nagoyastat #5 データ解析のための統計モデリング入門 第10章
TRANSCRIPT

データ解析のための統計モデリング入門
第10章階層ベイズモデル
-GLMMのベイズモデル化
NagoyaStat #5
@nishiokya

自己紹介
@nishiokya
atndではnishioka0902
カーナビのログとか航空写真とかのデータを扱っています

第10章 階層ベイズモデル-GLMMの階層ベイズモデル化
# 目次 概要 予定 (分)
10 はじめに 5
10.1 例題:個体差と生存種子数(個体差あり) 前提 3
10.2 GLMMの階層ベイズモデル化 GLMMをベイズ化すると階層ベイズモデルになる
5
10.3 階層ベイズモデルの推定・予測 5
10.3.1 階層ベイズモデルのMCMCサンプリング stanを使います 10
10.3.2 階層ベイズモデルの事後分布推定と予測 stanの結果と予測方法 5
10.4 ベイズモデルで使うさまざまな事前分布 まぜ階層ベイズモデルがよいの 5
10.5 個体差+場所差の階層ベイズモデル 複雑な階層ベイズモデルの作成 10
10.6 この章のまとめと参考文献 終わり 5

10章の概要と前提
階層ベイズモデルとMCMCサンプリングによってより複雑な統計モデルのパラメータ推定ができる
# 各章で学ぶこと
7章 個体差・場所差を組み込んだ 統計モデリングGLMMを学ぶ
9章 無情報事前分布を使ったベイズ統計モデルを設計を学ぶ
10章 階層事前分布を使ってGLMMを階層ベイズモデルとして扱う方法を学ぶ
まえがき vii

10.1 例題:個体差と生存種子数(個体差あり)
属性 値 補足
調査した個体数 (𝒴) 100 0 2 7 8 1 7 8 8 1 1 4 0 1 4 7 8 7 0 2 2 1 1 5 7 8 3 8 4 6 0 8 7 8 0 2 6 7 8 2 1 1 0 0 7 8 5 7 2 8 1 5 7 3 8 0 8 6 3 2 0 0 1 2 8 7 7 7 8 0 0 0 5 1 0 0 0 8 1 8 4 7 2 1 4 7 0 8 1 8 7 6 2 8 6 6 1 0 4 7 0
調査種子数(𝑁𝑖) 8
求めるもの(𝑦𝑖) 生存種子数 0以上8以下の整数
属性 値 補足
最尤推定値 (𝑞) 0.504 𝑦/100 = 504/(8*100)
分散(𝑣𝑎𝑟) 9.93 N=8の二項分布の分散の期待値は2.00
上限のあるカウントデータ(離散値)なので確率分布は「二項分布」
例題のデータについて
二項分布(𝑁 = 8)にあてはめた結果の統計量
例題のデータは過分散(5倍近く)である
観測できない個体差??

10.2 GLMMの階層ベイズモデル化
二項分布では観測データを説明できない(図10.1b)• 7章で扱ったGLMMをつかえば、個体差が存在する過分散な観測デー
タに二項分布をあてはめることが可能
• 10章では、GLMMのベイズモデル化に取り組む
属性 値 補足
確率分布 二項分布 𝑃 𝑋 − 𝑘 =𝑛
𝑘𝑝𝑘 1 − 𝑝 𝑛−𝑘 𝑓𝑜𝑟 𝑘 = 0,1,2,3, . . , 𝑛
リンク関数 𝑙𝑜𝑔𝑖𝑡 ロジスティック関数の逆関数 . 選定基準はP114表6.1参照
線形予測子 𝛽 + 𝑟𝑖 7章と同じ
固定効果 𝛽 全固体で共通のパラメータ
ランダム効果 𝑟𝑖 個体差、平均0,10^4の一様分布とする
統計モデル設計

