meeting recognition and understanding - microsoft.com · why meetings? • meetings are everywhere,...
TRANSCRIPT

Meeting Recognition and
UnderstandingPast, Present and a Guess at the Future
Andreas Stolcke
Microsoft Research
Mountain View, CA

Roadmap
• Preliminaries: what are meetings, why do we care
• Overview of relevant technologies
• Past and present project and products
• Data for research
• In depth topics:– How to couple diarization and recognition
– How to best leverage multi-channel recordings for recognition
– How to improve speaker diarization with trainable feature extractors
• Hard problems
• A guess at the future
Oct. 6, 2014PROPOR, São Carlos, Brasil 2

What are Meetings?
• Multiple (>= 2) speakers
• Conversational speaking style– But could be asymmetrical, i.e., lecture with Q&A
• One or multiple recording channels– Often more than one speaker per channel
Work meetings Movies, telenovelas, …
Oct. 6, 2014PROPOR, São Carlos, Brasil 3

Why Meetings?
Too many
meetings to
remember …
Oct. 6, 2014PROPOR, São Carlos, Brasil 4

Why Meetings?
• Meetings are everywhere, and take up too much time
• Make meeting content accessible for non-participants
and posterity
• But meetings have low information density – you don’t
want to listen to verbatim recording or read a transcript
• First step: turn meetings into documents
• Seconds steps: extract relevant information,
summarize, translate, … (all the things we know how
to do with documents)
Oct. 6, 2014PROPOR, São Carlos, Brasil 5

From Capture to Understanding
Beamforming,
Noise filtering, …SAD, Speaker
diarization
Addressee
detection
Transcription
(ASR)
Disfluency cleanup,
punctuation,
coreference
Dialog structure tagging,
entity tagging, emotion
detection
“Deep Understanding”Intent, slots, meeting graph, …
“Shallow understanding”Topics, hotspots, summarization, translation, …
Oct. 6, 2014PROPOR, São Carlos, Brasil 6

Research Projects (1)
• CMU, Karlsruhe, IBM– Meeting transcription, speaker localization
– Focus on lectures
• AMI (European consortium): meeting transcription and
(some) understanding– Collected corpus
– Multimodal (speech + video, gesture and gaze annotations)
• ICSI, SRI: conference meeting recording, speaker
tracking, transcription, understanding– ICSI meeting recorder corpus
– Dialog act segmentation/tagging, adjacency pairs
– Agreement/disagreement detection; “hot spots”
– Summarization
Oct. 6, 2014PROPOR, São Carlos, Brasil 7

Data Collection Efforts
• ICSI
• AMI
Oct. 6, 2014PROPOR, São Carlos, Brasil 8

Research Projects (2)
• SCIL (SRI, ICSI) (Sociocultural Content in Language)– Speaker role detection
– Supervised methods for agreement/disagreement and longer context labeling
– Dominance / authority
• SRI (2003-08): CALO-MA (Meeting Assistant)– VoIP recordings using personal laptops & headsets
– Real-time and offline recognition
– Dialog act segmentation/tagging
– Question/answer pair recognition
– Action item detection
Remote
sitesServers (SRI Menlo
Park)
8 U
Oct. 6, 2014PROPOR, São Carlos, Brasil 9

CALO Meeting Browser Meeting review interface
Oct. 6, 2014PROPOR, São Carlos, Brasil 10

Evaluations
• From 2002 until 2009, NIST (US Dept. of Commerce)
held evaluations in three tasks
• Speech-To-Text Transcription (STT)– Transcribe the spoken words
• Diarization “Who Spoke When” (SPKR)– Detect segments of speech and cluster them by speaker
• Speaker Attributed Speech-To-Text (SASTT)– Transcribe the spoken words and associate them with a speaker
• Data were multichannel round-table meeting
recordings from various sites
• Lecture and “coffee break” data was added in 2007
Oct. 6, 2014PROPOR, São Carlos, Brasil 11

1988 1989 1990 1991 1992 1993 1994 1995 1996 1997 1998 1999 2000 2001 2002 2003 2004 2005 2006 2007 2008 2009 2010 2011
100%
10%
1%
4%
ReadSpeech
20k
5k
1k
Noisy
Varied Microphones
Air Travel Planning Kiosk
Speech
2%
Range of Human Error In Transcription
Conversational Speech
(Non-English)
Switchboard Cellular
Switchboard II
CTS Arabic (UL)CTS Mandarin (UL)0
CTS Fisher (UL)
Switchboard
(Non-English)
News English 10X
BroadcastSpeech
News English 1XNews English unlimited
News Mandarin 10X
News Arabic 10X
Meeting – MDM OV4
Meeting - IHM
Meeting – SDM OV4
Meeting Speech
NIST STT Benchmark Test History – May. ’09W
ER
(%)
Oct. 6, 2014 13

