parallel programming with mpi jianfeng yang internet and information technology lab wuhan university...
TRANSCRIPT

Parallel programming Parallel programming with MPIwith MPI
Jianfeng YangJianfeng YangInternet and Information Technology LabInternet and Information Technology Lab
Wuhan universityWuhan [email protected]@whu.edu.cn

2
AgendaAgenda
Part Ⅰ: Part Ⅰ: Seeking Seeking Parallelism/ConcurrencyParallelism/Concurrency
Part Ⅱ: Part Ⅱ: Parallel Algorithm DesignParallel Algorithm Design Part Ⅲ: Part Ⅲ: Message-Passing Message-Passing
ProgrammingProgramming

Part ⅠPart Ⅰ
Seeking Seeking Parallel/ConcurrencyParallel/Concurrency

4
OutlineOutline
1 Introduction1 Introduction 2 Seeking Parallel2 Seeking Parallel

5
1 Introduction(1/6)1 Introduction(1/6)
Well done is quickly done – Caesar AugueWell done is quickly done – Caesar Auguestst
Fast, Fast, Fast---is not “fast” enough.Fast, Fast, Fast---is not “fast” enough. How to get Higher Performance How to get Higher Performance
Parallel Computing.Parallel Computing.

6
1 Introduction(2/6)1 Introduction(2/6)
What is parallel computing?What is parallel computing? is the use of a parallel computer to reduce is the use of a parallel computer to reduce
the time needed to solve a single the time needed to solve a single computational problem.computational problem.
is now considered a standard way for is now considered a standard way for computational scientists and engineers to computational scientists and engineers to solve problems in areas as diverse as solve problems in areas as diverse as galactic evolution, climate modeling, galactic evolution, climate modeling, aircraft design, molecular dynamics and aircraft design, molecular dynamics and economic analysis.economic analysis.

7
Parallel ComputingParallel Computing
A task is broken down into tasks, A task is broken down into tasks, performed by separate workers or performed by separate workers or processesprocesses
Processes interact by exchanging Processes interact by exchanging informationinformation
What do we basically need?What do we basically need? The ability to start the tasksThe ability to start the tasks A way for them to communicateA way for them to communicate

8
1 Introduction(3/6)1 Introduction(3/6)
What’s parallel computer?What’s parallel computer? Is a Multi-processor computer system supporting Is a Multi-processor computer system supporting
parallel programming.parallel programming. Multi-computerMulti-computer
Is a parallel computer constructed out of multiple Is a parallel computer constructed out of multiple computers and an interconnection network.computers and an interconnection network.
The processors on different computers interact by The processors on different computers interact by passing message to each other.passing message to each other.
Centralized multiprocessor (SMP: Symmetrical Centralized multiprocessor (SMP: Symmetrical multiprocessor) multiprocessor)
Is a more high integrated system in which all CPUs Is a more high integrated system in which all CPUs share access to a single global memory.share access to a single global memory.
The shared memory supports communications and The shared memory supports communications and synchronization among processors.synchronization among processors.

9
1 Introduction(4/6)1 Introduction(4/6)
Multi-core platformMulti-core platform Integrated duo/quad or more core in one Integrated duo/quad or more core in one
processor, and each core has their own processor, and each core has their own registers and Level 1 cache, all cores share registers and Level 1 cache, all cores share Level 2 cache, which supports communications Level 2 cache, which supports communications and synchronizations among cores.and synchronizations among cores.
All cores share access to a global memory.All cores share access to a global memory.

10
1 Introduction(5/6)1 Introduction(5/6)
What’s parallel programming?What’s parallel programming? Is programming in language that allows you to Is programming in language that allows you to
explicitly indicate how different portions of the explicitly indicate how different portions of the computation may be executed computation may be executed paralleled/concurrently by different paralleled/concurrently by different processors/cores.processors/cores.
Do I need parallel programming really?Do I need parallel programming really? YES, for the reasons of:YES, for the reasons of:
Although a lot of research has been invested in and Although a lot of research has been invested in and many experimental parallelizing compilers have been many experimental parallelizing compilers have been developed, there are still no commercial system thus far.developed, there are still no commercial system thus far.
The alternative is for you to write your own parallel The alternative is for you to write your own parallel programs.programs.

11
1 Introduction(6/6)1 Introduction(6/6) Why should I program using MPI and OpenMP?Why should I program using MPI and OpenMP?
MPI ( Message Passing Interface) is a standard MPI ( Message Passing Interface) is a standard specification for message passing libraries.specification for message passing libraries.
Which is available on virtually every parallel Which is available on virtually every parallel computer system.computer system.
Free.Free. If you develop programs using MPI, you will be able If you develop programs using MPI, you will be able
to reuse them when you get access to a newer, faster to reuse them when you get access to a newer, faster parallel computer.parallel computer.
On Multi-core platform or SMP, the cores/CPUs have On Multi-core platform or SMP, the cores/CPUs have a shared memory space. While MPI is a perfect a shared memory space. While MPI is a perfect satisfactory way for cores/processors to communicate satisfactory way for cores/processors to communicate with each other, OpenMP is a better way for with each other, OpenMP is a better way for cores/processors with a single Processor/SMP to cores/processors with a single Processor/SMP to interact.interact.
The The hybrid MPI/OpenMPhybrid MPI/OpenMP program can get even high program can get even high performance.performance.

12
2 Seeking Parallel(1/7)2 Seeking Parallel(1/7)
In order to take advantage of multi-In order to take advantage of multi-core/multiple processors, programmers core/multiple processors, programmers must be able to identify operations that must be able to identify operations that may be performed in parallel.may be performed in parallel.
Several ways:Several ways: Data Dependence GraphsData Dependence Graphs Data ParallelismData Parallelism Functional ParallelismFunctional Parallelism PipeliningPipelining …………

13
2 Seeking Parallel(2/7)2 Seeking Parallel(2/7)
Data Dependence GraphsData Dependence Graphs A directed graphA directed graph Each vertex: represent a task to be completed.Each vertex: represent a task to be completed. An edge from vertex An edge from vertex uu to vertex to vertex vv means: task means: task uu
must be completed before task must be completed before task vv begins. begins.----- ----- Task v is dependent on task u.Task v is dependent on task u.
If there is no path from u to v, then the tasks are If there is no path from u to v, then the tasks are independentindependent and may be performed and may be performed parallelized.parallelized.

14
2 Seeking Parallel(3/7)2 Seeking Parallel(3/7)
a
b b b
c
a
b c d
e
a
b
c
Data Dependence GraphsData Dependence Graphs
Tasks
a Operation
Dependence among tasks

15
2 Seeking Parallel(4/7)2 Seeking Parallel(4/7)
Data ParallelismData Parallelism Independent tasks applying the Independent tasks applying the samesame
operation to operation to differentdifferent elements of a data elements of a data set.set.
e.g.e.g. For( int i=0;i<99; i++){ a(i) = b(i) + c(i);}
a
b b b
c

16
2 Seeking Parallel(5/7)2 Seeking Parallel(5/7)
Functional ParallelismFunctional Parallelism Independent tasks applying Independent tasks applying differentdifferent operations operations
to to differentdifferent data elements of a data set. data elements of a data set.
A = 2;b = 3;m = (a + b) / 2;s = (a2 + b2) / 2;v = s - m2
May be Functi onalParal l el i zed
a
b c d
e

17
2 Seeking Parallel(6/7)2 Seeking Parallel(6/7)
PipeliningPipelining A data dependence graph forming a simple A data dependence graph forming a simple
path/chain path/chain admits no parallelism if admits no parallelism if only a single problem instanceonly a single problem instance
must be processed.must be processed. If If multiple problems instancemultiple problems instance to be processed: to be processed:
If a computation can be divided into several stage with the If a computation can be divided into several stage with the same time consumption.same time consumption.
Then, can support parallelism.Then, can support parallelism. E.g.E.g.
Assembly line.Assembly line.
a
b
c

