parallel programming in mpi part 2 - 九州大...
TRANSCRIPT

Parallel Programming in MPIpart 2
1 1

Today's Topic
• ノンブロッキング通信Non-Blocking Communication• 通信の完了を待つ間に他の処理を行う
Execute other instructions while waiting for the completion of a communication.
• 集団通信関数の実装Implementation of collective communications
• MPIプログラムの時間計測Measuring execution time of MPI programs
• デッドロック Deadlock
2

Today's Topic
• ノンブロッキング通信Non-Blocking Communication• 通信の完了を待つ間に他の処理を行う
Execute other instructions while waiting for the completion of a communication.
• 集団通信関数の実装Implementation of collective communications
• MPIプログラムの時間計測Measuring execution time of MPI programs
• デッドロック Deadlock
3

ノンブロッキング通信関数Non-blocking communication functions
• ノンブロッキング = ある命令の完了を待たずに次の命令に移るNon-blocking = Do not wait for the completion of an instruction and proceed to the next instruction
• Example) MPI_Irecv & MPI_Wait
4
MPI_Recv
Wait for the arrival of data
MPI_IrecvProceed to the next instruction without waiting for the data
data
Blocking
next instructions
next instructions
MPI_Wait data
Non-Blocking

MPI_Irecv
• Non-Blocking Receive• Parameters:
start address for storing received data,number of elements, data type,rank of the source, tag (= 0, in most cases), communicator (= MPI_COMM_WORLD, in most cases),request
• request: 通信要求 Communication Request• この通信の完了を待つ際に用いる
Used for Waiting completion of this communication
• Example)MPI_Request req;...MPI_Irecv(a, 100, MPI_INT, 0, 0, MPI_COMM_WORLD, &req);...MPI_Wait(&req, &status);
5 55
Usage:int MPI_Irecv(void *b, int c, MPI_Datatype d, int src,
int t, MPI_Comm comm, MPI_Request *r);

MPI_Isend
• Non-Blocking Send• Parameters:
start address for sending data,number of elements, data type,rank of the destination, tag (= 0, in most cases), communicator (= MPI_COMM_WORLD, in most cases),request
• Example)MPI_Request req;...MPI_Isend(a, 100, MPI_INT, 1, 0, MPI_COMM_WORLD, &req);...MPI_Wait(&req, &status);
6 66
Usage:int MPI_Isend(void *b, int c, MPI_Datatype d,
int dest, int t, MPI_Comm comm,MPI_Request *r);

Non-Blocking Send?
• Blocking send (MPI_Send):送信データが別の場所にコピーされるのを待つWait for the data to be copied to somewhere else.• ネットワークにデータを送出し終わるか、一時的にデータのコピーを作成するまで。
Until completion of the data to be transferred to the networkor, until completion of the data to be copied to a temporal memory.
• Non-Blocking send (MPI_Isend):待たない
7

Notice: ノンブロッキング通信中はデータが不定Data is not sure in non-blocking communications
• MPI_Irecv:• 受信データの格納場所と指定した変数の値は MPI_Waitまで不定
Value of the variable specified for receiving data is not fixed before MPI_Wait
8
MPI_Irecv to A
...~ = A
...
MPI_Wait
10A
50A
arriveddata
50Value of A at herecan be 10 or 50
~ = AValue of A is 50

Notice: ノンブロッキング通信中はデータが不定Data is not sure in non-blocking communications
• MPI_Isend:• 送信データを格納した変数を MPI_Waitより前に書き換えると、実際に送信される値は不定If the variable that stored the data to be sent is modified before MPI_Wait, the value to be actually sent is unpredictable.
9
MPI_Isend A
...A = 50...
MPI_Wait
10A
50A data sent
10 or 50
A = 100
Modifying value of A here causes incorrect communication
You can modify value of A at here without any problem

MPI_Wait
• ノンブロッキング通信(MPI_Isend、 MPI_Irecv)の完了を待つ。Wait for the completion of MPI_Isend or MPI_Irecv
• 送信データの書き換えや受信データの参照が行えるMake sure that sending data can be modified,or receiving data can be referred.
• Parameters:request, status
• status:MPI_Irecv 完了時に受信データの statusを格納The status of the received data is stored at the completion of
MPI_Irecv
10
Usage:int MPI_Wait(MPI_Request *req, MPI_Status *stat);

MPI_Waitall
• 指定した数のノンブロッキング通信の完了を待つWait for the completion of specified number of non-blocking communications
• Parameters:count, requests, statuses
• count:ノンブロッキング通信の数The number of non-blocking communications
• requests, statuses:少なくとも count個の要素を持つ MPI_Request と MPI_Statusの配列Arrays of MPI_Request or MPI_Status that consists at least 'count' number of elements.
11
Usage:int MPI_Waitall(int c,
MPI_Request *requests, MPI_Status *statuses);