Publicly Available Meeting Data
• ICSI Meeting Recorder corpus– About 75 hours
– Available from the Linguistic Data Consortium (LDC)
– ICSI also has annotated version of this data (dialog acts, hotspots)
• AMI Meeting corpus– About 100 hours, including video recordings
– Annotated transcripts (dialog structure, addressee, etc.)
– Available from amiproject.org
• NIST Meeting Pilot Corpus– About 15 hours of meetings
– Available from LDC
• These corpora are typically used for training
• NIST RT test sets– Contain a mix of data from various research sites
– Also available from LDC/NIST
Oct. 6, 2014 14PROPOR, São Carlos, Brasil

Meeting Summarization(Hakkani-Tür et al.)
PM: Are we -- we’re not allowed to dim the lights so people can see that a bit better.UI: YeahPM: Okay that is fine.ID: So,we got both of these clipped on?MA: Right, both of them, okay.PM: Yes. PM: Okay. PM: Hello everybody. PM: Um I'm Sarah, the Project Manager.UI: Hi, good morning.PM: And this is our first meeting , surprisingly enough.PM: Okay, this is our agenda, um-- We will do some stuff, get to know each other a bit better to feel more comfortable with each other.PM: Um-- then we'll go do tool training, talk about the project plan, discuss our own ideas and everything um-- and we've got twenty five minutes to do that, as far as I can understand.UI: Jesus, it’s gonna fall ofMA: Okay, Yep, yep.PM: Now, we’re developing ….
PM: Um I'm Sarah, the Project Manager.PM: And this is our first meeting , surprisingly enough.PM: Okay, this is our agenda, um-- We will do some stuff, get to know each other a bit better to feelmore comfortable with each other.PM: Um-- then we'll go do tool training, talk about the project plan, discuss our own ideas and everythingum-- and we've got twenty five minutes to do that, as far as I can understand.
about 70 words, sparse information
Oct. 6, 2014PROPOR, São Carlos, Brasil 15

Meeting Summarization Screen Shot
Oct. 6, 2014 16

Commercial Research and Products
• Spin-offs from research labs for lecture and meeting
transcription– SuperLectures (Brno)
– Dev-Audio/microcone (IDIAP)
• ReMeeting.com (Erlangen/ICSI)
– Recording, diarizing, keyword extraction & indexing, collaborative annotation
• Expect Labs/MindMeld– “Overhears” skype-like conversation, continuously display relevant web
content
• Cisco: corporate video management system– Transcription, speaker recognition
• Microsoft– Plugin for MS Office (Lync) product to transcribe online meetings (F. Seide)
– Speech-to-speech translation with Skype
Oct. 6, 2014PROPOR, São Carlos, Brasil 17

Meeting Recognition: In-depth Topics
• Three problems from our own work on meeting
processing
I. How to couple diarization and recognition
II. How to best leverage multi-channel recordings
for recognition
III. How to improve speaker diarization with
trainable feature extractors
• In the NIST evaluation framework
Oct. 6, 2014PROPOR, São Carlos, Brasil 18

I. How to couple diarization and
speech recognition?

Diarization
Reminder: Diarization = the task of
• separating speech from nonspeech, and
• grouping speech coming from the same speaker
• Implicitly estimating the number of speakers
Question:
How important is good diarization for good
transcription?
Oct. 6, 2014PROPOR, São Carlos, Brasil 20

Background
• SRI and ICSI had been working on distant microphone
meeting recognition for many years (since 2002)
• Used a simple acoustic clustering method that is not
optimized for speaker diarization accuracy
• Up until 2009, we had never managed to get a win
from using a “proper” diarization system
• Tranter et al. (2003) found that diarization error is
poorly correlated with WER on broadcast news
Oct. 6, 2014PROPOR, São Carlos, Brasil 21

Data
• Meeting data recorded with table-top microphones
• NIST Rich Transcription 2007 and 2009 evaluation
data sets
• Two conditions:– SDM: single distant microphone
– MDM: multiple distant microphone
Data statistic RT-07 RT-09
No. of meetings 8 7
Average no. of speakers /meeting 4.38 5.43
Maximum no. speakers / meeting 6 11
Total duration 180 min 181 min
Total speech duration 147 min 164 min
Total no. of words 35882 40110
Oct. 6, 2014PROPOR, São Carlos, Brasil 22

Metrics
• STT (speech-to-text) word error rate
• Diarization error rate
• Both WER and DER are scored for different maximum
degrees of speaker overlap– Overlap = 1: only one speaker at a time
– Overlap = 4: up to 4 speakers talking over each other
wordsreference all#
words deleted)insertedincorrect(#WER
framesspeech #
frames label)speaker or speech (incorrect#DER
Oct. 6, 2014PROPOR, São Carlos, Brasil 23

