next generation semantic web applications - eurolan 2013
TRANSCRIPT

Next GenerationSemantic Web Applications
Enrico Motta, Mathieu D’AquinSofia Angeletou, Claudio Baldassarre, Martin Dzbor, Laurian Gridinoc,
Davide Guidi, Ainhoa Llorente, Vanessa Lopez, Marta Sabou
Knowledge Media InstituteThe Open UniversityMilton Keynes, UK

Introduction
This talk presents a number of projects, which are part of an integrated effort at exploring the possibilities opened by the Semantic Web, viewed as a domain-independent, large scale supplier of formally encoded background knowledge, with respect to enabling intelligent problem solving.We call the resulting applications:Next Generation Semantic Web Applications

Organization of the Talk
• The Semantic Web• The Semantic Web in the context of AI research• Next Generation Semantic Web Applications
– What are they?– Why are they different from 1st generation SW
Applications?– Infrastructure needs
• Examples– Ontology Matching– Integrating Web2.0 and SW– Semantic Web Browsing– Question Answering
• Conclusions

The Semantic Web
The collection of all formal, machine processable, web accessible, ontology-based statements (semantic metadata) about web resources and other entities in the world, expressed in a knowledge representation language based on an XML syntax (e.g., OWL, DAML, DAML+OIL, RDF, etc…)

<RDF triple><RDF triple><RDF triple><RDF triple><RDF triple><RDF triple><RDF triple>
<RDF triple><RDF triple><RDF triple><RDF triple><RDF triple><RDF triple><RDF triple>
<RDF triple><RDF triple><RDF triple><RDF triple><RDF triple><RDF triple><RDF triple>
<RDF triple><RDF triple><RDF triple><RDF triple><RDF triple><RDF triple><RDF triple>
Ontology
Metadata
UoD


<foaf:PersonalProfileDocument rdf:about="http://kmi.open.ac.uk/peopl<dc:title>Sofia Angeletou's RDF Description</dc:title><rdfs:label>Sofia Angeletous RDF Description</rdfs:label><dc:description>RDF description for Sofia Angeletou in machine-read<dc:creator rdf:resource="http://identifiers.kmi.open.ac.uk/people/sofi<foaf:maker rdf:resource="http://identifiers.kmi.open.ac.uk/people/sof<foaf:primaryTopic rdf:resource="http://identifiers.kmi.open.ac.uk/peo
</foaf:PersonalProfileDocument>
<foaf:Person rdf:about="http://identifiers.kmi.open.ac.uk/people/sofia-a
<foaf:name>Sofia Angeletou</foaf:name><foaf:firstName>Sofia</foaf:firstName><foaf:surname>Angeletou</foaf:surname><f f b h 1 >F78114D4E45CFC6AC811E6191F50182FB98
Semantic WebDocument

Increasing Semantic Content
<rdf:RDF><Feature rdf:about="http://sws.geonames.org/26380<name>Shenley Church End</name><alternateName>Shenley</alternateName><inCountry rdf:resource="http://www.geonames.org</rdf:RDF>
Charting the web

Charting the web (2)
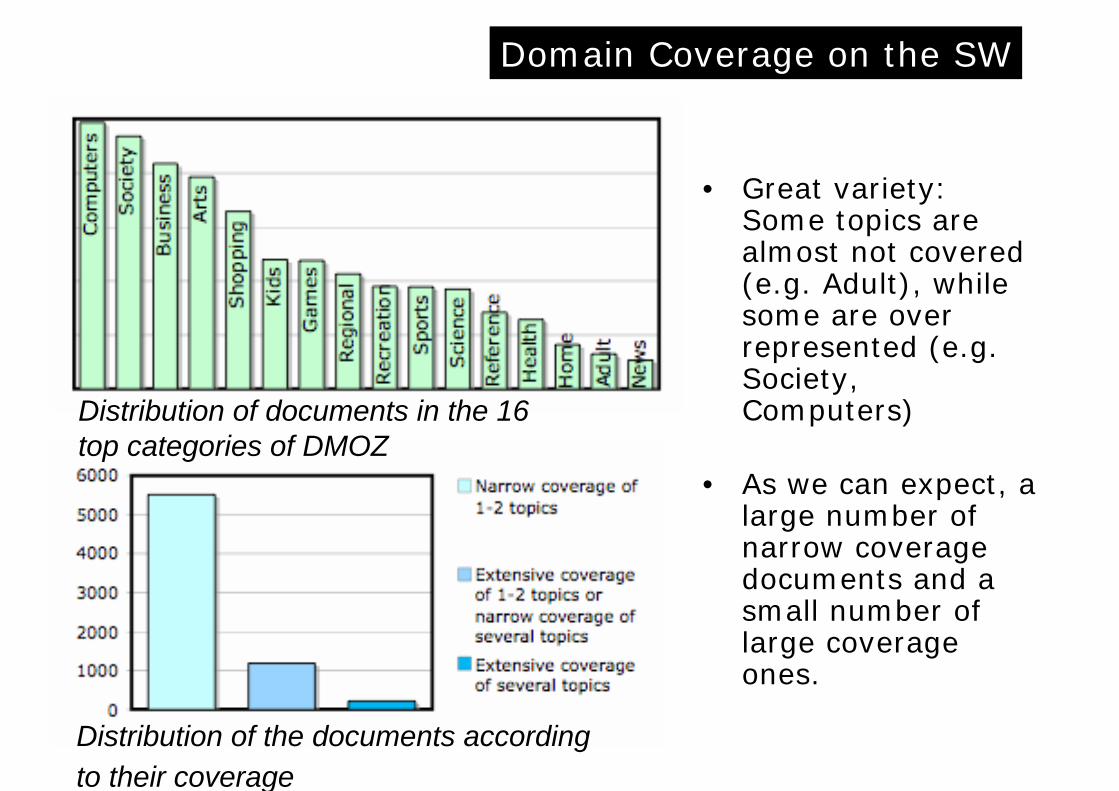
• Great variety: Some topics are almost not covered (e.g. Adult), while some are over represented (e.g. Society, Computers)
• As we can expect, a large number of narrow coverage documents and a small number oflarge coverage ones.
Distribution of documents in the 16top categories of DMOZ
Distribution of the documents accordingto their coverage
Domain Coverage on the SW

