optimisations - groupe calcul...
TRANSCRIPT

28 Janvier 2014 Ludovic Saugé, PhD
Optimisations: Impacts des architectures sur les performances des applications
Technical Director of the Center for Excellence in Parallel Programming Applications & Performance Team Bull Extreme Computing BU [email protected]
Séminaire calcul grenoblois

Agenda
• Introduction
• Instruction Level Parallelism – Procésseurs : Généraliés
• Architecture
• Fréquence
• Pipelining
– µarchitectures de l’intel Sandy Bridge • GFLops/sec !
• Roofline model
• Profiling
• Latence & Throughput d’instructions
• Data Level Parallelism: vectorisation – Pourquoi ?
– Comment ?
– Problèmes • Les diagnostiquer
• Les traiter
– Dépendance des données
– Aliasing
– Alignement
– Inlining
– …
• Aspects Mémoires

Introduction

Introduction
Calculer juste, de manière reproductible et de manière performante.
• Optimiser – « Donner le meilleur rendement possible .»
– Utiliser au mieux les ressources
• Optimisation de code – Loop transformation: unrolling, peeling,
spleeting/peeling, unroll-and-jam, merge …
– Software prefetch
– Cache blocking

Apparemment la même architecture mais pourtant …
❶Intel® Sandy Bridge E5-2670 • Architecture x86_64 • 2.6 GHz
• downclocké à 2.3 GHz • 8 cœurs (2threads/cœurs) • 4 canaux mémoire 1600 MT/s • 2 Liens QPI
❷AMD® Interlagos/Bulldozer 6276 • Architecture x86_64 • 2.3 GHz • 16 cœurs (8 modules FPU) • 4 canaux mémoire 1600 MT/s • 2 Liens HT3
Opteron 6200
DDR3
DDR3
DDR3
DDR3
HT3
HT3 Cores
Xeon® E5-2600
Cores
DDR3
DDR3
DDR3
QPI
QPI
DDR3
Performance pic @ 2.3 GHz d’un double socket: 294,4 Mflops/sec

Apparemment la même architecture mais pourtant …
270
228 241
292
249 279 268
147
0
50
100
150
200
250
300
350
400
32 cores 16 cores
DGEMM HPL CPU
Pe
rfo
rman
ce (
MFl
op
s/se
c)
AMD Opteron 6276 Inel E5-2670 downclocked to 2.3GHz
Higher is Better
❶Intel® Sandy Bridge E5-2670 • Architecture x86_64 • 2.6 GHz
• downclocké à 2.3 GHz • 8 cœurs (2threads/cœurs) • 4 canaux mémoire 1600 MT/s • 2 Liens QPI
❷AMD® Interlagos/Bulldozer 6276 • Architecture x86_64 • 2.3 GHz • 16 cœurs (8 modules FPU) • 4 canaux mémoire 1600 MT/s • 2 Liens HT3
Performance pic @ 2.3 GHz d’un double socket: 294,4 Mflops/sec
54.93 56.62 58.41
115.00
0.00
20.00
40.00
60.00
80.00
100.00
120.00
140.00
icc icc
naive opt intrinsic
Pe
rfo
rman
ce (
GFl
op
s/se
c) AMD Opteron 6276
Inel E5-2670
Higher is Better

Instruction Level Parallelism

Processeurs - caractéristiques
• 32- ou 64-bits
• Fréquence (unité : GHz)
• Cache : niveau, taille, organisation, associativité
• Gestion des accès à la mémoire centrale
– Bus, liens (contrôleur intégrés) → vitesse, débit (GT/sec, GiB/sec)
– Translation d'adresses, TLB ...
• Micro-architecture
– Jeu d’instructions: RISC, CISC, VLIW …
– Caractéristique du FPU
• Largeur
• Nombre d'instruction/cycle
– Nombre et taille des registres
– Les jeux d'instruction supportés (extension SIMD) – parallélisme de données
• MMX, SSE, 3D-Now!, AVX ...
– « Ordering » des instructions :
• IA64, Xeon Phi – In order
• AMD Opteron, Intel Xeon – Out of order
– Pipelinning - parallélisme d'instructions

Hiérarchie mémoire
Registres
Cache
Mémoire locale
Mémoire distante
Disque/Stockage pages
instruction
message
Ligne de cache
Ban
de p
assante
latence
taille
64 bits
32 kB256 kB/2MB
xGB
xGBxPB
1 cycle
4-40 cycles
>100 cycles

Cache
– Localité temporelle ou spatiale des données
– Les caches sont des éléments matériels complexes. • Cette complexité est cachée au programmeur.
– Par contre il existe des règles de bonne usage des caches • Il faut travailler sur la réutilisation des données
• Leur localité
– Le programmeur peut lui même (à avoir) gérer la cohérence de cache • “Explicit cache control”
• Utiliser par les compilateur dans les phases d’optimisation
• Exemple d’instruction ou principe :
– prefetching
– “non temporal stores” ou “streaming stores”
– fence
– flush
Intel IA64 Montecito (1.6 GHz)
Intel Xeon Nehalem (3.2 GHz)
– Design parameters – Capacity (size) – Line size
• Banking
– Coherency • Protocol (Ex. MESI), “snooping”
– Associativity • Direct-mapped • Set-associative • Fully associative
– Block replacement policy • LRU, LFU, FIFO, random
– Write policy • Write-back, write-through (write buffer)
– Allocate-on-write-miss policy
– Victim buffer – Cache unification – Prefetching

Puissance = Fréquence ?
Plus de parallélisme : Instructions, Threads, Données
1-3GHz

Memory
Control Unit
Arithmetic Logic Unit
Accumulator
Input Output
Circuiterie de principe des processeurs (block diagram)

