overcoming dataset bias: an unsupervised domain adaptation approach boqing gong university of...
TRANSCRIPT

1
Overcoming Dataset Bias:An Unsupervised Domain Adaptation Approach
Boqing Gong
University of Southern California
Joint work with Fei Sha and Kristen Grauman

2
Motivation
Vision datasetsKey to computer vision research
Instrumental to benchmark different algorithms
Recent trends
Growing fast in scale: Gbytes to web-scale
Providing better coverage: objects, scenes, activities, etc

3
Object recognitionMany factors affect visual appearance
Fundamentally, have to cover an exponentially large space
Example
Limitation: datasets are biased
Images from [Saenko et al.’10].
Amazon online catalogue Office
Monitor from two datasets/domains

4
Consequence: dataset-specific classifier
TRAIN TEST
Poor cross-dataset generalizationDatasets have different underlying distributions
Classifiers overfit to datasets’ idiosyncrasies
Images from [Saenko et al.’10].

5
Mismatch is common
Object recognition
Video analysis
Pedestrian detection
[Torralba & Efros’11, Perronnin et al.’10]
[Duan et al.’09, 10]
[Dollár et al.’09]

6
Our solution: unsupervised domain adaptation
Setup
Source domain (labeled dataset)
Target domain (unlabeled dataset)
ObjectiveTrain classification model to work well on the target
{( ), 1,2,, } ~ ( ,, )S i i Sx i P X Yy N D
The two distributions are not the same!
{( ), 1,2, ,, } ~ ( , )T i TMx i P X Y D ?

7
Our algorithms
Geodesic flow kernel (GFK): Learning domain-invariant representation
Mitigating domain idiosyncrasy
LandmarksBridging two domains to have similar distributions
Training discriminatively w.r.t. target without using labels
TS
,i jz z
(0)
( )
(1)
( )
T
T
T
z xt
t
( )t
[Gong, Shi, Sha, Grauman, CVPR’12]
[Gong, Sha, Grauman, ICML’13]

8
Correcting sample biasEx. [Shimodaira’00, Huang et al.’06, Bickel et al.’07]
Assumption: marginal distributions are the only difference
Learning transductivelyEx. [Bergamo & Torresani’10, Bruzzone & Marconcini’10]
Assumption: shift classifiers via high-confident predictions
Learning a shared representationEx. [Daumé III’07, Pan et al.’09, Gopalan et al.’11]
Assumption: a latent space exists s.t. Ps(X,Y)=Pt(X,Y)
Related work

9
Our algorithms
Geodesic flow kernel (GFK): learning domain-invariant representation
mitigating domain idiosyncrasy
LandmarksBridging two domains to have similar distributions
Training discriminatively w.r.t. target without using labels
TS
,i jz z
(0)
( )
(1)
( )
T
T
T
z xt
t
( )t
[Gong, Shi, Sha, Grauman, CVPR’12]
[Gong, Sha, Grauman, ICML’13]

10
Assume low-dimensional structure
Ex. PCA, Partial Least Squares (source only)
Modeling data with linear subspaces
Target
Source

11
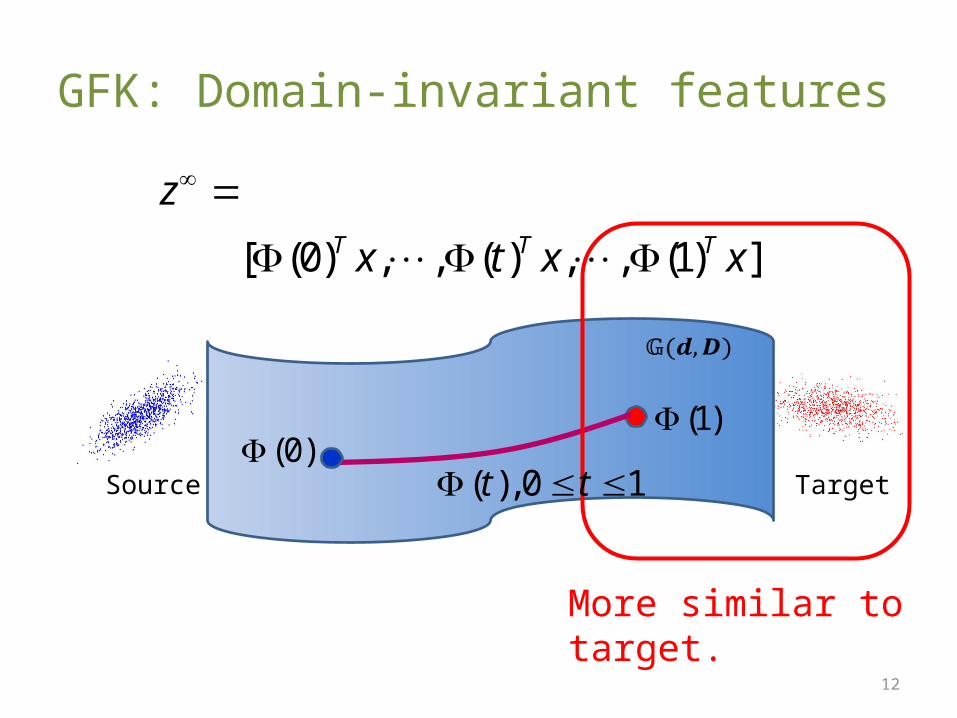
GFK: Domain-invariant features
(0) , , ( ) , , (1)[ ]T T Tx x
z
t x
TargetSource
(0)(1)
( ),0 1t t
More similar to source.
12
GFK: Domain-invariant features
(0) , , ( ) , , (1)[ ]T T Tx x
z
t x
TargetSource
(0)(1)
More similar to target.
( ),0 1t t

