modbase, a database of annotated comparative protein structure
TRANSCRIPT

ModBase a database of annotated comparativeprotein structure models and associated resourcesUrsula Pieper12 Benjamin M Webb12 Guang Qiang Dong12
Dina Schneidman-Duhovny12 Hao Fan12 Seung Joong Kim12 Natalia Khuri123
Yannick G Spill45 Patrick Weinkam12 Michal Hammel6 John A Tainer78
Michael Nilges4 and Andrej Sali12
1Department of Bioengineering and Therapeutic Sciences California Institute for Quantitative Biosciences ByersHall at Mission Bay Office 503B University of California at San Francisco 1700 4th Street San Francisco CA94158 USA 2Department of Pharmaceutical Chemistry California Institute for Quantitative Biosciences ByersHall at Mission Bay Office 503B University of California at San Francisco 1700 4th Street San Francisco CA94158 USA 3Graduate Group in Biophysics University of California at San Francisco CA 94158 USA4Structural Bioinformatics Unit Structural Biology and Chemistry department Institut Pasteur 25 rue duDocteur Roux 75015 Paris France 5Universite Paris Diderot-Paris 7 ecole doctorale iViv Paris Rive Gauche5 rue Thomas Mann 75013 Paris France 6Physical Biosciences Division Lawrence Berkeley NationalLaboratory Berkeley CA 94720 USA 7Department of Molecular Biology Skaggs Institute of Chemical BiologyThe Scripps Research Institute La Jolla CA 92037 USA 8Life Sciences Division Department of MolecularBiology Lawrence Berkeley National Laboratory Berkeley CA 94720 USA
Received September 13 2013 Revised October 23 2013 Accepted October 24 2013
ABSTRACT
ModBase (httpsalilaborgmodbase) is a databaseof annotated comparative protein structure modelsThe models are calculated by ModPipe an auto-mated modeling pipeline that relies primarily onModeller for fold assignment sequence-structurealignment model building and model assessment(httpsalilaborgmodeller) ModBase currentlycontains almost 30 million reliable models fordomains in 47 million unique protein sequencesModBase allows users to compute or update com-parative models on demand through an interface tothe ModWeb modeling server (httpsalilaborgmodweb) ModBase models are also availablethrough the Protein Model Portal (httpwwwproteinmodelportalorg) Recently developed associatedresources include the AllosMod server for modelingligand-induced protein dynamics (httpsalilaborgallosmod) the AllosMod-FoXS server for predictinga structural ensemble that fits an SAXS profile(httpsalilaborgallosmod-foxs) the FoXSDockserver for proteinndashprotein docking filtered by anSAXS profile (httpsalilaborgfoxsdock) the SAXSMerge server for automatic merging of SAXSprofiles (httpsalilaborgsaxsmerge) and the Pose
amp Rank server for scoring proteinndashligand complexes(httpsalilaborgposeandrank) In this update wealso highlight two applications of ModBase aPSIBiology initiative to maximize the structuralcoverage of the human alpha-helical transmem-brane proteome and a determination of structuraldeterminants of human immunodeficiency virus-1protease specificity
INTRODUCTION
The genome sequencing efforts provide us with thecomplete genetic blueprints of thousands of organismsincluding many eukaryotic genomes We are now facedwith the challenge of assigning investigating and modify-ing the functions of proteins encoded by these genomesThis task is generally facilitated by the knowledge of the3D protein structures which are best determined by ex-perimental methods such as X-ray crystallography andnuclear magnetic resonance-spectroscopy While thenumber of experimentally determined structures depositedin the Protein Data Bank (PDB) (1) increased by nearly40 to 93 000 in the past 3 years (September 2013) thenumber of sequences in the comprehensive sequence data-bases such as UniProtKB (2) and GenPept (3) continuesto grow even more rapidly for example the number ofsequences in UniProtKB has now reached gt41 million
To whom correspondence should be addressed Tel +1 415 514 4227 Fax +1 415 514 4231 Email salisalilaborg
Nucleic Acids Research 2013 1ndash11doi101093nargkt1144
The Author(s) 2013 Published by Oxford University PressThis is an Open Access article distributed under the terms of the Creative Commons Attribution License (httpcreativecommonsorglicensesby30) whichpermits unrestricted reuse distribution and reproduction in any medium provided the original work is properly cited
Nucleic Acids Research Advance Access published November 23 2013 at U
CSF L
ibrary on Decem
ber 2 2013httpnaroxfordjournalsorg
Dow
nloaded from
compared with 12 million only 3 years ago Thereforeprotein structure prediction is essential to bridge thisgap The need for accurate models can frequently be metby homology or comparative modeling (4ndash13) Compa-rative modeling is carried out in four sequential stepsidentifying known structures (templates) related to thesequence to be modeled (target) aligning the targetsequence with the templates building models and assess-ing the models For this reason comparative modeling isonly applicable when the target sequence is detectablyrelated to a known protein structureAs more proteins are modeled web-accessible resources
that assist biologists in evaluating and analyzing modelsbecome increasingly useful Here we describe the currentstate of the ModBase database of comparative proteinstructure models the ModWeb comparative modelingweb-server and several new associated resources includingweb-servers that use SAXS data in the context of com-parative modeling The AllosMod server for modelingligand-induced protein dynamics (httpsalilaborgallosmod) (14) the AllosMod-FoXS server for predictingthe ensemble of conformations that best fit a given SAXSprofile (httpsalilaborgallosmod-foxs) (Weinkam et alin preparation) the FoXSDock server that performsproteinndashprotein docking filtered by a SAXS profile(httpsalilaborgfoxsdock) (15) the SAXS Mergeserver for merging SAXS profiles (httpsalilaborgsaxsmerge) (Spill et al accepted) and the Pose amp Rankserver for scoring proteinndashligand complexes based on astatistical potential (httpsalilaborgposeandrank) (16)Finally we highlight applications of ModBase models tomaximize the structural coverage of the human a-helicaltransmembrane proteome in a PSIBiology effort and toan analysis of structural determinants of human immuno-deficiency virus-1 (HIV-1) protease specificity
CONTENTS
Model generation by comparative modeling (Modeller andModPipe)
Models in ModBase are calculated using our automatedsoftware pipeline for comparative protein structuremodeling ModPipe (17) ModPipe relies mostly onmodules of Modeller (18) as well as fold assignment andsequence-structure alignment by PSI-BLAST (19) andthe HHSuite modules HHBlits (20) and HHSearch (21)To be able to process a large number of sequences it isimplemented on a Linux clusterModPipe uses sequencendashsequence (22) sequencendashprofile
(1923) and profilendashprofile (524) methods for fold assign-ment and targetndashtemplate alignment using a promiscuousE-value threshold of 10 to increase the likelihood of iden-tifying the best available template structure In addition tothe previously implemented profile methods (ModellerrsquosBuild-Profile and PPScan and PSI-BLAST) we recentlyadded an option to use HHBlits and HHSearch These willbe included in the next public release of ModPipe (230expected December 2013) Alignments created by anyof these methods can cover the complete target sequenceor only a segment of it depending on the availability of
suitable PDB templates With the added functionality ofHHBlits and HHSearch some ModPipe models are nowbased on multiple templates
To increase efficiency the available targetndashtemplatealignments are filtered by sequence identity (ModPipetemplate option TOP) if the highest targetndashtemplatesequence identity is 40 ModPipe selects alignmentsfor all detected templates Otherwise the selection onlycontains alignments for each targetndashtemplate alignmentthat is created in a 20 sequence identity windowstarting from the highest sequence identity For eachselected targetndashtemplate alignment 10 models arecalculated (18) and the model with the best value of theDOPE statistical potential (25) is selected and thenevaluated by several additional quality criteria (i)targetndashtemplate sequence identity (ii) GA341 score (26)(iii) Z-DOPE score (25) (iv) MPQS score (ModPipequality score) (27) and (v) TSVMod score (28) Themodels that score best with at least one of these qualitycriteria are selected for further filtering If gt30 residues ofa target sequence are not covered by a selected modeladditional models are selected even if they do not scorebest with at least one of the quality criteria Finally onlythe models with quality criteria values above specifiedthresholds or with an E-value lt104 are included in thefinal model set
A key feature of the pipeline is that the validity ofsequencendashstructure relationships is not prejudged at thefold-assignment stage instead sequencendashstructure matchesare assessed after the construction of the models and theirevaluation This approach enables a thorough explorationof fold assignments sequencendashstructure alignments andconformations with the aim of finding the model withthe best evaluation score at the expense of increasingthe computational time significantly for some sequencesa few thousand models can be calculated For sequenceswith high-quality templates the optional lsquoTOPrsquo keywordcan reduce the amount of computer time by up to 60
The source code for ModPipe is freely accessible underthe Gnu Public license (httpsalilaborgmodpipe) Thebinary code for Modeller is also available freely to aca-demics for a number of different operating systems (httpsalilaborgmodeller)
Statistically optimized atomic potentials (SOAP) forassessing protein interfaces and loops
Both loop modeling and proteinndashprotein docking requireaccurate scoring functions for selecting the most accuratesampled models Statistically Optimized AtomicPotentials (SOAP)-PP and SOAP-Loop are atomic statis-tical potentials for assessing protein interfaces and loopsrespectively (httpsalilaborgSOAP also available inModeller) (29) They were derived using a Bayesian frame-work for inferring SOAP When using SOAP-PP forscoring proteinndashprotein docking models a near-nativemodel is within the top 10 scoring models in 52 ofthe PatchDock decoys (30) compared with 23 and 27for the state-of-the-art ZRANK (31) and FireDock(32) scoring functions respectively Similarly formodeling 12-residue loops in the PLOP benchmark (33)
2 Nucleic Acids Research 2013
at UC
SF Library on D
ecember 2 2013
httpnaroxfordjournalsorgD
ownloaded from
the average main-chain root-mean-square-deviation(RMSD) of the best-scored conformations by SOAP-Loop is 15 A close to the average RMSD of the best-sampled conformations (12 A) and significantly betterthan that selected by the Rosetta (34) (21 A) DFIRE(35) (23 A) DOPE (25 A) (25) and PLOP scoring func-tions (30 A) The SOAP-PP score is used by ourAllosMod-FoXS server (below) We are incorporatingSOAP scores into the modeling and model assessmentmodules of ModPipe
ModBase model sets
Models in ModBase are organized in datasets Because ofthe rapid growth of the public sequence databases weconcentrate our efforts on adding datasets that areuseful for specific projects rather than attempt to modelall known protein sequences based on all detectablyrelated known structures Currently ModBase includes amodel dataset for each of 65 complete genomes as well asdatasets for all sequences in the Structure FunctionLinkage Database (SFLD) (36) and for the completeSwissProtTrEMBL database as of 2005 (httpsalilaborgmodbasestatistics) Additionally available modelsfor new SFLD sequences are added weekly Togetherwith other project-oriented datasets ModBase currentlycontains 29 million reliable models for domains in 47million unique sequences The lsquoNominate a modelomersquofeature allows community users to request modeling ofadditional complete genomes as our computational re-sources allow This feature has been used for exampleto support the Tropical Disease Initiative (httptropicaldiseaseorg) (37ndash40)
ModWeb comparative modeling web-server
The ModWeb comparative modeling web-server is anintegral module of ModBase (httpsalilaborgmodweb)(17) In the default mode ModWeb accepts one or moresequences in the FASTA format followed by calculatingand evaluating their models using ModPipe based on thebest available templates from the PDB AlternativelyModWeb also accepts a protein structure as input(template-based calculation) calculates a multiplesequence profile and identifies all homologous sequencesin the UniProtKB database followed by modeling thesehomologs based on the user-provided structure This al-ternative protocol is a useful tool for measuring the impactof new structures such as those generated by structuralgenomics efforts (41) Moreover new members ofsequence superfamilies with at least one known structurecan be identified (42)
In addition to anonymous access registered users getunified access to all their ModWeb datasets and cansubmit template-based calculations
ASSOCIATED RESOURCES
A number of web services are associated with ModBaseSome of these are tightly integrated with ModBasewhereas others contain data that are derived throughModBase [eg single-nucleotide polymorphism (SNP)
annotations created by LS-SNP (43)] We alreadydescribed the interactions of ModBase with theModLoop server for loop modeling in protein structures(httpsalilaborgmodloop) (44) the PIBASE database ofproteinndashprotein interaction (httpsalilaborgpibase) (45)the DBAli database of structural alignments (httpsalilaborgdbali) (4647) the LS-SNP database of struc-tural annotations of human non-synonymous SNPs(httpsalilaborgLS-SNP) (434849) the SALIGNserver for multiple sequence and structure alignment(httpsalilaborgsalign) (2750) the ModEval server forpredicting the accuracy of protein structure models(httpsalilaborgmodeval) (27) the PCSS server for pre-dicting which peptides bind to a given protein (httpsalilaborgpcss) (27) and the FoXS server for calculatingand fitting small angle X-ray scattering profiles (httpsalilaborgfoxs) (2751) Here we describe several newservers that interact with ModBase
AllosMod a web-server for modeling ligand-inducedprotein dynamics
Conformational transitions of biomolecules are key tomany aspects of biology These dynamic changes span abroad range of time and size scales and include proteinfolding aggregation induced fit and allosteryThe AllosMod web server (httpsalilaborgallosmod)
predicts conformational changes that occur in the nativeensemble such as allosteric conformational transitionsThe input is one or more macromolecular coordinatefiles (including DNA RNA and sugar molecules) andthe corresponding sequence(s) The output is a set of mo-lecular dynamics trajectories based on a simplified energylandscape The documentation includes analysis examplesto help the user in interpreting the expected outputCarefully designed energy landscapes allow efficient mo-lecular dynamics sampling at constant temperaturesthereby providing ergodic sampling of conformationalspace AllosMod energy landscapes are constructedusing contacts in crystal structure(s) to define the energeticminima This model is referred to as a structure-based orGo model (52ndash54) The energy landscapes are sampledusing many short constant temperature moleculardynamics simulations Sampling occurs quickly even forlarge systems with up to 10 000 residues because thesimplified landscapes can be stored in memory The usercan also download Python scripts necessary to run andmodify the simulations which are performed usingModeller (18)The capabilities of the AllosMod server have been
demonstrated in a study of allosteric systems withknown effector bound and unbound crystal structures(1455) Effector bound and unbound simulations are per-formed using a landscape with a single minimum for theinteractions in the effector binding site corresponding tothe bound or unbound structure and dual minima forinteractions in the rest of the protein corresponding tothe bound and unbound structures AllosMod can alsobe used to predict coupling (ie G) between amutation site and the effector binding site
Nucleic Acids Research 2013 3
at UC
SF Library on D
ecember 2 2013
httpnaroxfordjournalsorgD
ownloaded from
A family of web-servers for computation and applicationof SAXS profiles
SAXS is a common technique for low-resolution struc-tural characterization of molecules in solution (5657)SAXS experiments determine the scattering intensity ofa molecule as a function of spatial frequency resultingin a SAXS profile that can be easily converted into theapproximate distribution of atomic distances in themeasured system The experiments can be performedwith the protein sample in solution and usually takeonly a few minutes on a well-equipped synchrotronbeamline (57) Here we describe new features of theFoXS server for calculating and fitting SAXS profilesthe AllosMod-FoXS server that predicts the structuralensemble that best fits a given SAXS profile theFoXSDock server that performs proteinndashprotein dockingfiltered by a SAXS profile and the SAXS Merge server formerging SAXS profiles measured at different concentra-tions and exposure timesFoXS (httpsalilaborgfoxs) is a rapid and accurate
server for calculating a SAXS profile of a given molecularstructure (51) The input is one or more macromolecularcoordinate files or PDB codes and an experimental profileThe output is a calculated SAXS profile for each inputstructure fitted onto the experimental profile Themethod explicitly computes all inter-atomic distancesand models the first solvation layer based on solvent ac-cessibility FoXS was tested on 11 protein 1 DNA and 2RNA structures revealing superior accuracy and speedversus CRYSOL (58) AquaSAXS (59) the Zernike poly-nomials-based method (60) and Fast-SAXS-pro (61) Inaddition we demonstrated a significant correlation ofthe SAXS score with the accuracy of a structural model(62) We have recently updated the server to an interactiveuser interface profiles are displayed via an HTML5canvas element and structures are shown in a Jmolwindow (Figure 1) If the user uploads multiple structuresthe server automatically performs the minimal ensemblecomputation with Minimal Ensemble Search (MES) (64)AllosMod-FoXS (httpsalilaborgallosmod-foxs) is a
server that predicts the structural ensemble that best fitsa given SAXS profile The input is one or more macromol-ecular coordinate files the corresponding sequence(s) andan lsquoexperimentalrsquo SAXS profile The output is the struc-tural ensemble that best fits the input SAXS profile Theserver relies on AllosMod conformational sampling (14)FoXS calculations of theoretical SAXS profiles minimalensemble computation with MES (64) and the SOAP-PPscore The server was motivated to describe conformationalchanges in proteins such as the allostery based on bothmodeling considerations (as represented by AllosMod) andexperimental SAXS data (as represented by FoXS)The AllosMod-FoXS server uses various sampling al-
gorithms in AllosMod to generate structures that aredirectly entered into FoXS Because FoXS explicitlycomputes all inter-atomic distances and models the firstsolvation layer based on solvent accessibility it can beused to score the similarity of the experimental SAXSprofile to the predicted SAXS profiles corresponding tostructures from the AllosMod simulations In addition
to the FoXS score each conformation is assessed forstructural quality using the SOAP-PP score These twoscores are combined to predict structures that collectivelybest explain the experimental SAXS profile
FoXSDock (httpsalilaborgfoxsdock) is a web serverthat uses SAXS profiles to filter the models produced byproteinndashprotein docking It accepts as input structures oftwo docked proteins and an experimental SAXS profile oftheir complex The output is a set of docking models andtheir calculated SAXS profiles fitted onto the experimentalprofile Although many structures of single protein compo-nents are becoming available structural characterization oftheir complexes remains challenging Although generalproteinndashprotein docking methods suffer from large errorsbecause of protein flexibility and inaccurate scoring func-tions However when additional information such as aSAXS profile is available it is possible to significantlyincrease the accuracy of the computational docking
FoXSDock combines rigid global docking byPatchDock filtering of the models based on the SAXSprofile and interface refinement by FireDock (15) Theapproach was benchmarked on 176 protein complexeswith simulated SAXS profiles as well as on 7 complexeswith experimentally determined SAXS profiles (30) Wheninduced fit is lt15 A interface Ca RMSD and the fractionof residues missing from the component structures islt3 FoXSDock can find a model close to the nativestructure within the top 10 predictions in 77 of thecases in comparison docking alone succeeds in only34 of the cases
SAXS Merge (httpsalilaborgsaxsmerge) is a webserver that uses automated statistical methods to mergeSAXS profiles determined at different concentrationsand exposure times High-throughput SAXS data collec-tion requires robust accurate and automated tools fordata processing and merging (5765) However SAXSdata are generally processed highly subjectively oftenmanually with the aid of the PRIMUS software package(66) The operation requires an experienced user who canmanually inspect each profile to be merged and decidewhether the SAXS profiles agree or not The SAXSMerge web-server alleviates user intervention through anautomated and statistically principled merging procedurebased on a Bayesian approach (Spill et al submitted) TheSAXS Merge web server was successfully validated on abenchmark of 16 SAXS datasets The input file consistsonly of the buffer-subtracted SAXS profiles in a commonthree-column text format The output comprises (i) a listof individual q points with associated source profiles (ii)an estimate of the mean profile along with a 95Bayesian credible interval and (iii) the most suitable para-metric mean function for the resulting profile an estimateof the noise level in the pooled dataset The output isvisualized interactively through the web-browser and canalso be downloaded
Pose amp rank a web-server for scoring proteinndashligandcomplexes
Molecular recognition between proteins and ligands playsan important role in many biological processes Predicting
4 Nucleic Acids Research 2013
at UC
SF Library on D
ecember 2 2013
httpnaroxfordjournalsorgD
ownloaded from
the structures of proteinndashligand complexes and findingligands by virtual screening of small molecule databasesare two long-standing goals in molecular biophysics andmedicinal chemistry Solving both problems requires thedevelopment of an accurate and efficient scoring functionto assess proteinndashligand interactions
The Pose amp Rank web server (httpsalilaborgposeandrank) (16) provides access to two atomicdistance-dependent statistical scoring functions based onprobability theory that can be used in proteinndashliganddocking The PoseScore was optimized for recognizingnative binding geometries of ligands from other posesand the RankScore was optimized for distinguishingligands from non-binding molecules The server acceptsas input a coordinate file of the target protein structurein the PDB format and docking poses of small moleculesThe output is a list of scores for each proteinndashsmallmolecule complex PoseScore ranks a near-nativebinding pose the best top 5 and top 10 for 88 97and 99 of targets respectively RankScore improvesthe overall ligand enrichment (logAUC) and early
enrichment (EF1) scores computed by DOCK 36 (67)for 68 and 74 of targets respectively The Pose ampRank resource can contribute to many applicationssuch as selecting ligand candidates from virtual screeningfor experimental testing predicting the binding geometriesfor known ligands and suggesting binding site mutationsthat alter the ligand binding properties and consequentlyprotein functions
APPLICATION EXAMPLES
Coordinating the impact of structural genomics on thehuman a-helical transmembrane proteome
With the recent successes in determining membraneprotein structures we explored the tractability of deter-mining representatives for the entire human transmem-brane proteome (68) (httpsalilaborgmembrane) Thisproteome contains 2925 unique integral a-helical trans-membrane domain sequences that cluster into 1201families sharing gt25 sequence identity We assessed
Figure 1 The computed profiles for filament models of the XLFndashXRCC4 complex (63) are fitted to the experimental SAXS profile with FoXS Theinteractive user interface displays the profiles in the left and the models in the right using the same color for each modelprofile pair The table belowthe panels displays the fit parameters and includes buttons to simultaneously show or hide each modelprofile pair Clicking on Minimal EnsembleSearch (MES) results (above the display panel) takes the user to the MES output page
Nucleic Acids Research 2013 5
at UC
SF Library on D
ecember 2 2013
httpnaroxfordjournalsorgD
ownloaded from
the modeling coverage by processing all sequencesthrough ModPipe and analyzing the resulting ModBasedataset We then clustered all sequences [BlastClust(69)]annotated them with cluster size modeling coverage andnumber of predicted transmembrane helices Finally weexplored several target selection strategies Structures of100 optimally selected targets would increase the fractionof modelable human alpha-helical transmembranedomains from 26 to 58 thus providing structurefunction information not otherwise availableTo leverage the results of this study the PSIBiology
Network (httpwwwnigmsnihgovResearchFeaturedProgramsPSIpsi_biology) including high-throughputand membrane PSI centers as well as the StructuralGenomics Consortium is attempting to express nearly100 human transmembrane proteins using their standardhigh-throughput methods The goal of this survey is todetermine which methods best express certain classes oftransmembrane proteins The sequences of our previousanalysis were further annotated by fraction of predicteddisordered regions (7071) number of glycosylation sites(27273) clone availability (74ndash76) HUGO annotations(77) sequence length and several additional metricsEighty-six targets were hand-picked from the largestclusters to represent a diverse selection of humanmembrane proteins with maximum coverage of the trans-membrane proteome Cloning expression and solubilityexperiments of these targets using the pipelines of the 10participating research groups are currently in progressParticipants also use shared and individual sets of sixcontrols A standard method will be used by all to visual-ize the protein bands to quantify yield A final full com-parison will determine the most successful methods foreach representative transmembrane protein Progress ofthe survey is cataloged by the portal of the ProteinStructure Initiative Structural Biology Knowledgebase[PSI SBKB (78) httphmppssbkborg] and will be ac-cessible to the public after the conclusion of the experi-ment A final publication will summarize the surveyrsquosfindings
Structural determinants of HIV-1 protease
The maturation of the HIV virion is facilitated by thecleavage of the Gag and Pol polyproteins (79) Ahomodimeric aspartic protease (HIV-1 protease) catalyzesthese processing events at 10 non-homologous sites and isthe target of some of the most effective antiretroviraldrugs (80ndash82) These sites are eight amino acid residuesin length the cleavage occurs between the third and fourthresidues (83ndash86) In addition to processing viral proteinsHIV-1 protease cleaves several human proteins during in-fection such as the eukaryotic translation initiation factor3 subunit D (eIF3D) (87ndash90)To predict cleavage sites in human proteins we began
by examining sequence and structural features of gt120cellular substrates of HIV-1 protease that were recentlyidentified in vitro (91) (for an example see Figure 2)First every residue of the cleaved and non-cleavedoctapeptides was encoded using gt512 physicochemicalamino acid indices (9394) To account for cooperativity
between residues in different positions of the octapeptidefrequencies of dipeptides and gapped dipeptides (ie twospecific residues separated by any residue) were also usedto train machine learning algorithms for binary classifica-tion Second a greedy feature selection procedure wasapplied to determine features of octapeptides importantfor protease activity Interestingly although featuresencoding known viral cleavage motif ELLE were import-ant for classification most discriminating features encodestructural preferences of amino acid residues in the secondand fifth positions of the octapeptide Therefore wecreated a ModBase dataset of 405 models for 118human proteins cleaved in vitro PSI-Pred (95) was usedto predict secondary structure elements for protein regionswithout templates Analysis of the structural modelsshowed the enrichment of alpha+beta protein class(SCOP ID=53 931) among cleaved proteins and coiledsecondary structure (41) among cleaved sites Weadded structure-based descriptors of cleaved and non-cleaved sites to the sequence-based features and assessedclassifiersrsquo performance in a 5-fold cross-validation pro-cedure The average area under the receiver operatingcharacteristic curve for the classifier trained with theRandom Forest algorithm(96) was 0965 (72 sensitivityand 98 specificity) and the entire human proteome wasscanned for putative human substrates of the HIV-1protease We are currently experimentally validatingseveral of the predicted cleavage sites
ACCESS AND INTERFACE
Direct access
The main access to ModBase is through its web interfaceat httpsalilaborgmodbase by querying with Uniprot-KB (23) and GI (97) identifiers gene names annotationkeywords PDB(1) codes dataset names organism namessequence similarity to the modeled sequences [BLAST(19)]and model-specific criteria such as model reliability modelsize and targetndashtemplate sequence identity Additionally it
Figure 2 Cleavage of human proteins by the HIV-1 protease crystalstructure of the N-terminal domain of human Lupus La protein (92)(left) Residues of the cleavage site (Ile-Asp-Tyr-Tyr-Phe-Gly-Glu-Phe)are shown in orange Scissile bond between Tyr and Phe in the alpha-helix is cleaved by the HIV-1 protease in vitro
6 Nucleic Acids Research 2013
at UC
SF Library on D
ecember 2 2013
httpnaroxfordjournalsorgD
ownloaded from
is possible to retrieve coordinate files and alignment filesof all models for a specific sequence as text files Metadatafor all current ModBase models (updated weekly) allgenome datasets and several additional project specificdatasets are also available from our FTP server (ftpsalilaborgdatabasesmodbaseprojects)
The output of a search is displayed on pages withvarying amounts of information about the modeled
sequences template structures alignments and functionalannotations Output examples from a search resulting inone model are shown in Figure 3 A ribbon diagram of themodel with the highest targetndashtemplate sequence identityis displayed by default together with some details of themodeling calculation Ribbon thumbprints of additionalmodels for this sequence link to corresponding pages withmore information Ribbon diagrams are generated on the
Figure 3 ModBase interface elements Search Form search options are available through the pull-down menu A quick overview of the availablerepresentations is displayed below the search form Model Details Sketch the Model details page provides information for all models of a givensequences The sketch comprises two parts the model coverage sketch that indicates the sequence coverage by all models (top line) and the sequencecoverage by the current model (second line) and a ribbon diagram of the current model Other models are available via thumbprints Update and
Remodel this box shows the date of the last modeling calculation for the current sequence and allows the user to request an update Chimera
Visualization the visualization includes the model and template structures and the alignment Cross-references links to the PMP UniProtKBGenbank UCSC Genome Browser and other databases Model Details Options the pull-down menu switches between representations and allowsdownloads of coordinate and alignment files Quality Criteria red indicates unreliable green reliable Model Overview a different representation forseveral sequences gives a quick overview on modeling coverage and quality Chimera Cavity View visualizes cavities predicted by ConCavity
Nucleic Acids Research 2013 7
at UC
SF Library on D
ecember 2 2013
httpnaroxfordjournalsorgD
ownloaded from
fly using Molscript (98) and Raster3D (99) A pull-downmenu provides links to additional functionalities the SNPmodule retrieval of coordinate and alignment files mo-lecular visualization by UCSF Chimera (100) that allowsthe user to display template and model coordinatestogether with their alignment and Chimera visualizationof predicted cavities [ConCavity (101)] If mutation infor-mation is available for a protein sequence links to thedetails are provided in the cross-references sectionAdditionally cross-references to various other databasesincluding PDB (102) UniProtKB (103) the UCSCGenome Browser (104) EBIrsquos InterPro (105)PharmGKB (106) and SFLD (36) are given OtherModBase pages provide overviews of more than onesequence or structure All ModBase pages are intercon-nected to facilitate easy navigation between differentviews
Access through external databases
The Protein Model PortalThe Protein Model Portal (PMP) has become a valuableoption for accessing ModBase models (httpproteinmo-delportalorg) (107) The PMP is a single point of entry foraccessing protein structure models from a number of dif-ferent databases PMP queries all participating sourcemodel databases and serves the user with the model co-ordinates alignments and quality criteria from a centrallocation It has been developed as a module of the ProteinStructure Initiative Knowledgebase (PSI KB) (79108)The PMP provides a flexible search interface for alldeposited models quality estimation cross-links to othersequence and structure databases annotations ofsequences and their models a central point of entry tocomparative modeling servers (including ModWeb) andquality estimation servers (including ModEval) anddetailed tutorials on all aspects of comparativemodeling Currently the PMP retrieves 450 000ModBase model coordinate files each week fromModBaseA sister web-service to PMP CAMEO (httpcameo3d
org) (107) continuously evaluates the accuracy and reli-ability of several comparative protein structure predictionservers in a fully automated manner The ModWeb servercurrently participates in the testing mode and is expectedto move into the production mode in the first quarter of2014
Access through external databasesModBase models in academic and public datasets arealso directly accessible from several databases includingthe PMP (107) UniProtKB (109) PIRrsquos iProClass(103) EBIrsquos InterPro (105) the UCSC Genome Browser(104) PubMed (LinkOut) (110) PharmGKB (106) andSFLD (36)
FUTURE DIRECTIONS
ModBase will grow by adding models calculated ondemand by external users (using ModWeb) as well asour own calculations of model datasets that are needed
for our research projects (using ModPipe ModWeb orModeller) These updates will reflect improvements inthe methods and software used for calculating themodels as well as new template structures in the PDBand new sequences in UniProtKB In the future weexpect that most of the users will access ModBasemodels through the PMP
CITATION
Users of ModBase are requested to cite this article in theirpublications
ACKNOWLEDGEMENTS
For linking to ModBase from their databases the authorsthank Torsten Schwede and Jurgen Haas (Protein ModelPortal) David Haussler and Jim Kent (UCSC GenomeBrowser) Rolf Apweiler Maria Jesus Martin and ClaireOrsquoDonovan (UniProt) Rolf Apweiler Sarah Hunter(InterPro) Patsy Babbitt (SFLD) Russ Altman(PharmGKB) and Kathy Wu (PIRiProClass) We arealso grateful for computing hardware gifts from MikeHomer Ron Conway NetApp IBM Hewlett Packardand Intel
FUNDING
National Institutes of Health [U54 GM094662 U54GM094625 U54 GM093342 MINOS R01GM105404 toJAT and MH] Sandler Family Supporting Foundation(AS) Department of Energy Lawrence BerkeleyNational Lab IDAT program (to JAT and MH)European Union [FP7-IDEAS-ERC 294809 to MN]The authors thank Tom Ferrin and the UCSF Resourcefor Biocomputing Visualization and Informatics formaking UCSF Chimera (supported by [NIGMS P41-GM103311]) available to the ModBase database andtools Funding for open access charge NIH
Conflict of interest statement None declared
REFERENCES
1 RosePW BiC BluhmWF ChristieCH DimitropoulosDDuttaS GreenRK GoodsellDS PrlicA QuesadaM et al(2013) The RCSB Protein Data Bank new resources for researchand education Nucleic Acids Res 41 D475ndashD482
2 The UniProt Consortium (2011) Ongoing and futuredevelopments at the Universal Protein Resource Nucleic AcidsRes 39 D214ndashD219
3 BensonDA Karsch-MizrachiI ClarkK LipmanDJ OstellJand SayersEW (2012) GenBank Nucleic Acids Res 40D48ndashD53
4 BakerD and SaliA (2001) Protein structure prediction andstructural genomics Science 294 93ndash96
5 EswarN WebbB Marti-RenomMA MadhusudhanMSEramianD ShenMY PieperU and SaliA (2006)Comparative protein structure modeling using MODELLERCurr Protoc Bioinformatics Chapter 5 Unit 561ndash5630
6 EswarN EramianD WebbB ShenMY and SaliA (2008)Protein structure modeling with MODELLER Methods MolBiol 426 145ndash159
8 Nucleic Acids Research 2013
at UC
SF Library on D
ecember 2 2013
httpnaroxfordjournalsorgD
ownloaded from
7 SchwedeT SaliA EswarN and PeitschMC (2008)In SchwedeT and PeitschMC (eds) Computational StructuralBiology World Scientific Publishing Ltd Singapore pp 3ndash35
8 ForrestLR TangCL and HonigB (2006) On the accuracy ofhomology modeling and sequence alignment methods applied tomembrane proteins Biophys J 91 508ndash517
9 LiuT TangGW and CapriottiE (2011) Comparativemodeling the state of the art and protein drug target structureprediction Comb Chem High Throughput Screen 14 532ndash547
10 FiserA (2010) Template-based protein structure modelingMethods Mol Biol 673 73ndash94
11 DagaPR PatelRY and DoerksenRJ (2010) Template-basedprotein modeling recent methodological advances Curr TopMed Chem 10 84ndash94
12 HillischA PinedaLF and HilgenfeldR (2004) Utility ofhomology models in the drug discovery process Drug DiscovToday 9 659ndash669
13 WallnerB and ElofssonA (2005) All are not equal abenchmark of different homology modeling programs ProteinSci 14 1315ndash1327
14 WeinkamP PonsJ and SaliA (2012) Structure-based model ofallostery predicts coupling between distant sites Proc Natl AcadSci USA 109 4875ndash4880
15 Schneidman-DuhovnyD HammelM and SaliA (2011)Macromolecular docking restrained by a small angle X-rayscattering profile J Struct Biol 3 461ndash471
16 FanH SchneidmanD IrwinJJ DongG ShoichetB andSaliA (2011) Statistical potential for modeling and rankingprotein-ligand interactions J Chem Inf Model 51 3078ndash3092
17 EswarN JohnB MirkovicN FiserA IlyinVA PieperUStuartAC Marti-RenomMA MadhusudhanMSYerkovichB et al (2003) Tools for comparative protein structuremodeling and analysis Nucleic Acids Res 31 3375ndash3380
18 SaliA and BlundellTL (1993) Comparative protein modellingby satisfaction of spatial restraints J Mol Biol 234 779ndash815
19 AltschulSF MaddenTL SchafferAA ZhangJ ZhangZMillerW and LipmanDJ (1997) Gapped BLAST and PSI-BLAST a new generation of protein database search programsNucleic Acids Res 25 3389ndash3402
20 RemmertM BiegertA HauserA and SodingJ (2012) HHblitslightning-fast iterative protein sequence searching by HMM-HMM alignment Nat Methods 9 173ndash175
21 SodingJ (2005) Protein homology detection by HMM-HMMcomparison Bioinformatics 21 951ndash960
22 SmithTF and WatermanMS (1981) Identification of commonmolecular subsequences J Mol Biol 147 195ndash197
23 EswarN WebbB Marti-RenomM MadhusudhanMEramianD ShenM PieperU and SaliA (2006) Comparativeprotein structure modeling using Modeller Curr ProtocBioinformatics Chapter 5 Unit 56
24 Marti-RenomMA MadhusudhanMS and SaliA (2004)Alignment of protein sequences by their profiles Protein Sci 131071ndash1087
25 ShenMY and SaliA (2006) Statistical potential for assessmentand prediction of protein structures Protein Sci 15 2507ndash2524
26 MeloF and SaliA (2007) Fold assessment for comparativeprotein structure modeling Protein Sci 16 2412ndash2426
27 PieperU WebbBM BarkanDT Schneidman-DuhovnyDSchlessingerA BrabergH YangZ MengEC PettersenEFHuangCC et al (2011) ModBase a database of annotatedcomparative protein structure models and associated resourcesNucleic Acids Res 39 465ndash474
28 EramianD EswarN ShenM and SaliA (2008) How well canthe accuracy of comparative protein structure models bepredicted Protein Sci 17 1881ndash1893
29 DongGQ FanH Schneidman-DuhovnyD WebbB andSaliA (2013) Optimized atomic statistical potentials Assessmentof protein interfaces and loops (epub ahead of print October 232013)
30 Schneidman-DuhovnyD RossiA Avila-SakarA KimSJVelazquez-MurielJ StropP LiangH KrukenbergKALiaoM KimHM et al (2012) A method for integrativestructure determination of protein-protein complexesBioinformatics 28 3282ndash3289
31 PierceB and WengZ (2007) ZRANK reranking protein dockingpredictions with an optimized energy function Proteins 671078ndash1086
32 AndrusierN NussinovR and WolfsonHJ (2007) FireDockfast interaction refinement in molecular docking Proteins 69139ndash159
33 JacobsonMP PincusDL RappCS DayTJ HonigBShawDE and FriesnerRA (2004) A hierarchical approach toall-atom protein loop prediction Proteins 55 351ndash367
34 GrontD KulpDW VernonRM StraussCE and BakerD(2011) Generalized fragment picking in Rosetta design protocolsand applications PloS One 6 e23294
