odn - technical introduction of the platform
TRANSCRIPT

Open Data Node
Technical introduction of the platform
Peter Hanečák <[email protected]>
OSS víkend, Bratislava, 9.4.2015

http://OpenDataNode.org
Agenda
● Introduction references
● Basic functions
● Deployment strategies
● High-level architecture
● HW And SW requirements
● Technologies used
● Integration
● Open Source
● Example of usage (eDemokracia project)

http://OpenDataNode.org
Introduction references
● COMSODE: http://www.comsode.eu/
● Open Data Node (ODN) home page: http://opendatanode.org/
● Documentation: https://utopia.sk/wiki/display/ODN/
● Main GitHub project: https://github.com/OpenDataNode/open-data-node
● On-line demo: http://demo.comsode.eu/
● Basic non-technical introduction blog post:
http://www.comsode.eu/index.php/2015/05/open-data-node-1-0-released/
● Basic non-technical presentation:
http://www.slideshare.net/comsode/201504-odnplatformandmethodology
http://OpenDataNode.org
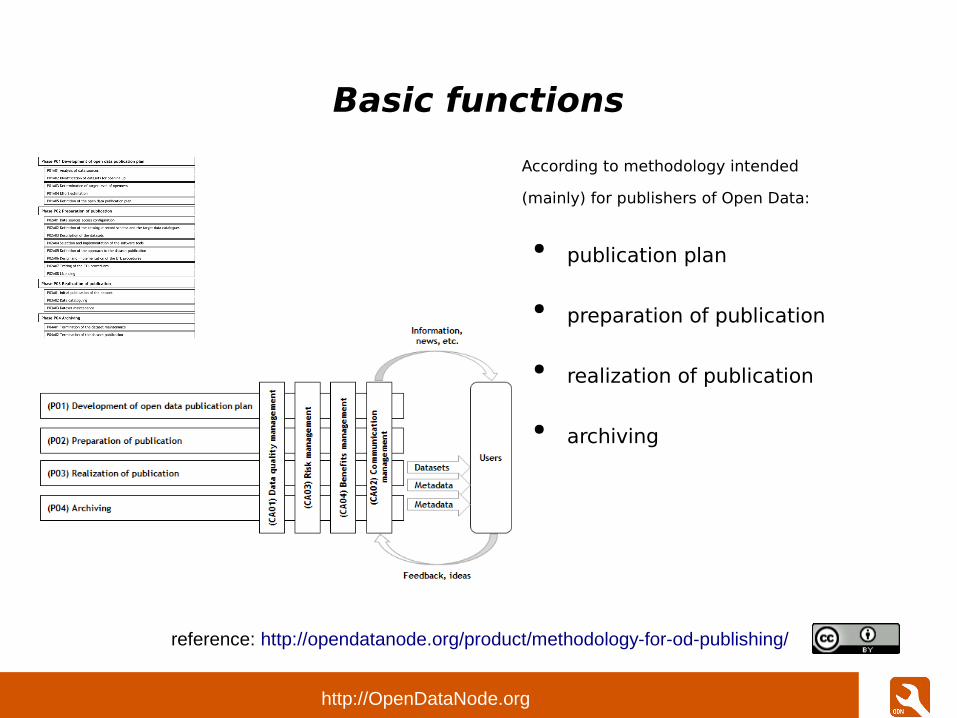
Basic functions
According to methodology intended
(mainly) for publishers of Open Data:
● publication plan
● preparation of publication
● realization of publication
● archiving
reference: http://opendatanode.org/product/methodology-for-od-publishing/
http://OpenDataNode.org
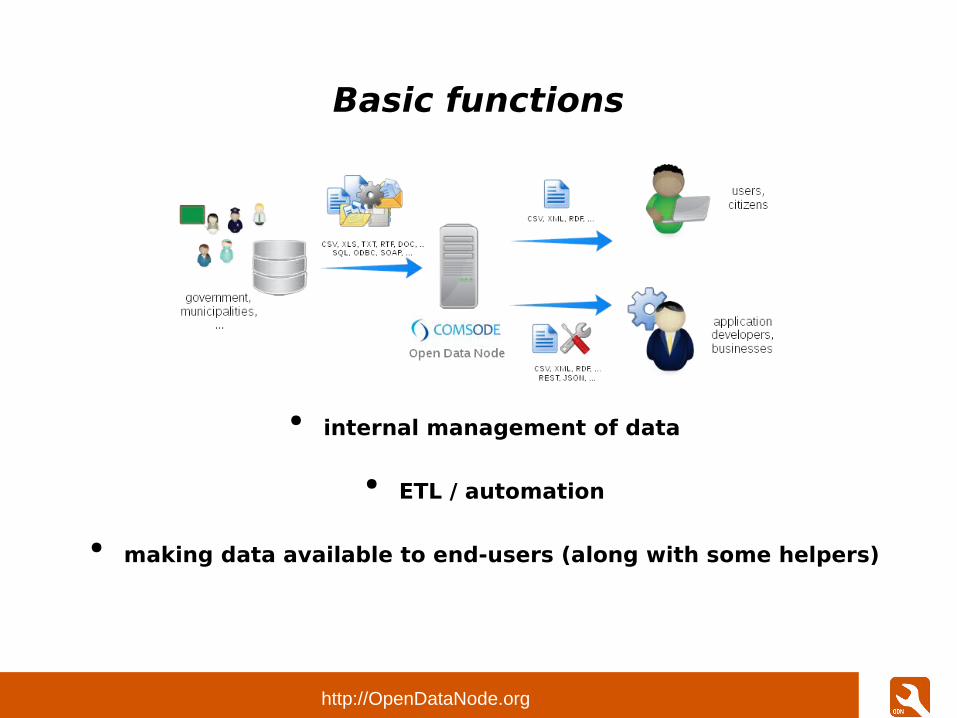
Basic functions
● internal management of data
● ETL / automation
● making data available to end-users (along with some helpers)
http://OpenDataNode.org
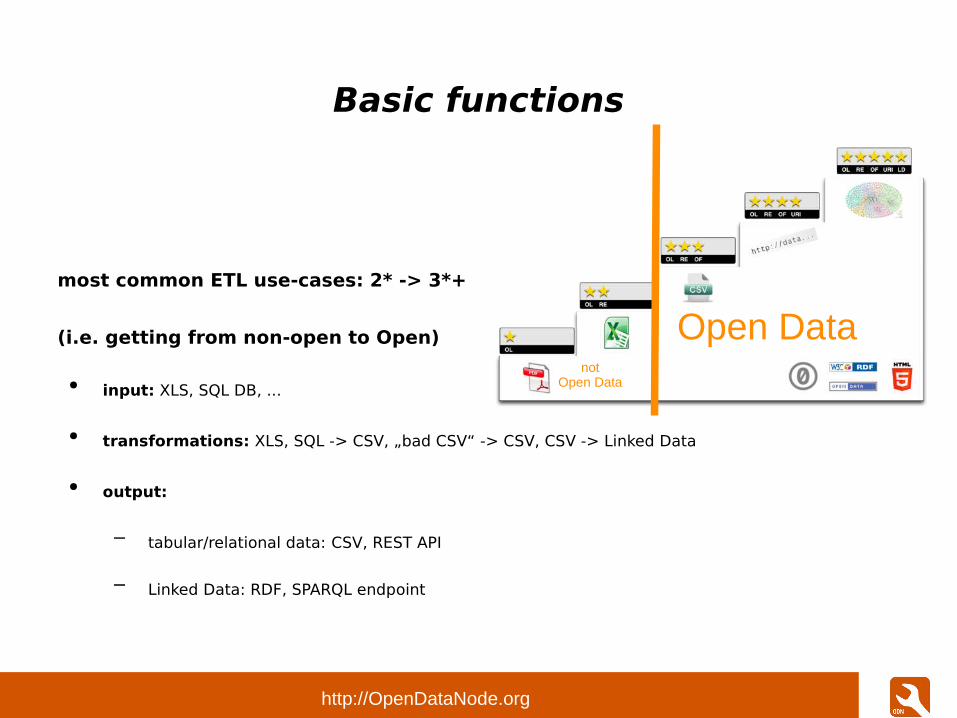
most common ETL use-cases: 2* -> 3*+
(i.e. getting from non-open to Open)
● input: XLS, SQL DB, ...
