mapreduce simplified data processing on large clusters google, inc. presented by prasad raghavendra
Post on 21-Dec-2015
220 views
TRANSCRIPT

MapReduce
Simplified Data Processing on Large Clusters Google, Inc.
Presented by Prasad Raghavendra

Introduction
Model for processing large data sets. Contains Map and Reduce functions. Runs on a large cluster of machines. A lot of MapReduce programs are executed on
Google’s cluster everyday.

Motivation
Very large data sets need to be processed. - The whole Web, billions of Pages
Lots of machines - Use them efficiently.

Processing of Large Data Sets
For example:
- Counting access frequency to URLs:
Input: list(RequestURL)
Output: list(RequestURL, total_number)
- Distributed Grep
- Distributed Sort

Programming model
Input & Output: each a set of key/value pairs Programmer specifies two functions:
map (in_key, in_value) -> list(out_key, intermediate_value) Name comes from map function in LISPEx. (map 'list #’+ '(1 2 3) '(1 2 3)) => (2 4 6)
-Processes input key/value pair
-Produces set of intermediate pairs map(document, content) {for each word in contentemit(word, “1”)}

reduce (out_key, list(intermediate_value)) -> list(out_value)
Name comes from reduce function in LISPEx. (reduce #’+ '(1 2 3 4 5)) => 15
- Combines all intermediate values for a particular key - Produces a set of merged output values (usually just one)
reduce(word, values) {result = 0;for each value in valuesresult += valueemitString(w, result)}

Example
The problem of counting the number of occurrences of each word in a large collection ofdocuments.
Page 1: the weather is good Page 2: today is good Page 3: good weather is good

Map output
Worker 1:
(the 1), (weather 1), (is 1), (good 1). Worker 2:
(today 1), (is 1), (good 1). Worker 3:
(good 1), (weather 1), (is 1), (good 1).

Reduce Input
Worker 1:(the 1) Worker 2: (is 1), (is 1), (is 1) Worker 3:(weather 1), (weather 1) Worker 4:(today 1) Worker 5:(good 1),(good 1), (good 1),
(good 1)

Reduce Output
Worker 1: (the 1) Worker 2: (is 3) Worker 3: (weather 2) Worker 4: (today 1) Worker 5: (good 4)
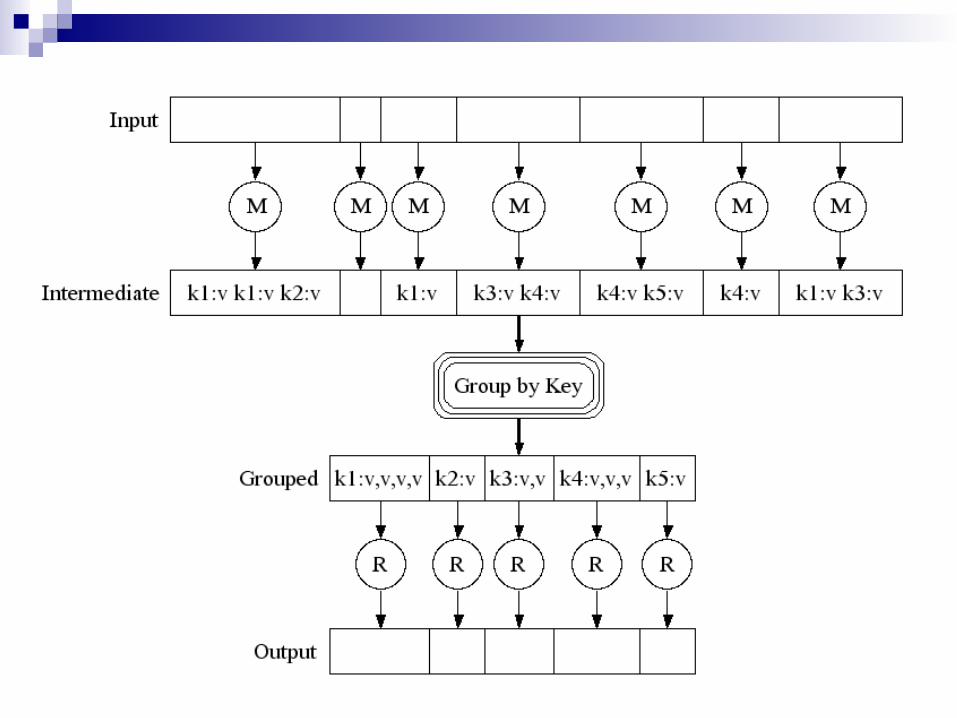

