new dinucleotide and trinucleotide microsatellite marker
TRANSCRIPT

MOLECULAR BIOLOGY
New Dinucleotide and Trinucleotide Microsatellite Marker Resources for Cotton Genome Research
O. Umesh K. Reddy,† Alan E. Pepper,†* Ibrokhim Abdurakhmonov, Sukumar Saha,† Johnie N. Jenkins, Thomas Brooks, Yuksel Bolek, and Kamal M. El-Zik
INTERPRETIVE SUMMARY
The use of microsatellite markers has greatlyaccelerated the mapping of important traits andthe characterization of genome structure in severalplant and animal species. Microsatellites (alsoknown as simple sequence repeats) are small,repetitive DNA structures, typically distributedthroughout the genome, which are highly mutableand show substantial variation in size(polymorphism). To exploit microsatellites asmolecular markers, they are amplified bypolymerase chain reaction (PCR); gelelectrophoresis or other analytical methodsdetermine the size of the resulting DNA product.In organisms with genomes as large and complexas those of tetraploid cottons, several thousandmicrosatellite markers will be required for geneticmapping and genome analysis. To date,microsatellites have not been used extensively incotton, in part because of the complex and labor-intensive methods for identifying microsatellitesfrom large genomes.
Here we address the problem of microsatellitemarker discovery, and present the initial resultsfrom a low-cost, easy-to-use, efficient method formicrosatellite capture. Using an optimizedprotocol, more than 10,000 microsatellite-containing fragments were obtained fromGossypium hirsutum L. genomic DNA. Sequencesfrom 588 of these DNA fragments weredetermined, and oligonucleotide primers for PCRamplification of 307 microsatellite markers weredesigned. A subset of markers was tested in a setof G. hirsutum L. and Gossypium barbadense L.varieties. Approximately 49% showed length
polymorphism. Intraspecific polymorphism wasobserved in some cases. A lack of redundancywith two independently derived microsatellitemarker sets implies that there is a large resource ofunique microsatellites that have yet to bedeveloped as molecular markers.
ABSTRACT
A collaborative multi-institutional program wasinitiated to streamline the process of microsatellitecapture and characterization, development ofmicrosatellites into informative molecular markers,and dissemination of marker information to thecotton research community. A simple and efficientbiotin capture method was optimized and used tocapture more than 10,000 fragments. Out of 588fragments sequenced, nearly all contained amicrosatellite repeat structure. Several repeat typeswere represented, including AGA, GA, CA, andACA. Primers were designed to amplify 307 uniquemicrosatellite loci (305 nuclear and two chloroplast-encoded). One hundred fifty-two microsatellite lociwere amplified from G. hirsutum L. cv. TM-1 andTamcot SP37, and G. barbadense L. cv. Pima 3-79and Pima S-7. In this comparison, 74 of the primers (~49% of the subset) showed detectablepolymorphism. In a comparison of upland G.hirsutum cultivars, ~26% of the primers exhibitedintraspecific polymorphism. Polymorphism waswidely distributed among the various repeat typesand structures (e.g., imperfect and compoundrepeats). Redundancy with two other previouslyderived microsatellite marker sets (BNL, CM) waslow, implying that the total pool of microsatellitespresent in the cotton genome is large enough tosatisfy the requirements of extensive genomemapping and marker-assisted selection projects.
The Journal of Cotton Science 5:103-113 (2001)http://journal.cotton.org, © The Cotton Foundation 2001
O.U.K. Reddy, A.E. Pepper, and I. Abdurakhmonov, Dep. ofBiology, and T. Brooks, Y. Bolek, and K.M. El-Zik, Dep. ofSoil and Crop Sciences, Texas A & M Univ., College Station,TX 77843; S. Saha and J. Jenkins, Crop Sci. Res. Lab.,USDA, ARS, P.O. Box 5367, Mississippi State, MS 39762.Received 28 Nov. 2000. †Contributed equally to work. *Corresponding author ([email protected]).
103
Abbreviations: AFLP, amplified fragment length polymor-phism; BNL, Brookhaven National Laboratory; CM, cottonmicrosatellite; EDTA, ethylene diamine tetraacetic acid;PCR, polymerase chain reaction; PVDF, polyvinylidene fluo-ride; RFLP, restriction fragment length polymorphism; SDS,sodium dodecyl sulfate; SSLP, simple sequence length poly-morphism; SSR, simple sequence repeat.

Use of molecular markers in genome analysis,the systematic mapping of agriculturally
important traits, and marker-assisted selectionhave been greatly advanced by the development ofreliable PCR-based markers. These includeamplified fragment length polymorphisms(AFLPs) (Zabeau and Vos, 1993; Vos et al., 1995);PCR-RFLP, also known as cleaved amplifiedpolymorphic sequences (Konieczny and Ausubel,1993); and microsatellites, also known as simplesequence repeats (SSRs) (Akkaya et al., 1992) orsimple sequence length polymorphisms (SSLPs)(Bell and Ecker, 1994). Of these PCR-basedmarkers, microsatellites are of particular utilitybecause they are typically both co-dominant andmultiallelic in nature. Furthermore, a given pair ofmicrosatellite primers often will amplify a specificmicrosatellite locus from a diversity of specieswithin a particular genus, sometimes out to thefamily level (Fredholm and Wintero, 1995;Plaschke et al., 1995; Zardoya et al., 1996;Steinkellner et al., 1997; Westman and Kresovich,1998). Microsatellite markers are, therefore,readily “portable” among mapping populations;they are potentially useful for studies of genomeevolution and comparative genomics and for theefficient utilization of wild and primitivegermplasm resources in marker-assisted selection(Tanksley and McCouch, 1997).
McCouch and co-workers (1997) estimatedthat 5700 to 10,000 microsatellite repeat loci arepresent in the relatively small rice genome. Manyof these loci have been incorporated into a high-density microsatellite marker map for rice (Akagiet al., 1996; Chen et al., 1997). High-densitymicrosatellite marker maps containing 5264 and7377 loci have been developed for the human (Dibet al., 1996) and mouse (Dietrich et al., 1996)genomes, respectively. Knapik et al. (1998)constructed a genetic linkage map of zebrafish(Danio rerio) consisting of 705 microsatellitemarkers with an average resolution of 3.3 cM. Thezebrafish map has been expanded recently toinclude more than 2000 microsatellite loci(Shimoda et al., 1999).
Microsatellite identification and mapping incotton lags far behind these milestones. More than500 microsatellite-containing clones, containingmostly (GA)n repeats, have been identified at theBrookhaven National Laboratory. Several of thesesequences are redundant. Primer-pairs for theamplification of ~240 of these loci (designated
BNL for Brookhaven National Laboratory) havebeen made available to the cotton researchcommunity through purchase from ResearchGenetics, Huntsville, AL. An additional 150(GA)n repeat loci (designated CM for cottonmicrosatellite) have been isolated at Texas A & MUniversity (Connell et al., 1998; Reddy andPepper, unpublished data, 1999). Liu et al. (2000)reported on the chromosomal assignment ofseveral BNL and CM microsatellite markers usingcytogenetic stocks. Despite these advances, a largenumber of additional microsatellite markers willbe needed to achieve the goals of the InternationalCotton Genome Initiative and to meet the needs ofmarker-assisted selection applications.
In the past, microsatellite loci were identifiedby surveys of genomic and cDNA sequencedatabases, and by systematic screening of DNAlibraries using colony hybridization withradioactively labeled repeat oligonucleotides(Condit and Hubbell, 1991; Akkaya et al., 1992;Morgante and Oliver, 1993; Wu and Tanksley,1993; Bell and Ecker, 1994). These methods aretypically costly, time-consuming, and labor-intensive. More recently, various approaches havebeen employed to enrich libraries inmicrosatellite-containing clones (Karagyozov etal., 1993; Edward et al., 1996; Lench et al., 1996),including methods employing the hybridization ofadapter-ligated genomic DNA fragments tobiotinylated oligonucleotides and their subsequentcapture using streptavidin-coated magnetic beads(Kijas et al., 1994; Prochazka, 1996; Connell etal., 1998).
In the present study, a large number of newmicrosatellite sequences, comprising a diversity ofdinucleotide and trinucleotide repeat structures,were retrieved from the G. hirsutum L. genomeusing an optimized and highly simplified biotincapture protocol. On the basis of sequenceanalysis of these captured fragments, appropriateprimers were designed for amplification of thesemicrosatellite loci in cotton genetic and genomicresearch. In addition, a subset of these markerswas tested for polymorphism in G. hirsutum L.and G. barbadense L. to evaluate theirinformativeness in interspecific and intraspecificmapping populations. The potential value of thesemicrosatellites in marker-assisted selection,comparative genomics, and efficient germplasmutilization is discussed.
JOURNAL OF COTTON SCIENCE, Volume 5, Issue 2, 2001 104

105
MATERIALS AND METHODS
Microsatellite Isolation
A microsatellite-enriched library was preparedby a highly modified and simplified protocolbased on the biotinylated-oligonucleotide capturemethods of Kijas et al. (1994) and Prochazka(1996). In our protocol, no size fractionation stepsor radioactive hybridizations were employed.Genomic DNA was isolated from G. hirsutum L.cv. Tamcot Sphinx by the method of Iqbal et al.(1997). A 2-µg sample of genomic DNA wasdigested for 3 h in a single reaction mixturecontaining restriction endonucleases HaeIII, RsaI,and DraI (20 units of each), as well as 50 ng ofRNaseA. This digestion resulted in a diversepopulation of blunt-ended restriction fragmentswith an average size of ~550 bp. Digested DNAswere purified using a QIA-quick PCR purificationcolumn (Qiagen, Valencia, CA), eluted with 50 µLof 5 mM Tris-pH 8.0, then dried completely undervacuum. The double-stranded adaptor moleculeAP11/12 was prepared by mixing equal molar amounts of oligonucleotides AP11(5´CTCTTGCTTAGATCTGGACTA3´) and AP12(5´pTAGTCCAGATCTAAGCA-AGAGCACA3´,where p = 5´ phosphate), heating to 94°C, thencooling to 25°C over a period of 5 h. Digestedgenomic DNA fragments were resuspended in a30-µL ligation reaction containing 100 ng ofAP11/12 double-stranded adaptor and 30 Weissunits of T4 DNA ligase. Ligation was carried outat 14°C for 16 h.
Preamplification of adaptor-ligated productswas performed using 2 µL of the ligation reactionas a template for 10 cycles of PCR in a 50-µLreaction volume using the single primer AP11. Anannealing temperature of 55°C was employed inall PCR reactions. Approximately 100 ng of thepreamplified product was then added to a single-reaction mixture containing 6X SSC (0.9 M NaCl,90 mM sodium citrate, pH 7), 0.1% SDS (sodiumdodecyl sulfate), and 200 ng each of biotinylatedoligos b(TA)30, b(CA)20, b(GA)20, b(AGA)15,b(TGA)15, and b(ACA)15 (b = 5´ biotinylation).After denaturation at 95°C for 5 min, preamplifiedgenomic DNA fragments were annealed in thepresence of biotinylated oligonucleotides for 1 hat 60°C, then added to 200 µg of freshstreptavidin-coated paramagnetic beads (Promega,Madison, WI) previously equilibrated with 6X
SSC. Beads were incubated at 60°C with gentleagitation for 15 min, then the liquid was removedby separation using a magnetic stand (Stratagene,San Diego, CA). Beads were washed twice in 300µL of 6X SSC, 0.1% SDS for 15 min at roomtemperature with gentle agitation. Beads werefurther washed twice in 300 µL 6X SSC, 0.1%SDS for 15 min at 60°C with gentle agitation.Finally, beads were briefly washed twice with 6XSSC at room temperature. After removing the finalwash, captured DNAs were eluted from the beadswith the addition of 100 µL of 60°C 0.1 M NaOH.After neutralization with 100 µL of 1 M Tris-pH7.5, captured DNAs were desalted andequilibrated with 10 mM Tris-pH 8.0, 1 mMEDTA-pH 8.0 (to a final volume of ~50 µL) usinga 100-kDa MW cutoff size filtration column(Millipore, Bedford, MA). Five µL of desaltedDNA sample were used as a template for 30 cyclesof PCR in a 50-µL reaction volume using primerAP11. Six microliters of the resulting PCRreaction (~60 ng) was cloned into the TA-cloningvector pCR4-TOPO through topoisomerase-mediated ligation (Invitrogen, San Diego, CA) andtransformed into chemically competentEscherichia coli TOP10. Recombinant colonieswere identified by positive selection throughinsertional inactivation of the ccdB (control of celldeath) open reading frame. Colonies weretransferred to 96-well microtiter plates for archivalstorage. Additional experimental details on themicrosatellite capture method can be found at ourcotton microsatellite resources Web site(http://plantbiol.tamu.edu/cottonSSRs/htm).
Sequence Analysis
Recombinant bacterial colonies wereinoculated into 300 µL of 2X YT broth in a 96-well0.6-mL-deep plate (Marsh Bioproducts, Rochester,NY). Cultures were agitated at 500 rpm in a HiGrohigh-density shaking-incubator (GeneMachines,San Carlos, CA) for 16 to 18 h at 37°C. Thebacteria were pelleted by centrifugation andresuspended in 50 µL of plasmid mini-prepSolution I (25 mM Tris-pH 7.5, 10 mM EDTA, 50mM glucose) containing 0.2 µg mL-1 RNaseA andmixed in a microplate shaker for 10 min. Cells werelysed with 100 µL of Solution II (0.2 M NaOH, 1%SDS); then 75 µL of Solution III (3 M K acetate-pH4.8) and 25 µL of Procipitate reagent (LigoChem,Fairfield, NJ) were added to precipitate proteins and
REDDY ET AL.: NEW MICROSATELLITE MARKER RESOURCES FOR COTTON
JOURNAL OF COTTON SCIENCE, Volume 5, Issue 2, 2001 104

