natural language processing and information...
TRANSCRIPT

Alessandro Moschitti Department of Computer Science and Information
Engineering University of Trento
Email: [email protected]
Natural Language Processing and Information Retrieval
Indexing and Vector Space Models
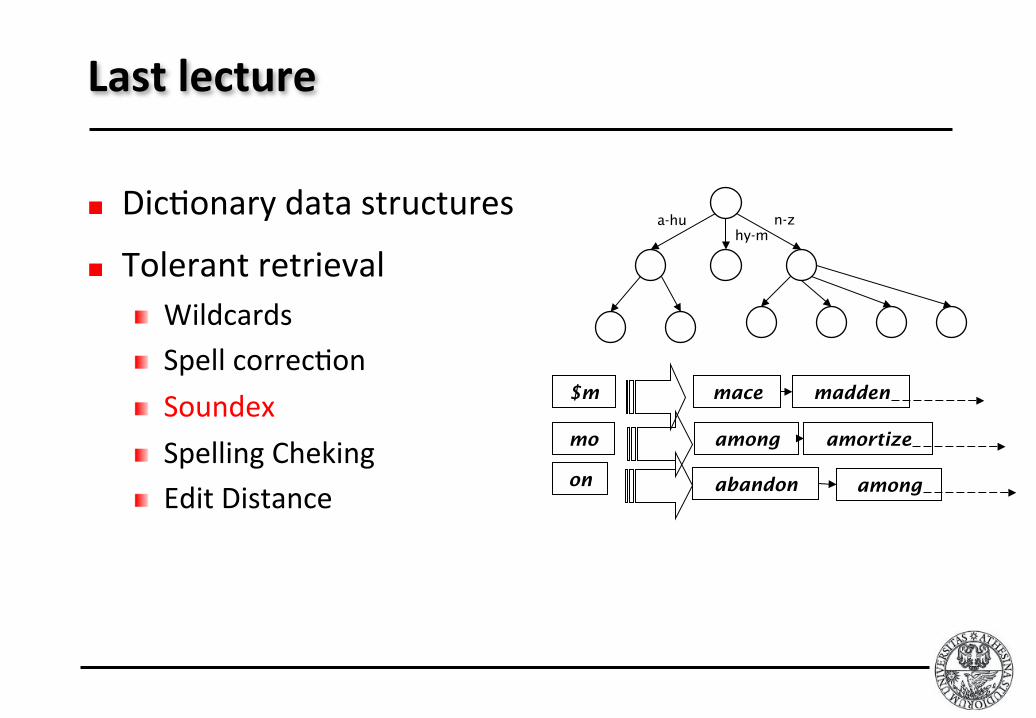
Lastlecture
Dic$onarydatastructures
Tolerantretrieval Wildcards Spellcorrec$on Soundex SpellingCheking EditDistance
a-hu hy-m
n-z
mo
on
among
$m mace
abandon
amortize
madden
among

Whatweskipped
IIRBook Lecture4:aboutindexconstruc$onalsoindistributedenvironment
Lecture5:indexcompression

Thislecture;IIRSec7ons6.2‐6.4.3
Rankedretrieval
Scoringdocuments
Termfrequency
Collec$onsta$s$cs
Weigh$ngschemes
Vectorspacescoring

Rankedretrieval
Sofar,ourquerieshaveallbeenBoolean. Documentseithermatchordon’t.
Goodforexpertuserswithpreciseunderstandingoftheirneedsandthecollec$on. Alsogoodforapplica$ons:Applica$onscaneasilyconsume1000sofresults.
Notgoodforthemajorityofusers. Mostusersincapableofwri$ngBooleanqueries(ortheyare,buttheythinkit’stoomuchwork).
Mostusersdon’twanttowadethrough1000sofresults. Thisispar$cularlytrueofwebsearch.
• Ch. 6

ProblemwithBooleansearch:feastorfamine
BooleanqueriesoTenresultineithertoofew(=0)ortoomany(1000s)results.
Query1:“standarduserdlink650”→200,000hits
Query2:“standarduserdlink650nocardfound”:0hits
Ittakesalotofskilltocomeupwithaquerythatproducesamanageablenumberofhits. ANDgivestoofew;ORgivestoomany
• Ch. 6