13
GFK: Domain-invariant features
(0) , , ( ) , , (1)[ ]T T Tx x
z
t x
TargetSource
(0)(1)
Blend the two.
( ),0 1t t

14
We define the geodesic flow kernel (GFK):
Advantages
Analytically computable
Encoded domain-invariant features
Broadly applicable: can kernelize many classifiers
GFK in closed form
1
0( ) (, ( ) ( ))T T T T
i j i j i jz t x t xz dt x Gx

15
Our algorithms
Geodesic flow kernel (GFK): learning domain-invariant representation
mitigating domain idiosyncrasy
LandmarksBridging two domains to have similar distributions
Training discriminatively w.r.t. target without using labels
[Gong, Shi, Sha, Grauman, CVPR’12]
[Gong, Sha, Grauman, ICML’13]

16
Landmarks
Labeled source instances that
are distributed as could be sampled from the target
serve as conduit for discriminative loss in target domain
Landmarks
Target
Source

17
Key steps
Landmarks
Target
Source
1 Identify landmarksat multiple scales.

18
Key steps
2 Construct auxiliary domain adaptation tasks
3 MKL
4

19
Identifying landmarks
Select landmarks
such that
1) landmark distribution ≈ target distribution
2) #landmarks are balanced across different categories
Select landmarks
Landmarks
Target

20
Identifying landmarks
Landmarks
Target
Select landmarks
1) landmark distribution
2) #landmarks are bala
Integer P QP
Distribution
Category balance

21
Multi-scale analysis
: GFK
σ : multi-scale analysis multiple sets of landmarks
Select landmarks
such that
1) landmark distribution
2) #landmarks are bala
QP

22
Headphone Mug
target
σ=2
σ=2
σ=2
unselected
Exemplar images of landmarks
TargetS
ource
6
0
-3

23
Use of multiple sets of landmarks
1. Auxiliary task
At each scale,
Target
Source
Landmarks
Source’ = source - landmarks Target’ = target + landmarks

24
Use of multiple sets of landmarks
1. Auxiliary task
At each scale,
Provably easier to solve
Target
Source
Landmarks
Source’ = source - landmarks Target’ = target + landmarks

25
Use of multiple sets of landmarks
2. Discriminative learning, w.r.t. target
Train classifiers using labeled landmarks
Discriminative loss is measured towards target via landmarks
Target
Source
Landmarks

Experimental study
Setup
Cross-dataset generalization for object recognition among four domains
Re-examine dataset’s values in light of domain adaptation
Evaluation
Caltech-256
Amazon
DSLR
Webcam
[Griffin et al.’07, Saenko et al.’10]

27
Classification accuracy: baseline
Acc
ura
cy (
%)
A-->C A-->D C-->A C-->W W-->A W-->C0
10
20
30
40
50
60
No adaptation Gopalan et al.'11 Pan et al.'09GFK-SVM Landmark
Source Target

28
Classification accuracy: existing methods
Acc
ura
cy (
%)
A-->C A-->D C-->A C-->W W-->A W-->C0
10
20
30
40
50
60
No adaptation Gopalan et al.'11 Pan et al.'09GFK-SVM Landmark
Source Target

29
Classification accuracy: GFK (ours)
Acc
ura
cy (
%)
A-->C A-->D C-->A C-->W W-->A W-->C0
10
20
30
40
50
60
No adaptation Gopalan et al.'11 Pan et al.'09GFK-SVM Landmark
Source Target

30
Classification accuracy: landmark (ours)
Acc
ura
cy (
%)
A-->C A-->D C-->A C-->W W-->A W-->C0
10
20
30
40
50
60
No adaptation Gopalan et al.'11 Pan et al.'09GFK-SVM Landmark
Source Target

31
Cross-dataset generalization [Torralba & Efros’11]
PASCAL ImageNet Caltech-10130
40
50
60
70
Self Cross (no adaptation) Cross (with adaptation)
Acc
ura
cy (
%)
Caltech-101 generalizes the worst.Performance drop of ImageNet is big.
Analyzing datasets in light of domain adaptation
Performance drop!

