multimodal integration for meeting group action segmentation and recognition m. al-hames, a....
TRANSCRIPT

Multimodal Integration for Meeting Group Action
Segmentation and Recognition
M. Al-Hames, A. Dielmann, D. Gatica-Perez, S. Reiter, S. Renals, G. Rigoll, and D. Zhang
Institute for Human-Machine Communication, Technische Universität MünchenCentre for Speech Technology Research, University of Edinburgh
IDIAP Research Institute

M. Al-Hames, A. Dielmann, D. Gatica-Perez, S. Reiter, S. Renals, G. Rigoll, and D. Zhang Multimodal Integration for Meeting Group Action Segmentation and Recognition 2
Overview
1. Introduction: Structuring of meetings
2. Audio-visual features
3. Models and experimental results• Segmentation using semantic features (BIC-like)• Multi-layer HMM• Multi-stream DBN• Noise robustness with a mixed-state DBN
4. Summary

M. Al-Hames, A. Dielmann, D. Gatica-Perez, S. Reiter, S. Renals, G. Rigoll, and D. Zhang Multimodal Integration for Meeting Group Action Segmentation and Recognition 3
Structuring of Meetings
Meetings can be modelled as a sequence of events,group, or individual actions from a set
A = {A1, A2, A3, …, AN}
A2 A1 A2 A6 A3
Time

M. Al-Hames, A. Dielmann, D. Gatica-Perez, S. Reiter, S. Renals, G. Rigoll, and D. Zhang Multimodal Integration for Meeting Group Action Segmentation and Recognition 4
Structuring of Meetings
Meetings can be modelled as a sequence of events,group, or individual actions from a set
A = {A1, A2, A3, …, AN}
Different sets represent different meeting views
Neutral LowHighGroup Interest
Group task Information sharing Decision Information sharing
Time
Presentation DiscussionDiscussion Phase Monologue
Idle Writing SpeakingPerson 1 Idle

M. Al-Hames, A. Dielmann, D. Gatica-Perez, S. Reiter, S. Renals, G. Rigoll, and D. Zhang Multimodal Integration for Meeting Group Action Segmentation and Recognition 5
Meeting Views
Group
Discussion Phase
• Discussion
• Monologue (with ID)
• Note-taking
• Presentation
• Whiteboard
• Monologue (ID) + Note-taking
• Presentation + Note-taking
• Whiteboard + Note-taking
Interest Level
• High
• Neutral
• Low
Task
• Brainstorming
• Decision making
• Information sharing
Individual
Interest Level
• High
• Neutral
• Low
Actions
• Speaking
• Writing
• Idle
Further sets could represent the current agenda item or the topic discussed, but may require higher semantic knowledge for an automatic analysis.
M. Al-Hames, A. Dielmann, D. Gatica-Perez, S. Reiter, S. Renals, G. Rigoll, and D. Zhang Multimodal Integration for Meeting Group Action Segmentation and Recognition 6
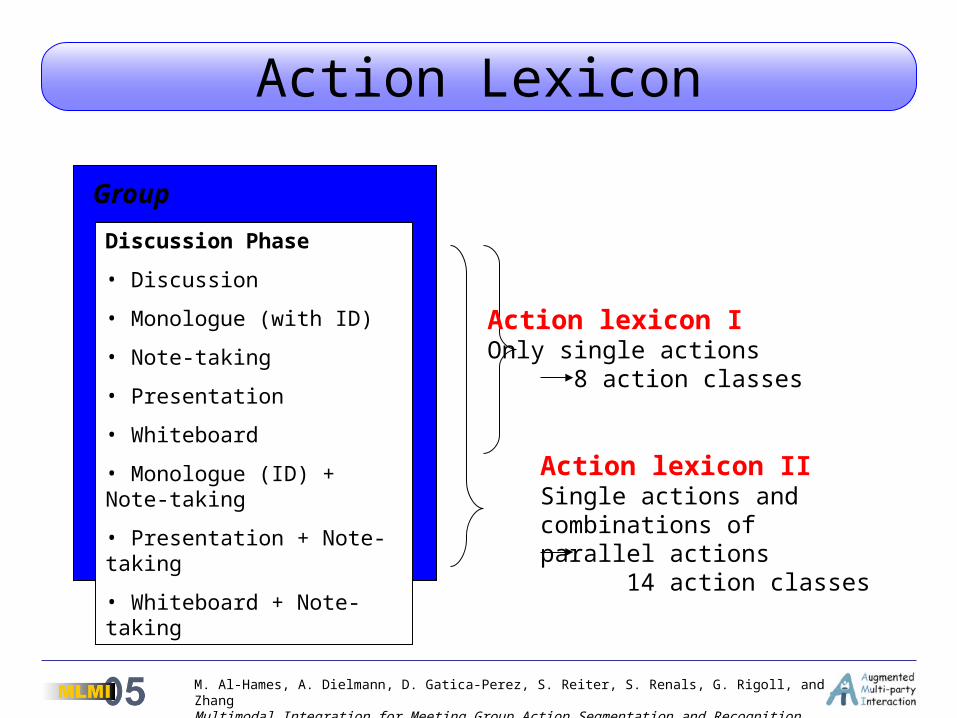
Action Lexicon
Group
Discussion Phase
• Discussion
• Monologue (with ID)
• Note-taking
• Presentation
• Whiteboard
• Monologue (ID) + Note-taking
• Presentation + Note-taking
• Whiteboard + Note-taking
Action lexicon IOnly single actions 8 action classes
Action lexicon IISingle actions and combinations of parallel actions 14 action classes

M. Al-Hames, A. Dielmann, D. Gatica-Perez, S. Reiter, S. Renals, G. Rigoll, and D. Zhang Multimodal Integration for Meeting Group Action Segmentation and Recognition 7
M4 Meeting Corpus
• Recorded at IDIAP• Three fixed cameras• Lapel microphones• Microphone array
• Four participants• 59 videos• Each 5 minutes

M. Al-Hames, A. Dielmann, D. Gatica-Perez, S. Reiter, S. Renals, G. Rigoll, and D. Zhang Multimodal Integration for Meeting Group Action Segmentation and Recognition 8
System Overview
Multimodal Feature Extraction
Action Segmentation
Action Classification
Cameras Microphone Array
…
Lapel Microphones
M. Al-Hames, A. Dielmann, D. Gatica-Perez, S. Reiter, S. Renals, G. Rigoll, and D. Zhang Multimodal Integration for Meeting Group Action Segmentation and Recognition 9
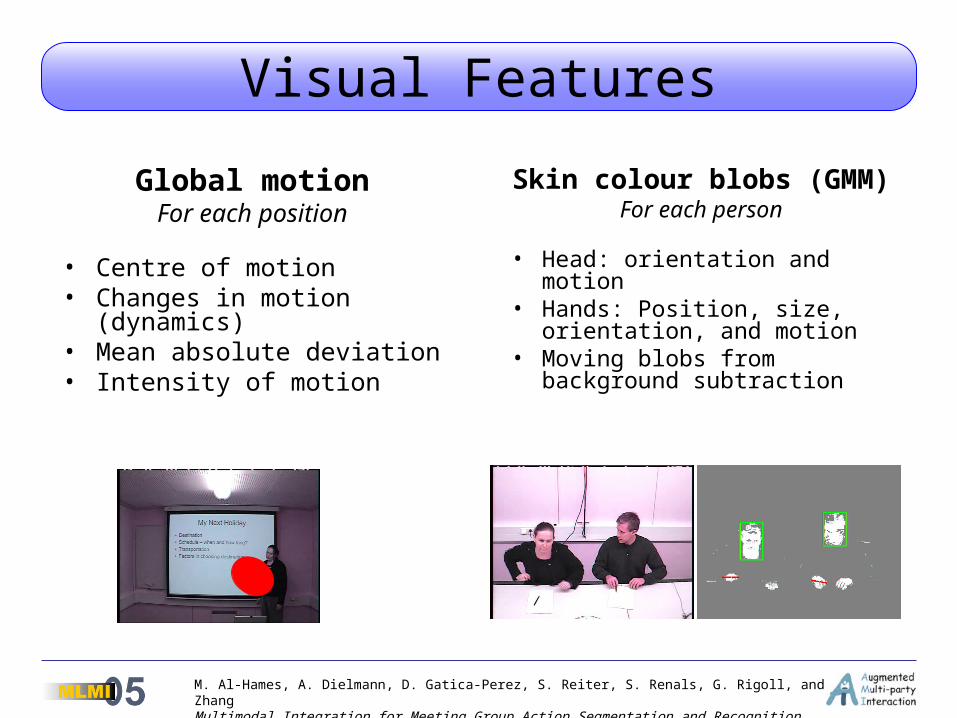
Visual Features
Global motionFor each position
• Centre of motion• Changes in motion
(dynamics)• Mean absolute deviation• Intensity of motion
Skin colour blobs (GMM)For each person
• Head: orientation and motion• Hands: Position, size,
orientation, and motion• Moving blobs from
background subtraction

