new results on mesh refinement benoît hudson, cmu joint work with gary miller and todd phillips...
Post on 21-Dec-2015
213 views
TRANSCRIPT

New results onmesh refinement
Benoît Hudson, CMU
Joint work with Gary Miller and Todd Phillips
Papers available athttp://www.cs.cmu.edu/~bhudson

CAD model

Will it work?

EquationsNavier-Stokes:
Heat transfer:

Run simulations!
CAD model
Partial Diff. Eqs.
Weak form
Mesh
SolveVisualize

Input
Points
Segments
Polygons

Input
Points
Segments
Polygons
‘P’ courtesy of Shewchuk

Output
‘P’ courtesy of Shewchuk

Simpler Input

Two possible meshes

Which is better?
Example:f(x,y) = 1-x2

This is a bad mesh
f(x,y) = 1-x2
At mesh vertices:• read the valueAt other points p:• Find t that contains p• Weighted average of
points of t
0
1
0
0
0
0
0
0
0
1
1

This is a better meshStill bad at boundaryf(x,y) = 1-x2
At mesh vertices:• read the valueAt other points p:• Find t that contains p• Weighted average of
points of t
0
1
0
0
0
0
0
0
0
1
1

Good aspect ratio good interpolation
R
r
Good aspect ratio if:
Equivalent: all angles

Aspect ratio
R r
Bad aspect ratio if:
Equivalent: some angle

This is a better meshStill bad at boundary0
1
0
0
0
0
0
0
0
1
1This mesh is Delaunay:
best possiblefor those points

This is a good mesh
Add Steiner points

This is a good mesh

Formal problem
• Input: – Piecewise Linear Complex (PLC)
• points, segments, polygons, …
– quality bound: angle • Output:
– quality triangulation (angle )– all features appear (perhaps subdivided)– O(mopt) vertices

Grading
Good aspect ratio good grading
Small featureSmall triangles
Big featuresBig triangles
Grade linearlyaway from smallfeature
Good aspect ratio bounded degree

Outline
• Two older methods– quadtree refinement– Delaunay refinement
• Our algorithm: SVR as a hybrid
• Parallel SVR
Dynamic meshing: too much for thistalk. See me afterwards.

Older Solutions
• 1950-now: construct mesh by hand!– Takes days to months.
• Automatic methods: ca. 1980-now– no quality, size, or time bounds
• BEG90: quality and size in O(n lg n + m)(buggy proof, fixed in BET93)
• Rup92: smaller in practice, no time bound.

Simpler input
Just points for now
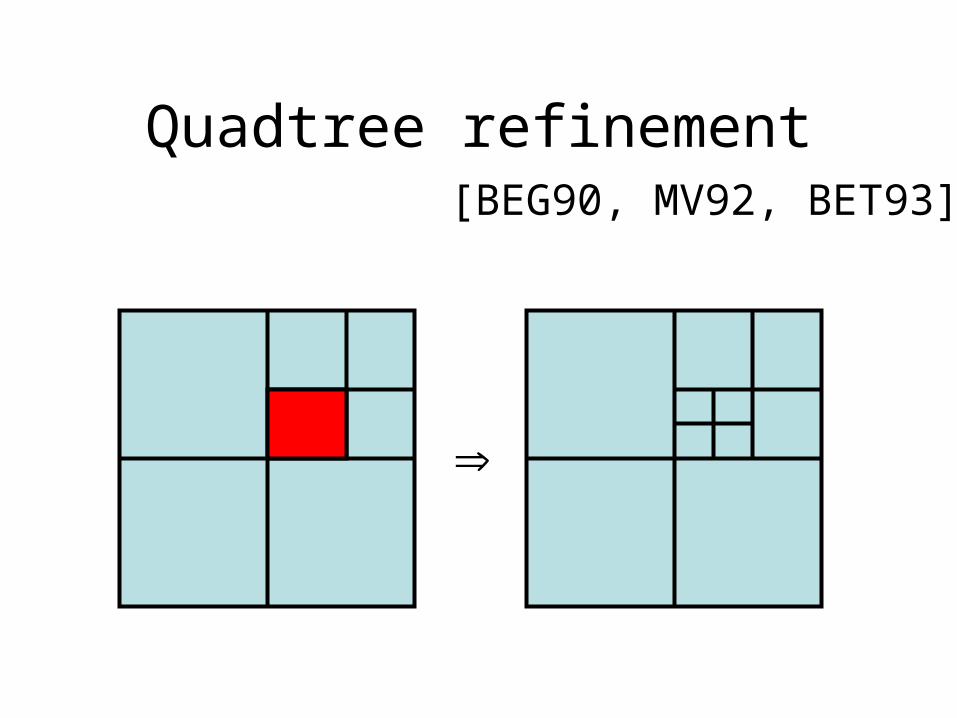
Quadtree refinement
[BEG90, MV92, BET93]