Acoustic Preprocessing
• MDM = multiple distant microphones
1. Per-channel noise reduction with ICSI-Qualcomm Aurora
Wiener filter
2. Delay-sum processing with Xavi Anguera’s BeamformIt 2.0
• SDM = single distant microphone
– Same as MDM, without beamforming
Oct. 6, 2014PROPOR, São Carlos, Brasil 24

ICSI/SRI Meeting Recognition System
• Multi-pass, multi-frontend
• MFCC, PLP, and discriminatively trained MLP features
• Models originally trained on telephone conversation
and broadcast data
• fMPE-MAP/MPE-MAP adapted to about 200 hours of
meetings data
• System assumes speech data is segmented into short
(< 60 second) chunk with small amounts of nonspeech
• Feature normalization and acoustic model adaptation
require pseudo-speaker clusters
• Comparatively excellent performance in RT-07 and
RT-09 evaluations
Oct. 6, 2014PROPOR, São Carlos, Brasil 25
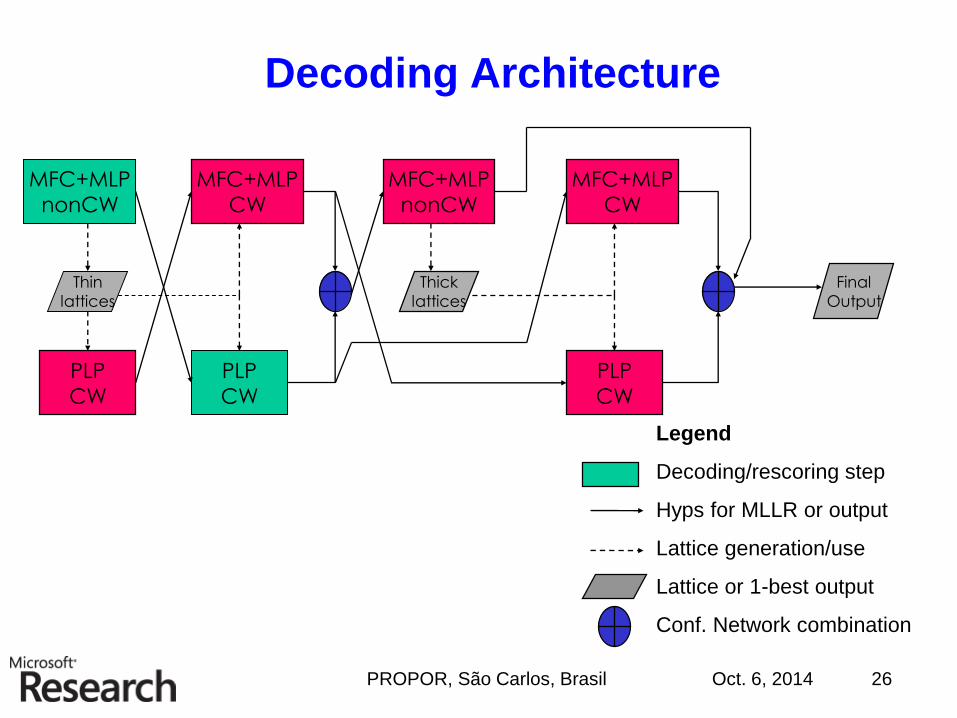
Decoding Architecture
MFC+MLP
nonCW
PLP
CW
PLP
CW
PLP
CW
Final
Output
Legend
Decoding/rescoring step
Hyps for MLLR or output
Lattice generation/use
Lattice or 1-best output
Conf. Network combination
MFC+MLP
CW
MFC+MLP
nonCW
MFC+MLP
CW
Thin
lattices
Thick
lattices
Oct. 6, 2014PROPOR, São Carlos, Brasil 26