chromosomal DNA. The supernatent was filteredthrough a 0.45-µm polyvinylidene fluoride (PVDF)membrane in 96-well format (Whatman Unifilter350, Whatman, Clifton, NJ) and nucleic acids wereprecipitated with an equal volume of isopropanol.After centrifugation, the pellet was washed in 70%ethanol, air-dried, and resuspended in 10 µL ofultrapure distilled, deionized water. From 1 to 2 µLof each template preparation were sequenced usingBigDye terminator cycle sequencing (Perkin-ElmerApplied Biosystems, Foster City, CA) using 8 pmolof M13-forward or M13-reverse primer in a 10-µLreaction. Standard cycle sequencing conditionswere employed. Sequencing products wereprecipitated with an equal volume of isopropanol,washed with 70% ethanol, air-dried, andresuspended in 10 µL of ultrapure water.Electrophoretic separation of sequencing productswas performed on an ABI PRISM 3700 DNAAnalyzer 96-capillary automated sequencer(Perkin-Elmer Applied Biosystems).
Base calling was performed using SequencingAnalysis ver. 3.6 software (Perkin-Elmer AppliedBiosystems). Assembly of double-stranded DNAsequence contigs from each clone, andidentification of redundancy and overlaps betweenclones were performed using Sequencher 3.0(Gene Codes, Ann Arbor, MI). Primers for theamplification of microsatellite loci were designedmanually using the following criteria, if possible:(i) amplified product should be less than 200 bp inlength for optimum resolution of polymorphicalleles; (ii) primers ideally should have a basecomposition of greater than 40% G+C; (iii)primers should not contain repetitive DNA.Primers selected by these criteria were evaluatedfurther for melting temperature, internal structure,and propensity for primer-dimer formation usingpublicly accessible Worldwide Web resources(Sigma-Genosys, The Woodlands, TX).
Microsatellite Analysis
Genomic DNA was obtained from G. hirsutumL. cv. TM-1 and Tamcot SP37, and G. barbadenseL. cv. Pima 3-79 and Pima S-7 by the method ofIqbal et al. (1997). Microsatellite loci wereamplified by standard PCR methods (Bell andEcker, 1994). A horizontal agarose gelelectrophoresis system, yielding resolution of twobase-pair polymorphisms, and a verticalacrylamide gel electrophoresis system, resolving
single base-pair polymorphisms, were used toevaluate polymorphism of microsatelliteamplification products. In the agarose system,samples were electophoresed on a 20-cm-longhorizontal gel (Owl Separation Systems,Portsmouth, NH) containing 2% agarose plus 2%Metaphor agarose (Cambrex, North Brunswick,NJ) at 5.3 V cm-1 in 0.5X TBE buffer (45 mM Tris-Borate, 1 mM EDTA, pH 8) with buffer-chilling to4°C. Gels were stained briefly with ethidiumbromide prior to photodocumentation. In theacrylamide system, samples were electrophoresed(20 V cm-1 in a 10-cm-high by 33-cm-wide by 1-mm-thick vertical gel rig (CBS Scientific, DelMar, CA) containing 6% polyacrylamide with10% Vol./Vol. Spreadex NAB polymer (ElchromScientific, Cham, Switzerland) in 1X TAE buffer(45 mM Tris-Acetate, 1 mM EDTA, pH 8)),stained with ethidium bromide, then visualized.Additional experimental details on the agaroseand acrylamide gel systems can be found at our cotton microsatellite resources Web site(http://plantbiol.tamu.edu/cottonSSRs/htm).
RESULTS
Several steps in the biotin capture protocolwere modified to optimize the frequency ofmicrosatellite repeats among captured genomicDNA fragments. Perhaps the most importantsingle factor was the age of the streptavidin-coatedparamagnetic beads. With beads only six monthspast the date of manufacture, stored at 4°C as perthe manufacturer’s recommendation (Promega),the yield of PCR product after the secondamplification diminished greatly, and the finalfrequency of microsatellite-containing clones fellfrom close to 100% to between 20 and 30%. Therelatively high quantity of T4 DNA ligase used inthe adapter-ligation step (30 Weiss units) was alsoan important factor affecting the overall efficiencyof the method.
A single capture reaction transformed into E.coli TOP10 cells (Invitrogen) yielded a total of >1× 104 colony-forming units, equivalent to >2 × 105
colony forming units µg-1 of pCR4-TOPO vector.A random survey of primary colonies by PCR(using M13-forward and M13-reverse primers)indicated >98% of the transformants containedplasmids with detectable DNA inserts. The typicalinsert size was 500 ± 100 bp—a range well suitedfor complete sequencing using vector-specific
JOURNAL OF COTTON SCIENCE, Volume 5, Issue 2, 2001 106

107
primers. A collection of 588 colonies, picked atrandom from primary transformation plates, wasinoculated into 96-well culture plates for high-throughput sequencing. Sequence analysisshowed that virtually all of the inserts containedmicrosatellite repeat motifs matching one or moreof the biotinylated oligonucleotides used in theselection process—although some motif lengthswere quite small [e.g., (AGA)2 or (GA)3]. Due tothe judicious selection of the restriction enzymesused in the initial fragmentation (HaeIII, RsaI, andDraI), none of the insert fragments were truncated within, or at the end of, a microsatelliterepeat. In all cases, the unique sequences flanking both ends of the microsatellite repeat wereobtained. This result is in contrast to that of theCM collection (Connell et al., 1998), in whichgenomic DNAs were mechanically fragmentedusing a high-pressure nebulizer, and a substantialportion of the clones were truncated within themicrosatellite.
Of the 588 clones sequenced, 50 (8.5%) wereredundant with other clones in the samecollection. Internal redundancy was expected,since two PCR amplification steps were employedin the isolation process. Of the remaining 526nonredundant clones, 309 were selected forfurther analysis on the basis of the followingcriteria: (i) the length of the microsatellite was fiverepeat units or greater; (ii) the unique 5′ and 3′flanking sequences were both of suitable structureand composition for the design of efficientprimers. Microsatellites with flanking sequencesthat were highly repetitive in nature and/or had avery high content of A+T nucleotides wereeliminated.
These 309 new microsatellite loci (describedin Table 1, appendix) were designated “JESPR”(after the names of the principle investigators, toreflect their collaborative development).Microsatellite loci containing a single repeat type
made up 75% of the JESPR collection, including98 (32%) with dinucleotide repeat types, 131(42%) with trinucleotide repeat types, and 4(1.3%) with hepta- and hexanucleotide repeattypes. Of the microsatellites containing a singlerepeat type, 92% had “perfect” repeats,uninterrupted by nonrepeat nucleotides (Fig. 1). Afurther 25% of the collection was composed of“compound repeats” consisting of more than onerepeat type at a single locus. Microsatellites withthe AGA repeat type were the most abundant inour collection, followed by the GA type, with CAand ACA types making up the bulk of theremaining collection (Fig. 2).
Only two clones (both GA-repeats) wereredundant with the more than 500 clones of theBNL microsatellites, and none were redundantwith the 150 GA-repeat microsatellites of the CMcollection. Thus, the overwhelming majority ofsequences in our collection represented newmicrosatellite loci, and the total number ofmicrosatellites present in the cotton genomeappears to be quite large. Because two PCRamplification steps were employed in our biotinselection procedure, the level of internalredundancy within the JESPR collection isuninformative with regard to abundance of variousmicrosatellite repeats in the genome.
To explore the potential utility of these new microsatellite loci in sequence-basedgenomic comparisons with the well-studied modelplant Arabidopsis thaliana (L.) Hyenh,the JESPR sequences were subjected to basic local alignment search tool searches (Altschul e t a l . , 1 9 9 0 ) a g a i n s t A r a b i d o p s i sg e n o m i c s e q u e n c e d a t a b a s e s(http://www.Arabidopsis.org/blast/). A significantfraction of the loci (~13%) could be aligned withsequences in the Arabidopsis genome with basic-local-alignment-search-tool probability scores of1 × e−20 or less - a level at which we confidently
REDDY ET AL.: NEW MICROSATELLITE MARKER RESOURCES FOR COTTON
Fig. 1. Examples of categories of microsatellite repeat structures identified in this study. Underlined nucleotides indicatethe distinguishing features of imperfect and compound repeats, respectively.

108JOURNAL OF COTTON SCIENCE, Volume 5, Issue 2, 2001
Fig. 2. Distribution of repeat lengths and types among 307 loci in the JESPR collection. Loci with repeat lengths of lessthan five units were not included in this collection.
could assign each G. hirsutum L. clone a single“most similar” sequence in the Arabidopsisgenome (Fig. 3A). A representative sequencealignment between Arabidopsis and cotton,showing the location of the microsatellite repeat,is shown in Fig. 3B. On the basis of basic localalignment search tool results, the annotation of theArabidopsis sequence database, and the presenceof open reading frames, nearly all of the sequenceswith this level of similarity were predicted to beeither protein-encoding genes or pseudogenes inboth cotton and Arabidopsis. Sequences adjacentto the JESPR53 microsatellite showed highsimilarity to the trnI and 16S ribosomal rRNA-encoding genes from several higher plantchloroplast genomes. Similarly, sequencesflanking the JESPR74 microsatellite showed highsimilarity to the chloroplast-encoded cytochrome-b 550 alpha subunit gene. None of these sequenceswere present in current publicly accessible cottonexpressed sequence tag databases(http://www.cugisearch.clemson.edu).
Primers were designed for the 307 selectedmicrosatellite loci using the criteria described in
materials and methods. These primers (Table 1)had an average length of 20.4 nucleotides, with anaverage G+C content of 48% and meltingtemperature of 62°C. Predicted products ranged insize from 100 to 250 bp. An initial set of 152primer-pairs was synthesized and tested in PCRusing G. hirsutum L. cv. TM-1 genomic DNA astemplate. Of these, 123 (81%) yieldedamplification products of approximately theexpected size, on the basis of the sequence of thecloned microsatellite fragment. However, aminority of these amplified more than one locus,as we have observed previously in tetraploidcotton with several of the BNL and CM primers(Reddy and Pepper, unpublished data,1999–2001). To determine the informativeness ofthe newly identified JESPR microsatellites in a G.hirsutum L. × G. barbadense L., interspecificmapping population amplification products fromG. hirsutum L. cv. TM-1 and G. barbadense L. cv.Pima 3-79 were compared. In these analyses, 69(45.4%) of 152 primer-pairs tested yieldedpolymorphic amplified products. Seventeen of the152 primer-pairs tested (11.2%) showed

109
intraspecific polymorphism between the G.hirsutum L. cv. TM-1 and Tamcot SP37. However,25.7% of the primers amplified loci that werepolymorphic between upland G. hirsutum L. cv.HS46 and MARCABUCAG8US-1-88, which arenot closely related on the basis of pedigree records(Calhoun et al., 1997) and have been used toproduce intraspecific genetic maps in uplandcotton (Shappley et al., 1998). Three of the 152primers (2%) amplified loci with intraspecificpolymorphism between G. barbadense L. cv.Pima 3-79 and Pima S-7, which are very closelyrelated (Calhoun et al., 1997).
In total, 74 primer sets (48.7%) showedpolymorphism among the tetraploid cottoncultivars tested (Table 1). A minority ofpolymorphisms (21%) was dominant in nature,with the recessive allele not producing anamplification product (Table 1, Fig. 4). Dominantand co-dominant polymorphisms were widelydistributed among the repeat types (AGA, GA,CA, etc.) as shown in Fig. 4. Approximately 34%
of the compound repeat loci were polymorphic,while ~54% of the simple repeat loci werepolymorphic. Furthermore, 38% of the imperfectrepeats were polymorphic, while 54% of theperfect repeats were polymorphic.
REDDY ET AL.: NEW MICROSATELLITE MARKER RESOURCES FOR COTTON
Fig. 4. Distribution of microsatellite polymorphism amongcategories and repeat types. COM indicates thevalues for compound repeats. Simple repeatsidentified by repeat type (GA, AGA, CA, etc.).
Fig. 3. Sequence-based comparison of unique sequences flanking JESPR microsatellite loci with Arabidopsis thaliana.(A) Distribution of basic local alignment search tool probability scores from 307 JESPR sequences searched against theArabidopsis genome database. (B) An alignment of Gossypium hirsutum L. clone JESPR238 with Arabidopsis EST cloneAV441998, a putative cCDC2-like kinase (p = 5.6 ¥ e-21, S = 370). The boxed GA dinucleotide corresponds to the locationof the (GA)n microsatellite repeat in cotton.