Example 2

Implementation
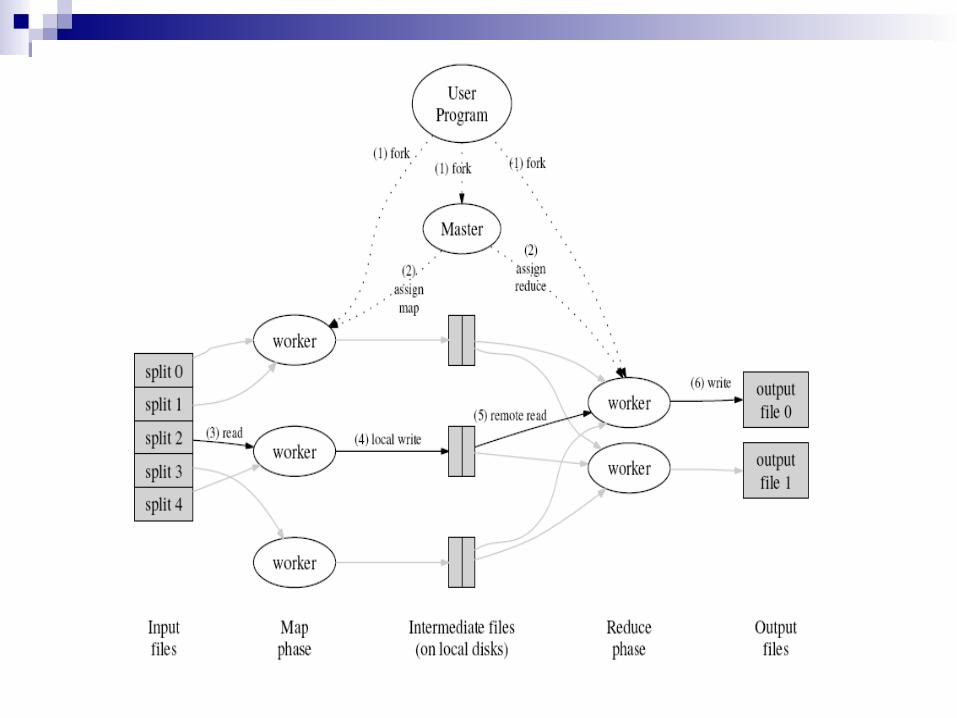

Flow of MapReduce Operation The MapReduce library in the user program splits the input files into M
pieces(16,64 MB).
One of the copies of the program is special . The master. The rest are workers .
A worker who is assigned a map task parses key/value pairs out of the input data.
Periodically, the buffered pairs are written to local disk.
When a reduce worker is notified by the master about these locations, it uses remote procedure calls to read the buffered data.
The output of the Reduce function is appended to a final output file.
When all map tasks and reduce tasks have been completed, the master wakes up the user program.

Problem: Stragglers
Often some machines are late in their replies - slow disk, overloaded, etc Approach: - when only few tasks left to execute, start backup tasks - a task completes when either primary or backup completes task Performance: - without backup, sort (->) takes 44% longer

Partition Function
Defines which worker processes which keys - default: hash(key2) mod R Other partition functions useful: - sort: prefix of k bytes of line - idea: based on known/sampled distribution of key2 to evenly distribute processed keys

Combiner Function
Problem: intermediate results can be quite verbose e.g., (“the”, 1) could occur many times in previous example
Approach: perform a local reduction before writing intermediate results typically, combiner same function as reduce func This will reduce the run-time because less writing to disk and across the network

Performance
Scan 10^10 100-byte records to extract records matching a rare pattern (92K matching records) : 150 seconds.
Sort 10^10 100-byte records (modeled after TeraSort benchmark) : normal 839 seconds.

Fault Tolerance
Crash of worker all - even finished - tasks are redone Crash of leader crash of leader process -> restart process with checkpoint crash of leader machine-> unlikely - restart computation redo computation

Conclusion
MapReduce has proven to be a useful abstraction
Easy to use Very large variety of problems are easily
expressible as MapReduce computations Greatly simplifies large-scale computations at

Questions?

Thank YouThank You