M. Al-Hames, A. Dielmann, D. Gatica-Perez, S. Reiter, S. Renals, G. Rigoll, and D. Zhang Multimodal Integration for Meeting Group Action Segmentation and Recognition 10
Audio Features
Microphone arrayFor each position
• For each seat (4), whiteboard, and projector screen
• SRP-PHAT measure to estimate a speech activity
• And a speech and silence segmentation
Lapel microphonesFor each person
• For each speech segment• Energy• Pitch (SIFT algorithm)• Speaking rate (combination of
estimators)• MFC-Coefficients
0.0 20.0 40.0 60.0 80.0 100.0 120.0 140.0 160.0 180.0 200.0 220.0 240.0 260.0 280.0
S1S2S3S4PRWH

M. Al-Hames, A. Dielmann, D. Gatica-Perez, S. Reiter, S. Renals, G. Rigoll, and D. Zhang Multimodal Integration for Meeting Group Action Segmentation and Recognition 11
Lexical Features
• Speech transcription (or output of ASR)
• Gesture transcription (or output of an automatic gesture recognizer)
• Gesture inventory
– Writing– Pointing– Standing up– Sitting down– Nodding– Shaking head
For each person

M. Al-Hames, A. Dielmann, D. Gatica-Perez, S. Reiter, S. Renals, G. Rigoll, and D. Zhang Multimodal Integration for Meeting Group Action Segmentation and Recognition 12
BIC-like approach
• Strategy similar to the Bayesian information criterion (BIC)• Segmentation and classification in one step
• Two windows with variable length shifted over the time scale• Inner border is shifted from left to right• Classify each window: different results for left and right window
-> inner border is considered as a boundary of a meeting event• No boundary is detected -> enlarge the whole window• Repeat until right border reaches end of meeting
M. Al-Hames, A. Dielmann, D. Gatica-Perez, S. Reiter, S. Renals, G. Rigoll, and D. Zhang Multimodal Integration for Meeting Group Action Segmentation and Recognition 13
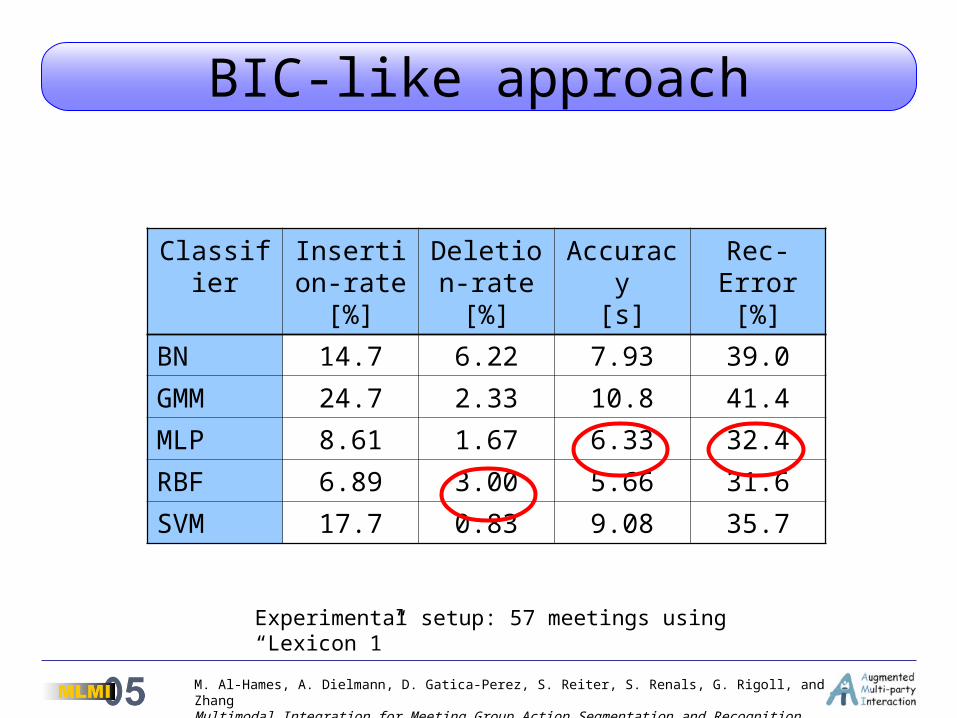
BIC-like approach
Classifier Insertion-rate [%]
Deletion-rate [%]
Accuracy[s]
Rec-Error[%]
BN 14.7 6.22 7.93 39.0
GMM 24.7 2.33 10.8 41.4
MLP 8.61 1.67 6.33 32.4
RBF 6.89 3.00 5.66 31.6
SVM 17.7 0.83 9.08 35.7
Experimental setup: 57 meetings using “Lexicon 1”

