este coeficientepara cada grupo, obtendremos,
Alumnos de Primero de E.S.O.
X =15(145 + +139 + 135 + 143 + 135) = 139′4
σx =√
16′64 = 4′0792
Cvx =σx
|X|=
4′0792139′4
= 0′02926
Alumnos de Cuarto de E.S.O.
X =16(163 + 174 + 175 + 169 + 171 + 178) = 171′6667
σx =√
23′2222 = 4′8189
Cvx =σx
|X|=
4′8189171′6667
= 0′02807
por lo que realmente las estaturas de los alumnos de Cuartos estan menos dispersas, enrelacion a su magnitud media, que las de los de Primero, a pesar de que estas ultimaspresenten menos varianza.
Jose A. Mayor Gallego. Universidad de Sevilla

F.Derecho[Diplom.Gest.Adm.Pub.]. Estadıstica Administrativa. Curso 2006-2007. Temas 4-5-6. 22
Otro problema que se presenta a veces es la influencia de las unidades. Consideremosun nuevo,
Ejemplo: Un ingeniero mide las longitudes de tres piezas en centımetros, obteniendo 1, 1′5y 1′2. Otro ingeniero emplea milımetros, siendo pues las longitudes 10, 15 y 12. La varianzade 1, 1′5 y 1′2 es σ2
x = 0′04222, mientras que la varianza de 10, 15 y 12 es σ2x = 4′2222.
Resulta obvio que comparar las dispersiones simplemente por medio de las varianzasparece un poco ilogico pues las medidas son las mismas y lo que ha cambiado es la unidadde medicion. En esta situacion no podemos pues emplear la varianza para comparar ladispersion real. Pero si calculamos los coeficientes de variacion, obtenemos,
1, 1′2 y 1′5.
X =13(1 + 1′2 + 1′5) = 1′2333 σx =
√0′04222 = 0′20548
Cvx =σx
|X|=
0′205481′2333
= 0′166606
10, 12 y 15.
X =13(10 + 12 + 15) = 12′3333 σx =
√4′2222 = 2′0548
Cvx =σx
|X|=
2′054812′333
= 0′166606
Como puede verse, los coeficientes de variacion son iguales lo que nos dice que la dis-persion intrınseca es la misma. Es decir, este coeficiente no esta afectado por la unidad demedida que se emplee.
Podemos pues concluir que el coeficiente de variacion es una medida de dispersion adi-mensional y ademas compensada del efecto que produce la mayor o menor magnitud globalde las cantidades.
3.3. El recorrido intercuartılico
Sabemos que el primer cuartil, Q1 deja a su izquierda el 25% de las observaciones,y que el tercer cuartil Q3 deja a su izquierda el 75 %. Esto significa que entre Q1 y Q3 seencuentran el 50 % central de las observaciones. El intervalo [Q1, Q3] se denomina intervalointercuartılico
La distancia entre ambos valores, Q1 y Q3, es decir, la longitud del intervalo inter-cuartılico, puede ser considerada como una medida de dispersion que se denomina recor-rido intercuartılico y se denota IQR, es decir,
IQR = Q3 −Q1
Esta medida de dispersion es robusta por serlo tambien los cuartiles, es decir, esta pocoinfluenciada por la presencia de valores muy extremos. Veamos algunos ejemplos.
Jose A. Mayor Gallego. Universidad de Sevilla

F.Derecho[Diplom.Gest.Adm.Pub.]. Estadıstica Administrativa. Curso 2006-2007. Temas 4-5-6. 23
Para los datos,1, 3, 7, 8, 9, 9, 10, 12, 13, 13, 14, 15
se tiene que,Q1 = 7′5 Q3 = 13
luego,IQR = 13− 7′5 = 5′5
Si tenemos los datos siguientes,
xi ni Ni
1 10 103 14 244 16 407 30 708 10 809 8 88
entonces,Q1 = 3 Q3 = 7 ⇒ IQR = Q3 −Q1 = 7− 3 = 4
Y para los datos,(ei−1, ei] xi ni Ni
(46′5, 55′5] 51 11 11(55′5, 64′5] 60 16 27(64′5, 73′5] 69 39 66(73′5, 82′5] 78 63 129(82′5, 91′5] 87 35 164(91′5, 100′5] 96 11 175
se tendra,
Q1 = 68′365.. Q3 = 83′078.. ⇒ IQR = Q3 −Q1 = 83′078− 68′365 = 14′713..
3.4. Coeficiente ∆x
Cuando se trata de comparar las dispersiones de dos conjuntos de datos nos encontramoscon el mismo problema que para la varianza, es decir, la influencia tanto de la unidad demedicion como de la magnitud media de las cantidades. Por esta razon, de la misma formaque en aquel caso se definio en coeficiente de variacion de Pearson, ahora podemos definirun coeficiente similar dividiendo IQR por el valor absoluto de la mediana. Obtenemos ası elsiguiente parametro que denominaremos coeficiente ∆x,
∆x =IQR
|Me|=
Q3 −Q1
|Me|
Jose A. Mayor Gallego. Universidad de Sevilla

