mass-storage systemscs325/spring2013/lec17-massstorage.pdf · – break disk into groups of...
TRANSCRIPT

CSE325 Principles of Operating Systems
Mass-Storage Systems
David P. Duggan [email protected]
March 26, 2013

Reading Assignment 11 • Chapters 14 & 15, Protection & Security, due 4/9
3/26/13 CSE325 - Storage 2

3/26/13 CSE325 - Storage 3
Outline • Storage Devices • Disk Scheduling
– FCFS – SSTF – SCAN, C-SCAN – LOOK, C-LOOK
• Redundant Arrays of Inexpensive Disks – RAID 0 - 6

4
Devices: Magnetic Disks • Purpose
– Long-term, nonvolatile storage – Large, inexpensive, slow level in
the storage hierarchy
• Characteristics – Seek Time
• positional latency • rotational latency
• Rotational rate – 60 to 200 times per second
• Capacity – Terabytes – Quadruples every 3 years

3/26/13 5
Moving-head Disk Mechanism

3/26/13 CSE325 - Storage 6
Disk Structure
• Disk drives are addressed as large 1-dimensional arrays of logical blocks, where the logical block is the smallest unit of transfer.
• The 1-dimensional array of logical blocks is mapped into the sectors of the disk sequentially. – Sector 0 is the first sector of the first track on the
outermost cylinder. – Mapping proceeds in order through that track, then the
rest of the tracks in that cylinder, and then through the rest of the cylinders from outermost to innermost.

Magnetic Tapes • Much slower than magnetic disk in positioning • Comparable speeds when reading and writing • Capacity from 20GB to 200GB • Long term storage
3/26/13 CSE325 - Storage 7

3/26/13 8
Network-Attached Storage • Network-attached storage (NAS) is storage made available over
a network rather than over a local connection (such as a bus) • NFS and CIFS are common protocols • Implemented via remote procedure calls (RPCs) between host
and storage • iSCSI protocol uses IP network to carry the SCSI protocol
Performance problems?
3/26/13 CSE325 - Storage 9
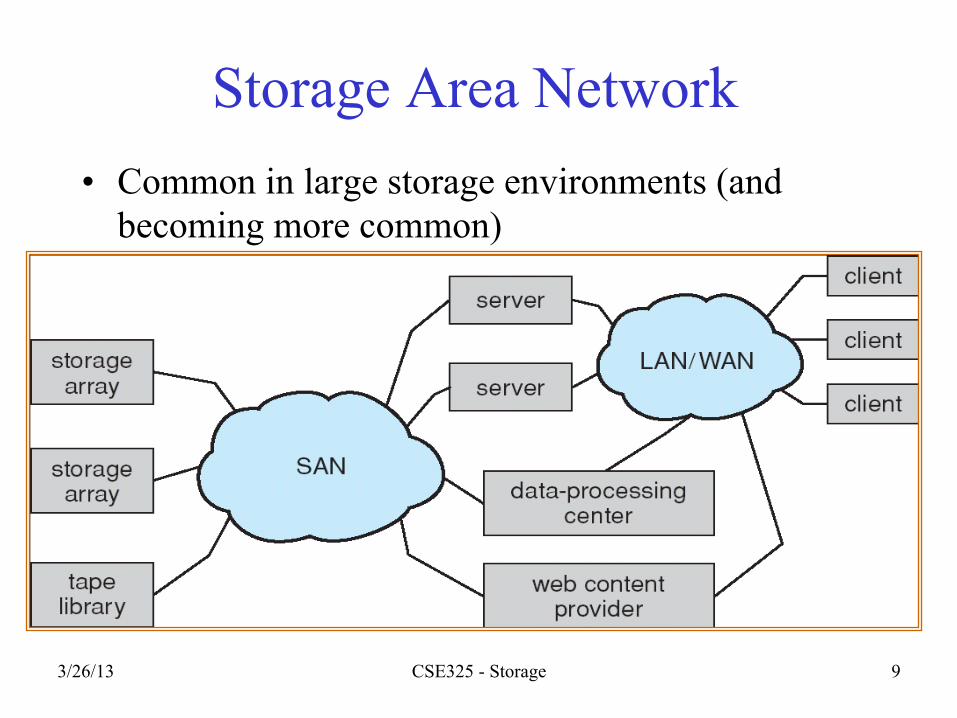
Storage Area Network • Common in large storage environments (and
becoming more common) • Multiple hosts attached to multiple storage arrays -
flexible

3/26/13 CSE325 - Storage 10
Disk Scheduling • The operating system is responsible for using hardware
efficiently — for the disk drives, this means having a fast access time and disk bandwidth.
• Access time has two major components – Seek time is the time for the disk to move the heads to the cylinder
containing the desired sector. – Rotational latency is the additional time waiting for the disk to rotate
the desired sector to the disk head.
• Minimize seek time • Seek time ≈ seek distance • Disk bandwidth is the total number of bytes transferred,
divided by the total time between the first request for service and the completion of the last transfer.