Rankedretrievalmodels
Ratherthanasetofdocumentssa$sfyingaqueryexpression,inrankedretrieval,thesystemreturnsanorderingoverthe(top)documentsinthecollec$onforaquery
Freetextqueries:Ratherthanaquerylanguageofoperatorsandexpressions,theuser’squeryisjustoneormorewordsinahumanlanguage
Inprinciple,therearetwoseparatechoiceshere,butinprac$ce,rankedretrievalhasnormallybeenassociatedwithfreetextqueriesandviceversa
• 7

Feastorfamine:notaprobleminrankedretrieval
Whenasystemproducesarankedresultset,largeresultsetsarenotanissue Indeed,thesizeoftheresultsetisnotanissue Wejustshowthetopk(≈10)results Wedon’toverwhelmtheuser
Premise:therankingalgorithmworks
• Ch. 6

Scoringasthebasisofrankedretrieval
Wewishtoreturninorderthedocumentsmostlikelytobeusefultothesearcher
Howcanwerank‐orderthedocumentsinthecollec$onwithrespecttoaquery?
Assignascore–sayin[0,1]–toeachdocument
Thisscoremeasureshowwelldocumentandquery“match”.
• Ch. 6

Query‐documentmatchingscores
Weneedawayofassigningascoretoaquery/documentpair
Let’sstartwithaone‐termquery
Ifthequerytermdoesnotoccurinthedocument:scoreshouldbe0
Themorefrequentthequeryterminthedocument,thehigherthescore(shouldbe)
Wewilllookatanumberofalterna$vesforthis.
• Ch. 6

Take1:Jaccardcoefficient
Recallfromlastlecture:AcommonlyusedmeasureofoverlapoftwosetsAandB
jaccard(A,B)=|A∩B|/|A∪B|
jaccard(A,A)=1
jaccard(A,B)=0ifA∩B=0
AandBdon’thavetobethesamesize.
Alwaysassignsanumberbetween0and1.
• Ch. 6

Jaccardcoefficient:Scoringexample
Whatisthequery‐documentmatchscorethattheJaccardcoefficientcomputesforeachofthetwodocumentsbelow?
Query:idesofmarch
Document1:caesardiedinmarch
Document2:thelongmarch
• Ch. 6

IssueswithJaccardforscoring
Itdoesn’tconsidertermfrequency(howmany$mesatermoccursinadocument)
Raretermsinacollec$onaremoreinforma$vethanfrequentterms.Jaccarddoesn’tconsiderthisinforma$on
Weneedamoresophis$catedwayofnormalizingforlength
Laterinthislecture,we’lluse ...insteadof|A∩B|/|A∪B|(Jaccard)forlengthnormaliza$on.
| B A|/| B A|
• Ch. 6

Recall(Lecture1):Binaryterm‐documentincidencematrix
Antony and Cleopatra Julius Caesar The Tempest Hamlet Othello Macbeth
Antony 1 1 0 0 0 1
Brutus 1 1 0 1 0 0
Caesar 1 1 0 1 1 1
Calpurnia 0 1 0 0 0 0
Cleopatra 1 0 0 0 0 0
mercy 1 0 1 1 1 1
worser 1 0 1 1 1 0
• Each document is represented by a binary vector ∈ {0,1}|V|
• Sec. 6.2

Term‐documentcountmatrices
Considerthenumberofoccurrencesofaterminadocument: Eachdocumentisacountvectorinℕv:acolumnbelow
Antony and Cleopatra Julius Caesar The Tempest Hamlet Othello Macbeth
Antony 157 73 0 0 0 0
Brutus 4 157 0 1 0 0
Caesar 232 227 0 2 1 1
Calpurnia 0 10 0 0 0 0
Cleopatra 57 0 0 0 0 0
mercy 2 0 3 5 5 1
worser 2 0 1 1 1 0
• Sec. 6.2

Bagofwordsmodel
Vectorrepresenta$ondoesn’tconsidertheorderingofwordsinadocument
JohnisquickerthanMaryandMaryisquickerthanJohnhavethesamevectors
Thisiscalledthebagofwordsmodel. Inasense,thisisastepback:Theposi$onalindexwasabletodis$nguishthesetwodocuments.
Wewilllookat“recovering”posi$onalinforma$onlaterinthiscourse.
Fornow:bagofwordsmodel