18
2 Seeking Parallel(7/7)2 Seeking Parallel(7/7)
PipeliningPipelining
p0← a0p1← a0 + a1
p2← a0 + a1+ a2p3← a0 + a1+ a2+ a3
p[0]=a[0]for (int i=1; i <=3; i ++){ p[ i ] = p[i -1]+a[i ] ;}
P[0] = a[0];P[1] = p[0]+a[1];P[2] = p[1]+a[2];P[3] = p[2]+a[3];
=
P[0]
a[0]
P[0]
+
P[1]
a[1]
P[1]+
P[2]
a[2]
P[2]+
P[3]
a[3]

19
For Example:For Example:
Landscape maintainsLandscape maintains Prepare for dinnerPrepare for dinner Data clusterData cluster …………

20
HomeworkHomework
Given a task that can be divided into m Given a task that can be divided into m subtasks, each require one unit of time, subtasks, each require one unit of time, how much time is needed for an m-stage how much time is needed for an m-stage pipeline to process n tasks?pipeline to process n tasks?
Consider the data dependence graph in Consider the data dependence graph in figure below.figure below. identify all sources of data parallelism;identify all sources of data parallelism; identify all sources of functional parallelism.identify all sources of functional parallelism.
I
A A A
B C
D A A A
O

Parallel Algorithm DesignParallel Algorithm Design
Part Part ⅡⅡ

22
1.Introduction1.Introduction 2.The Task/Channel Model2.The Task/Channel Model 3.Foster’s Design Methodology3.Foster’s Design Methodology
OutlineOutline

23
1.Introduction1.Introduction
Foster, Ian. Foster, Ian. Design and Building Design and Building Parallel Programs: Concepts and Tools Parallel Programs: Concepts and Tools for Parallel Software engineering.for Parallel Software engineering. Reading, MA: Addison-Wesley, 1995.Reading, MA: Addison-Wesley, 1995.
Describe the Task/Channel Model;Describe the Task/Channel Model; A few simple problems…A few simple problems…

24
2.The Task/Channel Model2.The Task/Channel Model The model represents a parallel computation as The model represents a parallel computation as
a set of tasks that may interact with each other a set of tasks that may interact with each other by sending message through channels.by sending message through channels.
Task: is a Task: is a program, its program, its local memory, local memory, and a and a collection of collection of I/O ports.I/O ports.
Local memory: Local memory: instructionsinstructionsprivate dataprivate data
Memory

25
2.The Task/Channel Model2.The Task/Channel Model
channel:channel: Via channel:Via channel:
A task can send local data to other tasks via output ports;A task can send local data to other tasks via output ports; A task can receive data value from other tasks via input ports.A task can receive data value from other tasks via input ports.
A channel is a A channel is a message queuemessage queue:: Connect one task’s output port with another task’s input pConnect one task’s output port with another task’s input p
ort.ort. Data value appears at the inputs port in the same order in whiData value appears at the inputs port in the same order in whi
ch they were placed in the output port of the other end of the ch they were placed in the output port of the other end of the channel.channel.
Receiving data can be blocked: Receiving data can be blocked: SynchronousSynchronous.. Sending data can never be blocked: Sending data can never be blocked: AsynchronousAsynchronous..
Access to local memory: faster than nonlocal data accAccess to local memory: faster than nonlocal data access.ess.

26
3.Foster’s Design Methodology3.Foster’s Design Methodology
Four-step process:Four-step process: PartitioningPartitioning CommunicationCommunication AgglomerationAgglomeration mappingmapping
Problem
Communication
Agglomeration
Mapping
Partitioning

27
3.Foster’s Design Methodology3.Foster’s Design Methodology PartitioningPartitioning
Is the process of dividing the computation and Is the process of dividing the computation and the data into pieces.the data into pieces.
More small pieces is good.More small pieces is good. How toHow to
Data-centric approachData-centric approach Function-centric approachFunction-centric approach
Domain DecompositionDomain Decomposition First, divide data into pieces;First, divide data into pieces; Then, determine how to associate computations with Then, determine how to associate computations with
the data.the data. Focus on:Focus on: the largest and/or most frequently accessed the largest and/or most frequently accessed
data structure in the program.data structure in the program. E.g.,E.g.,
Functional DecompositionFunctional Decomposition

28
3.Foster’s Design Methodology 3.Foster’s Design Methodology
Domain DecompositionDomain Decomposition1-D1-D
2-D2-D
3-D3-D
BetterBetter
Primitive TaskPrimitive Task

29
3.Foster’s Design Methodology 3.Foster’s Design Methodology Functional Decomposition Functional Decomposition
Yield collections of tasks that achieve Yield collections of tasks that achieve parallel through pipelining.parallel through pipelining.
E.g., a system supporting interactive E.g., a system supporting interactive image-guided surgery.image-guided surgery.
Acquire patientimages
Registerimages
Track position ofinstruments
Determine imagelocations
Display image

30
3.Foster’s Design Methodology3.Foster’s Design Methodology The quality of Partition (evaluation)The quality of Partition (evaluation)
At least an order of magnitude more primitive tasks At least an order of magnitude more primitive tasks than processors in the target parallel computer.than processors in the target parallel computer.
Otherwise: later design options may be too constrained.Otherwise: later design options may be too constrained. Redundant computations and redundant data Redundant computations and redundant data
structure storage are minimized.structure storage are minimized. Otherwise: the design may not work well when the size of Otherwise: the design may not work well when the size of
the problem increases.the problem increases. Primitive tasks are roughly the same size.Primitive tasks are roughly the same size.
Otherwise: it may be hard to balance work among the Otherwise: it may be hard to balance work among the processors/cores.processors/cores.
The number of tasks is an increasing function of the The number of tasks is an increasing function of the problem size.problem size.
Otherwise: it may be impossible to use more Otherwise: it may be impossible to use more processor/cores to solve large problem.processor/cores to solve large problem.

31
3.Foster’s Design Methodology3.Foster’s Design Methodology
CommunicationCommunication After identifying the primitive tasks, the After identifying the primitive tasks, the
communications type between those communications type between those primitive tasks should be determined.primitive tasks should be determined.
Two kinds of communication type:Two kinds of communication type: LocalLocal GlobalGlobal

32
3.Foster’s Design Methodology3.Foster’s Design Methodology
CommunicationCommunication Local:Local:
A task needs values from a small number of A task needs values from a small number of other tasks in order to perform a computation, other tasks in order to perform a computation, a channel is created from the tasks supplying a channel is created from the tasks supplying the data to the task consuming the data.the data to the task consuming the data.
Global:Global: When a significant number of the primitive When a significant number of the primitive
tasks must be contribute data in order to tasks must be contribute data in order to perform a computation.perform a computation.
E.g., computing the sums of the values held by E.g., computing the sums of the values held by the primitive processes.the primitive processes.

33
3.Foster’s Design Methodology3.Foster’s Design Methodology
CommunicationCommunication Evaluate the communication structure of Evaluate the communication structure of
the designed parallel algorithm.the designed parallel algorithm. The communication operations are balanced The communication operations are balanced
among the tasks.among the tasks. Each task communications with only a small Each task communications with only a small
number of neighbors.number of neighbors. Tasks can perform their communication in Tasks can perform their communication in
parallel/concurrently.parallel/concurrently. Tasks can perform their computations in Tasks can perform their computations in
parallel/concurrently.parallel/concurrently.