F.Derecho[Diplom.Gest.Adm.Pub.]. Estadıstica Administrativa. Curso 2006-2007. Temas 4-5-6. 24
Como en el caso del coeficiente de variacion de Pearson, este nuevo coeficiente es adi-mensional y esta liberado de la influencia de la mayor o menor magnitud media de lasobservaciones. Veamos un,
Ejemplo: Las estaturas, en centımetros, de cinco alumnos de Primero de Ensenanza Se-cundaria Obligatoria, son 145, 139, 135, 143 y 135. Y las de seis alumnos de Cuarto deEnsenanza Secundaria Obligatoria son 163, 174, 175, 169, 171 y 178. Calculemos el coefi-ciente ∆x para cada caso.
Primero de E.S.O. 145, 139, 135, 143, 135. Ordenadas son 135, 135, 139, 143, 145.
Q1 = 135 Q3 = 143 Me = 139 IQR = Q3 −Q1 = 8
∆x =IQR
|Me|=
8139
= 0′057553957
Cuarto de E.S.O. 163, 174, 175, 169, 171, 178. Ordenadas son 163, 169, 171, 174, 175,178.
Q1 = 169 Q3 = 175 Me = 172′5 IQR = Q3 −Q1 = 6
∆x =IQR
|Me|=
6172′5
= 0′034782609
Por consiguiente, segun este coeficiente, las estaturas de los alumnos de Cuarto presentanmenos dispersion que las de los alumnos de Primero. Recordemos que este resultado esta enconcordancia con la conclusion a la que llegamos con estos mismos datos pero empleandoel coeficiente de variacion.
OBSERVACION: Notemos que, al contrario que el coeficiente de variacion de Pearson, elcoeficiente ∆x sı es un parametro robusto, por lo que deberıa ser preferido a aquel cuandolos datos presenten algunas observaciones muy extremas.
4. TEMA 6. Medidas de forma. Otras medidas
4.1. Medidas o parametros de forma
4.1.1. Coeficiente de asimetrıa de Pearson
As =X −Mo
σx
As = 0, distribucion simetrica.
As < 0, distribucion asimetrica o sesgada a la izquierda.
As > 0, distribucion asimetrica o sesgada a la derecha.
Aunque a veces puede ser util, es un coeficiente poco preciso y solo tiene utilidad cuandola distribucion es unimodal y campaniforme.
Jose A. Mayor Gallego. Universidad de Sevilla