35 ZhangC LiuS and ZhouY (2004) Accurate and efficient loopselections by the DFIRE-based all-atom statistical potentialProtein Sci 13 391ndash399
36 PeggSC BrownSD OjhaS SeffernickJ MengECMorrisJH ChangPJ HuangCC FerrinTE andBabbittPC (2006) Leveraging enzyme structure-functionrelationships for functional inference and experimental design thestructure-function linkage database Biochemistry 45 2545ndash2555
37 MaurerSM RaiA and SaliA (2004) Finding cures for tropicaldiseases is open source an answer PLoS Med 1 e56
38 OrtiL CarbajoR PieperU EswarN MaurerS RaiATaylorG ToddM Pineda-LucenaA SaliA et al (2009) Akernel for open source drug discovery in tropical diseases PLoSNegl Trop Dis 3 e418
39 AgueroF Al-LazikaniB AslettM BerrimanM BucknerFCampbellR CarmonaS CarruthersI ChanA ChenF et al(2008) Genomic-scale prioritization of drug targets the TDRTargets database Nat Rev Drug Discov 7 900ndash907
40 Martinez-JimenezF PapadatosG YangL WallaceIMKumarV PieperU SaliA BrownJR OveringtonJP andMarti-RenomMA (2013) Target prediction for an open accessset of compounds active against Mycobacterium tuberculosisPLoS Comp Biol 9 e1003253
41 SampathkumarP LuF ZhaoX LiZ GilmoreJ BainKRutterME GheyiT SchwinnK BonannoJ et al (2010)Structure of a putative BenF-like porin from Pseudomanasfluorescens Pf-5 at 26 A resolution Proteins 78 3056ndash3062
42 PieperU ChiangR SeffernickJ BrownS GlasnerMKellyL EswarN SauderJ BonannoJ SwaminathanS et al(2009) Target selection and annotation for the structural genomicsof the amidohydrolase and enolase superfamilies J Struct FunctGenom 10 107ndash125
43 KarchinR DiekhansM KellyL ThomasDJ PieperUEswarN HausslerD and SaliA (2005) LS-SNP large-scaleannotation of coding non-synonymous SNPs based on multipleinformation sources Bioinformatics 21 2814ndash2820
44 FiserA and SaliA (2003) ModLoop automated modeling ofloops in protein structures Bioinformatics 19 2500ndash2501
45 DavisF and SaliA (2005) PIBASE a comprehensive databaseof structurally defined protein interfaces Bioinformatics 211901ndash1907
46 Marti-RenomMA PieperU MadhusudhanMS RossiAEswarN DavisFP Al-ShahrourF DopazoJ and SaliA(2007) DBAli tools mining the protein structure space NucleicAcids Res 35 W393ndashW397
47 Marti-RenomMA IlyinVA and SaliA (2001) DBAli adatabase of protein structure alignments Bioinformatics 17746ndash747
48 PieperU EswarN WebbB EramianD KellyL BarkanDCarterH MankooP KarchinR Marti-RenomM et al (2009)MODBASE a database of annotated comparative proteinstructure models and associated resources Nucleic Acids Res 37D347ndashD354
49 PieperU EswarN DavisFP BrabergH MadhusudhanMSRossiA Marti-RenomM KarchinR WebbBM EramianDet al (2006) MODBASE a database of annotated comparativeprotein structure models and associated resources Nucleic AcidsRes 34 D291ndashD295
50 BrabergH WebbB TjioeE PieperU SaliA andMadhusudhanMS (2012) SALIGN a webserver for alignmentof multiple protein sequences and structures Bioinformatics 152072ndash2073
Nucleic Acids Research 2013 9
at UC
SF Library on D
ecember 2 2013
httpnaroxfordjournalsorgD
ownloaded from
51 Schneidman-DuhovnyD HammelM and SaliA (2010) FoXS aweb server for rapid computation and fitting of SAXS ProfilesNucleic Acids Res 38 541ndash544
52 UedaY TaketomiH and GoN (1978) Studies on proteinfolding unfolding and fluctuations by computer simulation IIAThree dimensional lattice model of lysozyme Biopolymers 171531ndash1548
53 OkazakiK KogaN TakadaS OnuchicJN and WolynesPG(2006) Multiple-basin energy landscapes for large-amplitudeconformational motions of proteins Structure-based moleculardynamics simulations Proc Natl Acad Sci USA 10311844ndash11849
54 WhitfordPC NoelJK GosaviS SchugA SanbonmatsuKYand OnuchicJN (2009) An all-atom structure-based potential forproteins bridging minimal models with all-atom empiricalforcefields Proteins 75 430ndash441
55 WeinkamP ChenYC PonsJ and SaliA (2013) Impact ofmutations on the allosteric conformational equilibrium J MolBiol 425 647ndash661
56 PetoukhovMV and SvergunDI (2007) Analysis of X-ray andneutron scattering from biomacromolecular solutions Curr OpinStruct Biol 17 562ndash571
57 HuraGL MenonAL HammelM RamboRP PooleFL IITsutakawaSE JenneyFE Jr ClassenS FrankelKAHopkinsRC et al (2009) Robust high-throughput solutionstructural analyses by small angle X-ray scattering (SAXS) NatMethods 6 606ndash612
58 SvergunD BarberatoC and KochMHJ (1995) CRYSOL-aprogram to evaluate X-ray solution scattering of biologicalmacromolecules from atomic coordinates J Appl Crystallogr28 768ndash773
59 PoitevinF OrlandH DoniachS KoehlP and DelarueM(2011) AquaSAXS a web server for computation and fitting ofSAXS profiles with non-uniformally hydrated atomic modelsNucleic Acids Res 39 W184ndashW189
60 LiuH MorrisRJ HexemerA GrandisonS and ZwartPH(2012) Computation of small-angle scattering profiles with three-dimensional Zernike polynomials Acta Crystallogr A 68278ndash285
61 RavikumarKM HuangW and YangS (2013) Fast-SAXS-proa unified approach to computing SAXS profiles of DNA RNAprotein and their complexes J Chem Phys 138 024112
62 Schneidman-DuhovnyD HammelM TainerJA and SaliA(2013) Accurate SAXS profile computation and its assessment bycontrast variation experiments Biophys J 105 962ndash974
63 HammelM ReyM YuY ManiRS ClassenS LiuMPiqueME FangS MahaneyBL WeinfeldM et al (2011)XRCC4 protein interactions with XRCC4-like factor (XLF)create an extended grooved scaffold for DNA ligation and doublestrand break repair J Biol Chem 286 32638ndash32650
64 PelikanM HuraGL and HammelM (2009) Structure andflexibility within proteins as identified through small angle X-rayscattering Gen Physiol Biophys 28 174ndash189
65 GrantTD LuftJR WolfleyJR TsurutaH MartelAMontelioneGT and SnellEH (2011) Small angle X-rayscattering as a complementary tool for high-throughput structuralstudies Biopolymers 95 517ndash530
66 KonarevPV VolkovVV SokolovaAV KochMHJ andSvergunDI (2003) PRIMUS a Windows PC-based system forsmall-angle scattering data analysis J Appl Crystallogr 361277ndash1282
67 ShoichetBK and KuntzID (1991) Protein docking andcomplementarity J Mol Biol 221 327ndash346
68 PieperU SchlessingerA KloppmannE ChangGA ChouJJDumontM FoxB FrommeP HendricksonW MalkowskiMet al (2013) Coordinating the impact of structural genomics onthe human a-helical transmembrane proteome Nat Struct MolBiol 20 135ndash138
69 JohnsonM ZaretskayaI RaytselisY MerezhukYMcGinnisS and MaddenTL (2008) NCBI BLAST a betterweb interface Nucleic Acids Res 36 W5ndashW9
70 WardJJ McGuffinLJ BrysonK BuxtonBF and JonesDT(2004) The DISOPRED server for the prediction of proteindisorder Bioinformatics 20 2138ndash2139
71 DosztanyiZ CsizmokV TompaP and SimonI (2005) IUPredweb server for the prediction of intrinsically unstructured regionsof proteins based on estimated energy content Bioinformatics 213433ndash3434
72 SteentoftC VakhrushevSY JoshiHJ KongY Vester-ChristensenMB SchjoldagerKT LavrsenK DabelsteenSPedersenNB Marcos-SilvaL et al (2013) Precision mapping ofthe human O-GalNAc glycoproteome through SimpleCelltechnology EMBO J 32 1478ndash1488
73 GuptaR JungE GooleyAA WilliamsKL BrunakS andHansenJ (1999) Scanning the available Dictyostelium discoideumproteome for O-linked GlcNAc glycosylation sites using neuralnetworks Glycobiology 9 1009ndash1022
74 CormierCY ParkJG FiaccoM SteelJ HunterPKramerJ SinglaR and LaBaerJ (2011) PSIBiology-materialsrepository a biologistrsquos resource for protein expression plasmidsJ Struct Funct Genomics 12 55ndash62
75 LameschP LiN MilsteinS FanC HaoT SzaboG HuZVenkatesanK BethelG MartinP et al (2007) hORFeomev31 a resource of human open reading frames representing over10000 human genes Genomics 89 307ndash315
76 TempleG GerhardDS RasoolyR FeingoldEA GoodPJRobinsonC MandichA DergeJG LewisJ ShoafD et al(2009) The completion of the mammalian gene collection (MGC)Genome Res 19 2324ndash2333
77 SealRL GordonSM LushMJ WrightMW andBrufordEA (2011) genenamesorg the HGNC resources in 2011Nucleic Acids Res 39 D514ndashD519
78 GiffordLK CarterLG GabanyiMJ BermanHM andAdamsPD (2012) The protein structure initiative structuralbiology knowledgebase technology portal a structural biologyweb resource J Struct Funct Genomics 13 57ndash62
79 FreedEO (2001) HIV-1 replication Somatic Cell Mol Genet26 13ndash33
80 McDonaldCK and KuritzkesDR (1997) Humanimmunodeficiency virus type 1 protease inhibitors Arch IntMed 157 951ndash959
81 DragM and SalvesenGS (2010) Emerging principles inprotease-based drug discovery Nat Rev Drug Discov 9690ndash701
82 FlexnerC (1998) HIV-protease inhibitors N Engl J Med 3381281ndash1292
83 KohlNE EminiEA SchleifWA DavisLJ HeimbachJCDixonRA ScolnickEM and SigalIS (1988) Active humanimmunodeficiency virus protease is required for viral infectivityProc Natl Acad Sci USA 85 4686ndash4690
84 MurthyKH WinborneEL MinnichMD CulpJS andDebouckC (1992) The crystal structures at 22-A resolution ofhydroxyethylene-based inhibitors bound to humanimmunodeficiency virus type 1 protease show that the inhibitorsare present in two distinct orientations J Biol Chem 26722770ndash22778
85 Prabu-JeyabalanM NalivaikaE and SchifferCA (2000) Howdoes a symmetric dimer recognize an asymmetric substrate Asubstrate complex of HIV-1 protease J Mol Biol 3011207ndash1220
86 MahalingamB LouisJM HungJ HarrisonRW andWeberIT (2001) Structural implications of drug-resistantmutants of HIV-1 protease high-resolution crystal structures ofthe mutant proteasesubstrate analogue complexes Proteins 43455ndash464
87 NieZ PhenixBN LumJJ AlamA LynchDH BeckettBKrammerPH SekalyRP and BadleyAD (2002) HIV-1protease processes procaspase 8 to cause mitochondrial release ofcytochrome c caspase cleavage and nuclear fragmentation CellDeath Differ 9 1172ndash1184
88 Algeciras-SchimnichA Belzacq-CasagrandeAS BrenGDNieZ TaylorJA RizzaSA BrennerC and BadleyAD(2007) Analysis of HIV protease killing through caspase 8 revealsa novel interaction between caspase 8 and mitochondria OpenVirol J 1 39ndash46
89 NieZ BrenGD RizzaSA and BadleyAD (2008) HIVprotease cleavage of procaspase 8 is necessary for death of HIV-infected cells Open Virol J 2 1ndash7
10 Nucleic Acids Research 2013
at UC
SF Library on D
ecember 2 2013
httpnaroxfordjournalsorgD
ownloaded from
90 CastelloA FrancoD Moral-LopezP BerlangaJJAlvarezE WimmerE and CarrascoL (2009) HIV- 1 proteaseinhibits Cap- and poly(A)-dependent translation upon eIF4GIand PABP cleavage PloS One 4 e7997
91 ImpensF TimmermanE StaesA MoensK ArienKKVerhasseltB VandekerckhoveJ and GevaertK (2012) Acatalogue of putative HIV-1 protease host cell substrates BiolChem 393 915ndash931
92 Kotik-KoganO ValentineER SanfeliceD ConteMR andCurryS (2008) Structural analysis reveals conformationalplasticity in the recognition of RNA 3rsquo ends by the human Laprotein Structure 16 852ndash862
93 NakaiK KideraA and KanehisaM (1988) Cluster analysis ofamino acid indices for prediction of protein structure andfunction Protein Eng 2 93ndash100
94 TomiiK and KanehisaM (1996) Analysis of amino acid indicesand mutation matrices for sequence comparison and structureprediction of proteins Protein Eng 9 27ndash36
95 JonesDT (1999) Protein secondary structure prediction basedon position-specific scoring matrices J Mol Biol 292 195ndash202
96 BreimanL and SchapireE (2001) Random forests MachLearn 45 5ndash32
97 BensonDA Karsch-MizrachiI LipmanDJ OstellJ andSayersEW (2010) GenBank Nucleic Acids Res 38 D46ndashD51
98 KraulisPJ (1991) MOLSCRIPT a program to produce bothdetailed and schematic plorts of protein structures J ApplCrystallogr 24 946ndash950
99 MerrittEA and BaconDJ (1997) Raster3D photorealisticmolecular graphics Methods Enzymol 277 505ndash524
100 PettersenEF GoddardTD HuangCC CouchGSGreenblattDM MengEC and FerrinTE (2004) UCSFChimerandasha visualization system for exploratory research andanalysis J Comput Chem 25 1605ndash1612
101 CapraJA LaskowskiRA ThorntonJM SinghM andFunkhouserTA (2009) Predicting protein ligand binding sitesby combining evolutionary sequence conservation and 3Dstructure PLoS Comp Biol 5 e1000585
102 HenrickK FengZ BluhmWF DimitropoulosDDoreleijersJF DuttaS Flippen-AndersonJL IonidesJKamadaC KrissinelE et al (2008) Remediation of the proteindata bank archive Nucleic Acids Res 36 D426ndashD433
103 WuCH ApweilerR BairochA NataleDA BarkerWCBoeckmannB FerroS GasteigerE HuangH LopezR et al(2006) The Universal Protein Resource (UniProt) an expandinguniverse of protein information Nucleic Acids Res 34D187ndashD191
104 RheadB KarolchikD KuhnRM HinrichsAS ZweigASFujitaPA DiekhansM SmithKE RosenbloomKRRaneyBJ et al (2010) The UCSC Genome Browser databaseupdate 2010 Nucleic Acids Res 38 D613ndashD619
105 HunterS ApweilerR AttwoodTK BairochA BatemanABinnsD BorkP DasU DaughertyL DuquenneL et al(2009) InterPro the integrative protein signature databaseNucleic Acids Res 37 D211ndashD215
106 KleinTE ChangJT ChoMK EastonKL FergersonRHewettM LinZ LiuY LiuS OliverDE et al (2001)Integrating genotype and phenotype information an overview ofthe PharmGKB project Pharmacogenetics research network andknowledge base Pharmacogenomics J 1 167ndash170
107 HaasJ RothS ArnoldK KieferF SchmidtT BordoliLand SchwedeT (2013) The Protein Model Portalmdashacomprehensive resource for protein structure and modelinformation Database 2013 bat031
108 SchwedeT SaliA HonigB LevittM BermanH JonesDBrennerS BurleyS DasR DokholyanN et al (2009)Outcome of a workshop on applications of protein models inbiomedical research Structure 17 151ndash159
109 BairochA ApweilerR WuCH BarkerWC BoeckmannBFerroS GasteigerE HuangH LopezR MagraneM et al(2005) The Universal Protein Resource (UniProt) Nucleic AcidsRes 33 D154ndashD159
110 GigliaE (2009) New year new PubMed Eur J Phys RehabilMed 45 155ndash159
Nucleic Acids Research 2013 11
at UC
SF Library on D
ecember 2 2013
httpnaroxfordjournalsorgD
ownloaded from

compared with 12 million only 3 years ago Thereforeprotein structure prediction is essential to bridge thisgap The need for accurate models can frequently be metby homology or comparative modeling (4ndash13) Compa-rative modeling is carried out in four sequential stepsidentifying known structures (templates) related to thesequence to be modeled (target) aligning the targetsequence with the templates building models and assess-ing the models For this reason comparative modeling isonly applicable when the target sequence is detectablyrelated to a known protein structureAs more proteins are modeled web-accessible resources
that assist biologists in evaluating and analyzing modelsbecome increasingly useful Here we describe the currentstate of the ModBase database of comparative proteinstructure models the ModWeb comparative modelingweb-server and several new associated resources includingweb-servers that use SAXS data in the context of com-parative modeling The AllosMod server for modelingligand-induced protein dynamics (httpsalilaborgallosmod) (14) the AllosMod-FoXS server for predictingthe ensemble of conformations that best fit a given SAXSprofile (httpsalilaborgallosmod-foxs) (Weinkam et alin preparation) the FoXSDock server that performsproteinndashprotein docking filtered by a SAXS profile(httpsalilaborgfoxsdock) (15) the SAXS Mergeserver for merging SAXS profiles (httpsalilaborgsaxsmerge) (Spill et al accepted) and the Pose amp Rankserver for scoring proteinndashligand complexes based on astatistical potential (httpsalilaborgposeandrank) (16)Finally we highlight applications of ModBase models tomaximize the structural coverage of the human a-helicaltransmembrane proteome in a PSIBiology effort and toan analysis of structural determinants of human immuno-deficiency virus-1 (HIV-1) protease specificity
CONTENTS
Model generation by comparative modeling (Modeller andModPipe)
Models in ModBase are calculated using our automatedsoftware pipeline for comparative protein structuremodeling ModPipe (17) ModPipe relies mostly onmodules of Modeller (18) as well as fold assignment andsequence-structure alignment by PSI-BLAST (19) andthe HHSuite modules HHBlits (20) and HHSearch (21)To be able to process a large number of sequences it isimplemented on a Linux clusterModPipe uses sequencendashsequence (22) sequencendashprofile
(1923) and profilendashprofile (524) methods for fold assign-ment and targetndashtemplate alignment using a promiscuousE-value threshold of 10 to increase the likelihood of iden-tifying the best available template structure In addition tothe previously implemented profile methods (ModellerrsquosBuild-Profile and PPScan and PSI-BLAST) we recentlyadded an option to use HHBlits and HHSearch These willbe included in the next public release of ModPipe (230expected December 2013) Alignments created by anyof these methods can cover the complete target sequenceor only a segment of it depending on the availability of
suitable PDB templates With the added functionality ofHHBlits and HHSearch some ModPipe models are nowbased on multiple templates
To increase efficiency the available targetndashtemplatealignments are filtered by sequence identity (ModPipetemplate option TOP) if the highest targetndashtemplatesequence identity is 40 ModPipe selects alignmentsfor all detected templates Otherwise the selection onlycontains alignments for each targetndashtemplate alignmentthat is created in a 20 sequence identity windowstarting from the highest sequence identity For eachselected targetndashtemplate alignment 10 models arecalculated (18) and the model with the best value of theDOPE statistical potential (25) is selected and thenevaluated by several additional quality criteria (i)targetndashtemplate sequence identity (ii) GA341 score (26)(iii) Z-DOPE score (25) (iv) MPQS score (ModPipequality score) (27) and (v) TSVMod score (28) Themodels that score best with at least one of these qualitycriteria are selected for further filtering If gt30 residues ofa target sequence are not covered by a selected modeladditional models are selected even if they do not scorebest with at least one of the quality criteria Finally onlythe models with quality criteria values above specifiedthresholds or with an E-value lt104 are included in thefinal model set
A key feature of the pipeline is that the validity ofsequencendashstructure relationships is not prejudged at thefold-assignment stage instead sequencendashstructure matchesare assessed after the construction of the models and theirevaluation This approach enables a thorough explorationof fold assignments sequencendashstructure alignments andconformations with the aim of finding the model withthe best evaluation score at the expense of increasingthe computational time significantly for some sequencesa few thousand models can be calculated For sequenceswith high-quality templates the optional lsquoTOPrsquo keywordcan reduce the amount of computer time by up to 60
The source code for ModPipe is freely accessible underthe Gnu Public license (httpsalilaborgmodpipe) Thebinary code for Modeller is also available freely to aca-demics for a number of different operating systems (httpsalilaborgmodeller)
Statistically optimized atomic potentials (SOAP) forassessing protein interfaces and loops
Both loop modeling and proteinndashprotein docking requireaccurate scoring functions for selecting the most accuratesampled models Statistically Optimized AtomicPotentials (SOAP)-PP and SOAP-Loop are atomic statis-tical potentials for assessing protein interfaces and loopsrespectively (httpsalilaborgSOAP also available inModeller) (29) They were derived using a Bayesian frame-work for inferring SOAP When using SOAP-PP forscoring proteinndashprotein docking models a near-nativemodel is within the top 10 scoring models in 52 ofthe PatchDock decoys (30) compared with 23 and 27for the state-of-the-art ZRANK (31) and FireDock(32) scoring functions respectively Similarly formodeling 12-residue loops in the PLOP benchmark (33)
2 Nucleic Acids Research 2013
at UC
SF Library on D
ecember 2 2013
httpnaroxfordjournalsorgD
ownloaded from
the average main-chain root-mean-square-deviation(RMSD) of the best-scored conformations by SOAP-Loop is 15 A close to the average RMSD of the best-sampled conformations (12 A) and significantly betterthan that selected by the Rosetta (34) (21 A) DFIRE(35) (23 A) DOPE (25 A) (25) and PLOP scoring func-tions (30 A) The SOAP-PP score is used by ourAllosMod-FoXS server (below) We are incorporatingSOAP scores into the modeling and model assessmentmodules of ModPipe
ModBase model sets
Models in ModBase are organized in datasets Because ofthe rapid growth of the public sequence databases weconcentrate our efforts on adding datasets that areuseful for specific projects rather than attempt to modelall known protein sequences based on all detectablyrelated known structures Currently ModBase includes amodel dataset for each of 65 complete genomes as well asdatasets for all sequences in the Structure FunctionLinkage Database (SFLD) (36) and for the completeSwissProtTrEMBL database as of 2005 (httpsalilaborgmodbasestatistics) Additionally available modelsfor new SFLD sequences are added weekly Togetherwith other project-oriented datasets ModBase currentlycontains 29 million reliable models for domains in 47million unique sequences The lsquoNominate a modelomersquofeature allows community users to request modeling ofadditional complete genomes as our computational re-sources allow This feature has been used for exampleto support the Tropical Disease Initiative (httptropicaldiseaseorg) (37ndash40)
ModWeb comparative modeling web-server
The ModWeb comparative modeling web-server is anintegral module of ModBase (httpsalilaborgmodweb)(17) In the default mode ModWeb accepts one or moresequences in the FASTA format followed by calculatingand evaluating their models using ModPipe based on thebest available templates from the PDB AlternativelyModWeb also accepts a protein structure as input(template-based calculation) calculates a multiplesequence profile and identifies all homologous sequencesin the UniProtKB database followed by modeling thesehomologs based on the user-provided structure This al-ternative protocol is a useful tool for measuring the impactof new structures such as those generated by structuralgenomics efforts (41) Moreover new members ofsequence superfamilies with at least one known structurecan be identified (42)
In addition to anonymous access registered users getunified access to all their ModWeb datasets and cansubmit template-based calculations
ASSOCIATED RESOURCES
A number of web services are associated with ModBaseSome of these are tightly integrated with ModBasewhereas others contain data that are derived throughModBase [eg single-nucleotide polymorphism (SNP)
annotations created by LS-SNP (43)] We alreadydescribed the interactions of ModBase with theModLoop server for loop modeling in protein structures(httpsalilaborgmodloop) (44) the PIBASE database ofproteinndashprotein interaction (httpsalilaborgpibase) (45)the DBAli database of structural alignments (httpsalilaborgdbali) (4647) the LS-SNP database of struc-tural annotations of human non-synonymous SNPs(httpsalilaborgLS-SNP) (434849) the SALIGNserver for multiple sequence and structure alignment(httpsalilaborgsalign) (2750) the ModEval server forpredicting the accuracy of protein structure models(httpsalilaborgmodeval) (27) the PCSS server for pre-dicting which peptides bind to a given protein (httpsalilaborgpcss) (27) and the FoXS server for calculatingand fitting small angle X-ray scattering profiles (httpsalilaborgfoxs) (2751) Here we describe several newservers that interact with ModBase
AllosMod a web-server for modeling ligand-inducedprotein dynamics
Conformational transitions of biomolecules are key tomany aspects of biology These dynamic changes span abroad range of time and size scales and include proteinfolding aggregation induced fit and allosteryThe AllosMod web server (httpsalilaborgallosmod)
predicts conformational changes that occur in the nativeensemble such as allosteric conformational transitionsThe input is one or more macromolecular coordinatefiles (including DNA RNA and sugar molecules) andthe corresponding sequence(s) The output is a set of mo-lecular dynamics trajectories based on a simplified energylandscape The documentation includes analysis examplesto help the user in interpreting the expected outputCarefully designed energy landscapes allow efficient mo-lecular dynamics sampling at constant temperaturesthereby providing ergodic sampling of conformationalspace AllosMod energy landscapes are constructedusing contacts in crystal structure(s) to define the energeticminima This model is referred to as a structure-based orGo model (52ndash54) The energy landscapes are sampledusing many short constant temperature moleculardynamics simulations Sampling occurs quickly even forlarge systems with up to 10 000 residues because thesimplified landscapes can be stored in memory The usercan also download Python scripts necessary to run andmodify the simulations which are performed usingModeller (18)The capabilities of the AllosMod server have been
demonstrated in a study of allosteric systems withknown effector bound and unbound crystal structures(1455) Effector bound and unbound simulations are per-formed using a landscape with a single minimum for theinteractions in the effector binding site corresponding tothe bound or unbound structure and dual minima forinteractions in the rest of the protein corresponding tothe bound and unbound structures AllosMod can alsobe used to predict coupling (ie G) between amutation site and the effector binding site
Nucleic Acids Research 2013 3
at UC
SF Library on D
ecember 2 2013
httpnaroxfordjournalsorgD
ownloaded from
A family of web-servers for computation and applicationof SAXS profiles
SAXS is a common technique for low-resolution struc-tural characterization of molecules in solution (5657)SAXS experiments determine the scattering intensity ofa molecule as a function of spatial frequency resultingin a SAXS profile that can be easily converted into theapproximate distribution of atomic distances in themeasured system The experiments can be performedwith the protein sample in solution and usually takeonly a few minutes on a well-equipped synchrotronbeamline (57) Here we describe new features of theFoXS server for calculating and fitting SAXS profilesthe AllosMod-FoXS server that predicts the structuralensemble that best fits a given SAXS profile theFoXSDock server that performs proteinndashprotein dockingfiltered by a SAXS profile and the SAXS Merge server formerging SAXS profiles measured at different concentra-tions and exposure timesFoXS (httpsalilaborgfoxs) is a rapid and accurate
server for calculating a SAXS profile of a given molecularstructure (51) The input is one or more macromolecularcoordinate files or PDB codes and an experimental profileThe output is a calculated SAXS profile for each inputstructure fitted onto the experimental profile Themethod explicitly computes all inter-atomic distancesand models the first solvation layer based on solvent ac-cessibility FoXS was tested on 11 protein 1 DNA and 2RNA structures revealing superior accuracy and speedversus CRYSOL (58) AquaSAXS (59) the Zernike poly-nomials-based method (60) and Fast-SAXS-pro (61) Inaddition we demonstrated a significant correlation ofthe SAXS score with the accuracy of a structural model(62) We have recently updated the server to an interactiveuser interface profiles are displayed via an HTML5canvas element and structures are shown in a Jmolwindow (Figure 1) If the user uploads multiple structuresthe server automatically performs the minimal ensemblecomputation with Minimal Ensemble Search (MES) (64)AllosMod-FoXS (httpsalilaborgallosmod-foxs) is a
server that predicts the structural ensemble that best fitsa given SAXS profile The input is one or more macromol-ecular coordinate files the corresponding sequence(s) andan lsquoexperimentalrsquo SAXS profile The output is the struc-tural ensemble that best fits the input SAXS profile Theserver relies on AllosMod conformational sampling (14)FoXS calculations of theoretical SAXS profiles minimalensemble computation with MES (64) and the SOAP-PPscore The server was motivated to describe conformationalchanges in proteins such as the allostery based on bothmodeling considerations (as represented by AllosMod) andexperimental SAXS data (as represented by FoXS)The AllosMod-FoXS server uses various sampling al-
gorithms in AllosMod to generate structures that aredirectly entered into FoXS Because FoXS explicitlycomputes all inter-atomic distances and models the firstsolvation layer based on solvent accessibility it can beused to score the similarity of the experimental SAXSprofile to the predicted SAXS profiles corresponding tostructures from the AllosMod simulations In addition
to the FoXS score each conformation is assessed forstructural quality using the SOAP-PP score These twoscores are combined to predict structures that collectivelybest explain the experimental SAXS profile
FoXSDock (httpsalilaborgfoxsdock) is a web serverthat uses SAXS profiles to filter the models produced byproteinndashprotein docking It accepts as input structures oftwo docked proteins and an experimental SAXS profile oftheir complex The output is a set of docking models andtheir calculated SAXS profiles fitted onto the experimentalprofile Although many structures of single protein compo-nents are becoming available structural characterization oftheir complexes remains challenging Although generalproteinndashprotein docking methods suffer from large errorsbecause of protein flexibility and inaccurate scoring func-tions However when additional information such as aSAXS profile is available it is possible to significantlyincrease the accuracy of the computational docking
FoXSDock combines rigid global docking byPatchDock filtering of the models based on the SAXSprofile and interface refinement by FireDock (15) Theapproach was benchmarked on 176 protein complexeswith simulated SAXS profiles as well as on 7 complexeswith experimentally determined SAXS profiles (30) Wheninduced fit is lt15 A interface Ca RMSD and the fractionof residues missing from the component structures islt3 FoXSDock can find a model close to the nativestructure within the top 10 predictions in 77 of thecases in comparison docking alone succeeds in only34 of the cases
SAXS Merge (httpsalilaborgsaxsmerge) is a webserver that uses automated statistical methods to mergeSAXS profiles determined at different concentrationsand exposure times High-throughput SAXS data collec-tion requires robust accurate and automated tools fordata processing and merging (5765) However SAXSdata are generally processed highly subjectively oftenmanually with the aid of the PRIMUS software package(66) The operation requires an experienced user who canmanually inspect each profile to be merged and decidewhether the SAXS profiles agree or not The SAXSMerge web-server alleviates user intervention through anautomated and statistically principled merging procedurebased on a Bayesian approach (Spill et al submitted) TheSAXS Merge web server was successfully validated on abenchmark of 16 SAXS datasets The input file consistsonly of the buffer-subtracted SAXS profiles in a commonthree-column text format The output comprises (i) a listof individual q points with associated source profiles (ii)an estimate of the mean profile along with a 95Bayesian credible interval and (iii) the most suitable para-metric mean function for the resulting profile an estimateof the noise level in the pooled dataset The output isvisualized interactively through the web-browser and canalso be downloaded
Pose amp rank a web-server for scoring proteinndashligandcomplexes
Molecular recognition between proteins and ligands playsan important role in many biological processes Predicting
4 Nucleic Acids Research 2013
at UC
SF Library on D
ecember 2 2013
httpnaroxfordjournalsorgD
ownloaded from
the structures of proteinndashligand complexes and findingligands by virtual screening of small molecule databasesare two long-standing goals in molecular biophysics andmedicinal chemistry Solving both problems requires thedevelopment of an accurate and efficient scoring functionto assess proteinndashligand interactions
The Pose amp Rank web server (httpsalilaborgposeandrank) (16) provides access to two atomicdistance-dependent statistical scoring functions based onprobability theory that can be used in proteinndashliganddocking The PoseScore was optimized for recognizingnative binding geometries of ligands from other posesand the RankScore was optimized for distinguishingligands from non-binding molecules The server acceptsas input a coordinate file of the target protein structurein the PDB format and docking poses of small moleculesThe output is a list of scores for each proteinndashsmallmolecule complex PoseScore ranks a near-nativebinding pose the best top 5 and top 10 for 88 97and 99 of targets respectively RankScore improvesthe overall ligand enrichment (logAUC) and early
enrichment (EF1) scores computed by DOCK 36 (67)for 68 and 74 of targets respectively The Pose ampRank resource can contribute to many applicationssuch as selecting ligand candidates from virtual screeningfor experimental testing predicting the binding geometriesfor known ligands and suggesting binding site mutationsthat alter the ligand binding properties and consequentlyprotein functions
APPLICATION EXAMPLES
Coordinating the impact of structural genomics on thehuman a-helical transmembrane proteome
With the recent successes in determining membraneprotein structures we explored the tractability of deter-mining representatives for the entire human transmem-brane proteome (68) (httpsalilaborgmembrane) Thisproteome contains 2925 unique integral a-helical trans-membrane domain sequences that cluster into 1201families sharing gt25 sequence identity We assessed
Figure 1 The computed profiles for filament models of the XLFndashXRCC4 complex (63) are fitted to the experimental SAXS profile with FoXS Theinteractive user interface displays the profiles in the left and the models in the right using the same color for each modelprofile pair The table belowthe panels displays the fit parameters and includes buttons to simultaneously show or hide each modelprofile pair Clicking on Minimal EnsembleSearch (MES) results (above the display panel) takes the user to the MES output page
Nucleic Acids Research 2013 5
at UC
SF Library on D
ecember 2 2013
httpnaroxfordjournalsorgD
ownloaded from
the modeling coverage by processing all sequencesthrough ModPipe and analyzing the resulting ModBasedataset We then clustered all sequences [BlastClust(69)]annotated them with cluster size modeling coverage andnumber of predicted transmembrane helices Finally weexplored several target selection strategies Structures of100 optimally selected targets would increase the fractionof modelable human alpha-helical transmembranedomains from 26 to 58 thus providing structurefunction information not otherwise availableTo leverage the results of this study the PSIBiology
Network (httpwwwnigmsnihgovResearchFeaturedProgramsPSIpsi_biology) including high-throughputand membrane PSI centers as well as the StructuralGenomics Consortium is attempting to express nearly100 human transmembrane proteins using their standardhigh-throughput methods The goal of this survey is todetermine which methods best express certain classes oftransmembrane proteins The sequences of our previousanalysis were further annotated by fraction of predicteddisordered regions (7071) number of glycosylation sites(27273) clone availability (74ndash76) HUGO annotations(77) sequence length and several additional metricsEighty-six targets were hand-picked from the largestclusters to represent a diverse selection of humanmembrane proteins with maximum coverage of the trans-membrane proteome Cloning expression and solubilityexperiments of these targets using the pipelines of the 10participating research groups are currently in progressParticipants also use shared and individual sets of sixcontrols A standard method will be used by all to visual-ize the protein bands to quantify yield A final full com-parison will determine the most successful methods foreach representative transmembrane protein Progress ofthe survey is cataloged by the portal of the ProteinStructure Initiative Structural Biology Knowledgebase[PSI SBKB (78) httphmppssbkborg] and will be ac-cessible to the public after the conclusion of the experi-ment A final publication will summarize the surveyrsquosfindings
Structural determinants of HIV-1 protease
The maturation of the HIV virion is facilitated by thecleavage of the Gag and Pol polyproteins (79) Ahomodimeric aspartic protease (HIV-1 protease) catalyzesthese processing events at 10 non-homologous sites and isthe target of some of the most effective antiretroviraldrugs (80ndash82) These sites are eight amino acid residuesin length the cleavage occurs between the third and fourthresidues (83ndash86) In addition to processing viral proteinsHIV-1 protease cleaves several human proteins during in-fection such as the eukaryotic translation initiation factor3 subunit D (eIF3D) (87ndash90)To predict cleavage sites in human proteins we began
by examining sequence and structural features of gt120cellular substrates of HIV-1 protease that were recentlyidentified in vitro (91) (for an example see Figure 2)First every residue of the cleaved and non-cleavedoctapeptides was encoded using gt512 physicochemicalamino acid indices (9394) To account for cooperativity
between residues in different positions of the octapeptidefrequencies of dipeptides and gapped dipeptides (ie twospecific residues separated by any residue) were also usedto train machine learning algorithms for binary classifica-tion Second a greedy feature selection procedure wasapplied to determine features of octapeptides importantfor protease activity Interestingly although featuresencoding known viral cleavage motif ELLE were import-ant for classification most discriminating features encodestructural preferences of amino acid residues in the secondand fifth positions of the octapeptide Therefore wecreated a ModBase dataset of 405 models for 118human proteins cleaved in vitro PSI-Pred (95) was usedto predict secondary structure elements for protein regionswithout templates Analysis of the structural modelsshowed the enrichment of alpha+beta protein class(SCOP ID=53 931) among cleaved proteins and coiledsecondary structure (41) among cleaved sites Weadded structure-based descriptors of cleaved and non-cleaved sites to the sequence-based features and assessedclassifiersrsquo performance in a 5-fold cross-validation pro-cedure The average area under the receiver operatingcharacteristic curve for the classifier trained with theRandom Forest algorithm(96) was 0965 (72 sensitivityand 98 specificity) and the entire human proteome wasscanned for putative human substrates of the HIV-1protease We are currently experimentally validatingseveral of the predicted cleavage sites
ACCESS AND INTERFACE
Direct access
The main access to ModBase is through its web interfaceat httpsalilaborgmodbase by querying with Uniprot-KB (23) and GI (97) identifiers gene names annotationkeywords PDB(1) codes dataset names organism namessequence similarity to the modeled sequences [BLAST(19)]and model-specific criteria such as model reliability modelsize and targetndashtemplate sequence identity Additionally it
Figure 2 Cleavage of human proteins by the HIV-1 protease crystalstructure of the N-terminal domain of human Lupus La protein (92)(left) Residues of the cleavage site (Ile-Asp-Tyr-Tyr-Phe-Gly-Glu-Phe)are shown in orange Scissile bond between Tyr and Phe in the alpha-helix is cleaved by the HIV-1 protease in vitro
6 Nucleic Acids Research 2013
at UC
SF Library on D
ecember 2 2013
httpnaroxfordjournalsorgD
ownloaded from
is possible to retrieve coordinate files and alignment filesof all models for a specific sequence as text files Metadatafor all current ModBase models (updated weekly) allgenome datasets and several additional project specificdatasets are also available from our FTP server (ftpsalilaborgdatabasesmodbaseprojects)
The output of a search is displayed on pages withvarying amounts of information about the modeled
sequences template structures alignments and functionalannotations Output examples from a search resulting inone model are shown in Figure 3 A ribbon diagram of themodel with the highest targetndashtemplate sequence identityis displayed by default together with some details of themodeling calculation Ribbon thumbprints of additionalmodels for this sequence link to corresponding pages withmore information Ribbon diagrams are generated on the
Figure 3 ModBase interface elements Search Form search options are available through the pull-down menu A quick overview of the availablerepresentations is displayed below the search form Model Details Sketch the Model details page provides information for all models of a givensequences The sketch comprises two parts the model coverage sketch that indicates the sequence coverage by all models (top line) and the sequencecoverage by the current model (second line) and a ribbon diagram of the current model Other models are available via thumbprints Update and
Remodel this box shows the date of the last modeling calculation for the current sequence and allows the user to request an update Chimera
Visualization the visualization includes the model and template structures and the alignment Cross-references links to the PMP UniProtKBGenbank UCSC Genome Browser and other databases Model Details Options the pull-down menu switches between representations and allowsdownloads of coordinate and alignment files Quality Criteria red indicates unreliable green reliable Model Overview a different representation forseveral sequences gives a quick overview on modeling coverage and quality Chimera Cavity View visualizes cavities predicted by ConCavity