34
3.Foster’s Design Methodology3.Foster’s Design Methodology
AgglomerationAgglomeration Why we need agglomeration?Why we need agglomeration?
If the number of tasks exceeds the number of If the number of tasks exceeds the number of processors/cores by several orders of magnitude, simply processors/cores by several orders of magnitude, simply creating these tasks would be a source of significant creating these tasks would be a source of significant overheadoverhead..
So, combine primitive tasks into large tasks and So, combine primitive tasks into large tasks and map them into physical processors/cores to map them into physical processors/cores to reduce the amount of parallel overhead.reduce the amount of parallel overhead.
What’s agglomeration?What’s agglomeration? Is the process of grouping tasks into large tasks in order Is the process of grouping tasks into large tasks in order
to improve performance or simplify programming.to improve performance or simplify programming. When developing MPI programs, When developing MPI programs, ONE task per ONE task per
core/processorcore/processor is better. is better.

35
3.Foster’s Design Methodology3.Foster’s Design Methodology
AgglomerationAgglomeration Goals 1: lower communication overhead.Goals 1: lower communication overhead.
Eliminate communication among tasks.Eliminate communication among tasks. Increasing the locality of parallelism.Increasing the locality of parallelism. Combining groups of sending and receiving Combining groups of sending and receiving
tasks.tasks.

36
3.Foster’s Design Methodology3.Foster’s Design Methodology
AgglomerationAgglomeration Goals 2: Maintain the scalability of the Goals 2: Maintain the scalability of the
parallel design.parallel design. Enable that we have not combined so many Enable that we have not combined so many
tasks that we will not be able to port our tasks that we will not be able to port our program at some point in the future to a program at some point in the future to a computer with more processors/cores.computer with more processors/cores.
E.g. 3-D Matrix Operation E.g. 3-D Matrix Operation
size: 8*128*258size: 8*128*258

37
3.Foster’s Design Methodology3.Foster’s Design Methodology
AgglomerationAgglomeration Goals 3: reduce software engineering costs.Goals 3: reduce software engineering costs.
Make greater use of the existing sequential code.Make greater use of the existing sequential code. Reducing time;Reducing time; Reducing expense.Reducing expense.

38
3.Foster’s Design Methodology3.Foster’s Design Methodology Agglomeration evaluation:Agglomeration evaluation:
Has increased the locality of the parallel algorithm.Has increased the locality of the parallel algorithm. Replicated computations take less time than the Replicated computations take less time than the
computations the replace.computations the replace. The amount of replicated data is small enough to The amount of replicated data is small enough to
allow algorithm to scale.allow algorithm to scale. Agglomeration tasks have similar computational and Agglomeration tasks have similar computational and
communication costs.communication costs. The number of tasks is an increasing function of the The number of tasks is an increasing function of the
problem size.problem size. The number of tasks is as small as possible, yet at The number of tasks is as small as possible, yet at
least as great as the number of cores/processors in least as great as the number of cores/processors in the target computers.the target computers.
The trade-off between the chosen agglomeration and The trade-off between the chosen agglomeration and the cost of modifications to existing sequential code the cost of modifications to existing sequential code is reasonable.is reasonable.

39
3.Foster’s Design Methodology3.Foster’s Design Methodology
MappingMapping
A
B
C
E
F
D
H
G
A
B C
D E F
G H
Increasing processor utilizationIncreasing processor utilization Minimizing inter-processor communicationMinimizing inter-processor communication

Message-Passing Message-Passing ProgrammingProgramming
Part ⅢPart Ⅲ

41
PrefacePreface
prog_a
Load
Process
Store

42
prog_a
Node 1
Node 2
Node 3

43
process 0 process 1 process 2
Load
Process
Gather
Store

44
Hello World!Hello World!
##include <include <stdio.hstdio.h>>#include #include ““mpi.hmpi.h””int main(int argc,char *argv[]) {int main(int argc,char *argv[]) {
int size, rank;int size, rank;MPI _ I nit(&argc, &argv);MPI _ I nit(&argc, &argv);MPI _Comm_size(MPI _COMM_WORLDMPI _Comm_size(MPI _COMM_WORLD, &size);, &size);MPI _Comm_rank(MPI _COMM_WORLDMPI _Comm_rank(MPI _COMM_WORLD, &rank);, &rank);print(print(““Process %d of %d: Hello worldProcess %d of %d: Hello world””, rank, size);, rank, size);MPI _Finalize();MPI _Finalize();
}}
Hello world from process 0 of 4 Hello world from process 1 of 4 Hello world from process 2 of 4 Hello world from process 3 of 4

45
IntroductionIntroduction The Message-Passing ModelThe Message-Passing Model The Message-Passing Interface (MPI)The Message-Passing Interface (MPI) Communication ModeCommunication Mode Circuit satisfiabilityCircuit satisfiability Point-to-Point CommunicationPoint-to-Point Communication Collective CommunicationCollective Communication Benchmarking parallel performanceBenchmarking parallel performance
OutlineOutline

46
IntroductionIntroduction
MPI: MPI: Message Passing InterfaceMessage Passing Interface Is a library, not a parallel language.Is a library, not a parallel language.
C&MPI, Fortran&MPIC&MPI, Fortran&MPI Is a standard, not a implement for a Is a standard, not a implement for a
actually problem.actually problem. MPICHMPICH Intel MPIIntel MPI MSMPIMSMPI LAM MPILAM MPI
Is a Message Passing ModelIs a Message Passing Model

47
IntroductionIntroduction
The history of MPI:The history of MPI: Draft: 1992Draft: 1992 MPI-1: 1994MPI-1: 1994 MPI-2:1997MPI-2:1997
http://www.mpi-forum.orghttp://www.mpi-forum.org

48
IntroductionIntroduction MPICH:MPICH:
http://www-unix.mcs.anl.gov/mpi/mpich1/downloadhttp://www-unix.mcs.anl.gov/mpi/mpich1/download.html.html;;
http://www-unix.mcs.anl.gov/mpi/mpich2/index.htmhttp://www-unix.mcs.anl.gov/mpi/mpich2/index.htm#download#download
Main Features:Main Features: Open source;Open source; Synchronized on MPI standard;Synchronized on MPI standard; Supports MPMD (multiple Program Multiple Data) Supports MPMD (multiple Program Multiple Data)
and heterogeneous clusters. and heterogeneous clusters. Supports combining with C/C++, Fortran77 and Supports combining with C/C++, Fortran77 and
Fortran90;Fortran90; Supports Unix, Windows NT platform;Supports Unix, Windows NT platform; Supports multi-core, SMP, Cluster, Large Scale Supports multi-core, SMP, Cluster, Large Scale
Parallel Computer System. Parallel Computer System.

49
IntroductionIntroduction
Intel MPIIntel MPI According to According to
MPI-2 MPI-2 standard.standard.
Latest Latest version: 3.1version: 3.1
DAPL (Direct DAPL (Direct Access Access ProgramminProgramming Library)g Library)

50
Introduction-Intel MPIIntroduction-Intel MPI
Intel® MPI Intel® MPI Library Library Supports Supports Multiple Multiple Hardware Hardware FabricsFabrics

51
Introduction-Intel MPIIntroduction-Intel MPI
FeaturesFeatures is a multi-fabric message passing library.is a multi-fabric message passing library. implements the Message Passing Interface, implements the Message Passing Interface,
v2 (MPI-2) specification.v2 (MPI-2) specification. provides a standard library across Intel® provides a standard library across Intel®
platforms that:platforms that: Focuses on making applications perform best on Focuses on making applications perform best on
IA based clustersIA based clusters Enables adoption of the MPI-2 functions as the Enables adoption of the MPI-2 functions as the
customer needs dictatecustomer needs dictate Delivers best in class performance for Delivers best in class performance for
enterprise, divisional, departmental and enterprise, divisional, departmental and workgroup high performance computingworkgroup high performance computing

52
Introduction-Intel MPIIntroduction-Intel MPI
Why Intel MPI Library?Why Intel MPI Library? High performance MPI-2 implementationHigh performance MPI-2 implementation Linux and Windows CCS supportLinux and Windows CCS support Interconnect independenceInterconnect independence Smart fabric selectionSmart fabric selection Easy installationEasy installation Free Runtime EnvironmentFree Runtime Environment Close integration with the Intel and 3rd Close integration with the Intel and 3rd
party development toolsparty development tools Internet based licensing and technical Internet based licensing and technical
supportsupport

