mr. lda: a flexible large scale topic modeling package ...jbg/docs/2012_ · mr. lda: a flexible...
TRANSCRIPT

Mr. LDA: A Flexible Large Scale Topic ModelingPackage using Variational Inference in
MapReduce
Ke Zhai, Jordan Boyd-Graber, Nima Asadi, and MohamadAlkhouja

Mr. LDA: A Flexible Large Scale Topic ModelingPackage using Variational Inference in
MapReduce
Ke Zhai, Jordan Boyd-Graber, Nima Asadi, and MohamadAlkhouja

Introductions
MR LDA
MR = MapReduce
LDA = latent Dirichlet allocation
MR LDA = Ke
First author
Immigration issuesprevented presentation

Introductions
MR LDA
MR = MapReduce
LDA = latent Dirichlet allocation
MR LDA = Ke
First author
Immigration issuesprevented presentation

Roadmap
Review of topic models
The need for scalability
Variational inference vs. Gibbs sampling
Mr LDAA scalable topic modeling packageUsing variational inference
ExtensionsExtending psychologically-inspired word listsDiscovering topics consistent across languages

Outline
1 Topic Model Introduction
2 Inference
3 Extensions

Why topic models?
Suppose you have a hugenumber of documents
Want to know what’s going on
Can’t read them all (e.g. everyNew York Times article fromthe 90’s)
Topic models o↵er a way to geta corpus-level view of majorthemes
Unsupervised

Why topic models?
Suppose you have a hugenumber of documents
Want to know what’s going on
Can’t read them all (e.g. everyNew York Times article fromthe 90’s)
Topic models o↵er a way to geta corpus-level view of majorthemes
Unsupervised
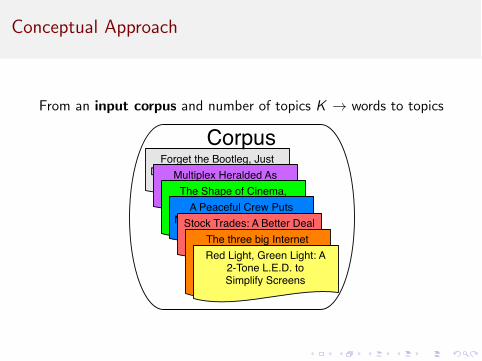
Conceptual Approach
From an input corpus and number of topics K ! words to topics
Forget the Bootleg, Just Download the Movie LegallyMultiplex Heralded As
Linchpin To GrowthThe Shape of Cinema, Transformed At the Click of
a MouseA Peaceful Crew Puts
Muppets Where Its Mouth IsStock Trades: A Better Deal For Investors Isn't SimpleThe three big Internet portals begin to distinguish
among themselves as shopping malls
Red Light, Green Light: A 2-Tone L.E.D. to Simplify Screens
Corpus

Conceptual Approach
From an input corpus and number of topics K ! words to topics
computer,
technology,
system,
service, site,
phone,
internet,
machine
play, film,
movie, theater,
production,
star, director,
stage
sell, sale,
store, product,
business,
advertising,
market,
consumer
TOPIC 1 TOPIC 2 TOPIC 3

Conceptual Approach
For each document, what topics are expressed by thatdocument?
Forget the Bootleg, Just Download the Movie Legally
Multiplex Heralded As Linchpin To Growth
The Shape of Cinema, Transformed At the Click of
a Mouse
A Peaceful Crew Puts Muppets Where Its Mouth Is
Stock Trades: A Better Deal For Investors Isn't Simple
The three big Internet portals begin to distinguish
among themselves as shopping mallsRed Light, Green Light: A
2-Tone L.E.D. to Simplify Screens
TOPIC 2
TOPIC 3
TOPIC 1

Topic Models: What’s Important
Topic modelsTopics to words - multinomial distributionDocuments to topics - multinomial distribution
Statistical structure inferred from data
Have semantic coherence because of language use
We use latent Dirichlet allocation (LDA) [Blei et al. 2003], afully Bayesian version of pLSI [Hofmann 1999], probabilisticversion of LSA [Landauer and Dumais 1997]

Applications
Computer Vision [Li Fei-Fei and Perona 2005]