Memory Access
Write Back
Instruction Fetch
Instr. Decode Reg. Fetch
Execute Addr. Calc
L M D
ALU
MU
X
Mem
ory
Reg File
MU
X
MU
X
Data
Mem
ory
MU
X
Sign Extend
4
Ad
de
r Zero?
Next SEQ PC
Ad
dress
Next PC
WB Data
Inst
RD
RS1
RS2
Imm
Pipelining : Exemple, le MIPS (1)
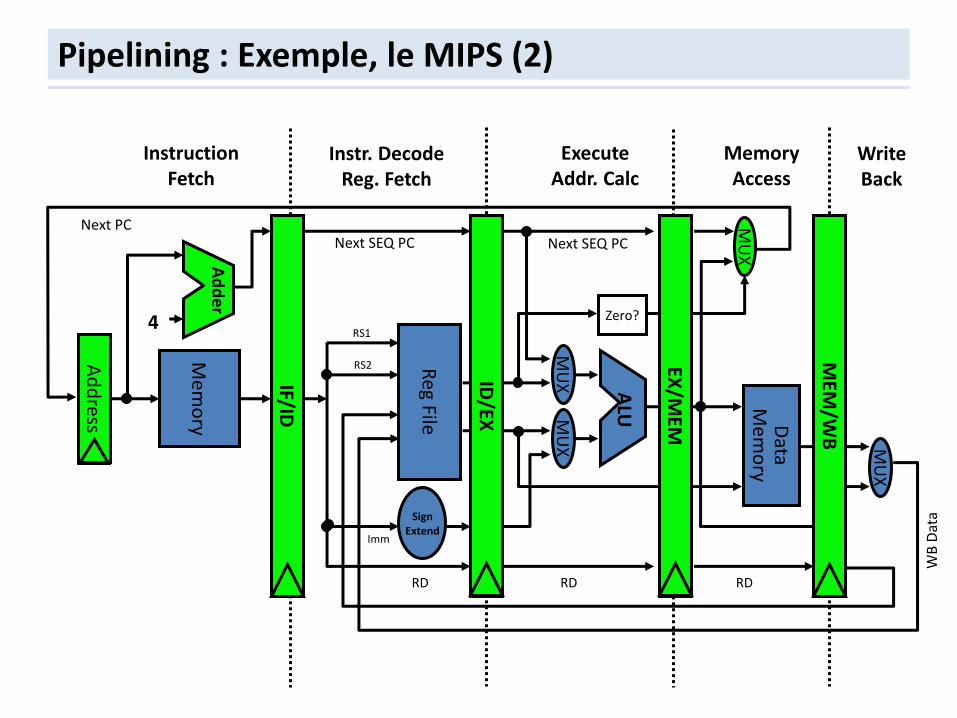
Pipelining : Exemple, le MIPS (2)
Memory Access
Write Back
Instruction Fetch
Instr. Decode Reg. Fetch
Execute Addr. Calc
ALU
Mem
ory
Reg File
MU
X
MU
X
Data
Mem
ory
MU
X
Sign Extend
Zero?
IF/ID
ID/EX
MEM
/WB
EX/M
EM
4
Ad
de
r
Next SEQ PC Next SEQ PC
RD RD RD
WB
Dat
a
Next PC
Ad
dress
RS1
RS2
Imm
MU
X

Pipelining
IF ID EX MEM WB
IF ID EX MEM WB
IF ID EX MEM WB
IF ID EX MEM WB
Inst 1
Inst 2
Inst 3
Inst 4
Cycle 1 Cycle 2 Cycle 3 Cycle 4 Cycle 5 Cycle 6 Cycle 7

s1 s2 e1 e2 m1 m2
1 8 56
Add/Sub
Rounding
Normalize
Add/sub
s3 e3 m3
Fixed-point mantissa mutliplier
330ns
20 ns
50 ns
= 400 ns

s1 s2 e1 e2 m1 m2
1 8 56
Add/Sub
Rounding
Normalize
Add/sub
Fixed-point mantissa mutliplier
s3 e3 m3
Partial Product Generation
Partial Product Reduction
Final Reduction
125 ns
150 ns
55 ns
20 ns
50 ns
= 400 ns

s1 s2 e1 e2 m1 m2
1 8 56
Add/Sub
Rounding
Normalize
Add/sub
s3 e3 m3
Partial Product Generation
Partial Product Reduction
Final Reduction
clock
17
2 n
s 1
72
ns
17
2 n
s
Stage 1
Stage 2
Stage 3
= 172 ns Latence: 516 ns

Exemple de pipelining
3-stage pipeline
– Longest path: product reduction
module, 150ns • +22 ns pour la gestion d’horloge, et
les délais induits par l’ajout des registres
– Augmentation du nombre de transistors (+40%)
– Augmentation du « throughput » • 172 ns vs 400 ns : x2,3
– Augmentation de la latence: 516 ns vs 400 ns

Pipelining : stalls
Le pipeline peut se mettre à “buller”
– Bulles (“bubbles”), “breaks ou pipeline “Stalls” sous certaines conditions (“hazards”): • Structural hazards: conflit de ressources
– Solution: out-of-ordering
• Data hazards: possible quand une instruction depend du résultat de la précédente.
– 3 types » RAW: “Read after Write” ou “Flow dependency”
ADD r0,r1
MUL r2,r0
» WAR: “Write after Read” ou “Anti-dependency”
ADD r4,r1,r3
MUL r1,r2,r3 » WAW: “Write after Write”
ADD r1,r4,r3
MUL r1,r2,r3 – Solutions: Register forwarding, Register renaming, re-ordering, insertion de bulles … – Instruction reordering
• Control hazards: branches, ou autres instructions modifiant la valeur du PC – Solution: prediction de branch
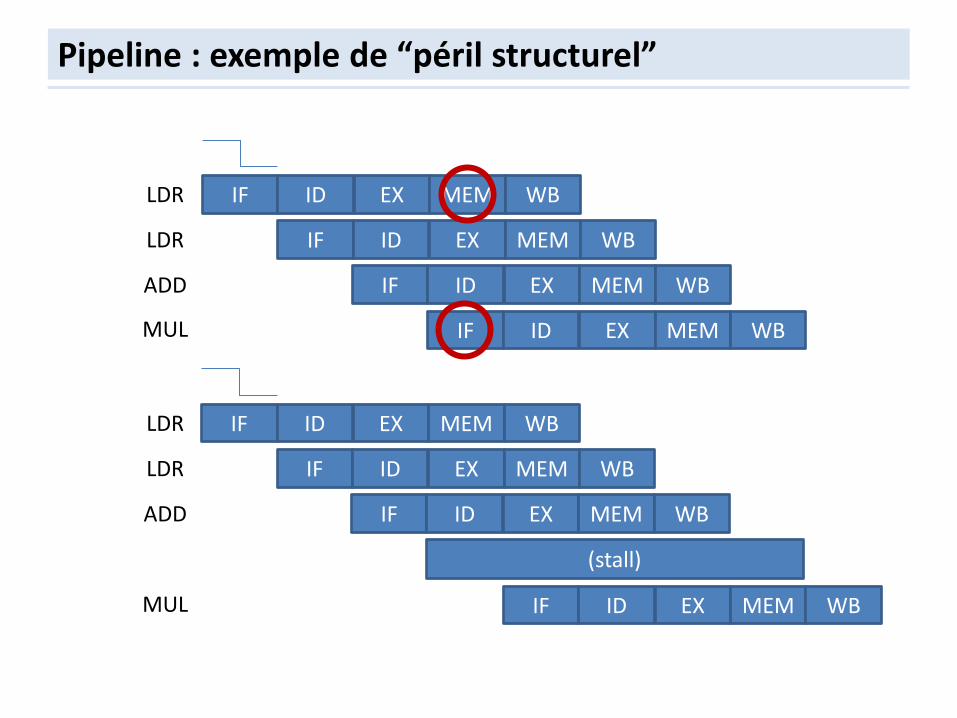
Pipeline : exemple de “péril structurel”
IF ID EX MEM WB
IF ID EX MEM WB
IF ID EX MEM WB
IF ID EX MEM WB
LDR
LDR
ADD
MUL
IF ID EX MEM WB
IF ID EX MEM WB
IF ID EX MEM WB
IF ID EX MEM WB
LDR
LDR
ADD
MUL
(stall)