DISCUSSION
Microsatellite markers possess severalimportant positive qualities for cotton genomicresearch. Among these is the broad spectrum ofanalytical detection methods that can be employedto detect polymorphisms. These methods includesimple low-cost “low-technology” methods such asthe Metaphor-agarose and Spreadex NAB-acrylamide gel systems described here, whichutilize equipment and technical expertise that areubiquitous in typical molecular biologylaboratories. Such low-tech methods areparticularly appropriate to researchers indeveloping countries where “hard currency” formajor equipment and expensive reagents may belimiting, but labor costs are low. These methods canbe performed at field stations and satelliteexperiment stations, without the need for majorcapital equipment or the logistical complicationsinvolved in shipping large numbers of samples foranalysis. Consequently they are also appropriatefor some marker-assisted selection projectsinvolving analysis of only one or a few markers.However, the same microsatellite resources are alsowell-suited to more costly high-tech solutions,including detection of fluorescently labeled PCRproducts using automated and semiautomatedDNA-sequencing instruments (Mitchell et al.,1997; Ponce et al., 1999), including high-throughput capillary electrophoresis devices (Baba,1996). Future microsatellite detection methodsprobably will include matrix-assisted laserdesorption ionization time-of-flight massspectroscopy (Taranenko et al., 1999) andmicroarrays (Cheung and Nelson, 1998).
An improved biotin selection method, alongwith the declining cost of DNA sequencing, hasenabled us to identify more than 307 newmicrosatellite loci for cotton. The method wasoptimized using A. thaliana (where microsatellitecomposition and abundance are largely knownfrom genome sequencing efforts) and recently hasbeen used in our laboratory to isolatemicrosatellite-containing clones from species inthe genera Arabis (Brassicaceae), Caulanthus(Brassicaceae), Populus (Salicaceae), Silphium(Asteraceae), and Compsonurea (Myisticaceae)(A. Pepper, T. Mitchell-Olds, L. Norwood, C.Loopstra, J. Manhart, and J. Janovec, unpublisheddata, 2001). In each case, the results were similar– nearly all clones contained at least a small repeat
motif, and from 50 to 100% of the clones pickedat random contained microsatellite repeats of asufficient length (>5 repeat units) that they mightbe polymorphic in natural populations (Innan etal., 1997).
One of the key elements of our method wasthe use of a complex mixture of biotinylatedoligonucleotides in order to cast a wide net forcapturing several repeat types. Each of the repeatoligonucleotides used in our procedure capturedseveral microsatellite-containing fragments (Fig.2). The distribution of repeat types in ourcollection does not strictly represent their relativeabundance in the cotton genome, but reflects therelative efficiency with which they were captured.For example, the lowest frequency of isolationwas observed with the b(TA)30 oligo, whichidentified only two repeat loci. This finding wasprobably due to the low melting temperature of the(TA)30 repeat structure (Tmelt = 51°C) relative to the60°C hybridization temperature employed duringthe capture. Interestingly, a few (CTTTCT)n and(CTTTT)n repeat units also were captured in ourisolation procedure. The (CTTTCT)n repeat wasisolated in ~5% of the genomic DNA fragmentscaptured from Caulanthus amplexicaulis(Brassicaceae) using a protocol that employedonly the b(CA)20, b(GA)20, and b(AGA)15 primers(L. Norwood and A. Pepper, unpublished data,2001). We surmise that capture of this particularrepeat motif probably was due to hybridizationwith the b(GA)20 oligo. Similar mechanisms canbe postulated for the capture of the GGA and GGTrepeats, which also were not among our collectionof biotinylated oligonucleotides. The mechanismof capture of (CTTTT)n repeats remains obscure.
A large percentage (~49%) of themicrosatellite loci in the JESPR collection werepolymorphic in tetraploid cottons. This value washighest in simple, perfect repeats (~54%), butother repeat structures also yielded informativepolymorphisms at a significant frequency.Furthermore, ~46% of the microsatellite loci inthe JESPR collection were informative formapping in a G. hirsutum L. cv. TM-1 × G.barbadense L. cv. Pima 3-79 interspecificmapping population targeted by the InternationalCotton Genome Initiative. A wide distribution ofproduct sizes (~100–250 bp) will facilitate theassignment to appropriate “bins” for multiplexanalysis (Mitchell et al., 1997; Ponce et al., 1999).A substantial fraction of loci (~11–26%) were
JOURNAL OF COTTON SCIENCE, Volume 5, Issue 2, 2001 110

polymorphic within upland cotton, and may beuseful for intraspecific marker-assisted selectionapplications. Furthermore, in a set of 79 JESPR-primer-pairs tested on the diploid speciesGossypium raimondii Ulbrich and G. arboreumL., all amplified a product of similar size to theexpected product from tetraploid cotton,indicating that the primer binding sites may havebeen conserved in genomic DNA over severalmillion years of evolution. These results implythat microsatellites will be useful—along withother DNA-based marker systems—in thecomparative genetic mapping of tetraploid anddiploid Gossypium species (Brubaker et al., 1999)and in tracking the introgression of agriculturallyimportant traits from exotic diploid and tetraploidgermplasm sources.
A significant proportion (>13%) of ourmicrosatellite loci could be directly linked, viasubstantial sequence similarity, to sequences in thefully sequenced Arabidopsis genome. Bothtraditional taxonomic treatments and modernmolecular phylogenetics (Soltis et al., 1999)indicate a close evolutionary proximity ofGossypium (Malvaceae) to A. thaliana(Brassicaceae). When these microsatellites aremapped in cotton, they will contribute to thedetection and delineation of regions ofchromosomal colinearity (“synteny”) betweenArabidopsis and the A and D genomes of tetraploidGossypium species and, in so doing, potentiallyaccelerate gene discovery efforts based on positionalcloning and candidate gene approaches.
Given the low level of redundancy betweenthe JESPR, CM, and BNL marker sets, and thecomparatively large 1C value of G. hirsutum L.(~2 × 109 bp [Arumuganathan and Earle, 1991]),the number of microsatellite repeat structurespresent in the cotton genomes is probably vast.The development of a high-density molecularmarker map for tetraploid cotton, similar to thoseused for genetic mapping in humans, mouse, andzebrafish, probably will require the identificationof more than 1000 polymorphic loci. A mapdeveloped from such a marker set would have anaverage density of markers of less than 5 cM, andprobably give coverage of all chromosome arms.In our present collection, we have more than 1 ×104 additional, uncharacterized clones. Althoughsome of these clones will be redundant with thosealready in hand, further development of thisresource probably will satisfy the needs of the
cotton research community for a sizable collectionof polymorphic microsatellite markers. Ifrequired, additional biotin selections could beperformed at a lower hybridization temperature toidentify (T)n, (AT)n, and other A+T-rich repeat locithat are also abundant in many plant species. Asnew markers in our collection are developed,this information will be disseminated rapidly via the Worldwide Web through CottonDB(http://algodon.tamu.edu/cottondb.html) andthrough Web resources under development at Mississippi State University and at Texas A & M University (http://plantbiol.tamu.edu/cottonSSRs/htm).
ACKNOWLEDGMENT
This work was supported by USDA-NRICGP(Plant Genome) grant 97-35300-4585 (to A.E.Pand K.M.E.) and the USDA-ARS. I.A. wassupported by a President’s Fellowship from thegovernment of the Republic of Uzbekistan. Theauthors thank Geoff Waldbieser and Mary Duke ofthe USDA-ARS Mid-South Area GenomicsLaboratory at Stoneville, MS, for technicalassistance with template preparation andsequencing; and Robert Creelman, James Connell,and Avutu S. Reddy for helpful discussions onmicrosatellite isolation.
REFERENCES
Akagi, H., Y. Yokozeki, A. Inagaki, and T. Fujimura. 1996.Microsatellite DNA markers for rice chromosomes.Theor. Appl. Genet. 93:1071–1077.
Akkaya, M.S., A.A. Bhagwat, and P.B. Cregan. 1992. Lengthpolymorphisms of simple sequence repeat DNA insoybean genetics. Genetics 132:1131–1139.
Altschul, S.F., W. Gish, W. Miller, E.W. Myers, and D.J.Lipman. 1990. Basic local alignment search tool. J. Mol.Biol. 215:403–410.
Arumuganathan, K., and E.D. Earle. 1991. Nuclear DNAcontent of some important plant species. Plant Mol. Biol.Rep. 9:208–218.
Baba, Y. 1996. Analysis of disease-causing genes and DNA-based drugs by capillary electrophoresis: Towards DNAdiagnosis and gene therapy for human diseases. J.Chromatogr. 687:271–302.
REDDY ET AL.: NEW MICROSATELLITE MARKER RESOURCES FOR COTTON 111

Bell, C.J., and J.R. Ecker. 1994. Assignment of 30microsatellite loci to the linkage map of Arabidopsis.Genomics 19:137–144.
Brubaker, C.L., A.H. Paterson, and J.F. Wendel. 1999.Comparative genetic mapping of allotetraploid cottonand its diploid progenitors. Genome 42:184–203.
Calhoun, D.S., D.T. Bowman, and O.L. May. 1997. Pedigreesof upland and pima cotton cultivars released between1970 and 1995. Bull. 1069. Mississippi Agric. For. Exp. Stn.
Chen, X., S. Temnykh, Y. Xu, Y.G. Cho, and S.R. McCouch.1997. Development of a microsatellite framework mapproviding genome-wide coverage in rice (Oryza sativaL.). Theor. Appl. Genet. 95:553–567.
Cheung, V.G., and S.F. Nelson. 1998. Genomic mismatchscanning identifies human genomic DNA sharedidentical by descent. Genomics 47:1–6.
Condit, R., and S.P. Hubbell. 1991. Abundance and DNAsequence of two-base repeat regions in tropical treegenomics. Genome 34:66–71.
Connell, J.P., S. Pammi, M.J. Iqbal, T. Huizinga, and A.S.Reddy. 1998. A high through-put procedure for capturingmicrosatellites from complex plant genomes. Plant Mol.Biol. 16:341–349.
Dib, C., S. Faure, C. Fizames, D. Samson, N. Drouot, A.Vignal, P. Millasseau, S. Marc, J. Hazan, E. Seboun, M.Lathrop, G. Gyapay, J. Morissette, and J. Weissenbach.1996. A comprehensive genetic map of the humangenome based on 5264 microsatellites. Nature380:152–154.
Dietrich, W.F., J. Miller, R. Steen, M.A. Merchant, D.Damronboles, Z. Husain, R. Dredge, M.J. Daly, K.A.Ingalls, T.J. O’Connor, C.A. Evans, M.M. DeAngeilis,D.M Levinson, L.L. Kruglyak, N. Goodman, N.G.Copeland, N.A. Jenkins, T.L. Hawkins, L. Stein, D.C.Page, and E.S. Lander. 1996. A comprehensive geneticmap of the mouse genome. Nature 380:149–152.
Edward, K., J. Barker, A. Daly, C. Jones, and A. Karp. 1996.Microsatellite libraries enriched for severalmicrosatellite sequences in plants. Biotechniques20:758–760.
Fredholm, M., and A.K. Wintero. 1995. Variation of shorttandem repeats within and between species belonging tothe Canidae family. Mamm. Genome 6:11–18.
Innan, H., R. Terauchi, and T.N. Miyashita. 1997.Microsatellite polymorphism in natural populations ofthe wild plant Arabidopsis thaliana. Genetics146:1441–1452.
Iqbal, M.J., N. Aziz, N.A. Saeed, and Y. Zafar. 1997. Geneticdiversity evaluation of some elite cotton varieties byRAPD analysis. Theor. Appl. Genet. 94:139–144.
Karagyozov, L., I.D. Kalcheva, and V.M. Chapman. 1993.Construction of random small-insert genomic librarieshighly enriched for simple sequence repeats. Nucl. AcidsRes. 21:3911–3912.
Kijas, J.M.H., J.C.S. Fowler, C.A. Garbett, and M.R. Thomas.1994. Enrichment of microsatellites from the citrusgenome using biotinylated oligonulectide sequencesbound to streptavidin-coated magnetic particles.Biotechniques 16:657–662.
Knapik, E.W., A. Goodman, M. Ekker, M. Chevrette, J.Delgado, S. Neuhauss, N. Shimoda, W. Driever, M.C.Fishman, and H.J. Jacob. 1998. A microsatellite geneticlinkage map for zebrafish (Danio rerio). Nature Genet.18:338–343.
Konieczny, A., and F. Ausubel. 1993. A procedure for quickmapping of Arabidopsis mutants using ecotype specificmarkers. Plant J. 4:403–410.
Lench, N.J., A. Norris, A. Bailey, A. Booth, and A.F.Markham. 1996. Vectorette PCR isolation ofmicrosatellite repeat sequences using anchoreddinucleotide primers. Nucl. Acids Res. 24:2190–2191.
Liu, S., S. Saha, D. Stelly, B. Burr, and R.G. Cantrell. 2000.Chromosomal assignment of microsatellite loci incotton. J. Hered. 91:326–332.
McCouch, S.R., X. Chen, O. Panaud, S. Temnykh,Y. Xu,Y.G.Cho, N. Huang, T. Ishii, and M. Blair. 1997.Microsatellite marker development, mappingapplications in rice genetics and breeding. Plant Mol.Biol. 35:89–99.
Mitchell, S.E., S. Kresovich, C.A. Jester, C.J. Hernandez, andA.K. Szewc-McFadden. 1997. Application of multiplexPCR and fluorescence-based semi-automated allelesizing technology for genotyping plant geneticresources. Crop Sci. 37:617–624.
Morgante, M., and A.M. Oliver. 1993. PCR-amplifiedmicrosatellite markers in plant genetics. Plant J.3:175–182.
Plaschke J., M.W. Ganal, and M.S. Roder. 1995. Detection ofgenetic diversity in closely related bread wheat usingmicrosatellite markers. Theor. Appl. Genet.91:1001–1007.
Ponce, M.R., P. Robles, and J.L. Micol. 1999. High-throughput genetic mapping in Arabidopsis thaliana.Mol. Gen. Genet. 261:408–415.
JOURNAL OF COTTON SCIENCE, Volume 5, Issue 2, 2001 112