F.Derecho[Diplom.Gest.Adm.Pub.]. Estadıstica Administrativa. Curso 2006-2007. Temas 4-5-6. 25
4.1.2. Coeficiente de asimetrıa de Fisher
• Distribucion Tipo I.
γ1 =1
n σ3x
n∑i=1
(Xi −X)3
• Distribuciones Tipo II y Tipo III.
γ1 =1
n σ3x
k∑i=1
ni(xi −X)3
γ1 = 0, distribucion simetrica.
γ1 < 0, distribucion asimetrica o sesgada a la izquierda.
γ1 > 0, distribucion asimetrica o sesgada a la derecha.
4.1.3. Coeficiente de curtosis o aplastamiento
• Distribucion Tipo I.
γ2 =
(1
n σ4x
n∑i=1
(Xi −X)4)− 3
• Distribuciones Tipo II y Tipo III.
γ2 =
(1
n σ4x
k∑i=1
ni(xi −X)4)− 3
γ2 = 0, distribucion mesocurtica. Ni muy aplastada ni muy apuntada.
γ2 > 0, distribucion leptocurtica. Distribucion apuntada.
γ2 < 0, distribucion platicurtica. Distribucion aplastada.
2 COMPLEMENTO NO EVALUABLE: Indice de diversidad. No es posible aplicarlas medidas de dispersion estudiadas cuando la caracterıstica que se estudia es cualitativa.Para esta situacion, se emplea el concepto de diversidad, que se basa en lo siguiente: silas observaciones realizadas estan distribuidas uniformemente entre las diversas modalidades,existe una gran diversidad, por contra si la mayorıa de las observaciones estan distribuidas enun numero muy reducido de modalidades, entonces hay poca diversidad. Tomando como basela Teorıa de la Informacion, es posible definir la siguiente medida de diversidad, denominadaındice de diversidad de Shanon, estudiado por Shanon en 1948,
J = − 1lnn
k∑i=1
fi ln fi
donde lnn indica la funcion logaritmo neperiano de n. Esta funcion se encuentra programadaen cualquier calculadora cientıfica.
El valor de J esta siempre entre CERO y UNO. Conforme mas proximo este a 1, indica masdiversidad. Conforme mas proximo este a 0, indica menos diversidad.
2
Jose A. Mayor Gallego. Universidad de Sevilla

F.Derecho[Diplom.Gest.Adm.Pub.]. Estadıstica Administrativa. Curso 2006-2007. Temas 4-5-6. 26
4.2. Medidas de concentracion. Curva de Lorenz. Indice de Gini
Ya hemos visto como la dispersion hace referencia al grado de separacion o desviacionde los datos u observaciones, con respecto a valores medios y/o entre ellos mismos. Unconcepto que guarda bastante relacion es el de concentracion, y hace referencia al gradode uniformidad en el reparto del total de la variable sobre cada uno de los individuos oelementos.
Ası, el estudio de la concentracion es de gran interes en el ambito economico, cuando setrata de estudiar el grado de equidad en el reparto de la riqueza, los salarios, o bienes engeneral. De hecho, este concepto se emplea frecuentemente en estudios sobre el reparto debienes como riqueza o salario, en empresas, clases sociales, paıses o regiones geograficas engeneral.
Por ejemplo, los cinco trabajadores de la empresa A ganan mensualmente 1400, 1500,1390, 1600, 1550 Euros. Los cuatro empleados de la empresa B ganan mensualmente 1300,1400, 1350, 5000 Euros. Los sueldos de la empresa A presentan menos concentracion quelos de la empresa B pues el total esta mas uniformemente repartido en A que en B.
En primer lugar, veremos como se hace el estudio para una distribucion de Tipo II.Utilizaremos el ejemplo del numero de hijos de 150 familias. Construiremos la tabla usual,ampliandola con otras cantidades que se ven a continuacion,
xi ni fi Fi si Si Pi % Ti %0 20 0′13333 0′13333 0 0 13′333 0′0001 35 0′23333 0′36666 35 35 36′666 12′8682 62 0′41333 0′78000 124 159 78′000 58′4563 24 0′16000 0′94000 72 231 94′000 84′9264 5 0′03333 0′97333 20 251 97′333 92′2795 3 0′02000 0′99333 15 266 99′333 97′7946 1 0′00666 1′00000 6 272 100′000 100′000
150 272
Observemos que se han construido una serie de columnas adicionales a las usuales. Lasnuevas cantidades empleadas se explican a continuacion.
si. Es la suma de las observaciones en cada modalidad. En nuestro caso se obtienemultiplicando el valor de la modalidad por la frecuencia absoluta, es decir, si = ni xi.Por ejemplo, s3 = 2 × 62 = 124, o sea, las familias con 2 hijos reunen en total 124hijos.
Si. Es la cantidad anterior, acumulada, es decir, Si = s1 + s2 + · · ·+ si.
Pi. Representa el porcentaje de observaciones menores o iguales que xi, es decir,Pi = 100× Fi. Observemos que siempre se verificara Pk = 100.
Ti. Es el porcentaje que representa Si con respecto a la suma total Sk, es decir,Ti = 100× Si/Sk. Observemos que siempre se verificara Tk = 100.
Observemos que la modalidad 1, es decir, CERO hijos, representa un porcentaje igual aP1 del numero total de elementos, familias en este caso, pero su valor asociado de la variable,
Jose A. Mayor Gallego. Universidad de Sevilla