● transformations: XLS, SQL -> CSV, „bad CSV“ -> CSV, CSV -> Linked Data
● output:
– tabular/relational data: CSV, REST API
– Linked Data: RDF, SPARQL endpoint
Open Datanot
Open Data
Basic functions
http://OpenDataNode.org
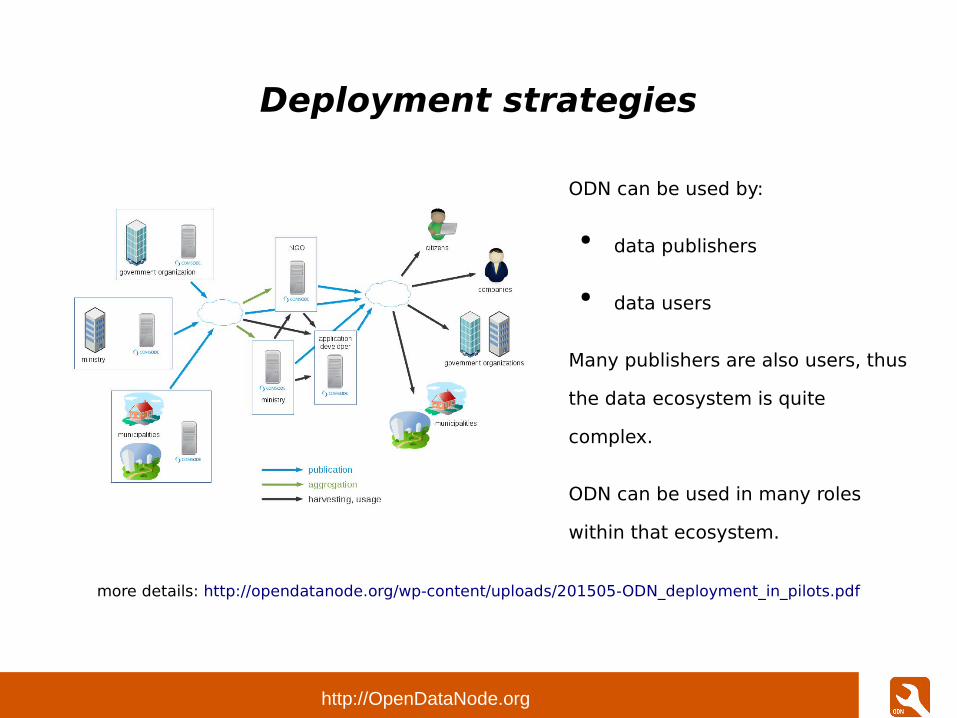
Deployment strategies
ODN can be used by:
● data publishers
● data users
Many publishers are also users, thus
the data ecosystem is quite
complex.
ODN can be used in many roles
within that ecosystem.
more details: http://opendatanode.org/wp-content/uploads/201505-ODN_deployment_in_pilots.pdf
http://OpenDataNode.org
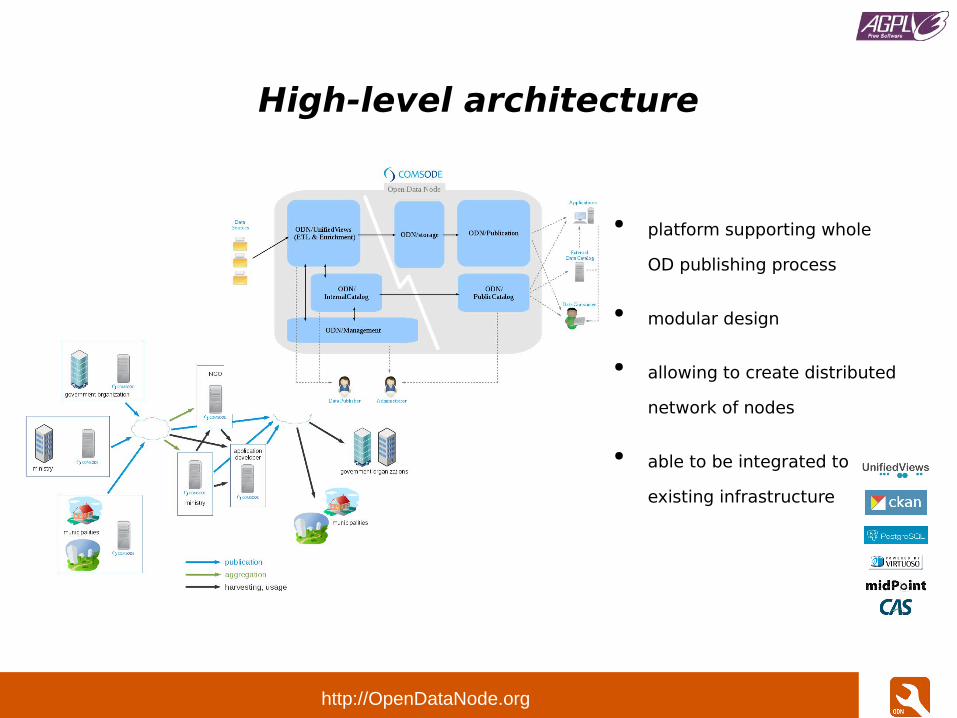
High-level architecture
● platform supporting whole
OD publishing process
● modular design
● allowing to create distributed
network of nodes
● able to be integrated to
existing infrastructure
http://OpenDataNode.org
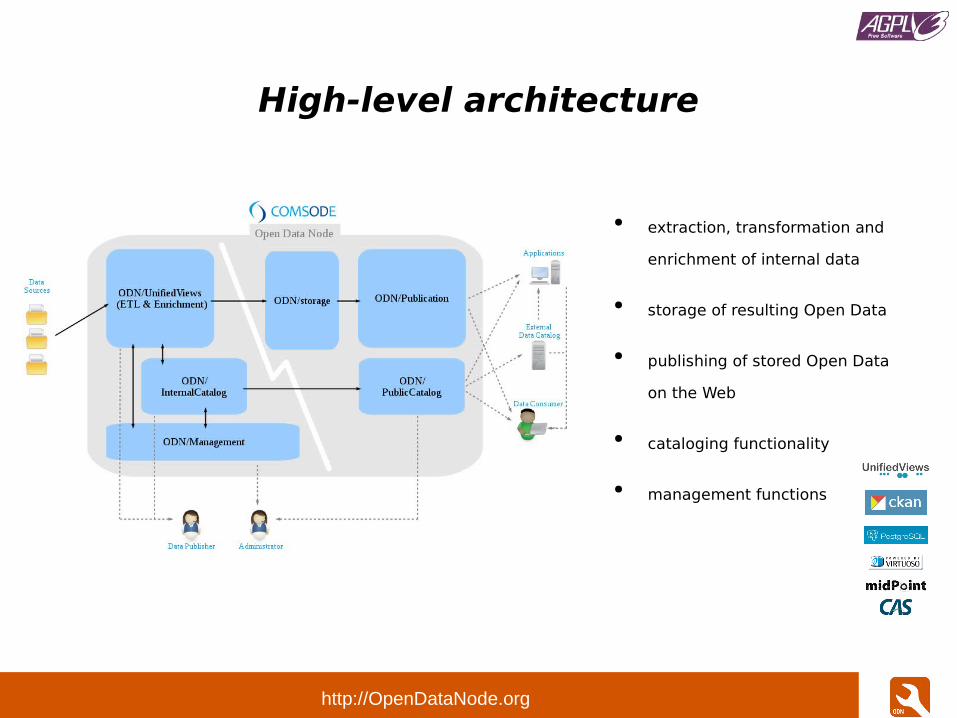
High-level architecture
● extraction, transformation and
enrichment of internal data
● storage of resulting Open Data
● publishing of stored Open Data
on the Web
● cataloging functionality
● management functions
http://OpenDataNode.org
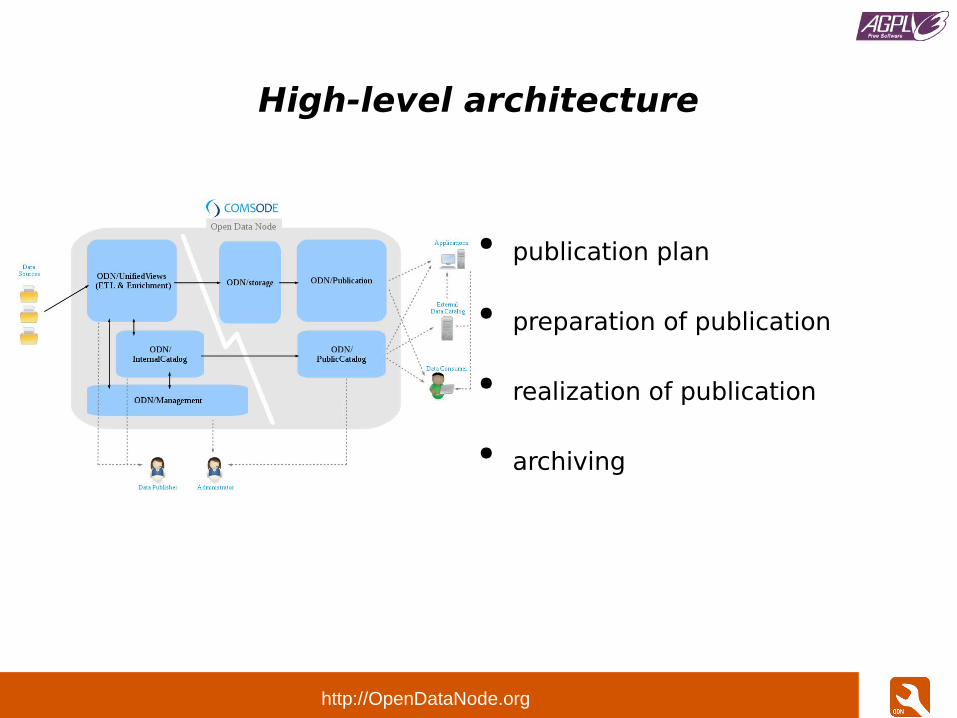
High-level architecture
● publication plan