Prochazka, M. 1996. Microsatellite hybrid capture techniquefor simultaneous isolation of various STR markers.Genome Res. 6:646–649.
Shappley, Z.W., J.N. Jenkins, W.R. Meredith, and J.C.McCarty Jr. 1998. An RFLP linkage map of Uplandcotton, Gossypium hirsutum L. Theor. Appl. Genet.97:756–761.
Shimoda, N., E.W. Knapik, J. Ziniti, C. Sim, E. Yamada, S.Kaplan, D. Jackson, F. de Sauvage, H. Jacob, and M.C.Fishman. 1999. Zebrafish genetic map with 2000microsatellite markers. Genomics 58:219–232.
Soltis, P.S., D.E. Soltis, and M.W. Chase. 1999. Angiospermphylogeny inferred from multiple genes as a tool forcomparative biology. Nature 402:402–404.
Steinkellner, H., C. Lexer, E. Turetschek, and J. Gloessl.1997. Conservation of (GA)n microsatellite loci betweenQuercus species. Mol. Ecol. 6:1189–1194.
Tanksley, S.D., and S.R. McCouch. 1997. Seed banks andmolecular maps: Unlocking genetic potential from thewild. Science 277:1063–1066.
Taranenko, N.I., N.T. Potter, S.L. Allman, V.V. Golovlev, andC.H. Chen. 1999. Detection of trinucleotide expansion inneurodegenerative disease by matrix-assisted laserdesorption/ionization time-of-flight mass spectrometry.Genet. Anal. Biomol. Eng. 15:25–31.
Vos, P., R. Hogersn, M. Bleeker, M. Reijans, T. van de Lee,M. Hornes, A. Freijters, J. Pot, J. Peleman, M. Kuiper,and M. Zabeau. 1995. AFLP: A new technique for DNAfingerprinting. Nucl. Acids Res. 23:4407–4414.
Westman, A.L., and S. Kresovich. 1998. The potential forcross-taxa simple-sequence repeat (SSR) amplificationbetween Arabidopsis thaliana L. and crop brassicas.Theor. Appl. Genet. 96:272–281.
Wu, K., and S.D. Tanksley. 1993. Abundance, polymorphismand genetic mapping of microsatellites in rice. Mol. Gen.Genet. 241:225–235.
Zabeau, M., and P. Vos. 1993. Selective restriction fragmentamplification: A general method for DNA fingerprinting.European Patent Application 92 402 629.7. Publ. EP 0534 858.
Zardoya, R., D.M. Vollmer, C. Craddock, J.T. Streelman, S.Karl, and A. Meyer. 1996. Evolutionary conservation ofmicrosatellite flanking regions and their use in resolvingthe phylogeny of cichlid fishes (Pisces: Perciformes).Proc. R. Soc. Lond. Ser. B 263:1589–1598.
REDDY ET AL.: NEW MICROSATELLITE MARKER RESOURCES FOR COTTON 113
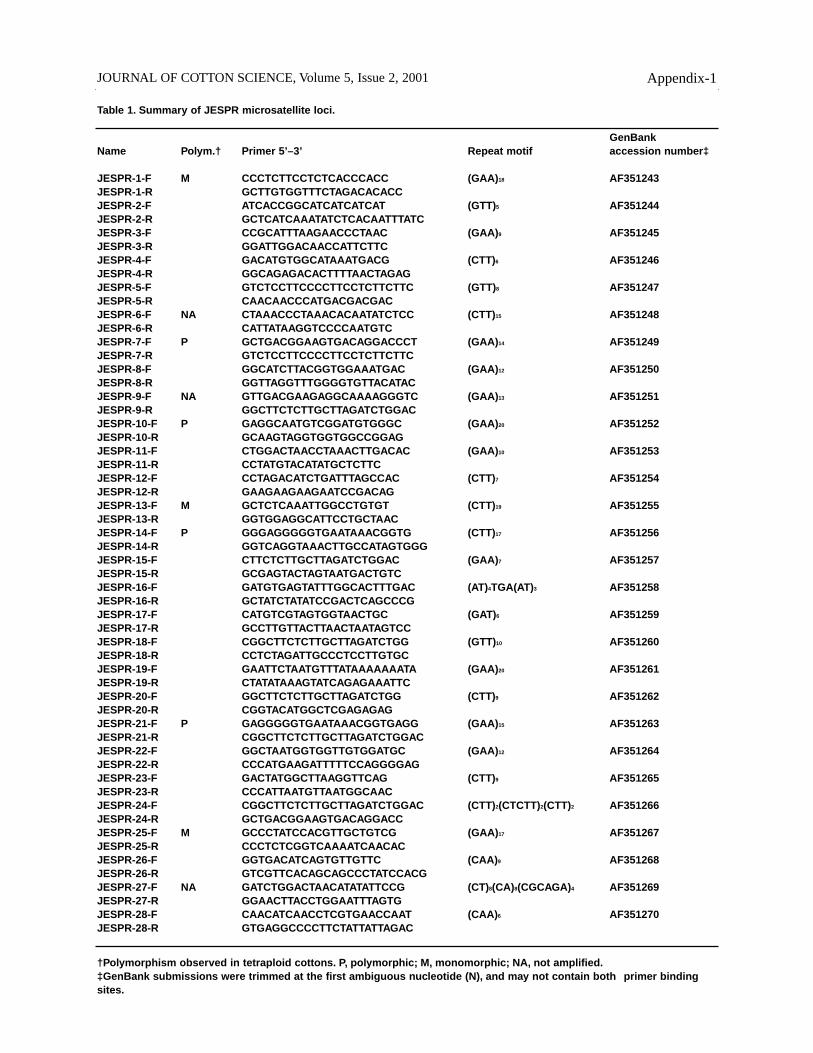
Table 1. Summary of JESPR microsatellite loci.
GenBankName Polym.† Primer 5’–3’ Repeat motif accession number‡
JESPR-1-F M CCCTCTTCCTCTCACCCACC (GAA)18 AF351243 JESPR-1-R GCTTGTGGTTTCTAGACACACCJESPR-2-F ATCACCGGCATCATCATCAT (GTT)5 AF351244JESPR-2-R GCTCATCAAATATCTCACAATTTATCJESPR-3-F CCGCATTTAAGAACCCTAAC (GAA)9 AF351245JESPR-3-R GGATTGGACAACCATTCTTCJESPR-4-F GACATGTGGCATAAATGACG (CTT)6 AF351246JESPR-4-R GGCAGAGACACTTTTAACTAGAGJESPR-5-F GTCTCCTTCCCCTTCCTCTTCTTC (GTT)8 AF351247JESPR-5-R CAACAACCCATGACGACGACJESPR-6-F NA CTAAACCCTAAACACAATATCTCC (CTT)15 AF351248JESPR-6-R CATTATAAGGTCCCCAATGTCJESPR-7-F P GCTGACGGAAGTGACAGGACCCT (GAA)14 AF351249JESPR-7-R GTCTCCTTCCCCTTCCTCTTCTTCJESPR-8-F GGCATCTTACGGTGGAAATGAC (GAA)12 AF351250JESPR-8-R GGTTAGGTTTGGGGTGTTACATACJESPR-9-F NA GTTGACGAAGAGGCAAAAGGGTC (GAA)13 AF351251JESPR-9-R GGCTTCTCTTGCTTAGATCTGGACJESPR-10-F P GAGGCAATGTCGGATGTGGGC (GAA)20 AF351252JESPR-10-R GCAAGTAGGTGGTGGCCGGAGJESPR-11-F CTGGACTAACCTAAACTTGACAC (GAA)10 AF351253JESPR-11-R CCTATGTACATATGCTCTTCJESPR-12-F CCTAGACATCTGATTTAGCCAC (CTT)7 AF351254JESPR-12-R GAAGAAGAAGAATCCGACAGJESPR-13-F M GCTCTCAAATTGGCCTGTGT (CTT)19 AF351255JESPR-13-R GGTGGAGGCATTCCTGCTAACJESPR-14-F P GGGAGGGGGTGAATAAACGGTG (CTT)17 AF351256JESPR-14-R GGTCAGGTAAACTTGCCATAGTGGGJESPR-15-F CTTCTCTTGCTTAGATCTGGAC (GAA)7 AF351257JESPR-15-R GCGAGTACTAGTAATGACTGTCJESPR-16-F GATGTGAGTATTTGGCACTTTGAC (AT)4TGA(AT)3 AF351258 JESPR-16-R GCTATCTATATCCGACTCAGCCCGJESPR-17-F CATGTCGTAGTGGTAACTGC (GAT)6 AF351259JESPR-17-R GCCTTGTTACTTAACTAATAGTCCJESPR-18-F CGGCTTCTCTTGCTTAGATCTGG (GTT)10 AF351260JESPR-18-R CCTCTAGATTGCCCTCCTTGTGCJESPR-19-F GAATTCTAATGTTTATAAAAAAATA (GAA)20 AF351261JESPR-19-R CTATATAAAGTATCAGAGAAATTC JESPR-20-F GGCTTCTCTTGCTTAGATCTGG (CTT)9 AF351262JESPR-20-R CGGTACATGGCTCGAGAGAGJESPR-21-F P GAGGGGGTGAATAAACGGTGAGG (GAA)15 AF351263JESPR-21-R CGGCTTCTCTTGCTTAGATCTGGACJESPR-22-F GGCTAATGGTGGTTGTGGATGC (GAA)12 AF351264JESPR-22-R CCCATGAAGATTTTTCCAGGGGAGJESPR-23-F GACTATGGCTTAAGGTTCAG (CTT)9 AF351265JESPR-23-R CCCATTAATGTTAATGGCAACJESPR-24-F CGGCTTCTCTTGCTTAGATCTGGAC (CTT)2(CTCTT)2(CTT)2 AF351266JESPR-24-R GCTGACGGAAGTGACAGGACCJESPR-25-F M GCCCTATCCACGTTGCTGTCG (GAA)17 AF351267JESPR-25-R CCCTCTCGGTCAAAATCAACACJESPR-26-F GGTGACATCAGTGTTGTTC (CAA)9 AF351268JESPR-26-R GTCGTTCACAGCAGCCCTATCCACGJESPR-27-F NA GATCTGGACTAACATATATTCCG (CT)8(CA)8(CGCAGA)4 AF351269JESPR-27-R GGAACTTACCTGGAATTTAGTGJESPR-28-F CAACATCAACCTCGTGAACCAAT (CAA)6 AF351270JESPR-28-R GTGAGGCCCCTTCTATTATTAGAC
JOURNAL OF COTTON SCIENCE, Volume 5, Issue 2, 2001 Appendix-1
†Polymorphism observed in tetraploid cottons. P, polymorphic; M, monomorphic; NA, not amplified.‡GenBank submissions were trimmed at the first ambiguous nucleotide (N), and may not contain both primer bindingsites.

