mstar’s extensible search engine and model...
TRANSCRIPT

MSTAR’s Extensible Search Engine and Model-based Inferencing Toolkit
John Wissinger Robert Ristroph ALPHATECH, Inc.
Burlington, MA 01803
Joseph Diemunsch AFRL/SNAA
Wright-Patterson AFB OH 45433
William Severson Lockheed-Martin Corporation
Denver, CO 80201
Eric Freudenthal New York University New York, NY 10012
ABSTRACT The DARPA/AFRL “Moving and Stationary Target Acquisition and Recognition” (MSTAR) program is developing a model-based vision approach to Synthetic Aperture Radar (SAR) Automatic Target Recognition (ATR). The motivation for this work is to develop a high performance ATR capability that can identify ground targets in highly unconstrained imaging scenarios that include variable image acquisition geometry, arbitrary target pose and configuration state, differences in target deployment situation, and strong intra-class variations. The MSTAR approach utilizes radar scattering models in an on-line hypothesize-and-test operation that compares predicted target signature statistics with features extracted from image data in an attempt to determine a “best fit” explanation of the observed image. Central to this processing paradigm is the Search algorithm, which provides intelligent control in selecting features to measure and hypotheses to test, as well as in making the decision about when to stop processing and report a specific target type or clutter. Intelligent management of computation performed by the Search module is a key enabler to scaling the model-based approach to the large hypothesis spaces typical of realistic ATR problems. In this paper, we describe the present state of design and implementation of the MSTAR Search engine, as it has matured over the last three years of the MSTAR program. The evolution has been driven by a continually expanding problem domain that now includes 30 target types, viewed under arbitrary squint/depression, with articulations, re-configurations, revetments, variable background, and up to 30% blocking occlusion. We believe that the research directions that have been inspired by MSTAR’s challenging problem domain are leading to broadly applicable search methodologies that are relevant to computer vision systems in many areas. KEYWORDS: synthetic aperture radar (SAR), automatic target recognition (ATR), search algorithms, MSTAR,
computation management, scheduling, optimization
1. INTRODUCTION Since its inception, the MSTAR program has focused on recognizing ground targets in a single look of high quality (research grade), high resolution (1 ft range and cross range), HH-polarity, magnitude SAR imagery. In data of this quality and resolution, the impact of variations in target geometry on radar signatures can be significant enough that it must be addressed as part of the recognition process. MSTAR’s strategy for addressing target variability is founded on concepts from model-based vision [3]. In the model-based approach to SAR ATR, radar scattering models are derived offline by applying an electromagnetic signature prediction code (Xpatch) to detailed characterizations of target geometry (CAD models). The resulting 3D scattering representations allow projection of signatures to arbitrary SAR image planes as well as rigid-body manipulations of scattering centers that model repositioning of components like turrets, fuel drums, hatches, etc. The scattering representations are utilized by the ATR in an on-line hypothesize-and-test operation that compares predicted target signature statistics with features from image data in an attempt to determine a “best fit” explanation of the observed image.

The goal of search is to interpret the image with high performance and a minimal computation. Mathematical formulations of the “best fit” processing objective as a maximum likelihood (ML) or maximum a posteriori (MAP) Bayesian estimation problem have previously been provided in [1] and will not be repeated here. The resulting optimization faced by Search is difficult, as it is nonlinear, with both discrete and continuous components, and can be high dimensional with many modes, as illustrated by the likelihood function (match surface) shown in Figure 1-1.
FIGURE 1-1. Actual enumerated likelihood function, based on the peak feature, for a test input of articulated M109 with ground truth pose of 32 deg and articulation of –50. The hypothesis space includes 15 target types
(discrete components), target pose (continuous), and articulation (continuous) for two target types, the M109 and the T72. Red indicates a good score. While a single global maximum is evident in the correct location, note the
presence of multiple additional confounding local maxima.
The goal of this paper is to summarize the state of development of MSTAR’s search algorithm, which effectively provides solutions to difficult optimization problems like the one illustrated in Figure 1-1. In the remainder of this short paper we do the following: we first review in Section 2 some of the key challenges that are driving our design and implementation; we then present in Section 3 our technical approach, which can be described as utility-driven hierarchical control and inference; we work from the generic to the specific as we flesh these terms out and provide concrete examples in Section 4; finally, in Section 5 we conclude the discussion with some areas for future work.
2. KEY CHALLENGES Among the challenges faced by MSTAR search developers, we highlight three that have had significant impact: a continually expanding problem domain, the need to characterize cost-benefit tradeoffs in building algorithms, and the limits on search computations imposed by the expense of component calculations. These challenges, and the responses they have stimulated, are the topics of the next three subsections.

2.1 Expanding Problem Domain The MSTAR ATR is being designed to address highly unconstrained imaging conditions. The program office has pushed the development team in this direction by continually expanding the problem domain, e.g., by adding more target types, articulated targets, obscured targets, etc., as illustrated below in Figure 2-1. The system’s progress is then tested against these problems with annual large-scale evaluations (measured in the tens of thousands of test ROIs). The goal for the search algorithm has been to address these increases in the size of the input space with scalable search strategies, or strategies that exhibit favorable growth in computation as the size of the input problem space grows. A simple example of a scalable strategy would be one that achieves sub-linear growth in computation with the number of target types added to the ATR mission, while continuing to maintain high ID performance. A complication to meeting this goal is that rarely does a single algorithm, such as the combination of a feature type with a match technique, uniformly outperform other reasonable algorithms as the problem domain is changed, particularly when the processing and storage costs of individual algorithm components are taken into consideration, and particularly when the problem domain is expanded through introduction of EOCs like those depicted in Figure 2-1. Indeed, throughout the course of the MSTAR program, we have observed that the features, match metrics, and search algorithms have continued to evolve and proliferate as developers have sought to push performance up in the face of expanding problem domains.
Occlusion Revetments Articulation
FIGURE 2-1. Example extended operating conditions (EOCs) from the MSTAR data sets that have pushed
search algorithm development forward. Particularly challenging are so-called compound EOCs, in which a single image may exhibit multiple simultaneous nuisance conditions that increase the search space, such as in the case
of a revetted, articulated target with open hatches. The search team has responded to the expanding problem domain and the challenge it has presented for development of scalable processing approaches by pursuing the following research avenues:
• Incorporation of data-driven image understanding (IU) and cueing components that support smart hypothesis initialization and hypothesis space restriction
• Development of a rich algorithm toolkit of high performance recognition tests • Development of several notions of hierarchy that can be exploited in a situation-dependent, dynamic fashion using
conditional branching constructs • Incorporation of offline-derived target-type-specific and system-performance-specific heuristic rules • Development of a facility for rapidly prototyping end-to-end search algorithms • Development of constructs to support concurrent processing
We expand on a number of these areas in the remainder of the paper. In addition, a significant amount of search development effort has gone into providing an organizational framework, both conceptual and in software, to assemble and use in an