Nucleic Acids Research 2013 7
at UC
SF Library on D
ecember 2 2013
httpnaroxfordjournalsorgD
ownloaded from
fly using Molscript (98) and Raster3D (99) A pull-downmenu provides links to additional functionalities the SNPmodule retrieval of coordinate and alignment files mo-lecular visualization by UCSF Chimera (100) that allowsthe user to display template and model coordinatestogether with their alignment and Chimera visualizationof predicted cavities [ConCavity (101)] If mutation infor-mation is available for a protein sequence links to thedetails are provided in the cross-references sectionAdditionally cross-references to various other databasesincluding PDB (102) UniProtKB (103) the UCSCGenome Browser (104) EBIrsquos InterPro (105)PharmGKB (106) and SFLD (36) are given OtherModBase pages provide overviews of more than onesequence or structure All ModBase pages are intercon-nected to facilitate easy navigation between differentviews
Access through external databases
The Protein Model PortalThe Protein Model Portal (PMP) has become a valuableoption for accessing ModBase models (httpproteinmo-delportalorg) (107) The PMP is a single point of entry foraccessing protein structure models from a number of dif-ferent databases PMP queries all participating sourcemodel databases and serves the user with the model co-ordinates alignments and quality criteria from a centrallocation It has been developed as a module of the ProteinStructure Initiative Knowledgebase (PSI KB) (79108)The PMP provides a flexible search interface for alldeposited models quality estimation cross-links to othersequence and structure databases annotations ofsequences and their models a central point of entry tocomparative modeling servers (including ModWeb) andquality estimation servers (including ModEval) anddetailed tutorials on all aspects of comparativemodeling Currently the PMP retrieves 450 000ModBase model coordinate files each week fromModBaseA sister web-service to PMP CAMEO (httpcameo3d
org) (107) continuously evaluates the accuracy and reli-ability of several comparative protein structure predictionservers in a fully automated manner The ModWeb servercurrently participates in the testing mode and is expectedto move into the production mode in the first quarter of2014
Access through external databasesModBase models in academic and public datasets arealso directly accessible from several databases includingthe PMP (107) UniProtKB (109) PIRrsquos iProClass(103) EBIrsquos InterPro (105) the UCSC Genome Browser(104) PubMed (LinkOut) (110) PharmGKB (106) andSFLD (36)
FUTURE DIRECTIONS
ModBase will grow by adding models calculated ondemand by external users (using ModWeb) as well asour own calculations of model datasets that are needed
for our research projects (using ModPipe ModWeb orModeller) These updates will reflect improvements inthe methods and software used for calculating themodels as well as new template structures in the PDBand new sequences in UniProtKB In the future weexpect that most of the users will access ModBasemodels through the PMP
CITATION
Users of ModBase are requested to cite this article in theirpublications
ACKNOWLEDGEMENTS
For linking to ModBase from their databases the authorsthank Torsten Schwede and Jurgen Haas (Protein ModelPortal) David Haussler and Jim Kent (UCSC GenomeBrowser) Rolf Apweiler Maria Jesus Martin and ClaireOrsquoDonovan (UniProt) Rolf Apweiler Sarah Hunter(InterPro) Patsy Babbitt (SFLD) Russ Altman(PharmGKB) and Kathy Wu (PIRiProClass) We arealso grateful for computing hardware gifts from MikeHomer Ron Conway NetApp IBM Hewlett Packardand Intel
FUNDING
National Institutes of Health [U54 GM094662 U54GM094625 U54 GM093342 MINOS R01GM105404 toJAT and MH] Sandler Family Supporting Foundation(AS) Department of Energy Lawrence BerkeleyNational Lab IDAT program (to JAT and MH)European Union [FP7-IDEAS-ERC 294809 to MN]The authors thank Tom Ferrin and the UCSF Resourcefor Biocomputing Visualization and Informatics formaking UCSF Chimera (supported by [NIGMS P41-GM103311]) available to the ModBase database andtools Funding for open access charge NIH
Conflict of interest statement None declared
REFERENCES
1 RosePW BiC BluhmWF ChristieCH DimitropoulosDDuttaS GreenRK GoodsellDS PrlicA QuesadaM et al(2013) The RCSB Protein Data Bank new resources for researchand education Nucleic Acids Res 41 D475ndashD482
2 The UniProt Consortium (2011) Ongoing and futuredevelopments at the Universal Protein Resource Nucleic AcidsRes 39 D214ndashD219
3 BensonDA Karsch-MizrachiI ClarkK LipmanDJ OstellJand SayersEW (2012) GenBank Nucleic Acids Res 40D48ndashD53
4 BakerD and SaliA (2001) Protein structure prediction andstructural genomics Science 294 93ndash96
5 EswarN WebbB Marti-RenomMA MadhusudhanMSEramianD ShenMY PieperU and SaliA (2006)Comparative protein structure modeling using MODELLERCurr Protoc Bioinformatics Chapter 5 Unit 561ndash5630
6 EswarN EramianD WebbB ShenMY and SaliA (2008)Protein structure modeling with MODELLER Methods MolBiol 426 145ndash159
8 Nucleic Acids Research 2013
at UC
SF Library on D
ecember 2 2013
httpnaroxfordjournalsorgD
ownloaded from
7 SchwedeT SaliA EswarN and PeitschMC (2008)In SchwedeT and PeitschMC (eds) Computational StructuralBiology World Scientific Publishing Ltd Singapore pp 3ndash35
8 ForrestLR TangCL and HonigB (2006) On the accuracy ofhomology modeling and sequence alignment methods applied tomembrane proteins Biophys J 91 508ndash517
9 LiuT TangGW and CapriottiE (2011) Comparativemodeling the state of the art and protein drug target structureprediction Comb Chem High Throughput Screen 14 532ndash547
10 FiserA (2010) Template-based protein structure modelingMethods Mol Biol 673 73ndash94
11 DagaPR PatelRY and DoerksenRJ (2010) Template-basedprotein modeling recent methodological advances Curr TopMed Chem 10 84ndash94
12 HillischA PinedaLF and HilgenfeldR (2004) Utility ofhomology models in the drug discovery process Drug DiscovToday 9 659ndash669
13 WallnerB and ElofssonA (2005) All are not equal abenchmark of different homology modeling programs ProteinSci 14 1315ndash1327
14 WeinkamP PonsJ and SaliA (2012) Structure-based model ofallostery predicts coupling between distant sites Proc Natl AcadSci USA 109 4875ndash4880
15 Schneidman-DuhovnyD HammelM and SaliA (2011)Macromolecular docking restrained by a small angle X-rayscattering profile J Struct Biol 3 461ndash471
16 FanH SchneidmanD IrwinJJ DongG ShoichetB andSaliA (2011) Statistical potential for modeling and rankingprotein-ligand interactions J Chem Inf Model 51 3078ndash3092
17 EswarN JohnB MirkovicN FiserA IlyinVA PieperUStuartAC Marti-RenomMA MadhusudhanMSYerkovichB et al (2003) Tools for comparative protein structuremodeling and analysis Nucleic Acids Res 31 3375ndash3380
18 SaliA and BlundellTL (1993) Comparative protein modellingby satisfaction of spatial restraints J Mol Biol 234 779ndash815
19 AltschulSF MaddenTL SchafferAA ZhangJ ZhangZMillerW and LipmanDJ (1997) Gapped BLAST and PSI-BLAST a new generation of protein database search programsNucleic Acids Res 25 3389ndash3402
20 RemmertM BiegertA HauserA and SodingJ (2012) HHblitslightning-fast iterative protein sequence searching by HMM-HMM alignment Nat Methods 9 173ndash175
21 SodingJ (2005) Protein homology detection by HMM-HMMcomparison Bioinformatics 21 951ndash960
22 SmithTF and WatermanMS (1981) Identification of commonmolecular subsequences J Mol Biol 147 195ndash197
23 EswarN WebbB Marti-RenomM MadhusudhanMEramianD ShenM PieperU and SaliA (2006) Comparativeprotein structure modeling using Modeller Curr ProtocBioinformatics Chapter 5 Unit 56
24 Marti-RenomMA MadhusudhanMS and SaliA (2004)Alignment of protein sequences by their profiles Protein Sci 131071ndash1087
25 ShenMY and SaliA (2006) Statistical potential for assessmentand prediction of protein structures Protein Sci 15 2507ndash2524
26 MeloF and SaliA (2007) Fold assessment for comparativeprotein structure modeling Protein Sci 16 2412ndash2426
27 PieperU WebbBM BarkanDT Schneidman-DuhovnyDSchlessingerA BrabergH YangZ MengEC PettersenEFHuangCC et al (2011) ModBase a database of annotatedcomparative protein structure models and associated resourcesNucleic Acids Res 39 465ndash474
28 EramianD EswarN ShenM and SaliA (2008) How well canthe accuracy of comparative protein structure models bepredicted Protein Sci 17 1881ndash1893
29 DongGQ FanH Schneidman-DuhovnyD WebbB andSaliA (2013) Optimized atomic statistical potentials Assessmentof protein interfaces and loops (epub ahead of print October 232013)
30 Schneidman-DuhovnyD RossiA Avila-SakarA KimSJVelazquez-MurielJ StropP LiangH KrukenbergKALiaoM KimHM et al (2012) A method for integrativestructure determination of protein-protein complexesBioinformatics 28 3282ndash3289
31 PierceB and WengZ (2007) ZRANK reranking protein dockingpredictions with an optimized energy function Proteins 671078ndash1086
32 AndrusierN NussinovR and WolfsonHJ (2007) FireDockfast interaction refinement in molecular docking Proteins 69139ndash159
33 JacobsonMP PincusDL RappCS DayTJ HonigBShawDE and FriesnerRA (2004) A hierarchical approach toall-atom protein loop prediction Proteins 55 351ndash367
34 GrontD KulpDW VernonRM StraussCE and BakerD(2011) Generalized fragment picking in Rosetta design protocolsand applications PloS One 6 e23294
35 ZhangC LiuS and ZhouY (2004) Accurate and efficient loopselections by the DFIRE-based all-atom statistical potentialProtein Sci 13 391ndash399
36 PeggSC BrownSD OjhaS SeffernickJ MengECMorrisJH ChangPJ HuangCC FerrinTE andBabbittPC (2006) Leveraging enzyme structure-functionrelationships for functional inference and experimental design thestructure-function linkage database Biochemistry 45 2545ndash2555
37 MaurerSM RaiA and SaliA (2004) Finding cures for tropicaldiseases is open source an answer PLoS Med 1 e56
38 OrtiL CarbajoR PieperU EswarN MaurerS RaiATaylorG ToddM Pineda-LucenaA SaliA et al (2009) Akernel for open source drug discovery in tropical diseases PLoSNegl Trop Dis 3 e418
39 AgueroF Al-LazikaniB AslettM BerrimanM BucknerFCampbellR CarmonaS CarruthersI ChanA ChenF et al(2008) Genomic-scale prioritization of drug targets the TDRTargets database Nat Rev Drug Discov 7 900ndash907
40 Martinez-JimenezF PapadatosG YangL WallaceIMKumarV PieperU SaliA BrownJR OveringtonJP andMarti-RenomMA (2013) Target prediction for an open accessset of compounds active against Mycobacterium tuberculosisPLoS Comp Biol 9 e1003253
41 SampathkumarP LuF ZhaoX LiZ GilmoreJ BainKRutterME GheyiT SchwinnK BonannoJ et al (2010)Structure of a putative BenF-like porin from Pseudomanasfluorescens Pf-5 at 26 A resolution Proteins 78 3056ndash3062
42 PieperU ChiangR SeffernickJ BrownS GlasnerMKellyL EswarN SauderJ BonannoJ SwaminathanS et al(2009) Target selection and annotation for the structural genomicsof the amidohydrolase and enolase superfamilies J Struct FunctGenom 10 107ndash125
43 KarchinR DiekhansM KellyL ThomasDJ PieperUEswarN HausslerD and SaliA (2005) LS-SNP large-scaleannotation of coding non-synonymous SNPs based on multipleinformation sources Bioinformatics 21 2814ndash2820
44 FiserA and SaliA (2003) ModLoop automated modeling ofloops in protein structures Bioinformatics 19 2500ndash2501
45 DavisF and SaliA (2005) PIBASE a comprehensive databaseof structurally defined protein interfaces Bioinformatics 211901ndash1907
46 Marti-RenomMA PieperU MadhusudhanMS RossiAEswarN DavisFP Al-ShahrourF DopazoJ and SaliA(2007) DBAli tools mining the protein structure space NucleicAcids Res 35 W393ndashW397
47 Marti-RenomMA IlyinVA and SaliA (2001) DBAli adatabase of protein structure alignments Bioinformatics 17746ndash747
48 PieperU EswarN WebbB EramianD KellyL BarkanDCarterH MankooP KarchinR Marti-RenomM et al (2009)MODBASE a database of annotated comparative proteinstructure models and associated resources Nucleic Acids Res 37D347ndashD354
49 PieperU EswarN DavisFP BrabergH MadhusudhanMSRossiA Marti-RenomM KarchinR WebbBM EramianDet al (2006) MODBASE a database of annotated comparativeprotein structure models and associated resources Nucleic AcidsRes 34 D291ndashD295
50 BrabergH WebbB TjioeE PieperU SaliA andMadhusudhanMS (2012) SALIGN a webserver for alignmentof multiple protein sequences and structures Bioinformatics 152072ndash2073
Nucleic Acids Research 2013 9
at UC
SF Library on D
ecember 2 2013
httpnaroxfordjournalsorgD
ownloaded from
51 Schneidman-DuhovnyD HammelM and SaliA (2010) FoXS aweb server for rapid computation and fitting of SAXS ProfilesNucleic Acids Res 38 541ndash544
52 UedaY TaketomiH and GoN (1978) Studies on proteinfolding unfolding and fluctuations by computer simulation IIAThree dimensional lattice model of lysozyme Biopolymers 171531ndash1548
53 OkazakiK KogaN TakadaS OnuchicJN and WolynesPG(2006) Multiple-basin energy landscapes for large-amplitudeconformational motions of proteins Structure-based moleculardynamics simulations Proc Natl Acad Sci USA 10311844ndash11849
54 WhitfordPC NoelJK GosaviS SchugA SanbonmatsuKYand OnuchicJN (2009) An all-atom structure-based potential forproteins bridging minimal models with all-atom empiricalforcefields Proteins 75 430ndash441
55 WeinkamP ChenYC PonsJ and SaliA (2013) Impact ofmutations on the allosteric conformational equilibrium J MolBiol 425 647ndash661
56 PetoukhovMV and SvergunDI (2007) Analysis of X-ray andneutron scattering from biomacromolecular solutions Curr OpinStruct Biol 17 562ndash571
57 HuraGL MenonAL HammelM RamboRP PooleFL IITsutakawaSE JenneyFE Jr ClassenS FrankelKAHopkinsRC et al (2009) Robust high-throughput solutionstructural analyses by small angle X-ray scattering (SAXS) NatMethods 6 606ndash612
58 SvergunD BarberatoC and KochMHJ (1995) CRYSOL-aprogram to evaluate X-ray solution scattering of biologicalmacromolecules from atomic coordinates J Appl Crystallogr28 768ndash773
59 PoitevinF OrlandH DoniachS KoehlP and DelarueM(2011) AquaSAXS a web server for computation and fitting ofSAXS profiles with non-uniformally hydrated atomic modelsNucleic Acids Res 39 W184ndashW189
60 LiuH MorrisRJ HexemerA GrandisonS and ZwartPH(2012) Computation of small-angle scattering profiles with three-dimensional Zernike polynomials Acta Crystallogr A 68278ndash285
61 RavikumarKM HuangW and YangS (2013) Fast-SAXS-proa unified approach to computing SAXS profiles of DNA RNAprotein and their complexes J Chem Phys 138 024112
62 Schneidman-DuhovnyD HammelM TainerJA and SaliA(2013) Accurate SAXS profile computation and its assessment bycontrast variation experiments Biophys J 105 962ndash974
63 HammelM ReyM YuY ManiRS ClassenS LiuMPiqueME FangS MahaneyBL WeinfeldM et al (2011)XRCC4 protein interactions with XRCC4-like factor (XLF)create an extended grooved scaffold for DNA ligation and doublestrand break repair J Biol Chem 286 32638ndash32650
64 PelikanM HuraGL and HammelM (2009) Structure andflexibility within proteins as identified through small angle X-rayscattering Gen Physiol Biophys 28 174ndash189
65 GrantTD LuftJR WolfleyJR TsurutaH MartelAMontelioneGT and SnellEH (2011) Small angle X-rayscattering as a complementary tool for high-throughput structuralstudies Biopolymers 95 517ndash530
66 KonarevPV VolkovVV SokolovaAV KochMHJ andSvergunDI (2003) PRIMUS a Windows PC-based system forsmall-angle scattering data analysis J Appl Crystallogr 361277ndash1282
67 ShoichetBK and KuntzID (1991) Protein docking andcomplementarity J Mol Biol 221 327ndash346
68 PieperU SchlessingerA KloppmannE ChangGA ChouJJDumontM FoxB FrommeP HendricksonW MalkowskiMet al (2013) Coordinating the impact of structural genomics onthe human a-helical transmembrane proteome Nat Struct MolBiol 20 135ndash138
69 JohnsonM ZaretskayaI RaytselisY MerezhukYMcGinnisS and MaddenTL (2008) NCBI BLAST a betterweb interface Nucleic Acids Res 36 W5ndashW9
70 WardJJ McGuffinLJ BrysonK BuxtonBF and JonesDT(2004) The DISOPRED server for the prediction of proteindisorder Bioinformatics 20 2138ndash2139
71 DosztanyiZ CsizmokV TompaP and SimonI (2005) IUPredweb server for the prediction of intrinsically unstructured regionsof proteins based on estimated energy content Bioinformatics 213433ndash3434
72 SteentoftC VakhrushevSY JoshiHJ KongY Vester-ChristensenMB SchjoldagerKT LavrsenK DabelsteenSPedersenNB Marcos-SilvaL et al (2013) Precision mapping ofthe human O-GalNAc glycoproteome through SimpleCelltechnology EMBO J 32 1478ndash1488
73 GuptaR JungE GooleyAA WilliamsKL BrunakS andHansenJ (1999) Scanning the available Dictyostelium discoideumproteome for O-linked GlcNAc glycosylation sites using neuralnetworks Glycobiology 9 1009ndash1022
74 CormierCY ParkJG FiaccoM SteelJ HunterPKramerJ SinglaR and LaBaerJ (2011) PSIBiology-materialsrepository a biologistrsquos resource for protein expression plasmidsJ Struct Funct Genomics 12 55ndash62
75 LameschP LiN MilsteinS FanC HaoT SzaboG HuZVenkatesanK BethelG MartinP et al (2007) hORFeomev31 a resource of human open reading frames representing over10000 human genes Genomics 89 307ndash315
76 TempleG GerhardDS RasoolyR FeingoldEA GoodPJRobinsonC MandichA DergeJG LewisJ ShoafD et al(2009) The completion of the mammalian gene collection (MGC)Genome Res 19 2324ndash2333
77 SealRL GordonSM LushMJ WrightMW andBrufordEA (2011) genenamesorg the HGNC resources in 2011Nucleic Acids Res 39 D514ndashD519
78 GiffordLK CarterLG GabanyiMJ BermanHM andAdamsPD (2012) The protein structure initiative structuralbiology knowledgebase technology portal a structural biologyweb resource J Struct Funct Genomics 13 57ndash62
79 FreedEO (2001) HIV-1 replication Somatic Cell Mol Genet26 13ndash33
80 McDonaldCK and KuritzkesDR (1997) Humanimmunodeficiency virus type 1 protease inhibitors Arch IntMed 157 951ndash959
81 DragM and SalvesenGS (2010) Emerging principles inprotease-based drug discovery Nat Rev Drug Discov 9690ndash701
82 FlexnerC (1998) HIV-protease inhibitors N Engl J Med 3381281ndash1292
83 KohlNE EminiEA SchleifWA DavisLJ HeimbachJCDixonRA ScolnickEM and SigalIS (1988) Active humanimmunodeficiency virus protease is required for viral infectivityProc Natl Acad Sci USA 85 4686ndash4690
84 MurthyKH WinborneEL MinnichMD CulpJS andDebouckC (1992) The crystal structures at 22-A resolution ofhydroxyethylene-based inhibitors bound to humanimmunodeficiency virus type 1 protease show that the inhibitorsare present in two distinct orientations J Biol Chem 26722770ndash22778
85 Prabu-JeyabalanM NalivaikaE and SchifferCA (2000) Howdoes a symmetric dimer recognize an asymmetric substrate Asubstrate complex of HIV-1 protease J Mol Biol 3011207ndash1220
86 MahalingamB LouisJM HungJ HarrisonRW andWeberIT (2001) Structural implications of drug-resistantmutants of HIV-1 protease high-resolution crystal structures ofthe mutant proteasesubstrate analogue complexes Proteins 43455ndash464
87 NieZ PhenixBN LumJJ AlamA LynchDH BeckettBKrammerPH SekalyRP and BadleyAD (2002) HIV-1protease processes procaspase 8 to cause mitochondrial release ofcytochrome c caspase cleavage and nuclear fragmentation CellDeath Differ 9 1172ndash1184
88 Algeciras-SchimnichA Belzacq-CasagrandeAS BrenGDNieZ TaylorJA RizzaSA BrennerC and BadleyAD(2007) Analysis of HIV protease killing through caspase 8 revealsa novel interaction between caspase 8 and mitochondria OpenVirol J 1 39ndash46
89 NieZ BrenGD RizzaSA and BadleyAD (2008) HIVprotease cleavage of procaspase 8 is necessary for death of HIV-infected cells Open Virol J 2 1ndash7
10 Nucleic Acids Research 2013
at UC
SF Library on D
ecember 2 2013
httpnaroxfordjournalsorgD
ownloaded from
90 CastelloA FrancoD Moral-LopezP BerlangaJJAlvarezE WimmerE and CarrascoL (2009) HIV- 1 proteaseinhibits Cap- and poly(A)-dependent translation upon eIF4GIand PABP cleavage PloS One 4 e7997
91 ImpensF TimmermanE StaesA MoensK ArienKKVerhasseltB VandekerckhoveJ and GevaertK (2012) Acatalogue of putative HIV-1 protease host cell substrates BiolChem 393 915ndash931
92 Kotik-KoganO ValentineER SanfeliceD ConteMR andCurryS (2008) Structural analysis reveals conformationalplasticity in the recognition of RNA 3rsquo ends by the human Laprotein Structure 16 852ndash862
93 NakaiK KideraA and KanehisaM (1988) Cluster analysis ofamino acid indices for prediction of protein structure andfunction Protein Eng 2 93ndash100
94 TomiiK and KanehisaM (1996) Analysis of amino acid indicesand mutation matrices for sequence comparison and structureprediction of proteins Protein Eng 9 27ndash36
95 JonesDT (1999) Protein secondary structure prediction basedon position-specific scoring matrices J Mol Biol 292 195ndash202
96 BreimanL and SchapireE (2001) Random forests MachLearn 45 5ndash32
97 BensonDA Karsch-MizrachiI LipmanDJ OstellJ andSayersEW (2010) GenBank Nucleic Acids Res 38 D46ndashD51
98 KraulisPJ (1991) MOLSCRIPT a program to produce bothdetailed and schematic plorts of protein structures J ApplCrystallogr 24 946ndash950
99 MerrittEA and BaconDJ (1997) Raster3D photorealisticmolecular graphics Methods Enzymol 277 505ndash524
100 PettersenEF GoddardTD HuangCC CouchGSGreenblattDM MengEC and FerrinTE (2004) UCSFChimerandasha visualization system for exploratory research andanalysis J Comput Chem 25 1605ndash1612
101 CapraJA LaskowskiRA ThorntonJM SinghM andFunkhouserTA (2009) Predicting protein ligand binding sitesby combining evolutionary sequence conservation and 3Dstructure PLoS Comp Biol 5 e1000585
102 HenrickK FengZ BluhmWF DimitropoulosDDoreleijersJF DuttaS Flippen-AndersonJL IonidesJKamadaC KrissinelE et al (2008) Remediation of the proteindata bank archive Nucleic Acids Res 36 D426ndashD433
103 WuCH ApweilerR BairochA NataleDA BarkerWCBoeckmannB FerroS GasteigerE HuangH LopezR et al(2006) The Universal Protein Resource (UniProt) an expandinguniverse of protein information Nucleic Acids Res 34D187ndashD191
104 RheadB KarolchikD KuhnRM HinrichsAS ZweigASFujitaPA DiekhansM SmithKE RosenbloomKRRaneyBJ et al (2010) The UCSC Genome Browser databaseupdate 2010 Nucleic Acids Res 38 D613ndashD619
105 HunterS ApweilerR AttwoodTK BairochA BatemanABinnsD BorkP DasU DaughertyL DuquenneL et al(2009) InterPro the integrative protein signature databaseNucleic Acids Res 37 D211ndashD215
106 KleinTE ChangJT ChoMK EastonKL FergersonRHewettM LinZ LiuY LiuS OliverDE et al (2001)Integrating genotype and phenotype information an overview ofthe PharmGKB project Pharmacogenetics research network andknowledge base Pharmacogenomics J 1 167ndash170
107 HaasJ RothS ArnoldK KieferF SchmidtT BordoliLand SchwedeT (2013) The Protein Model Portalmdashacomprehensive resource for protein structure and modelinformation Database 2013 bat031
108 SchwedeT SaliA HonigB LevittM BermanH JonesDBrennerS BurleyS DasR DokholyanN et al (2009)Outcome of a workshop on applications of protein models inbiomedical research Structure 17 151ndash159
109 BairochA ApweilerR WuCH BarkerWC BoeckmannBFerroS GasteigerE HuangH LopezR MagraneM et al(2005) The Universal Protein Resource (UniProt) Nucleic AcidsRes 33 D154ndashD159
110 GigliaE (2009) New year new PubMed Eur J Phys RehabilMed 45 155ndash159
Nucleic Acids Research 2013 11
at UC
SF Library on D
ecember 2 2013
httpnaroxfordjournalsorgD
ownloaded from

the average main-chain root-mean-square-deviation(RMSD) of the best-scored conformations by SOAP-Loop is 15 A close to the average RMSD of the best-sampled conformations (12 A) and significantly betterthan that selected by the Rosetta (34) (21 A) DFIRE(35) (23 A) DOPE (25 A) (25) and PLOP scoring func-tions (30 A) The SOAP-PP score is used by ourAllosMod-FoXS server (below) We are incorporatingSOAP scores into the modeling and model assessmentmodules of ModPipe
ModBase model sets
Models in ModBase are organized in datasets Because ofthe rapid growth of the public sequence databases weconcentrate our efforts on adding datasets that areuseful for specific projects rather than attempt to modelall known protein sequences based on all detectablyrelated known structures Currently ModBase includes amodel dataset for each of 65 complete genomes as well asdatasets for all sequences in the Structure FunctionLinkage Database (SFLD) (36) and for the completeSwissProtTrEMBL database as of 2005 (httpsalilaborgmodbasestatistics) Additionally available modelsfor new SFLD sequences are added weekly Togetherwith other project-oriented datasets ModBase currentlycontains 29 million reliable models for domains in 47million unique sequences The lsquoNominate a modelomersquofeature allows community users to request modeling ofadditional complete genomes as our computational re-sources allow This feature has been used for exampleto support the Tropical Disease Initiative (httptropicaldiseaseorg) (37ndash40)
ModWeb comparative modeling web-server
The ModWeb comparative modeling web-server is anintegral module of ModBase (httpsalilaborgmodweb)(17) In the default mode ModWeb accepts one or moresequences in the FASTA format followed by calculatingand evaluating their models using ModPipe based on thebest available templates from the PDB AlternativelyModWeb also accepts a protein structure as input(template-based calculation) calculates a multiplesequence profile and identifies all homologous sequencesin the UniProtKB database followed by modeling thesehomologs based on the user-provided structure This al-ternative protocol is a useful tool for measuring the impactof new structures such as those generated by structuralgenomics efforts (41) Moreover new members ofsequence superfamilies with at least one known structurecan be identified (42)
In addition to anonymous access registered users getunified access to all their ModWeb datasets and cansubmit template-based calculations
ASSOCIATED RESOURCES
A number of web services are associated with ModBaseSome of these are tightly integrated with ModBasewhereas others contain data that are derived throughModBase [eg single-nucleotide polymorphism (SNP)
annotations created by LS-SNP (43)] We alreadydescribed the interactions of ModBase with theModLoop server for loop modeling in protein structures(httpsalilaborgmodloop) (44) the PIBASE database ofproteinndashprotein interaction (httpsalilaborgpibase) (45)the DBAli database of structural alignments (httpsalilaborgdbali) (4647) the LS-SNP database of struc-tural annotations of human non-synonymous SNPs(httpsalilaborgLS-SNP) (434849) the SALIGNserver for multiple sequence and structure alignment(httpsalilaborgsalign) (2750) the ModEval server forpredicting the accuracy of protein structure models(httpsalilaborgmodeval) (27) the PCSS server for pre-dicting which peptides bind to a given protein (httpsalilaborgpcss) (27) and the FoXS server for calculatingand fitting small angle X-ray scattering profiles (httpsalilaborgfoxs) (2751) Here we describe several newservers that interact with ModBase
AllosMod a web-server for modeling ligand-inducedprotein dynamics
Conformational transitions of biomolecules are key tomany aspects of biology These dynamic changes span abroad range of time and size scales and include proteinfolding aggregation induced fit and allosteryThe AllosMod web server (httpsalilaborgallosmod)
predicts conformational changes that occur in the nativeensemble such as allosteric conformational transitionsThe input is one or more macromolecular coordinatefiles (including DNA RNA and sugar molecules) andthe corresponding sequence(s) The output is a set of mo-lecular dynamics trajectories based on a simplified energylandscape The documentation includes analysis examplesto help the user in interpreting the expected outputCarefully designed energy landscapes allow efficient mo-lecular dynamics sampling at constant temperaturesthereby providing ergodic sampling of conformationalspace AllosMod energy landscapes are constructedusing contacts in crystal structure(s) to define the energeticminima This model is referred to as a structure-based orGo model (52ndash54) The energy landscapes are sampledusing many short constant temperature moleculardynamics simulations Sampling occurs quickly even forlarge systems with up to 10 000 residues because thesimplified landscapes can be stored in memory The usercan also download Python scripts necessary to run andmodify the simulations which are performed usingModeller (18)The capabilities of the AllosMod server have been
demonstrated in a study of allosteric systems withknown effector bound and unbound crystal structures(1455) Effector bound and unbound simulations are per-formed using a landscape with a single minimum for theinteractions in the effector binding site corresponding tothe bound or unbound structure and dual minima forinteractions in the rest of the protein corresponding tothe bound and unbound structures AllosMod can alsobe used to predict coupling (ie G) between amutation site and the effector binding site
Nucleic Acids Research 2013 3
at UC
SF Library on D
ecember 2 2013
httpnaroxfordjournalsorgD
ownloaded from
A family of web-servers for computation and applicationof SAXS profiles
SAXS is a common technique for low-resolution struc-tural characterization of molecules in solution (5657)SAXS experiments determine the scattering intensity ofa molecule as a function of spatial frequency resultingin a SAXS profile that can be easily converted into theapproximate distribution of atomic distances in themeasured system The experiments can be performedwith the protein sample in solution and usually takeonly a few minutes on a well-equipped synchrotronbeamline (57) Here we describe new features of theFoXS server for calculating and fitting SAXS profilesthe AllosMod-FoXS server that predicts the structuralensemble that best fits a given SAXS profile theFoXSDock server that performs proteinndashprotein dockingfiltered by a SAXS profile and the SAXS Merge server formerging SAXS profiles measured at different concentra-tions and exposure timesFoXS (httpsalilaborgfoxs) is a rapid and accurate
server for calculating a SAXS profile of a given molecularstructure (51) The input is one or more macromolecularcoordinate files or PDB codes and an experimental profileThe output is a calculated SAXS profile for each inputstructure fitted onto the experimental profile Themethod explicitly computes all inter-atomic distancesand models the first solvation layer based on solvent ac-cessibility FoXS was tested on 11 protein 1 DNA and 2RNA structures revealing superior accuracy and speedversus CRYSOL (58) AquaSAXS (59) the Zernike poly-nomials-based method (60) and Fast-SAXS-pro (61) Inaddition we demonstrated a significant correlation ofthe SAXS score with the accuracy of a structural model(62) We have recently updated the server to an interactiveuser interface profiles are displayed via an HTML5canvas element and structures are shown in a Jmolwindow (Figure 1) If the user uploads multiple structuresthe server automatically performs the minimal ensemblecomputation with Minimal Ensemble Search (MES) (64)AllosMod-FoXS (httpsalilaborgallosmod-foxs) is a
server that predicts the structural ensemble that best fitsa given SAXS profile The input is one or more macromol-ecular coordinate files the corresponding sequence(s) andan lsquoexperimentalrsquo SAXS profile The output is the struc-tural ensemble that best fits the input SAXS profile Theserver relies on AllosMod conformational sampling (14)FoXS calculations of theoretical SAXS profiles minimalensemble computation with MES (64) and the SOAP-PPscore The server was motivated to describe conformationalchanges in proteins such as the allostery based on bothmodeling considerations (as represented by AllosMod) andexperimental SAXS data (as represented by FoXS)The AllosMod-FoXS server uses various sampling al-
gorithms in AllosMod to generate structures that aredirectly entered into FoXS Because FoXS explicitlycomputes all inter-atomic distances and models the firstsolvation layer based on solvent accessibility it can beused to score the similarity of the experimental SAXSprofile to the predicted SAXS profiles corresponding tostructures from the AllosMod simulations In addition
to the FoXS score each conformation is assessed forstructural quality using the SOAP-PP score These twoscores are combined to predict structures that collectivelybest explain the experimental SAXS profile
FoXSDock (httpsalilaborgfoxsdock) is a web serverthat uses SAXS profiles to filter the models produced byproteinndashprotein docking It accepts as input structures oftwo docked proteins and an experimental SAXS profile oftheir complex The output is a set of docking models andtheir calculated SAXS profiles fitted onto the experimentalprofile Although many structures of single protein compo-nents are becoming available structural characterization oftheir complexes remains challenging Although generalproteinndashprotein docking methods suffer from large errorsbecause of protein flexibility and inaccurate scoring func-tions However when additional information such as aSAXS profile is available it is possible to significantlyincrease the accuracy of the computational docking
FoXSDock combines rigid global docking byPatchDock filtering of the models based on the SAXSprofile and interface refinement by FireDock (15) Theapproach was benchmarked on 176 protein complexeswith simulated SAXS profiles as well as on 7 complexeswith experimentally determined SAXS profiles (30) Wheninduced fit is lt15 A interface Ca RMSD and the fractionof residues missing from the component structures islt3 FoXSDock can find a model close to the nativestructure within the top 10 predictions in 77 of thecases in comparison docking alone succeeds in only34 of the cases
SAXS Merge (httpsalilaborgsaxsmerge) is a webserver that uses automated statistical methods to mergeSAXS profiles determined at different concentrationsand exposure times High-throughput SAXS data collec-tion requires robust accurate and automated tools fordata processing and merging (5765) However SAXSdata are generally processed highly subjectively oftenmanually with the aid of the PRIMUS software package(66) The operation requires an experienced user who canmanually inspect each profile to be merged and decidewhether the SAXS profiles agree or not The SAXSMerge web-server alleviates user intervention through anautomated and statistically principled merging procedurebased on a Bayesian approach (Spill et al submitted) TheSAXS Merge web server was successfully validated on abenchmark of 16 SAXS datasets The input file consistsonly of the buffer-subtracted SAXS profiles in a commonthree-column text format The output comprises (i) a listof individual q points with associated source profiles (ii)an estimate of the mean profile along with a 95Bayesian credible interval and (iii) the most suitable para-metric mean function for the resulting profile an estimateof the noise level in the pooled dataset The output isvisualized interactively through the web-browser and canalso be downloaded
Pose amp rank a web-server for scoring proteinndashligandcomplexes
Molecular recognition between proteins and ligands playsan important role in many biological processes Predicting
4 Nucleic Acids Research 2013
at UC
SF Library on D
ecember 2 2013
httpnaroxfordjournalsorgD
ownloaded from
the structures of proteinndashligand complexes and findingligands by virtual screening of small molecule databasesare two long-standing goals in molecular biophysics andmedicinal chemistry Solving both problems requires thedevelopment of an accurate and efficient scoring functionto assess proteinndashligand interactions
The Pose amp Rank web server (httpsalilaborgposeandrank) (16) provides access to two atomicdistance-dependent statistical scoring functions based onprobability theory that can be used in proteinndashliganddocking The PoseScore was optimized for recognizingnative binding geometries of ligands from other posesand the RankScore was optimized for distinguishingligands from non-binding molecules The server acceptsas input a coordinate file of the target protein structurein the PDB format and docking poses of small moleculesThe output is a list of scores for each proteinndashsmallmolecule complex PoseScore ranks a near-nativebinding pose the best top 5 and top 10 for 88 97and 99 of targets respectively RankScore improvesthe overall ligand enrichment (logAUC) and early
enrichment (EF1) scores computed by DOCK 36 (67)for 68 and 74 of targets respectively The Pose ampRank resource can contribute to many applicationssuch as selecting ligand candidates from virtual screeningfor experimental testing predicting the binding geometriesfor known ligands and suggesting binding site mutationsthat alter the ligand binding properties and consequentlyprotein functions
APPLICATION EXAMPLES
Coordinating the impact of structural genomics on thehuman a-helical transmembrane proteome
With the recent successes in determining membraneprotein structures we explored the tractability of deter-mining representatives for the entire human transmem-brane proteome (68) (httpsalilaborgmembrane) Thisproteome contains 2925 unique integral a-helical trans-membrane domain sequences that cluster into 1201families sharing gt25 sequence identity We assessed
Figure 1 The computed profiles for filament models of the XLFndashXRCC4 complex (63) are fitted to the experimental SAXS profile with FoXS Theinteractive user interface displays the profiles in the left and the models in the right using the same color for each modelprofile pair The table belowthe panels displays the fit parameters and includes buttons to simultaneously show or hide each modelprofile pair Clicking on Minimal EnsembleSearch (MES) results (above the display panel) takes the user to the MES output page
Nucleic Acids Research 2013 5
at UC
SF Library on D
ecember 2 2013
httpnaroxfordjournalsorgD
ownloaded from
the modeling coverage by processing all sequencesthrough ModPipe and analyzing the resulting ModBasedataset We then clustered all sequences [BlastClust(69)]annotated them with cluster size modeling coverage andnumber of predicted transmembrane helices Finally weexplored several target selection strategies Structures of100 optimally selected targets would increase the fractionof modelable human alpha-helical transmembranedomains from 26 to 58 thus providing structurefunction information not otherwise availableTo leverage the results of this study the PSIBiology
Network (httpwwwnigmsnihgovResearchFeaturedProgramsPSIpsi_biology) including high-throughputand membrane PSI centers as well as the StructuralGenomics Consortium is attempting to express nearly100 human transmembrane proteins using their standardhigh-throughput methods The goal of this survey is todetermine which methods best express certain classes oftransmembrane proteins The sequences of our previousanalysis were further annotated by fraction of predicteddisordered regions (7071) number of glycosylation sites(27273) clone availability (74ndash76) HUGO annotations(77) sequence length and several additional metricsEighty-six targets were hand-picked from the largestclusters to represent a diverse selection of humanmembrane proteins with maximum coverage of the trans-membrane proteome Cloning expression and solubilityexperiments of these targets using the pipelines of the 10participating research groups are currently in progressParticipants also use shared and individual sets of sixcontrols A standard method will be used by all to visual-ize the protein bands to quantify yield A final full com-parison will determine the most successful methods foreach representative transmembrane protein Progress ofthe survey is cataloged by the portal of the ProteinStructure Initiative Structural Biology Knowledgebase[PSI SBKB (78) httphmppssbkborg] and will be ac-cessible to the public after the conclusion of the experi-ment A final publication will summarize the surveyrsquosfindings
Structural determinants of HIV-1 protease
The maturation of the HIV virion is facilitated by thecleavage of the Gag and Pol polyproteins (79) Ahomodimeric aspartic protease (HIV-1 protease) catalyzesthese processing events at 10 non-homologous sites and isthe target of some of the most effective antiretroviraldrugs (80ndash82) These sites are eight amino acid residuesin length the cleavage occurs between the third and fourthresidues (83ndash86) In addition to processing viral proteinsHIV-1 protease cleaves several human proteins during in-fection such as the eukaryotic translation initiation factor3 subunit D (eIF3D) (87ndash90)To predict cleavage sites in human proteins we began
by examining sequence and structural features of gt120cellular substrates of HIV-1 protease that were recentlyidentified in vitro (91) (for an example see Figure 2)First every residue of the cleaved and non-cleavedoctapeptides was encoded using gt512 physicochemicalamino acid indices (9394) To account for cooperativity
between residues in different positions of the octapeptidefrequencies of dipeptides and gapped dipeptides (ie twospecific residues separated by any residue) were also usedto train machine learning algorithms for binary classifica-tion Second a greedy feature selection procedure wasapplied to determine features of octapeptides importantfor protease activity Interestingly although featuresencoding known viral cleavage motif ELLE were import-ant for classification most discriminating features encodestructural preferences of amino acid residues in the secondand fifth positions of the octapeptide Therefore wecreated a ModBase dataset of 405 models for 118human proteins cleaved in vitro PSI-Pred (95) was usedto predict secondary structure elements for protein regionswithout templates Analysis of the structural modelsshowed the enrichment of alpha+beta protein class(SCOP ID=53 931) among cleaved proteins and coiledsecondary structure (41) among cleaved sites Weadded structure-based descriptors of cleaved and non-cleaved sites to the sequence-based features and assessedclassifiersrsquo performance in a 5-fold cross-validation pro-cedure The average area under the receiver operatingcharacteristic curve for the classifier trained with theRandom Forest algorithm(96) was 0965 (72 sensitivityand 98 specificity) and the entire human proteome wasscanned for putative human substrates of the HIV-1protease We are currently experimentally validatingseveral of the predicted cleavage sites