<RDF triple><RDF triple><RDF triple><RDF triple><RDF triple><RDF triple><RDF triple><RDF triple><RDF triple><RDF triple><RDF triple><RDF triple>
Example: Annotating the queen's birthday dinner
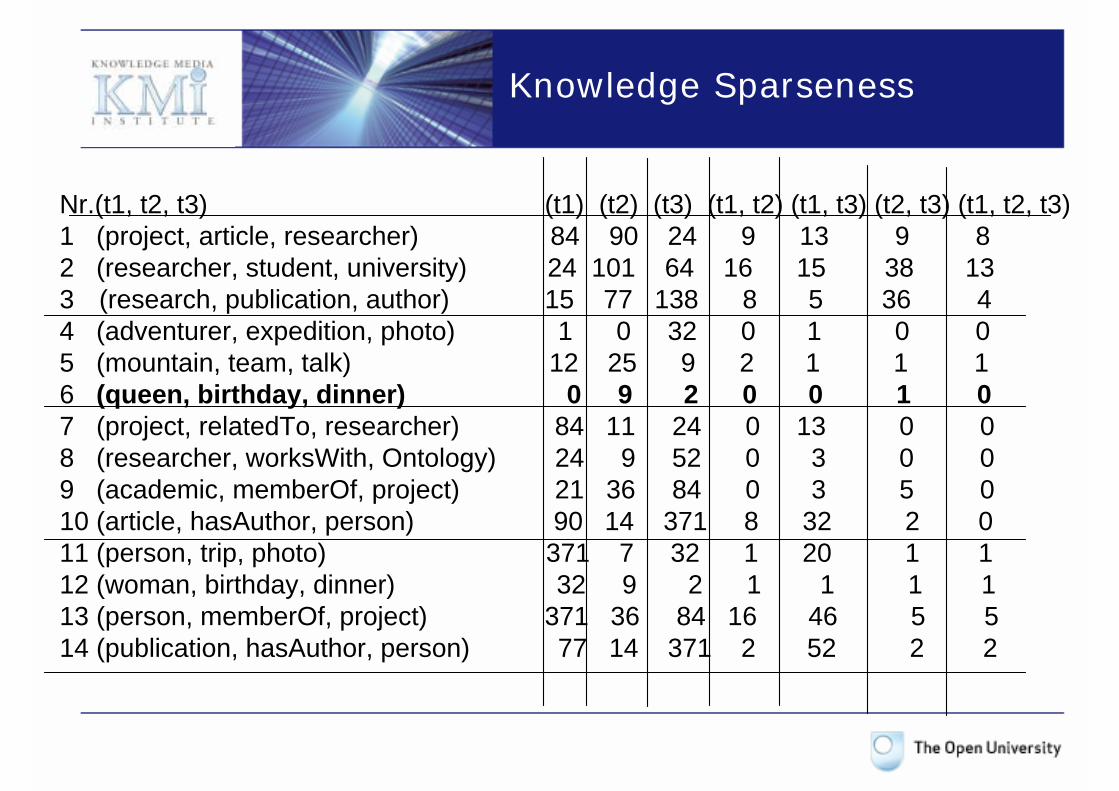
Nr.(t1, t2, t3) (t1) (t2) (t3) (t1, t2) (t1, t3) (t2, t3) (t1, t2, t3)1 (project, article, researcher) 84 90 24 9 13 9 82 (researcher, student, university) 24 101 64 16 15 38 133 (research, publication, author) 15 77 138 8 5 36 44 (adventurer, expedition, photo) 1 0 32 0 1 0 05 (mountain, team, talk) 12 25 9 2 1 1 1 6 (queen, birthday, dinner) 0 9 2 0 0 1 07 (project, relatedTo, researcher) 84 11 24 0 13 0 08 (researcher, worksWith, Ontology) 24 9 52 0 3 0 09 (academic, memberOf, project) 21 36 84 0 3 5 010 (article, hasAuthor, person) 90 14 371 8 32 2 011 (person, trip, photo) 371 7 32 1 20 1 112 (woman, birthday, dinner) 32 9 2 1 1 1 113 (person, memberOf, project) 371 36 84 16 46 5 514 (publication, hasAuthor, person) 77 14 371 2 52 2 2
Knowledge Sparseness

Example: Annotating the queen's birthday dinner
The Rise of Semantics

Thesis #1
The SW today has already reached a level of scale good enough to make it a very useful source of knowledge to support intelligent applications
In other words: the Semantic Web is no longer an aspiration but a reality
The availability of such large scale amounts of formalised knowledge is unprecedented in the history of AI

Thesis #2
The SW may well provide a solution to one of the classic AI challenges: how to acquire and manage large volumes of knowledge to develop truly intelligent problem solvers and address the brittleness of traditional KBS

Knowledge Representation Hypothesis in AI
Any mechanically embodied intelligent process will be comprised of structural ingredients that we as external observers naturally take to represent a propositional account of the knowledge that the overall process exhibits, and independent of such external semantic attribution, play a formal but causal and essential role in engendering the behaviour that manifests that knowledge
Brian Smith, 1982

Intelligence as a function of possessing domain knowledge
Large Bodyof Knowledge
Intelligent Behaviour
KA Bottleneck

The Knowledge Acquisition Bottleneck
Large Bodyof Knowledge
Intelligent Behaviour
KA Bottleneck
Knowledge

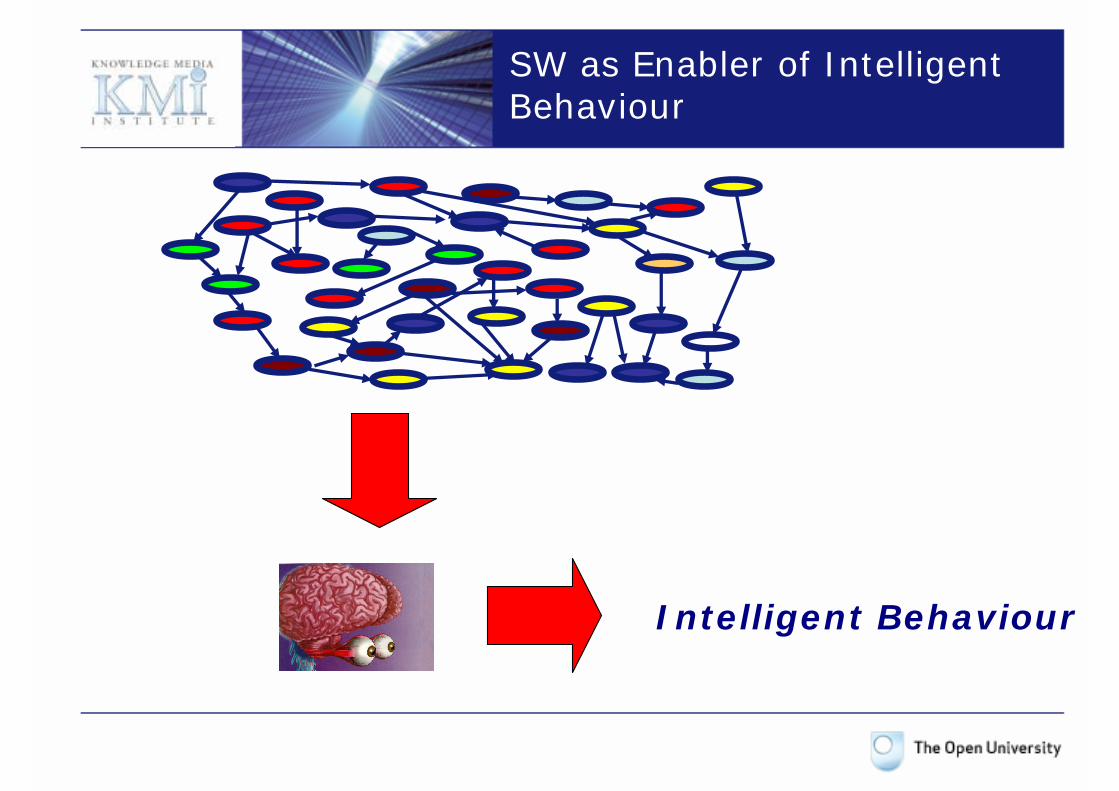
SW as Enabler of Intelligent Behaviour
Intelligent Behaviour

Overall Goal
Our research programme is to contribute to the development of this large-scale web of data and develop a new generation of web applications able to exploit it to provide intelligent functionalities

First GenerationSemantic Web Applications


<rdf :Description rdf :about=" ht t p:/ /ww w.ecs. sot on.ac.uk/info/#p erson-01 269"> <ns 0 :family -name>Gibbins</ns0:family -name> <ns 0 :full -name>Nicholas Gibbins</ns0:full -name> <ns 0 :given-name>N icholas</ns0:g iven-name> <ns 0 :has-email -address> [email protected] t on.ac.u k</ns0:has -email -address> <ns 0 :has-affi liation -to -unit rdf: resource=" ht t p:// 194 .66 .1 83.26/ WEBSITE/GOW/Vie wDepartme nt.aspx?Dep art ment =750"/> < / rdf :Descriptio n> </ rdf :RDF>
CS Dept Data
AKT Reference Ontology
RDF Data
Bibliographic Data

• Typically use a single ontology – Usually providing a homogeneous view over
heterogeneous data sources. – Limited use of existing SW data
• Closed to semantic resources
Features of 1st generation SW Applications
Hence: current SW applications are more similar to traditional KBS (closed semantic systems) than to 'real' SW applications (open semantic systems)

1895 2007
It is still early days..