TermfrequencyR
Thetermfrequencylt,doftermtindocumentdisdefinedasthenumberof$mesthattoccursind.
Wewanttouselwhencompu$ngquery‐documentmatchscores.Buthow?
Rawtermfrequencyisnotwhatwewant: Adocumentwith10occurrencesofthetermismorerelevantthanadocumentwith1occurrenceoftheterm.
Butnot10$mesmorerelevant.
Relevancedoesnotincreasepropor$onallywithtermfrequency.
NB: frequency = count in IR

Log‐frequencyweigh7ng
Thelogfrequencyweightoftermtindis
0→0,1→1,2→1.3,10→2,1000→4,etc.
Scoreforadocument‐querypair:sumovertermstinbothqandd:
score
Thescoreis0ifnoneofthequerytermsispresentinthedocument.
>+
=otherwise 0,
0 tfif, tflog 1 10 t,dt,d
t,dw
∑ ∩∈+=
dqt dt ) tflog (1 ,
• Sec. 6.2

Documentfrequency
Raretermsaremoreinforma$vethanfrequentterms Recallstopwords
Consideraterminthequerythatisrareinthecollec$on(e.g.,arachnocentric)
Adocumentcontainingthistermisverylikelytoberelevanttothequeryarachnocentric
→Wewantahighweightforraretermslikearachnocentric.
• Sec. 6.2.1

Documentfrequency,con7nued
Frequenttermsarelessinforma$vethanrareterms Consideraquerytermthatisfrequentinthecollec$on(e.g.,high,increase,line)
Adocumentcontainingsuchatermismorelikelytoberelevantthanadocumentthatdoesn’t
Butit’snotasureindicatorofrelevance. →Forfrequentterms,wewanthighposi$veweightsforwordslikehigh,increase,andline
Butlowerweightsthanforrareterms. Wewillusedocumentfrequency(df)tocapturethis.
• Sec. 6.2.1

idfweight
dftisthedocumentfrequencyoft:thenumberofdocumentsthatcontaint dftisaninversemeasureoftheinforma$venessoft dft≤N
Wedefinetheidf(inversedocumentfrequency)oftby
Weuselog(N/dft)insteadofN/dftto“dampen”theeffectofidf.
)/df( log idf 10 tt N=
Will turn out the base of the log is immaterial.
• Sec. 6.2.1

idfexample,supposeN=1million
term dft idft
calpurnia 1
animal 100
sunday 1,000
fly 10,000
under 100,000
the 1,000,000
There is one idf value for each term t in a collection.
• Sec. 6.2.1
)/df( log idf 10 tt N=

Effectofidfonranking
Doesidfhaveaneffectonrankingforone‐termqueries,like iPhone
idfhasnoeffectonrankingonetermqueries idfaffectstherankingofdocumentsforquerieswithatleasttwoterms
Forthequerycapriciousperson,idfweigh$ngmakesoccurrencesofcapriciouscountformuchmoreinthefinaldocumentrankingthanoccurrencesofperson.
• 23

Collec7onvs.Documentfrequency
Thecollec$onfrequencyoftisthenumberofoccurrencesoftinthecollec$on,coun$ngmul$pleoccurrences.
Example:
Whichwordisabepersearchterm(andshouldgetahigherweight)?
Word Collection frequency Document frequency
insurance 10440 3997
try 10422 8760
• Sec. 6.2.1

R‐idfweigh7ng
Thel‐idfweightofatermistheproductofitslweightanditsidfweight.
Bestknownweigh$ngschemeininforma$onretrieval Note:the“‐”inl‐idfisahyphen,notaminussign! Alterna$venames:l.idf,lxidf
Increaseswiththenumberofoccurrenceswithinadocument
Increaseswiththerarityoftheterminthecollec$on
)df/(log)tf1log(w 10,, tdt Ndt
×+=
• Sec. 6.2.2