ACCESS AND INTERFACE
Direct access
The main access to ModBase is through its web interfaceat httpsalilaborgmodbase by querying with Uniprot-KB (23) and GI (97) identifiers gene names annotationkeywords PDB(1) codes dataset names organism namessequence similarity to the modeled sequences [BLAST(19)]and model-specific criteria such as model reliability modelsize and targetndashtemplate sequence identity Additionally it
Figure 2 Cleavage of human proteins by the HIV-1 protease crystalstructure of the N-terminal domain of human Lupus La protein (92)(left) Residues of the cleavage site (Ile-Asp-Tyr-Tyr-Phe-Gly-Glu-Phe)are shown in orange Scissile bond between Tyr and Phe in the alpha-helix is cleaved by the HIV-1 protease in vitro
6 Nucleic Acids Research 2013
at UC
SF Library on D
ecember 2 2013
httpnaroxfordjournalsorgD
ownloaded from
is possible to retrieve coordinate files and alignment filesof all models for a specific sequence as text files Metadatafor all current ModBase models (updated weekly) allgenome datasets and several additional project specificdatasets are also available from our FTP server (ftpsalilaborgdatabasesmodbaseprojects)
The output of a search is displayed on pages withvarying amounts of information about the modeled
sequences template structures alignments and functionalannotations Output examples from a search resulting inone model are shown in Figure 3 A ribbon diagram of themodel with the highest targetndashtemplate sequence identityis displayed by default together with some details of themodeling calculation Ribbon thumbprints of additionalmodels for this sequence link to corresponding pages withmore information Ribbon diagrams are generated on the
Figure 3 ModBase interface elements Search Form search options are available through the pull-down menu A quick overview of the availablerepresentations is displayed below the search form Model Details Sketch the Model details page provides information for all models of a givensequences The sketch comprises two parts the model coverage sketch that indicates the sequence coverage by all models (top line) and the sequencecoverage by the current model (second line) and a ribbon diagram of the current model Other models are available via thumbprints Update and
Remodel this box shows the date of the last modeling calculation for the current sequence and allows the user to request an update Chimera
Visualization the visualization includes the model and template structures and the alignment Cross-references links to the PMP UniProtKBGenbank UCSC Genome Browser and other databases Model Details Options the pull-down menu switches between representations and allowsdownloads of coordinate and alignment files Quality Criteria red indicates unreliable green reliable Model Overview a different representation forseveral sequences gives a quick overview on modeling coverage and quality Chimera Cavity View visualizes cavities predicted by ConCavity
Nucleic Acids Research 2013 7
at UC
SF Library on D
ecember 2 2013
httpnaroxfordjournalsorgD
ownloaded from
fly using Molscript (98) and Raster3D (99) A pull-downmenu provides links to additional functionalities the SNPmodule retrieval of coordinate and alignment files mo-lecular visualization by UCSF Chimera (100) that allowsthe user to display template and model coordinatestogether with their alignment and Chimera visualizationof predicted cavities [ConCavity (101)] If mutation infor-mation is available for a protein sequence links to thedetails are provided in the cross-references sectionAdditionally cross-references to various other databasesincluding PDB (102) UniProtKB (103) the UCSCGenome Browser (104) EBIrsquos InterPro (105)PharmGKB (106) and SFLD (36) are given OtherModBase pages provide overviews of more than onesequence or structure All ModBase pages are intercon-nected to facilitate easy navigation between differentviews
Access through external databases
The Protein Model PortalThe Protein Model Portal (PMP) has become a valuableoption for accessing ModBase models (httpproteinmo-delportalorg) (107) The PMP is a single point of entry foraccessing protein structure models from a number of dif-ferent databases PMP queries all participating sourcemodel databases and serves the user with the model co-ordinates alignments and quality criteria from a centrallocation It has been developed as a module of the ProteinStructure Initiative Knowledgebase (PSI KB) (79108)The PMP provides a flexible search interface for alldeposited models quality estimation cross-links to othersequence and structure databases annotations ofsequences and their models a central point of entry tocomparative modeling servers (including ModWeb) andquality estimation servers (including ModEval) anddetailed tutorials on all aspects of comparativemodeling Currently the PMP retrieves 450 000ModBase model coordinate files each week fromModBaseA sister web-service to PMP CAMEO (httpcameo3d
org) (107) continuously evaluates the accuracy and reli-ability of several comparative protein structure predictionservers in a fully automated manner The ModWeb servercurrently participates in the testing mode and is expectedto move into the production mode in the first quarter of2014
Access through external databasesModBase models in academic and public datasets arealso directly accessible from several databases includingthe PMP (107) UniProtKB (109) PIRrsquos iProClass(103) EBIrsquos InterPro (105) the UCSC Genome Browser(104) PubMed (LinkOut) (110) PharmGKB (106) andSFLD (36)
FUTURE DIRECTIONS
ModBase will grow by adding models calculated ondemand by external users (using ModWeb) as well asour own calculations of model datasets that are needed
for our research projects (using ModPipe ModWeb orModeller) These updates will reflect improvements inthe methods and software used for calculating themodels as well as new template structures in the PDBand new sequences in UniProtKB In the future weexpect that most of the users will access ModBasemodels through the PMP
CITATION
Users of ModBase are requested to cite this article in theirpublications
ACKNOWLEDGEMENTS
For linking to ModBase from their databases the authorsthank Torsten Schwede and Jurgen Haas (Protein ModelPortal) David Haussler and Jim Kent (UCSC GenomeBrowser) Rolf Apweiler Maria Jesus Martin and ClaireOrsquoDonovan (UniProt) Rolf Apweiler Sarah Hunter(InterPro) Patsy Babbitt (SFLD) Russ Altman(PharmGKB) and Kathy Wu (PIRiProClass) We arealso grateful for computing hardware gifts from MikeHomer Ron Conway NetApp IBM Hewlett Packardand Intel
FUNDING
National Institutes of Health [U54 GM094662 U54GM094625 U54 GM093342 MINOS R01GM105404 toJAT and MH] Sandler Family Supporting Foundation(AS) Department of Energy Lawrence BerkeleyNational Lab IDAT program (to JAT and MH)European Union [FP7-IDEAS-ERC 294809 to MN]The authors thank Tom Ferrin and the UCSF Resourcefor Biocomputing Visualization and Informatics formaking UCSF Chimera (supported by [NIGMS P41-GM103311]) available to the ModBase database andtools Funding for open access charge NIH
Conflict of interest statement None declared
REFERENCES
1 RosePW BiC BluhmWF ChristieCH DimitropoulosDDuttaS GreenRK GoodsellDS PrlicA QuesadaM et al(2013) The RCSB Protein Data Bank new resources for researchand education Nucleic Acids Res 41 D475ndashD482
2 The UniProt Consortium (2011) Ongoing and futuredevelopments at the Universal Protein Resource Nucleic AcidsRes 39 D214ndashD219
3 BensonDA Karsch-MizrachiI ClarkK LipmanDJ OstellJand SayersEW (2012) GenBank Nucleic Acids Res 40D48ndashD53
4 BakerD and SaliA (2001) Protein structure prediction andstructural genomics Science 294 93ndash96
5 EswarN WebbB Marti-RenomMA MadhusudhanMSEramianD ShenMY PieperU and SaliA (2006)Comparative protein structure modeling using MODELLERCurr Protoc Bioinformatics Chapter 5 Unit 561ndash5630
6 EswarN EramianD WebbB ShenMY and SaliA (2008)Protein structure modeling with MODELLER Methods MolBiol 426 145ndash159
8 Nucleic Acids Research 2013
at UC
SF Library on D
ecember 2 2013
httpnaroxfordjournalsorgD
ownloaded from
7 SchwedeT SaliA EswarN and PeitschMC (2008)In SchwedeT and PeitschMC (eds) Computational StructuralBiology World Scientific Publishing Ltd Singapore pp 3ndash35
8 ForrestLR TangCL and HonigB (2006) On the accuracy ofhomology modeling and sequence alignment methods applied tomembrane proteins Biophys J 91 508ndash517
9 LiuT TangGW and CapriottiE (2011) Comparativemodeling the state of the art and protein drug target structureprediction Comb Chem High Throughput Screen 14 532ndash547
10 FiserA (2010) Template-based protein structure modelingMethods Mol Biol 673 73ndash94
11 DagaPR PatelRY and DoerksenRJ (2010) Template-basedprotein modeling recent methodological advances Curr TopMed Chem 10 84ndash94
12 HillischA PinedaLF and HilgenfeldR (2004) Utility ofhomology models in the drug discovery process Drug DiscovToday 9 659ndash669
13 WallnerB and ElofssonA (2005) All are not equal abenchmark of different homology modeling programs ProteinSci 14 1315ndash1327
14 WeinkamP PonsJ and SaliA (2012) Structure-based model ofallostery predicts coupling between distant sites Proc Natl AcadSci USA 109 4875ndash4880
15 Schneidman-DuhovnyD HammelM and SaliA (2011)Macromolecular docking restrained by a small angle X-rayscattering profile J Struct Biol 3 461ndash471
16 FanH SchneidmanD IrwinJJ DongG ShoichetB andSaliA (2011) Statistical potential for modeling and rankingprotein-ligand interactions J Chem Inf Model 51 3078ndash3092
17 EswarN JohnB MirkovicN FiserA IlyinVA PieperUStuartAC Marti-RenomMA MadhusudhanMSYerkovichB et al (2003) Tools for comparative protein structuremodeling and analysis Nucleic Acids Res 31 3375ndash3380
18 SaliA and BlundellTL (1993) Comparative protein modellingby satisfaction of spatial restraints J Mol Biol 234 779ndash815
19 AltschulSF MaddenTL SchafferAA ZhangJ ZhangZMillerW and LipmanDJ (1997) Gapped BLAST and PSI-BLAST a new generation of protein database search programsNucleic Acids Res 25 3389ndash3402
20 RemmertM BiegertA HauserA and SodingJ (2012) HHblitslightning-fast iterative protein sequence searching by HMM-HMM alignment Nat Methods 9 173ndash175
21 SodingJ (2005) Protein homology detection by HMM-HMMcomparison Bioinformatics 21 951ndash960
22 SmithTF and WatermanMS (1981) Identification of commonmolecular subsequences J Mol Biol 147 195ndash197
23 EswarN WebbB Marti-RenomM MadhusudhanMEramianD ShenM PieperU and SaliA (2006) Comparativeprotein structure modeling using Modeller Curr ProtocBioinformatics Chapter 5 Unit 56
24 Marti-RenomMA MadhusudhanMS and SaliA (2004)Alignment of protein sequences by their profiles Protein Sci 131071ndash1087
25 ShenMY and SaliA (2006) Statistical potential for assessmentand prediction of protein structures Protein Sci 15 2507ndash2524
26 MeloF and SaliA (2007) Fold assessment for comparativeprotein structure modeling Protein Sci 16 2412ndash2426
27 PieperU WebbBM BarkanDT Schneidman-DuhovnyDSchlessingerA BrabergH YangZ MengEC PettersenEFHuangCC et al (2011) ModBase a database of annotatedcomparative protein structure models and associated resourcesNucleic Acids Res 39 465ndash474
28 EramianD EswarN ShenM and SaliA (2008) How well canthe accuracy of comparative protein structure models bepredicted Protein Sci 17 1881ndash1893
29 DongGQ FanH Schneidman-DuhovnyD WebbB andSaliA (2013) Optimized atomic statistical potentials Assessmentof protein interfaces and loops (epub ahead of print October 232013)
30 Schneidman-DuhovnyD RossiA Avila-SakarA KimSJVelazquez-MurielJ StropP LiangH KrukenbergKALiaoM KimHM et al (2012) A method for integrativestructure determination of protein-protein complexesBioinformatics 28 3282ndash3289
31 PierceB and WengZ (2007) ZRANK reranking protein dockingpredictions with an optimized energy function Proteins 671078ndash1086
32 AndrusierN NussinovR and WolfsonHJ (2007) FireDockfast interaction refinement in molecular docking Proteins 69139ndash159
33 JacobsonMP PincusDL RappCS DayTJ HonigBShawDE and FriesnerRA (2004) A hierarchical approach toall-atom protein loop prediction Proteins 55 351ndash367
34 GrontD KulpDW VernonRM StraussCE and BakerD(2011) Generalized fragment picking in Rosetta design protocolsand applications PloS One 6 e23294
35 ZhangC LiuS and ZhouY (2004) Accurate and efficient loopselections by the DFIRE-based all-atom statistical potentialProtein Sci 13 391ndash399
36 PeggSC BrownSD OjhaS SeffernickJ MengECMorrisJH ChangPJ HuangCC FerrinTE andBabbittPC (2006) Leveraging enzyme structure-functionrelationships for functional inference and experimental design thestructure-function linkage database Biochemistry 45 2545ndash2555
37 MaurerSM RaiA and SaliA (2004) Finding cures for tropicaldiseases is open source an answer PLoS Med 1 e56
38 OrtiL CarbajoR PieperU EswarN MaurerS RaiATaylorG ToddM Pineda-LucenaA SaliA et al (2009) Akernel for open source drug discovery in tropical diseases PLoSNegl Trop Dis 3 e418
39 AgueroF Al-LazikaniB AslettM BerrimanM BucknerFCampbellR CarmonaS CarruthersI ChanA ChenF et al(2008) Genomic-scale prioritization of drug targets the TDRTargets database Nat Rev Drug Discov 7 900ndash907
40 Martinez-JimenezF PapadatosG YangL WallaceIMKumarV PieperU SaliA BrownJR OveringtonJP andMarti-RenomMA (2013) Target prediction for an open accessset of compounds active against Mycobacterium tuberculosisPLoS Comp Biol 9 e1003253
41 SampathkumarP LuF ZhaoX LiZ GilmoreJ BainKRutterME GheyiT SchwinnK BonannoJ et al (2010)Structure of a putative BenF-like porin from Pseudomanasfluorescens Pf-5 at 26 A resolution Proteins 78 3056ndash3062
42 PieperU ChiangR SeffernickJ BrownS GlasnerMKellyL EswarN SauderJ BonannoJ SwaminathanS et al(2009) Target selection and annotation for the structural genomicsof the amidohydrolase and enolase superfamilies J Struct FunctGenom 10 107ndash125
43 KarchinR DiekhansM KellyL ThomasDJ PieperUEswarN HausslerD and SaliA (2005) LS-SNP large-scaleannotation of coding non-synonymous SNPs based on multipleinformation sources Bioinformatics 21 2814ndash2820
44 FiserA and SaliA (2003) ModLoop automated modeling ofloops in protein structures Bioinformatics 19 2500ndash2501
45 DavisF and SaliA (2005) PIBASE a comprehensive databaseof structurally defined protein interfaces Bioinformatics 211901ndash1907
46 Marti-RenomMA PieperU MadhusudhanMS RossiAEswarN DavisFP Al-ShahrourF DopazoJ and SaliA(2007) DBAli tools mining the protein structure space NucleicAcids Res 35 W393ndashW397
47 Marti-RenomMA IlyinVA and SaliA (2001) DBAli adatabase of protein structure alignments Bioinformatics 17746ndash747
48 PieperU EswarN WebbB EramianD KellyL BarkanDCarterH MankooP KarchinR Marti-RenomM et al (2009)MODBASE a database of annotated comparative proteinstructure models and associated resources Nucleic Acids Res 37D347ndashD354
49 PieperU EswarN DavisFP BrabergH MadhusudhanMSRossiA Marti-RenomM KarchinR WebbBM EramianDet al (2006) MODBASE a database of annotated comparativeprotein structure models and associated resources Nucleic AcidsRes 34 D291ndashD295
50 BrabergH WebbB TjioeE PieperU SaliA andMadhusudhanMS (2012) SALIGN a webserver for alignmentof multiple protein sequences and structures Bioinformatics 152072ndash2073
Nucleic Acids Research 2013 9
at UC
SF Library on D
ecember 2 2013
httpnaroxfordjournalsorgD
ownloaded from
51 Schneidman-DuhovnyD HammelM and SaliA (2010) FoXS aweb server for rapid computation and fitting of SAXS ProfilesNucleic Acids Res 38 541ndash544
52 UedaY TaketomiH and GoN (1978) Studies on proteinfolding unfolding and fluctuations by computer simulation IIAThree dimensional lattice model of lysozyme Biopolymers 171531ndash1548
53 OkazakiK KogaN TakadaS OnuchicJN and WolynesPG(2006) Multiple-basin energy landscapes for large-amplitudeconformational motions of proteins Structure-based moleculardynamics simulations Proc Natl Acad Sci USA 10311844ndash11849
54 WhitfordPC NoelJK GosaviS SchugA SanbonmatsuKYand OnuchicJN (2009) An all-atom structure-based potential forproteins bridging minimal models with all-atom empiricalforcefields Proteins 75 430ndash441
55 WeinkamP ChenYC PonsJ and SaliA (2013) Impact ofmutations on the allosteric conformational equilibrium J MolBiol 425 647ndash661
56 PetoukhovMV and SvergunDI (2007) Analysis of X-ray andneutron scattering from biomacromolecular solutions Curr OpinStruct Biol 17 562ndash571
57 HuraGL MenonAL HammelM RamboRP PooleFL IITsutakawaSE JenneyFE Jr ClassenS FrankelKAHopkinsRC et al (2009) Robust high-throughput solutionstructural analyses by small angle X-ray scattering (SAXS) NatMethods 6 606ndash612
58 SvergunD BarberatoC and KochMHJ (1995) CRYSOL-aprogram to evaluate X-ray solution scattering of biologicalmacromolecules from atomic coordinates J Appl Crystallogr28 768ndash773
59 PoitevinF OrlandH DoniachS KoehlP and DelarueM(2011) AquaSAXS a web server for computation and fitting ofSAXS profiles with non-uniformally hydrated atomic modelsNucleic Acids Res 39 W184ndashW189
60 LiuH MorrisRJ HexemerA GrandisonS and ZwartPH(2012) Computation of small-angle scattering profiles with three-dimensional Zernike polynomials Acta Crystallogr A 68278ndash285
61 RavikumarKM HuangW and YangS (2013) Fast-SAXS-proa unified approach to computing SAXS profiles of DNA RNAprotein and their complexes J Chem Phys 138 024112
62 Schneidman-DuhovnyD HammelM TainerJA and SaliA(2013) Accurate SAXS profile computation and its assessment bycontrast variation experiments Biophys J 105 962ndash974
63 HammelM ReyM YuY ManiRS ClassenS LiuMPiqueME FangS MahaneyBL WeinfeldM et al (2011)XRCC4 protein interactions with XRCC4-like factor (XLF)create an extended grooved scaffold for DNA ligation and doublestrand break repair J Biol Chem 286 32638ndash32650
64 PelikanM HuraGL and HammelM (2009) Structure andflexibility within proteins as identified through small angle X-rayscattering Gen Physiol Biophys 28 174ndash189
65 GrantTD LuftJR WolfleyJR TsurutaH MartelAMontelioneGT and SnellEH (2011) Small angle X-rayscattering as a complementary tool for high-throughput structuralstudies Biopolymers 95 517ndash530
66 KonarevPV VolkovVV SokolovaAV KochMHJ andSvergunDI (2003) PRIMUS a Windows PC-based system forsmall-angle scattering data analysis J Appl Crystallogr 361277ndash1282
67 ShoichetBK and KuntzID (1991) Protein docking andcomplementarity J Mol Biol 221 327ndash346
68 PieperU SchlessingerA KloppmannE ChangGA ChouJJDumontM FoxB FrommeP HendricksonW MalkowskiMet al (2013) Coordinating the impact of structural genomics onthe human a-helical transmembrane proteome Nat Struct MolBiol 20 135ndash138
69 JohnsonM ZaretskayaI RaytselisY MerezhukYMcGinnisS and MaddenTL (2008) NCBI BLAST a betterweb interface Nucleic Acids Res 36 W5ndashW9
70 WardJJ McGuffinLJ BrysonK BuxtonBF and JonesDT(2004) The DISOPRED server for the prediction of proteindisorder Bioinformatics 20 2138ndash2139
71 DosztanyiZ CsizmokV TompaP and SimonI (2005) IUPredweb server for the prediction of intrinsically unstructured regionsof proteins based on estimated energy content Bioinformatics 213433ndash3434
72 SteentoftC VakhrushevSY JoshiHJ KongY Vester-ChristensenMB SchjoldagerKT LavrsenK DabelsteenSPedersenNB Marcos-SilvaL et al (2013) Precision mapping ofthe human O-GalNAc glycoproteome through SimpleCelltechnology EMBO J 32 1478ndash1488
73 GuptaR JungE GooleyAA WilliamsKL BrunakS andHansenJ (1999) Scanning the available Dictyostelium discoideumproteome for O-linked GlcNAc glycosylation sites using neuralnetworks Glycobiology 9 1009ndash1022
74 CormierCY ParkJG FiaccoM SteelJ HunterPKramerJ SinglaR and LaBaerJ (2011) PSIBiology-materialsrepository a biologistrsquos resource for protein expression plasmidsJ Struct Funct Genomics 12 55ndash62
75 LameschP LiN MilsteinS FanC HaoT SzaboG HuZVenkatesanK BethelG MartinP et al (2007) hORFeomev31 a resource of human open reading frames representing over10000 human genes Genomics 89 307ndash315
76 TempleG GerhardDS RasoolyR FeingoldEA GoodPJRobinsonC MandichA DergeJG LewisJ ShoafD et al(2009) The completion of the mammalian gene collection (MGC)Genome Res 19 2324ndash2333
77 SealRL GordonSM LushMJ WrightMW andBrufordEA (2011) genenamesorg the HGNC resources in 2011Nucleic Acids Res 39 D514ndashD519
78 GiffordLK CarterLG GabanyiMJ BermanHM andAdamsPD (2012) The protein structure initiative structuralbiology knowledgebase technology portal a structural biologyweb resource J Struct Funct Genomics 13 57ndash62
79 FreedEO (2001) HIV-1 replication Somatic Cell Mol Genet26 13ndash33
80 McDonaldCK and KuritzkesDR (1997) Humanimmunodeficiency virus type 1 protease inhibitors Arch IntMed 157 951ndash959
81 DragM and SalvesenGS (2010) Emerging principles inprotease-based drug discovery Nat Rev Drug Discov 9690ndash701
82 FlexnerC (1998) HIV-protease inhibitors N Engl J Med 3381281ndash1292
83 KohlNE EminiEA SchleifWA DavisLJ HeimbachJCDixonRA ScolnickEM and SigalIS (1988) Active humanimmunodeficiency virus protease is required for viral infectivityProc Natl Acad Sci USA 85 4686ndash4690
84 MurthyKH WinborneEL MinnichMD CulpJS andDebouckC (1992) The crystal structures at 22-A resolution ofhydroxyethylene-based inhibitors bound to humanimmunodeficiency virus type 1 protease show that the inhibitorsare present in two distinct orientations J Biol Chem 26722770ndash22778
85 Prabu-JeyabalanM NalivaikaE and SchifferCA (2000) Howdoes a symmetric dimer recognize an asymmetric substrate Asubstrate complex of HIV-1 protease J Mol Biol 3011207ndash1220
86 MahalingamB LouisJM HungJ HarrisonRW andWeberIT (2001) Structural implications of drug-resistantmutants of HIV-1 protease high-resolution crystal structures ofthe mutant proteasesubstrate analogue complexes Proteins 43455ndash464
87 NieZ PhenixBN LumJJ AlamA LynchDH BeckettBKrammerPH SekalyRP and BadleyAD (2002) HIV-1protease processes procaspase 8 to cause mitochondrial release ofcytochrome c caspase cleavage and nuclear fragmentation CellDeath Differ 9 1172ndash1184
88 Algeciras-SchimnichA Belzacq-CasagrandeAS BrenGDNieZ TaylorJA RizzaSA BrennerC and BadleyAD(2007) Analysis of HIV protease killing through caspase 8 revealsa novel interaction between caspase 8 and mitochondria OpenVirol J 1 39ndash46
89 NieZ BrenGD RizzaSA and BadleyAD (2008) HIVprotease cleavage of procaspase 8 is necessary for death of HIV-infected cells Open Virol J 2 1ndash7
10 Nucleic Acids Research 2013
at UC
SF Library on D
ecember 2 2013
httpnaroxfordjournalsorgD
ownloaded from
90 CastelloA FrancoD Moral-LopezP BerlangaJJAlvarezE WimmerE and CarrascoL (2009) HIV- 1 proteaseinhibits Cap- and poly(A)-dependent translation upon eIF4GIand PABP cleavage PloS One 4 e7997
91 ImpensF TimmermanE StaesA MoensK ArienKKVerhasseltB VandekerckhoveJ and GevaertK (2012) Acatalogue of putative HIV-1 protease host cell substrates BiolChem 393 915ndash931
92 Kotik-KoganO ValentineER SanfeliceD ConteMR andCurryS (2008) Structural analysis reveals conformationalplasticity in the recognition of RNA 3rsquo ends by the human Laprotein Structure 16 852ndash862
93 NakaiK KideraA and KanehisaM (1988) Cluster analysis ofamino acid indices for prediction of protein structure andfunction Protein Eng 2 93ndash100
94 TomiiK and KanehisaM (1996) Analysis of amino acid indicesand mutation matrices for sequence comparison and structureprediction of proteins Protein Eng 9 27ndash36
95 JonesDT (1999) Protein secondary structure prediction basedon position-specific scoring matrices J Mol Biol 292 195ndash202
96 BreimanL and SchapireE (2001) Random forests MachLearn 45 5ndash32
97 BensonDA Karsch-MizrachiI LipmanDJ OstellJ andSayersEW (2010) GenBank Nucleic Acids Res 38 D46ndashD51
98 KraulisPJ (1991) MOLSCRIPT a program to produce bothdetailed and schematic plorts of protein structures J ApplCrystallogr 24 946ndash950
99 MerrittEA and BaconDJ (1997) Raster3D photorealisticmolecular graphics Methods Enzymol 277 505ndash524
100 PettersenEF GoddardTD HuangCC CouchGSGreenblattDM MengEC and FerrinTE (2004) UCSFChimerandasha visualization system for exploratory research andanalysis J Comput Chem 25 1605ndash1612
101 CapraJA LaskowskiRA ThorntonJM SinghM andFunkhouserTA (2009) Predicting protein ligand binding sitesby combining evolutionary sequence conservation and 3Dstructure PLoS Comp Biol 5 e1000585
102 HenrickK FengZ BluhmWF DimitropoulosDDoreleijersJF DuttaS Flippen-AndersonJL IonidesJKamadaC KrissinelE et al (2008) Remediation of the proteindata bank archive Nucleic Acids Res 36 D426ndashD433
103 WuCH ApweilerR BairochA NataleDA BarkerWCBoeckmannB FerroS GasteigerE HuangH LopezR et al(2006) The Universal Protein Resource (UniProt) an expandinguniverse of protein information Nucleic Acids Res 34D187ndashD191
104 RheadB KarolchikD KuhnRM HinrichsAS ZweigASFujitaPA DiekhansM SmithKE RosenbloomKRRaneyBJ et al (2010) The UCSC Genome Browser databaseupdate 2010 Nucleic Acids Res 38 D613ndashD619
105 HunterS ApweilerR AttwoodTK BairochA BatemanABinnsD BorkP DasU DaughertyL DuquenneL et al(2009) InterPro the integrative protein signature databaseNucleic Acids Res 37 D211ndashD215
106 KleinTE ChangJT ChoMK EastonKL FergersonRHewettM LinZ LiuY LiuS OliverDE et al (2001)Integrating genotype and phenotype information an overview ofthe PharmGKB project Pharmacogenetics research network andknowledge base Pharmacogenomics J 1 167ndash170
107 HaasJ RothS ArnoldK KieferF SchmidtT BordoliLand SchwedeT (2013) The Protein Model Portalmdashacomprehensive resource for protein structure and modelinformation Database 2013 bat031
108 SchwedeT SaliA HonigB LevittM BermanH JonesDBrennerS BurleyS DasR DokholyanN et al (2009)Outcome of a workshop on applications of protein models inbiomedical research Structure 17 151ndash159
109 BairochA ApweilerR WuCH BarkerWC BoeckmannBFerroS GasteigerE HuangH LopezR MagraneM et al(2005) The Universal Protein Resource (UniProt) Nucleic AcidsRes 33 D154ndashD159
110 GigliaE (2009) New year new PubMed Eur J Phys RehabilMed 45 155ndash159
Nucleic Acids Research 2013 11
at UC
SF Library on D
ecember 2 2013
httpnaroxfordjournalsorgD
ownloaded from

A family of web-servers for computation and applicationof SAXS profiles
SAXS is a common technique for low-resolution struc-tural characterization of molecules in solution (5657)SAXS experiments determine the scattering intensity ofa molecule as a function of spatial frequency resultingin a SAXS profile that can be easily converted into theapproximate distribution of atomic distances in themeasured system The experiments can be performedwith the protein sample in solution and usually takeonly a few minutes on a well-equipped synchrotronbeamline (57) Here we describe new features of theFoXS server for calculating and fitting SAXS profilesthe AllosMod-FoXS server that predicts the structuralensemble that best fits a given SAXS profile theFoXSDock server that performs proteinndashprotein dockingfiltered by a SAXS profile and the SAXS Merge server formerging SAXS profiles measured at different concentra-tions and exposure timesFoXS (httpsalilaborgfoxs) is a rapid and accurate
server for calculating a SAXS profile of a given molecularstructure (51) The input is one or more macromolecularcoordinate files or PDB codes and an experimental profileThe output is a calculated SAXS profile for each inputstructure fitted onto the experimental profile Themethod explicitly computes all inter-atomic distancesand models the first solvation layer based on solvent ac-cessibility FoXS was tested on 11 protein 1 DNA and 2RNA structures revealing superior accuracy and speedversus CRYSOL (58) AquaSAXS (59) the Zernike poly-nomials-based method (60) and Fast-SAXS-pro (61) Inaddition we demonstrated a significant correlation ofthe SAXS score with the accuracy of a structural model(62) We have recently updated the server to an interactiveuser interface profiles are displayed via an HTML5canvas element and structures are shown in a Jmolwindow (Figure 1) If the user uploads multiple structuresthe server automatically performs the minimal ensemblecomputation with Minimal Ensemble Search (MES) (64)AllosMod-FoXS (httpsalilaborgallosmod-foxs) is a
server that predicts the structural ensemble that best fitsa given SAXS profile The input is one or more macromol-ecular coordinate files the corresponding sequence(s) andan lsquoexperimentalrsquo SAXS profile The output is the struc-tural ensemble that best fits the input SAXS profile Theserver relies on AllosMod conformational sampling (14)FoXS calculations of theoretical SAXS profiles minimalensemble computation with MES (64) and the SOAP-PPscore The server was motivated to describe conformationalchanges in proteins such as the allostery based on bothmodeling considerations (as represented by AllosMod) andexperimental SAXS data (as represented by FoXS)The AllosMod-FoXS server uses various sampling al-
gorithms in AllosMod to generate structures that aredirectly entered into FoXS Because FoXS explicitlycomputes all inter-atomic distances and models the firstsolvation layer based on solvent accessibility it can beused to score the similarity of the experimental SAXSprofile to the predicted SAXS profiles corresponding tostructures from the AllosMod simulations In addition
to the FoXS score each conformation is assessed forstructural quality using the SOAP-PP score These twoscores are combined to predict structures that collectivelybest explain the experimental SAXS profile
FoXSDock (httpsalilaborgfoxsdock) is a web serverthat uses SAXS profiles to filter the models produced byproteinndashprotein docking It accepts as input structures oftwo docked proteins and an experimental SAXS profile oftheir complex The output is a set of docking models andtheir calculated SAXS profiles fitted onto the experimentalprofile Although many structures of single protein compo-nents are becoming available structural characterization oftheir complexes remains challenging Although generalproteinndashprotein docking methods suffer from large errorsbecause of protein flexibility and inaccurate scoring func-tions However when additional information such as aSAXS profile is available it is possible to significantlyincrease the accuracy of the computational docking
FoXSDock combines rigid global docking byPatchDock filtering of the models based on the SAXSprofile and interface refinement by FireDock (15) Theapproach was benchmarked on 176 protein complexeswith simulated SAXS profiles as well as on 7 complexeswith experimentally determined SAXS profiles (30) Wheninduced fit is lt15 A interface Ca RMSD and the fractionof residues missing from the component structures islt3 FoXSDock can find a model close to the nativestructure within the top 10 predictions in 77 of thecases in comparison docking alone succeeds in only34 of the cases
SAXS Merge (httpsalilaborgsaxsmerge) is a webserver that uses automated statistical methods to mergeSAXS profiles determined at different concentrationsand exposure times High-throughput SAXS data collec-tion requires robust accurate and automated tools fordata processing and merging (5765) However SAXSdata are generally processed highly subjectively oftenmanually with the aid of the PRIMUS software package(66) The operation requires an experienced user who canmanually inspect each profile to be merged and decidewhether the SAXS profiles agree or not The SAXSMerge web-server alleviates user intervention through anautomated and statistically principled merging procedurebased on a Bayesian approach (Spill et al submitted) TheSAXS Merge web server was successfully validated on abenchmark of 16 SAXS datasets The input file consistsonly of the buffer-subtracted SAXS profiles in a commonthree-column text format The output comprises (i) a listof individual q points with associated source profiles (ii)an estimate of the mean profile along with a 95Bayesian credible interval and (iii) the most suitable para-metric mean function for the resulting profile an estimateof the noise level in the pooled dataset The output isvisualized interactively through the web-browser and canalso be downloaded
Pose amp rank a web-server for scoring proteinndashligandcomplexes
Molecular recognition between proteins and ligands playsan important role in many biological processes Predicting
4 Nucleic Acids Research 2013
at UC
SF Library on D
ecember 2 2013
httpnaroxfordjournalsorgD
ownloaded from
the structures of proteinndashligand complexes and findingligands by virtual screening of small molecule databasesare two long-standing goals in molecular biophysics andmedicinal chemistry Solving both problems requires thedevelopment of an accurate and efficient scoring functionto assess proteinndashligand interactions
The Pose amp Rank web server (httpsalilaborgposeandrank) (16) provides access to two atomicdistance-dependent statistical scoring functions based onprobability theory that can be used in proteinndashliganddocking The PoseScore was optimized for recognizingnative binding geometries of ligands from other posesand the RankScore was optimized for distinguishingligands from non-binding molecules The server acceptsas input a coordinate file of the target protein structurein the PDB format and docking poses of small moleculesThe output is a list of scores for each proteinndashsmallmolecule complex PoseScore ranks a near-nativebinding pose the best top 5 and top 10 for 88 97and 99 of targets respectively RankScore improvesthe overall ligand enrichment (logAUC) and early
enrichment (EF1) scores computed by DOCK 36 (67)for 68 and 74 of targets respectively The Pose ampRank resource can contribute to many applicationssuch as selecting ligand candidates from virtual screeningfor experimental testing predicting the binding geometriesfor known ligands and suggesting binding site mutationsthat alter the ligand binding properties and consequentlyprotein functions
APPLICATION EXAMPLES
Coordinating the impact of structural genomics on thehuman a-helical transmembrane proteome
With the recent successes in determining membraneprotein structures we explored the tractability of deter-mining representatives for the entire human transmem-brane proteome (68) (httpsalilaborgmembrane) Thisproteome contains 2925 unique integral a-helical trans-membrane domain sequences that cluster into 1201families sharing gt25 sequence identity We assessed
Figure 1 The computed profiles for filament models of the XLFndashXRCC4 complex (63) are fitted to the experimental SAXS profile with FoXS Theinteractive user interface displays the profiles in the left and the models in the right using the same color for each modelprofile pair The table belowthe panels displays the fit parameters and includes buttons to simultaneously show or hide each modelprofile pair Clicking on Minimal EnsembleSearch (MES) results (above the display panel) takes the user to the MES output page
Nucleic Acids Research 2013 5
at UC
SF Library on D
ecember 2 2013
httpnaroxfordjournalsorgD
ownloaded from
the modeling coverage by processing all sequencesthrough ModPipe and analyzing the resulting ModBasedataset We then clustered all sequences [BlastClust(69)]annotated them with cluster size modeling coverage andnumber of predicted transmembrane helices Finally weexplored several target selection strategies Structures of100 optimally selected targets would increase the fractionof modelable human alpha-helical transmembranedomains from 26 to 58 thus providing structurefunction information not otherwise availableTo leverage the results of this study the PSIBiology
Network (httpwwwnigmsnihgovResearchFeaturedProgramsPSIpsi_biology) including high-throughputand membrane PSI centers as well as the StructuralGenomics Consortium is attempting to express nearly100 human transmembrane proteins using their standardhigh-throughput methods The goal of this survey is todetermine which methods best express certain classes oftransmembrane proteins The sequences of our previousanalysis were further annotated by fraction of predicteddisordered regions (7071) number of glycosylation sites(27273) clone availability (74ndash76) HUGO annotations(77) sequence length and several additional metricsEighty-six targets were hand-picked from the largestclusters to represent a diverse selection of humanmembrane proteins with maximum coverage of the trans-membrane proteome Cloning expression and solubilityexperiments of these targets using the pipelines of the 10participating research groups are currently in progressParticipants also use shared and individual sets of sixcontrols A standard method will be used by all to visual-ize the protein bands to quantify yield A final full com-parison will determine the most successful methods foreach representative transmembrane protein Progress ofthe survey is cataloged by the portal of the ProteinStructure Initiative Structural Biology Knowledgebase[PSI SBKB (78) httphmppssbkborg] and will be ac-cessible to the public after the conclusion of the experi-ment A final publication will summarize the surveyrsquosfindings
Structural determinants of HIV-1 protease
The maturation of the HIV virion is facilitated by thecleavage of the Gag and Pol polyproteins (79) Ahomodimeric aspartic protease (HIV-1 protease) catalyzesthese processing events at 10 non-homologous sites and isthe target of some of the most effective antiretroviraldrugs (80ndash82) These sites are eight amino acid residuesin length the cleavage occurs between the third and fourthresidues (83ndash86) In addition to processing viral proteinsHIV-1 protease cleaves several human proteins during in-fection such as the eukaryotic translation initiation factor3 subunit D (eIF3D) (87ndash90)To predict cleavage sites in human proteins we began
by examining sequence and structural features of gt120cellular substrates of HIV-1 protease that were recentlyidentified in vitro (91) (for an example see Figure 2)First every residue of the cleaved and non-cleavedoctapeptides was encoded using gt512 physicochemicalamino acid indices (9394) To account for cooperativity
between residues in different positions of the octapeptidefrequencies of dipeptides and gapped dipeptides (ie twospecific residues separated by any residue) were also usedto train machine learning algorithms for binary classifica-tion Second a greedy feature selection procedure wasapplied to determine features of octapeptides importantfor protease activity Interestingly although featuresencoding known viral cleavage motif ELLE were import-ant for classification most discriminating features encodestructural preferences of amino acid residues in the secondand fifth positions of the octapeptide Therefore wecreated a ModBase dataset of 405 models for 118human proteins cleaved in vitro PSI-Pred (95) was usedto predict secondary structure elements for protein regionswithout templates Analysis of the structural modelsshowed the enrichment of alpha+beta protein class(SCOP ID=53 931) among cleaved proteins and coiledsecondary structure (41) among cleaved sites Weadded structure-based descriptors of cleaved and non-cleaved sites to the sequence-based features and assessedclassifiersrsquo performance in a 5-fold cross-validation pro-cedure The average area under the receiver operatingcharacteristic curve for the classifier trained with theRandom Forest algorithm(96) was 0965 (72 sensitivityand 98 specificity) and the entire human proteome wasscanned for putative human substrates of the HIV-1protease We are currently experimentally validatingseveral of the predicted cleavage sites
ACCESS AND INTERFACE
Direct access
The main access to ModBase is through its web interfaceat httpsalilaborgmodbase by querying with Uniprot-KB (23) and GI (97) identifiers gene names annotationkeywords PDB(1) codes dataset names organism namessequence similarity to the modeled sequences [BLAST(19)]and model-specific criteria such as model reliability modelsize and targetndashtemplate sequence identity Additionally it
Figure 2 Cleavage of human proteins by the HIV-1 protease crystalstructure of the N-terminal domain of human Lupus La protein (92)(left) Residues of the cleavage site (Ile-Asp-Tyr-Tyr-Phe-Gly-Glu-Phe)are shown in orange Scissile bond between Tyr and Phe in the alpha-helix is cleaved by the HIV-1 protease in vitro
6 Nucleic Acids Research 2013
at UC
SF Library on D
ecember 2 2013
httpnaroxfordjournalsorgD
ownloaded from
is possible to retrieve coordinate files and alignment filesof all models for a specific sequence as text files Metadatafor all current ModBase models (updated weekly) allgenome datasets and several additional project specificdatasets are also available from our FTP server (ftpsalilaborgdatabasesmodbaseprojects)
The output of a search is displayed on pages withvarying amounts of information about the modeled
sequences template structures alignments and functionalannotations Output examples from a search resulting inone model are shown in Figure 3 A ribbon diagram of themodel with the highest targetndashtemplate sequence identityis displayed by default together with some details of themodeling calculation Ribbon thumbprints of additionalmodels for this sequence link to corresponding pages withmore information Ribbon diagrams are generated on the
Figure 3 ModBase interface elements Search Form search options are available through the pull-down menu A quick overview of the availablerepresentations is displayed below the search form Model Details Sketch the Model details page provides information for all models of a givensequences The sketch comprises two parts the model coverage sketch that indicates the sequence coverage by all models (top line) and the sequencecoverage by the current model (second line) and a ribbon diagram of the current model Other models are available via thumbprints Update and