F.Derecho[Diplom.Gest.Adm.Pub.]. Estadıstica Administrativa. Curso 2006-2007. Temas 4-5-6. 27
numero de hijos en este caso, representa un porcentaje igual a T1. Las modalidades primeray segunda representan un porcentaje igual a P2 del numero total de elementos, familias eneste caso, pero su valor asociado de la variable, numero de hijos en este caso, representa unporcentaje igual a T2, y ası sucesivamente.
Representando entonces los puntos (0, 0), (T1, P1), (T2, P2),...,(Tk, Pk) = (100, 100), yuniendolos por segmentos rectilıneos obtendremos una lınea que se mantiene siempre porencima de la bisectriz del primer cuadrante, como puede verse en la grafica adjunta, en laque hemos representado dicha poligonal y tambien la bisectriz.
Dicha poligonal se denomina curva de Lorenz o curva de concentracion. Observe-mos que la mınima concentracion corresponderıa a un reparto equitativo o uniforme deltotal, con lo cual la curva de Lorenz coincidirıa con la bisectriz. Por contra, conforme estereparto es menos equitativo, es decir, el total tiende a concentrarse mas en uno o variosvalores, dicha curva tiende a separarse de la bisectriz. De esta forma, la observacion de lacurva de Lorenz nos permite formar un juicio sobre la concentracion de una variable.
��
��
��
��
��
��
��
��
��
��
��
�
(0, 0)
(100, 100)
δ
���������%
%%
%%%
##
##
##
##
T1
P1
T2
P2
"""
!!!!!!
Con objeto de construir un parametro que cuantifique la concentracion, podemos razonarde la siguiente forma. La superficie, δ, de la region comprendida entre la bisectriz y la curvade Lorenz sera tanto mas pequena cuanto menor concentracion haya. El mınimo valor dedicha superficie es 0 y la cota superior 1002/2 = 5000. Podemos pues construir el siguienteparametro de concentracion,
IG =δ
5000que verifica 0 ≤ IG ≤ 1. Dicho parametro se denomina ındice de Gini o coeficiente de
Jose A. Mayor Gallego. Universidad de Sevilla

F.Derecho[Diplom.Gest.Adm.Pub.]. Estadıstica Administrativa. Curso 2006-2007. Temas 4-5-6. 28
Gini. Para calcularlo, emplearemos la siguiente formula,
IG =1
10000
k∑i=2
(Pi−1Ti − PiTi−1)
que aplicada a los datos de nuestro ejemplo, proporciona,
IG =1
10000((13′333× 12′868− 36′666× 0′000)
+(36′666× 58′456− 78′000× 12′868) + · · ·+ 99′333× 100, 00− 100′00× 97′794))
= 0′3355
que nos indica la presencia de cierto grado de concentracion, aunque no excesivo.
Notese que para el calculo anterior se van multiplicando de forma cruzada las Pi por lasTi. estos productos se restan, y los resultados se suman.
Veamos como se hace el estudio de la concentracion si los datos estan agrupados enintervalos, es decir, distribuciones Tipo III. Cuando estemos en esta situacion, proced-eremos de la siguiente forma, que ilustraremos directamente sobre un ejemplo concreto.Consideremos la siguiente tabla de frecuencias, obtenida al agrupar en intervalos una seriede datos numericos, donde x1, x2, · · · , xk son ahora las marcas de clase,
Intervalo xi ni Fi si Si Pi Ti
(0′5, 1′5] 1 5 5/50 = 0′10 5 5 10′00 3′16(1′5, 2′5] 2 14 19/50 = 0′38 28 33 38′00 20′88(2′5, 3′5] 3 15 34/50 = 0′68 45 78 68′00 49′36(3′5, 4′5] 4 7 41/50 = 0′82 28 106 82′00 67′08(4′5, 5′5] 5 4 45/50 = 0′90 20 126 90′00 79′74(5′5, 6′5] 6 3 48/50 = 0′96 18 144 96′00 91′14(6′5, 7′5] 7 2 50/50 = 1′00 14 158 100′00 100′00
Nuevamente observamos que se han construido una serie de columnas adicionales a lasusuales. Las nuevas cantidades empleadas se explican a continuacion.
si. Es la suma de las observaciones en cada intervalo. Usualmente no se dispone deestas observaciones, empleandose entonces como aproximacion la suma de las marcasde clase, es decir, si = ni xi.
Si. Es la cantidad anterior, acumulada, es decir, Si = s1 + s2 + · · ·+ si.
Pi. Representa el porcentaje de observaciones menores o iguales que xi, es decir,Pi = 100× Fi. Observemos que siempre se verificara Pk = 100.
Ti. Es el porcentaje que representa Si con respecto a la suma total Sk, es decir,Ti = 100× Si/Sk. Observemos que siempre se verificara Tk = 100.
Jose A. Mayor Gallego. Universidad de Sevilla