Diarization Systems
• ICSI RT-09 diarization system– To be described
• SRI ASR speech segmentation and clustering– To be described
• IIT/NTU Singapore RT-09– Excellent performance, better than ICSI on RT-09 data
• Reference diarization– Derived from NIST reference file
Oct. 6, 2014PROPOR, São Carlos, Brasil 27
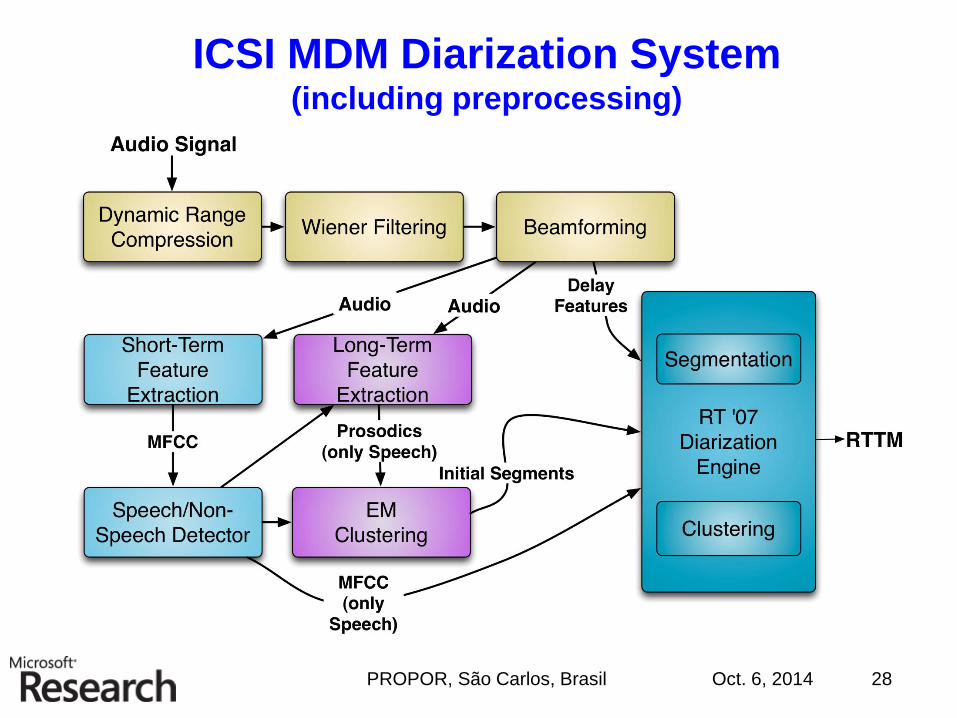
ICSI MDM Diarization System(including preprocessing)
Oct. 6, 2014PROPOR, São Carlos, Brasil 28

ICSI Diarization:
Agglomerative Speaker Clustering
1. Create k random segments
and train k GMMs with g
Gaussians each
2. Assign frames to clusters
according to likelihoods
3. Use Bayes information
criterion (BIC) to determine if
two clusters should be
merged
Oct. 6, 2014PROPOR, São Carlos, Brasil 29

SRI (Baseline) Diarization System
• Not really a diarization system (optimized for ASR only)
• Segmentation: speech/nonspeech HMM with
minimum/maximum duration constraints and
nonspeech padding
• Clustering– Train GMM for all frames of a meeting
– Represent each speech segment by a mixture weight vector
– Compute information loss for each potential merging step
– Merge clusters until a fixed number of cluster is reached
• Earlier evaluations showed that 4 clusters work best– Close to the average number of speakers in older data
Oct. 6, 2014PROPOR, São Carlos, Brasil 30

Diarization-based STT
• Speech segments are merged, padded, and filtered– Merge segments by same speaker, separated by less than 0.4s nonspeech
– Add 0.2s nonspeech around each segment
– Remaining segments shorter than 0.2 s are discarded
• This is the most critical process for good ASR (also
found by Tranter et al. 2003)
• Parameters tuned on eval06 MDM, for ICSI diarization
• Results with overlap=1
• Modest gains from clustering, but not from segmentation
eval06
MDM
eval06
SDM
eval07
MDM
eval07
SDM
Baseline (seg + cluster) 30.3 40.6 26.2 33.1
Diarization seg + base clustering 29.5 40.8 26.4 33.1
Diarization (seg + clustering) 29.3 39.3 25.9 32.5
Oct. 6, 2014PROPOR, São Carlos, Brasil 31
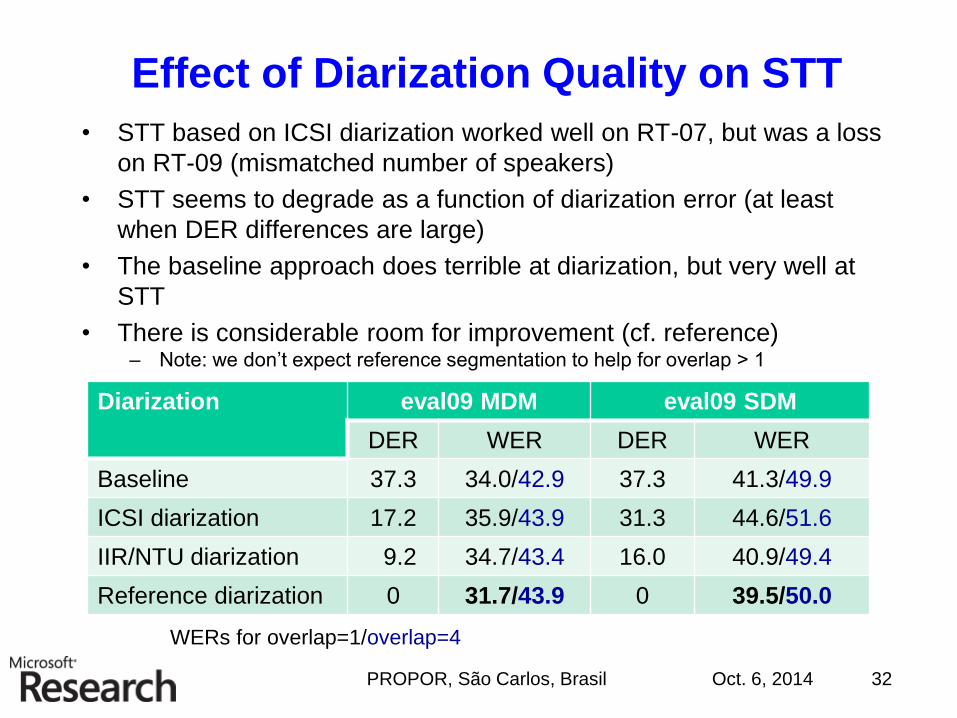
Effect of Diarization Quality on STT
• STT based on ICSI diarization worked well on RT-07, but was a loss
on RT-09 (mismatched number of speakers)
• STT seems to degrade as a function of diarization error (at least
when DER differences are large)
• The baseline approach does terrible at diarization, but very well at
STT
• There is considerable room for improvement (cf. reference)– Note: we don’t expect reference segmentation to help for overlap > 1
Diarization eval09 MDM eval09 SDM
DER WER DER WER
Baseline 37.3 34.0/42.9 37.3 41.3/49.9
ICSI diarization 17.2 35.9/43.9 31.3 44.6/51.6
IIR/NTU diarization 9.2 34.7/43.4 16.0 40.9/49.4
Reference diarization 0 31.7/43.9 0 39.5/50.0
WERs for overlap=1/overlap=4
Oct. 6, 2014PROPOR, São Carlos, Brasil 32

