parallel filter-based feature selection based on balanced incomplete block designs (ecai2016)
TRANSCRIPT

Parallel Filter-Based Feature SelectionBased on Balanced Incomplete Block
Designs
Antonio Salmerón1, Anders L. Madsen2,3, Frank Jensen2,Helge Langseth4, Thomas D. Nielsen3, Darío Ramos-López1,
Ana M. Martínez3, Andrés R. Masegosa4
1Department of Mathematics, University of Almería, Spain2 Hugin Expert A/S, Aalborg, Denmark
3Department of Computer Science, Aalborg University, Denmark4 Department of Computer and Information Science,
The Norwegian University of Science and Technology, Norway
22nd European Conference on Artificial Inteligence, The Hague, 1st September 2016 1

The AMIDST Toolbox for probabilisticmachine learning
You can download our open source Java toolbox:
http://www.amidsttoolbox.com
Software demonstration today at 12in the Lobby!
22nd European Conference on Artificial Inteligence, The Hague, 1st September 2016 2

Outline
1 Motivation
2 Preliminaries
3 Scaling up filter-based feature selection
4 Experimental results
5 Conclusions
22nd European Conference on Artificial Inteligence, The Hague, 1st September 2016 3

Outline
1 Motivation
2 Preliminaries
3 Scaling up filter-based feature selection
4 Experimental results
5 Conclusions
22nd European Conference on Artificial Inteligence, The Hague, 1st September 2016 4

Feature Selection Approaches
Before learning a classification model, a key step is choosing themost informative variables, and excluding the redundant ones. Agood feature selection prevents overfitting and reduces thecomputational load of the learning process.
Main groups of feature selection methods:I Wrapper: normally requiring a model fit for each subset of
variables (time consuming).I Embedded methods: also model-dependent, guided by some
specific property of the model.I Filter: independent from the model, usually features are
ranked according to a univariate score (less computationalcomplexity).
22nd European Conference on Artificial Inteligence, The Hague, 1st September 2016 5

Our proposal
We propose an algorithm for scaling up filter-based featureselection in classification problems, such that:
I It makes use of conditional mutual information as filtermeasure.
I It parallelize the workload while avoiding unnecessarycalculations.
I It uses the balanced incomplete blocks (BIB) designs to reducedisk access and to distribute the calculations.
I It is able to significantly reduce the computational load in amulti-core shared-memory environment.
22nd European Conference on Artificial Inteligence, The Hague, 1st September 2016 6

Outline
1 Motivation
2 Preliminaries
3 Scaling up filter-based feature selection
4 Experimental results
5 Conclusions
22nd European Conference on Artificial Inteligence, The Hague, 1st September 2016 7

Entropy and Conditional Entropy
X = X1, . . . ,Xn: discrete variables; C : the class variable.
Entropy of X ∈ X :
H(X ) = −∑x∈ΩX
p(x) log p(x)
(uncertainty in the distribution of X )
Conditional entropy of Xi given Xj :
H(Xi |Xj) = −∑
xj∈ΩXj
p(xj)∑
xi∈ΩXi
p(xi |xj) log p(xi |xj)
(remaining uncertainty in the distribution of Xi after observing Xj)
22nd European Conference on Artificial Inteligence, The Hague, 1st September 2016 8

Mutual Information
Mutual Information of Xi and Xj :
I (Xi ,Xj) = H(Xi )− H(Xi |Xj)
(amount of information shared by two variables)The mutual information is symmetric: I (Xi ,Xj) = I (Xj ,Xi )
Conditional Mutual Information between Xi and Xj given Xk :
I (Xi ,Xj |Xk) = H(Xi |Xk)− H(Xi |Xj ,Xk).
(amount of information shared by two variables, given a third one)
22nd European Conference on Artificial Inteligence, The Hague, 1st September 2016 9

Information Theoretic Filter Methods
Information-theoretic filter methods have been analyzed using theconditional likelihood:
L(S , τ |D) =n∏
i=1
q(c i |x i , τ ),
S : features included in the model,τ : parameters of the distributions involved in the model,D: a dataset, D = (x i , c i ), i = 1, . . . , nq: the learnt model
The conditional likelihood is maximized by minimizingI (X \ S ,C |S) (the mutual information between the class and thefeatures not included in the model, given the variables actuallyincluded).
22nd European Conference on Artificial Inteligence, The Hague, 1st September 2016 10