F.Derecho[Diplom.Gest.Adm.Pub.]. Estadıstica Administrativa. Curso 2006-2007. Temas 4-5-6. 29
Representando entonces los puntos (0, 0), (T1, P1), (T2, P2),...,(Tk, Pk) = (100, 100), yuniendolos por segmentos rectilıneos obtendremos una poligonal que sera la curva deLorenz o curva de concentracion, cuya interpretacion es la misma que hemos vistoanteriormente. Nuevamente, se puede calcular el ındice de Gini como IG = 2δ/1002, dondela division por 1002 se hace a efectos de normalizar la cantidad para que siga verificando0 ≤ IG ≤ 1. La expresion para calcular dicho ındice es, por supuesto, la misma de antes, esdecir,
IG =1
10000
k∑i=2
(Pi−1Ti − PiTi−1)
que aplicada a los datos de nuestro ejemplo, proporciona,
IG =1
10000(10′0× 20′88− 38′00× 3′16 + · · ·+ 96′00× 100, 00− 100′00× 91′14)
= 0′2594
es decir, poca concentracion.
Finalmente veremos como calcular el ındice de Gini para distribuciones Tipo I. Loharemos con un pequeno ejemplo, pero suficiente para mostrar el metodo. Supongamoscinco sueldos, en miles de Euros, 4, 3, 2, 2, 1. Primero de ordenan de menor a mayor, y seconstruye la siguiente tabla, que es analoga a las calculadas para las distribuciones TiposII y III,
Xi ni fi Fi si Si Pi % Ti %1 1 1/5 = 0′2 1/5 = 0′2 1 1 20′000 100× 1/12 = 8′3332 1 1/5 = 0′2 2/5 = 0′4 2 3 40′000 100× 3/12 = 25′0002 1 1/5 = 0′2 3/5 = 0′6 2 5 60′000 100× 5/12 = 41′6673 1 1/5 = 0′2 4/5 = 0′8 3 8 80′000 100× 8/12 = 66′6674 1 1/5 = 0′2 5/5 = 1′0 4 12 100′000 100× 12/12 = 100′00
y ahora el ındice de Gini se calcula de la forma habitual, es decir,
IG =1
10000((20′000× 25′000− 40′000× 8′333)
+(40′000× 41′667− 60′000× 25′000) + · · ·+ 80′000× 100, 00− 100′00× 66′667))
= 0′2333
es decir, hay concentracion pero baja. De forma similar se dibuja la curva de Lorenz.
5. Complementos: Deteccion de valores singulares. Diagra-mas de caja
5.1. Introduccion
El objetivo principal de la Estadıstica es la obtencion de informacion relevante y utila partir de los datos, por ello, es imprescindible que estos tengan la mayor precision y
Jose A. Mayor Gallego. Universidad de Sevilla