53
Introduction-Intel MPIIntroduction-Intel MPI
Standards BasedStandards Based Argonne National Laboratory's MPICH-2 implArgonne National Laboratory's MPICH-2 impl
ementation.ementation. Integration, can be easily integrated with:Integration, can be easily integrated with:
• • Platform LSF 6.1 and higherPlatform LSF 6.1 and higher• Altair PBS Pro* 7.1 and higher• Altair PBS Pro* 7.1 and higher• OpenPBS* 2.3• OpenPBS* 2.3• Torque* 1.2.0 and higher• Torque* 1.2.0 and higher• Parallelnavi* NQS* for Linux V2.0L10 and h• Parallelnavi* NQS* for Linux V2.0L10 and higherigher• Parallelnavi for Linux Advanced Edition V1.• Parallelnavi for Linux Advanced Edition V1.0L10A and higher0L10A and higher• NetBatch* 6.x and higher • NetBatch* 6.x and higher

54
Introduction-Intel MPIIntroduction-Intel MPI
System Requirements:System Requirements: Host and Target Systems hardware:Host and Target Systems hardware:
• • IA-32, Intel® 64, or IA-64 architecture using IA-32, Intel® 64, or IA-64 architecture using Intel® Pentium® 4,Intel® Pentium® 4,Intel® Xeon® processor, Intel® Itanium Intel® Xeon® processor, Intel® Itanium processor family and compatible platformsprocessor family and compatible platforms• 1 GB of RAM - 4 GB recommended• 1 GB of RAM - 4 GB recommended• Minimum 100 MB of free hard disk space - • Minimum 100 MB of free hard disk space - 10GB recommended.10GB recommended.

55
Introduction-Intel MPIIntroduction-Intel MPI Operating Systems Requirements:Operating Systems Requirements:
Microsoft Windows* Compute Cluster Server 2003 (Intel® 64 arMicrosoft Windows* Compute Cluster Server 2003 (Intel® 64 architecture only)chitecture only)
Red Hat Enterprise Linux* 3.0, 4.0, or 5.0Red Hat Enterprise Linux* 3.0, 4.0, or 5.0 SUSE* Linux Enterprise Server 9 or 10SUSE* Linux Enterprise Server 9 or 10 SUSE Linux 9.0 thru 10.0 (all except Intel® 64 architecture startSUSE Linux 9.0 thru 10.0 (all except Intel® 64 architecture start
s at 9.1)s at 9.1) HaanSoft Linux 2006 Server*HaanSoft Linux 2006 Server* Miracle Linux* 4.0Miracle Linux* 4.0 Red Flag* DC Server 5.0Red Flag* DC Server 5.0 Asianux* Linux 2.0Asianux* Linux 2.0 Fedora Core 4, 5, or 6 (IA-32 and Intel 64 architectures only)Fedora Core 4, 5, or 6 (IA-32 and Intel 64 architectures only) TurboLinux*10 (IA-32 and Intel® 64 architecture)TurboLinux*10 (IA-32 and Intel® 64 architecture) Mandriva/Mandrake* 10.1 (IA-32 architecture only)Mandriva/Mandrake* 10.1 (IA-32 architecture only) SGI* ProPack 4.0 (IA-64 architecture only) or 5.0 (IA-64 and InteSGI* ProPack 4.0 (IA-64 architecture only) or 5.0 (IA-64 and Inte
l 64 architectures)l 64 architectures)

56
The Message-Passing ModelThe Message-Passing Model
Interconnectionnetwork
Processor
Memory
Processor
Memory
Processor
Memory
Processor
Memory
Processor
Memory
Processor
Memory
Processor
Memory
Processor
Memory

57
The Message-Passing ModelThe Message-Passing Model
A task in task/channel model become a A task in task/channel model become a process in Message-Passing Model;process in Message-Passing Model;
The number of processes:The number of processes: Is specified by user;Is specified by user; Is specified when the program begins;Is specified when the program begins; Is constant throughout the execution of the Is constant throughout the execution of the
program;program; Each process:Each process:
Has a unique ID number;Has a unique ID number; Interconnectionnetwork
Processor
Memory
Processor
Memory
Processor
Memory
Processor
Memory
Processor
Memory
Processor
Memory
Processor
Memory
Processor
Memory

58
The Message-Passing ModelThe Message-Passing Model
Goals of Message-Passing Model:Goals of Message-Passing Model: Communication with each other;Communication with each other;
Synchronization with each other;Synchronization with each other;

59
The Message-Passing Interface The Message-Passing Interface (MPI)(MPI)
Advantages:Advantages: Run well on a wide variety of MPMD Run well on a wide variety of MPMD
architectures;architectures;
Easily to debugging;Easily to debugging;
Threading safeThreading safe

60
What is in MPIWhat is in MPI
Point-to-point message passing Point-to-point message passing Collective communication Collective communication Support for process groups Support for process groups Support for communication contexts Support for communication contexts Support for application topologies Support for application topologies Environmental inquiry routines Environmental inquiry routines Profiling interface Profiling interface

61
Introduction to Groups & Introduction to Groups & CommunicatorCommunicator
Process model and groups Process model and groups Communication scope Communication scope Communicators Communicators

62
Process model and groupsProcess model and groups Fundamental computational unit is the process. Fundamental computational unit is the process.
Each process has: Each process has: an independent thread of control, an independent thread of control, a separate address space a separate address space
MPI processes execute in MIMD style, but: MPI processes execute in MIMD style, but: No mechanism for loading code onto processors, or No mechanism for loading code onto processors, or
assigning processes to processors assigning processes to processors No mechanism for creating or destroying processes No mechanism for creating or destroying processes
MPI supports dynamic process groups. MPI supports dynamic process groups. Process groups can be created and destroyed Process groups can be created and destroyed Membership is static Membership is static Groups may overlap Groups may overlap
No explicit support for multithreading, but MPI is No explicit support for multithreading, but MPI is designed to be thread-safe. designed to be thread-safe.

63
Communication scopeCommunication scope In MPI, a process is specified by: In MPI, a process is specified by:
a group a group a rank relative to the group ( ) a rank relative to the group ( )
A message label is specified by: A message label is specified by: a message context a message context a message tag relative to the context a message tag relative to the context
Groups are used to partition process space Groups are used to partition process space Contexts are used to partition ``message Contexts are used to partition ``message
label space'' label space'' Groups and contexts are bound together to Groups and contexts are bound together to
form a form a communicatorcommunicator object. Contexts are object. Contexts are not visible at the application level. not visible at the application level.
A communicator defines the A communicator defines the scopescope of a of a communication operationcommunication operation

64
CommunicatorsCommunicators Communicators are used to create independent Communicators are used to create independent
``message universes''. ``message universes''. Communicators are used to disambiguate Communicators are used to disambiguate
message selection when an application calls a message selection when an application calls a library routine that performs message passing. library routine that performs message passing. Nondeterminacy may arise Nondeterminacy may arise if processes enter the library routine asynchronously, if processes enter the library routine asynchronously, if processes enter the library routine synchronously, if processes enter the library routine synchronously,
but there are outstanding communication operations. but there are outstanding communication operations. A communicator A communicator
binds together groups and contexts binds together groups and contexts defines the scope of a communication operation defines the scope of a communication operation is represented by an opaque object is represented by an opaque object

65
A communicator handle defines which A communicator handle defines which processes a particular command will processes a particular command will apply toapply to
All MPI communication calls take a All MPI communication calls take a communicator handle as a parameter, communicator handle as a parameter, which is effectively the context in which which is effectively the context in which the communication will take placethe communication will take place
MPI_INITMPI_INIT defines a communicator defines a communicator called MPI_COMM_WORLD for each called MPI_COMM_WORLD for each process that calls itprocess that calls it

66
Every communicator contains a group Every communicator contains a group which is a list of processeswhich is a list of processes
The processes are ordered and The processes are ordered and numbered consecutively from 0.numbered consecutively from 0.
The number of each process is known The number of each process is known as its rankas its rank The rank identifies each process within The rank identifies each process within
the communicatorthe communicator The group of MPI_COMM_WORLD is The group of MPI_COMM_WORLD is
the set of all MPI processesthe set of all MPI processes

67
Skeleton MPI ProgramSkeleton MPI Program
#include <mpi.h>
main( int argc, char** argv ) { MPI_Init( &argc, &argv );
/* main part of the program */
MPI_Finalize();}

68
Circuit satisfiabilityCircuit satisfiabilitya
b
cd
e
f
g
hi
j
k
l
m
n
o
p
What What combinations combinations of input value of input value will the circuit will the circuit output the output the value of 1?value of 1?