Filter measures
We shall make this technical assumption:For Xi ,Xj ∈ S , Xk ∈ X \ S , it holds that Xi and Xj areconditionally independent both when conditioning on Xk and onXk ,C.
This allows us to select features greedily, using as a filter measurethe following quantity based on the conditional mutual information(cmi):
Jcmi(Xi ) = I (Xi ,C |S) = I (Xi ,C )−∑Xj∈S
(I (Xi ,Xj)− I (Xi ,Xj |C )
),
where Xi is the candidate variable to include in the model.
22nd European Conference on Artificial Inteligence, The Hague, 1st September 2016 11

Filter measures
Another remarkable filter measure is the joint mutual information(jmi) that is defined as:
Jjmi(Xi ) =∑Xj∈S
I (Xi ,Xj,C ) =
= I (Xi ,C )− 1|S |
∑Xj∈S
(I (Xi ,Xj)− I (Xi ,Xj |C )
),
According to the literature, Jjmi is the metric showing the bestaccuracy/stability tradeoff, and is therefore the one we utilize in thefollowing.
22nd European Conference on Artificial Inteligence, The Hague, 1st September 2016 12

Outline
1 Motivation
2 Preliminaries
3 Scaling up filter-based feature selection
4 Experimental results
5 Conclusions
22nd European Conference on Artificial Inteligence, The Hague, 1st September 2016 13

Filter-based feature selection algorithm
1 Function Filter(X ,C ,M)Input: The set of features, X = X1, . . . ,XN. The class
variable, C . The maximum number of features to beselected, M.
Output: S , a set of selected features.2 begin3 for i ← 1 to N do
4 Compute I (Xi ,C );
5 for j ← i + 1 to N do6 Compute I (Xi ,Xj |C );
7 Compute I (Xi ,Xj);8 end9 end
10 X ∗ ← argmax1≤i≤N I (Xi ,C );11 S ← X ∗;12 for i ← 1 to M − 1 do
13 R ← X \ S ;14 for X ∈ R do15 Compute Jjmi(X ) using the statistics computed
in Steps 4, 6, and 7;16 end17 X ∗ ← argmaxX∈R Jjmi(X );18 S ← S ∪ X ∗;19 end
20 return S ;21 end
22nd European Conference on Artificial Inteligence, The Hague, 1st September 2016 14

Optimizing the calculation of the scores
To compute all the necessary information theory scores, onepossibility is to create a thread for each pair of features. However,for n variables, this requires accessing the dataset
(n2
)times,
inducing a significant overhead due to disk/network access.
We propose making groups of variables (blocks), each of which willonly access the dataset a single time.
To do this, two key issues:I Finding an appropriate block size.I Ensure that every pair of variables appears in exactly one block
(to avoid duplicated calculations).
22nd European Conference on Artificial Inteligence, The Hague, 1st September 2016 15

Balanced incomplete block (BIB) designs
What we seek can be done by using Balanced Incomplete Block(BIB) designs.
Given a set of variables X , we will say (X ,A) is a design if A is acollection of non-empty subsets of X (blocks).
A design is a (v , k , λ)-BIB design if:I v = |X | is the number of variables in X .I each block in A contains exactly k variables.I every pair of distinct variables is contained in exactly λ blocks.
We have found that (q, 6, 1)-BIB designs (blocks of 6 variables) areappropriate for practical use.
22nd European Conference on Artificial Inteligence, The Hague, 1st September 2016 16

Balanced incomplete block (BIB) designs
Some considerations about BIB designs:I A (v , k , λ)-BIB might not exist, for some combinations of the
parameters.I Finding a BIB design is a NP-complete problem.I To efficiently use BIB designs, we have pre-calculated a
number of them, and those are utilized on run-time.I BIB designs can be generated from difference sets, avoiding
the need of storing the full design.
Check the paper for more details on this!
22nd European Conference on Artificial Inteligence, The Hague, 1st September 2016 17