F.Derecho[Diplom.Gest.Adm.Pub.]. Estadıstica Administrativa. Curso 2006-2007. Temas 4-5-6. 30
fiabilidad posibles, por lo que uno de los procesos mas importantes de esta ciencia es elrelacionado con la depuracion de datos.
Como ilustracion, vamos a considerar los siguientes datos numericos, relativos a las tallasde 20 alumnos de Tercero de Ensenanza Secundaria Obligatoria, en centımetros,
150 151 150 147 155 145 151 152 150 149160 142 158 153 144 190 145 147 151 156
Observemos que existe un valor singular, 190, que se puede considerar como atıpico oanomalo, y sobre el que se pueden plantear algunos interrogantes, por ejemplo,
¿Es posible que dicho valor provenga de la misma fuente o poblacion?
¿Estara afectado de algun error?
En caso afirmativo, ¿Que tipo de error?
5.2. Deteccion de valores singulares
A la vista de lo anterior, podemos clasificar las observaciones singulares, atıpicas oanomalas como,
Observacion ATIPICA. Es aquel valor que presenta una gran variabilidad de tipoinherente.
Observacion ERRONEA. Es aquel valor que se encuentra afectado de algun tipode error.
Definicion 1 Se llamara “OUTLIER” a aquella observacion que siendo atıpica y/o erronea,tiene un comportamiento muy diferente respecto al resto de los datos, en relacion al analisisque se desea realizar sobre las observaciones.
A continuacion veremos un metodo para detectar “outliers” Este metodo se basa en loscuartiles, que como sabemos, son parametros resistentes o robustos. Consiste en calcular, apartir de Q1, Q3 e IQR los siguientes valores,
f1 = Q1 − 1′5× IQR f2 = Q3 + 1′5× IQR
que se denominan vallas interiores. Y los valores,
F1 = Q1 − 3× IQR F2 = Q3 + 3× IQR
denominados vallas exteriores.
Toda observacion que quede fuera de las vallas interiores sera considerada como “OUT-LIER”, y se conceptua como valor anomalo. Los “OUTLIERS” que ademas esten fuera delas vallas exteriores se conceptuan como valores muy anomalos.
Jose A. Mayor Gallego. Universidad de Sevilla

F.Derecho[Diplom.Gest.Adm.Pub.]. Estadıstica Administrativa. Curso 2006-2007. Temas 4-5-6. 31
Por ejemplo, para los datos del ejemplo introductorio,
Q1 = 147 Q3 = 154 IQR = 7
siendo pues,
Vallas interiores,
f1 = 147− 1′5× 7 = 136′5 f2 = 154 + 1′5× 7 = 164′5
Vallas exteriores,
F1 = 147− 3× 7 = 126 F2 = 154 + 3× 7 = 175
Luego el valor 190 es un valor muy anomalo, que requiere un estudio pormenorizado.Puede ser un error en las observaciones, o que realmente existe un alumno de elevadaestatura.
5.3. Diagrama de caja o “Box-Plot”
Este tipo de diagramas expresa muy claramente la distribucion de los datos: su valorcentral, simetrıa, concentracion y observaciones anomalas que se diferencian marcadamentedel resto. Para construirlo seguiremos los siguientes pasos,
1. Fijar la escala de acuerdo con los valores mınimo y maximo.
2. Localizar la mediana y los cuartiles, Q1 y Q3, y dibujar un rectangulo o caja queconecte estos ultimos, y dentro del mismo, marcar la mediana con un segmento. Clara-mente, la amplitud de la caja sera el recorrido intercuartılico, IQR.
3. Hallar las vallas interiores y exteriores para detectar valores extremos. Las observa-ciones que queden fuera de las vallas interiores pero dentro de las exteriores se repre-sentan como pequenos cuadrados o pequenos cırculos, y las que queden fuera de lasvallas exteriores con asteriscos o cruces. Esta regla varıa segun las implementacionesde los programas informaticos.
4. A cada lado de la caja se trazan segmentos rectilıneos que terminan en las obser-vaciones mas extremas dentro de las vallas interiores. Dichas observaciones sedenominan valores adyacentes.
En la Figura 1., se expone de forma esquematica un diagrama de caja. Notese la nomen-clatura empleada para denotar y distinguir las observaciones “outlier”, segun esten fuerade los diferentes tipos de vallas.
Jose A. Mayor Gallego. Universidad de Sevilla