Combining Multiple Diarizations
• Inspired by– Cambridge BN STT: combine subsystems using different segmentations
– SRI/ICSI meeting STT: combine systems using different spkr clusterings
• Here: combine baseline and diarization-based systems
• Simple approach: NIST ROVER on 1-best outputs (Fiscus 1997)
– Voting based on word confidences
– Works even though input systems use different segmentations
• Better approach: Confusion network combination Stolcke et al. 2000, Everman & Woodland 2000
Oct. 6, 2014PROPOR, São Carlos, Brasil 33

Confusion Network Combination (CNC)
• Aligns multiple alternative
word hypothesis from each
system
• Picks words by highest
combined posterior
probability
• Cannot be applied directly to
incompatible waveform
segmentations
• Cannot be applied to whole-
meeting confusion networks
(O(n2) run time)
Oct. 6, 2014PROPOR, São Carlos, Brasil 34
+
=

Confusion Network Combination for
Heterogeneous Segmentations
• Solution: resegment hypotheses at nonspeech regions agreed upon by all systems
1. Consensus segmentation:Seg A ____ _____ __ ____ ___ ___ ___ __________
Seg B ___ _____ ______ ______ ________ ___ _____
Consensus ___________ _________________ ____________________
2. Concatenate old CNs within each new segment
3. Perform CNC within each consensus segment
Diarization System RT07 MDM RT07 SDM RT09 MDM RT09 SDM
Baseline 26.2/40.5 33.1/45.2 34.0/42.9 41.3/49.9
ROVER(base + ICSI) 25.0/37.5 31.9/43.8 34.2/43.8 42.2/51.1
CNC(base + ICSI) 24.9/37.4 31.3/43.6 33.3/43.0 40.8/50.1
Results for overlap=1/overlap=4
Oct. 6, 2014PROPOR, São Carlos, Brasil 35

Combining Diarizations: More Results
• Confusion-network based STT combination fairly
robust to degradation in diarization accuracy
• Best gain (combining best diarization with baseline):
1.1% to 1.4% absolute lower error
Segmentation /
clustering
RT09 MDM RT09 SDM
WER WER
Baseline 34.0/42.9 41.3/49.9
ICSI diarization 35.9/43.9 44.6/51.6
+ baseline system 33.3/43.0 40.8/50.1
IIR/NTU diarization 34.7/43.4 40.9/49.4
+ baseline system 32.7/41.5 40.0/48.8
WERs for overlap=1/overlap=4
Oct. 6, 2014PROPOR, São Carlos, Brasil 36

So, Does STT need Diarization?
Yes, but …• The requirements for STT are not expressed well by DER.
A simple segmentation and clustering, with terrible DER
(our baseline) does well for STT, and is robust.
• Even the best diarization systems can be fragile, and if run
on mismatched data, they might hurt your speech
recognizer
• The problem can be mitigated (or additional gains
achieved) by combining multiple segmentations for
recognition, using a confusion network-based method that
combines outputs with differing segmentations.
Oct. 6, 2014PROPOR, São Carlos, Brasil 37