GenBankName Polym.† Primer 5’–3’ Repeat motif accession number‡
JESPR-29-F CACCGTTTCCAAGTAAGATT (CTT)9 AF351271JESPR-29-R GGTTAATCTTAGTTGAGGTC JESPR-30-F CAAGCTAAGCCACTTGTATTACC (GAA)5A(GAA)3 AF351272JESPR-30-R GAAGAGAATAAGAATAGCCCJESPR-31-F CCAGTTAACTTGCCACGGTG (GGA)5 AF351273JESPR-31R CCCCACCAATATAGTTGTTTCAAATJESPR-33-F M GGATTTGCTTCCTAGTTCCCTTC (GTT)9 AF351274JESPR-33-R GACAGATTGTAATCAATCCAACACGJESPR-34-F TGGTACCGGGGATTCAGTGTGCCAC (CTT)11 AF351275JESPR-34-R ATGTGGCGCATCAGATCCGGTCJESPR-35-F GGTTCAGTTTCCTTTCAGCTCT (CTT)9 AF351276JESPR-35-R TTGGGAGGAAGGAAGGAAGGAAJESPR-36-F NA GGACTAAACTTGCCACGTTGG (CTT)20 AF351277JESPR-36-R GATGTTGGGTTAAGAAGTGGAGTGJESPR-37-F GATCTGGACTAACTGTAGGGTC (CTT)14 AF351278JESPR-37-R GTCAGCGTAATTGATTGCTTCJESPR-38-F GAATCTTACAGTGGAGCAAGG (GAA)12 AF351279JESPR-38-R GGG AAA GGC TAA TGT GGT TGJESPR-39-F GGTTCAGTTTCCTTTCAGCTCT (CTT)9(CCTT)3 AF351280JESPR-39-R TTGGGAGGAAGGAAGGAAGGAAG JESPR-40-F CTTCTCTTGCTTAGATCTGGACT (CTT)9 AF351281JESPR-40-R GTGTGCTTATTATATGTGAATGTAGJESPR-41-F GACCATTGGGAATTGCTGATACG (CTT)8 AF351282 JESPR-41-R GGGTAATCGACATAGGTAACGGG JESPR-42-F M CGTTGCCGTCTTCGACTCCTT (CTT)12 AF352073 JESPR-42-R GTGGGTGGCTAATATGTAGTAGTCG JESPR-43-F M CGGCTTACAACAACAACAAC (CAA)15 AF351283 JESPR-43-R GCTTCTCTTGCTTAGATCTGGAC JESPR-44-F CTCTTGCTTAGATCTGGACTAAC (GTT)9 AF351284 JESPR-44-R CCTGTACCAGTAGTAATAGTAGC JESPR-45-F GAAACTCGATCCCTCAAGATATG (GTT)6 AF351285 JESPR-45-R ATGAAATGAAAGAAAAGAAGGGAGG JESPR-46-F M GCTGTTGACTAACACATAAATAC (GAA)9 AF351286 JESPR-46-R ATTGTAAATGTTACTGTATGATGCC JESPR-47-F M GGG GTG AGG GAT TGG ACA ACA (CTT)10 AF351287 JESPR-47-R CCC CCT AAC TGG CCA GGT AG JESPR-49-F GCT GGA GAA GGA AAA GGT GG (GA)5 AF351288 JESPR-49-R CCTTGCTCTCACTGTACCTCTG JESPR-50-F GTA GTC TTC TCA ACT CCA CTG TT (CAA)5 AF351289 JESPR-50-R GGTGACATCAGTGTTGTTC JESPR-51-F M CTTGGTACCGGGGATTCAGTGTGCC (GAA)11 AF351290JESPR-51-R CATAACATCTAGGTCAGGTTTGGGGJESPR-52-F GCCGTACAATCACAGATTGGGAC (GAA)12 AF351291JESPR-52-R GCGCTTCTCATTGAGTCATCCTGJESPR-53-F GCCAATGGGACTATATACCGGTG (GAA)9 AF351292JESPR-53-R CCATGTCCCACGCCAGATTG (Chloroplast)JESPR-54-F CTCACCTGAATCGCCCCATCTATC (GAA)6(Y)9GAAGA(GAA)4 AF351293JESPR-54-R GCTTAATTTGGCTGGGTCTCCACJESPR-55-F P GTTCGAGGAGGATTGAGGTAGAGGA (CT)6A(CA)11 AF351294JESPR-55-R CCCCTTCTCTTGCTTAGATCTGGACJESPR-56-F P CCAGTTAGCACCAATTTAGG (GAA)23 AF351295JESPR-56-R CCACAATAACACACTGGAATCJESPR-57-F CGCCCTTCTCTTGCTTAGATCTGG (TA)6 AF351296JESPR-57-R CTCAAGAGCAAAAGGAACTTAACTCGJESPR-58-F P CCGCCCTTCTCTTGCTTAGATCTGG (CTT)10 AF351297JESPR-58-R GGAGCCAATTGAGAAGTGAATCCAAJESPR-59-F M CGCCCTTCTCTTGCTTAGATCTGGA (CTTTT)6 AF351298JESPR-59-R TAGTAGAAGGATTCGGCTATGGGGGJESPR-60-F M CGCCCTTCTCTTGCTTAGATCTGG (AT)4(GT)4GA(GT)14 AF351299JESPR-60-R TAGATCTGGACTACCTACGAGACCCJESPR-61-F CGCCCTTCTCTTGCTTAGATCTGGA (CA)10 AF351300
REDDY ET AL.: NEW MICROSATELLITE MARKER RESOURCES FOR COTTON Appendix-2

GenBankName Polym.† Primer 5’–3’ Repeat motif accession number‡
JESPR-61-R CACATCCTCCTCCCTACTCCCTCCJESPR-62-F P GAATTGAGTGGAAAAGGGGGG (GA)14(Y)4(GT)11 AF351301JESPR-62-R CCTTCTCTTGCTTAGATCTGGJESPR-63-F CATCTTGGGTATTTTTTGAGTG GAAA(GAA)5AAA(GAA)5 AF351302JESPR-63-R GACTACCAAATGCACCATCTCJESPR-64-F P CGCCCTTCTCTTGCTTAGATCTGGA (CCCACA)5 AF351303JESPR-64-R GCAATTGAGGGGTGGGGTTGTCTGJESPR-65-F P CCACCCAATTTAAGAAGAAATTG (GAA)25 AF351304JESPR-65-R GGTTAGTTGTATTAGGGTCGTTGJESPR-66-F P CTGGACTAACTATTTGGTATCCCTC (GA)20 AF351305JESPR-66-R GATCTGGACTACCGCTAATCAC
JESPR-67-F P GTAAAGAGCAACCTACACCTACCT (GAA)31 AF351306JESPR-67-R CCAAGATAGTTCATACTTCCCTCJESPR-68-F GATATTTATTGTGTTTAACAGCAG GAAA(GAA)3AAAGAA AF351307JESPR-68-R TACTCTTATCGATGTCCTTTTCAJESPR-69-F M CGCCCTTCTCTTGCTTAGATCTGG (CA)15 AF351308JESPR-69-R AAACTTTGCCGTTGATGGAGACCCJESPR-70-F P CTGGACTAAAAGGAAGATGAGAG (GA)17 AF351309JESPR-70-R GAATACAGGTTCAAAGTTGATAJESPR-71-F CGCCCTTCTCTTGCTTAGATCTGG (GA)11 AF351310JESPR-71-R GCACCCTGCTCCAATCCTCTTTCJESPR-72-F P CGCCCTTCTCTTGCTTAGATCTGG (CTT)10 AF351311JESPR-72-R GGGCAAGCTGACGATGAGGAATGJESPR-73-F P CCACCGAAATCGATAGAGAGCAAT (GA)5G(GA)2 AF351312JESPR-73-R CACTGTCCGACTAGGCCAATACJESPR-74-F CCCTTCTCTTGCTTAGATCTGGAC (CA)12 AF351313JESPR-74-R GCATTATGCTTGCTAGTTCCCTGC (Chloroplast)JESPR-75-F P CTTCTCACGTTACCATTGATTCTTC (CT)9 AF351314JESPR-75-R GGCTGTTCACGGACTAGCTGTAJESPR-76-F NA CCCTTCTCTTGCTTAGATCTGGAC (GT)5(Y)7(GA)20 AF351315JESPR-76-R CAGTTGCTTCCAATGCAGCTACAGJESPR-77-F TCTCTTGCTTAGATCTGGACT (GA)11 AF351316JESPR-77-R CTTATCCTTACTTTGTGGCGJESPR-78-F GAAGTGCTCATAGTCCATCATAG (GA)14 AF351317JESPR-78-R GTCTGGCAGGACATAGAGAAGJESPR-79-F GGGACAAATGTAATCTTGCATCCAG (GGT)7 AF351318JESPR-79-R CGCAGTGTCTGAATCGCCTTCJESPR-80-F CTCTTGCTTAGATCTGGACT (CTT)7 AF351319JESPR-80-R ATGACTATGATTTAGCAGCGJESPR-81-F GTGGAATGGTTGATAAGCATGTTG (AT)5 AF351320JESPR-81-R GGATATAACACCAGGCACAAATACJESPR-82-F GCAAAACATGGAATTTAAGTC (CTCTT)CTA(CTCTT)3 AF351321JESPR-82-R CTAGATATTAGTTCCCGAATCACJESPR-83-F CATAGGCAAGCCTTGTAGCAATC (CT)6 AF351322JESPR-83-R CCTCTTCTTTCACTACCACCTGCJESPR-84-F P GACTCCCGGAGGCAATCAGAG (CTT)20 AF351323JESPR-84-R CCAGGGCTCATACTATCGCTGCJESPR-85-F P CCACCCAAATTTTTCATGGAGAG (GA)14 AF351324JESPR-85-R CCTTCCTCATGTATGACATTGATGGJESPR-86-F M GGAGGAAGTTAGGAGCATGTCTCAG (GT)2TGG(GT)4 AF351325JESPR-86-R ACAGGGTAGTCACGTAACAACTGCJESPR-87-F P GCCCTTCTCTTGCTTAGATCTGGA (GAA)22 AF351326JESPR-87-R CAAAACGGTCGTAGCTAGGGTATGJESPR-88-F GTCAGCACAGTGAGGGTAAGAG (GA)4GG(GA)2(GAA)2(GA)2 AF351327JESPR-88-R GAATACTCCCTCTTCCCTCGJESPR-89-F P CCCCAACCCACGAACATTCCA (GAA)10(GAAAAA)2(GAA)3 AF351328JESPR-89-R GGTGTTAACTGGATTGCTGACGTGGJESPR-90-F CATGGAGTTTCAATGGCGAAGAATC (CTT)7 AF351329JESPR-90-R GGAACCGCTGATGTGGCTAGTTAACJESPR-91-F GGGGTGTTGAGTAGAATGGTAG (GAA)8 AF351330JESPR-91-R CGACATTTGCGATAAGTTGTG
JOURNAL OF COTTON SCIENCE, Volume 5, Issue 2, 2001 Appendix-3

GenBankName Polym.† Primer 5’–3’ Repeat motif accession number‡
JESPR-92-F P GGGACCTCTATTGAATAGCTGGAG (GAA)23 AF351331JESPR-92-R CTCTTGGCATCATTAGTTCCTGGJESPR-93-F GCTTAGATCTGGACTACCCGTTG (GAA)5 AF351332JESPR-93-R GGTCGTGGTGGTGGTCTTGCJESPR-94-F GCAAGACCACCACCACGACC (GAA)5 AF351333JESPR-94-R GTCTGAATCGCCCTTCTCTTGCJESPR-95-F GCTTTTCTCGTAGACGTATG (CTT)9 AF351334JESPR-95-R GCATATTTATATACCAAGTCCCTCJESPR-96-F CATCAGGTTCGAGATTGTCCCTCTG (GT)5 AF351335JESPR-96-R CGTCCTGCTGCACACTCTACTCTCJESPR-97-F P CTTCTCTTGCTTAGATCTGGAC (CT)11 AF351336JESPR-97-R GAAGAGGCTTTTCTTTATGATTCJESPR-98-F CTTGATGAGGACCTATTTCCC (GA)3G(GA)2A(GA)3 AF351337JESPR-98-R CACATCTCATCTTCACACTCTCJESPR-99-F GCTATGCAGGCTCTGGGAAGGCTC (GT)10 AF351338JESPR-99-R CCCCTTCTCTTGCTTAGATCTGGACJESPR-100-F CACATGGTTGACCGTACCGCCTCG (CA)8 AF351339JESPR-100-R GCTAGGTCCTGGAGTGCTCGGTGJESPR-101-F P CCAAGTCAAGGTGAGTTATATG (TA)3(GT)15 AF351340JESPR-101-R GCTCTTTGTTACTGAAATGGGJESPR-102-F P CTTGTGAAGTCCTTTAGGGC (CTT)5TT(CTT)5 AF351341JESPR-102-R GTTATCCATCATGGTCAAATGCJESPR-103-F CTATGAAACTCAAAGCCAAACTC (GAA)7 AF351342JESPR-103-R CCAAGATTCGTTCGATCGACCJESPR-104-F GATGTTTAAGAATAACTATG (GA)10 AF351343JESPR-104-R GGAAATTTTGATACACATCCACJESPR-105-F M GGAAGACCAACCAAGTCAAG (TA)6(GT)19 AF351344JESPR-105-R GGATATGATATTCCAAAGCCCJESPR-106-F M CTAACAACTCTAACCTCTAACTG (CAA)10 AF351345JESPR-106-R GGACTAAAAGTTGTTATTTGJESPR-107-F GACAATCCAGGCAGTCAGAG (CA)11 AF351346JESPR-107-R CATACTAATTAGCCATTCTCACCCJESPR-108-F CGATAGTCTCTAGCCTCAAATTC (CTT)3(CT)3 AF351347JESPR-108-R CGTAACACTAGTCGAACGAGCJESPR-109-F GATTACAGTATGTTCTCTGAGG (GAA)7 AF352074JESPR-109-R CACACAATATCTCTCTTCTCJESPR-110-F P GGCGAAGAGCTACCTGTGAATGGC (GA)16 AF351348JESPR-110-R CCAATGGGGACTCTACATGTGGCJESPR-111-F CTCTTGCTTAGATCTGGACTACC (GAA)2GA(Y)4GAAGAAA AF351349JESPR-111-R CTCCTTCCTCATCATCCTCTCJESPR-112-F NA CTTCTCTTGCTTAGATCTGGAC (CA)9(TA)5 AF351350JESPR-112-R CAATGGCTCTCTAGCTTACTTGJESPR-113-F M CCCCCGAAGCCTTCAAGTAAGTTAC (GAA)11 AF351351JESPR-113-R CCCTTCTCCTTGCTTAGATCTGGACJESPR-114-F P GATTTAAGGTCTTTGATCCG (GT)12 AF351352JESPR-114-R CAAGGGTTAGTAGGTGTGTATACJESPR-115-F M GAAACATGATTGTATGGTAATG (TA)5T(GT)10 AF351353JESPR-115-R CAGGAATCACTATTTTGGACJESPR-116-F GGTCACATTCAAACTAAATGTTCC (GAA)2GAG(GAA)2GAG AF351354JESPR-116-R CAAATAGCCTCTTTAGCAGTGGJESPR-117-F CAAACATCTGGCTTTTTAACTC (GA)2CA(GA)2CAGA AF351355JESPR-117-R CTGTCTTCCAGTTTCAGAGCJESPR-118-F CTTTTTCTCTTTTCAACACGTG (CT)12 AF351356JESPR-118-R GTTGAAAGGAAGACTCCAAACJESPR-119-F CTCAGGGAACTATTTGTAGTAGC (CA)10 AF351357JESPR-119-R GATCCACAAGAAACTGAAACTAGJESPR-120-F GTAACCGAATACCCCTCAACTTAAG (CT)8 AF351358JESPR-120-R ACAGCCGCTTTGTCGAAGATJESPR-121-F CCTCAGATCAATTAACTATGATTC (CA)12 AF351359JESPR-121-R CGGTTGTAAAACTATACTATTTGTCJESPR-122-F GCTGCTGGTTTTACTTGTTGG (CAT)5 AF351360JESPR-122-R CTATGGTGGAGGAGCAACAAC
REDDY ET AL.: NEW MICROSATELLITE MARKER RESOURCES FOR COTTON Appendix-4

