papers we love january 2015 - flat datacenter storage
TRANSCRIPT

Flat Datacenter Storage
Presented by Alex Rasmussen Papers We Love SF #11
2015-01-22
Edmund B. Nightingale, Jeremy Elson, Jinliang Fan, Owen Hofmann, Jon Howell, and Yutaka Suzue

@alexras

Sort Really Fast
THEMISMapReduce Really Fast

Image Credit: http://bit.ly/17Vf8Hb

A Perfect World

“Magic RAID”



The Real World


Move the Computation to
the Data!

Location Awareness
Adds Complexity

Why “Move the
Computation to the Data”?

Remote Data Access is Slow.
Why?

The Network is Oversubscribed

Core
Aggregation
Edge
Figure 1: Common data center interconnect topology. Host to switch links are GigE and links between switches are 10 GigE.
0
5
10
15
20
25
30
35
40
1000 10000
Estim
ated
cos
t (U
SD m
illio
ns)
Number of hosts
1:13:17:1
Fat-tree
Figure 2: Current cost estimate vs. maximum possible numberof hosts for different oversubscription ratios.
We also include the cost to deliver an oversubscription of 1:1 usingour proposed fat-tree architecture for comparison.
Overall, we find that existing techniques for delivering high lev-els of bandwidth in large clusters incur significant cost and thatfat-tree based cluster interconnects hold significant promise for de-livering scalable bandwidth at moderate cost. However, in somesense, Figure 2 understates the difficulty and expense of employingthe highest-end components in building data center architectures.In 2008, 10 GigE switches are on the verge of becoming commod-ity parts; there is roughly a factor of 5 differential in price per portper bit/sec when comparing GigE to 10 GigE switches, and thisdifferential continues to shrink. To explore the historical trend,we show in Table 1 the cost of the largest cluster configurationthat could be supported using the highest-end switches availablein a particular year. We based these values on a historical study ofproduct announcements from various vendors of high-end 10 GigEswitches in 2002, 2004, 2006, and 2008.
We use our findings to build the largest cluster configuration thattechnology in that year could support while maintaining an over-subscription of 1:1. Table 1 shows the largest 10 GigE switch avail-able in a particular year; we employ these switches in the core andaggregation layers for the hierarchical design. Tables 1 also showsthe largest commodity GigE switch available in that year; we em-
Hierarchical design Fat-tree
Year 10 GigE Hosts Cost/ GigE Hosts Cost/GigE GigE
2002 28-port 4,480 $25.3K 28-port 5,488 $4.5K2004 32-port 7,680 $4.4K 48-port 27,648 $1.6K2006 64-port 10,240 $2.1K 48-port 27,648 $1.2K2008 128-port 20,480 $1.8K 48-port 27,648 $0.3K
Table 1: The maximum possible cluster size with an oversub-scription ratio of 1:1 for different years.
ploy these switches at all layers of the fat-tree and at the edge layerfor the hierarchical design.
The maximum cluster size supported by traditional techniquesemploying high-end switches has been limited by available portdensity until recently. Further, the high-end switches incurred pro-hibitive costs when 10 GigE switches were initially available. Notethat we are being somewhat generous with our calculations for tra-ditional hierarchies since commodity GigE switches at the aggre-gation layer did not have the necessary 10 GigE uplinks until quiterecently. Clusters based on fat-tree topologies on the other handscale well, with the total cost dropping more rapidly and earlier (asa result of following commodity pricing trends earlier). Also, thereis no requirement for higher-speed uplinks in the fat-tree topology.
Finally, it is interesting to note that, today, it is technically in-feasible to build a 27,648-node cluster with 10 Gbps bandwidthpotentially available among all nodes. On the other hand, a fat-tree switch architecture would leverage near-commodity 48-port 10GigE switches and incur a cost of over $690 million. While likelycost-prohibitive in most settings, the bottom line is that it is noteven possible to build such a configuration using traditional aggre-gation with high-end switches because today there is no product oreven Ethernet standard for switches faster than 10 GigE.
2.2 Clos Networks/Fat-TreesToday, the price differential between commodity and non-
commodity switches provides a strong incentive to build large-scalecommunication networks from many small commodity switchesrather than fewer larger and more expensive ones. More than fiftyyears ago, similar trends in telephone switches led Charles Clos todesign a network topology that delivers high levels of bandwidthfor many end devices by appropriately interconnecting smallercommodity switches [11].
65
Aggregate Bandwidth Above Less Than Aggregate Demand Below
Sometimes by 100x or more
A B

What if I told you the network isn’t oversubscribed?

Consequences• No local vs. remote disk distinction
• Simpler work schedulers
• Simpler programming models

FDS Object Storage
Assuming No Oversubscription

Motivation Architecture and API Metadata Management Replication and Recovery Data Transport Why FDS Matters


Blob 0xbadf00d
Tract 0 Tract 1 Tract 2 Tract n...
8 MB
CreateBlob OpenBlob CloseBlob DeleteBlob
GetBlobSize ExtendBlob ReadTract WriteTract

API Guarantees• Tractserver writes are atomic
• Calls are asynchronous
- Allows deep pipelining
• Weak consistency to clients

Motivation Architecture and API Metadata Management Replication and Recovery Data Transport Why FDS Matters

Tract Locator Version TS
1 0 A2 0 B3 2 D4 0 A5 3 C6 0 F... ... ...
Tract Locator Table

Tract_Locator = TLT[(Hash(GUID) + Tract) % len(TLT)]

Randomize blob’s tractserver, even if GUIDs aren’t random
(uses SHA-1)
Tract_Locator = TLT[(Hash(GUID) + Tract) % len(TLT)]

Large blobs use all TLT entries uniformly
Tract_Locator = TLT[(Hash(GUID) + Tract) % len(TLT)]

Blob Metadata is Distributed
Tract_Locator = TLT[(Hash(GUID) - 1) % len(TLT)]

TLT Construction• m Permutations of Tractserver List
• Weighted by disk speed
• Served by metadata server to clients
• Only update when cluster changes

Tract Locator Version TS
1 0 A2 0 B3 2 D4 0 A5 3 C6 0 F... ... ...
Cluster Growth

Tract Locator Version TS
1 1 NEW / A2 0 B3 2 D4 1 NEW / A5 4 NEW / C6 0 F... ... ...
Cluster Growth

Tract Locator Version TS
1 2 NEW2 0 A3 2 A4 2 NEW5 5 NEW6 0 A... ... ...
Cluster Growth

Motivation Architecture and API Metadata Management Replication and Recovery Data Transport Why FDS Matters

Tract Locator Version Replica 1 Replica 2 Replica 3
1 0 A B C2 0 A C Z3 0 A D H4 0 A E M5 0 A F G6 0 A G P... ... ... ... ...
Replication

Tract Locator Version Replica 1 Replica 2 Replica 3
1 0 A B C2 0 A C Z3 0 A D H4 0 A E M5 0 A F G6 0 A G P... ... ... ... ...
Replication

Replication• Create, Delete, Extend:
- client writes to primary
- primary 2PC to replicas
• Write to all replicas
• Read from random replica

Tract Locator Version Replica 1 Replica 2 Replica 3
1 0 A B C2 0 A C Z3 0 A D H4 0 A E M5 0 A F G6 0 A G P... ... ... ... ...
Recovery

Tract Locator Version Replica 1 Replica 2 Replica 3
1 0 A B C2 0 A C Z3 0 A D H4 0 A E M5 0 A F G6 0 A G P... ... ... ... ...
Recovery
Recover 1TB from 3000 disks in < 20 seconds
HEALME

MIND BLOWN

Motivation Architecture and API Metadata Management Replication and Recovery Data Transport Why FDS Matters

Networking
Pod 0
10.0.2.1
10.0.1.1
Pod 1 Pod 3Pod 210.2.0.2 10.2.0.3
10.2.0.1
10.4.1.1 10.4.1.2 10.4.2.1 10.4.2.2Core
10.2.2.1
10.0.1.2
Edge
Aggregation
Figure 3: Simple fat-tree topology. Using the two-level routing tables described in Section 3.3, packets from source 10.0.1.2 todestination 10.2.0.3 would take the dashed path.
Prefix10.2.0.0/2410.2.1.0/240.0.0.0/0
Output port01
Suffix0.0.0.2/80.0.0.3/8
Output port23
Figure 4: Two-level table example. This is the table at switch10.2.2.1. An incoming packet with destination IP address10.2.1.2 is forwarded on port 1, whereas a packet with desti-nation IP address 10.3.0.3 is forwarded on port 3.
than one first-level prefix. Whereas entries in the primary table areleft-handed (i.e., /m prefix masks of the form 1m032−m), entriesin the secondary tables are right-handed (i.e. /m suffix masks ofthe form 032−m1m). If the longest-matching prefix search yieldsa non-terminating prefix, then the longest-matching suffix in thesecondary table is found and used.
This two-level structure will slightly increase the routing tablelookup latency, but the parallel nature of prefix search in hardwareshould ensure only a marginal penalty (see below). This is helpedby the fact that these tables are meant to be very small. As shownbelow, the routing table of any pod switch will contain no morethan k/2 prefixes and k/2 suffixes.
3.4 Two-Level Lookup ImplementationWe now describe how the two-level lookup can be implemented
in hardware using Content-Addressable Memory (CAM) [9].CAMs are used in search-intensive applications and are fasterthan algorithmic approaches [15, 29] for finding a match againsta bit pattern. A CAM can perform parallel searches among allits entries in a single clock cycle. Lookup engines use a specialkind of CAM, called Ternary CAM (TCAM). A TCAM can storedon’t care bits in addition to matching 0’s and 1’s in particularpositions, making it suitable for storing variable length prefixes,such as the ones found in routing tables. On the downside, CAMshave rather low storage density, they are very power hungry, and
Next hop10.2.0.110.2.1.110.4.1.110.4.1.2
Address00011011
Output port0123
RAM
Encoder
10.2.0.X10.2.1.XX.X.X.2X.X.X.3
TCAM
Figure 5: TCAM two-level routing table implementation.
expensive per bit. However, in our architecture, routing tables canbe implemented in a TCAM of a relatively modest size (k entrieseach 32 bits wide).
Figure 5 shows our proposed implementation of the two-levellookup engine. A TCAM stores address prefixes and suffixes,which in turn indexes a RAM that stores the IP address of the nexthop and the output port. We store left-handed (prefix) entries innumerically smaller addresses and right-handed (suffix) entries inlarger addresses. We encode the output of the CAM so that theentry with the numerically smallest matching address is output.This satisfies the semantics of our specific application of two-levellookup: when the destination IP address of a packet matches both aleft-handed and a right-handed entry, then the left-handed entry ischosen. For example, using the routing table in Figure 5, a packetwith destination IP address 10.2.0.3 matches the left-handed entry10.2.0.X and the right-handed entry X.X.X.3. The packet iscorrectly forwarded on port 0. However, a packet with destinationIP address 10.3.1.2 matches only the right-handed entry X.X.X.2and is forwarded on port 2.
3.5 Routing AlgorithmThe first two levels of switches in a fat-tree act as filtering traf-
fic diffusers; the lower- and upper-layer switches in any given podhave terminating prefixes to the subnets in that pod. Hence, if ahost sends a packet to another host in the same pod but on a dif-ferent subnet, then all upper-level switches in that pod will have aterminating prefix pointing to the destination subnet’s switch.
For all other outgoing inter-pod traffic, the pod switches havea default /0 prefix with a secondary table matching host IDs (the
67
CLOS topology: small switches + ECMP = full bisection bandwidth

Networking• Network bandwidth = disk bandwidth
• Full bisection bandwidth is stochastic
• Short flows good for ECMP
• TCP hates short flows
• RTS/CTS to mitigate incast; see paper

Motivation Architecture and API Metadata Management Replication and Recovery Data Transport Why FDS Matters