32
Cross-dataset generalization [Torralba & Efros’11]
PASCAL ImageNet Caltech-10130
40
50
60
70
Self Cross (no adaptation) Cross (with adaptation)
Acc
ura
cy (
%) Performance
drop becomes smaller!
Caltech-101 generalizes the worst (w/ or w/o adaptation).There is nearly no performance drop of ImageNet.
Analyzing datasets in light of domain adaptation

33
Summary
Datasets are biased
Overcome by domain adaptation (DA)
Our solutions: new learning methods for DA
Geodesic flow kernel (GFK)
Learn a shared representation of domains
Landmarks
Discriminative loss is measured towards target via landmarks
Data collection guided by DAInformative data: those cannot be classified well by
adapting from existing datasets

34
Thank you!Headphone Mug
target
σ=2
σ=2
σ=2
unselected
TargetS
ource
6
0
-3

35

36
Discussion
ScalabilityGFK: eigen-decomposition, Landmarks: QP
Overall, polynomial time
Target
Source
Landmarks

37
Which domain should be used as the source?
?
?
?
DSLR
Caltech-256
Webcam
Amazon

38
We introduce the Rank of Domains measure:
Intuition– Geometrically, how subspaces disagree– Statistically, how distributions disagree
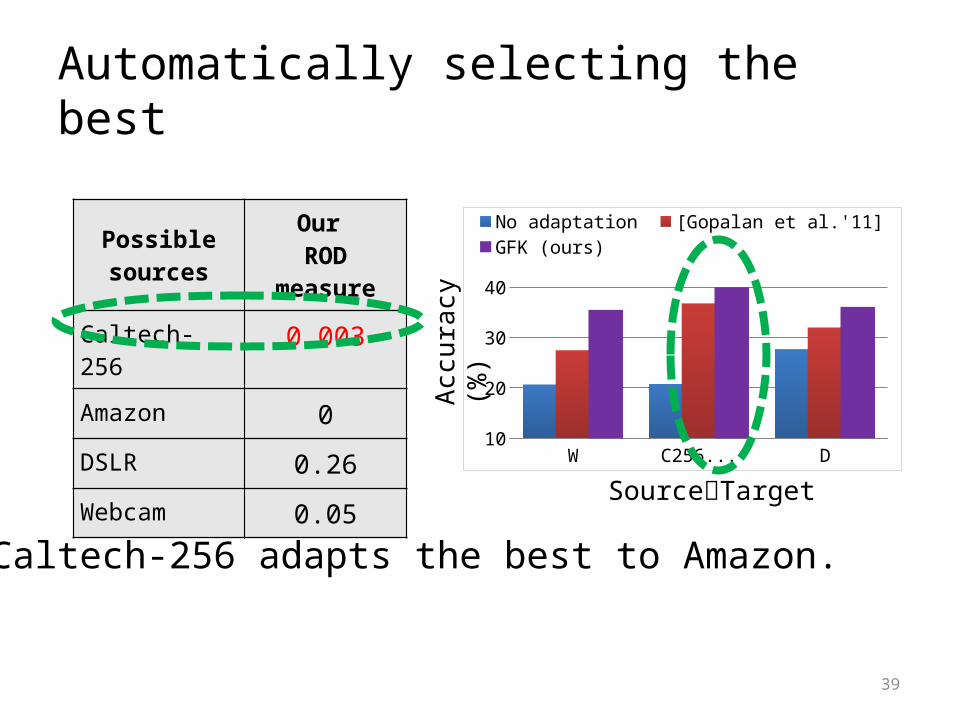
Automatically selecting the best
39
Possible sources
Our ROD
measure
Caltech-256 0.003
Amazon 0
DSLR 0.26
Webcam 0.05
Caltech-256 adapts the best to Amazon.
Acc
ura
cy (
%)
W-->A C256-->A D-->A10
20
30
40
No adaptation [Gopalan et al.'11] GFK (ours)
SourceTarget
Automatically selecting the best