multiple comparisons in m/eeg analysis gareth barnes wellcome trust centre for neuroimaging...
TRANSCRIPT

Multiple comparisons in M/EEG analysis
Gareth Barnes
Wellcome Trust Centre for Neuroimaging
University College London
SPM M/EEG Course
London, May 2013

Format
What problem ?- multiple comparisons and post-hoc testing.
Some possible solutions Random field theory
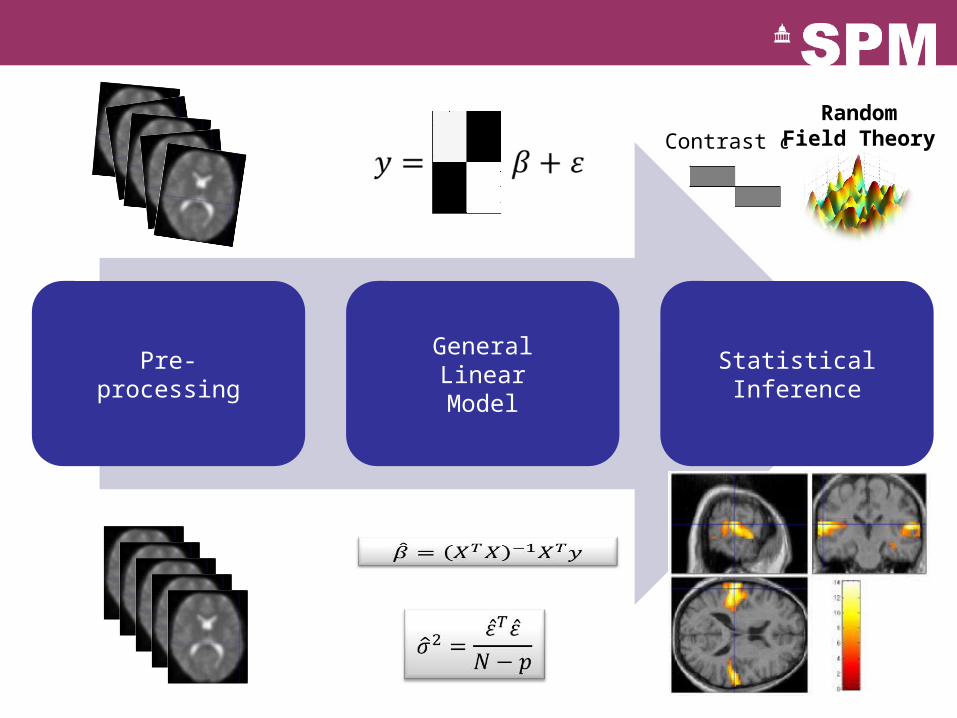
Pre-processing
GeneralLinearModel
Statistical Inference
Contrast cRandom
Field Theory
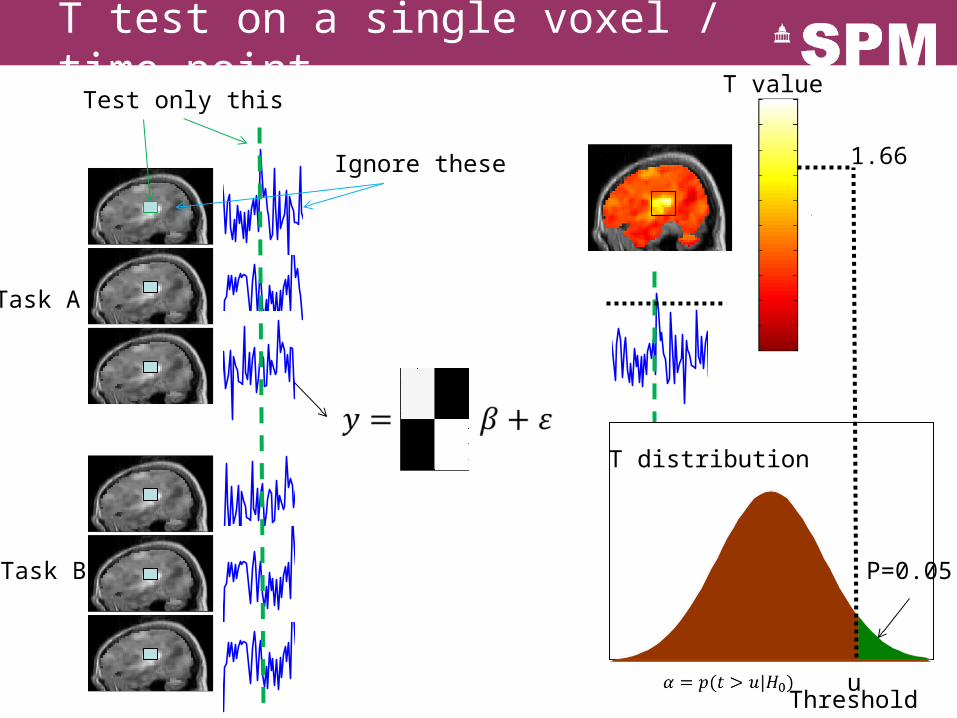
T test on a single voxel / time point
Task A
Task B
T value
1.66
0 20 40 60 80 100-4
-2
0
2
4
0 20 40 60 80 100-4
-2
0
2
4
0 20 40 60 80 100-4
-2
0
2
4
0 20 40 60 80 100-4
-2
0
2
4
0 20 40 60 80 100-4
-2
0
2
4
0 20 40 60 80 100-4
-2
0
2
4
0 20 40 60 80 100-4
-2
0
2
4
Test only this
Ignore these
uThreshold
T distribution
P=0.05