II. How to make best use of multiple
(distant) microphones for recognition?

Audio 1
Audio 2
Audio 3
ASR 1
ASR 2
ASR 3
Hypothesis 1
Hypothesis 2
Hypothesis 3
Final hypothesis
CNC
Audio 1
Audio 2
Audio 3
Final hypothesisASRCombined
audio
Beamfor
ming
Two Approaches
• Multiple recognition and hypothesis combination
• Signal combination by blind beamforming
Oct. 6, 2014PROPOR, São Carlos, Brasil 39

MDM System Design Questions
• Which approach gives better accuracy?
• By how much?
• Which approach scales better on processing time?
• Prior work: Wölfel (U. Karlsruhe)– Papers comparing both approaches, suggesting variants (like speeding up
multiple recognition by selecting a subset of “good” channels)
– Concluded that parallel processing gives better accuracy
– That’s what UKA did in their RT meeting recognition systems
• Revisit the question because– Their comparison study used lecture meetings only
– Word error rates overall were very high (~ 50%)
– Report gains from beamforming were lower than seen in our systems
Oct. 6, 2014PROPOR, São Carlos, Brasil 40

Data• Meeting data recorded with table-top microphones
• NIST Rich Transcription 2007 and 2009 eval data
• Two genres: lectures and conference meetings
• Two conditions:– SDM: single distant microphone (for comparison only)
– MDM: multiple distant microphones
Data statistic RT-07 RT-07 RT-09
Meeting genre Lecture Conference
No. of meetings 32 8 7
Average no. of speakers /meeting 4.41 4.38 5.43
No. of mics / meeting 3-4 3-16 7-16
Total duration 164 min 180 min 181 min
Total speech duration 138 min 156 min 162 min
Total no. of words 25239 36800 36734
Oct. 6, 2014PROPOR, São Carlos, Brasil 41

Recap: Metric, Conditions, ASR System
• Metric– WER
– Versions for 1 simultaneous speaker, up to 4 overlapping speakers.
• Test conditions– MDM:
• noise-suppression with Wiener filter,
• followed by blind beamforming (BF)
– SDM: Wiener filtering, 1 microphone only
• Recognition system– ICSI/SRI multipass system
Oct. 6, 2014PROPOR, São Carlos, Brasil 42

Processing Times
• Wiener filtering: 0.03 xRT (single core)
• Beamforming: 0.01 xRT (single core)
• Segmentation, clustering, and recognition:
3.8 x RT (8 cores)
(measured on Intel 3.1GHz CPU, 2007 vintage)
Oct. 6, 2014PROPOR, São Carlos, Brasil 43

Experiments
• Compare beamforming and parallel recognition on both
lecture and conference meetings
• Three simplifications– Limit number of input channels to 4 (to keep parallel recognition times
reasonable)
– All system use the same waveform segmentation, obtained from beamforming
output: This favors the multiple recognition system
– All systems use the same acoustic models, trained from all single-channel
recordings, without beamforming: This should also favor the multiple
recognition system, but many years ago we found that recognition on
beamformed signals also benefits!
• Also try multiple recognition with BF channel added as
extra input (suggested by Wölfel)
Oct. 6, 2014PROPOR, São Carlos, Brasil 44

Results
• Both BF and MR give substantial gains over SDM
• MR gives typically less than half as much gain as BF
• Adding BF channel to MR helps, but not very much,
and not always (loss on RT-07 conf)
• BF is better choice, esp. considering processing time
WERs for overlap=1/overlap=4
RT-07
Lecture
RT-07
Conference
RT-09
Conference
Single mic (SDM) 50.6 54.5 33.1 45.2 41.3 49.9
BF, ≤ 4 mics 44.6 49.1 28.1 40.8 37.2 45.5
MR, ≤ 4 mics 47.9 52.5 31.6 45.7 39.7 49.6
BF + MR, ≤ 4 mics 44.0 48.8 28.2 41.5 36.8 45.9
BF, all mics (MDM) 44.6 49.1 26.5 39.3 33.6 42.7
Oct. 6, 2014PROPOR, São Carlos, Brasil 45

Final hypothesis
Audio 1
Audio 2
Audio 3
ASR 1
ASR 2
ASR 3
Hypothesis 1
Hypothesis 2
Hypothesis 3
CNC
Beamfor
ming
Leave-one-out Beamforming Combination
• Better combining signal- and hypothesis fusion
• Leave-one-out beamforming, followed by parallel
recognition and hypothesis combination
• Leave-one-out BF preserves diversity of recognition
ouputs to be combined later
• BF processing is fast, can afford to do it many times
• We can also add all-mic BF signal into final CNC
Oct. 6, 2014PROPOR, São Carlos, Brasil 46