Prédiction de branches et exécution spéculative
• Eviter la “famine” au niveau du pipeline – Prédire l’avenir avec la connaissance du passé – Spéculer et exécuter ce qu’on pense le plus à même de se passer
• Le coût d’une mauvaise prédiction est important (vidange et remplissage/réamorçage du pipeline)
• Le coût d’une branche est de manière générale important • Attention aux “if”
– Ne pas abuser du “if” • Réduire leur utilisation au strict minimum
– Réserver au débogage – Quand c’est possible, remplacer par des directives de pré-proccesing #if…#else…#endif
• Cf. programmation du kernel: fonctions courtes, “outlinés” • Certaines architectures (ARM) définissent des instructions “conditionnelles”

Need for speed ?
❶ Parallélisme d’instructions (ILP) – Pipelining
• Simple ou super- ou hyper- pipelinning • Instruction : latence (latency) et debit (troughput)
– Superscalaire • Multiplication des unités fonctionnelles (FU ou Port)
– Execution out-of-order (OoO) • “Reordering” et “Register Renaming”
– Prediction de branches et Execution speculative – “Hyperthreading”
❷ Parallèlisme de données (DLP) : SIMD (vectorisation) – NEON, 3DNow!, Altivitec, MMX, SSE(x.y), AVX, AVX-2, AVX-512 …
❸ Parallèlisme sur les tâches (TLP) – Multi- many-cores (intranœud) – Interconnexion de nœuds …

32K Instruction
Cache BPU
MSROM Decoded
ICache
Rename/retirement
Load Store (address)
Integer
MMX/SSE/AVX Low
MMX/SSE/AVX High
Scheduler
Store Data
Legacy Decode Pipeline
256K L2 Cache
32K Data Cache
Micro-op queue
0
1
2
4
5
3
0
1
5
0
1
5
Out-of-order Engine
uncore
Front End

Integer ALU & Shift
Integer ALU & LEA
Load & Store Addr.
Store Data Integer
ALU & LEA
FP Mul
Vector Int Multiply
Vector Logicals
Branch
Divide
Vector Shifts
FP Add
Vector Int ALU
Vector Logicals
Vector Shuffle
Vector Int ALU
Vector Logicals
Po
rt 0
Po
rt 1
Po
rt 4
Po
rt 5
Microarchitecture Sandy Bridge: Unités d’exécution
Po
rt 2
Po
rt 3
- Jusqu’à 6 instructions par cycle: • 3 instructions
mémoires (P2,3,4) • 3 instructions de
calculs (P0,1,5) • En particulier 2
instructions ADD ou MUL en FP
Instruction Set
SP FLOPs per cycle per core
DP FLOPs per cycle per core
L1 Cache Bandwidth (Bytes/cycle)
L2 Cache Bandwidth
(Bytes/cycle)
AVX
(256-bits) 16 8
48 (32B read + 16B write)
32

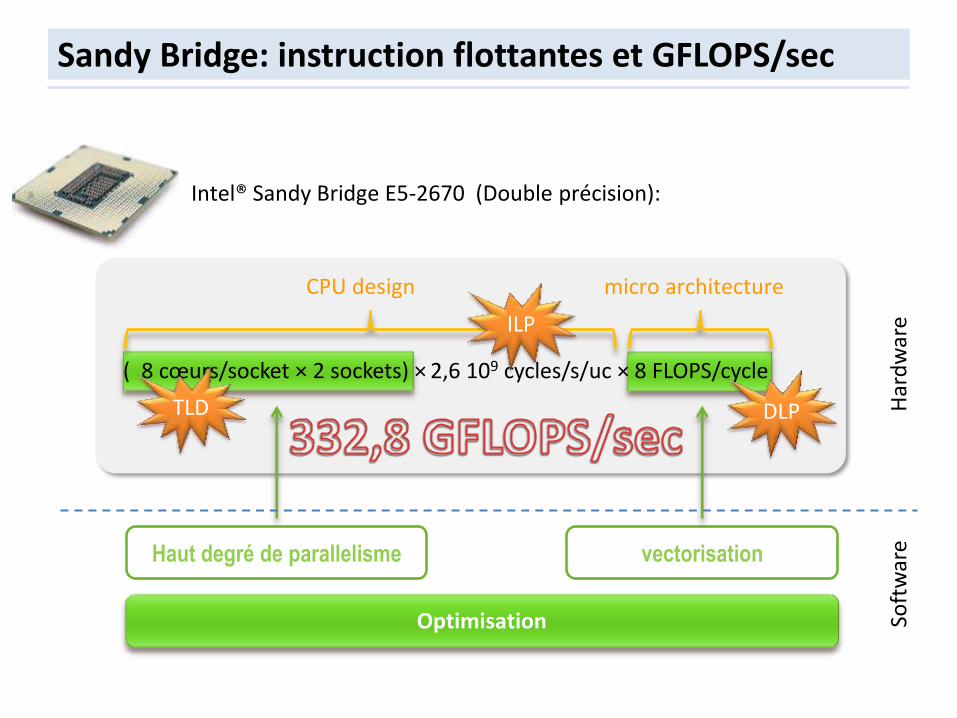
Sandy Bridge: instruction flottantes et GFLOPS/sec
FP Mul FP Add 2 instructions par cycle Instructions
Opérandes 8 opérations FP32
ou 4 operations par instruction
FP32
YMM: 256 bits
FP32
FP32
FP32
FP32
FP32
FP32
FP32
FP64 FP64 FP64 FP64
16 opérations FP32 ou
8 operations par cycle

Sandy Bridge: instruction flottantes et GFLOPS/sec
FP Mul FP Add 2 instructions par cycle Instructions
Opérandes 8 opérations FP32
ou 4 operations par instruction
FP32
YMM: 256 bits
FP32
FP32
FP32
FP32
FP32
FP32
FP32
FP64 FP64 FP64 FP64
16 opérations FP32 ou
8 operations par cycle
src1 FP64
FP64
FP64
op
FP64
FP64
FP64
op
FP64
FP64
FP64
op
FP64
FP64
FP64
op
src2
dest
Sandy Bridge: instruction flottantes et GFLOPS/sec
Haut degré de parallelisme vectorisation
Intel® Sandy Bridge E5-2670 (Double précision):
micro architecture CPU design
Optimisation
2,6 109 cycles/s/uc × 8 FLOPS/cycle ( 8 cœurs/socket × 2 sockets) ×
Har
dw
are
So
ftw
are
ILP
TLD DLP

