national center for supercomputing applications mpi for better scalability & application...
TRANSCRIPT

National Center for Supercomputing Applications
MPI for better scalability & application performance
Byoung-Do Kim, Ph.D.
National Center for Supercomputing Applications
University of Illinois at Urbana-Champaign
Seungdo Hong
Dept. Of Mechanical Engineering
Pusan National University, Pusan, Korea

National Center for Supercomputing Applications
Outline
• MPI basic
• MPI collective communication
• MPI datatype
• Data parallelism: domain decomposition
• Algorithm Implementation
• Examples
• Conclusion

National Center for Supercomputing Applications
MPI Basics• MPI_Init starts up the MPI runtime
environment at the beginning of a run.• MPI_Finalize shuts down the MPI runtime
environment at the end of a run.• MPI_Comm_size gets the number of
processes in a run, Np (typically called just after MPI_Init).
• MPI_Comm_rank gets the process ID that the current process uses, which is between 0 and Np-1 inclusive (typically called just after MPI_Init).

National Center for Supercomputing Applications
PROGRAM my_mpi_program IMPLICIT NONE INCLUDE "mpif.h" [other includes] INTEGER :: my_rank, num_procs, mpi_error_code [other declarations] CALL MPI_Init(mpi_error_code) !! Start up
MPI CALL MPI_Comm_Rank(my_rank, mpi_error_code) CALL MPI_Comm_size(num_procs, mpi_error_code) [actual work goes here] CALL MPI_Finalize(mpi_error_code) !! Shut down
MPIEND PROGRAM my_mpi_program
MPI example code in Fortran

National Center for Supercomputing Applications
MPI example code in C#include <stdio.h>#include "mpi.h" [other includes]
int main (int argc, char* argv[]){ /* main */ int my_rank, num_procs, mpi_error; [other declarations] MPI_Init(&argc, &argv); /* Start up MPI */ MPI_Comm_rank(MPI_COMM_WORLD, &my_rank); MPI_Comm_size(MPI_COMM_WORLD, &num_procs); [actual work goes here] MPI_Finalize(); /* Shut down MPI */} /* main */

National Center for Supercomputing Applications
How an MPI Run Works
• Every process gets a copy of the executable: Single Program, Multiple Data (SPMD).
• They all start executing it.• Each looks at its own rank to determine which
part of the problem to work on.• Each process works completely
independently of the other processes, except when communicating.

National Center for Supercomputing Applications
Send & ReceiveMPI_SEND(buf,count,datatype,dest,tag,comm)MPI_SEND(buf,count,datatype,source,tag,comm,status)
• When MPI sends a message, it doesn’t just send the contents; it also sends an “envelope” describing the contents:
• Buf: initial address of send buffer• Count: number of entries to send• Data type: datatype of each entry• Source: rank of sending process• Dest: rank of process to receive• Tag (message ID)• Comm: communicator (e.g., MPI_COMM_WORLD)

National Center for Supercomputing Applications
MPI_SENDRECV
MPI_SendRecv(sendbuf,sendcount,sendtype,dest,sendtag,recvbuf,recvcount,recvtype,source,recvtag,comm,status)
• Useful for communications patterns where each node both sends and receives messages.
• Executes a blocking send & receive operation• Both function use the same communicator,
but have distinct tag argument

National Center for Supercomputing Applications
Collective Communication• Broadcast (MPI_Bcast)
– A single proc sends the same data to every proc• Reduction (MPI_Reduce)
– All the procs contribute data that is combined using a binary operation (min, max, sum, etc.): One proc obtains the final answer
• Allreduce (MPI_Allreduce)– Same as MPI_Reduce, but every proc contains the final
answer• Gather (MPI_Gather)
– Collect the data from every proc and store the data on proc root
• Scatter (MPI_Scatter)– Split the data on proc root into np segment

National Center for Supercomputing Applications

National Center for Supercomputing Applications
MPI Datatype
C Fortran 90
char MPI_CHAR CHARACTER MPI_CHARACTER
int MPI_INT INTEGER MPI_INTEGER
float MPI_FLOAT REAL MPI_REAL
double MPI_DOUBLE DOUBLE PRECISION
MPI_DOUBLE_PRECISION
MPI supports several other data types, but most are variations of these, and probably these are all you’ll use.