Next GenerationSemantic Web Applications
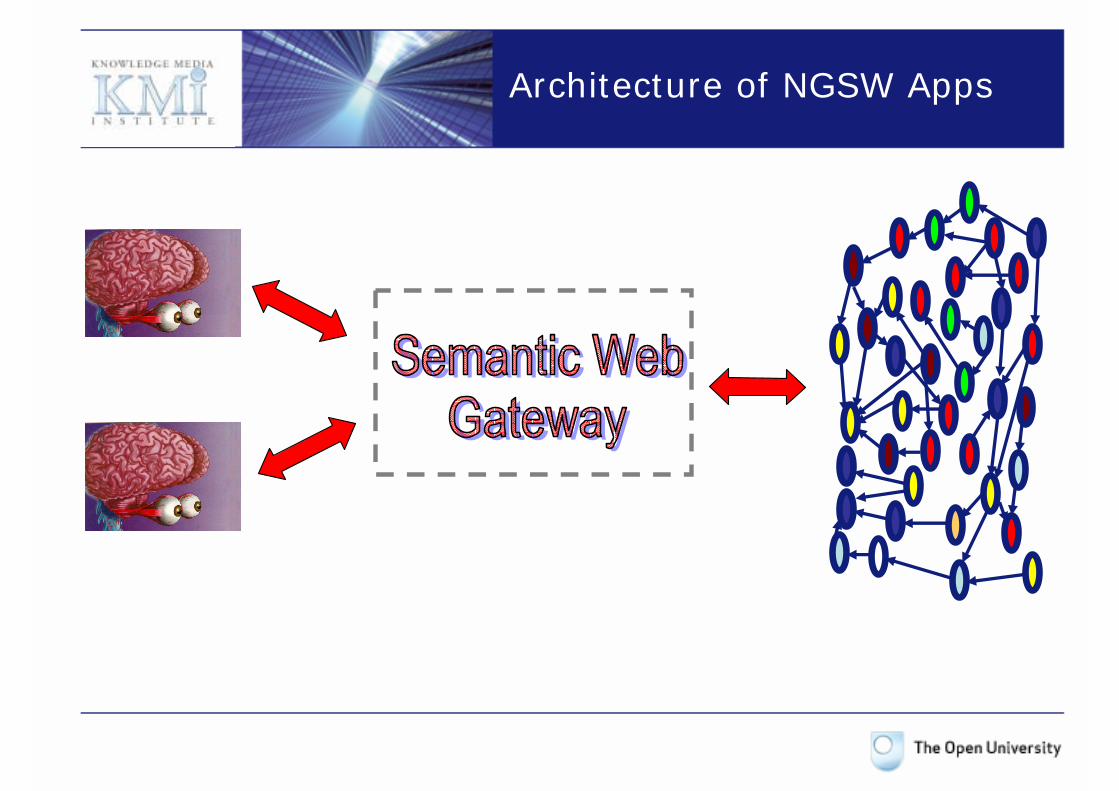
Architecture of NGSW Apps

Issue: Semantic Web Infrastructure

Current Gateway to the Semantic Web

Limitations of Swoogle
• Limited quality control mechanisms– Many ontologies are duplicated
• Limited Query/Search mechanisms– Only keyword search; no distinction between types of
elements– No support for formal query languages (such as SPARQL)
• Limited range of ontology ranking mechanisms– Swoogle only uses a 'popularity-based' one
• Limited API• No support for ontology modularization and
combination

A New Gateway to the Semantic Web
http://watson.kmi.open.ac.uk

• Sophisticated quality control mechanism– Detects duplications– Fixes obvious syntax problems
• E.g., duplicated ontology IDs, namespaces, etc..
• Structures ontologies in a network– Using relations such as: extends, inconsistentWith,
duplicates• Provides efficient API• Supports formal queries (SPARQL)• Variety of ontology ranking mechanisms• Modularization/Combination support• Plug-ins for Protégé and NeOn Toolkit (under devpt.)• Very cool logo!

O1 O1‘priorVersionOf
O2
M1
relatedWith
sourcetarget
O3 O4
depe
ndsO
nO1‘‘
incompatibleWith
M2
source
extends
priorVersionOf
Networked Ontologies

• Sophisticated quality control mechanism– Detects duplications– Fixes obvious syntax problems
• E.g., duplicated ontology IDs, namespaces, etc..
• Structures ontologies in a network– Using relations such as: extends, inconsistentWith, duplicates
• Provides efficient API• Supports formal queries (SPARQL)• Variety of ontology ranking mechanisms• Modularization/Combination support• Plug-ins for Protégé and NeOn Toolkit (under devpt.)• Very cool logo!





Examples ofNext Generation Semantic Web Applications

Example #1: Ontology Matching

1
0.9
0.9 0.91
–Label similarity methods•e.g., Full_Professor = FullProfessor
Ontology Matching
0.5
0.5
–Structure similarity methods•Using taxonomic/property related information

New paradigm: use of background knowledge
A B
Background Knowledge(external source)
A’ B’R
R

External Source = One Ontology
Aleksovski et al. EKAW’06• Map (anchor) terms into concepts from a richly axiomatized domain ontology • Derive a mapping based on the relation of the anchor terms
Assumes that a suitable (rich, large) domain ontology (DO) is available.

External Source = Web
van Hage et al. ISWC’05• rely on Google and an online dictionary in the food domain to extract semantic relations between candidate terms using IR techniques
A Brel
+ OnlineDictionary
IR MethodsPrecision increases significantly if domain specific sources are used:50% - Web; 75% - domain texts.
Does not rely on a rich Domain Ont,

Proposal: • rely on online ontologies (Semantic Web) to derive mappings• ontologies are dynamically discovered and combined
A Brel
Semantic Web
Does not rely on any pre-selected knowledge sources.
M. Sabou, M. d’Aquin, E. Motta, “Using the Semantic Web as Background Knowledge inOntology Mapping", Ontology Mapping Workshop, ISWC’06. Best Paper Award
External Source = SW

Strategy 1 - Definition
Find ontologies that contain equivalent classes for A and B and use their relationship in the ontologies to derive the mapping.
A Brel
Sem
antic
Web
A1’B1’
A2’B2’
An’Bn’
O1O2 On
BABABABABABABABA
⊥⇒⊥⊇=>⊇⊆=>⊆≡⇒≡
''''''''
For each ontology use these rules:
…
These rules can be extended to take into account indirect relations between A’ and B’, e.g., between parents of A’ and B’:
'''' BABCCA ⊥⇒⊥∧⊆
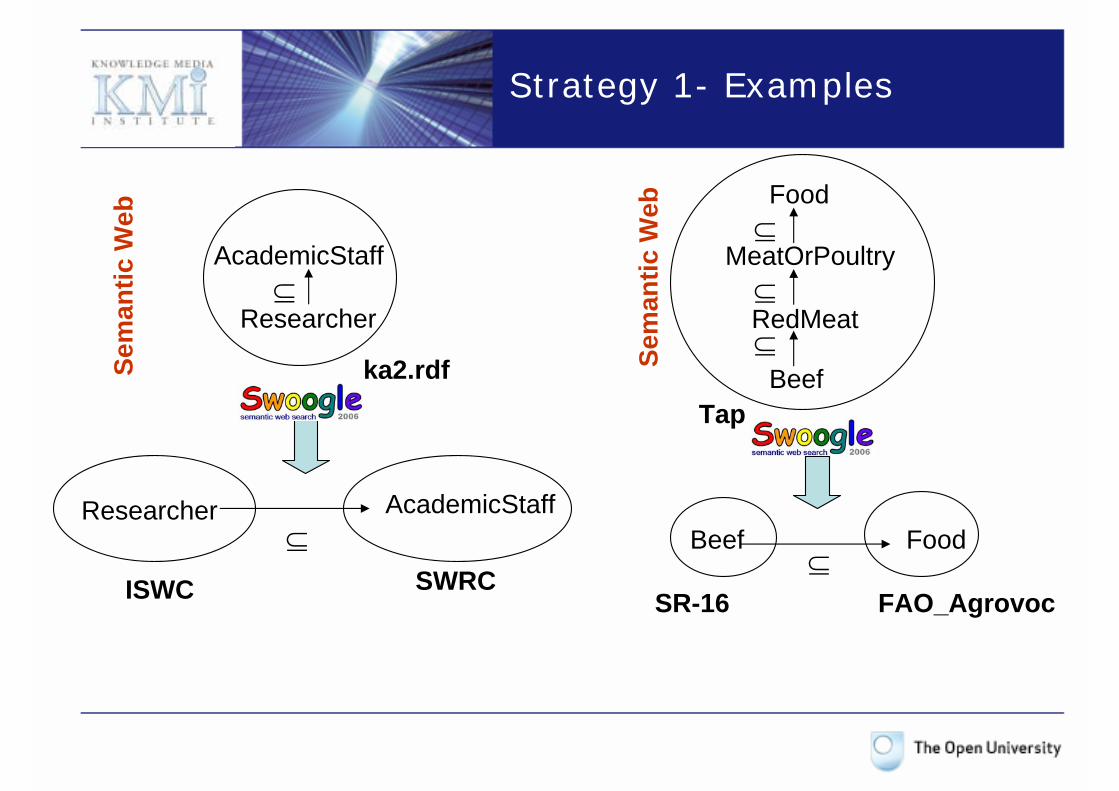
Strategy 1- Examples
Beef Food
Sem
antic
Web
Beef
RedMeat
Tap
Food
MeatOrPoultry
⊆
⊆
⊆
⊆
SR-16 FAO_Agrovoc
ka2.rdf
Researcher AcademicStaff
Sem
antic
Web
Researcher
AcademicStaff
⊆
⊆
ISWC SWRC