Remodel this box shows the date of the last modeling calculation for the current sequence and allows the user to request an update Chimera
Visualization the visualization includes the model and template structures and the alignment Cross-references links to the PMP UniProtKBGenbank UCSC Genome Browser and other databases Model Details Options the pull-down menu switches between representations and allowsdownloads of coordinate and alignment files Quality Criteria red indicates unreliable green reliable Model Overview a different representation forseveral sequences gives a quick overview on modeling coverage and quality Chimera Cavity View visualizes cavities predicted by ConCavity
Nucleic Acids Research 2013 7
at UC
SF Library on D
ecember 2 2013
httpnaroxfordjournalsorgD
ownloaded from
fly using Molscript (98) and Raster3D (99) A pull-downmenu provides links to additional functionalities the SNPmodule retrieval of coordinate and alignment files mo-lecular visualization by UCSF Chimera (100) that allowsthe user to display template and model coordinatestogether with their alignment and Chimera visualizationof predicted cavities [ConCavity (101)] If mutation infor-mation is available for a protein sequence links to thedetails are provided in the cross-references sectionAdditionally cross-references to various other databasesincluding PDB (102) UniProtKB (103) the UCSCGenome Browser (104) EBIrsquos InterPro (105)PharmGKB (106) and SFLD (36) are given OtherModBase pages provide overviews of more than onesequence or structure All ModBase pages are intercon-nected to facilitate easy navigation between differentviews
Access through external databases
The Protein Model PortalThe Protein Model Portal (PMP) has become a valuableoption for accessing ModBase models (httpproteinmo-delportalorg) (107) The PMP is a single point of entry foraccessing protein structure models from a number of dif-ferent databases PMP queries all participating sourcemodel databases and serves the user with the model co-ordinates alignments and quality criteria from a centrallocation It has been developed as a module of the ProteinStructure Initiative Knowledgebase (PSI KB) (79108)The PMP provides a flexible search interface for alldeposited models quality estimation cross-links to othersequence and structure databases annotations ofsequences and their models a central point of entry tocomparative modeling servers (including ModWeb) andquality estimation servers (including ModEval) anddetailed tutorials on all aspects of comparativemodeling Currently the PMP retrieves 450 000ModBase model coordinate files each week fromModBaseA sister web-service to PMP CAMEO (httpcameo3d
org) (107) continuously evaluates the accuracy and reli-ability of several comparative protein structure predictionservers in a fully automated manner The ModWeb servercurrently participates in the testing mode and is expectedto move into the production mode in the first quarter of2014
Access through external databasesModBase models in academic and public datasets arealso directly accessible from several databases includingthe PMP (107) UniProtKB (109) PIRrsquos iProClass(103) EBIrsquos InterPro (105) the UCSC Genome Browser(104) PubMed (LinkOut) (110) PharmGKB (106) andSFLD (36)
FUTURE DIRECTIONS
ModBase will grow by adding models calculated ondemand by external users (using ModWeb) as well asour own calculations of model datasets that are needed
for our research projects (using ModPipe ModWeb orModeller) These updates will reflect improvements inthe methods and software used for calculating themodels as well as new template structures in the PDBand new sequences in UniProtKB In the future weexpect that most of the users will access ModBasemodels through the PMP
CITATION
Users of ModBase are requested to cite this article in theirpublications
ACKNOWLEDGEMENTS
For linking to ModBase from their databases the authorsthank Torsten Schwede and Jurgen Haas (Protein ModelPortal) David Haussler and Jim Kent (UCSC GenomeBrowser) Rolf Apweiler Maria Jesus Martin and ClaireOrsquoDonovan (UniProt) Rolf Apweiler Sarah Hunter(InterPro) Patsy Babbitt (SFLD) Russ Altman(PharmGKB) and Kathy Wu (PIRiProClass) We arealso grateful for computing hardware gifts from MikeHomer Ron Conway NetApp IBM Hewlett Packardand Intel
FUNDING
National Institutes of Health [U54 GM094662 U54GM094625 U54 GM093342 MINOS R01GM105404 toJAT and MH] Sandler Family Supporting Foundation(AS) Department of Energy Lawrence BerkeleyNational Lab IDAT program (to JAT and MH)European Union [FP7-IDEAS-ERC 294809 to MN]The authors thank Tom Ferrin and the UCSF Resourcefor Biocomputing Visualization and Informatics formaking UCSF Chimera (supported by [NIGMS P41-GM103311]) available to the ModBase database andtools Funding for open access charge NIH
Conflict of interest statement None declared
REFERENCES
1 RosePW BiC BluhmWF ChristieCH DimitropoulosDDuttaS GreenRK GoodsellDS PrlicA QuesadaM et al(2013) The RCSB Protein Data Bank new resources for researchand education Nucleic Acids Res 41 D475ndashD482
2 The UniProt Consortium (2011) Ongoing and futuredevelopments at the Universal Protein Resource Nucleic AcidsRes 39 D214ndashD219
3 BensonDA Karsch-MizrachiI ClarkK LipmanDJ OstellJand SayersEW (2012) GenBank Nucleic Acids Res 40D48ndashD53
4 BakerD and SaliA (2001) Protein structure prediction andstructural genomics Science 294 93ndash96
5 EswarN WebbB Marti-RenomMA MadhusudhanMSEramianD ShenMY PieperU and SaliA (2006)Comparative protein structure modeling using MODELLERCurr Protoc Bioinformatics Chapter 5 Unit 561ndash5630
6 EswarN EramianD WebbB ShenMY and SaliA (2008)Protein structure modeling with MODELLER Methods MolBiol 426 145ndash159
8 Nucleic Acids Research 2013
at UC
SF Library on D
ecember 2 2013
httpnaroxfordjournalsorgD
ownloaded from
7 SchwedeT SaliA EswarN and PeitschMC (2008)In SchwedeT and PeitschMC (eds) Computational StructuralBiology World Scientific Publishing Ltd Singapore pp 3ndash35
8 ForrestLR TangCL and HonigB (2006) On the accuracy ofhomology modeling and sequence alignment methods applied tomembrane proteins Biophys J 91 508ndash517
9 LiuT TangGW and CapriottiE (2011) Comparativemodeling the state of the art and protein drug target structureprediction Comb Chem High Throughput Screen 14 532ndash547
10 FiserA (2010) Template-based protein structure modelingMethods Mol Biol 673 73ndash94
11 DagaPR PatelRY and DoerksenRJ (2010) Template-basedprotein modeling recent methodological advances Curr TopMed Chem 10 84ndash94
12 HillischA PinedaLF and HilgenfeldR (2004) Utility ofhomology models in the drug discovery process Drug DiscovToday 9 659ndash669
13 WallnerB and ElofssonA (2005) All are not equal abenchmark of different homology modeling programs ProteinSci 14 1315ndash1327
14 WeinkamP PonsJ and SaliA (2012) Structure-based model ofallostery predicts coupling between distant sites Proc Natl AcadSci USA 109 4875ndash4880
15 Schneidman-DuhovnyD HammelM and SaliA (2011)Macromolecular docking restrained by a small angle X-rayscattering profile J Struct Biol 3 461ndash471
16 FanH SchneidmanD IrwinJJ DongG ShoichetB andSaliA (2011) Statistical potential for modeling and rankingprotein-ligand interactions J Chem Inf Model 51 3078ndash3092
17 EswarN JohnB MirkovicN FiserA IlyinVA PieperUStuartAC Marti-RenomMA MadhusudhanMSYerkovichB et al (2003) Tools for comparative protein structuremodeling and analysis Nucleic Acids Res 31 3375ndash3380
18 SaliA and BlundellTL (1993) Comparative protein modellingby satisfaction of spatial restraints J Mol Biol 234 779ndash815
19 AltschulSF MaddenTL SchafferAA ZhangJ ZhangZMillerW and LipmanDJ (1997) Gapped BLAST and PSI-BLAST a new generation of protein database search programsNucleic Acids Res 25 3389ndash3402
20 RemmertM BiegertA HauserA and SodingJ (2012) HHblitslightning-fast iterative protein sequence searching by HMM-HMM alignment Nat Methods 9 173ndash175
21 SodingJ (2005) Protein homology detection by HMM-HMMcomparison Bioinformatics 21 951ndash960
22 SmithTF and WatermanMS (1981) Identification of commonmolecular subsequences J Mol Biol 147 195ndash197
23 EswarN WebbB Marti-RenomM MadhusudhanMEramianD ShenM PieperU and SaliA (2006) Comparativeprotein structure modeling using Modeller Curr ProtocBioinformatics Chapter 5 Unit 56
24 Marti-RenomMA MadhusudhanMS and SaliA (2004)Alignment of protein sequences by their profiles Protein Sci 131071ndash1087
25 ShenMY and SaliA (2006) Statistical potential for assessmentand prediction of protein structures Protein Sci 15 2507ndash2524
26 MeloF and SaliA (2007) Fold assessment for comparativeprotein structure modeling Protein Sci 16 2412ndash2426
27 PieperU WebbBM BarkanDT Schneidman-DuhovnyDSchlessingerA BrabergH YangZ MengEC PettersenEFHuangCC et al (2011) ModBase a database of annotatedcomparative protein structure models and associated resourcesNucleic Acids Res 39 465ndash474
28 EramianD EswarN ShenM and SaliA (2008) How well canthe accuracy of comparative protein structure models bepredicted Protein Sci 17 1881ndash1893
29 DongGQ FanH Schneidman-DuhovnyD WebbB andSaliA (2013) Optimized atomic statistical potentials Assessmentof protein interfaces and loops (epub ahead of print October 232013)
30 Schneidman-DuhovnyD RossiA Avila-SakarA KimSJVelazquez-MurielJ StropP LiangH KrukenbergKALiaoM KimHM et al (2012) A method for integrativestructure determination of protein-protein complexesBioinformatics 28 3282ndash3289
31 PierceB and WengZ (2007) ZRANK reranking protein dockingpredictions with an optimized energy function Proteins 671078ndash1086
32 AndrusierN NussinovR and WolfsonHJ (2007) FireDockfast interaction refinement in molecular docking Proteins 69139ndash159
33 JacobsonMP PincusDL RappCS DayTJ HonigBShawDE and FriesnerRA (2004) A hierarchical approach toall-atom protein loop prediction Proteins 55 351ndash367
34 GrontD KulpDW VernonRM StraussCE and BakerD(2011) Generalized fragment picking in Rosetta design protocolsand applications PloS One 6 e23294
35 ZhangC LiuS and ZhouY (2004) Accurate and efficient loopselections by the DFIRE-based all-atom statistical potentialProtein Sci 13 391ndash399
36 PeggSC BrownSD OjhaS SeffernickJ MengECMorrisJH ChangPJ HuangCC FerrinTE andBabbittPC (2006) Leveraging enzyme structure-functionrelationships for functional inference and experimental design thestructure-function linkage database Biochemistry 45 2545ndash2555
37 MaurerSM RaiA and SaliA (2004) Finding cures for tropicaldiseases is open source an answer PLoS Med 1 e56
38 OrtiL CarbajoR PieperU EswarN MaurerS RaiATaylorG ToddM Pineda-LucenaA SaliA et al (2009) Akernel for open source drug discovery in tropical diseases PLoSNegl Trop Dis 3 e418
39 AgueroF Al-LazikaniB AslettM BerrimanM BucknerFCampbellR CarmonaS CarruthersI ChanA ChenF et al(2008) Genomic-scale prioritization of drug targets the TDRTargets database Nat Rev Drug Discov 7 900ndash907
40 Martinez-JimenezF PapadatosG YangL WallaceIMKumarV PieperU SaliA BrownJR OveringtonJP andMarti-RenomMA (2013) Target prediction for an open accessset of compounds active against Mycobacterium tuberculosisPLoS Comp Biol 9 e1003253
41 SampathkumarP LuF ZhaoX LiZ GilmoreJ BainKRutterME GheyiT SchwinnK BonannoJ et al (2010)Structure of a putative BenF-like porin from Pseudomanasfluorescens Pf-5 at 26 A resolution Proteins 78 3056ndash3062
42 PieperU ChiangR SeffernickJ BrownS GlasnerMKellyL EswarN SauderJ BonannoJ SwaminathanS et al(2009) Target selection and annotation for the structural genomicsof the amidohydrolase and enolase superfamilies J Struct FunctGenom 10 107ndash125
43 KarchinR DiekhansM KellyL ThomasDJ PieperUEswarN HausslerD and SaliA (2005) LS-SNP large-scaleannotation of coding non-synonymous SNPs based on multipleinformation sources Bioinformatics 21 2814ndash2820
44 FiserA and SaliA (2003) ModLoop automated modeling ofloops in protein structures Bioinformatics 19 2500ndash2501
45 DavisF and SaliA (2005) PIBASE a comprehensive databaseof structurally defined protein interfaces Bioinformatics 211901ndash1907
46 Marti-RenomMA PieperU MadhusudhanMS RossiAEswarN DavisFP Al-ShahrourF DopazoJ and SaliA(2007) DBAli tools mining the protein structure space NucleicAcids Res 35 W393ndashW397
47 Marti-RenomMA IlyinVA and SaliA (2001) DBAli adatabase of protein structure alignments Bioinformatics 17746ndash747
48 PieperU EswarN WebbB EramianD KellyL BarkanDCarterH MankooP KarchinR Marti-RenomM et al (2009)MODBASE a database of annotated comparative proteinstructure models and associated resources Nucleic Acids Res 37D347ndashD354
49 PieperU EswarN DavisFP BrabergH MadhusudhanMSRossiA Marti-RenomM KarchinR WebbBM EramianDet al (2006) MODBASE a database of annotated comparativeprotein structure models and associated resources Nucleic AcidsRes 34 D291ndashD295
50 BrabergH WebbB TjioeE PieperU SaliA andMadhusudhanMS (2012) SALIGN a webserver for alignmentof multiple protein sequences and structures Bioinformatics 152072ndash2073
Nucleic Acids Research 2013 9
at UC
SF Library on D
ecember 2 2013
httpnaroxfordjournalsorgD
ownloaded from
51 Schneidman-DuhovnyD HammelM and SaliA (2010) FoXS aweb server for rapid computation and fitting of SAXS ProfilesNucleic Acids Res 38 541ndash544
52 UedaY TaketomiH and GoN (1978) Studies on proteinfolding unfolding and fluctuations by computer simulation IIAThree dimensional lattice model of lysozyme Biopolymers 171531ndash1548
53 OkazakiK KogaN TakadaS OnuchicJN and WolynesPG(2006) Multiple-basin energy landscapes for large-amplitudeconformational motions of proteins Structure-based moleculardynamics simulations Proc Natl Acad Sci USA 10311844ndash11849
54 WhitfordPC NoelJK GosaviS SchugA SanbonmatsuKYand OnuchicJN (2009) An all-atom structure-based potential forproteins bridging minimal models with all-atom empiricalforcefields Proteins 75 430ndash441
55 WeinkamP ChenYC PonsJ and SaliA (2013) Impact ofmutations on the allosteric conformational equilibrium J MolBiol 425 647ndash661
56 PetoukhovMV and SvergunDI (2007) Analysis of X-ray andneutron scattering from biomacromolecular solutions Curr OpinStruct Biol 17 562ndash571
57 HuraGL MenonAL HammelM RamboRP PooleFL IITsutakawaSE JenneyFE Jr ClassenS FrankelKAHopkinsRC et al (2009) Robust high-throughput solutionstructural analyses by small angle X-ray scattering (SAXS) NatMethods 6 606ndash612
58 SvergunD BarberatoC and KochMHJ (1995) CRYSOL-aprogram to evaluate X-ray solution scattering of biologicalmacromolecules from atomic coordinates J Appl Crystallogr28 768ndash773
59 PoitevinF OrlandH DoniachS KoehlP and DelarueM(2011) AquaSAXS a web server for computation and fitting ofSAXS profiles with non-uniformally hydrated atomic modelsNucleic Acids Res 39 W184ndashW189
60 LiuH MorrisRJ HexemerA GrandisonS and ZwartPH(2012) Computation of small-angle scattering profiles with three-dimensional Zernike polynomials Acta Crystallogr A 68278ndash285
61 RavikumarKM HuangW and YangS (2013) Fast-SAXS-proa unified approach to computing SAXS profiles of DNA RNAprotein and their complexes J Chem Phys 138 024112
62 Schneidman-DuhovnyD HammelM TainerJA and SaliA(2013) Accurate SAXS profile computation and its assessment bycontrast variation experiments Biophys J 105 962ndash974
63 HammelM ReyM YuY ManiRS ClassenS LiuMPiqueME FangS MahaneyBL WeinfeldM et al (2011)XRCC4 protein interactions with XRCC4-like factor (XLF)create an extended grooved scaffold for DNA ligation and doublestrand break repair J Biol Chem 286 32638ndash32650
64 PelikanM HuraGL and HammelM (2009) Structure andflexibility within proteins as identified through small angle X-rayscattering Gen Physiol Biophys 28 174ndash189
65 GrantTD LuftJR WolfleyJR TsurutaH MartelAMontelioneGT and SnellEH (2011) Small angle X-rayscattering as a complementary tool for high-throughput structuralstudies Biopolymers 95 517ndash530
66 KonarevPV VolkovVV SokolovaAV KochMHJ andSvergunDI (2003) PRIMUS a Windows PC-based system forsmall-angle scattering data analysis J Appl Crystallogr 361277ndash1282
67 ShoichetBK and KuntzID (1991) Protein docking andcomplementarity J Mol Biol 221 327ndash346
68 PieperU SchlessingerA KloppmannE ChangGA ChouJJDumontM FoxB FrommeP HendricksonW MalkowskiMet al (2013) Coordinating the impact of structural genomics onthe human a-helical transmembrane proteome Nat Struct MolBiol 20 135ndash138
69 JohnsonM ZaretskayaI RaytselisY MerezhukYMcGinnisS and MaddenTL (2008) NCBI BLAST a betterweb interface Nucleic Acids Res 36 W5ndashW9
70 WardJJ McGuffinLJ BrysonK BuxtonBF and JonesDT(2004) The DISOPRED server for the prediction of proteindisorder Bioinformatics 20 2138ndash2139
71 DosztanyiZ CsizmokV TompaP and SimonI (2005) IUPredweb server for the prediction of intrinsically unstructured regionsof proteins based on estimated energy content Bioinformatics 213433ndash3434
72 SteentoftC VakhrushevSY JoshiHJ KongY Vester-ChristensenMB SchjoldagerKT LavrsenK DabelsteenSPedersenNB Marcos-SilvaL et al (2013) Precision mapping ofthe human O-GalNAc glycoproteome through SimpleCelltechnology EMBO J 32 1478ndash1488
73 GuptaR JungE GooleyAA WilliamsKL BrunakS andHansenJ (1999) Scanning the available Dictyostelium discoideumproteome for O-linked GlcNAc glycosylation sites using neuralnetworks Glycobiology 9 1009ndash1022
74 CormierCY ParkJG FiaccoM SteelJ HunterPKramerJ SinglaR and LaBaerJ (2011) PSIBiology-materialsrepository a biologistrsquos resource for protein expression plasmidsJ Struct Funct Genomics 12 55ndash62
75 LameschP LiN MilsteinS FanC HaoT SzaboG HuZVenkatesanK BethelG MartinP et al (2007) hORFeomev31 a resource of human open reading frames representing over10000 human genes Genomics 89 307ndash315
76 TempleG GerhardDS RasoolyR FeingoldEA GoodPJRobinsonC MandichA DergeJG LewisJ ShoafD et al(2009) The completion of the mammalian gene collection (MGC)Genome Res 19 2324ndash2333
77 SealRL GordonSM LushMJ WrightMW andBrufordEA (2011) genenamesorg the HGNC resources in 2011Nucleic Acids Res 39 D514ndashD519
78 GiffordLK CarterLG GabanyiMJ BermanHM andAdamsPD (2012) The protein structure initiative structuralbiology knowledgebase technology portal a structural biologyweb resource J Struct Funct Genomics 13 57ndash62
79 FreedEO (2001) HIV-1 replication Somatic Cell Mol Genet26 13ndash33
80 McDonaldCK and KuritzkesDR (1997) Humanimmunodeficiency virus type 1 protease inhibitors Arch IntMed 157 951ndash959
81 DragM and SalvesenGS (2010) Emerging principles inprotease-based drug discovery Nat Rev Drug Discov 9690ndash701
82 FlexnerC (1998) HIV-protease inhibitors N Engl J Med 3381281ndash1292
83 KohlNE EminiEA SchleifWA DavisLJ HeimbachJCDixonRA ScolnickEM and SigalIS (1988) Active humanimmunodeficiency virus protease is required for viral infectivityProc Natl Acad Sci USA 85 4686ndash4690
84 MurthyKH WinborneEL MinnichMD CulpJS andDebouckC (1992) The crystal structures at 22-A resolution ofhydroxyethylene-based inhibitors bound to humanimmunodeficiency virus type 1 protease show that the inhibitorsare present in two distinct orientations J Biol Chem 26722770ndash22778
85 Prabu-JeyabalanM NalivaikaE and SchifferCA (2000) Howdoes a symmetric dimer recognize an asymmetric substrate Asubstrate complex of HIV-1 protease J Mol Biol 3011207ndash1220
86 MahalingamB LouisJM HungJ HarrisonRW andWeberIT (2001) Structural implications of drug-resistantmutants of HIV-1 protease high-resolution crystal structures ofthe mutant proteasesubstrate analogue complexes Proteins 43455ndash464
87 NieZ PhenixBN LumJJ AlamA LynchDH BeckettBKrammerPH SekalyRP and BadleyAD (2002) HIV-1protease processes procaspase 8 to cause mitochondrial release ofcytochrome c caspase cleavage and nuclear fragmentation CellDeath Differ 9 1172ndash1184
88 Algeciras-SchimnichA Belzacq-CasagrandeAS BrenGDNieZ TaylorJA RizzaSA BrennerC and BadleyAD(2007) Analysis of HIV protease killing through caspase 8 revealsa novel interaction between caspase 8 and mitochondria OpenVirol J 1 39ndash46
89 NieZ BrenGD RizzaSA and BadleyAD (2008) HIVprotease cleavage of procaspase 8 is necessary for death of HIV-infected cells Open Virol J 2 1ndash7
10 Nucleic Acids Research 2013
at UC
SF Library on D
ecember 2 2013
httpnaroxfordjournalsorgD
ownloaded from
90 CastelloA FrancoD Moral-LopezP BerlangaJJAlvarezE WimmerE and CarrascoL (2009) HIV- 1 proteaseinhibits Cap- and poly(A)-dependent translation upon eIF4GIand PABP cleavage PloS One 4 e7997
91 ImpensF TimmermanE StaesA MoensK ArienKKVerhasseltB VandekerckhoveJ and GevaertK (2012) Acatalogue of putative HIV-1 protease host cell substrates BiolChem 393 915ndash931
92 Kotik-KoganO ValentineER SanfeliceD ConteMR andCurryS (2008) Structural analysis reveals conformationalplasticity in the recognition of RNA 3rsquo ends by the human Laprotein Structure 16 852ndash862
93 NakaiK KideraA and KanehisaM (1988) Cluster analysis ofamino acid indices for prediction of protein structure andfunction Protein Eng 2 93ndash100
94 TomiiK and KanehisaM (1996) Analysis of amino acid indicesand mutation matrices for sequence comparison and structureprediction of proteins Protein Eng 9 27ndash36
95 JonesDT (1999) Protein secondary structure prediction basedon position-specific scoring matrices J Mol Biol 292 195ndash202
96 BreimanL and SchapireE (2001) Random forests MachLearn 45 5ndash32
97 BensonDA Karsch-MizrachiI LipmanDJ OstellJ andSayersEW (2010) GenBank Nucleic Acids Res 38 D46ndashD51
98 KraulisPJ (1991) MOLSCRIPT a program to produce bothdetailed and schematic plorts of protein structures J ApplCrystallogr 24 946ndash950
99 MerrittEA and BaconDJ (1997) Raster3D photorealisticmolecular graphics Methods Enzymol 277 505ndash524
100 PettersenEF GoddardTD HuangCC CouchGSGreenblattDM MengEC and FerrinTE (2004) UCSFChimerandasha visualization system for exploratory research andanalysis J Comput Chem 25 1605ndash1612
101 CapraJA LaskowskiRA ThorntonJM SinghM andFunkhouserTA (2009) Predicting protein ligand binding sitesby combining evolutionary sequence conservation and 3Dstructure PLoS Comp Biol 5 e1000585
102 HenrickK FengZ BluhmWF DimitropoulosDDoreleijersJF DuttaS Flippen-AndersonJL IonidesJKamadaC KrissinelE et al (2008) Remediation of the proteindata bank archive Nucleic Acids Res 36 D426ndashD433
103 WuCH ApweilerR BairochA NataleDA BarkerWCBoeckmannB FerroS GasteigerE HuangH LopezR et al(2006) The Universal Protein Resource (UniProt) an expandinguniverse of protein information Nucleic Acids Res 34D187ndashD191
104 RheadB KarolchikD KuhnRM HinrichsAS ZweigASFujitaPA DiekhansM SmithKE RosenbloomKRRaneyBJ et al (2010) The UCSC Genome Browser databaseupdate 2010 Nucleic Acids Res 38 D613ndashD619
105 HunterS ApweilerR AttwoodTK BairochA BatemanABinnsD BorkP DasU DaughertyL DuquenneL et al(2009) InterPro the integrative protein signature databaseNucleic Acids Res 37 D211ndashD215
106 KleinTE ChangJT ChoMK EastonKL FergersonRHewettM LinZ LiuY LiuS OliverDE et al (2001)Integrating genotype and phenotype information an overview ofthe PharmGKB project Pharmacogenetics research network andknowledge base Pharmacogenomics J 1 167ndash170
107 HaasJ RothS ArnoldK KieferF SchmidtT BordoliLand SchwedeT (2013) The Protein Model Portalmdashacomprehensive resource for protein structure and modelinformation Database 2013 bat031
108 SchwedeT SaliA HonigB LevittM BermanH JonesDBrennerS BurleyS DasR DokholyanN et al (2009)Outcome of a workshop on applications of protein models inbiomedical research Structure 17 151ndash159
109 BairochA ApweilerR WuCH BarkerWC BoeckmannBFerroS GasteigerE HuangH LopezR MagraneM et al(2005) The Universal Protein Resource (UniProt) Nucleic AcidsRes 33 D154ndashD159
110 GigliaE (2009) New year new PubMed Eur J Phys RehabilMed 45 155ndash159
Nucleic Acids Research 2013 11
at UC
SF Library on D
ecember 2 2013
httpnaroxfordjournalsorgD
ownloaded from

the structures of proteinndashligand complexes and findingligands by virtual screening of small molecule databasesare two long-standing goals in molecular biophysics andmedicinal chemistry Solving both problems requires thedevelopment of an accurate and efficient scoring functionto assess proteinndashligand interactions
The Pose amp Rank web server (httpsalilaborgposeandrank) (16) provides access to two atomicdistance-dependent statistical scoring functions based onprobability theory that can be used in proteinndashliganddocking The PoseScore was optimized for recognizingnative binding geometries of ligands from other posesand the RankScore was optimized for distinguishingligands from non-binding molecules The server acceptsas input a coordinate file of the target protein structurein the PDB format and docking poses of small moleculesThe output is a list of scores for each proteinndashsmallmolecule complex PoseScore ranks a near-nativebinding pose the best top 5 and top 10 for 88 97and 99 of targets respectively RankScore improvesthe overall ligand enrichment (logAUC) and early
enrichment (EF1) scores computed by DOCK 36 (67)for 68 and 74 of targets respectively The Pose ampRank resource can contribute to many applicationssuch as selecting ligand candidates from virtual screeningfor experimental testing predicting the binding geometriesfor known ligands and suggesting binding site mutationsthat alter the ligand binding properties and consequentlyprotein functions
APPLICATION EXAMPLES
Coordinating the impact of structural genomics on thehuman a-helical transmembrane proteome
With the recent successes in determining membraneprotein structures we explored the tractability of deter-mining representatives for the entire human transmem-brane proteome (68) (httpsalilaborgmembrane) Thisproteome contains 2925 unique integral a-helical trans-membrane domain sequences that cluster into 1201families sharing gt25 sequence identity We assessed
Figure 1 The computed profiles for filament models of the XLFndashXRCC4 complex (63) are fitted to the experimental SAXS profile with FoXS Theinteractive user interface displays the profiles in the left and the models in the right using the same color for each modelprofile pair The table belowthe panels displays the fit parameters and includes buttons to simultaneously show or hide each modelprofile pair Clicking on Minimal EnsembleSearch (MES) results (above the display panel) takes the user to the MES output page
Nucleic Acids Research 2013 5
at UC
SF Library on D
ecember 2 2013
httpnaroxfordjournalsorgD
ownloaded from
the modeling coverage by processing all sequencesthrough ModPipe and analyzing the resulting ModBasedataset We then clustered all sequences [BlastClust(69)]annotated them with cluster size modeling coverage andnumber of predicted transmembrane helices Finally weexplored several target selection strategies Structures of100 optimally selected targets would increase the fractionof modelable human alpha-helical transmembranedomains from 26 to 58 thus providing structurefunction information not otherwise availableTo leverage the results of this study the PSIBiology
Network (httpwwwnigmsnihgovResearchFeaturedProgramsPSIpsi_biology) including high-throughputand membrane PSI centers as well as the StructuralGenomics Consortium is attempting to express nearly100 human transmembrane proteins using their standardhigh-throughput methods The goal of this survey is todetermine which methods best express certain classes oftransmembrane proteins The sequences of our previousanalysis were further annotated by fraction of predicteddisordered regions (7071) number of glycosylation sites(27273) clone availability (74ndash76) HUGO annotations(77) sequence length and several additional metricsEighty-six targets were hand-picked from the largestclusters to represent a diverse selection of humanmembrane proteins with maximum coverage of the trans-membrane proteome Cloning expression and solubilityexperiments of these targets using the pipelines of the 10participating research groups are currently in progressParticipants also use shared and individual sets of sixcontrols A standard method will be used by all to visual-ize the protein bands to quantify yield A final full com-parison will determine the most successful methods foreach representative transmembrane protein Progress ofthe survey is cataloged by the portal of the ProteinStructure Initiative Structural Biology Knowledgebase[PSI SBKB (78) httphmppssbkborg] and will be ac-cessible to the public after the conclusion of the experi-ment A final publication will summarize the surveyrsquosfindings
Structural determinants of HIV-1 protease
The maturation of the HIV virion is facilitated by thecleavage of the Gag and Pol polyproteins (79) Ahomodimeric aspartic protease (HIV-1 protease) catalyzesthese processing events at 10 non-homologous sites and isthe target of some of the most effective antiretroviraldrugs (80ndash82) These sites are eight amino acid residuesin length the cleavage occurs between the third and fourthresidues (83ndash86) In addition to processing viral proteinsHIV-1 protease cleaves several human proteins during in-fection such as the eukaryotic translation initiation factor3 subunit D (eIF3D) (87ndash90)To predict cleavage sites in human proteins we began
by examining sequence and structural features of gt120cellular substrates of HIV-1 protease that were recentlyidentified in vitro (91) (for an example see Figure 2)First every residue of the cleaved and non-cleavedoctapeptides was encoded using gt512 physicochemicalamino acid indices (9394) To account for cooperativity
between residues in different positions of the octapeptidefrequencies of dipeptides and gapped dipeptides (ie twospecific residues separated by any residue) were also usedto train machine learning algorithms for binary classifica-tion Second a greedy feature selection procedure wasapplied to determine features of octapeptides importantfor protease activity Interestingly although featuresencoding known viral cleavage motif ELLE were import-ant for classification most discriminating features encodestructural preferences of amino acid residues in the secondand fifth positions of the octapeptide Therefore wecreated a ModBase dataset of 405 models for 118human proteins cleaved in vitro PSI-Pred (95) was usedto predict secondary structure elements for protein regionswithout templates Analysis of the structural modelsshowed the enrichment of alpha+beta protein class(SCOP ID=53 931) among cleaved proteins and coiledsecondary structure (41) among cleaved sites Weadded structure-based descriptors of cleaved and non-cleaved sites to the sequence-based features and assessedclassifiersrsquo performance in a 5-fold cross-validation pro-cedure The average area under the receiver operatingcharacteristic curve for the classifier trained with theRandom Forest algorithm(96) was 0965 (72 sensitivityand 98 specificity) and the entire human proteome wasscanned for putative human substrates of the HIV-1protease We are currently experimentally validatingseveral of the predicted cleavage sites
ACCESS AND INTERFACE
Direct access
The main access to ModBase is through its web interfaceat httpsalilaborgmodbase by querying with Uniprot-KB (23) and GI (97) identifiers gene names annotationkeywords PDB(1) codes dataset names organism namessequence similarity to the modeled sequences [BLAST(19)]and model-specific criteria such as model reliability modelsize and targetndashtemplate sequence identity Additionally it
Figure 2 Cleavage of human proteins by the HIV-1 protease crystalstructure of the N-terminal domain of human Lupus La protein (92)(left) Residues of the cleavage site (Ile-Asp-Tyr-Tyr-Phe-Gly-Glu-Phe)are shown in orange Scissile bond between Tyr and Phe in the alpha-helix is cleaved by the HIV-1 protease in vitro
6 Nucleic Acids Research 2013
at UC
SF Library on D
ecember 2 2013
httpnaroxfordjournalsorgD
ownloaded from
is possible to retrieve coordinate files and alignment filesof all models for a specific sequence as text files Metadatafor all current ModBase models (updated weekly) allgenome datasets and several additional project specificdatasets are also available from our FTP server (ftpsalilaborgdatabasesmodbaseprojects)
The output of a search is displayed on pages withvarying amounts of information about the modeled
sequences template structures alignments and functionalannotations Output examples from a search resulting inone model are shown in Figure 3 A ribbon diagram of themodel with the highest targetndashtemplate sequence identityis displayed by default together with some details of themodeling calculation Ribbon thumbprints of additionalmodels for this sequence link to corresponding pages withmore information Ribbon diagrams are generated on the
Figure 3 ModBase interface elements Search Form search options are available through the pull-down menu A quick overview of the availablerepresentations is displayed below the search form Model Details Sketch the Model details page provides information for all models of a givensequences The sketch comprises two parts the model coverage sketch that indicates the sequence coverage by all models (top line) and the sequencecoverage by the current model (second line) and a ribbon diagram of the current model Other models are available via thumbprints Update and
Remodel this box shows the date of the last modeling calculation for the current sequence and allows the user to request an update Chimera
Visualization the visualization includes the model and template structures and the alignment Cross-references links to the PMP UniProtKBGenbank UCSC Genome Browser and other databases Model Details Options the pull-down menu switches between representations and allowsdownloads of coordinate and alignment files Quality Criteria red indicates unreliable green reliable Model Overview a different representation forseveral sequences gives a quick overview on modeling coverage and quality Chimera Cavity View visualizes cavities predicted by ConCavity
Nucleic Acids Research 2013 7
at UC
SF Library on D
ecember 2 2013
httpnaroxfordjournalsorgD
ownloaded from
fly using Molscript (98) and Raster3D (99) A pull-downmenu provides links to additional functionalities the SNPmodule retrieval of coordinate and alignment files mo-lecular visualization by UCSF Chimera (100) that allowsthe user to display template and model coordinatestogether with their alignment and Chimera visualizationof predicted cavities [ConCavity (101)] If mutation infor-mation is available for a protein sequence links to thedetails are provided in the cross-references sectionAdditionally cross-references to various other databasesincluding PDB (102) UniProtKB (103) the UCSCGenome Browser (104) EBIrsquos InterPro (105)PharmGKB (106) and SFLD (36) are given OtherModBase pages provide overviews of more than onesequence or structure All ModBase pages are intercon-nected to facilitate easy navigation between differentviews
Access through external databases
The Protein Model PortalThe Protein Model Portal (PMP) has become a valuableoption for accessing ModBase models (httpproteinmo-delportalorg) (107) The PMP is a single point of entry foraccessing protein structure models from a number of dif-ferent databases PMP queries all participating sourcemodel databases and serves the user with the model co-ordinates alignments and quality criteria from a centrallocation It has been developed as a module of the ProteinStructure Initiative Knowledgebase (PSI KB) (79108)The PMP provides a flexible search interface for alldeposited models quality estimation cross-links to othersequence and structure databases annotations ofsequences and their models a central point of entry tocomparative modeling servers (including ModWeb) andquality estimation servers (including ModEval) anddetailed tutorials on all aspects of comparativemodeling Currently the PMP retrieves 450 000ModBase model coordinate files each week fromModBaseA sister web-service to PMP CAMEO (httpcameo3d
org) (107) continuously evaluates the accuracy and reli-ability of several comparative protein structure predictionservers in a fully automated manner The ModWeb servercurrently participates in the testing mode and is expectedto move into the production mode in the first quarter of2014
Access through external databasesModBase models in academic and public datasets arealso directly accessible from several databases includingthe PMP (107) UniProtKB (109) PIRrsquos iProClass(103) EBIrsquos InterPro (105) the UCSC Genome Browser(104) PubMed (LinkOut) (110) PharmGKB (106) andSFLD (36)
FUTURE DIRECTIONS
ModBase will grow by adding models calculated ondemand by external users (using ModWeb) as well asour own calculations of model datasets that are needed
for our research projects (using ModPipe ModWeb orModeller) These updates will reflect improvements inthe methods and software used for calculating themodels as well as new template structures in the PDBand new sequences in UniProtKB In the future weexpect that most of the users will access ModBasemodels through the PMP
CITATION
Users of ModBase are requested to cite this article in theirpublications
ACKNOWLEDGEMENTS
For linking to ModBase from their databases the authorsthank Torsten Schwede and Jurgen Haas (Protein ModelPortal) David Haussler and Jim Kent (UCSC GenomeBrowser) Rolf Apweiler Maria Jesus Martin and ClaireOrsquoDonovan (UniProt) Rolf Apweiler Sarah Hunter(InterPro) Patsy Babbitt (SFLD) Russ Altman(PharmGKB) and Kathy Wu (PIRiProClass) We arealso grateful for computing hardware gifts from MikeHomer Ron Conway NetApp IBM Hewlett Packardand Intel
FUNDING
National Institutes of Health [U54 GM094662 U54GM094625 U54 GM093342 MINOS R01GM105404 toJAT and MH] Sandler Family Supporting Foundation(AS) Department of Energy Lawrence BerkeleyNational Lab IDAT program (to JAT and MH)European Union [FP7-IDEAS-ERC 294809 to MN]The authors thank Tom Ferrin and the UCSF Resourcefor Biocomputing Visualization and Informatics formaking UCSF Chimera (supported by [NIGMS P41-GM103311]) available to the ModBase database andtools Funding for open access charge NIH
Conflict of interest statement None declared
REFERENCES
1 RosePW BiC BluhmWF ChristieCH DimitropoulosDDuttaS GreenRK GoodsellDS PrlicA QuesadaM et al(2013) The RCSB Protein Data Bank new resources for researchand education Nucleic Acids Res 41 D475ndashD482
2 The UniProt Consortium (2011) Ongoing and futuredevelopments at the Universal Protein Resource Nucleic AcidsRes 39 D214ndashD219
3 BensonDA Karsch-MizrachiI ClarkK LipmanDJ OstellJand SayersEW (2012) GenBank Nucleic Acids Res 40D48ndashD53
4 BakerD and SaliA (2001) Protein structure prediction andstructural genomics Science 294 93ndash96
5 EswarN WebbB Marti-RenomMA MadhusudhanMSEramianD ShenMY PieperU and SaliA (2006)Comparative protein structure modeling using MODELLERCurr Protoc Bioinformatics Chapter 5 Unit 561ndash5630
6 EswarN EramianD WebbB ShenMY and SaliA (2008)Protein structure modeling with MODELLER Methods MolBiol 426 145ndash159
8 Nucleic Acids Research 2013
at UC
SF Library on D
ecember 2 2013
httpnaroxfordjournalsorgD
ownloaded from
7 SchwedeT SaliA EswarN and PeitschMC (2008)In SchwedeT and PeitschMC (eds) Computational StructuralBiology World Scientific Publishing Ltd Singapore pp 3ndash35
8 ForrestLR TangCL and HonigB (2006) On the accuracy ofhomology modeling and sequence alignment methods applied tomembrane proteins Biophys J 91 508ndash517
9 LiuT TangGW and CapriottiE (2011) Comparativemodeling the state of the art and protein drug target structureprediction Comb Chem High Throughput Screen 14 532ndash547
10 FiserA (2010) Template-based protein structure modelingMethods Mol Biol 673 73ndash94
11 DagaPR PatelRY and DoerksenRJ (2010) Template-basedprotein modeling recent methodological advances Curr TopMed Chem 10 84ndash94
12 HillischA PinedaLF and HilgenfeldR (2004) Utility ofhomology models in the drug discovery process Drug DiscovToday 9 659ndash669
13 WallnerB and ElofssonA (2005) All are not equal abenchmark of different homology modeling programs ProteinSci 14 1315ndash1327
14 WeinkamP PonsJ and SaliA (2012) Structure-based model ofallostery predicts coupling between distant sites Proc Natl AcadSci USA 109 4875ndash4880
15 Schneidman-DuhovnyD HammelM and SaliA (2011)Macromolecular docking restrained by a small angle X-rayscattering profile J Struct Biol 3 461ndash471
16 FanH SchneidmanD IrwinJJ DongG ShoichetB andSaliA (2011) Statistical potential for modeling and rankingprotein-ligand interactions J Chem Inf Model 51 3078ndash3092
17 EswarN JohnB MirkovicN FiserA IlyinVA PieperUStuartAC Marti-RenomMA MadhusudhanMSYerkovichB et al (2003) Tools for comparative protein structuremodeling and analysis Nucleic Acids Res 31 3375ndash3380
18 SaliA and BlundellTL (1993) Comparative protein modellingby satisfaction of spatial restraints J Mol Biol 234 779ndash815
19 AltschulSF MaddenTL SchafferAA ZhangJ ZhangZMillerW and LipmanDJ (1997) Gapped BLAST and PSI-BLAST a new generation of protein database search programsNucleic Acids Res 25 3389ndash3402
20 RemmertM BiegertA HauserA and SodingJ (2012) HHblitslightning-fast iterative protein sequence searching by HMM-HMM alignment Nat Methods 9 173ndash175
21 SodingJ (2005) Protein homology detection by HMM-HMMcomparison Bioinformatics 21 951ndash960
22 SmithTF and WatermanMS (1981) Identification of commonmolecular subsequences J Mol Biol 147 195ndash197
23 EswarN WebbB Marti-RenomM MadhusudhanMEramianD ShenM PieperU and SaliA (2006) Comparativeprotein structure modeling using Modeller Curr ProtocBioinformatics Chapter 5 Unit 56
24 Marti-RenomMA MadhusudhanMS and SaliA (2004)Alignment of protein sequences by their profiles Protein Sci 131071ndash1087
25 ShenMY and SaliA (2006) Statistical potential for assessmentand prediction of protein structures Protein Sci 15 2507ndash2524
26 MeloF and SaliA (2007) Fold assessment for comparativeprotein structure modeling Protein Sci 16 2412ndash2426
27 PieperU WebbBM BarkanDT Schneidman-DuhovnyDSchlessingerA BrabergH YangZ MengEC PettersenEFHuangCC et al (2011) ModBase a database of annotatedcomparative protein structure models and associated resourcesNucleic Acids Res 39 465ndash474
28 EramianD EswarN ShenM and SaliA (2008) How well canthe accuracy of comparative protein structure models bepredicted Protein Sci 17 1881ndash1893
29 DongGQ FanH Schneidman-DuhovnyD WebbB andSaliA (2013) Optimized atomic statistical potentials Assessmentof protein interfaces and loops (epub ahead of print October 232013)
30 Schneidman-DuhovnyD RossiA Avila-SakarA KimSJVelazquez-MurielJ StropP LiangH KrukenbergKALiaoM KimHM et al (2012) A method for integrativestructure determination of protein-protein complexesBioinformatics 28 3282ndash3289
31 PierceB and WengZ (2007) ZRANK reranking protein dockingpredictions with an optimized energy function Proteins 671078ndash1086
32 AndrusierN NussinovR and WolfsonHJ (2007) FireDockfast interaction refinement in molecular docking Proteins 69139ndash159
33 JacobsonMP PincusDL RappCS DayTJ HonigBShawDE and FriesnerRA (2004) A hierarchical approach toall-atom protein loop prediction Proteins 55 351ndash367
34 GrontD KulpDW VernonRM StraussCE and BakerD(2011) Generalized fragment picking in Rosetta design protocolsand applications PloS One 6 e23294
35 ZhangC LiuS and ZhouY (2004) Accurate and efficient loopselections by the DFIRE-based all-atom statistical potentialProtein Sci 13 391ndash399
36 PeggSC BrownSD OjhaS SeffernickJ MengECMorrisJH ChangPJ HuangCC FerrinTE andBabbittPC (2006) Leveraging enzyme structure-functionrelationships for functional inference and experimental design thestructure-function linkage database Biochemistry 45 2545ndash2555
37 MaurerSM RaiA and SaliA (2004) Finding cures for tropicaldiseases is open source an answer PLoS Med 1 e56
38 OrtiL CarbajoR PieperU EswarN MaurerS RaiATaylorG ToddM Pineda-LucenaA SaliA et al (2009) Akernel for open source drug discovery in tropical diseases PLoSNegl Trop Dis 3 e418
39 AgueroF Al-LazikaniB AslettM BerrimanM BucknerFCampbellR CarmonaS CarruthersI ChanA ChenF et al(2008) Genomic-scale prioritization of drug targets the TDRTargets database Nat Rev Drug Discov 7 900ndash907
40 Martinez-JimenezF PapadatosG YangL WallaceIMKumarV PieperU SaliA BrownJR OveringtonJP andMarti-RenomMA (2013) Target prediction for an open accessset of compounds active against Mycobacterium tuberculosisPLoS Comp Biol 9 e1003253
41 SampathkumarP LuF ZhaoX LiZ GilmoreJ BainKRutterME GheyiT SchwinnK BonannoJ et al (2010)Structure of a putative BenF-like porin from Pseudomanasfluorescens Pf-5 at 26 A resolution Proteins 78 3056ndash3062
42 PieperU ChiangR SeffernickJ BrownS GlasnerMKellyL EswarN SauderJ BonannoJ SwaminathanS et al(2009) Target selection and annotation for the structural genomicsof the amidohydrolase and enolase superfamilies J Struct FunctGenom 10 107ndash125
43 KarchinR DiekhansM KellyL ThomasDJ PieperUEswarN HausslerD and SaliA (2005) LS-SNP large-scaleannotation of coding non-synonymous SNPs based on multipleinformation sources Bioinformatics 21 2814ndash2820
44 FiserA and SaliA (2003) ModLoop automated modeling ofloops in protein structures Bioinformatics 19 2500ndash2501
45 DavisF and SaliA (2005) PIBASE a comprehensive databaseof structurally defined protein interfaces Bioinformatics 211901ndash1907
46 Marti-RenomMA PieperU MadhusudhanMS RossiAEswarN DavisFP Al-ShahrourF DopazoJ and SaliA(2007) DBAli tools mining the protein structure space NucleicAcids Res 35 W393ndashW397
47 Marti-RenomMA IlyinVA and SaliA (2001) DBAli adatabase of protein structure alignments Bioinformatics 17746ndash747
48 PieperU EswarN WebbB EramianD KellyL BarkanDCarterH MankooP KarchinR Marti-RenomM et al (2009)MODBASE a database of annotated comparative proteinstructure models and associated resources Nucleic Acids Res 37D347ndashD354
49 PieperU EswarN DavisFP BrabergH MadhusudhanMSRossiA Marti-RenomM KarchinR WebbBM EramianDet al (2006) MODBASE a database of annotated comparativeprotein structure models and associated resources Nucleic AcidsRes 34 D291ndashD295
50 BrabergH WebbB TjioeE PieperU SaliA andMadhusudhanMS (2012) SALIGN a webserver for alignmentof multiple protein sequences and structures Bioinformatics 152072ndash2073
Nucleic Acids Research 2013 9
at UC
SF Library on D
ecember 2 2013
httpnaroxfordjournalsorgD
ownloaded from
51 Schneidman-DuhovnyD HammelM and SaliA (2010) FoXS aweb server for rapid computation and fitting of SAXS ProfilesNucleic Acids Res 38 541ndash544
52 UedaY TaketomiH and GoN (1978) Studies on proteinfolding unfolding and fluctuations by computer simulation IIAThree dimensional lattice model of lysozyme Biopolymers 171531ndash1548
53 OkazakiK KogaN TakadaS OnuchicJN and WolynesPG(2006) Multiple-basin energy landscapes for large-amplitudeconformational motions of proteins Structure-based moleculardynamics simulations Proc Natl Acad Sci USA 10311844ndash11849
54 WhitfordPC NoelJK GosaviS SchugA SanbonmatsuKYand OnuchicJN (2009) An all-atom structure-based potential forproteins bridging minimal models with all-atom empiricalforcefields Proteins 75 430ndash441
55 WeinkamP ChenYC PonsJ and SaliA (2013) Impact ofmutations on the allosteric conformational equilibrium J MolBiol 425 647ndash661
56 PetoukhovMV and SvergunDI (2007) Analysis of X-ray andneutron scattering from biomacromolecular solutions Curr OpinStruct Biol 17 562ndash571
57 HuraGL MenonAL HammelM RamboRP PooleFL IITsutakawaSE JenneyFE Jr ClassenS FrankelKAHopkinsRC et al (2009) Robust high-throughput solutionstructural analyses by small angle X-ray scattering (SAXS) NatMethods 6 606ndash612
58 SvergunD BarberatoC and KochMHJ (1995) CRYSOL-aprogram to evaluate X-ray solution scattering of biologicalmacromolecules from atomic coordinates J Appl Crystallogr28 768ndash773
59 PoitevinF OrlandH DoniachS KoehlP and DelarueM(2011) AquaSAXS a web server for computation and fitting ofSAXS profiles with non-uniformally hydrated atomic modelsNucleic Acids Res 39 W184ndashW189
60 LiuH MorrisRJ HexemerA GrandisonS and ZwartPH(2012) Computation of small-angle scattering profiles with three-dimensional Zernike polynomials Acta Crystallogr A 68278ndash285
61 RavikumarKM HuangW and YangS (2013) Fast-SAXS-proa unified approach to computing SAXS profiles of DNA RNAprotein and their complexes J Chem Phys 138 024112
62 Schneidman-DuhovnyD HammelM TainerJA and SaliA(2013) Accurate SAXS profile computation and its assessment bycontrast variation experiments Biophys J 105 962ndash974
63 HammelM ReyM YuY ManiRS ClassenS LiuMPiqueME FangS MahaneyBL WeinfeldM et al (2011)XRCC4 protein interactions with XRCC4-like factor (XLF)create an extended grooved scaffold for DNA ligation and doublestrand break repair J Biol Chem 286 32638ndash32650
64 PelikanM HuraGL and HammelM (2009) Structure andflexibility within proteins as identified through small angle X-rayscattering Gen Physiol Biophys 28 174ndash189
65 GrantTD LuftJR WolfleyJR TsurutaH MartelAMontelioneGT and SnellEH (2011) Small angle X-rayscattering as a complementary tool for high-throughput structuralstudies Biopolymers 95 517ndash530
66 KonarevPV VolkovVV SokolovaAV KochMHJ andSvergunDI (2003) PRIMUS a Windows PC-based system forsmall-angle scattering data analysis J Appl Crystallogr 361277ndash1282
67 ShoichetBK and KuntzID (1991) Protein docking andcomplementarity J Mol Biol 221 327ndash346
68 PieperU SchlessingerA KloppmannE ChangGA ChouJJDumontM FoxB FrommeP HendricksonW MalkowskiMet al (2013) Coordinating the impact of structural genomics onthe human a-helical transmembrane proteome Nat Struct MolBiol 20 135ndash138
69 JohnsonM ZaretskayaI RaytselisY MerezhukYMcGinnisS and MaddenTL (2008) NCBI BLAST a betterweb interface Nucleic Acids Res 36 W5ndashW9
70 WardJJ McGuffinLJ BrysonK BuxtonBF and JonesDT(2004) The DISOPRED server for the prediction of proteindisorder Bioinformatics 20 2138ndash2139
71 DosztanyiZ CsizmokV TompaP and SimonI (2005) IUPredweb server for the prediction of intrinsically unstructured regionsof proteins based on estimated energy content Bioinformatics 213433ndash3434
72 SteentoftC VakhrushevSY JoshiHJ KongY Vester-ChristensenMB SchjoldagerKT LavrsenK DabelsteenSPedersenNB Marcos-SilvaL et al (2013) Precision mapping ofthe human O-GalNAc glycoproteome through SimpleCelltechnology EMBO J 32 1478ndash1488
73 GuptaR JungE GooleyAA WilliamsKL BrunakS andHansenJ (1999) Scanning the available Dictyostelium discoideumproteome for O-linked GlcNAc glycosylation sites using neuralnetworks Glycobiology 9 1009ndash1022
74 CormierCY ParkJG FiaccoM SteelJ HunterPKramerJ SinglaR and LaBaerJ (2011) PSIBiology-materialsrepository a biologistrsquos resource for protein expression plasmidsJ Struct Funct Genomics 12 55ndash62
75 LameschP LiN MilsteinS FanC HaoT SzaboG HuZVenkatesanK BethelG MartinP et al (2007) hORFeomev31 a resource of human open reading frames representing over10000 human genes Genomics 89 307ndash315
76 TempleG GerhardDS RasoolyR FeingoldEA GoodPJRobinsonC MandichA DergeJG LewisJ ShoafD et al(2009) The completion of the mammalian gene collection (MGC)Genome Res 19 2324ndash2333
77 SealRL GordonSM LushMJ WrightMW andBrufordEA (2011) genenamesorg the HGNC resources in 2011Nucleic Acids Res 39 D514ndashD519
78 GiffordLK CarterLG GabanyiMJ BermanHM andAdamsPD (2012) The protein structure initiative structuralbiology knowledgebase technology portal a structural biologyweb resource J Struct Funct Genomics 13 57ndash62
79 FreedEO (2001) HIV-1 replication Somatic Cell Mol Genet26 13ndash33
80 McDonaldCK and KuritzkesDR (1997) Humanimmunodeficiency virus type 1 protease inhibitors Arch IntMed 157 951ndash959
81 DragM and SalvesenGS (2010) Emerging principles inprotease-based drug discovery Nat Rev Drug Discov 9690ndash701
82 FlexnerC (1998) HIV-protease inhibitors N Engl J Med 3381281ndash1292
83 KohlNE EminiEA SchleifWA DavisLJ HeimbachJCDixonRA ScolnickEM and SigalIS (1988) Active humanimmunodeficiency virus protease is required for viral infectivityProc Natl Acad Sci USA 85 4686ndash4690
84 MurthyKH WinborneEL MinnichMD CulpJS andDebouckC (1992) The crystal structures at 22-A resolution ofhydroxyethylene-based inhibitors bound to humanimmunodeficiency virus type 1 protease show that the inhibitorsare present in two distinct orientations J Biol Chem 26722770ndash22778
85 Prabu-JeyabalanM NalivaikaE and SchifferCA (2000) Howdoes a symmetric dimer recognize an asymmetric substrate Asubstrate complex of HIV-1 protease J Mol Biol 3011207ndash1220
86 MahalingamB LouisJM HungJ HarrisonRW andWeberIT (2001) Structural implications of drug-resistantmutants of HIV-1 protease high-resolution crystal structures ofthe mutant proteasesubstrate analogue complexes Proteins 43455ndash464
87 NieZ PhenixBN LumJJ AlamA LynchDH BeckettBKrammerPH SekalyRP and BadleyAD (2002) HIV-1protease processes procaspase 8 to cause mitochondrial release ofcytochrome c caspase cleavage and nuclear fragmentation CellDeath Differ 9 1172ndash1184
88 Algeciras-SchimnichA Belzacq-CasagrandeAS BrenGDNieZ TaylorJA RizzaSA BrennerC and BadleyAD(2007) Analysis of HIV protease killing through caspase 8 revealsa novel interaction between caspase 8 and mitochondria OpenVirol J 1 39ndash46
89 NieZ BrenGD RizzaSA and BadleyAD (2008) HIVprotease cleavage of procaspase 8 is necessary for death of HIV-infected cells Open Virol J 2 1ndash7
10 Nucleic Acids Research 2013
at UC
SF Library on D
ecember 2 2013
httpnaroxfordjournalsorgD
ownloaded from
90 CastelloA FrancoD Moral-LopezP BerlangaJJAlvarezE WimmerE and CarrascoL (2009) HIV- 1 proteaseinhibits Cap- and poly(A)-dependent translation upon eIF4GIand PABP cleavage PloS One 4 e7997
91 ImpensF TimmermanE StaesA MoensK ArienKKVerhasseltB VandekerckhoveJ and GevaertK (2012) Acatalogue of putative HIV-1 protease host cell substrates BiolChem 393 915ndash931
92 Kotik-KoganO ValentineER SanfeliceD ConteMR andCurryS (2008) Structural analysis reveals conformationalplasticity in the recognition of RNA 3rsquo ends by the human Laprotein Structure 16 852ndash862
93 NakaiK KideraA and KanehisaM (1988) Cluster analysis ofamino acid indices for prediction of protein structure andfunction Protein Eng 2 93ndash100
94 TomiiK and KanehisaM (1996) Analysis of amino acid indicesand mutation matrices for sequence comparison and structureprediction of proteins Protein Eng 9 27ndash36
95 JonesDT (1999) Protein secondary structure prediction basedon position-specific scoring matrices J Mol Biol 292 195ndash202
96 BreimanL and SchapireE (2001) Random forests MachLearn 45 5ndash32
97 BensonDA Karsch-MizrachiI LipmanDJ OstellJ andSayersEW (2010) GenBank Nucleic Acids Res 38 D46ndashD51
98 KraulisPJ (1991) MOLSCRIPT a program to produce bothdetailed and schematic plorts of protein structures J ApplCrystallogr 24 946ndash950
99 MerrittEA and BaconDJ (1997) Raster3D photorealisticmolecular graphics Methods Enzymol 277 505ndash524
100 PettersenEF GoddardTD HuangCC CouchGSGreenblattDM MengEC and FerrinTE (2004) UCSFChimerandasha visualization system for exploratory research andanalysis J Comput Chem 25 1605ndash1612
101 CapraJA LaskowskiRA ThorntonJM SinghM andFunkhouserTA (2009) Predicting protein ligand binding sitesby combining evolutionary sequence conservation and 3Dstructure PLoS Comp Biol 5 e1000585
102 HenrickK FengZ BluhmWF DimitropoulosDDoreleijersJF DuttaS Flippen-AndersonJL IonidesJKamadaC KrissinelE et al (2008) Remediation of the proteindata bank archive Nucleic Acids Res 36 D426ndashD433
103 WuCH ApweilerR BairochA NataleDA BarkerWCBoeckmannB FerroS GasteigerE HuangH LopezR et al(2006) The Universal Protein Resource (UniProt) an expandinguniverse of protein information Nucleic Acids Res 34D187ndashD191
104 RheadB KarolchikD KuhnRM HinrichsAS ZweigASFujitaPA DiekhansM SmithKE RosenbloomKRRaneyBJ et al (2010) The UCSC Genome Browser databaseupdate 2010 Nucleic Acids Res 38 D613ndashD619
105 HunterS ApweilerR AttwoodTK BairochA BatemanABinnsD BorkP DasU DaughertyL DuquenneL et al(2009) InterPro the integrative protein signature databaseNucleic Acids Res 37 D211ndashD215
106 KleinTE ChangJT ChoMK EastonKL FergersonRHewettM LinZ LiuY LiuS OliverDE et al (2001)Integrating genotype and phenotype information an overview ofthe PharmGKB project Pharmacogenetics research network andknowledge base Pharmacogenomics J 1 167ndash170
107 HaasJ RothS ArnoldK KieferF SchmidtT BordoliLand SchwedeT (2013) The Protein Model Portalmdashacomprehensive resource for protein structure and modelinformation Database 2013 bat031
108 SchwedeT SaliA HonigB LevittM BermanH JonesDBrennerS BurleyS DasR DokholyanN et al (2009)Outcome of a workshop on applications of protein models inbiomedical research Structure 17 151ndash159
109 BairochA ApweilerR WuCH BarkerWC BoeckmannBFerroS GasteigerE HuangH LopezR MagraneM et al(2005) The Universal Protein Resource (UniProt) Nucleic AcidsRes 33 D154ndashD159
110 GigliaE (2009) New year new PubMed Eur J Phys RehabilMed 45 155ndash159
Nucleic Acids Research 2013 11
at UC
SF Library on D
ecember 2 2013
httpnaroxfordjournalsorgD
ownloaded from

the modeling coverage by processing all sequencesthrough ModPipe and analyzing the resulting ModBasedataset We then clustered all sequences [BlastClust(69)]annotated them with cluster size modeling coverage andnumber of predicted transmembrane helices Finally weexplored several target selection strategies Structures of100 optimally selected targets would increase the fractionof modelable human alpha-helical transmembranedomains from 26 to 58 thus providing structurefunction information not otherwise availableTo leverage the results of this study the PSIBiology
Network (httpwwwnigmsnihgovResearchFeaturedProgramsPSIpsi_biology) including high-throughputand membrane PSI centers as well as the StructuralGenomics Consortium is attempting to express nearly100 human transmembrane proteins using their standardhigh-throughput methods The goal of this survey is todetermine which methods best express certain classes oftransmembrane proteins The sequences of our previousanalysis were further annotated by fraction of predicteddisordered regions (7071) number of glycosylation sites(27273) clone availability (74ndash76) HUGO annotations(77) sequence length and several additional metricsEighty-six targets were hand-picked from the largestclusters to represent a diverse selection of humanmembrane proteins with maximum coverage of the trans-membrane proteome Cloning expression and solubilityexperiments of these targets using the pipelines of the 10participating research groups are currently in progressParticipants also use shared and individual sets of sixcontrols A standard method will be used by all to visual-ize the protein bands to quantify yield A final full com-parison will determine the most successful methods foreach representative transmembrane protein Progress ofthe survey is cataloged by the portal of the ProteinStructure Initiative Structural Biology Knowledgebase[PSI SBKB (78) httphmppssbkborg] and will be ac-cessible to the public after the conclusion of the experi-ment A final publication will summarize the surveyrsquosfindings
Structural determinants of HIV-1 protease
The maturation of the HIV virion is facilitated by thecleavage of the Gag and Pol polyproteins (79) Ahomodimeric aspartic protease (HIV-1 protease) catalyzesthese processing events at 10 non-homologous sites and isthe target of some of the most effective antiretroviraldrugs (80ndash82) These sites are eight amino acid residuesin length the cleavage occurs between the third and fourthresidues (83ndash86) In addition to processing viral proteinsHIV-1 protease cleaves several human proteins during in-fection such as the eukaryotic translation initiation factor3 subunit D (eIF3D) (87ndash90)To predict cleavage sites in human proteins we began
by examining sequence and structural features of gt120cellular substrates of HIV-1 protease that were recentlyidentified in vitro (91) (for an example see Figure 2)First every residue of the cleaved and non-cleavedoctapeptides was encoded using gt512 physicochemicalamino acid indices (9394) To account for cooperativity
between residues in different positions of the octapeptidefrequencies of dipeptides and gapped dipeptides (ie twospecific residues separated by any residue) were also usedto train machine learning algorithms for binary classifica-tion Second a greedy feature selection procedure wasapplied to determine features of octapeptides importantfor protease activity Interestingly although featuresencoding known viral cleavage motif ELLE were import-ant for classification most discriminating features encodestructural preferences of amino acid residues in the secondand fifth positions of the octapeptide Therefore wecreated a ModBase dataset of 405 models for 118human proteins cleaved in vitro PSI-Pred (95) was usedto predict secondary structure elements for protein regionswithout templates Analysis of the structural modelsshowed the enrichment of alpha+beta protein class(SCOP ID=53 931) among cleaved proteins and coiledsecondary structure (41) among cleaved sites Weadded structure-based descriptors of cleaved and non-cleaved sites to the sequence-based features and assessedclassifiersrsquo performance in a 5-fold cross-validation pro-cedure The average area under the receiver operatingcharacteristic curve for the classifier trained with theRandom Forest algorithm(96) was 0965 (72 sensitivityand 98 specificity) and the entire human proteome wasscanned for putative human substrates of the HIV-1protease We are currently experimentally validatingseveral of the predicted cleavage sites
ACCESS AND INTERFACE
Direct access
The main access to ModBase is through its web interfaceat httpsalilaborgmodbase by querying with Uniprot-KB (23) and GI (97) identifiers gene names annotationkeywords PDB(1) codes dataset names organism namessequence similarity to the modeled sequences [BLAST(19)]and model-specific criteria such as model reliability modelsize and targetndashtemplate sequence identity Additionally it
Figure 2 Cleavage of human proteins by the HIV-1 protease crystalstructure of the N-terminal domain of human Lupus La protein (92)(left) Residues of the cleavage site (Ile-Asp-Tyr-Tyr-Phe-Gly-Glu-Phe)are shown in orange Scissile bond between Tyr and Phe in the alpha-helix is cleaved by the HIV-1 protease in vitro
6 Nucleic Acids Research 2013
at UC
SF Library on D
ecember 2 2013
httpnaroxfordjournalsorgD
ownloaded from
is possible to retrieve coordinate files and alignment filesof all models for a specific sequence as text files Metadatafor all current ModBase models (updated weekly) allgenome datasets and several additional project specificdatasets are also available from our FTP server (ftpsalilaborgdatabasesmodbaseprojects)
The output of a search is displayed on pages withvarying amounts of information about the modeled
sequences template structures alignments and functionalannotations Output examples from a search resulting inone model are shown in Figure 3 A ribbon diagram of themodel with the highest targetndashtemplate sequence identityis displayed by default together with some details of themodeling calculation Ribbon thumbprints of additionalmodels for this sequence link to corresponding pages withmore information Ribbon diagrams are generated on the
Figure 3 ModBase interface elements Search Form search options are available through the pull-down menu A quick overview of the availablerepresentations is displayed below the search form Model Details Sketch the Model details page provides information for all models of a givensequences The sketch comprises two parts the model coverage sketch that indicates the sequence coverage by all models (top line) and the sequencecoverage by the current model (second line) and a ribbon diagram of the current model Other models are available via thumbprints Update and
Remodel this box shows the date of the last modeling calculation for the current sequence and allows the user to request an update Chimera
Visualization the visualization includes the model and template structures and the alignment Cross-references links to the PMP UniProtKBGenbank UCSC Genome Browser and other databases Model Details Options the pull-down menu switches between representations and allowsdownloads of coordinate and alignment files Quality Criteria red indicates unreliable green reliable Model Overview a different representation forseveral sequences gives a quick overview on modeling coverage and quality Chimera Cavity View visualizes cavities predicted by ConCavity
Nucleic Acids Research 2013 7
at UC
SF Library on D
ecember 2 2013
httpnaroxfordjournalsorgD
ownloaded from
fly using Molscript (98) and Raster3D (99) A pull-downmenu provides links to additional functionalities the SNPmodule retrieval of coordinate and alignment files mo-lecular visualization by UCSF Chimera (100) that allowsthe user to display template and model coordinatestogether with their alignment and Chimera visualizationof predicted cavities [ConCavity (101)] If mutation infor-mation is available for a protein sequence links to thedetails are provided in the cross-references sectionAdditionally cross-references to various other databasesincluding PDB (102) UniProtKB (103) the UCSCGenome Browser (104) EBIrsquos InterPro (105)PharmGKB (106) and SFLD (36) are given OtherModBase pages provide overviews of more than onesequence or structure All ModBase pages are intercon-nected to facilitate easy navigation between differentviews
Access through external databases
The Protein Model PortalThe Protein Model Portal (PMP) has become a valuableoption for accessing ModBase models (httpproteinmo-delportalorg) (107) The PMP is a single point of entry foraccessing protein structure models from a number of dif-ferent databases PMP queries all participating sourcemodel databases and serves the user with the model co-ordinates alignments and quality criteria from a centrallocation It has been developed as a module of the ProteinStructure Initiative Knowledgebase (PSI KB) (79108)The PMP provides a flexible search interface for alldeposited models quality estimation cross-links to othersequence and structure databases annotations ofsequences and their models a central point of entry tocomparative modeling servers (including ModWeb) andquality estimation servers (including ModEval) anddetailed tutorials on all aspects of comparativemodeling Currently the PMP retrieves 450 000ModBase model coordinate files each week fromModBaseA sister web-service to PMP CAMEO (httpcameo3d
org) (107) continuously evaluates the accuracy and reli-ability of several comparative protein structure predictionservers in a fully automated manner The ModWeb servercurrently participates in the testing mode and is expectedto move into the production mode in the first quarter of2014
Access through external databasesModBase models in academic and public datasets arealso directly accessible from several databases includingthe PMP (107) UniProtKB (109) PIRrsquos iProClass(103) EBIrsquos InterPro (105) the UCSC Genome Browser(104) PubMed (LinkOut) (110) PharmGKB (106) andSFLD (36)
FUTURE DIRECTIONS
ModBase will grow by adding models calculated ondemand by external users (using ModWeb) as well asour own calculations of model datasets that are needed
for our research projects (using ModPipe ModWeb orModeller) These updates will reflect improvements inthe methods and software used for calculating themodels as well as new template structures in the PDBand new sequences in UniProtKB In the future weexpect that most of the users will access ModBasemodels through the PMP
CITATION
Users of ModBase are requested to cite this article in theirpublications
ACKNOWLEDGEMENTS
For linking to ModBase from their databases the authorsthank Torsten Schwede and Jurgen Haas (Protein ModelPortal) David Haussler and Jim Kent (UCSC GenomeBrowser) Rolf Apweiler Maria Jesus Martin and ClaireOrsquoDonovan (UniProt) Rolf Apweiler Sarah Hunter(InterPro) Patsy Babbitt (SFLD) Russ Altman(PharmGKB) and Kathy Wu (PIRiProClass) We arealso grateful for computing hardware gifts from MikeHomer Ron Conway NetApp IBM Hewlett Packardand Intel
FUNDING
National Institutes of Health [U54 GM094662 U54GM094625 U54 GM093342 MINOS R01GM105404 toJAT and MH] Sandler Family Supporting Foundation(AS) Department of Energy Lawrence BerkeleyNational Lab IDAT program (to JAT and MH)European Union [FP7-IDEAS-ERC 294809 to MN]The authors thank Tom Ferrin and the UCSF Resourcefor Biocomputing Visualization and Informatics formaking UCSF Chimera (supported by [NIGMS P41-GM103311]) available to the ModBase database andtools Funding for open access charge NIH
Conflict of interest statement None declared
REFERENCES
1 RosePW BiC BluhmWF ChristieCH DimitropoulosDDuttaS GreenRK GoodsellDS PrlicA QuesadaM et al(2013) The RCSB Protein Data Bank new resources for researchand education Nucleic Acids Res 41 D475ndashD482
2 The UniProt Consortium (2011) Ongoing and futuredevelopments at the Universal Protein Resource Nucleic AcidsRes 39 D214ndashD219
3 BensonDA Karsch-MizrachiI ClarkK LipmanDJ OstellJand SayersEW (2012) GenBank Nucleic Acids Res 40D48ndashD53
4 BakerD and SaliA (2001) Protein structure prediction andstructural genomics Science 294 93ndash96
5 EswarN WebbB Marti-RenomMA MadhusudhanMSEramianD ShenMY PieperU and SaliA (2006)Comparative protein structure modeling using MODELLERCurr Protoc Bioinformatics Chapter 5 Unit 561ndash5630
6 EswarN EramianD WebbB ShenMY and SaliA (2008)Protein structure modeling with MODELLER Methods MolBiol 426 145ndash159
8 Nucleic Acids Research 2013
at UC
SF Library on D
ecember 2 2013
httpnaroxfordjournalsorgD
ownloaded from
7 SchwedeT SaliA EswarN and PeitschMC (2008)In SchwedeT and PeitschMC (eds) Computational StructuralBiology World Scientific Publishing Ltd Singapore pp 3ndash35
8 ForrestLR TangCL and HonigB (2006) On the accuracy ofhomology modeling and sequence alignment methods applied tomembrane proteins Biophys J 91 508ndash517
9 LiuT TangGW and CapriottiE (2011) Comparativemodeling the state of the art and protein drug target structureprediction Comb Chem High Throughput Screen 14 532ndash547
10 FiserA (2010) Template-based protein structure modelingMethods Mol Biol 673 73ndash94
11 DagaPR PatelRY and DoerksenRJ (2010) Template-basedprotein modeling recent methodological advances Curr TopMed Chem 10 84ndash94
12 HillischA PinedaLF and HilgenfeldR (2004) Utility ofhomology models in the drug discovery process Drug DiscovToday 9 659ndash669
13 WallnerB and ElofssonA (2005) All are not equal abenchmark of different homology modeling programs ProteinSci 14 1315ndash1327
14 WeinkamP PonsJ and SaliA (2012) Structure-based model ofallostery predicts coupling between distant sites Proc Natl AcadSci USA 109 4875ndash4880
15 Schneidman-DuhovnyD HammelM and SaliA (2011)Macromolecular docking restrained by a small angle X-rayscattering profile J Struct Biol 3 461ndash471
16 FanH SchneidmanD IrwinJJ DongG ShoichetB andSaliA (2011) Statistical potential for modeling and rankingprotein-ligand interactions J Chem Inf Model 51 3078ndash3092
17 EswarN JohnB MirkovicN FiserA IlyinVA PieperUStuartAC Marti-RenomMA MadhusudhanMSYerkovichB et al (2003) Tools for comparative protein structuremodeling and analysis Nucleic Acids Res 31 3375ndash3380
18 SaliA and BlundellTL (1993) Comparative protein modellingby satisfaction of spatial restraints J Mol Biol 234 779ndash815
19 AltschulSF MaddenTL SchafferAA ZhangJ ZhangZMillerW and LipmanDJ (1997) Gapped BLAST and PSI-BLAST a new generation of protein database search programsNucleic Acids Res 25 3389ndash3402
20 RemmertM BiegertA HauserA and SodingJ (2012) HHblitslightning-fast iterative protein sequence searching by HMM-HMM alignment Nat Methods 9 173ndash175
21 SodingJ (2005) Protein homology detection by HMM-HMMcomparison Bioinformatics 21 951ndash960
22 SmithTF and WatermanMS (1981) Identification of commonmolecular subsequences J Mol Biol 147 195ndash197
23 EswarN WebbB Marti-RenomM MadhusudhanMEramianD ShenM PieperU and SaliA (2006) Comparativeprotein structure modeling using Modeller Curr ProtocBioinformatics Chapter 5 Unit 56
24 Marti-RenomMA MadhusudhanMS and SaliA (2004)Alignment of protein sequences by their profiles Protein Sci 131071ndash1087
25 ShenMY and SaliA (2006) Statistical potential for assessmentand prediction of protein structures Protein Sci 15 2507ndash2524
26 MeloF and SaliA (2007) Fold assessment for comparativeprotein structure modeling Protein Sci 16 2412ndash2426
27 PieperU WebbBM BarkanDT Schneidman-DuhovnyDSchlessingerA BrabergH YangZ MengEC PettersenEFHuangCC et al (2011) ModBase a database of annotatedcomparative protein structure models and associated resourcesNucleic Acids Res 39 465ndash474
28 EramianD EswarN ShenM and SaliA (2008) How well canthe accuracy of comparative protein structure models bepredicted Protein Sci 17 1881ndash1893
29 DongGQ FanH Schneidman-DuhovnyD WebbB andSaliA (2013) Optimized atomic statistical potentials Assessmentof protein interfaces and loops (epub ahead of print October 232013)
30 Schneidman-DuhovnyD RossiA Avila-SakarA KimSJVelazquez-MurielJ StropP LiangH KrukenbergKALiaoM KimHM et al (2012) A method for integrativestructure determination of protein-protein complexesBioinformatics 28 3282ndash3289
31 PierceB and WengZ (2007) ZRANK reranking protein dockingpredictions with an optimized energy function Proteins 671078ndash1086
32 AndrusierN NussinovR and WolfsonHJ (2007) FireDockfast interaction refinement in molecular docking Proteins 69139ndash159
33 JacobsonMP PincusDL RappCS DayTJ HonigBShawDE and FriesnerRA (2004) A hierarchical approach toall-atom protein loop prediction Proteins 55 351ndash367
34 GrontD KulpDW VernonRM StraussCE and BakerD(2011) Generalized fragment picking in Rosetta design protocolsand applications PloS One 6 e23294
35 ZhangC LiuS and ZhouY (2004) Accurate and efficient loopselections by the DFIRE-based all-atom statistical potentialProtein Sci 13 391ndash399
36 PeggSC BrownSD OjhaS SeffernickJ MengECMorrisJH ChangPJ HuangCC FerrinTE andBabbittPC (2006) Leveraging enzyme structure-functionrelationships for functional inference and experimental design thestructure-function linkage database Biochemistry 45 2545ndash2555
37 MaurerSM RaiA and SaliA (2004) Finding cures for tropicaldiseases is open source an answer PLoS Med 1 e56
38 OrtiL CarbajoR PieperU EswarN MaurerS RaiATaylorG ToddM Pineda-LucenaA SaliA et al (2009) Akernel for open source drug discovery in tropical diseases PLoSNegl Trop Dis 3 e418
39 AgueroF Al-LazikaniB AslettM BerrimanM BucknerFCampbellR CarmonaS CarruthersI ChanA ChenF et al(2008) Genomic-scale prioritization of drug targets the TDRTargets database Nat Rev Drug Discov 7 900ndash907
40 Martinez-JimenezF PapadatosG YangL WallaceIMKumarV PieperU SaliA BrownJR OveringtonJP andMarti-RenomMA (2013) Target prediction for an open accessset of compounds active against Mycobacterium tuberculosisPLoS Comp Biol 9 e1003253
41 SampathkumarP LuF ZhaoX LiZ GilmoreJ BainKRutterME GheyiT SchwinnK BonannoJ et al (2010)Structure of a putative BenF-like porin from Pseudomanasfluorescens Pf-5 at 26 A resolution Proteins 78 3056ndash3062
42 PieperU ChiangR SeffernickJ BrownS GlasnerMKellyL EswarN SauderJ BonannoJ SwaminathanS et al(2009) Target selection and annotation for the structural genomicsof the amidohydrolase and enolase superfamilies J Struct FunctGenom 10 107ndash125
43 KarchinR DiekhansM KellyL ThomasDJ PieperUEswarN HausslerD and SaliA (2005) LS-SNP large-scaleannotation of coding non-synonymous SNPs based on multipleinformation sources Bioinformatics 21 2814ndash2820
44 FiserA and SaliA (2003) ModLoop automated modeling ofloops in protein structures Bioinformatics 19 2500ndash2501
45 DavisF and SaliA (2005) PIBASE a comprehensive databaseof structurally defined protein interfaces Bioinformatics 211901ndash1907
46 Marti-RenomMA PieperU MadhusudhanMS RossiAEswarN DavisFP Al-ShahrourF DopazoJ and SaliA(2007) DBAli tools mining the protein structure space NucleicAcids Res 35 W393ndashW397
47 Marti-RenomMA IlyinVA and SaliA (2001) DBAli adatabase of protein structure alignments Bioinformatics 17746ndash747
48 PieperU EswarN WebbB EramianD KellyL BarkanDCarterH MankooP KarchinR Marti-RenomM et al (2009)MODBASE a database of annotated comparative proteinstructure models and associated resources Nucleic Acids Res 37D347ndashD354
49 PieperU EswarN DavisFP BrabergH MadhusudhanMSRossiA Marti-RenomM KarchinR WebbBM EramianDet al (2006) MODBASE a database of annotated comparativeprotein structure models and associated resources Nucleic AcidsRes 34 D291ndashD295
50 BrabergH WebbB TjioeE PieperU SaliA andMadhusudhanMS (2012) SALIGN a webserver for alignmentof multiple protein sequences and structures Bioinformatics 152072ndash2073
Nucleic Acids Research 2013 9
at UC
SF Library on D
ecember 2 2013
httpnaroxfordjournalsorgD
ownloaded from
51 Schneidman-DuhovnyD HammelM and SaliA (2010) FoXS aweb server for rapid computation and fitting of SAXS ProfilesNucleic Acids Res 38 541ndash544
52 UedaY TaketomiH and GoN (1978) Studies on proteinfolding unfolding and fluctuations by computer simulation IIAThree dimensional lattice model of lysozyme Biopolymers 171531ndash1548
53 OkazakiK KogaN TakadaS OnuchicJN and WolynesPG(2006) Multiple-basin energy landscapes for large-amplitudeconformational motions of proteins Structure-based moleculardynamics simulations Proc Natl Acad Sci USA 10311844ndash11849
54 WhitfordPC NoelJK GosaviS SchugA SanbonmatsuKYand OnuchicJN (2009) An all-atom structure-based potential forproteins bridging minimal models with all-atom empiricalforcefields Proteins 75 430ndash441
55 WeinkamP ChenYC PonsJ and SaliA (2013) Impact ofmutations on the allosteric conformational equilibrium J MolBiol 425 647ndash661
56 PetoukhovMV and SvergunDI (2007) Analysis of X-ray andneutron scattering from biomacromolecular solutions Curr OpinStruct Biol 17 562ndash571
57 HuraGL MenonAL HammelM RamboRP PooleFL IITsutakawaSE JenneyFE Jr ClassenS FrankelKAHopkinsRC et al (2009) Robust high-throughput solutionstructural analyses by small angle X-ray scattering (SAXS) NatMethods 6 606ndash612
58 SvergunD BarberatoC and KochMHJ (1995) CRYSOL-aprogram to evaluate X-ray solution scattering of biologicalmacromolecules from atomic coordinates J Appl Crystallogr28 768ndash773
59 PoitevinF OrlandH DoniachS KoehlP and DelarueM(2011) AquaSAXS a web server for computation and fitting ofSAXS profiles with non-uniformally hydrated atomic modelsNucleic Acids Res 39 W184ndashW189
60 LiuH MorrisRJ HexemerA GrandisonS and ZwartPH(2012) Computation of small-angle scattering profiles with three-dimensional Zernike polynomials Acta Crystallogr A 68278ndash285
61 RavikumarKM HuangW and YangS (2013) Fast-SAXS-proa unified approach to computing SAXS profiles of DNA RNAprotein and their complexes J Chem Phys 138 024112
62 Schneidman-DuhovnyD HammelM TainerJA and SaliA(2013) Accurate SAXS profile computation and its assessment bycontrast variation experiments Biophys J 105 962ndash974
63 HammelM ReyM YuY ManiRS ClassenS LiuMPiqueME FangS MahaneyBL WeinfeldM et al (2011)XRCC4 protein interactions with XRCC4-like factor (XLF)create an extended grooved scaffold for DNA ligation and doublestrand break repair J Biol Chem 286 32638ndash32650
64 PelikanM HuraGL and HammelM (2009) Structure andflexibility within proteins as identified through small angle X-rayscattering Gen Physiol Biophys 28 174ndash189
65 GrantTD LuftJR WolfleyJR TsurutaH MartelAMontelioneGT and SnellEH (2011) Small angle X-rayscattering as a complementary tool for high-throughput structuralstudies Biopolymers 95 517ndash530
66 KonarevPV VolkovVV SokolovaAV KochMHJ andSvergunDI (2003) PRIMUS a Windows PC-based system forsmall-angle scattering data analysis J Appl Crystallogr 361277ndash1282
67 ShoichetBK and KuntzID (1991) Protein docking andcomplementarity J Mol Biol 221 327ndash346
68 PieperU SchlessingerA KloppmannE ChangGA ChouJJDumontM FoxB FrommeP HendricksonW MalkowskiMet al (2013) Coordinating the impact of structural genomics onthe human a-helical transmembrane proteome Nat Struct MolBiol 20 135ndash138
69 JohnsonM ZaretskayaI RaytselisY MerezhukYMcGinnisS and MaddenTL (2008) NCBI BLAST a betterweb interface Nucleic Acids Res 36 W5ndashW9
70 WardJJ McGuffinLJ BrysonK BuxtonBF and JonesDT(2004) The DISOPRED server for the prediction of proteindisorder Bioinformatics 20 2138ndash2139
71 DosztanyiZ CsizmokV TompaP and SimonI (2005) IUPredweb server for the prediction of intrinsically unstructured regionsof proteins based on estimated energy content Bioinformatics 213433ndash3434
72 SteentoftC VakhrushevSY JoshiHJ KongY Vester-ChristensenMB SchjoldagerKT LavrsenK DabelsteenSPedersenNB Marcos-SilvaL et al (2013) Precision mapping ofthe human O-GalNAc glycoproteome through SimpleCelltechnology EMBO J 32 1478ndash1488
73 GuptaR JungE GooleyAA WilliamsKL BrunakS andHansenJ (1999) Scanning the available Dictyostelium discoideumproteome for O-linked GlcNAc glycosylation sites using neuralnetworks Glycobiology 9 1009ndash1022
74 CormierCY ParkJG FiaccoM SteelJ HunterPKramerJ SinglaR and LaBaerJ (2011) PSIBiology-materialsrepository a biologistrsquos resource for protein expression plasmidsJ Struct Funct Genomics 12 55ndash62
75 LameschP LiN MilsteinS FanC HaoT SzaboG HuZVenkatesanK BethelG MartinP et al (2007) hORFeomev31 a resource of human open reading frames representing over10000 human genes Genomics 89 307ndash315
76 TempleG GerhardDS RasoolyR FeingoldEA GoodPJRobinsonC MandichA DergeJG LewisJ ShoafD et al(2009) The completion of the mammalian gene collection (MGC)Genome Res 19 2324ndash2333
77 SealRL GordonSM LushMJ WrightMW andBrufordEA (2011) genenamesorg the HGNC resources in 2011Nucleic Acids Res 39 D514ndashD519
78 GiffordLK CarterLG GabanyiMJ BermanHM andAdamsPD (2012) The protein structure initiative structuralbiology knowledgebase technology portal a structural biologyweb resource J Struct Funct Genomics 13 57ndash62
79 FreedEO (2001) HIV-1 replication Somatic Cell Mol Genet26 13ndash33
80 McDonaldCK and KuritzkesDR (1997) Humanimmunodeficiency virus type 1 protease inhibitors Arch IntMed 157 951ndash959
81 DragM and SalvesenGS (2010) Emerging principles inprotease-based drug discovery Nat Rev Drug Discov 9690ndash701
82 FlexnerC (1998) HIV-protease inhibitors N Engl J Med 3381281ndash1292
83 KohlNE EminiEA SchleifWA DavisLJ HeimbachJCDixonRA ScolnickEM and SigalIS (1988) Active humanimmunodeficiency virus protease is required for viral infectivityProc Natl Acad Sci USA 85 4686ndash4690
84 MurthyKH WinborneEL MinnichMD CulpJS andDebouckC (1992) The crystal structures at 22-A resolution ofhydroxyethylene-based inhibitors bound to humanimmunodeficiency virus type 1 protease show that the inhibitorsare present in two distinct orientations J Biol Chem 26722770ndash22778
85 Prabu-JeyabalanM NalivaikaE and SchifferCA (2000) Howdoes a symmetric dimer recognize an asymmetric substrate Asubstrate complex of HIV-1 protease J Mol Biol 3011207ndash1220
86 MahalingamB LouisJM HungJ HarrisonRW andWeberIT (2001) Structural implications of drug-resistantmutants of HIV-1 protease high-resolution crystal structures ofthe mutant proteasesubstrate analogue complexes Proteins 43455ndash464
87 NieZ PhenixBN LumJJ AlamA LynchDH BeckettBKrammerPH SekalyRP and BadleyAD (2002) HIV-1protease processes procaspase 8 to cause mitochondrial release ofcytochrome c caspase cleavage and nuclear fragmentation CellDeath Differ 9 1172ndash1184
88 Algeciras-SchimnichA Belzacq-CasagrandeAS BrenGDNieZ TaylorJA RizzaSA BrennerC and BadleyAD(2007) Analysis of HIV protease killing through caspase 8 revealsa novel interaction between caspase 8 and mitochondria OpenVirol J 1 39ndash46
89 NieZ BrenGD RizzaSA and BadleyAD (2008) HIVprotease cleavage of procaspase 8 is necessary for death of HIV-infected cells Open Virol J 2 1ndash7
10 Nucleic Acids Research 2013
at UC
SF Library on D
ecember 2 2013
httpnaroxfordjournalsorgD
ownloaded from