● preparation of publication
● realization of publication
● archiving
http://OpenDataNode.org
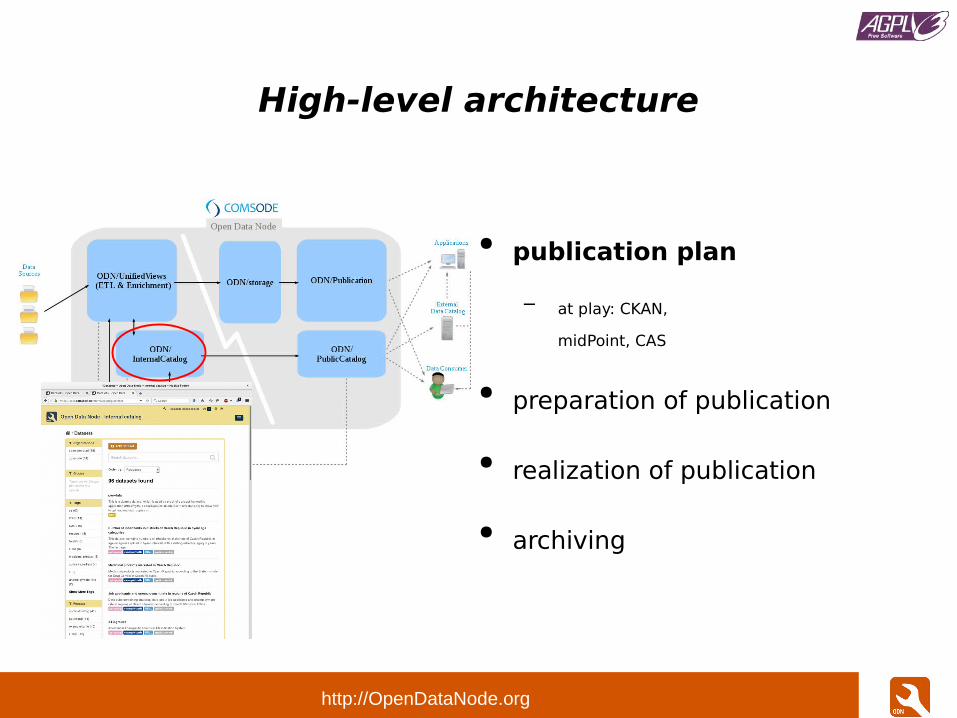
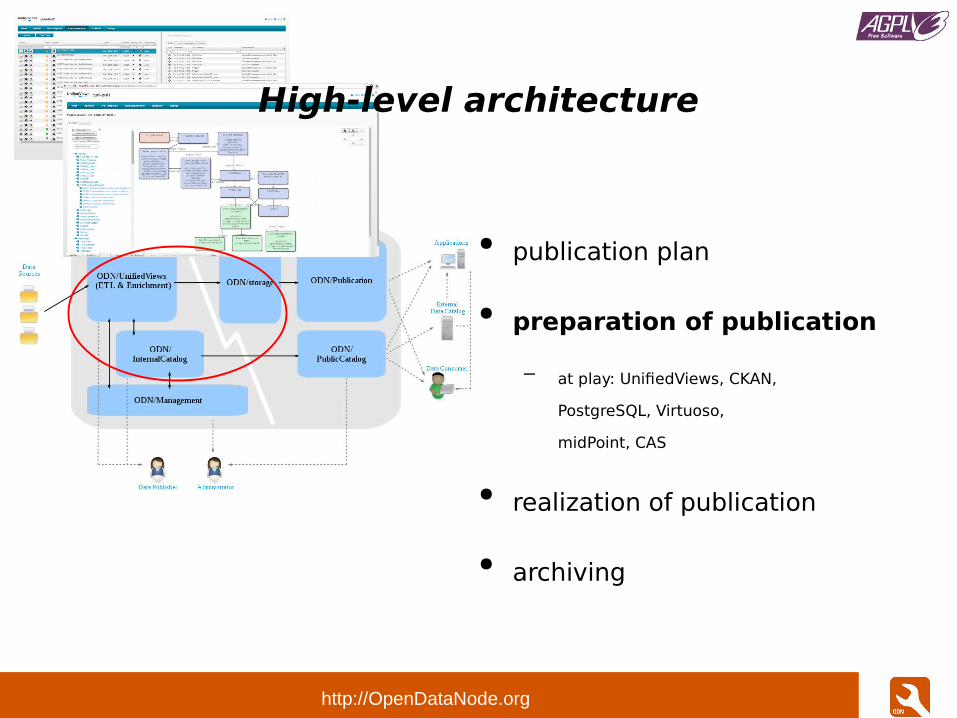
High-level architecture
● publication plan
– at play: CKAN,
midPoint, CAS
● preparation of publication
● realization of publication
● archiving
http://OpenDataNode.org
● publication plan
● preparation of publication
– at play: UnifiedViews, CKAN,
PostgreSQL, Virtuoso,
midPoint, CAS
● realization of publication
● archiving
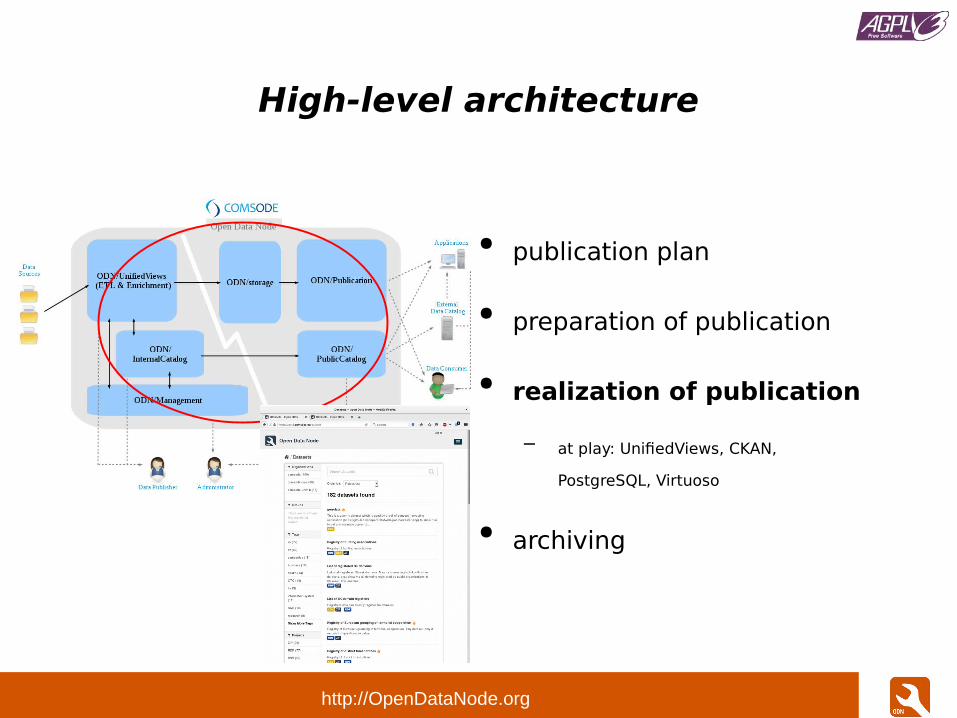
High-level architecture
http://OpenDataNode.org
High-level architecture
● publication plan
● preparation of publication
● realization of publication
– at play: UnifiedViews, CKAN,
PostgreSQL, Virtuoso
● archiving
http://OpenDataNode.org
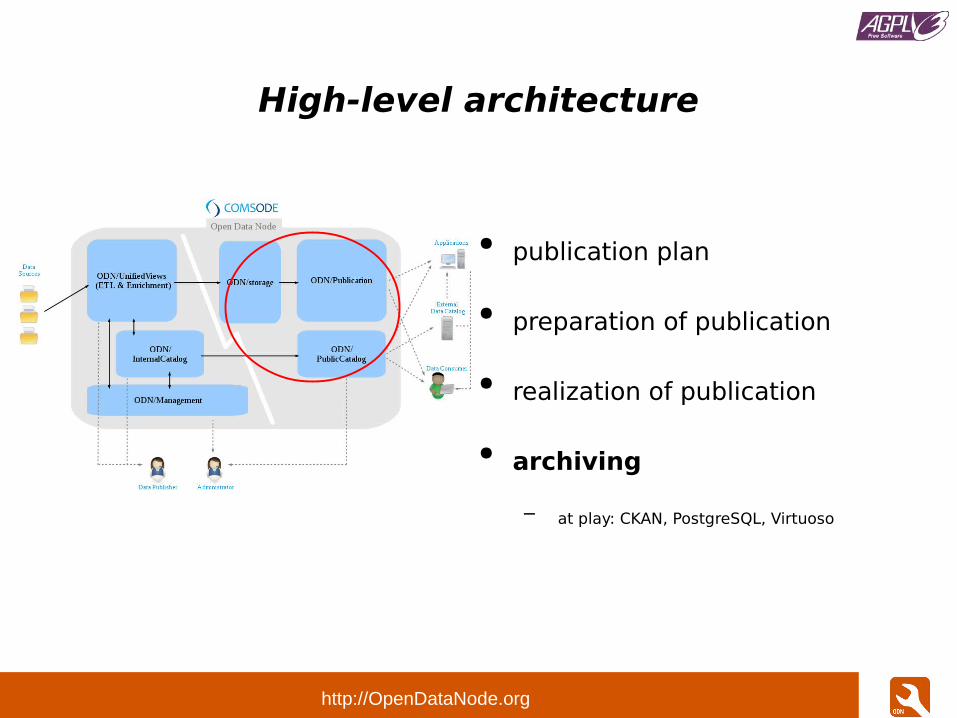
High-level architecture
● publication plan
● preparation of publication
● realization of publication
● archiving
– at play: CKAN, PostgreSQL, Virtuoso

http://OpenDataNode.org
HW and SW requirements
HW:
● CPU: common x86_64 compatible (dual/quad core is recommended)
● memory: minimum 4 GB (recommended 8 GB) (*)
● storage: minimum 40 GB (*)
SW:
● OS: Debian 7.x „Wheezy“ and 8.x „Jessie“
● OpenJDK 7