Scoreforadocumentgivenaquery
Therearemanyvariants How“l”iscomputed(with/withoutlogs) Whetherthetermsinthequeryarealsoweighted …
• 26
!
Score(q,d) = tf.idft,dt"q#d
$
• Sec. 6.2.2
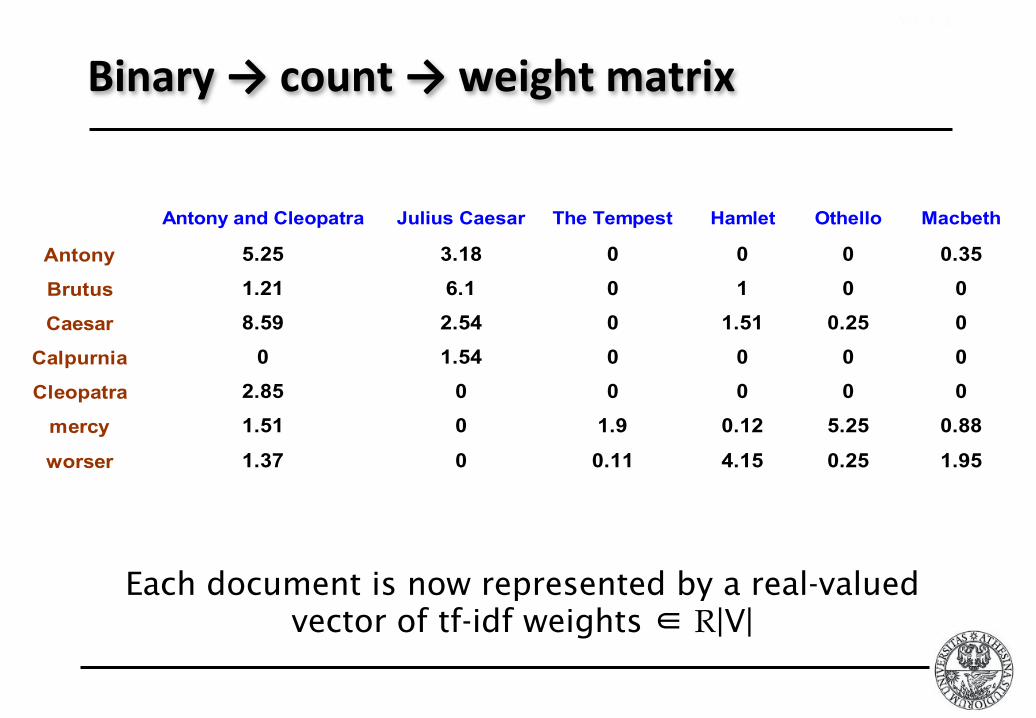
Binary→count→weightmatrix
Antony and Cleopatra Julius Caesar The Tempest Hamlet Othello Macbeth
Antony 5.25 3.18 0 0 0 0.35
Brutus 1.21 6.1 0 1 0 0
Caesar 8.59 2.54 0 1.51 0.25 0
Calpurnia 0 1.54 0 0 0 0
Cleopatra 2.85 0 0 0 0 0
mercy 1.51 0 1.9 0.12 5.25 0.88
worser 1.37 0 0.11 4.15 0.25 1.95
Each document is now represented by a real-valued vector of tf-idf weights ∈ R|V|
• Sec. 6.3

Documentsasvectors
Sowehavea|V|‐dimensionalvectorspace
Termsareaxesofthespace
Documentsarepointsorvectorsinthisspace
Veryhigh‐dimensional:tensofmillionsofdimensionswhenyouapplythistoawebsearchengine
Theseareverysparsevectors‐mostentriesarezero.
• Sec. 6.3

Queriesasvectors
Keyidea1:Dothesameforqueries:representthemasvectorsinthespace
Keyidea2:Rankdocumentsaccordingtotheirproximitytothequeryinthisspace
proximity=similarityofvectors proximity≈inverseofdistance Recall:Wedothisbecausewewanttogetawayfromtheyou’re‐either‐in‐or‐outBooleanmodel.
Instead:rankmorerelevantdocumentshigherthanlessrelevantdocuments
• Sec. 6.3

Formalizingvectorspaceproximity
Firstcut:distancebetweentwopoints (=distancebetweentheendpointsofthetwovectors)
Euclideandistance?
Euclideandistanceisabadidea...
...becauseEuclideandistanceislargeforvectorsofdifferentlengths.
• Sec. 6.3

WhydistanceisabadideaTheEuclideandistancebetweenqandd2islargeeventhoughthedistribu$onoftermsinthequeryqandthedistribu$onoftermsinthedocumentd2areverysimilar.
• Sec. 6.3