3/26/13 CSE325 - Storage 11
Disk Scheduling (Cont.) • Several algorithms exist to schedule the servicing
of disk I/O requests. • We illustrate them with a request queue (0-199).
98, 183, 37, 122, 14, 124, 65, 67
Head pointer 53
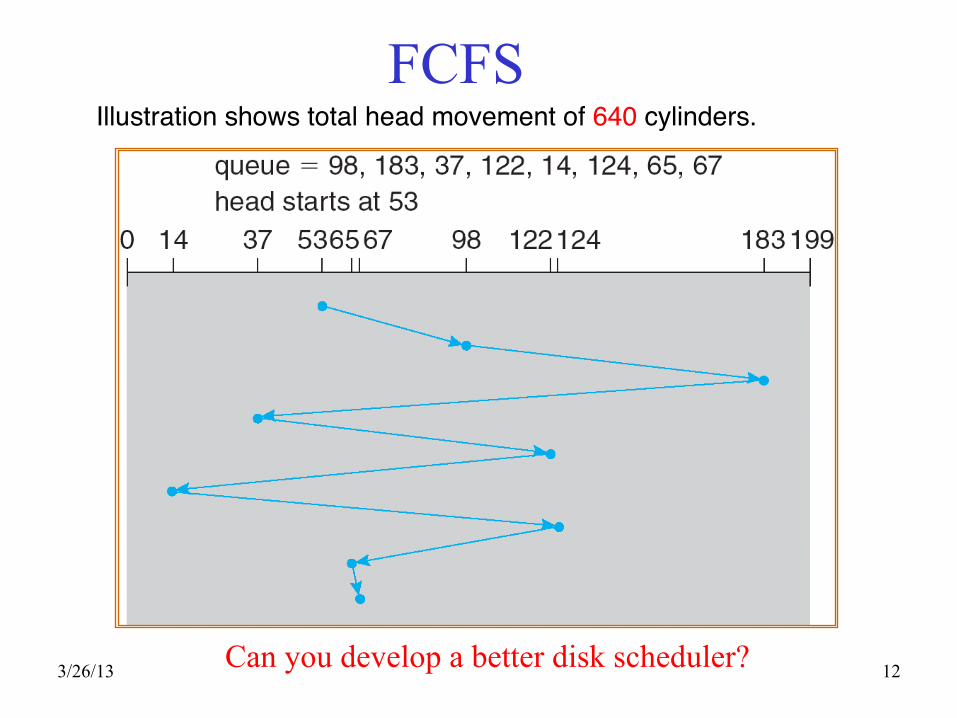
3/26/13 12
FCFS Illustration shows total head movement of 640 cylinders."
Can you develop a better disk scheduler?

3/26/13 13
SSTF
Can you further improve the performance?
• Selects the request with the minimum seek time from the current head position.
• SSTF scheduling is a form of SJF scheduling; may cause starvation of some requests.

3/26/13 CSE325 - Storage 14
SCAN • The disk arm starts at one end of the disk, and
moves toward the other end, servicing requests until it gets to the other end of the disk, where the head movement is reversed and servicing continues.
• Sometimes called the elevator algorithm.

3/26/13 CSE325 - Storage 15
SCAN (Cont.)
Head movement of 236 cylinders.

3/26/13 CSE325 - Storage 16
C-SCAN • Provides a more uniform wait time than SCAN. • The head moves from one end of the disk to the
other, servicing requests as it goes. When it reaches the other end, however, it immediately returns to the beginning of the disk, without servicing any requests on the return trip.
• Treats the cylinders as a circular list that wraps around from the last cylinder to the first one.

3/26/13 CSE325 - Storage 17
C-SCAN (Cont.)
Is there a problem here?