(*) Subject to size of transformed data and requirements on transformation operations.
http://OpenDataNode.org
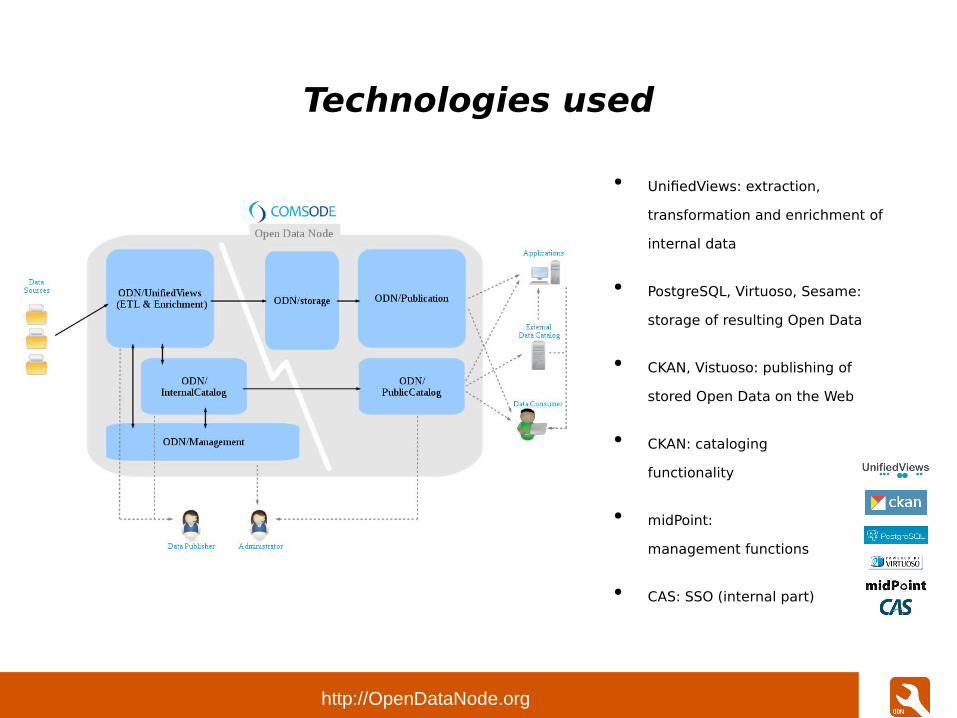
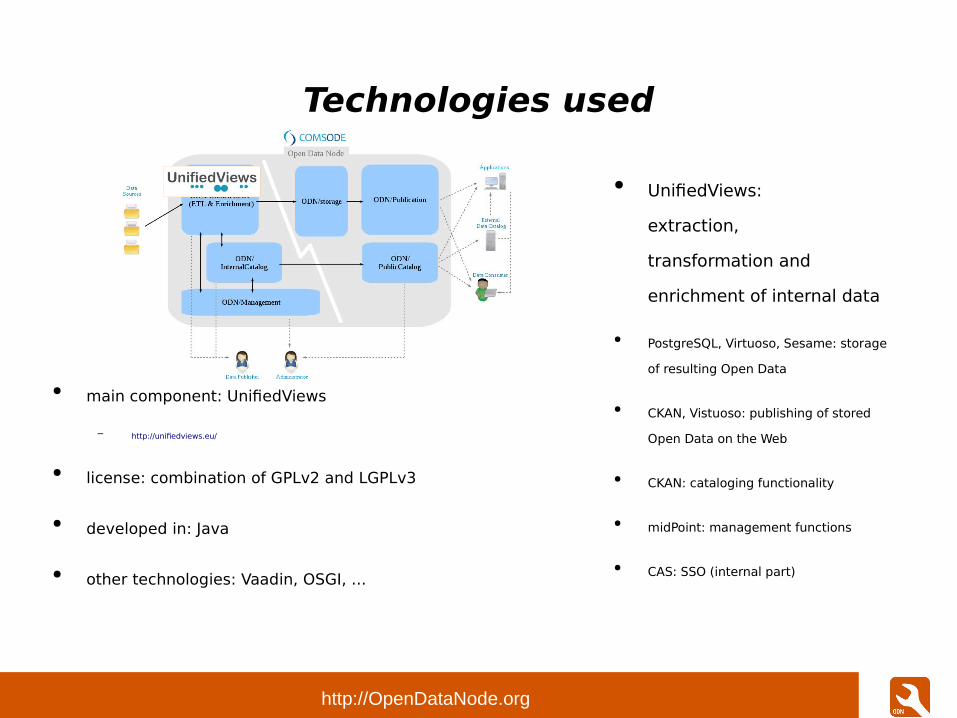
Technologies used
● UnifiedViews: extraction,
transformation and enrichment of
internal data
● PostgreSQL, Virtuoso, Sesame:
storage of resulting Open Data
● CKAN, Vistuoso: publishing of
stored Open Data on the Web
● CKAN: cataloging
functionality
● midPoint:
management functions
● CAS: SSO (internal part)
http://OpenDataNode.org
Technologies used
● UnifiedViews:
extraction,
transformation and
enrichment of internal data
● PostgreSQL, Virtuoso, Sesame: storage
of resulting Open Data
● CKAN, Vistuoso: publishing of stored
Open Data on the Web
● CKAN: cataloging functionality
● midPoint: management functions
● CAS: SSO (internal part)
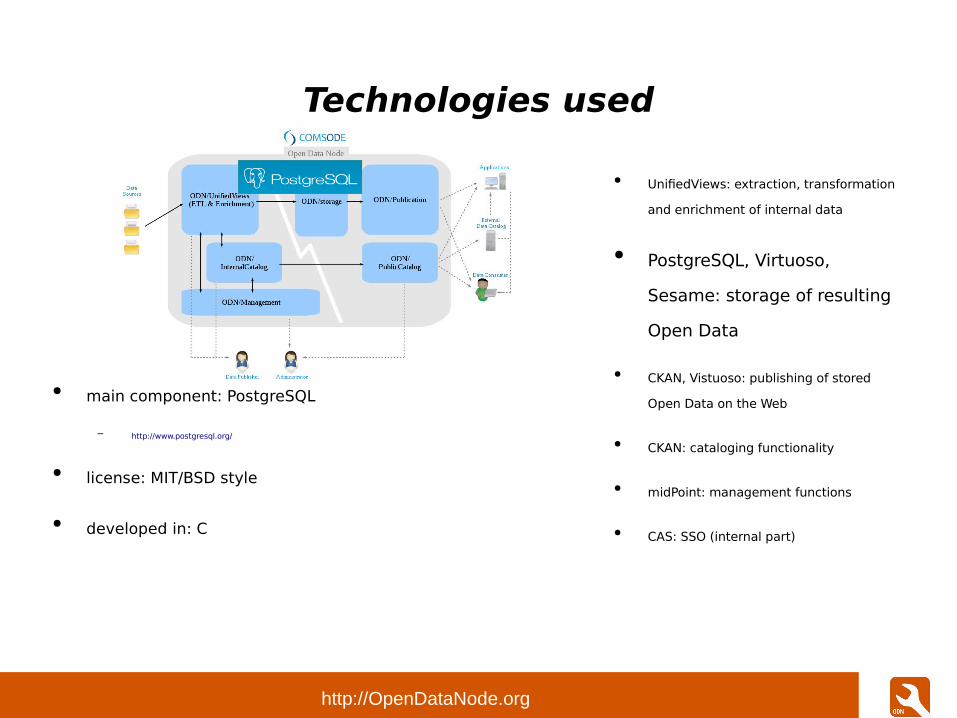
● main component: UnifiedViews
– http://unifiedviews.eu/
● license: combination of GPLv2 and LGPLv3
● developed in: Java
● other technologies: Vaadin, OSGI, ...
http://OpenDataNode.org
Technologies used
● UnifiedViews: extraction, transformation
and enrichment of internal data
● PostgreSQL, Virtuoso,
Sesame: storage of resulting
Open Data
● CKAN, Vistuoso: publishing of stored
Open Data on the Web
● CKAN: cataloging functionality
● midPoint: management functions
● CAS: SSO (internal part)
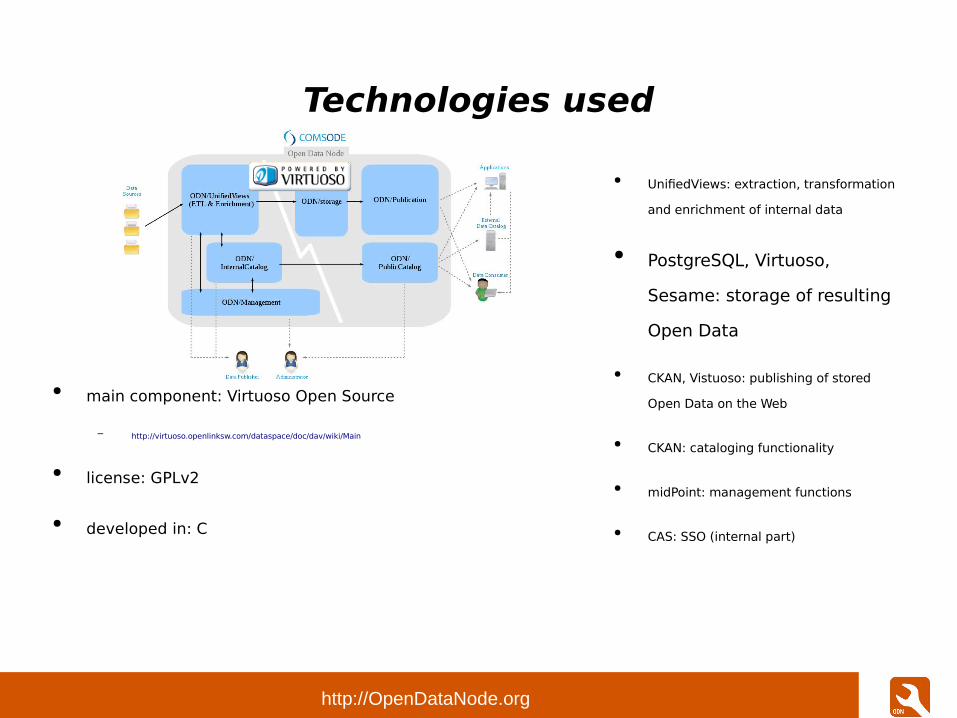
● main component: PostgreSQL
– http://www.postgresql.org/
● license: MIT/BSD style
● developed in: C
http://OpenDataNode.org
Technologies used
● UnifiedViews: extraction, transformation
and enrichment of internal data
● PostgreSQL, Virtuoso,
Sesame: storage of resulting
Open Data
● CKAN, Vistuoso: publishing of stored
Open Data on the Web
● CKAN: cataloging functionality
● midPoint: management functions
● CAS: SSO (internal part)
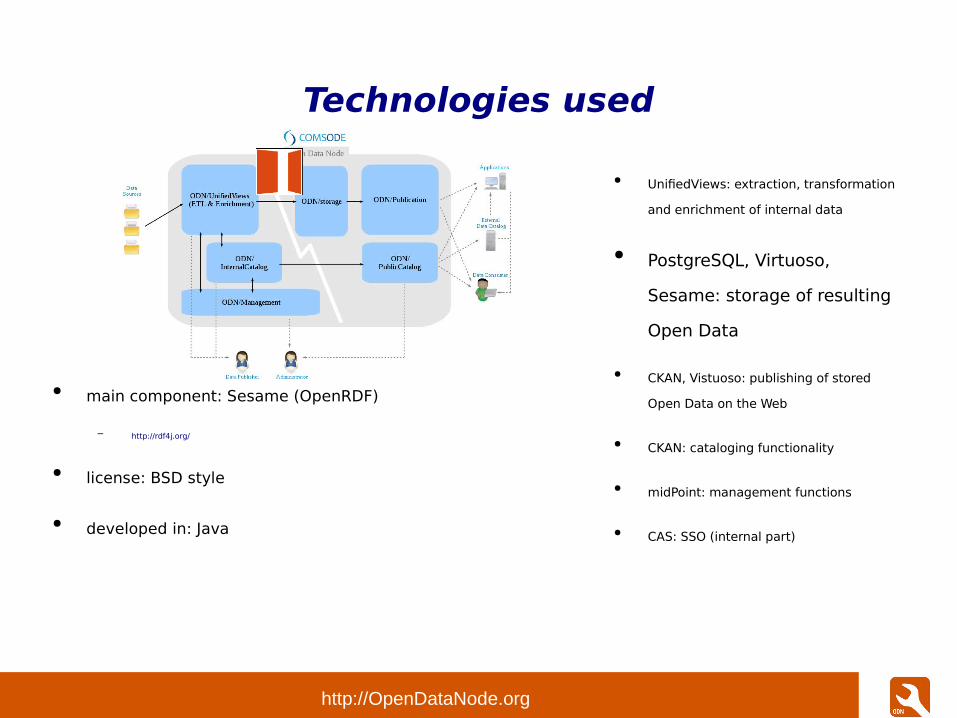
● main component: Virtuoso Open Source
– http://virtuoso.openlinksw.com/dataspace/doc/dav/wiki/Main
● license: GPLv2
● developed in: C
http://OpenDataNode.org
Technologies used
● UnifiedViews: extraction, transformation
and enrichment of internal data
● PostgreSQL, Virtuoso,
Sesame: storage of resulting
Open Data
● CKAN, Vistuoso: publishing of stored
Open Data on the Web
● CKAN: cataloging functionality
● midPoint: management functions
● CAS: SSO (internal part)
● main component: Sesame (OpenRDF)
– http://rdf4j.org/
● license: BSD style
● developed in: Java
http://OpenDataNode.org
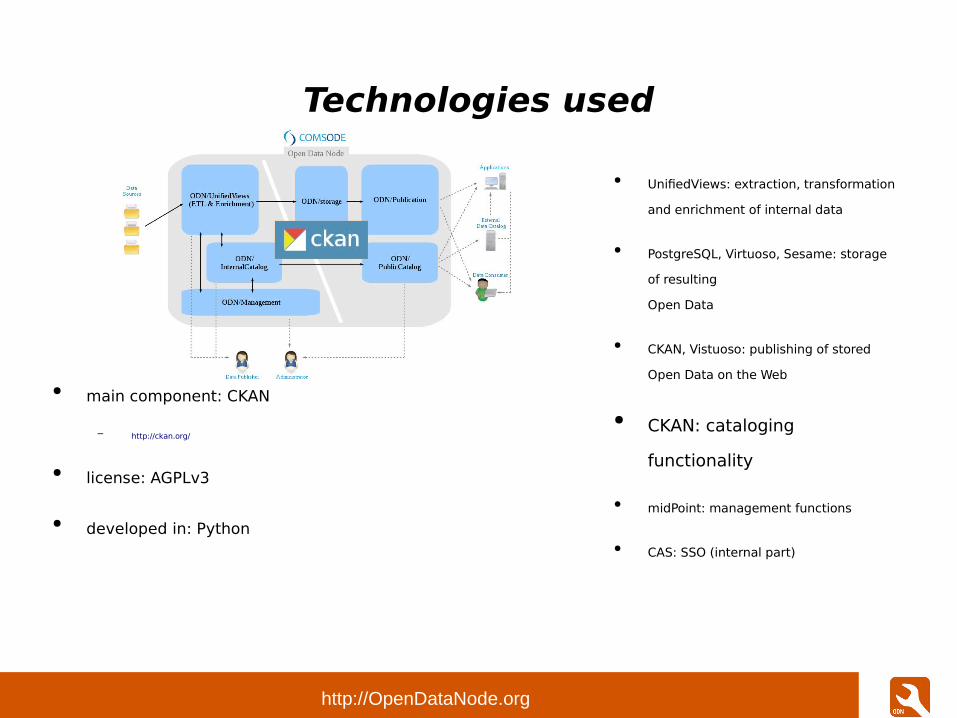
Technologies used
● UnifiedViews: extraction, transformation
and enrichment of internal data
● PostgreSQL, Virtuoso, Sesame: storage
of resulting
Open Data
● CKAN, Vistuoso: publishing of stored
Open Data on the Web
● CKAN: cataloging
functionality
● midPoint: management functions
● CAS: SSO (internal part)
● main component: CKAN
– http://ckan.org/
● license: AGPLv3
● developed in: Python
http://OpenDataNode.org
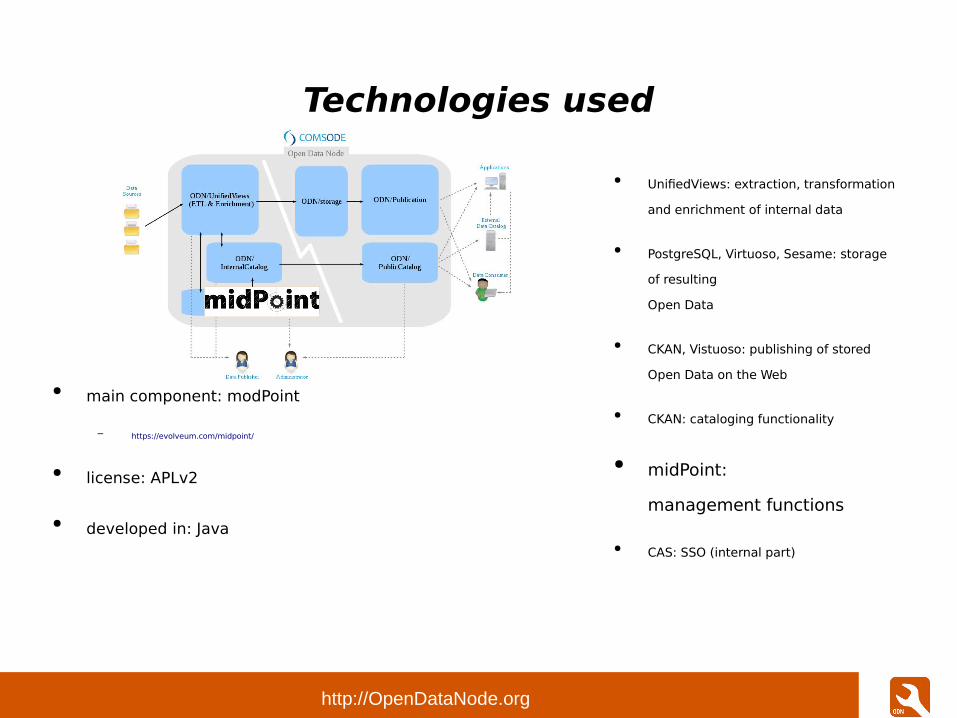
Technologies used
● UnifiedViews: extraction, transformation
and enrichment of internal data
● PostgreSQL, Virtuoso, Sesame: storage
of resulting
Open Data
● CKAN, Vistuoso: publishing of stored
Open Data on the Web
● CKAN: cataloging functionality
● midPoint:
management functions
● CAS: SSO (internal part)
● main component: modPoint
– https://evolveum.com/midpoint/
● license: APLv2
● developed in: Java
http://OpenDataNode.org
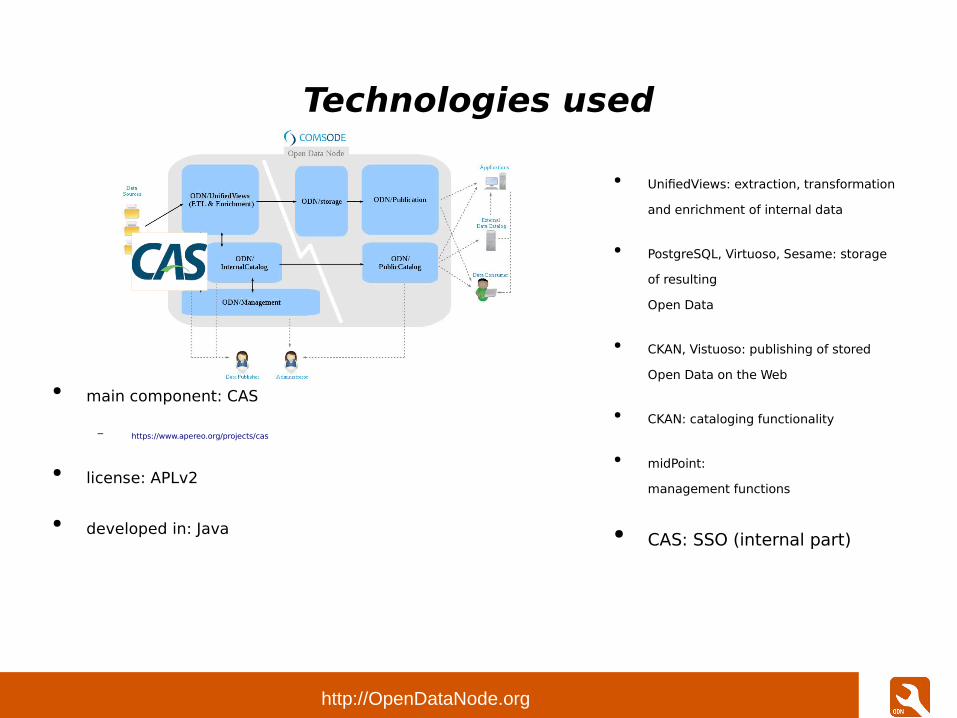
Technologies used
● UnifiedViews: extraction, transformation
and enrichment of internal data
● PostgreSQL, Virtuoso, Sesame: storage
of resulting
Open Data
● CKAN, Vistuoso: publishing of stored
Open Data on the Web
● CKAN: cataloging functionality
● midPoint:
management functions
● CAS: SSO (internal part)
● main component: CAS
– https://www.apereo.org/projects/cas
● license: APLv2
● developed in: Java
http://OpenDataNode.org
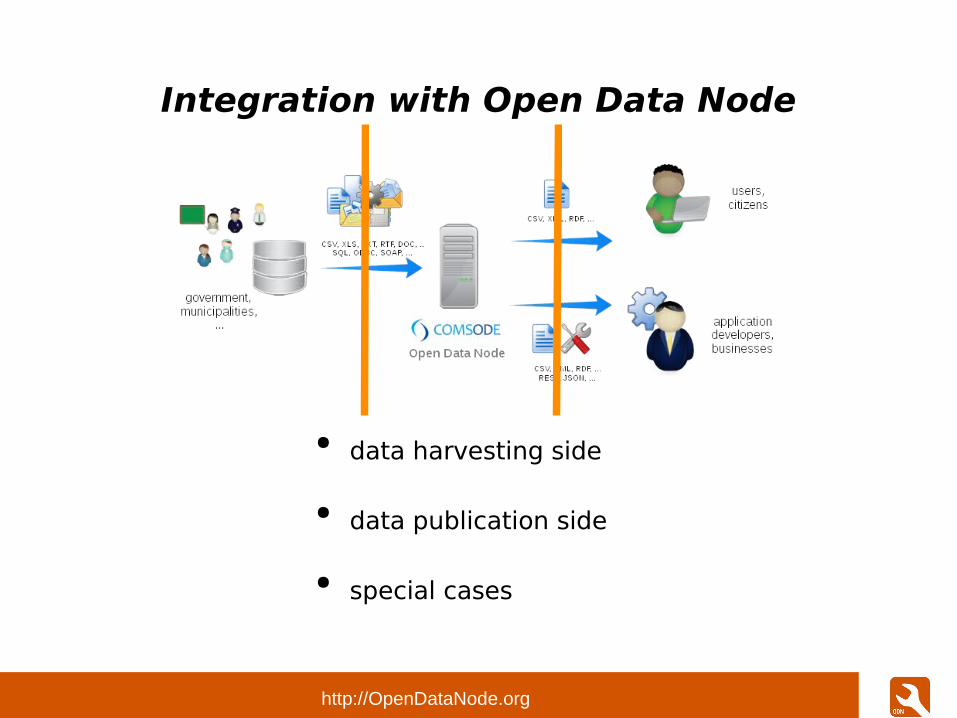
Integration with Open Data Node
● data harvesting side
● data publication side
● special cases

http://OpenDataNode.org
Integration with Open Data Node
data publication side: as implied by most common use-cases
● files: CSV, RDF
● API: REST API, SPARQL endpoint
http://OpenDataNode.org
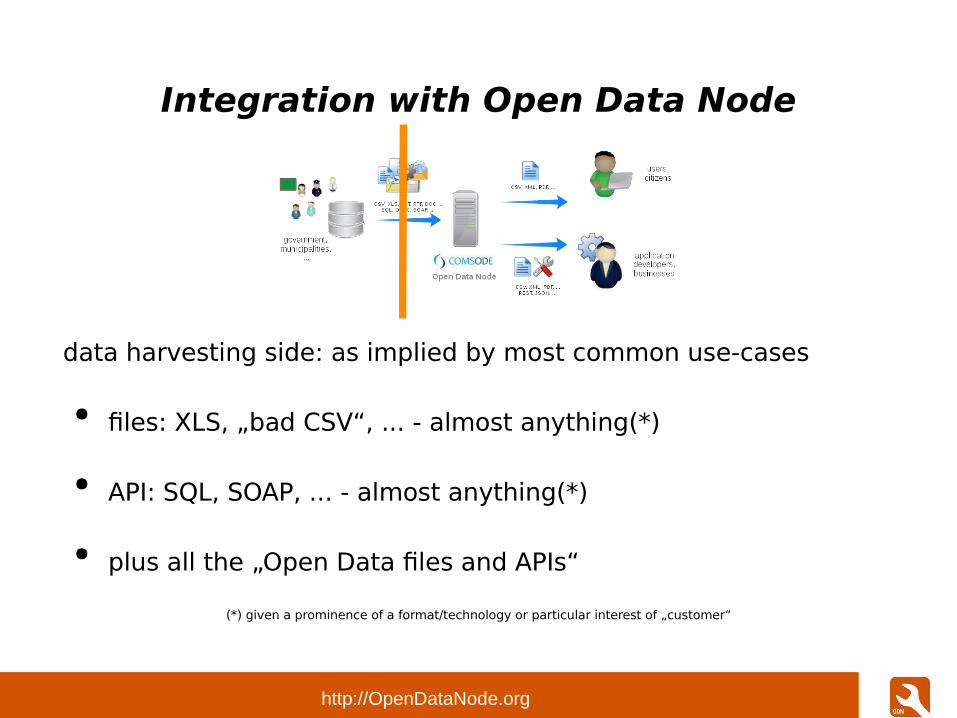
Integration with Open Data Node
data harvesting side: as implied by most common use-cases
● files: XLS, „bad CSV“, ... - almost anything(*)
● API: SQL, SOAP, ... - almost anything(*)
● plus all the „Open Data files and APIs“
(*) given a prominence of a format/technology or particular interest of „customer“
http://OpenDataNode.org
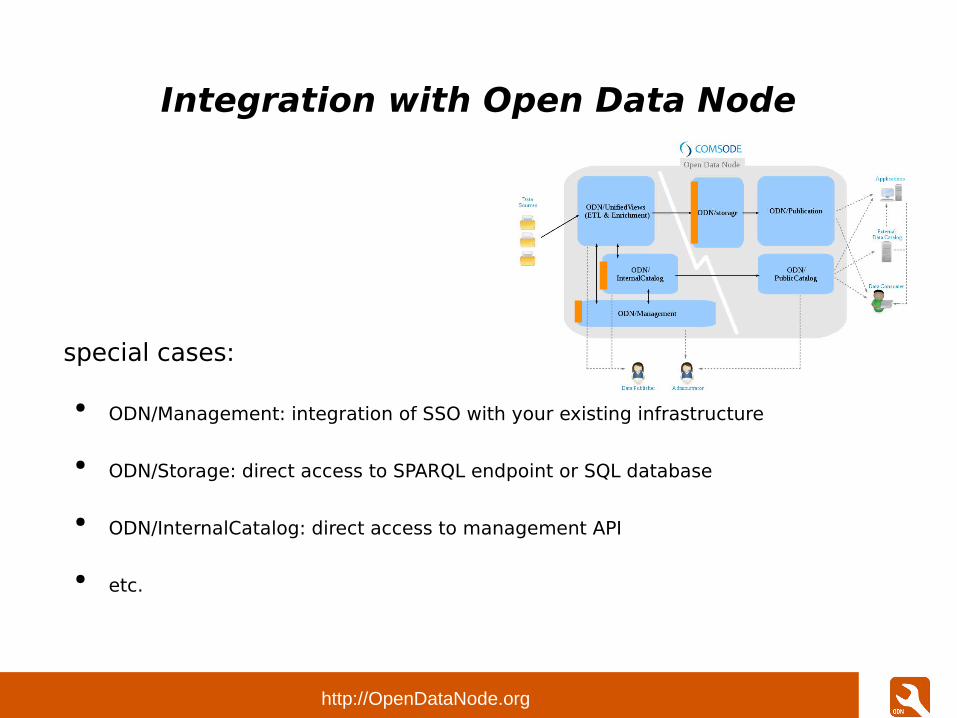
Integration with Open Data Node
special cases:
● ODN/Management: integration of SSO with your existing infrastructure
● ODN/Storage: direct access to SPARQL endpoint or SQL database
● ODN/InternalCatalog: direct access to management API
● etc.