GenBankName Polym.† Primer 5’–3’ Repeat motif accession number‡
JESPR-123-F CTCTTGCTTAGATCTGGACTACC (GT)9 AF351361JESPR-123-R CTAAAACTACAGTCGAAAGGGGJESPR-124-F GGATATCGCTCTCCCTCT (GT)9 AF351362JESPR-124-R CTCTTGCTTAGATCTGGACTAACJESPR-125-F CATTGTGATCAACCCCACCAAC (CA)11 AF351363JESPR-125-R GTTGGTGGGGATGGTCACATGCJESPR-126-F GCATGTGACCATCCCCACCAAC (CA)6 AF351364JESPR-126-R GCCAGTGTGCTGAATCGCCCTTCJESPR-127-F P GATTTGGGTAACATTGGCTC (GA)9AA(GA)5 AF351365JESPR-127-R CTGCAGTGTTGTGTTGGGTAGAJESPR-128-F CTGAAAAATCTGCATTTCCG (GT)10 AF351366JESPR-128-R CTCCTAGATTTTGCTCTCCTGTCJESPR-129-F M CCTAACCTTTATCATCATGATC (CA)26(TA)5 AF351367JESPR-129-R CAGTATTGAAAAGCATTTGATCJESPR-130-F GCCCAATTACAACATTTCCAAC (CA)5 AF351368JESPR-130-R GGTAGAGCCCACTTTTATGTCTCJESPR-131-F M GGCACTACCGGTTTGTCTTTC (CT)3CC(CT)7(CA)4 AF351369JESPR-131-R GAGGTGAATGGATATCATGAATGJESPR-132-F GATCGAACAGATGGGTTAGTG CTCTTCTTTCTTTTT AF351370JESPR-132-R GCTTAGATTGGACTAACATCTTGJESPR-133-F CAAGGATAAGGTTGAAGCTTC (GAA)6 AF351371JESPR-133-R CCTCATCACCTACGGCTCTACJESPR-134-F GTCAGAGTCTTCGGGTTGTC (CTTTT)(CTT)6(CTTTT) AF351372JESPR-134-R GTAACAGCAGAGAAGTCGGTGJESPR-135-F P CAAAACCATCATCACTCTCAAG (CT)11 AF351373JESPR-135-R CGAGAGCCCACTAACAGAAAAGJESPR-136-F GCAGGAAGCATTGGTATCTC (TAC)6 AF351374JESPR-136-R CTCTGATGTAAGAGTTGAATCAAGJESPR-137-F M CTTCTCTTGCTTAGATCTGGAC (CA)9 AF351375JESPR-137-R GCAAGTGGTGATGTAATAAGTTGJESPR-138-F GATCAACTATCAGTCCAATTGG (GT)10 AF351376JESPR-138-R GTACTGCAATGAACATATATTCCJESPR-139-F M CCTTCTCTTGCTTAGATCTGG (CTT)10 AF351377JESPR-139-R CTTGCATGTCCTGAGAATACCJESPR-140-F CTTCTCTTGCTTAGATCTGGAC (CA)4T(CA)3 AF351378JESPR-140-R GGAGCAACTGTGTATGTGTGJESPR-141-F M CTCAAGCTCTTCCCCCTTC (CTTTT)6 AF351379JESPR-141-R ACTACCATGACAAGGAAGGTGGJESPR-142-F M CTCTTGCTTAGATCTGGACTAAC (CTT)10 AF351380JESPR-142-R GAGCAATAATGCCTTTCTTGJESPR-143-F CCTTCTCTTGCTTAGATCTGG (GAAAA)4 AF351381JESPR-143-R GCCTCTGATAATGAAGATAACTGJESPR-144-F NA CTCTTATTTGTGTAACTACTGTTCC (GTGTAT)14 AF351382JESPR-144-R CATACACATACACATACACATACACJESPR-145-F M CGCCCTTCTCTTGCTTAGATCTGG (CTT)9 AF351383JESPR-145-R GCGAGCAACAATCAATTTCACCTCJESPR-146-F CGCCCTTCTCTTGCTTAGATCTGGA (CA)7 AF351384JESPR-146-R CGTTTCAGCCATCAGAATAGCTCCJESPR-147-F GCTTAGATCTGGACTACCGAATCCT (GAA)7 AF351385JESPR-147-R CCAAATCAACATCCTCCATTACCCJESPR-148-F P GCTTCTCTTGCTTAGATCTGG (CTT)11 AF351386JESPR-148-R GTCGCTTTGTAAGTGAATGAGJESPR-149-F GTTCTTAAGTGAGGATTGGACG CTTCT(CTT)6CTTTTTCT AF351387JESPR-149-R CTCATTAAGACCCTAGGTAGGCJESPR-150-F M GCTTAGATCTGGACTAACATACG (GAA)9 AF351388JESPR-150-R GATAATTTCATGTAAAATCCCTGJESPR-151-F P CTGGACTAAAAACCTTAACTGG (GAA)9(Y)4(GAA)10 AF351389JESPR-151-R CTCGATTCTAACTCAATCACGJESPR-152-F P GATGCACCAGATCCTTTTATTAG (GAA)50 AF351390JESPR-152-R GGTACATCGGAATCACAGTGJESPR-153-F P GATTACCTTCATAGGCCACTG (CTA)18 AF351391JESPR-153-R GAAAACATGAGCATCCTGTG
JOURNAL OF COTTON SCIENCE, Volume 5, Issue 2, 2001 Appendix-5

GenBankName Polym.† Primer 5’–3’ Repeat motif accession number‡
JESPR-154-F GTTCCCTCAGTTGCTCAGAAG (CTT)9 AF351392JESPR-154-R GGAGGAGTTGGCAGAAAATAGCJESPR-155-F M GCTTAGATCTGGACTAAAATAGCC (GAA)23 AF351393JESPR-155-R GATTTACAGAGGAGGGAACATGJESPR-156-F GCCTTCAATCAATTCATACG (CTT)6CCTT AF351394JESPR-156-R GAAGGAGAAAGCAACGAATTAGJESPR-157-F P CAAGTTCCCACCATCTTTAC (CTT)9(Y)10(CTT)4(Y)3(CTT)4 AF351395JESPR-157-R CTTCTTTGACTGAAATTGCTCJESPR-158-F CACCATTCGGCAGCTATTTC (CTT)12 AF351396JESPR-158-R CTGCAAACCCTAGCCTAGACGJESPR-159-F CAGCTGACTGCATTGGTTCAATCTC (CTT)9 AF351397JESPR-159-R AACGAGTTGAAGAGAGTGAGGATCCJESPR-160-F P CTTGCTTAGATCTGGACTAACC (GAA)4(Y)27(GAA)4 AF351398JESPR-160-R CACCGAGACATTCATATCACJESPR-161-F CGGAAGGGCTGCTGATGGAG (GAA)5 AF351399JESPR-161-R CTACCCCCATTTTTTGGATTCACCJESPR-162-F CGGCTTCTCTTGCTTAGATCTGG (CTT)9 AF351400JESPR-162-R CATGTTGATCGTCAATCTGGGGJESPR-163-F CTCCAGTTCACTCCAAATTATC (CTT)6 AF351401JESPR-163-R GGCACTACTACTGAGAAACAAGJESPR-164-F M GCGCCTATTAGCCATGAACTCAAGG (CTT)8(CTTTT)5 AF351402JESPR-164-R GACGTTGGCTCGAGTTGTTAAAGGJESPR-165-F CAAAACTCACCATGGGGAAAC (CTT)10 AF351403JESPR-165-R GAATCAATGGCAGAAGTGTTGAAGJESPR-166-F M GGCTTCTCTTGCTTAGATCTG (CTT)3CTC(CTTTTT)4 AF351404JESPR-166-R CAAGCTTGAGTTTCGGGAACJESPR-167-F CTCCCCTCTTCTCTTGTTGTC (CTCTT)5(CT)2G(CTCTT)2 AF351405JESPR-167-R GTCAACAACACTTGAAGCACJESPR-168-F GGCTTCTCTTGCTTAGATCTG (TAG)2(Y)3(TAG)5(Y)3(TAG)5 AF351406JESPR-168-R GTGCTAATAGAGACCAGCTGJESPR-169-F P CTCAGATCTAATGATTGGGTTGG (GA)5(CTT)10 AF351407JESPR-169-R GAGTAAATTGACCACTTGTTCGCJESPR-170-F CCCATATTTCAACGTTGACAC (CTT)10 AF351408JESPR-170-R CTTATCCTCCAGGTTTCACCJESPR-171-F P CTGCAAGGTGGAAACTGAACCTG (CTT)15 AF351409JESPR-171-R CCATGCATGTATTAAATTGTGAGJESPR-172-F CAATCTGAAAAACCATAAGACC (GAA)5 AF351410JESPR-172-R ACCATTGAAACACCATGTCJESPR-173-F GACCATTTTAGTCCCTTCATC (CTT)6 AF351411JESPR-173-R GGAGAAACAAATAGATGTCGAAGJESPR-174-F M CAACAGGTTCCTACAGGTCTG (CTT)9 AF351412JESPR-174-R GATTGCTGAAATCACAGAGGJESPR-175-F CCCCTATTGGCTGCTGAAAG (CTT)12 AF351413JESPR-175-R GTTTCTTTTTTTTTTCCCCTGTAJESPR-176-F P CGGCTTCTCTTGCTTAGATCTGGAC (GAA)15 AF351414JESPR-176-R GGGCATGATAAATGACAATCCTCCJESPR-177-F GCTTAATCTGGACTAACATATGC (CTT)9 AF351415JESPR-177-R CGGTACATACAGCAAAATGCJESPR-178-F M CCGCTGATGTGGCCAGTTAACTTGCC (GAA)21 AF351416JESPR-178-R GATGCTTGTCCAACATGGCTTTCJESPR-179-F CTGACACTGTATGCTTGCAG (CTT)12 AF351417JESPR-179-R CATATTTGGCATATCACATAGAGJESPR-180-F P GCGTAGTACATATAGATGCCC (GA)5(GA)20 AF351418JESPR-180-R CTTGGAGTATGTATGCTCTATTCJESPR-181-F CAACTTTTAGATTTGGAAATGG (GAA)8 AF351419JESPR-181-R GAGTTGAAGCTTGACCTGTCJESPR-182-F M CTTAGATCTGGACTAGGAGCC (CTT)6CTC(CTT)2 AF351420JESPR-182-R GGAAGTGGATTGATAATGAGGJESPR-183-F CATTTGTTTCACTTCAGGTCC (CTT)6 AF351421JESPR-183-R CATGCTACCATTGCTTCTCATCJESPR-184-F M CTTAGATCTGGACTAAACTCTTGC (CTT)16 AF351422JESPR-184-R GTTGATGGGGATAGTTCAAGTG
REDDY ET AL.: NEW MICROSATELLITE MARKER RESOURCES FOR COTTON Appendix-6