3/26/13 CSE325 - Storage 18
C-LOOK • Version of C-SCAN • Arm only goes as far as the last request in each
direction, then reverses direction immediately, without first going all the way to the end of the disk.
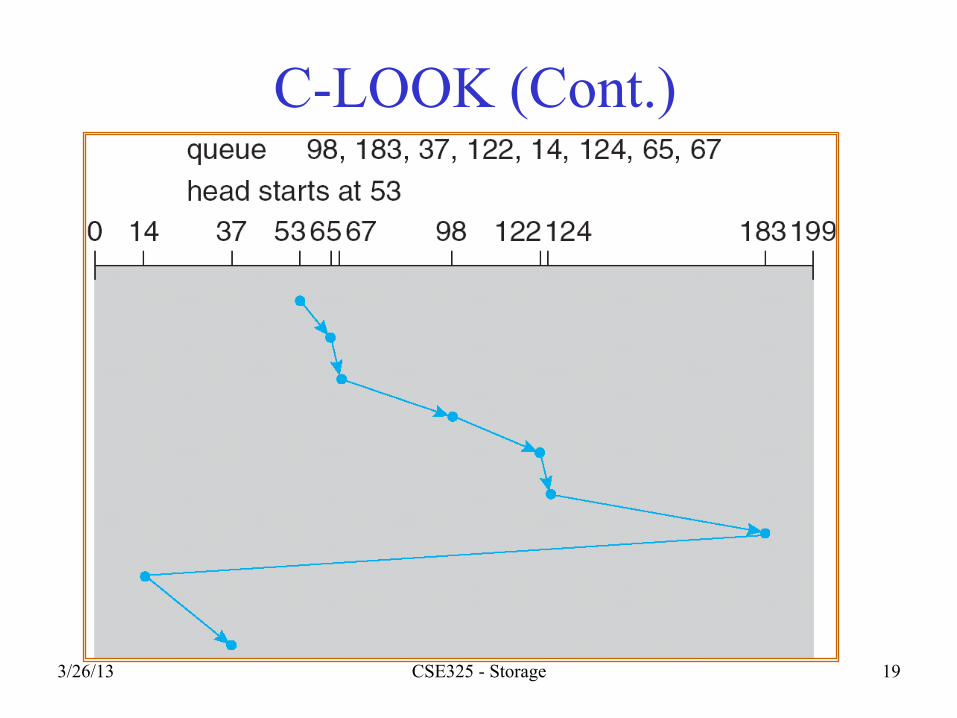
3/26/13 CSE325 - Storage 19
C-LOOK (Cont.)

3/26/13 CSE325 - Storage 20
Selecting a Disk-Scheduling Algorithm • SSTF is common and has a natural appeal • SCAN and C-SCAN perform better for systems that place
a heavy load on the disk. • Performance depends on the number and types of requests. • Requests for disk service can be influenced by the file-
allocation method. • The disk-scheduling algorithm should be written as a
separate module of the operating system, allowing it to be replaced with a different algorithm if necessary.
• Either SSTF or C-LOOK is a reasonable choice for the default algorithm.

Disk Management • Disk initialization • Booting from disk • Bad blocks
3/26/13 CSE325 - Storage 21

Disk Initialization • Formatting
– Low-level or physical – Usually done at factory now – Sectors contain ECC for fixing errors
• Partitioning – Break disk into groups of cylinders (logical disks)
• Formatting – Creating filesystem
3/26/13 CSE325 - Storage 22

Booting from Disk • Boot block
– Bootstrap code finds and loads OS kernel – Uses boot partition
• Boot sequence/process – Read Master-Boot-Record – Located in first sector on bootable disk – Directs load to come from first sector of boot partition
3/26/13 CSE325 - Storage 23

Bad Blocks • Disks can fail!
– Poor manufacturing – Tight tolerances – Plain old use
• Sector sparing – Spare sectors used when OS or disk finds bad blocks – Could invalidate efficiencies OS has made
• Sector slipping – Slide sectors down to first free spare sector
3/26/13 CSE325 - Storage 24

Swap Space Management • Use
– Overestimate rather than underestimate – Separate disks can spread out I/O load
• Location – In filesystem – Separate partition
• Decisions – When to use swap space?
3/26/13 CSE325 - Storage 25