Crowded
• two points in cell, or
• one point in cell, one in neighbour
Quadtree rules
Unbalanced• Neighbor is small

Quadtree

Quadtree

Quadtree

Quadtree in a word
• Quality mesh (17)• O(mopt) output size
• O(n lg n + m) runtime
• General approach: top-down
(think: binary search tree)

Delaunay Refinement[Rup92, She97]

Add a bounding box

Triangulate (use Delaunay)

Identify skinny triangle

Find circumcenter

Insert, retriangulate

Find more skinny triangles

Find more skinny triangles

Find more skinny triangles

Find more skinny triangles

Find more skinny triangles

Find more skinny triangles

Ruppert’s algorithm in a word
• Quality mesh (any 20.7)• O(mopt) output size
• O(n2 + m) runtime worst case– works fast in practice
• General approach: bottom-up
In practice, 35 often works.

Compare and contrast
35 triangles, 30 69 triangles, 17

Ruppert’s algorithm in a word
• Quality mesh
• O(mopt) output size
– smaller than quadtree in practice
• O(n2 + m) runtime worst case– works fast in practice
• General approach: bottom-up

Restrictions
• Ruppert’s algorithm handles segments only at 60 angles to each other.
• 3d extensions [She97, MPW02]:
segmentsegment
face
segmentfaceface
60~7090
Smaller anglesmay cause
infinite loops

Meshing well, quickly
Hudson, Miller, Phillips 2006Sparse Voronoi Refinement
15th International Meshing Roundtable

The Goal
Ruppert’s small meshes
Quadtree’s fast runtime
In dimension 3+!

The intuitionQuadtree’s fast time: slowly zero in on smallfeatures, keep mesh good quality always. Largesize: warp to input too late.
Ruppert’s small size: immediately resolve allfeatures. Ruppert’s bad timing: allow horridmesh quality.
SVR: always good quality, resolve when necessary

SVR

Add a bounding box
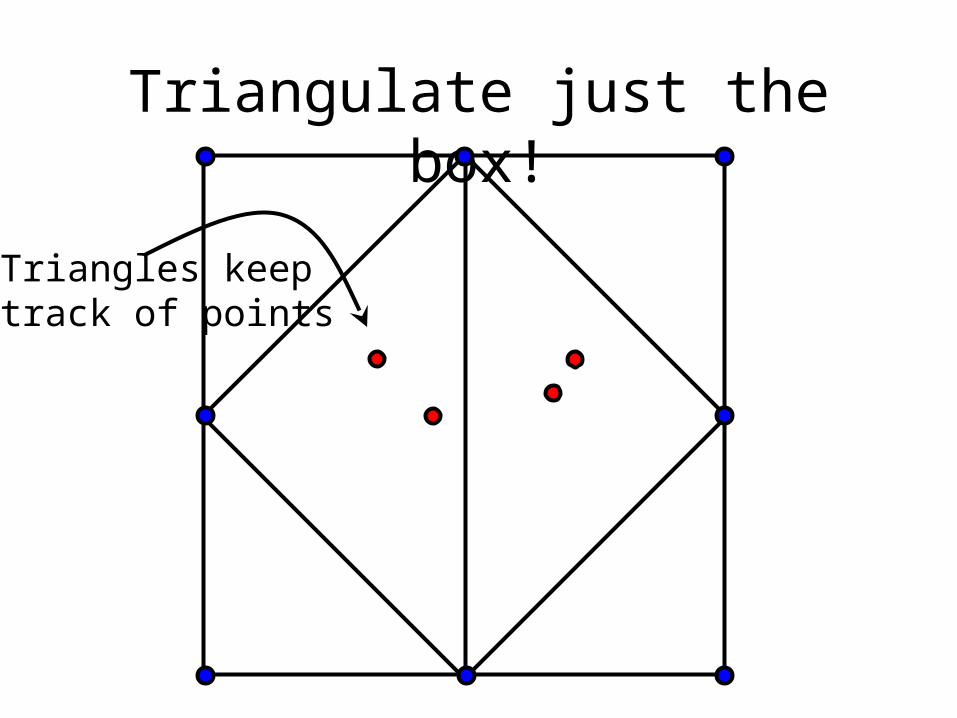
Triangulate just the box!
Triangles keeptrack of points