F.Derecho[Diplom.Gest.Adm.Pub.]. Estadıstica Administrativa. Curso 2006-2007. Temas 4-5-6. 32
Q1 Me Q3 f2 F2f1F1
2 ∗
Figura 1. Diagrama de caja o “box-plot”. Las observaciones que queden fuera de las vallasinteriores pero dentro de las exteriores se han representado con 2, y las que queden fuera de
las vallas exteriores con ∗.
Es interesante emplear este diagrama para comparar varios conjuntos de datos, suponien-do por supuesto que dicha comparacion tenga sentido. Por ejemplo, para los conjuntos dedatos relativos a las puntuaciones de 175 alumnos por una parte, y de 120 por otra, podemosconstruir los correspondientes diagramas de caja, y ubicarlos en un mismo grafico, con unaescala comun. Se tiene,
Puntuaciones de 175 alumnos.
76 66 77 50 81 69 75 73 84 62 6571 93 54 70 55 86 63 84 76 80 8878 69 77 75 52 60 68 71 84 70 8978 87 98 80 76 55 65 77 64 82 7075 73 82 72 84 75 85 78 83 74 8168 76 77 61 66 85 58 92 96 51 8778 77 90 75 62 81 63 72 68 76 7286 80 92 79 84 70 50 70 71 77 6975 91 80 87 83 64 85 61 77 65 6774 90 78 82 73 88 85 89 65 75 7684 55 81 75 77 69 83 70 86 69 9679 98 51 97 63 90 54 74 71 89 7682 71 83 77 84 78 90 53 98 75 6964 70 81 77 67 83 79 85 76 72 5776 65 71 74 94 75 66 95 80 91 8056 83 82 60 74 81 79 80 61 79
Mediante el programa EXCEL, hemos calculado los parametros,
Q1 = 69 Q2 = Me = 76 Q3 = 83
a partir de los cuales tenemos,
IQR = Q3−Q1 = 14 f1 = Q1−1′5×IQR = 48 f2 = Q3+1′5×IQR = 104
Jose A. Mayor Gallego. Universidad de Sevilla

F.Derecho[Diplom.Gest.Adm.Pub.]. Estadıstica Administrativa. Curso 2006-2007. Temas 4-5-6. 33
F1 = Q1 − 3× IQR = 27 F2 = Q3 + 3× IQR = 125
La puntuacion mınima es 50, y la maxima 98. Ası pues, todas las observaciones quedandentro de las vallas interiores, y no detectamos “outliers”. Los valores adyacentes son pues50 y 98.
Puntuaciones de 120 alumnos.
41 46 54 60 54 61 50 50 53 5551 58 61 48 51 60 43 53 62 5556 62 45 49 55 59 56 53 59 5358 55 50 48 61 62 57 58 58 5361 50 62 49 53 60 54 34 49 5860 53 56 53 59 52 61 53 56 6039 54 50 60 57 52 55 59 53 5554 59 54 60 57 50 45 57 60 5555 59 55 54 49 58 52 53 60 5451 56 58 53 54 49 61 50 60 5358 55 51 56 62 54 58 50 53 5561 60 54 51 53 54 55 48 58 62
Mediante el programa EXCEL, hemos calculado los parametros,
Q1 = 52 Q2 = Me = 55 Q3 = 58′5
a partir de los cuales tenemos,
IQR = Q3−Q1 = 6′5 f1 = Q1−1′5×IQR = 42′25 f2 = Q3+1′5×IQR = 68′25
F1 = Q1 − 3× IQR = 32′5 F2 = Q3 + 3× IQR = 78
La puntuacion mınima es ahora 34, y la maxima 62. Ası pues, existen observacionespor debajo de la valla interior inferior, en concreto, 34, 39 y 41, que son consideradascomo “outliers”. Por encima de la valla interior superior no hay observaciones. Los valoresadyacentes son ahora las observaciones 43 y 62. Notese que no hay observaciones fuera delas vallas exteriores, es decir, muy anomalas.
En la Figura 2. exponemos los diagramas de caja correspondientes, realizados a mano.Esta grafica nos permite captar globalmente las particularidades de cada conjunto de datos,y tambien realizar una comparacion entre ellos. Observese como las puntuaciones del grupode 175 estudiantes son globalmente mejores que las del grupo de 120 estudiantes. Por ejem-plo, se puede observar que las medianas de ambos grupos de puntuaciones difieren en casi20 unidades.
Observese tambien que el grupo de 175 estudiantes no se detectan “outliers”, al contrariode lo que sucede en el grupo de 120 estudiantes en el que se observan tres “outliers”, quepor estar dentro de las vallas los hemos representados por pequenos cuadrados, es decir, 2.Recuerdese que algunos programas de ordenador, emplean sımbolos distintos, por ejemplopequenos cırculos, es decir, ◦.
Jose A. Mayor Gallego. Universidad de Sevilla

F.Derecho[Diplom.Gest.Adm.Pub.]. Estadıstica Administrativa. Curso 2006-2007. Temas 4-5-6. 34
Figura 2. Diagramas de caja para los datos correspondientes a 175 alumnos y 120 alumnos.Realizado a mano.
Jose A. Mayor Gallego. Universidad de Sevilla