integrated fashion the various algorithm technologies being developed by the program to address the extended operating conditions. The development of this framework has motivated innovative approaches to modular and extensible software organization as we review in Section 3.
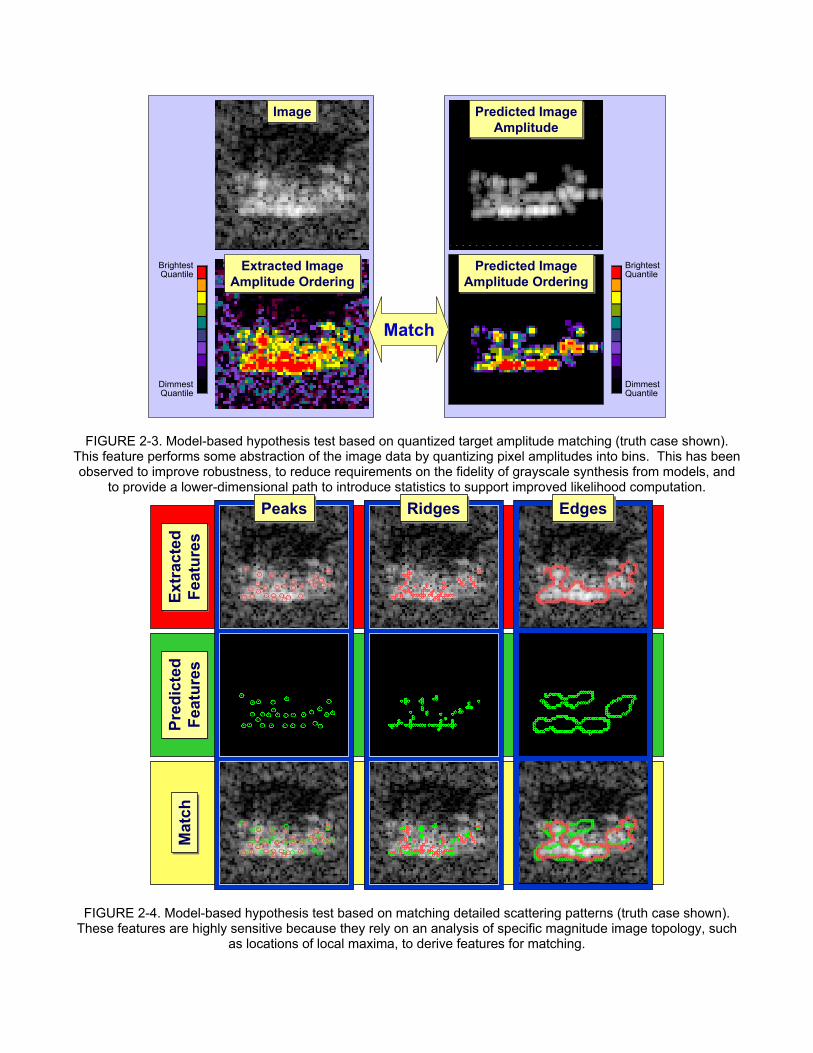
2.2 Robustness vs. Reasoning Tradeoffs Radar scattering models represent some aspects of target variability to a sufficient level of fidelity to improve recognition performance if the variability is accounted for, such as turret articulation, but the price for this additional performance is increased dimensionality of the hypothesis spaces that must be searched, leading to increased computation and longer runtimes. We have spent considerable effort attempting to understand the various computational cost versus performance tradeoffs that impact search strategy construction, with the ultimate aim of modeling it so that we can intelligently schedule computation within the online system. For example, a critical search function is the selection of feature types on which to base specific hypothesis tests at certain stages of the search process. The current set of MSTAR features provide a broad range of capability to match target and shadow shape, image amplitude, and detailed scattering patterns, as illustrated for the M1 MBT in Figures 2-2, 2-3, and 2-4. The search problem is made interesting by the fact that these features present different computational cost / performance profiles and exhibit distinct performance characteristics under different operating conditions. In addition, because they embody different levels of abstraction of the raw image data, this set of features supports a natural notion of hierarchy that can be exploited in developing coarse-to-fine reasoning strategies (see Section 3).
HighLikelihood
LowLikelihood
HighLikelihood
LowLikelihood
Shadow Likelihoodfrom Relative Image Dimness
Shadow Likelihoodfrom Relative Image Dimness
Target Likelihoodfrom Relative Image Brightness
Target Likelihoodfrom Relative Image Brightness
Extracted Shape LikelihoodsExtracted Shape Likelihoods
PredictedShapes
PredictedShapes MatchMatch
TargetTargetShadowShadow
FIGURE 2-2. Model-based hypothesis test based on target and shadow shape matching (truth case shown). This feature, also referred to as the “label feature”, because it effectively labels pixels as belonging to illuminated on-
target, shadow, or background, abstracts much of the information in the image, providing a robust metric that does not require a full EM signature prediction to compute.
PredictedShapes
PredictedShapes
Predicted ImageAmplitude
Predicted ImageAmplitude
BrightestQuantile
DimmestQuantile
BrightestQuantile
DimmestQuantile
Match
ImageImage
Extracted ImageAmplitude Ordering
Extracted ImageAmplitude Ordering
Predicted ImageAmplitude Ordering
Predicted ImageAmplitude Ordering
FIGURE 2-3. Model-based hypothesis test based on quantized target amplitude matching (truth case shown). This feature performs some abstraction of the image data by quantizing pixel amplitudes into bins. This has been observed to improve robustness, to reduce requirements on the fidelity of grayscale synthesis from models, and
to provide a lower-dimensional path to introduce statistics to support improved likelihood computation.
Extr
acte
dFe
atur
esEx
trac
ted
Feat
ures
Pred
icte
dFe
atur
esPr
edic
ted
Feat
ures
Mat
chM
atch
PeaksPeaks RidgesRidges EdgesEdges
FIGURE 2-4. Model-based hypothesis test based on matching detailed scattering patterns (truth case shown). These features are highly sensitive because they rely on an analysis of specific magnitude image topology, such
as locations of local maxima, to derive features for matching.