GenBankName Polym.† Primer 5’–3’ Repeat motif accession number‡
ESPR-185-F P CCCAAGCTACAGAGATAACC (GAA)13 AF351423JESPR-185-R CACACAAATTGGGTAAGAATAGJESPR-186-F CCGTGTTGTGAGTGGTACAGGTC (GAA)13 AF351424JESPR-186-R AGGTTAGGTTTGGGGTGTTACATACJESPR-187-F CAGGTCATGAGGAGCAGAAG (CTT)11 AF351425JESPR-187-R GTGCTTAATTTGCAAAAAGGACCJESPR-188-F GGCTTCTCTTGCTTAGATCTG (CTT)9 AF351426JESPR-188-R GGTTTATTTGATTGCTAAGTCCJESPR-189-F CCATAGACTTGGTTCATGACC (CTT)8 AF351427JESPR-189-R GTTCCAGAGTCGTACAGTCGJESPR-190-F GCCCGCCATCTTTGAGGATCCG (CTT)9 AF351428JESPR-190-R GGCAAAACTTGACAATTTTCTCGGCJESPR-191-F GGTCTAGCCTTTCGGAATTTG (GAA)10 AF351429JESPR-191-R GAATCATTCTCGTTCTCGGACJESPR-192-F GGAACCTCTACTGAATAGTCGGAG (GAA)9 AF351430JESPR-192-R CAGGGATTTCAGCTGACTGCJESPR-193-F GATCTGGACTAACTATCTTCTTG (CTTTCT)3 AF351431JESPR-193-R GTGGTATAAGTTAGTACTTGATGGJESPR-194-F GAGTTTATTGAGAAAGGCTTTCC (GAA)11 AF351432JESPR-194-R CTCAAAGTGGCTGTGCTTTGJESPR-195-F P GATCTGGACTAAACTAGTTGATGTG (GAA)20 AF351433JESPR-195-R GCCAATAATGGATGAAGGTTACJESPR-196-F CCCTAACACCTCTCAGTTTCACAGC (CTT)6 AF351434JESPR-196-R GGGGGCTGCTGATGGAGTTAAGACCJESPR-197-F P CAATACCTGGAACATAGACAAATG (TAC)11 AF351435JESPR-197-R CTTGAGGCTTGCAAAAAATGJESPR-198-F GCTTCTCTTGCTTAGATCTGG (GAA)12 AF351436JESPR-198-R GTTTGAATGGCTTCACAAAGJESPR-199-F GGCAAAGTCCAAAGGCGGTGG (GAA)8 AF351437JESPR-199-R CCATCAAAACAGGTGATTGTATTTGGJESPR-200-F CTTCTCTTGCTTAGATCTGGAC (CTT)13 AF351438JESPR-200-R GTGATGTGACCAGTTAACTAGCJESPR-201-F TCGATCAGTTAGGGTTTTGG (GAA)6 AF351439JESPR-201-R CGAATCTCAACCAGATTTCCJESPR-202-F CACCCGGGAAAAGCTAATGTGGTTG (GAAA)4(GAA)10 AF351440JESPR-202-R GCCATGAACTCAAGGTACCCATTGJESPR-203-F M CTCTTGCTTAGATCTGGACTAAC (GAA)11 AF351441JESPR-203-R CTGCTGAAAGAAATTGTTACCCCJESPR-204-F P CTCCAGGTTCAATGGTCTG (CTT20 AF351442JESPR-204-R GCCATGTTGGACAAGTAGTCJESPR-205-F P CCCAACTCTTTCCAAACTTGAG (CTT)9(CT)9 AF351443JESPR-205-R GTACATATAGATGCCCTCGTGJESPR-206-F P CACAGTCTCCCAGAAGCTCCC (GA)52 AF351444JESPR-206-R TAGTTGCGTGTGTCTCCTCTTCTCJESPR-207-F M CAGCAAAGGAACAAGAAACCAGA (GA)35 AF351445JESPR-207-R GTTAATGCACTAAGACTTGGAAGJESPR-208-F P CGCAACCAAACATATACTTCACAC (CT)15 AF351446JESPR-208-R CCCTTTCCATCCATAGAACGJESPR-209-F M ATTGAGAGGCATTTTGGTC (GA)41 AF351447JESPR-209-R AGATGACTAAAAATTGTGCCJESPR-210-F P GCATGTTCTACAATGGTAAGCATA (CT)26 AF351448JESPR-210-R GAATTCTGCTTCTCTTGCTTAGATJESPR-211-F CATCATTTTTCCAAGTTCCAATTTC (CT)25 AF351449JESPR-211-R CAAACCGTTAAGGCTCCAGCJESPR-212-F M CCAAAGGTTTTTGTTGTTGCTC (CT)21(CA)7 AF351450JESPR-212-R CAGATTCTGCTTCTCTTGCTTAGJESPR-213-F NA TATGGAAACCCTAGGAGAG (GA)17 AF351451JESPR-213-R GACAAGAGAACTTACCCAATTAAGCJESPR-214-F P GTAACATTGACGCGATTTATCC (GA)62 AF351452JESPR-214-R CCCTCGACGGATACATATGGJESPR-215-F P CGAGAAGATGAGATTGGAGGAG (GA)22 AF351453JESPR-215-R CCCTTCTGAGTTTTCTTTGG
JOURNAL OF COTTON SCIENCE, Volume 5, Issue 2, 2001 Appendix-7
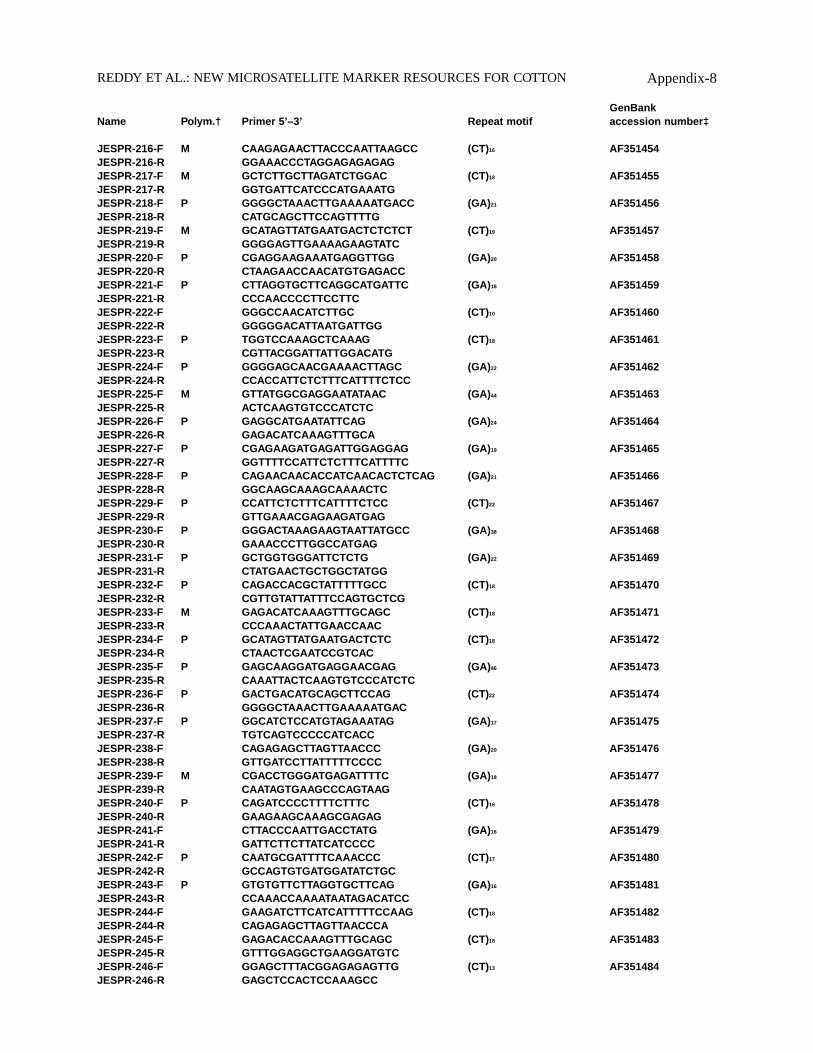
GenBankName Polym.† Primer 5’–3’ Repeat motif accession number‡
JESPR-216-F M CAAGAGAACTTACCCAATTAAGCC (CT)16 AF351454JESPR-216-R GGAAACCCTAGGAGAGAGAGJESPR-217-F M GCTCTTGCTTAGATCTGGAC (CT)18 AF351455JESPR-217-R GGTGATTCATCCCATGAAATGJESPR-218-F P GGGGCTAAACTTGAAAAATGACC (GA)21 AF351456JESPR-218-R CATGCAGCTTCCAGTTTTGJESPR-219-F M GCATAGTTATGAATGACTCTCTCT (CT)19 AF351457JESPR-219-R GGGGAGTTGAAAAGAAGTATCJESPR-220-F P CGAGGAAGAAATGAGGTTGG (GA)20 AF351458JESPR-220-R CTAAGAACCAACATGTGAGACCJESPR-221-F P CTTAGGTGCTTCAGGCATGATTC (GA)18 AF351459JESPR-221-R CCCAACCCCTTCCTTCJESPR-222-F GGGCCAACATCTTGC (CT)10 AF351460JESPR-222-R GGGGGACATTAATGATTGGJESPR-223-F P TGGTCCAAAGCTCAAAG (CT)18 AF351461JESPR-223-R CGTTACGGATTATTGGACATGJESPR-224-F P GGGGAGCAACGAAAACTTAGC (GA)22 AF351462JESPR-224-R CCACCATTCTCTTTCATTTTCTCCJESPR-225-F M GTTATGGCGAGGAATATAAC (GA)44 AF351463JESPR-225-R ACTCAAGTGTCCCATCTCJESPR-226-F P GAGGCATGAATATTCAG (GA)24 AF351464JESPR-226-R GAGACATCAAAGTTTGCAJESPR-227-F P CGAGAAGATGAGATTGGAGGAG (GA)19 AF351465JESPR-227-R GGTTTTCCATTCTCTTTCATTTTCJESPR-228-F P CAGAACAACACCATCAACACTCTCAG (GA)21 AF351466JESPR-228-R GGCAAGCAAAGCAAAACTCJESPR-229-F P CCATTCTCTTTCATTTTCTCC (CT)22 AF351467JESPR-229-R GTTGAAACGAGAAGATGAGJESPR-230-F P GGGACTAAAGAAGTAATTATGCC (GA)38 AF351468JESPR-230-R GAAACCCTTGGCCATGAGJESPR-231-F P GCTGGTGGGATTCTCTG (GA)22 AF351469JESPR-231-R CTATGAACTGCTGGCTATGGJESPR-232-F P CAGACCACGCTATTTTTGCC (CT)18 AF351470JESPR-232-R CGTTGTATTATTTCCAGTGCTCGJESPR-233-F M GAGACATCAAAGTTTGCAGC (CT)18 AF351471JESPR-233-R CCCAAACTATTGAACCAACJESPR-234-F P GCATAGTTATGAATGACTCTC (CT)18 AF351472JESPR-234-R CTAACTCGAATCCGTCACJESPR-235-F P GAGCAAGGATGAGGAACGAG (GA)46 AF351473JESPR-235-R CAAATTACTCAAGTGTCCCATCTCJESPR-236-F P GACTGACATGCAGCTTCCAG (CT)22 AF351474JESPR-236-R GGGGCTAAACTTGAAAAATGACJESPR-237-F P GGCATCTCCATGTAGAAATAG (GA)17 AF351475JESPR-237-R TGTCAGTCCCCCATCACCJESPR-238-F CAGAGAGCTTAGTTAACCC (GA)20 AF351476JESPR-238-R GTTGATCCTTATTTTTCCCCJESPR-239-F M CGACCTGGGATGAGATTTTC (GA)18 AF351477JESPR-239-R CAATAGTGAAGCCCAGTAAGJESPR-240-F P CAGATCCCCTTTTCTTTC (CT)16 AF351478JESPR-240-R GAAGAAGCAAAGCGAGAGJESPR-241-F CTTACCCAATTGACCTATG (GA)16 AF351479JESPR-241-R GATTCTTCTTATCATCCCCJESPR-242-F P CAATGCGATTTTCAAACCC (CT)17 AF351480JESPR-242-R GCCAGTGTGATGGATATCTGCJESPR-243-F P GTGTGTTCTTAGGTGCTTCAG (GA)16 AF351481JESPR-243-R CCAAACCAAAATAATAGACATCCJESPR-244-F GAAGATCTTCATCATTTTTCCAAG (CT)18 AF351482JESPR-244-R CAGAGAGCTTAGTTAACCCAJESPR-245-F GAGACACCAAAGTTTGCAGC (CT)18 AF351483JESPR-245-R GTTTGGAGGCTGAAGGATGTCJESPR-246-F GGAGCTTTACGGAGAGAGTTG (CT)13 AF351484JESPR-246-R GAGCTCCACTCCAAAGCC
REDDY ET AL.: NEW MICROSATELLITE MARKER RESOURCES FOR COTTON Appendix-8
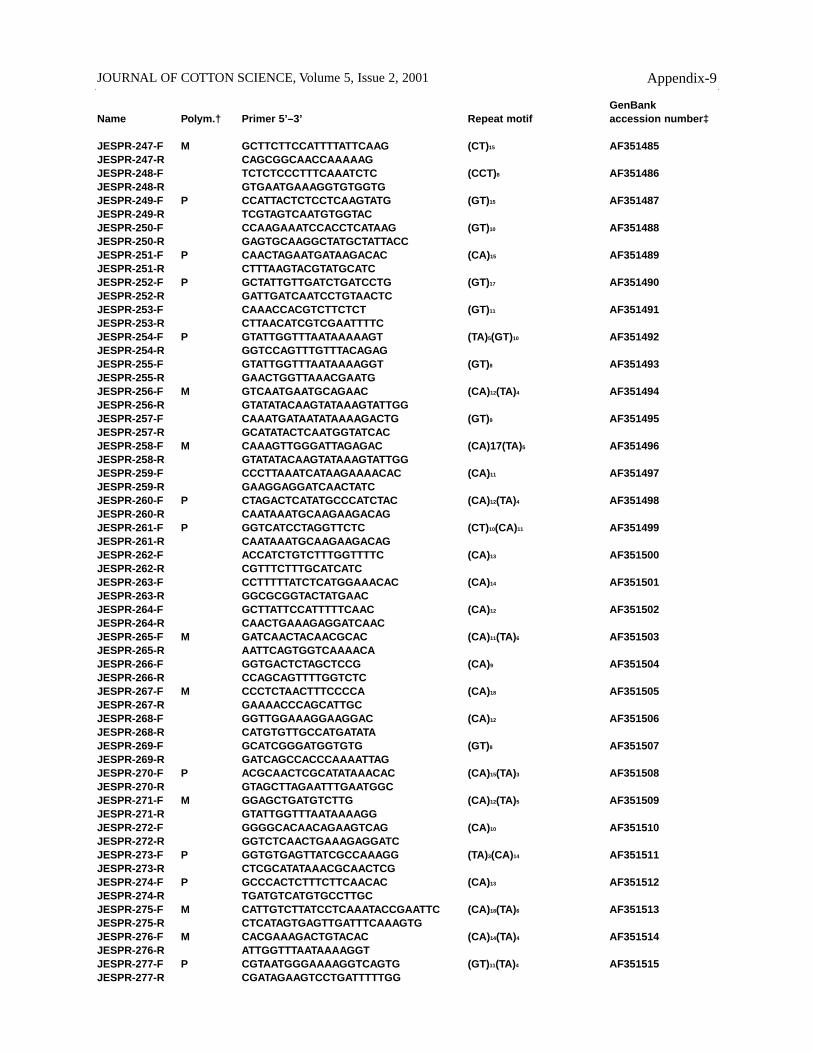
GenBankName Polym.† Primer 5’–3’ Repeat motif accession number‡
JESPR-247-F M GCTTCTTCCATTTTATTCAAG (CT)15 AF351485JESPR-247-R CAGCGGCAACCAAAAAGJESPR-248-F TCTCTCCCTTTCAAATCTC (CCT)8 AF351486JESPR-248-R GTGAATGAAAGGTGTGGTGJESPR-249-F P CCATTACTCTCCTCAAGTATG (GT)15 AF351487JESPR-249-R TCGTAGTCAATGTGGTACJESPR-250-F CCAAGAAATCCACCTCATAAG (GT)10 AF351488JESPR-250-R GAGTGCAAGGCTATGCTATTACCJESPR-251-F P CAACTAGAATGATAAGACAC (CA)15 AF351489JESPR-251-R CTTTAAGTACGTATGCATCJESPR-252-F P GCTATTGTTGATCTGATCCTG (GT)17 AF351490JESPR-252-R GATTGATCAATCCTGTAACTCJESPR-253-F CAAACCACGTCTTCTCT (GT)11 AF351491JESPR-253-R CTTAACATCGTCGAATTTTCJESPR-254-F P GTATTGGTTTAATAAAAAGT (TA)5(GT)10 AF351492JESPR-254-R GGTCCAGTTTGTTTACAGAGJESPR-255-F GTATTGGTTTAATAAAAGGT (GT)8 AF351493JESPR-255-R GAACTGGTTAAACGAATGJESPR-256-F M GTCAATGAATGCAGAAC (CA)12(TA)4 AF351494JESPR-256-R GTATATACAAGTATAAAGTATTGGJESPR-257-F CAAATGATAATATAAAAGACTG (GT)9 AF351495JESPR-257-R GCATATACTCAATGGTATCACJESPR-258-F M CAAAGTTGGGATTAGAGAC (CA)17(TA)5 AF351496JESPR-258-R GTATATACAAGTATAAAGTATTGGJESPR-259-F CCCTTAAATCATAAGAAAACAC (CA)11 AF351497JESPR-259-R GAAGGAGGATCAACTATCJESPR-260-F P CTAGACTCATATGCCCATCTAC (CA)12(TA)4 AF351498JESPR-260-R CAATAAATGCAAGAAGACAGJESPR-261-F P GGTCATCCTAGGTTCTC (CT)10(CA)11 AF351499JESPR-261-R CAATAAATGCAAGAAGACAGJESPR-262-F ACCATCTGTCTTTGGTTTTC (CA)13 AF351500JESPR-262-R CGTTTCTTTGCATCATCJESPR-263-F CCTTTTTATCTCATGGAAACAC (CA)14 AF351501JESPR-263-R GGCGCGGTACTATGAACJESPR-264-F GCTTATTCCATTTTTCAAC (CA)12 AF351502JESPR-264-R CAACTGAAAGAGGATCAACJESPR-265-F M GATCAACTACAACGCAC (CA)11(TA)6 AF351503JESPR-265-R AATTCAGTGGTCAAAACAJESPR-266-F GGTGACTCTAGCTCCG (CA)9 AF351504JESPR-266-R CCAGCAGTTTTGGTCTCJESPR-267-F M CCCTCTAACTTTCCCCA (CA)18 AF351505JESPR-267-R GAAAACCCAGCATTGCJESPR-268-F GGTTGGAAAGGAAGGAC (CA)12 AF351506JESPR-268-R CATGTGTTGCCATGATATAJESPR-269-F GCATCGGGATGGTGTG (GT)8 AF351507JESPR-269-R GATCAGCCACCCAAAATTAGJESPR-270-F P ACGCAACTCGCATATAAACAC (CA)15(TA)3 AF351508JESPR-270-R GTAGCTTAGAATTTGAATGGCJESPR-271-F M GGAGCTGATGTCTTG (CA)12(TA)5 AF351509JESPR-271-R GTATTGGTTTAATAAAAGGJESPR-272-F GGGGCACAACAGAAGTCAG (CA)10 AF351510JESPR-272-R GGTCTCAACTGAAAGAGGATCJESPR-273-F P GGTGTGAGTTATCGCCAAAGG (TA)3(CA)14 AF351511JESPR-273-R CTCGCATATAAACGCAACTCGJESPR-274-F P GCCCACTCTTTCTTCAACAC (CA)13 AF351512JESPR-274-R TGATGTCATGTGCCTTGCJESPR-275-F M CATTGTCTTATCCTCAAATACCGAATTC (CA)18(TA)6 AF351513JESPR-275-R CTCATAGTGAGTTGATTTCAAAGTGJESPR-276-F M CACGAAAGACTGTACAC (CA)14(TA)4 AF351514JESPR-276-R ATTGGTTTAATAAAAGGTJESPR-277-F P CGTAATGGGAAAAGGTCAGTG (GT)11(TA)4 AF351515JESPR-277-R CGATAGAAGTCCTGATTTTTGG
JOURNAL OF COTTON SCIENCE, Volume 5, Issue 2, 2001 Appendix-9