Applications
Social Networks [Airoldi et al. 2008]

Applications
Music [Hu and Saul 2009]
Figure 2: The C major and C minor key-profiles learned by our model, as encoded by the � matrix.Resulting key-profiles are obtained by transposition.
Figure 3: Key judgments for the first 6 measures of Bach’s Prelude in C minor, WTC-II. Annotationsfor each measure show the top three keys (and relative strengths) chosen for each measure. The topset of three annotations are judgments from our LDA-based model; the bottom set of three are fromhuman expert judgments [3].
identified with the 24 major and minor modes of classical western music. We note that our approachis still regarded as unsupervised because we do not learn from labeled or annotated data.
2.3 Results & Applications
Our learnt key-profiles are shown in Figure 2. We note that these key-profiles are consistent withmusic theory principals: In both major and minor modes, weights are given in descending order todegrees of the triad, diatonic, and finally chromatic scales. Intuitively, these key-profiles representthe underlying distributions that are used to characterize all the songs in the corpus.
We also show how to do key-finding and modulation-tracking using the representations learned byour model. The goal of key-finding is to determine the overall key of a musical piece, given thenotes of the composition. Since the key weight vector � represents the most likely keys present ineach song, we classify each song as the key that is given the largest weight in �. A related task ismodulation-tracking, which identifies where the modulations occur within a piece. We achieve thisby determining the key of each segment from the most probable values of its topic latent variable z.
We estimated our model from a collection of 235 MIDI files compiled fromclassicalmusicmidipage.com. The collection included works by Bach, Vivaldi, Mozart,Beethoven, Chopin, and Rachmaninoff. These composers were chosen to span the baroque throughromantic periods of western, classical music. Our results for key-finding achieved an accuracy of86%, out-performing several other key-finding algorithms, including the popular KS model [3]. Wealso show in Figure 3 that our annotations for modulation-tracking are comparable to those givenby music theory experts. More results can be found in our paper [1].
3

Why large-scale?
The most interesting datasets are the big ones
These datasets don’t fit on a single machine
Thus we can’t depend on analysis that sits on a single machine

MapReduce
Framework proposed by Google [Dean and Ghemawat 2004]
Hadoop, OSS implementation by Yahoo [White 2010]
Central conceptMappers process small units of dataReducers aggregate / combine results of mappers into finalresultDrivers Run a series of jobs to get the work doneOverall framework distributes intermediate results where theyneed to go

Outline
1 Topic Model Introduction
2 Inference
3 Extensions

Inference
βkK
zn
wn
θdα
MNd
ηk

Inference
βkK
zn
wn
θdα
MNd
ηk Forget the Bootleg, Just Download the Movie Legally
Multiplex Heralded As Linchpin To
GrowthThe Shape of
Cinema, Transformed At the Click of a
Mouse A Peaceful Crew Puts Muppets
Where Its Mouth Is
Stock Trades: A Better Deal For Investors Isn't
Simple
Internet portals begin to distinguish among themselves as shopping malls
Red Light, Green Light: A
2-Tone L.E.D. to Simplify Screens
TOPIC 2"BUSINESS"
TOPIC 3"ENTERTAINMENT"
TOPIC 1"TECHNOLOGY"
computer,
technology,
system,
service, site,
phone,
internet,
machine
play, film,
movie, theater,
production,
star, director,
stage
sell, sale,
store, product,
business,
advertising,
market,
consumer
TOPIC 1
TOPIC 2
TOPIC 3

Inference
βkK
zn
wn
θdα
MNd
ηk
Generative models tell a story ofhow your data came to be
There are missing pieces to thatstory (e.g. the topics)
Statistical inference fills in themissing pieces
Hard problem - requires looking atthe entire dataset
Why we need large scale solutions
Use MapReduce!

Inference
βkK
zn
wn
θdα
MNd
ηk
Generative models tell a story ofhow your data came to be
There are missing pieces to thatstory (e.g. the topics)
Statistical inference fills in themissing pieces
Hard problem - requires looking atthe entire dataset
Why we need large scale solutions
Use MapReduce!