Useangleinsteadofdistance
Thoughtexperiment:takeadocumentdandappendittoitself.Callthisdocumentd′.
“Seman$cally”dandd′havethesamecontent TheEuclideandistancebetweenthetwodocumentscanbequitelarge
Theanglebetweenthetwodocumentsis0,correspondingtomaximalsimilarity.
Keyidea:Rankdocumentsaccordingtoanglewithquery.
• Sec. 6.3

Fromanglestocosines
Thefollowingtwono$onsareequivalent. Rankdocumentsindecreasingorderoftheanglebetweenqueryanddocument
Rankdocumentsinincreasingorderofcosine(query,document)
Cosineisamonotonicallydecreasingfunc$onfortheinterval[0o,180o]
• Sec. 6.3
Fromanglestocosines
Buthow–andwhy–shouldwebecompu$ngcosines?
• Sec. 6.3

Lengthnormaliza7on
Avectorcanbe(length‐)normalizedbydividingeachofitscomponentsbyitslength–forthisweusetheL2norm:
DividingavectorbyitsL2normmakesitaunit(length)vector(onsurfaceofunithypersphere)
Effectonthetwodocumentsdandd′(dappendedtoitself)fromearlierslide:theyhaveiden$calvectorsaTerlength‐normaliza$on. Longandshortdocumentsnowhavecomparableweights
∑=i ixx 2
2
• Sec. 6.3

cosine(query,document)
∑∑∑
==
==•=•
=V
i iV
i i
V
i ii
dq
dq
dd
dqdqdq
12
12
1),cos(
Dot product
qi is the tf-idf weight of term i in the query di is the tf-idf weight of term i in the document
cos(q,d) is the cosine similarity of q and d … or,
equivalently, the cosine of the angle between q and d.
• Sec. 6.3

Cosineforlength‐normalizedvectors
Forlength‐normalizedvectors,cosinesimilarityissimplythedotproduct(orscalarproduct):
forq,dlength‐normalized.
• 37
!
cos(! q ,! d ) =! q •! d = qidi
i=1
V
"