T test on many voxels / time points
Task A
Task B
T value
0 20 40 60 80 100-4
-2
0
2
4
0 20 40 60 80 100-4
-2
0
2
4
0 20 40 60 80 100-4
-2
0
2
4
0 20 40 60 80 100-4
-2
0
2
4
0 20 40 60 80 100-4
-2
0
2
4
0 20 40 60 80 100-4
-2
0
2
4
0 20 40 60 80 100-4
-2
0
2
4
Test all of this
uThreshold ?
T distribution
P= ?

What not to do..
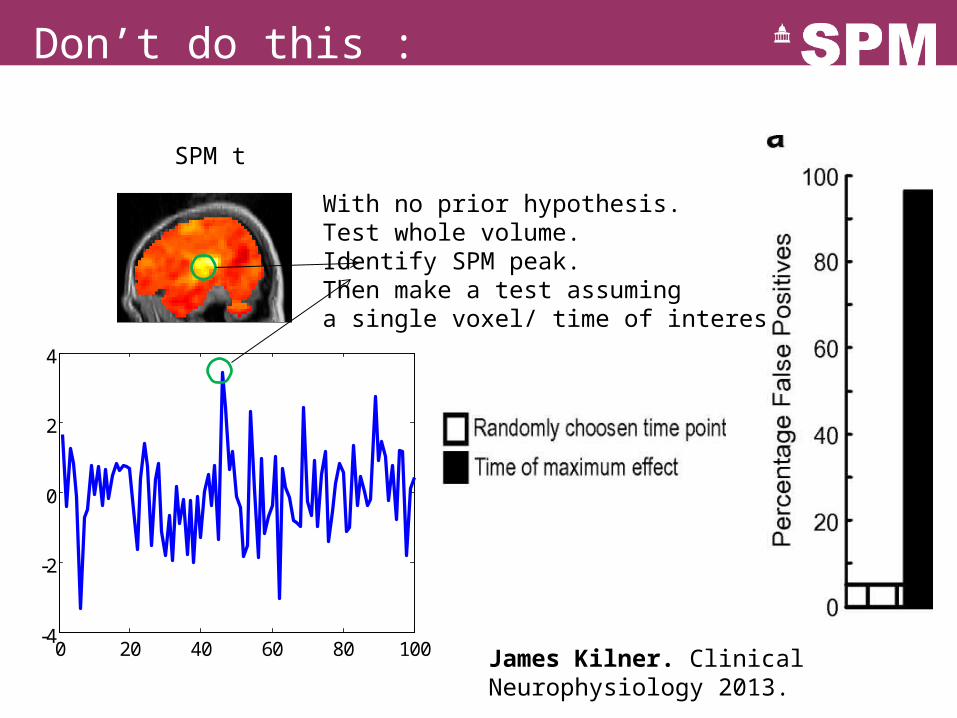
Don’t do this :
0 20 40 60 80 100-4
-2
0
2
4
With no prior hypothesis.Test whole volume.Identify SPM peak. Then make a test assuminga single voxel/ time of interest.
James Kilner. Clinical Neurophysiology 2013.
SPM t