Today's Topic
• ノンブロッキング通信Non-Blocking Communication• 通信の完了を待つ間に他の処理を行う
Execute other instructions while waiting for the completion of a communication.
• 集団通信関数の実装Implementation of collective communications
• MPIプログラムの時間計測Measuring execution time of MPI programs
• デッドロック Deadlock
12

集団通信関数の中身Inside of the functions of collective communications
• 通常,集団通信関数は,MPI_Send, MPI_Recv, MPI_Isend, MPI_Irecv
等の一対一通信で実装されるUsually, functions of collective communications are implemented by using message passing functions.
13

Inside of MPI_Bcast
• One of the most simple implementations
14
int MPI_Bcast(char *a, int c, MPI_Datatype d, int root, MPI_Comm comm)
{int i, myid, procs;MPI_Status st;
MPI_Comm_rank(comm, &myid);MPI_Comm_size(comm, &procs);if (myid == root){
for (i = 0; i < procs)if (i != root)MPI_Send(a, c, d, i, 0, comm);
} else{MPI_Recv(a, c, d, root, 0, comm, &st);
}return 0;
}

Another implementation: With MPI_Isend
15
int MPI_Bcast(char *a, int c, MPI_Datatype d, int root, MPI_Comm comm)
{int i, myid, procs, cntr;MPI_Status st, *stats;MPI_Request *reqs;MPI_Comm_rank(comm, &myid);MPI_Comm_rank(comm, &procs);if (myid == root){stats = (MPI_Status *)malloc(sizeof(MPI_Status)*procs);reqs = (MPI_Request *)malloc(sizeof(MPI_Request)*procs);cntr = 0;for (i = 0; i < procs)if (i != root)MPI_Isend(a, c, d, i, 0, comm, &(reqs[cntr++]));
MPI_Waitall(procs-1, reqs, stats);free(stats);free(reqs);
} else{MPI_Recv(a, c, d, root, 0, comm, &st);
}return 0;
}
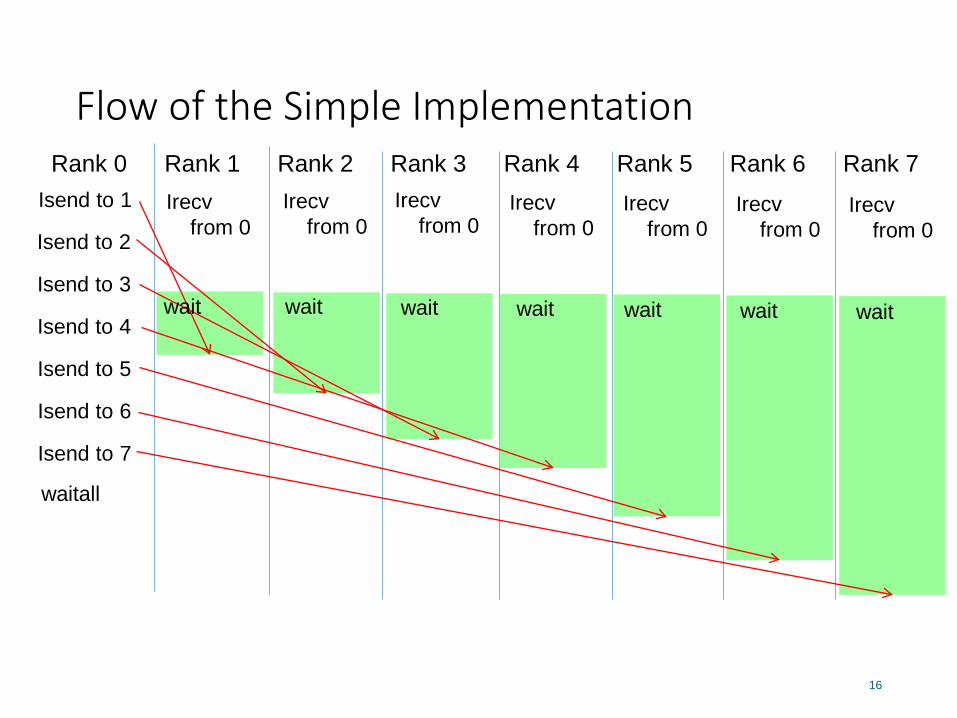
Flow of the Simple Implementation
16
Rank 0 Rank 1 Rank 2 Rank 3 Rank 4 Rank 5 Rank 6 Rank 7Isend to 1 Irecv
from 0Isend to 2
Irecvfrom 0
Irecvfrom 0
Irecvfrom 0
Irecvfrom 0
Irecvfrom 0
Irecvfrom 0
wait wait wait wait wait waitIsend to 3
Isend to 4
Isend to 5
Isend to 6
Isend to 7
wait
waitall
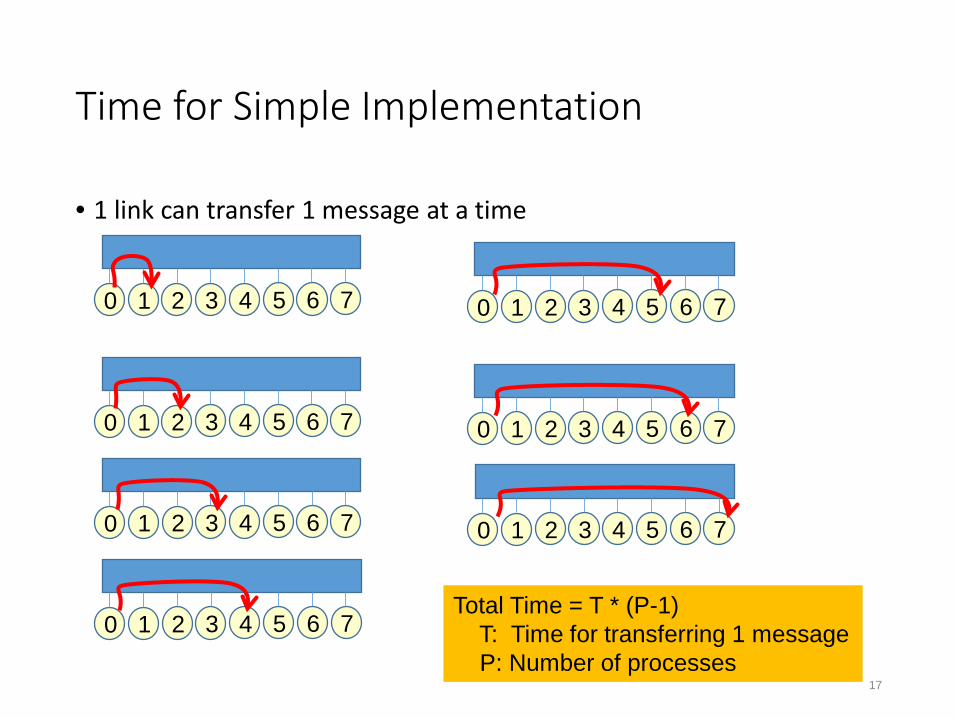
Time for Simple Implementation
• 1 link can transfer 1 message at a time
17
0 1 2 3 4 5 6 7
0 1 2 3 4 5 6 7
0 1 2 3 4 5 6 7
0 1 2 3 4 5 6 7
0 1 2 3 4 5 6 7
0 1 2 3 4 5 6 7
0 1 2 3 4 5 6 7
Total Time = T * (P-1) T: Time for transferring 1 messageP: Number of processes