Xeon Phi™: instruction flottantes et GFLOPS/sec
Haut degré de parallelisme vectorisation
Intel® Xeon Phi™ 5110P (Double précision):
micro architecture CPU design
Optimisation
1,1 109 cycles/s/uc × 16 FLOPS/cycle (60 cœurs/socket × 1 socket ) ×
Har
dw
are
So
ftw
are

Performance, Puissance, FLOPS/sec …
• Est-ce que seul les GFLOPS/Sec comptent ?
– Top500
• Il faut aussi « bouger les données » et alimenter le processeur.
𝑡 = 𝑡𝑀 + 𝑡𝐶 = 𝑛𝑚𝑡𝑚 + 𝑛𝑐𝑡𝑐 = 𝑛𝑐𝑡𝑐 1 +𝑡𝑚
𝑡𝑐
1
𝑞 avec 𝑞 =
𝑛𝑐
𝑛𝑚 [FLOPS/bytes]
❶ Code Memory bound
❷ Code CPU bound
A
B
𝒒 =𝒏𝒄
𝒏𝒎 [FLOPS/bytes]

Performance, Puissance, FLOPS/sec …
DAXPY DGEMM (naive) DGEMM (mkl)
6.4 GFLops/sec 27.2 GFlops/sec 487.8 GFlops/sec
Ne réinventer pas la roue: utiliser des librairies optimisées! Intel® MKL, AMD® ACML, OpenBLAS …

Roofline Model
• « Roofline model » – La performance est bornée par le « pic
FLOP » théorique de la machine et le produit de la bande passante avec q
1
2
4
8
16
32
64
128
256
512
1024
2048
0.031250.06250.125 0.25 0.5 1 2 4 8 16 32 64 128
Att
ain
able
GFl
op
s/se
c
Compute Intensity (Flops/bytes)
Quel est le « pic » atteignable pour mon application (disons mon kernel) ?
E5-2697v2
CPU bound Domain
Memory bound Domain

Roofline Model
• « Roofline model » – La performance est bornée par le « pic
FLOP » théorique de la machine et le produit de la bande passante avec q
• Il faut estimer le pic réellement atteignable en fonction des caractéristiques de sont code – vectorisation
– Utilisation des opérations flottantes
– …
• Le modèle a ces limites. – Par exemple, Le modèle ne prends pas
en compte les comunications
1
2
4
8
16
32
64
128
256
512
1024
2048
0.031250.06250.125 0.25 0.5 1 2 4 8 16 32 64 128
Att
ain
able
GFl
op
s/se
c
Compute Intensity (Flops/bytes)
Quel est le « pic » atteignable pour mon application (disons mon kernel) ?
Mesure
Pic atteignable
E5-2697v2
Pas de vectorisation
Pas de prefetch

Roofline Model
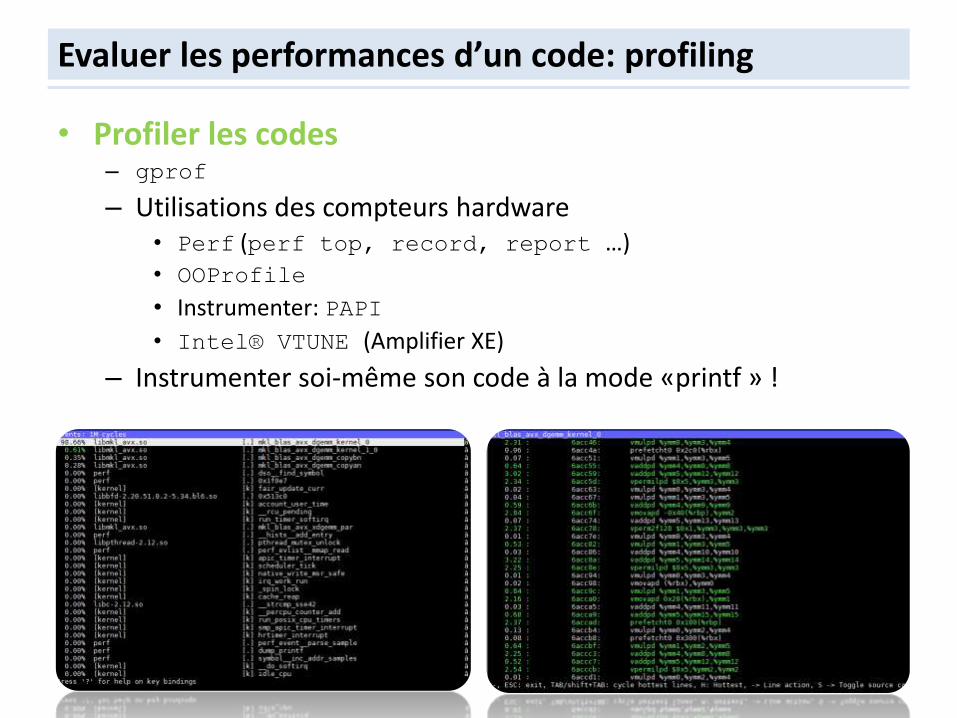
Evaluer les performances d’un code: profiling
• Profiler les codes – gprof
– Utilisations des compteurs hardware • Perf (perf top, record, report …)
• OOProfile
• Instrumenter: PAPI
• Intel® VTUNE (Amplifier XE)
– Instrumenter soi-même son code à la mode «printf » !

Evaluer les performances d’un code: VTUNE Amplifier

Evaluer les performances d’un code: VTUNE Amplifier
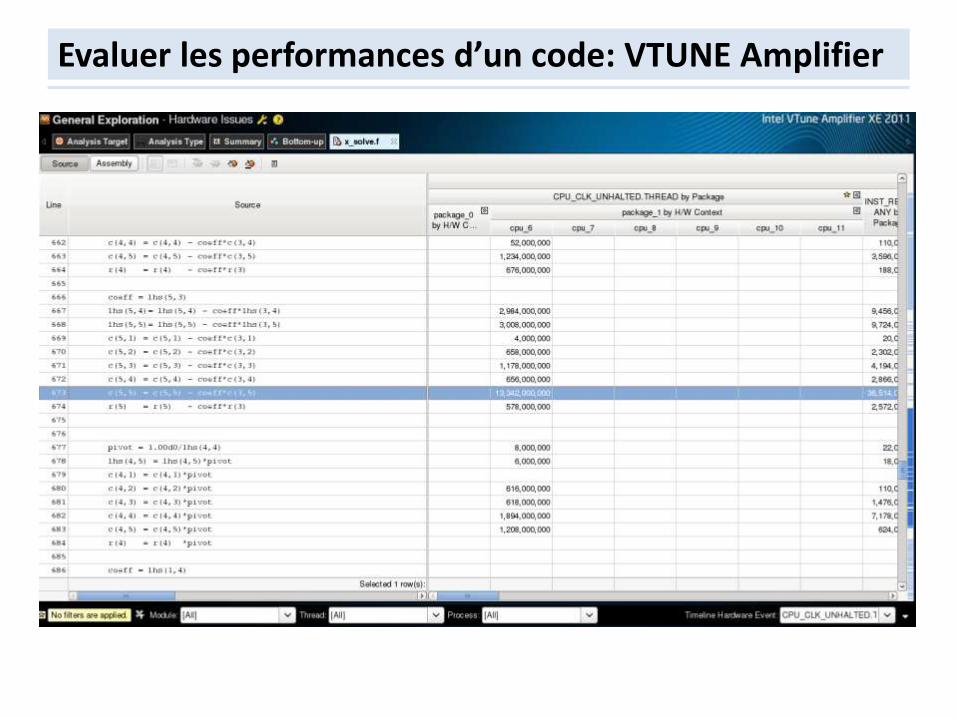
Evaluer les performances d’un code: VTUNE Amplifier

