on evaluating gpfs research work that has been done at hlrs by alejandro calderon
Post on 19-Dec-2015
213 views
TRANSCRIPT

On evaluating GPFS
Research work that has been done at HLRS byAlejandro Calderon

acaldero @ arcos.inf.uc3m.es
HPC-Europa (HLRS) 2
On evaluating GPFS
Short description
Metadata evaluation fdtree
Bandwidth evaluation Bonnie Iozone
IODD IOP

acaldero @ arcos.inf.uc3m.es
HPC-Europa (HLRS) 3
GPFS description http://www.ncsa.uiuc.edu/UserInfo/Data/filesystems/index.html
General Parallel File System (GPFS) is a parallel file system package developed by IBM.
History: Originally developed for IBM's AIX operating system then ported to Linux Systems.
Features: Appears to work just like a traditional UNIX file system from the user application level. Provides additional functionality and enhanced performance when accessed via parallel interfaces such as MPI-I/O. High performance is obtained by GPFS by striping data across multiple nodes and disks. Striping is performed automatically at the block level. Therefore, all files (larger than the designated block size) will be striped. Can be deployed in NSD or SAN configurations. Clusters hosting a GPFS file system can allow other clusters at different geographical locations to mount that file system.

acaldero @ arcos.inf.uc3m.es
HPC-Europa (HLRS) 4
GPFS (Simple NSD Configuration)

acaldero @ arcos.inf.uc3m.es
HPC-Europa (HLRS) 5
GPFS evaluation (metadata)
fdtree Used for testing the metadata performance of a file system Create several directories and files, in several levels
Used on: Computers:
noco-xyz Storage systems:
Local, GPFS

acaldero @ arcos.inf.uc3m.es
HPC-Europa (HLRS) 6
fdtree [local,NFS,GPFS]
0
500
1000
1500
2000
2500
Op
era
tio
ns
/Se
c.
Directory creates persecond
File creates per second File removals persecond
Directory removals persecond
./fdtree.bash -f 3 -d 5 -o X
/gpfs
/tmp
/mscratch

acaldero @ arcos.inf.uc3m.es
HPC-Europa (HLRS) 7
fdtree on GPFS (Scenario 1)ssh {x,...} fdtree.bash -f 3 -d 5 -o /gpfs...
Scenario 1: several nodes, several process per node, different subtrees, many small files
P1 Pm…
nodex
…
… …

acaldero @ arcos.inf.uc3m.es
HPC-Europa (HLRS) 8
fdtree on GPFS (scenario 1)ssh {x,...} fdtree.bash -f 3 -d 5 -o /gpfs...
0
100
200
300
400
500
600
1n-1p 4n-4p 4n-8p 4n-16p 8n-8p 8n-16p
Op
erat
ion
s/S
ec.
Directory creates per second
File creates per second
File removals per second
Directory removals per second

acaldero @ arcos.inf.uc3m.es
HPC-Europa (HLRS) 9
fdtree on GPFS (Scenario 2)ssh {x,...} fdtree.bash -l 1 -d 1 -f 1000 -s 500 -o /gpfs...
Scenario 2: several nodes, one process per node, same subtree, many small files
P1 Px…
…
nodex

acaldero @ arcos.inf.uc3m.es
HPC-Europa (HLRS) 10
fdtree on GPFS (scenario 2)ssh {x,...} fdtree.bash -l 1 -d 1 -f 1000 -s 500 -o /gpfs...
0
5
10
15
20
25
30
35
40
45
1 2 4 8
number of process (1 per node)
File
s c
rea
tes
pe
r s
ec
on
d
working in the same directory
working in different directories

acaldero @ arcos.inf.uc3m.es
HPC-Europa (HLRS) 11
Metadata cache on GPFS ‘client’
hpc13782 noco186.nec 304$ time ls -als | wc -l894
real 0m0.466suser 0m0.010ssys 0m0.052s
Working in a GPFS directory with 894 entries ls –las need to get each file attribute from GPFS
metadata server
In a couple of seconds, the contents of the cache seams disappear
hpc13782 noco186.nec 305$ time ls -als | wc -l894
real 0m0.222suser 0m0.011ssys 0m0.064s
hpc13782 noco186.nec 306$ time ls -als | wc -l894
real 0m0.033suser 0m0.009ssys 0m0.025s
hpc13782 noco186.nec 307$ time ls -als | wc -l894
real 0m0.034suser 0m0.010ssys 0m0.024s

acaldero @ arcos.inf.uc3m.es
HPC-Europa (HLRS) 12
fdtree results
Main conclusions
Contention at directory level: If two o more process from a parallel application need to write
data, please be sure each one use different subdirectories from GPFS workspace
Better results than NFS (but lower that the local file system)

