pal v5 combining modality specific deep neural networks ... · pdf fileaddional authors : lisa...
TRANSCRIPT

CombiningModalitySpecificDeepNeuralNetworksforEmo=onRecogni=oninVideoICMI2013,Emo-W2013GrandChallenge
SamiraEbrahimiKahou([email protected])
with:ChristopherPal,XavierBouthillier,PierreFroumenty,ÇaglarGülçehre,RolandMemisevic,PascalVincent,AaronCourville,YoshuaBengioand…
Sydney,Australia.December9‐13th,2013

Addi=onalAuthors:LISA‐UniversitédeMontréal:RaulChandiasFerrari,MehdiMirza,SébasQenJean,Pierre‐LucCarrier,YannDauphin,NicolasBoulanger‐Lewandowski,AbhishekAggarwal,JeremieZumer,PascalLamblin,Jean‐PhilippeRaymond,GuillaumeDesjardins,RazvanPascanu,DavidWarde‐Farley,AtousaTorabi,ArjunSharma,EmmanuelBengio,andMyriamCôté.GoetheUniversität‐Frankfurt:KishoreReddyKonda.McGillUniversity:ZhenzhouWu.
Acknowledgements:WethankNSERC,Ubiso_andtheGermanBMBF,project01GQ0841.

OurModelsandCombinaQonTechniques
Models1. FacesandConvoluQonalNetwork#1
YieldshigherperformanceonthechallengevalidaQonset2. FacesandConvoluQonalNetwork#23. DeepRestrictedBoltzmannmachinebasedaudiomodel4. DeepAuto‐encoderbasedtechniqueforacQvityrecogniQon5. Shallowneuralnetworkmodelbasedonbagofmouthfeatures
CombiningModels1. SVMcombinaQonofmodels2. FlatAveragingofModels3. WeightedAveragesobtainedviaRandomSearch
ResultsThechallengebaseline:27.56%AccuracyOurbestsinglemodel:35.6%Ourbestsubmission:41.03%
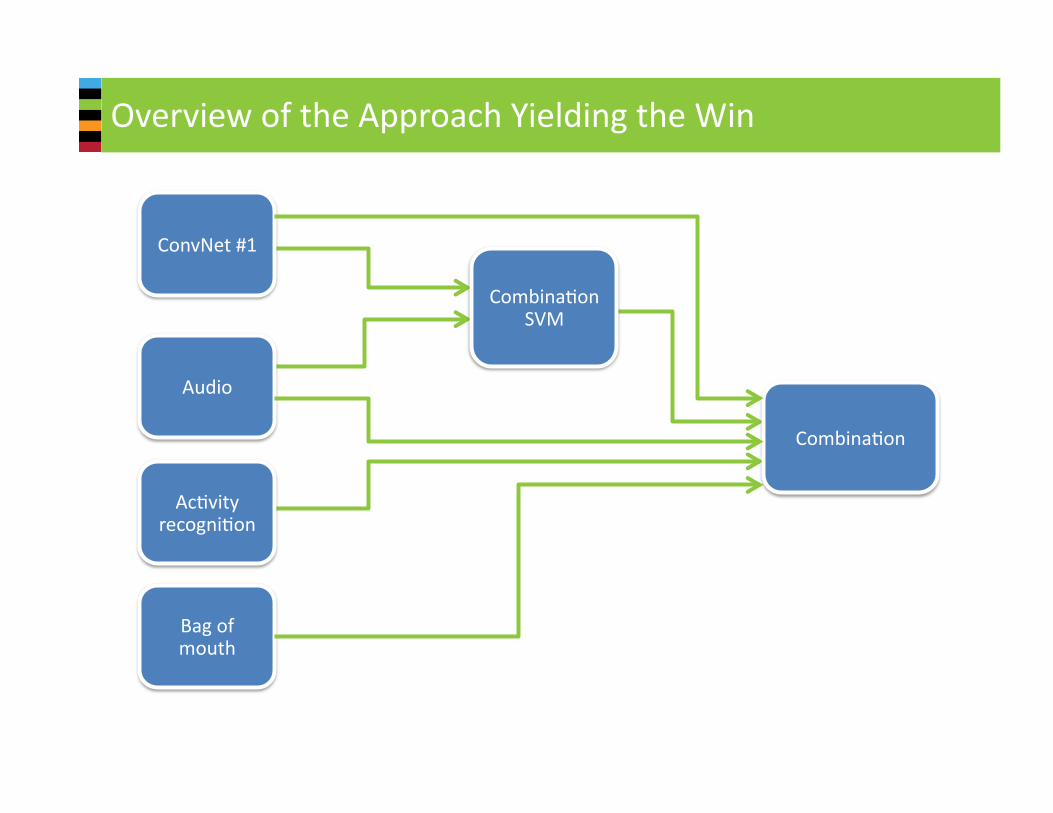
OverviewoftheApproachYieldingtheWin
Bagofmouth
CombinaQon
AcQvityrecogniQon
Audio
ConvNet#1
CombinaQonSVM