Cosinesimilarityillustrated
• 38
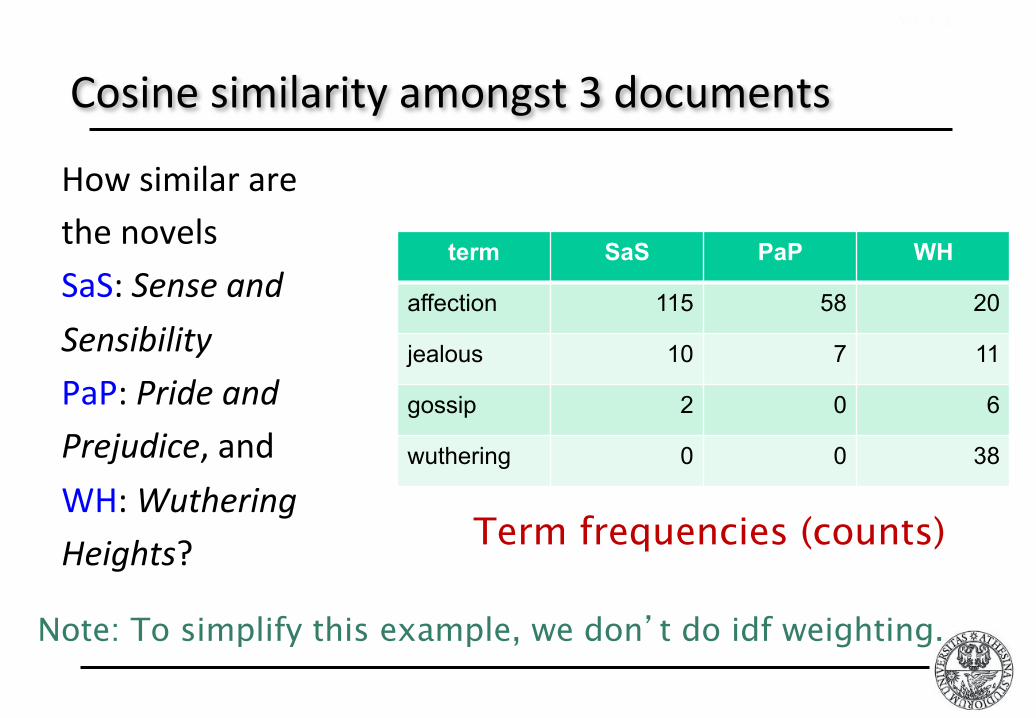
Cosinesimilarityamongst3documents
term SaS PaP WH
affection 115 58 20
jealous 10 7 11
gossip 2 0 6
wuthering 0 0 38
HowsimilararethenovelsSaS:SenseandSensibilityPaP:PrideandPrejudice,andWH:WutheringHeights? Term frequencies (counts)
• Sec. 6.3
Note: To simplify this example, we don’t do idf weighting.
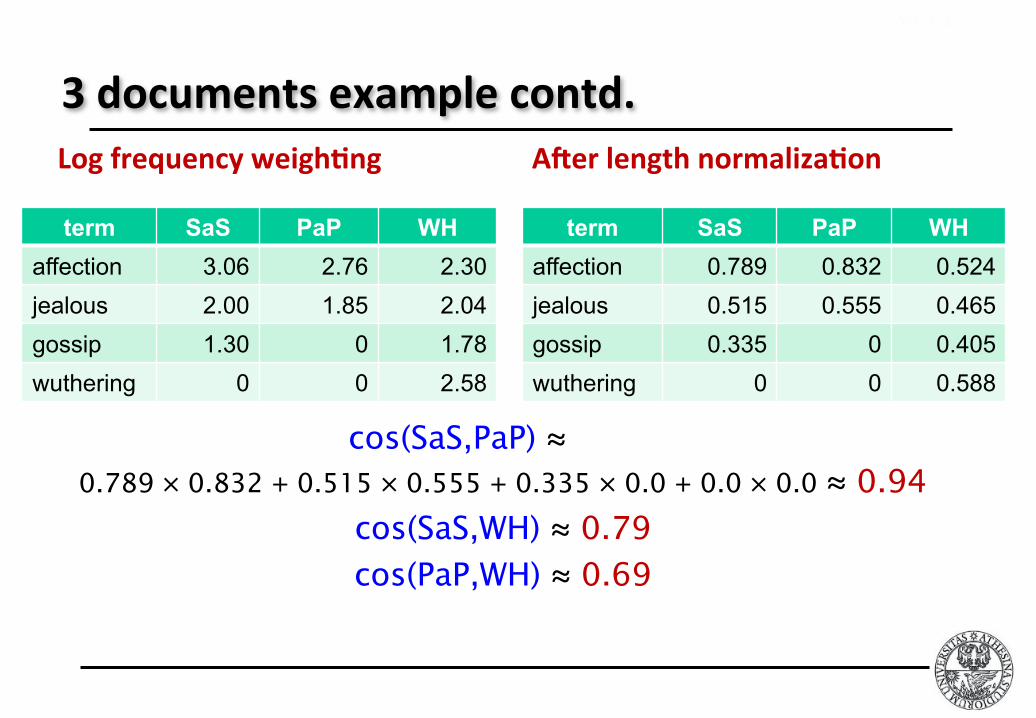
3documentsexamplecontd.Logfrequencyweigh7ng
term SaS PaP WH
affection 3.06 2.76 2.30
jealous 2.00 1.85 2.04
gossip 1.30 0 1.78
wuthering 0 0 2.58
A]erlengthnormaliza7on
term SaS PaP WH
affection 0.789 0.832 0.524
jealous 0.515 0.555 0.465
gossip 0.335 0 0.405
wuthering 0 0 0.588
cos(SaS,PaP) ≈ 0.789 × 0.832 + 0.515 × 0.555 + 0.335 × 0.0 + 0.0 × 0.0 ≈ 0.94
cos(SaS,WH) ≈ 0.79
cos(PaP,WH) ≈ 0.69
• Sec. 6.3

Compu7ngcosinescores
• Sec. 6.3

R‐idfweigh7nghasmanyvariants
Columns headed ‘n’ are acronyms for weight schemes.
Why is the base of the log in idf immaterial?
• Sec. 6.4