GenBankName Polym.† Primer 5’–3’ Repeat motif accession number‡
JESPR-278-F M ACCCTTAAATCATAAGAGAAC (CA)10(GA)3 AF351516JESPR-278-R CCGTAAGTTAAGGTACAAGGJESPR-279-F M GGAGTGAAAGCTAATGCCTG (CA)28 AF351517JESPR-279-R CGGGTCATTGGTTGTTTTTGJESPR-280-F GGAGTACAAGGACCAGCAG (GT)10 AF351518JESPR-280-R GGATTAACTAATTAGTTTCCGCJESPR-281-F M TGATTGATCCTAGTTCTACG (TA)4(GT)12 AF351519JESPR-281-R GTCTCCTTACTTCGCAACJESPR-282-F GGAGTACAAGGACCAGCAG (TG)10 AF351520JESPR-282-R CATAAGCCATGGTTGTACJESPR-283-F M TCATCATGCTATTCATTGAACTAA (TA)5(TG)14 AF351521JESPR-283-R GCAGCGAGAATTATCATGGJESPR-284-F M CAAGATCCATCTGCTGATTAG (CA)25(TA)5 AF351522JESPR-284-R GTATATACAAGTATAAAGTATTGGJESPR-285-F CCCGGATATAGTACTAAGGC (CA)10 AF351523JESPR-285-R ATGTATGGTGTTGAGTGCJESPR-286-F P GGAGGACATGGGTTTGAAC (CA)30 AF351524JESPR-286-R GCATGCATGTAAAATGTAATGGJESPR-287-F TGATTATGTATTGAGGTTCTGG (GT)12 AF351525JESPR-287-R CGTTAAACTCATGGGAGCJESPR-288-F M CATGTATATACAAGTATAAAG (TA)5(GT)11 AF351526JESPR-288-R CAATATAAGCACGTAACJESPR-289-F CATTGCATTTTGCCCC (GAA)9 AF351527JESPR-289-R AATCTAGCGCACAAGGGCJESPR-290-F ACCGGTCAGTCCTCATAATC (CTT)6 AF351528JESPR-290-R GCCAAGGTCGTAGTCCAGGJESPR-291-F P CATTCCCCACTTTGCTCTTAC (CTT)8 AF351529JESPR-291-R CATGTTTCTTTGCCCATCJESPR-292-F GCTTGCAATCTCCTACACC (CTT)7 AF351530JESPR-292-R GAATATGTTTCATAGAATGGCJESPR-293-F CGAGATTTTAAGATTGTGC (GAA)7 AF351531JESPR-293-R TGATGGCAAAAGCACCJESPR-294-F M CTCCTCATTTTGCACGTCCTCTTC (AGA)10 AF351532JESPR-294-R AGGGCTTCATTCTTCTTCGJESPR-295-F GCCTCGTTTAAGCCCATAAAC (CTT)7 AF351533JESPR-295-R GAGGGCCATAGTCACCGGJESPR-296-F P GGGTGTTACATAGAGTGTATAAAATTG (TCA)8(CTT)13 AF351534JESPR-296-R TGACCTCAATTTAGAAACCCJESPR-297-F P GAGAACTCGTTAAAGCACAATG (GAA)12 AF351535JESPR-297-R GTTAATAGAGTTGGGTTTCTCATGJESPR-298-F P GATGCCCTCGTGTTAAAG (GAA)17 AF351536JESPR-298-R GGACCTTCGGAATAATTACCJESPR-299-F P CTGAACCTGCTCCTGAATC (CAT)9 AF351537JESPR-299-R GCCTAGGTGGAGTTCGTGJESPR-300-F P CGCATCACAAACCAAACAC (CTT)5(CAT)6 AF351538JESPR-300-R CGGAAAATGATGATGATGAAGAAGJESPR-301-F TGAGTTCCGAATTCCTTGG (CAT)8 AF351539JESPR-301-R CGGGCTAAGTGTTTTTCGJESPR-302-F CACTCCTAGCTTCTTGGCATC (GAT)5 AF351540JESPR-302-R CTGCGATCTTGGCACAGJESPR-303-F CATCGGAAAACTCTGAAC (CAT)6 AF351541JESPR-303-R GTAGCAGTACAGATGAAAGAGJESPR-304-F GAAATGCATTCCCTCAAAAGC (GAT)8 AF351542JESPR-304-R AGACTCTATCGAATGACCCTGJESPR-305-F CGATCCATCAAAGGCGAC (GAT)6 AF352075JESPR-305-R CCGCCTCAGCACCATTTACJESPR-306-F M CCCCTTACATTATATTGACCTGC (CT)10(CAT)8 AF351543JESPR-306-R CCATGTGAAAAGGGGATAJESPR-307-F CTTGGCCATGTATTCCTTCA (TGA)11 AF351544JESPR-307-R GAAAGACACTAAGCTGAGGCJESPR-308-F P GGCATCATCAGATTCTTTC (GAT)7(GA)4 AF351545JESPR-308-R GCTGGTGGATATTTTATTC
REDDY ET AL.: NEW MICROSATELLITE MARKER RESOURCES FOR COTTON Appendix-10

GenBankName Polym.† Primer 5’–3’ Repeat motif accession number‡
JESPR-309-F CGAGACTCACANCGAGGACAC (TG)5(GAT)9 AF351546JESPR-309-R GGGATTGAACAACACATGAAGCJESPR-310-F GAGGCACATTGAGAAATGTTC (CAT)8 AF351547JESPR-310-R CAATGAGTGGGTTAGTATTGGJESPR-311-F M GGGGCTCGGTTAAAGGTAG (CT)20 AF351548JESPR-311-R GGATATCTGCAGAATACGGC
JOURNAL OF COTTON SCIENCE, Volume 5, Issue 2, 2001 Appendix-11