Comptage empirique | mesurer le temps
Différentes “sources de temps” sont disponibles
– appel système gettimeofday() – Time Stamp Counter (TSC)
• compteur 64 bits, compte le nombre de cycles depuis le reset • Attention: la façon exacte dont il est incrémenté dépend du processeur • peut être lu avec l'instruction rdtsc
– Disponible pour l’utilisateur
• Problemes : – La fonction n’est pas sérialisante (out-of-ordering)
» Solution : faire précéder la rdtsc d’un appel à l’instruction cpuid – Cache instruction miss … – Overhead rtdsc+cpuid : >200 cycles ! Il faut le prendre en compte …
– Autres compteurs matériels • Précis • Nécessite d’utiliser les instruction privilégiées rdmsr et wrmsr (“ring 0”).
– Module d’interfaçage avec le noyau, au moins pour “enabler” les compteurs de performances …
cpuid
rdtsc ; read time stamp
mov time, eax ; move counter into variable
fdiv ; floating-point divide
cpuid
rdtsc ; read time stamp
sub eax, time ; find the differenc

Comptage empirique | mesurer le temps
#define SERIALIZE() { \
asm volatile ("xorl %%eax,%%eax":::"eax");\
asm volatile ("cpuid":::"eax","ebx","ecx","edx"); \
}
typedef unsigned long long ticks;
ticks getticks(void)
{
unsigned a, d;
SERIALIZE();
asm volatile("rdtsc" : "=a" (a), "=d" (d));
return ((ticks)a) | (((ticks)d) << 32);
}
int main () {
double t0,t1;
ticks T0,T1;
T0=getticks();
t0=dtime();
sleep(1);
t1=dtime();
T1=getticks();
printf("%.1f\n",(double)(T1-T0)/(t1-t0)*1e-6) ;
return 0;
}

Sandy Bridge: instruction flottantes et GFLOPS/sec
Kernel Code Cycles par opération(*)
SAXPY for(inti=1; i<N; i++)
s[i] = a * x[i] + y[i]; 2.32 cycles
SASPY for(inti=1; i<N; i++)
s[i] = a * s[i-1] + y[i]; 14.1 cycles
(*) nombre total de cycle / N Pas de vectorisation, ni unrolling, données résidant dans le cache L1
movsd xmm1, QWORD PTR [array+rdx*8]
mulsd xmm1, xmm0
addsd xmm1, QWORD PTR [r9+rdx*8]
movsd QWORD PTR [r8+rdx*8], xmm1
inc rdx
cmp rdx, 2048
jb ..B1.35
movsd xmm1, QWORD PTR [65528+array+rdx*8]
mulsd xmm1, xmm0
addsd xmm1, QWORD PTR [r13+rdx*8]
movsd QWORD PTR [r8+rdx*8], xmm1
inc rdx
cmp rdx, 2048
jb ..B1.27
for(inti=1; i<N; i++) // SASPY
s[i] = a * S[i-1] + y[i]; :w
for(inti=1; i<N; i++) // SAXPY
s[i] = a * x[i] + y[i];
Inspection du code Assembleur: (-S –masm=intel)
Même séquence d’instructions !

Throughput et Latence d’instructions
Deux notions importantes: – Throughput: fréquence à laquelle une instruction peut-être émise,
dans le meilleur des cas sans dépendance de données;
– Latence: temps nécessaire pour qu’une instruction se termine et fournisse son résultat ;
Timing (cycles) Inst r0,r1
Inst r2,r1
5 cycles de latence 1 instruction par cycle
Timing (cycles)
4 cycles de latence
2 instructions par cycle
Timing (cycles) Inst r0, r1
Inst r2, r0
Inst r3, r1
Inst r4, r3

Throughput et Latence d’instructions
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
movsd xmm1, QWORD PTR [] 1 CP
mulsd xmm1, xmm0 1 CP
addsd xmm1, QWORD PTR [r9+rdx*8] 1 CP
movsd QWORD PTR [r8+rdx*8], xmm1
inc rdx
cmp rdx, 2048
jb ..B1.35
Cycles
iaca -64 -arch SNB -analysis LATENCY saspy.o
Intel(R) Architecture Code Analyzer Version - 2.1
…
Latency Analysis Report
---------------------------
Latency: 15 Cycles
…
| Inst | Resource Delay In Cycles | |
| Num | 0 - DV | 1 | 2 - D | 3 - D | 4 | 5 | FE | |
---------------------------------------------------------------
| 0 | | | | | | | | CP | movsd xmm1, qword ptr [r8+rdx*8-0x8]
| 1 | | | | | | | | CP | mulsd xmm1, xmm0
| 2 | | | | | | | | CP | addsd xmm1, qword ptr [r13+rdx*8]
| 3 | | | | | | | 1 | CP | movsd qword ptr [r8+rdx*8], xmm1
| 4 | | | | | | | 1 | | inc rdx
| 5 | | | | | | | | | cmp rdx, 0x800
| 6 | | | | | | | | | jb 0xffffffffffffffd6
Latence 15 cycles
Throughput 1-2 cycles

Throughput et Latence d’instructions
Sandy Bridge DIVPS SQRTPS DIVPS SQRTPD
Latence 28 28 42 42
Troughput 28 28 42 42
Ivy Bridge DIVPS SQRTPS DIVPS SQRTPD
Latence 21 21 35 35
Troughput 14 14 28 28

Data Level Parallelism:
La vectorisation

Vectorisation | Exemple de SSE et AVX
x x
XMM0
XMM1
XMM2
x x
YMM0
YMM1
YMM2
x x
SSE AVX
128-bits 256-bits
= 2 opérations simultanées = 4 opérations simultanées
Une Instruction …
YMM0
256-bits
XMM0
128-bits

Quelles méthodes pour vectoriser ?
Compiler: Auto-vectorization (no change of code)
Compiler: Auto-vectorization hints (#pragma vector, …)
SIMD intrinsic class (e.g.: F32vec, F64vec, …)
Vector intrinsic (e.g.: _mm_fmadd_pd(…), _mm_add_ps(…), …)
Assembler code (e.g.: [v]addps, [v]addss, …)
Compiler: Intel® Cilk™ Plus Array Notation Extensions
Co
mp
ilate
ur
Low
-lev
el p
rogr
amm
ing
Facilité d’utilisation
Contrôle