More Results
• LOO-BF improves on both BF and BF + MR– One exception (RT-07 conf, overlap 4)
• Adding all-mic BF channel to LOO-BF helps a little,
consistently
• Also tried doing cross-adaptation between multiple
recognition paths: no gains
WERs for overlap=1/overlap=4
RT-07
Lecture
RT-07
Conference
RT-09
Conference
BF, ≤ 4 mics 44.6 49.1 28.1 40.8 37.2 45.5
BF + MR, ≤ 4 mics 44.0 48.8 28.2 41.5 36.8 45.9
LOO-BF, ≤ 4 mics 42.8 47.9 28.1 41.5 36.4 45.4
BF + LOO-BF, ≤ 4 mic 42.7 47.7 27.5 40.8 36.2 45.2
Oct. 6, 2014PROPOR, São Carlos, Brasil 47

Conclusions for Multi-mic Processing
• Between multiple recognition and
beamforming approach, BF is clearly better
(better accuracy, faster processing)
• Consistent results on lectures and conference
meetings, at different WER levels (20% - 50%)
• Improved results with a new variant of both
approaches: multiple recognition based on
leave-one-out beamforming
Oct. 6, 2014PROPOR, São Carlos, Brasil 48

III. Diarization with trainable feature
extractors

Diarization with HMM/GMM
• Speech/nonspeech are separated first (VAD)
• Each speaker is modeled as an HMM state
with minimum duration
• Emission probability distribution of a state is
modeled by GMM (speaker model)
• Initialized with uniform linear segmentation
• A modified version of Bayesian Information
Criterion (BIC) is used as both distance
measure and stopping criterion
• Iterative model estimation and realignment
Oct. 6, 2014PROPOR, São Carlos, Brasil 50

Diarization with HMM/GMM, cont.
• Modified BIC criterion– Number of parameters is held constant, so BIC complexity term cancels out
– BIC(Ci , Cj ) = L(Ci+j | Mi+j ) − [ L(Ci | Mi ) + L(Cj | Mj ) ]
– L(.) = data likelihood
• Clusters with highest value of BIC are merged
• Clustering stops when BIC(Ci , Cj ) < 0 for all i, j
• Block diagram of the system
Oct. 6, 2014PROPOR, São Carlos, Brasil 51

Problems with Standard Diarization
• Typical features: 19-dim MFCC every 10 ms
• Acoustic features are affected by lots of variability not
associated with speaker identity– Background noise, room acoustics
– Movement of speakers
– What is being said
• The system can only be tuned by adjusting meta-
parameters, there is no training or adaptation!
• Idea: Use neural nets to learn features for this task
Oct. 6, 2014PROPOR, São Carlos, Brasil 52

ANNs for Diarization Feature Extraction
• Learn a transform that projects the acoustic features
into a speaker discriminant space
• Network trained to predict if two given speech
segments belong to same or different speakers
• Classifier bottleneck (BKC) architecture
Oct. 6, 2014PROPOR, São Carlos, Brasil 53
Tied matrices
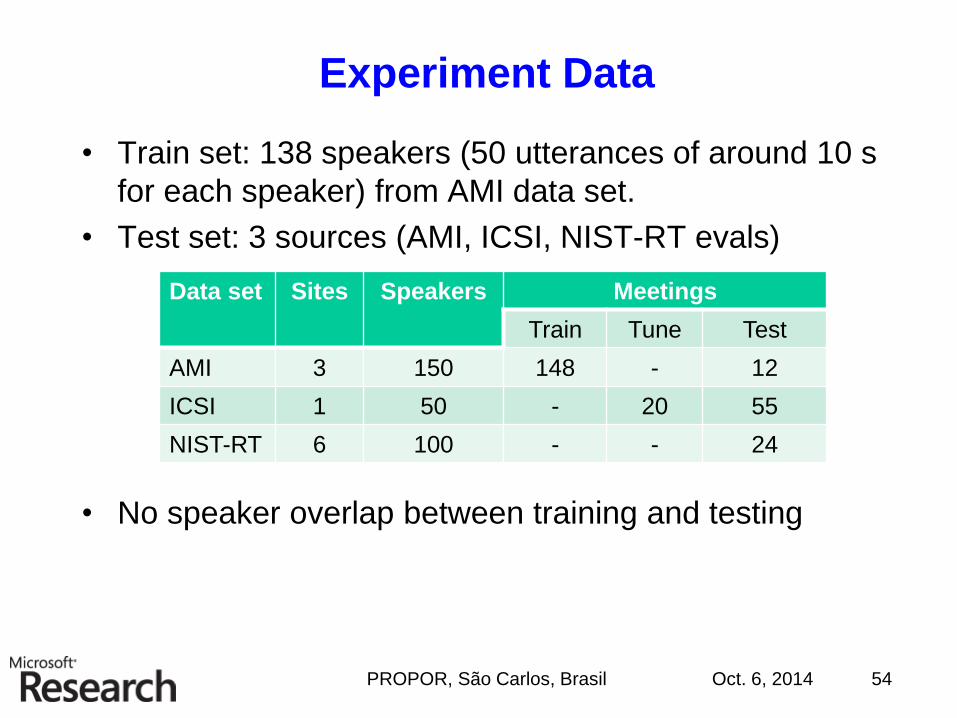
Experiment Data
• Train set: 138 speakers (50 utterances of around 10 s
for each speaker) from AMI data set.
• Test set: 3 sources (AMI, ICSI, NIST-RT evals)
• No speaker overlap between training and testing
Oct. 6, 2014PROPOR, São Carlos, Brasil 54
Data set Sites Speakers Meetings
Train Tune Test
AMI 3 150 148 - 12
ICSI 1 50 - 20 55
NIST-RT 6 100 - - 24