Inference
βkK
zn
wn
θdα
MNd
ηk
Generative models tell a story ofhow your data came to be
There are missing pieces to thatstory (e.g. the topics)
Statistical inference fills in themissing pieces
Hard problem - requires looking atthe entire dataset
Why we need large scale solutions
Use MapReduce!

Inference
Variational
Few, expensive iterations
Deterministic
Conjugate easier, tractablewithout
Easy convergence diagnosis
MCMC / Gibbs
Many, cheap iterations
Random
E↵ective for conjugatedistributions
Tricky convergence diagnosis

Inference
Variational
First LDA implementation[Blei et al. 2003]
Master-Slave LDA[Nallapati et al. 2007]
Apache Mahout
MCMC / Gibbs
Popular[Gri�ths and Steyvers 2004]
Sparsity helps [Yao et al. 2009]
Assume shared memory?[Asuncion et al. 2008]
YahooLDA[Smola and Narayanamurthy 2010]

Expectation Maximization Algorithm
Input: z (hidden variables), ⇠ (parameters), D (data)
Start with initial guess of z , parameters ⇠
RepeatCompute the expected value of latent variables zCompute the parameters ⇠ that maximize likelihood L (usecalculus)
With each iteration, objective function L goes up

Expectation Maximization Algorithm
Input: z (hidden variables), ⇠ (parameters), D (data)
Start with initial guess of z , parameters ⇠
RepeatE-Step Compute the expected value of latent variables zCompute the parameters ⇠ that maximize likelihood L (usecalculus)
With each iteration, objective function L goes up

Expectation Maximization Algorithm
Input: z (hidden variables), ⇠ (parameters), D (data)
Start with initial guess of z , parameters ⇠
RepeatE-Step Compute the expected value of latent variables zM-Step Compute the parameters ⇠ that maximize likelihood L(use calculus)
With each iteration, objective function L goes up

Theory
Sometimes you can’t actually optimize L
So we instead optimize a lower bound based on a“variational” distribution q
L = Eq [log (p(D|Z )p(Z |⇠))]� Eq [log q(Z )] (1)
L� L = KL(q||p)This is called variational EM (normal EM is when p = q)
Makes the math possible to optimize L

Variational distribution
βkK
zn
wn
θdα
MNd
ηk
(a) LDA
MNd
θdγd
znφn
Kβkλk
(b) Variational
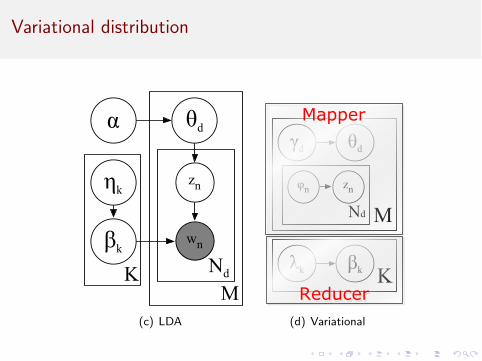
Variational distribution
βkK
zn
wn
θdα
MNd
ηk
(c) LDA
MNd
θdγd
znφn
Kβkλk
Mapper
Reducer(d) Variational

Updates - Important Part
� How much the nth word ina document expressed topick
�d ,k How much the k th topicis expressed in a document d
�v ,k How much word v isassociated with topic k
�d ,n,k / �wd,n,k · e (�k )
�d ,k = ↵k +NdX
n=1
�d ,n,k ,
�v ,k / ⌘ +CX
d=1
(w (d)v �d ,v ,k)
This is the algorithm!

Updates - Important Part
� How much the nth word ina document expressed topick (Mapper)
�d ,k How much the k th
topic is expressed in adocument d (Mapper)
�v ,k How much word v isassociated with topic k
�d ,n,k / �wd,n,k · e (�k )
�d ,k = ↵k +NdX
n=1
�d ,n,k ,
�v ,k / ⌘ +CX
d=1
(w (d)v �d ,v ,k)
This is the algorithm!

Updates - Important Part
� How much the nth word ina document expressed topick (Mapper)
�d ,k How much the k th
topic is expressed in adocument d (Mapper)
�v ,k How much word v isassociated with topic k(Reducer)
�d ,n,k / �wd,n,k · e (�k )
�d ,k = ↵k +NdX
n=1
�d ,n,k ,
�v ,k / ⌘ +CX
d=1
(w (d)v �d ,v ,k)
This is the algorithm!

Updates - Important Part
� How much the nth word ina document expressed topick (Mapper)
�d ,k How much the k th
topic is expressed in adocument d (Mapper)
�v ,k How much word v isassociated with topic k(Reducer)
�d ,n,k / �wd,n,k · e (�k )
�d ,k = ↵k +NdX
n=1
�d ,n,k ,
�v ,k / ⌘ +CX
d=1
(w (d)v �d ,v ,k)
This is the algorithm!

Other considerations
Thus far, no di↵erence from Mahout or [Nallapati et al. 2007]
Computing objective function L to assess convergence
Updating hyperparametersMany implementations don’t do thisCritical for topic quality and good likelihood

Objective Function
Expanding Equation 1 gives us L(�, �;↵, �) for one document:
L(�,�;↵,�) =CX
d=1
Ld (�,�;↵,�)
=CX
d=1
Ld (↵)
| {z }Driver
+CX
d=1
(Ld (�,�) + Ld (�) + Ld (�)| {z }computed in mapper
)
| {z }computed in Reducer
,

Updating hyperparameters
We use a Newton-Raphson method which requires the Hessianmatrix and the gradient,
↵new = ↵old �H�1(↵old) · g(↵old),
where the Hessian matrix H and gradient g(↵) are
H(k , l) =�(k , l)C 0 (↵k)� C 0⇣PK
l=1 ↵l
⌘,
g(k) =C
KX
l=1
↵l
!� (↵k)
!
| {z }computed in driver
+CX
d=1
(�d ,k)�
KX
l=1
�d ,l
!
| {z }computed in mapper| {z }
computed in reducer
.
Complexity
Removing document-dependence: update O(K 2) in the driver

Updating hyperparameters
We use a Newton-Raphson method which requires the Hessianmatrix and the gradient,
↵new = ↵old �H�1(↵old) · g(↵old),
where the Hessian matrix H and gradient g(↵) are
H(k , l) =�(k , l)C 0 (↵k)� C 0⇣PK
l=1 ↵l
⌘,
g(k) =C
KX
l=1
↵l
!� (↵k)
!
| {z }computed in driver
+CX
d=1
(�d ,k)�
KX
l=1
�d ,l
!
| {z }computed in mapper| {z }
computed in reducer
.
Complexity
Removing document-dependence: update O(K 2) in the driver

Document Mapper: Update γ, φ
Test Likelihood Convergence
Parameters
Reducer
Document Mapper: Update γ, φ
Document Mapper: Update γ, φ
Document Mapper: Update γ, φ
Reducer
Reducer
Write β
SufficientStatistics forβ Update
Driver: Update α
Write α
HessianTerms
Distributed Cache

Other implementation details
Computing function is expensive, so we cache /approximate values
The number of intermediate values swamp the system, so weemploy in-mapper combiners [Lin and Dyer 2010]
Initialization

Other implementation details
Computing function is expensive, so we cache /approximate values
Always helps
The number of intermediate values swamp the system, so weemploy in-mapper combiners [Lin and Dyer 2010]
Only helps with many topics
InitializationHelps in first iterations

Comparison with Mahout
0 1 2 3 4 5
x 104
!1.15
!1.1
!1.05
!1
!0.98x 10
8
Mahout
Mr. LDA
Held-out likelihood vs. time (sec)TREC (100 topics, 500k documents)

Outline
1 Topic Model Introduction
2 Inference
3 Extensions

How are psychological factors expressed in blogs?
Linguistic Inquiry in WordCount [Pennebaker and Francis 1999]
Example psychological processes:Anger: hate, kill, annoyedNegative Emotions: hurt, ugly, nasty
What words cooccur with these words in a particular corpus?
Use LIWC categories as an informed prior to “seed” topics
�v ,k / ⌘v ,k +CX
d=1
(w (d)v �d ,v ,k)
Not possible in SparseLDA-based models

How are psychological factors expressed in blogs?
Linguistic Inquiry in WordCount [Pennebaker and Francis 1999]
Example psychological processes:Anger: hate, kill, annoyedNegative Emotions: hurt, ugly, nasty
What words cooccur with these words in a particular corpus?
Use LIWC categories as an informed prior to “seed” topics
�v ,k / ⌘v ,k +CX
d=1
(w (d)v �d ,v ,k)
Not possible in SparseLDA-based models

How are psychological factors expressed in blogs?
Linguistic Inquiry in WordCount [Pennebaker and Francis 1999]
Example psychological processes:Anger: hate, kill, annoyedNegative Emotions: hurt, ugly, nasty
What words cooccur with these words in a particular corpus?
Use LIWC categories as an informed prior to “seed” topics
�v ,k / ⌘v ,k +CX
d=1
(w (d)v �d ,v ,k)
Not possible in SparseLDA-based models

Workflow for Informed Prior
Document Map: Update γ, φ
Test Likelihood
Convergence
Parameters
Reducer
Document Map: Update γ, φ
Document Map: Update γ, φ
Document Map: Update γ, φ
Reducer
Reducer
Write λ
SufficientStatistics forλ Update
Driver: Update α
Write α
HessianTerms
Distributed Cache
Inf. Prior
Inf. Prior
Inf. Prior

Psychologically-Informed Topics from Blogs
A↵ectiveProcesses
NegativeEmotions
PositiveEmotions
Anxiety Anger Sadness
easili sorri lord bird iraq leveldare crappi prayer diseas american grieftruli bullshit pray shi countri disordlol goddamn merci infect militari moderneedi messi etern blood nation miserijealousi shitti truli snake unit lbsfriendship bitchi humbl anxieti america lonelibetray angri god creatur force painUsing 50 topics on Blog Authorship corpus [Koppel et al. 2006]

Polylingual LDA
Assumes documentshave multiple“faces” [Mimno et al. 2009]
Topics also assumedto have per-languagedistribution
As long as documentstalk about the samething, learnsconsistent topicsacross languages
First variationalinference algorithm
M
NLd K
N1d Kβ1,kz1n w1n
θdα
βL,kzLn wLn
... ...

Workflow for Polylingual LDA
Document Map: Update γ, φ
Test Likelihood
Convergence
Parameters
Reducer
Document Map: Update γ, φ
Document Map: Update γ, φ
Document Map: Update γ, φ
Reducer
Write λ (English)
Write α
Distributed Cache
Reducer
Reducer
Driver: Update α
Write λ (German)

Aligned topics from all of WikipediaEnglish
game opera greek league said italian sovietgames musical turkish cup family church politicalplayer composer region club could pope militaryplayers orchestra hugarian played childernitaly unionreleased piano wine football death catholic russiancomics works hungary games father bishop powercharacters symphony greece career wrote roman israelcharacter instruments turkey game mother rome empireversion composers ottoman championshipnever st republic
German
spiel musik ungarn saison frau papst regierungspieler komponist turkei gewann the rom republikserie oper turkischen spielte familie ii sowjetunionthe komponisten griechenland karriere mutter kirche kamerschien werke rumanien fc vater di krieggibt orchester ungarischen spielen leben bishof landcommics wiener griechischen wechselte starb italien bevolkerungvero↵entlic komposition istanbul mannschaft tod italienisch ende2 klavier serbien olympischen kinder konig reich

Which large-scale implementation is right for me?
Yahoo LDA [Smola and Narayanamurthy 2010]FastestSparse Gibbs samplingGreat when you can use memcached
MahoutVariationalSimplest
Mr LDA
Designed for extensibilityMultilingualHyperparameter updating [Wallach et al. 2009]Likelihood monitoring

Conclusion
Mr LDA: A scalable implementation for topic modeling
Extensible variational inference
Next stepsSupporting more modeling assumptions (includingnon-conjugacy)Nonparametrics (over topics and vocabulary)Multiple starts
Download the Code
http://mrlda.cc

Ke Zhai
First author
Immigration issuesprevented presentation
MR LDA
MR = MapReduce
LDA = latent Dirichlet allocation
MR LDA = Ke