Quelles méthodes pour vectoriser ?
High level programming
Low level programming
Standard Propriétaire
Auto-vectorization
Auto-vectorization hints
SIMD intrinsic class
Vector intrinsic
Assembler code
Intel® Cilk™ Plus Array Notation Extensions
OpenMP 4.0
Diagnostiquer …
• Demander le reporting au compilateur

Ecouter les conseils du compilateur: reporting
n Diagnostic Messages
0 Tells the vectorizer to report no diagnostic information. Useful for turning off reporting in case it was enabled on command line earlier.
1 Tells the vectorizer to report on vectorized loops. [default if n missing]
2 Tells the vectorizer to report on vectorized and non-vectorized loops.
3 Tells the vectorizer to report on vectorized and non-vectorized loops and any proven or assumed data dependences.
4 Tells the vectorizer to report on non-vectorized loops.
5 Tells the vectorizer to report on non-vectorized loops and the reason why they were not vectorized.
6*
Tells the vectorizer to use greater detail when reporting on vectorized and non-vectorized loops and any proven or assumed data dependences.
Compilateur Intel: -vec-report=<n>
Compilateur gcc: -ftree-vectorizer-verbose=<n>

Diagnostiquer …
vmulpd ymm1, ymm0, YMMWORD PTR [rax+r14]
vaddpd ymm2, ymm1, YMMWORD PTR [rdx+r14]
vmovntpd YMMWORD PTR [rdi+r14], ymm2
#pragma omp parallel for
#pragma unroll(4)
for(i=0;i<N;i+=1) {
C[i]=alpha*A[i]+B[i];
}
Sans vectorisation
Avec vectorisation
[s,d]
Single Double
AVX
{v} OP
Scalar Packed
[s,p] movsd xmm1, QWORD PTR [8+r9+rdi]
mulsd xmm0, xmm4
addsd xmm0, QWORD PTR [r9+rcx]
movsd QWORD PTR [r9+r8], xmm0
• Demander le reporting au compilateur
• Editer l’assembleur …
– Générer l’assembleur à la compilation: « -S –masm=intel »
– Désassembler un binaire ou un fichier objet: « objdump -M intel –D mon_binaire.x»

Diagnostiquer …
• Demander le reporting au compilateur
• Editer l’assembleur …
– Générer l’assembleur à la compilation: « -S –masm=intel »
– Désassembler un binaire ou un fichier objet: « objdump -M intel –D mon_binaire.x»
• Par l’expérience:
– Comparer les différents niveaux de vectorisation: • AVX, SSE
• Sans vectorisation: « -no-vec »
• Malgré tout je n’observe pas de bénéfice de la vectorisation, pourquoi ?

Diagnostiquer …
vmulpd ymm1, ymm0, YMMWORD PTR [rax+r14]
vaddpd ymm2, ymm1, YMMWORD PTR [rdx+r14]
vmovntpd YMMWORD PTR [rdi+r14], ymm2
movups xmm1, XMMWORD PTR [r8+r11]
mulpd xmm1, xmm0
addpd xmm1, XMMWORD PTR [r9+r11]
movntpd XMMWORD PTR [rdx+r11], xmm1
export OMP_NUM_THREADS=16
export KMP_AFFINITY=verbose,compact
./triad.x 1.000001
movsd xmm1, QWORD PTR [8+r9+rdi]
mulsd xmm0, xmm4
addsd xmm0, QWORD PTR [r9+rcx]
movsd QWORD PTR [r9+r8], xmm0
Mbytes/sec MFLops/sec
AVX 76,065 6,338
SSE 76,382 6,365 no-vec 60,382 5,031
-no-vec
SSE 4.2
AVX
#pragma omp parallel for
#pragma unroll(4)
for(i=0;i<N;i+=1) {
C[i]=alpha*A[i]+B[i];
}
0
1000
2000
3000
4000
5000
6000
7000
AVX SSE no-vec
MFLops/sec
Bande Passante mémoire est un facteur limitant !

Problèmes à la vectorisation
● Dépendance des données : attention à l’“aliasing”, design,
pragma “hints”

Dépendances des données
for(i=2;i<=N; i++)
a[i]=a[i-1]+b[i];
a[2] = a[1] + b[2];
a[3] = a[2] + b[3];
a[4] = a[3] + b[4];
a[5] = a[4] + b[5];
for(i=1;i<=N-1;i++)
a[i]=a[i+1]+b[i];
a[1] = a[2] + b[1];
a[2] = a[3] + b[2];
a[3] = a[4] + b[3];
a[4] = a[5] + b[4];
WAR : « write after read » RAW : « read after write »
Non vectorisable Vectorisable

Dépendances des données
• Autres dépendances:
– RAR : « read after read »
• Vectorisable Pas réellement un dépendance.
– WAW : « read after write »
• Non vectorisable
for(i=1;i<=N; i++)
a[i]=b[i%M]+c[i];
for(i=1;i<=N; i++)
a[i%M]=b[i]+c[i];

Dépendances des données
void scale(double *A,const int k, const double alpha,const int N)
{
int i;
#pragma ivdep
for(i=0;i<N;i+=1)
A[i] = alpha*A[i+k];
}
icc -c vec.c -vec-report=6
vec.c(6): (col. 2) remark: vectorization support: unroll factor set to 4.
vec.c(6): (col. 2) remark: LOOP WAS VECTORIZED.
vec.c(6): (col. 2) remark: loop was not vectorized: existence of vector dependence.
vec.c(7): (col. 3) remark: vector dependence: assumed ANTI dependence between A line 7 and A line 7.
vec.c(7): (col. 3) remark: vector dependence: assumed FLOW dependence between A line 7 and A line 7.
vec.c(7): (col. 3) remark: vector dependence: assumed FLOW dependence between A line 7 and A line 7.
vec.c(7): (col. 3) remark: vector dependence: assumed ANTI dependence between A line 7 and A line 7.
vec.c(6): (col. 2) remark: loop skipped: multiversioned.
icc -c vec.c -vec-report=6
vec.c(7): (col. 2) remark: vectorization support: unroll factor set to 4.
vec.c(7): (col. 2) remark: LOOP WAS VECTORIZED.
gcc -c vec.c \
-O3 -ftree-vectorize -ftree-vectorizer-verbose=2 \
-march=corei7-avx -mtune=corei7-avx

Vectoriser …
alloc_section
distribute_point
inline, noinline,forceinline
ivdep
loop_count
memref_control
novector
optimize
optimization_level
prefetch/noprefetch
simd
unroll/nounroll
unroll_and_jam/nounroll_and_jam
Vector (always/aligned/assert/unaligned/nontemporal/temp
oral)
C/C++ #pragma <keyword>
Fortran !DEC$ <keyword>

Dépendances des données et aliasing
void my_combine(int * ioff, int nx, double * a, double * b, double * c)
{
int i;
#pragma ivdep
for(i=0; i<nx; i++)
a[i]=b[i]+c[i+*ioff];
}
icc -c combine.c -vec-report=3
combine.c(4): (col. 2) remark: loop was not vectorized: existence of vector dependence.
combine.c(5): (col. 3) remark: vector dependence: assumed ANTI dependence between c line 5 and a line 5.
combine.c(5): (col. 3) remark: vector dependence: assumed FLOW dependence between a line 5 and c line 5.
combine.c(5): (col. 3) remark: vector dependence: assumed FLOW dependence between a line 5 and c line 5.
combine.c(5): (col. 3) remark: vector dependence: assumed ANTI dependence between c line 5 and a line 5.
combine.c(5): (col. 3) remark: vector dependence: assumed ANTI dependence between ioff line 5 and a line 5.
combine.c(5): (col. 3) remark: vector dependence: assumed FLOW dependence between a line 5 and ioff line 5.
combine.c(5): (col. 3) remark: vector dependence: assumed FLOW dependence between a line 5 and ioff line 5.
combine.c(5): (col. 3) remark: vector dependence: assumed ANTI dependence between ioff line 5 and a line 5.
combine.c(5): (col. 3) remark: vector dependence: assumed ANTI dependence between b line 5 and a line 5.
combine.c(5): (col. 3) remark: vector dependence: assumed FLOW dependence between a line 5 and b line 5.
combine.c(5): (col. 3) remark: vector dependence: assumed FLOW dependence between a line 5 and b line 5.
combine.c(5): (col. 3) remark: vector dependence: assumed ANTI dependence between b line 5 and a line 5.
icc -c combine.c -vec-report=3
combine.c(5): (col. 2) remark: loop was not vectorized: vectorization possible but seems inefficient.

Dépendances des données et aliasing
void my_combine(int * ioff, int nx, double * a, double * b, double * c)
{
int i;
#pragma simd
for(i=0; i<nx; i++)
a[i]=b[i]+c[i+*ioff];
}
icc -c combine.c -vec-report=3
combine.c(4): (col. 2) remark: loop was not vectorized: existence of vector dependence.
combine.c(5): (col. 3) remark: vector dependence: assumed ANTI dependence between c line 5 and a line 5.
combine.c(5): (col. 3) remark: vector dependence: assumed FLOW dependence between a line 5 and c line 5.
combine.c(5): (col. 3) remark: vector dependence: assumed FLOW dependence between a line 5 and c line 5.
combine.c(5): (col. 3) remark: vector dependence: assumed ANTI dependence between c line 5 and a line 5.
combine.c(5): (col. 3) remark: vector dependence: assumed ANTI dependence between ioff line 5 and a line 5.
combine.c(5): (col. 3) remark: vector dependence: assumed FLOW dependence between a line 5 and ioff line 5.
combine.c(5): (col. 3) remark: vector dependence: assumed FLOW dependence between a line 5 and ioff line 5.
combine.c(5): (col. 3) remark: vector dependence: assumed ANTI dependence between ioff line 5 and a line 5.
combine.c(5): (col. 3) remark: vector dependence: assumed ANTI dependence between b line 5 and a line 5.
combine.c(5): (col. 3) remark: vector dependence: assumed FLOW dependence between a line 5 and b line 5.
combine.c(5): (col. 3) remark: vector dependence: assumed FLOW dependence between a line 5 and b line 5.
combine.c(5): (col. 3) remark: vector dependence: assumed ANTI dependence between b line 5 and a line 5.
icc -c combine.c -vec-report=3
combine.c(5): (col. 2) remark: loop was not vectorized: vectorization possible but seems inefficient.
icc -c combine.c -vec-report=6
combine.c(5): (col. 2) remark: vectorization support: unroll factor set to 4.
combine.c(5): (col. 2) remark: SIMD LOOP WAS VECTORIZED.

Dépendances des données et aliasing
void my_combine(
int * ioff, int nx,
double * a, double * b, double * c)
{
int i;
for(i=0; i<nx; i++)
a[i]=b[i]+c[i+*ioff];
}
icc -c combine.c -vec-report=6 -ansi-alias
combine.c(5): (col. 2) remark: vectorization support: unroll factor set to 4.
combine.c(5): (col. 2) remark: LOOP WAS VECTORIZED.
combine.c(5): (col. 2) remark: loop skipped: multiversioned.
Indiquer au compilateur que vous adhérer (!) au ISO C Standard aliasability rules dans votre style de programmation (pas d’aliasing de pointeurs).
Attention: portée globale de l’option …

Dépendances des données et aliasing
void my_combine(
int * ioff, int nx,
double * restrict a, double * restrict b, double * restrict c)
{
int i;
for(i=0; i<nx; i++)
a[i]=b[i]+c[i+*ioff];
}
icc -c combine.c -vec-report=6 -restrict
combine.c(4): (col. 2) remark: vectorization support: unroll factor set to 4.
combine.c(4): (col. 2) remark: LOOP WAS VECTORIZED.
icc -c combine.c -vec-report=6 -ansi-alias
combine.c(5): (col. 2) remark: vectorization support: unroll factor set to 4.
combine.c(5): (col. 2) remark: LOOP WAS VECTORIZED.
combine.c(5): (col. 2) remark: loop skipped: multiversioned.
Indiquer au compilateur que vous adhérer (!) au ISO C Standard aliasability rules dans votre style de programmation (pas d’aliasing de pointeurs).
Attention: portée globale de l’option …

Problèmes à la vectorisation
● Dépendance des données : attention à l’“aliasing” design,
pragma “hints”
● Alignement des données : aligner vos données, pragma “hints”

Alignement des données
64 bytes 64 bytes
16 16 16 16 16 16 16 16
16 16 16 16 16 16 16 16
32 32 32 32
32 32 32 32
Lignes de cache
Non-alignées
Non-alignées
Alignées
Alignées
• Peut être pénalisant. Mieux vaut aligner les données sur la taille des vecteurs.
64 bytes

Alignement des données
• Peut être pénalisant. Mieux vaut aligner les données sur la taille des vecteurs – Différentes méthodes:
• Allocation: posix_memalign(),_mm_malloc(),…
• Statique: __attribute__((aligned(32))),__declspec(align(32))
• Indiquer au compilateur que les données sont alignées – Attention: il ne suffit de le dire, il faut le faire ;-)
#define N 1000000000
double A[N] ;
double B[N] ;
double S[N] ;
#pragma vector aligned(A,B,C)
for(i=0;i<N;i+=1)
{
C[i]=0.0;
A[i]=1.0;
B[i]=0.1;
}
#define N 1000000000
double A[N] __attribute__((aligned(64)));
double B[N] __attribute__((aligned(64)));
double S[N] __attribute__((aligned(64)));
#pragma vector aligned(A,B,C)
for(i=0;i<N;i+=1)
{
C[i]=0.0;
A[i]=1.0;
B[i]=0.1;
}
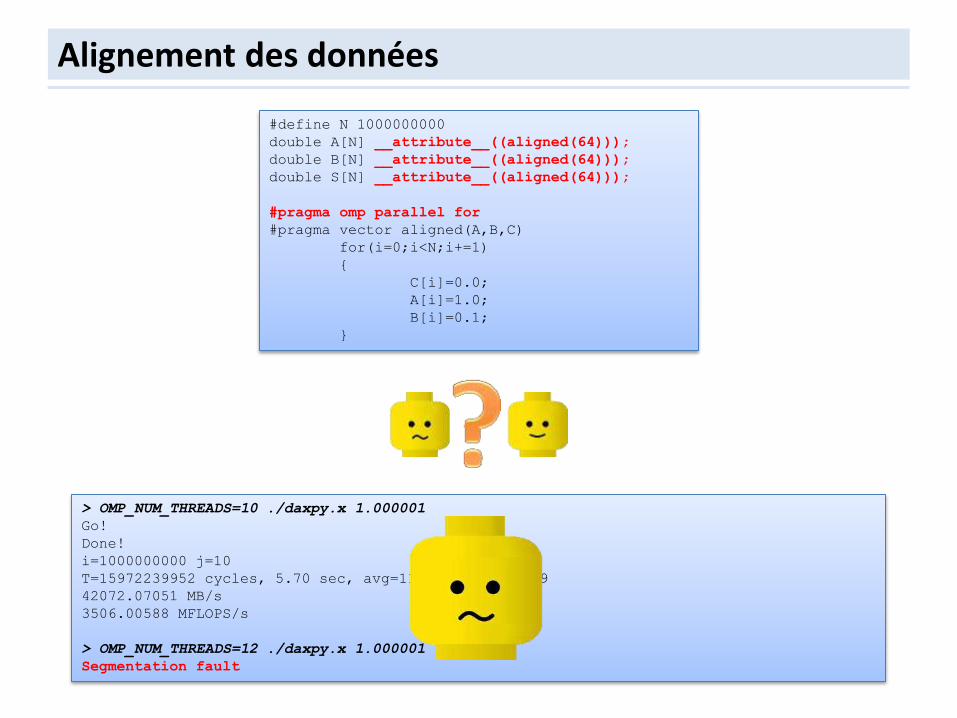
Alignement des données
#define N 1000000000
double A[N] __attribute__((aligned(64)));
double B[N] __attribute__((aligned(64)));
double S[N] __attribute__((aligned(64)));
#pragma omp parallel for
#pragma vector aligned(A,B,C)
for(i=0;i<N;i+=1)
{
C[i]=0.0;
A[i]=1.0;
B[i]=0.1;
}
> OMP_NUM_THREADS=10 ./daxpy.x 1.000001
Go!
Done!
i=1000000000 j=10
T=15972239952 cycles, 5.70 sec, avg=11.33 sum=1.1e+09
42072.07051 MB/s
3506.00588 MFLOPS/s
> OMP_NUM_THREADS=12 ./daxpy.x 1.000001
Segmentation fault

Problèmes à la vectorisation
● Dépendance des données : attention à l’“aliasing” design,
pragma “hints”
● Alignement des données : aligner vos données, pragma “hints”
● Appel de fonctions dans les boucles : in-lining (aggressif: IPO)

Inlining (aggressif …)
double scale(double scale, double x) {
return(scale*x) ;};
void saxpy(float *A,float *B, float *C, const float
alpha, const int N)
{
int i;
for(i=0;i<N;i+=1)
C[i] = A[i]+scale(alpha,B[i]);
}
> icc -o main.x main.c scale.c saxpy.c -vec-report=3 -O2 -ipo
main.c(11): (col. 2) remark: LOOP WAS VECTORIZED.
main.c(11): (col. 2) remark: REMAINDER LOOP WAS VECTORIZED.
main.c(14): (col. 2) remark: loop was not vectorized: existence of vector dependence.
> icc -o main.x main.c scale.c saxpy.c -vec-report=3 -O2
main.c(14): (col. 2) remark: loop was not vectorized: existence of vector dependence.
saxpy.c(5): (col. 1) remark: routine skipped: no vectorization candidates.
scale.c
saxpy.c
movaps xmm1,XMMWORD PTR [rax*4+0x602360]
movaps xmm2,XMMWORD PTR [rax*4+0x602370]
movaps xmm3,XMMWORD PTR [rax*4+0x602380]
movaps xmm4,XMMWORD PTR [rax*4+0x602390]
mulps xmm1,xmm0
mulps xmm2,xmm0
mulps xmm3,xmm0
addps xmm1,XMMWORD PTR [rax*4+0x601260]
mulps xmm4,xmm0
addps xmm2,XMMWORD PTR [rax*4+0x601270]
addps xmm3,XMMWORD PTR [rax*4+0x601280]
addps xmm4,XMMWORD PTR [rax*4+0x601290]
movaps XMMWORD PTR [rax*4+0x603460],xmm1
movaps XMMWORD PTR [rax*4+0x603470],xmm2
movaps XMMWORD PTR [rax*4+0x603480],xmm3
movaps XMMWORD PTR [rax*4+0x603490],xmm4
add rax,0x10
cmp rax,0x3e0
jb 400600 <main+0x40>

Inlining …
icc -O2 -ip -c trigo.c -vec-report=2
trigo.c(4): (col. 2) remark: LOOP WAS VECTORIZED.
trigo.c(4): (col. 2) remark: loop skipped: multiversioned.
void trigo(float *A,float *B, float *C, const int N)
{
int i;
for(i=0;i<N;i+=1)
C[i] = cosf(A[i])+sinf(B[i]);
}
movaps xmm0, XMMWORD PTR [r13+rbp*4]
call __svml_cosf4
movaps xmm8, xmm0
movaps xmm0, XMMWORD PTR [r14+rbp*4]
call __svml_sinf4
addps xmm8, xmm0
movaps XMMWORD PTR [r15+rbp*4], xmm8
add rbp, 4
cmp rbp, rbx
jb ..B1.4
Short Vector Math Library

Problèmes à la vectorisation
● Dépendance des données : attention à l’“aliasing” design,
pragma “hints”
● Alignement des données : aligner vos données, pragma “hints”
● Appel de fonctions dans les boucles : in-lining (aggressif: IPO)
● Branches dans les boucles: créer plusieurs version de la boucle
en sortant la condition
● “Loop body too complex reports” : Design, Loop splitting …
● Stride non unitaire: design, gather (Haswell, Xeon Phi)
● “Vectorization seems inefficient reports” : Design, pragma
“hints”
● “Not inner loop” : unroll and jam, loop interchange …