What to do:

Multiple tests in space
t
u
t
u
t
u
t
u
t
u
t
u
11.3% 11.3% 12.5% 10.8% 11.5% 10.0% 10.7% 11.2% 10.2% 9.5%
Use of ‘uncorrected’ p-value, α =0.1
Percentage of Null Pixels that are False Positives
If we have 100,000 voxels,
α=0.05 5,000 false positive voxels.
This is clearly undesirable; to correct for this we can define a null hypothesis for a collection of tests.
signal

P<0.05
(independent samples)
0 50 100 150 200-4
-2
0
2
4
6t
stat
istic
Sample
signal
Multiple tests in time

Bonferroni correction
The Family-Wise Error rate (FWER), αFWE, for a family of N tests follows the inequality:
where α is the test-wise error rate.
Therefore, to ensure a particular FWER choose:
This correction does not require the tests to be independent but becomes very stringent if they are not.

Family-Wise Null Hypothesis
Falsepositive
Use of ‘corrected’ p-value, α =0.1
Use of ‘uncorrected’ p-value, α =0.1
Family-Wise Null Hypothesis:Activation is zero everywhere
If we reject a voxel null hypothesis at any voxel,we reject the family-wise Null hypothesis
A FP anywhere in the image gives a Family Wise Error (FWE)
Family-Wise Error rate (FWER) = ‘corrected’ p-value

P<0.05
P<0.05 200
(independent samples)
0 50 100 150 200-4
-2
0
2
4
6
t st
atis
tic
Sample
Multiple tests- FWE corrected

What about data with different topologies and smoothness..
Smooth time
Diff
eren
t sm
ooth
ness
In
tim
e a
nd s
pace
Volumetric ROIs
Surfaces0 50 100 150 200-1
-0.5
0
0.5
1
1.5
2
Bonferroni works fine for independent tests but ..

Non-parametric inference: permutation tests
5%
5%
Parametric methods– Assume distribution of
max statistic under nullhypothesis
Nonparametric methods– Use data to find
distribution of max statisticunder null hypothesis
– any max statistic
to control FWER

Random Field Theory
Keith Worsley, Karl Friston, Jonathan Taylor, Robert Adler and colleagues
Number peaks= intrinsic volume * peak density
In a nutshell :

Number peaks= intrinsic volume * peak density
Currant bun analogy
Number of currants = volume of bun * currant density

Number peaks= intrinsic volume* peak density
How do we specify the number of peaks

EC=2
EC=1
Euler characteristic (EC) at threshold u = Number blobs- Number holes
At high thresholds there are no holes so EC= number blobs
How do we specify the number of peaks

Number peaks= intrinsic volume * peak density
How do we specify peak (or EC) density

Number peaks= intrinsic volume * peak density
The EC density - depends only on the type of random field (t, F, Chi etc ) and the dimension of the test.
See J.E. Taylor, K.J. Worsley. J. Am. Stat. Assoc., 102 (2007), pp. 913–928
Number of currants = bun volume * currant density
EC density, ρd(u)
t FX2
peak densities for the different fields are known

Number peaks= intrinsic volume * peak density
Currant bun analogy
Number of currants = bun volume * currant density