M. Al-Hames, A. Dielmann, D. Gatica-Perez, S. Reiter, S. Renals, G. Rigoll, and D. Zhang Multimodal Integration for Meeting Group Action Segmentation and Recognition 14
Multi-layer Hidden Markov Model
Two-layer HMM
GroupHMM
Individual
I-HMM 1
I-HMM 2
I-HMM 3
I-HMM 4
Person 1features
Person 2features
Person 3features
Person 4features
Groupfeatures
• Individual action layer: I-HMM– Speaking, Writing, Idle
• Group action layer: G-HMM– Discussion, Monologue, …
• Each layer trained independently
• Simultaneous segmentation and recognition

M. Al-Hames, A. Dielmann, D. Gatica-Perez, S. Reiter, S. Renals, G. Rigoll, and D. Zhang Multimodal Integration for Meeting Group Action Segmentation and Recognition 15
Multi-layer Hidden Markov Model
Two-layer HMM
GroupHMM
Individual
I-HMM 1
I-HMM 2
I-HMM 3
I-HMM 4
Person 1features
Person 2features
Person 3features
Person 4features
Groupfeatures
• Smaller observation space-> stable for limited training data
• I-HMMs are person independent-> much more training data from different persons available
• G-HMM less sensitive to small changes in the low-level features
• Two layers are trained independently-> different HMM combinations can be explored

M. Al-Hames, A. Dielmann, D. Gatica-Perez, S. Reiter, S. Renals, G. Rigoll, and D. Zhang Multimodal Integration for Meeting Group Action Segmentation and Recognition 16
Multi-layer Hidden Markov Model
Experimental setup: 59 meetings using “Lexicon 2”
Method AER (%)
Single-layer HMM
Visual only 48.2
Audio only 36.7
Early integration 23.7
Multi-stream 23.1
Asynchronous 22.2
Multi-layer HMM
Visual only 42.4
Audio only 32.3
Early Integration 16.5
Multi-stream 15.8
Asynchronous 15.1