10.2 GLMMの階層ベイズモデル化事後分布 ∝尤度 × 事前分布
事後分布 ∝ 𝑝 𝑌 𝛽, 𝑟𝑖 × 事前分布尤度はデータが得られる確率(全個体の二項分布の積)
p 𝑌 𝛽, 𝑟𝑖 = 8
𝑦𝑖𝑞𝑖
𝑦𝑖 1 − 𝑞𝑖8−𝑦𝑖
事後分布 ∝尤度 × 事前分布
事後分布 ∝ p 𝑌 𝛽, 𝑟𝑖 × p 𝛽 p 𝑟𝑖𝛽の事前分布は無情報事前分布とする (s = 100; 𝜇 = 0)
𝑝 𝛽 =1
2𝜋 × 1002𝑒𝑥𝑝
−𝛽2
2 × 1002
𝑟𝑖の事前分布は7章とおなじと仮定
p 𝑟𝑖 𝑠 =1
2𝜋×𝑠2𝑒𝑥𝑝
−𝑟𝑖2
2×𝑠2⋯ 𝑝 𝑠 = 0から104までの連続一様分布

10.2 GLMMの階層ベイズモデル化個体差𝑟𝑖の事前分布の𝑝 𝑟𝑖 𝑠 に従う未知のパラメータs(0から
階層事前分布という
「階層事前分布」を使っているベイズ統計モデルを階層ベイズモデル「階層」とは、事前分布のパラメータにさらに事前分布が設定されていること
• 𝑠を「超パラメータ」• 𝑝 𝑠 を「超事前分布」

10.3階層ベイズモデルの推定・予測
例題の階層ベイズモデルの式
𝑝 𝛽, 𝑠, 𝑟𝑖 𝑌 ∝ 𝑝 𝑌 𝛽, 𝑟𝑖 𝜌 𝛽 𝑝 𝑠
𝑖
𝑝 𝑟𝑖 𝑠
モデルの設計
図10.2 生存種子数の階層ベイズモデルの概要
データY 全N件種子8個中のY[i]個が生存
二項分布生存確率q i
リンク関数logit
階層事前分布s
個体差のばらつき(下限0)
無情報事前分布無情報事前分布(超事前分布)
個体差 r[i]
固定効果 beta