Strategy 2 - Definition
BABCCArBABCCArBABCCArBABCCArBABCCAr
⊇⇒≡∧⊇⊇⇒⊇∧⊇⊥⇒⊥∧⊆≡⇒≡∧⊆⊆⇒⊆∧⊆
')5(')4(')3(')2(
')1(
Principle: If no ontologies are found that contain the two terms then combine information from multiple ontologies to find a mapping.
A Brel
Sem
antic
Web
A’BC
C’B’rel
rel
Details:(1) Select all ontologies containing A’ equiv. with A(2) For each ontology containing A’:
(a) if find relation between C and B.(b) if find relation between C and B.
CA ⊆'CA ⊇'
Details:(1) Select all ontologies containing A’ equiv. with A(2) For each ontology containing A’:
(a) if find relation between C and B.(b) if find relation between C and B.

Strategy 2 - Examples
PoultryChicken⊆FoodPoultry ⊆
Chicken Vs. Food(midlevel-onto)(Tap)
Ex1:
FoodChicken ⊆
Ham Vs. FoodEx2:
(r1)
MeatHam⊆FoodMeat ⊆
(pizza-to-go)(SUMO) FoodHam ⊆
(Same results for Duck, Goose, Turkey)
(r1)
Ham Vs. SeafoodEx3:
MeatHam⊆SeafoodMeat ⊥
(pizza-to-go)(wine.owl) SeafoodHam ⊥
(r3)

Evaluation: 1600 mappings, two teamsOverall performance comparable to best in class
(derived from 180 different ontologies)
Matching AGROVOC (16k terms) and NALT(41k terms)
Large Scale Evaluation
M. Sabou, M. d’Aquin, W.R. van Hage, E. Motta, “Improving Ontology Matching byDynamically Exploring Online Knowledge“. In Press

Chart 2
Ontologies (180) used to derive mappings. TAP
CPE
Mid-level-ontology.daml
SUMO.daml
Economy.daml

Thesis #3
Using the SW to provide dynamically background knowledge to tackle the Agrovoc/NALT mapping problem provides the first ever test case in which the SW, viewed as a large scale heterogeneous resource, has been successfully used to address a real-world problem


Thesis #4
The claim that the information on the SW is of poor quality and therefore not useful to support intelligent problem solving is a myth not supported by concrete experience:Our experience in the NALT/Agrovoc ontology matching benchmark problem shows that without any particularly intelligent filter, the info available on the SW already allows a 85% theoretical precision for our algorithm, well beyond the performance of any other ontology matching algorithm

Example #2: Integrating SW and Web2.0

• Tagging as opposed to rigid classification
• Dynamic vocabulary does not require much annotation effort and evolves easily
• Shared vocabulary emerge over time – certain tags become
particularly popular
Features of Web2.0 sites

Limitations of tagging
• Different granularity of tagging– rome vs colosseum vs roman monument– Flower vs tulip– Etc..
• Multilinguality• Spelling errors, different terminology, plural vs
singular, etc…
This has a number of negative implications for the effective use of tagged resources– e.g., Search exhibits very poor recall

Giving meaning to tags
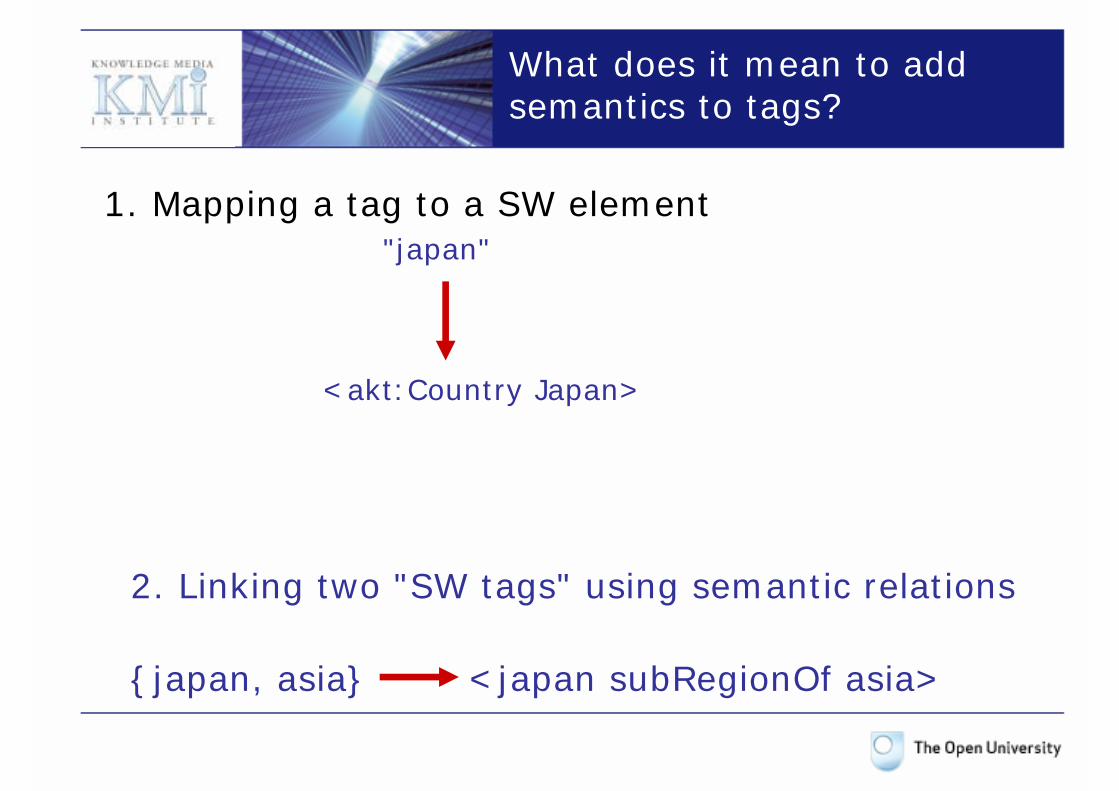
1. Mapping a tag to a SW element"japan"
<akt:Country Japan>
What does it mean to add semantics to tags?
2. Linking two "SW tags" using semantic relations
{japan, asia} <japan subRegionOf asia>

Applications of the approach
• To improve recall in keyword search
• To support annotation by dynamically suggesting relevant tags or visualizing the structure of relevant tags
• To enable formal queries over a space of tags– Hence, going beyond keyword search
• To support new forms of intelligent navigation– i.e., using the 'semantic layer' to support navigation

Concept and relation identification
No
END
Remainingtags?
Clustering
Folksonomy
Cluster tags
Cluster1 Cluster2 Clustern…
2 “related” tags
Find mappings & relation for pair of tags
Yes
Analyze co-occurrence of tags
Co-occurence matrix
Pre-processingTags
Group similar tags
Filter infrequent tags
Concise tags
Clean tags
Wikipedia
SW search engine
<concept, relation, concept>

Pre-processing
• Scope: Subsets of Flickr and del.icio.us tags.
• Pre-processing (thresholds):– To be “similar”, Levenshtein >= 0.83; – A tag has to occur at least 10 times.
Total Distinct# entries # tags # users # resources # tags
del.icio.us 19,605 89,978 7,164 14,211 11,960Flickr 49,087 167,130 6,140 49,087 17,956
Total Distinct# entries # tags # users # resources # tags
del.icio.us 18,882 70,194 7,090 13,579 1,265Flickr 44,032 127,098 5,321 44,032 2,696