Train:45.834.058.296.3100.0Valid:38.130.829.330.125.5Test:35.6
CN#1CN#2AudioBoMAct.Rec.
ComparingModelswithConfusionMatrices
• ConvoluQonalnetworkshavesimilarerrorprofiles• NoQcedifferenterrorprofilesforothermodelclasses• TriedusingMLPsandSVMstocombineallmodels,buttheyoverfit(QuesQon:Why?)

CombiningModels
CN#1&Audio
Train:71.897.192.4
Valid:42.240.149.5Test:38.537.141.0
All,averagedRandomsearch,weightedavg.
• BoMandAcQvityrecogniQontechniquesoverfitthedata• Challenge:HowcouldweexploitallthemeaningfulinformaQonprovidedbyallmodels(includingoverfisers)

FacesandConvoluQonalNetwork#1
TheConvoluQonalneuralnetworkarchitecture:
• BasedontheC++andCudaimplementaQonofKrizhevskyetal• Inputsareimagesofsize40x40,croppedrandomly• Fourlayers,3convoluQonsfollowedbymaxoraveragepooling
andafully‐connectedlayer

WhyareDeepNeuralNetworkssoHot?
• TopresultsontheImageNetcontest(Krizhevsky,Sutskever&Hinton,2012)1000classesin1.2millionimages
DeepNeuralNetwork:15%top‐5errorrateSecondbestentry:26%top‐5errorrate
• SignificantincreaseinperformanceforLarge‐VocabularySpeechRecogniQon(Dahl,Yu,Deng&Acero,2012)
DeepNeuralNetwork:16‐23%relaQveerrorratereducQonoverthepreviousstate‐of‐the‐art(context‐dependentGaussianmixturemodel(GMM)‐HMMs)

KeyAspectofOurApproachUsingConvNet#1
Ournetworkistrainedwithtwolargesta-cimagedatabasesofsevenemo-ons
1.TheTorontoFaceDataset(TFD)• 4,178imagesoffrontalfaces• Pre‐processedbasedonregisteringtheeyesandthenresizedto48x48
2.ALargefacialexpressiondatabaseharvestedfromGoogleimagesearch(createdbyus)
• 35,887imageswithmoreposevariability• BuiltbyharvesQngimageryreturnedfromGoogle’simagesearchusingkeywordsrelatedtoexpressions

• IgnoringtheChallengetrainingdata,justusingGoogleandtheTFDtotrainthedeepnetwork,thentraininganSVMaggregatoronthedeepnetworkpredicQonsusingthechallengetrainingdata:46.87%accuracyontrainand38.96%onthevalidaQonset
• OurbestnetworkwasthereforetrainedontheGoogleandTFD,usingearlystoppingbasedonthechallengetrainandvalidaQonsets
KeyTraining&AggregaQonStrategiesforConvNet#1
• TrainingtheconvoluQonalneuralnetworkonframescontainingafaceextractedfromthevideoclipsofthechallengetrainingsetplustheGoogle&TFDdatasets:96.73%accuracyontrainingsetand35.32%onthevalidaQonset
ConvNet1classificaQonerrorontrainingandvalidaQonsets(beforeaggregaQon)

Averaging Expansion• UsingConvNet1,weclassifiedallframesfromtrain,validaQonandtest
challengedata• Foreachframetheoutputisa7‐classprobabilityvector• TheseprobabiliQesareaggregatedtobuildafixed‐lengthrepresentaQonfor
eachvideo‐clip• Finally,wetrainedanSVMwithRBFkernelonthenewrepresentaQonfor
challengetrainsetandtunedhyper‐parametersusingvalidaQonset
ConvNet#1:PerframepredicQonaggregaQonwithanSVM