As may be evident from Figures 2-2 through 2-4, the sensitivity of MSTAR’s feature suite to target variability such as articulated turrets, raised cannons, or the presence or absence of fuel barrels, differs widely. From the perspective of search, it is clearly desirable to search explicitly as few of the model state variables as possible - only the ones that really need to be estimated to achieve high performance should be addressed. Specifically, there are computational cost/performance tradeoffs to be made, where relatively inexpensive techniques which sacrifice some performance must be measured against more computationally expensive approaches that buy additional performance. As we emphasize below, a significant complication is that ATR performance metrics emphasize not only the capability to distinguish from among a set of mission targets (Pid), but also the capability to reject objects outside the mission (false alarm rejection, Pfa or FAR). The term "reasoning” is often heard in conjunction with a discussion of model-based technology in this context. The term simply means performing explicit search over conditioning variables, but in a way that is "non-enumerative" and efficient. In particular, the process of guided and selective hypothesis testing has been termed "reasoning". The term is often applied in the context of problems containing variations like turret articulation, where to obtain the highest possible recognition performance, it may be necessary to estimate the turret position. More "classical" template approaches would “reason” by storing additional image exemplars to handle these cases. In the model-based paradigm, these situations are addressed by searching additional model states in the online process. A key property required to enable reasoning to succeed is that the condition be observable with respect to the model, i.e., the model fidelity must be sufficient to ensure that a model configured to the truth state scores higher (has a higher likelihood of explaining the data) than one that does not. The range of non-enumerative approaches to searching multiple conditioning nuisance variables that are tractable, and that we have employed thus far on MSTAR are: • Ignore Effects: this obvious statement simply means that if the target type can be identified with high performance, even
when matched against a nominally configured model which has ignored the possibility of the condition, the problem is solvable with no additional processing overhead. This approach is most desirable from an efficiency perspective. We find that this is often a reasonable strategy in the case of open/closed hatches.
• Build Robustness (Invariance): if algorithms can be devised that deliberately incorporate insensitivity to the condition,
this is highly desirable, since additional computational overhead is minimized. Some techniques for building robustness we have used successfully are:
• development of articulation or configuration-invariant features, e.g., label matching with cannons disabled • development of robust match algorithms which can tolerate mismatches, such as zero-penalty saturating metrics • statistical treatments that implicitly model a range of states in the model • composite hypothesis testing based on feature composites or signature averaging
• Reason: dynamically estimate nuisance parameters by testing alternative (multiple) models. This approach is most
computationally burdensome, but can provide the highest performance. Some example reasoning techniques are: • hierarchical strategies: apply a sequence of hypothesis tests ranging from coarse-to-fine along one or more of
the following dimensions: • features • hypothesis granularity • hypothesis dimensionality • model fidelity
• decomposition strategies: break a high dimensional problem apart into a collection of lower-dimensional sub-problems; this may neglect inherent coupling in the larger problem space. Some examples: • first estimate pose, then articulation and configuration; possibly iterate • first test configurations independent of articulation (possibly with an articulation-invariant feature), select a
small set of the best, then test articulation • perform structural decomposition from whole target down to its component parts, as in subpart-level
matching Figure 2-5 provides an illustration of the tradeoffs intrinsic to these approaches. A problem with the first two approaches is that they tend to result in lower scores of model-to-data, even in cases where the type discrimination has been performed correctly, due to the presence of unmodeled or only-generically-modeled (e.g., averaged) effects. This in turn creates a