Co-Design

Hardware/Software Combination Designed for a
Specific Workload

FDS Works Great for Blob Storage on CLOS Networks


Indy
Daytona

MinuteSort - DaytonaSystem!(Nodes) Year Data
SortedSpeed
per Disk
Hadoop (1408) 2009 500GB 3 MB/s
FDS (256) 2012 1470GB 46 MB/s
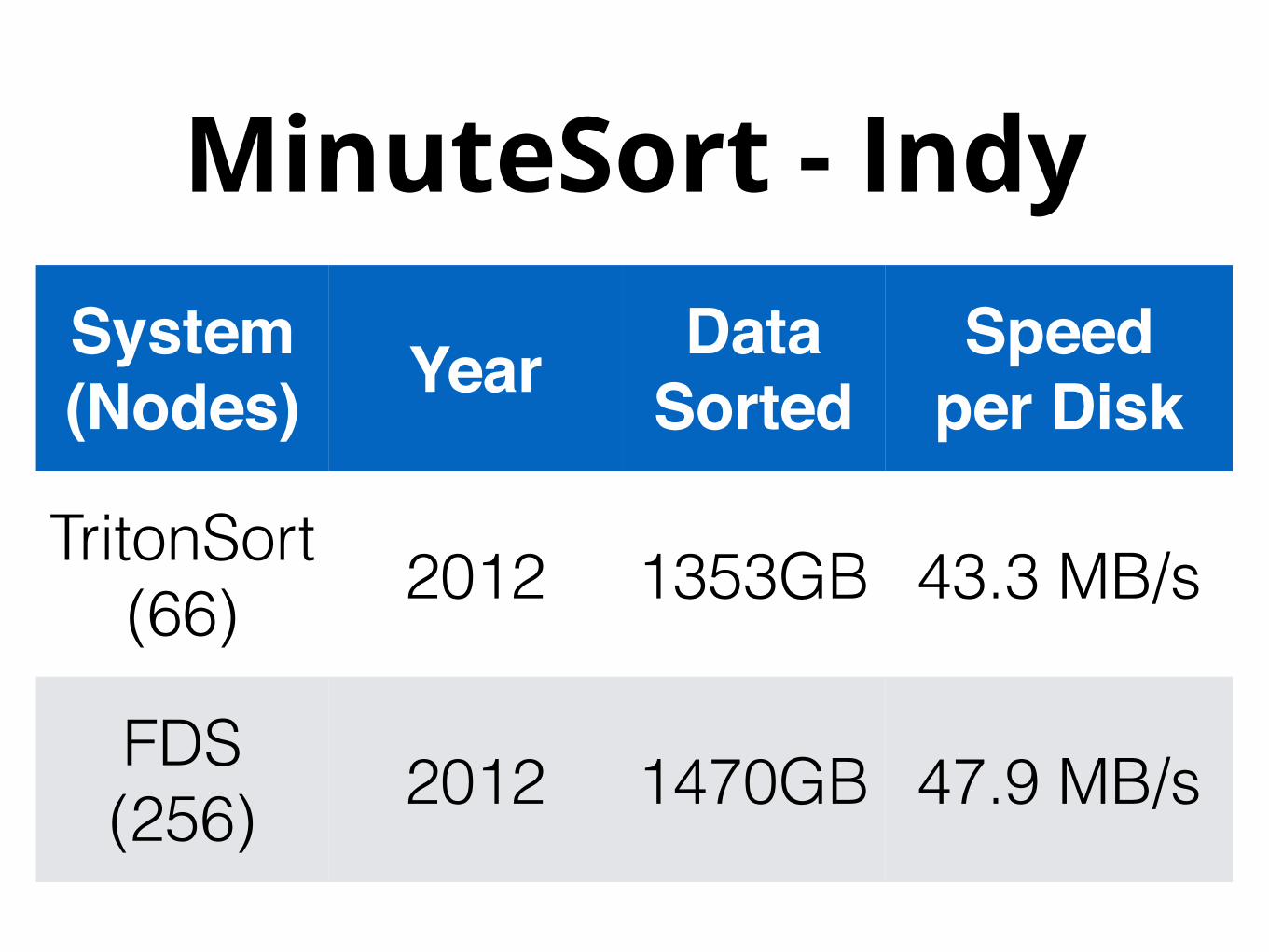
MinuteSort - IndySystem!(Nodes) Year Data
SortedSpeed
per Disk
TritonSort (66) 2012 1353GB 43.3 MB/s
FDS (256) 2012 1470GB 47.9 MB/s

FDS isn’t built for oversubscribed
networks. It’s also not a DBMS.

MapReduce and GFS: Thousands of
Cheap PCs, Bulk Synchronous
Processing

10x
MapReduce and GFS Aren’t Designed for
or Iterative, or OLAP

FDS’ Lessons• Great example of ground-up rethink
- Ambitious but implementable
• Big wins possible with co-design
• Constantly re-examine assumptions


TritonSort & Themis• Balanced hardware architecture
• Full bisection-bandwidth network
• Job-level fault tolerance
• Huge wins possible
- Beat 3000+ node cluster by 35% with 52 nodes
• NSDI 2012, SoCC 2013