69
Circuit satisfiabilityCircuit satisfiability
Analysis:Analysis: 16 input, a-p, each take on 2 values of 0 16 input, a-p, each take on 2 values of 0
or 1.or 1. 221616=65536=65536 design a parallel algorithmdesign a parallel algorithm
PartitionPartition Function decompositionFunction decomposition No channel between tasksNo channel between tasks
Tasks are independent;Tasks are independent; Suit for parallelism;Suit for parallelism;
1 2 655363
Output
Partition
Communication
Agglomeration
Mapping

70
Circuit satisfiabilityCircuit satisfiability
Communication:Communication: Tasks are Tasks are
independent;independent; Partition
Communication
Agglomeration
Mapping

71
Circuit satisfiabilityCircuit satisfiability
Agglomeration and MappingAgglomeration and Mapping Fixed number of tasks;Fixed number of tasks; The time for each task to complete is variable. The time for each task to complete is variable.
WHY?WHY? How to How to balancebalance the computation load? the computation load?
Mapping tasks in Mapping tasks in cyclic fashioncyclic fashion..Partition
Communication
Agglomeration
Mapping
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 190Tasks
Processors/Cores 0 1 2 3 4 5

72
Circuit satisfiabilityCircuit satisfiability
Each process Each process will examine a will examine a combination combination of inputs in of inputs in turn.turn.
#include <mpi.h>#include <stdio.h>
int main(int argc, char * argv[]){ int i; int id; int p; void check_circuit(int,int); MPI_Init(&argc, &argv); MPI_Comm_rank(MPI_COMM_WORLD, &id); MPI_Comm_size(MPI_COMM_WORLD, &p);
for( i=id; i< 65536;i++) check_circuit(id,i); printf(“process %d is done\n”,id); fflush(stdout); MPI_Finalize(); return 0 ;}

73
Circuit satisfiabilityCircuit satisfiability#define EXTRACT_BIT(n,i) ((n&(1<<i))?1:0)void check_circuit(int id,int z){ int v[16]; int i; for( i=0;i<16;i++) v[i] = EXTRACT_BIT(z,i) ; if((v[0] || v[1]) && (!v[1] || !v[3]) && (v[2] || v[3]) && (!v[3] || !v[4]) && (v[4] || !v[5]) && ( v[5] || !v[6]) && (v[5] || v[6]) && ( v[6] || !v[15]) && (v[7] || !v[8]) && (!v[7] || !v[13]) && (v[8] || v[9]) && ( v[9] || v[11]) && (v[10] || v[11]) && ( v[12] || v[13]) && (v[13] || !v[14]) && (v[14] || v[15]) ) { printf(“%d)%d%d%d%d%d%d%d%d%d%d%d%d%d%d%d%d”,id,v[0],v[1],v[2],v[3],v[4],v[5],v[6],v[7],v[8],v[9],v[10],v[11],v[12],v[13],v[14],v[15]);fflush(stdout); }}

74
Point-to-Point CommunicationPoint-to-Point Communication
OverviewOverview Blocking BehaviorsBlocking Behaviors Non-Blocking BehaviorsNon-Blocking Behaviors

75
overviewoverview
A message is sent from a sender tA message is sent from a sender to a receivero a receiver
There are several variations on hThere are several variations on how the sending of a message can ow the sending of a message can interact with the programinteract with the program

76
SynchronousSynchronous does not complete does not complete
until the message until the message has been receivedhas been received A FAX or registered A FAX or registered
mailmail

77
AsynchronousAsynchronous completes as soon as completes as soon as
the message is on the the message is on the way.way. A post card or emailA post card or email

78
communication modes communication modes
is selected with send routine.is selected with send routine. synchronous mode ("safest") synchronous mode ("safest") ready mode (lowest system overhead) ready mode (lowest system overhead) buffered mode (decouples sender from receivebuffered mode (decouples sender from receive
r) r) standard mode (compromise) standard mode (compromise)
Calls are also blocking or nonblocking.Calls are also blocking or nonblocking. Blocking stops the program until the message Blocking stops the program until the message
buffer is safe to use buffer is safe to use Non-blocking separates communication from Non-blocking separates communication from
computation computation

79
Blocking Behavior Blocking Behavior
int MPI_Send(void *buf, int count, MPI_Datatint MPI_Send(void *buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm coype datatype, int dest, int tag, MPI_Comm comm) mm)
bufbuf is the beginning of the buffer containing the data to is the beginning of the buffer containing the data to be sent. For Fortran, this is often the name of an array ibe sent. For Fortran, this is often the name of an array in your program. For C, it is an address. n your program. For C, it is an address.
countcount is the number of elements to be sent (not bytes) is the number of elements to be sent (not bytes) datatypedatatype is the type of data is the type of data destdest is the rank of the process which is the destination f is the rank of the process which is the destination f
or the message or the message tagtag is an arbitrary number which can be used to disting is an arbitrary number which can be used to disting
uish among messages uish among messages commcomm is the communicator is the communicator

80
Temporary KnowledgeTemporary Knowledge
MessageMessage Msg: buf, count, datatypeMsg: buf, count, datatype Msg envelop: dest, tag, commMsg envelop: dest, tag, comm
Tag----why?Tag----why?
Process P: send( A,32,Q) ; send( B,16,Q) ;
Process Q: recv( X, 32, P) ; recv( Y, 16, P) ;
Process P: send( A,32,Q,tag1) ; send( B,16,Q,tag2) ; Process Q: recv ( X, 32, P, tag1) ; recv ( Y, 16, P, tag2)

81

82
When using standard-mode sendWhen using standard-mode send It is up to MPI to decide whether outgoing It is up to MPI to decide whether outgoing
messages will be buffered.messages will be buffered. Completes once the message has been sent, Completes once the message has been sent,
which may or may not imply that the which may or may not imply that the massage has arrived at its destinationmassage has arrived at its destination
Can be started whether or not a matching Can be started whether or not a matching receive has been posted. It may complete receive has been posted. It may complete before a matching receive is posted.before a matching receive is posted.
Has non-local completion semantics, since Has non-local completion semantics, since successful completion of the send operation successful completion of the send operation may depend on the occurrence of a may depend on the occurrence of a matching receive. matching receive.