Clustering
1. Each pair of similar tags, as determined by a co-occurrence analysis (e.g., audio and mp3), is a seed constituting an initial cluster;
2. The cluster is enlarged by including tags that are similar to both the initial tags;
3. Repeat procedure recursively for all tags: each new “candidate” tag for a cluster must be similar to the whole (possibly enlarged) set of tags in that cluster.
4. If there are no more candidates for the cluster, go to step 1 with a new seed (e.g., audio and music).
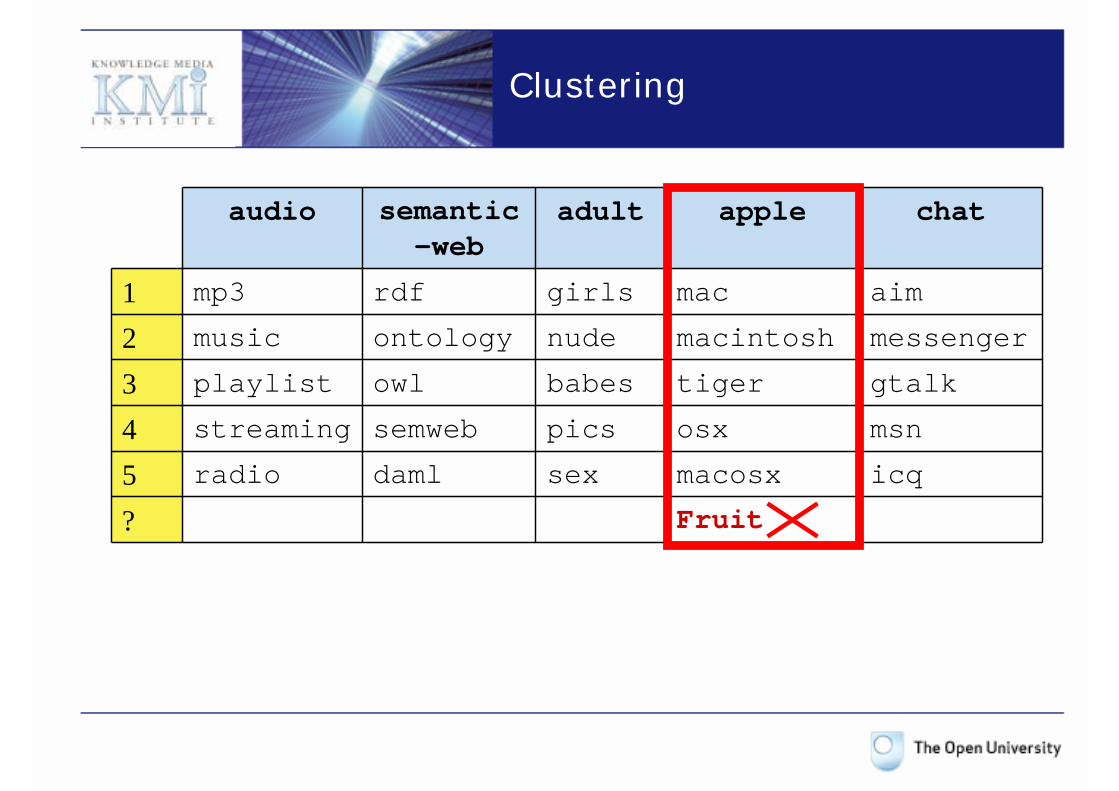
Clustering
audio semantic-web
adult apple chat
1 mp3 rdf girls mac aim
2 music ontology nude macintosh messenger
3 playlist owl babes tiger gtalk
4 streaming semweb pics osx msn
5 radio daml sex macosx icq
? Fruit

Combining Clusters
• Smoothing heuristics are applied to avoid having a number of very similar clusters – originated from distinct seeds that are similar amongst
each other.
• For every two clusters: 1. If one cluster contains the other, i.e., if the larger cluster
contains all the tags of the smaller, remove the smaller cluster;
2. If clusters differ within a small margin, i.e., the number of different tags in the smaller cluster represents less than a percentage of the number of tags in the smaller and larger clusters, add the distinct words from the smaller to the larger cluster and remove the smaller.

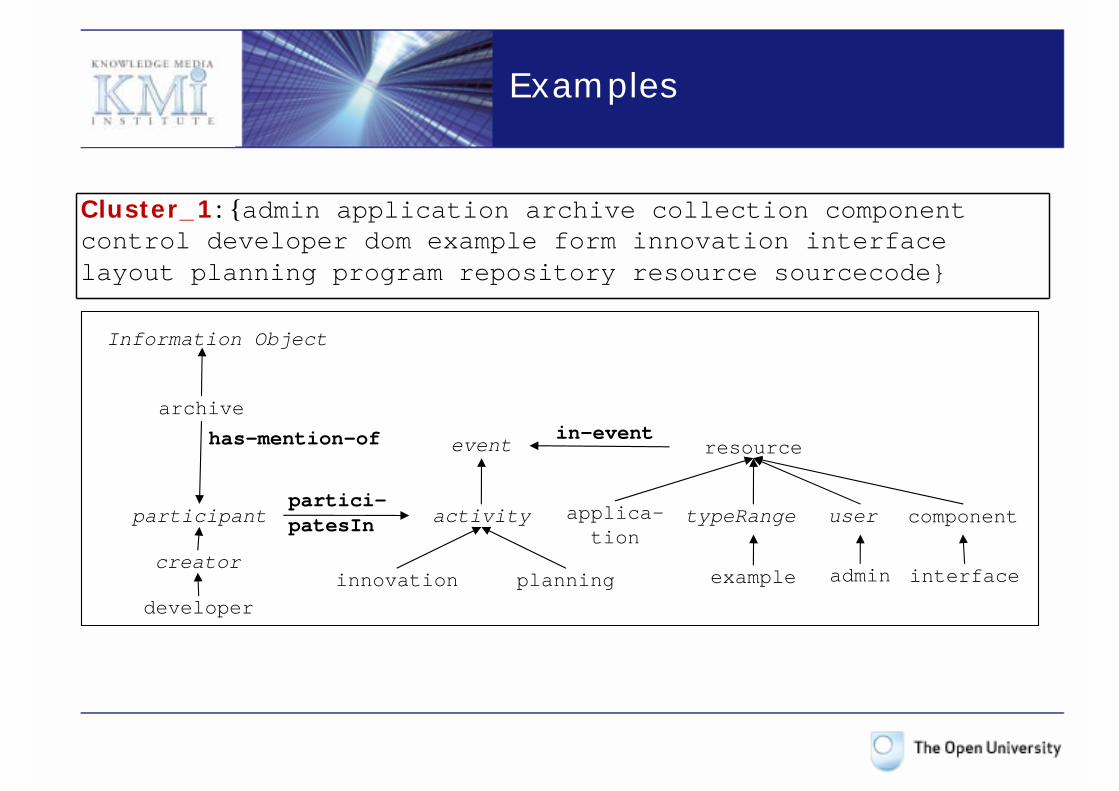
Extracting relations
• For each pair of tags for which the search engine retrieved information, investigate the possible relationships: 1. A tag can be an ancestor of the other. For example, in the FOOD
ontology, apple is a subclass of fruit.2. A tag is the range or the value of a property of another tag. E.g., Class
Zinfandel has a property hasColor, with value red3. Both tags have the same direct parent: apple and pear are subclasses
of fruit4. Both tags have the same ancestors: assembly has as ancestors
building (1st level) and construction (2nd), while formation has fabrication (1st) and construction (2nd) in WordNet.
participant
innovation
event
developer
activity
creatorplanning example
applica-tion
user
admin
resource
typeRange component
interface
partici-patesIn
in-eventarchive
Information Object
has-mention-of
Examples
Cluster_1: {admin application archive collection component control developer dom example form innovation interface layout planning program repository resource sourcecode}

Examples
Cluster_2: {college commerce corporate course education high instructing learn learning lms school student}
education
training1,4 qualification
corporate1 institution
university2,3 college2
postSecondarySchool2
school2
student3 studiesAt
course3offersCoursetakesCourse
activities4
learning4 teaching4
1http://gate.ac.uk/projects/htechsight/Employment.daml.2http://reliant.teknowledge.com/DAML/Mid-level-ontology.daml. 3http://www.mondeca.com/owl/moses/ita.owl.4http://www.cs.utexas.edu/users/mfkb/RKF/tree/CLib-core-office.owl.

Faceted Ontology
• Ontology creation and maintenance is automated
• Ontology evolution is driven by task features and by user changes
• Large scale integration of ontology elements from massively distributed online ontologies
• Very different from traditional top-down-designed ontologies

Lessons Learnt
• Approach proven to be feasible and promising.• However…
– Assumptions in initial experiments (e.g., single ontology coverage for pairs of tags; focus on classes, clustering-based approach, etc..) too restrictive
– Swoogle is too limited to support a fully automated approach
we are now using Watson for the current experiments– Integration with SW-enabled ontology matching
algorithm is essential to improve term matching

Example #3: Semantics-Enhanced Web Browsing
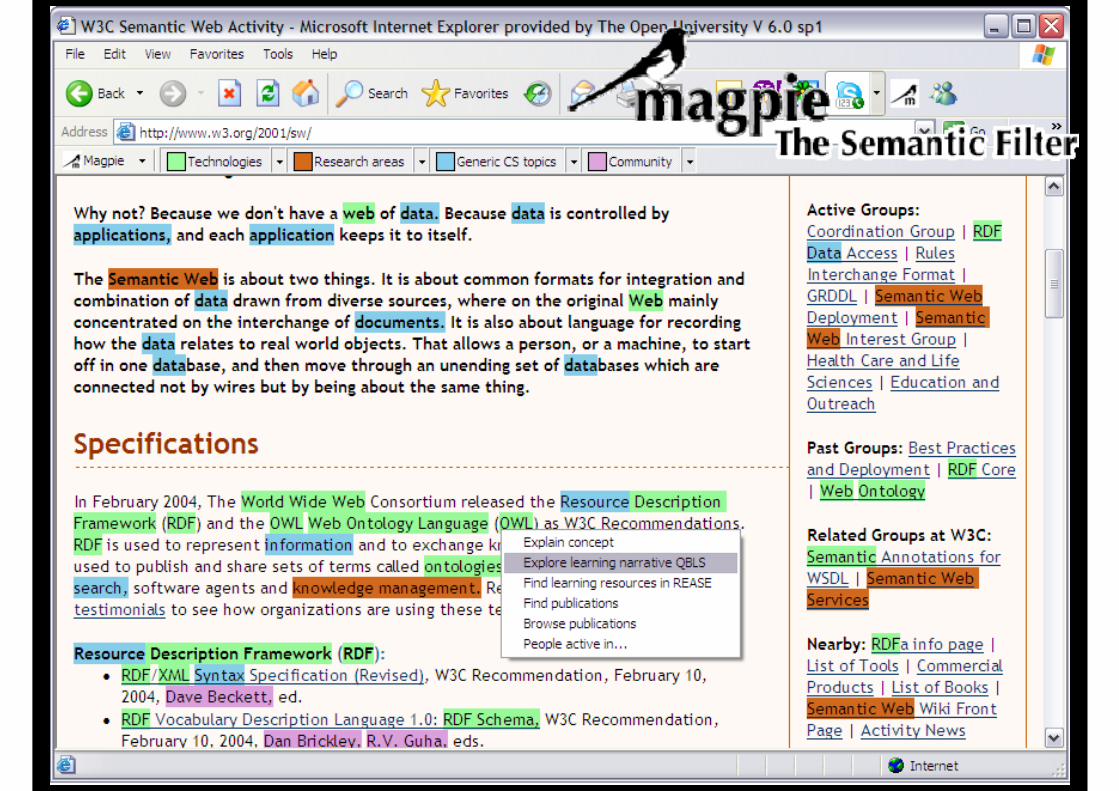

Enriched Web Page
Semantic Log
(found-item 3275578832 localhost #u"http://localhost/people/motta/" john-domingue john-domingue)(found-item 3275578832 localhost
Jabber Server
Magpie Hub
Ontology cache (Lexicon)
Problem Domain & Resources
Ontology based Proxy Server
Web Page
Magpie Architecture


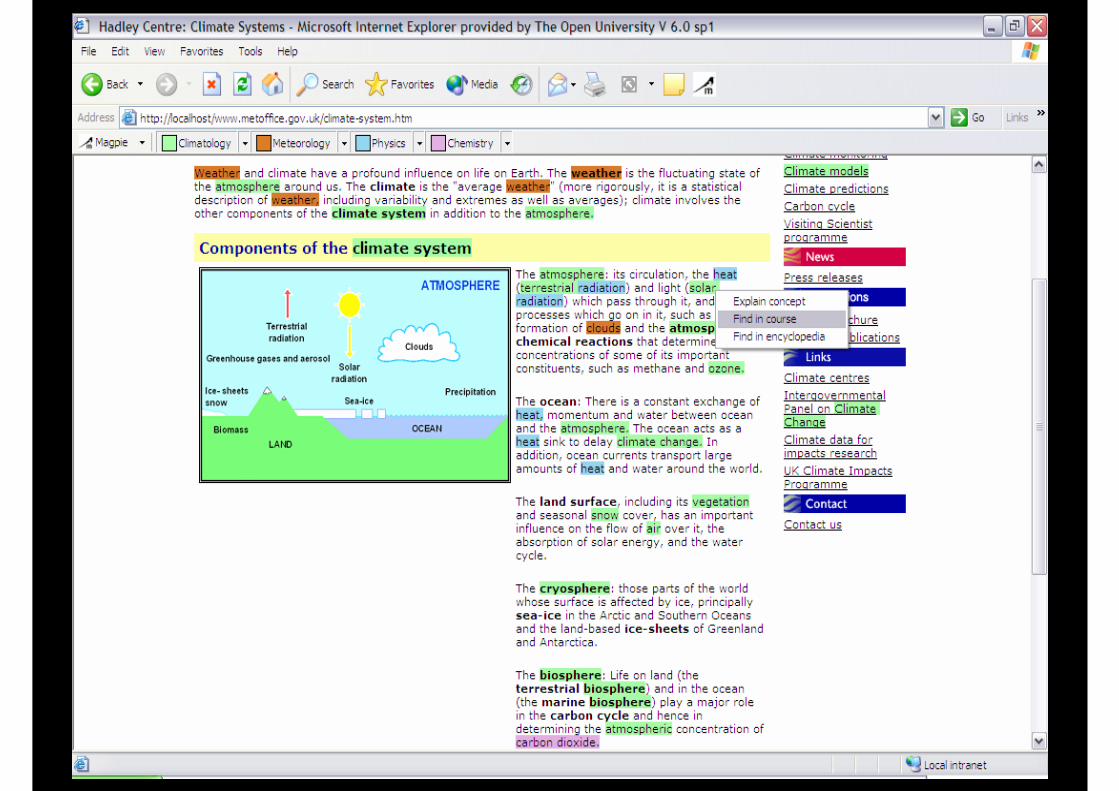
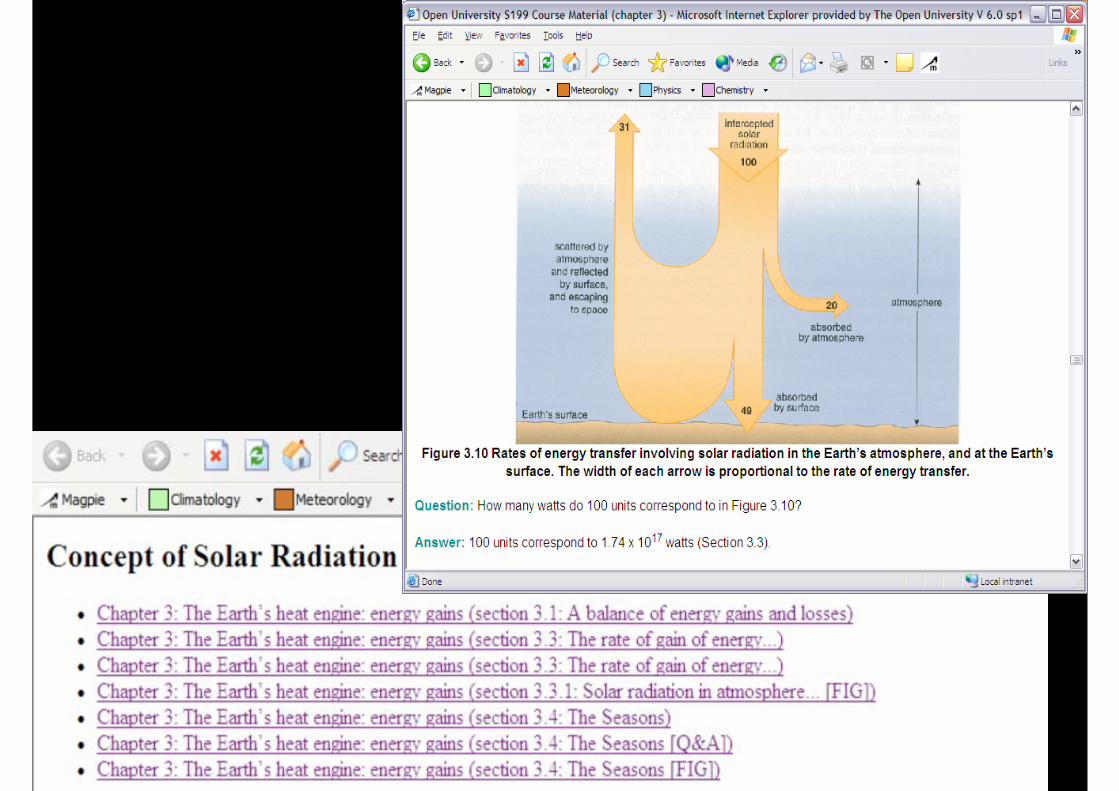