90 CastelloA FrancoD Moral-LopezP BerlangaJJAlvarezE WimmerE and CarrascoL (2009) HIV- 1 proteaseinhibits Cap- and poly(A)-dependent translation upon eIF4GIand PABP cleavage PloS One 4 e7997
91 ImpensF TimmermanE StaesA MoensK ArienKKVerhasseltB VandekerckhoveJ and GevaertK (2012) Acatalogue of putative HIV-1 protease host cell substrates BiolChem 393 915ndash931
92 Kotik-KoganO ValentineER SanfeliceD ConteMR andCurryS (2008) Structural analysis reveals conformationalplasticity in the recognition of RNA 3rsquo ends by the human Laprotein Structure 16 852ndash862
93 NakaiK KideraA and KanehisaM (1988) Cluster analysis ofamino acid indices for prediction of protein structure andfunction Protein Eng 2 93ndash100
94 TomiiK and KanehisaM (1996) Analysis of amino acid indicesand mutation matrices for sequence comparison and structureprediction of proteins Protein Eng 9 27ndash36
95 JonesDT (1999) Protein secondary structure prediction basedon position-specific scoring matrices J Mol Biol 292 195ndash202
96 BreimanL and SchapireE (2001) Random forests MachLearn 45 5ndash32
97 BensonDA Karsch-MizrachiI LipmanDJ OstellJ andSayersEW (2010) GenBank Nucleic Acids Res 38 D46ndashD51
98 KraulisPJ (1991) MOLSCRIPT a program to produce bothdetailed and schematic plorts of protein structures J ApplCrystallogr 24 946ndash950
99 MerrittEA and BaconDJ (1997) Raster3D photorealisticmolecular graphics Methods Enzymol 277 505ndash524
100 PettersenEF GoddardTD HuangCC CouchGSGreenblattDM MengEC and FerrinTE (2004) UCSFChimerandasha visualization system for exploratory research andanalysis J Comput Chem 25 1605ndash1612
101 CapraJA LaskowskiRA ThorntonJM SinghM andFunkhouserTA (2009) Predicting protein ligand binding sitesby combining evolutionary sequence conservation and 3Dstructure PLoS Comp Biol 5 e1000585
102 HenrickK FengZ BluhmWF DimitropoulosDDoreleijersJF DuttaS Flippen-AndersonJL IonidesJKamadaC KrissinelE et al (2008) Remediation of the proteindata bank archive Nucleic Acids Res 36 D426ndashD433
103 WuCH ApweilerR BairochA NataleDA BarkerWCBoeckmannB FerroS GasteigerE HuangH LopezR et al(2006) The Universal Protein Resource (UniProt) an expandinguniverse of protein information Nucleic Acids Res 34D187ndashD191
104 RheadB KarolchikD KuhnRM HinrichsAS ZweigASFujitaPA DiekhansM SmithKE RosenbloomKRRaneyBJ et al (2010) The UCSC Genome Browser databaseupdate 2010 Nucleic Acids Res 38 D613ndashD619
105 HunterS ApweilerR AttwoodTK BairochA BatemanABinnsD BorkP DasU DaughertyL DuquenneL et al(2009) InterPro the integrative protein signature databaseNucleic Acids Res 37 D211ndashD215
106 KleinTE ChangJT ChoMK EastonKL FergersonRHewettM LinZ LiuY LiuS OliverDE et al (2001)Integrating genotype and phenotype information an overview ofthe PharmGKB project Pharmacogenetics research network andknowledge base Pharmacogenomics J 1 167ndash170
107 HaasJ RothS ArnoldK KieferF SchmidtT BordoliLand SchwedeT (2013) The Protein Model Portalmdashacomprehensive resource for protein structure and modelinformation Database 2013 bat031
108 SchwedeT SaliA HonigB LevittM BermanH JonesDBrennerS BurleyS DasR DokholyanN et al (2009)Outcome of a workshop on applications of protein models inbiomedical research Structure 17 151ndash159
109 BairochA ApweilerR WuCH BarkerWC BoeckmannBFerroS GasteigerE HuangH LopezR MagraneM et al(2005) The Universal Protein Resource (UniProt) Nucleic AcidsRes 33 D154ndashD159
110 GigliaE (2009) New year new PubMed Eur J Phys RehabilMed 45 155ndash159
Nucleic Acids Research 2013 11
at UC
SF Library on D
ecember 2 2013
httpnaroxfordjournalsorgD
ownloaded from
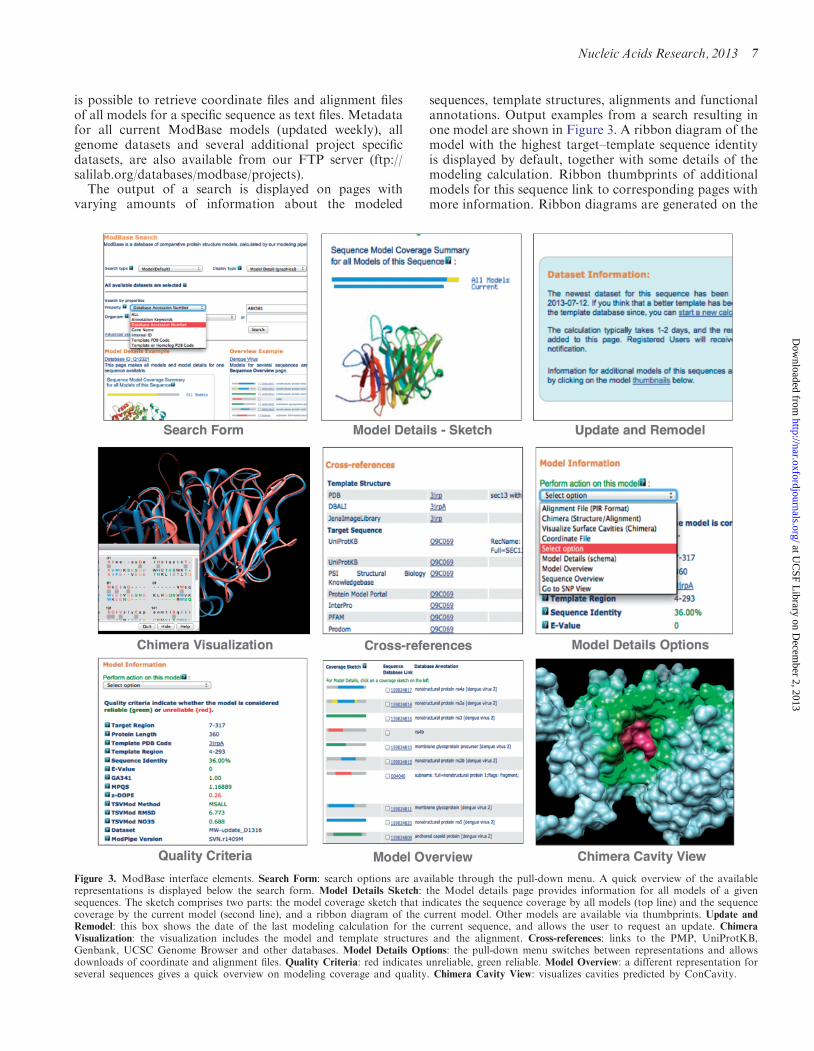
is possible to retrieve coordinate files and alignment filesof all models for a specific sequence as text files Metadatafor all current ModBase models (updated weekly) allgenome datasets and several additional project specificdatasets are also available from our FTP server (ftpsalilaborgdatabasesmodbaseprojects)
The output of a search is displayed on pages withvarying amounts of information about the modeled
sequences template structures alignments and functionalannotations Output examples from a search resulting inone model are shown in Figure 3 A ribbon diagram of themodel with the highest targetndashtemplate sequence identityis displayed by default together with some details of themodeling calculation Ribbon thumbprints of additionalmodels for this sequence link to corresponding pages withmore information Ribbon diagrams are generated on the
Figure 3 ModBase interface elements Search Form search options are available through the pull-down menu A quick overview of the availablerepresentations is displayed below the search form Model Details Sketch the Model details page provides information for all models of a givensequences The sketch comprises two parts the model coverage sketch that indicates the sequence coverage by all models (top line) and the sequencecoverage by the current model (second line) and a ribbon diagram of the current model Other models are available via thumbprints Update and
Remodel this box shows the date of the last modeling calculation for the current sequence and allows the user to request an update Chimera
Visualization the visualization includes the model and template structures and the alignment Cross-references links to the PMP UniProtKBGenbank UCSC Genome Browser and other databases Model Details Options the pull-down menu switches between representations and allowsdownloads of coordinate and alignment files Quality Criteria red indicates unreliable green reliable Model Overview a different representation forseveral sequences gives a quick overview on modeling coverage and quality Chimera Cavity View visualizes cavities predicted by ConCavity
Nucleic Acids Research 2013 7
at UC
SF Library on D
ecember 2 2013
httpnaroxfordjournalsorgD
ownloaded from
fly using Molscript (98) and Raster3D (99) A pull-downmenu provides links to additional functionalities the SNPmodule retrieval of coordinate and alignment files mo-lecular visualization by UCSF Chimera (100) that allowsthe user to display template and model coordinatestogether with their alignment and Chimera visualizationof predicted cavities [ConCavity (101)] If mutation infor-mation is available for a protein sequence links to thedetails are provided in the cross-references sectionAdditionally cross-references to various other databasesincluding PDB (102) UniProtKB (103) the UCSCGenome Browser (104) EBIrsquos InterPro (105)PharmGKB (106) and SFLD (36) are given OtherModBase pages provide overviews of more than onesequence or structure All ModBase pages are intercon-nected to facilitate easy navigation between differentviews
Access through external databases
The Protein Model PortalThe Protein Model Portal (PMP) has become a valuableoption for accessing ModBase models (httpproteinmo-delportalorg) (107) The PMP is a single point of entry foraccessing protein structure models from a number of dif-ferent databases PMP queries all participating sourcemodel databases and serves the user with the model co-ordinates alignments and quality criteria from a centrallocation It has been developed as a module of the ProteinStructure Initiative Knowledgebase (PSI KB) (79108)The PMP provides a flexible search interface for alldeposited models quality estimation cross-links to othersequence and structure databases annotations ofsequences and their models a central point of entry tocomparative modeling servers (including ModWeb) andquality estimation servers (including ModEval) anddetailed tutorials on all aspects of comparativemodeling Currently the PMP retrieves 450 000ModBase model coordinate files each week fromModBaseA sister web-service to PMP CAMEO (httpcameo3d
org) (107) continuously evaluates the accuracy and reli-ability of several comparative protein structure predictionservers in a fully automated manner The ModWeb servercurrently participates in the testing mode and is expectedto move into the production mode in the first quarter of2014
Access through external databasesModBase models in academic and public datasets arealso directly accessible from several databases includingthe PMP (107) UniProtKB (109) PIRrsquos iProClass(103) EBIrsquos InterPro (105) the UCSC Genome Browser(104) PubMed (LinkOut) (110) PharmGKB (106) andSFLD (36)
FUTURE DIRECTIONS
ModBase will grow by adding models calculated ondemand by external users (using ModWeb) as well asour own calculations of model datasets that are needed
for our research projects (using ModPipe ModWeb orModeller) These updates will reflect improvements inthe methods and software used for calculating themodels as well as new template structures in the PDBand new sequences in UniProtKB In the future weexpect that most of the users will access ModBasemodels through the PMP
CITATION
Users of ModBase are requested to cite this article in theirpublications
ACKNOWLEDGEMENTS
For linking to ModBase from their databases the authorsthank Torsten Schwede and Jurgen Haas (Protein ModelPortal) David Haussler and Jim Kent (UCSC GenomeBrowser) Rolf Apweiler Maria Jesus Martin and ClaireOrsquoDonovan (UniProt) Rolf Apweiler Sarah Hunter(InterPro) Patsy Babbitt (SFLD) Russ Altman(PharmGKB) and Kathy Wu (PIRiProClass) We arealso grateful for computing hardware gifts from MikeHomer Ron Conway NetApp IBM Hewlett Packardand Intel
FUNDING
National Institutes of Health [U54 GM094662 U54GM094625 U54 GM093342 MINOS R01GM105404 toJAT and MH] Sandler Family Supporting Foundation(AS) Department of Energy Lawrence BerkeleyNational Lab IDAT program (to JAT and MH)European Union [FP7-IDEAS-ERC 294809 to MN]The authors thank Tom Ferrin and the UCSF Resourcefor Biocomputing Visualization and Informatics formaking UCSF Chimera (supported by [NIGMS P41-GM103311]) available to the ModBase database andtools Funding for open access charge NIH
Conflict of interest statement None declared
REFERENCES
1 RosePW BiC BluhmWF ChristieCH DimitropoulosDDuttaS GreenRK GoodsellDS PrlicA QuesadaM et al(2013) The RCSB Protein Data Bank new resources for researchand education Nucleic Acids Res 41 D475ndashD482
2 The UniProt Consortium (2011) Ongoing and futuredevelopments at the Universal Protein Resource Nucleic AcidsRes 39 D214ndashD219
3 BensonDA Karsch-MizrachiI ClarkK LipmanDJ OstellJand SayersEW (2012) GenBank Nucleic Acids Res 40D48ndashD53
4 BakerD and SaliA (2001) Protein structure prediction andstructural genomics Science 294 93ndash96
5 EswarN WebbB Marti-RenomMA MadhusudhanMSEramianD ShenMY PieperU and SaliA (2006)Comparative protein structure modeling using MODELLERCurr Protoc Bioinformatics Chapter 5 Unit 561ndash5630
6 EswarN EramianD WebbB ShenMY and SaliA (2008)Protein structure modeling with MODELLER Methods MolBiol 426 145ndash159
8 Nucleic Acids Research 2013
at UC
SF Library on D
ecember 2 2013
httpnaroxfordjournalsorgD
ownloaded from
7 SchwedeT SaliA EswarN and PeitschMC (2008)In SchwedeT and PeitschMC (eds) Computational StructuralBiology World Scientific Publishing Ltd Singapore pp 3ndash35
8 ForrestLR TangCL and HonigB (2006) On the accuracy ofhomology modeling and sequence alignment methods applied tomembrane proteins Biophys J 91 508ndash517
9 LiuT TangGW and CapriottiE (2011) Comparativemodeling the state of the art and protein drug target structureprediction Comb Chem High Throughput Screen 14 532ndash547
10 FiserA (2010) Template-based protein structure modelingMethods Mol Biol 673 73ndash94
11 DagaPR PatelRY and DoerksenRJ (2010) Template-basedprotein modeling recent methodological advances Curr TopMed Chem 10 84ndash94
12 HillischA PinedaLF and HilgenfeldR (2004) Utility ofhomology models in the drug discovery process Drug DiscovToday 9 659ndash669
13 WallnerB and ElofssonA (2005) All are not equal abenchmark of different homology modeling programs ProteinSci 14 1315ndash1327
14 WeinkamP PonsJ and SaliA (2012) Structure-based model ofallostery predicts coupling between distant sites Proc Natl AcadSci USA 109 4875ndash4880
15 Schneidman-DuhovnyD HammelM and SaliA (2011)Macromolecular docking restrained by a small angle X-rayscattering profile J Struct Biol 3 461ndash471
16 FanH SchneidmanD IrwinJJ DongG ShoichetB andSaliA (2011) Statistical potential for modeling and rankingprotein-ligand interactions J Chem Inf Model 51 3078ndash3092
17 EswarN JohnB MirkovicN FiserA IlyinVA PieperUStuartAC Marti-RenomMA MadhusudhanMSYerkovichB et al (2003) Tools for comparative protein structuremodeling and analysis Nucleic Acids Res 31 3375ndash3380
18 SaliA and BlundellTL (1993) Comparative protein modellingby satisfaction of spatial restraints J Mol Biol 234 779ndash815
19 AltschulSF MaddenTL SchafferAA ZhangJ ZhangZMillerW and LipmanDJ (1997) Gapped BLAST and PSI-BLAST a new generation of protein database search programsNucleic Acids Res 25 3389ndash3402
20 RemmertM BiegertA HauserA and SodingJ (2012) HHblitslightning-fast iterative protein sequence searching by HMM-HMM alignment Nat Methods 9 173ndash175
21 SodingJ (2005) Protein homology detection by HMM-HMMcomparison Bioinformatics 21 951ndash960
22 SmithTF and WatermanMS (1981) Identification of commonmolecular subsequences J Mol Biol 147 195ndash197
23 EswarN WebbB Marti-RenomM MadhusudhanMEramianD ShenM PieperU and SaliA (2006) Comparativeprotein structure modeling using Modeller Curr ProtocBioinformatics Chapter 5 Unit 56
24 Marti-RenomMA MadhusudhanMS and SaliA (2004)Alignment of protein sequences by their profiles Protein Sci 131071ndash1087
25 ShenMY and SaliA (2006) Statistical potential for assessmentand prediction of protein structures Protein Sci 15 2507ndash2524
26 MeloF and SaliA (2007) Fold assessment for comparativeprotein structure modeling Protein Sci 16 2412ndash2426
27 PieperU WebbBM BarkanDT Schneidman-DuhovnyDSchlessingerA BrabergH YangZ MengEC PettersenEFHuangCC et al (2011) ModBase a database of annotatedcomparative protein structure models and associated resourcesNucleic Acids Res 39 465ndash474
28 EramianD EswarN ShenM and SaliA (2008) How well canthe accuracy of comparative protein structure models bepredicted Protein Sci 17 1881ndash1893
29 DongGQ FanH Schneidman-DuhovnyD WebbB andSaliA (2013) Optimized atomic statistical potentials Assessmentof protein interfaces and loops (epub ahead of print October 232013)
30 Schneidman-DuhovnyD RossiA Avila-SakarA KimSJVelazquez-MurielJ StropP LiangH KrukenbergKALiaoM KimHM et al (2012) A method for integrativestructure determination of protein-protein complexesBioinformatics 28 3282ndash3289
31 PierceB and WengZ (2007) ZRANK reranking protein dockingpredictions with an optimized energy function Proteins 671078ndash1086
32 AndrusierN NussinovR and WolfsonHJ (2007) FireDockfast interaction refinement in molecular docking Proteins 69139ndash159
33 JacobsonMP PincusDL RappCS DayTJ HonigBShawDE and FriesnerRA (2004) A hierarchical approach toall-atom protein loop prediction Proteins 55 351ndash367
34 GrontD KulpDW VernonRM StraussCE and BakerD(2011) Generalized fragment picking in Rosetta design protocolsand applications PloS One 6 e23294
35 ZhangC LiuS and ZhouY (2004) Accurate and efficient loopselections by the DFIRE-based all-atom statistical potentialProtein Sci 13 391ndash399
36 PeggSC BrownSD OjhaS SeffernickJ MengECMorrisJH ChangPJ HuangCC FerrinTE andBabbittPC (2006) Leveraging enzyme structure-functionrelationships for functional inference and experimental design thestructure-function linkage database Biochemistry 45 2545ndash2555
37 MaurerSM RaiA and SaliA (2004) Finding cures for tropicaldiseases is open source an answer PLoS Med 1 e56
38 OrtiL CarbajoR PieperU EswarN MaurerS RaiATaylorG ToddM Pineda-LucenaA SaliA et al (2009) Akernel for open source drug discovery in tropical diseases PLoSNegl Trop Dis 3 e418
39 AgueroF Al-LazikaniB AslettM BerrimanM BucknerFCampbellR CarmonaS CarruthersI ChanA ChenF et al(2008) Genomic-scale prioritization of drug targets the TDRTargets database Nat Rev Drug Discov 7 900ndash907
40 Martinez-JimenezF PapadatosG YangL WallaceIMKumarV PieperU SaliA BrownJR OveringtonJP andMarti-RenomMA (2013) Target prediction for an open accessset of compounds active against Mycobacterium tuberculosisPLoS Comp Biol 9 e1003253
41 SampathkumarP LuF ZhaoX LiZ GilmoreJ BainKRutterME GheyiT SchwinnK BonannoJ et al (2010)Structure of a putative BenF-like porin from Pseudomanasfluorescens Pf-5 at 26 A resolution Proteins 78 3056ndash3062
42 PieperU ChiangR SeffernickJ BrownS GlasnerMKellyL EswarN SauderJ BonannoJ SwaminathanS et al(2009) Target selection and annotation for the structural genomicsof the amidohydrolase and enolase superfamilies J Struct FunctGenom 10 107ndash125
43 KarchinR DiekhansM KellyL ThomasDJ PieperUEswarN HausslerD and SaliA (2005) LS-SNP large-scaleannotation of coding non-synonymous SNPs based on multipleinformation sources Bioinformatics 21 2814ndash2820
44 FiserA and SaliA (2003) ModLoop automated modeling ofloops in protein structures Bioinformatics 19 2500ndash2501
45 DavisF and SaliA (2005) PIBASE a comprehensive databaseof structurally defined protein interfaces Bioinformatics 211901ndash1907
46 Marti-RenomMA PieperU MadhusudhanMS RossiAEswarN DavisFP Al-ShahrourF DopazoJ and SaliA(2007) DBAli tools mining the protein structure space NucleicAcids Res 35 W393ndashW397
47 Marti-RenomMA IlyinVA and SaliA (2001) DBAli adatabase of protein structure alignments Bioinformatics 17746ndash747
48 PieperU EswarN WebbB EramianD KellyL BarkanDCarterH MankooP KarchinR Marti-RenomM et al (2009)MODBASE a database of annotated comparative proteinstructure models and associated resources Nucleic Acids Res 37D347ndashD354
49 PieperU EswarN DavisFP BrabergH MadhusudhanMSRossiA Marti-RenomM KarchinR WebbBM EramianDet al (2006) MODBASE a database of annotated comparativeprotein structure models and associated resources Nucleic AcidsRes 34 D291ndashD295
50 BrabergH WebbB TjioeE PieperU SaliA andMadhusudhanMS (2012) SALIGN a webserver for alignmentof multiple protein sequences and structures Bioinformatics 152072ndash2073
Nucleic Acids Research 2013 9
at UC
SF Library on D
ecember 2 2013
httpnaroxfordjournalsorgD
ownloaded from
51 Schneidman-DuhovnyD HammelM and SaliA (2010) FoXS aweb server for rapid computation and fitting of SAXS ProfilesNucleic Acids Res 38 541ndash544
52 UedaY TaketomiH and GoN (1978) Studies on proteinfolding unfolding and fluctuations by computer simulation IIAThree dimensional lattice model of lysozyme Biopolymers 171531ndash1548
53 OkazakiK KogaN TakadaS OnuchicJN and WolynesPG(2006) Multiple-basin energy landscapes for large-amplitudeconformational motions of proteins Structure-based moleculardynamics simulations Proc Natl Acad Sci USA 10311844ndash11849
54 WhitfordPC NoelJK GosaviS SchugA SanbonmatsuKYand OnuchicJN (2009) An all-atom structure-based potential forproteins bridging minimal models with all-atom empiricalforcefields Proteins 75 430ndash441
55 WeinkamP ChenYC PonsJ and SaliA (2013) Impact ofmutations on the allosteric conformational equilibrium J MolBiol 425 647ndash661
56 PetoukhovMV and SvergunDI (2007) Analysis of X-ray andneutron scattering from biomacromolecular solutions Curr OpinStruct Biol 17 562ndash571
57 HuraGL MenonAL HammelM RamboRP PooleFL IITsutakawaSE JenneyFE Jr ClassenS FrankelKAHopkinsRC et al (2009) Robust high-throughput solutionstructural analyses by small angle X-ray scattering (SAXS) NatMethods 6 606ndash612
58 SvergunD BarberatoC and KochMHJ (1995) CRYSOL-aprogram to evaluate X-ray solution scattering of biologicalmacromolecules from atomic coordinates J Appl Crystallogr28 768ndash773
59 PoitevinF OrlandH DoniachS KoehlP and DelarueM(2011) AquaSAXS a web server for computation and fitting ofSAXS profiles with non-uniformally hydrated atomic modelsNucleic Acids Res 39 W184ndashW189
60 LiuH MorrisRJ HexemerA GrandisonS and ZwartPH(2012) Computation of small-angle scattering profiles with three-dimensional Zernike polynomials Acta Crystallogr A 68278ndash285
61 RavikumarKM HuangW and YangS (2013) Fast-SAXS-proa unified approach to computing SAXS profiles of DNA RNAprotein and their complexes J Chem Phys 138 024112
62 Schneidman-DuhovnyD HammelM TainerJA and SaliA(2013) Accurate SAXS profile computation and its assessment bycontrast variation experiments Biophys J 105 962ndash974
63 HammelM ReyM YuY ManiRS ClassenS LiuMPiqueME FangS MahaneyBL WeinfeldM et al (2011)XRCC4 protein interactions with XRCC4-like factor (XLF)create an extended grooved scaffold for DNA ligation and doublestrand break repair J Biol Chem 286 32638ndash32650
64 PelikanM HuraGL and HammelM (2009) Structure andflexibility within proteins as identified through small angle X-rayscattering Gen Physiol Biophys 28 174ndash189
65 GrantTD LuftJR WolfleyJR TsurutaH MartelAMontelioneGT and SnellEH (2011) Small angle X-rayscattering as a complementary tool for high-throughput structuralstudies Biopolymers 95 517ndash530
66 KonarevPV VolkovVV SokolovaAV KochMHJ andSvergunDI (2003) PRIMUS a Windows PC-based system forsmall-angle scattering data analysis J Appl Crystallogr 361277ndash1282
67 ShoichetBK and KuntzID (1991) Protein docking andcomplementarity J Mol Biol 221 327ndash346
68 PieperU SchlessingerA KloppmannE ChangGA ChouJJDumontM FoxB FrommeP HendricksonW MalkowskiMet al (2013) Coordinating the impact of structural genomics onthe human a-helical transmembrane proteome Nat Struct MolBiol 20 135ndash138
69 JohnsonM ZaretskayaI RaytselisY MerezhukYMcGinnisS and MaddenTL (2008) NCBI BLAST a betterweb interface Nucleic Acids Res 36 W5ndashW9
70 WardJJ McGuffinLJ BrysonK BuxtonBF and JonesDT(2004) The DISOPRED server for the prediction of proteindisorder Bioinformatics 20 2138ndash2139
71 DosztanyiZ CsizmokV TompaP and SimonI (2005) IUPredweb server for the prediction of intrinsically unstructured regionsof proteins based on estimated energy content Bioinformatics 213433ndash3434
72 SteentoftC VakhrushevSY JoshiHJ KongY Vester-ChristensenMB SchjoldagerKT LavrsenK DabelsteenSPedersenNB Marcos-SilvaL et al (2013) Precision mapping ofthe human O-GalNAc glycoproteome through SimpleCelltechnology EMBO J 32 1478ndash1488
73 GuptaR JungE GooleyAA WilliamsKL BrunakS andHansenJ (1999) Scanning the available Dictyostelium discoideumproteome for O-linked GlcNAc glycosylation sites using neuralnetworks Glycobiology 9 1009ndash1022
74 CormierCY ParkJG FiaccoM SteelJ HunterPKramerJ SinglaR and LaBaerJ (2011) PSIBiology-materialsrepository a biologistrsquos resource for protein expression plasmidsJ Struct Funct Genomics 12 55ndash62
75 LameschP LiN MilsteinS FanC HaoT SzaboG HuZVenkatesanK BethelG MartinP et al (2007) hORFeomev31 a resource of human open reading frames representing over10000 human genes Genomics 89 307ndash315
76 TempleG GerhardDS RasoolyR FeingoldEA GoodPJRobinsonC MandichA DergeJG LewisJ ShoafD et al(2009) The completion of the mammalian gene collection (MGC)Genome Res 19 2324ndash2333
77 SealRL GordonSM LushMJ WrightMW andBrufordEA (2011) genenamesorg the HGNC resources in 2011Nucleic Acids Res 39 D514ndashD519
78 GiffordLK CarterLG GabanyiMJ BermanHM andAdamsPD (2012) The protein structure initiative structuralbiology knowledgebase technology portal a structural biologyweb resource J Struct Funct Genomics 13 57ndash62
79 FreedEO (2001) HIV-1 replication Somatic Cell Mol Genet26 13ndash33
80 McDonaldCK and KuritzkesDR (1997) Humanimmunodeficiency virus type 1 protease inhibitors Arch IntMed 157 951ndash959
81 DragM and SalvesenGS (2010) Emerging principles inprotease-based drug discovery Nat Rev Drug Discov 9690ndash701
82 FlexnerC (1998) HIV-protease inhibitors N Engl J Med 3381281ndash1292
83 KohlNE EminiEA SchleifWA DavisLJ HeimbachJCDixonRA ScolnickEM and SigalIS (1988) Active humanimmunodeficiency virus protease is required for viral infectivityProc Natl Acad Sci USA 85 4686ndash4690
84 MurthyKH WinborneEL MinnichMD CulpJS andDebouckC (1992) The crystal structures at 22-A resolution ofhydroxyethylene-based inhibitors bound to humanimmunodeficiency virus type 1 protease show that the inhibitorsare present in two distinct orientations J Biol Chem 26722770ndash22778
85 Prabu-JeyabalanM NalivaikaE and SchifferCA (2000) Howdoes a symmetric dimer recognize an asymmetric substrate Asubstrate complex of HIV-1 protease J Mol Biol 3011207ndash1220
86 MahalingamB LouisJM HungJ HarrisonRW andWeberIT (2001) Structural implications of drug-resistantmutants of HIV-1 protease high-resolution crystal structures ofthe mutant proteasesubstrate analogue complexes Proteins 43455ndash464
87 NieZ PhenixBN LumJJ AlamA LynchDH BeckettBKrammerPH SekalyRP and BadleyAD (2002) HIV-1protease processes procaspase 8 to cause mitochondrial release ofcytochrome c caspase cleavage and nuclear fragmentation CellDeath Differ 9 1172ndash1184
88 Algeciras-SchimnichA Belzacq-CasagrandeAS BrenGDNieZ TaylorJA RizzaSA BrennerC and BadleyAD(2007) Analysis of HIV protease killing through caspase 8 revealsa novel interaction between caspase 8 and mitochondria OpenVirol J 1 39ndash46
89 NieZ BrenGD RizzaSA and BadleyAD (2008) HIVprotease cleavage of procaspase 8 is necessary for death of HIV-infected cells Open Virol J 2 1ndash7
10 Nucleic Acids Research 2013
at UC
SF Library on D
ecember 2 2013
httpnaroxfordjournalsorgD
ownloaded from
90 CastelloA FrancoD Moral-LopezP BerlangaJJAlvarezE WimmerE and CarrascoL (2009) HIV- 1 proteaseinhibits Cap- and poly(A)-dependent translation upon eIF4GIand PABP cleavage PloS One 4 e7997
91 ImpensF TimmermanE StaesA MoensK ArienKKVerhasseltB VandekerckhoveJ and GevaertK (2012) Acatalogue of putative HIV-1 protease host cell substrates BiolChem 393 915ndash931
92 Kotik-KoganO ValentineER SanfeliceD ConteMR andCurryS (2008) Structural analysis reveals conformationalplasticity in the recognition of RNA 3rsquo ends by the human Laprotein Structure 16 852ndash862
93 NakaiK KideraA and KanehisaM (1988) Cluster analysis ofamino acid indices for prediction of protein structure andfunction Protein Eng 2 93ndash100
94 TomiiK and KanehisaM (1996) Analysis of amino acid indicesand mutation matrices for sequence comparison and structureprediction of proteins Protein Eng 9 27ndash36
95 JonesDT (1999) Protein secondary structure prediction basedon position-specific scoring matrices J Mol Biol 292 195ndash202
96 BreimanL and SchapireE (2001) Random forests MachLearn 45 5ndash32
97 BensonDA Karsch-MizrachiI LipmanDJ OstellJ andSayersEW (2010) GenBank Nucleic Acids Res 38 D46ndashD51
98 KraulisPJ (1991) MOLSCRIPT a program to produce bothdetailed and schematic plorts of protein structures J ApplCrystallogr 24 946ndash950
99 MerrittEA and BaconDJ (1997) Raster3D photorealisticmolecular graphics Methods Enzymol 277 505ndash524
100 PettersenEF GoddardTD HuangCC CouchGSGreenblattDM MengEC and FerrinTE (2004) UCSFChimerandasha visualization system for exploratory research andanalysis J Comput Chem 25 1605ndash1612
101 CapraJA LaskowskiRA ThorntonJM SinghM andFunkhouserTA (2009) Predicting protein ligand binding sitesby combining evolutionary sequence conservation and 3Dstructure PLoS Comp Biol 5 e1000585
102 HenrickK FengZ BluhmWF DimitropoulosDDoreleijersJF DuttaS Flippen-AndersonJL IonidesJKamadaC KrissinelE et al (2008) Remediation of the proteindata bank archive Nucleic Acids Res 36 D426ndashD433
103 WuCH ApweilerR BairochA NataleDA BarkerWCBoeckmannB FerroS GasteigerE HuangH LopezR et al(2006) The Universal Protein Resource (UniProt) an expandinguniverse of protein information Nucleic Acids Res 34D187ndashD191
104 RheadB KarolchikD KuhnRM HinrichsAS ZweigASFujitaPA DiekhansM SmithKE RosenbloomKRRaneyBJ et al (2010) The UCSC Genome Browser databaseupdate 2010 Nucleic Acids Res 38 D613ndashD619
105 HunterS ApweilerR AttwoodTK BairochA BatemanABinnsD BorkP DasU DaughertyL DuquenneL et al(2009) InterPro the integrative protein signature databaseNucleic Acids Res 37 D211ndashD215
106 KleinTE ChangJT ChoMK EastonKL FergersonRHewettM LinZ LiuY LiuS OliverDE et al (2001)Integrating genotype and phenotype information an overview ofthe PharmGKB project Pharmacogenetics research network andknowledge base Pharmacogenomics J 1 167ndash170
107 HaasJ RothS ArnoldK KieferF SchmidtT BordoliLand SchwedeT (2013) The Protein Model Portalmdashacomprehensive resource for protein structure and modelinformation Database 2013 bat031
108 SchwedeT SaliA HonigB LevittM BermanH JonesDBrennerS BurleyS DasR DokholyanN et al (2009)Outcome of a workshop on applications of protein models inbiomedical research Structure 17 151ndash159
109 BairochA ApweilerR WuCH BarkerWC BoeckmannBFerroS GasteigerE HuangH LopezR MagraneM et al(2005) The Universal Protein Resource (UniProt) Nucleic AcidsRes 33 D154ndashD159
110 GigliaE (2009) New year new PubMed Eur J Phys RehabilMed 45 155ndash159
Nucleic Acids Research 2013 11
at UC
SF Library on D
ecember 2 2013
httpnaroxfordjournalsorgD
ownloaded from

fly using Molscript (98) and Raster3D (99) A pull-downmenu provides links to additional functionalities the SNPmodule retrieval of coordinate and alignment files mo-lecular visualization by UCSF Chimera (100) that allowsthe user to display template and model coordinatestogether with their alignment and Chimera visualizationof predicted cavities [ConCavity (101)] If mutation infor-mation is available for a protein sequence links to thedetails are provided in the cross-references sectionAdditionally cross-references to various other databasesincluding PDB (102) UniProtKB (103) the UCSCGenome Browser (104) EBIrsquos InterPro (105)PharmGKB (106) and SFLD (36) are given OtherModBase pages provide overviews of more than onesequence or structure All ModBase pages are intercon-nected to facilitate easy navigation between differentviews
Access through external databases
The Protein Model PortalThe Protein Model Portal (PMP) has become a valuableoption for accessing ModBase models (httpproteinmo-delportalorg) (107) The PMP is a single point of entry foraccessing protein structure models from a number of dif-ferent databases PMP queries all participating sourcemodel databases and serves the user with the model co-ordinates alignments and quality criteria from a centrallocation It has been developed as a module of the ProteinStructure Initiative Knowledgebase (PSI KB) (79108)The PMP provides a flexible search interface for alldeposited models quality estimation cross-links to othersequence and structure databases annotations ofsequences and their models a central point of entry tocomparative modeling servers (including ModWeb) andquality estimation servers (including ModEval) anddetailed tutorials on all aspects of comparativemodeling Currently the PMP retrieves 450 000ModBase model coordinate files each week fromModBaseA sister web-service to PMP CAMEO (httpcameo3d
org) (107) continuously evaluates the accuracy and reli-ability of several comparative protein structure predictionservers in a fully automated manner The ModWeb servercurrently participates in the testing mode and is expectedto move into the production mode in the first quarter of2014
Access through external databasesModBase models in academic and public datasets arealso directly accessible from several databases includingthe PMP (107) UniProtKB (109) PIRrsquos iProClass(103) EBIrsquos InterPro (105) the UCSC Genome Browser(104) PubMed (LinkOut) (110) PharmGKB (106) andSFLD (36)
FUTURE DIRECTIONS
ModBase will grow by adding models calculated ondemand by external users (using ModWeb) as well asour own calculations of model datasets that are needed
for our research projects (using ModPipe ModWeb orModeller) These updates will reflect improvements inthe methods and software used for calculating themodels as well as new template structures in the PDBand new sequences in UniProtKB In the future weexpect that most of the users will access ModBasemodels through the PMP
CITATION
Users of ModBase are requested to cite this article in theirpublications
ACKNOWLEDGEMENTS
For linking to ModBase from their databases the authorsthank Torsten Schwede and Jurgen Haas (Protein ModelPortal) David Haussler and Jim Kent (UCSC GenomeBrowser) Rolf Apweiler Maria Jesus Martin and ClaireOrsquoDonovan (UniProt) Rolf Apweiler Sarah Hunter(InterPro) Patsy Babbitt (SFLD) Russ Altman(PharmGKB) and Kathy Wu (PIRiProClass) We arealso grateful for computing hardware gifts from MikeHomer Ron Conway NetApp IBM Hewlett Packardand Intel
FUNDING
National Institutes of Health [U54 GM094662 U54GM094625 U54 GM093342 MINOS R01GM105404 toJAT and MH] Sandler Family Supporting Foundation(AS) Department of Energy Lawrence BerkeleyNational Lab IDAT program (to JAT and MH)European Union [FP7-IDEAS-ERC 294809 to MN]The authors thank Tom Ferrin and the UCSF Resourcefor Biocomputing Visualization and Informatics formaking UCSF Chimera (supported by [NIGMS P41-GM103311]) available to the ModBase database andtools Funding for open access charge NIH
Conflict of interest statement None declared
REFERENCES
1 RosePW BiC BluhmWF ChristieCH DimitropoulosDDuttaS GreenRK GoodsellDS PrlicA QuesadaM et al(2013) The RCSB Protein Data Bank new resources for researchand education Nucleic Acids Res 41 D475ndashD482
2 The UniProt Consortium (2011) Ongoing and futuredevelopments at the Universal Protein Resource Nucleic AcidsRes 39 D214ndashD219
3 BensonDA Karsch-MizrachiI ClarkK LipmanDJ OstellJand SayersEW (2012) GenBank Nucleic Acids Res 40D48ndashD53
4 BakerD and SaliA (2001) Protein structure prediction andstructural genomics Science 294 93ndash96
5 EswarN WebbB Marti-RenomMA MadhusudhanMSEramianD ShenMY PieperU and SaliA (2006)Comparative protein structure modeling using MODELLERCurr Protoc Bioinformatics Chapter 5 Unit 561ndash5630
6 EswarN EramianD WebbB ShenMY and SaliA (2008)Protein structure modeling with MODELLER Methods MolBiol 426 145ndash159
8 Nucleic Acids Research 2013
at UC
SF Library on D
ecember 2 2013
httpnaroxfordjournalsorgD
ownloaded from
7 SchwedeT SaliA EswarN and PeitschMC (2008)In SchwedeT and PeitschMC (eds) Computational StructuralBiology World Scientific Publishing Ltd Singapore pp 3ndash35
8 ForrestLR TangCL and HonigB (2006) On the accuracy ofhomology modeling and sequence alignment methods applied tomembrane proteins Biophys J 91 508ndash517
9 LiuT TangGW and CapriottiE (2011) Comparativemodeling the state of the art and protein drug target structureprediction Comb Chem High Throughput Screen 14 532ndash547
10 FiserA (2010) Template-based protein structure modelingMethods Mol Biol 673 73ndash94
11 DagaPR PatelRY and DoerksenRJ (2010) Template-basedprotein modeling recent methodological advances Curr TopMed Chem 10 84ndash94
12 HillischA PinedaLF and HilgenfeldR (2004) Utility ofhomology models in the drug discovery process Drug DiscovToday 9 659ndash669
13 WallnerB and ElofssonA (2005) All are not equal abenchmark of different homology modeling programs ProteinSci 14 1315ndash1327
14 WeinkamP PonsJ and SaliA (2012) Structure-based model ofallostery predicts coupling between distant sites Proc Natl AcadSci USA 109 4875ndash4880
15 Schneidman-DuhovnyD HammelM and SaliA (2011)Macromolecular docking restrained by a small angle X-rayscattering profile J Struct Biol 3 461ndash471
16 FanH SchneidmanD IrwinJJ DongG ShoichetB andSaliA (2011) Statistical potential for modeling and rankingprotein-ligand interactions J Chem Inf Model 51 3078ndash3092
17 EswarN JohnB MirkovicN FiserA IlyinVA PieperUStuartAC Marti-RenomMA MadhusudhanMSYerkovichB et al (2003) Tools for comparative protein structuremodeling and analysis Nucleic Acids Res 31 3375ndash3380
18 SaliA and BlundellTL (1993) Comparative protein modellingby satisfaction of spatial restraints J Mol Biol 234 779ndash815
19 AltschulSF MaddenTL SchafferAA ZhangJ ZhangZMillerW and LipmanDJ (1997) Gapped BLAST and PSI-BLAST a new generation of protein database search programsNucleic Acids Res 25 3389ndash3402
20 RemmertM BiegertA HauserA and SodingJ (2012) HHblitslightning-fast iterative protein sequence searching by HMM-HMM alignment Nat Methods 9 173ndash175
21 SodingJ (2005) Protein homology detection by HMM-HMMcomparison Bioinformatics 21 951ndash960
22 SmithTF and WatermanMS (1981) Identification of commonmolecular subsequences J Mol Biol 147 195ndash197
23 EswarN WebbB Marti-RenomM MadhusudhanMEramianD ShenM PieperU and SaliA (2006) Comparativeprotein structure modeling using Modeller Curr ProtocBioinformatics Chapter 5 Unit 56
24 Marti-RenomMA MadhusudhanMS and SaliA (2004)Alignment of protein sequences by their profiles Protein Sci 131071ndash1087
25 ShenMY and SaliA (2006) Statistical potential for assessmentand prediction of protein structures Protein Sci 15 2507ndash2524
26 MeloF and SaliA (2007) Fold assessment for comparativeprotein structure modeling Protein Sci 16 2412ndash2426
27 PieperU WebbBM BarkanDT Schneidman-DuhovnyDSchlessingerA BrabergH YangZ MengEC PettersenEFHuangCC et al (2011) ModBase a database of annotatedcomparative protein structure models and associated resourcesNucleic Acids Res 39 465ndash474
28 EramianD EswarN ShenM and SaliA (2008) How well canthe accuracy of comparative protein structure models bepredicted Protein Sci 17 1881ndash1893
29 DongGQ FanH Schneidman-DuhovnyD WebbB andSaliA (2013) Optimized atomic statistical potentials Assessmentof protein interfaces and loops (epub ahead of print October 232013)
30 Schneidman-DuhovnyD RossiA Avila-SakarA KimSJVelazquez-MurielJ StropP LiangH KrukenbergKALiaoM KimHM et al (2012) A method for integrativestructure determination of protein-protein complexesBioinformatics 28 3282ndash3289
31 PierceB and WengZ (2007) ZRANK reranking protein dockingpredictions with an optimized energy function Proteins 671078ndash1086
32 AndrusierN NussinovR and WolfsonHJ (2007) FireDockfast interaction refinement in molecular docking Proteins 69139ndash159
33 JacobsonMP PincusDL RappCS DayTJ HonigBShawDE and FriesnerRA (2004) A hierarchical approach toall-atom protein loop prediction Proteins 55 351ndash367
34 GrontD KulpDW VernonRM StraussCE and BakerD(2011) Generalized fragment picking in Rosetta design protocolsand applications PloS One 6 e23294
35 ZhangC LiuS and ZhouY (2004) Accurate and efficient loopselections by the DFIRE-based all-atom statistical potentialProtein Sci 13 391ndash399
36 PeggSC BrownSD OjhaS SeffernickJ MengECMorrisJH ChangPJ HuangCC FerrinTE andBabbittPC (2006) Leveraging enzyme structure-functionrelationships for functional inference and experimental design thestructure-function linkage database Biochemistry 45 2545ndash2555
37 MaurerSM RaiA and SaliA (2004) Finding cures for tropicaldiseases is open source an answer PLoS Med 1 e56
38 OrtiL CarbajoR PieperU EswarN MaurerS RaiATaylorG ToddM Pineda-LucenaA SaliA et al (2009) Akernel for open source drug discovery in tropical diseases PLoSNegl Trop Dis 3 e418
39 AgueroF Al-LazikaniB AslettM BerrimanM BucknerFCampbellR CarmonaS CarruthersI ChanA ChenF et al(2008) Genomic-scale prioritization of drug targets the TDRTargets database Nat Rev Drug Discov 7 900ndash907
40 Martinez-JimenezF PapadatosG YangL WallaceIMKumarV PieperU SaliA BrownJR OveringtonJP andMarti-RenomMA (2013) Target prediction for an open accessset of compounds active against Mycobacterium tuberculosisPLoS Comp Biol 9 e1003253
41 SampathkumarP LuF ZhaoX LiZ GilmoreJ BainKRutterME GheyiT SchwinnK BonannoJ et al (2010)Structure of a putative BenF-like porin from Pseudomanasfluorescens Pf-5 at 26 A resolution Proteins 78 3056ndash3062
42 PieperU ChiangR SeffernickJ BrownS GlasnerMKellyL EswarN SauderJ BonannoJ SwaminathanS et al(2009) Target selection and annotation for the structural genomicsof the amidohydrolase and enolase superfamilies J Struct FunctGenom 10 107ndash125
43 KarchinR DiekhansM KellyL ThomasDJ PieperUEswarN HausslerD and SaliA (2005) LS-SNP large-scaleannotation of coding non-synonymous SNPs based on multipleinformation sources Bioinformatics 21 2814ndash2820
44 FiserA and SaliA (2003) ModLoop automated modeling ofloops in protein structures Bioinformatics 19 2500ndash2501
45 DavisF and SaliA (2005) PIBASE a comprehensive databaseof structurally defined protein interfaces Bioinformatics 211901ndash1907
46 Marti-RenomMA PieperU MadhusudhanMS RossiAEswarN DavisFP Al-ShahrourF DopazoJ and SaliA(2007) DBAli tools mining the protein structure space NucleicAcids Res 35 W393ndashW397
47 Marti-RenomMA IlyinVA and SaliA (2001) DBAli adatabase of protein structure alignments Bioinformatics 17746ndash747
48 PieperU EswarN WebbB EramianD KellyL BarkanDCarterH MankooP KarchinR Marti-RenomM et al (2009)MODBASE a database of annotated comparative proteinstructure models and associated resources Nucleic Acids Res 37D347ndashD354
49 PieperU EswarN DavisFP BrabergH MadhusudhanMSRossiA Marti-RenomM KarchinR WebbBM EramianDet al (2006) MODBASE a database of annotated comparativeprotein structure models and associated resources Nucleic AcidsRes 34 D291ndashD295
50 BrabergH WebbB TjioeE PieperU SaliA andMadhusudhanMS (2012) SALIGN a webserver for alignmentof multiple protein sequences and structures Bioinformatics 152072ndash2073
Nucleic Acids Research 2013 9
at UC
SF Library on D
ecember 2 2013
httpnaroxfordjournalsorgD
ownloaded from
51 Schneidman-DuhovnyD HammelM and SaliA (2010) FoXS aweb server for rapid computation and fitting of SAXS ProfilesNucleic Acids Res 38 541ndash544
52 UedaY TaketomiH and GoN (1978) Studies on proteinfolding unfolding and fluctuations by computer simulation IIAThree dimensional lattice model of lysozyme Biopolymers 171531ndash1548
53 OkazakiK KogaN TakadaS OnuchicJN and WolynesPG(2006) Multiple-basin energy landscapes for large-amplitudeconformational motions of proteins Structure-based moleculardynamics simulations Proc Natl Acad Sci USA 10311844ndash11849
54 WhitfordPC NoelJK GosaviS SchugA SanbonmatsuKYand OnuchicJN (2009) An all-atom structure-based potential forproteins bridging minimal models with all-atom empiricalforcefields Proteins 75 430ndash441
55 WeinkamP ChenYC PonsJ and SaliA (2013) Impact ofmutations on the allosteric conformational equilibrium J MolBiol 425 647ndash661
56 PetoukhovMV and SvergunDI (2007) Analysis of X-ray andneutron scattering from biomacromolecular solutions Curr OpinStruct Biol 17 562ndash571
57 HuraGL MenonAL HammelM RamboRP PooleFL IITsutakawaSE JenneyFE Jr ClassenS FrankelKAHopkinsRC et al (2009) Robust high-throughput solutionstructural analyses by small angle X-ray scattering (SAXS) NatMethods 6 606ndash612
58 SvergunD BarberatoC and KochMHJ (1995) CRYSOL-aprogram to evaluate X-ray solution scattering of biologicalmacromolecules from atomic coordinates J Appl Crystallogr28 768ndash773
59 PoitevinF OrlandH DoniachS KoehlP and DelarueM(2011) AquaSAXS a web server for computation and fitting ofSAXS profiles with non-uniformally hydrated atomic modelsNucleic Acids Res 39 W184ndashW189
60 LiuH MorrisRJ HexemerA GrandisonS and ZwartPH(2012) Computation of small-angle scattering profiles with three-dimensional Zernike polynomials Acta Crystallogr A 68278ndash285
61 RavikumarKM HuangW and YangS (2013) Fast-SAXS-proa unified approach to computing SAXS profiles of DNA RNAprotein and their complexes J Chem Phys 138 024112
62 Schneidman-DuhovnyD HammelM TainerJA and SaliA(2013) Accurate SAXS profile computation and its assessment bycontrast variation experiments Biophys J 105 962ndash974
63 HammelM ReyM YuY ManiRS ClassenS LiuMPiqueME FangS MahaneyBL WeinfeldM et al (2011)XRCC4 protein interactions with XRCC4-like factor (XLF)create an extended grooved scaffold for DNA ligation and doublestrand break repair J Biol Chem 286 32638ndash32650
64 PelikanM HuraGL and HammelM (2009) Structure andflexibility within proteins as identified through small angle X-rayscattering Gen Physiol Biophys 28 174ndash189
65 GrantTD LuftJR WolfleyJR TsurutaH MartelAMontelioneGT and SnellEH (2011) Small angle X-rayscattering as a complementary tool for high-throughput structuralstudies Biopolymers 95 517ndash530
66 KonarevPV VolkovVV SokolovaAV KochMHJ andSvergunDI (2003) PRIMUS a Windows PC-based system forsmall-angle scattering data analysis J Appl Crystallogr 361277ndash1282
67 ShoichetBK and KuntzID (1991) Protein docking andcomplementarity J Mol Biol 221 327ndash346
68 PieperU SchlessingerA KloppmannE ChangGA ChouJJDumontM FoxB FrommeP HendricksonW MalkowskiMet al (2013) Coordinating the impact of structural genomics onthe human a-helical transmembrane proteome Nat Struct MolBiol 20 135ndash138
69 JohnsonM ZaretskayaI RaytselisY MerezhukYMcGinnisS and MaddenTL (2008) NCBI BLAST a betterweb interface Nucleic Acids Res 36 W5ndashW9
70 WardJJ McGuffinLJ BrysonK BuxtonBF and JonesDT(2004) The DISOPRED server for the prediction of proteindisorder Bioinformatics 20 2138ndash2139
71 DosztanyiZ CsizmokV TompaP and SimonI (2005) IUPredweb server for the prediction of intrinsically unstructured regionsof proteins based on estimated energy content Bioinformatics 213433ndash3434
72 SteentoftC VakhrushevSY JoshiHJ KongY Vester-ChristensenMB SchjoldagerKT LavrsenK DabelsteenSPedersenNB Marcos-SilvaL et al (2013) Precision mapping ofthe human O-GalNAc glycoproteome through SimpleCelltechnology EMBO J 32 1478ndash1488
73 GuptaR JungE GooleyAA WilliamsKL BrunakS andHansenJ (1999) Scanning the available Dictyostelium discoideumproteome for O-linked GlcNAc glycosylation sites using neuralnetworks Glycobiology 9 1009ndash1022
74 CormierCY ParkJG FiaccoM SteelJ HunterPKramerJ SinglaR and LaBaerJ (2011) PSIBiology-materialsrepository a biologistrsquos resource for protein expression plasmidsJ Struct Funct Genomics 12 55ndash62
75 LameschP LiN MilsteinS FanC HaoT SzaboG HuZVenkatesanK BethelG MartinP et al (2007) hORFeomev31 a resource of human open reading frames representing over10000 human genes Genomics 89 307ndash315
76 TempleG GerhardDS RasoolyR FeingoldEA GoodPJRobinsonC MandichA DergeJG LewisJ ShoafD et al(2009) The completion of the mammalian gene collection (MGC)Genome Res 19 2324ndash2333
77 SealRL GordonSM LushMJ WrightMW andBrufordEA (2011) genenamesorg the HGNC resources in 2011Nucleic Acids Res 39 D514ndashD519
78 GiffordLK CarterLG GabanyiMJ BermanHM andAdamsPD (2012) The protein structure initiative structuralbiology knowledgebase technology portal a structural biologyweb resource J Struct Funct Genomics 13 57ndash62
79 FreedEO (2001) HIV-1 replication Somatic Cell Mol Genet26 13ndash33
80 McDonaldCK and KuritzkesDR (1997) Humanimmunodeficiency virus type 1 protease inhibitors Arch IntMed 157 951ndash959
81 DragM and SalvesenGS (2010) Emerging principles inprotease-based drug discovery Nat Rev Drug Discov 9690ndash701
82 FlexnerC (1998) HIV-protease inhibitors N Engl J Med 3381281ndash1292
83 KohlNE EminiEA SchleifWA DavisLJ HeimbachJCDixonRA ScolnickEM and SigalIS (1988) Active humanimmunodeficiency virus protease is required for viral infectivityProc Natl Acad Sci USA 85 4686ndash4690
84 MurthyKH WinborneEL MinnichMD CulpJS andDebouckC (1992) The crystal structures at 22-A resolution ofhydroxyethylene-based inhibitors bound to humanimmunodeficiency virus type 1 protease show that the inhibitorsare present in two distinct orientations J Biol Chem 26722770ndash22778
85 Prabu-JeyabalanM NalivaikaE and SchifferCA (2000) Howdoes a symmetric dimer recognize an asymmetric substrate Asubstrate complex of HIV-1 protease J Mol Biol 3011207ndash1220
86 MahalingamB LouisJM HungJ HarrisonRW andWeberIT (2001) Structural implications of drug-resistantmutants of HIV-1 protease high-resolution crystal structures ofthe mutant proteasesubstrate analogue complexes Proteins 43455ndash464
87 NieZ PhenixBN LumJJ AlamA LynchDH BeckettBKrammerPH SekalyRP and BadleyAD (2002) HIV-1protease processes procaspase 8 to cause mitochondrial release ofcytochrome c caspase cleavage and nuclear fragmentation CellDeath Differ 9 1172ndash1184
88 Algeciras-SchimnichA Belzacq-CasagrandeAS BrenGDNieZ TaylorJA RizzaSA BrennerC and BadleyAD(2007) Analysis of HIV protease killing through caspase 8 revealsa novel interaction between caspase 8 and mitochondria OpenVirol J 1 39ndash46
89 NieZ BrenGD RizzaSA and BadleyAD (2008) HIVprotease cleavage of procaspase 8 is necessary for death of HIV-infected cells Open Virol J 2 1ndash7
10 Nucleic Acids Research 2013
at UC
SF Library on D
ecember 2 2013
httpnaroxfordjournalsorgD
ownloaded from
90 CastelloA FrancoD Moral-LopezP BerlangaJJAlvarezE WimmerE and CarrascoL (2009) HIV- 1 proteaseinhibits Cap- and poly(A)-dependent translation upon eIF4GIand PABP cleavage PloS One 4 e7997
91 ImpensF TimmermanE StaesA MoensK ArienKKVerhasseltB VandekerckhoveJ and GevaertK (2012) Acatalogue of putative HIV-1 protease host cell substrates BiolChem 393 915ndash931
92 Kotik-KoganO ValentineER SanfeliceD ConteMR andCurryS (2008) Structural analysis reveals conformationalplasticity in the recognition of RNA 3rsquo ends by the human Laprotein Structure 16 852ndash862
93 NakaiK KideraA and KanehisaM (1988) Cluster analysis ofamino acid indices for prediction of protein structure andfunction Protein Eng 2 93ndash100
94 TomiiK and KanehisaM (1996) Analysis of amino acid indicesand mutation matrices for sequence comparison and structureprediction of proteins Protein Eng 9 27ndash36
95 JonesDT (1999) Protein secondary structure prediction basedon position-specific scoring matrices J Mol Biol 292 195ndash202
96 BreimanL and SchapireE (2001) Random forests MachLearn 45 5ndash32
97 BensonDA Karsch-MizrachiI LipmanDJ OstellJ andSayersEW (2010) GenBank Nucleic Acids Res 38 D46ndashD51
98 KraulisPJ (1991) MOLSCRIPT a program to produce bothdetailed and schematic plorts of protein structures J ApplCrystallogr 24 946ndash950
99 MerrittEA and BaconDJ (1997) Raster3D photorealisticmolecular graphics Methods Enzymol 277 505ndash524
100 PettersenEF GoddardTD HuangCC CouchGSGreenblattDM MengEC and FerrinTE (2004) UCSFChimerandasha visualization system for exploratory research andanalysis J Comput Chem 25 1605ndash1612
101 CapraJA LaskowskiRA ThorntonJM SinghM andFunkhouserTA (2009) Predicting protein ligand binding sitesby combining evolutionary sequence conservation and 3Dstructure PLoS Comp Biol 5 e1000585
102 HenrickK FengZ BluhmWF DimitropoulosDDoreleijersJF DuttaS Flippen-AndersonJL IonidesJKamadaC KrissinelE et al (2008) Remediation of the proteindata bank archive Nucleic Acids Res 36 D426ndashD433
103 WuCH ApweilerR BairochA NataleDA BarkerWCBoeckmannB FerroS GasteigerE HuangH LopezR et al(2006) The Universal Protein Resource (UniProt) an expandinguniverse of protein information Nucleic Acids Res 34D187ndashD191
104 RheadB KarolchikD KuhnRM HinrichsAS ZweigASFujitaPA DiekhansM SmithKE RosenbloomKRRaneyBJ et al (2010) The UCSC Genome Browser databaseupdate 2010 Nucleic Acids Res 38 D613ndashD619
105 HunterS ApweilerR AttwoodTK BairochA BatemanABinnsD BorkP DasU DaughertyL DuquenneL et al(2009) InterPro the integrative protein signature databaseNucleic Acids Res 37 D211ndashD215
106 KleinTE ChangJT ChoMK EastonKL FergersonRHewettM LinZ LiuY LiuS OliverDE et al (2001)Integrating genotype and phenotype information an overview ofthe PharmGKB project Pharmacogenetics research network andknowledge base Pharmacogenomics J 1 167ndash170
107 HaasJ RothS ArnoldK KieferF SchmidtT BordoliLand SchwedeT (2013) The Protein Model Portalmdashacomprehensive resource for protein structure and modelinformation Database 2013 bat031
108 SchwedeT SaliA HonigB LevittM BermanH JonesDBrennerS BurleyS DasR DokholyanN et al (2009)Outcome of a workshop on applications of protein models inbiomedical research Structure 17 151ndash159
109 BairochA ApweilerR WuCH BarkerWC BoeckmannBFerroS GasteigerE HuangH LopezR MagraneM et al(2005) The Universal Protein Resource (UniProt) Nucleic AcidsRes 33 D154ndashD159
110 GigliaE (2009) New year new PubMed Eur J Phys RehabilMed 45 155ndash159
Nucleic Acids Research 2013 11
at UC
SF Library on D
ecember 2 2013
httpnaroxfordjournalsorgD
ownloaded from

7 SchwedeT SaliA EswarN and PeitschMC (2008)In SchwedeT and PeitschMC (eds) Computational StructuralBiology World Scientific Publishing Ltd Singapore pp 3ndash35
8 ForrestLR TangCL and HonigB (2006) On the accuracy ofhomology modeling and sequence alignment methods applied tomembrane proteins Biophys J 91 508ndash517
9 LiuT TangGW and CapriottiE (2011) Comparativemodeling the state of the art and protein drug target structureprediction Comb Chem High Throughput Screen 14 532ndash547
10 FiserA (2010) Template-based protein structure modelingMethods Mol Biol 673 73ndash94
11 DagaPR PatelRY and DoerksenRJ (2010) Template-basedprotein modeling recent methodological advances Curr TopMed Chem 10 84ndash94
12 HillischA PinedaLF and HilgenfeldR (2004) Utility ofhomology models in the drug discovery process Drug DiscovToday 9 659ndash669
13 WallnerB and ElofssonA (2005) All are not equal abenchmark of different homology modeling programs ProteinSci 14 1315ndash1327
14 WeinkamP PonsJ and SaliA (2012) Structure-based model ofallostery predicts coupling between distant sites Proc Natl AcadSci USA 109 4875ndash4880
15 Schneidman-DuhovnyD HammelM and SaliA (2011)Macromolecular docking restrained by a small angle X-rayscattering profile J Struct Biol 3 461ndash471
16 FanH SchneidmanD IrwinJJ DongG ShoichetB andSaliA (2011) Statistical potential for modeling and rankingprotein-ligand interactions J Chem Inf Model 51 3078ndash3092
17 EswarN JohnB MirkovicN FiserA IlyinVA PieperUStuartAC Marti-RenomMA MadhusudhanMSYerkovichB et al (2003) Tools for comparative protein structuremodeling and analysis Nucleic Acids Res 31 3375ndash3380
18 SaliA and BlundellTL (1993) Comparative protein modellingby satisfaction of spatial restraints J Mol Biol 234 779ndash815
19 AltschulSF MaddenTL SchafferAA ZhangJ ZhangZMillerW and LipmanDJ (1997) Gapped BLAST and PSI-BLAST a new generation of protein database search programsNucleic Acids Res 25 3389ndash3402
20 RemmertM BiegertA HauserA and SodingJ (2012) HHblitslightning-fast iterative protein sequence searching by HMM-HMM alignment Nat Methods 9 173ndash175
21 SodingJ (2005) Protein homology detection by HMM-HMMcomparison Bioinformatics 21 951ndash960
22 SmithTF and WatermanMS (1981) Identification of commonmolecular subsequences J Mol Biol 147 195ndash197
23 EswarN WebbB Marti-RenomM MadhusudhanMEramianD ShenM PieperU and SaliA (2006) Comparativeprotein structure modeling using Modeller Curr ProtocBioinformatics Chapter 5 Unit 56
24 Marti-RenomMA MadhusudhanMS and SaliA (2004)Alignment of protein sequences by their profiles Protein Sci 131071ndash1087
25 ShenMY and SaliA (2006) Statistical potential for assessmentand prediction of protein structures Protein Sci 15 2507ndash2524
26 MeloF and SaliA (2007) Fold assessment for comparativeprotein structure modeling Protein Sci 16 2412ndash2426
27 PieperU WebbBM BarkanDT Schneidman-DuhovnyDSchlessingerA BrabergH YangZ MengEC PettersenEFHuangCC et al (2011) ModBase a database of annotatedcomparative protein structure models and associated resourcesNucleic Acids Res 39 465ndash474
28 EramianD EswarN ShenM and SaliA (2008) How well canthe accuracy of comparative protein structure models bepredicted Protein Sci 17 1881ndash1893
29 DongGQ FanH Schneidman-DuhovnyD WebbB andSaliA (2013) Optimized atomic statistical potentials Assessmentof protein interfaces and loops (epub ahead of print October 232013)
30 Schneidman-DuhovnyD RossiA Avila-SakarA KimSJVelazquez-MurielJ StropP LiangH KrukenbergKALiaoM KimHM et al (2012) A method for integrativestructure determination of protein-protein complexesBioinformatics 28 3282ndash3289
31 PierceB and WengZ (2007) ZRANK reranking protein dockingpredictions with an optimized energy function Proteins 671078ndash1086
32 AndrusierN NussinovR and WolfsonHJ (2007) FireDockfast interaction refinement in molecular docking Proteins 69139ndash159
33 JacobsonMP PincusDL RappCS DayTJ HonigBShawDE and FriesnerRA (2004) A hierarchical approach toall-atom protein loop prediction Proteins 55 351ndash367
34 GrontD KulpDW VernonRM StraussCE and BakerD(2011) Generalized fragment picking in Rosetta design protocolsand applications PloS One 6 e23294
35 ZhangC LiuS and ZhouY (2004) Accurate and efficient loopselections by the DFIRE-based all-atom statistical potentialProtein Sci 13 391ndash399
36 PeggSC BrownSD OjhaS SeffernickJ MengECMorrisJH ChangPJ HuangCC FerrinTE andBabbittPC (2006) Leveraging enzyme structure-functionrelationships for functional inference and experimental design thestructure-function linkage database Biochemistry 45 2545ndash2555
37 MaurerSM RaiA and SaliA (2004) Finding cures for tropicaldiseases is open source an answer PLoS Med 1 e56
38 OrtiL CarbajoR PieperU EswarN MaurerS RaiATaylorG ToddM Pineda-LucenaA SaliA et al (2009) Akernel for open source drug discovery in tropical diseases PLoSNegl Trop Dis 3 e418
39 AgueroF Al-LazikaniB AslettM BerrimanM BucknerFCampbellR CarmonaS CarruthersI ChanA ChenF et al(2008) Genomic-scale prioritization of drug targets the TDRTargets database Nat Rev Drug Discov 7 900ndash907
40 Martinez-JimenezF PapadatosG YangL WallaceIMKumarV PieperU SaliA BrownJR OveringtonJP andMarti-RenomMA (2013) Target prediction for an open accessset of compounds active against Mycobacterium tuberculosisPLoS Comp Biol 9 e1003253
41 SampathkumarP LuF ZhaoX LiZ GilmoreJ BainKRutterME GheyiT SchwinnK BonannoJ et al (2010)Structure of a putative BenF-like porin from Pseudomanasfluorescens Pf-5 at 26 A resolution Proteins 78 3056ndash3062
42 PieperU ChiangR SeffernickJ BrownS GlasnerMKellyL EswarN SauderJ BonannoJ SwaminathanS et al(2009) Target selection and annotation for the structural genomicsof the amidohydrolase and enolase superfamilies J Struct FunctGenom 10 107ndash125
43 KarchinR DiekhansM KellyL ThomasDJ PieperUEswarN HausslerD and SaliA (2005) LS-SNP large-scaleannotation of coding non-synonymous SNPs based on multipleinformation sources Bioinformatics 21 2814ndash2820
44 FiserA and SaliA (2003) ModLoop automated modeling ofloops in protein structures Bioinformatics 19 2500ndash2501
45 DavisF and SaliA (2005) PIBASE a comprehensive databaseof structurally defined protein interfaces Bioinformatics 211901ndash1907
46 Marti-RenomMA PieperU MadhusudhanMS RossiAEswarN DavisFP Al-ShahrourF DopazoJ and SaliA(2007) DBAli tools mining the protein structure space NucleicAcids Res 35 W393ndashW397
47 Marti-RenomMA IlyinVA and SaliA (2001) DBAli adatabase of protein structure alignments Bioinformatics 17746ndash747
48 PieperU EswarN WebbB EramianD KellyL BarkanDCarterH MankooP KarchinR Marti-RenomM et al (2009)MODBASE a database of annotated comparative proteinstructure models and associated resources Nucleic Acids Res 37D347ndashD354
49 PieperU EswarN DavisFP BrabergH MadhusudhanMSRossiA Marti-RenomM KarchinR WebbBM EramianDet al (2006) MODBASE a database of annotated comparativeprotein structure models and associated resources Nucleic AcidsRes 34 D291ndashD295
50 BrabergH WebbB TjioeE PieperU SaliA andMadhusudhanMS (2012) SALIGN a webserver for alignmentof multiple protein sequences and structures Bioinformatics 152072ndash2073
Nucleic Acids Research 2013 9
at UC
SF Library on D
ecember 2 2013
httpnaroxfordjournalsorgD
ownloaded from
51 Schneidman-DuhovnyD HammelM and SaliA (2010) FoXS aweb server for rapid computation and fitting of SAXS ProfilesNucleic Acids Res 38 541ndash544
52 UedaY TaketomiH and GoN (1978) Studies on proteinfolding unfolding and fluctuations by computer simulation IIAThree dimensional lattice model of lysozyme Biopolymers 171531ndash1548
53 OkazakiK KogaN TakadaS OnuchicJN and WolynesPG(2006) Multiple-basin energy landscapes for large-amplitudeconformational motions of proteins Structure-based moleculardynamics simulations Proc Natl Acad Sci USA 10311844ndash11849
54 WhitfordPC NoelJK GosaviS SchugA SanbonmatsuKYand OnuchicJN (2009) An all-atom structure-based potential forproteins bridging minimal models with all-atom empiricalforcefields Proteins 75 430ndash441
55 WeinkamP ChenYC PonsJ and SaliA (2013) Impact ofmutations on the allosteric conformational equilibrium J MolBiol 425 647ndash661
56 PetoukhovMV and SvergunDI (2007) Analysis of X-ray andneutron scattering from biomacromolecular solutions Curr OpinStruct Biol 17 562ndash571
57 HuraGL MenonAL HammelM RamboRP PooleFL IITsutakawaSE JenneyFE Jr ClassenS FrankelKAHopkinsRC et al (2009) Robust high-throughput solutionstructural analyses by small angle X-ray scattering (SAXS) NatMethods 6 606ndash612
58 SvergunD BarberatoC and KochMHJ (1995) CRYSOL-aprogram to evaluate X-ray solution scattering of biologicalmacromolecules from atomic coordinates J Appl Crystallogr28 768ndash773
59 PoitevinF OrlandH DoniachS KoehlP and DelarueM(2011) AquaSAXS a web server for computation and fitting ofSAXS profiles with non-uniformally hydrated atomic modelsNucleic Acids Res 39 W184ndashW189
60 LiuH MorrisRJ HexemerA GrandisonS and ZwartPH(2012) Computation of small-angle scattering profiles with three-dimensional Zernike polynomials Acta Crystallogr A 68278ndash285
61 RavikumarKM HuangW and YangS (2013) Fast-SAXS-proa unified approach to computing SAXS profiles of DNA RNAprotein and their complexes J Chem Phys 138 024112
62 Schneidman-DuhovnyD HammelM TainerJA and SaliA(2013) Accurate SAXS profile computation and its assessment bycontrast variation experiments Biophys J 105 962ndash974
63 HammelM ReyM YuY ManiRS ClassenS LiuMPiqueME FangS MahaneyBL WeinfeldM et al (2011)XRCC4 protein interactions with XRCC4-like factor (XLF)create an extended grooved scaffold for DNA ligation and doublestrand break repair J Biol Chem 286 32638ndash32650
64 PelikanM HuraGL and HammelM (2009) Structure andflexibility within proteins as identified through small angle X-rayscattering Gen Physiol Biophys 28 174ndash189
65 GrantTD LuftJR WolfleyJR TsurutaH MartelAMontelioneGT and SnellEH (2011) Small angle X-rayscattering as a complementary tool for high-throughput structuralstudies Biopolymers 95 517ndash530
66 KonarevPV VolkovVV SokolovaAV KochMHJ andSvergunDI (2003) PRIMUS a Windows PC-based system forsmall-angle scattering data analysis J Appl Crystallogr 361277ndash1282
67 ShoichetBK and KuntzID (1991) Protein docking andcomplementarity J Mol Biol 221 327ndash346
68 PieperU SchlessingerA KloppmannE ChangGA ChouJJDumontM FoxB FrommeP HendricksonW MalkowskiMet al (2013) Coordinating the impact of structural genomics onthe human a-helical transmembrane proteome Nat Struct MolBiol 20 135ndash138
69 JohnsonM ZaretskayaI RaytselisY MerezhukYMcGinnisS and MaddenTL (2008) NCBI BLAST a betterweb interface Nucleic Acids Res 36 W5ndashW9
70 WardJJ McGuffinLJ BrysonK BuxtonBF and JonesDT(2004) The DISOPRED server for the prediction of proteindisorder Bioinformatics 20 2138ndash2139
71 DosztanyiZ CsizmokV TompaP and SimonI (2005) IUPredweb server for the prediction of intrinsically unstructured regionsof proteins based on estimated energy content Bioinformatics 213433ndash3434
72 SteentoftC VakhrushevSY JoshiHJ KongY Vester-ChristensenMB SchjoldagerKT LavrsenK DabelsteenSPedersenNB Marcos-SilvaL et al (2013) Precision mapping ofthe human O-GalNAc glycoproteome through SimpleCelltechnology EMBO J 32 1478ndash1488
73 GuptaR JungE GooleyAA WilliamsKL BrunakS andHansenJ (1999) Scanning the available Dictyostelium discoideumproteome for O-linked GlcNAc glycosylation sites using neuralnetworks Glycobiology 9 1009ndash1022
74 CormierCY ParkJG FiaccoM SteelJ HunterPKramerJ SinglaR and LaBaerJ (2011) PSIBiology-materialsrepository a biologistrsquos resource for protein expression plasmidsJ Struct Funct Genomics 12 55ndash62
75 LameschP LiN MilsteinS FanC HaoT SzaboG HuZVenkatesanK BethelG MartinP et al (2007) hORFeomev31 a resource of human open reading frames representing over10000 human genes Genomics 89 307ndash315
76 TempleG GerhardDS RasoolyR FeingoldEA GoodPJRobinsonC MandichA DergeJG LewisJ ShoafD et al(2009) The completion of the mammalian gene collection (MGC)Genome Res 19 2324ndash2333
77 SealRL GordonSM LushMJ WrightMW andBrufordEA (2011) genenamesorg the HGNC resources in 2011Nucleic Acids Res 39 D514ndashD519
78 GiffordLK CarterLG GabanyiMJ BermanHM andAdamsPD (2012) The protein structure initiative structuralbiology knowledgebase technology portal a structural biologyweb resource J Struct Funct Genomics 13 57ndash62
79 FreedEO (2001) HIV-1 replication Somatic Cell Mol Genet26 13ndash33
80 McDonaldCK and KuritzkesDR (1997) Humanimmunodeficiency virus type 1 protease inhibitors Arch IntMed 157 951ndash959
81 DragM and SalvesenGS (2010) Emerging principles inprotease-based drug discovery Nat Rev Drug Discov 9690ndash701
82 FlexnerC (1998) HIV-protease inhibitors N Engl J Med 3381281ndash1292
83 KohlNE EminiEA SchleifWA DavisLJ HeimbachJCDixonRA ScolnickEM and SigalIS (1988) Active humanimmunodeficiency virus protease is required for viral infectivityProc Natl Acad Sci USA 85 4686ndash4690
84 MurthyKH WinborneEL MinnichMD CulpJS andDebouckC (1992) The crystal structures at 22-A resolution ofhydroxyethylene-based inhibitors bound to humanimmunodeficiency virus type 1 protease show that the inhibitorsare present in two distinct orientations J Biol Chem 26722770ndash22778
85 Prabu-JeyabalanM NalivaikaE and SchifferCA (2000) Howdoes a symmetric dimer recognize an asymmetric substrate Asubstrate complex of HIV-1 protease J Mol Biol 3011207ndash1220
86 MahalingamB LouisJM HungJ HarrisonRW andWeberIT (2001) Structural implications of drug-resistantmutants of HIV-1 protease high-resolution crystal structures ofthe mutant proteasesubstrate analogue complexes Proteins 43455ndash464
87 NieZ PhenixBN LumJJ AlamA LynchDH BeckettBKrammerPH SekalyRP and BadleyAD (2002) HIV-1protease processes procaspase 8 to cause mitochondrial release ofcytochrome c caspase cleavage and nuclear fragmentation CellDeath Differ 9 1172ndash1184
88 Algeciras-SchimnichA Belzacq-CasagrandeAS BrenGDNieZ TaylorJA RizzaSA BrennerC and BadleyAD(2007) Analysis of HIV protease killing through caspase 8 revealsa novel interaction between caspase 8 and mitochondria OpenVirol J 1 39ndash46
89 NieZ BrenGD RizzaSA and BadleyAD (2008) HIVprotease cleavage of procaspase 8 is necessary for death of HIV-infected cells Open Virol J 2 1ndash7
10 Nucleic Acids Research 2013
at UC
SF Library on D
ecember 2 2013
httpnaroxfordjournalsorgD
ownloaded from
90 CastelloA FrancoD Moral-LopezP BerlangaJJAlvarezE WimmerE and CarrascoL (2009) HIV- 1 proteaseinhibits Cap- and poly(A)-dependent translation upon eIF4GIand PABP cleavage PloS One 4 e7997
91 ImpensF TimmermanE StaesA MoensK ArienKKVerhasseltB VandekerckhoveJ and GevaertK (2012) Acatalogue of putative HIV-1 protease host cell substrates BiolChem 393 915ndash931
92 Kotik-KoganO ValentineER SanfeliceD ConteMR andCurryS (2008) Structural analysis reveals conformationalplasticity in the recognition of RNA 3rsquo ends by the human Laprotein Structure 16 852ndash862
93 NakaiK KideraA and KanehisaM (1988) Cluster analysis ofamino acid indices for prediction of protein structure andfunction Protein Eng 2 93ndash100
94 TomiiK and KanehisaM (1996) Analysis of amino acid indicesand mutation matrices for sequence comparison and structureprediction of proteins Protein Eng 9 27ndash36
95 JonesDT (1999) Protein secondary structure prediction basedon position-specific scoring matrices J Mol Biol 292 195ndash202
96 BreimanL and SchapireE (2001) Random forests MachLearn 45 5ndash32
97 BensonDA Karsch-MizrachiI LipmanDJ OstellJ andSayersEW (2010) GenBank Nucleic Acids Res 38 D46ndashD51
98 KraulisPJ (1991) MOLSCRIPT a program to produce bothdetailed and schematic plorts of protein structures J ApplCrystallogr 24 946ndash950
99 MerrittEA and BaconDJ (1997) Raster3D photorealisticmolecular graphics Methods Enzymol 277 505ndash524
100 PettersenEF GoddardTD HuangCC CouchGSGreenblattDM MengEC and FerrinTE (2004) UCSFChimerandasha visualization system for exploratory research andanalysis J Comput Chem 25 1605ndash1612
101 CapraJA LaskowskiRA ThorntonJM SinghM andFunkhouserTA (2009) Predicting protein ligand binding sitesby combining evolutionary sequence conservation and 3Dstructure PLoS Comp Biol 5 e1000585
102 HenrickK FengZ BluhmWF DimitropoulosDDoreleijersJF DuttaS Flippen-AndersonJL IonidesJKamadaC KrissinelE et al (2008) Remediation of the proteindata bank archive Nucleic Acids Res 36 D426ndashD433
103 WuCH ApweilerR BairochA NataleDA BarkerWCBoeckmannB FerroS GasteigerE HuangH LopezR et al(2006) The Universal Protein Resource (UniProt) an expandinguniverse of protein information Nucleic Acids Res 34D187ndashD191
104 RheadB KarolchikD KuhnRM HinrichsAS ZweigASFujitaPA DiekhansM SmithKE RosenbloomKRRaneyBJ et al (2010) The UCSC Genome Browser databaseupdate 2010 Nucleic Acids Res 38 D613ndashD619
105 HunterS ApweilerR AttwoodTK BairochA BatemanABinnsD BorkP DasU DaughertyL DuquenneL et al(2009) InterPro the integrative protein signature databaseNucleic Acids Res 37 D211ndashD215
106 KleinTE ChangJT ChoMK EastonKL FergersonRHewettM LinZ LiuY LiuS OliverDE et al (2001)Integrating genotype and phenotype information an overview ofthe PharmGKB project Pharmacogenetics research network andknowledge base Pharmacogenomics J 1 167ndash170
107 HaasJ RothS ArnoldK KieferF SchmidtT BordoliLand SchwedeT (2013) The Protein Model Portalmdashacomprehensive resource for protein structure and modelinformation Database 2013 bat031
108 SchwedeT SaliA HonigB LevittM BermanH JonesDBrennerS BurleyS DasR DokholyanN et al (2009)Outcome of a workshop on applications of protein models inbiomedical research Structure 17 151ndash159
109 BairochA ApweilerR WuCH BarkerWC BoeckmannBFerroS GasteigerE HuangH LopezR MagraneM et al(2005) The Universal Protein Resource (UniProt) Nucleic AcidsRes 33 D154ndashD159
110 GigliaE (2009) New year new PubMed Eur J Phys RehabilMed 45 155ndash159
Nucleic Acids Research 2013 11
at UC
SF Library on D
ecember 2 2013
httpnaroxfordjournalsorgD
ownloaded from

51 Schneidman-DuhovnyD HammelM and SaliA (2010) FoXS aweb server for rapid computation and fitting of SAXS ProfilesNucleic Acids Res 38 541ndash544
52 UedaY TaketomiH and GoN (1978) Studies on proteinfolding unfolding and fluctuations by computer simulation IIAThree dimensional lattice model of lysozyme Biopolymers 171531ndash1548
53 OkazakiK KogaN TakadaS OnuchicJN and WolynesPG(2006) Multiple-basin energy landscapes for large-amplitudeconformational motions of proteins Structure-based moleculardynamics simulations Proc Natl Acad Sci USA 10311844ndash11849
54 WhitfordPC NoelJK GosaviS SchugA SanbonmatsuKYand OnuchicJN (2009) An all-atom structure-based potential forproteins bridging minimal models with all-atom empiricalforcefields Proteins 75 430ndash441
55 WeinkamP ChenYC PonsJ and SaliA (2013) Impact ofmutations on the allosteric conformational equilibrium J MolBiol 425 647ndash661
56 PetoukhovMV and SvergunDI (2007) Analysis of X-ray andneutron scattering from biomacromolecular solutions Curr OpinStruct Biol 17 562ndash571
57 HuraGL MenonAL HammelM RamboRP PooleFL IITsutakawaSE JenneyFE Jr ClassenS FrankelKAHopkinsRC et al (2009) Robust high-throughput solutionstructural analyses by small angle X-ray scattering (SAXS) NatMethods 6 606ndash612
58 SvergunD BarberatoC and KochMHJ (1995) CRYSOL-aprogram to evaluate X-ray solution scattering of biologicalmacromolecules from atomic coordinates J Appl Crystallogr28 768ndash773
59 PoitevinF OrlandH DoniachS KoehlP and DelarueM(2011) AquaSAXS a web server for computation and fitting ofSAXS profiles with non-uniformally hydrated atomic modelsNucleic Acids Res 39 W184ndashW189
60 LiuH MorrisRJ HexemerA GrandisonS and ZwartPH(2012) Computation of small-angle scattering profiles with three-dimensional Zernike polynomials Acta Crystallogr A 68278ndash285
61 RavikumarKM HuangW and YangS (2013) Fast-SAXS-proa unified approach to computing SAXS profiles of DNA RNAprotein and their complexes J Chem Phys 138 024112
62 Schneidman-DuhovnyD HammelM TainerJA and SaliA(2013) Accurate SAXS profile computation and its assessment bycontrast variation experiments Biophys J 105 962ndash974
63 HammelM ReyM YuY ManiRS ClassenS LiuMPiqueME FangS MahaneyBL WeinfeldM et al (2011)XRCC4 protein interactions with XRCC4-like factor (XLF)create an extended grooved scaffold for DNA ligation and doublestrand break repair J Biol Chem 286 32638ndash32650
64 PelikanM HuraGL and HammelM (2009) Structure andflexibility within proteins as identified through small angle X-rayscattering Gen Physiol Biophys 28 174ndash189
65 GrantTD LuftJR WolfleyJR TsurutaH MartelAMontelioneGT and SnellEH (2011) Small angle X-rayscattering as a complementary tool for high-throughput structuralstudies Biopolymers 95 517ndash530
66 KonarevPV VolkovVV SokolovaAV KochMHJ andSvergunDI (2003) PRIMUS a Windows PC-based system forsmall-angle scattering data analysis J Appl Crystallogr 361277ndash1282
67 ShoichetBK and KuntzID (1991) Protein docking andcomplementarity J Mol Biol 221 327ndash346
68 PieperU SchlessingerA KloppmannE ChangGA ChouJJDumontM FoxB FrommeP HendricksonW MalkowskiMet al (2013) Coordinating the impact of structural genomics onthe human a-helical transmembrane proteome Nat Struct MolBiol 20 135ndash138
69 JohnsonM ZaretskayaI RaytselisY MerezhukYMcGinnisS and MaddenTL (2008) NCBI BLAST a betterweb interface Nucleic Acids Res 36 W5ndashW9
70 WardJJ McGuffinLJ BrysonK BuxtonBF and JonesDT(2004) The DISOPRED server for the prediction of proteindisorder Bioinformatics 20 2138ndash2139
71 DosztanyiZ CsizmokV TompaP and SimonI (2005) IUPredweb server for the prediction of intrinsically unstructured regionsof proteins based on estimated energy content Bioinformatics 213433ndash3434
72 SteentoftC VakhrushevSY JoshiHJ KongY Vester-ChristensenMB SchjoldagerKT LavrsenK DabelsteenSPedersenNB Marcos-SilvaL et al (2013) Precision mapping ofthe human O-GalNAc glycoproteome through SimpleCelltechnology EMBO J 32 1478ndash1488
73 GuptaR JungE GooleyAA WilliamsKL BrunakS andHansenJ (1999) Scanning the available Dictyostelium discoideumproteome for O-linked GlcNAc glycosylation sites using neuralnetworks Glycobiology 9 1009ndash1022
74 CormierCY ParkJG FiaccoM SteelJ HunterPKramerJ SinglaR and LaBaerJ (2011) PSIBiology-materialsrepository a biologistrsquos resource for protein expression plasmidsJ Struct Funct Genomics 12 55ndash62
75 LameschP LiN MilsteinS FanC HaoT SzaboG HuZVenkatesanK BethelG MartinP et al (2007) hORFeomev31 a resource of human open reading frames representing over10000 human genes Genomics 89 307ndash315
76 TempleG GerhardDS RasoolyR FeingoldEA GoodPJRobinsonC MandichA DergeJG LewisJ ShoafD et al(2009) The completion of the mammalian gene collection (MGC)Genome Res 19 2324ndash2333
77 SealRL GordonSM LushMJ WrightMW andBrufordEA (2011) genenamesorg the HGNC resources in 2011Nucleic Acids Res 39 D514ndashD519
78 GiffordLK CarterLG GabanyiMJ BermanHM andAdamsPD (2012) The protein structure initiative structuralbiology knowledgebase technology portal a structural biologyweb resource J Struct Funct Genomics 13 57ndash62
79 FreedEO (2001) HIV-1 replication Somatic Cell Mol Genet26 13ndash33
80 McDonaldCK and KuritzkesDR (1997) Humanimmunodeficiency virus type 1 protease inhibitors Arch IntMed 157 951ndash959
81 DragM and SalvesenGS (2010) Emerging principles inprotease-based drug discovery Nat Rev Drug Discov 9690ndash701
82 FlexnerC (1998) HIV-protease inhibitors N Engl J Med 3381281ndash1292
83 KohlNE EminiEA SchleifWA DavisLJ HeimbachJCDixonRA ScolnickEM and SigalIS (1988) Active humanimmunodeficiency virus protease is required for viral infectivityProc Natl Acad Sci USA 85 4686ndash4690
84 MurthyKH WinborneEL MinnichMD CulpJS andDebouckC (1992) The crystal structures at 22-A resolution ofhydroxyethylene-based inhibitors bound to humanimmunodeficiency virus type 1 protease show that the inhibitorsare present in two distinct orientations J Biol Chem 26722770ndash22778
85 Prabu-JeyabalanM NalivaikaE and SchifferCA (2000) Howdoes a symmetric dimer recognize an asymmetric substrate Asubstrate complex of HIV-1 protease J Mol Biol 3011207ndash1220
86 MahalingamB LouisJM HungJ HarrisonRW andWeberIT (2001) Structural implications of drug-resistantmutants of HIV-1 protease high-resolution crystal structures ofthe mutant proteasesubstrate analogue complexes Proteins 43455ndash464
87 NieZ PhenixBN LumJJ AlamA LynchDH BeckettBKrammerPH SekalyRP and BadleyAD (2002) HIV-1protease processes procaspase 8 to cause mitochondrial release ofcytochrome c caspase cleavage and nuclear fragmentation CellDeath Differ 9 1172ndash1184
88 Algeciras-SchimnichA Belzacq-CasagrandeAS BrenGDNieZ TaylorJA RizzaSA BrennerC and BadleyAD(2007) Analysis of HIV protease killing through caspase 8 revealsa novel interaction between caspase 8 and mitochondria OpenVirol J 1 39ndash46
89 NieZ BrenGD RizzaSA and BadleyAD (2008) HIVprotease cleavage of procaspase 8 is necessary for death of HIV-infected cells Open Virol J 2 1ndash7
10 Nucleic Acids Research 2013
at UC
SF Library on D
ecember 2 2013
httpnaroxfordjournalsorgD
ownloaded from
90 CastelloA FrancoD Moral-LopezP BerlangaJJAlvarezE WimmerE and CarrascoL (2009) HIV- 1 proteaseinhibits Cap- and poly(A)-dependent translation upon eIF4GIand PABP cleavage PloS One 4 e7997
91 ImpensF TimmermanE StaesA MoensK ArienKKVerhasseltB VandekerckhoveJ and GevaertK (2012) Acatalogue of putative HIV-1 protease host cell substrates BiolChem 393 915ndash931
92 Kotik-KoganO ValentineER SanfeliceD ConteMR andCurryS (2008) Structural analysis reveals conformationalplasticity in the recognition of RNA 3rsquo ends by the human Laprotein Structure 16 852ndash862
93 NakaiK KideraA and KanehisaM (1988) Cluster analysis ofamino acid indices for prediction of protein structure andfunction Protein Eng 2 93ndash100
94 TomiiK and KanehisaM (1996) Analysis of amino acid indicesand mutation matrices for sequence comparison and structureprediction of proteins Protein Eng 9 27ndash36
95 JonesDT (1999) Protein secondary structure prediction basedon position-specific scoring matrices J Mol Biol 292 195ndash202
96 BreimanL and SchapireE (2001) Random forests MachLearn 45 5ndash32
97 BensonDA Karsch-MizrachiI LipmanDJ OstellJ andSayersEW (2010) GenBank Nucleic Acids Res 38 D46ndashD51
98 KraulisPJ (1991) MOLSCRIPT a program to produce bothdetailed and schematic plorts of protein structures J ApplCrystallogr 24 946ndash950
99 MerrittEA and BaconDJ (1997) Raster3D photorealisticmolecular graphics Methods Enzymol 277 505ndash524
100 PettersenEF GoddardTD HuangCC CouchGSGreenblattDM MengEC and FerrinTE (2004) UCSFChimerandasha visualization system for exploratory research andanalysis J Comput Chem 25 1605ndash1612
101 CapraJA LaskowskiRA ThorntonJM SinghM andFunkhouserTA (2009) Predicting protein ligand binding sitesby combining evolutionary sequence conservation and 3Dstructure PLoS Comp Biol 5 e1000585
102 HenrickK FengZ BluhmWF DimitropoulosDDoreleijersJF DuttaS Flippen-AndersonJL IonidesJKamadaC KrissinelE et al (2008) Remediation of the proteindata bank archive Nucleic Acids Res 36 D426ndashD433
103 WuCH ApweilerR BairochA NataleDA BarkerWCBoeckmannB FerroS GasteigerE HuangH LopezR et al(2006) The Universal Protein Resource (UniProt) an expandinguniverse of protein information Nucleic Acids Res 34D187ndashD191
104 RheadB KarolchikD KuhnRM HinrichsAS ZweigASFujitaPA DiekhansM SmithKE RosenbloomKRRaneyBJ et al (2010) The UCSC Genome Browser databaseupdate 2010 Nucleic Acids Res 38 D613ndashD619
105 HunterS ApweilerR AttwoodTK BairochA BatemanABinnsD BorkP DasU DaughertyL DuquenneL et al(2009) InterPro the integrative protein signature databaseNucleic Acids Res 37 D211ndashD215
106 KleinTE ChangJT ChoMK EastonKL FergersonRHewettM LinZ LiuY LiuS OliverDE et al (2001)Integrating genotype and phenotype information an overview ofthe PharmGKB project Pharmacogenetics research network andknowledge base Pharmacogenomics J 1 167ndash170
107 HaasJ RothS ArnoldK KieferF SchmidtT BordoliLand SchwedeT (2013) The Protein Model Portalmdashacomprehensive resource for protein structure and modelinformation Database 2013 bat031
108 SchwedeT SaliA HonigB LevittM BermanH JonesDBrennerS BurleyS DasR DokholyanN et al (2009)Outcome of a workshop on applications of protein models inbiomedical research Structure 17 151ndash159
109 BairochA ApweilerR WuCH BarkerWC BoeckmannBFerroS GasteigerE HuangH LopezR MagraneM et al(2005) The Universal Protein Resource (UniProt) Nucleic AcidsRes 33 D154ndashD159
110 GigliaE (2009) New year new PubMed Eur J Phys RehabilMed 45 155ndash159
Nucleic Acids Research 2013 11
at UC
SF Library on D
ecember 2 2013
httpnaroxfordjournalsorgD
ownloaded from

90 CastelloA FrancoD Moral-LopezP BerlangaJJAlvarezE WimmerE and CarrascoL (2009) HIV- 1 proteaseinhibits Cap- and poly(A)-dependent translation upon eIF4GIand PABP cleavage PloS One 4 e7997
91 ImpensF TimmermanE StaesA MoensK ArienKKVerhasseltB VandekerckhoveJ and GevaertK (2012) Acatalogue of putative HIV-1 protease host cell substrates BiolChem 393 915ndash931
92 Kotik-KoganO ValentineER SanfeliceD ConteMR andCurryS (2008) Structural analysis reveals conformationalplasticity in the recognition of RNA 3rsquo ends by the human Laprotein Structure 16 852ndash862
93 NakaiK KideraA and KanehisaM (1988) Cluster analysis ofamino acid indices for prediction of protein structure andfunction Protein Eng 2 93ndash100
94 TomiiK and KanehisaM (1996) Analysis of amino acid indicesand mutation matrices for sequence comparison and structureprediction of proteins Protein Eng 9 27ndash36
95 JonesDT (1999) Protein secondary structure prediction basedon position-specific scoring matrices J Mol Biol 292 195ndash202
96 BreimanL and SchapireE (2001) Random forests MachLearn 45 5ndash32
97 BensonDA Karsch-MizrachiI LipmanDJ OstellJ andSayersEW (2010) GenBank Nucleic Acids Res 38 D46ndashD51
98 KraulisPJ (1991) MOLSCRIPT a program to produce bothdetailed and schematic plorts of protein structures J ApplCrystallogr 24 946ndash950
99 MerrittEA and BaconDJ (1997) Raster3D photorealisticmolecular graphics Methods Enzymol 277 505ndash524
100 PettersenEF GoddardTD HuangCC CouchGSGreenblattDM MengEC and FerrinTE (2004) UCSFChimerandasha visualization system for exploratory research andanalysis J Comput Chem 25 1605ndash1612
101 CapraJA LaskowskiRA ThorntonJM SinghM andFunkhouserTA (2009) Predicting protein ligand binding sitesby combining evolutionary sequence conservation and 3Dstructure PLoS Comp Biol 5 e1000585
102 HenrickK FengZ BluhmWF DimitropoulosDDoreleijersJF DuttaS Flippen-AndersonJL IonidesJKamadaC KrissinelE et al (2008) Remediation of the proteindata bank archive Nucleic Acids Res 36 D426ndashD433
103 WuCH ApweilerR BairochA NataleDA BarkerWCBoeckmannB FerroS GasteigerE HuangH LopezR et al(2006) The Universal Protein Resource (UniProt) an expandinguniverse of protein information Nucleic Acids Res 34D187ndashD191
104 RheadB KarolchikD KuhnRM HinrichsAS ZweigASFujitaPA DiekhansM SmithKE RosenbloomKRRaneyBJ et al (2010) The UCSC Genome Browser databaseupdate 2010 Nucleic Acids Res 38 D613ndashD619
105 HunterS ApweilerR AttwoodTK BairochA BatemanABinnsD BorkP DasU DaughertyL DuquenneL et al(2009) InterPro the integrative protein signature databaseNucleic Acids Res 37 D211ndashD215
106 KleinTE ChangJT ChoMK EastonKL FergersonRHewettM LinZ LiuY LiuS OliverDE et al (2001)Integrating genotype and phenotype information an overview ofthe PharmGKB project Pharmacogenetics research network andknowledge base Pharmacogenomics J 1 167ndash170
107 HaasJ RothS ArnoldK KieferF SchmidtT BordoliLand SchwedeT (2013) The Protein Model Portalmdashacomprehensive resource for protein structure and modelinformation Database 2013 bat031
108 SchwedeT SaliA HonigB LevittM BermanH JonesDBrennerS BurleyS DasR DokholyanN et al (2009)Outcome of a workshop on applications of protein models inbiomedical research Structure 17 151ndash159
109 BairochA ApweilerR WuCH BarkerWC BoeckmannBFerroS GasteigerE HuangH LopezR MagraneM et al(2005) The Universal Protein Resource (UniProt) Nucleic AcidsRes 33 D154ndashD159
110 GigliaE (2009) New year new PubMed Eur J Phys RehabilMed 45 155ndash159
Nucleic Acids Research 2013 11
at UC
SF Library on D
ecember 2 2013
httpnaroxfordjournalsorgD
ownloaded from