M. Al-Hames, A. Dielmann, D. Gatica-Perez, S. Reiter, S. Renals, G. Rigoll, and D. Zhang Multimodal Integration for Meeting Group Action Segmentation and Recognition 17
Multi-stream DBN Model
• Counter structure– Improves state-duration
modelling– Action counter C is incremented
after each “action transition”
• Hierarchical approach
• State-space decomposition:– Two feature related sub-action
nodes (S1 and S2)– Each sub-state corresponds to a
cluster of feature vectors– Unsupervised training
• Independent modality processing
S01
Y01
St1
Yt1
St+11
Yt+11
….
A0 AtAt+1….
S02
Y02
St2
Yt2
St+12….
C0
E0
Ct
Et
Ct+1
Et+1
….
Yt2 Yt+1
2
….
M. Al-Hames, A. Dielmann, D. Gatica-Perez, S. Reiter, S. Renals, G. Rigoll, and D. Zhang Multimodal Integration for Meeting Group Action Segmentation and Recognition 18
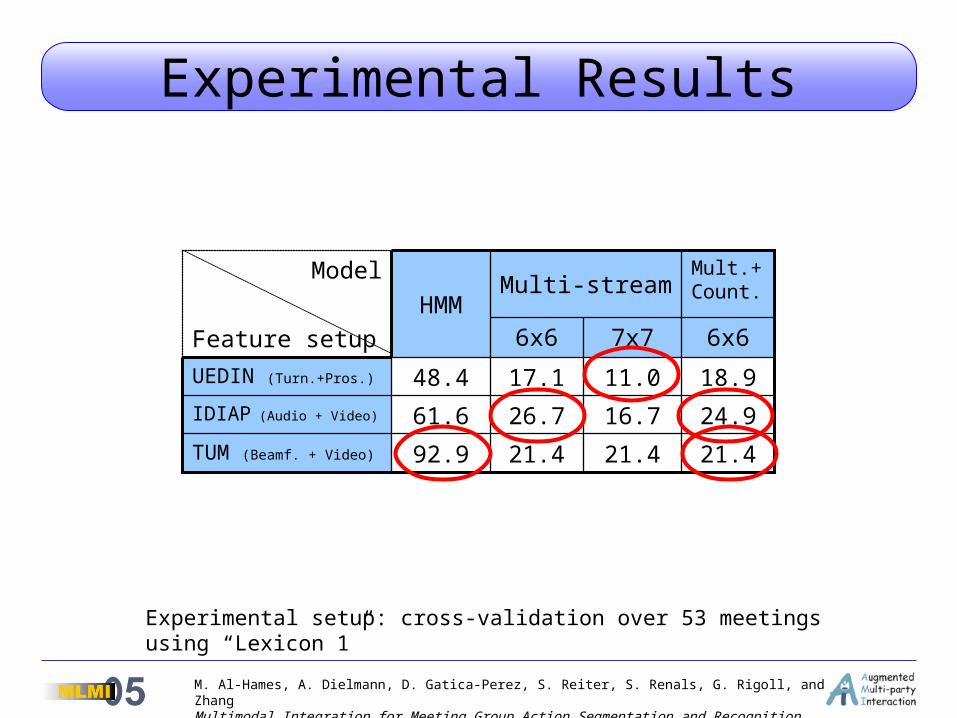
Experimental Results
21.4
16.7
11.0
7x7 6x66x6
21.421.492.9TUM (Beamf. + Video)
24.926.761.6IDIAP (Audio + Video)
18.917.148.4UEDIN (Turn.+Pros.)
Mult.+ Count.
Multi-streamHMM
Model
Feature setup
Experimental setup: cross-validation over 53 meetings using “Lexicon 1”
M. Al-Hames, A. Dielmann, D. Gatica-Perez, S. Reiter, S. Renals, G. Rigoll, and D. Zhang Multimodal Integration for Meeting Group Action Segmentation and Recognition 19
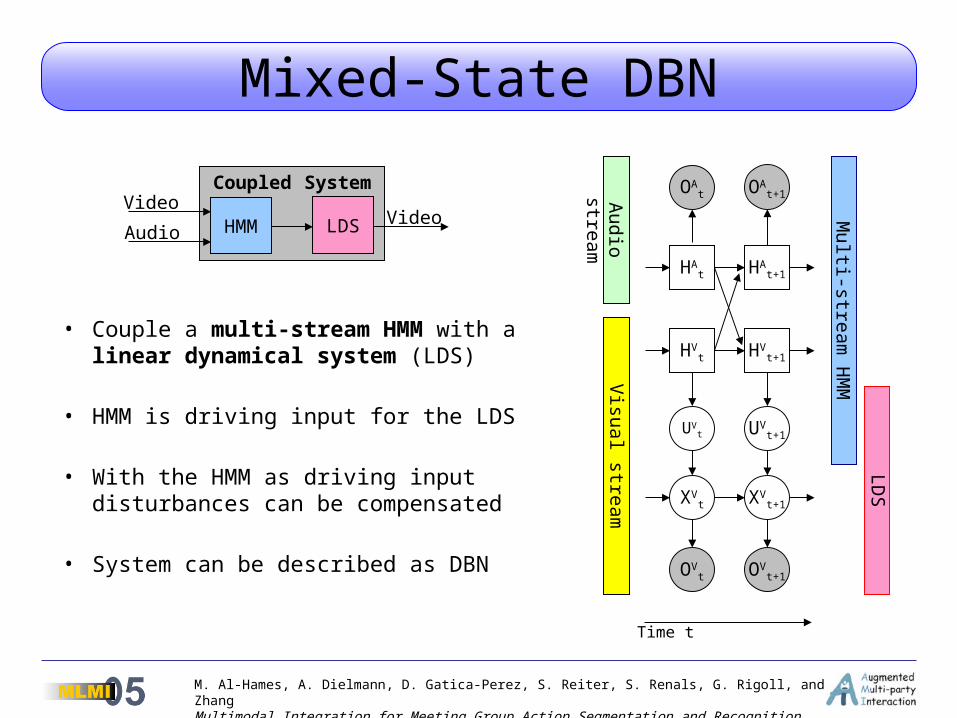
Mixed-State DBNLD
S
Multi-strea
m H
MM
HAt+1HA
t
HVt+1HV
t
OAt
UVt UV
t+1
XVt XV
t+1
OVt OV
t+1
Time t
Aud
io streamV