problem for false alarm rejection, where very target-like false alarms may receive comparably good scores. A power of the model-based approach is that it provides the ability to dynamically estimate nuisance parameters, achieving precise fits between target representations and data. This can help by shifting target score distributions away from confuser / clutter distributions, improving false alarm rejection performance. Of course, a key enabler to take advantage of the power of this approach is the ability to search the required variables efficiently.
Rel
ativ
e Pe
rfor
man
ce
Articulation
Figure 2-5. Illustration of the reasoning versus robustness tradeoff in terms of relative recognition performance on
a particular serial number articulated M109 in the MSTAR dataset. Note the payoff for each feature type as articulation is fit (-50 is ground truth correct). Unarticulated labels (cannon off) provide a fixed level of
performance for no search cost that may be acceptable in some applications. The label feature is visibly more robust, and interestingly, in this case provides higher performance for a lower sampling of turret positions than the
other features, which require turret position to be estimated to within 20 degrees.
2.3 Limits on Computation A final challenge for search that we have faced has been the restrictive nature of MSTAR’s computational budget. A significant fraction of search runtime is devoted to the control of the Predict-Extract-Match (PEM) modules, which together provide a hypothesis evaluation [1]. Each evaluation of a likelihood function, like the one depicted in Figure 1-1, that Search requests requires a PEM test to be performed, so that the number of search operations that it is feasible to perform is highly dependent on the expense of this particular operation. At present, a PEM test averages about 30 seconds of runtime on an Ultra1 class machine. This means it is only feasible to perform between 20-30 PEM tests on each ROI, and still live within the runtime budget set by the MSTAR Evaluation team to support large-scale evaluation of the system. This is a small fraction of the number of tests one might imagine to be required to recognize targets in the difficult conditions described in Section 2.1. So to this point, MSTAR Search has been forced to develop “small-sample” optimization approaches. In contrast, consider the level of computation performed in applications like IBM’s touted “Deep Blue” chess program, which performs literally millions of heuristic board evaluations as part of every move it makes using an N-depth lookahead dynamic programming strategy. Certainly, MSTAR is still a maturing research system, and no serious attempt has yet been made to speed it up, either through software or hardware. But in the future such efforts will no doubt be made, and these will open up whole new avenues for algorithm development that have heretofore been difficult to pursue.
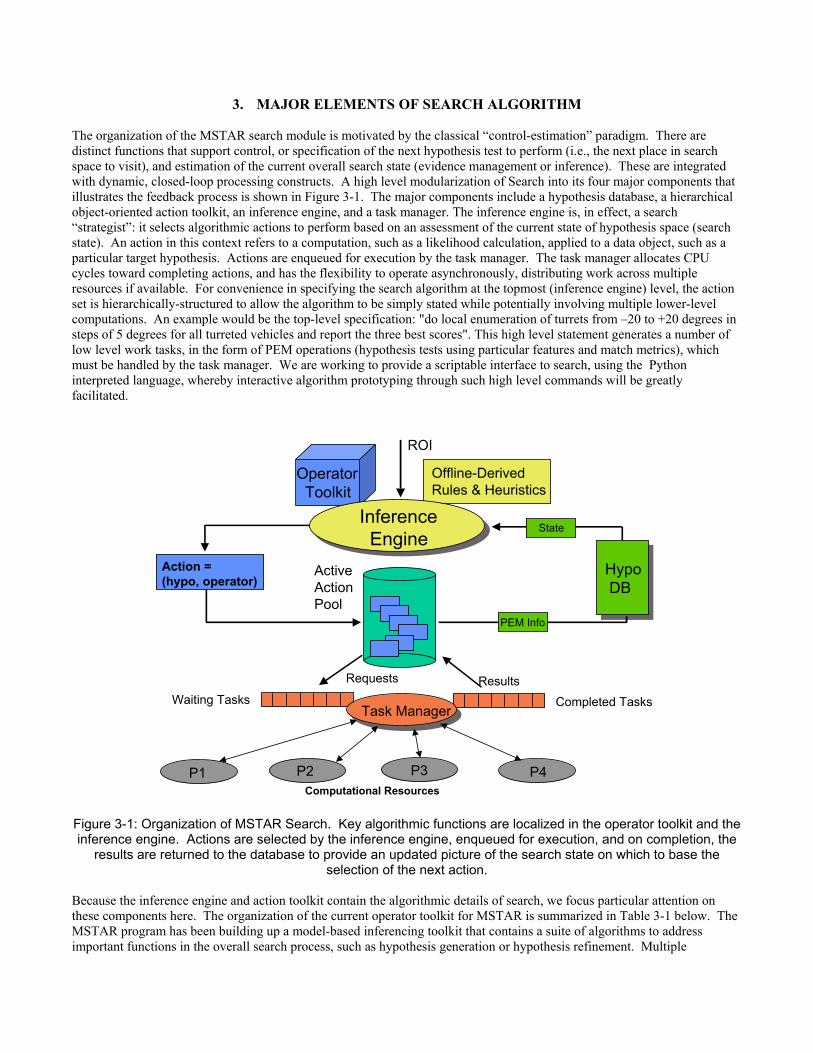
3. MAJOR ELEMENTS OF SEARCH ALGORITHM The organization of the MSTAR search module is motivated by the classical “control-estimation” paradigm. There are distinct functions that support control, or specification of the next hypothesis test to perform (i.e., the next place in search space to visit), and estimation of the current overall search state (evidence management or inference). These are integrated with dynamic, closed-loop processing constructs. A high level modularization of Search into its four major components that illustrates the feedback process is shown in Figure 3-1. The major components include a hypothesis database, a hierarchical object-oriented action toolkit, an inference engine, and a task manager. The inference engine is, in effect, a search “strategist”: it selects algorithmic actions to perform based on an assessment of the current state of hypothesis space (search state). An action in this context refers to a computation, such as a likelihood calculation, applied to a data object, such as a particular target hypothesis. Actions are enqueued for execution by the task manager. The task manager allocates CPU cycles toward completing actions, and has the flexibility to operate asynchronously, distributing work across multiple resources if available. For convenience in specifying the search algorithm at the topmost (inference engine) level, the action set is hierarchically-structured to allow the algorithm to be simply stated while potentially involving multiple lower-level computations. An example would be the top-level specification: "do local enumeration of turrets from –20 to +20 degrees in steps of 5 degrees for all turreted vehicles and report the three best scores". This high level statement generates a number of low level work tasks, in the form of PEM operations (hypothesis tests using particular features and match metrics), which must be handled by the task manager. We are working to provide a scriptable interface to search, using the Python interpreted language, whereby interactive algorithm prototyping through such high level commands will be greatly facilitated.
Hypo DB
Operator Toolkit
Offline-DerivedRules & Heuristics
Action = (hypo, operator)
Inference Engine
Active ActionPool
Task Manager
PEM Info
State
Waiting Tasks Completed Tasks
P1 P2 P3 P4Computational Resources
Requests Results
ROI
Figure 3-1: Organization of MSTAR Search. Key algorithmic functions are localized in the operator toolkit and the inference engine. Actions are selected by the inference engine, enqueued for execution, and on completion, the
results are returned to the database to provide an updated picture of the search state on which to base the selection of the next action.
Because the inference engine and action toolkit contain the algorithmic details of search, we focus particular attention on these components here. The organization of the current operator toolkit for MSTAR is summarized in Table 3-1 below. The MSTAR program has been building up a model-based inferencing toolkit that contains a suite of algorithms to address important functions in the overall search process, such as hypothesis generation or hypothesis refinement. Multiple

alternative algorithms may be available for performing the same functions. This toolkit approach is motivated by the fact that different algorithms often make distinct computational cost / performance tradeoffs, and typically have different domains of superior performance when compared with one another. Obtaining robust performance over a wide-ranging problem domain may require use of several algorithmic techniques in concert with one another. In addition, users who would like to see the search algorithm adapt to user-supplied constraints and restrictions, such as runtime or storage limitations, will benefit from these options.
Table 3-1. Organization of search operator toolkit. The various algorithmic pieces of search are encoded in operators which can broadly be grouped as indicated in the table.
Operator Type Function Example Algorithms
Algorithm Context Identification
(from image data)
Provide indications of target in-the-clear, occluded; detect interference from local scene, e.g., revetment
Detect disrupted or uprange shadows Detect multiple connected components
Hypothesis Space Restriction
(from image data)
Limit alternatives in target type and pose through data-derived cues and
measured features
Coarse size/shape metrics Bright sidelobing peak detection Gun tube detection Image analyst (IA) geometric features
Hypothesis Generation
(using target models)
Generate hypotheses as to possible target type, pose, and EOC state
Indexing module (MSTAR IXS) Model-based indexing Geometric hashing Composite feature indexing
Hypothesis Refinement (with PEMs)
Refine estimates of target type, pose, and other state variables
Jacobian-based (linearized) refinement Local enumeration Hierarchical grid search Branch & bound thread scheduling Hypothesis aggregation with limited PEMs Geometric hashing (fine tables) Adaptive sampling Heuristic search
Final Discrimination/ Verification
(with model-based tests)
Distinguish among set of closely competing target hypotheses;
distinguish targets from clutter
Feature fusion Mismatch analysis Component-level scoring IA features Type-dependent LR test
A particular search strategy is instantiated by identifying a set of actions to perform and specifying the conditions under which they are to be executed. Strategies can have the following forms, presented in order of increasing sophistication:
• Scripts without choices, run to completion (open-loop control) • Script segments with hardwired decision points (open-loop feedback, change behavior based on new information) • Supervised script segments, rule-based systems (more elaborate open-loop feedback) • General rule system with dynamic utility functions (fully closed-loop, frequent replanning)
The search algorithms on MSTAR are presently formed through a concatenation of supervised script segments, as illustrated in Figure 3-2. In this scheme, a sequence of processing stages is advanced through in open-loop scripted sequence. However, within the hypothesis refinement stage, closed-loop dynamic planning occurs until the stage is completed. We elaborate on this in Section 4-3.

Analyze SceneComplexity
Analyze SceneComplexity
• Dynamically select features• Segment interfering objects
Identify CoarseCues from DataIdentify CoarseCues from Data
• Identify coarse pose range• Determine general target size/class
DynamicallyRefine Hypotheses
DynamicallyRefine Hypotheses
• Incorporate more detailed features• Incorporate more state variables• Refine estimates of state variables• Utility-based control
Verify SolutionVerify Solution• Analyze residual mis-matches• Combine features• Select best target(s), reject clutter
Off-line Coarse Models (2D image plane)Off-line Coarse Models (2D image plane)
3D Geometric Models3D Geometric Models
Scattering Center ModelsScattering Center Models
Generate InitalHypotheses (IX)Generate Inital
Hypotheses (IX)• Improved pose estimate• Reduced set of target classes
ROI
FinalType
Figure 3-2. Generic search strategy implemented as a concatenation of supervised script segments.
As an alternative to scripted search behavior, we are working to develop adaptive reasoning techniques, based on utility-driven action selection, where utilities are computed on-the-fly. The adaptive search engine will dynamically select actions such as hypothesis generation, hypothesis refinement, or verification based on a current interpretation of the viewed scene and the nature of the conflicting hypotheses that are being considered. Such adaptation can arise from specific sources such as:
• analysis of the ROI, e.g., scene parameters and data-derived cues • past history of matches, e.g., best match seen to date • matches obtained against particular hypotheses, e.g., mismatch patterns or component-level matches • exogenous inputs such as context • pre-computed performance data such as system confusion data • heuristic selection processes motivated by offline-derived knowledge or rules • user-supplied constraints, such as runtime limitations, storage constraints, etc.
The algorithm selection operation performed by the inference engine will ultimately be structured as a utility optimization. Static utility assignments essentially map to an open-loop, scripted search process that applies algorithmic actions in a fixed sequence. But more desirable solutions, from the perspective of increasing efficiency, would take the form of closed-loop feedback computations of utility based on knowledge of current search state captured in the contents of the hypothesis database. Properly constructed utility computations must attempt to take into account performance versus cost payoffs for particular algorithmic options over particular problem domains. We also believe that a key to enabling MSTAR’s approach to scale to realistic-sized problems is to employ hierarchical strategies where inexpensive, but less discriminating, tests are applied in early stages of the search to eliminate low payoff areas of hypothesis space from further consideration, followed by exploration of the surviving areas with more computationally expensive, but more discriminating, tests that narrow the set of alternatives to a single best explanation of the data. Some of the important aspects to the hierarchical approaches we are investigating are:
i) dynamic formulation and execution of hypothesis tests that range from coarse-to-fine along the following dimensions (illustrated in Figure 3-3):

• Hypothesis Granularity: gross values to specific values, e.g., T72@[0, 50] deg aspect -> T72@32 deg • Hypothesis Dimensionality: M109@132 deg aspect -> M109@132 deg aspect with turret @ 34 deg in
a revetment; whole to part reasoning • Image Features: global on-target and shadow regions -> locations of specific persistent scatterers • Model Fidelity: coarse shape information to detailed phenomenological information, e.g., geometry-
based features such as target shadow silhouette -> full EM scattering prediction ii) effective balance in the use of offline vs. online generated reference data (intelligent pre-computation) iii) application of the results of each hypothesis to the selection of subsequent tests (closed-loop processing)
A useful attribute of hierarchical, utility-based recognition systems is that at any point during the reasoning chain one can interrupt the processing and obtain a meaningful picture of the hypothesis state. For example, after a small amount of processing one may only have an indication of turreted versus non-turreted vehicles or large versus small vehicles—i.e., an evaluation of coarse model matches—which is then refined with further processing to more specific target types and states. This processing behavior is in sharp contrast with conventional linear template matchers that sequence through a set of template matches with minimal feedback from data cues or previous matches. As a result, if these linear template matchers are interrupted half way through processing, all one can say is which is the best match that has been seen thus far, with no indication of whether or not better matches may be obtained further on. We have found that the use of 3D target models provides an especially powerful framework around which to construct hierarchical approaches because of the degree of control provided to the developer in structuring coarse-to-fine computations.
Features
Model Representation
HypothesisDimensionality
coarse-to-finesearch path
Hypot
hesis
Gra
nular
ity
Figure 3-3. MSTAR’s evolving hierarchical reasoning space.
4. EXAMPLE SEARCH STRATEGY In this section, we add some concreteness to the discussion by presenting a few examples of specific algorithms in MSTAR’s model-based toolkit. Each example corresponds to a major functional stage of the generic search strategy illustrated in Figure 3-2.
4.1 Measure Data-derived Cues An initial analysis of the input image, prior to testing target models against it, can yield valuable clues that may improve the performance and efficiency of downstream model-based processing. Some specific examples include: • coarse target metrics: measurement of length / width / aspect ratio, weighted fill, etc., can give some indication of likely
target class based on coarse estimates of properties related to object size • corrupted shadow check: if the target-like object in the ROI appears to have a good shadow (crisp boundaries, reasonable
size), use it as a feature for matching, otherwise do not rely on the shadow

• target occlusion detection: if the target object has up-range shadow, or cross-range immediately adjacent shadow, consider the possibility that the target may be occluded
• bright sidelobing peak: if very bright scatterer indicative of large trihedral is detected, test cargo truck hypothesis first • gun barrel signature: detect linear scattering and/or shadow pattern indicative of gun tube Coarse target metrics can be very effective in restricting the working hypotheses to a smaller set of target types, but application of these algorithms to targets that are actually occluded can cause failures. It is therefore useful to have an estimate of the conditions that prevail in the scene to make informed decisions concerning what type of operations to apply, or to cue the testing of multiple hypothesized conditions. To date, MSTAR has concentrated on building a fully-automated reasoning strategy that bootstraps itself from the image data alone: no exogenous context inputs are used, and no human-aided support is provided. While the effort to construct fully-automated strategies has met with some success, it is a difficult problem that needs additional work, and the inclusion of additional context and/or human support could provide near-term solutions. For cueing target type, the MSTAR Feature Extraction module has implemented a gun barrel cue that detects the presence of a large cannon based on a matched filtering for linear signature and shadow features. This cue can be operated at a very low probability of false alarm point, such that it misses many targets that actually have cannons, but when it finds a case, it is correct with high probability. In these cases, the target type is localized to a MBT or SPG. The development and use of this cue was inspired by studies with image analysts, who make ready use of gun barrels in this fashion [2].
Gun-barrel matchedfilter rotated abouttarget-label centroid:integrated pixelbrightness (IPB) underthe filter is plotted versusorientation of the filter
IPB height to average IPB:presence of gun barrel
IPB peak placement:orientation of gun barrel
orientation
IPB
Figure 4-1. Gun barrel detection algorithm. From W. Smith, SAIC-Tucson.
4.2 Index Hypotheses The objective of indexing is to restrict downstream search to high payoff regions of hypothesis space, and eliminate low payoff areas from further consideration. The output of indexing is the portion of hypothesis space that requires additional search to resolve. The more effective the indexing operation, the smaller the reduced hypothesis space it produces while still containing the correct hypothesis with very high probability. Because indexing operations must generally consider a full hypothesis space, they must be very efficient, and are therefore usually based on pre-computed target representations, either in the form of libraries of stored examples, or parameter weights that have been trained over truthed datasets. We have been investigating the use of model-based indexing operations based on pre-computed feature composites in the image plane that we generate with the MSTAR Predictor, such as those shown in Figure 4-2. The idea is to build and database composite features offline by aggregating together features corresponding to point hypotheses into feature “wedges”. These wedges are then used in the online system as part of a “point-to-set” match that computes a composite hypothesis test by matching a “point” extracted feature with a set of predicted features. For example, the hypothesis “T72 at [0, 25] deg of pose” would be scored by matching a wedge of predicted features generated over this pose range to a single observed extraction. With certain metrics, such as a one-side Hausdorff (distance transform),

the match score obtained for the wedge is guaranteed to be a lower bound (where lower is better) on the match score that can be obtained with any element in the wedge. This property allows rigorous branch-and-bound strategies for “divide-and-conquer” hierarchical search through the wedges to determine a best match. We have observed other metrics, such as two-sided Bayesian metrics for which this property is not guaranteed, to nevertheless work well in practice. The key technical issue, from the perspective of indexing, is to make the point-to-set matches fast, certainly much faster than matching to every individual element that comprises the set.
M109 M113
(a) (b)
(c) (d)
Label Composites
Peak Composites
Figure 4-2. Model-based indexing operations based on pre-computed feature composites can be used in a “point-to-set” matching process to evaluate composite hypotheses. In the left panel, label predictions generated every degree over 5 deg of pose are unioned together to produce the label composite shown in the lower right quadrant. Note the fattened gun barrel. In the right panel, peak features generated every degree of pose are
unioned into peak composites that clearly show persistent peak tracks as pose is stepped. We are investigating the possibility of modeling the composite feature with parametric curves that represent only the most persistent and pose-stable features for both speed and compactness. Compositing also provides an approach for building
in robustness against nuisance parameters like squint or articulation by essentially averaging it into the representations.
4.3 Refine Target State-Variables Hypotheses which have been indexed using pre-computed and stored target representations are subsequently refined using online predictions based on scattering center models. Because the scattering centers provide a 3D representation of target scattering properties, the image acquisition geometry, including depression and squint, can be precisely accounted for in generating reference features. The online refinement seeks to improve estimates of target pose, and account for other important state variables such as turret position for the M109 and fuel barrel configuration for the T72. Since the indexed space also generally includes a number of candidate hypotheses which are incorrect, and online hypothesize-and-test operations are expensive, a key objective in the refinement stage is to converge rapidly on the correct hypothesis thread, and exert the majority of computational effort on it. We have formulated this problem in a way that gives rise to a goal-directed search process by making an analogy to a multi-armed bandit scheduling problem. From this perspective, we view the indexing operation as providing cues to local maxima in the likelihood function. Given an algorithm for performing a local search in the vicinity of these indexed local maxima,

e.g., based on a linearization, the problem becomes one of selecting which thread to process (do a local search step on) next, given the results of previous tests. The problem is to balance making “probes” on all threads with rapid convergence to the highest payoff thread, similar to the problem of deciding which of a set of fixed but unknown payoff slot machine (bandit) arms to play.
IndexIndex
11
33
22
44
XX
XX
Index provides n=4initial searchhypotheses which formn threads for Search toinvestigate
The n-armed bandit determineswhich hypothesis thread toexamine next and when to stopand declare a target hypothesisas the most likely one.
GLOBAL SEARCH
LOCAL SEARCH
Figure 4-3. Search modeled as an N-armed bandit decision problem.
Our thread-selection algorithm is essentially a branch-and-bound computation. The key computation which must be performed, and which unfortunately cannot be readily computed, is to obtain a bound on the maximum payoff possible for each thread, based on previous measurements along that thread. As with all branch and bound algorithms, the efficiency of the resulting search is related to the tightness of the bound. We have devised several heuristic schemes for estimating the bounding payoff. The one currently being employed is based on a simple estimate of the payoff of the next local search step (a myopic estimate), in combination with the observed rate of decrease in payoff along the thread. This scheme works well in practice. The thread with the highest marginal gain, as given by the difference between the maximal estimated payoff and current best measured along the thread is selected for processing at the next step. Processing terminates when significant improvements, as measured by estimated improvement over current overall best, are not possible for any thread. We decompose the problem into a refinement of pose, followed by articulation/configuration, although at times this can cause problems because the two may be strongly coupled. This is most often the case with the articulated M109 - note the shape of the joint pose-articulation local maximum in Figure 1-1. This simple algorithm is an example of a closed-loop (because processing at next step is a function of results from all previous steps), dynamic strategy that has a well-defined stopping rule based on comparing estimated payoff against a tolerance. It also has an obvious cost-benefit knob (the value of the tolerance).
4.4 Discriminate Final Target Type and Reject Clutter Following refinement, the search process has identified one or more target hypotheses that provide best candidate fits to the data. We have had success with approaches that first attempt to resolve remaining ambiguity to yield a single “best fit” target hypothesis, then use this as part of a type-dependent likelihood ratio test to reject clutter. In other words, counter to conventional approaches which first detect / reject, then classify, the search algorithm in MSTAR, which by construction of the system is forced to deal with highly target-like false alarms, first computes a best fit classification and then does detection as a final step. The rationale for this is that decision rules for affecting a type-dependent likelihood ratio test, e.g., deciding “is it an M35 at 22 deg aspect or is it clutter”, have considerably more flexibility for fine-tuning than decision rules that simply attempt to discriminate a generic target object from clutter.

The MSTAR system currently computes the feature-level fusions illustrated in Figure 4-4 to perform the final classification and detection functions. The best target hypothesis, determined based on a fusion of the quantized grayscale and label metrics, is used in a final detection step based on a fusion of ridges, peaks, and edges. This combination was arrived at through extensive experimentation.
ShapeShape
ChooseBest Model
Match(which target?)
ChooseBest Model
Match(which target?)
AssessSufficiency
of Match(false alarm?)
AssessSufficiency
of Match(false alarm?)
+
+ +
PeaksPeaks RidgesRidges EdgesEdges
RelativeAmplitudeRelativeAmplitude
Figure 4-4. Feature-level Bayesian fusions used for final classification and detection.
Final classification and detection are areas that will continue to receive focused research effort because it appears that additional performance gains can still be made through inclusion of the following “finer-scale” technologies:
• mismatch analysis: analysis of the spatial error patterns resulting from testing closely competing hypotheses, or matching target hypotheses against clutter
• model-based final discrimination: final hypothesis tests are based on particular salient scattering patterns that arise from known geometric structures on targets; IAs provide useful insight in this regard [2]
• component-based scoring: decomposition of whole target likelihoods into major component sub-likelihoods We expand on these and other directions for future research in the following section.
5. FUTURE WORK In this final section, we conclude by identifying a few of the areas in which we expect to concentrate future research and development efforts.
5.1 Hierarchical Utility-based Control and Inference Framework The most significant technical issue we have to address, with respect to the vision of building a fully-automated utility-driven search algorithm, is the computation of utilities to guide action selection. The challenge here is not unlike the challenge of inventing heuristics to evaluate board positions for automated chess programs. The heuristic board evaluation is the site of much of a chess algorithm’s “smarts”, separating very good programs from mediocre ones. It is derived by combining significant human chess-playing expertise with engineering judgement, then fine-tuning the computations through repeated cycles of modification and empirical evaluation. We plan to pursue a similar course, although it is fair to say that chess is a highly-structured problem in comparison with the “real world” target recognition scenarios we are attempting to address. We intend to characterize the computational complexity / performance tradeoff of the various algorithmic tools we have been constructing, at least to some level. The ultimate goal is to be able to adjust the system behavior to produce a broad range of coarse quick scene interpretations to detailed but slow scene interpretations. These adjustments may be parameterized by scene content (cluttered hilly environments vs homogeneous flat scenes) or available processing resources (single limited