Pre‐processingforConvoluQonalNetwork#1
Facetubeextrac=onprocedure• FrameswereextractedinawaythatthemovieaspectraQowaspreserved• GooglePicasafacedetectorwasusedtodetectfaces• InordertorecoverboundingboxesforthefacesreturnedbyPicasa,weused
Haar‐likefeature‐basedmatchingmethodasdirectpixeltopixelmatchingdidnotyieldsaQsfactoryperformance.
Registra=on• ThechallengedatasetandTFDimagesareregisteredtotheGoogledataset
using51facialkeypointsextractedfromRamananmethod• Toreducethenoisecomputedmean‐shapewithno‐poseforeachdataset• ComputedasimilaritytransformaQonbetweenthetwoshapes• WealsoaddedarandomnoisybordertoTFDdata
Illumina=onnormaliza=on• Weusedadiffusion‐basedapproachcalled
IsotropicSmoothing(fromINfacetoolbox) RawimagesatthetopandtheirIS‐preprocessedcorrespondingimagesbelow

• AsimplerConvNet,trainedon48x48imagesfromtheTFD
• Pre‐processedwithlocalcontrastnormalizaQon
• AsingleconvoluQonallayerandamaxpooling,followedbyahiddenlayeranda7‐classso_maxoutput
• FacesfromchallengevideoframesarealignedtohaveroughlythesameeyeposiQonsasTFDusingtheaverageofeyerelatedlandmarks
• EachsequencewassummarizedusingafewstaQsQcssuchas:average,max,averageofmaximumsuppressionvectors
• Here,insteadofSVMweusedamulQlayerperceptrontrainedonfixed‐lengthfeaturevectorswehaveproduced
• TheMLPwascomposedofonerecQfiedlinearlayerfollowedbyalinearoutputof7units
• EarlystoppingbasedonvalidaQonset
FacesandConvoluQonalNetwork#2

Features• Mel‐frequencycepstralcoefficients(MFCC)developedforspeechrecogniQon• Backgroundnoiseandthesoundtrackofthemoviecanalsobesignificant
indicators• Featuresareextractedfromthemp3filesextractedfromthemovieclipsusing
yafeelibrarywithasamplingrateof48kHz• DifferenttypesofMFCCfeaturesareusedand909featuresperQmescalewere
selectedbyonlinePCA
Pre‐training• Unsupervisedpre‐trainingwithdeepbeliefnetworks(DBN)ontheextracted
audiofeatures• DBNhastwolayersofRBMs.FirstlayerRBMwasaGaussianRBMwithnoisy
recQfiedlinearunit(ReLU)nonlinearity.SecondlayerRBMwasaGaussian‐BernoulliRBM
• TheMLPwasiniQalizedwithReLUnonlinearityfor1stlayerandsigmoidnonlinearityfor2ndlayerusingtheweightsandbiasesoftheDBN
AudioandDeepRBMs

Temporalpoolingforaudioclassifica=on• ThelasthiddenrepresentaQonlayerofanMLPwaspooledtoaggregate
informaQonacrossframesbeforeafinalso_maxlayer
Supervisedfine‐tuning• Onlychallengetrainingdatawasusedforfine‐tuningandtheearlystopping
wasbasedonerrorrateonvalidaQonset
OtherAspectsoftheDeepRBMAudioModel

• BasedonspaQo‐temporalmoQonpasernsinthevideo• RecogniQonpipelineusesspaQo‐temporalauto‐encoderfor
featurelearning
• ModelwastrainedonPCA‐whitenedinputpatchesofsize10x16x16croppedrandomlyfromtrainingvideos
• Astrideof4wasusedtogenerate8subblocksfromsuperblocks,thenusingPCAwebuiltdescriptors
• UsingK‐meansonsuperblockdescriptorswelearnedavocabularyof3000words
• EachvideoisrepresentedasthehistogramofthesewordsandthenclassifiedusinganSVM
AcQvityRecogniQonandDeepAuto‐encoders