Weigh7ngmaydifferinqueriesvsdocuments
Manysearchenginesallowfordifferentweigh$ngsforqueriesvs.documents
SMARTNota$on:denotesthecombina$oninuseinanengine,withthenota$onddd.qqq,usingtheacronymsfromtheprevioustable
Averystandardweigh$ngschemeis:lnc.ltc Document:logarithmicl(lasfirstcharacter),noidfandcosinenormaliza$on
Query:logarithmicl(linleTmostcolumn),idf(tinsecondcolumn),nonormaliza$on…
A bad idea?
• Sec. 6.4
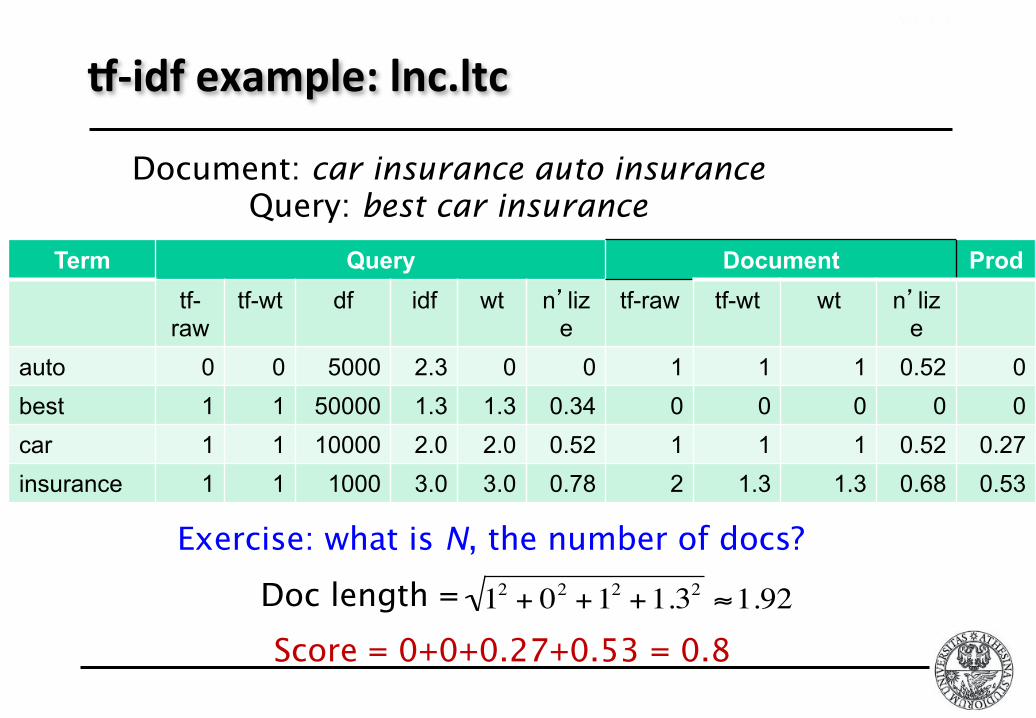
R‐idfexample:lnc.ltc
Term Query Document Prod
tf-raw
tf-wt df idf wt n’lize
tf-raw tf-wt wt n’lize
auto 0 0 5000 2.3 0 0 1 1 1 0.52 0
best 1 1 50000 1.3 1.3 0.34 0 0 0 0 0
car 1 1 10000 2.0 2.0 0.52 1 1 1 0.52 0.27
insurance 1 1 1000 3.0 3.0 0.78 2 1.3 1.3 0.68 0.53
Document: car insurance auto insurance Query: best car insurance
Exercise: what is N, the number of docs?
Score = 0+0+0.27+0.53 = 0.8
Doc length =
!
12
+ 02
+12
+1.32"1.92
• Sec. 6.4

Summary–vectorspaceranking
Representthequeryasaweightedl‐idfvector
Representeachdocumentasaweightedl‐idfvector
Computethecosinesimilarityscoreforthequeryvectorandeachdocumentvector
Rankdocumentswithrespecttothequerybyscore
ReturnthetopK(e.g.,K=10)totheuser

End Lesson

The Vector Space Model
Berlusconi
Bush
Totti
Bush declares war. Berlusconi gives support
Wonderful Totti in the yesterday match against Berlusconi’s Milan
Berlusconi acquires Inzaghi before elections
d1: Politic
d1
d2
d3
q1
q1 : Berlusconi visited Bush
d2: Sport d3:Economic
q2 q2 : Totti will not
play against Berlusconi’s
milan

VSM: formal definition
VSM (Salton89’)
Features are dimensions of a Vector Space.
Documents and Queries are vectors of feature weights.
A set of documents is retrieved based on
where are the vectors representing documents and query and th is
!d !!q
!d, !q
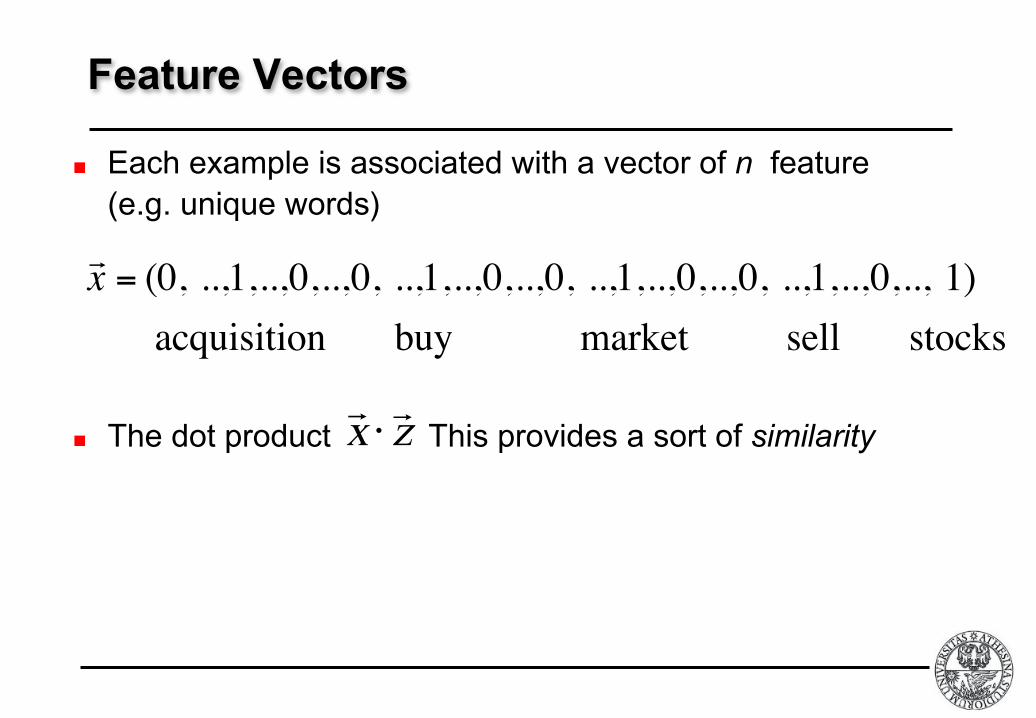
Feature Vectors
Each example is associated with a vector of n feature (e.g. unique words)
The dot product This provides a sort of similarity zx!!!
!
! x = (0, ..,1,..,0,..,0, ..,1,..,0,..,0, ..,1,..,0,..,0, ..,1,..,0,.., 1)
acquisition buy market sell stocks

Feature Selection
Some words, i.e. features, may be irrelevant
For example, “function words” as: “the”, “on”,”those”…
Two benefits: efficiency
Sometime the accuracy
Sort features by relevance and select the m-best

Document weighting: an example
N, the overall number of documents,
Nf, the number of documents that contain the feature f
the occurrences of the features f in the document d
The weight f in a document is:
The weight can be normalized:
!
"f
d= log
N
Nf
#
$ %
&
' ( )of
d= IDF( f ) )o
f
d
!
" 'f
d=
"f
d
("t
d
t#d
$ )2
!
ofd

, the weight of f in d Several weighting schemes (e.g. TF * IDF, Salton 91’)
, the profile weights of f in Ci:
, the training documents in q
Relevance Feeback and query expansion: the Rocchio’s formula
!qf
!
"f
d
!qf =max 0,
!
T" f
d
d!T
"#$%
&%!
!
T" f
d
d"T
#$%&
'&
iT

Similarity estimation between query and documents
Given the document and the category representation
It can be defined the following similarity function (cosine measure
d is assigned to if
!d !!q >!
!d = ! f1
d,..., !fn
d, !q = ! f1
,..., ! fn
sd, i = cos(!d ,!q) =
!d !!q
!d "
!q=
! f
d "
f
# $ f
i
!d "
!q
!q

Performance Measurements
Given a set of document T
Precision = # Correct Retrieved Document / # Retrieved Documents Recall = # Correct Retrieved Document/ # Correct Documents
Correct Documents
Retrieved Documents
(by the system)
Correct Retrieved Documents
(by the system)