Example of BIB designs
Figure 1: Example illustrating the use of (q, 6, 1) and (3, 2, 1) designs.
22nd European Conference on Artificial Inteligence, The Hague, 1st September 2016 18

Outline
1 Motivation
2 Preliminaries
3 Scaling up filter-based feature selection
4 Experimental results
5 Conclusions
22nd European Conference on Artificial Inteligence, The Hague, 1st September 2016 19

Experimental setup
I Goal: empirical evaluation of the time performanceimprovement using BIB designs.
I Shared memory computer with multiple cores: Intel (TM)i7-5820K 3.3GHz processor (6 physical and 12 logical cores),with 64 GB RAM, running Red Hat Enterprise Linux 7.
I Time measurements: averaged over 10 runs with each dataset,elapsed (wall-clock) time.
I Datasets: randomly simulated from well-known Bayesiannetworks, and a real-world dataset from a Spanish bank.
22nd European Conference on Artificial Inteligence, The Hague, 1st September 2016 20
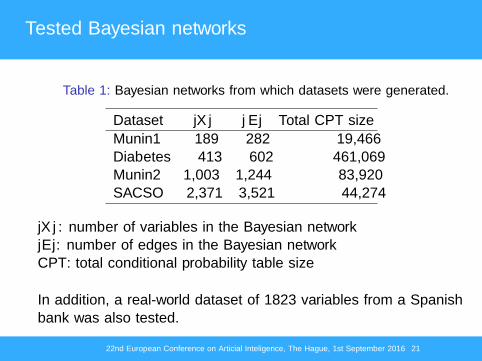
Tested Bayesian networks
Table 1: Bayesian networks from which datasets were generated.
Dataset |X | |E | Total CPT sizeMunin1 189 282 19,466Diabetes 413 602 461,069Munin2 1,003 1,244 83,920SACSO 2,371 3,521 44,274
|X |: number of variables in the Bayesian network|E |: number of edges in the Bayesian networkCPT: total conditional probability table size
In addition, a real-world dataset of 1823 variables from a Spanishbank was also tested.
22nd European Conference on Artificial Inteligence, The Hague, 1st September 2016 21

Speed-up for Munin1 datasets
100.000 cases
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
0 2 4 6 8 10 12
0
0.5
1
1.5
2
2.5
3
3.5
4
4.5
Aver
age
run t
ime
in s
econds
Aver
age
spee
d-u
p f
acto
r
Number of threads
Time
Speed-up
250.000 cases
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
1.8
0 2 4 6 8 10 12
0
0.5
1
1.5
2
2.5
3
3.5
4
4.5
5
Aver
age
run t
ime
in s
econds
Aver
age
spee
d-u
p f
acto
r
Number of threads
Time
Speed-up
500.000 cases
0
0.5
1
1.5
2
2.5
3
0 2 4 6 8 10 12
0
0.5
1
1.5
2
2.5
3
3.5
4
4.5
5
Aver
age
run t
ime
in s
econds
Aver
age
spee
d-u
p f
acto
r
Number of threads
Time
Speed-up
22nd European Conference on Artificial Inteligence, The Hague, 1st September 2016 22

Speed-up for Munin2 datasets
100.000 cases
0
5
10
15
20
25
30
35
40
45
0 2 4 6 8 10 12
0
1
2
3
4
5
6
Aver
age
run t
ime
in s
econds
Aver
age
spee
d-u
p f
acto
r
Number of threads
Time
Speed-up
250.000 cases
0
10
20
30
40
50
60
70
0 2 4 6 8 10 12
0
0.5
1
1.5
2
2.5
3
3.5
4
Aver
age
run t
ime
in s
econds
Aver
age
spee
d-u
p f
acto
r
Number of threads
Time
Speed-up
500.000 cases
0
20
40
60
80
100
120
0 2 4 6 8 10 12
0
1
2
3
4
5
6
7
Aver
age
run t
ime
in s
econds
Aver
age
spee
d-u
p f
acto
r
Number of threads
Time
Speed-up
22nd European Conference on Artificial Inteligence, The Hague, 1st September 2016 23