PowerMagpieArchitecture
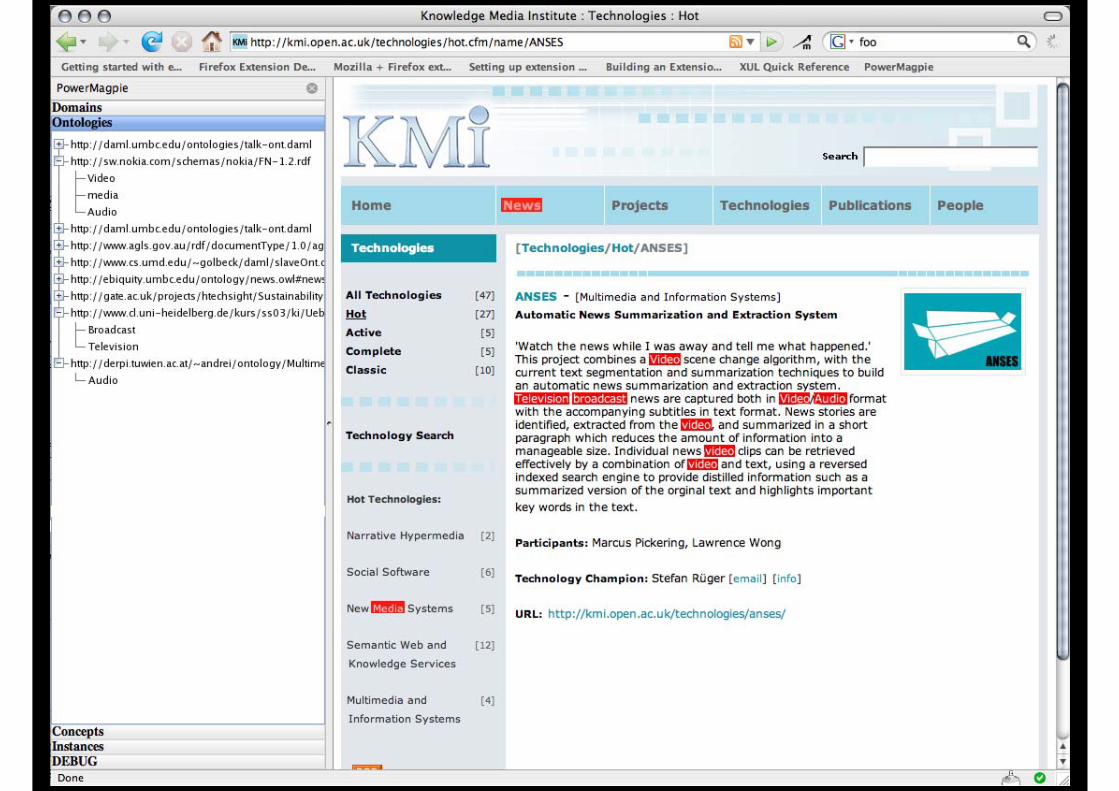




Example #4: Question Answering on the Semantic Web

Aqualog: QA for Corporate Semantic Webs
Which KMi researcherswork on the Semantic Web?
<akt:Person rdf:about="akt:PeterScott"><rdfs:label>Peter Scott</rdfs:label><akt:hasAffiliation rdf:resource="akt:TheOpenUniversity"/><akt:hasJobTitle>kmi deputy director</akt:hasJobTitle><akt:worksInUnit rdf:resource="akt:KnowledgeMediaInstitute"/><akt:hasGivenName>Peter</akt:hasGivenName><akt:hasFamilyName>Scott</akt:hasFamilyName><akt:hasPrettyName>Peter Scott</akt:hasPrettyName><akt:hasPostalAddress rdf:resource="akt:KmiPostalAddress"/><akt:hasEmailAddress>[email protected]</akt:hasEmailAddress><akt:hasHomePage rdf:resource="http://kmi.open.ac.uk/people/scott/"/>
</akt:Person>
Answer…

An Ontology-Modular System
Which premiership footballershave played for Leeds and Chelsea? <ftb:Footballer rdf:about=”ftb:WayneRooney">
<rdfs:label>Wayne Rooney</rdfs:label><ftb:playsFor ftb:ManUnited><ftb:hasPosition ftb:Forward><ftb:hasPreviousClub ftb:Everton> </ftb:Footballer><ftb:Footballer rdf:about=”ftb:DavidBeckham"><rdfs:label>David Beckham</rdfs:label><ftb:playsFor ftb:RealMadrid><ftb:hasPosition ftb:RightMidfield><ftb:hasPreviousClub ftb:ManUnited></ftb:Footballer>
AquaLog
Answer…

Coarse-grained Architecture
NL SENTENCEINPUT
LINGUISTIC&
QUERY CLASSIFICATION
RELATIONSIMILARITY
SERVICE
INFERENCEENGINE
QUERY
TRIPLES
ONTOLOGY
COMPATIBLE
TRIPLES
ANSWER
Linguistic Component obtains intermediate representation from the input query
Relation Similarity Service maps the intermediate representation to the ontology/kb