Apply splitting rules
1. If a triangle is skinny,split it.
2. If a triangle containsinput, split it.

Apply splitting rules
1. If a triangle is skinny,split it.
2. If a triangle containsinput, split it.

Split
Split(t)
2. Shrink by k3. Choose a point4. Insert it, retriangulate
1. If a triangle is skinny,split it.
2. If a triangle containsinput, split it.
1. Draw circle

Apply splitting rules
1. If a triangle is skinny,split it.
2. If a triangle containsinput, split it.
Split(t)
2. Shrink by k3. Choose a point4. Insert it, retriangulate
1. Draw circle

Apply splitting rules
1. If a triangle is skinny,split it.
2. If a triangle containsinput, split it.
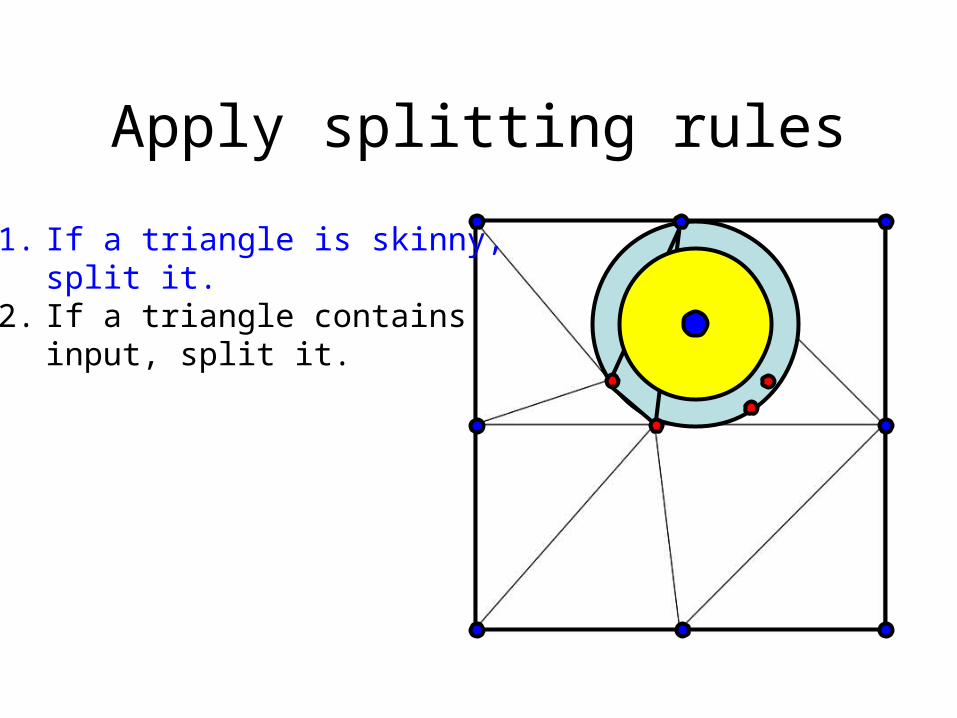
Apply splitting rules
1. If a triangle is skinny,split it.
2. If a triangle containsinput, split it.