National Center for Supercomputing Applications
Data packaging• Use MPI derived datatype constructor if data
to be transmitted consists of a subset of the entries in an array
• MPI_type_contiguous: builds a derived type whose elements are contiguous entries in an array
• MPI_Type_vector: for equally spaced entries
• MPI_Type_indexed: for binary entries of an array

National Center for Supercomputing Applications
MPI_Type_Vector
• MPI_TYPE_VECTOR(count,blocklength,stride, oldtype, newtype)
IN count number of blocks (int)
IN blocklength number of elements in each block (int)
IN stride spacing between start of each block, measured as number of elements
(int)
IN oldtype old datatype (handle)
OUT newtype new datatype (handle)
oldtype blocklength
stride = 3
1 2 3 = count

National Center for Supercomputing Applications
Virtual Topology• MPI_cart_creat(comm_old,ndims,dims,period,reorder,comm,cart)– Describe Cartesian structure of arbitrary dimension– Create a new communicator, contains information on the
structure of the Cartesian topology.– Returns a handle to a new communicator with the topology
information.
• MPI_cart_rank(comm,coords,rank)• MPI_cart_coords(comm,rank,maxdims,coords)
• Mpi_cart_shift(comm,direction,disp,rank_source,rank_dest)
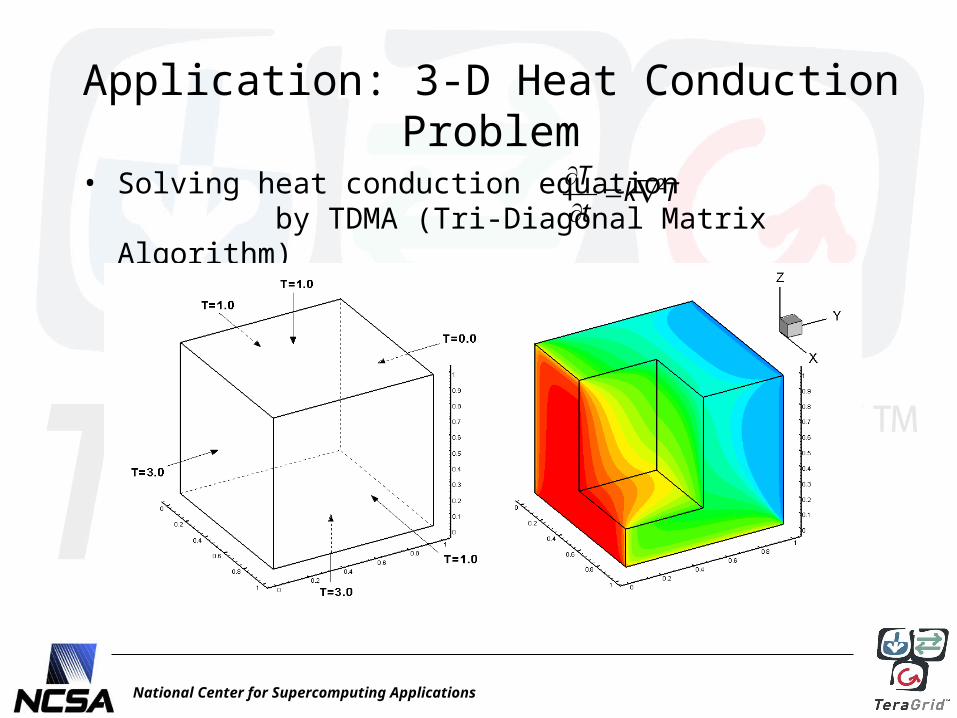
National Center for Supercomputing Applications
Application: 3-D Heat Conduction Problem
• Solving heat conduction equation by TDMA (Tri-Diagonal Matrix Algorithm)
2Tk T
t

National Center for Supercomputing Applications
Domain Decomposition• Data parallelization: Extensibility, Portability• Divide computational domain into many sub-domains
based on number of processors• Solves the same problem on the sub-domians, need
to transfer the b.c. information of overlapping boundary area
• Requires communication between the subdomains in every time step
• Major parallelization method in CFD applications• In order to get a good scalability, need to implement
algorithms carefully.

National Center for Supercomputing Applications
1-D decomposition!---------------------------------------------------------------! MPI Cartesian Coordinate Communicator!---------------------------------------------------------------CALL MPI_CART_CREATE
(MPI_COMM_WORLD, NDIMS, DIMS, PERIODIC,REORDER,CommZ,ierr)
CALL MPI_COMM_RANK (CommZ,myPE,ierr)CALL MPI_CART_COORDS
(CommZ,myPE, NDIMS,CRDS,ierr)
CALL MPI_CART_SHIFT (CommZ,0,1,PEb,PEt,ierr)!------------------------------------------------------------! MPI Datatype creation!------------------------------------------------------------ CALL MPI_TYPE_CONTIGUOUS
(Nx*Ny,MPI_DOUBLE_PRECISION,XY_p,ierr)
CALL MPI_TYPE_COMMIT(XY_p,ierr)X
Y
Z

National Center for Supercomputing Applications
2-D decompositionCALL MPI_CART_CREATE
(MPI_COMM_WORLD, NDIMS, DIMS, PERIODIC,REORDER,CommXY,ierr)
CALL MPI_COMM_RANK (CommXY,myPE,ierr)CALL MPI_CART_COORDS
(CommXY,myPE,NDIMS,CRDS,ierr)
CALL MPI_CART_SHIFT (CommXY,1,1,PEw,PEe,ierr)CALL MPI_CART_SHIFT (CommXY,0,1,PEs,PEn,ierr)!------------------------------------------------------------! MPI Datatype creation!------------------------------------------------------------CALL MPI_TYPE_VECTOR (cnt_yz,block_yz,strd_yz,MPI_DOUBLE_PRECISION,YZ_p,ierr)CALL MPI_TYPE_COMMIT (YZ_p,ierr)
CALL MPI_TYPE_VECTOR (cnt_xz,block_xz,strd_xz,MPI_DOUBLE_PRECISION,XZ_p,ierr)CALL MPI_TYE_COMMIT (XZ_p,ierr)
Z
X
Y

National Center for Supercomputing Applications
3-D decompositionCALL MPI_CART_CREATE
(MPI_COMM_WORLD,…,commXYZ,ierr)CALL MPI_COMM_RANK (CommXYZ,myPE,ierr)CALL MPI_CART_COORDS
(CommXYZ,myPE,NDIMS,CRDS,ierr)
CALL MPI_CART_SHIFT (CommXYZ,2,1,PEw,PEe,ierr)CALL MPI_CART_SHIFT (CommXYZ,1,1,PEs,PEn,ierr)CALL MPI_CART_SHIFT (CommXYZ,0,1,PEb,PEt,ierr)!------------------------------------------------------------CALL MPI_TYPE_VECTOR (cnt_yz,block_yz,strd_yz,
MPI_DOUBLE_PRECISION,YZ_p,ierr)CALL_MPI_TYPE_COMMIT (YZ_p,ierr)
CALL MPI_TYPE_VECTOR (cnt_xz,block_xz,strd_xz, MPI_DOUBLE_PRECISION,XZ_p,ierr)
CALL MPI_TYEP_COMMIT (XZ_p,ierr)
CALL MPI_TYPE_CONTIGUOUS (cnt_xy, MPI_DOUBLE_PRECISION,XY_p,ierr)
CALL MPI_TYPE_COMMIT (XY_p,ierr)
Z
X
Y

National Center for Supercomputing Applications
Scalability : 1-D
• Good Scalability up to small number of processors (16)
• After choke point, communication overhead becomes dominant.
• Performance degrade with large number of processors
No. of CPU
Ela
pse
dT
ime
(se
c)
0.0E+00
4.0E+03
8.0E+03
1.2E+04
1.6E+04
2.0E+04
2.4E+04
2.8E+04
Avg Comm TimeAvg Comp Time
2 4 8 16 32 64

National Center for Supercomputing Applications
Scalability: 2-D
• Strong Scalability up to large number of processors
• Actual runtime larger than 1-D case in the case of small number of processors
• Sweep direction of TDMA solver affects the parallel performance due to communication overhead
No. of CPU
Ela
pse
dT
ime
(se
c)
0.0E+00
5.0E+03
1.0E+04
1.5E+04
2.0E+04
2.5E+04
Avg Comm TimeAvg Comp Time
4 8 16 32 64 128 256

National Center for Supercomputing Applications
Scalability: 3-D
• Superior scalability behavior over the other two cases
• No choke point observed up to 512 processors
• Communication overhead ignorable compared to total runtime.
No. of CPU
Ela
pse
dT
ime
(se
c)
0.0E+00
1.0E+03
2.0E+03
3.0E+03
4.0E+03
5.0E+03
6.0E+03
Avg Comm TimeAvg Comp Time
8 16 32 64 128 256 512

National Center for Supercomputing Applications
SpeedUps
No. of CPU
Sp
ee
du
p
100 101 102 103100
101
102
103
104
Ideal1-D2-D3-D
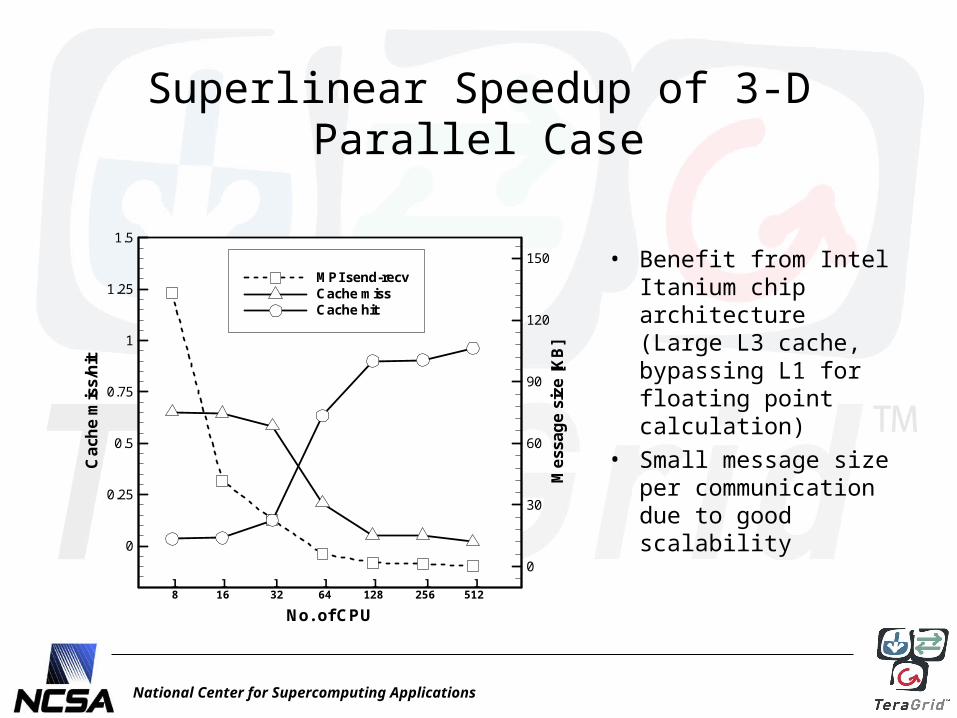
National Center for Supercomputing Applications
Superlinear Speedup of 3-D Parallel Case
• Benefit from Intel Itanium chip architecture (Large L3 cache, bypassing L1 for floating point calculation)
• Small message size per communication due to good scalability
No. of CPU
Ca
che
mis
s/h
it
Me
ssa
ge
size
[KB
]0
0.25
0.5
0.75
1
1.25
1.5
0
30
60
90
120
150
MPI send-recvCache missCache hit
l l l l l l l8 16 32 64 128 256 512

National Center for Supercomputing Applications
Conclusion• 1-D decomposition is OK for small application size, but has
communication overhead problem when the size increases• 2-D shows strong scaling behavior, but need to be careful
when apply due to influences from numerical solvers’ characteristics.
• 3-D demonstrates superior scalability over the other two, have superlinear problem due to hardware architecture.
• There is no one-size-fit-all magic solution. In order to get the best scalability & application performance, the MPI algorithm, application characteristics, and hardware architectures are in harmony for the best possible solution.