83
Blocking Standard SendBlocking Standard Send

84
MPI_RecvMPI_Recv int MPI_Recv(void *buf, int count, MPI_Datatypint MPI_Recv(void *buf, int count, MPI_Datatyp
e datatype, int source, int tag, MPI_Comm come datatype, int source, int tag, MPI_Comm comm, MPI_Status *status) m, MPI_Status *status)
bufbuf is the beginning of the buffer where the incoming data are is the beginning of the buffer where the incoming data are to be stored. For Fortran, this is often the name of an array in yto be stored. For Fortran, this is often the name of an array in your program. For C, it is an address. our program. For C, it is an address.
countcount is the number of elements (not bytes) in your receive buf is the number of elements (not bytes) in your receive buffer fer
datatypedatatype is the type of data is the type of data sourcesource is the rank of the process from which data will be accep is the rank of the process from which data will be accep
ted (This can be a wildcard, by specifying the parameter MPI_ted (This can be a wildcard, by specifying the parameter MPI_ANY_SOURCE.) ANY_SOURCE.)
tagtag is an arbitrary number which can be used to distinguish a is an arbitrary number which can be used to distinguish among messages (This can be a wildcard, by specifying the paramong messages (This can be a wildcard, by specifying the parameter MPI_ANY_TAG.) meter MPI_ANY_TAG.)
commcomm is the communicator is the communicator statusstatus is an array or structure of information that is returned. F is an array or structure of information that is returned. F
or example, if you specify a wildcard for source or tag, status wor example, if you specify a wildcard for source or tag, status will tell you the actual rank or tag for the message received ill tell you the actual rank or tag for the message received

85

86

87
Blocking Synchronous Send Blocking Synchronous Send

88
Cont.Cont.
can be started whether or not a matching can be started whether or not a matching receive was postedreceive was posted
will complete successfully only if a will complete successfully only if a matching receive is posted, and the receive matching receive is posted, and the receive operation has started to receive the operation has started to receive the message sent by the synchronous send.message sent by the synchronous send.
provides synchronous communication provides synchronous communication semantics: a communication does not semantics: a communication does not complete at either end before both complete at either end before both processes rendezvous at the processes rendezvous at the communication. communication.
has non-local completion semantics. has non-local completion semantics.

89
Blocking Ready Send Blocking Ready Send

90
completes immediatelycompletes immediately may be started only if the matching recmay be started only if the matching rec
eive has already been posted.eive has already been posted. has the same semantics as a standard-has the same semantics as a standard-
mode send.mode send. saves on overhead by avoiding handshasaves on overhead by avoiding handsha
king and bufferingking and buffering

91
Blocking Buffered Send Blocking Buffered Send

92
Can be started whether or not a Can be started whether or not a matching receive has been posted. It matching receive has been posted. It may complete before a matching receive may complete before a matching receive is posted.is posted.
Has local completion semantics: its Has local completion semantics: its completion does not depend on the completion does not depend on the occurrence of a matching receive.occurrence of a matching receive.
In order to complete the operation, it In order to complete the operation, it may be necessary to buffer the outgoing may be necessary to buffer the outgoing message locally. For that purpose, buffer message locally. For that purpose, buffer space is provided by the application.space is provided by the application.

93
Non-Blocking Behavior Non-Blocking Behavior
MPI_MPI_IIsendsend (buf,count,dtype,dest,tag,comm, (buf,count,dtype,dest,tag,comm,requestrequest))
MPI_WaitMPI_Wait ( (requestrequest,status) ,status) requestrequest matches request on matches request on IsendIsend or or IrecvIrecv status status returns status equivalent toreturns status equivalent to
status for status for RecvRecv when complete when complete Blocks for send until message is buffered or sent Blocks for send until message is buffered or sent
so message variable is freeso message variable is free Blocks for receive until message is received and Blocks for receive until message is received and
readyready

94
Non-blocking Synchronous SendNon-blocking Synchronous Send
int MPI_Issend (void *buf, int count, MPI_Dataint MPI_Issend (void *buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm cotype datatype, int dest, int tag, MPI_Comm comm, MPI_Request *request) mm, MPI_Request *request)
ININ = provided by programmer, = provided by programmer, OUTOUT = set by routi = set by routine ne bufbuf: starting address of message buffer (: starting address of message buffer (ININ) ) countcount: number of elements in message (: number of elements in message (ININ) ) datatypedatatype: type of elements in message (: type of elements in message (ININ) ) destdest: rank of destination task in communicator : rank of destination task in communicator ccommomm ( (ININ) ) tagtag: message tag (: message tag (ININ) ) commcomm: communicator (: communicator (ININ) ) requestrequest: identifies a communication event (: identifies a communication event (OUOUTT) )

95
Non-blocking Ready Send Non-blocking Ready Send
int MPI_Irsend (void *buf, int count, MPIint MPI_Irsend (void *buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm, MPI_Request *request) _Comm comm, MPI_Request *request)

96
Non-blocking Buffered Send Non-blocking Buffered Send
int MPI_Ibsend (void *buf, int count, MPIint MPI_Ibsend (void *buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm, MPI_Request *request) _Comm comm, MPI_Request *request)

97
Non-blocking Standard Send Non-blocking Standard Send
int MPI_Isend (void *buf, int count, MPI_int MPI_Isend (void *buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm, MPI_Request *request) Comm comm, MPI_Request *request)

98
Non-blocking Receive Non-blocking Receive ININ = provided by programmer, = provided by programmer, OUTOUT = set by = set by
routine routine bufbuf: starting address of message buf: starting address of message buffer (fer (OUT-buffer contents writtenOUT-buffer contents written) ) countcount: number of elements in message (: number of elements in message (ININ) ) datatypedatatype: type of elements in message (: type of elements in message (ININ) ) sourcesource: rank of source task in communicato: rank of source task in communicator r commcomm ( (ININ) ) tagtag: message tag (: message tag (ININ) ) commcomm: communicator (: communicator (ININ) ) requestrequest: identifies a communication event : identifies a communication event ((OUTOUT) )

99
int MPI_Irecv (void* buf, int count, MPI_int MPI_Irecv (void* buf, int count, MPI_Datatype datatype, int source, int tag, MPDatatype datatype, int source, int tag, MPI_Comm comm, MPI_Request *request) I_Comm comm, MPI_Request *request)

100
requestrequest: identifies a communication event (: identifies a communication event (ININOUTOUT) ) statusstatus: status of communication event (: status of communication event (OUTOUT) ) countcount: number of communication events (: number of communication events (ININ) ) indexindex: index in array of requests of completed : index in array of requests of completed event (event (OUTOUT) ) incountincount: number of communication events (: number of communication events (IINN) ) outcountoutcount: number of completed events (: number of completed events (OUTOUT) )

101
int MPI_Wait (MPI_Request *request, MPI_Staint MPI_Wait (MPI_Request *request, MPI_Status *status) tus *status)
int MPI_Waitall (int count, MPI_Request *arraint MPI_Waitall (int count, MPI_Request *array_of_requests, MPI_Status *array_of_statuses) y_of_requests, MPI_Status *array_of_statuses)
int MPI_Waitany (int count, MPI_Request *arrint MPI_Waitany (int count, MPI_Request *array_of_requests, int *index, MPI_Status *statuay_of_requests, int *index, MPI_Status *status) s)
int MPI_Waitsome (int incount, MPI_Request int MPI_Waitsome (int incount, MPI_Request *array_of_requests, int *outcount, int* array_o*array_of_requests, int *outcount, int* array_of_indices, MPI_Status *array_of_statuses) f_indices, MPI_Status *array_of_statuses)

102
MPI_IRECVMPI_RECV
MPI_ISENDMPI_SENDStandard
MPI_IBSENDMPI_BSENDBuffered
MPI_IRSENDMPI_RSENDReady
MPI_ISSENDMPI_SSENDSynchronous
Non-Blocking RoutinesBlocking RoutinesCommunication Mode

103
Your program may not be suitableGood for many casesStandard
Additional system overhead incurred by copy to buffer
Decouples SEND from RECVNo sync overhead on SENDOrder of SEND/RECV irrelevantProgrammer can control size of buffer space
Buffered
RECV must precede SENDLowest total overhead
SEND/RECV handshake not required
Ready
Can incur substantial synchronization overhead
Safest, and therefore most portableSEND/RECV order not criticalAmount of buffer space irrelevant
Synchronous
DisadvantagesAdvantages