acaldero @ arcos.inf.uc3m.es
HPC-Europa (HLRS) 13
GPFS performance (bandwidth)
Bonnie Read and write a 2 GB file Write, rewrite and read
Used on: Computers:
Cacau1 Noco075
Storage systems: GPFS
acaldero @ arcos.inf.uc3m.es
HPC-Europa (HLRS) 14
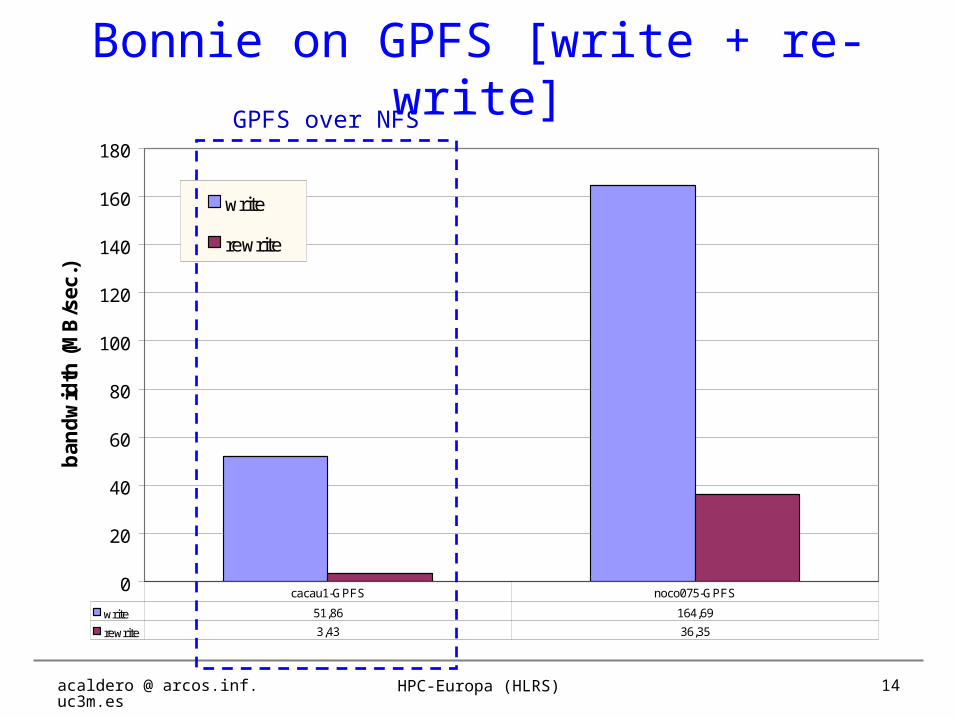
Bonnie on GPFS [write + re-write]
0
20
40
60
80
100
120
140
160
180
ban
dw
idth
(M
B/s
ec.)
write
rewrite
write 51,86 164,69
rewrite 3,43 36,35
cacau1-GPFS noco075-GPFS
GPFS over NFS

acaldero @ arcos.inf.uc3m.es
HPC-Europa (HLRS) 15
Bonnie on GPFS [read]
0
50
100
150
200
250
ban
dw
idth
(M
B/s
ec.)
read
read 75,85 232,38
cacau1-GPFS noco075-GPFS
GPFS over NFS

acaldero @ arcos.inf.uc3m.es
HPC-Europa (HLRS) 16
GPFS performance (bandwidth)
Iozone Write and read with several file size and access size Write and read bandwidth
Used on: Computers:
Noco075 Storage systems:
GPFS

acaldero @ arcos.inf.uc3m.es
HPC-Europa (HLRS) 17
64
12
8
25
6
51
2
10
24
20
48
40
96
81
92
16
38
4
32
76
8
65
53
6
13
10
72
26
21
44
52
42
88
4
32
256
2048
16384
0,00
200,00
400,00
600,00
800,00
1000,00
1200,00
Ba
nd
wid
th (
MB
/s)
File size (KB)
RecLen
(byt
es)
Write on GPFS
1000,00-1200,00
800,00-1000,00
600,00-800,00
400,00-600,00
200,00-400,00
0,00-200,00
Iozone on GPFS [write]

acaldero @ arcos.inf.uc3m.es
HPC-Europa (HLRS) 18
Iozone on GPFS [read]
64
128
256
512
1024
2048
4096
8192
1638
4
3276
8
6553
6
1310
72
2621
44
5242
884
16
64
256
10244096
16384
0,00
500,00
1000,00
1500,00
2000,00
2500,00
Ba
nd
wid
th (
MB
/s)
File size (KB)
RecLen
(byt
es)
Read on GPFS
2000,00-2500,00
1500,00-2000,00
1000,00-1500,00
500,00-1000,00
0,00-500,00

acaldero @ arcos.inf.uc3m.es
HPC-Europa (HLRS) 19
GPFS evaluation (bandwidth)
IODD Evaluation of disk performance by using several nodes:
disk and networking A dd-like command that can be run from MPI
Used on: 2, and 4 nodes,
4, 8, 16, and 32 process (1, 2, 3, and 4 per node) that write a file of 1, 2, 4, 8, 16, and 32 GB
By using both, POSIX interface and MPI-IO interface
next ->

acaldero @ arcos.inf.uc3m.es
HPC-Europa (HLRS) 20
How IODD works…
a b .. n a b .. n a b .. n
P1 P2 Pm…
…
nodex = 2, 4 nodes processm = 4, 8, 16, and 32 process (1, 2, 3, 4 per node)
file sizen = 1, 2, 4, 8, 16 and 32 GB
nodex