General flavour
Like quadtree, refinetop-down
Like Ruppert, use inputpoints and circumcenters

SVR in a word
• Quality mesh
• O(mopt) output size
• O(n lg L/s + m) runtime worst case
• General approach: hybrid
Early evidence:indistinguishable from Ruppert’s
L: largest distances: smallest distance
L/s spreadNormally: L/s poly(n)
lg L/s lg n

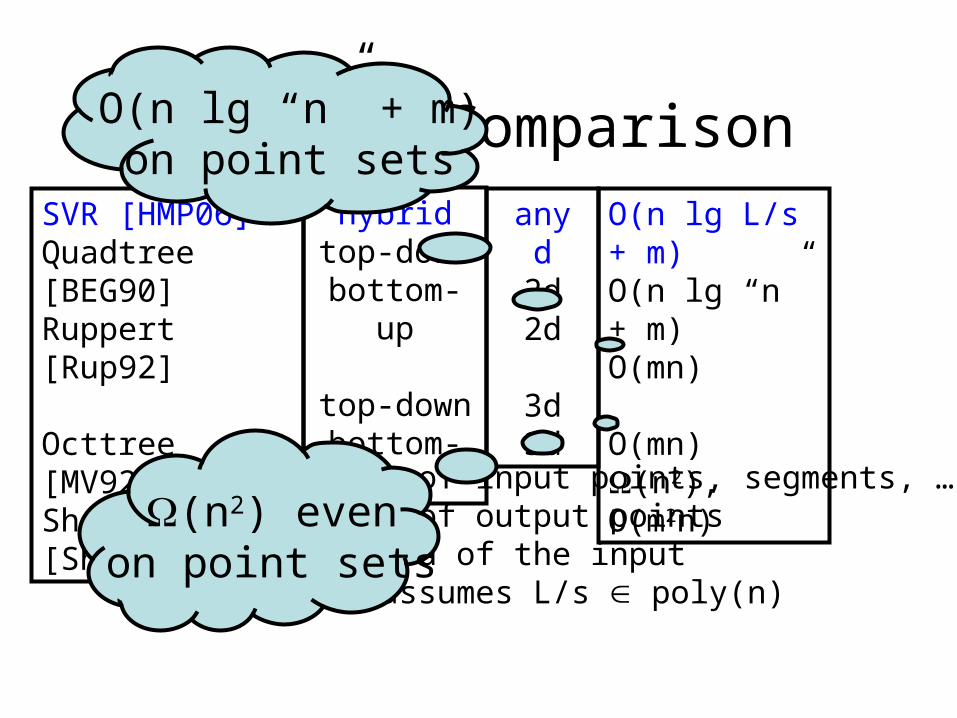
Overall ComparisonSVR [HMP06]Quadtree [BEG90]Ruppert [Rup92]
Octtree [MV92]Shewchuk [She97]
any d2d2d
3d3d
O(n lg L/s + m)O(n lg “n” + m)O(mn)
O(mn)(n2), O(m2n)
n: number of input points, segments, …m: number of output pointsL/s: spread of the inputlg “n”: assumes L/s poly(n)
hybridtop-downbottom-up
top-downbottom-up
[Miller04]: O((n lg + m) lg m)
[HPU05]:O(n lg L/s + m)
on point sets
Overall ComparisonSVR [HMP06]Quadtree [BEG90]Ruppert [Rup92]
Octtree [MV92]Shewchuk [She97]
any d2d2d
3d3d
O(n lg L/s + m)O(n lg “n” + m)O(mn)
O(mn)(n2), O(m2n)
n: number of input points, segments, …m: number of output pointsL/s: spread of the inputlg “n”: assumes L/s poly(n)
hybridtop-downbottom-up
top-downbottom-up
O(n lg “n” + m)on point sets
(n2) evenon point sets

In practice
n/2 pointsaround circle
n/2 pointsalong line
Delaunay hasn2/4 tets

In practice: n=2000
AlgorithmSVR
Shewchuk
Max #tets81K
1.014M
Max degree39
~1,000
Output #tets81K87K
n/2 pointsaround circle
n/2 pointsalong line

In practice: n=20000
n/2 pointsaround circle
n/2 pointsalong line
SVR: outputs 774K tets in 8 minutesShewchuk: thrashes, ^c after 4 hours
(Calculate: Pyramidneeds 108 tets, eachtet is 8 pointers ~ 3.2 GB)

Parallel SVR
Hudson, Miller, Phillips 2007Sparse Parallel Delaunay Refinement
To appear, SPAA.