Another implementation: Binomial Tree
18
int MPI_Bcast(char *a, int c, MPI_Datatype d,int root, MPI_Comm comm)
{int i, myid, procs;MPI_Status st;int mask, relative_rank, src, dst;int tag = 1, success = 0;
MPI_Comm_rank(comm, &myid);MPI_Comm_rank(comm, &procs);relative_rank = myid - root;if (relative_rank < 0)
relative_rank += procs;mask = 1;while (mask < num_procs){
if (relative_rank & mask){src = myid - mask;if (src < 0) src += procs;MPI_Recv(a, c, d, src, 0, comm, &st);break;
}mask <<= 1;
}
mask >>= 1;while (mask > 0){
if (relative_rank + mask < procs){dst = myid + mask;if (dst >= procs) dst -= procs;MPI_Send (a, c, d, dst, 0, comm);
}mask >>= 1;
}return 0;
}

Flow of Binomial Tree
• Use 'mask' to determine when and how to Send/Recv
19
Rank 0 Rank 1 Rank 2 Rank 3 Rank 4 Rank 5 Rank 6 Rank 7
mask = 1mask = 2mask = 4mask = 4
mask = 2
mask = 1
Send to 4
Send to 2
Send to 1
mask = 1Recv
from 0
mask = 1mask = 2
mask = 1mask = 2mask = 4
mask = 1mask = 2mask = 1
Recvfrom 2
mask = 1Recv
from 4
mask = 1Recv
from 6Recvfrom 0 Recv
from 0
Recvfrom 4
mask = 1Send to 3
mask = 2Send to 6
mask = 1Send to 7
mask = 1Send to 5
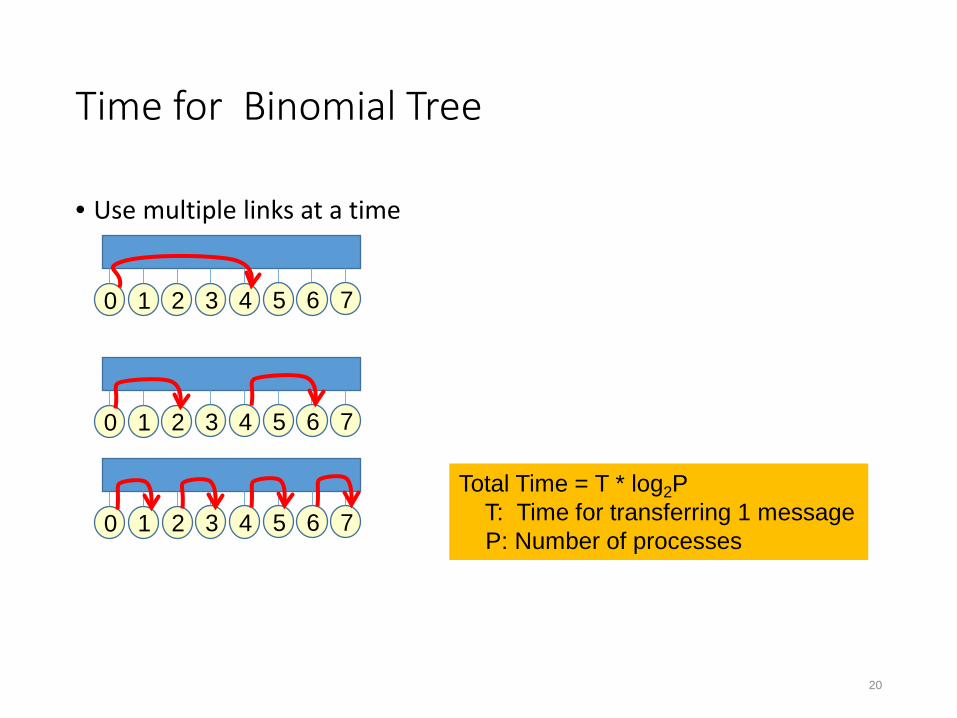
Time for Binomial Tree
• Use multiple links at a time
20
0 1 2 3 4 5 6 7
0 1 2 3 4 5 6 7
0 1 2 3 4 5 6 7Total Time = T * log2P
T: Time for transferring 1 messageP: Number of processes

Today's Topic
• ノンブロッキング通信Non-Blocking Communication• 通信の完了を待つ間に他の処理を行う
Execute other instructions while waiting for the completion of a communication.
• 集団通信関数の実装Implementation of collective communications
• MPIプログラムの時間計測Measuring execution time of MPI programs
• デッドロック Deadlock
21

MPIプログラムの時間計測Measure the time of MPI programs
• MPI_Wtime• 現在時間(秒)を実数で返す関数 Returns the current time in seconds.• Example)
Measuretime here
...double t1, t2; ...t1 = MPI_Wtime();処理t2 = MPI_Wtime();
printf("Elapsed time: %e sec.¥n", t2 – t1);

並列プログラムにおける時間計測の問題Problem on measuring time in parallel programs
• プロセス毎に違う時間を測定:どの時間が本当の所要時間か?
Each process measures different time. Which time is the time we want?
23
Read
Read
Send
Read
Send
Rank 0
ReceiveReceive
Rank 1Rank 2
t1 = MPI_Wtime();
t1 = MPI_Wtime();
t1 = MPI_Wtime();
t1 = MPI_Wtime();
t1 = MPI_Wtime();
t1 = MPI_Wtime();
Measuretime here

集団通信 MPI_Barrierを使った解決策Use MPI_Barrier
• 時間計測前にMPI_Barrierで同期Synchronize processes before each measurement• For measuring total execution time.
24
Read
Read
Send
Read
Send
Rank 0
Receive Receive
Rank 1Rank 2
t1 = MPI_Wtime();
t1 = MPI_Wtime();
MPI_BarrierMPI_Barrier MPI_Barrier
MPI_Barrier
MPI_BarrierMPI_Barrier
Measuretime here