Ke Zhai
First author
Immigration issuesprevented presentation
MR LDA
MR = MapReduce
LDA = latent Dirichlet allocation
MR LDA = Ke

Merci!
Jimmy Lin
NSF #1018625

Edoardo M. Airoldi, David M. Blei, Stephen E. Fienberg, and Eric P. Xing.
2008.Mixed membership stochastic blockmodels.Journal of Machine Learning Research, 9:1981–2014.
Arthur Asuncion, Padhraic Smyth, and Max Welling.
2008.Asynchronous distributed learning of topic models.In Proceedings of Advances in Neural Information Processing Systems.
David M. Blei, Andrew Ng, and Michael Jordan.
2003.Latent Dirichlet allocation.Journal of Machine Learning Research, 3:993–1022.
Je↵rey Dean and Sanjay Ghemawat.
2004.MapReduce: Simplified data processing on large clusters.pages 137–150, San Francisco, California.
Thomas L. Gri�ths and Mark Steyvers.
2004.Finding scientific topics.Proceedings of the National Academy of Sciences, 101(Suppl 1):5228–5235.
Thomas Hofmann.
1999.Probabilistic latent semantic analysis.In Proceedings of Uncertainty in Artificial Intelligence.
Diane Hu and Lawrence K. Saul.
2009.A probabilistic model of unsupervised learning for musical-key profiles.In International Society for Music Information Retrieval Conference.
Moshe Koppel, J. Schler, Shlomo Argamon, and J. Pennebaker.
2006.E↵ects of age and gender on blogging.In In AAAI 2006 Symposium on Computational Approaches to Analysing Weblogs.
T. Landauer and S. Dumais.
1997.Solutions to Plato’s problem: The latent semantic analsyis theory of acquisition, induction andrepresentation of knowledge.Psychological Review, (104).
Li Fei-Fei and Pietro Perona.
2005.A Bayesian hierarchical model for learning natural scene categories.In CVPR ’05 - Volume 2, pages 524–531, Washington, DC, USA. IEEE Computer Society.
Jimmy Lin and Chris Dyer.
2010.Data-Intensive Text Processing with MapReduce.Synthesis Lectures on Human Language Technologies. Morgan & Claypool Publishers.
David Mimno, Hanna Wallach, Jason Naradowsky, David Smith, and Andrew McCallum.
2009.Polylingual topic models.In Proceedings of Emperical Methods in Natural Language Processing, page 880–889.
Ramesh Nallapati, William Cohen, and John La↵erty.
2007.Parallelized variational EM for latent Dirichlet allocation: An experimental evaluation of speed andscalability.In ICDMW.
James W. Pennebaker and Martha E. Francis.
1999.Linguistic Inquiry and Word Count.Lawrence Erlbaum, 1 edition, August.
Alexander J. Smola and Shravan Narayanamurthy.
2010.An architecture for parallel topic models.3.
David Talbot and Miles Osborne.
2007.Smoothed bloom filter language models: Tera-scale lms on the cheap.In ACL, pages 468–476.
Hanna Wallach, David Mimno, and Andrew McCallum.
2009.Rethinking LDA: Why priors matter.In Proceedings of Advances in Neural Information Processing Systems.
Tom White.
2010.Hadoop: The Definitive Guide (Second Edition).O’Reilly, 2 edition.
Limin Yao, David Mimno, and Andrew McCallum.
2009.E�cient methods for topic model inference on streaming document collections.In Knowledge Discovery and Data Mining.

Map(d , ~w)
1: repeat
2: for all v 2 [1,V ] do3: for all k 2 [1,K ] do4: Update �v,k = �v,k ⇥ exp(
��d,k
�).
5: end for
6: Normalize row �v,⇤, such thatKX
k=1
�v,k = 1.
7: Update � = � + ~wv�v , where �v is a K -dimensional vector, and ~wv is thecount of v in this document.
8: end for
9: Update row vector �d,⇤ = ↵+ �.10: until convergence11: for all k 2 [1,K ] do12: for all v 2 [1,V ] do13: Emit key-value pair hk,4i : ~wv�v .
14: Emit key-value pair hk, vi : ~wv�v . {order inversion}15: end for
16: Emit key-value pair h4, ki : ( ��d,k
��
⇣PKl=1 �d,l
⌘).
{emit the �-tokens for ↵ update}17: Output key-value pair hk, di � �d,k to file.18: end for
19: Emit key-value pair h4,4i � L, where L is log-likelihood of this document.

Map(d , ~w)
1: repeat
2: for all v 2 [1,V ] do3: for all k 2 [1,K ] do4: Update �v,k = �v,k ⇥ exp(
��d,k
�).
5: end for
6: Normalize row �v,⇤, such thatKX
k=1
�v,k = 1.
7: Update � = � + ~wv�v , where �v is a K -dimensional vector, and ~wv is thecount of v in this document.
8: end for
9: Update row vector �d,⇤ = ↵+ �.10: until convergence11: for all k 2 [1,K ] do12: for all v 2 [1,V ] do13: Emit key-value pair hk,4i : ~wv�v .
14: Emit key-value pair hk, vi : ~wv�v . {order inversion}15: end for
16: Emit key-value pair h4, ki : ( ��d,k
��
⇣PKl=1 �d,l
⌘).
{emit the �-tokens for ↵ update}17: Output key-value pair hk, di � �d,k to file.18: end for
19: Emit key-value pair h4,4i � L, where L is log-likelihood of this document.

Map(d , ~w)
1: repeat
2: for all v 2 [1,V ] do3: for all k 2 [1,K ] do4: Update �v,k = �v,k ⇥ exp(
��d,k
�).
5: end for
6: Normalize row �v,⇤, such thatKX
k=1
�v,k = 1.
7: Update � = � + ~wv�v , where �v is a K -dimensional vector, and ~wv is thecount of v in this document.
8: end for
9: Update row vector �d,⇤ = ↵+ �.10: until convergence11: for all k 2 [1,K ] do12: for all v 2 [1,V ] do13: Emit key-value pair hk,4i : ~wv�v .
14: Emit key-value pair hk, vi : ~wv�v . {order inversion}15: end for
16: Emit key-value pair h4, ki : ( ��d,k
��
⇣PKl=1 �d,l
⌘).
{emit the �-tokens for ↵ update}17: Output key-value pair hk, di � �d,k to file.18: end for
19: Emit key-value pair h4,4i � L, where L is log-likelihood of this document.

Input:
Key - key pair hpleft, prighti.Value - an iterator I over sequence of values.
Reduce
1: Compute the sum � over all values in the sequence I.2: if pleft = 4 then
3: if pright = 4 then
4: Output key-value pair h4,4i � � to file.{output the model likelihood L for convergence checking}
5: else
6: Output key-value pair h4, prighti � � to file.{output the �-tokens to update ↵-vectors, Section ??}
7: end if
8: else
9: if pright = 4 then
10: Update the normalization factor n = �. {order inversion}11: else
12: Output key-value pair hk, vi : �n. {output normalized � value}
13: end if
14: end if

Input:
Key - key pair hpleft, prighti.Value - an iterator I over sequence of values.
Reduce
1: Compute the sum � over all values in the sequence I.2: if pleft = 4 then
3: if pright = 4 then
4: Output key-value pair h4,4i � � to file.{output the model likelihood L for convergence checking}
5: else
6: Output key-value pair h4, prighti � � to file.{output the �-tokens to update ↵-vectors, Section ??}
7: end if
8: else
9: if pright = 4 then
10: Update the normalization factor n = �. {order inversion}11: else
12: Output key-value pair hk, vi : �n. {output normalized � value}
13: end if
14: end if

Input:
Key - key pair hpleft, prighti.Value - an iterator I over sequence of values.
Reduce
1: Compute the sum � over all values in the sequence I.2: if pleft = 4 then
3: if pright = 4 then
4: Output key-value pair h4,4i � � to file.{output the model likelihood L for convergence checking}
5: else
6: Output key-value pair h4, prighti � � to file.{output the �-tokens to update ↵-vectors, Section ??}
7: end if
8: else
9: if pright = 4 then
10: Update the normalization factor n = �. {order inversion}11: else
12: Output key-value pair hk, vi : �n. {output normalized � value}
13: end if
14: end if