processor vs parallel high performance computing) and may be user- or system-controlled. While such a trade-off has been a unique motivating factor for model-based recognition systems, it has not been well-quantified in previous development efforts. We also need better mechanisms for evaluating the potential payoff of search, particularly over target geometry variation, since we clearly do not want to search these parameters unless strongly cued. Consider that a typical main battle tank can require searching 20 turret positions (continuous sampled), 3 gun elevations (continuous sampled), 2 major configurable parts, and 4 hatches/doors. This gives 480 combinations of geometry variables that may potentially have to be tested for a single target hypothesis, a number that would be difficult if not impossible to address using online PEM operations in the current MSTAR system. Furthermore, if these variables are not searched, and the scores on a particular ROI are low, it is difficult to rule out the possibility that we have not visited a properly configured target hypothesis over the possibility that the chip contains clutter. So we require a fast computation for answering the following question: given a current hypothesis as to target type and pose, from a particular viewing geometry, which of the potential geometry variations for this target are worth searching, and what is the likely ordering of their signature impact? To address this, we plan to develop a fast online sensitivity analysis based purely on target geometry. The outputs of this analysis will directly feed the utility computation that schedules search operations. Given reasonable approaches to computing utilities, and a rich set of high performance algorithmic options to schedule, it should be possible to devise efficient, high performance algorithms that operate automatically on a wide range of problem domains.
5.2 More EOC Search The MSTAR problem domain already includes conditions such as the blocking occlusion shown in Figure 5-1 below. Automated strategies for addressing these situations have been developed, but are somewhat tailored to the specific examples provided in the MSTAR data sets. For example, for this data, the presence of a large contiguous shadow, larger than would be expected for the given depression angle and size of our largest mission target, that infringes on the adjacent cross-range side of the target, cues the presence of a possible occlusion. The wall and shadow are subsequently segmented and masked, creating a “no-show” region on the image. As pose refinements move portions of hypothesized targets into the no-show region, these features are eliminated from the match. While promising, techniques such as these need to be validated against more diverse datasets.
ConfoundingWall Features
ConfoundingWall Features
OccludedTarget
OccludedTarget
Intelligent Match:• Remove wall
features• Allow model to be
occluded (slidebehind wall)
Intelligent Match:• Remove wall
features• Allow model to be
occluded (slidebehind wall)
Figure 5-1. Occlusion processing (aka “Stonehenge” target array). Targets are occluded up to 30% by iron-reinforced concrete walls. These scenarios test MSTAR’s capability to do partial matching and operate in the
face of lost signature information. Another area that will certainly receive more attention is the use of Predict “class models” as part of an integrated reasoning strategy. Class models will provide statistical characterization of feature variability across intra-class variations typical of particular targets such as T72s. This will allow prediction of a “fuzzy” T72, with features broadly characteristic of the full ensemble of members in the class, creating a statistical version of a feature composite like those describe previously in

Section 4.2. High performance recognition may require resolving this ambiguity to a sufficient level through explicit divide-and-conquer search.
5.2 Image Analyst Studies and Model-based Reasoning In Section 4.4, we pointed out the prospect of improving performance by using more type-specific processing, particularly the kinds of geometry-driven exploitation heuristics employed successfully by image analysts (IAs). In ongoing studies we are cataloguing these heuristics, and measuring IA’s success rates in using them [2], with the ultimate goal of automating the most promising techniques.
T72 Fender Scattering
Figure 5-3: Model-based reasoning. The lower right image was captured from the MSTAR Search interface, which allows texture-mapping of measured 2D SAR images (left), as well as the ambiguity contours associated with the locations of point features in the 2D image, back onto 3D target models (upper right). This permits the association of “direct” scattering mechanisms, i.e., non-multibounce sources, with specific target geometry that could give rise to it. In this case, note the alignment of fenders, fuel barrels, grenade launchers, etc., with bright
regions of the SAR image. The model-based approach to ATR has the significant advantage of providing tieback information that links signature features in the 2D predicted image to geometric components on the model. In Figure 5-3, we have illustrated this notion from the reverse direction, a projection of the 2D observed image back onto a hypothesized 3D geometry model. We expect that a more direct application of both forward and reverse tieback information will help to relate salient aspects of observed signatures to models, further improving target recognition performance. This may be particularly true as even higher resolution data becomes available in which the number of pixels on a target component is comparable to what we see on an entire target today. Acknowledgements: The authors wish to thank Doug Morgan of Morgan Consulting, and Gil Ettinger of Alphatech, both of whom are important parts of the MSTAR Search team and provided graphics that are included in this paper. They also wish to note that the work of Tom Ryan of SAIC-Tucson, the MSTAR Index PI, inspired much of the technology development that has transpired in the area of model-based indexing using feature composites.
REFERENCES 1. Wissinger, J. et. al., “Search Algorithms for Model-based SAR ATR,” Proceedings of SPIE, March 1996. 2. Diemunsch, J., Wissinger J., and C. Brenke, “Assessment of Image Analyst Performance on the MSTAR Problem”,
Proceedings of the ATR Working Group, Monterey CA, March 1999. 3. Grimson, E.L., Object Recognition by Computer: The Role of Geometric Constraints, MIT Press, Cambridge MA, 1990.