Why parallel?
• Low-end desktops have dual-core CPUs.
• Understanding the dependencies:– Helps with constant factors in sequential case– Helps with out-of-core, distributed,
compression, dynamic case, …

Parallel Comparison
SVR [HMP07]Quadtree [BET93]Ruppert [STU02]
any d2d
2d, 3d
O(lg (L/s) lg(m))O(lg “n”)O(polylog(L/s))
n: number of input points, segments, …m: number of output pointsL/s: spread of the inputlg “n”: assumes L/s poly(n)
O(n lg L/s + m)O(n lg “n” + m)O( ??? )
Depth Work
A sample work set
What can wedo in parallel?

Conflict

Block

Moot

Independent events

The algorithm: parallel
• Build a bounding box
• While workset not empty– Compute conflicts, blocking, mooting– Defer blocked moves to later– Colour the conflict graph in colours {1..}– for 1..
• perform all the moves in parallel
• remove mooted moves
• collect new moves for next round

Why does it work?
• No move is blocked more than O(1) rounds– either it happens
– or it gets mooted
• Proof:– If a break move blocks, there is a clean move nearby.
– Clean moves don’t block.
– By packing, only O(1) clean moves can be nearby.
– QED.

Summary
• No move is blocked long
• Break moves are discovered quickly
• Thus the time bound of O(lg L/s) rounds– And O(lg m) per round overhead
• In practice: we can use any number of shared-memory processors

Conclusions: SVR
• O(n lg (L/s) + m) time– Matches best 2d bound– First sub-quadratic 3d time bound– First 4+d mesh refinement algorithm– Practical
• Parallelizes!

Open problems

(1) Constrained Delaunay Refinement
• SVR meshes tiny gap.• Gap is exterior: how
can we ignore it?• Traditional method:
Constrained Delaunay Triangulation.
• Hope: CDT/SVR

(2) Slivers
• Points almost coplanar• Good radius/edge ratio• Bad solid angles
numerically bad
• Best proofs guarantee 0.00…1
• In practice get ~10

(3) Small(ish) angles
• SVR needs 90 angles between faces
• 80? 60? 30?

(4) Small angles
• What if angle is 1?– What’s a legal output?
• MPS07: guarantee no large angles in 2d– Extends to 3d?

(5) Curves
• CAD models use curves, curved surfaces
• No good theoretical bounds on refining curved surfaces

(6) Laundry list
• Dynamic meshing– (my thesis topic)
• Moving meshes• Streaming• Distributed-memory• CAD cleaning
• Handling large spread• Non-Euclidian metrics• Better constant bounds

Bibliography
[BEG90]: Bern, Eppstein, Gilbert “Provably good mesh generation”, 1994[MV92]: Mitchell, Vavasis “Quality mesh generation …”, 2000[Rup92]: Ruppert “A Delaunay refinement algorithm for …”, 1995[BET93]: Bern, Eppstein, Teng “Parallel construction …”, 1999[She97]: Shewchuk “Delaunay refinement mesh generation”, 1997[MPW02]: Miller, Pav, Walkington “Fully incremental …”, 2002[STU02]: Spielman, Teng, Ungor “Parallel Delaunay …”, 2002[Mil04]: Miller, “A time-efficient Delaunay Refinement …”, 2004[HPU05]: Har-Peled, Ungor, “A time-optimal Delaunay …”, 2005[HMP06]: Hudson, Miller, Phillips, “Sparse Voronoi Refinement”, 2006[HMP07]: ~, “Sparse Parallel Delaunay Refinement”, 2007[MPS07]: Miller, Phillips, Sheehy, “Size competitive …”, submitted[HA07]: Hudson, Acar, “Dynamic quad-tree mesh refinement”, submitted