Speed-up for SACSO datasets
250.000 cases
0
50
100
150
200
250
300
350
0 2 4 6 8 10 12
0
1
2
3
4
5
6
Aver
age
run t
ime
in s
econds
Aver
age
spee
d-u
p f
acto
r
Number of threads
Time
Speed-up
500.000 cases
0
100
200
300
400
500
600
700
800
0 2 4 6 8 10 12
0
1
2
3
4
5
6
Aver
age
run t
ime
in s
econds
Aver
age
spee
d-u
p f
acto
r
Number of threads
Time
Speed-up
22nd European Conference on Artificial Inteligence, The Hague, 1st September 2016 24

Speed-up for Diabetes datasets
100k cases
0
100
200
300
400
500
600
700
0 2 4 6 8 10 12
0
0.5
1
1.5
2
2.5
3
3.5
4A
ver
age
run
tim
e in
sec
on
ds
Av
erag
e sp
eed
-up
fac
tor
Number of threads
Time
Speed-up
22nd European Conference on Artificial Inteligence, The Hague, 1st September 2016 25
Speed-up for Bank datasets
100k cases
0
10
20
30
40
50
60
70
80
0 2 4 6 8 10 12
0
1
2
3
4
5
6
Aver
age
run t
ime
in s
econds
Aver
age
spee
d-u
p f
acto
r
Number of threads
Time
Speed-up
250k cases
0
20
40
60
80
100
120
140
160
0 2 4 6 8 10 12
0
1
2
3
4
5
6
7
Aver
age
run t
ime
in s
econds
Aver
age
spee
d-u
p f
acto
r
Number of threads
Time
Speed-up
500k cases
0
50
100
150
200
250
300
0 2 4 6 8 10 12
0
1
2
3
4
5
6
7
Aver
age
run t
ime
in s
econds
Aver
age
spee
d-u
p f
acto
r
Number of threads
Time
Speed-up
22nd European Conference on Artificial Inteligence, The Hague, 1st September 2016 26

Impact of using the (q, 6, 1)-BIB designs
Bank dataset
100k cases with BIB designs
0
10
20
30
40
50
60
70
80
0 2 4 6 8 10 12
0
1
2
3
4
5
6
Aver
age
run t
ime
in s
econds
Aver
age
spee
d-u
p f
acto
r
Number of threads
Time
Speed-up
100k cases, using pairs directly
0
50
100
150
200
250
300
0 2 4 6 8 10 12
0
1
2
3
4
5
6
Aver
age
run t
ime
in s
econds
Aver
age
spee
d-u
p f
acto
r
Number of threads
Time
Speed-up
22nd European Conference on Artificial Inteligence, The Hague, 1st September 2016 27

Outline
1 Motivation
2 Preliminaries
3 Scaling up filter-based feature selection
4 Experimental results
5 Conclusions
22nd European Conference on Artificial Inteligence, The Hague, 1st September 2016 28

Conclusions
I A parallel filter-based feature selection algorithm has beenproposed.
I It makes use of information theoretic measures (conditionalmutual information) for filtering.
I Also, a two-steps Balanced Incomplete Blocks (BIB) designhas been used to distribute and optimize the computationsasynchronously ((q, 6, 1) and then (3, 2, 1)).
I For variables with a large number of states, it might bepreferable to skip the first step (Diabetes).
I The performance improvement when using (q, 6, 1) designs isin most cases substantial.
I Speed-up factors of about 4-6 were obtained running on a 6physical cores computer.
22nd European Conference on Artificial Inteligence, The Hague, 1st September 2016 29

Future work
I Horizontal parallelization: each computing unit holding only asubset of the data over all variables.
I This will support parallelization on a distributed memorysystem.
22nd European Conference on Artificial Inteligence, The Hague, 1st September 2016 30

Thank you for your attentionYou can download our open source Java toolbox:
http://www.amidsttoolbox.com
Acknowledgments: This project has received funding from the European Union’sSeventh Framework Programme for research, technological development and
demonstration under grant agreement no 619209
22nd European Conference on Artificial Inteligence, The Hague, 1st September 2016 31