http://OpenDataNode.org
Open Source
Key point, giving advantages:
● easier to customize
● re-use of existing tools, avoiding reinvention of the wheel
● lower chance of vendor lock-in
● more transparent (advantage also in public procurements)
● etc.
http://OpenDataNode.org
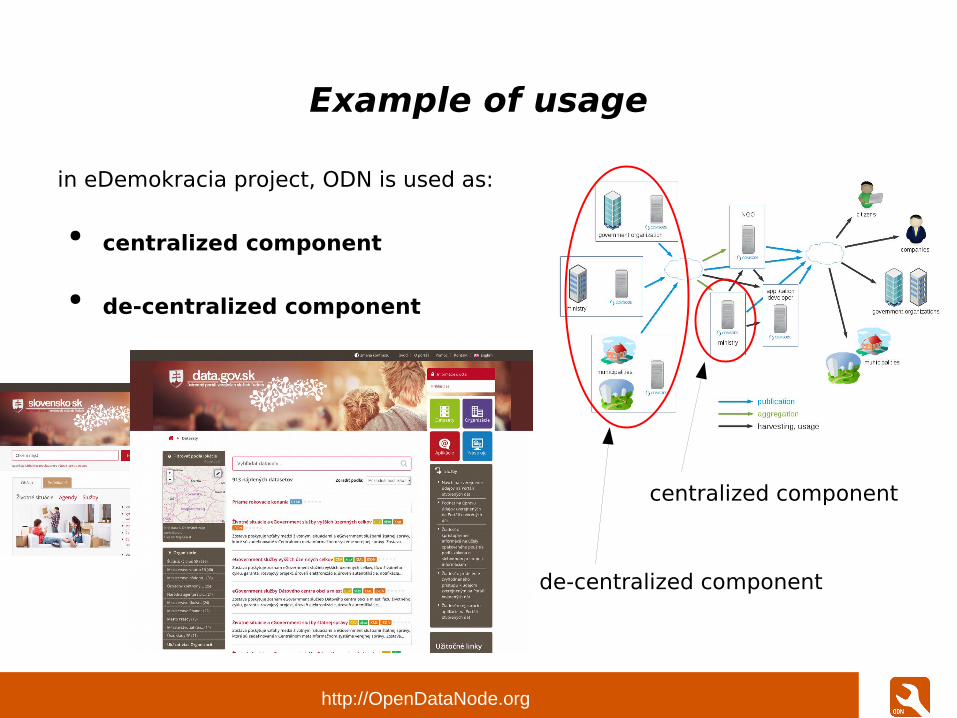
Example of usage
in eDemokracia project, ODN is used as:
● centralized component
● de-centralized component
de-centralized component
centralized component
http://OpenDataNode.org
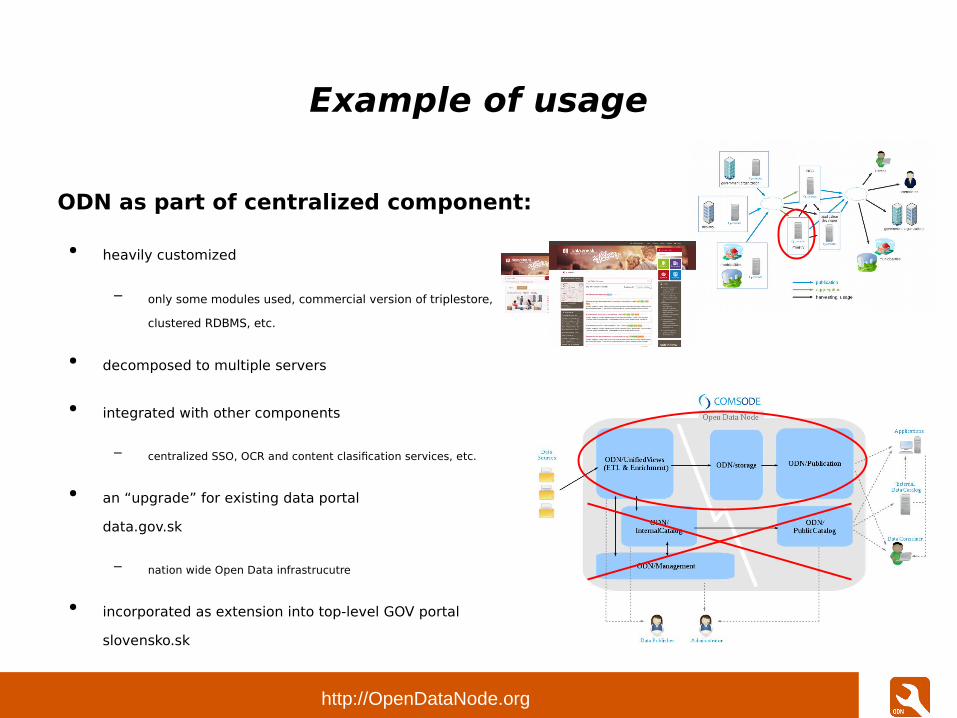
Example of usage
ODN as part of centralized component:
● heavily customized
– only some modules used, commercial version of triplestore,
clustered RDBMS, etc.
● decomposed to multiple servers
● integrated with other components
– centralized SSO, OCR and content clasification services, etc.
● an “upgrade” for existing data portal
data.gov.sk
– nation wide Open Data infrastrucutre
● incorporated as extension into top-level GOV portal
slovensko.sk
http://OpenDataNode.org
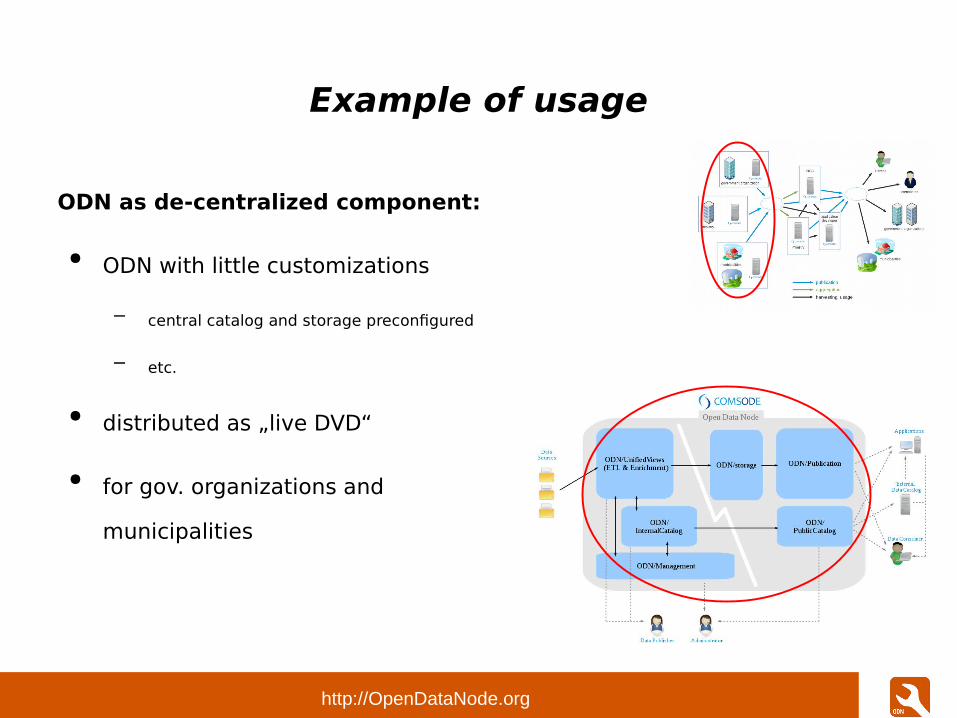
Example of usage
ODN as de-centralized component:
● ODN with little customizations
– central catalog and storage preconfigured
– etc.
● distributed as „live DVD“
● for gov. organizations and
municipalities

http://OpenDataNode.org