Relation Similarity Service
MECHANISMS: Ontology relationships and taxonomy, String
algorithms, WordNet, Learning Mechanism, User’s feedback
http://sourceforge.net/projects/jwordnet
http://secondstring.sourceforge.net/
Translated query Ontological structures
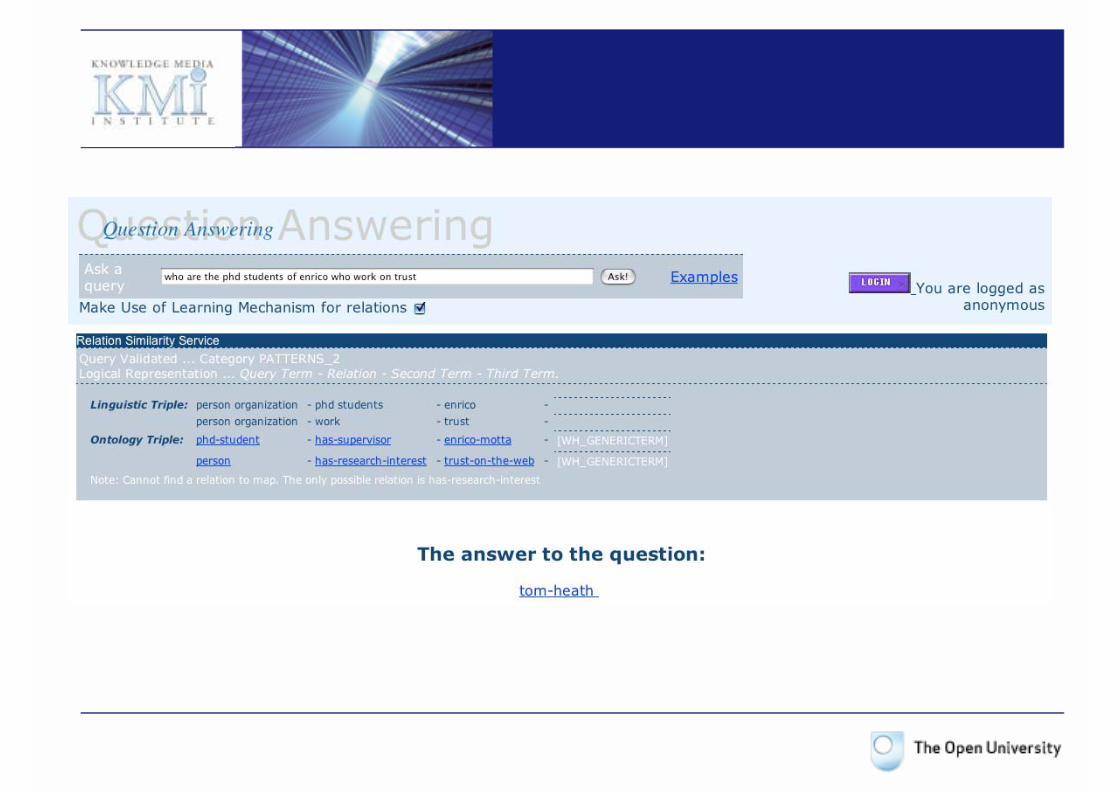
KMi researchers(person/organization, semantic web area)
Has-research-interest (kmi-research-staff-member,Semantic-web-area)
Which are the KMi researchers in the semantic web area?
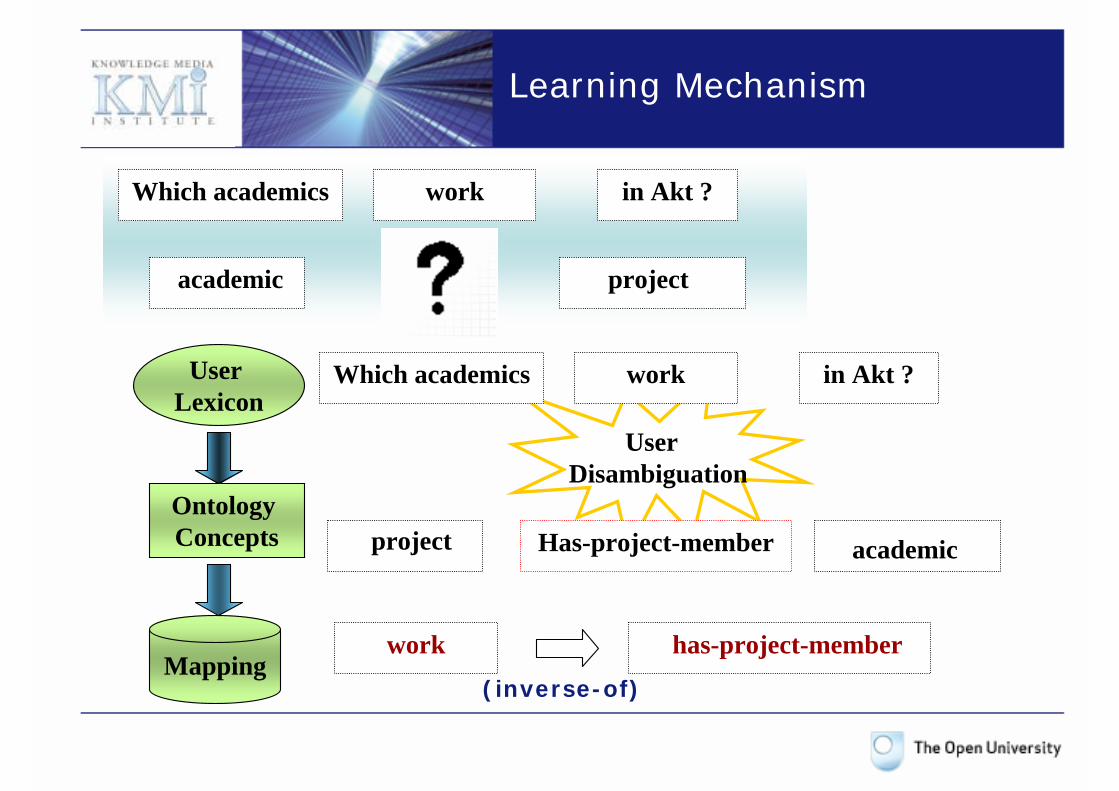
Learning Mechanism
User Lexicon
Ontology Concepts
Mapping
Which academics work in Akt ?
academic project
User Disambiguation
Has-project-member
Which academics work in Akt ?
project
work has-project-member
academic
(inverse-of)

Learning Mechanism
- Key : the CONTEXT of a mapping is given by its particular place within the ontology, namely, since we work with triples, by the two arguments that the relation connects.
academic Has-project-member project
work
- How can we generalize what we have learned? we take the highest concepts in the ontology, which can handle the same relation
academic
work
Databaseperson Has-project-member project

Interpretation Mechanisms: Ontology structure, String algorithms,
WordNet, Machine Learning, User’s feedback

User Feedback

AquaLog --> PowerAqua
NL Query<akt:Person rdf:about="akt:PeterScott"><rdfs:label>Peter Scott</rdfs:label><akt:hasAffiliation rdf:resource="akt:TheOpenUniversity"/></akt:Person>
Answer…
PowerAqua
<ftb:Footballer rdf:about=”ftb:WayneRooney"><rdfs:label>Wayne Rooney</rdfs:label><ftb:playsFor ftb:ManUnited><ftb:hasPosition ftb:Forward><ftb:hasPreviousClub ftb:Everton></ftb:Footballer>
<ptb:Builder rdf:about=”ptb:Bob><rdfs:label>Bob the Builder</rdfs:label><ptb:playedBy……> </ptb:Builder>

PowerAqua vs AquaLog
• Challenges when consulting and aggregating (dynamically mapping) information derived from multiple heterogeneous ontologies:– Locating the right ontologies– Intra-ontology semantic relevance analysis
• Filtering the right mappings– Intg. heterogeneous information to provide an
answer• This reduces to deciding whether two instances
specified according to different ontologies denote the same entity


Conclusions
• SW provides an unprecedented opportunity to build a new generation of intelligent systems, able to exploit large scale background knowledge
• The large scale background knowledge provided by the SW may address one of the fundamental premises (and holy grails) of AI
• The SW is not an aspiration: it is a concrete technology that is already in place today and is steadily becoming larger and more robust
• The new class of systems enabled by the SW is fundamentally different in many respects both from traditional KBS and even from early SW applications
• The examples shown in this talk provide an initial taste of the new generation of applications which will be made possible by the emerging Semantic Web

References
• Ontology Mapping– Lopez, V., Sabou, M., Motta, E. (2006). "Mapping the real
semantic web on the fly". ISWC 2006– Sabou, M., D'Aquin, M., Motta, E. (2006). "Using the semantic
web as background knowledge for ontology mapping". ISWC 2006 Workshop on Ontology Mapping.
• Integration of Web2.0 and Semantic Web– L.Specia, E. Motta, "Integrating Folksonomies with the
Semantic Web", ESWC 2007.– Angeletou, S., Sabou, M., Specia, L., and Motta, E., (2007).
“Bridging the Gap Between Folksonomies and the Semantic Web: An Experience Report”. ESWC 2007 Workshop on Bridging the Gap between Semantic Web and Web 2.0.
• Watson– d’Aquin, M., Sabou, M., Dzbor, M., Baldassarre, C., Gridinoc, L.,
Angeletou, S. and Motta, E.: "WATSON: A Gateway for the Semantic Web". Poster Session at ESWC 2007

'Vision' Papers
• Motta, E., Sabou, M. (2006). "Next Generation Semantic Web Applications". 1st Asian Semantic Web Conference, Beijing.
• Motta, E., Sabou, M. (2006). "Language Technologies and the Evolution of the Semantic Web". LREC 2006, Genoa, Italy.
• Motta, E. (2006). "Knowledge Publishing and Access on the Semantic Web: A Socio-Technological Analysis". IEEE Intelligent Systems, Vol.21, 3, (88-90).