acaldero @ arcos.inf.uc3m.es
HPC-Europa (HLRS) 21
IODD on 2 nodes [MPI-IO]
1 2 4 816
32
8
2
0
20
40
60
80
100
120
140
160
180GPFS (writing, 2 nodes)bandwidth (MB/sec.)
process per node
file size (GB)
160-180140-160120-140100-12080-10060-8040-6020-400-20

acaldero @ arcos.inf.uc3m.es
HPC-Europa (HLRS) 22
1 2 4 816
32
8
2
0
20
40
60
80
100
120
140
160
180GPFS (writing, 4 nodes)
bandwidth (MB/sec.)
process per node
file size (GB)
160-180140-160120-140100-12080-10060-8040-6020-400-20
IODD on 4 nodes [MPI-IO]

acaldero @ arcos.inf.uc3m.es
HPC-Europa (HLRS) 23
Differences by using different APIs
12
48
1632
16
8
4
21
0
20
40
60
80
100
120
140
160
180GPFS (writing, 2 nodes)
bandwidth (MB/sec.)
process per node
file size (GB)
160-180140-160120-140100-12080-10060-8040-6020-400-20
GPFS (2 nodes, POSIX) GPFS (2 nodes, MPI-IO)
1 2 48
32
16
84
21
0
10
20
30
40
50
60
70GPFS (writing, 2 nodes)
bandwidth (MB/sec.)
process per node
file size (GB)
60-7050-6040-5030-4020-3010-200-10

acaldero @ arcos.inf.uc3m.es
HPC-Europa (HLRS) 24
IODD on 2 GB [MPI-IO, = directory]
1
2
4
8
16
32
0
20
40
60
80
100
120
140
160
Number of nodes
GPFS (writing, 1-32 nodes, same directory)bandwidth (MB/sec.)

acaldero @ arcos.inf.uc3m.es
HPC-Europa (HLRS) 25
IODD on 2 GB [MPI-IO, ≠ directory]
1
2
4
8
16
32
0
20
40
60
80
100
120
140
160
Number of nodes
GPFS (writing, 1-32 nodes, different directories)bandwidth (MB/sec.)

acaldero @ arcos.inf.uc3m.es
HPC-Europa (HLRS) 26
IODD results
Main conclusions
The bandwidth decrease with the number of processes per node Beware of multithread application with medium-high I/O
bandwidth requirements for each thread
It is very important to use MPI-IO because this API let users get more bandwidth
The bandwidth decrease with more than 4 nodes too With large files, the metadata management seams not to be the main
bottleneck

acaldero @ arcos.inf.uc3m.es
HPC-Europa (HLRS) 27
GPFS evaluation (bandwidth)
IOP Get the bandwidth obtained by writing and reading in parallel
from several processes The file size is divided between the process number so each
process work in an independent part of the file
Used on: GPFS through MPI-IO (ROMIO on Open MPI) Two nodes writing a 2 GB files in parallel
On independent files (non-shared) On the same file (shared)

acaldero @ arcos.inf.uc3m.es
HPC-Europa (HLRS) 28
How IOP works…
2 nodes m = 2 process (1 per node)
n = 2 GB file size
a a .. b b .. x x ..
P1 P2 Pm…
…
File per process (non-shared)
a b .. x a b .. x … a b .. x
P1 P2 Pm…
Segmented access (shared)
n n

acaldero @ arcos.inf.uc3m.es
HPC-Europa (HLRS) 29
IOP: Differences by using shared/non-sharedwriting on file(s) over GPFS
0
20
40
60
80
100
120
140
160
180
1KB
2KB
4KB
8KB
16KB
32KB
64KB
128K
B
256K
B
512K
B1M
B
access size
Ban
dw
idth
(M
B/s
ec.)
NON-shared
shared

acaldero @ arcos.inf.uc3m.es
HPC-Europa (HLRS) 30
reading on file(s) over GPFS
0
20
40
60
80
100
120
140
160
180
200
1KB
2KB
4KB
8KB
16KB
32KB
64KB
128K
B
256K
B
512K
B1M
B
access size
Ban
dw
idth
(M
B/s
ec.)
NON-shared
shared
IOP: Differences by using shared/non-shared

acaldero @ arcos.inf.uc3m.es
HPC-Europa (HLRS) 31
GPFS writing in non-shared files
GPFS writing in a shared file

acaldero @ arcos.inf.uc3m.es
HPC-Europa (HLRS) 32
0
20
40
60
80
100
120
1401
MB
51
2 K
B
25
6 K
B
12
8 K
B
64
KB
32
KB
16
KB
8 K
B
4 K
B
2 K
B
1 K
B
access size
ban
dw
ith
(M
B/s
ec)
writereadRreadBread
GPFS writing in shared file:the 128 KB magic number

acaldero @ arcos.inf.uc3m.es
HPC-Europa (HLRS) 33
IOP results
Main conclusions
If several process try to write to the same file but on independent areas then the performance decrease
With several independent files results are similar on several tests, but with shared file are more irregular
Appears a magic number: 128 KBSeams that at that point the internal algorithm changes and it increases the bandwidth