3/26/13 CSE325 - Storage 26
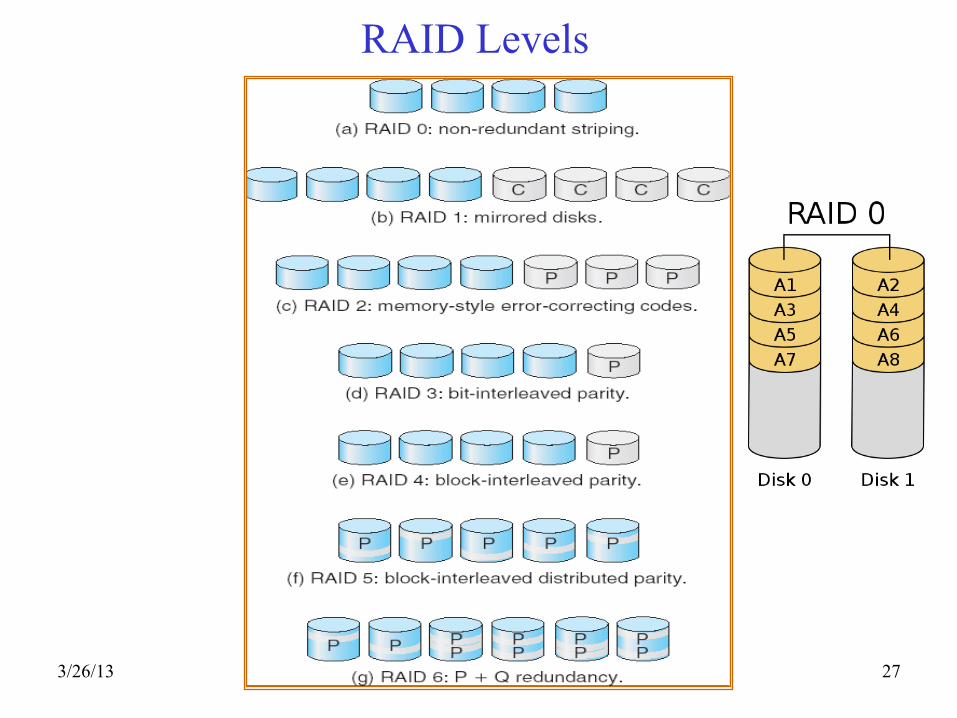
Redundant Arrays of (Inexpensive) Disks
• Files are "striped" across multiple disks • Redundancy yields high data availability
– Availability: service still provided to user, even if some components failed
• Disks will still fail • Contents reconstructed from data redundantly
stored in the array ⇒ Capacity penalty to store redundant info ⇒ Bandwidth penalty to update redundant info
3/26/13 CSE325 - Storage 27
RAID Levels

3/26/13 28
Redundant Arrays of Inexpensive Disks RAID 1: Disk Mirroring/Shadowing
• Each disk is fully duplicated onto its “mirror” Very high availability can be achieved • Bandwidth sacrifice on write: Logical write = two physical writes
• Reads may be optimized (How?) • Most expensive solution: 100% capacity overhead • RAID 2: Disks are synchronized and striped in single bytes/words; Hamming code parity.
recovery!group!

29
RAID 3: Bit-Interleaved Parity Organization Parity Disk
P!
10010011!11001101!10010011!
. . .!logical record!
Byte-level striping P contains sum of other disks per stripe mod 2 (“parity”) If disk fails, subtract P from sum of other disks to find missing information
Bit Interleaved Parity

3/26/13 CSE325 - Storage 30
RAID 3 • Sum computed across recovery group to protect
against hard disk failures, stored in P disk • Logically, a single high capacity, high transfer rate
disk: good for large transfers • 33% capacity cost for parity if 3 data disks and 1
parity disk • Wider arrays reduce capacity costs, but decreases
availability

3/26/13 CSE325 - Storage 31
Inspiration for RAID 4 • Allows independent reads to different disks
simultaneously • Block-level parity with parity on a separate
disk from all data blocks • Can add new disks by initializing data to 0

32
RAID 4 Block-Interleaved Parity Organization High I/O Rate Parity
D0! D1! D2! D3! P!
D4! D5! D6! P!D7!
D8! D9! P!D10! D11!
D12! P!D13! D14! D15!
P!D16! D17! D18! D19!
D20! D21! D22! D23! P!.!.!.!
.!
.!
.!
.!
.!
.!
.!
.!
.!
.!
.!
.!Disk Columns!
Increasing"Logical"
Disk "Address"
Stripe!
Insides of 5 disks!
Example:!small read D0 & D5, large write D12-D15!
Block Interleaved Parity

3/26/13 33
Inspiration for RAID 5 • RAID 4 works well for large reads • Small writes (write to one disk):
– Option 1: read other data disks, create new sum and write to Parity Disk
– Option 2: since P has old sum, compare old data to new data, add the difference to P
• Small writes are limited by Parity Disk: Write to D0, D5 both also write to P disk
D0! D1! D2! D3! P!
D4! D5! D6! P!D7!

34
RAID 5: Block-Interleaved Distributed Parity High I/O Rate Interleaved Parity
Independent writes!possible because of!interleaved parity!
D0! D1! D2! D3! P!
D4! D5! D6! P! D7!
D8! D9! P! D10! D11!
D12! P! D13! D14! D15!
P! D16! D17! D18! D19!
D20! D21! D22! D23! P!.!.!.!
.!
.!
.!
.!
.!
.!
.!
.!
.!
.!
.!
.!Disk Columns!
Increasing!Logical!
Disk !Addresses!
Example: write to D0, D5 uses disks 0, 1, 3, 4!
35
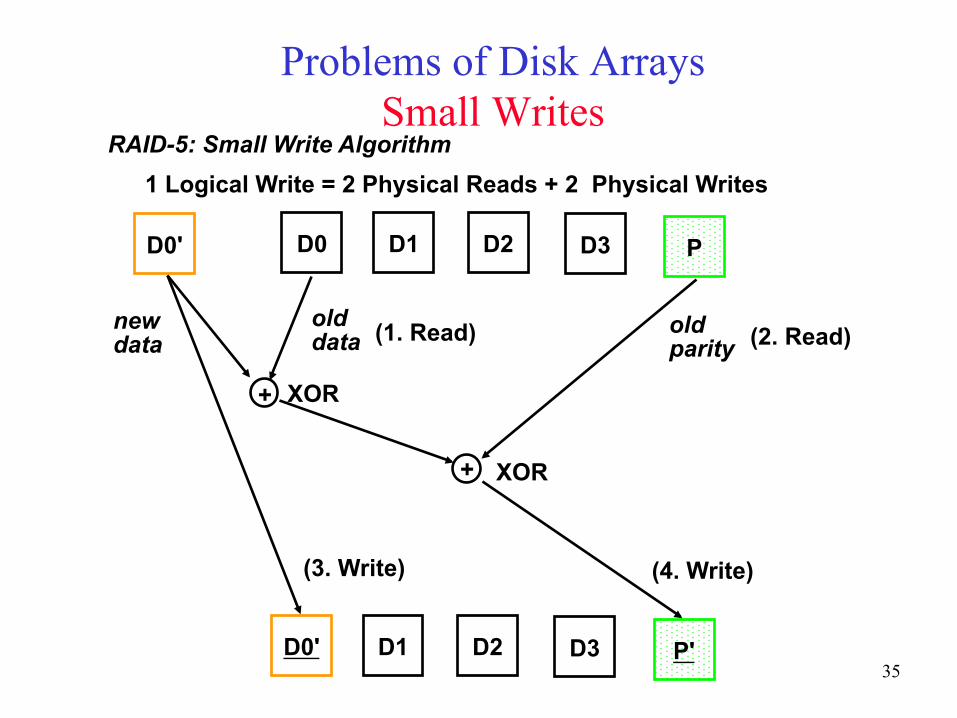
Problems of Disk Arrays Small Writes
D0 D1 D2 D3 P D0'
+
+
D0' D1 D2 D3 P'
new data
old data
old parity
XOR
XOR
(1. Read) (2. Read)
(3. Write) (4. Write)
RAID-5: Small Write Algorithm 1 Logical Write = 2 Physical Reads + 2 Physical Writes

3/26/13 CSE325 - Storage 36
RAID Levels

3/26/13 CSE325 - Storage 37
RAID (0 + 1) and (1 + 0)

3/26/13 CSE325 - Storage 38
Operating System Issues • Major OS jobs are to manage physical devices and
to present a virtual machine abstraction to applications
• For hard disks, the OS provides two abstraction: – Raw device – an array of data blocks. – File system – the OS queues and schedules the
interleaved requests from several applications.