10.3.1 階層ベイズモデルのMCMCサンプリング• WinBUGSがインストールが面倒なのでStanでやりました
評価項目 Stan WinBUGS
OS マルチ Windows(Macでもインストール可能)
長所 収束が速い 空間統計学で適用
短所 1stepの計算は遅い メンテナンスされていない
サンプリング NUTSのみHMC(ハミルトニアンモンテカルロ法)の実装方法の一つ
ギブズサンプラー他
StanとWinBUGSの比較
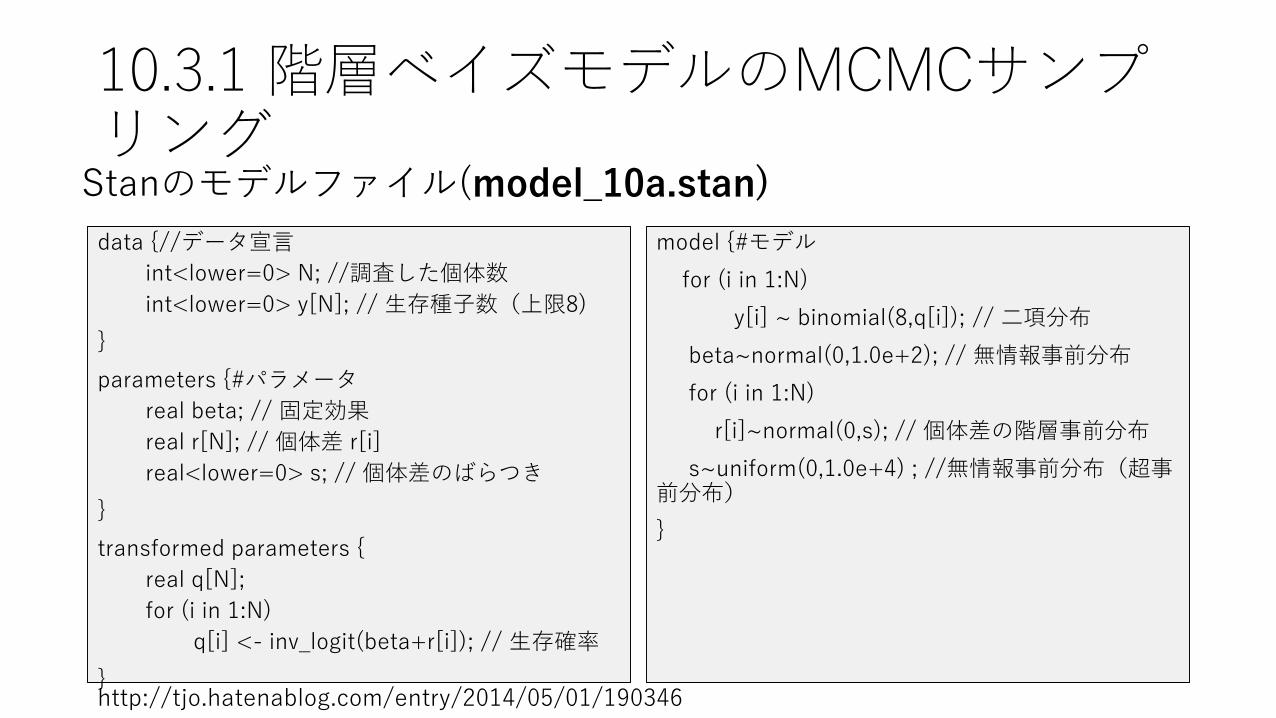
10.3.1 階層ベイズモデルのMCMCサンプリング
data {//データ宣言
int<lower=0> N; //調査した個体数
int<lower=0> y[N]; // 生存種子数(上限8)
}
parameters {#パラメータ
real beta; // 固定効果
real r[N]; // 個体差 r[i]
real<lower=0> s; // 個体差のばらつき
}
transformed parameters {
real q[N];
for (i in 1:N)
q[i] <- inv_logit(beta+r[i]); // 生存確率
}
model {#モデル
for (i in 1:N)
y[i] ~ binomial(8,q[i]); // 二項分布
beta~normal(0,1.0e+2); // 無情報事前分布
for (i in 1:N)
r[i]~normal(0,s); // 個体差の階層事前分布
s~uniform(0,1.0e+4) ; //無情報事前分布(超事前分布)
}
Stanのモデルファイル(model_10a.stan)
http://tjo.hatenablog.com/entry/2014/05/01/190346

10.3.1 階層ベイズモデルのMCMCサンプリング
#ファイルの読み込み
d <- read.csv(url("data7a.csv"))
#
dat<-list(N=nrow(d),y=d$y)
#MCMCサンプリングの実行
d.fit<-stan(file='model_10a.stan',data=dat,iter=1000,chains=4)
#MCMCサンプリング結果を保存
write.table(data.frame(summary(d.fit)$summary), file='fit-summary2.txt', sep='\t', quote=FALSE, col.names=NA)
Rの実行
http://tjo.hatenablog.com/entry/2014/05/01/190346

#MCMCサンプリングの評価
ggmcmc(ggs(d.fit, inc_warmup=TRUE, stan_include_auxiliar=TRUE), file='fit-traceplot2.pdf', plot='traceplot')
#summary
summary(d.fit)
#plot
d.fit.coda<-mcmc.list(lapply(1:ncol(d.fit),function(x) mcmc(as.array(d.fit)[,x,])))
plot(d.fit.coda)
10.3.1 階層ベイズモデルのMCMCサンプリング