より細かい解析Detailed analysis
• Average• MPI_Reduce can be used to achieve the average:
• MAX and MIN• Use MPI_Gather to gather all of the results to Rank 0.• Let Rank 0 to find MAX and MIN
25
double t1, t2, t, total;
t1 = MPI_Wtime();...
t2 = MPI_Wtime();t = t2 – t1;MPI_Reduce(&t, &total, 1, MPI_DOUBLE, MPI_SUM,
0, MPI_COMM_WORLD);if (myrank == 0)printf("Ave. elapsed: %e sec.¥n", total/procs);

最大(Max)、平均(Ave)、最小(Min)の関係Relationships among Max, Ave and Min
• プロセス毎の負荷(仕事量)のばらつき検証に利用Can be used for checking the load-balance.
26
Max – Aveis large
Max – Ave is small
Ave – Min is large
NG Mostly OK
Ave – Min is small
NG OK
Time includes Computation Time and Communication Time

通信時間の計測Measuring time for communications
27
double t1, t2, t3, t4 comm=0;t3 = MPI_Wtime();for (i = 0; i < N; i++){
computationt1 = MPI_Wtime();communicationt2 = MPI_Wtime(); comm += t2 – t1;computationt1 = MPI_Wtime();communicationt2 = MPI_Wtime(); comm += t2 – t1;
}t4 = MPI_Wtime();

Analyze computation time
• Computation time = Total time - Communication time• Or, just measure the computation time
• 計算時間のばらつき = 負荷の不均衡の度合いBalance of computation time shows balance of the amount of computation
• 注意: 通信時間には、負荷の不均衡によって生じた待ち時間が含まれるので、単純な評価は難しいCommunication time is difficult to analyze sinceit consists waiting time caused by load-imbalance.==> Balance computation first.
28

Today's Topic
• ノンブロッキング通信Non-Blocking Communication• 通信の完了を待つ間に他の処理を行う
Execute other instructions while waiting for the completion of a communication.
• 集団通信関数の実装Implementation of collective communications
• MPIプログラムの時間計測Measuring execution time of MPI programs
• デッドロック Deadlock
29

Deadlock • 何らかの理由で、プログラムを進行させることができなくなった状態
A status of a program in which it cannot proceed by some reasons.
• MPIプログラムでデッドロックが発生しやすい場所:Places you need to be careful for deadlocks:1. MPI_Recv, MPI_Wait, MPI_Waitall
2. Collective communications全部のプロセスが同じ集団通信関数を実行するまで先に進めないA program cannot proceed until all processes callthe same collective communication function
if (myid == 0){MPI_Recv from rank 1MPI_Send to rank 1
}if (myid == 1){
MPI_Recv from rank 0MPI_Send to rank 0
}
if (myid == 0){MPI_Irecv from rank 1MPI_Send to rank 1MPI_Wait
}if (myid == 1){
MPI_Irecv from rank 0MPI_Send to rank 0MPI_Wait
}
Wrong case: One solution:use MPI_Irecv

Summary • ノンブロッキング通信の効果
Effect of non-blocking communication• 通信開始と通信完了待ちを分離
Split the start and the completion of a communication• 通信と計算のオーバラップを可能にする
Enable overlapping of communication and computation .
• 集団通信の実装Implementation of collective communication.
• 内部で送信と受信を組み合わせて実装Construct algorithms with sends and receives.
• 所要時間はアルゴリズムに依存Time depends on the algorithm.
• MPIプログラムの時間計測Measuring execution time of MPI programs
• 並列プログラムではデッドロックに注意Be careful about deadlocks.
31

Report) Make Reduce function by yourself
• 次のページのプログラムの my_reduce関数の中身を追加してプログラムを完成させるFill the inside of 'my_reduce' function in the programshown in the next slide
• my_reduce: MPI_Reduceの簡略版Simplified version of MPI_Reduce• 整数の総和のみ. ルートランクは 0限定.コミュニケータは MPI_COMM_WORLDCalculates total sum of integer numbers. The root rank is always 0.The communicator is always MPI_COMM_WORLD.
• アルゴリズムは好きなものを考えてよいAny algorithm is OK.
32

33
#include <stdio.h>#include <stdlib.h>#include "mpi.h"#define N 20int my_reduce(int *a, int *b, int c){
return 0;}
int main(int argc, char *argv[]){
int i, myid, procs;int a[N], b[N];
MPI_Init(&argc, &argv);MPI_Comm_rank(MPI_COMM_WORLD, &myid);MPI_Comm_size(MPI_COMM_WORLD, &procs);for (i = 0; i < N; i++){
a[i] = i;b[i] = 0;
}my_reduce(a, b, N);if (myid == 0)
for (i = 0; i < N; i++)printf("b[%d] = %d , correct answer = %d¥n", i, b[i], i*procs);
MPI_Finalize();return 0;
}
complete here by yourself