104
MPI Quick StartMPI Quick Start
MPI_Init
MPI_Comm_rank
MPI_Comm_size
MPI_Send
MPI_Recv
MPI_Finalize
MPI_BCast
MPI_Scatter
MPI_Gather
MPI_Reduce
MPI_Barrier
MPI_Wtime
MPI_Wtick
MPI_XxxxxMPI_Xxxxx

105
MPI RoutinesMPI Routines
MPI_InitMPI_Init To Initialize MPI execution environment To Initialize MPI execution environment .. argc:argc: Pointer to the number of arguments Pointer to the number of arguments argv:argv: Pointer to the argument vector Pointer to the argument vector The First MPI function call;The First MPI function call; Allow system to do any setup needed to hander fuAllow system to do any setup needed to hander fu
rther calls to MPI Library.rther calls to MPI Library. defines a communicator calleddefines a communicator called MPI_COMM_WO MPI_COMM_WO
RLD RLD for each process that calls itfor each process that calls it MPI_Init must be called before any other MPI funMPI_Init must be called before any other MPI fun
ctions.ctions. ExceptionException: MPI_Initializes, checks to see if MPI has been : MPI_Initializes, checks to see if MPI has been
initialzed. May be called before MPI_Init.initialzed. May be called before MPI_Init.
MPI_Init(&argc, &argv);

106
MPI RoutinesMPI Routines
MPI_Comm_rankMPI_Comm_rank
To determine a process’s ID number.To determine a process’s ID number. Return: Process’s ID by rankReturn: Process’s ID by rank Communicator: Communicator:
MPI_Comm: MPI_COMM_WORLD, include all process MPI_Comm: MPI_COMM_WORLD, include all process when MPI initialized.when MPI initialized.
MPI_Comm_rank(MPI_COMM_WORLD, &id);
int MPI_Comm_rank(MPI_comm com, int* rank)

107
MPI RoutinesMPI Routines
MPI_Comm_sizeMPI_Comm_size
To find the number of processes -- sizeTo find the number of processes -- size
MPI_Comm_size(MPI_COMM_WORLD, &p);
int MPI_Comm_size(MPI_comm com, int* size)

108
MPI RoutinesMPI Routines MPI_SendMPI_Send
The source process send the data The source process send the data in buffer to destination process.in buffer to destination process.
bufbuf The starting address of the data to be transmitted.
countcount The number of data items.The number of data items.
datatydatatypepe
The type of data items.(all of the data items mThe type of data items.(all of the data items must be in the same type)ust be in the same type)
destdest The rank of the process to receive the data.The rank of the process to receive the data.
tagtag An integer “label” for the message, An integer “label” for the message, allowing messages serving different allowing messages serving different purpose to be identified.purpose to be identified.
commcomm Indicates the communicator in which this Indicates the communicator in which this message is being sent.message is being sent.
int MPI_Send(void* buf,int count,MPI_Datatype datatype,int dest,int tag,MPI_Comm comm)

109
MPI RoutinesMPI Routines
MPI_SendMPI_Send Blocks until the message buffer is once again Blocks until the message buffer is once again
availabel.availabel. MPI constants for C data types.MPI constants for C data types.

110
MPI RoutinesMPI Routines
MPI_RecvMPI_Recv
int MPI_Recv(void* buf,int count,MPI_Datatype datatype,int source,int tag,MPI_Comm comm,MPI_Status * status)
bufbuf The starting address where the received data is to be stored.
countcount The maximum number of data items the The maximum number of data items the receiving process is willing to receive.receiving process is willing to receive.
datatydatatypepe
The type of data itemsThe type of data items
sourcesource The rank of the process sending this message.The rank of the process sending this message.
tagtag The desired tag value for the messageThe desired tag value for the message
commcomm Indicates the communicator in which this Indicates the communicator in which this message is being passed.message is being passed.
statusstatus MPI data structure. Return the status.MPI data structure. Return the status.

111
MPI RoutinesMPI Routines
MPI_RecvMPI_Recv Receive the message from the source process.Receive the message from the source process. The data type and tag of message received musThe data type and tag of message received mus
t be in according with the data type and tag deft be in according with the data type and tag define in MPI_Recv funciton.ine in MPI_Recv funciton.
The count of data items received must be less tThe count of data items received must be less than the count define in this function. Otherwihan the count define in this function. Otherwise, will cause the overflow error condition.se, will cause the overflow error condition.
If count equal to zero, then message is empty.If count equal to zero, then message is empty. Blocks until the message has been recived.Blocks until the message has been recived.
Or an error conditions cause the function to return.Or an error conditions cause the function to return.

112
MPI RoutinesMPI Routines
MPI_RecvMPI_Recv
status->MPI_Sourstatus->MPI_Sourcece
The rank of the The rank of the process sending the process sending the msg.msg.
status->MPI_Tagstatus->MPI_Tag The msg’s tag value.The msg’s tag value.status-status->MPI_ERROE>MPI_ERROE
The error condition.The error condition.
int MPI_Abort ( MPI_Comm comm, int errorcode)

113
MPI RoutinesMPI Routines
MPI_FinalizeMPI_Finalize Allowing system to free up resources, such as mAllowing system to free up resources, such as m
emory, that have been allocated to MPI.emory, that have been allocated to MPI. Without MPI_Finalize, the result of program wilWithout MPI_Finalize, the result of program wil
l unknowns.l unknowns.
MPI_Finalize();

114
summarysummary
MPI_Init
MPI_Comm_rank
MPI_Comm_size
MPI_Send
MPI_Recv
MPI_Finalize

115
Collective communicationCollective communication
Communication operationCommunication operation A group of processes work together to A group of processes work together to
distribute or gather together a set of distribute or gather together a set of one or more values.one or more values. Process
RunTime
Process 0 Process 1 Process 2
Parallel Executing
WaitWait
Syn point
Call Syn (1)
Call Syn (3)
Call Syn (2)

116
Collective communicationCollective communication
MPI_BcastMPI_Bcast A root process broadcast one or more data items of thA root process broadcast one or more data items of th
e same type to all other processed in a communicator.e same type to all other processed in a communicator.
rootBefore
broadcast
A A A A AAfter
broadcast
broadcast

117
Collective communicationCollective communication
MPI_BcastMPI_Bcast
int MPI_Bcast(void* buffer, //addr of 1st broadcast elementint count, // #element to be broadcastMPI_Datatype datatype, // type of element to be broadcastint root, // ID of process doing broadcastMPI_Comm comm) //communicator

118
Collective communicationCollective communication
MPI_ScatterMPI_Scatter The root process send the different parts of datThe root process send the different parts of dat
a item to other processes.a item to other processes.
A B C D ... h
A B C D h
Scatter different parts of data to other process in turn.
Sending bufferof root process
Receivingbuffer of other
processRoot

119
Collective communicationCollective communication
MPI_ScatterMPI_Scatter
int MPI_Scatter(void* buffer, //starting addr of sending bufferint sendcount, // #element to be scatteredMPI_Datatype sendtype, // type of element to be sent.void* recvbuf,int recvcount,MPI_Datatype recvtype,int root, // ID of root process doing scatteredMPI_Comm comm) //communicator