Which field has highest intrinsic volume ?
0 200 400 600 800 1000-3
-2
-1
0
1
2
3
thre
shol
d
Sample
0 200 400 600 800 1000-4
-2
0
2
4
thre
shol
d
Sample
N=1000, FWHM= 4
0 200 400 600 800 1000-2
-1
0
1
2
thre
shol
d
Sample
0 200 400 600 800 1000-4
-2
0
2
4
thre
shol
d
Sample
A B
C D
More sam
ples (higher volume)
Smoother ( lower volume)
Equal
volume
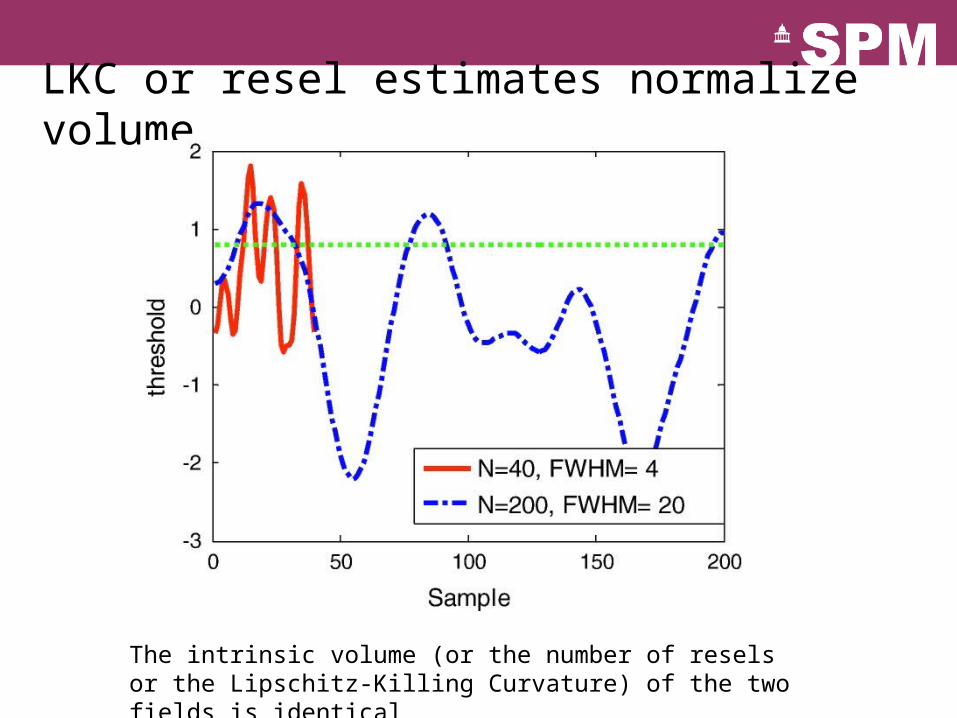
LKC or resel estimates normalize volume
The intrinsic volume (or the number of resels or the Lipschitz-Killing Curvature) of the two fields is identical

From Expected Euler Characteristic
Intrinsic volume(depends on shape and smoothness of space)
Depends only on typeof test and dimension
=2.9 (in this example)
Threshold u
Gaussian Kinematic formula

-- EC observedo EC predicted
Expected Euler Characteristic
Gaussian Kinematic formula
Intrinsic volume (depends on shape and smoothness of space)
EC=1-0
Depends only on typeof test and dimension
Number peaks= intrinsic volume * peak density
From

From Expected Euler Characteristic
Gaussian Kinematic formula
Intrinsic volume (depends on shape and smoothness of space)
EC=2-1
Depends only on typeof test and dimension
0.05
FWE threshold
Exp
ecte
d E
CThreshold
i.e. we want one false positive every 20 realisations (FWE=0.05)
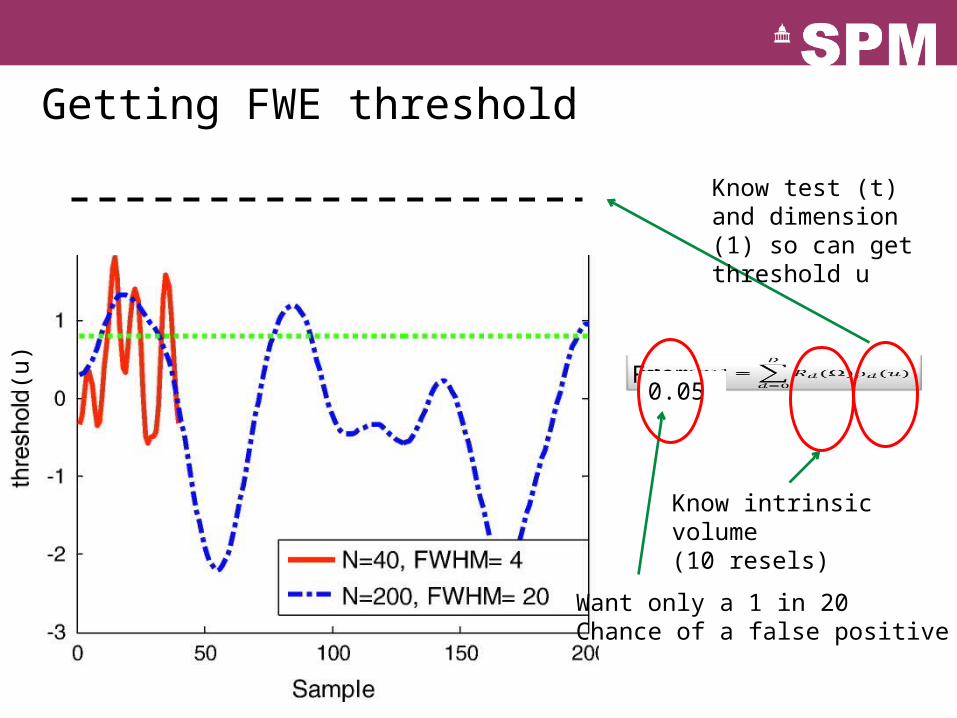
Getting FWE threshold
From
Know intrinsic volume(10 resels)
0.05
Want only a 1 in 20Chance of a false positive
Know test (t) and dimension (1) so can get threshold u
(u)