10.3.2 階層ベイズモデルの事後分布推定と予測
パラメータ 2.5% 50% 97.5 sd 𝑅
beta -0.63 0.04 0.28 0.34 1.0150238
s 2.43 3.01 3.88 0.38 -
生存種子数𝑦の確率分布は二項分布𝑝(𝑦|𝛽,𝑟) と正規分布𝑝(𝑟|𝑠) の 無限混合分布として表せる
p 𝑦 𝛽, 𝑠 = −∞
∞
𝑝 𝑦 𝛽, 𝑟 𝑝 𝑟 𝑠 𝑑𝑟
𝑅がすべて1.05以下なので収束していると判断できる

10.3.2 階層ベイズモデルの事後分布推定と予測
推定方法はいろいろある
・ハ ラメータβとsにはMCMCサンフルを使用
・stanの推定方法がわかりませんでした
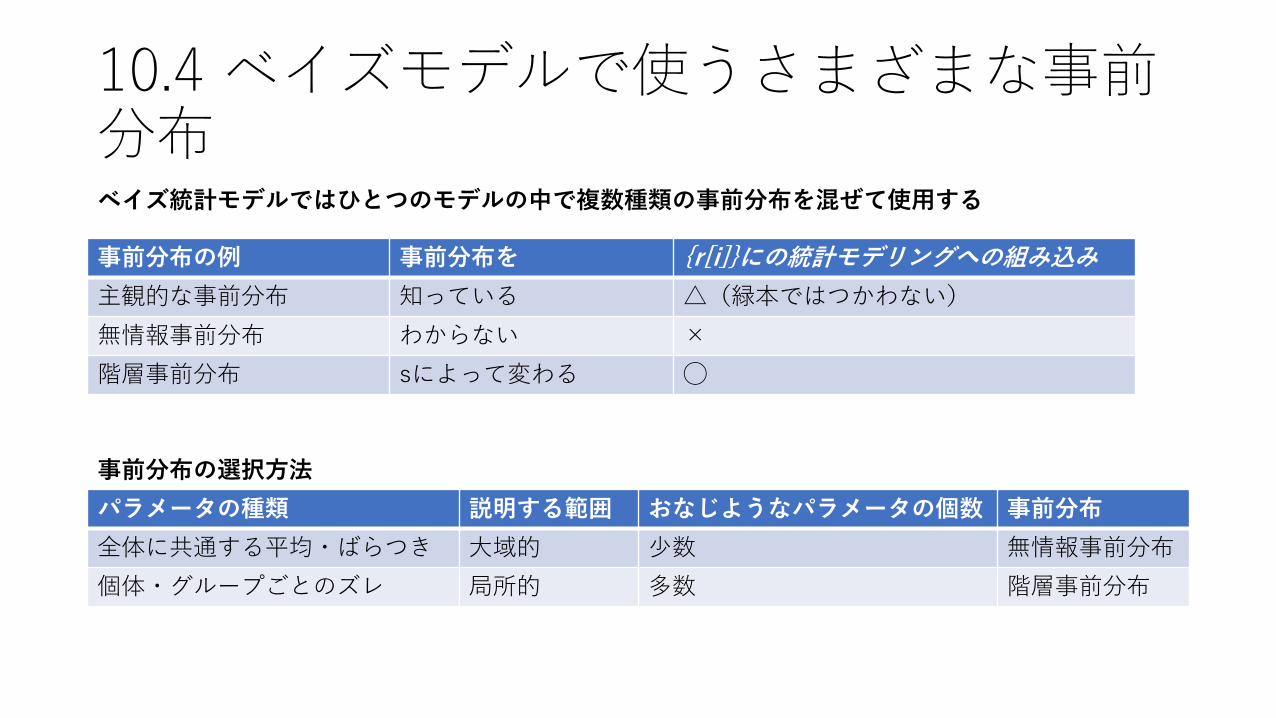
10.4 ベイズモデルで使うさまざまな事前分布
パラメータの種類 説明する範囲 おなじようなパラメータの個数 事前分布
全体に共通する平均・ばらつき 大域的 少数 無情報事前分布
個体・グループごとのズレ 局所的 多数 階層事前分布
事前分布の例 事前分布を {r[i]}にの統計モデリングへの組み込み
主観的な事前分布 知っている △(緑本ではつかわない)
無情報事前分布 わからない ×
階層事前分布 sによって変わる ◯
ベイズ統計モデルではひとつのモデルの中で複数種類の事前分布を混ぜて使用する
事前分布の選択方法

10.4 ベイズモデルで使うさまざまな事前分布
• 個体差{𝑟𝑖}はデータのごく一部を説明しているだけ
• 個体差{𝑟𝑖}は 似たようなパラメータの集まりとかんがえられる
個体差{𝑟𝑖}のような多数(𝑟1 …𝑟100)の局所的なパラメータを大域的なパラメータ(s)で支配する
言い換えると新しい個体(x)が来たときにその個体差{𝑟𝑥}がわからない場合でも、大域的なパラメータ(s)から予測できるようになる。
属性 値 範囲 利用する分布
切片 𝛽 大局的 無情報事前分布をつかう
個体差 𝑟𝑖 局所的 階層事前分布を使う

10.5 GLMMの階層ベイズモデル化
標本平均は8程度、ホアソン分布を仮定した場合の分散は 8 = 2.83
• (A)を見るとそれ以上 → 過分散• (B)からは植木鉢毎の差か見て取れる
個体差(A) と 場所差(B)を考慮 する必要がある
属性 値
調査した個体数 (𝒴) 100
植木鉢の数 10
植木鉢あたりの個体数 10
施肥料処理をした鉢(個体数) 5(50)
無処理の鉢(個体数) 5(50)
求めるもの(𝑦𝑖) 種子数
例題:個体差+場所差から種子数を予測

10.5 GLMMの階層ベイズモデル化
例題:個体差+場所差から種子数を予測
• 個体差に施肥処理+場所差を組み込む
属性 値 補足
確率分布 ポアソン分布 植物の種子すべてをカウントするため、上限なしの離散値
リンク関数 𝑙𝑜𝑔 選定基準はP114表6.1参照
線形予測子 𝛽1 + 𝛽2𝑓𝑖 + 𝑟𝑖 + 𝑟𝑗 𝑖 切片+施肥効果+個体差+場所差
固定効果1 𝛽1 切片
固定効果2 𝛽2𝑓𝑖 施肥効果の有無を表す因子𝑓𝑖の係数𝛽2
ランダム効果1 𝑟𝑖 個体iの効果 sとする
ランダム効果2 𝑟𝑗 𝑖 植木鉢jの効果
統計モデル設計

10.5 個体差+場所差の階層ベイズモデル
図10.8 個体差+植木鉢差の階層ベイズモデルの概要
データ各個体の種子数𝑌 𝑖 個
ポアソン分布平均lambda 𝑖
階層事前分布s個体差のばら
つき
無情報事前分布無情報事前分布(超事前分布)
個体差r[i]
切片beta1
データ(説明変数)施肥処理F 𝑖
植木鉢差 rp[Pot[i]]
beta2
例題の階層ベイズモデルの式
𝑝 𝛽1, 𝛽2, 𝑠, 𝑠𝑝, 𝑟𝑖 , 𝑟𝑗 𝑖 𝑌 ∝ 𝑝 𝑌 𝛽1, 𝛽2, 𝑠, 𝑠𝑝, 𝑟𝑖 , 𝑟𝑗 𝑖 𝑝 𝛽1 𝑝 𝛽2 𝑝 𝑠 𝑝 𝑠𝑝
𝑖
𝑝 𝑟𝑖 𝑠
𝑖
𝑝 𝑟𝑖 𝑠𝑝
モデルの設計
階層事前分布sp植木鉢差のば
らつき