120
Collective communicationCollective communication
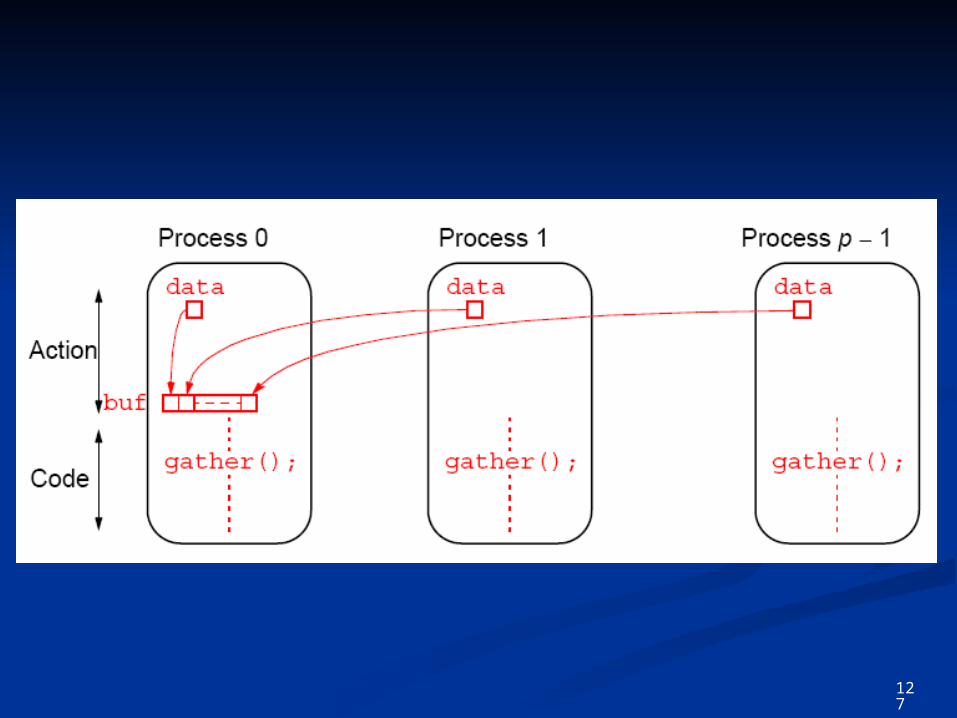
MPI_GatherMPI_Gather Each process sending data of its buffer to root proceEach process sending data of its buffer to root proce
ss.ss.
A B C D ... h
A B C D h
Gather
Receivingbuffer of root
process
Sending bufferof otherprocess
Root

121
Collective communicationCollective communication
MPI_GatherMPI_Gather
int MPI_Gather(void* sendbuffer, //starting addr of sending bufferint sendcount, // #element to be scatteredMPI_Datatype sendtype, // type of element to be sent.void* recvbuf,int recvcount,MPI_Datatype recvtype,int root, // ID of root process doing scatteredMPI_Comm comm) //communicator

122
Collective communicationCollective communication
MPI_ReduceMPI_Reduce After a process has completed its share of thAfter a process has completed its share of th
e work, it is ready to participate in the reducte work, it is ready to participate in the reduction operation.ion operation.
MPI_Reduce perform one or more reduction MPI_Reduce perform one or more reduction operations on values submitted by all the prooperations on values submitted by all the processed in a communicator.cessed in a communicator.

123
Collective communicationCollective communication
MPI_ReduceMPI_Reduce
int MPI_Reduce(void* operand, //addr of 1st reduction elementvoid* result, // addr of 1st reduction resultint count, // reductions to performMPI_Datatype type, // type of element to be sent.MPI_OP operator, // reduction operatorint root, // process getting result(s)MPI_Comm comm) //communicator

124
Collective communicationCollective communication MPI_Reduce MPI’s built-in reduction operatorsMPI_Reduce MPI’s built-in reduction operators
MPI_BAND
MPI_BOR
MPI_BXOR
MPI_LAND
MPI_LOR
MPI_LXOR
MPI_MAX
MPI_MAXLOC
MPI_MIN
MPI_MINLOC
MPI_PORD
MPI_SUM
Bitwise and
Bitwise or
Bitwise exclusive or
logical and
logical or
Logical exclusive or
Maximum
Maximum and location of maximum
Minimum
Minimum and location of maximum
Product
Sum

125
summarysummary

126
127

128

129
Benchmarking parallel Benchmarking parallel performanceperformance
Measure the performance of a parallel appliMeasure the performance of a parallel application.cation.
How?How? Measuring the number of seconds that elapse frMeasuring the number of seconds that elapse fr
om the time we initiate execution until the progrom the time we initiate execution until the program terminates.am terminates.
double MPI_Wtime(void)double MPI_Wtime(void) Returns the numbers of seconds that have elapsed sinReturns the numbers of seconds that have elapsed sin
ce some point of time in the past.ce some point of time in the past. double MPI_Wtick(void)double MPI_Wtick(void)
Returns the precision of the result returned by MPI_Returns the precision of the result returned by MPI_Wtime.Wtime.

130
Benchmarking parallel Benchmarking parallel performanceperformance
MPI_BarrierMPI_Barrier int MPI_Barrier(MPI_Comm comm)int MPI_Barrier(MPI_Comm comm)
comm: indicate in which communicator the processes will comm: indicate in which communicator the processes will participate the barrier synchronization.participate the barrier synchronization.
Function of MPI_Barrier is….Function of MPI_Barrier is….
double elapsed_time;MPI_Init(&agrc,&argv);elapsed_time = -MPI_Wtime;….MPI_Reduce(&solutions, &global_solutions,1,MPI_INT,MPI_SUM,0,MPI_COMM_WORLD);elapsed_time += MPI_Wtime;

131
For exampleFor example
Send and receive Send and receive operationoperation#include “mpi.h”void main(int argc, char * argv[]){ …. MPI_Inti(&argc,&argv); MPI_Comm_rank(MPI_COMM_WORLD,&myrank); MPI_Comm_size(MPI_COMM_WORLD,&numprocs); if( myrank == 0 ) {
MPI_Send(message,length,MPI_CHAR,1,99,MPI_COMM_WORLD); } else if(myrank == 1) {
MPI_Recv(message,length,MPI_CHAR,0,99,MPI_COMM_WORLD,&status); } MPI_Finalize();}

132
For exampleFor example Compute piCompute pi
4/)1arctan()0arctan()1arctan(|)arctan(1
1 10
1
0 2
xdxx
)1(
4)(
2xxf
1
0)( dxxf

133
For exampleFor example
0 1
4
N
i
N
i N
if
NNN
if
1 1
)5.0
(11
)2
12(

134
For exampleFor example
Compute piCompute pi
MPI_Bcast(&n,1,MPI_INT,0,MPI_COMM_WORLD);
h= 1.0/(double)n;sum = 0.0;for( int i=myrank +1; i<= n; i+= numprocs){ x= h * (I - 0.5 ); sum += 4.0/(1.0 + x* x);}mypi = h * sum;
MPI_Reduce(&mypi, &pi, 1, MPI_DOUBLE, MPI_SUM, 0, MPI_COMM_WORLD);

135
For exampleFor example
Matrix MultiplicationMatrix Multiplication
MPI_Scatter(&iaA[0][0],N,MPI_INT,&iaA[iRank][0],N,MPI_INT,0,MPI_COMM_WORLD);MPI_Bcast(&iaB[0][0],N*N,MPI_INT,0,MPI_COMM_WORLD);for(i=0;i<N;i++){ temp = 0; for(j=0;j<N;j++) {
remp = temp+iaA[iRank][j] * iaB[j][i]; } iaC[iRank][i] = temp;}
MPI_Gather(&iaC[iRank][0],N,MPI_INT,&iaC[0][0],N,MPI_INT,0,MPI_COMM_WORLD);

136

137
1
0,,,
l
kjkkiji baC
where A is an n x l matrix and B is an l x m matrix.

138

139

140
for (i = 0; i < n; i++)for (j = 0; j < n; j++) {
c[i][j] = 0;for (k = 0; k < n; k++)
c[i][j] = c[i][j] + a[i][k] * b[k][j];}

141

142
SummarySummary
MPI is a Library.MPI is a Library. Six foundational functions of MPI.Six foundational functions of MPI. collective communication.collective communication. MPI communication Model.MPI communication Model.

Fell free to contact me viaFell free to contact me [email protected]@whu.edu.cn
for any questions or suggestions.for any questions or suggestions.AndAnd
Welcome to Wuhan University!Welcome to Wuhan University!
Thanks!Thanks!