isual stream
OAt+1
Coupled System
HMM LDSVideo
AudioVideo
• Couple a multi-stream HMM with a linear dynamical system (LDS)
• HMM is driving input for the LDS
• With the HMM as driving input disturbances can be compensated
• System can be described as DBN
M. Al-Hames, A. Dielmann, D. Gatica-Perez, S. Reiter, S. Renals, G. Rigoll, and D. Zhang Multimodal Integration for Meeting Group Action Segmentation and Recognition 20
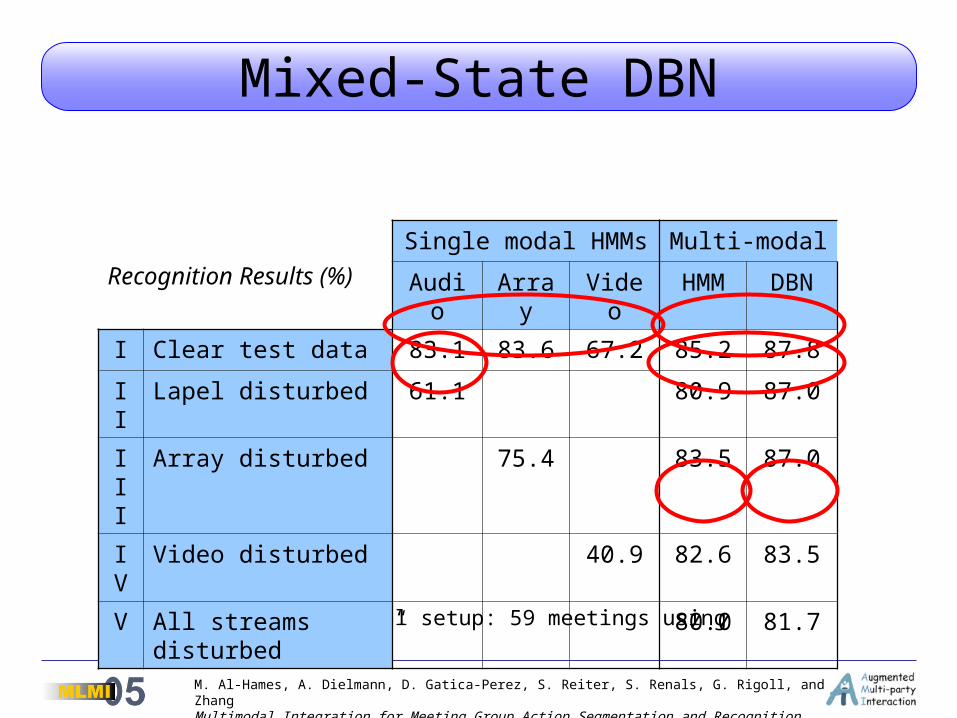
Mixed-State DBN
Experimental setup: 59 meetings using “Lexicon 1”
Recognition Results (%)Single modal HMMs Multi-modal
Audio Array Video HMM DBN
I Clear test data 83.1 83.6 67.2 85.2 87.8
II Lapel disturbed 61.1 80.9 87.0
III Array disturbed 75.4 83.5 87.0
IV Video disturbed 40.9 82.6 83.5
V All streams disturbed 80.0 81.7

M. Al-Hames, A. Dielmann, D. Gatica-Perez, S. Reiter, S. Renals, G. Rigoll, and D. Zhang Multimodal Integration for Meeting Group Action Segmentation and Recognition 21
Summary• Joint effort of TUM, IDIAP, and UEDIN
• Modelling meetings as a sequence of individual and group actions
• Large number of audio-visual features
• Four different group action modelling frameworks:• Algorithm based on BIC• Multi-layer HMM• Multi-stream DBN• A mixed-state DBN
• Good performances of the proposed frameworks
• Future work– Space for further improvements: Both in the feature domain and
in the model structures– Investigate combinations of the proposed models