10.5 個体差+場所差の階層ベイズモデル
data {//データ宣言
int<lower=0> N_sample; // number of observations int<lower=0> N_pot; // number of pots
int<lower=0> N_sigma; // number of sigmasint<lower=0> Y[N_sample]; // number of seeds int<lower=0> F[N_sample]; // fertilizer
int<lower=0> Pot[N_sample]; // pot}
}
parameters {#パラメータ
real beta1;
real beta2;
real r[N_sample];
real rp[N_pot];
real<lower=0> s;
real<lower=0> sp;
}
transformed parameters {
real<lower=0> lambda[N_sample];
for (i in 1:N_sample) {
lambda[i] <- exp(beta1 + beta2 * F[i] + r[i] + rp[Pot[i]]);
}
}
model {#モデル
for (i in 1:N_sample) {
Y[i] ~ poisson(lambda[i]);
}
beta1 ~ normal(0, 100);
beta2 ~ normal(0, 100);
r ~ normal(0, s);
rp ~ normal(0, sp);
s~ uniform(0, 1.0e+4);
sp~ uniform(0, 1.0e+4);
}
Stanのモデルファイル(model_10b.stan)
http://ito-hi.blog.so-net.ne.jp/2012-09-04

10.5 個体差+場所差の階層ベイズモデル
d2 <-read.csv(url("http://hosho.ees.hokudai.ac.jp/~kubo/stat/iwanamibook/fig/hbm/nested/d1.csv"))
dat2<-list(N=nrow(d),y=d2$y,N_sample=nrow(d2),N_pot=length(levels(d2$pot)),N_sigma=2 ,Y=d2$y,F=as.numeric(d2$f == "T"),Pot=as.numeric(d2$pot))
d2.fit<-stan(file='model_10_2.stan',data=dat2,iter=1000,chains=4)

10.5 個体差+場所差の階層ベイズモデル
パラメータ
2.5% 50% 97.5 sd 𝑅
beta1 0.03 1.35 2.35 0.48 1.01
beta2 -2.27 -0.88 0.68 0.69 1.01
s1 0.81 1.00 1.26 0,12 -
s2 0.54 0.94 1.72 0.32 -

10.6 まとめ
今時のデータ解析なら 階層ベイズモデルが標準
• GLMMをベイズモデル化すると階層ベイズモデルになる
• 階層ベイズモデルとは事前分布となる確率分布のパラメータにも事前分布が指定
されている統計モデル
• 無情報事前分布と階層事前分布を使うことでベイズ統計モデルから主観的な事前
分布を排除できる
• 個体差+場所差といった複雑な構造のデータの統計モデリングは階層ベイズモデ
ルとMCMCサンプリングがよい

appendix

二項分布の最尤法
二項分布の確率分布の確率質量関数
𝑃 𝑋 − 𝑘 =𝑛
𝑘𝑝𝑘 1 − 𝑝 𝑛−𝑘 𝑓𝑜𝑟 𝑘 = 0,1,2,3, . . , 𝑛
n 個中k個種が生存している確率p
データYの最も当てはまりの良い確率pの求め方
𝑙𝑜𝑔 𝑃 𝑋 − 𝑘 = 𝑙𝑜𝑔𝑛
𝑘𝑝𝑘 1 − 𝑝 𝑛−𝑘
=𝑙𝑜𝑔 𝑛𝑘
+ 𝑙𝑜𝑔 𝑝𝑘 1 − 𝑝 𝑛−𝑘
https://stat.biopapyrus.net/statistic/mle-binomial.html

参考資料
• 行動計量学のための ヘイス推定における モテル選択・評価• http://www3.psy.senshu-u.ac.jp/~ken/BSJ2015spring_okada.pdf
• 六本木で働くデータサイエンティストのブログ• http://tjo.hatenablog.com/entry/2014/05/01/190346
• 10章の個体差+場所差モデル• http://ito-hi.blog.so-net.ne.jp/2012-09-04