Can get correct FWE for any of these..
mm
mm
mm
mm
time
mm
time
freq
uenc
y
fMRI, VBM,M/EEG source reconstruction
M/EEG2D time-frequency
M/EEG 2D+t scalp-time
M/EEG1D channel-time
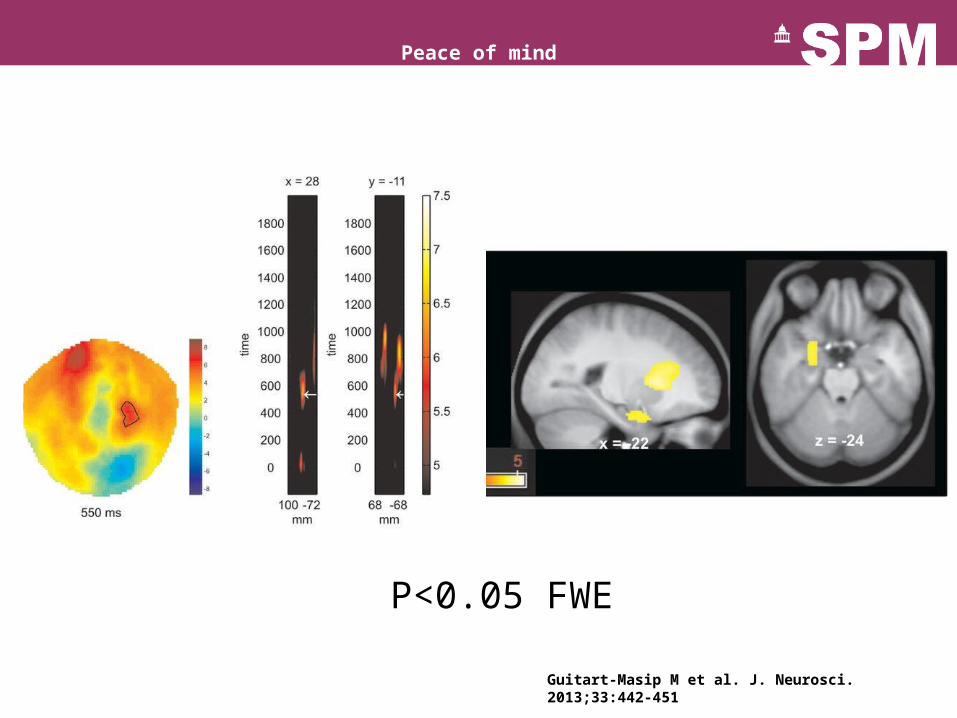
Peace of mind
Guitart-Masip M et al. J. Neurosci. 2013;33:442-451
P<0.05 FWE

Conclusions
Strong prior hypotheses can reduce the multiple comparisons problem.
Random field theory is a way of predicting the number of peaks you would expect in a purely random field (without signal).
Can control FWE rate for a space of any dimension and shape.