Usesalignedfacesprovidedbytheorganizers• Imagesarecroppedtoonlykeepasmallregionaroundthemouth• Themouthimagesaresubdividedinto16regions,thenmany8x8patchesare
extractedfromtrainingimages• Thepatchesarenormalizedandwhitenedkeeping90%ofthevariance• AdicQonaryislearnedforeachofthe16regionsusingK‐meansclustering
Learning• Forallimagesoftrain,patchesareextracteddensely• Eachpatchisthenrepresentedbya400dimensionalfeaturevector(number
ofclusters)byusingtriangleacQvaQon• AframebyframeclassifierusinglogisQcregressionistrained
Classifica=on• Probabilityofaclipiscomputedbyaveragingprobabilityvectorsofframes
BagofMouthFeaturesandShallowNetworks
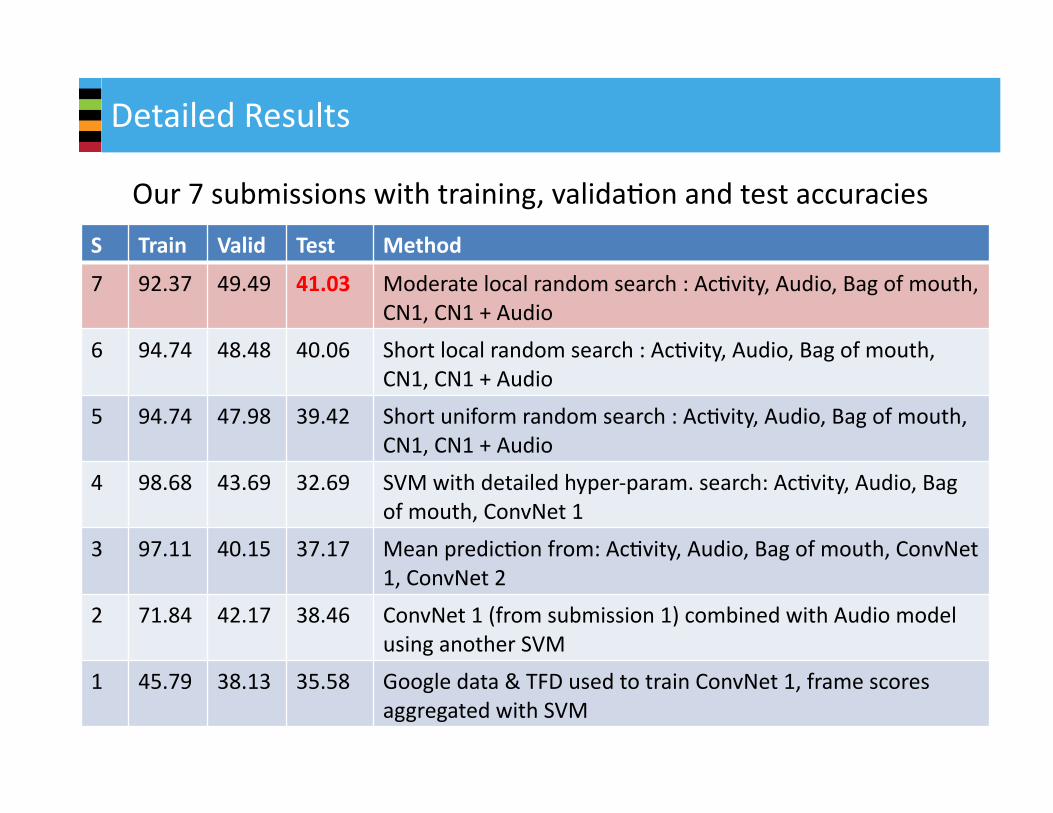
DetailedResults
Our7submissionswithtraining,validaQonandtestaccuracies
S Train Valid Test Method
7 92.37 49.49 41.03 Moderatelocalrandomsearch:AcQvity,Audio,Bagofmouth,CN1,CN1+Audio
6 94.74 48.48 40.06 Shortlocalrandomsearch:AcQvity,Audio,Bagofmouth,CN1,CN1+Audio
5 94.74 47.98 39.42 Shortuniformrandomsearch:AcQvity,Audio,Bagofmouth,CN1,CN1+Audio
4 98.68 43.69 32.69 SVMwithdetailedhyper‐param.search:AcQvity,Audio,Bagofmouth,ConvNet1
3 97.11 40.15 37.17 MeanpredicQonfrom:AcQvity,Audio,Bagofmouth,ConvNet1,ConvNet2
2 71.84 42.17 38.46 ConvNet1(fromsubmission1)combinedwithAudiomodelusinganotherSVM
1 45.79 38.13 35.58 Googledata&TFDusedtotrainConvNet1,framescoresaggregatedwithSVM

MainContribuQons,ConclusionsandFindings
• UsinglargequanQQesofaddiQonaldatatotrainadeepconvoluQonalneuralnetwork‐Allowsustotrainhighcapacitymodelwithoutover‐fixngtotherelaQvelysmallEmoQWchallengetrainingdata
• ThestrategyofusingthechallengetrainingdataonlytolearnhowtoaggregatetheperframepredicQons‐HighlightstheissueofoverfixngwhenusingarelaQvelysmallamountoflabeledvideodata
• Anoveltechniquetoaggregate(mulQmodal)modelsbasedonrandomsearch‐ExploitsthecomplementaryinformaQonwithinthepredicQonsofallmodelsMorerobustinthepresenceofmodelsthatoverfit

ThankYou