Results
• Speech/nonspeech segmentation was obtained from
ground-truth segmentation
ANN + MFCC combines likelihoods with weights (0.1,0.9)
(tuned on ICSI heldout data)
Oct. 6, 2014PROPOR, São Carlos, Brasil 55
Dataset MFCC ANN ANN + MFCC
AMI 25.1 32.0 21.5
ICSI 20.6 25.8 18.4
RT-06 14.1 32.5 13.9
RT-07 11.3 25.3 11.8
RT-09 16.8 25.9 18.7

Effect of Corpus Mismatch
• RT datasets are very heterogeneous
• What if we can obtain training data from a source
similar to test data?
Oct. 6, 2014PROPOR, São Carlos, Brasil 56
Train Test MFCC ANN+MFCC Rel.
change
AMI AMI 25.1 21.5 -14.3%
AMI ICSI 20.6 18.4 -10.7%
ICSI ICSI 20.6 15.1 -26.7%

Conclusions
• Trainable feature extraction with ANNs gives
substantial gains on matched data
• Key is to devise ANN architecture that classifies
speech samples as same/different speakers
• Approach makes clustering-based diarization systems
adaptable (including to known speakers)
• Further work is needed to tune metaparameters and
explore other ANN architectures
Oct. 6, 2014PROPOR, São Carlos, Brasil 57

Open Problems
• Recognition of overlapping speech
• Diarization of overlapping speech– Some IDIAP/ICSI work on detecting overlap, then using heuristics
• Distant microphones are still a challenge– 2x WER compared to close microphones
• Combine signal combination and acoustic modeling?– some recent work using DNN models
• Can we combine diarization and recognition?
• Data in large quantities lacking– E.g., for exploring some of the modern DNN-based methods
• “Transcription” of non-textual content of meetings?– Power dynamics, sentiments towards people and issues
Oct. 6, 2014PROPOR, São Carlos, Brasil 58

A Guess at the Future
• Meeting processing is taking off– .. but then we thought that 10 years ago..
• We will see meetings turned into textual documents on
a routine basis– Software will allow you to find meetings that are relevant to you that you
missed
• We will see Siri and Cortana-type agents in meetings– No more minutes-taking by humans
Oct. 6, 2014PROPOR, São Carlos, Brasil 59

References
• N. Morgan et al., The meeting project at ICSI, Proc. HLT, 2001
• AMI Project, www.amiproject.org
• G. Tur et al., The CALO Meeting Assistant System, IEEE Trans.
Audio Speech Lang. Proc. 18(6), 2010.
• J. G. Fiscus et al., The Rich Transcription 2007 Meeting
Recognition Evaluation, in R. Stiefelhagen et al. (eds), Multimodal
Technologies for Perception of Humans, Springer, 2008.
• A. Stolcke, G. Friedland, D. Imseng, Leveraging Speaker
Diarization for Meeting Recognition from Distant Microphones,
Proc. IEEE ICASSP, 2010
• A. Stolcke, Making the Most out of Multiple Microphones in
Meeting Recognition, Proc. IEEE ICASSP, 2011
• S. H. Yella, A. Stolcke, M. Slaney, Artificial Neural Network
Features for Speaker Diarization, to appear in Proc. IEEE SLT
Workshop, 2014
Oct. 6, 2014PROPOR, São Carlos, Brasil 60

Thank You!
Collaborators and coauthors:
Xavi Anguera, Gerald Friedland, Dilek Hakkani-Tür,
David Imseng, Elizabeth Shriberg, Malcolm Slaney,
Frank Seide, Gokhan Tür, Sree Yella
ICSI Speech Group
SRI STAR Lab