Acknowledgments
Guillaume Flandin
Vladimir Litvak
James Kilner
Stefan Kiebel
Rik Henson
Karl Friston
Methods group at the FIL

References Friston KJ, Frith CD, Liddle PF, Frackowiak RS. Comparing functional
(PET) images: the assessment of significant change. J Cereb Blood Flow Metab. 1991 Jul;11(4):690-9.
Worsley KJ, Marrett S, Neelin P, Vandal AC, Friston KJ, Evans AC. A unified statistical approach for determining significant signals in images of cerebral activation. Human Brain Mapping 1996;4:58-73.
Chumbley J, Worsley KJ , Flandin G, and Friston KJ. Topological FDR for neuroimaging. NeuroImage, 49(4):3057-3064, 2010.
Chumbley J and Friston KJ. False Discovery Rate Revisited: FDR and Topological Inference Using Gaussian Random Fields. NeuroImage, 2008.
Kilner J and Friston KJ. Topological inference for EEG and MEG data. Annals of Applied Statistics, in press.
Bias in a common EEG and MEG statistical analysis and how to avoid it. Kilner J. Clinical Neurophysiology 2013.
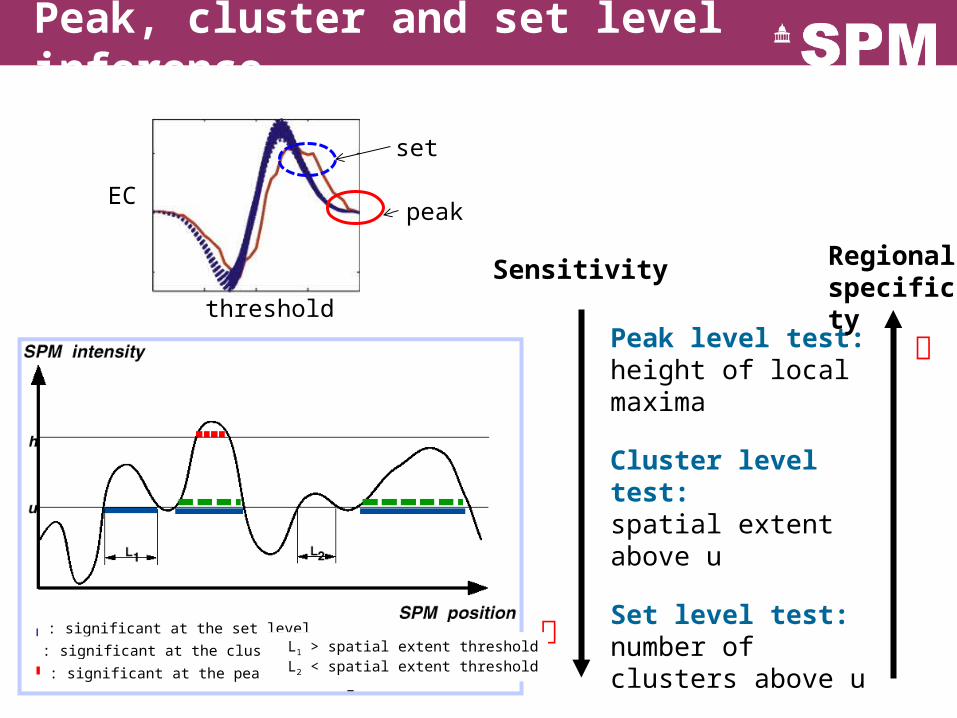
Peak, cluster and set level inference
Peak level test:height of local maxima
Cluster level test:spatial extent above u
Set level test:number of clusters above u
Sensitivity
Regional specificity
: significant at the set level
: significant at the cluster level
: significant at the peak level
L1 > spatial extent threshold L2 < spatial extent threshold
peak
set
EC
threshold

Random Field Theory The statistic image is assumed to be a good lattice
representation of an underlying continuous stationary random field. Typically, FWHM > 3 voxels
Smoothness of the data is unknown and estimated:very precise estimate by pooling over voxels stationarity assumptions (esp. relevant for cluster size results).
But can also use non-stationary random field theory to correct over volumes with inhomogeneous smoothness
A priori hypothesis about where an activation should be, reduce search volume Small Volume Correction: