page 1 © hortonworks inc. 2011 – 2015. all rights reserved fly the coop! getting big data to soar...
TRANSCRIPT

Page 1 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Fly the Coop!Getting Big Data to Soar With Apache Falcon
2015
Michael Miklavcic

Page 2 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Who Am I?
• Michael Miklavcic - Systems Architect at Hortonworks• Coach teams through their journey to using Hadoop
–ETL–Workflow automation–Optimization training–SDLC with Hadoop–Custom processing of structured/unstructured data–Everything between
• In short, I help people make sense of Hadoop

Page 3 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
What Is Workflow Automation?
• We want a process to run on schedule – think Cron or Control-M• Setup a data flow pipeline
– [input data] -> process A -> process B -> process C -> [output data]
• We could use cron and bash scripts when we first start–Won’t scale and most of the error-handling will be home-grown
• Hadoop has had a project called “Oozie” for years now–Handles ad-hoc workflows–Great for scheduling recurring runs–Has data availability features for HDFS and Hive datasets–Retries
• Both of these approaches miss some things

Page 4 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Common Automation Problems
• No holistic view of pipelines:–data (feeds) and applications (processes)
• Ingest/process details scattered in local process log files• Non-uniform boilerplate shell scripts• Ad-hoc or manual:
–process success/fail verification mechanism–data replication for disaster recovery– retention policy for archiving or deleting “cold” data– job execution – developer initiated– feed availability checks
– via custom code, or literally can be via emails between engineers
Page 5 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Oozie

Page 6 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Basic Automation With Oozie
Raw Input Table Output Table
Oozie Workflow
PigJob
HiveJob
Hive/HCatalog
Partition2014-05-12
Partition2014-05-13
Partitionn
Partition2014-05-12
Partition2014-05-13
Partitionn
my_db.raw_input_table my_db.output_table
Hadoop

Page 7 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
What About The Rest?
Oozie Workflow
PigJob
HiveJob
Retention
Replication
Late DataArrival
ExceptionHandling
Monitoring
Lineage
Audit

Page 8 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Falcon To the Rescue!

Page 9 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Falcon: Features
• Create complex data pipelines• Web UI for building workflows• Replicate or Mirror Hive & HDFS data sets
–DR/Backup/Archival
• Handle retention–Schedule purging
• Handle retries–Specify periodic retries, exponential backoff, etc.
• Specify late data arrival processing• Track Lineage
–View pipeline dependencies
• Audit trail• JMS messaging for pipeline status

Page 10 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Falcon: What it Offers Developers
• Abstracts away from Oozie primitives• Automatically generates boilerplate Oozie code• View workflow status more easily• Formalizes dataset concept
– reusable sources for workflow composition
• Easier to see how datasets used across many workflows• Provides a UI for those less-inclined to direct XML manipulation• Data availability checks handled for you• Provide hooks for notifications• Templating mechanism for building your applications

Page 11 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Falcon: Architecture
Falcon Orchestration Framework
Hadoop ecosystem tools
Falcon Server JMS
API&UI
AMBARI
HDFS / Hive
Oozie
Entity Specs Schedule Jobs Process
Status
MapRed / Pig / Hive / Sqoop / Flume / DistCP
Mirror
Status
Emails
Data stewards &
Hadoop admins

Page 12 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Falcon: Access Points• Command line client
– Submit, schedule, delete, etc. instances– Rerun workflows
$falcon entity type -cluster -file primary-cluster.xml –submit
• Web Gui– View/edit/create entities and relationship graph– View feed/process instances and status– Process & dataset instances link directly to the Oozie UI
• RESTful API– Call admin, entity, and job instance operations
• JMS– Feed/process scheduling, instance status updates
• Logs– /var/log/oozie/

Page 13 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Falcon: Metamodel
3 Basic Entities–Cluster
–Represents interfaces to a Hadoop Cluster
–Define colos, clusters, services (JobTracker, Oozie, HDFS)
–Feed–Defines “dataset” with location, replication schedule and retention policy
(Hive/HDFS)
–Process–Defines the configuration required to run workflow job(s) (Oozie Job)

Page 14 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Falcon: Metamodel
Cluster
Dataset/Feed
Process
Readonly – hdfs read via hftp
Write – hdfs write (fs.default.name)
Execute – job tracker/resource manager
Workflow – Oozie url
Registry – Hcatalog/Hive metastore address
Messaging – JMS broker URL
HDFS
Hive/HCatalog

Page 15 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Backup Cluster
Primary Cluster
A Falcon Data Pipeline
PigJob 1
PigJob 2
Input 1External datasource A
Input 2
External dataSource B
Output 1
Input 3
Output 2
SqoopExternal data
Source C
Input 1
Input 2
Output 1
Input 3
Output 2
FalconProcess
FalconDataset
Key

Page 16 © Hortonworks Inc. 2011 – 2015. All Rights Reserved

Page 17 © Hortonworks Inc. 2011 – 2015. All Rights Reserved

Page 18 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Building Pipelines
• Get data into Hadoop, then let Falcon take it from there• Use fine grained entities
– typically, single pig or hive script per Falcon process
• Datasets need to use datestamps as primary partition• Let Falcon/Oozie/HCatalog handle variables for data references
Falcon Process XML<process name=”expedia-money-saver" xmlns="uri:falcon:process:0.1”>...<inputs> <input end="today(0,0)" start="today(0,0)" feed=”my-raw-feed" name="input"/></inputs><outputs> <output instance="now(0,2)" feed=”my-tr-feed" name="output"/></outputs>...
Pig ScriptA = load '$falcon_input_database.$falcon_input_table' using org.apache.hcatalog.pig.HCatLoader();B = FILTER A BY $falcon_input_filter;C = foreach B generate id, value;store C into '$falcon_output_database.$falcon_output_table' USING org.apache.hcatalog.pig.HCatStorer('$falcon_output_dataout_partitions');

Page 19 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
SDLC With Falcon

Page 20 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Falcon: Does Not Quite Do
• Make your workflows readily part of an SDLC–You’ll have some coding to do for Maven/Jenkins/Artifactory SDLC
• Provide code for the JMS notifications–Write your own client to do what you need
• Allow you to leverage file or directory timestamps for replication or retention• HBase replication (use native HBase tools for this)• Ingest your data
–Can wrap an Oozie workflow with Sqoop action– local filesystem won’t work w/Oozie. NFS mount requires mount to all nodes.
• Provide a native test framework (UPDATE: 0.7 release will have Falcon Unit)• Provide feed recipes

Page 21 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
What is a Falcon Recipe ?
• Falcon provides a Process abstraction that encapsulates the configuration for a user workflow with scheduling controls.
• All recipes can be modeled as a Process within Falcon which executes the user workflow periodically. The process and its associated workflow are parameterized.
• Name/value pair properties file - values substituted by falcon before scheduling
• Falcon translates these recipes as a Process entity by replacing the parameters in the workflow definition.
ASF documentation: https://falcon.apache.org/0.6-incubating/Recipes.html

Page 22 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Built-in Recipes: Mirroring HDFS & Hive
• Mirroring for Disaster Recovery and Business continuity use cases.
• Customizable for multiple targets and frequency of synchronization.
• Streamlined: Dynamic screens to improve ease of use.
Recipe
Reduce
Cleanse
Replicate
Properties
WorkflowTemplate
Recipe
Reduce
Cleanse
Replicate
Properties
Recipe
Reduce
Cleanse
Replicate
Properties
WorkflowTemplate

Page 23 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Falcon: Recipes• The Good
Token replacement with property file + template fileReusable templatesCopies apps to hdfs from local file systemEasily mirror datasets
• The Badx Process entity only (even with custom recipe tool)x Recipe locations dictated by client.propertiesx Still difficult to include in a rich SDLC

Page 24 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Falcon: Test and Deployment Strategies
• If using one Hadoop cluster for dev, test and prod, we need separate:–Entities for both environments (except for the cluster entity)–Directory structures, e.g. /prod/foo/bar, /qa/foo/bar–Hive databases and tables
–Prod = foo_data_source.member
–Test = qa_foo_data_source.member
• Want parameterization for generating entities for multiple envs–<frequency>days(1)</frequency> becomes–<frequency>${{feed_frequency}}</frequency>–Supply values via env vars at runtime

Page 25 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Falcon: Test and Deployment Strategies
• But Falcon recipes don’t offer full token replacement• What does this mean for my SDLC?...

Page 26 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
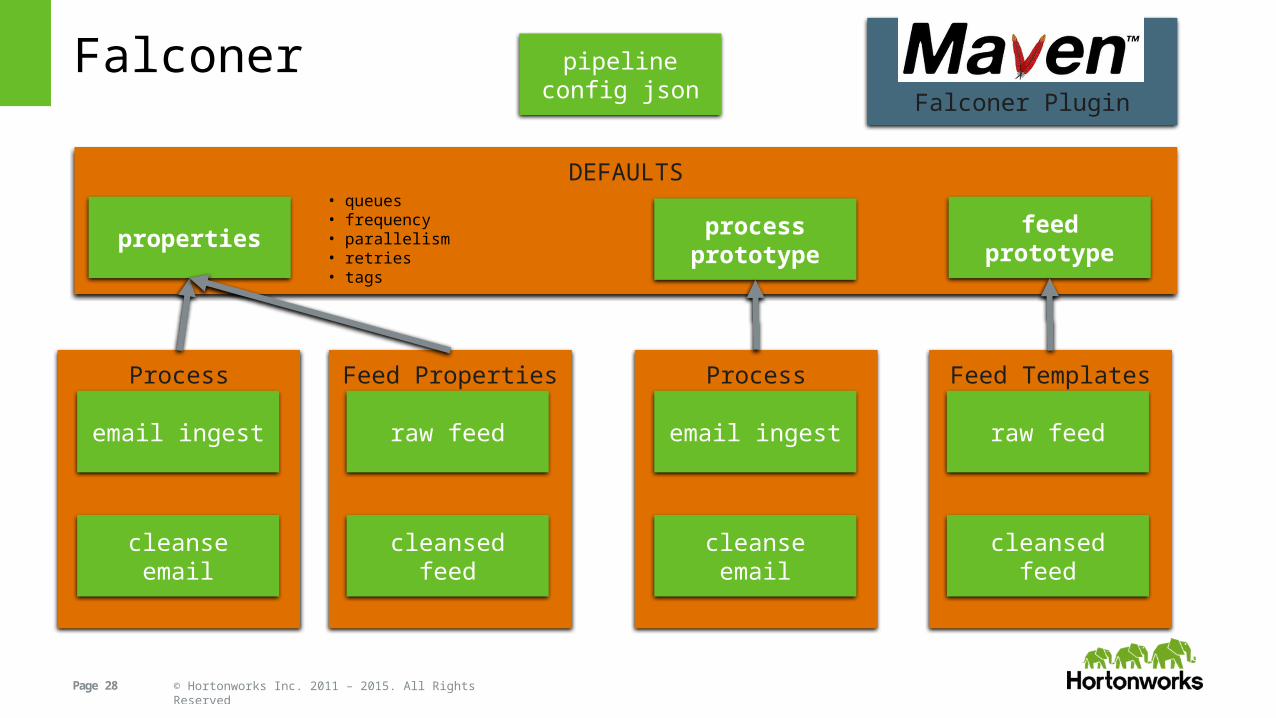
Falcon: SDLC Options• I wrote Falconer to help with this
– https://github.com/mmiklavc/falcon-tools/tree/master/falconer
• Features– Property inheritance– Entity prototyping– Entity templates– Easy to include in SDLC
• Usage– Java CLI tool– Maven plugin– Maven archetype

Page 27 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Sample Pipeline
Page 28 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Falconer Plugin
DEFAULTS
Falconer
properties
pipelineconfig json
processprototype
feedprototype
Process Templates
email ingest
cleanse email
Feed Templates
raw feed
cleansed feed
• queues• frequency• parallelism• retries• tags
Process Properties
email ingest
cleanse email
Feed Properties
raw feed
cleansed feed

Page 29 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Falconer Artifacts
Falconer
propertiesfiles
processtemplates
feedtemplates
email ingest cleanse emailraw feed cleansed feed
+ +
=
Data Pipeline

Page 30 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Falcon: feed-prototype.xml

Page 31 © Hortonworks Inc. 2011 – 2015. All Rights Reserved
Falcon: rawEmailFeed.xml
